# Rasa Documentation
> Documentation for building conversational AI with Rasa Pro, Rasa Studio, and the Rasa platform.
## API Specifications
### Rasa - Server Endpoints (1.0.0)
[Skip to main content](#__docusaurus_skipToContent_fallback)
Build your first agent in just a few minutes with [Rasa Copilot](https://hello.rasa.com/?utm_source=docs\&utm_medium=referral\&utm_campaign=docs_cta).
[](https://rasa.com/docs/docs/)
[Home](https://rasa.com/docs/docs/)[Rasa](https://rasa.com/docs/docs/pro/intro/)[Studio](https://rasa.com/docs/docs/studio/intro/)[Reference](https://rasa.com/docs/docs/reference/overview/)
[Blog](https://blog.rasa.com/)
[Community](#)
* [Community Hub](https://rasa.com/community/join/)
* [Forum](https://forum.rasa.com)
* [How to Contribute](https://rasa.com/community/contribute/)
* [Community Showcase](https://rasa.com/showcase/)
Search...
* Server Information
* getHealth endpoint of Rasa Server
* getInformation about your Rasa Pro License
* getVersion of Rasa
* getStatus of the Rasa server
* Tracker
* getRetrieve a conversations tracker
* delDelete tracker for a specific conversation
* postAppend events to a tracker
* putReplace a trackers events
* getRetrieve an end-to-end story corresponding to a conversation
* postRun an action in a conversation
* postInject an intent into a conversation
* postPredict the next action
* postAdd a message to a tracker
* Model
* postTrain a Rasa model
* postEvaluate stories
* postPerform an intent evaluation
* postPredict an action on a temporary state
* postParse a message using the Rasa model
* putReplace the currently loaded model
* delUnload the trained model
* Flows
* getRetrieve the flows of the assistant
* Domain
* getRetrieve the loaded domain
* Channel Webhooks
* postPost user message from a REST channel
* postPost user message from a custom channel
[API docs by Redocly](https://redocly.com/redoc/)
Download OpenAPI specification:[Download](https://rasa.com/docs/redocusaurus/pro.yaml)
The Rasa server provides endpoints to retrieve trackers of conversations as well as endpoints to modify them. Additionally, endpoints for training and testing models are provided.
#### [](#tag/Server-Information)Server Information
#### [](#tag/Server-Information/operation/getHealth)Health endpoint of Rasa Server
This URL can be used as an endpoint to run health checks against. When the server is running this will return 200.
##### Responses
**200**
Up and running
get/
Local development server
http://localhost:5005/
##### Response samples
* 200
Content type
text/plain
Copy
```
Hello from Rasa: 1.0.0
```
#### [](#tag/Server-Information/operation/getLicense)Information about your Rasa Pro License
Returns the license information about your Rasa Pro License
##### Responses
**200**
Rasa Pro License Information
get/license
Local development server
http://localhost:5005/license
##### Response samples
* 200
Content type
application/json
Copy
`{
"id": "u5fn8888-e213-4c12-9542-0baslfdkjas",
"company": "acme",
"scope": "rasa:pro rasa:voice",
"email": "acme@email.com",
"expires": "2026-01-01T00:00:00+00:00"
}`
#### [](#tag/Server-Information/operation/getVersion)Version of Rasa
Returns the version of Rasa.
##### Responses
**200**
Version of Rasa
get/version
Local development server
http://localhost:5005/version
##### Response samples
* 200
Content type
application/json
Copy
`{
"version": "1.0.0",
"minimum_compatible_version": "1.0.0"
}`
#### [](#tag/Server-Information/operation/getStatus)Status of the Rasa server
Information about the server and the currently loaded Rasa model.
###### Authorizations:
*TokenAuth\*\*JWT*
##### Responses
**200**
Success
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
get/status
Local development server
http://localhost:5005/status
##### Response samples
* 200
* 401
* 403
* 409
Content type
application/json
Copy
`{
"model_id": "75a985b7b86d442ca013d61ea4781b22",
"model_file": "20190429-103105.tar.gz",
"num_active_training_jobs": 2
}`
#### [](#tag/Tracker)Tracker
#### [](#tag/Tracker/operation/getConversationTracker)Retrieve a conversations tracker
The tracker represents the state of the conversation. The state of the tracker is created by applying a sequence of events, which modify the state. These events can optionally be included in the response.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
| until | numberDefault:"None"Example:until=1559744410All events previous to the passed timestamp will be replayed. Events that occur exactly at the target time will be included. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
get/conversations/{conversation\_id}/tracker
Local development server
http://localhost:5005/conversations/{conversation\_id}/tracker
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}`
#### [](#tag/Tracker/operation/deleteConversationTracker)Delete tracker for a specific conversation
Deletes the tracker of a conversation.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
##### Responses
**204**
Tracker successfully deleted.
**401**
User is not authenticated.
**403**
User has insufficient permission.
**404**
Conversation not found.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
delete/conversations/{conversation\_id}/tracker
Local development server
http://localhost:5005/conversations/{conversation\_id}/tracker
##### Response samples
* 401
* 403
* 409
* 500
Content type
application/json
Copy
`{
"version": "1.0.0",
"status": "failure",
"reason": "NotAuthenticated",
"message": "User is not authenticated to access resource.",
"code": 401
}`
#### [](#tag/Tracker/operation/addConversationTrackerEvents)Append events to a tracker
Appends one or multiple new events to the tracker state of the conversation. Any existing events will be kept and the new events will be appended, updating the existing state. If events are appended to a new conversation ID, the tracker will be initialised with a new session.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| ---------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
| output\_channel | stringEnum: "latest" "slack" "callback" "facebook" "rocketchat" "telegram" "twilio" "webexteams" "socketio"Example:output\_channel=slackThe bot's utterances will be forwarded to this channel. It uses the credentials listed in `credentials.yml` to connect. In case the channel does not support this, the utterances will be returned in the response body. Use `latest` to try to send the messages to the latest channel the user used. Currently supported channels are listed in the permitted values for the parameter. |
| execute\_side\_effects | booleanDefault:falseIf `true`, any `BotUttered` event will be forwarded to the channel specified in the `output_channel` parameter. Any `ReminderScheduled` or `ReminderCancelled` event will also be processed. |
###### Request Body schema: application/jsonrequired
One of
EventEventList
Any of
UserEventBotEventSessionStartedEventActionEventSlotEventResetSlotsEventRestartEventReminderEventCancelReminderEventPauseEventResumeEventFollowupEventExportEventUndoEventRewindEventAgentEventEntitiesAddedEventUserFeaturizationEventActionExecutionRejectedEventFormValidationEventLoopInterruptedEventFormEventActiveLoopEvent
| | |
| -------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| eventrequired | stringValue: "user"Event name |
| timestamp | integerTime of application |
| metadata | object |
| text | string or nullText of user message. |
| input\_channel | string or null |
| message\_id | string or null |
| parse\_data | object (ParseResult)NLU parser information. If set, message will not be passed through NLU, but instead this parsing information will be used. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/tracker/events
Local development server
http://localhost:5005/conversations/{conversation\_id}/tracker/events
##### Request samples
* Payload
Content type
application/json
Example
EventEvent
Copy
Expand all Collapse all
`{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}`
#### [](#tag/Tracker/operation/replaceConversationTrackerEvents)Replace a trackers events
Replaces all events of a tracker with the passed list of events. This endpoint should not be used to modify trackers in a production setup, but rather for creating training data.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
###### Request Body schema: application/jsonrequired
Array
Any of
UserEventBotEventSessionStartedEventActionEventSlotEventResetSlotsEventRestartEventReminderEventCancelReminderEventPauseEventResumeEventFollowupEventExportEventUndoEventRewindEventAgentEventEntitiesAddedEventUserFeaturizationEventActionExecutionRejectedEventFormValidationEventLoopInterruptedEventFormEventActiveLoopEvent
| | |
| -------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| eventrequired | stringValue: "user"Event name |
| timestamp | integerTime of application |
| metadata | object |
| text | string or nullText of user message. |
| input\_channel | string or null |
| message\_id | string or null |
| parse\_data | object (ParseResult)NLU parser information. If set, message will not be passed through NLU, but instead this parsing information will be used. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
put/conversations/{conversation\_id}/tracker/events
Local development server
http://localhost:5005/conversations/{conversation\_id}/tracker/events
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`[
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
]`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}`
#### [](#tag/Tracker/operation/getConversationStory)Retrieve an end-to-end story corresponding to a conversation
The story represents the whole conversation in end-to-end format. This can be posted to the '/test/stories' endpoint and used as a test.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| ------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| until | numberDefault:"None"Example:until=1559744410All events previous to the passed timestamp will be replayed. Events that occur exactly at the target time will be included. |
| all\_sessions | booleanDefault:falseWhether to fetch all sessions in a conversation, or only the latest session- `true` - fetch all conversation sessions.
- `false` - \[default] fetch only the latest conversation session. |
##### Responses
**200**
Success
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
get/conversations/{conversation\_id}/story
Local development server
http://localhost:5005/conversations/{conversation\_id}/story
##### Response samples
* 200
* 401
* 403
* 409
* 500
Content type
text/yml
Copy
```
- story: story_00055028
steps:
- user: |
hello
intent: greet
- action: utter_ask_howcanhelp
- user: |
I'm looking for a [moderately priced]{"entity": "price", "value": "moderate"} [Indian]{"entity": "cuisine"} restaurant for [two]({"entity": "people"}) people
intent: inform
- action: utter_on_it
- action: utter_ask_location
```
#### [](#tag/Tracker/operation/executeConversationAction)Run an action in a conversation Deprecated
DEPRECATED. Runs the action, calling the action server if necessary. Any responses sent by the executed action will be forwarded to the channel specified in the output\_channel parameter. If no output channel is specified, any messages that should be sent to the user will be included in the response of this endpoint.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
| output\_channel | stringEnum: "latest" "slack" "callback" "facebook" "rocketchat" "telegram" "twilio" "webexteams" "socketio"Example:output\_channel=slackThe bot's utterances will be forwarded to this channel. It uses the credentials listed in `credentials.yml` to connect. In case the channel does not support this, the utterances will be returned in the response body. Use `latest` to try to send the messages to the latest channel the user used. Currently supported channels are listed in the permitted values for the parameter. |
###### Request Body schema: application/jsonrequired
| | |
| ------------ | ----------------------------------------------------------- |
| namerequired | stringName of the action to be executed. |
| policy | string or nullName of the policy that predicted the action. |
| confidence | number or nullConfidence of the prediction. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/execute
Local development server
http://localhost:5005/conversations/{conversation\_id}/execute
##### Request samples
* Payload
Content type
application/json
Copy
`{
"name": "utter_greet",
"policy": "string",
"confidence": 0.987232
}`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
},
"messages": [
{
"recipient_id": "string",
"text": "string",
"image": "string",
"buttons": [
{
"title": "string",
"payload": "string"
}
],
"attachement": [
{
"title": "string",
"payload": "string"
}
]
}
]
}`
#### [](#tag/Tracker/operation/triggerConversationIntent)Inject an intent into a conversation
Sends a specified intent and list of entities in place of a user message. The bot then predicts and executes a response action. Any responses sent by the executed action will be forwarded to the channel specified in the `output_channel` parameter. If no output channel is specified, any messages that should be sent to the user will be included in the response of this endpoint.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
| output\_channel | stringEnum: "latest" "slack" "callback" "facebook" "rocketchat" "telegram" "twilio" "webexteams" "socketio"Example:output\_channel=slackThe bot's utterances will be forwarded to this channel. It uses the credentials listed in `credentials.yml` to connect. In case the channel does not support this, the utterances will be returned in the response body. Use `latest` to try to send the messages to the latest channel the user used. Currently supported channels are listed in the permitted values for the parameter. |
###### Request Body schema: application/jsonrequired
| | |
| ------------ | ---------------------------------------- |
| namerequired | stringName of the intent to be executed. |
| entities | object or nullEntities to be passed on. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/trigger\_intent
Local development server
http://localhost:5005/conversations/{conversation\_id}/trigger\_intent
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"name": "greet",
"entities": {
"temperature": "high"
}
}`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
},
"messages": [
{
"recipient_id": "string",
"text": "string",
"image": "string",
"buttons": [
{
"title": "string",
"payload": "string"
}
],
"attachement": [
{
"title": "string",
"payload": "string"
}
]
}
]
}`
#### [](#tag/Tracker/operation/predictConversationAction)Predict the next action
Runs the conversations tracker through the model's policies to predict the scores of all actions present in the model's domain. Actions are returned in the 'scores' array, sorted on their 'score' values. The state of the tracker is not modified.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/predict
Local development server
http://localhost:5005/conversations/{conversation\_id}/predict
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"scores": [
{
"action": "utter_greet",
"score": 1
}
],
"policy": "policy_2_TEDPolicy",
"confidence": 0.057,
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}
}`
#### [](#tag/Tracker/operation/addConversationMessage)Add a message to a tracker
Adds a message to a tracker. This doesn't trigger the prediction loop. It will log the message on the tracker and return, no actions will be predicted or run. This is often used together with the predict endpoint.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
###### Request Body schema: application/jsonrequired
| | |
| -------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| textrequired | stringMessage text |
| senderrequired | stringValue: "user"Origin of the message - who sent it |
| parse\_data | object (ParseResult)NLU parser information. If set, message will not be passed through NLU, but instead this parsing information will be used. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/messages
Local development server
http://localhost:5005/conversations/{conversation\_id}/messages
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"text": "Hello!",
"sender": "user",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}`
#### [](#tag/Model)Model
#### [](#tag/Model/operation/trainModel)Train a Rasa model
Trains a new Rasa model. Depending on the data given only a dialogue model, only a NLU model, or a model combining a trained dialogue model with an NLU model will be trained. The new model is not loaded by default.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| ----------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| save\_to\_default\_model\_directory | booleanDefault:trueIf `true` (default) the trained model will be saved in the default model directory, if `false` it will be saved in a temporary directory |
| force\_training | booleanDefault:falseForce a model training even if the data has not changed |
| augmentation | stringDefault:50How much data augmentation to use during training |
| num\_threads | stringDefault:1Maximum amount of threads to use when training |
| callback\_url | stringDefault:"None"Example:callback\_url=https://example.com/rasa\_evaluationsIf specified the call will return immediately with an empty response and status code 204. The actual result or any errors will be sent to the given callback URL as the body of a post request. |
###### Request Body schema: application/yamlrequired
The training data should be in YAML format.
| | |
| ----------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| pipeline | Array of arraysPipeline list |
| policies | Array of arraysPolicies list |
| entities | Array of arraysEntity list |
| slots | Array of arraysSlots list |
| actions | Array of arraysAction list |
| forms | Array of arraysForms list |
| e2e\_actions | Array of arraysE2E Action list |
| responses | objectBot response templates |
| session\_config | objectSession configuration options |
| nlu | Array of arraysRasa NLU data, array of intents |
| rules | Array of arraysRule list |
| stories | Array of arraysRasa Core stories in YAML format |
| flows | objectRasa Pro flows in YAML format |
| force | booleanDeprecatedForce a model training even if the data has not changed |
| save\_to\_default\_model\_directory | booleanDeprecatedIf `true` (default) the trained model will be saved in the default model directory, if `false` it will be saved in a temporary directory |
##### Responses
**200**
Zipped Rasa model
**204**
The incoming request specified a `callback_url` and hence the request will return immediately with an empty response. The actual response will be sent to the provided `callback_url` via POST request.
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**500**
An unexpected error occurred.
post/model/train
Local development server
http://localhost:5005/model/train
##### Request samples
* Payload
Content type
application/yaml
Copy
```
pipeline: []
policies: []
intents:
- greet
- goodbye
entities: []
slots:
contacts_list:
type: text
mappings:
- type: custom
action: list_contacts
actions:
- list_contacts
forms: {}
e2e_actions: []
responses:
utter_greet:
- text: "Hey! How are you?"
utter_goodbye:
- text: "Bye"
utter_list_contacts:
- text: "You currently have the following contacts:\n{contacts_list}"
utter_no_contacts:
- text: "You have no contacts in your list."
session_config:
session_expiration_time: 60
carry_over_slots_to_new_session: true
nlu:
- intent: greet
examples: |
- hey
- hello
- intent: goodbye
examples: |
- bye
- goodbye
rules:
- rule: Say goodbye anytime the user says goodbye
steps:
- intent: goodbye
- action: utter_goodbye
stories:
- story: happy path
steps:
- intent: greet
- action: utter_greet
- intent: goodbye
- action: utter_goodbye
flows:
list_contacts:
name: list your contacts
description: show your contact list
steps:
- action: list_contacts
next:
- if: "slots.contacts_list"
then:
- action: utter_list_contacts
next: END
- else:
- action: utter_no_contacts
next: END
```
##### Response samples
* 400
* 401
* 403
* 500
Content type
application/json
Copy
`{
"version": "1.0.0",
"status": "failure",
"reason": "BadRequest",
"code": 400
}`
#### [](#tag/Model/operation/testModelStories)Evaluate stories
Evaluates one or multiple stories against the currently loaded Rasa model.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| --- | ------------------------------------------------------------------------------------------- |
| e2e | booleanDefault:falsePerform an end-to-end evaluation on the posted stories. |
###### Request Body schema: text/ymlrequired
string (
StoriesTrainingData
)
Rasa Core stories in YAML format
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/model/test/stories
Local development server
http://localhost:5005/model/test/stories
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"actions": [
{
"action": "utter_ask_howcanhelp",
"predicted": "utter_ask_howcanhelp",
"policy": "policy_0_MemoizationPolicy",
"confidence": 1
}
],
"is_end_to_end_evaluation": true,
"precision": 1,
"f1": 0.9333333333333333,
"accuracy": 0.9,
"in_training_data_fraction": 0.8571428571428571,
"report": {
"conversation_accuracy": {
"accuracy": 0.19047619047619047,
"correct": 18,
"with_warnings": 1,
"total": 20
},
"property1": {
"intent_name": "string",
"classification_report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
}
},
"property2": {
"intent_name": "string",
"classification_report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
}
}
}
}`
#### [](#tag/Model/operation/testModelIntent)Perform an intent evaluation
Evaluates NLU model against a model or using cross-validation.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| ------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| model | stringExample:model=rasa-model.tar.gzModel that should be used for evaluation. If the parameter is set, the model will be fetched with the currently loaded configuration setup. However, the currently loaded model will not be updated. The state of the server will not change. If the parameter is not set, the currently loaded model will be used for the evaluation. |
| callback\_url | stringDefault:"None"Example:callback\_url=https://example.com/rasa\_evaluationsIf specified the call will return immediately with an empty response and status code 204. The actual result or any errors will be sent to the given callback URL as the body of a post request. |
| cross\_validation\_folds | integerDefault:nullNumber of cross validation folds. If this parameter is specified the given training data will be used for a cross-validation instead of using it as test set for the specified model. Note that this is only supported for YAML data. |
###### Request Body schema:application/x-yamlapplication/x-yamlrequired
string
NLU training data and model configuration. The model configuration is only required if cross-validation is used.
##### Responses
**200**
NLU evaluation result
**204**
The incoming request specified a `callback_url` and hence the request will return immediately with an empty response. The actual response will be sent to the provided `callback_url` via POST request.
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/model/test/intents
Local development server
http://localhost:5005/model/test/intents
##### Request samples
* Payload
Content type
application/x-yamlapplication/x-yaml
No sample
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"intent_evaluation": {
"report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
},
"accuracy": 0.19047619047619047,
"f1_score": 0.06095238095238095,
"precision": 0.036281179138321996,
"predictions": [
{
"intent": "greet",
"predicted": "greet",
"text": "hey",
"confidence": 0.9973567
}
],
"errors": [
{
"text": "are you alright?",
"intent_response_key_target": "string",
"intent_response_key_prediction": {
"confidence": 0.6323,
"name": "greet"
}
}
]
},
"response_selection_evaluation": {
"report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
},
"accuracy": 0.19047619047619047,
"f1_score": 0.06095238095238095,
"precision": 0.036281179138321996,
"predictions": [
{
"intent": "greet",
"predicted": "greet",
"text": "hey",
"confidence": 0.9973567
}
],
"errors": [
{
"text": "are you alright?",
"intent_response_key_target": "string",
"intent_response_key_prediction": {
"confidence": 0.6323,
"name": "greet"
}
}
]
},
"entity_evaluation": {
"property1": {
"report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
},
"accuracy": 0.19047619047619047,
"f1_score": 0.06095238095238095,
"precision": 0.036281179138321996,
"predictions": [
{
"intent": "greet",
"predicted": "greet",
"text": "hey",
"confidence": 0.9973567
}
],
"errors": [
{
"text": "are you alright?",
"intent_response_key_target": "string",
"intent_response_key_prediction": {
"confidence": 0.6323,
"name": "greet"
}
}
]
},
"property2": {
"report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
},
"accuracy": 0.19047619047619047,
"f1_score": 0.06095238095238095,
"precision": 0.036281179138321996,
"predictions": [
{
"intent": "greet",
"predicted": "greet",
"text": "hey",
"confidence": 0.9973567
}
],
"errors": [
{
"text": "are you alright?",
"intent_response_key_target": "string",
"intent_response_key_prediction": {
"confidence": 0.6323,
"name": "greet"
}
}
]
}
}
}`
#### [](#tag/Model/operation/predictModelAction)Predict an action on a temporary state
Predicts the next action on the tracker state as it is posted to this endpoint. Rasa will create a temporary tracker from the provided events and will use it to predict an action. No messages will be sent and no action will be run.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
###### Request Body schema: application/jsonrequired
Array
Any of
UserEventBotEventSessionStartedEventActionEventSlotEventResetSlotsEventRestartEventReminderEventCancelReminderEventPauseEventResumeEventFollowupEventExportEventUndoEventRewindEventAgentEventEntitiesAddedEventUserFeaturizationEventActionExecutionRejectedEventFormValidationEventLoopInterruptedEventFormEventActiveLoopEvent
| | |
| -------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| eventrequired | stringValue: "user"Event name |
| timestamp | integerTime of application |
| metadata | object |
| text | string or nullText of user message. |
| input\_channel | string or null |
| message\_id | string or null |
| parse\_data | object (ParseResult)NLU parser information. If set, message will not be passed through NLU, but instead this parsing information will be used. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/model/predict
Local development server
http://localhost:5005/model/predict
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`[
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
]`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"scores": [
{
"action": "utter_greet",
"score": 1
}
],
"policy": "policy_2_TEDPolicy",
"confidence": 0.057,
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}
}`
#### [](#tag/Model/operation/parseModelMessage)Parse a message using the Rasa model
Predicts the intent and entities of the message posted to this endpoint. No messages will be stored to a conversation and no action will be run. This will just retrieve the NLU parse results.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| emulation\_mode | stringEnum: "WIT" "LUIS" "DIALOGFLOW"Example:emulation\_mode=LUISSpecify the emulation mode to use. Emulation mode transforms the response JSON to the format expected by the service specified as the emulation\_mode. Requests must still be sent in the regular Rasa format. |
###### Request Body schema: application/jsonrequired
| | |
| ----------- | ------------------------------------------ |
| text | stringMessage to be parsed |
| message\_id | stringOptional ID for message to be parsed |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**500**
An unexpected error occurred.
post/model/parse
Local development server
http://localhost:5005/model/parse
##### Request samples
* Payload
Content type
application/json
Copy
`{
"text": "Hello, I am Rasa!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a"
}`
##### Response samples
* 200
* 400
* 401
* 403
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"text": "Hello!",
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
]
}`
#### [](#tag/Model/operation/replaceModel)Replace the currently loaded model
Updates the currently loaded model. First, tries to load the model from the local (note: local to Rasa server) storage system. Secondly, tries to load the model from the provided model server configuration. Last, tries to load the model from the provided remote storage.
###### Authorizations:
*TokenAuth\*\*JWT*
###### Request Body schema: application/jsonrequired
| | |
| --------------- | ---------------------------------------------------------------------------- |
| model\_file | stringPath to model file |
| model\_server | object (EndpointConfig) |
| remote\_storage | stringEnum: "aws" "gcs" "azure"Name of remote storage system |
##### Responses
**204**
Model was successfully replaced.
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**500**
An unexpected error occurred.
put/model
Local development server
http://localhost:5005/model
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"model_file": "/absolute-path-to-models-directory/models/20190512.tar.gz",
"model_server": {
"url": "string",
"params": { },
"headers": { },
"basic_auth": { },
"token": "string",
"token_name": "string",
"wait_time_between_pulls": 0
},
"remote_storage": "aws"
}`
##### Response samples
* 400
* 401
* 403
* 500
Content type
application/json
Copy
`{
"version": "1.0.0",
"status": "failure",
"reason": "BadRequest",
"code": 400
}`
#### [](#tag/Model/operation/unloadModel)Unload the trained model
Unloads the currently loaded trained model from the server.
###### Authorizations:
*TokenAuth\*\*JWT*
##### Responses
**204**
Model was sucessfully unloaded.
**401**
User is not authenticated.
**403**
User has insufficient permission.
delete/model
Local development server
http://localhost:5005/model
##### Response samples
* 401
* 403
Content type
application/json
Copy
`{
"version": "1.0.0",
"status": "failure",
"reason": "NotAuthenticated",
"message": "User is not authenticated to access resource.",
"code": 401
}`
#### [](#tag/Flows)Flows
#### [](#tag/Flows/operation/getFlows)Retrieve the flows of the assistant
Returns the assistant was trained on.
###### Authorizations:
*TokenAuth\*\*JWT*
##### Responses
**200**
Flows were successfully retrieved.
**401**
User is not authenticated.
**403**
User has insufficient permission.
**406**
Invalid header provided.
**500**
An unexpected error occurred.
get/flows
Local development server
http://localhost:5005/flows
##### Response samples
* 200
* 401
* 403
* 406
* 500
Content type
application/json
Copy
Expand all Collapse all
`[
{
"id": "check_balance",
"name": "check balance",
"description": "check the user's account balance",
"steps": [
{ }
]
}
]`
#### [](#tag/Domain)Domain
#### [](#tag/Domain/operation/getDomain)Retrieve the loaded domain
Returns the domain specification the currently loaded model is using.
###### Authorizations:
*TokenAuth\*\*JWT*
##### Responses
**200**
Domain was successfully retrieved.
**401**
User is not authenticated.
**403**
User has insufficient permission.
**406**
Invalid header provided.
**500**
An unexpected error occurred.
get/domain
Local development server
http://localhost:5005/domain
##### Response samples
* 200
* 401
* 403
* 406
* 500
Content type
application/jsonapplication/json
Copy
Expand all Collapse all
`{
"config": {
"store_entities_as_slots": false
},
"intents": [
{
"property1": {
"use_entities": true
},
"property2": {
"use_entities": true
}
}
],
"entities": [
"person",
"location"
],
"slots": {
"property1": {
"auto_fill": true,
"initial_value": "string",
"type": "string",
"values": [
"string"
]
},
"property2": {
"auto_fill": true,
"initial_value": "string",
"type": "string",
"values": [
"string"
]
}
},
"responses": {
"property1": {
"text": "string"
},
"property2": {
"text": "string"
}
},
"actions": [
"action_greet",
"action_goodbye",
"action_listen"
]
}`
#### [](#tag/Channel-Webhooks)Channel Webhooks
#### [](#tag/Channel-Webhooks/operation/postMessageRestChannel)Post user message from a REST channel
Post a message from the user and forward it to the assistant. Return the message of the assistant to the user.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| --------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| rest\_channelrequired | stringEnum: "rest" "callback"The REST channel used for custom integrations. They provide a URL where you can post messages and either receive response messages directly, or asynchronously via a webhook. |
###### Request Body schema: application/jsonrequired
The user message payload
| | |
| ------- | ---------------------- |
| sender | stringThe sender ID |
| message | stringThe message text |
##### Responses
**200**
The message was processed successfully
**401**
User is not authenticated.
**403**
User has insufficient permission.
**406**
Invalid header provided.
**500**
An unexpected error occurred.
post/webhooks/{rest\_channel}/webhook
Local development server
http://localhost:5005/webhooks/{rest\_channel}/webhook
##### Request samples
* Payload
Content type
application/json
Copy
`{
"sender": "default",
"message": "Hello!"
}`
##### Response samples
* 200
* 401
* 403
* 406
* 500
Content type
application/json
Copy
Expand all Collapse all
`[
{
"recipient_id": "default",
"text": "Hello!"
}
]`
#### [](#tag/Channel-Webhooks/operation/postMessageCustomChannel)Post user message from a custom channel
Post a message from the user and forward it to the assistant. Return the message of the assistant to the user. This is from a custom channel.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ----------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| custom\_channelrequired | stringExample:my\_custom\_channelThe custom channel connector used for integration. They provide a URL where you can post and receive messages. |
###### Request Body schema: application/jsonrequired
The user message payload
| | |
| -------------- | ---------------------------------------- |
| sender | stringThe sender ID |
| message | stringThe message text |
| stream | booleanWhether to use streaming response |
| input\_channel | stringInput channel name |
| metadata | objectAdditional metadata |
##### Responses
**200**
The message was processed successfully
**401**
User is not authenticated.
**403**
User has insufficient permission.
**406**
Invalid header provided.
**500**
An unexpected error occurred.
post/webhooks/{custom\_channel}/webhook
Local development server
http://localhost:5005/webhooks/{custom\_channel}/webhook
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"sender": "string",
"message": "string",
"stream": true,
"input_channel": "string",
"metadata": { }
}`
##### Response samples
* 200
* 401
* 403
* 406
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"messages": [
{
"recipient_id": "string",
"text": "string",
"image": "string",
"buttons": [
{
"title": "string",
"payload": "string"
}
],
"attachement": [
{
"title": "string",
"payload": "string"
}
]
}
],
"metadata": { },
"conversation_id": "string",
"tracker_state": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}
}`
Copyright © 2026 Rasa Technologies GmbH
---
### Rasa SDK - Action Server Endpoint (0.0.0)
[Skip to main content](#__docusaurus_skipToContent_fallback)
Build your first agent in just a few minutes with [Rasa Copilot](https://hello.rasa.com/?utm_source=docs\&utm_medium=referral\&utm_campaign=docs_cta).
[](https://rasa.com/docs/docs/)
[Home](https://rasa.com/docs/docs/)[Rasa](https://rasa.com/docs/docs/pro/intro/)[Studio](https://rasa.com/docs/docs/studio/intro/)[Reference](https://rasa.com/docs/docs/reference/overview/)
[Blog](https://blog.rasa.com/)
[Community](#)
* [Community Hub](https://rasa.com/community/join/)
* [Forum](https://forum.rasa.com)
* [How to Contribute](https://rasa.com/community/contribute/)
* [Community Showcase](https://rasa.com/showcase/)
Search...
* postCore request to execute a custom action
[API docs by Redocly](https://redocly.com/redoc/)
Download OpenAPI specification:[Download](https://rasa.com/docs/redocusaurus/action-server.yaml)
HTTP API of the action server which is used by Rasa to execute custom actions.
#### [](#operation/call_action)Core request to execute a custom action
Rasa Core sends a request to the action server to execute a certain custom action. As a response to the action call from Core, you can modify the tracker, e.g. by setting slots and send responses back to the user.
###### Request Body schema: application/jsonrequired
Describes the action to be called and provides information on the current state of the conversation.
| | |
| ------------ | ----------------------------------------------------------------------------------------- |
| next\_action | stringThe name of the action which should be executed. |
| sender\_id | stringUnique id of the user who is having the current conversation. |
| tracker | object (Tracker)Conversation tracker which stores the conversation state. |
| domain | object (Domain)The bot's domain. |
##### Responses
**200**
Action was executed succesfully.
**400**
Action execution was rejected. This is the same as returning an `ActionExecutionRejected` event.
**500**
The action server encountered an exception while running the action.
post/
Local development action server
http://localhost:5055/webhook/
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"next_action": "string",
"sender_id": "string",
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
},
"domain": {
"config": {
"store_entities_as_slots": false
},
"intents": [
{
"property1": {
"use_entities": true
},
"property2": {
"use_entities": true
}
}
],
"entities": [
"person",
"location"
],
"slots": {
"property1": {
"auto_fill": true,
"initial_value": "string",
"type": "string",
"values": [
"string"
]
},
"property2": {
"auto_fill": true,
"initial_value": "string",
"type": "string",
"values": [
"string"
]
}
},
"responses": {
"property1": {
"text": "string"
},
"property2": {
"text": "string"
}
},
"actions": [
"action_greet",
"action_goodbye",
"action_listen"
]
}
}`
##### Response samples
* 200
* 400
Content type
application/json
Copy
Expand all Collapse all
`{
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"responses": [
{
"text": "string"
}
]
}`
Copyright © 2026 Rasa Technologies GmbH
---
## Docs
### Introduction to Rasa Action Server
A Rasa action server runs [custom actions](https://rasa.com/docs/docs/reference/primitives/custom-actions/) for a Rasa conversational assistant.
#### How it works[](#how-it-works "Direct link to How it works")
When your assistant predicts a custom action, the Rasa server sends a `POST` request to the action server with a json payload including the name of the predicted action, the conversation ID, the contents of the tracker and the contents of the domain.
When the action server finishes running a custom action, it returns a json payload of [responses](https://rasa.com/docs/docs/reference/primitives/responses/) and [events](https://rasa.com/docs/docs/reference/integrations/action-server/events/). See the [API spec](https://rasa.com/docs/docs/reference/api/pro/action-server-api/) for details about the request and response payloads.
The Rasa server then returns the responses to the user and adds the events to the conversation tracker.
To optimise the network traffic, the rasa server will not send a domain with each request to the action server. Instead, it will first send the digest of the domain to the action server and if action server does not have the domain with the given digest cached, it will reply to the action server with code 449 (HTTP retry) or in case of gRPC it will send error code NOT\_FOUND and in the details it will outline that domain was not found. This indicates that the rasa server must resend the request with domain included. [See more](https://rasa.com/docs/docs/reference/integrations/action-server/actions/#domain_digest).
#### SDKs for Custom Actions[](#sdks-for-custom-actions "Direct link to SDKs for Custom Actions")
You can use an action server written in any language to run your custom actions, as long as it implements the [required APIs](https://rasa.com/docs/docs/reference/api/pro/action-server-api/).
##### Rasa SDK (Python)[](#rasa-sdk-python "Direct link to Rasa SDK (Python)")
Rasa SDK is a Python SDK for running custom actions. Besides implementing the required APIs, it offers methods for interacting with the conversation tracker and composing events and responses. If you don't yet have an action server and don't need it to be in a language other than Python, using the Rasa SDK will be the easiest way to get started.
##### Other Action Servers[](#other-action-servers "Direct link to Other Action Servers")
If you have legacy code or existing business logic in another language, you may not want to use the Rasa SDK. In this case you can write your own action server in any language you want. The only requirement for the action server is that it provide a `/webhook` endpoint which accepts HTTP `POST` requests from the Rasa server and returns a payload of [events](https://rasa.com/docs/docs/reference/integrations/action-server/events/) and responses. See the [API spec](https://rasa.com/docs/docs/reference/api/pro/action-server-api/) for details about the required `/webhook` endpoint.
##### Running Custom Actions Directly by the Assistant[](#running-custom-actions-directly-by-the-assistant "Direct link to Running Custom Actions Directly by the Assistant")
For users looking to streamline their architecture by eliminating the need for an Action Server, you can explore how to run custom actions directly on the Rasa Assistant by following the guidelines [here](https://rasa.com/docs/docs/reference/primitives/custom-actions/#running-custom-actions-directly-by-the-assistant).
---
## Learn
### AI-Assisted Development
AI coding assistants work best when they have the right context. Rasa publishes machine-readable documentation files that you can feed to your AI assistant so it understands Rasa concepts, syntax, and best practices.
***
#### llms.txt[](#llmstxt "Direct link to llms.txt")
The Rasa docs publish an [llms.txt](https://rasa.com/docs/docs/llms.txt) file following the [llms.txt convention](https://llmstxt.org/). This is a machine-readable index of every documentation page, organized by section.
| File | Description |
| --------------------------------------------------------- | ---------------------------------------------------------- |
| [llms.txt](https://rasa.com/docs/docs/llms.txt) | Hierarchical index of all docs with links and descriptions |
| [llms-full.txt](https://rasa.com/docs/docs/llms-full.txt) | Full content of every page in a single file |
Use `llms.txt` when your tool needs to discover available pages. Use `llms-full.txt` when you want to give an AI assistant access to the entire documentation at once.
***
#### Documentation Modules[](#documentation-modules "Direct link to Documentation Modules")
For more focused context, Rasa provides topic-specific documentation modules. These are self-contained markdown files covering a single area, built from the same source as the docs you're reading now. They're useful when you want to give your AI assistant deep knowledge of a specific topic without loading the entire documentation.
##### Core[](#core "Direct link to Core")
These cover the fundamentals that most Rasa developers need:
| Module | Description |
| ------------------------------------------------------------------------- | ----------------------------------------------------------- |
| [flows.md](https://rasa.com/docs/docs/llms/flows) | Writing & configuring flows -- the core CALM building block |
| [slots-and-memory.md](https://rasa.com/docs/docs/llms/slots-and-memory) | Slot types, mappings, and assistant memory |
| [responses.md](https://rasa.com/docs/docs/llms/responses) | Response syntax, variations, and the contextual rephraser |
| [actions.md](https://rasa.com/docs/docs/llms/actions) | Custom actions, MCP, A2A, action server SDK |
| [configuration.md](https://rasa.com/docs/docs/llms/configuration) | Domain file, LLM config, and environment variables |
| [rasa-pro-overview.md](https://rasa.com/docs/docs/llms/rasa-pro-overview) | Rasa Pro intro + tutorial |
##### Specialized[](#specialized "Direct link to Specialized")
Install these based on what you're building:
| Module | Description |
| ------------------------------------------------------------------------------- | ---------------------------------------------------------- |
| [patterns.md](https://rasa.com/docs/docs/llms/patterns) | Conversation repair and deviation handling |
| [enterprise-search.md](https://rasa.com/docs/docs/llms/enterprise-search) | RAG pipelines and enterprise search |
| [testing.md](https://rasa.com/docs/docs/llms/testing) | E2E tests, assertions, coverage, and the Inspector |
| [voice.md](https://rasa.com/docs/docs/llms/voice) | Voice assistants with AudioCodes, Twilio, Jambonz, Genesys |
| [deployment.md](https://rasa.com/docs/docs/llms/deployment) | Docker, Kubernetes, CI/CD, and load testing |
| [channels.md](https://rasa.com/docs/docs/llms/channels) | Slack, Messenger, Telegram, Twilio, and custom connectors |
| [rasa-studio-overview.md](https://rasa.com/docs/docs/llms/rasa-studio-overview) | Rasa Studio intro + tutorial |
##### How to Use[](#how-to-use "Direct link to How to Use")
Download a `.md` file and add it to your AI assistant's context. For example, in Cursor or Claude Code, you can reference it directly as a file in your project, or paste its contents into a conversation.
A full index of all available modules is at [llms/index.md](https://rasa.com/docs/docs/llms/index).
---
### How to Use the Platform
### **How to Use the Platform**
Rasa makes it easy for teams to build, test, and improve AI assistants through an iterative development process. Below, you'll find the key stages of the conversational AI development lifecycle and how Rasa can help streamline your workflows. With each iteration, you can refine your assistant based on real user insights, ensuring continuous improvement and better business outcomes.
#### **Workflow with the Rasa Platform**[](#workflow-with-the-rasa-platform "Direct link to workflow-with-the-rasa-platform")
##### **1. Build**[](#1-build "Direct link to 1-build")
Design, develop, and configure user journeys while improving existing ones. Use these platform tools to streamline development:
###### Write Content Studio[](#write-content-studio "Direct link to write-content-studio")
* Create, edit, and delete templated responses centrally in the Rasa Studio CMS.
* Create, edit, and delete intents directly within the CMS when using Rasa NLU.
* Empower copywriters, designers, and AI trainers to maintain conversational content efficiently.
###### Build Flows Studio[](#build-flows-studio "Direct link to build-flows-studio")
* Visually build conversational experiences using the flow builder in Rasa Studio.
* Structure the business logic of customer interactions into modular, reusable flows.
* Combine different elements to build everything from simple Q\&As to complex, multi-turn conversations—without writing code.
###### Train Models Studio[](#train-models-studio "Direct link to train-models-studio")
* Train your assistant to apply updates after defining flows and content.
###### Integrate Channels Pro[](#integrate-channels-pro "Direct link to integrate-channels-pro")
* Configure and manage channel integrations in Rasa Pro.
* Add and maintain integrations across iterations, making modifications as needed.
###### Configure Models Pro[](#configure-models-pro "Direct link to configure-models-pro")
* Integrate and fine-tune language models to optimize dialogue management.
* Enhance responses using retrieval-augmented generation (RAG) services.
###### Build Actions Pro[](#build-actions-pro "Direct link to build-actions-pro")
* Write custom Python actions to handle complex logic, integrate APIs, and extend conversational capabilities.
* Surface custom actions in Rasa Studio for reuse across your assistant.
***
##### **2. Test**[](#2-test "Direct link to 2-test")
Verify and refine your assistant’s behavior before deployment.
###### Inspect and Debug Studio[](#inspect-and-debug-studio "Direct link to inspect-and-debug-studio")
* Use Rasa Studio’s Inspector to test and debug the conversation flows you built.
* Visualize flow navigation, track collected information (slots), and analyze responses.
* Quickly identify issues and refine conversations for a smoother user experience.
###### Run Automated Tests Pro[](#run-automated-tests-pro "Direct link to run-automated-tests-pro")
* Execute automated tests written in Rasa Studio or Rasa Pro.
* Validate end-to-end assistant behavior to ensure consistency and reliability.
* Use automated testing to verify integrations and prevent regressions.
***
##### **3. Deploy**[](#3-deploy "Direct link to 3-deploy")
Promote your tested assistant into production using your preferred infrastructure.
###### Deploy Pro[](#deploy-pro "Direct link to deploy-pro")
* Deploy in a scalable, production-ready environment with Rasa Pro.
* Choose on-prem, cloud, or Kubernetes deployment options.
* Leverage built-in versioning, rollback support, and monitoring for smooth rollouts.
***
##### **4. Review**[](#4-review "Direct link to 4-review")
Analyze real conversations and refine your assistant based on user interactions.
###### Conversation Review Studio[](#conversation-review-studio "Direct link to conversation-review-studio")
* Access and analyze production conversation logs in the Conversation Review panel.
* Filter by topic or key metrics to identify patterns and optimize responses.
* Debug and refine assistant behavior using real-world data.
###### Monitor Performance Pro[](#monitor-performance-pro "Direct link to monitor-performance-pro")
* Use Rasa Pro’s monitoring tools for real-time visibility into your assistant’s performance.
* Track logs, analytics, and dashboards to optimize dialogue flows and detect issues early.
**Next Steps:**
* [Set up your conversational AI team](https://rasa.com/docs/docs/learn/best-practices/conversational-ai-teams/)
* [Start building a Rasa assistant for free](https://rasa.com/docs/docs/learn/quickstart/pro/)
---
### Introduction
Get started building conversational AI assistants with Rasa.
The Rasa Platform is a comprehensive suite of tools that makes creating, deploying, and managing intelligent conversational AI assistants easier. It includes:
**Rasa Studio**: A low-code interface for visually designing workflows and testing your assistant.
**Rasa Pro**: Advanced features for managing environments, custom actions, and enterprise-scale deployments.
#### How to Get Started[](#how-to-get-started "Direct link to How to Get Started")
There are two ways to begin building with the Rasa Platform:
##### **Automated Setup**[](#automated-setup "Direct link to automated-setup")
Use a guided setup to create a project, configure your environment, and start building assistants with all the tools you need pre-configured. [Get started with automated setup](#).
##### **Quickstart Documentation**[](#quickstart-documentation "Direct link to quickstart-documentation")
Follow the [Quickstart Guide](#) to set up your environment, create your first assistant, and explore the platform step-by-step.
Start your journey today and create conversational AI assistants that delight users and drive real impact!
---
### Introduction to the Rasa Platform
The Rasa Platform is designed to enable teams to **build, test, deploy, and review** conversational AI solutions collaboratively. Teams can update and maintain assistants in two ways when working on AI assistants:
1. **No-code:** Use [Rasa Studio](https://rasa.com/docs/docs/studio/intro/), our no-code graphical user interface to build, analyze, and improve your AI assistants.
2. **Pro-code:** Use Rasa's [pro-code interface](https://rasa.com/docs/docs/pro/intro/) for developers and engineers who want advanced flexibility to customize, test, and deploy AI assistants. Sometimes you will notice references to "Rasa Pro" for this part of the platform in the documentation, which is used to reference the pro-code part of the platform.
You can build, test, and improve your AI assistant in either interface.
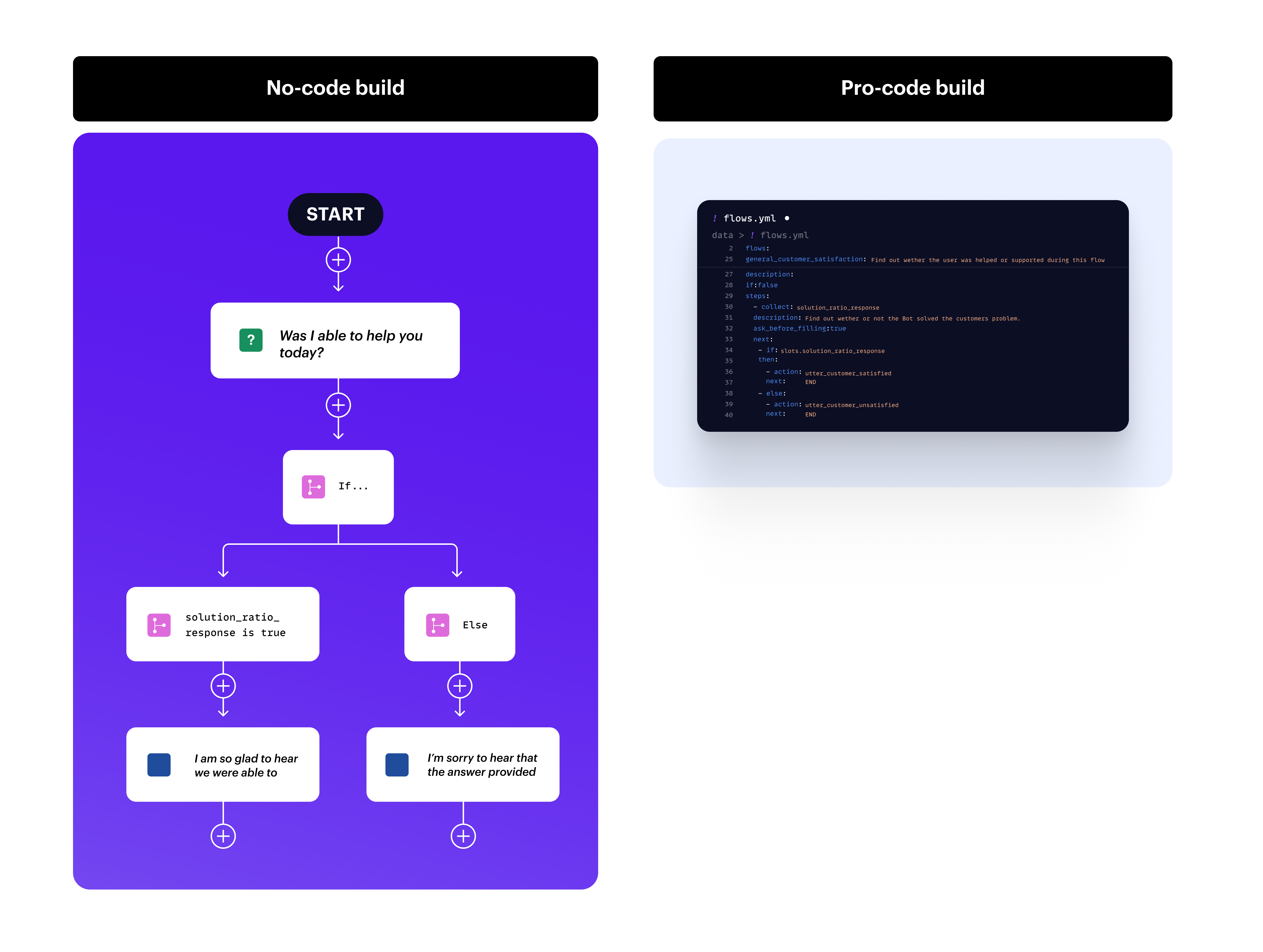
#### **When to Use No Code, When to Use Pro Code**[](#when-to-use-no-code-when-to-use-pro-code "Direct link to when-to-use-no-code-when-to-use-pro-code")
In a conversational AI project, some tasks are best done quickly in a no-code interface like Rasa Studio, while others call for the flexibility of code. The Rasa Platform provides an integrated workflow, allowing teams to collaborate across pro-code and no-code interfaces. Below is an example of jobs you can do in the two interfaces:

#### **Components of the Rasa Platform**[](#components-of-the-rasa-platform "Direct link to components-of-the-rasa-platform")
Understanding how the platform’s interfaces integrate can help you better understand the Rasa Platform:
* **Rasa** is the platform’s underlying conversational AI framework. It contains [**CALM**](https://rasa.com/docs/docs/learn/concepts/calm/), Rasa’s dialogue system, and provides a transparent file structure for configuring AI assistants, building flows, creating custom integrations, and managing monitoring, fine-tuning, testing, and deployment.
* **Rasa Studio** runs on Rasa. One of the core functions of Rasa Studio is to allow business users to build flows visually in the no-code interface, which can be converted into deployable code.

Some concepts in Rasa’s dialogue management system that you might see in the image above are unique. Follow the links below to learn about the core concepts behind the Rasa Platform.
#### **Ready to dive deeper?**[](#ready-to-dive-deeper "Direct link to ready-to-dive-deeper")
* [What you can do with Rasa](https://rasa.com/docs/docs/learn/use-cases/)
* [How to use the Platform](https://rasa.com/docs/docs/learn/platform-workflow/)
---
### What you can build with Rasa
##### High-trust, fluent AI assistants[](#high-trust-fluent-ai-assistants "Direct link to High-trust, fluent AI assistants")
Rasa assistants are great at handling tasks that require back-and-forth with a user. When real users interact with a chatbot or voice assistant, they rarely provide all the information you need in one go. Assistants have to ask clarifying questions, gather more information, query APIs, and follow dynamic branching logic to complete a task.
You can trust a Rasa assistant to handle that back and forth. Out of the box, Rasa already knows a lot about how conversations work: it automatically handles disambiguation, topic changes, clarification, corrections, implicatures, negation, interjections, and more. And while LLMs help power that out-of-the-box fluency, Rasa executes the steps in your task deterministically. So no matter how complex and high-stakes your business logic might be, Rasa will follow it faithfully.
Here are some of the conversation patterns that Rasa handles automatically:
* Clarification
* Implicit Answers
* Topic Changes
* Change of mind
* Interjections
User:
I lost my wallet
💡 Multiple flows could be relevant to this user, so Rasa asks for clarification
Bot:
Do you want to freeze your card or cancel it?
Bot:
Would you like to add anything else to your order?
User:
I've spent too much already!
💡 Set continue\_shopping to False and continue with the checkout process
Bot:
Can I interest you in next-day shipping for $4.99?
User:
I want to pay my credit card bill.
Bot:
Do you want to pay the whole balance of $3,421?
User:
how much do I have in my account?
💡 switching flows, show the user's balance
Bot:
your checking account balance is $1,304.21.
pick up where we left off
Bot:
how much would you like to pay into your credit card?
User: I need to send $50
Bot: Who would you like to send money to?
User: Jen
Bot:
Please confirm: you want to transfer $50.0 to Jen?
User: actually no 60
💡 the user changed their mind about how much money to send
Bot: Ok, I corrected the amount.
Bot:
Please confirm: you want to transfer $60.0 to Jen?
User: yes.
Bot: All done. $60.00 has been sent to Jen.
Bot: Is there anything else I can help you with?
Change of mind
Bot:
Would you like that gift wrapped?
User:
how much is that?
💡 the user is asking a question, consult the knowledge base
Bot:
As your order is over $25, our gift-wrapping service is free of charge!
pick up where we left off
Bot:
Shall I go ahead and get it wrapped?
##### Real-time voice assistants that take action[](#real-time-voice-assistants-that-take-action "Direct link to Real-time voice assistants that take action")
Rasa handles the core elements of spoken conversations. These include natural conversation elements like pauses and turn-taking, as well as phone-specific capabilities such as DTMF processing and call control. The platform integrates with speech recognition services and contact center systems for automating call center operations.
Rasa's dialogue understanding approach allows small LLMs (under 10B parameters) to match the accuracy of much larger models. These models can be self-hosted and respond quickly enough for real-time voice conversations. Here's a demonstration using a fine-tuned Llama 8B model:
##### Multilingual, personalized support assistants that handle hundreds of tasks[](#multilingual-personalized-support-assistants-that-handle-hundreds-of-tasks "Direct link to Multilingual, personalized support assistants that handle hundreds of tasks")
Each customer interaction is different, shaped by language, location, and context. With Rasa you can build personalized experiences using real-time contextual data about the user.
* Anisha
* Alex
* Ricardo
user profile loaded: language preference, subscription tier, recent activity
User:
you messed up my order
Bot:
Hi, Anisha! I'm sorry to hear that. I can see two recent orders - was the problem with the umbrella or with the kitchenware?
user profile loaded: language preference, subscription tier, recent activity
User:
you messed up my order
Bot:
Hi, Alex! I'm sorry to hear that. What was the issue with your microwave?
User:
I ordered it in black but the one you sent is grey
Bot:
Oh dear. Yes I can see that you ordered Combi Microwave 800W - Black.
Bot:
Sorry about the mix-up, we'll send out the right one by next-day delivery. You'll also get a return label to send back the grey one. Sorry for the inconvenience.
user profile loaded: language preference, subscription tier, recent activity
User:
😡
Bot:
Ricardo, je suis désolé d'apprendre que tu es malheureux. Comment puis-je t'aider ?
Rasa is especially helpful as you scale across domains and departments to cover the full breadth of support requests with:
* A centralized content hub for translation & localization
* Reusable dialog components across languages
* Collaborative workflows to review and update assistant versions.
| Order status | Refunds | Subscription Management | Product Search | Appointments | Complaints | ... |
| ------------ | ------- | ----------------------- | -------------- | ------------ | ---------- | --- |
##### Custom, controllable conversational AI[](#custom-controllable-conversational-ai "Direct link to Custom, controllable conversational AI")
Rasa lets you build assistants where you need:
* Complete data control and privacy, with all processing happening in your infrastructure
* Full visibility into decision-making, with structured, traceable paths from input to output
* The ability to override & customize the AI engine of your assistant
* Deep integration with your existing systems
* A CI/CD-driven approach to deploying your assistant
With Rasa, you can:
* Self-host fine-tuned language models optimized for your domain
* Add custom components to modify any part of the conversation pipeline
* Build native integrations with your mobile apps and enterprise systems
##### Ready to start?[](#ready-to-start "Direct link to Ready to start?")
Check out the [Platform at a Glance](https://rasa.com/docs/docs/learn/platform-introduction/)
---
### Best Practices
#### Building a Conversational AI Team
### **Building a Conversational AI Team**
Conversational AI teams vary based on project scope, budget, and maturity. While there’s no single blueprint, successful teams rely on a core set of roles to drive development and iteration. As projects scale or evolve, specialized roles become essential. This guide outlines key team structures and responsibilities to help you build an effective team, whether you are launching your first AI assistant or expanding an existing one.
#### **Proof of Concept (POC) Team**[](#proof-of-concept-poc-team "Direct link to proof-of-concept-poc-team")
When evaluating an AI assistant platform and proving value, you can start with a lean team—sometimes as small as two people.
##### **Project Owner/Manager**[](#project-ownermanager "Direct link to project-ownermanager")
In a POC, the **Project Owner** defines the scope, shapes the initial user experience with subject matter expertise, and secures buy-in from key stakeholders. They align business objectives with technical feasibility, facilitate collaboration, and drive the project toward actionable insights and next steps.
##### **Developer**:[](#developer "Direct link to developer")
The **Developer** is the technical backbone of the POC, turning ideas into a working AI assistant. They handle setup and installation, build the first conversational flows, and connect the assistant to key systems. As the project evolves, they fine-tune functionality, troubleshoot issues, and explore ways to optimize performance. With a mix of problem-solving, integration, and hands-on development, they help prove feasibility and lay the foundation for future scaling.

#### **Pilot Team**[](#pilot-team "Direct link to pilot-team")
Once you decide to bring your assistant into production, expanding the team helps ensure a successful launch. Here’s what a pilot team might look like:
##### **Project Owner/Manager**[](#project-ownermanager-1 "Direct link to project-ownermanager-1")
As the assistant moves into production, the **Project Owner/Manager** plays a larger role in keeping projects on track. They align teams, timelines, and goals while coordinating developers, designers, and stakeholders. From defining requirements to tracking milestones, they ensure the assistant ships on time, meets scope, and aligns with business objectives.
##### **Builder**[](#builder "Direct link to builder")
The **Builder** implements conversation designs, ensuring the assistant understands user inputs and manages dialogue effectively. They collaborate with Conversation Designers to create user journeys using no-code tools or custom code and conduct initial testing to verify flow functionality. Depending on their skills and project needs, designers may also contribute to implementation.
##### **Conversation Designer**[](#conversation-designer "Direct link to conversation-designer")
The **Conversation Designer** defines user interactions with the AI assistant. Bringing a designer into the project early ensures a strong foundation for success. They map out conversational flows, write dialogue, and balance user needs with system capabilities. Working closely with developers and builders, they refine experiences to drive better outcomes.
##### **Test Manager**[](#test-manager "Direct link to test-manager")
The **Test Manager** ensures the AI assistant performs reliably by writing and automating test cases, catching errors before deployment, and evaluating conversation flows. By identifying edge cases and validating responses, they help maintain a high-quality assistant.
##### **Developer**[](#developer-1 "Direct link to developer-1")
The **Developer** extends the assistant’s capabilities, integrating it with backend systems, APIs, and custom responses. They customize behavior, scale deployments, and optimize performance. Developers may also set up CI/CD pipelines to streamline updates and maintenance.
#### **Scaling/Extended Team**[](#scalingextended-team "Direct link to scalingextended-team")
As the assistant expands across business units, channels, and modalities, you may need additional roles, either full-time or on a consulting basis.
##### **Subject Matter Experts (SMEs)**[](#subject-matter-experts-smes "Direct link to subject-matter-experts-smes")
As the assistant grows, **SMEs** help expand its knowledge base, ensuring responses remain accurate and relevant to evolving business needs.
##### **Content Manager/Copywriter**[](#content-managercopywriter "Direct link to content-managercopywriter")
Maintaining consistent, high-quality responses across languages and channels is crucial at scale. The **Content Manager** ensures accuracy, brand alignment, and clarity—whether responses are dynamically generated or template-based. As the assistant scales, they may also manage the Retrieval-Augmented Generation (RAG) knowledge base.
##### **Analyst and/or Data Scientist**[](#analyst-andor-data-scientist "Direct link to analyst-andor-data-scientist")
The **Analyst** tracks key metrics, analyzes real user interactions, and identifies areas for improvement. As the assistant scales, their insights help refine performance and enhance user experience.
##### **Machine Learning Engineer**[](#machine-learning-engineer "Direct link to machine-learning-engineer")
The **ML Engineer** fine-tunes models to improve accuracy, reduce latency, and optimize infrastructure costs. Whether full-time or consulting, they enhance the assistant’s intelligence and efficiency.
##### **Solution Architect**[](#solution-architect "Direct link to solution-architect")
The **Solution Architect** designs scalable, secure architectures and integrates backend systems. Their role is most critical during implementation, ensuring reliability and flexibility.
##### **Front-End Developer**[](#front-end-developer "Direct link to front-end-developer")
The **Front-End Developer** builds and integrates the assistant’s UI, ensuring smooth, intuitive interactions. Their work is most active during the setup phase but may continue to refine the experience.
##### **DevOps Specialist**[](#devops-specialist "Direct link to devops-specialist")
The **DevOps Specialist** ensures stability, scalability, and efficient deployment. They manage infrastructure, CI/CD pipelines, security, and monitoring, keeping the assistant running smoothly.
##### **Scrum Master**[](#scrum-master "Direct link to scrum-master")
Conversational AI teams iterate quickly, and the **Scrum Master** is key in keeping development efficient. They ensure smooth workflows, align teams on delivering value, and remove blockers. By fostering collaboration across practitioners, developers, and product managers, they drive continuous improvement and help teams focus on their goals.
***
For questions about conversational AI teams, visit the [Rasa Forum](https://forum.rasa.com) or contact your Customer Success Manager.
---
#### Designing Natural and Engaging Conversations
This guide is intended as an introduction to how to create conversations that are helpful and feel natural.
It's designed specifically with **designers** in mind, but it's also useful for anyone who wants to learn how to get the most out of Rasa.
##### Topics covered[](#topics-covered "Direct link to Topics covered")
* What makes a good conversation? CxD
* How CxD works with CALM
* How to write responses that feel human
* How to test and improve through feedback
#### What is Conversation Design (CxD)?[](#what-is-conversation-design-cxd "Direct link to What is Conversation Design (CxD)?")
**Conversation Design** is the process of researching, conceptualizing, and creating conversational interactions between human users and AI. It is an interdisciplinary field drawing from UX design, linguistics, conversation analysis, content management, human-computer interaction, and related studies.
Conversation design is both human-centered and data-driven.
#### What is CALM?[](#what-is-calm "Direct link to What is CALM?")
**Rasa CALM** is a state-of-the-art hybrid approach to building conversational AI assistants. It combines 'flows' — predefined sets of steps to complete tasks that represent business processes — with the power of language models to:
* Understand user intentions
* Handle edge cases
* Repair conversations
* Generate responses where appropriate
To read more about CALM, see the [CALM documentation](https://rasa.com/docs/docs/learn/concepts/calm/).
#### How does CALM affect the CxD process?[](#how-does-calm-affect-the-cxd-process "Direct link to How does CALM affect the CxD process?")
As a conversation designer, each project starts with **discovery**, focusing on the use cases, scope, and tasks for the AI assistant. Extensive research is conducted on:
* Target audience interaction goals and needs
* Conversation habits
* Language styles
##### Outcomes of the Discovery Phase:[](#outcomes-of-the-discovery-phase "Direct link to Outcomes of the Discovery Phase:")
The research leads to user journeys that are converted into *conversational flows* — dynamic representations of possible conversation paths between the user and AI assistant. These flows execute **Business Logic** in CALM.
##### Designing with CALM:[](#designing-with-calm "Direct link to Designing with CALM:")
You don't need complex flowcharts with many interlinked branches. Instead, each flow can focus on specific tasks, such as:
* Responding to user questions
* Connecting to a knowledge base for requested information
* Collecting user information in a series of steps
* Performing actions (e.g., checking a balance, blocking a card, booking an appointment)
* Transferring to a human operator
##### Building a Flow in CALM:[](#building-a-flow-in-calm "Direct link to Building a Flow in CALM:")
While building flows in CALM, you can predefine:
* The assistant's responses (which could also be generated)
* Information to collect from the user (*slots*) and subsequent actions
* How to act based on user inputs (*logic*)
* Next steps in the conversation (*links*)
CALM's **Dialogue Understanding** module leverages language models to interpret user statements and intentions. As a designer:
* You aren't required to build sets of intents, entities, and variations for every scenario.
* However, you can still do so for specific scenarios if desired.
##### LLM-Based `CommandGenerator`:[](#llm-based-commandgenerator "Direct link to llm-based-commandgenerator")
The `CommandGenerator` translates user input into commands that drive the conversation forward by triggering flows, operations, repair patterns, and more. It considers:
* Conversation history
* Context
###### Key Customization Options:[](#key-customization-options "Direct link to Key Customization Options:")
* **Prompting the LLM:** Use flow descriptions and slot definitions to guide the LLM in generating appropriate commands. [Learn more about prompting](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#customization).
* **Flow Retrieval:** Pre-select relevant flows for a given conversation. [Learn more about flow retrieval](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#retrieving-relevant-flows).
#### CxD Workflow in CALM[](#cxd-workflow-in-calm "Direct link to CxD Workflow in CALM")
##### Outside of Rasa: Designer Responsibilities[](#outside-of-rasa-designer-responsibilities "Direct link to Outside of Rasa: Designer Responsibilities")
* Gather data on user needs, language style, and conversational habits
* Define user personas, map content, and user journeys
* Create an AI assistant personality
* Write sample dialogues
* Draft conversational flows
* Plan error handling, escalation strategies, and handovers (if needed)
* Prepare user testing rounds and protocols
##### Inside Rasa: Builder Responsibilities[](#inside-rasa-builder-responsibilities "Direct link to Inside Rasa: Builder Responsibilities")
* Build flows based on designs and user journeys
* Write efficient flow and slot descriptions to guide the LLM
* Create responses (if needed) that align with personality guidelines
* Prompt the LLM to generate or rephrase responses (if needed)
* Customize conversation repair patterns per error handling strategies
* Write end-to-end (e2e) tests based on sample dialogues
* Connect the assistant to knowledge sources and implement RAG
* Instruct the LLM on generating texts for RAG responses
* Debug designs and test the assistant using Rasa Inspector
---
### Concepts
#### Conversation Patterns
Real conversations are rarely linear—users switch topics, correct themselves, and ask follow-up questions. **Conversation patterns** are reusable system flows that are **provided by CALM** and enable your AI assistant to handle these non-linear interactions cooperatively, and repair the conversation when customers don’t follow the path you expect them to.
#### Use conversation patterns for smarter AI assistants[](#use-conversation-patterns-for-smarter-ai-assistants "Direct link to Use conversation patterns for smarter AI assistants")
You can’t predict everything a user will say—and with **conversation patterns**, you don’t have to. Conversation patterns make your assistant more flexible and effective by:
* **Keeping conversations on track:** Handle unexpected inputs seamlessly, leading to more successful outcomes and a better user experience.
* **Simplifying design and development:** Helps the team focus on crafting great user journeys and business logic instead of accounting for every possible detour.
#### How Conversation Patterns work[](#how-conversation-patterns-work "Direct link to How Conversation Patterns work")
**Here’s an overview of the different types of conversation patterns:**
| **Category** | **Conversation Patterns** |
| --------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Conversation Repair** | Correct mistakes and misunderstandings with **correction**, **clarification**, and **interruption** patterns. |
| **Conversation Navigation** | Navigate conversations helping users to **cancel** , **restart**, or **complete** a process. |
| **External Support** | Provide external support with **search**, **human handoff**, or **chitchat** patterns. |
| **Voice** | Prepare to **repeat** something and handle scenarios where the user remains **silent**. |
| **System Error** | Inform the user of unexpected system issues, like an **internal error** or **code change**. Activate **cannot handle** (fallback) pattern if no flow or relevant documents apply. |
#### Conversation Patterns in Action[](#conversation-patterns-in-action "Direct link to Conversation Patterns in Action")
Here is an example of a conversation pattern in each category listed above:
1. **Correction (repair pattern)**: Update and correct previously stored conversational information.
User:
My name is Jonathan, not John.
correction triggered
Bot:
Thanks for letting me know! It’s important to get things right. Should I update your name to Jonathan in my records?
User:
Yes, please.
updated first name to Jonathan
Bot:
Great! I’ve updated your name to Jonathan. Let me know if there’s anything else I can assist with.
Example showcasing corrections
2. **Cancellation (navigation pattern)**: Allows a user to stop a task in the middle of one topic or task.
User:
I want to send some money to Dimitri
Bot:
How much money do you want to send?
User:
Ah, never mind. I see I have already sent it earlier.
cancellation triggered
Bot:
Okay, I am canceling the transfer.
Example showcasing error handling
3. **Start a conversation (navigation pattern)**: Conversations can be initiated by either your assistant or the user.
session started
Bot:
Hi there! How can I assist you today?
Example showcasing a simple assistant greeting
4. **Search (external support pattern)**: Enables your assistant to query data from your knowledge base with Rasa's enterprise search feature and provide helpful answers.
User:
What is your policy on returns?
pattern search started
Bot:
We accept returns within 30 days of purchase if they are returned in new condition and original packaging. Would you like to start a return process?
Example showcasing enterprise search
5. **Repeat (voice pattern)**: Enables your assistant to repeat a previous message.
Bot:
Your order #1377 is on it's way. Would you like to track it?
User:
Can you repeat that?
repeat triggered
Bot:
Of course, your order #1377 is on its way. Would you like to track it?
Example showcasing a user asking the assistant to repeat the last message
6. **Errors (system pattern)**: Invalid responses or technical issues might require apologies or alternative actions. In these scenarios, you might need to re-ask questions, confirm intent, or escalate to a human agent.
User:
Update my order details.
internal error: request timed out
Bot:
Oops! It looks like something went wrong while processing your request. Let me try that again or escalate this issue.
Example showcasing error handling
#### Customizing Conversation Patterns[](#customizing-conversation-patterns "Direct link to Customizing Conversation Patterns")
Rasa provides a default structure for each pattern, but you are free to [customize](https://rasa.com/docs/docs/pro/customize/patterns/) them to fit your use case. Since patterns are system flows, you can edit them like any other flow in Rasa Pro or Rasa Studio. We recommend keeping the [contextual response rephraser](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/) enabled for pattern flows as it helps your assistant sound more natural, especially when repairing dynamic interactions.
#### Learn more about Patterns[](#learn-more-about-patterns "Direct link to Learn more about Patterns")
* Read the complete [pattern reference documentation](https://rasa.com/docs/docs/reference/primitives/patterns/)
* Use Rasa Studio to [edit conversation patterns](https://rasa.com/docs/docs/studio/build/flow-building/system-flows/)
---
#### Conversational AI with Language Models
**CALM (Conversational AI with Language Models)** is the dialogue system that runs Rasa text and voice assistants. It interprets user input, manages dialogue, and keeps interactions on track. By combining language model flexibility with predefined logic, Rasa enables fluent, high-trust conversations that reliably resolve user requests.
#### Key Benefits[](#key-benefits "Direct link to Key Benefits")
* **Separation of concerns:** In CALM assistants, LLMs keep the conversation fluent but don't guess your business logic.
* **Built-in conversational awareness:** Detects and handles common conversational patterns like topic changes, corrections, and clarifications for smoother interactions.
* **Deterministic execution:** Follows structured workflows for reliable, debuggable interactions.
* **Designed for efficiency:** Optimized for smaller, fine-tuned models (e.g., Llama 8B) to reduce latency and inference costs.
* **Works with your existing stack:** Integrates with NLU classifiers, entity extractors, and tools, so you can enhance your assistant without starting from scratch.
#### Who is CALM For?[](#who-is-calm-for "Direct link to Who is CALM For?")
* **AI/ML practitioners and developers** looking to build scalable conversational assistants.
* **Conversation designers** who care about user experience and want to build high-trust AI assistants.
* **Businesses** seeking robust, next-gen AI applications without sacrificing control or reliability.
*Note for researchers: If you use CALM in your research, please consider citing [our research paper](https://arxiv.org/abs/2402.12234).*
#### How CALM Works[](#how-calm-works "Direct link to How CALM Works")
CALM is a controlled framework that uses an LLM to interpret user input and suggest the next steps—ensuring the assistant follows predefined logic without guessing or inventing the next steps on the fly. Instead, it understands what the user wants and dynamically routes them through structured “Flows,” which are predefined business processes broken down into clear steps.
Let’s walk through how CALM processes user input to see how this works in practice.
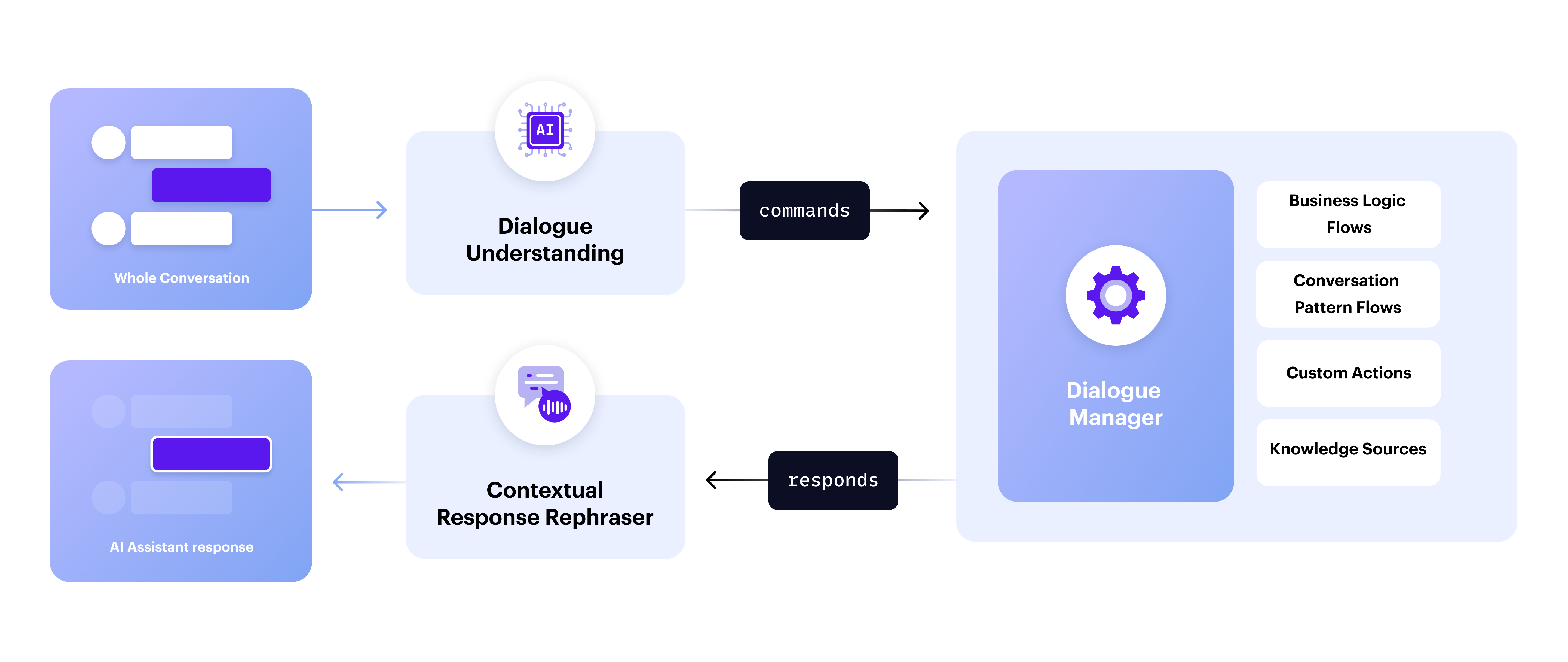
##### 1. Dialogue Understanding[](#1-dialogue-understanding "Direct link to 1. Dialogue Understanding")
With every incoming user message, CALM performs [dialogue understanding](https://rasa.com/docs/docs/learn/concepts/dialogue-understanding/):
* Uses a language model to interpret the message in the context of the conversation
* Generates a set of internal commands that represent how the user wants to progress the conversation
* Passes these commands on to the Dialogue Manager to perform the next steps
##### 2. Dialogue Management[](#2-dialogue-management "Direct link to 2. Dialogue Management")
Once commands are issued, the [dialogue manager](https://rasa.com/docs/docs/learn/concepts/dialogue-management/) decides how to execute them. Commands could instruct the dialogue manager to:
* Start, stop, or resume a flow
* Leverage a [conversation pattern](https://rasa.com/docs/docs/learn/concepts/conversation-patterns/) flow to handle unexpected interactions automatically
* Activate a backend integration (custom action)
* Answer a question with a knowledge base using RAG (Retrieval Augmented Generation)
##### 3. Contextual Response Rephraser[](#3-contextual-response-rephraser "Direct link to 3. Contextual Response Rephraser")
By default, your assistant sends templated messages to the user, however:
* You can optionally use the [contextual response rephraser](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/) to improve fluency and coherence
* You can customize the rephraser's prompt and use it only for specific messages
#### CALM compared to ReAct-Style Agents & Classic Chatbots[](#calm-compared-to-react-style-agents--classic-chatbots "Direct link to CALM compared to ReAct-Style Agents & Classic Chatbots")
This section compares CALM assistants with ReAct-style agents and classic NLU bots, highlighting key differences in how each approach handles user understanding, task execution, scalability, troubleshooting, and production costs.
| Concern | LLM-Centric Approach (ReAct-Style Agents) | Hybrid Approach (CALM Assistants) | Classic Approach (NLU Bots) |
| -------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Suitable Use Cases** | Best for open-ended, exploratory tasks where flexibility outweighs structure and accuracy. | Ideal for structured tasks with clear goals, balancing conversational fluency and reliability. | Best for scenarios where you are not able to use an LLM, delivers deterministic outcomes. |
| **Understanding the User** | ReAct combines understanding and action into the same process. In each exchange, an LLM is used to process user input and decide what should happen next. | CALM uses LLM to understand user input in the context of the conversation. This is separate from task execution, which is handled by Flows. | NLU bots understand users by classifying the last user input, without the context of the full conversation. The model cannot understand messages that don’t fit into an intent. |
| **Deciding the Next Step(s)** | Business logic embedded in LLM prompts leads to inconsistent, on-the-fly decisions. | Business logic, step-by-step outlines of how to solve a problem, is defined in Flows. The LLM can dynamically route from flow to flow. | Business logic is predefined in large dialogue trees, breaking if users deviate from the expected path. |
| **Scaling to a large number of tasks** | Performance degrades as more agents/tasks are added, increasing resource use and introducing cascading errors that require complex guardrails. | Scales reliably to many topics and Flows. Reusable, modular Flows help maintain performance. | As NLU models scale, accuracy suffers due to topic overlap, and expanding dialogue trees becomes difficult to maintain. |
| **Ease of Troubleshooting** | Debugging is tough because you have to read through lots of unstructured text to guess why things went wrong, and fixing it means trying random changes until something works. | Simplifies debugging by separating reasoning from task execution. LLMs output discrete commands, allowing you to pinpoint why the system behaved a certain way. | NLU debugging and root cause analysis are straightforward since every part of the dialogue is pre-planned. However, it is often tough to implement a user-friendly fix due to rigidity. |
| **Cost in Production** | High costs and latency due to calling LLMs multiple times in series. | More cost-efficient, using smaller, fine-tuned models like Llama 8B to reduce latency and costs. | NLU models are very inexpensive and have low latency. |
#### Smaller Models, Big Results[](#smaller-models-big-results "Direct link to Smaller Models, Big Results")
CALM works out of the box with state-of-the-art models, such as OpenAI’s GPT 4. It is also designed to work with fine-tuned models as small as Llama 8B, enabling:
* **Faster Response Times:** Essential for real-time applications like voice assistants.
* **Cost Efficiency:** Shift from token-based pricing to predictable hosting costs with self-hosted models.
* **Scalability:** Deploy on Hugging Face or private infrastructure for better control over performance and security.
#### Learn more about CALM[](#learn-more-about-calm "Direct link to Learn more about CALM")
Take the next step in building reliable, scalable conversational AI:
* [Follow the CALM video tutorial](https://youtu.be/6vaQP1VC95k?feature=shared)
* [Get certified with CALM](https://learning.rasa.com/#rasa-pro-courses)
* [Check out smaller models](https://rasa.com/blog/reliable-agentic-bots-with-llama-8b/)
---
#### Designing the Logic Behind Conversations
The dialogue manager is the part of Rasa that decides how to take the best next step based on the user’s input and the current conversation state. In CALM, you guide these decisions by creating Flows—high-level outlines that define the key steps and business logic your assistant follows to complete a task. Instead of mapping every possible turn, you can focus on the essential steps. This keeps interactions structured while allowing for flexible, dynamic conversations.
#### How dialogue management works[](#how-dialogue-management-works "Direct link to How dialogue management works")
In the last section, we learned how Rasa's [dialogue understanding](https://rasa.com/docs/docs/learn/concepts/dialogue-understanding/) component uses an LLM to generate a set of internal commands representing how the user wants to progress the conversation. Once commands are issued, they are passed on to the dialogue manager to guide the next steps:
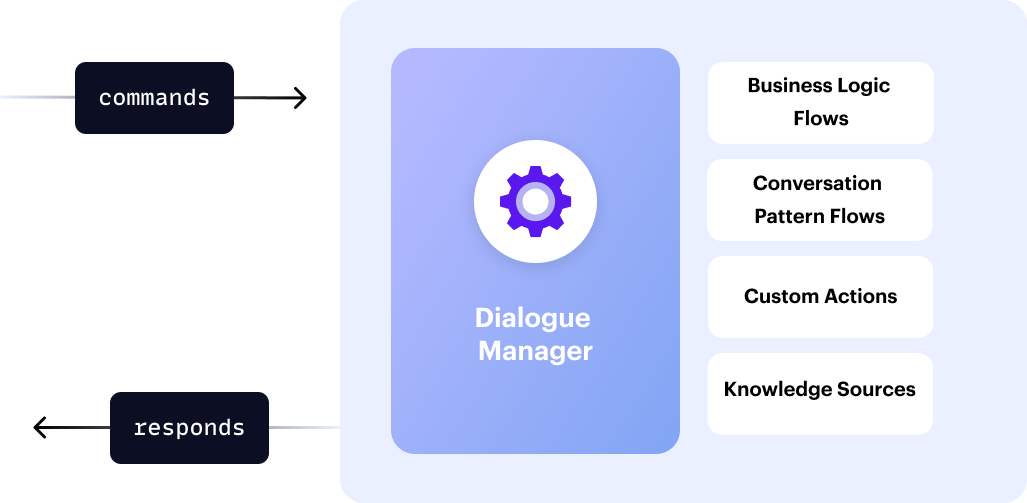
Here’s how the dialogue manager processes these commands, step by step:
* **Receive the commands:** The dialogue understanding component delivers a set of commands to the dialogue manager, these commands might include something like `StartFlow("transfer_money")` or `SetSlot(transfer_amount, 100)`
* **Take the next steps:** Based on these commands, the dialogue manager will begin to take the next steps. This might involve routing to and from flows, collecting information, interacting with backend systems, and delivering responses —all while staying within the boundaries of the business logic defined in the flows.
* **Handle exceptions:** Sometimes, users will deviate from the paths outlined in flows—asking questions outside the scope of the AI assistant, changing topics, correcting, or interrupting the conversation. In these cases, the dialogue understanding module will issue commands that leverage conversation pattern flows —system flows provided by Rasa that can handle unexpected interactions and guide the assistant back on course.
If you are curious how Rasa manages multiple active flows, dive into how the system activates and moves through [flows](https://rasa.com/docs/docs/reference/config/policies/flow-policy/).
#### Anatomy of a flow[](#anatomy-of-a-flow "Direct link to Anatomy of a flow")
A flow represents a structured sequence of steps that guide a conversation toward completing a specific task or process. Flows define what should happen at each stage of the interaction—this is known as **business logic**. Each step in a flow determines how the assistant responds, gathers information, or moves to the next part of the conversation.
A flow is made up of one or more steps, which serve as the building blocks of conversation logic:
* **Action**: Performs a task, such as sending a response or calling an API.
* **Collect**: Gathers useful user input and stores it in a variable (a "slot" in Rasa).
* **Set Slots**: Directly assigns a value to a slot.
* **Link**: Connects one flow to another after completion (e.g., directing users to a CSAT form after a successful flow).
* **Call**: Calls another flow mid-conversation (e.g., triggering user authentication) and returns upon completion.
* **Conditions**: Creates branching logic based on customer profiles, collected information, channels, and more.
#### Flow building in action[](#flow-building-in-action "Direct link to Flow building in action")
Let’s build a simple flow to help users reset their password by collecting their email and sending a reset link.
##### Steps to build the flow[](#steps-to-build-the-flow "Direct link to Steps to build the flow")
1. **Describe the flow** – Give the flow a description so the system knows when to trigger it.
2. **Collect information** – Ask for the user's email (`collect` step).
3. **Trigger a backend service** – Send a reset email (`action` step).
4. **Confirm with the user** – Inform them that the reset email is on its way (`action` step).
##### Visualization of the flow[](#visualization-of-the-flow "Direct link to Visualization of the flow")
Below, you can see the password reset flow visualized in both **Rasa Studio** (no-code UI) and **Rasa Pro** (pro-code UI). The arrows illustrate how UI elements map to code-based steps.
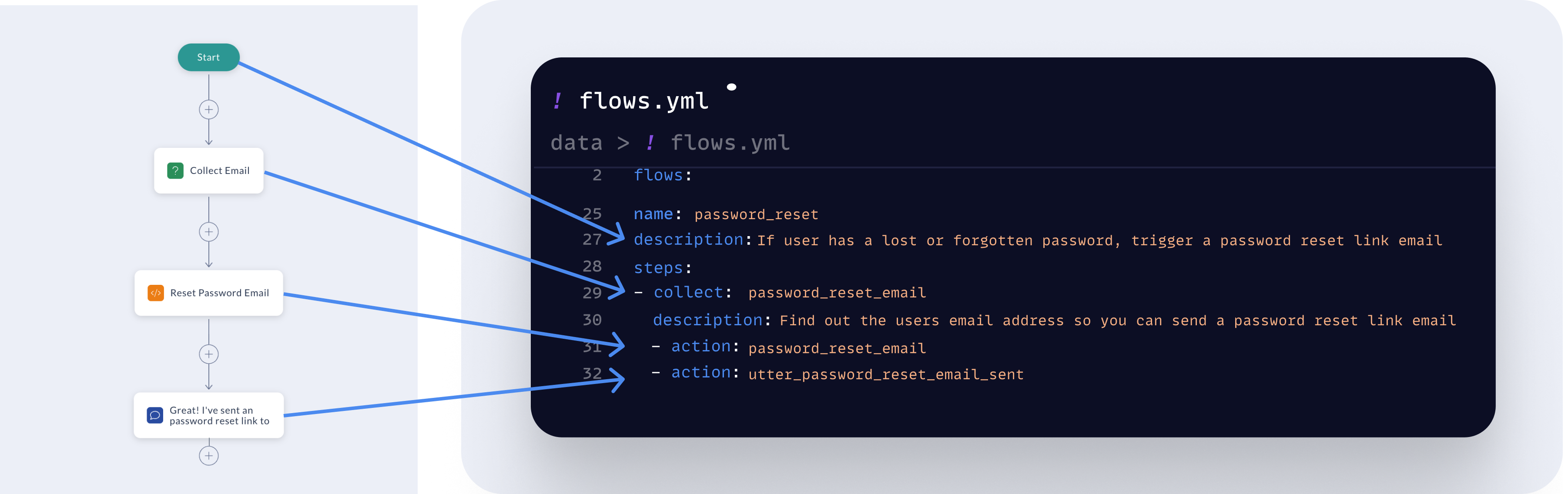
The most important thing to understand about business logic in Rasa is that it does *not* define all the possible paths a conversation can take.
A flow defines:
* What information you need to collect from the user
* What data you need to read & write via APIs
* Any branching logic based on the information that's gathered
If you previously designed AI assistants using flowcharts of possible conversation paths, you'll find that flows in Rasa are much simpler to build, modular, and easy to maintain.
#### Learn more[](#learn-more "Direct link to Learn more")
* Learn how to build flows in [Rasa Studio](https://rasa.com/docs/docs/studio/build/flow-building/introduction/)
* Learn how to build flows in [Rasa Pro](https://rasa.com/docs/docs/pro/build/writing-flows/)
* How to use conditions to build [branching logic](https://rasa.com/docs/docs/reference/primitives/conditions/)
---
#### Helping Your Assistant Understand Users
Dialogue understanding is defined as the assistant's ability to interpret user input, and determine the next best step in the conversation. When a user sends a message to a Rasa assistant, the dialogue understanding component interprets the input and generates a list of commands that represent *how the user wants to progress the conversation*.
#### How dialogue understanding works[](#how-dialogue-understanding-works "Direct link to How dialogue understanding works")
CALM assistants use an LLM for dialogue understanding within a controlled framework. A structured prompt ensures reliable and predictable interpretation, allowing the system to suggest the next steps but not execute them. This ensures the assistant follows predefined logic and operates strictly with the guidelines and responses you define.
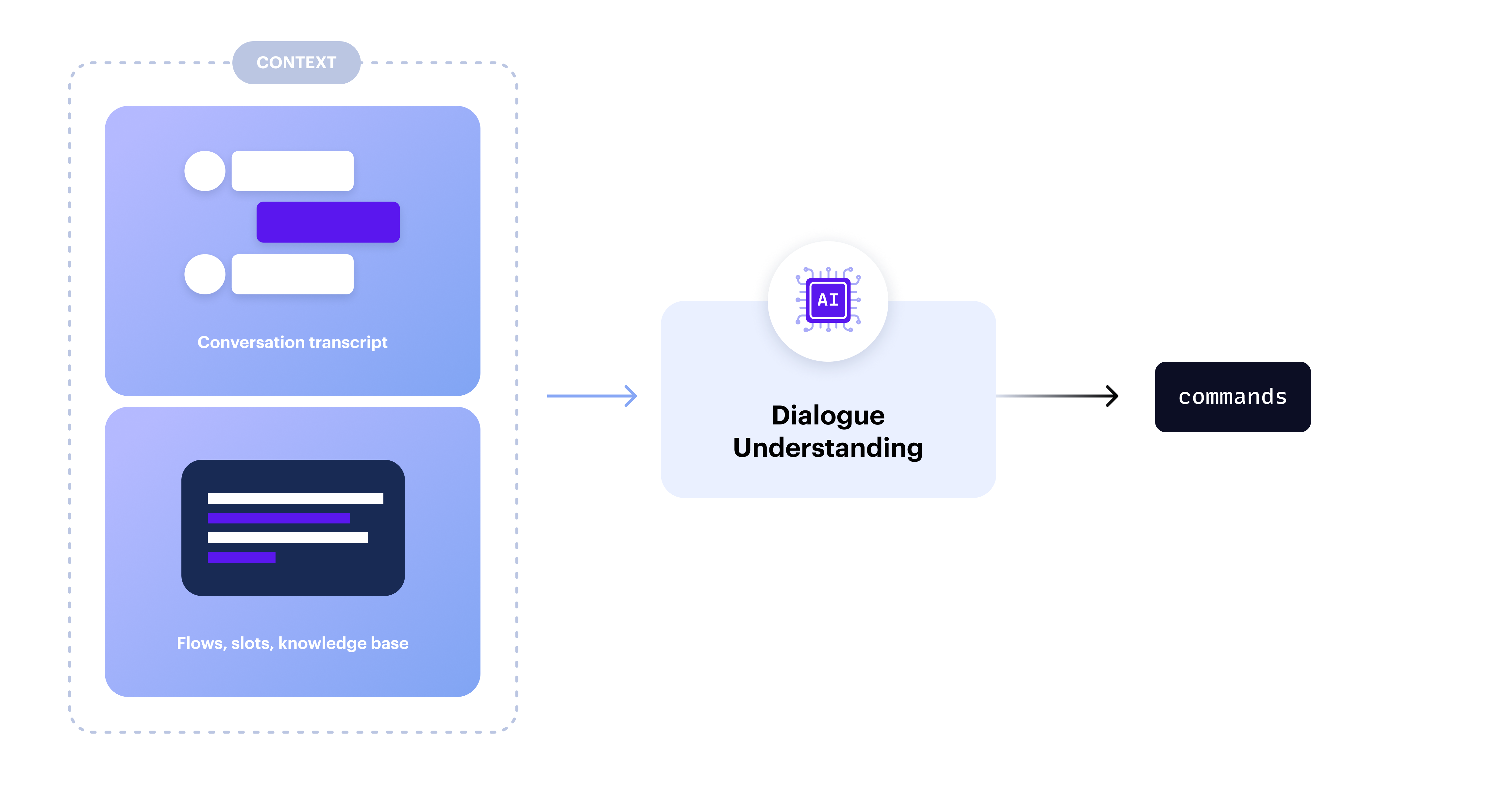
Here’s how it works, step by step:
1. **Context-aware understanding:** When a user messages a CALM assistant, the system is prompted to read the full conversation transcript, including the latest message and collected slots, ensuring it understands the input in context.
2. **Identifying the next best steps:** The system is additionally prompted to outline the most relevant next steps for the user. These next steps are communicated as a set of "commands" for the [dialogue manager](https://rasa.com/docs/docs/learn/concepts/dialogue-management/) to follow and might include instructions to continue a flow, start a new flow, or activate conversation pattern flows to handle something unexpected.
3. **Keeping the conversation on track:** Each command issued by the dialogue understanding module can only leverage existing flows and knowledge bases. That means the system cannot create new workflows or generate responses beyond what has already been designed.
If you're curious to learn more about how these commands are generated, check out the reference page on Rasa's [command generators](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/).
#### Dialogue understanding in action[](#dialogue-understanding-in-action "Direct link to Dialogue understanding in action")
Let's look at the dialogue understanding component in action to understand how this works in practice.
##### 1. Common commands[](#1-common-commands "Direct link to 1. Common commands")
The simplest and most common commands involve the `start flow` and `set slot` commands. For those familiar with NLU-based chatbots, these commands resemble intents and entities. In the example below, the system selects these commands because the user initiated a new topic (`start flow book_flight`) and provided key information (`set slot destination: Singapore`).
User:
I want to book a flight from London to Singapore.
start flow book\_flight; set slot origin London; set slot destination Singapore
##### 2. Advanced commands[](#2-advanced-commands "Direct link to 2. Advanced commands")
Other commands are useful when it isn't clear what the user wants to do. Sometimes you might need commands like `clarify` or `cancel` to help the user progress the conversation.
User: card
clarify flows freeze\_card, cancel\_card, order\_new\_card
Bot: Would you like to freeze or cancel your card, or order a new one?
User: cancel
start flow cancel\_card
Let's examine how the system works to find the best way to assist:
* The user sends a single-word message: *card*
* Your assistant has multiple flows defined that could be relevant to the user
* The dialogue understanding component generates a `clarify` command with the potentially relevant flows
* The user sends another single-word message: *cancel*
* Looking at the whole conversation, the dialogue understanding component has enough information to start the `cancel_card` flow.
It's important to understand how the dialogue understanding component interprets context:
* The `clarify flows` command appears because your assistant has multiple card-related flows defined. This demonstrates how the DU component considers your defined business logic. If only one card-related flow existed, it would have directly generated a `start flow` command instead.
* When the user responds with a single word, "cancel," the system correctly interprets this as a request to cancel a card. This happens because the dialogue understanding component analyzes the entire conversation history. The same word "cancel" might result in different commands in a different context.
##### Key dialogue understanding commands[](#key-dialogue-understanding-commands "Direct link to Key dialogue understanding commands")
| Command | Meaning |
| ------------------ | ------------------------------------------------------------------------------ |
| `start flow` | The user wants to complete a specific flow |
| `cancel flow` | The user does not want to continue with the current flow |
| `clarify flows` | Multiple flows could be relevant to what the user is asking for |
| `set slot` | The user has provided a value for one of the slots required for this flow |
| `correct slot` | The user has provided an updated value for a slot |
| `chitchat` | The user is making small-talk |
| `knowledge answer` | The user is asking a question that should have an answer in the knowledge base |
| `human handoff` | The user wants to speak to a human |
#### LLM vs. NLU vs Hybrid approaches[](#llm-vs-nlu-vs-hybrid-approaches "Direct link to LLM vs. NLU vs Hybrid approaches")
Choosing between an LLM and an NLU model for dialogue understanding depends on factors like accuracy, cost, latency, and system requirements. With CALM, you can use both an LLM for more flexible, context-aware conversations and an NLU model for faster, cost-effective processing.
##### Benefits of an LLM[](#benefits-of-an-llm "Direct link to Benefits of an LLM")
LLMs outperform NLU classifiers in key dialogue understanding tasks. Below are key advantages of using LLMs for dialogue understanding:
* **Context awareness:** Analyzes the full conversation history, not just the latest input, leading to more accurate and contextually relevant decisions.
* **Less maintenance required:** Minimizes the need for intent classification, data labeling, and retraining, making system management easier.
* **Nuanced interactions:** Handles ambiguous, indirect, or nuanced language, improving user experience and reducing failure rates.
##### Benefits of an NLU model[](#benefits-of-an-nlu-model "Direct link to Benefits of an NLU model")
You can use an NLU model for dialogue understanding if you prefer. Here’s why you might choose to stick with NLU:
* **No LLM approval or readiness:** If you cannot use LLMs, NLU provides a stable alternative. However, remember that when you choose this path, you can still use flows, but CALM dialogue understanding output is limited to `set slot` and `start flow` commands. You won't benefit from additional commands and conversation patterns.
* **Optimizing Cost and Latency:** LMs require more resources than NLU models, increasing cost and latency. This can be a critical factor if you're scaling your assistant or building a voice application. Sometimes, it makes sense to use NLU, where it performs well, reserving LLMs for more complex tasks to optimize efficiency.
##### Benefits of a hybrid approach[](#benefits-of-a-hybrid-approach "Direct link to Benefits of a hybrid approach")
CALM lets you combine NLU and language models within the same system for the best of both worlds. This means you continue to define business logic in Flows and choose whether NLU or an LLM activates each flow. This helps:
* **Freedom to choose** Use NLU where it works well, and LLMs to provide extra resilience where you need them.
* **Unified System** Many other platforms simply orchestrate to and from an NLU system and an agentic framework. With CALM the systems don't compete but are connected.
#### Evaluating dialogue understanding accuracy[](#evaluating-dialogue-understanding-accuracy "Direct link to Evaluating dialogue understanding accuracy")
You can use a set of test cases to evaluate and monitor the accuracy of your Dialogue Understanding component. These should ideally be sourced from production conversations and reflect the way that users actually speak. A dialogue understanding test case contains:
* The transcript of a conversation between a user and your assistant.
* The correct commands which should be predicted after each user message.
You can then run Rasa's [end-to-end test](https://rasa.com/docs/docs/pro/testing/evaluating-assistant/) to evaluate accuracy with your test cases. This will generate a report with different metrics.
#### Learn more[](#learn-more "Direct link to Learn more")
* Learn to write flow descriptions in [code](https://rasa.com/docs/docs/pro/build/writing-flows/)
* Learn to write flow descriptions in [Rasa Studio](https://rasa.com/docs/docs/studio/build/flow-building/trigger-flows/)
---
### Deployment
#### AWS Cleanup Infrastructure [Optional]
warning
Following these steps will delete all of the infrastructure and configuration you have deployed in all the previous steps. You'll need to set the environment variables defined in [Setup Steps](https://rasa.com/docs/docs/learn/deployment/aws/aws-playbook-setup/) before you begin.
You should only perform this step after you're finished with the Rasa Platform and wish to destroy all of the infrastructure you've deployed.
If you would like to clean up everything created in this playbook, you can run the following script. It will delete all of the Kubernetes resources created on your cluster, and then tear down and permanently delete all of the AWS infrastructure. Only run this if you're absolutely sure you wish to delete everything. The command may take up to an hour to run to completion if you deployed all of the resources in the playbook.
```
./aws/cleanup/cleanup.sh
```
---
#### Azure Cleanup Infrastructure [Optional]
warning
Following these steps will delete all of the infrastructure and configuration you have deployed in all the previous steps. You'll need to set the environment variables defined in [Setup Steps](https://rasa.com/docs/docs/learn/deployment/azure/azure-playbook-setup/) before you begin.
You should only perform this step after you're finished with the Rasa Platform and wish to destroy all of the infrastructure you've deployed.
If you would like to clean up everything created in this playbook, you can run the following script. It will delete all of the Kubernetes resources created on your cluster, and then tear down and permanently delete all of the Azure infrastructure. Only run this if you're absolutely sure you wish to delete everything. The command may take up to an hour to run to completion if you deployed all of the resources in the playbook.
```
./azure/cleanup/cleanup.sh
```
---
#### Configure Your Kubernetes Cluster
warning
Before you begin, ensure you've completed all the previous sections to deploy required infrastructure and to set environment variables that this section requires.
Now that we've deployed all the infrastructure into AWS, we'll set up some tools on your Kubernetes cluster:
* Istio, a service mesh that will ensure that communication between different Rasa product components is encrypted in transit.
* ExternalDNS, a tool that will allow the cluster to create the DNS records it needs automatically using Amazon Route 53.
* Cert-manager, a tool to ensure we can automatically issue and renew TLS certificates for secure communication.
We'll use scripts from our [deployment-playbooks](https://github.com/RasaHQ/rasa-deployment-playbooks) repo throughout this section to make things easier. If you'd like to understand more about exactly what each script is doing, open it in your IDE of choice and review the comments which explain what is being deployed at each step.
##### Cluster Setup[](#cluster-setup "Direct link to Cluster Setup")
Firstly, we'll set Istio on your cluster, the service mesh that will ensure that communication between different Rasa product components is encrypted in transit, on your cluster.
To deploy the required infrastructure into your AWS environment, use the provided script in our companion repo:
```
./aws/configure/configure-cluster.sh
```
The final output of this script will instruct you to create an `NS` DNS record for the domain you're using. Check your DNS provider's documentation for more information about how to do this. Once you have updated your DNS registrar with the zone name servers, wait for the DNS propagation. You cam verify if zone is properly delegated to AWS with command:
```
dig +short NS $DOMAIN
```
It should print the same AWS nameservers that were output at the end when you ran `./aws/configure/configure-cluster.sh` above. If so, you can continue further on with the playbook.
##### Collect Required Parameters[](#collect-required-parameters "Direct link to Collect Required Parameters")
Most of the infrastructure work is now done, so we'll gather together some info that we'll use later in the playbook to make deploying the Rasa applications a bit easier.
Collect some information about the AWS infrastructure you've deployed and set them as environment variables:
```
source ./aws/configure/get-infra-values.sh
```
These environment variables are now set and ready to be used in your application configurations.
##### Setup Database[](#setup-database "Direct link to Setup Database")
We need to set up some users and permissions on the database so that the Rasa products can authenticate with it and make use of it.
```
./aws/configure/setup-db.sh
```
##### Install external-dns[](#install-external-dns "Direct link to Install external-dns")
We will now install external-dns onto our cluster. This tool allows your Kubernetes cluster to create the DNS records it needs automatically using the Amazon Route 53 DNS zone that you've just configured.
```
./aws/configure/install-external-dns.sh
```
##### Install cert-manager[](#install-cert-manager "Direct link to Install cert-manager")
We will now install cert-manager which will handle issuing TLS certificates automatically using LetsEncrypt.
```
./aws/configure/install-cert-manager.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
##### Test Ingress Setup[](#test-ingress-setup "Direct link to Test Ingress Setup")
We've deployed and configured tooling onto the cluster to manage the creation of DNS records and TLS certificates. In this section, we'll test whether it's all working properly by temporarily deploying a tiny HTTP server called HTTPBin to check. If the test fails, the script will suggest some commands you can run to help identify the source of the issue.
```
./aws/configure/test-ingress.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
---
#### Configure Your Kubernetes Cluster
warning
Before you begin, ensure you've completed all of the previous sections to deploy required infrastructure and to set environment variables that this section requires.
Now that we've deployed all of the infrastructure into Azure, we'll set up some tools on your Kubernetes cluster:
* Istio, a service mesh that will ensure that communication between different Rasa product components is encrypted in transit.
* ExternalDNS, a tool that will allow the cluster to create the DNS records it needs automatically using Azure DNS.
* Cert-manager, a tool to ensure we can automatically issue and renew TLS certificates for secure communication.
We'll use scripts from our [deployment-playbooks](https://github.com/RasaHQ/rasa-deployment-playbooks) repo throughout this section to make things easier. If you'd like to understand more about exactly what each script is doing, open it in your IDE of choice and review the comments which explain what is being deployed at each step.
##### Cluster Setup[](#cluster-setup "Direct link to Cluster Setup")
Firstly, we'll set Istio on your cluster, the service mesh that will ensure that communication between different Rasa product components is encrypted in transit, on your cluster.
To deploy the required infrastructure into your Azure environment, use the provided script in our companion repo:
```
./azure/configure/configure-cluster.sh
```
The final output of this script will instruct you to create an `NS` DNS record for the domain you're using. Check your DNS provider's documentation for more information about how to do this. Once you have updated your DNS registrar with the zone name servers, wait for the DNS propagation. You cam verify if zone is properly delegated to Azure with command:
```
dig +short NS $DOMAIN
```
It should print the same Azure nameservers that were output at the end when you ran `./azure/configure/configure-cluster.sh` above. If so, you can continue further on with the playbook.
##### Collect Required Parameters[](#collect-required-parameters "Direct link to Collect Required Parameters")
Most of the infrastructure work is now done, so we'll gather together some info that we'll use later in the playbook to make deploying the Rasa applications a bit easier.
Collect some information about the Azure infrastructure you've deployed and set them as environment variables:
```
source ./azure/configure/get-infra-values.sh
```
These environment variables are now set and ready to be used in your application configurations.
##### Setup Database[](#setup-database "Direct link to Setup Database")
We need to set up some users and permissions on the database so that the Rasa products can authenticate with it and make use of it.
```
./azure/configure/setup-db.sh
```
##### Install external-dns[](#install-external-dns "Direct link to Install external-dns")
We will now install external-dns onto our cluster. This tool allows your Kubernetes cluster to create the DNS records it needs automatically using the Azure DNS zone that you've just configured.
```
./azure/configure/install-external-dns.sh
```
##### Install cert-manager[](#install-cert-manager "Direct link to Install cert-manager")
We will now install cert-manager which will handle issuing TLS certificates automatically using LetsEncrypt.
```
./azure/configure/install-cert-manager.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
##### Test Ingress Setup[](#test-ingress-setup "Direct link to Test Ingress Setup")
We've deployed and configured tooling onto the cluster to manage the creation of DNS records and TLS certificates. In this section, we'll test whether it's all working properly by temporarily deploying a tiny HTTP server called HTTPBin to check. If the test fails, the script will suggest some commands you can run to help identify the source of the issue.
```
./azure/configure/test-ingress.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
---
#### Configure Your Kubernetes Cluster
warning
Before you begin, ensure you've completed all of the previous sections to deploy required infrastructure and to set environment variables that this section requires.
Now that we've deployed all of the infrastructure into Google Cloud, we'll set up some tools on your Kubernetes cluster:
* Istio, a service mesh that will ensure that communication between different Rasa product components is encrypted in transit.
* ExternalDNS, a tool that will allow the cluster to create the DNS records it needs automatically using GCP Cloud DNS.
* Cert-manager, a tool to ensure we can automatically issue and renew TLS certificates for secure communication.
We'll use scripts from our [deployment-playbooks](https://github.com/RasaHQ/rasa-deployment-playbooks) repo throughout this section to make things easier. If you'd like to understand more about exactly what each script is doing, open it in your IDE of choice and review the comments which explain what is being deployed at each step.
##### Cluster Setup[](#cluster-setup "Direct link to Cluster Setup")
Firstly, we'll set Istio on your cluster, the service mesh that will ensure that communication between different Rasa product components is encrypted in transit, on your cluster.
To deploy the required infrastructure into your GCP environment, use the provided script in our companion repo:
```
./gcp/configure/configure-cluster.sh
```
The final output of this script will instruct you to create an `NS` DNS record for the domain you're using. Check your DNS provider's documentation for more information about how to do this. Once you have updated your DNS registrar with the zone name servers, wait for the DNS propagation. You cam verify if zone is properly delegated to GCP with command:
```
dig +short NS $DOMAIN
```
It should print the same GCP nameservers that were output at the end when you ran `./gcp/configure/configure-cluster.sh` above. If so, you can continue further on with the playbook.
##### Install external-dns[](#install-external-dns "Direct link to Install external-dns")
We will now install external-dns onto our cluster. This tool allows your Kubernetes cluster to create the DNS records it needs automatically using the GCP Cloud DNS zone that you've just configured.
```
./gcp/configure/install-external-dns.sh
```
##### Install cert-manager[](#install-cert-manager "Direct link to Install cert-manager")
We will now install cert-manager which will handle issuing TLS certificates automatically using LetsEncrypt.
```
./gcp/configure/install-cert-manager.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
##### Collect Required Parameters[](#collect-required-parameters "Direct link to Collect Required Parameters")
Most of the infrastructure work is now done, so we'll gather together some info that we'll use later in the playbook to make deploying the Rasa applications a bit easier.
Collect some information about the GCP infrastructure you've deployed and set them as environment variables:
```
source ./gcp/configure/get-infra-values.sh
```
These environment variables are now set and ready to be used in your application configurations.
##### Test Ingress Setup[](#test-ingress-setup "Direct link to Test Ingress Setup")
We've deployed and configured tooling onto the cluster to manage the creation of DNS records and TLS certificates. In this section, we'll test whether it's all working properly by temporarily deploying a tiny HTTP server called HTTPBin to check. If the test fails, the script will suggest some commands you can run to help identify the source of the issue.
```
./gcp/configure/test-ingress.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
---
#### Deploy Infrastructure
warning
Before you begin, ensure you've completed the [Setup Steps](https://rasa.com/docs/docs/learn/deployment/aws/aws-playbook-setup/) to set environment variables and clone a repo that this section requires.
To deploy the required infrastructure into your AWS environment, use the provided script in our [deployment-playbooks](https://github.com/RasaHQ/rasa-deployment-playbooks) repo.
```
./aws/deploy/deploy-infrastructure.sh
```
If you'd like to understand more about exactly what the script is doing, open it in your IDE of choice and review the comments which explain what is being deployed at each step.
---
#### Deploy Infrastructure
warning
Before you begin, ensure you've completed the [Setup Steps](https://rasa.com/docs/docs/learn/deployment/azure/azure-playbook-setup/) to set environment variables and clone a repo that this section requires.
To deploy the required infrastructure into your Azure environment, use the provided script in our [deployment-playbooks](https://github.com/RasaHQ/rasa-deployment-playbooks) repo.
```
./azure/deploy/deploy-infrastructure.sh
```
If you'd like to understand more about exactly what the script is doing, open it in your IDE of choice and review the comments which explain what is being deployed at each step.
---
#### Deploy Infrastructure
warning
Before you begin, ensure you've completed the [Setup Steps](https://rasa.com/docs/docs/learn/deployment/gcp/gcp-playbook-setup/) to set environment variables and clone a repo that this section requires.
To deploy the required infrastructure into your GCP environment, use the provided script in our [deployment-playbooks](https://github.com/RasaHQ/rasa-deployment-playbooks) repo.
```
./gcp/deploy/deploy-infrastructure.sh
```
If you'd like to understand more about exactly what the script is doing, open it in your IDE of choice and review the comments which explain what is being deployed at each step.
The first part of this script will attempt to enable the following GCP Services in your project which are required for the deployment.
* [Compute Engine API](https://docs.cloud.google.com/compute/docs/reference/rest/v1), for creating the virtual network.
* [Service Networking API](https://docs.cloud.google.com/service-infrastructure/docs/service-networking/reference/rest), to allow us to automatically manage networking.
* [Kubernetes Engine API](https://console.developers.google.com/apis/api/container.googleapis.com), to allow us to deploy a Google Kubernetes Engine (GKE) cluster.
* [Cloud SQL API](https://console.developers.google.com/apis/api/sqladmin.googleapis.com), to allow us to deploy a managed Cloud SQL PostgreSQL instance.
* [Google Cloud Memorystore for Redis API](https://console.developers.google.com/apis/api/redis.googleapis.com), to allow us to deploy a managed Redis instance.
* [Cloud DNS API](https://console.developers.google.com/apis/api/dns.googleapis.com), to allow us to create the required DNS records for the services.
* [IAM API](https://console.developers.google.com/apis/api/iam.googleapis.com), to allow us to manage IAM roles and service accounts.
This process will fail if you haven't linked the project to a billing account, which enables you to pay for the resources you deploy.
---
#### GCP Cleanup Infrastructure [Optional]
warning
Following these steps will delete all of the infrastructure and configuration you have deployed in all the previous steps. You'll need to set the environment variables defined in [Setup Steps](https://rasa.com/docs/docs/learn/deployment/gcp/gcp-playbook-setup/) before you begin.
You should only perform this step after you're finished with the Rasa Platform and wish to destroy all of the infrastructure you've deployed.
If you would like to clean up everything created in this playbook, you can run the following script. It will delete all of the Kubernetes resources created on your cluster, and then tear down and permanently delete all of the GCP infrastructure. Only run this if you're absolutely sure you wish to delete everything. The command may take up to an hour to run to completion if you deployed all of the resources in the playbook.
```
./gcp/cleanup/cleanup.sh
```
---
#### Install Rasa
warning
Before you begin, ensure you've completed all the previous sections to deploy required infrastructure and to set environment variables that this section requires.
We have now deployed all the required infrastructure and configured everything required on our cluster. We will now proceed to actually install Rasa Pro using the Rasa Helm Chart. In this section, we will:
* Install Kafka, which is used by components of Rasa and Studio to communicate.
* Install Rasa itself using its Helm chart.
* Deploy a TLS certificate and Kubernetes Ingress to make your assistant available outside the cluster via HTTPS.
#### Kafka Installation[](#kafka-installation "Direct link to Kafka Installation")
We will begin by setting up Kafka, which is used by Rasa Pro and Rasa Studio to communicate with each other, as well as for internal purposes.
You can run the following script to deploy Kafka with an autogenerated random password for authentication. When we setup the assistant in the next step, it will automatically fetch this password and save it in a Kubernetes secret so that other Rasa components can connect to Kafka. You will see some warnings about authentication failures until everything is up and running and it should eventually succeed.
```
./aws/rasa/kafka/install-kafka.sh
```
At the end, you should see here that topics called `rasa` and `rasa-events-dlq` have been created. This means that you have now successfully deployed Kafka into the cluster.
#### Assistant Setup[](#assistant-setup "Direct link to Assistant Setup")
Now that we've set up Kafka, we can set up the Rasa assistant using the Rasa Helm Chart.
You can run our script to perform the initial setup for the Assistant, and then we'll walk you through the setup that it's most important to understand.
```
./aws/rasa/assistant/setup-assistant.sh
```
##### Values File[](#values-file "Direct link to Values File")
The `values.yaml` file will contain all the configuration that gets applied to your assistant by Helm. You can read about all the available configuration options [here](https://github.com/RasaHQ/rasa-helm-charts/tree/main/charts/rasa), and you can fully customise your setup to meet your organisation's needs and security policies. For simplicity, we've provided a file in the playbook repo `aws/rasa/assistant/values.template.yaml` that sets all the key values we need to integrate Rasa with the AWS infrastructure we've already deployed, leaving placeholder values for things we want to inject as environment variables. You can set these values manually and add any others you require, but we recommend you begin by automatically creating a version with all the environment variables set from the previous sections:
```
envsubst "$(printf '$%s ' $(env | cut -d= -f1))" < aws/rasa/assistant/values.template.yaml > aws/rasa/assistant/values.yaml
```
If you open this newly created file, you should see that all of your values have been automatically populated from the environment variables we've been setting as we go along.
#### Deploy Rasa[](#deploy-rasa "Direct link to Deploy Rasa")
Now that all the configuration is done, you can deploy Rasa using all the configuration that you've set:
```
helm upgrade --install -n $NAMESPACE rasa aws/rasa/assistant/repos/rasa-helm/rasa -f aws/rasa/assistant/values.yaml
```
You can ignore the instructions that will be printed by the above command to use port forwarding to access the deployment.
Check yourself if the Rasa pod has a status of `RUNNING` by running:
```
kubectl get pods --namespace $NAMESPACE -l "app.kubernetes.io/name=rasa,app.kubernetes.io/instance=rasa"
```
#### Configure Ingress & TLS Certificate[](#configure-ingress--tls-certificate "Direct link to Configure Ingress & TLS Certificate")
Finally, we can deploy a Kubernetes Ingress and a TLS certificate for the Rasa Pro deployment. This will allow us to interact with the bot from outside the cluster.
We'll create a certificate and deploy an ingress with another script:
```
./aws/rasa/ingress/setup-ingress.sh
```
You will need to wait a few minutes while your certificate is issued and the DNS records propagate. Finally, you will be able to visit your assistant's URL: `https://assistant.$DOMAIN`. For example, if the value you used for `$DOMAIN` was `example.com`, you could visit your assistant on `https://assistant.example.com` If you receive "Hello from Rasa" response, you have successfully deployed Rasa Pro. If you receive an error, there may just be a delay in issuing the certificate or having the DNS records propagate - wait a few minutes and try again!
---
#### Install Rasa
warning
Before you begin, ensure you've completed all of the previous sections to deploy required infrastructure and to set environment variables that this section requires.
We have now deployed all of the required infrastructure and configured everything required on our cluster. We will now proceed to actually install Rasa Pro using the Rasa Helm Chart. In this section, we will:
* Install Kafka, which is used by components of Rasa and Studio to communicate.
* Install Rasa itself using its Helm chart.
* Deploy a TLS certificate and Kubernetes Ingress to make your assistant available outside of the cluster via HTTPS.
#### Kafka Installation[](#kafka-installation "Direct link to Kafka Installation")
We will begin by setting up Kafka, which is used by Rasa Pro and Rasa Studio to communicate with each other, as well as for internal purposes.
You can run the following script to deploy Kafka with an autogenerated random password for authentication. When we setup the assistant in the next step, it will automatically fetch this password and save it in a Kubernetes secret so that other Rasa components can connect to Kafka.
```
./azure/rasa/kafka/install-kafka.sh
```
Before continuing to the next step, wait for the `kafka` secret to be created. Run the following command to check for its existence:
```
kubectl get secret kafka --namespace $NAMESPACE
```
#### Assistant Setup[](#assistant-setup "Direct link to Assistant Setup")
Now that we've set up Kafka, we can set up the Rasa assistant using the Rasa Helm Chart.
You can run our script to perform the initial setup for the Assistant, and then we'll walk you through the setup that it's most important to understand.
```
./azure/rasa/assistant/setup-assistant.sh
```
##### Values File[](#values-file "Direct link to Values File")
The `values.yaml` file will contain all of the configuration that gets applied to your assistant by Helm. You can read about all of the available configuration options [here](https://github.com/RasaHQ/rasa-helm-charts/tree/main/charts/rasa), and you can fully customise your setup to meet your organisation's needs and security policies. For simplicity, we've provided a file in the playbook repo `azure/rasa/assistant/values.template.yaml` that sets all of the key values we need to integrate Rasa with the Azure infrastructure we've already deployed, leaving placeholder values for things we want to inject as environment variables. You can set these values manually and add any others you require, but we recommend you begin by automatically creating a version with all the environment variables set from the previous sections:
```
envsubst "$(printf '$%s ' $(env | cut -d= -f1))" < azure/rasa/assistant/values.template.yaml > azure/rasa/assistant/values.yaml
```
If you open this newly created file, you should see that all of your values have been automatically populated from the environment variables we've been setting as we go along.
#### Deploy Rasa[](#deploy-rasa "Direct link to Deploy Rasa")
Now that all the configuration is done, you can deploy Rasa using all of the configuration that you've set:
```
helm upgrade --install -n $NAMESPACE rasa azure/rasa/assistant/repos/rasa-helm/rasa -f azure/rasa/assistant/values.yaml
```
You can ignore the instructions that will be printed by the above command to use port forwarding to access the deployment.
Check yourself if the Rasa pod has a status of `RUNNING` by running:
```
kubectl get pods --namespace $NAMESPACE -l "app.kubernetes.io/name=rasa,app.kubernetes.io/instance=rasa"
```
#### Configure Ingress & TLS Certificate[](#configure-ingress--tls-certificate "Direct link to Configure Ingress & TLS Certificate")
Finally, we can deploy a Kubernetes Ingress and a TLS certificate for the Rasa Pro deployment. This will allow us to interact with the bot from outside the cluster.
We'll create a certificate and deploy an ingress with another script:
```
./azure/rasa/ingress/setup-ingress.sh
```
You will need to wait a few minutes while your certificate is issued and the DNS records propagate. Finally, you will be able to visit your assistant's URL: `https://assistant.$DOMAIN`. For example, if the value you used for `$DOMAIN` was `example.com`, you could visit your assistant on `https://assistant.example.com` If you receive "Hello from Rasa" response, you have successfully deployed Rasa Pro. If you receive an error, there may just be a delay in issuing the certificate or having the DNS records propagate - wait a few minutes and try again!
---
#### Install Rasa
warning
Before you begin, ensure you've completed all of the previous sections to deploy required infrastructure and to set environment variables that this section requires.
We have now deployed all of the required infrastructure and configured everything required on our cluster. We will now proceed to actually install Rasa Pro using the Rasa Helm Chart. In this section, we will:
* Install Kafka, which is used by components of Rasa and Studio to communicate.
* Install Rasa itself using its Helm chart.
* Deploy a TLS certificate and Kubernetes Ingress to make your assistant available outside of the cluster via HTTPS.
#### Kafka Installation[](#kafka-installation "Direct link to Kafka Installation")
We will begin by setting up Kafka, which is used by Rasa Pro and Rasa Studio to communicate with each other, as well as for internal purposes.
You can run the following script to deploy Kafka with an autogenerated random password for authentication. When we setup the assistant in the next step, it will automatically fetch this password and save it in a Kubernetes secret so that other Rasa components can connect to Kafka. You will see some warnings about authentication failures until everything is up and running and it should eventually succeed.
```
./gcp/rasa/kafka/install-kafka.sh
```
At the end, you should see here that topics called `rasa` and `rasa-events-dlq` have been created. This means that you have now successfully deployed Kafka into the cluster.
#### Assistant Setup[](#assistant-setup "Direct link to Assistant Setup")
Now that we've set up Kafka, we can set up the Rasa assistant using the Rasa Helm Chart.
You can run our script to perform the initial setup for the Assistant, and then we'll walk you through the setup that it's most important to understand.
```
./gcp/rasa/assistant/setup-assistant.sh
```
##### Values File[](#values-file "Direct link to Values File")
The `values.yaml` file will contain all of the configuration that gets applied to your assistant by Helm. You can read about all of the available configuration options [here](https://github.com/RasaHQ/rasa-helm-charts/tree/main/charts/rasa), and you can fully customise your setup to meet your organisation's needs and security policies. For simplicity, we've provided a file in the playbook repo `gcp/rasa/assistant/values.template.yaml` that sets all of the key values we need to integrate Rasa with the GCP infrastructure we've already deployed, leaving placeholder values for things we want to inject as environment variables. You can set these values manually and add any others you require, but we recommend you begin by automatically creating a version with all the environment variables set from the previous sections:
```
envsubst "$(printf '$%s ' $(env | cut -d= -f1))" < gcp/rasa/assistant/values.template.yaml > gcp/rasa/assistant/values.yaml
```
If you open this newly created file, you should see that all of your values have been automatically populated from the environment variables we've been setting as we go along.
#### Deploy Rasa[](#deploy-rasa "Direct link to Deploy Rasa")
Now that all the configuration is done, you can deploy Rasa using all of the configuration that you've set:
```
helm upgrade --install -n $NAMESPACE rasa gcp/rasa/assistant/repos/rasa-helm/rasa -f gcp/rasa/assistant/values.yaml
```
You can ignore the instructions that will be printed by the above command to use port forwarding to access the deployment.
Check yourself if the Rasa pod has a status of `RUNNING` by running:
```
kubectl get pods --namespace $NAMESPACE -l "app.kubernetes.io/name=rasa,app.kubernetes.io/instance=rasa"
```
#### Configure Ingress & TLS Certificate[](#configure-ingress--tls-certificate "Direct link to Configure Ingress & TLS Certificate")
Finally, we can deploy a Kubernetes Ingress and a TLS certificate for the Rasa Pro deployment. This will allow us to interact with the bot from outside the cluster.
We'll create a certificate and deploy an ingress with another script:
```
./gcp/rasa/ingress/setup-ingress.sh
```
You will need to wait a few minutes while your certificate is issued and the DNS records propagate. Finally, you will be able to visit your assistant's URL: `https://assistant.$DOMAIN`. For example, if the value you used for `$DOMAIN` was `example.com`, you could visit your assistant on `https://assistant.example.com` If you receive "Hello from Rasa" response, you have successfully deployed Rasa Pro. If you receive an error, there may just be a delay in issuing the certificate or having the DNS records propagate - wait a few minutes and try again!
---
#### Install Rasa Studio
warning
Before you begin, ensure you've completed all of the previous sections to deploy required infrastructure and to set environment variables that this section requires.
In the previous step we deployed Kafka and Rasa Pro onto your Kubernetes cluster. We will now deploy Rasa Studio onto the same cluster and connect it to the Kafka broker to allow it to communicate with Rasa Pro. This will involve:
* Configuring the Studio application and its constituent components.
* Configuring Keycloak, the authentication platform that Studio uses.
* Deploying Studio onto your cluster and making it accessible from outside the cluster.
#### Studio Setup[](#studio-setup "Direct link to Studio Setup")
First, we'll perform some initial setup for installing Rasa Studio. This script will:
* Pull the Rasa Studio Helm chart.
* Ensure some secret values are set and create a Kubernetes secret for them.
```
./aws/studio/setup-studio.sh
```
This script will output the admin credentials for Keycloak at the end, which is the authentication provider you use to manage users for Rasa Studio. Be sure to take note of these credentials as you'll need them later.
##### Values File[](#values-file "Direct link to Values File")
The `values.yaml` file will contain all of the configuration that gets applied to your assistant by Helm. You can read about all of the available configuration options [here](https://github.com/RasaHQ/rasa-helm-charts/tree/main/charts/studio), and you can fully customise your setup to meet your organisation's needs and security policies. For simplicity, we've provided a file in the playbook repo `aws/studio/values.template.yaml` that sets all of the key values we need to integrate Rasa with the AWS infrastructure we've already deployed. You can set these values manually and add any others you require, but we recommend you begin by automatically creating a version with all the environment variables set from the previous sections:
```
envsubst < aws/studio/values.template.yaml > aws/studio/values.yaml
```
If you open this newly created file, you should see that all of your values have been automatically populated from the environment variables we've been setting as we go along.
#### Deploy studio[](#deploy-studio "Direct link to Deploy studio")
Now that all the configuration is done, you can deploy Studio using all of the configuration that you've set:
```
helm upgrade --install -n $NAMESPACE studio aws/studio/repos/studio-helm/studio -f aws/studio/values.yaml
```
#### Configure TLS Certificate[](#configure-tls-certificate "Direct link to Configure TLS Certificate")
Finally, we can deploy the TLS certificate for your Studio deployment. Rasa Studio deploys its own Ingress, so you don't need to do that like you did with Rasa Pro.
Run the helper script for this:
```
./aws/studio/deploy-certificate.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
Finally, you will be able to visit your assistant's URL: . For example, if the value you used for $DOMAIN was example.com, you could visit your assistant on . If you receive an error, there may just be a delay in issuing the certificate - wait a few minutes and try again! You may see a few different error messages as components finish up deploying and certificates are issued, so don't worry if this happens. Your deployment is complete when you see a login page.
**Congratulations, you have now completed the playbook and successfully installed the Rasa Platform!**
#### Next Steps[](#next-steps "Direct link to Next Steps")
* [Set up users and roles for Studio](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/).
* If you ever need to uninstall Rasa Platform and remove the deployed infrastructure, you can do so by following the instructions in the [Cleanup](https://rasa.com/docs/docs/learn/deployment/aws/aws-playbook-cleanup/) section.
---
#### Install Rasa Studio
warning
Before you begin, ensure you've completed all of the previous sections to deploy required infrastructure and to set environment variables that this section requires.
In the previous step we deployed Kafka and Rasa Pro onto your Kubernetes cluster. We will now deploy Rasa Studio onto the same cluster and connect it to the Kafka broker to allow it to communicate with Rasa Pro. This will involve:
* Configuring the Studio application and its constituent components.
* Configuring Keycloak, the authentication platform that Studio uses.
* Deploying Studio onto your cluster and making it accessible from outside the cluster.
#### Studio Setup[](#studio-setup "Direct link to Studio Setup")
First, we'll perform some initial setup for installing Rasa Studio. This script will:
* Pull the Rasa Studio Helm chart.
* Ensure some secret values are set and create a Kubernetes secret for them.
```
./azure/studio/setup-studio.sh
```
This script will output the admin credentials for Keycloak at the end, which is the authentication provider you use to manage users for Rasa Studio. Be sure to take note of these credentials as you'll need them later.
##### Values File[](#values-file "Direct link to Values File")
The `values.yaml` file will contain all of the configuration that gets applied to your assistant by Helm. You can read about all of the available configuration options [here](https://github.com/RasaHQ/rasa-helm-charts/tree/main/charts/studio), and you can fully customise your setup to meet your organisation's needs and security policies. For simplicity, we've provided a file in the playbook repo `azure/studio/values.template.yaml` that sets all of the key values we need to integrate Rasa with the Azure infrastructure we've already deployed. You can set these values manually and add any others you require, but we recommend you begin by automatically creating a version with all the environment variables set from the previous sections:
```
envsubst < azure/studio/values.template.yaml > azure/studio/values.yaml
```
If you open this newly created file, you should see that all of your values have been automatically populated from the environment variables we've been setting as we go along.
#### Deploy studio[](#deploy-studio "Direct link to Deploy studio")
Now that all the configuration is done, you can deploy Studio using all of the configuration that you've set:
```
helm upgrade --install -n $NAMESPACE studio azure/studio/repos/studio-helm/studio -f azure/studio/values.yaml
```
#### Configure TLS Certificate[](#configure-tls-certificate "Direct link to Configure TLS Certificate")
Finally, we can deploy the TLS certificate for your Studio deployment. Rasa Studio deploys its own Ingress, so you don't need to do that like you did with Rasa Pro.
Run the helper script for this:
```
./azure/studio/deploy-certificate.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
Finally, you will be able to visit your assistant's URL: . For example, if the value you used for $DOMAIN was example.com, you could visit your assistant on . If you receive an error, there may just be a delay in issuing the certificate - wait a few minutes and try again! You may see a few different error messages as components finish up deploying and certificates are issued, so don't worry if this happens. Your deployment is complete when you see a login page.
**Congratulations, you have now completed the playbook and successfully installed the Rasa Platform!**
#### Next Steps[](#next-steps "Direct link to Next Steps")
* [Set up users and roles for Studio](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/).
* If you ever need to uninstall Rasa Platform and remove the deployed infrastructure, you can do so by following the instructions in the [Cleanup](https://rasa.com/docs/docs/learn/deployment/azure/azure-playbook-cleanup/) section.
---
#### Install Rasa Studio
warning
Before you begin, ensure you've completed all of the previous sections to deploy required infrastructure and to set environment variables that this section requires.
In the previous step we deployed Kafka and Rasa Pro onto your Kubernetes cluster. We will now deploy Rasa Studio onto the same cluster and connect it to the Kafka broker to allow it to communicate with Rasa Pro. This will involve:
* Configuring the Studio application and its constituent components.
* Configuring Keycloak, the authentication platform that Studio uses.
* Deploying Studio onto your cluster and making it accessible from outside the cluster.
#### Studio Setup[](#studio-setup "Direct link to Studio Setup")
First, we'll perform some initial setup for installing Rasa Studio. This script will:
* Pull the Rasa Studio Helm chart.
* Ensure some secret values are set and create a Kubernetes secret for them.
```
./gcp/studio/setup-studio.sh
```
This script will output the admin credentials for Keycloak at the end, which is the authentication provider you use to manage users for Rasa Studio. Be sure to take note of these credentials as you'll need them later.
##### Values File[](#values-file "Direct link to Values File")
The `values.yaml` file will contain all of the configuration that gets applied to your assistant by Helm. You can read about all of the available configuration options [here](https://github.com/RasaHQ/rasa-helm-charts/tree/main/charts/studio), and you can fully customise your setup to meet your organisation's needs and security policies. For simplicity, we've provided a file in the playbook repo `gcp/studio/values.template.yaml` that sets all of the key values we need to integrate Rasa with the GCP infrastructure we've already deployed. You can set these values manually and add any others you require, but we recommend you begin by automatically creating a version with all the environment variables set from the previous sections:
```
envsubst < gcp/studio/values.template.yaml > gcp/studio/values.yaml
```
If you open this newly created file, you should see that all of your values have been automatically populated from the environment variables we've been setting as we go along.
Now that all the configuration is done, you can deploy Studio using all of the configuration that you've set:
```
helm upgrade --install -n $NAMESPACE studio gcp/studio/repos/studio-helm/studio -f gcp/studio/values.yaml
```
#### Configure TLS Certificate[](#configure-tls-certificate "Direct link to Configure TLS Certificate")
Finally, we can deploy the TLS certificate for your Studio deployment. Rasa Studio deploys its own Ingress, so you don't need to do that like you did with Rasa Pro. Deploy the certificate with:
```
./gcp/studio/deploy-certificate.sh
```
You may see a warning stating `Warning: spec.privateKey.rotationPolicy: In cert-manager >= v1.18.0, the default value changed from Never to Always.`. This is fine.
Finally, you will be able to visit your assistant's URL: . For example, if the value you used for $DOMAIN was example.com, you could visit your assistant on . If you receive an error, there may just be a delay in issuing the certificate - wait a few minutes and try again! You may see a few different error messages as components finish up deploying and certificates are issued, so don't worry if this happens. Your deployment is complete when you see a login page.
**Congratulations, you have now completed the playbook and successfully installed the Rasa Platform!**
#### Next Steps[](#next-steps "Direct link to Next Steps")
* [Set up users and roles for Studio](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/).
* If you ever need to uninstall Rasa Platform and remove the deployed infrastructure, you can do so by following the instructions in the [Cleanup](https://rasa.com/docs/docs/learn/deployment/gcp/gcp-playbook-cleanup/) section.
---
#### Installing on Amazon Web Services (AWS)
This playbook outlines an opinionated, best-practice way to install Rasa Pro and Rasa Studio on AWS. You may wish to adapt steps and configuration to meet your needs or organisational policies as required.
The playbook will walk you through the following sections:
###### Setup[](#setup "Direct link to Setup")
Set up your local machine to perform the setup and installation, getting us ready to deploy the infrastructure and install applications on top. We'll use our [companion Github repository](https://github.com/RasaHQ/rasa-deployment-playbooks) to make this easier, which contains scripts and sample configuration files.
###### Deploy Infrastructure[](#deploy-infrastructure "Direct link to Deploy Infrastructure")
Deploy the actual underlying cloud infrastructure on AWS, including a Kubernetes cluster, PostgreSQL database and associated services like networking and DNS.
###### Configure Cluster[](#configure-cluster "Direct link to Configure Cluster")
Configure and install some tools on the Kubernetes cluster, including:
* Istio, a service mesh that will ensure that communication between different Rasa product components is encrypted in transit.
* ExternalDNS, a tool that will allow the cluster to create the DNS records it needs automatically using Amazon Route 53.
* Cert-manager, a tool to ensure we can automatically issue and renew TLS certificates for secure communication.
###### Install Rasa Pro[](#install-rasa-pro "Direct link to Install Rasa Pro")
Configure and install Rasa Pro onto the cluster ready for production usage.
###### Install Rasa Studio[](#install-rasa-studio "Direct link to Install Rasa Studio")
Configure and install Rasa Studio onto the cluster ready for production usage.
###### Cleanup[](#cleanup "Direct link to Cleanup")
Optionally clear up all the infrastructure and services you've deployed through the course of this playbook.
warning
The steps in this playbook will deploy infrastructure in your AWS account meant for hosting a production, scalable deployment of Rasa Pro and Studio. This can be quite expensive - if you're just looking to try out Rasa, you should use our [Docker Compose setup](https://github.com/RasaHQ/developer-edition-docker-compose) instead.
---
#### Installing on Google Cloud Platform
This playbook outlines an opinionated, best-practice way to install Rasa Pro and Rasa Studio on Google Cloud Platform. You may wish to adapt steps and configuration to meet your needs or organisational policies as required.
The playbook will walk you through the following sections:
###### Setup[](#setup "Direct link to Setup")
Set up your local machine to perform the setup and installation, getting us ready to deploy the infrastructure and install applications on top. We'll use our [companion Github repository](https://github.com/RasaHQ/rasa-deployment-playbooks) to make this easier, which contains scripts and sample configuration files.
###### Deploy Infrastructure[](#deploy-infrastructure "Direct link to Deploy Infrastructure")
Deploy the actual underlying cloud infrastructure on GCP, including a Kubernetes cluster, PostgreSQL database and associated services like networking and DNS.
###### Configure Cluster[](#configure-cluster "Direct link to Configure Cluster")
Configure and install some tools on the Kubernetes cluster, including:
* Istio, a service mesh that will ensure that communication between different Rasa product components is encrypted in transit.
* ExternalDNS, a tool that will allow the cluster to create the DNS records it needs automatically using GCP Cloud DNS.
* Cert-manager, a tool to ensure we can automatically issue and renew TLS certificates for secure communication.
###### Install Rasa Pro[](#install-rasa-pro "Direct link to Install Rasa Pro")
Configure and install Rasa Pro onto the cluster ready for production usage.
###### Install Rasa Studio[](#install-rasa-studio "Direct link to Install Rasa Studio")
Configure and install Rasa Studio onto the cluster ready for production usage.
###### Cleanup[](#cleanup "Direct link to Cleanup")
Optionally clear up all the infrastructure and services you've deployed through the course of this playbook.
warning
The steps in this playbook will deploy infrastructure in your Google Cloud account meant for hosting a production, scalable deployment of Rasa Pro and Studio. This can be quite expensive - if you're just looking to try out Rasa, you should use our [Docker Compose setup](https://github.com/RasaHQ/developer-edition-docker-compose) instead.
---
#### Installing on Microsoft Azure
This playbook outlines an opinionated, best-practice way to install Rasa Pro and Rasa Studio on Azure. You may wish to adapt steps and configuration to meet your needs or organisational policies as required.
The playbook will walk you through the following sections:
###### Setup[](#setup "Direct link to Setup")
Set up your local machine to perform the setup and installation, getting us ready to deploy the infrastructure and install applications on top. We'll use our [companion Github repository](https://github.com/RasaHQ/rasa-deployment-playbooks) to make this easier, which contains scripts and sample configuration files.
###### Deploy Infrastructure[](#deploy-infrastructure "Direct link to Deploy Infrastructure")
Deploy the actual underlying cloud infrastructure on Azure, including a Kubernetes cluster, PostgreSQL database and associated services like networking and DNS.
###### Configure Cluster[](#configure-cluster "Direct link to Configure Cluster")
Configure and install some tools on the Kubernetes cluster, including:
* Istio, a service mesh that will ensure that communication between different Rasa product components is encrypted in transit.
* ExternalDNS, a tool that will allow the cluster to create the DNS records it needs automatically using Azure DNS.
* Cert-manager, a tool to ensure we can automatically issue and renew TLS certificates for secure communication.
###### Install Rasa Pro[](#install-rasa-pro "Direct link to Install Rasa Pro")
Configure and install Rasa Pro onto the cluster ready for production usage.
###### Install Rasa Studio[](#install-rasa-studio "Direct link to Install Rasa Studio")
Configure and install Rasa Studio onto the cluster ready for production usage.
###### Cleanup[](#cleanup "Direct link to Cleanup")
Optionally clear up all the infrastructure and services you've deployed through the course of this playbook.
warning
The steps in this playbook will deploy infrastructure in your Azure account meant for hosting a production, scalable deployment of Rasa Pro and Studio. This can be quite expensive - if you're just looking to try out Rasa, you should use our [Docker Compose setup](https://github.com/RasaHQ/developer-edition-docker-compose) instead.
---
#### Set Up Your Agent On AWS
note
Before you begin, ensure you've finished installing Rasa Pro on Amazon Web Services: [Installation Guide](https://rasa.com/docs/docs/learn/deployment/aws/aws-playbook-intro/)
#### Recommended Next Steps[](#recommended-next-steps "Direct link to Recommended Next Steps")
Now that you have successfully deployed Rasa Pro on AWS, you can proceed with getting a live Rasa agent in place that you can interact with.
**Plan of Action:**
* Confirm Your Agent Runs Locally
* Upload Trained Model to AWS
* Run Your Deployed Rasa Agent
***
#### Confirm Your Agent Runs Locally[](#confirm-your-agent-runs-locally "Direct link to Confirm Your Agent Runs Locally")
If you already have a Rasa agent, make sure it trains and runs successfully on your local machine.
##### Don’t Have an Agent Yet?[](#dont-have-an-agent-yet "Direct link to Don’t Have an Agent Yet?")
If you already have a Rasa agent you’ve built, you can skip this section and go directly to [Upload Trained Model to AWS](#upload-trained-model-to-aws).
If not, feel free to use one of our pre-built **Starter Packs**. These agents come ready-made for specific industries, and you can run them as-is or customize them for your own use case.
Download the latest release of one of the following:
* [Starter Pack - Insurance](https://github.com/rasa-customers/starterpack-insurance-en/releases)
* [Starter Pack - Retail Banking](https://github.com/rasa-customers/starterpack-retail-banking-en/releases/)
* [Starter Pack - Telecom](https://github.com/rasa-customers/starterpack-telco-en/releases)
##### Run Your Starter Pack Locally[](#run-your-starter-pack-locally "Direct link to Run Your Starter Pack Locally")
Once you have downloaded your Starter Pack, follow the corresponding instructions linked below to train and run your Rasa agent locally:
* [Instructions - Insurance](https://learning.rasa.com/rasa-starter-packs/insurance/)
* [Instructions - Retail Banking](https://learning.rasa.com/rasa-starter-packs/retail-banking/)
* [Instructions - Telecom](https://learning.rasa.com/rasa-starter-packs/telecom/)
note
Make sure your local agent's `endpoints.yaml` matches the one in the deployed agent, so that the agent behaves identically in both environments. You can see the default values set by the deployment playbook [here](https://github.com/RasaHQ/rasa-deployment-playbooks/blob/main/aws/rasa/assistant/values.template.yaml). If you want to change the configuration of models for the deployed agent, change `aws/rasa/assistant/values.yaml` and rerun your `helm upgrade` command.
#### Upload Trained Model to AWS[](#upload-trained-model-to-aws "Direct link to Upload Trained Model to AWS")
After you have successfully run your Rasa agent locally, you can now move it to the cloud to share with others. This consists of two steps:
1. Upload the Rasa Model
2. Restart Rasa Kubernetes Pod
##### Upload the Rasa Model[](#upload-the-rasa-model "Direct link to Upload the Rasa Model")
Navigate to your Rasa project directory
```
cd /path/to/your/rasa/project
```
Ensure you are logged in and [authenticated with AWS](https://rasa.com/docs/docs/learn/deployment/aws/aws-playbook-setup/#install-tools)
Upload the model to your bucket
```
aws s3 cp models/ s3://$MODEL_BUCKET/models.tar.gz
```
Verify upload
```
aws s3 ls s3://$MODEL_BUCKET/
```
##### Restart Rasa[](#restart-rasa "Direct link to Restart Rasa")
Restart Rasa to create a new pod which will pull your new model from your bucket.
Authenticate to your AWS cluster
```
aws eks --region $AWS_REGION update-kubeconfig --name $NAME
```
note
If you changed the Kubernetes deployment name from the default `rasa`, use your custom deployment name in place of `rasa` in the commands below.
Restart deployments
```
kubectl -n $NAMESPACE rollout restart deployment rasa
```
To check if the Rasa pod is up and running yet, run the following command and see if the status of the new Rasa pod is "Running".
```
kubectl -n $NAMESPACE rollout status deployment/rasa
# or
kubectl -n $NAMESPACE get pods -w
```
**Tip:** You can view info, warning and error messages in your pod logs:
View the pod's logs
```
kubectl -n $NAMESPACE logs
```
You have now successfully updated the model and restarted your Rasa Pro environment. Next, you’ll set up a simple front-end web page to interact with your agent.
#### Interact With Your Rasa Agent[](#interact-with-your-rasa-agent "Direct link to Interact With Your Rasa Agent")
##### Interact With Your Rasa Agent from Your Browser[](#interact-with-your-rasa-agent-from-your-browser "Direct link to Interact With Your Rasa Agent from Your Browser")
Up to now, you’ve been running and interacting with your Rasa agent **locally** from your browser, connected to your **local instance** of Rasa Pro.
Now, you'll update the connection so your browser connects to your **deployed (cloud) instance** of Rasa Pro. This way, you’ll be interacting with your Rasa agent running in the cloud rather than on your local machine.
1. In your Starter Pack project folder, go to the `chatwidget` directory
2. Open up the `index.html` file in a text editor
3. Replace
```
--name models.tar.gz
```
Verify upload
```
az storage blob list --account-name $NAME --container-name $ASSISTANT_STORAGE_CONTAINER
```
##### Restart Rasa[](#restart-rasa "Direct link to Restart Rasa")
Restart Rasa to create a new pod which will pull your new model from your bucket.
Authenticate to your Azure cluster
```
az aks get-credentials --resource-group $NAME --name $NAME
```
note
If you changed the Kubernetes deployment name from the default `rasa`, use your custom deployment name in place of `rasa` in the commands below.
Restart deployments
```
kubectl -n $NAMESPACE rollout restart deployment rasa
```
To check if the Rasa pod is up and running yet, run the following command and see if the status of the new Rasa pod is "Running".
```
kubectl -n $NAMESPACE rollout status deployment/rasa
# or
kubectl -n $NAMESPACE get pods -w
```
**Tip:** You can view info, warning and error messages in your pod logs:
View the pod's logs
```
kubectl -n $NAMESPACE logs
```
You have now successfully updated the model and restarted your Rasa Pro environment. Next, you’ll set up a simple front-end web page to interact with your agent.
#### Interact With Your Rasa Agent[](#interact-with-your-rasa-agent "Direct link to Interact With Your Rasa Agent")
##### Interact With Your Rasa Agent from Your Browser[](#interact-with-your-rasa-agent-from-your-browser "Direct link to Interact With Your Rasa Agent from Your Browser")
Up to now, you’ve been running and interacting with your Rasa agent **locally** from your browser, connected to your **local instance** of Rasa Pro.
Now, you'll update the connection so your browser connects to your **deployed (cloud) instance** of Rasa Pro. This way, you’ll be interacting with your Rasa agent running in the cloud rather than on your local machine.
1. In your Starter Pack project folder, go to the `chatwidget` directory
2. Open up the `index.html` file in a text editor
3. Replace
```
gs://$MODEL_BUCKET/models.tar.gz
```
Verify upload
```
gsutil ls gs://$MODEL_BUCKET/
```
###### Alternatively, via Google Cloud Console UI:[](#alternatively-via-google-cloud-console-ui "Direct link to Alternatively, via Google Cloud Console UI:")
1. Go to your Google Cloud Console UI
2. Make sure you have the same project selected that you used to create your deployment
3. Go to **Cloud Storage > Buckets**
4. Select the bucket that you assigned to `BUCKET_NAME_ENTROPY` during the deployment process: `gcp/setup/environment-variables.sh`
* Example: `rasa-xbuc-ab-se-x2-rasa-model`
* **Tip:** Do not select the bucket that ends with `-studio`
5. Click **Upload** to upload your local `models.tar.gz` into the bucket
##### Restart Rasa[](#restart-rasa "Direct link to Restart Rasa")
Restart Rasa to create a new pod which will pull your new model from your bucket.
Authenticate to your GCP cluster
```
gcloud container clusters get-credentials $NAME --region $REGION --project $PROJECT_ID
```
note
If you changed the Kubernetes deployment name from the default `rasa`, use your custom deployment name in place of `rasa` in the commands below.
Restart deployments
```
kubectl -n $NAMESPACE rollout restart deployment rasa
```
To check if the Rasa pod is up and running yet, run the following command and see if the status of the new Rasa pod is "Running".
```
kubectl -n $NAMESPACE rollout status deployment/rasa
# or
kubectl -n $NAMESPACE get pods -w
```
**Tip:** You can view info, warning and error messages in your pod logs:
View the pod's logs
```
kubectl -n rasa logs
```
###### Alternatively, via Google Cloud Console UI:[](#alternatively-via-google-cloud-console-ui-1 "Direct link to Alternatively, via Google Cloud Console UI:")
1. Go to your Google Cloud Console UI
2. Make sure you have the same project selected that you used to create your deployment
3. Go to **Kubernetes Engine > Workloads**
4. Click on the `rasa` workload
5. In **Deployment Details menu:** Actions > Scale > Edit Replicas > Replicas: `0`
6. Press **Scale**
7. Wait until the pod has been terminated
8. In **Deployment Details menu:** Actions > Scale > Edit Replicas > Replicas: `1`
9. Press **Scale**
You have now successfully updated the model and restarted your Rasa Pro environment. Next, you’ll set up a simple front-end web page to try out your agent.
#### Interact With Your Rasa Agent[](#interact-with-your-rasa-agent "Direct link to Interact With Your Rasa Agent")
##### Interact With Your Rasa Agent from Your Browser[](#interact-with-your-rasa-agent-from-your-browser "Direct link to Interact With Your Rasa Agent from Your Browser")
Up to now, you’ve been running and interacting with your Rasa agent **locally** from your browser, connected to your **local instance** of Rasa Pro.
Now, you'll update the connection so your browser interacts with your **deployed (cloud) instance** of Rasa Pro. This way, you’ll be testing your Rasa agent running in the cloud rather than on your local machine.
1. In your Starter Pack project folder, go to the `chatwidget` directory
2. Open up the `index.html` file in a text editor
3. Replace
```
"
```
#### Specify Input Parameters[](#specify-input-parameters "Direct link to Specify Input Parameters")
You'll need to configure some values which the rest of the deployment process will use. We'll configure these as environment variables - make sure you change these to values that are correct for your situation:
If you haven't already, clone our [deployment-playbooks](https://github.com/RasaHQ/deployment-playbooks) repo locally with:
```
git clone https://github.com/RasaHQ/deployment-playbooks.git
```
Next, open the file `azure/setup/environment-variables.sh` and follow the instructions to edit the required values inside. Once you're happy with the values you've set, let's ensure these values are available for you to use in your shell throughout the rest of the playbook. Be especially sure to set all of the values in the first section to ensure you can proceed with the rest of the playbook. A valid Rasa Pro license key must also be set in here or the deployment steps will not work.
```
source azure/setup/environment-variables.sh
```
---
#### Setup
#### Prerequisites[](#prerequisites "Direct link to Prerequisites")
Before you begin, you will need to have access to a Google Cloud Platform project - you can use an existing one but we recommend [creating a new project](https://cloud.google.com/resource-manager/docs/creating-managing-projects#creating_a_project) to ensure there's no resource conflicts and you can easily track billing and access controls.
Within the project, your user will need to have the following roles, which you can check in the Google Cloud console under IAM & Admin > IAM:
* Compute Admin
* Service Networking Admin
* Kubernetes Engine Admin
* Cloud SQL Admin
* Cloud Memorystore Redis Admin
* DNS Administrator
* Service Usage Admin
Alternatively, you can grant yourself the Owner or Editor role on the project which will be sufficient.
Your GCP project must be linked to a billing account to ensure that you can pay for the resources you deploy.
Finally, you must have a valid Rasa license key with entitlements for Rasa Pro and Rasa Studio.
#### Install Tools[](#install-tools "Direct link to Install Tools")
Next, you'll need to install some tools on your local machine. If you already have these tools installed, please ensure they are updated to the latest version.
* gcloud CLI allows you to interact with GCP to deploy the infrastructure. Installation instructions are [here](https://cloud.google.com/sdk/docs/install).
* kubectl allows you to interact with the Kubernetes cluster you deploy to configure it. Installation instructions are [here](https://kubernetes.io/docs/tasks/tools/#kubectl).
* The gke-cloud-auth-plugin allows you to authenticate with your Google Kubernetes Engine cluster and interact with it using kubectl. Install if after you've set up gcloud with `gcloud components install gke-gcloud-auth-plugin`.
* helm which allows you to deploy the Rasa products onto your cluster. Installation instructions are [here](https://helm.sh/docs/intro/install/).
* envsubst which allows us to easily inject the values of environment variables into our deployment commands. This is included with most Linux distros and can be installed on MacOS with `brew install gettext`. Windows users can utilise it via Git Bash.
Once you've installed these tools, you should authenticate with GCP:
```
gcloud auth login
```
#### Specify Input Parameters[](#specify-input-parameters "Direct link to Specify Input Parameters")
You'll need to configure some values which the rest of the deployment process will use. We'll configure these as environment variables - make sure you change these to values that are correct for your situation:
Begin by cloning our [deployment-playbooks](https://github.com/RasaHQ/rasa-deployment-playbooks) repo locally with:
```
git clone https://github.com/RasaHQ/rasa-deployment-playbooks.git
```
Next, open the file `gcp/setup/environment-variables.sh` and follow the instructions to edit the required values inside. Once you're happy with the values you've set, let's ensure these values are available for you to use in your shell throughout the rest of the playbook. Be especially sure to set all of the values in the first section to ensure you can proceed with the rest of the playbook. **A valid Rasa Pro license key must also be set in here or the deployment steps will not work.**
```
source gcp/setup/environment-variables.sh
```
#### Set Up gcloud CLI[](#set-up-gcloud-cli "Direct link to Set Up gcloud CLI")
Finally, let's set up the gcloud CLI for the rest of the deployment process:
```
gcloud config set project $PROJECT_ID
gcloud config set disable_prompts True
```
You can safely ignore a warning that says `Your active project does not match the quota project in your local Application Default Credentials file. This might result in unexpected quota issues.`.
You can then validate your configuration with:
```
gcloud auth list
gcloud config list
```
You should see here that the active account is your Google user and that you're working in the correct project you expect.
---
### Guides
#### Custom Actions in Rasa
Imagine you’re developing a digital banking assistant. A user asks, “What’s my account balance?” Instead of delivering a simple response or handing the chat over to an agent, your assistant reaches out to your banking API, retrieves the current balance, and responds with personalized information.
You can achieve this using custom actions in Rasa. **Custom Actions** are a flexible code interface to extend your assistant's capabilities beyond conversations.
Using custom actions, you can:
* **Query databases:** Retrieve user information in real-time.
* **Call APIs:** Connect to external services for up-to-date data.
* **Execute business logic:** Process information and make decisions dynamically.
* **Generate dynamic responses:** Tailor interactions based on current data.
#### How it works[](#how-it-works "Direct link to How it works")
Custom actions are run during conversations—you can specify whether you'd like them to be called as part of a flow by including it as a step or based off of a set of conditions. Once triggered, the custom action runs your code, and returns values that you can use to influence the business logic of your conversation.
##### Key components[](#key-components "Direct link to Key components")
Custom Actions in Rasa have two key methods:
* **Action name** `name`: A unique identifier that Rasa uses to trigger the action.
* **Run method** `run`: The custom logic that you want the action to run
##### Input and output of actions[](#input-and-output-of-actions "Direct link to Input and output of actions")
Actions can reference parts of the conversation state and the responses can be stored as values in the assistant's memory (as slots) or directly sent to the user as a message.
In an action you can:
* **Reference the conversation state**: This is accessible through the tracker (ie. reading slot values or checking the latest message)
* **Return events**: Save values by returning events (ie. setting slots)
* **Send messages**: Send messages directly back to the user through the dispatcher (note: we recommend to leverage responses rather than using this method for better validation support)
###### Example[](#example "Direct link to Example")
In this example, the assistant supports the user in booking a restaurant. It first asks for some details about the user's preference and then uses that input to query an API for availability based on the user's preferences. The custom action might look something like this:
* Pro
* Studio
actions.py
```
from typing import Any, Text, Dict, List
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
class ActionCheckRestaurants(Action):
def name(self) -> Text:
return "action_check_restaurants"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
cuisine = tracker.get_slot('cuisine') # Get what cuisine the user wants from the tracker
results = search_database(cuisine) # Do something with that information
return [SlotSet("matches", results)] # Store the results in a slot
```
You can also reference actions in the Studio flow builder:
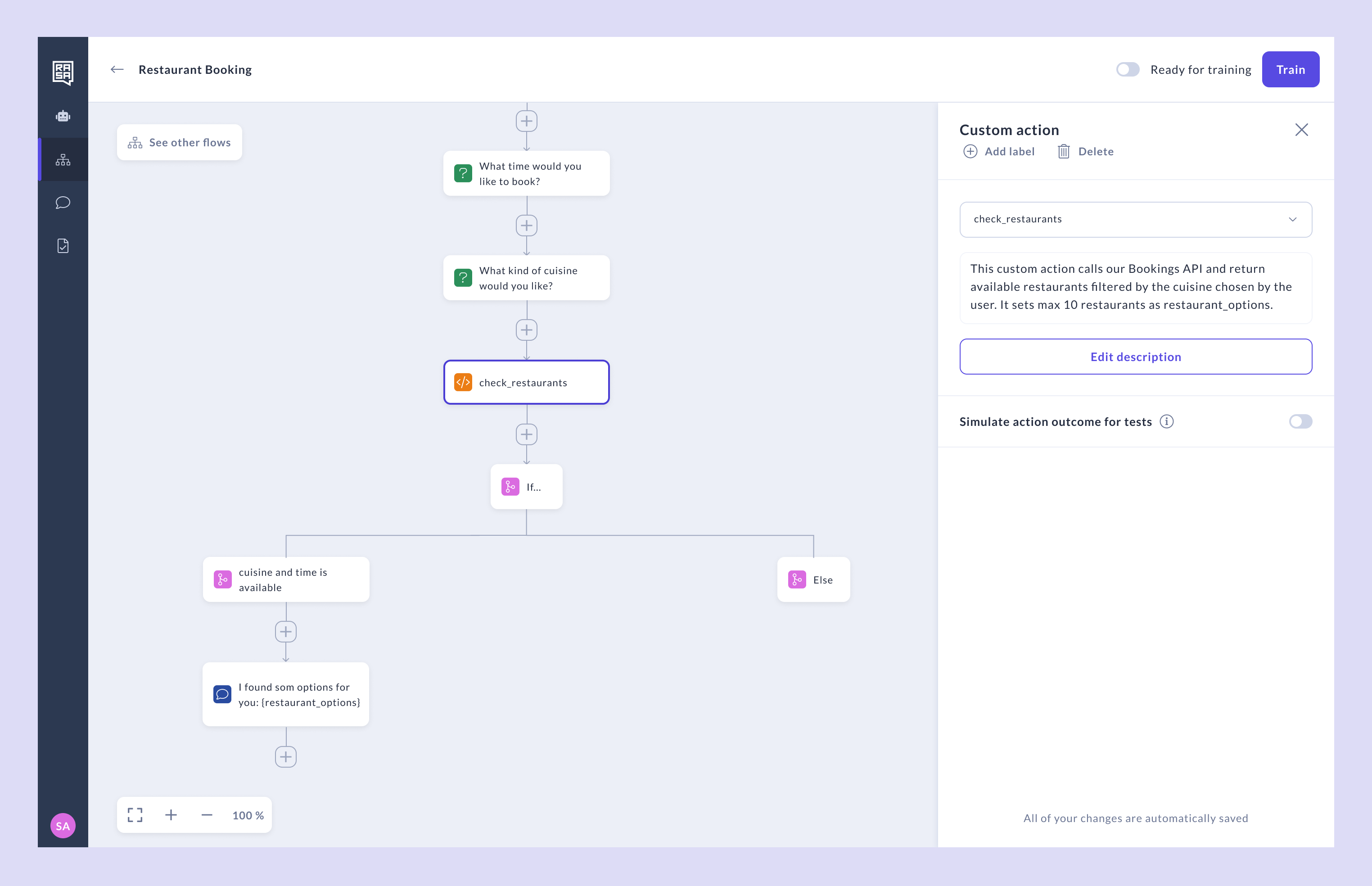
##### Storing response values[](#storing-response-values "Direct link to Storing response values")
A typical usecase for actions is to use the return response as a stored value in your assistant's memory so that you can reference it in conditional logic or in flows. When a Custom Action queries a database or calls an API, it can store the retrieved information in slots, which your assistant can then use to, make decisions about the conversation flow, provide personalized responses to the user, remember important details for future interactions or validate user inputs against business rules.
In the previous example, once the custom action has returned the response from the API, you can then use the response values to set a slot that renders some buttons that allow your user to select their preferred booking option.
#### Trying out your Actions[](#trying-out-your-actions "Direct link to Trying out your Actions")
Rasa determines that a custom action needs to be executed based on the flow. Rasa sends conversation information, such as the conversation history, slots, and domain information to your custom action. Your custom action then sends a response back to Rasa, which might include updated slot values, responses to be sent to the user, or follow-up events.
Once you're happy with your action, you have a few different options to try it out in your assistant.
In **server mode**, an action server communicates with the main Rasa server through HTTP/HTTPS protocol. We recommend this approach for use in a production, staging or development environment. You can read more about how to deploy an action server here (../link-to-reference)
In **module mode**, custom actions are executed directly within the Rasa Assistant without the need for a separate Action Server. This method works well for local testing testing, and simpler deployments where ease of use is a priority.
#### Next Steps[](#next-steps "Direct link to Next Steps")
Custom actions form the bridge between your assistant and your business systems. As you build your custom actions, we recommend implementing a comprehensive error handling system (e.g. APIs being unavailable) and providing clear feedback to users when operations don't go as planned.
For more detailed information, check our [Custom Actions Reference](https://rasa.com/docs/docs/reference/primitives/custom-actions/).
---
#### Integrate RAG in Rasa
Many AI assistants need to handle both structured workflows and open-ended knowledge queries. Rasa's approach to Enterprise Search and Retrieval-Augmented Generation (RAG) enables you to build assistants that can blend these capabilities, ensuring users get the information and support they need.
#### Types of AI Assistant Conversations[](#types-of-ai-assistant-conversations "Direct link to Types of AI Assistant Conversations")
Conversations with AI assistants typically fall into two categories: **Transactional** and **Informational**.
**Transactional**:
These conversations are structured, goal-oriented, and designed to complete specific tasks. They guide users through predefined processes—such as booking a flight, checking an account balance, or filing a support ticket—where every input and response is precisely managed to ensure a successful transaction.
**Informational**:
These conversations are designed to answer questions and provide insights. Whether users are inquiring about product features, technical details, or pricing, these dialogues rely on current data and strong contextual understanding to deliver clear, relevant answers.
Real conversations often mix both types - a user might start booking a flight (transactional) but then ask about baggage policies (informational) before completing their booking.
#### Understanding RAG[](#understanding-rag "Direct link to Understanding RAG")
To enable building assistants that can handle different conversational usecases, Rasa enables you to integrate Retrieval-Augmented Generation (RAG) into your assistants. RAG is a method that leverages LLMs to produce more accurate and up-to-date responses by providing them access to external knowledge sources.
RAG involves three steps:
1. **Retrieval**: When a user asks a question, we search through a knowledge base (documents, databases, or other structured information) to find relevant information.
2. **Augmentation**: The retrieved information is combined with the user's query and conversation context to create a comprehensive prompt.
3. **Generation**: This enriched prompt is sent to an LLM which generates a response that incorporates the retrieved information.
#### How RAG Works in Rasa[](#how-rag-works-in-rasa "Direct link to How RAG Works in Rasa")
Rasa enables assistants to handle informational dialogue at any point in the conversation.
When a user asks an informational question, Rasa's **Dialogue Understanding** component will produce a `SearchAndReply` command. This command triggers the search pattern, which processes the knowledge query and then returns back to the ongoing conversation.
User:
Yes the 17:30 flight to San Fransisco works fine.
action\_flight\_booking triggered
Bot:
Great! It's confirmed. You're going to SF at 17:30 tomorrow, anything else I can help you with?
User:
Actually - how big a bag can I bring again?
pattern\_search triggered
Bot:
One moment, let me check the latest baggage policy information for the flight.
Bot:
I found that your flight includes one carry-on bag and one checked bag up to 50 lbs. Extra checked bags are available for an additional fee.
User:
Thanks! Please add an extra checked bag to my booking.
action\_flight\_booking\_update triggered
Bot:
Got it. I’ve updated your reservation to include an extra checked bag. Let’s proceed with your booking details.
Example illustrating Rasa's RAG and Enterprise Search in a Flight Booking Scenario
**📌 Pro tip:** You can also trigger enterprise search at specific points in a conversation by adding it as a step in your flow.
#### Getting Started with Enterprise Search[](#getting-started-with-enterprise-search "Direct link to Getting Started with Enterprise Search")
##### Step One: Prep your Knowledge Base[](#step-one-prep-your-knowledge-base "Direct link to Step One: Prep your Knowledge Base")
Rasa offers flexible options for configuring your knowledge base when setting up Retrieval-Augmented Generation (RAG). You can choose from two primary storage methods:
###### Folder-Based Storage[](#folder-based-storage "Direct link to Folder-Based Storage")
For a quick and simple setup, you can store text documents in your project’s `/docs` folder. This approach is ideal for rapid development and prototyping, as it provides an easy-to-use source of information for the LLM to generate responses.
###### Vector Database[](#vector-database "Direct link to Vector Database")
For a production-ready solution, consider connecting to a vector database like [Qdrant](https://qdrant.tech/) or [Milvus](https://github.com/milvus-io/milvus/). This method supports dynamic updates and enables sharing your knowledge base among multiple assistants.
* Pro
* Studio
> **Note:** In this example, we use the simple folder-based storage approach to demonstrate how to prepare your knowledge base, configure Enterprise Search, and override the search flow. This is a quickstart approach using Pro.
docs/sampleDocument.txt
```
We have five type of cards: debit card, credit card, and loyalty card.
The price of a debit card is between 5 euros and 10, depending on the options you want to have.
Debit cards are directly linked to the user's bank account.
If the borrowed amount is not paid in full, credit card users may incur interest charges.
Loyalty cards are designed to reward customers for their repeat business.
Customers typically earn points or receive discounts based on their purchases.
Loyalty cards are often part of broader membership programs that may include additional benefits.
```
> **Note:** In Studio it's more straightforward to integrate enterprise search when you have set up your vector database already.
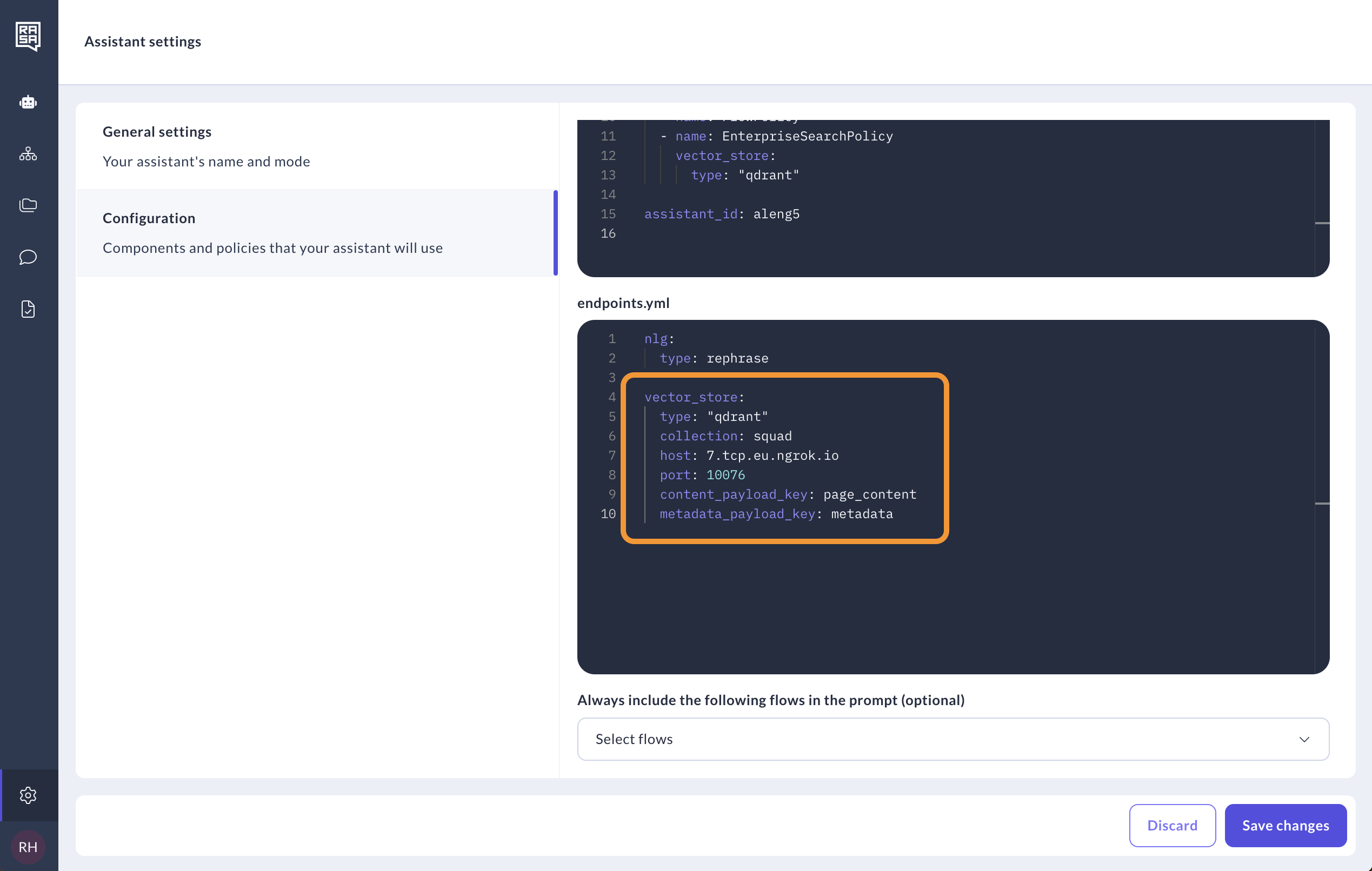
##### Step Two: Configure the Command Generator and Enterprise Search[](#step-two-configure-the-command-generator-and-enterprise-search "Direct link to Step Two: Configure the Command Generator and Enterprise Search")
Include the correct command generator (`SearchReadyLLMCommandGenerator`) in your assistant's configuration -
* Pro
* Studio
config.yml
```
pipeline:
- name: SearchReadyLLMCommandGenerator
llm: # The model for command generation
model_group: command_generator_llm
policies:
- name: EnterpriseSearchPolicy
llm: # The model for response generation
model_group: enterprise_search_generation
embeddings: # The model for your embeddings
model_group: enterprise_search_embeddings
vector_store:
type: "faiss"
source: "./docs" # The path to the folder where your text files are stored
```
endpoints.yml
```
model_groups:
- id: command_generator_llm
models:
- provider: "openai"
model: "gpt-4o-2024-11-20"
- id: enterprise_search_generation
models:
- provider: "openai"
model: "gpt-4.1-mini-2025-04-14"
- id: enterprise_search_embeddings
models:
- provider: "openai"
model: "text-embedding-3-large"
```
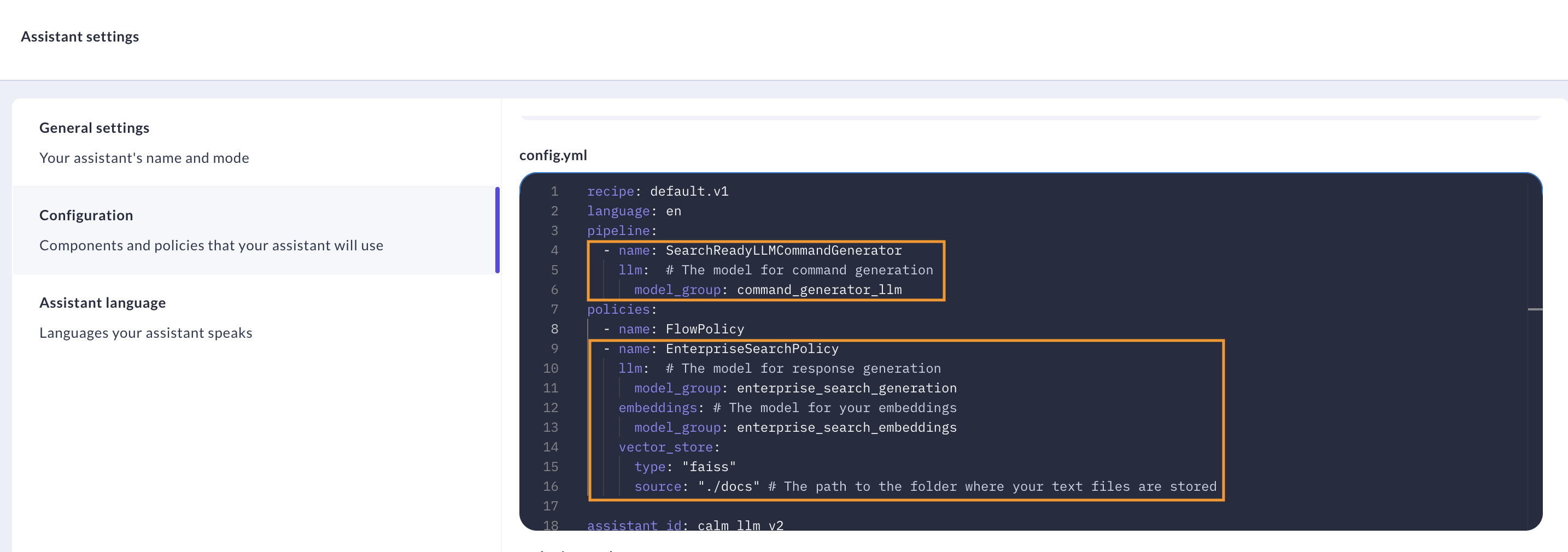 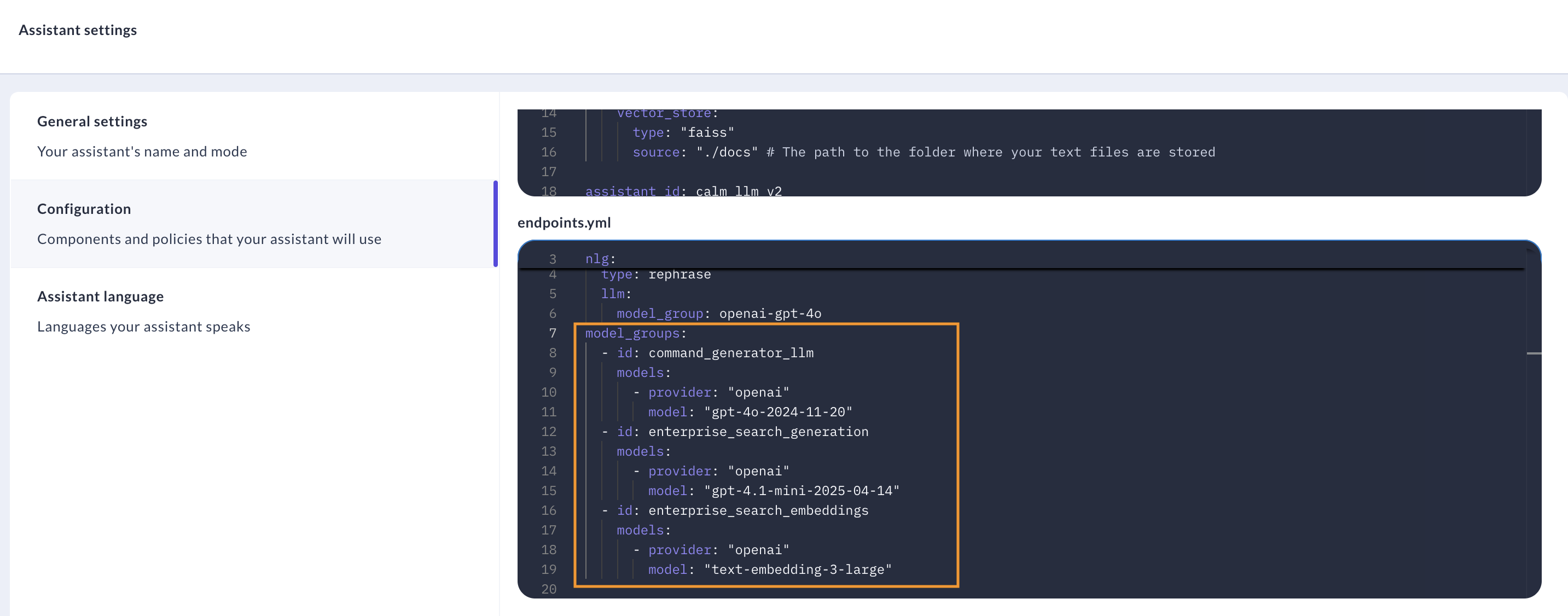
##### Step Three: Override pattern\_search[](#step-three-override-pattern_search "Direct link to Step Three: Override pattern_search")
* Pro
* Studio
Modify `flows.yml` by adding a new system flow called `pattern_search` to trigger document search for knowledge-based questions:
flows.yml
```
flows:
pattern_search:
description: Handle knowledge-based questions.
steps:
- action: action_trigger_search
```
Go to the "System flows" tab and open `pattern_search` to modify it.
Delete the message and add the custom action step instead. In the right panel, select the action named `action_trigger_search`.
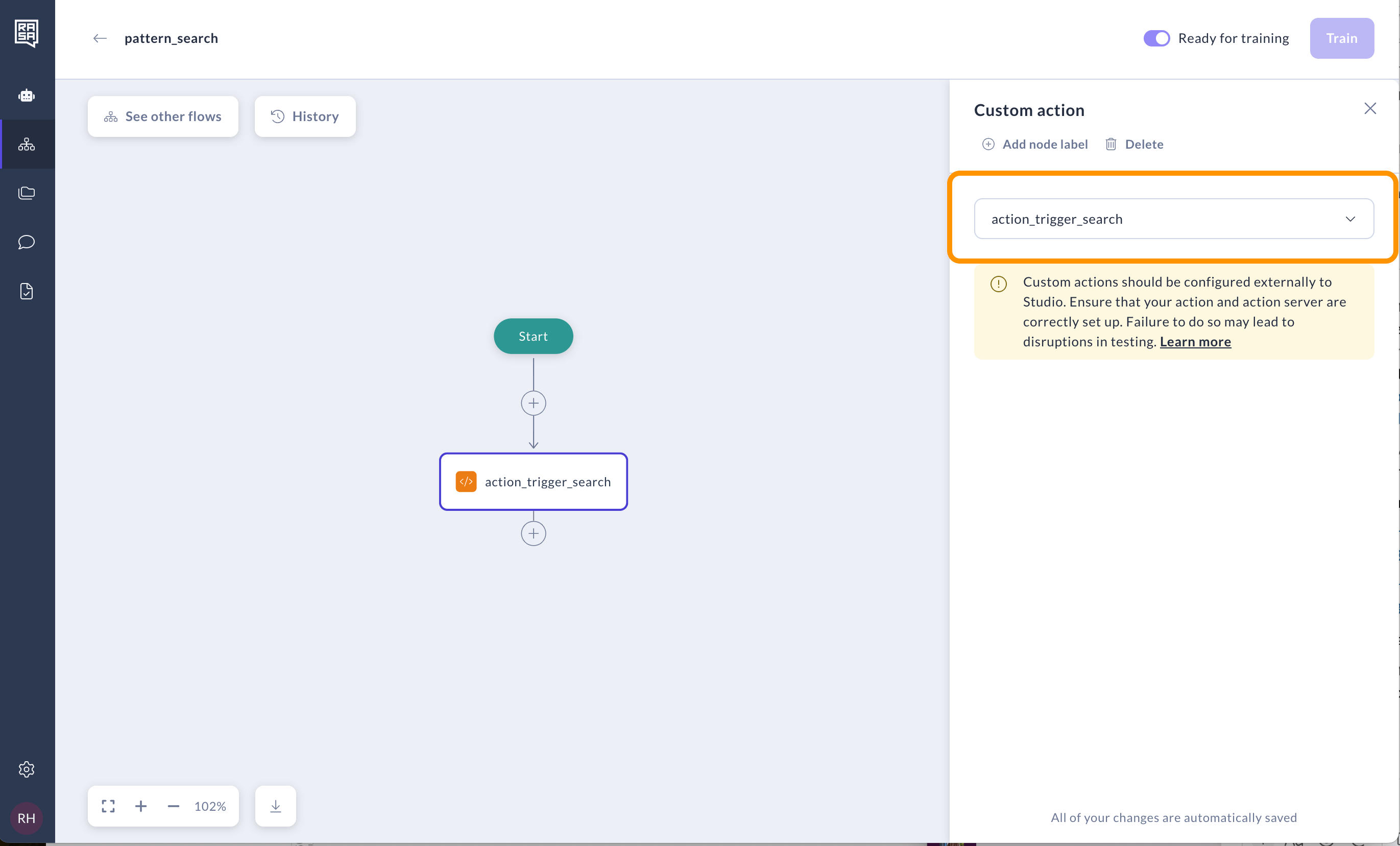
This will send relevant queries to the default action `action_trigger_search`.
##### Step Four: Try out your assistant[](#step-four-try-out-your-assistant "Direct link to Step Four: Try out your assistant")
Once you have indexed your documents and trained your assistant, you should be ready to try out your new informational conversation!

Example conversation with a Rasa assistant using Enterprise Search
#### Customization Options[](#customization-options "Direct link to Customization Options")
##### LLM and Prompt Customization (Optional)[](#llm-and-prompt-customization-optional "Direct link to LLM and Prompt Customization (Optional)")
Rasa ships with default prompts for RAG interactions, but you can customize these to better match your use case. This ensures that generated responses align with your specific needs.
You can also choose the LLM that best fits your needs. Rasa supports various LLM providers and can also work with your hosted LLMs, allowing you to balance factors like response quality, speed, and cost. For more details on customizing your model configuration [see this reference](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/#embeddings).
##### Extractive Search (Optional)[](#extractive-search-optional "Direct link to Extractive Search (Optional)")
For scenarios where you want to deliver pre-approved answers from your knowledge base directly to your user, Rasa supports **Extractive Search**. This method bypasses the LLM generation step, reducing both cost and latency and ensuring complete control and consistency over responses. You can read more about this feature in the [technical reference](https://rasa.com/docs/docs/reference/config/policies/extractive-search/).
---
### Quickstart
#### Try Rasa
You can start using Rasa in your browser right away, no installation required.
##### Prerequisites[](#prerequisites "Direct link to Prerequisites")
**Rasa License Key** - you'll need a license key to use Rasa. You can request a Rasa Developer Edition license key [here](https://rasa.com/rasa-pro-developer-edition-license-key-request/) and read more about our licensing [here](https://rasa.com/docs/docs/pro/installation/licensing/).
##### Steps[](#steps "Direct link to Steps")
###### Create a Codespace:[](#create-a-codespace "Direct link to Create a Codespace:")
* Navigate to our [quickstart repository](https://github.com/RasaHQ/codespaces-quickstart/) on GitHub.
* Click on "Code", then on "Create codespace on main".
###### Set Up Environment[](#set-up-environment "Direct link to Set Up Environment")
Edit the file called `.env` with the following content:
.env
```
RASA_LICENSE='your_rasa_license_key_here'
```
Load this environment variable from your file by running:
```
source .env
```
Then activate your python environment by running:
```
source .venv/bin/activate
```
###### Follow the tutorial[](#follow-the-tutorial "Direct link to Follow the tutorial")
Your codespace is set up so you can now run commands like `rasa train` and `rasa inspect`. Now, check out the [tutorial](https://rasa.com/docs/docs/pro/tutorial/) to build your first CALM assistant.
---
## Overview
### Welcome to the Rasa Docs
The Rasa Platform helps teams build, test, deploy, and analyze AI assistants at scale. Whether launching your first assistant or scaling enterprise AI, Rasa is set up to adapt and grow with you.
#### [Quickstart](https://hello.rasa.com/?utm_source=docs\&utm_medium=referral\&utm_campaign=docs_cta)
[Build your first agent in just a few minutes with Rasa Copilot.](https://hello.rasa.com/?utm_source=docs\&utm_medium=referral\&utm_campaign=docs_cta)
##### [Hello, Rasa](https://hello.rasa.com/?utm_source=docs\&utm_medium=referral\&utm_campaign=docs_cta)
[Beta](https://hello.rasa.com/?utm_source=docs\&utm_medium=referral\&utm_campaign=docs_cta)
###### [Quickstart](https://rasa.com/docs/docs/learn/quickstart/pro/)
[Start building with Rasa today.](https://rasa.com/docs/docs/learn/quickstart/pro/)
##### Learn More[](#learn-more "Direct link to Learn More")
Grow your understanding of Rasa concepts.
###### [Core Concepts](https://rasa.com/docs/docs/learn/concepts/calm/)
[Dive deeper into the concepts behind Rasa.](https://rasa.com/docs/docs/learn/concepts/calm/)
###### [Guides](https://rasa.com/docs/docs/learn/guides/adding-custom-actions/)
[Have a usecase in mind? Check out our Guides for how Rasa helps you build assistants.](https://rasa.com/docs/docs/learn/guides/adding-custom-actions/)
###### [Team Resources](https://rasa.com/docs/docs/learn/best-practices/conversation-design/)
[Jumpstart your assistant and setup your team for success with some best practices.](https://rasa.com/docs/docs/learn/best-practices/conversation-design/)
##### Dive into the Products[](#dive-into-the-products "Direct link to Dive into the Products")
Find detailed guidance for each step of building assistants in our product docs.
###### [Rasa](https://rasa.com/docs/docs/pro/intro/)
[The powerful pro-code interface for building assistants.](https://rasa.com/docs/docs/pro/intro/)
###### [Studio](https://rasa.com/docs/docs/studio/intro/)
[The intuitive no-code interface for building assistants.](https://rasa.com/docs/docs/studio/intro/)
---
## Rasa Pro
### Rasa Tutorial
**Welcome!** In this tutorial, you'll learn how to build a reliable, scalable AI agent using **CALM**, Rasa's LLM-powered dialogue engine. You’ll define a simple process (called a *flow* in Rasa), and see first-hand how [**Process Calling**](https://rasa.com/blog/process-calling-agentic-tools-need-state/) with **Conversation Patterns** enable you to build steerable conversational experiences, without the risks of ungrounded LLM reasoning and answer generation.
#### What are you building?[](#what-are-you-building "Direct link to What are you building?")
In this tutorial, you will build an LLM-powered assistant that can complete a money transfer, reliably executing your business logic while allowing for fluid conversation.
Here are some of the conversations your assistant will be able to handle, just by defining the money transfer process:
* Happy path
* All at once
* Change of mind
User: I want to send money
Bot: Who would you like to send money to?
User: to Jen
Bot: How much would you like to send?
User: $50
Bot:
Please confirm: you want to transfer $50.0 to Jen?
User: yes
Bot: All done. $50.0 has been sent to Jen.
Bot: Is there anything else I can help you with?!
happy path
User: I want to send 100 dollars to Joe
Bot:
Please confirm: you want to transfer $100.0 to Joe?
User: yes.
Bot: All done. $100.00 has been sent to Joe.
Bot: Is there anything else I can help you with?
All info given
User: I need to send $50
Bot: Who would you like to send money to?
User: Jen
Bot:
Please confirm: you want to transfer $50.0 to Jen?
User: actually no 60
Bot: Ok, I corrected the amount.
Bot:
Please confirm: you want to transfer $60.0 to Jen?
User: yes.
Bot: All done. $60.00 has been sent to Jen.
Bot: Is there anything else I can help you with?
Change of mind
#### Following This Tutorial[](#following-this-tutorial "Direct link to Following This Tutorial")
You'll need a free Rasa [Developer Edition license](https://rasa.com/docs/docs/pro/intro/)
This tutorial contains a mix of explanations and instructions. Whenever there are instructions you need to follow, you'll see this 'Action Required' label:
Action Required
This assistant is powered by [an LLM that we fine-tuned and uploaded to huggingface](https://huggingface.co/rasa/command-generator-llama-3.1-8b-instruct). For convenience, this tutorial will use a deployment that we host and make available for users working through the tutorial. If you prefer, you don't have to use any 3rd party API and just [run this model yourself](https://rasa.com/docs/docs/pro/deploy/deploy-fine-tuned-model/) or use [another LLM](https://rasa.com/docs/docs/reference/config/components/llm-configuration/)
#### Setup[](#setup "Direct link to Setup")
Action Required
For new users, the easiest way to get started is in the browser with a [GitHub Codespace](https://rasa.com/docs/docs/learn/quickstart/pro/#create-a-codespace).
You can also [install rasa-pro locally](https://rasa.com/docs/docs/pro/installation/python/) and use your own machine.
info
A GitHub codespace gives you a working environment to explore Rasa in under a minute. We really suggest you start there!
To code along with this tutorial, navigate to an empty directory in your terminal, and run:
```
rasa init --template tutorial
```
If you're using a [codespace](https://rasa.com/docs/docs/learn/quickstart/pro/#create-a-codespace), you already set your environment variables during setup. If you've installed Rasa locally, set your Rasa license in an environment variable:
* Linux/MacOS
* Windows
```
export RASA_LICENSE="your-rasa-pro-license-key"
```
```
setx RASA_LICENSE your-rasa-license-key
```
The variable will now be correctly set when you create a new cmd prompt window.
Remember to replace `your-rasa-license-key` with the your actual license key.
#### Overview[](#overview "Direct link to Overview")
Open up the project folder in your IDE to see the files that make up your new project. In this tutorial you will primarily work with the following files:
* `data/flows.yml`
* `domain.yml`
* `actions/actions.py`
#### Testing your money transfer flow[](#testing-your-money-transfer-flow "Direct link to Testing your money transfer flow")
Action Required
Train your assistant by running:
```
rasa train
```
Now, try telling the assistant that you'd like to transfer some money to a friend. Start talking to it in the browser by running:
```
rasa inspect
```
info
When you run the `rasa inspect` command in a GitHub Codespace, you'll see a notification that your application is available on port 5005. Click 'Open in Browser' to access the inspector and start chatting. 
info
This template bot responds to chitchat by generating a response. If you want to disable this, delete the file `data/patterns.yml` and re-train.
#### Understanding your money transfer flow.[](#understanding-your-money-transfer-flow "Direct link to Understanding your money transfer flow.")
The file `data/flows.yml` contains the definition of a `flow` called `transfer_money`. Let's look at this definition to see what is going on:
flows.yml
```
flows:
transfer_money:
description: Help users send money to friends and family.
steps:
- collect: recipient
- collect: amount
description: the number of US dollars to send
- action: utter_transfer_complete
```
The two key attributes of the `transfer_money` flow are the `description` and the `steps`. The `description` is used to help decide *when* to activate this flow. But it is also helpful for anyone who inspects your code to understand what is going on. If a user says "I need to transfer some money", the description helps Rasa understand that this is the relevant flow. The `steps` describe the business logic required to do what the user asked for.
The first step in your flow is a `collect` step, which is used to fill a `slot`. A `collect` step sends a message to the user requesting information, and waits for an answer.
#### Collecting Information in Slots[](#collecting-information-in-slots "Direct link to Collecting Information in Slots")
`Slots` are variables that your assistant can read and write throughout a conversation. Slots are defined in your `domain.yml` file. For example, the definition of your `recipient` slot looks like this:
domain.yml
```
slots:
recipient:
type: text
mappings:
- type: from_llm
# ...
```
Slots can be used to store information that users provide during the conversation, or information that has been fetched via an API call. First, you're going to see how to store information provided by the end user in a slot. To do this, you define a `collect` step like the first step in your flow above.
flows.yml
```
flows:
transfer_money:
description: Help users send money to friends and family.
steps:
- collect: recipient
- collect: amount
description: the number of US dollars to send
- action: utter_transfer_complete
```
Rasa will look for a `response` called `utter_ask_recipient` in your domain file and use this to phrase the question to the user.
domain.yml
```
responses:
utter_ask_recipient:
- text: "Who would you like to send money to?"
```
After sending this message, Rasa will wait for a response from the user. When the user responds, Rasa will try to use their answer to fill the slot `recipient`. Read about [slot validation](https://rasa.com/docs/docs/reference/primitives/flow-steps/#slot-validation) to learn how you can run extra checks on the slot values Rasa has extracted.
The diagram below summarizes how slot values are used to collect and store information, and how they can be used to create branching logic.
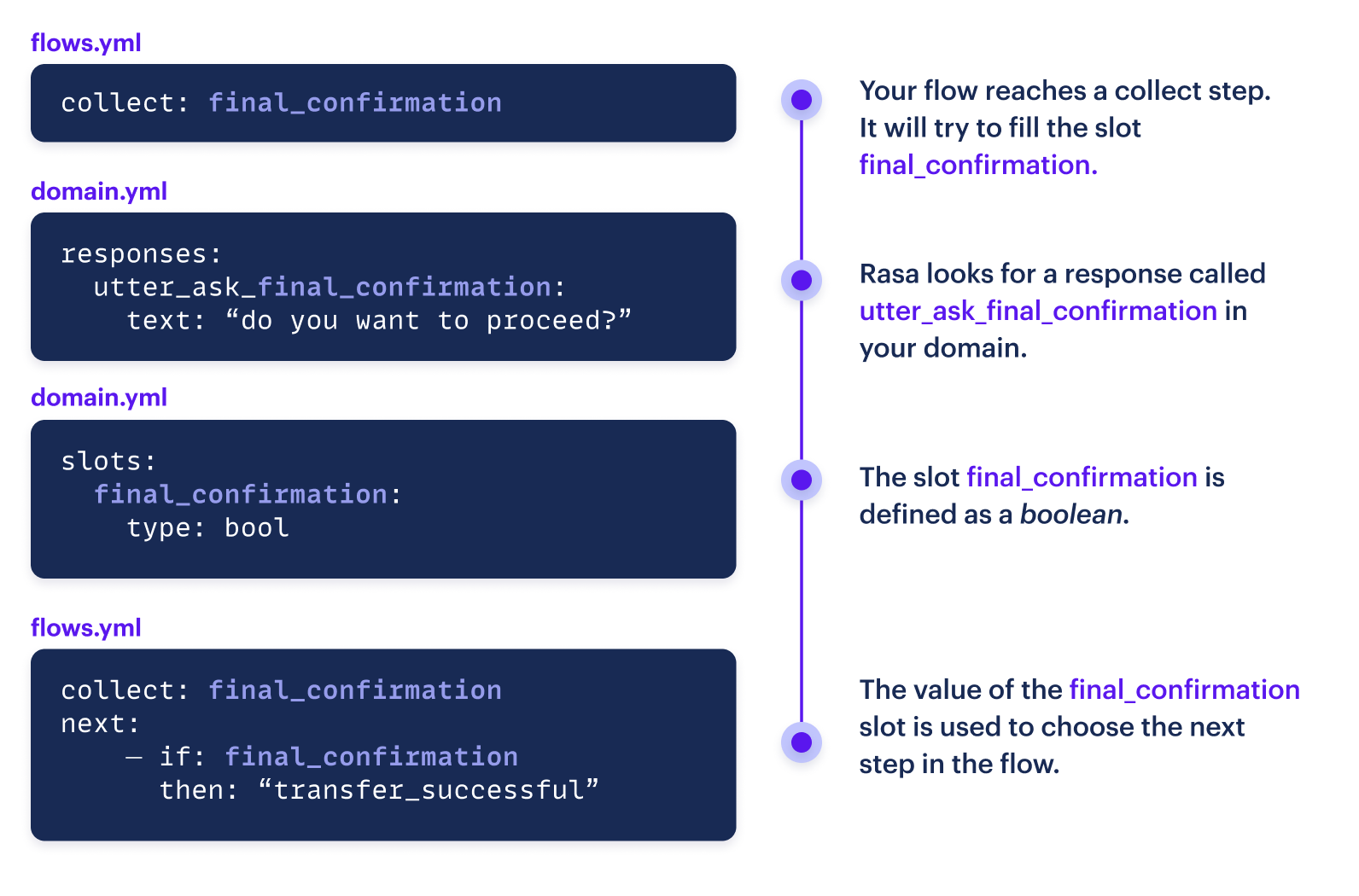
##### Descriptions in collect steps[](#descriptions-in-collect-steps "Direct link to Descriptions in collect steps")
The second `collect` step includes a description of the information your assistant will request from the user. Descriptions are optional, but can help Rasa extract slot values more reliably.
flows.yml
```
flows:
transfer_money:
description: Help users send money to friends and family.
steps:
- collect: recipient
- collect: amount
description: the number of US dollars to send
- action: utter_transfer_complete
```
#### Action Steps[](#action-steps "Direct link to Action Steps")
The third `step` in your `transfer_money` flow is not a `collect` step but an `action` step. When you reach an action step in a flow, your assistant will execute the corresponding action and then proceed to the next step. It will not stop to wait for the user's next message. For now, this is the final step in the flow, so there is no next step to execute and the flow completes.
flows.yml
```
flows:
transfer_money:
description: Help users send money to friends and family.
steps:
- collect: recipient
- collect: amount
description: the number of US dollars to send
- action: utter_transfer_complete
```
#### Branching Logic[](#branching-logic "Direct link to Branching Logic")
Slots are also used to build branching logic in flows.
Action Required
You're going to introduce an extra step to your flow, asking the user to confirm the amount and the recipient before sending the transfer. Since you are asking a yes/no question, you can store the result in a boolean `slot` which you will call `final_confirmation`.
In your domain file, add the definition of the `final_confirmation` slot and the corresponding response: `utter_ask_final_confirmation`. Also add a response to confirm the transfer has been cancelled.
domain.yml
```
slots:
recipient:
type: Text
mappings:
- type: from_llm
# ...
final_confirmation:
type: bool
mappings:
- type: from_llm
```
domain.yml
```
responses:
utter_ask_recipient:
- text: "Who would you like to send money to?"
# ...
utter_ask_final_confirmation:
- text: "Please confirm: you want to transfer {amount} to {recipient}?"
utter_transfer_cancelled:
- text: "Your transfer has been cancelled."
```
Notice that your confirmation question uses curly brackets `{}` to include slot values in your response.
Add a `collect` step to your flow for the slot `final_confirmation`. This step includes a `next` attribute with your branching logic. The expression after the `if` key will be evaluated to true or false to determine the next step in your flow. The `then` and `else` keys can contain either a list of steps or the `id` of a step to jump to. In this case, the `then` key contains an `action` step to inform the user their transfer was cancelled. The `else` key contains the id `transfer_successful`. Notice that you've added this `id` to the final step in your flow.
flows.yml
```
flows:
transfer_money:
description: Help users send money to friends and family.
steps:
- collect: recipient
- collect: amount
description: the number of US dollars to send
- collect: final_confirmation
next:
- if: not slots.final_confirmation
then:
- action: utter_transfer_cancelled
next: END
- else: transfer_successful
- action: utter_transfer_complete
id: transfer_successful
```
To try out the updated version of your assistant, run `rasa train`, and then `rasa inspect` to talk to your assistant. It should now ask you to confirm before completing the transfer.
#### Integrating an API call[](#integrating-an-api-call "Direct link to Integrating an API call")
An `action` step in a flow can describe two types of actions. If the name of the action starts with `utter_`, then this action sends a message to the user. The name of the action has to match the name of one of the `responses` defined in your domain. The final step in your flow contains the action `utter_transfer_complete`, and this response is also defined in your domain. Responses can contain buttons, images, and custom payloads. You can learn more about everything you can do with responses [here](https://rasa.com/docs/docs/reference/primitives/responses/).
The second type of `action` is a custom action. The name of a custom action starts with `action_`.
You are going to create a custom action, `action_check_sufficient_funds`, to check whether the user has enough money to make the transfer, and then add logic to your flow to handle both cases.
Your custom action is defined in the file `actions/actions.py`. To learn more about custom actions, go [here](https://rasa.com/docs/docs/reference/primitives/custom-actions/).
Your `actions.py` file should look like this:
actions.py
```
from typing import Any, Text, Dict, List
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
from rasa_sdk.events import SlotSet
class ActionCheckSufficientFunds(Action):
def name(self) -> Text:
return "action_check_sufficient_funds"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
# hard-coded balance for tutorial purposes. in production this
# would be retrieved from a database or an API
balance = 1000
transfer_amount = tracker.get_slot("amount")
has_sufficient_funds = transfer_amount <= balance
return [SlotSet("has_sufficient_funds", has_sufficient_funds)]
```
Slots are the primary way to pass information to and from custom actions. In the `run()` method above, you access the value of the `amount` slot that was set during the conversation, and you pass information back to the conversation by returning a `SlotSet` event to update the `has_sufficient_funds` slot.
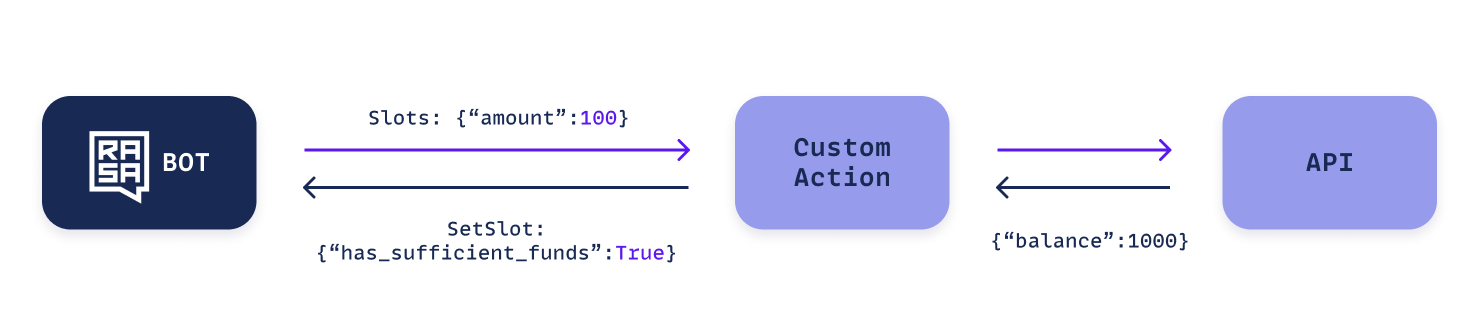
Action Required
Now you are going to make three additions to your `domain.yml`. You will add a top-level section listing your custom actions. You will add the new boolean slot `has_sufficient_funds`, and you will add a new response to send to the user in case they do not have sufficient funds.
domain.yml
```
actions:
- action_check_sufficient_funds
slots:
# ...
has_sufficient_funds:
type: bool
mappings:
- type: controlled
responses:
# ...
utter_insufficient_funds:
- text: "You do not have enough funds to make this transaction."
```
Now you are going to update your flow logic to handle the cases where the user does or does not have enough money in their account to make the transfer.
Notice that your `collect: final_confirmation` step now also has an id so that your branching logic can jump to it.
flows.yml
```
flows:
transfer_money:
description: Help users send money to friends and family.
steps:
- collect: recipient
- collect: amount
description: the number of US dollars to send
- action: action_check_sufficient_funds
next:
- if: not slots.has_sufficient_funds
then:
- action: utter_insufficient_funds
next: END
- else: final_confirmation
- collect: final_confirmation
id: final_confirmation
next:
- if: not slots.final_confirmation
then:
- action: utter_transfer_cancelled
next: END
- else: transfer_successful
- action: utter_transfer_complete
id: transfer_successful
```
#### Testing your Custom Action[](#testing-your-custom-action "Direct link to Testing your Custom Action")
Action Required
Double check that in the file `endpoints.yml`, that the section for your custom action server is uncommented:
endpoints.yml
```
action_endpoint:
actions_module: actions
```
In the terminal, stop and restart the inspector by running `rasa inspect`. When you reach the `"check_funds"` step in your flow, Rasa will call the custom action `action_check_sufficient_funds`. We have hardcoded the user's balance to be `1000`, so if you try to send more, the assistant will tell you that you don't have enough funds in your account.
At this point you have experience using some of the key concepts involved in building with Rasa. Congratulations!
#### Adding Voice to Your Assistant[](#adding-voice-to-your-assistant "Direct link to Adding Voice to Your Assistant")
Now that you've built a text-based assistant that handles money transfers, let's expand its capabilities to support voice interactions.
Here's a demo of what you'll be building,
##### What You'll Need for Voice[](#what-youll-need-for-voice "Direct link to What You'll Need for Voice")
To enable voice capabilities, you'll need:
* An API key from [Deepgram](https://deepgram.com/) for both speech recognition and speech synthesis.
Alternatively, you can use any of our other supported [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/).
##### Setting Up Your Voice Assistant[](#setting-up-your-voice-assistant "Direct link to Setting Up Your Voice Assistant")
Action Required
Configure your speech service API keys:
* Linux/MacOS
* Windows
```
export DEEPGRAM_API_KEY="your-deepgram-api-key"
```
```
setx DEEPGRAM_API_KEY your-deepgram-api-key
```
This will apply to future command prompt windows, so you will need to open a new one to use these variables.
##### Testing Your Voice Assistant[](#testing-your-voice-assistant "Direct link to Testing Your Voice Assistant")
Action Required
To test your voice assistant in the browser:
```
rasa inspect --voice
```
Try saying "I want to send money to Sarah" and experience how your assistant handles the voice interaction. The voice inspector allows you to speak to your assistant and hear its responses, simulating a phone call experience.
#### Next Steps[](#next-steps "Direct link to Next Steps")
Now you are ready to apply what you've learned to building your own assistant.
1. Create a new project by running:
```
rasa init --template calm
```
2. Choose which LLM you want to use. This tutorial used an LLM that Rasa fine-tuned for this use case. For new projects created with `rasa init --template calm`, Rasa defaults to a general-purpose model (gpt-4-0613) that doesn't require fine-tuning. You can configure which LLM to use by editing [the config.yml file in your project](https://rasa.com/docs/docs/reference/config/components/llm-configuration/). When you're ready, you can [fine-tune your own model](https://rasa.com/docs/docs/pro/customize/fine-tuning-llm/).
3. Start writing your own [flows](https://rasa.com/docs/docs/reference/primitives/flows/) and [custom actions](https://rasa.com/docs/docs/reference/primitives/custom-actions/).
---
### Welcome to Rasa
Rasa is a framework for building scalable, high-trust conversational AI agents. It uses large language models (LLMs) to enable more contextually aware and agentic interactions. Whether you're new to conversational AI or an experienced developer, Rasa offers flexibility, control, and performance for mission-critical applications.
Rasa manages dialogue with [CALM (Conversational AI with Language Models)](https://rasa.com/docs/docs/learn/concepts/calm/), an approach that enables you to shift from traditional intent-driven systems to LLM-based agents. It allows you to build more robust agents that are easier to create and maintain, adhering to business logic and guarding against prompt injection and hallucination.
Sometimes you will notice references to "Rasa Pro" in the documentation, which is to highlight the pro-code part of the platform covered in this section.
###### [Developer Edition](https://rasa.com/rasa-pro-developer-edition-license-key-request/)
[Interested in trying Rasa? Get a free Developer License to start building CALM agents today.](https://rasa.com/rasa-pro-developer-edition-license-key-request/)
[](https://rasa.com/rasa-pro-developer-edition-license-key-request/)
[](https://rasa.com/rasa-pro-developer-edition-license-key-request/)[Get it here](https://rasa.com/rasa-pro-developer-edition-license-key-request/)
**Key Features:**
* **Flows for Business Logic:** Easily define business logic through Flows, a simple and scalable way to implement the tasks your AI agent can handle.
* **Automatic Conversation Patterns:** Common conversation patterns like topic changes, corrections, or unexpected inputs are handled automatically, while giving you full control to customize this behavior.
* **Scalable Integrations:** Easily scale integrations to backend APIs via [MCP](https://modelcontextprotocol.io/docs/getting-started/intro) or other agents via [A2A](https://a2a-protocol.org/latest/#what-is-a2a-protocol).
* **Customizable and Open**: Make Rasa yours by creating custom components, and dig in to the source code to understand every detail of Rasa's AI engine.
* **Robustness and Composability:** Know that your business logic will always be followed correctly, and break down tasks into reusable pieces.
* **Built-in Security:** CALM is resistant to hallucination, prompt injection, and jailbreaking by design. And you can run it fully on-premise with no calls to external LLMs.
#### Who Rasa is For[](#who-rasa-is-for "Direct link to Who Rasa is For")
The Rasa Platform includes a pro-code interface for developers. It can be used together with [Rasa Studio](https://rasa.com/docs/docs/studio/intro/), our no-code interface for business users.
The Rasa Developer Edition is free and allows you to run Rasa locally and in production. A free developer edition license is valid for up to 1000 conversations per month (or 100/ month for internal agents used by your employees).
[Get a developer license](https://rasa.com/rasa-pro-developer-edition-license-key-request/)

#### Jump Right In[](#jump-right-in "Direct link to Jump Right In")
To get started, you can:
* [Take the Rasa tutorial here to build your first CALM agent](https://rasa.com/docs/docs/pro/tutorial/)
* [Learn more about CALM (Conversational AI with Language Models), an LLM-native approach to building reliable conversational AI.](https://rasa.com/docs/docs/learn/concepts/calm/)
---
### Analyze and Improve
#### Analytics
The Analytics Pipeline in Rasa streams conversation data from your deployed assistant to a data warehouse of your choice. By default, Rasa connects to your production assistant via Kafka and forwards any conversation events—user messages, commands from the LLM prompt, flow status updates, actions triggered, etc.—to a database. From there, you can hook up a Business Intelligence (BI) tool, data warehouse, or data-processing framework to visualize and process your conversation metrics.
##### Why No Out-of-the-Box Dashboards?[](#why-no-out-of-the-box-dashboards "Direct link to Why No Out-of-the-Box Dashboards?")
Rasa aims to be flexible enough to support an extensive range of use cases. Since every assistant has different requirements, business goals, and domain-specific metrics (e.g. drop-off rates in a financial flow vs. average handle time in a customer support flow), providing universal, out-of-the-box dashboards is rarely sufficient. Instead, Rasa outputs complete raw conversation data to your system of choice so you can build dashboards, analytics, and monitoring pipelines that best match your organization’s needs.
Some of the benefits of this approach:
* **Full control of your data**: You can choose a preferred data lake or warehouse solution (e.g. PostgreSQL, Redshift, BigQuery, Snowflake) and how to store, transform, or query events.
* **Flexible analytics**: You decide how to aggregate, slice, or visualize the data. Integrate with any BI tool, from open-source Metabase to enterprise-grade Tableau or Power BI.
* **Customizable KPIs**: You can easily blend conversation metrics with business data to track outcomes relevant to your specific domain (e.g. lead conversions, purchase completions, chat escalation reasons, etc.).
#### Installation Prerequisites[](#installation-prerequisites "Direct link to Installation Prerequisites")
1. **A Kafka Instance**
Rasa Pro Services require a production-ready Kafka broker to stream real-time conversation data. Kafka is where all conversation events get published (e.g. user messages, commands from the LLM prompt). We recommend using a managed service such as Amazon MSK to simplify maintenance and scaling.
2. **Rasa Pro Services**
You need to deploy Rasa Pro Services alongside (or as part of) your assistant’s infrastructure. Rasa Pro Services handle the ingestion of events from Kafka and can transform them before streaming them to your configured data warehouse. Once set up, you can start computing analytics as soon as Rasa Pro Services connect successfully to Kafka and your data storage.
3. **(Optional) A Data Warehouse**
By default, you can configure Rasa to store raw conversation data in PostgreSQL or Redshift. If you prefer other warehousing solutions such as BigQuery or Snowflake, you can sync them via intermediate steps (e.g. streaming from PostgreSQL into Snowflake). This stage is optional in a local/testing setup but strongly recommended for production.
#### What Can You Track with Analytics?[](#what-can-you-track-with-analytics "Direct link to What Can You Track with Analytics?")
Once your assistant is streaming events to the Analytics Pipeline, you can capture many types of conversation data. You can categorize these into four broad areas:
1. **User Analytics**
Identify who your assistant’s users are and how they feel about the assistant.
* **Examples**: user demographics, session frequency per user, feedback/sentiment
2. **Usage Analytics**
Discover overall traffic and assistant health.
* **Examples**: total number of sessions, average session duration, error rates, active channels
3. **Conversation Analytics**
Gain insights into how dialogues unfold.
* **Examples**: top flows triggered (in CALM-based assistants), top NLU intents (in NLU-based assistants), average number of turns, drop-off at specific flow steps, escalation or human-handoff patterns
4. **Business Analytics**
Measure how the assistant performs against business-critical objectives.
* **Examples**: ROI per line of business, containment rate (how many conversations were fully automated vs. handed to a human), interruption rates, success rates on business flows
In short, you can use these analytics to continuously refine and monitor your assistant’s behavior. For example, you might track how frequently users trigger a specific flow, whether that flow gets interrupted, how often those interruptions lead to a fallback pattern or a brand-new flow, or how many interactions escalate to a human agent.
#### Example Queries[](#example-queries "Direct link to Example Queries")
This section helps you get started with analyzing your assistant's conversations. The examples use SQL queries together with an example visualization in Metabase.
##### Number of Sessions per Month[](#number-of-sessions-per-month "Direct link to Number of Sessions per Month")
A common high-level usage metric of your assistant is the number of sessions per month. Here is how it would look as an SQL query:
```
SELECT
date_trunc('month', "public"."rasa_session"."timestamp") AS "first_seen",
count(*) AS "count"
FROM "public"."rasa_session"
GROUP BY 1
ORDER BY 1 ASC
```
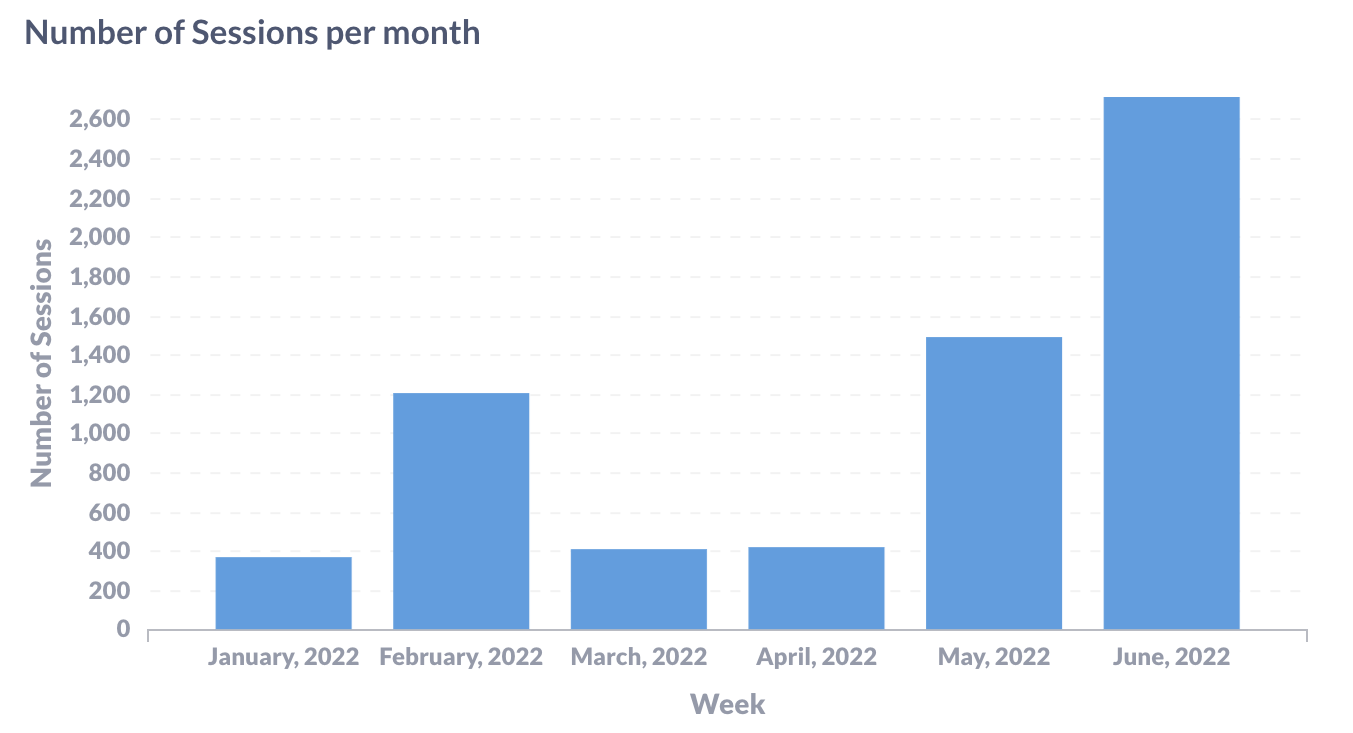
Number of sessions per month visualized in Metabase.
##### Number of Sessions per Channel[](#number-of-sessions-per-channel "Direct link to Number of Sessions per Channel")
If you're connecting your assistant to multiple channels, it could be useful to look at the number of sessions per channel, let's say per week. The query you would need for this metric is:
```
SELECT
"public"."rasa_sender"."channel" AS "channel",
"public"."rasa_sender"."first_seen" AS "timestamp",
count(distinct "public"."rasa_sender"."sender_key") AS "count"
FROM "public"."rasa_sender"
GROUP BY 1, 2
ORDER BY 1 ASC, 2 ASC
```
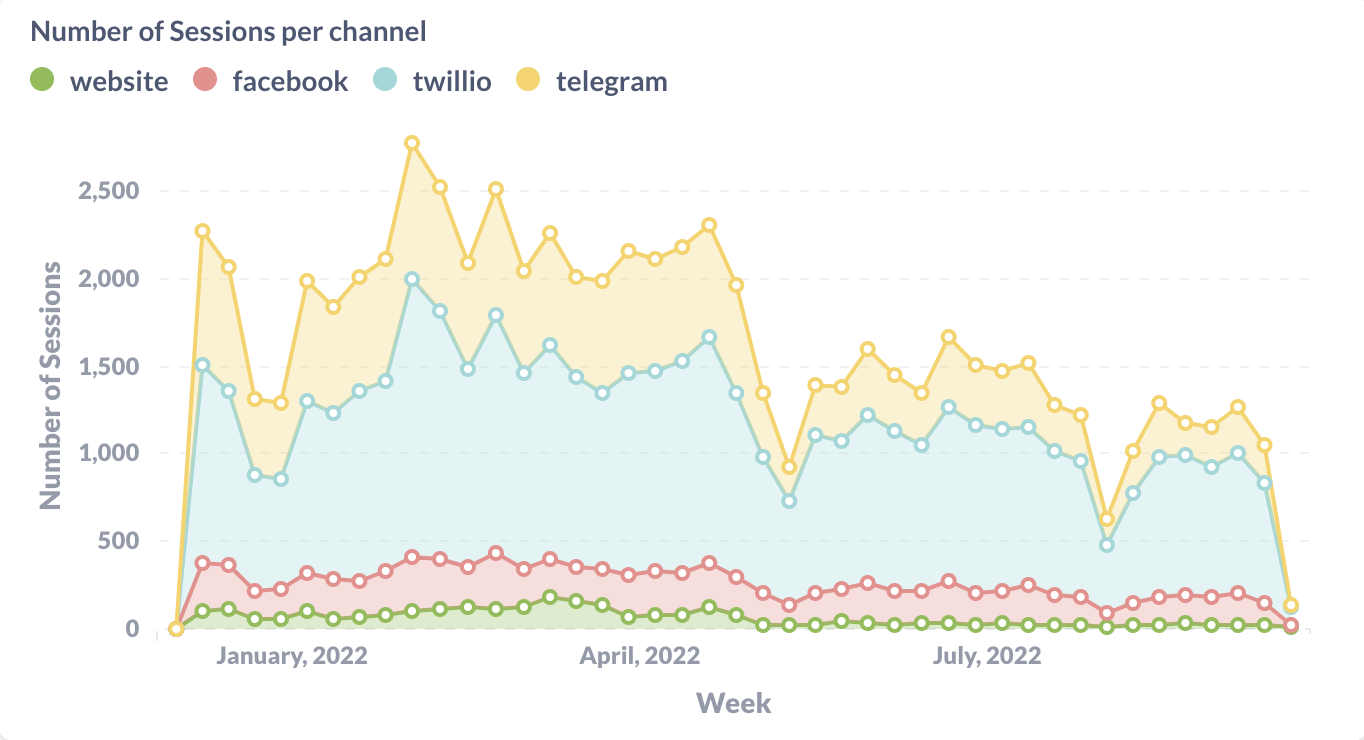
The number of sessions per channel as visualized in Metabase.
##### Abandonment Rate[](#abandonment-rate "Direct link to Abandonment Rate")
Abandonment rate can be defined in many different custom ways, however here we'll define it as a session ending without a user message after a specific message was uttered by the bot, e.g. `utter_ask_name`. You could adapt the metric to detect sessions ending without a user message after a specific set of intents. The SQL query would look like this:
```
WITH "sessions" AS (
SELECT
DISTINCT ON ("public"."rasa_event"."session_id") "public"."rasa_event"."session_id",
"public"."rasa_event"."timestamp" AS "timestamp",
(
CASE
WHEN "public"."rasa_bot_message"."template_name" = 'utter_ask_name'
THEN 1 ELSE 0
END
) AS "is_abandoned"
FROM "public"."rasa_event"
INNER JOIN "public"."rasa_bot_message"
ON "public"."rasa_event"."id" = "public"."rasa_bot_message"."event_id"
WHERE "public"."rasa_event"."event_type" = 'bot'
ORDER BY 1, 2 DESC
)
SELECT
date_trunc('month', "timestamp") AS "timestamp",
SUM("is_abandoned")::float / count(*) AS "abandonment_rate"
FROM "sessions"
GROUP BY 1
ORDER BY 1 ASC
```
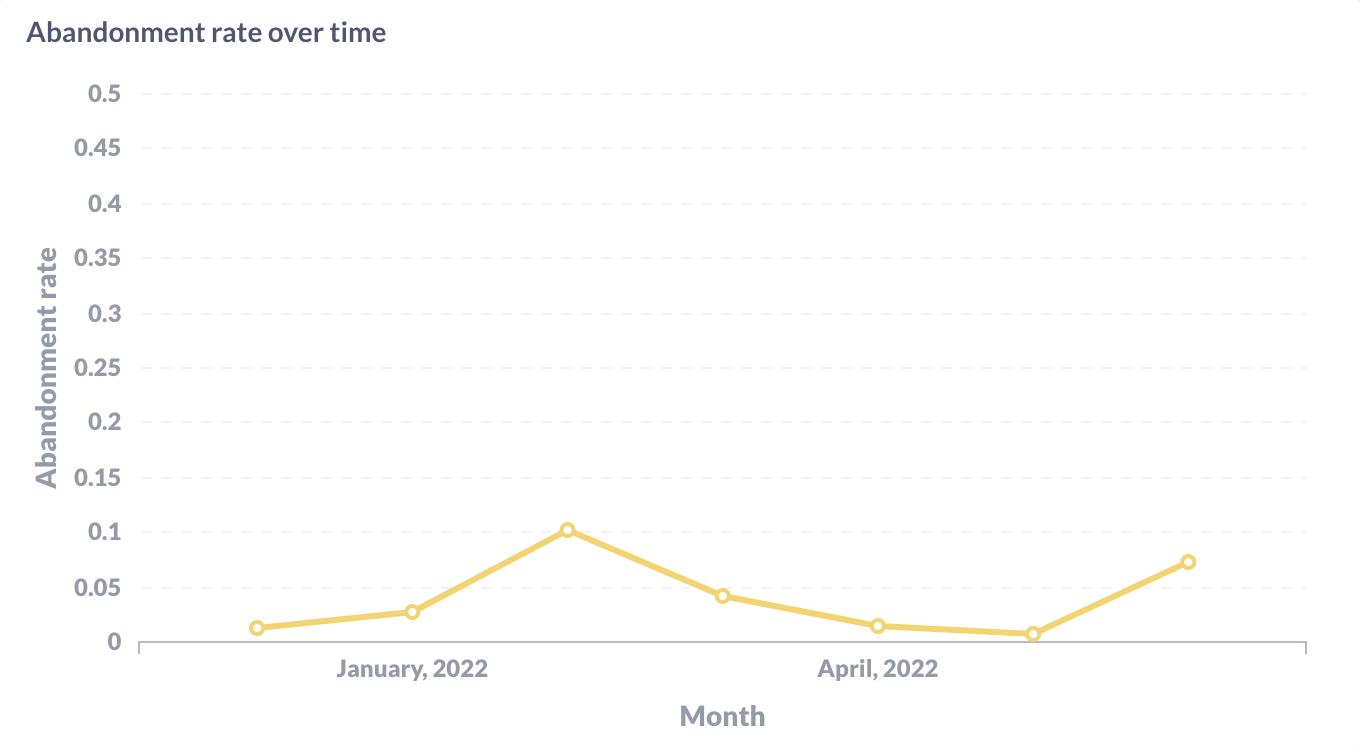
Abandonment rate visualized in Metabase.
##### Top N Flows in a Given Time Period[](#top-n-flows-in-a-given-time-period "Direct link to Top N Flows in a Given Time Period")
The query below selects the top 5 flows in a given time period (e.g. last 7 days):
```
SELECT rasa_flow_status.flow_identifier, COUNT(DISTINCT rasa_flow_status.session_id) AS "count"
FROM rasa_flow_status
# we only want the top 5 user defined flows, not the built-in flow usage
WHERE rasa_flow_status.flow_identifier NOT LIKE 'pattern_%' AND rasa_flow_status.inserted_at >= NOW() AT TIME ZONE 'UTC' - INTERVAL '7 days'
GROUP BY 1
ORDER BY 2 DESC, 1 ASC
LIMIT 5;
```
##### Escalation Rate[](#escalation-rate "Direct link to Escalation Rate")
To calculate the escalation rate for CALM-based assistants, you can use this query:
```
WITH "sessions" AS (
SELECT
rasa_llm_command.session_id AS "session_id",
date_trunc('month', rasa_llm_command.inserted_at) AS "timestamp",
(
CASE rasa_llm_command.command
WHEN 'human handoff'
THEN 1 ELSE 0
END
) AS "has_handoff_to_support"
FROM rasa_llm_command
),
"sessions_with_handoff" AS (
SELECT
"session_id",
"timestamp",
SUM("has_handoff_to_support") AS "has_handoff_to_support"
FROM "sessions"
GROUP BY 1, 2
)
SELECT
"timestamp",
100.0 * SUM("has_handoff_to_support") / count(*) AS "escalation_rate"
FROM "sessions_with_handoff"
GROUP BY 1
ORDER BY 1 ASC;
```
##### Resolution Rate[](#resolution-rate "Direct link to Resolution Rate")
The resolution rate is a measure of the number of conversations the assistant can resolve without human intervention. This metric can help you gain a better understanding of what happens during a conversation. To understand which conversations are resolved, you can identify which flows are completed in the `rasa_flow_status` table. You'll get the resolution rate for a particular flow with this sample query for CALM-based assistants:
```
WITH "completed_sessions" AS (
SELECT COUNT(DISTINCT rasa_flow_status.session_id) as "completed_count"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'transfer_money' AND rasa_flow_status.flow_status = 'completed'
)
SELECT 100 * (SELECT "completed_sessions". "completed_count" FROM "completed_sessions") / NULLIF(COUNT(DISTINCT rasa_flow_status.SESSION_ID), 0) as "resolution_rate_percentage"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'transfer_money' AND rasa_flow_status.flow_status = 'started';
```
##### Drop-Off Rate for a specific Flow[](#drop-off-rate-for-a-specific-flow "Direct link to Drop-Off Rate for a specific Flow")
The drop-off rate is a measure of the number of conversations that do not result in a completed flow. This metric is the inverse of the [resolution rate](#resolution-rate) (e.g. 100% - resolution\_rate).
You can further drill down in finding the interruption rate for a specific flow:
```
WITH "interrupted_sessions" AS (
SELECT COUNT(DISTINCT rasa_flow_status.session_id) as "interrupted_count"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'setup_recurrent_payment' AND rasa_flow_status.flow_status = 'interrupted'
)
SELECT 100 * (SELECT "interrupted_sessions". "interrupted_count" FROM "interrupted_sessions") / NULLIF(COUNT(DISTINCT rasa_flow_status.SESSION_ID), 0) as "resumption_rate_percentage"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'setup_recurrent_payment' AND rasa_flow_status.flow_status = 'started';
```
In addition, you can also calculate the % of interrupted flows which were resumed:
```
WITH "resumed_sessions" AS (
SELECT COUNT(DISTINCT rasa_flow_status.session_id) as "resumed_count"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'book_restaurant' AND rasa_flow_status.flow_status = 'resumed'
)
SELECT 100 * (SELECT "resumed_sessions". "resumed_count" FROM "resumed_sessions") / NULLIF(COUNT(DISTINCT rasa_flow_status.SESSION_ID), 0) as "resumption_rate_percentage"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'book_restaurant' AND rasa_flow_status.flow_status = 'interrupted';
```
##### Funnel Metrics[](#funnel-metrics "Direct link to Funnel Metrics")
Funnel metrics are a great way to understand how users are interacting with your assistant. You can use funnel metrics to understand how many users are completing each step of a flow or how many users are progressing through linked flows.
###### Count of Unique Sessions for Each Step in a Flow[](#count-of-unique-sessions-for-each-step-in-a-flow "Direct link to Count of Unique Sessions for Each Step in a Flow")
The query below selects the number of unique sessions for each step in a flow:
```
SELECT DISTINCT t1.flow_step_id, COUNT(DISTINCT t1.session_id) AS "session_count"
FROM rasa_dialogue_stack_frame t1
JOIN rasa_flow_status t2 ON t1.session_id = t2.session_id
WHERE t1.active_flow_identifier = 'setup_recurrent_payment' AND t2.flow_status NOT IN ('cancelled', 'completed')
GROUP BY 1
ORDER BY 1;
```
We remove the flows that were cancelled or completed to get a better understanding of the drop-off numbers.
###### Count of Unique Sessions for each Linked Flow[](#count-of-unique-sessions-for-each-linked-flow "Direct link to Count of Unique Sessions for each Linked Flow")
The query below selects the number of unique sessions for each linked flow in the chain formed of flow `replace_card` linking to flow `replace_eligible_card`:
```
SELECT
COUNT(DISTINCT CASE WHEN active_flow_identifier='replace_card' THEN session_id ELSE null END) as "replace_card_starts",
COUNT(DISTINCT CASE WHEN active_flow_identifier='replace_eligible_card' THEN session_id ELSE null END) as "replace_eligible_card_starts"
FROM rasa_dialogue_stack_frame;
```
For an overview of how conversation data is structured within the Analytics Pipeline, see the **Reference** section in the documentation on [Data Structure Reference](https://rasa.com/docs/docs/reference/api/analytics-data-structure-reference/)
---
#### Observability Metrics
Metrics are runtime measurements that capture indicators of a service’s availability and performance. Unlike tracing—which helps you understand the sequence of operations for a single request—metrics provide an aggregated statistical view across multiple requests or conversations. Typical examples include **average response time**, **throughput**, and **CPU/memory consumption**. Monitoring these helps you:
* Track the health of your service.
* Quickly detect and alert on outages or anomalies.
* Quantify the impact of code or infrastructure changes on performance.
When combined with tracing, metrics give you a complete view of your deployment behavior, making it easier to debug issues and optimize resource usage.
#### How To Use Metrics[](#how-to-use-metrics "Direct link to How To Use Metrics")
##### Enabling Metrics in Rasa[](#enabling-metrics-in-rasa "Direct link to Enabling Metrics in Rasa")
Rasa uses an [OpenTelemetry (OTEL) Collector](https://opentelemetry.io/docs/collector/) to collect metrics and send them to your desired backend (e.g., Prometheus, Datadog, etc.).
1. **Configure OTEL in your endpoints file (or Helm values):**
endpoints.yml
```
metrics:
type: otlp
endpoint: my-otlp-host:4318
insecure: false
service_name: rasa
root_certificates: ./tests/unit/tracing/fixtures/ca.pem
```
* `type: otlp` indicates you are using OpenTelemetry’s OTLP format.
* `endpoint` is the URL of the OTEL Collector or metrics backend.
* `service_name` is an identifier for your Rasa Pro service.
* `insecure`/`root_certificates` specify how TLS is handled.
2. **Use Tracing for a Complete View (Recommended):**
Metrics become even more powerful when paired with Tracing because tracing surfaces the sequence of internal method calls, while metrics aggregate their performance.
##### Custom Metrics Collected by Rasa[](#custom-metrics-collected-by-rasa "Direct link to Custom Metrics Collected by Rasa")
Once configured, Rasa automatically collects several custom metrics relevant to large language model (LLM) usage and overall assistant performance:
* **CPU and Memory Usage** of any LLM-based command generator (e.g., `CompactLLMCommandGenerator`, `SearchReadyLLMCommandGenerator`) at the time of making an LLM call.
* **Prompt Token Usage** for LLM-based command generators, provided the `trace_prompt_tokens` config property is enabled.
* **Method Call Durations** for LLM-specific components, such as:
* `EnterpriseSearchPolicy`
* `ContextualResponseRephraser`
* `CompactLLMCommandGenerator`
* `SearchReadyLLMCommandGenerator`
* **HTTP Request Metrics** for the Rasa client:
* Duration of requests to external services (action server, NLG server, etc.).
* Request size in bytes.
By collecting these telemetry metrics, you gain robust insights into how your assistant performs under real-world usage. You can proactively detect issues, understand resource consumption, and tailor your assistant’s architecture to provide the best possible experience for your users.
---
#### Tracing
Tracing is a key element of observability, providing visibility into how requests flow through your assistant’s distributed components (e.g. Rasa runtime, custom actions server, external services).
Observability is the practice of instrumenting systems so you can monitor, troubleshoot, and optimize them in production. In a conversational assistant, observability typically consists of:
* **Metrics**: Quantitative measurements (e.g. average response time)
* **Logs**: Event logs emitted by various components
* **Tracing**: Detailed timelines of requests and their paths across distributed services
**Tracing** stands out by focusing on the life cycle of each individual request. When a user sends a message, the request might pass through your assistant’s LLM-based command generator, custom action server, flow logic, and external APIs. Tracing captures these hops along with relevant metadata—giving you a precise picture of where bottlenecks or unexpected behaviors may be occurring.
#### Why Do You Need Tracing in Your Assistant[](#why-do-you-need-tracing-in-your-assistant "Direct link to Why Do You Need Tracing in Your Assistant")
When building pro-code conversational AI solutions, teams need to quickly answer questions like:
* **What exactly happened when the assistant processed a user message?**
See which flows were invoked, which custom actions ran, which commands got generated, and why.
* **Why is my assistant slow or occasionally unresponsive?**
Is the slowness coming from an LLM call, a vector store query, or a custom action HTTP request?
* **How can I debug or optimize custom action performance?**
Pinpoint exactly where your code is spending time—e.g. upstream or downstream dependencies in your custom actions.
* **How can I track LLM input and outputs, its usage and costs?**
Trace the LLM’s prompt token usage, temperature settings, etc. to monitor usage in real time.
By having trace data in one place, you can correlate user behavior, system logs, and LLM calls to rapidly diagnose and fix issues. In production, distributed tracing is often the fastest path to root-cause analysis and performance tuning.
#### How to Enable Tracing in Rasa[](#how-to-enable-tracing-in-rasa "Direct link to How to Enable Tracing in Rasa")
Enabling tracing in Rasa is straightforward—simply connect it to a supported tracing backend or collector. Once configured, Rasa emits trace spans for conversation processing, LLM calls, flow transitions, custom actions, and more.
##### 1. Choose Your Tracing Backend or Collector[](#1-choose-your-tracing-backend-or-collector "Direct link to 1. Choose Your Tracing Backend or Collector")
Rasa supports:
* **Jaeger** A popular open source end-to-end distributed tracing system.
* **OTEL Collector (OpenTelemetry Collector)** A vendor-agnostic approach that can forward data to Jaeger, Zipkin, or other tracing backends.
In addition, Rasa also supports a direct integration to an LLM focussed tracing and observability tool - **[Langfuse](https://langfuse.com/)**. Traces in Langfuse provide an in-depth analysis of each LLM call made during each turn of a conversation allowing for quicker accuracy, speed and cost optimizations of LLM calls.
##### 2. Configure `tracing` in Your Endpoints[](#2-configure-tracing-in-your-endpoints "Direct link to 2-configure-tracing-in-your-endpoints")
In your `endpoints.yml` or Helm values, add a `tracing:` block. For example, to configure Jaeger and Langfuse as tracing tools:
endpoints.yml
```
tracing:
- type: jaeger
host: localhost
port: 6831
service_name: rasa
sync_export: ~
- type: langfuse
host: https://cloud.langfuse.com # can be localhost if self-hosted
public_key: ${LANGFUSE_PUBLIC_KEY}
private_key: ${LANGFUSE_PRIVATE_KEY}
```
Or to configure an OTEL collector and langfuse:
endpoints.yml
```
tracing:
- type: otlp
endpoint: my-otlp-host:4318
insecure: false
service_name: rasa
root_certificates: ./path/to/ca.pem
- type: langfuse
host: https://cloud.langfuse.com # can be localhost if self-hosted
public_key: ${LANGFUSE_PUBLIC_KEY}
private_key: ${LANGFUSE_PRIVATE_KEY}
```
Once you’ve done this, tracing is automatically enabled for both the runtime, the custom action server and each of the LLM calls made in between. No additional code is needed to start collecting standard spans.
For more detailed information on configuration options, head over to the reference section of [Jaegar/OLTP collectors](https://rasa.com/docs/docs/reference/integrations/tracing/) and [langfuse integration](https://rasa.com/docs/docs/reference/integrations/langfuse/)
##### 3. (Optional) Instrument Custom Code[](#3-optional-instrument-custom-code "Direct link to 3. (Optional) Instrument Custom Code")
If you want deeper insights into custom action performance, you can add custom spans to specific parts of your code. For example, you can retrieve the tracer in your action server and wrap code sections in manual spans. This is especially useful for investigating complex logic or third-party dependencies.
info
For a full list of traced events and code snippets for custom instrumentation, see our [reference documentation](https://rasa.com/docs/docs/reference/integrations/tracing/).
#### Best Practices for Tracing[](#best-practices-for-tracing "Direct link to Best Practices for Tracing")
1. **Start Tracing Early**
Instrument your assistant from the beginning of development—waiting until there’s a performance issue might make it harder to diagnose.
2. **Trace Only Where Needed**
While you can trace everything, capturing very verbose details (like prompt token usage) in production can add overhead. Often, it’s better to enable advanced tracing features in test or staging environments, then turn them off once you identify the root cause.
3. **Use a Single Runtime Trace Collector**
Sending data to a single OTEL or Jaeger collector is simpler to maintain and ensures all trace spans appear in one place—important for diagnosing end-to-end issues.
4. **Correlate with Logs & Metrics**
Traces alone might not be sufficient. Combine them with logs (e.g. error messages) and metrics (e.g. average token usage per conversation) to get a 360° view of system health.
5. **Leverage the Dialogue Stack**
CALM’s dialogue stack concept means multiple flows can be active at once. Tracing helps you see which flow is top-of-stack at any given time—and why that flow was triggered.
6. **Trace LLM Calls Separately**
Rasa uses multiple LLM based components that are all critical to fulfilling a single turn of a conversation. A lot of low effort high value runtime optimizations are found by deeply analyzing input and output of each LLM call, token usage to monitor costs, latencies to manage responsiveness of the agent. Ensure you have a langfuse instance connected and configured to your rasa agent to catch issues early on in production.
7. **Focus on Action Server Performance**
Custom actions are often the biggest source of latencies. Use tracing spans around external API calls in your action code to detect slow dependencies.
Once configured, tracing gives you a powerful lens into how your assistant orchestrates the user conversation, dialogues, LLM calls, and custom actions. It is an essential tool for ensuring your assistant runs reliably in production, and for enabling fast, data-driven debugging when issues arise.
---
### Build
#### Assistant Memory (Slots)
In a conversational experience, context matters just as much as the latest user message. Information derived either from the situational context, user profiles or user provided information—like a user’s age, an appointment date, or a selected product—often influences how the assistant behaves later on.
**Slots** provide this memory in CALM. They preserve data about the user or the external world so that your assistant can leverage it for business logic, personalization, or simply to maintain continuity. If a user provides their email address once, you don’t want them to repeat it in every subsequent interaction. Slots let you store that information and use it across the entire conversation.
Slots in CALM are key-value pairs that represent stateful information your assistant has collected or inferred. Each slot has:
* A **name** (e.g., `phone_number` or `user_name`)
* A **type** (e.g., `text`, `boolean`, `categorical`, etc.)
* (Optionally) a **default** or **initial** value
CALM primarily depends on an [LLM-based **Command Generator**](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/) to decide what to do next—**including** issuing commands that set slot values. However, you can still configure slot mappings to rely on an NLU pipeline if you choose to combine NLU-based extraction with CALM. In that case, the `NLUCommandAdapter` can issue `set slot` commands based on extracted entities or intents.
When building flows, you’ll often see [collect steps](https://rasa.com/docs/docs/reference/primitives/flow-steps/#collect) that explicitly request slot values from users. But at any point in the conversation, the LLM can also set or update slots—if you permit it via the slot’s configuration.
#### How to Write Slots[](#how-to-write-slots "Direct link to How to Write Slots")
Slots are defined in your **domain** file under the `slots:` key. Each slot entry includes at least:
* The slot **name**
* The slot **type** (e.g., `text`, `bool`, `float`, `categorical`, `any`, etc.)
* (Optionally) `mappings` that specify how the slot should be filled
Below is a minimal example of a slot definition using LLM-based filling:
domain.yml
```
slots:
user_name:
type: text
mappings:
- type: from_llm
```
In this example:
* `user_name` is a `text` slot.
* It will be **filled by the LLM** at any point in the conversation, if the LLM issues the correct `set slot` command.
You can also combine an NLU pipeline (for classic intent/entity extraction) with CALM by giving the slot an NLU-based mapping as well, for example:
domain.yml
```
slots:
user_name:
type: text
mappings:
- type: from_entity
entity: person
- type: from_llm
```
In this case, the `NLUCommandAdapter` uses the recognized `person` entity to set the `user_name` slot. However, if no value is extracted for the `person` entity, then the LLM gets a chance to issue a value for it.
You can read more [here](https://rasa.com/docs/docs/reference/primitives/slots/#impact-of-slot-mappings-in-different-scenarios) about how a combination of NLU-based extractors and LLMs can be used to efficiently extract slots.
##### Defining Slots in Flows[](#defining-slots-in-flows "Direct link to Defining Slots in Flows")
Within a flow, you often collect slot values using the `collect` step:
flows.yml
```
flows:
my_flow:
description: My flow
steps:
# ...
- collect: user_name
description: "The user’s full name"
```
This step instructs the LLM that you want to retrieve `user_name` from the user. If the user’s response is accepted, the LLM issues a `set slot` command, and `user_name` gets stored in the conversation state.
#### How Does Slot Validation Work in CALM?[](#how-does-slot-validation-work-in-calm "Direct link to How Does Slot Validation Work in CALM?")
Slot validation ensures that the values you store are meaningful or properly formatted for your use case. CALM offers three paths for validating slots:
1. **Global slot validation defined on a domain level**
Domain-level slot validation lives in the domain.yml file under each slot definition and it enforces universal, technical constraints (e.g., correct formatting, correct data type) whenever a slot is set or updated during the conversation, which ensures that if the user or the LLM tries to set a slot that doesn’t meet the condition, the assistant rejects it right away—before continuing the conversation. This behaviour is controlled by the `refill_utter` property.
Example:
domain.yml
```
slots:
phone_number:
type: text
mappings:
- type: from_llm
validation:
rejections:
- if: not (slots.phone_number matches "^\([0-9]{3}\) [0-9]{3}-[0-9]{4}$")
utter: utter_invalid_phone_number
refill_utter: "utter_refill_phone_number"
```
This domain-level validation is strictly for basic data correctness—things like format, range, or type checks. It’s not meant to handle more advanced, contextual logic (like checking if the phone number is already associated with an account in your database).
2. **Lightweight validations with rejections on a flow-level**
In the flow’s `collect` step, you can define `rejections` that check the format or basic conditions on the extracted slot value. If the condition is not met, the assistant rejects the slot value and prompts the user again.
flows.yml
```
flows:
my_flow:
description: My flow
steps:
# ...
- collect: phone_number
description: "User's phone number in (xxx) xxx-xxxx format"
rejections:
- if: not ( slots.phone_number matches "^\([0-9]{3}\) [0-9]{3}-[0-9]{4}$" )
utter: utter_invalid_phone_number
```
This allows validation checks on the level of the collect step (e.g., contextual logic, matching a regex, ensuring a numeric range, etc.) without writing any custom code.
3. **Advanced validations with custom actions**
If you need to call an external API or database to decide whether a slot value is valid, you can move the validation logic to a custom action:
flows.yml
```
flows:
my_flow:
description: My flow
steps:
# ...
- action: action_check_phone_number_has_account
next:
- if: slots.phone_number_has_account
then:
- action: utter_inform_phone_number_has_account
- set_slots:
- phone_number: null
next: "collect_phone_number"
```
The [custom action](https://rasa.com/docs/docs/pro/build/custom-actions/) can accept or reject the new slot value. Rejecting the value might reset the slot and re-ask for the user input, or redirect the user to a different flow.
For more detail on advanced slot mappings, slot types and slot validation, visit the [page on Slots](https://rasa.com/docs/docs/reference/primitives/slots/) in the Reference.
---
#### Configuring Enterprise Search (RAG)
A conversational assistant can broadly serve two types of user journeys:
* **Transactional**: Focus on structured steps and business logic (for example, filling in a form, canceling an order, or updating a user’s personal information). These are typically orchestrated by **flows** that strictly follow a guided script.
* **Informational**: Focus on generating free-form answers to user queries by retrieving knowledge from large or varied sources of information.
For informational use cases, the recommended approach in CALM is based on [Enterprise Search](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/), a feature that integrates RAG (Retrieval-Augmented Generation) Pipelines. When users ask an open-ended or factual question, the system finds relevant documents from a vector store or a custom data source and then uses an LLM to generate the best possible answer. This allows you to create knowledge-driven experiences without manually coding every possible Q\&A flow.
##### What is RAG?[](#what-is-rag "Direct link to What is RAG?")
Retrieval-Augmented Generation (RAG) is a two-step pipeline:
1. **Retrieve**: Search for relevant content in a document store or vector database based on the user’s latest query (and potentially some conversation history).
2. **Generate**: Use an LLM to produce a response guided by the retrieved content.
This approach keeps your domain knowledge centralized and up-to-date, rather than hard-coding static answers or duplicating content in many flows.
#### How to Connect RAG Pipelines[](#how-to-connect-rag-pipelines "Direct link to How to Connect RAG Pipelines")
In Rasa Pro, retrieval-based capabilities are provided by the **Enterprise Search Policy**. A typical setup involves:
1. **Collecting and Vectorizing Documents**
* Prepare your knowledge-base documents (e.g., PDF text, product manuals, FAQ data) and store them in your chosen vector database.
* You can ingest documents with a data ingestion pipeline (owned by you).
* Ensure the same embedding model is configured for both your ingestion pipeline and the assistant’s Enterprise Search Policy so that document vectors match queries.
2. **Configuring the Command Generator**
* In your `config.yml`, ensure that you are using the [`SearchReadyLLMCommandGenerator`](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#searchreadyllmcommandgenerator).
3. **Configuring Enterprise Search Policy**
* In your `config.yml`, add or enable the [`EnterpriseSearchPolicy`](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/).
* Configure it to point to the vector store where your documents live (e.g. “faiss,” “milvus,” “qdrant,” or a custom retriever).
* Optionally, set the LLM and embeddings provider if you want to customize them (for instance, using your own fine-tuned model).
4. **Linking the Assistant to the Vector Store**
* In your `endpoints.yml`, specify the connection details for the vector store (host, port, collection name, etc.).
* During runtime, when a user query arrives, the policy uses the vector store to fetch relevant content.
5. **Triggering Enterprise Search**
* Whenever the assistant (command generator) detects a knowledge-oriented question, it triggers the Enterprise Search Policy (via the built-in `pattern_search` pattern).
* The policy retrieves relevant documents, constructs a prompt including those documents, and asks the LLM to generate a final answer.
For more details on each step (e.g., how to configure your Qdrant or Milvus hosts, how to ingest documents with a script, or advanced prompt engineering), see the [Enterprise Search Policy reference](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/).
#### When to Use RAG vs. When to Use Flows[](#when-to-use-rag-vs-when-to-use-flows "Direct link to When to Use RAG vs. When to Use Flows")
Transactional interactions—where precise multi-step logic or data gathering is required—are best handled by **flows**. They let you define a structured, guided path through conversation steps: for example, filling out a form, verifying identity, or applying consistent logic for an enterprise workflow.
RAG is more suitable for **open-ended or informational** content:
* **Single Source of Truth**: Documents are stored and updated centrally, so answers are always drawn from the latest company data. This allows multiple teams or lines of business (LOBs) to tap into one knowledge backbone rather than duplicating content in separate assistants.
* **Long-Tail Query Handling**: RAG can address a wide variety of user questions—even ones you didn’t explicitly anticipate—by retrieving information from your vector store.
* **Scalability**: You don’t need to write new flows every time documentation changes. As your knowledge base grows, RAG answers can adapt automatically.
Often, a **hybrid** approach works well:
* Transactional requests (e.g., “Open a support ticket” or “Cancel my subscription flow”) are handled by flows on the **dialogue stack**.
* Informational requests (e.g., “How do I reset my password?”) trigger a retrieval call to your knowledge base.
If the user switches from an in-progress flow to an informational question, the assistant can **push** the “knowledge search” pattern onto the dialogue stack, answer it via RAG, and then continue the previous flow. CALM’s dialogue stack will manage which flow is on top.
#### How to Connect Vector Stores[](#how-to-connect-vector-stores "Direct link to How to Connect Vector Stores")
Rasa supports an out-of-the-box integration with:
* [FAISS](https://ai.meta.com/tools/faiss/) (default, in-memory for quick prototyping)
* [Milvus](https://github.com/milvus-io/milvus/)
* [Qdrant](https://qdrant.tech/)
You can configure any of these by:
1. **Setting `vector_store.type`** in `config.yml` to `faiss`, `milvus`, or `qdrant`.
2. **Adding Connection Details** in `endpoints.yml`. For example, if you’re using Qdrant, you’ll include things like `host`, `port`, and `collection`.
3. **(Optional) Adjusting Thresholds** for similarity filtering, or specifying advanced parameters (like gRPC ports or custom authentication).
Head to the [reference documentation](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/#vector-store) of above vector stores to know more about their integration with CALM.
#### Custom Information Retrievers[](#custom-information-retrievers "Direct link to Custom Information Retrievers")
For use cases where you’re:
* Using a proprietary search engine,
* Working with specialized data sources or security constraints,
* Or you simply want more control over the retrieval logic,
Rasa allows you to plug in a **Custom Information Retriever**. This means you can override how the assistant executes a “search” step—whether it’s via a custom REST endpoint, a local database, or a special re-ranking algorithm.
**High-Level Steps to Implement a Custom Retriever**:
1. **Create a Python Class** that inherits from Rasa’s `InformationRetrieval` interface and implements:
* A `connect` method to establish a connection (if needed).
* A `search` method to query your system and return relevant documents in the expected format.
2. **Reference Your Custom Class** in `config.yml` under `vector_store.type`, using the Python module path, e.g.:
config.yml
```
# ...
policies:
- name: EnterpriseSearchPolicy
vector_store:
type: "my_custom_module.MyRetriever"
```
3. **Implement Any Additional Logic** needed for features like slot-based filtering, custom embeddings, or advanced caching.
By extending the information retrieval flow yourself, you can control precisely how documents are found, scored, and returned—while still benefiting from Rasa Pro’s LLM-driven prompt generation and conversation management.
**Further Reading**
1. For more details on custom information retrieval, head over to the Reference section on [Custom Information Retrievers](https://rasa.com/docs/docs/reference/config/policies/custom-information-retrievers/)
2. For in-depth instructions on connecting a specific database, examples of ingestion scripts, or advanced policy parameters (such as customizing the LLM prompt template), head to [Enterprise Search Policy reference](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/).
---
#### Configuring Your Assistant
You can customise many aspects of how your assistant project works by modifying the following files: `config.yml`, `endpoints.yml`, and `domain.yml`.
#### Configuration File[](#configuration-file "Direct link to Configuration File")
The `config.yml` file defines how your Rasa assistant processes user messages. It specifies which components, policies, and language settings your assistant will use. Here's the minimal configuration required to run a CALM assistant:
config.yml
```
recipe: default.v1
language: en
pipeline:
- name: CompactLLMCommandGenerator
policies:
- name: FlowPolicy
```
Below are the main parameters you can configure.
##### Recipe[](#recipe "Direct link to Recipe")
* Rasa provides a default graph recipe: `default.v1`. For most projects, the default value is sufficient.
* In case you're running ML experiments or ablation studies and want to add a custom graph recipe, [this guide has you covered](https://rasa.com/docs/docs/reference/config/components/graph-recipe/).
##### Language[](#language "Direct link to Language")
* The `language` key sets the primary language your assistant supports. Use a [two-letter ISO 639-1 code](https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes) (e.g., `"en"` for English).
* The `additional_languages` key lists codes of other languages your assistant supports.
👉 [Learn more about language configuration](https://rasa.com/docs/docs/reference/config/overview/#language)
##### Pipeline[](#pipeline "Direct link to Pipeline")
The `pipeline` section lists the components that process the latest user message and produce **commands** for the conversation. The main component in your pipeline is the `LLMCommandGenerator`.
```
pipeline:
- name: CompactLLMCommandGenerator
llm:
model_group: openai_llm
flow_retrieval:
embeddings:
model_group: openai_embeddings
user_input:
max_characters: 420
```
👉 [See the full set of configurable parameters](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/)
##### Policies[](#policies "Direct link to Policies")
The `policies` key lists the dialogue policies your assistant will use to progress the conversation. For CALM, you need at least the `FlowPolicy`. It doesn’t require any additional configuration parameters.
👉 [Learn more about policies](https://rasa.com/docs/docs/reference/config/policies/overview/)
##### Assistant ID[](#assistant-id "Direct link to Assistant ID")
The `assistant_id` key defines the unique identifier of your assistant. This ID is included in every event’s metadata, alongside the model ID. Use a distinct value to help differentiate between multiple deployed assistants.
```
assistant_id: my_assistant
```
caution
If this required key is missing or still set to the default placeholder, a random assistant ID will be generated and added to your configuration each time you run `rasa train`.
#### Endpoints[](#endpoints "Direct link to Endpoints")
The `endpoints.yml` file defines how your assistant connects to key services — like where to store conversations, execute custom actions, fetch trained models, or generate responses.
Below are the main parameters you can configure.
##### Tracker Store — Where conversations are stored[](#tracker-store--where-conversations-are-stored "Direct link to Tracker Store — Where conversations are stored")
The `tracker_store` determines where Rasa keeps track of conversations. This is where your assistant remembers past interactions and makes decisions based on conversation context. You can store trackers in a file, a database (like PostgreSQL or MongoDB), or other storage backends.
👉 [How to configure tracker stores](https://rasa.com/docs/docs/reference/integrations/tracker-stores/)
##### Event Broker — Where conversation events are sent[](#event-broker--where-conversation-events-are-sent "Direct link to Event Broker — Where conversation events are sent")
Conversation history is comprised of **events** — every user message, action, or slot update is one. The `event_broker` sends these to other systems (e.g. for monitoring, analytics, or syncing with a data warehouse). It’s especially useful in production setups.
👉 [How to configure event brokers](https://rasa.com/docs/docs/reference/integrations/event-brokers/)
##### Action Endpoint — Where custom code runs[](#action-endpoint--where-custom-code-runs "Direct link to Action Endpoint — Where custom code runs")
When your assistant needs to do something dynamic — like fetching user data or making an API call — it uses custom actions. The `action_endpoint` tells Rasa where your action server is running so it can call it when needed.
👉 [How to configure action server](https://rasa.com/docs/docs/reference/integrations/action-server/actions/)
##### Models — Where trained models live[](#models--where-trained-models-live "Direct link to Models — Where trained models live")
The `models` section lets you configure remote model storage, such as a cloud bucket or server, where Rasa can automatically fetch the latest trained model at runtime. This is useful for CI/CD workflows where models are trained and uploaded externally.
👉 [How to configure model storage](https://rasa.com/docs/docs/reference/integrations/model-storage/)
##### Model Groups — LLM and embedding models[](#model-groups--llm-and-embedding-models "Direct link to Model Groups — LLM and embedding models")
The `model_groups` section is used to define LLMs and embedding models used by features like retrieval, rephraser, and command generator. You specify provider, type, and settings for each group.
👉 [How to configure model groups](https://rasa.com/docs/docs/reference/config/components/llm-configuration/#model-groups)
##### Lock Stores — Prevent processing conflicts[](#lock-stores--prevent-processing-conflicts "Direct link to Lock Stores — Prevent processing conflicts")
The `lock_store` manages conversation-level locks to ensure that only one message processor handles a message at a time. This prevents race conditions when multiple messages for the same user arrive close together — a common scenario in voice assistants or high-traffic setups.
Message processors are tied to Rasa processes, and deployment setup affects the lock store you should use:
* Single Rasa process (typically for development): the in-memory lock store is sufficient.
* Multiple Rasa processes in one pod (i.e. multiple Sanic workers): use the `RedisLockStore` or `ConcurrentRedisLockStore`.
* Multiple Rasa processes across multiple pods: we recommend using the `ConcurrentRedisLockStore`, as described [here](https://rasa.com/docs/docs/reference/integrations/lock-stores/#description).
👉 [How to configure lock store](https://rasa.com/docs/docs/reference/integrations/lock-stores/#custom-lock-store)
##### Vector Stores — Enterprise search and flow retrieval[](#vector-stores--enterprise-search-and-flow-retrieval "Direct link to Vector Stores — Enterprise search and flow retrieval")
If your assistant uses Enterprise Search Policy, the `vector_store` allows you to define where the vector embeddings of the source documents are stored. It can also be used to connect to a search API that returns a set of relevant documents given a keyword or a search query.
👉 [How to configure Enterprise Search (RAG)](https://rasa.com/docs/docs/pro/build/configuring-enterprise-search/)
👉 [How to customize flow retrieval](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#customizing-flow-retrieval)
##### NLG Server — External response generator[](#nlg-server--external-response-generator "Direct link to NLG Server — External response generator")
If you want the assistant’s responses to be generated dynamically by an external system (like an LLM-based server), you can configure an `nlg` endpoint. This allows you to update responses without retraining your model. To use this, the endpoint must point to an HTTP server with a `/nlg` path. For example:
```
nlg:
url: http://localhost:5055/nlg
```
👉 [How to configure NLG server](https://rasa.com/docs/docs/reference/integrations/nlg/)
##### Contextual Response Rephraser — Rephrase responses with LLMs[](#contextual-response-rephraser--rephrase-responses-with-llms "Direct link to Contextual Response Rephraser — Rephrase responses with LLMs")
Rasa’s built-in rephraser can automatically rewrite your templated responses using an LLM. It preserves intent and facts while making responses sound more natural or varied based on conversation context.
To enable it:
```
nlg:
type: rephrase
```
👉 [Learn more about the rephraser](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/)
##### Silence Handling — Timeout before triggering fallback[](#silence-handling--timeout-before-triggering-fallback "Direct link to Silence Handling — Timeout before triggering fallback")
The `silence_timeout` setting controls how long the assistant waits for a response before assuming the user is silent. Silence timeouts help your assistant handle situations where the user doesn’t respond. For now, this setting only works with voice-stream channels, such as:
* Twilio Media Streams
* Browser Audio
* Genesys
* Jambonz Stream
* Audiocodes Stream
Default is 7 seconds, but you can override the value:
```
interaction_handling:
global_silence_timeout: 7
```
👉 [Learn more about silence handling](https://rasa.com/docs/docs/reference/config/overview/#silence-timeout-handling)
#### Domain[](#domain "Direct link to Domain")
The `domain.yml` file defines the universe your assistant operates in — including its responses, memory (slots), and supported actions. Example:
domain.yml
```
version: "3.1"
session_config:
session_expiration_time: 60 # value in minutes, 0 means no timeout
carry_over_slots_to_new_session: true
responses:
utter_greeting:
- text: "Hello! How can I help you today?"
slots:
user_name:
type: text
initial_value: null
actions:
- action_greet_user
```
##### What’s in the Domain[](#whats-in-the-domain "Direct link to What’s in the Domain")
* [Responses](https://rasa.com/docs/docs/reference/primitives/responses/): Templated messages your assistant can send.
* [Slots](https://rasa.com/docs/docs/reference/primitives/slots/): Data your assistant stores about the user.
* [Actions](https://rasa.com/docs/docs/reference/primitives/actions/): Logic or service calls your assistant can perform.
* [Session Configuration](https://rasa.com/docs/docs/reference/config/domain/#session-configuration): Controls when conversations reset.
👉 [Learn more about Domain file](https://rasa.com/docs/docs/reference/config/domain/)
---
#### Integrating an MCP server
New Beta Feature in 3.14
Rasa supports native integration of MCP servers.
This feature is in a beta (experimental) stage and may change in future Rasa versions. We welcome your feedback on this feature.
#### Overview[](#overview "Direct link to Overview")
Rasa integrates with [Model Context Protocol (MCP)](https://modelcontextprotocol.io/) servers to connect your agent to external APIs, databases, and other services. MCP servers expose tools that your agent can [use directly in flows](https://rasa.com/docs/docs/pro/build/mcp-integration/#using-an-mcp-tool-in-a-flow) or provide to [ReAct style sub agents](https://rasa.com/docs/docs/pro/build/mcp-integration/#dynamic-selection-of-tools-in-an-autonomous-step) for dynamic decision-making.
#### Defining an MCP Server[](#defining-an-mcp-server "Direct link to Defining an MCP Server")
Define your MCP servers in the `endpoints.yml` file:
endpoints.yml
```
mcp_servers:
- name: trade_server
url: http://localhost:8080
type: http
```
For detailed information on available authentication methods and other parameters, head over to the [reference page](https://rasa.com/docs/docs/reference/integrations/mcp-servers/).
#### Using an MCP tool in a flow[](#using-an-mcp-tool-in-a-flow "Direct link to Using an MCP tool in a flow")
Use MCP tools directly in flows with the [`call` step](https://rasa.com/docs/docs/reference/primitives/flow-steps/#calling-an-mcp-tool), specifying input/output mappings:
flows.yml
```
flows:
buy_order:
description: helps users place a buy order for a particular stock
steps:
- collect: stock_name
- collect: order_quantity
- action: check_feasibility
next:
- if: slots.order_feasible is True
then:
- call: place_buy_order # MCP tool name
mcp_server: trade_server # MCP server where tool is available
mapping:
input:
- param: ticker_symbol # tool parameter name
slot: stock_name # slot to send as value
- param: quantity
slot: order_quantity
output:
- slot: order_status # slot to store results
value: result.structuredContent.order_status.success
- else:
- action: utter_invalid_order
next: END
```
This way of directly invoking tools from flows avoids having to write any [custom action code](https://rasa.com/docs/docs/pro/build/custom-actions/) just for the purpose of integrating with external APIs.
##### Tool Results and Output Handling[](#tool-results-and-output-handling "Direct link to Tool Results and Output Handling")
MCP tools return results in two possible formats:
###### Structured Content[](#structured-content "Direct link to Structured Content")
When tools provide an output schema (see [for example](https://modelcontextprotocol.io/specification/2025-06-18/server/tools#output-schema)), you get structured data as output:
```
{
"result": {
"structuredContent": {
"order_status": {"success": true, "order_id": "bcde786f1"}
}
}
}
```
In such a case, specific values from the resulting dictionary can be accessed using the dot notation:
```
- call: place_buy_order
mcp_server: trade_server
...
output:
- slot: order_status
value: result.structuredContent.order_status.success
```
###### Unstructured Content[](#unstructured-content "Direct link to Unstructured Content")
When the invoked tool has no output schema is defined, the entire output is captured as a serialized string:
```
{
"result": {
"content": [
{
"type": "text",
"text": "{\"order_status\": {\"success\": true, \"order_id\": \"bcde786f1\"}"
}
],
}
}
```
You can still use the dot notation to capture the output but the complete serialized string will have to be captured in the slot.
```
output:
- slot: order_data
value: result.content
```
#### Dynamic selection of tools in an autonomous step[](#dynamic-selection-of-tools-in-an-autonomous-step "Direct link to Dynamic selection of tools in an autonomous step")
Flows can also contain [**autonomous** steps](https://rasa.com/docs/docs/reference/primitives/flow-steps/#autonomous-steps), where the business logic is dynamically figured out at runtime, based on the available context and tools from the MCP server. In order to do so, Rasa requires creation of [ReAct sub agents](https://rasa.com/docs/docs/reference/config/agents/react-sub-agents/).
##### Sub agent Configuration[](#sub-agent-configuration "Direct link to Sub agent Configuration")
Each sub agent which has access to MCP tools operates in a [ReAct](https://arxiv.org/abs/2210.03629) loop, determining which tools to call based on the conversation context.
To create a sub agent, add a folder specific to that agent in the `sub_agents/` directory of your rasa agent:
```
your_project/
├── config.yml
├── domain/
├── data/flows/
└── sub_agents/
└── stock_explorer/
├── config.yml
└── prompt_template.jinja2 # optional
```
Configure the agent in `sub_agents/stock_explorer/config.yml`:
sub\_agents/stock\_explorer/config.yml
```
# Basic agent information
agent:
name: stock_explorer
description: "Agent that helps users research and analyze stock options"
# MCP server connections
connections:
mcp_servers:
- name: trade_server
include_tools: # optional - specify which tools to include
- find_symbol
- get_company_news
- apply_technical_analysis
- fetch_live_price
exclude_tools: # optional - tools to exclude
- place_buy_order
- view_positions
```
More details on available configuration parameters can be found in the [reference section](https://rasa.com/docs/docs/reference/config/agents/react-sub-agents/#configuration).
##### Invoking a sub agent[](#invoking-a-sub-agent "Direct link to Invoking a sub agent")
A sub agent can be invoked from a flow using the [`call` step](https://rasa.com/docs/docs/reference/primitives/flow-steps/#autonomous-steps):
flows.yml
```
flows:
stock_investment_research:
description: helps research and analyze stock investment options
steps:
- call: stock_explorer # runs until agent signals completion
```
A sub agent remains active until it signals a completion by itself or it meets a defined criteria, for e.g. -
flows.yml
```
flows:
stock_investment_research:
description: helps research and analyze stock investment options
steps:
- call: stock_explorer
exit_if:
- slots.user_satisfied is True
```
Here, `stock_explorer` agent will keep running until the `user_satisfied` slot is not set to `True`.
To read more details about the runtime execution of a ReAct style sub agent inside Rasa, head over to the [reference documentation](https://rasa.com/docs/docs/reference/config/agents/overview-agents/#how-rasa-interacts-with-sub-agents).
##### Selective Tool Access[](#selective-tool-access "Direct link to Selective Tool Access")
You can have fine-grained control over the specific MCP tools a sub agent can access by using the `include_tools` and `exclude_tools` properties in the agent configuration:
sub\_agents/restricted\_agent/config.yml
```
connections:
mcp_servers:
- name: trade_server
include_tools: # only allow specific tools
- find_symbol
- get_company_news
exclude_tools: # explicitly block dangerous operations
- place_buy_order
- delete_account
- name: analytics_server
exclude_tools: # block admin-only tools
- admin_analytics
```
##### Customization[](#customization "Direct link to Customization")
A React style sub agent's behaviour can be customized by one of the three modes:
1. **Custom prompt templates** - Include specific instructions and slot context
2. **Python customization modules** - Override agent behavior with custom python classes
3. **Additional tools** - Add Python-based tools alongside existing tools from MCP servers
See the [Sub Agents Reference](https://rasa.com/docs/docs/reference/config/agents/react-sub-agents/#customization) for detailed customization options.
#### Best Practices[](#best-practices "Direct link to Best Practices")
##### MCP Server Setup[](#mcp-server-setup "Direct link to MCP Server Setup")
* Define servers in `endpoints.yml` for consistency with other Rasa endpoints.
* Use descriptive server names that indicate their purpose.
* Ensure MCP servers are accessible from your Rasa environment.
##### Tool Usage in Flows[](#tool-usage-in-flows "Direct link to Tool Usage in Flows")
* Always account for both structured and unstructured response content from tools.
* Use clear parameter and slot names for maintainability.
##### Security Considerations[](#security-considerations "Direct link to Security Considerations")
* Use `include_tools` to provide only necessary tools for security.
* Use `exclude_tools` to block sensitive or dangerous operations.
* Set clear exit conditions to prevent infinite loops.
* Limit context sharing to necessary slots only.
* Regularly audit agent permissions and access to tools.
---
#### Integrating External Agents via A2A
New Beta Feature in 3.14
Rasa supports stateful execution of external agents via A2A protocol.
This feature is in a beta (experimental) stage and may change in future Rasa versions. We welcome your feedback on this feature.
#### Overview[](#overview "Direct link to Overview")
Rasa can act as an intelligent orchestrator that coordinates a network of multiple agents through the [Agent-to-Agent (A2A) protocol](https://a2a-protocol.org/latest/#what-is-a2a-protocol). This is particularly useful when at least one of the agents is externally built, i.e. by a different department, by a third party, or it's a legacy project on a different tech stack. Integrating each of these agents into a single system enables contextually rich conversations through single unified conversational interface.
#### The Orchestrator Model[](#the-orchestrator-model "Direct link to The Orchestrator Model")
In this architecture, your Rasa agent serves as the **orchestrator** that:
1. **Owns the conversation flow** - Determines when and which external agents to involve
2. **Manages business logic** - Enforces business rules, compliance, and conversation patterns
3. **Controls agent handoffs** - Decides when to delegate tasks and when to resume control
4. **Maintains conversation context** - Preserves user context across different agent interactions
5. **Allows context engineering** - Allows fine-grained control over context passed between agents
6. **Handles final responses** - Ensures consistent user experience regardless of which agent provided the information
#### Configuring External Sub-Agents[](#configuring-external-sub-agents "Direct link to Configuring External Sub-Agents")
##### Registering the sub agent[](#registering-the-sub-agent "Direct link to Registering the sub agent")
Configure external sub agents in the `sub_agents/` folder of your Rasa agent:
```
your_project/
├── config.yml
├── domain/
├── data/flows/
└── sub_agents/
├── analytics_agent/
└── config.yml
```
The A2A protocol prescribes using an [agent card](https://a2a-protocol.org/latest/specification/#55-agentcard-object-structure) to expose any externally running agent's capabilities. The agent card can be provided as part of the `config.yml` defined for each external agent -
sub\_agents/analytics\_agent/config.yml
```
# Basic agent information
agent:
name: analytics_agent
protocol: a2a
description: "External agent that provides analytical capabilities"
# A2A configuration
configuration:
agent_card: ./sub_agents/shopping_agent/agent_card.json
```
More configuration options can be found in the [reference page](https://rasa.com/docs/docs/reference/config/agents/external-sub-agents/#configuration).
#### Invoking the External Agent[](#invoking-the-external-agent "Direct link to Invoking the External Agent")
The orchestrating layer in Rasa provides you the control to invoke an external agent when your business logic needs you to do so by using the [`call` step](https://rasa.com/docs/docs/reference/primitives/flow-steps/#autonomous-steps) in a flow -
flows.yml
```
flows:
product_enquiry:
description: Handle questions related to analysis needed on the product
steps:
- collect: query
- call: analytics_agent # External A2A agent
```
For more information on how Rasa passes control and receives response from an external agent via A2A, head over to the documentation on [External Sub Agents](https://rasa.com/docs/docs/reference/config/agents/overview-agents/#how-rasa-interacts-with-sub-agents).
#### Context Management[](#context-management "Direct link to Context Management")
The orchestrating agent in Rasa can control what context is shared with external agents by customizing the client interfacing with the external agent.
To do so, define a custom python module -
sub\_agents/analytics\_agent/custom\_agent.py
```
from rasa.agents.protocol.a2a.a2a_agent import A2AAgent
from rasa.agents.schemas import AgentInput
class AnalyticsAgent(A2AAgent):
async def process_input(self, input: AgentInput) -> AgentInput:
# Filter slots to only include relevant context
filtered_slots = [
slot for slot in input.slots
if slot.name in ["user_id", "account_type", "inquiry_category"]
]
# Create new input with filtered context
return AgentInput(
id=input.id,
user_message=input.user_message,
slots=filtered_slots, # Only share necessary slots
conversation_history=input.conversation_history,
events=input.events,
metadata=input.metadata,
timestamp=input.timestamp
)
```
Provide the customized interface to your sub agent's config:
sub\_agents/analytics\_agent/config.yml
```
agent:
name: analytics_agent
protocol: a2a
description: "External agent that provides analytical capabilities"
configuration:
agent_card: ./sub_agents/analytics_agent/agent_card.json
module: sub_agents.analytics_agent.custom_agent.AnalyticsAgent
```
For more information on possible customizations, head over to the [reference documentation](https://rasa.com/docs/docs/reference/config/agents/external-sub-agents/#customization).
---
#### Translating Your Assistant
Supporting your users in their preferred language helps create more engaging, accessible, and inclusive assistants. Rasa enables you to easily build multilingual AI assistants that connect naturally with a global user base.
This page explains how you can set up multilingual capabilities in Rasa — from configuring supported languages and translating responses and flow names, to dynamically generating language-specific responses using the Response Rephraser.
***
#### Configuring Languages in Rasa Pro[](#configuring-languages-in-rasa-pro "Direct link to Configuring Languages in Rasa Pro")
For full instructions on configuring your assistant’s languages, including setting the primary language and supported additional languages, please refer to our [Configuring Your Assistant](https://rasa.com/docs/docs/pro/build/configuring-assistant/#language) guide.
***
#### Response Translations[](#response-translations "Direct link to Response Translations")
You can manage multilingual responses easily by using the `translation` key within each response. You can define a single response and keep all translations organized in one place.
* Simple response
* Response with buttons
Here's how you can create a simple multilingual response:
domain.yml
```
responses:
utter_ask_help:
- text: "How can I help you?"
translation:
es: "¿En qué puedo ayudarte?"
fr: "Comment puis-je vous aider ?"
de: "Wie kann ich Ihnen helfen?"
```
This example shows a multilingual response with buttons:
domain.yml
```
responses:
utter_select_color:
- text: "Choose your favorite color:"
translation:
es: "Elige tu color favorito:"
fr: "Choisissez votre couleur préférée:"
de: "Wählen Sie Ihre Lieblingsfarbe:"
buttons:
- title: "Red"
payload: '/choose_color{"color":"red"}'
translation:
es:
title: "Rojo"
payload: '/choose_color{"color":"red"}'
fr:
title: "Rouge"
payload: '/choose_color{"color":"red"}'
de:
title: "Rot"
payload: '/choose_color{"color":"red"}'
- title: "Blue"
payload: '/choose_color{"color":"blue"}'
translation:
es:
title: "Azul"
payload: '/choose_color{"color":"blue"}'
fr:
title: "Bleu"
payload: '/choose_color{"color":"blue"}'
de:
title: "Blau"
payload: '/choose_color{"color":"blue"}'
```
You can apply this translation syntax to any text-based content your assistant sends to the user, including standard messages, button labels, and link descriptions. This keeps your multilingual assistant consistent, easy to manage, and clearly organized.
***
#### Translating Flow Names[](#translating-flow-names "Direct link to Translating Flow Names")
When your assistant handles common [conversation patterns](https://rasa.com/docs/docs/reference/primitives/patterns/) (like confirming or canceling flows), it references your flow names directly. To ensure system messages use the correct localized names, you can define translations directly within your flows configuration.
Here's an example of translating a simple "Greet User" flow in your `flows.yml`:
flows.yml
```
flows:
greet_user:
name: "Greet User"
description: "Greets the user at the start of the conversation."
translation:
es:
name: "Saludar al usuario"
fr:
name: "Saluer l'utilisateur"
de:
name: "Benutzer begrüßen"
steps:
- action: utter_greet
```
By including these translations, your assistant automatically uses the correct localized name of the flow when handling built-in patterns like cancellations, confirmations, and clarifications.
***
#### Enhancing Rephraser for Multilingual Output[](#enhancing-rephraser-for-multilingual-output "Direct link to Enhancing Rephraser for Multilingual Output")
The [**Response Rephraser**](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/) dynamically rewords your assistant's messages during conversation by leveraging a Large Language Model (LLM). Its output language depends on the current conversation's language, determined by the assistant's built-in `language` slot.
Here's the default prompt used by the Response Rephraser:
rephraser\_prompt.py
```
The following is a conversation with an AI assistant.
The assistant is helpful, creative, clever, and very friendly.
Rephrase the suggested AI response staying close to the original message and retaining its meaning. Use simple {{language}}.
Context / previous conversation with the user:
{{history}}
{{current_input}}
Suggested AI Response: {{suggested_response}}
Rephrased AI Response:
```
Because the prompt contains `"Use simple {{language}}"`, the Rephraser automatically generates responses in the language currently set in the user's conversation. This allows your assistant to dynamically provide localized responses whenever the detected or selected language changes.
***
#### Built-In Language Slot[](#built-in-language-slot "Direct link to Built-In Language Slot")
Rasa provides a built-in `language` slot to manage the current conversation language.
warning
`language` is a private keyword used by Rasa internally to manage language - to avoid naming collisions, you cannot use this keyword for custom slots. Please see more details on migration below.
This slot ensures that your assistant only uses supported language codes defined in your configuration (`language` and `additional_languages` in `config.yml`).
It is your responsibility to set the `language` slot based on your users' preferences. You can choose how to determine the appropriate language — such as from user-provided preferences, browser settings, detected IP geolocation, or any other relevant parameter.
For example, you can set the language when the conversation session starts:
```
class ActionSessionStart(Action):
def name(self) -> str:
return "action_session_start"
def run(self, dispatcher: CollectingDispatcher, tracker: Tracker, domain: dict) -> list:
# Determine the user's language (implement your logic here)
language = get_assistant_language_code()
return [SlotSet("language", language)]
```
***
#### Validation[](#validation "Direct link to Validation")
To ensure that your assistant's multilingual setup is consistent and correct, Rasa provides dedicated multilingual validation commands. Run these commands from your terminal to validate your language configurations and translations:
* **General validation** - checks domain configuration, stories, rules, slots, and other related files during training:
```
rasa data validate
```
This command provides aggregate counts, generating one consolidated warning for missing response translations and another consolidated warning for missing flow translations.
* **Translations validation** - specifically verifies that translations are complete and correctly formatted:
```
rasa data validate translations
```
This command shows individual warnings for each missing translation.
###### Validation Warnings[](#validation-warnings "Direct link to Validation Warnings")
When rephraser is enabled globally you will not receive these warnings as it the LLM will generate the translations during conversation runtime. When rephraser is disabled on a global or response level - the command will output warning for the following scenarios to alert you to missing translated content:
* A response is missing translated content for one of your configured languages
* A flow name translations is missing for one of your configured languages
###### Errors[](#errors "Direct link to Errors")
There are a few cases where validation will trigger an error with translations to ensure that your configuration is compatible:
* Your default `language` appearing within the `additional_languages`.
* You have configured language with an invalid or incorrectly formatted language code.
***
#### Migrations[](#migrations "Direct link to Migrations")
If you have an existing assistant that uses conditional responses to manage language and would like to migrate to use Rasa's multi-language features - please reach out to the Rasa team and your dedicated support who can assist you with automating the migration.
To migrate from the conditional responses format to the new translation format, you can follow the example below. In this example we consider that the assistant's default language is English.
* Conditional Responses
* Translation Format
Old example using conditions:
```
utter_ask_callback_wanted:
- text: "Would you like to arrange a callback?"
condition:
- type: slot
name: language
value: "English"
- text: "Möchten Sie einen Termin vereinbaren?"
condition:
- type: slot
name: language
value: "German"
- text: "Souhaitez-vous fixer un rendez-vous?"
condition:
- type: slot
name: language
value: "French"
- text: "Would you like to arrange a callback?"
```
New example with translations:
```
utter_ask_callback_wanted:
- text: "Would you like to arrange a callback?" # Default English text
translation:
de: "Möchten Sie einen Termin vereinbaren?"
fr: "Souhaitez-vous fixer un rendez-vous?"
```
---
#### Voice Assistants
Developer Edition
If you started building your assistant with [the Rasa **Developer Edition**](https://rasa.com/docs/docs/pro/intro/#who-rasa-is-for) before Rasa Pro 3.11 and want to try voice features, please request a new license. Licenses issued before this version don't contain the necessary feature scopes to run voice assistants.
#### Building Voice Assistants[](#building-voice-assistants "Direct link to Building Voice Assistants")
Voice assistants provide a natural and intuitive way to interact with digital devices and services. They are particularly useful for hands-free operation, accessibility, and multitasking. They also offer a familiar and frictionless experience to the customers of contact centers. At the same time, voice solutions present distinct technical challenges and require elaborate user experience design.
Rasa provides voice channel connectors that require specialized handling to address nuanced complexities in voice conversations. The connectors are described in detail below.
##### Voice Ready[](#voice-ready "Direct link to Voice Ready")
Voice Ready Channel Connectors in Rasa process input and output as text while enabling communication through audio. Rasa relies on external services for Speech Recognition (STT) and Text-to-Speech (TTS) to facilitate this.
For example, the [Twilio Voice](https://rasa.com/docs/docs/reference/channels/twilio-voice/) built-in channel in Rasa is a Voice Ready Channel Connector.
##### Voice Stream[](#voice-stream "Direct link to Voice Stream")
Voice Stream Channel Connectors in Rasa process both input and output in audio. They transcribe incoming audio into text, process it within Rasa, and then convert the response back into audio. The assistant is communicating with the user through Audio, just as well.
For example, the [Twilio Media Streams](https://rasa.com/docs/docs/reference/channels/twilio-media-streams/) channel connector in Rasa is a Voice Stream Channel Connector.
#### How to Start Building a Voice Assistant[](#how-to-start-building-a-voice-assistant "Direct link to How to Start Building a Voice Assistant")
To build an optimized voice assistant, it is recommended to develop it separately from text-based assistants. Although a text assistant can serve as a foundation, maintaining and evolving the assistant is easier when voice and text assistants are developed separately.
Following CDD best practices, start your voice project with rigorous user research and include iterative user tests in the development process. Make sure to design your voice flows with the unique requirements of the modality in mind.
Apart from connecting and configuring your channel connector, you will need to configure the speech services. More information on those here:
* [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/) for connecting to Speech Recognition and Text to Speech Services
* Voice connectors:
* [Audiocodes VoiceAI Connect](https://rasa.com/docs/docs/reference/channels/audiocodes-voiceai-connect/) Channel connector (Voice Ready)
* [Audiocodes Voice Stream](https://rasa.com/docs/docs/reference/channels/audiocodes-stream/) Channel connector (Voice Stream)
* [Jambonz](https://rasa.com/docs/docs/reference/channels/jambonz/) Channel connector (Voice Ready)
* [Twilio Voice](https://rasa.com/docs/docs/reference/channels/twilio-voice/) Channel connector (Voice Ready)
* [Twilio Media Streams](https://rasa.com/docs/docs/reference/channels/twilio-media-streams/) Channel connector (Voice Stream)
* [Genesys Cloud](https://rasa.com/docs/docs/reference/channels/genesys-cloud-voice/) Channel connector (Voice Stream)
You can also [Test your voice assistant](https://rasa.com/docs/docs/pro/testing/trying-assistant/) directly in your browser, allowing for an iterative building process.
#### Voice-Specific Primitives and Conversation Repair[](#voice-specific-primitives-and-conversation-repair "Direct link to Voice-Specific Primitives and Conversation Repair")
Voice assistants rely on the same core building blocks as text-based assistants (like responses, actions, and flows), but they require **additional configuration and design adjustments** to handle the nuances of spoken interactions.
These include:
* Fine-tuning how conversations are initiated and ended
* Managing voice-specific metadata
* Handling silence or no-input cases
* Repeating or rephrasing messages when users don’t respond
These tweaks ensure voice conversations feel natural and responsive, even when user behavior is unpredictable.
👉 [Explore voice conversation patterns](https://rasa.com/docs/docs/reference/primitives/patterns/#common-voice-specific-pattern-modifications)
##### Handling User Silence[](#handling-user-silence "Direct link to Handling User Silence")
In voice conversations, silence can signal confusion, hesitation, or distraction. With the **silence timeout** setting, you can control how long the assistant waits before responding — and tweak what it does when that happens.
👉 [How to configure user silence parameters](https://rasa.com/docs/docs/reference/config/overview/#silence-timeout-handling)
##### Collecting Input via DTMF (Keypad)[](#collecting-input-via-dtmf-keypad "Direct link to Collecting Input via DTMF (Keypad)")
For voice assistants, you can collect user input through DTMF (Dual-Tone Multi-Frequency) signals — the tones generated when users press keys on their phone keypad. This is particularly useful for:
* **High-accuracy input**: Account numbers, PINs, or numeric codes where speech recognition errors could be problematic
* **PCI DSS compliance**: Securely collecting sensitive information like credit card numbers or passwords
* **Accessibility**: Providing an alternative input method for users who prefer or need keypad entry
DTMF input can be configured on individual `collect` steps in your flows, allowing you to specify:
* Fixed-length input (auto-submit after a specific number of digits)
* Variable-length input (user presses a termination key like `#` to submit)
* Whether to allow voice input alongside keypad input
👉 [How to configure DTMF input in collect steps](https://rasa.com/docs/docs/reference/primitives/flow-steps/#requesting-dtmf-input)
##### Using Channel-Specific Responses[](#using-channel-specific-responses "Direct link to Using Channel-Specific Responses")
Tailor your responses for voice channels like phone calls using channel-specific response variations.
👉 [How to configure channel-specific responses](https://rasa.com/docs/docs/reference/primitives/responses/#channel-specific-response-variations)
##### Using Filler Responses for Slow Operations[](#using-filler-responses-for-slow-operations "Direct link to Using Filler Responses for Slow Operations")
When certain operations may take time (such as certain custom actions), include "filler" responses to keep users informed about the ongoing process. These responses confirm that the system is processing the request, reducing user uncertainty and abandonment. This technique is especially important for voice-based channels like phone calls, where users don't have visual UI indicators of progress. This is an example of a filler response:
flows.yml
```
flows:
check_balance:
name: check your balance
description: check the user's account balance
steps:
- action: utter_please_wait # a response that tells user to wait a moment
- action: check_balance # let's say if this is a slow custom action
- action: utter_current_balance
```
##### Managing Interruptions (Barge-Ins)[](#managing-interruptions-barge-ins "Direct link to Managing Interruptions (Barge-Ins)")
In voice conversations, users may interrupt the assistant while it's speaking — a natural behavior that your assistant should handle gracefully. This behaviour is also called Barge-In. Interruption handling is available for Voice Stream Channels (Browser Audio, Twilio Media Streams, and Jambonz Stream) and uses partial transcripts from the ASR engine to detect when a user is speaking over the bot.
👉 [How to configure interruption handling](https://rasa.com/docs/docs/reference/primitives/patterns/#interruption-handling)
---
#### Writing Custom Actions
A Rasa assistant can execute different types of actions to respond to the user or update conversation state:
* **Responses** *User-facing messages* defined in your assistant. This is what you will use most frequently to send text, images, buttons, etc.
* **Default Actions** *Built-in actions* that handle certain events or conversation situations out-of-the-box (e.g., `action_restart`, `action_session_start`). These can be overridden with your own custom logic if needed.
* **Custom Actions** *User-defined actions* that can run any code you want (e.g., call external APIs, query databases, or retrieve specific data). Custom actions are the focus of this page.
#### What Are Custom Actions?[](#what-are-custom-actions "Direct link to What Are Custom Actions?")
A **custom action** lets you execute arbitrary logic within your assistant—for example, retrieving data from an external API or performing a complex database query. Because you can run any code, custom actions offer maximum flexibility.
Keep Logic Out of Custom Actions and Inside Flows
You should avoid hiding your core business logic inside a custom action. Flows (in YAML or via the Studio UI) define how the conversation should proceed in a transparent, maintainable way. A custom action should do just the “raw work”—for example, fetching an API response or returning a database record—and let your flow decide what happens next based on that result.
**Example of “flow-first” design**:
flows.yml
```
flows:
restaurant_booking:
description: "Book a table at a restaurant"
steps:
# ...
- action: check_restaurant_availability
next:
- if: has_availability
then:
- action: utter_has_availability
- else:
- action: utter_no_availability
```
actions.py
```
# Minimal custom action code
class CheckRestaurantAvailability(Action):
def name(self):
return "check_restaurant_availability"
def run(self, dispatcher, tracker, domain):
# Example: call an API to see if there's availability
has_availability = True
# Return the result in a slot so the flow can branch deterministically
return [SlotSet("has_availability", has_availability)]
```
By keeping the branching logic in the flow, anyone inspecting it can quickly understand how your assistant behaves.
#### Rasa Action Server[](#rasa-action-server "Direct link to Rasa Action Server")
When your assistant predicts a custom action, it needs to run your custom code. You can do this in two ways:
1. **Use a standalone Action Server**
* The Rasa server calls the Action Server with information about the conversation.
* The Action Server executes your code and returns any responses or events to Rasa.
* This keeps your custom code isolated from the main assistant server (helpful for security or scaling).
2. **Run custom actions directly on the Rasa Assistant**
* Write your custom actions in Python and configure them to run directly in the same process as the assistant.
* This may simplify deployment and reduce latency but requires that your Rasa environment be set up securely to handle sensitive credentials.
Run custom actions directly on the Rasa Assistant if you want simpler deployment, lower latency, and a unified environment for faster development. However, if you need to secure sensitive credentials or prefer isolating resource-intensive components, an external action server gives you greater flexibility, control, and security.
For more details on either approach, see the Reference section on the [Action Server](https://rasa.com/docs/docs/action-server/) and [Custom Actions](https://rasa.com/docs/docs/reference/primitives/custom-actions/).
#### How to Write Custom Actions[](#how-to-write-custom-actions "Direct link to How to Write Custom Actions")
1. **Create Your Action File**
* If using Python, you typically write an `Action` class.
* If using another language, you need to implement the [webhook API spec](https://rasa.com/docs/docs/reference/api/pro/action-server-api/).
2. **Implement the Logic**
* Perform the external API calls, database queries, or any other needed logic.
* Store retrieved data in slots (e.g., `SlotSet("customer_id", customer_id)`) so that your flow can condition on it.
3. **Return Events and Responses**
* Return the events (e.g. `SlotSet`, `FollowupAction`) needed to update the conversation state.
* Optionally, return responses to immediately send messages back to the user.
4. **Add Your Action to the Assistant Configuration**
* List the custom action’s name in your assistant domain or configuration so that your flows can call it.
5. **Decide on Hosting**
* **Standalone Action Server**: Configure your `endpoints.yml` to point to the Action Server’s URL.
* **Integrated Execution**: In your `endpoints.yml`, set `actions_module` to point to your Python module.
6. **Train & Test**
* Once your custom actions are properly listed in your flows and domain, re-train (compile) your assistant and test by running a conversation.
##### Next Steps[](#next-steps "Direct link to Next Steps")
* For a deeper look at the parameters and payloads involved, see the Reference section on [Custom Actions](https://rasa.com/docs/docs/reference/primitives/custom-actions/).
---
#### Writing Flows
A **flow** in CALM is a structured sequence of steps for completing a specific user goal, like blocking a credit card, changing an address, adding a payee or researching stocks to invest in. It helps the agent orchestrate between -
1. Well-defined prescriptive business logic.
2. Dynamic business logic run by ReAct sub agents inside Rasa.
3. Externalized business logic by invoking sub agents outside Rasa.
This is done via [prescriptive steps](https://rasa.com/docs/docs/reference/primitives/flow-steps/#prescriptive-steps) for well-defined business logic, [autonomous steps](https://rasa.com/docs/docs/reference/primitives/flow-steps/#autonomous-steps) for business logic determined at runtime, or a mix of both approaches in a single flow. This hybrid approach gives you the flexibility to enforce critical business rules while letting AI handle complex, undefined, or tedious-to-script logic.
By separating the business logic from the rest of the conversation, you get:
* **Clarity**: Each flow focuses on a single job or outcome (e.g., “Block Credit Card”).
* **Reusability**: Flow logic can be called from other flows or triggered on its own.
* **Maintainability**: You can refine or change the flow logic without affecting the entire conversation design.
There are two types of flows in CALM: flows that you write to express your business logic and patterns or system flows that come out of the box with CALM. Before we move on to explain how flows work, a word on these conversation patterns:
##### Conversation Patterns (System Flows)[](#conversation-patterns-system-flows "Direct link to Conversation Patterns (System Flows)")
In addition to the flows you write for your domain-specific tasks, Rasa provides **patterns**—pre-defined, reusable flows that handle “meta” conversational situations or repairs. For instance, if a user cancels a flow midway or wants to clarify a previously collected piece of information, a **pattern** steps in to handle this detour. These patterns work like templates: they can be triggered whenever relevant, so your assistant can handle common conversational patterns consistently.
Read more about customizing patterns under [Customizing Patterns](https://rasa.com/docs/docs/pro/customize/patterns/)
#### How Do Flows Work?[](#how-do-flows-work "Direct link to How Do Flows Work?")
##### Triggering Flows[](#triggering-flows "Direct link to Triggering Flows")
CALM uses an [LLM “command generator” prompt](https://rasa.com/docs/docs/pro/customize/command-generator/) that contains the conversation history, the relevant flows, slots, and conversation patterns. Essentially, CALM leverages the LLM to parse the user’s request into structured commands, referencing all pertinent context—including conversation history, current state, and flow definitions. This approach ensures that when the user’s goal matches the description of a given flow, that flow will be triggered. Flows can also be:
* Started by a direct [NLU trigger](https://rasa.com/docs/docs/reference/primitives/starting-flows/#nlu-trigger) (e.g., when a recognized intent maps to a flow).
* [Linked](https://rasa.com/docs/docs/reference/primitives/flow-steps/#link) or [called](https://rasa.com/docs/docs/reference/primitives/flow-steps/#call) from inside another flow (for subflows or follow-up tasks).
##### Dialogue Stack[](#dialogue-stack "Direct link to Dialogue Stack")
When a flow (or pattern) is activated, it’s placed on top of a **dialogue stack** (like stacking plates). The topmost flow is always active. Once that flow finishes or is canceled, the system returns to the next flow on the stack. This structure ensures that your assistant’s logic remains organized, even when users interrupt or pivot to new tasks.
#### How to Write Flows[](#how-to-write-flows "Direct link to How to Write Flows")
Flows support three approaches: **prescriptive steps**, **autonomous steps**, and **hybrid flows** that combine both. Use prescriptive steps for critical business logic that must be enforced consistently. Use autonomous steps when business logic is undefined, highly variable, or too complex to script manually.
Writing a flow in CALM involves capturing the *essential steps* to fulfill a user request without hardcoding every possible conversation path. You define flows as YAML in your `flows.yml` (or multiple YAML files), focusing on the business logic:
1. **Give the flow an ID and a clear description**
flows.yml
```
flows:
block_card:
description: Block a user's credit card when requested
steps: []
```
* The `description` is critical for the LLM to understand when to pick this flow.
2. **Add the steps**
Each step specifies what your assistant should do:
* **Collect** user information:
flows.yml
```
flows:
block_card:
description: Block a user's credit card when requested
steps:
- collect: card_number
description: “The 16-digit card number to block”
```
* **Take an action** (e.g., a [custom action](https://rasa.com/docs/docs/pro/build/custom-actions/) or a response):
flows.yml
```
flows:
block_card:
description: Block a user's credit card when requested
steps:
# ...
- action: action_block_card_in_backend
```
* **Set or reset slots**:
flows.yml
```
flows:
block_card:
description: Block a user's credit card when requested
steps:
# ...
- set_slots:
- card_number: null
```
* **Call or link other flows** for subflows or follow-ups:
flows.yml
```
flows:
block_card:
description: Block a user's credit card when requested
steps:
# ...
- call: authenticate_user_flow
```
flows.yml
```
flows:
block_card:
description: Block a user's credit card when requested
steps:
# ...
- link: collect_feedback
```
* **Include LLM driven autonomous steps** for dynamic logic:
flows.yml
```
flows:
investment_research:
description: Help user research and analyze investment options
steps:
- call: research_stocks
```
Here, `research_stocks` can be either a ReAct style [autonomous sub agent interacting with tools from an MCP server](https://rasa.com/docs/docs/pro/build/mcp-integration/#dynamic-selection-of-tools-in-an-autonomous-step) or an [external agent connected via A2A](https://rasa.com/docs/docs/pro/build/integrating-external-agents/).
More information on different step types can be found on the [reference page](https://rasa.com/docs/docs/reference/primitives/flow-steps/).
3. **Include branching if needed**
You can add simple conditional logic (like checking if a slot is filled or if a user is already authenticated):
flows.yml
```
flows:
block_card:
description: Block a user's credit card when requested
steps:
# ...
- collect: user_authenticated
next:
- if: not slots.user_authenticated
then:
- action: utter_ask_for_login
- link: authenticate_user_flow
```
4. **Force slot collection (suppress interruptions) in collect steps if needed**
You can choose to set the `force_slot_filling` property to `true` if you want the assistant to ignore any other commands and only focus on filling text type slots. This is especially useful when you want to collect feedback or longer text input from the user in collect steps.
flows.yml
```
flows:
block_card:
description: Block a user's credit card when requested
steps:
# ...
- collect: feedback
force_slot_filling: true
```
More information on forcing slot collection can be found on the [Flow reference page](https://rasa.com/docs/docs/reference/primitives/flow-steps/#suppressing-interruptions).
5. **Leverage conversation patterns**
You don’t need to write custom branching logic for every possible user detour. Flows represent the business logic your assistant is supposed to drive throughout conversation. Instead, rely on patterns (built-in flows) to accommodate user detours.
Flows in CALM can do more than these basics—such as advanced branching, slot validation, or subflow calls. For a deeper look at each property, step type, or YAML configuration, check out the [Flows reference](https://rasa.com/docs/docs/reference/primitives/flows/).
#### Importance of Clear Descriptions[](#importance-of-clear-descriptions "Direct link to Importance of Clear Descriptions")
Each flow has a **description** that briefly explains what the flow accomplishes. The LLM reads these descriptions to decide which flow to start. A concise, specific description reduces errors in flow selection. For example:
> Good: “Block a user’s credit card if they suspect fraud or want to freeze it”
> Less useful: “Card blocking request”
#### Key Takeaways[](#key-takeaways "Direct link to Key Takeaways")
1. **Flows define business logic**: They can use prescriptive steps for guaranteed processes, autonomous steps for dynamic logic, or combine both approaches as needed.
2. **LLMs + flows**: The LLM remains flexible in interpreting user input and context, while flows make sure the assistant sticks to rules and processes.
3. **Choose the right approach**: Use prescriptive steps for critical business rules, autonomous steps for undefined or complex logic, and hybrid flows to get the best of both worlds.
4. **Write clear and detailed descriptions**: They help the LLM reliably select the right flow at the right time.
5. **Use patterns for conversation repair**: Don't clutter your flow with every possible detour. Let patterns handle cancellations, clarifications, or other unexpected conversation turns.
With flows, you maintain control over complex processes while giving the LLM room to shine in adapting to user input. Start by mapping out the tasks your assistant must support, split them into distinct flows, choose the right mix of prescriptive and autonomous steps, and keep descriptions tight. That's all you need to harness the best of both worlds: rigid business logic and flexible, human-like conversations.
---
#### Writing Responses
Responses are the messages your assistant sends to end users. These can be simple text messages or more complex UI elements such as images and buttons. In CALM, a “response” is one of the fundamental building blocks your assistant uses to communicate information, ask clarifying questions, and guide the user.
* **Where:** You define responses as YAML entries (usually in a file such as `domain.yml` or `responses.yml`).
* **Usage:** When an assistant flow or pattern decides to “say” something, it references one of these response definitions.
Below are the core steps to define and use responses in your CALM assistant. For advanced options—like channel-specific messages, conditional responses, and dynamic button creation—refer to [Responses](https://rasa.com/docs/docs/reference/primitives/responses/) in the Reference section.
##### 1. Define Your Responses[](#1-define-your-responses "Direct link to 1. Define Your Responses")
In CALM, you typically define all your responses under a `responses` key in your domain or responses file. Each response name starts with `utter_`. For example:
domain.yml
```
responses:
utter_greet:
- text: "Hi there!"
utter_bye:
- text: "See you next time!"
```
* **Purpose:** Each `utter_` response is a distinct piece of content your assistant can send to the user.
* **Where It’s Used:** You can reference the response by its name (e.g., `utter_greet`) in a flow step, or even in a custom action.
##### 2. Use Variables in Responses (Optional)[](#2-use-variables-in-responses-optional "Direct link to 2. Use Variables in Responses (Optional)")
If you want the assistant to include slot values or other dynamic content, enclose variable names in curly braces:
domain.yml
```
responses:
utter_greet:
- text: "Hey, {name}. How are you?"
```
* **How It Works**
CALM will replace `{name}` with the value of the `name` slot (if it’s filled).
* **From Custom Actions**
In a custom action, you can pass extra data to fill those variables:
actions.py
```
# ...
dispatcher.utter_message(
template="utter_greet",
name="Sara"
)
```
##### 3. Provide Response Variations (Optional)[](#3-provide-response-variations-optional "Direct link to 3. Provide Response Variations (Optional)")
To keep your assistant more engaging, you can define multiple text entries for the same `utter_` response. CALM will randomly pick one at runtime:
domain.yml
```
responses:
utter_greet:
- text: "Hey, {name}. How are you?"
- text: "Hi there, {name}! Hope you’re well."
```
##### 4. Add Rich Content (Buttons, Images, etc.)[](#4-add-rich-content-buttons-images-etc "Direct link to 4. Add Rich Content (Buttons, Images, etc.)")
A response can go beyond text. You can add buttons, images, or custom JSON payloads for richer channels.
**Buttons Example**:
domain.yml
```
responses:
utter_ask_insurance_type:
- text: "Would you like motor or home insurance?"
buttons:
- title: "Motor insurance"
# Overwrites NLU with the /inform intent + entity
payload: '/inform{"insurance":"motor"}'
- title: "Home insurance"
payload: '/inform{"insurance":"home"}'
```
When the user clicks a button, it sends the specified payload directly to your assistant.
For more details—e.g., setting multiple slots or using `/SetSlots()`—see the [Reference → Responses → Buttons](https://rasa.com/docs/docs/reference/primitives/responses/#buttons).
**Images Example**:
domain.yml
```
responses:
utter_cheer_up:
- text: "Here is something to cheer you up:"
image: "https://i.imgur.com/nGF1K8f.jpg"
```
##### 5. Use Responses in Flows or Actions[](#5-use-responses-in-flows-or-actions "Direct link to 5. Use Responses in Flows or Actions")
Once your response definitions are in place, you can use them in:
* **Flows -** In a flow step, simply call the response by name—e.g., `utter_greet`.
* **Custom Actions -** From a custom action, dispatch the response via `dispatcher.utter_message(template="utter_greet")`.
For example, in a flow:
flows.yml
```
flows:
greet_user:
description: "Greet the user"
steps:
- action: utter_greet
# ...
```
When the assistant runs the `utter_greet` step, it sends one of the variations you defined for `utter_greet`.
---
### CALM with NLU
#### How does Coexistence work?
#### Key Terms[](#key-terms "Direct link to Key Terms")
##### System
Whenever we use phrases like “the two systems” or “either of the systems” we refer to CALM or the NLU-based system.
##### Stickiness
Stickiness means that once a routing decision is made by the router, it remains in place until it is reset, which normally happens at the end of a flow, story, or rule. This prevents CALM from taking over midway through a story or rule or the NLU-based system from taking over midway through a flow. Such interruptions can be problematic as the two systems handle different skills and switching from one to the other require a cleanup in order to be able to complete a skill without errors. Non-sticky routing is only used for single-turn interactions such as, for example, chit-chat.
##### Skill
A small self-contained piece of business logic that lets the user achieve a goal or answer one or multiple questions. Examples of skills are transferring money, checking account balance, or answering frequently asked questions. Oftentimes, skills require the user to provide multiple pieces of information across multiple steps.
##### Topic Area
A collection of skills that are closely related and oftentimes happen together and interrupt one another. An example for a topic area would be “investment” containing skills such as providing security quotes, buying and selling securities, portfolio management, providing quarterly and yearly results of a company, etc.
#### Overview[](#overview "Direct link to Overview")
The following graphic depicts how coexistence works on a high level.
The coexistence of [CALM](https://rasa.com/docs/docs/learn/concepts/calm/) and the NLU-based system depends on a routing mechanism, that routes messages based on their content to either system. The routing happens in the [router component](https://rasa.com/docs/docs/reference/config/components/coexistence-routers/). We currently offer two different router components, in the Figure 1 the [`IntentBasedRouter`](https://rasa.com/docs/docs/reference/config/components/coexistence-routers/#intentbasedrouter) is used.
If the routing session is not yet active, e.g. the dedicated routing slot [`route_session_to_calm`](https://rasa.com/docs/docs/pro/calm-with-nlu/migrating-from-nlu/#adding-the-routing-slot-to-your-domain) is not yet set, the router is engaged and the message is routed depending on the outcome of the routing mechanism. Once the router decided to route the message to either of the system, the routing slot will be set and a routing session is active. The routing is usually sticky. That means that the subsequent messages are routed to the same system without engaging the router again. E.g. if the routing slot is already set, the router component is not engaged and the message is routed according to the value set in the routing slot.
Once the message is routed to either of the systems, the message is processed as that system would process it usually. The message annotated with either commands or intents and entities is passed to the policies. Here, the routing slot together with CALM's dialogue stack coordinates the policies. In general, the policies of one system will not run when the other system is activated to save compute.
For the user to be able to achieve multiple skills in a single session, CALM and the NLU-based system have to signal when they are finished and ready to give control back. Skills are split across the two systems such as making a loan payment and checking on some investment news, and so it is important that the routing can be reset. CALM and the NLU-based system policies can signal that they are done with all started skills in their system and reset the routing by calling the new default action [`action_reset_routing`](https://rasa.com/docs/docs/reference/primitives/default-actions/#action_reset_routing). The router will be engaged again on the next incoming user message.
#### Intent triggers[](#intent-triggers "Direct link to Intent triggers")
Intents can be triggered in rasa using the slash syntax as in `/initialise_conversation`. These intent triggers are not processed by the NLU pipeline and thus the router will never see them. At the same time, there might be starting skills requiring the session to be assigned to either CALM or the NLU-based system. To support intent triggers while using the coexistence feature we have devised the following heuristic:
* If a route to either the NLU-based system or CALM is active, the routing is not changed.
* If no route is active:
* We route to CALM if given the intent any of the NLU triggers of flows are activated (see [NLU triggers documentation](https://rasa.com/docs/docs/reference/primitives/starting-flows/#nlu-trigger)).
* We route to the NLU-based system otherwise.
This way you can design intent triggers that will start specific NLU-based system or CALM skills.
Getting Started
The *Coexistence* feature helps you to [migrate from your NLU-based](https://rasa.com/docs/docs/pro/calm-with-nlu/migrating-from-nlu/) assistant to the [Conversational AI with Language Models (CALM)](https://rasa.com/docs/docs/learn/concepts/calm/) approach and is available starting with version `3.8.0`. In order to start using the *Coexistence* feature, follow the steps in the [user guide](https://rasa.com/docs/docs/pro/calm-with-nlu/migrating-from-nlu/).
---
#### Migrating an NLU-based assistant to CALM
New in 3.8
The *Coexistence* feature helps you to migrate from your NLU-based assistant to the [Conversational AI with Language Models (CALM)](https://rasa.com/docs/docs/learn/concepts/calm/) approach and is available starting with version `3.8.0`.
Coexistence allows you to run a single assistant that uses both the [Conversational AI with Language Models](https://rasa.com/docs/docs/learn/concepts/calm/) (CALM) approach and an [NLU-based system](https://legacy-docs-oss.rasa.com/docs/rasa/model-configuration) in parallel for the purpose of migrating from NLU-based assistants to CALM in an iterative fashion. This way you do not need to do a waterfall migration and can instead start gathering confidence in using CALM in production with small steps.
info
For an in-depth explanation of the *Coexistence* feature please take a look at [Coexistence](https://rasa.com/docs/docs/pro/calm-with-nlu/coexistence/).
#### Glossary[](#glossary "Direct link to Glossary")
* **CALM**: [CALM](https://rasa.com/docs/docs/learn/concepts/calm/) (Conversational AI with Language Models), Rasa’s new system for creating powerful yet steerable conversational experiences with large language models fast.
* **NLU-based system**: [NLU-based systems](https://legacy-docs-oss.rasa.com/docs/rasa/model-configuration) rely on NLU components to process incoming user messages and detect intents and entities. Further, rules and stories are used to steer the next action.
* **System**: Whenever we use phrases like “the two systems” or “either of the systems” we refer to CALM or the NLU-based system.
* **Skill**: A small self-contained piece of business logic that lets the user achieve a goal or answer one or multiple questions. Examples of skills are transferring money, checking account balance, or answering frequently asked questions. Oftentimes, skills require the user to provide multiple pieces of information across multiple steps.
* **Skill interruption**: A skill is interrupted when during its execution another skill is started without stopping the earlier skill. For example, while in the process of sending money and being asked to confirm the transaction, users might do a final check of of their account balance or transaction history before giving the final confirmation. In many cases, it is desirable to return to the interrupted skill after the interrupting skill is finished.
* **Topic area**: A collection of skills that are closely related and oftentimes happen together and interrupt one another. An example for a topic area would be “investment” containing skills such as providing security quotes, buying and selling securities, portfolio management, providing quarterly and yearly results of a company, etc.
#### Getting Started[](#getting-started "Direct link to Getting Started")
important
In coexistence, CALM and the NLU-based system both live in the same assistant but are separated. While it is possible to use both systems sequentially, i.e. triggering a NLU-based system skill after CALM skills are finished and vice versa, it is not possible for a NLU-based system skill to interrupt a CALM skill and vice versa. Skill interruptions are limited to happening within one of the systems.
##### Identification of Topic Areas[](#identification-of-topic-areas "Direct link to Identification of Topic Areas")
To get started using coexistence, it is of ample importance that you identify individual skills and at least one topic area in your assistant for migration. Individual skills are useful to identify because they most commonly turn into individual flows in CALM. Topic areas are important because they group skills that should be migrated together and allow for easy skill interruptions in a single conversation session.
For example, if your bot allows for transferring money and you want to move that skill to CALM, you probably also want to move:
* skills such as
* checking balance
* seeing transaction history
* adding contacts (if users first have to add someone as a contact before sending money)
* answering of frequently asked questions around the topic of money transfer
Moving these other skills as well will allow users to start these skills while having started a money transfer. If the other skills would remain in the NLU-based system only, they could only be started after the money transfer is finished or aborted.
In some cases, you might want skills to be available in both systems, in that case you should keep a copy of that skill in the NLU-based system as well. There can be two reasons to keep a skill in the NLU-based system:
* The skill is commonly used by topics in both systems.
* It's a high stakes skill, but because skill interruptions can happen within one system only, you would like the bot to still be able to handle it in both systems.
Once you have identified skills and a first topic area to migrate, you can start writing [flows](https://rasa.com/docs/docs/reference/primitives/flows/).
In the next steps we take a look at how to integrate your new flows with the remainder of your NLU-based system.
#### Updating your NLU pipeline and policies[](#updating-your-nlu-pipeline-and-policies "Direct link to Updating your NLU pipeline and policies")
First of all you need to decide whether the routing mechanism should be based on intents or whether an LLM should decide where incoming messages should be routed to. You can choose between two different [router components](https://rasa.com/docs/docs/reference/config/components/coexistence-routers/): `IntentBasedRouter` and `LLMBasedRouter`. [`IntentBasedRouter`](https://rasa.com/docs/docs/reference/config/components/coexistence-routers/#intentbasedrouter) routes the messages based on the predicted intent of your NLU components. The [`LLMBasedRouter`](https://rasa.com/docs/docs/reference/config/components/coexistence-routers/#llmbasedrouter) leverages an LLM to decide whether an incoming message should be routed to the NLU-based system or CALM. For more information on those components, please read the [router components documentation](https://rasa.com/docs/docs/reference/config/components/coexistence-routers/).
Once you have decided which router component to use, you need to add it to your config file together with a LLM-based command generator and `FlowPolicy`. For more information on the LLM-based command generators or the `FlowPolicy`, please consult the documentation for [flows](https://rasa.com/docs/docs/pro/build/writing-flows/).
After adding the components, your `config.yml` might look like the following, depending on which router you chose and which NLU-based system components you employ:
```
recipe: default.v1
language: en
pipeline:
- name: LLMBasedRouter
calm_entry:
sticky: "handles everything around contacts"
- name: WhitespaceTokenizer
- name: CountVectorsFeaturizer
- name: CountVectorsFeaturizer
analyzer: char_wb
min_ngram: 1
max_ngram: 4
- name: LogisticRegressionClassifier
- name: CompactLLMCommandGenerator
llm:
provider: openai
model: gpt-4-0613
timeout: 7
max_tokens: 256
policies:
- name: FlowPolicy
- name: RulePolicy
- name: MemoizationPolicy
max_history: 10
- name: TEDPolicy
```
##### Adding the routing slot to your domain[](#adding-the-routing-slot-to-your-domain "Direct link to Adding the routing slot to your domain")
The routing slot is used to store the routing decision of the router component, e.g. whether a message should be routed to the NLU-based system or CALM.
It’s important that you add the routing slot to your domain like the following:
```
version: "3.1"
slots:
route_session_to_calm:
type: bool
influence_conversation: false
```
This needs to be exactly this way. It needs to be a boolean slot to capture the three cases based on its value:
* `None`: no routing active, router will be engaged
* `True`: routing to CALM is active
* `False`: routing to the NLU-based system is active
A routing session is active when the routing slot is either set to `True` or `False`. Incoming messages are routed accordingly. If the routing slot is reset and no routing is active, e.g. set to `None`, the router will be engaged again on the next incoming message. To reset the routing slot the new default action [`action_reset_routing`](https://rasa.com/docs/docs/reference/primitives/default-actions/#action_reset_routing) can be called (see [section](#managing-routing-resets)).
The `influence_conversation: false` is important to not trip up the NLU-based system policies based on the value of this slot.
If you want to have one of the system active right from the beginning of the conversation, you can give the slot an `initial_value`. During routing resets, this slot will always be set to `None` and not to its initial value.
warning
If you want to reset the routing slot, call the new default action [`action_reset_routing`](https://rasa.com/docs/docs/reference/primitives/default-actions/#action_reset_routing). Do not update the value of the routing slot in isolation, e.g. in a custom action, as it might lead to unexpected behaviour of the assistant. Always use [`action_reset_routing`](https://rasa.com/docs/docs/reference/primitives/default-actions/#action_reset_routing) if your objective is to reset routing.
##### Managing routing resets[](#managing-routing-resets "Direct link to Managing routing resets")
Resetting the routing slot is important to be able to achieve multiple skills in a single session. To reset the routing the new default action [`action_reset_routing`](https://rasa.com/docs/docs/reference/primitives/default-actions/#action_reset_routing) needs to be called.
**Resetting when CALM is finished**
Resetting once CALM is finished is relatively straightforward. Whenever all started flows are finished, CALM triggers the flow `pattern_completed`. We can leverage this fact and adjust this pattern slightly as follows:
```
flows:
pattern_completed:
description: all flows have been completed and there is nothing else to be done
name: pattern completed
steps:
- action: utter_can_do_something_else
- action: action_reset_routing
```
In the original [definition of `pattern_completed`](https://rasa.com/docs/docs/reference/primitives/patterns/#reference-default-pattern-configuration), we just ask the user whether we can do something else for them. In this version, we also reset the routing. Make sure to add this snippet to your flows to overwrite the default implementation of `pattern_completed` that comes with CALM.
This setup will take care of all the following cases:
* User starts a flow and finishes or cancels it.
* User starts multiple flows in sequence or simultaneously and finishes or cancels them all.
* User starts a flow and asks knowledge questions or uses chitchat while in a flow and then finishes or cancels the flow.
* User starts a CALM session directly with a knowledge related question.
**Resetting when the NLU-based system is finished**
In contrast to CALM, where the boundaries of skills are well defined, the NLU-based system policies use more loosely connected fragments of business logic to describe skills. If you want to allow the user to use the CALM part of your assistant after a skill was completed in the NLU-based system, you will have to add the [`action_reset_routing`](https://rasa.com/docs/docs/reference/primitives/default-actions/#action_reset_routing) at the appropriate places in your rules and stories.
Usually, this will be at the end of different stories and rules. Potentially you have some conversation parts that you carry out at the end of each interaction. These parts can be great places at whose end you can reset the routing as in the following:
```
version: "3.1"
stories:
- story: feedback
steps:
- checkpoint: start_of_feedback
- action: utter_ask_feedback
- intent: submit_rating
- action: store_rating
- action: utter_thank_you_rating
- action: utter_do_something_else
- action: action_reset_routing
```
It is very likely that you have to add the `action_reset_routing` at the end of multiple stories or rules, whenever you are sure that the user has just finished a skill and nothing else needs to be wrapped up in the NLU-based system such as an interrupted skill.
#### Managing shared slots between CALM and the NLU-based system[](#managing-shared-slots-between-calm-and-the-nlu-based-system "Direct link to Managing shared slots between CALM and the NLU-based system")
To prevent slots from being reset during the [`action_reset_routing`](https://rasa.com/docs/docs/reference/primitives/default-actions/#action_reset_routing) you can configure slots with the option [`shared_for_coexistence: True`](https://rasa.com/docs/docs/reference/primitives/slots/#persistence-of-slots-during-coexistence).
Alternatively, you can store user profile information in a database and retrieve it in different places during your stories and flows and store it in slots temporarily. In this case, you won’t need to worry about the persistence of shared slots as the data is persisted in the database.
#### Custom Actions[](#custom-actions "Direct link to Custom Actions")
When moving functionality to CALM you might have to adjust your custom actions to varying degrees. Some concepts, such as dynamic forms have been integrated into the core flow functionality and should be implemented using branches in flows. It is best to reconsider the implementation of all custom actions that are moved to CALM and assess whether they should be adjusted to better play with the new paradigm.
Generally speaking, it is also possible to use the same action both in CALM and the NLU-based system. Both systems share the same action server.
#### Testing your assistant[](#testing-your-assistant "Direct link to Testing your assistant")
Testing your assistant using both CALM and NLU-based system can be achieved using [e2e tests](https://rasa.com/docs/docs/pro/testing/evaluating-assistant/). The definition of these tests is not very dependent on the underlying implementation and should thus not need to change significantly when more and more skills are moved from the NLU-based system to CALM subsequently. e2e tests help you to test skill interruptions and skill triggers across paradigms.
You can still evaluate just the NLU-based system of your assistant using the command [`rasa test`](https://legacy-docs-oss.rasa.com/docs/rasa/command-line-interface/#rasa-test).
---
### Customize
#### Assistant Tone
From a conversation design and linguistics perspective, the “how” of messaging is as important as the “what.” If the wording shifts abruptly from formal to casual, or if the assistant’s style changes in the middle of a conversation, it can reduce user trust and satisfaction.
CALM decouples business logic and conversation patterns from actual spoken or written content:
* **Flows** determine the overall conversation structure (the “what” and “when”).
* **Patterns** are triggered when users deviate, clarify, or repair parts of the conversation.
* **Responses** are the assistant’s prompts, messages, or follow-ups.
While you can script your Responses in your domain according to your brand voice, patterns (for repairs or clarifications) also need to reflect your assistant’s brand voice. You don’t want your default pattern responses to sound generic; they should adhere to your brand voice as well.
Because CALM uses conversation patterns that can be triggered in the context of many flows, you can use the Contextual Response Rephraser to “centralize” how messages are “finalized” according to your brand voice before being shown to users.
#### Ways of Customizing Assistant Tone in Rasa[](#ways-of-customizing-assistant-tone-in-rasa "Direct link to Ways of Customizing Assistant Tone in Rasa")
There are two main ways to adapt your assistant’s messaging style:
1. **Response Rephraser**
Dynamically rewrites your responses using an LLM prompt. You can instruct the LLM to adopt or maintain a specific personality or tone.
2. **Conditional Response Variations**
Predefine different text variations (often for different slot conditions, contexts, or channels). This method is more static, but ensures each user scenario has a hand-crafted, on-brand response.
#### What Is the Response Rephraser?[](#what-is-the-response-rephraser "Direct link to What Is the Response Rephraser?")
The Response Rephraser is an LLM-powered component that takes a templated response (for example, “I’m sorry, I can’t help with that”) and rephrases it while preserving your original meaning and factual content. Its key benefits are:
* **Dynamically adapting tone**: Use a single base response but produce many variations, all preserving your brand guidelines.
* **Contextual awareness**: The rephraser can read the conversation history and user input, ensuring rephrasings make sense in context.
* **Easy maintenance**: If you decide to tweak your brand style (e.g., become more informal), you can simply update the LLM prompt, rather than rewriting all your responses.
See the [Response Rephraser reference page](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/) for more detail on parameters like the LLM model, temperature, or how to provide a custom prompt template.
#### What Are Conditional Response Variations?[](#what-are-conditional-response-variations "Direct link to What Are Conditional Response Variations?")
Conditional response variations let you define **several static message templates** under the same response name but tailor them to different states of the conversation. For example, you might have:
* A casual greeting if the `user_is_repeat_customer` slot is set to `true`.
* A more formal greeting otherwise.
When the assistant triggers the response, CALM checks any conditions you’ve set (slot values, channel, etc.) and picks the matching variant. These variations are not LLM-based—they are “what you see is what you get” messages, drawn from your domain or responses files.
See the [Conditional Response Variations reference](https://rasa.com/docs/docs/reference/primitives/responses/#conditional-response-variations) for detailed YAML examples and capabilities.
#### When to Use Which?[](#when-to-use-which "Direct link to When to Use Which?")
* **Use the Response Rephraser** if you want:
* *Dynamic, LLM-powered rewording* that can adapt to your brand voice, summarizing or refining the text while retaining the original meaning.
* A simpler way to unify tone across your entire assistant, especially for messages that appear in repair patterns or emergent flows.
* **Use Conditional Response Variations** if you want:
* *Strict control* over the exact wording in specific contexts or channels (e.g., “VIP members get a special greeting”).
* Variation without an external LLM call, or you need a guaranteed brand-approved statement for certain user segments.
Of course, you can also combine them—some responses can have multiple static variants, and you still run them through the Rephraser for final polishing.
#### How to Create Conditional Response Variations[](#how-to-create-conditional-response-variations "Direct link to How to Create Conditional Response Variations")
1. **In your domain file**, provide multiple responses under the same response name.
2. **Add a `condition` block** for each variant to specify which slot values must match (or which channel must match).
3. Always **include a default fallback** response (with no condition) in case none of the conditions are met.
domain.yml
```
responses:
utter_greet:
- condition:
- type: slot
name: logged_in
value: true
text: "Hey, welcome back! How are you?"
- text: "Hello! How can I help you today?
```
For more on advanced usage, see the Reference → Conditional Response Variations.
#### How to Customize the Response Rephraser[](#how-to-customize-the-response-rephraser "Direct link to How to Customize the Response Rephraser")
You can configure the Response Rephraser to ensure it outputs messages aligned with your desired personality or brand identity.
##### 1. Enabling Rephraser Across All Responses[](#1-enabling-rephraser-across-all-responses "Direct link to 1. Enabling Rephraser Across All Responses")
In your `endpoints.yml` file, add:
endpoints.yml
```
nlg:
type: rephrase
rephrase_all: true
```
This automatically attempts to rephrase every utterance. If you want some responses left untouched, annotate them with `metadata: { rephrase: false }` in your domain.
##### 2. Enabling Rephraser for Specific Responses[](#2-enabling-rephraser-for-specific-responses "Direct link to 2. Enabling Rephraser for Specific Responses")
If you prefer a more selective approach:
* Enable `type: rephrase` in `endpoints.yml` **without** setting `rephrase_all: true`.
* Add `metadata: { rephrase: true }` to only the responses you’d like rephrased:
domain.yml
```
responses:
utter_greet:
- text: "Hello there!"
metadata:
rephrase: true
```
##### 3. Setting a Custom Prompt[](#3-setting-a-custom-prompt "Direct link to 3. Setting a Custom Prompt")
You can supply your own Jinja2 prompt template to the rephraser. This is especially important to define a *tone or style*. For example:
endpoints.yml
```
nlg:
type: rephrase
prompt: "prompts/brand-tone-rephraser-template.jinja2"
```
Inside that `.jinja2` file, you could add instructions such as:
> “Use a casual, friendly tone in second-person. Always address the user by name if available.”
You can also override the default prompt for a *single* response by setting `rephrase_prompt` in its metadata (see the reference docs for an example).
#### How to Test Rephrased Responses?[](#how-to-test-rephrased-responses "Direct link to How to Test Rephrased Responses?")
Because the final assistant message may be partially (or entirely) generated by an LLM, it’s crucial to **test for both correctness and style**:
1. [**Generative Response Is Relevant**](https://rasa.com/docs/docs/reference/testing/assertions/#generative-response-is-relevant-assertion)
Ensures the rephrased message is on-topic and aligns with the user’s query.
tests/e2e\_test\_cases.yml
```
assertions:
- generative_response_is_relevant:
threshold: 0.90
```
2. [**Generative Response Is Grounded**](https://rasa.com/docs/docs/reference/testing/assertions/#generative-response-is-grounded-assertion)
Ensures the rephrased message remains factually accurate to the original domain response or RAG context.
tests/e2e\_test\_cases.yml
```
assertions:
- generative_response_is_grounded:
threshold: 0.90
ground_truth: "Free upgrades require a Platinum membership."
```
You can add these assertions in end-to-end tests to confirm that the LLM’s rewriting (1) remains brand-appropriate, (2) is accurate, and (3) is still relevant to the user’s input. See E2E Testing for more on these assertion types.
---
#### Command Generator
At the heart of CALM’s [dialogue understanding](https://rasa.com/docs/docs/learn/concepts/dialogue-understanding/) is a component called the [Command Generator](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/). Whenever a new user message arrives, this component takes the entire conversation context—such as active flows on the **dialogue stack**, previously filled slots, relevant patterns, and the user’s conversation history—and generates a list of high-level **commands**.
**[Commands](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#command-reference) can:**
* Begin a new flow.
* Terminate the current flow.
* Intercept user messages to bypass the current collection step.
* Assign a specified value to a slot.
* Request clarification.
* Provide a chitchat-style response, whether predefined or generated.
* Deliver a free-form, knowledge-based response.
* Transition the conversation to a human operator.
* Signal an internal error in handling the dialogue.
* Indicate a failure in generating any commands.
By framing user intent as commands rather than single-label “intents,” you can handle more complex scenarios—like when a user answers a question and requests a new flow simultaneously.
Tip
For more details on all command generator types, advanced configurations, and usage examples, see the [LLM Command Generators reference](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/).
#### What Is the CompactLLMCommandGenerator?[](#what-is-the-compactllmcommandgenerator "Direct link to What Is the CompactLLMCommandGenerator?")
The **CompactLLMCommandGenerator** is the simplest LLM-based approach for converting user messages into commands. It operates on a single prompt that encapsulates:
1. **Conversation History**: The full or partial conversation so far, including user and assistant messages.
2. **Active Flow and Slots**: Which flow is currently on top of the dialogue stack and which slot (if any) is currently being asked for.
3. **Relevant Flows**: A subset of the flows in your assistant that are likely relevant to the user’s request (handled automatically by CALM’s *flow retrieval* mechanism).
4. **Patterns / Repairs**: Predefined flows or patterns that can “interrupt” if the user changes their mind, wants to cancel, or triggers some other conversation repair scenario.
This single in-context prompt is passed to the underlying LLM (e.g., GPT-4o) whenever the assistant needs to interpret the user’s latest message. The LLM’s response is turned into a list of commands, which the system executes in a single step.
##### Flow Retrieval[](#flow-retrieval "Direct link to Flow Retrieval")
By default, CALM does not include all possible flows in the LLM prompt. Instead, it matches the incoming user message to each flow and includes only the top matching flows in the prompt. This keeps the prompt size manageable (and your costs lower). If you do want to disable or tweak flow retrieval, or always include certain flows, you can adjust that in your assistant configuration. For more details, see the [Flow Retrieval reference](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#retrieving-relevant-flows).
#### Customizing the Prompt Template[](#customizing-the-prompt-template "Direct link to Customizing the Prompt Template")
One of the main benefits of an LLM-based approach is **in-context learning**—that is, the ability to guide the model through instructions and context in the prompt. By default, the CompactLLMCommandGenerator uses a built-in **prompt template** that dynamically assembles relevant flows, the current conversation, and other context. However, you can override and customize this template to further tailor the model’s behavior.
##### When Should You Customize?[](#when-should-you-customize "Direct link to When Should You Customize?")
1. **Flow Descriptions Aren’t Enough**
Usually, you can steer the LLM by enriching your flows with clear, unambiguous descriptions and step-by-step instructions. But if you find the model still isn’t producing the commands you expect, or if you have domain-specific language the model often confuses, you may want to go further and rewrite the template.
2. **You Want Specific Formatting or Additional Examples**
Suppose you need to show the LLM a set of few-shot examples or domain-specific instructions that can’t be captured solely in the flow/slot descriptions. A custom prompt template gives you full control over how that context appears.
##### How to Customize[](#how-to-customize "Direct link to How to Customize")
1. **Create a Jinja2 Template**
You’ll provide a custom `.jinja2` file that contains the static text you want plus references to dynamic variables (like `{{ current_flow }}`, `{{ flow_slots }}`, etc.).
2. **Reference That File in Your config.yml**
Under `CompactLLMCommandGenerator`, set the `prompt_template` property:
config.yml
```
pipeline:
- name: CompactLLMCommandGenerator
prompt_template: prompts/my_custom_generator.jinja2
```
3. **Leverage Available Variables**
In your Jinja2 file, you have access to multiple variables, such as:
| Variable | Description |
| ---------------------- | --------------------------------------------------------------- |
| `current_conversation` | A readable transcript of the conversation so far. |
| `user_message` | The latest user message. |
| `available_flows` | A list of all flows potentially relevant to this conversation. |
| `current_flow` | The name of the currently active flow. |
| `flow_slots` | The slots associated with the current flow (name, value, etc.). |
You can iterate over lists to print out details about flows or slots. For example:
```
{% for flow in available_flows %}
{{ flow.name }}: {{ flow.description }}
{% endfor %}
```
4. **Make Your Template Clear and Consistent**
* If your slot descriptions are long or bullet-pointed, consider adjusting how you render them. Use numbered lists or add separators so the LLM easily distinguishes the slot’s name from its instructions.
* Keep the entire prompt in one language if your assistant is multilingual or works in a language other than English. Smaller LLMs often do better if the entire prompt is consistently in a single language.
Reference: Find the complete list of variables and more advanced ways to structure your prompt in the [Reference](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/) section on the command generator.
#### Important Note on Customizing the Command Set[](#important-note-on-customizing-the-command-set "Direct link to Important Note on Customizing the Command Set")
For more technical details on configuration parameters, advanced prompt tuning, or combining multiple Command Generators, head over to the [Command Generators reference](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/).
While CALM’s Command Generator is designed to be flexible, the **Rasa team actively tests and maintains a fixed set of built-in commands** (e.g., `StartFlowCommand`, `CancelFlowCommand`, `SetSlotCommand`, etc.) to ensure the highest level of performance and accuracy. If you override or replace these built-in commands:
* **Reduced Accuracy Guarantees**
We can’t guarantee that your assistant will maintain the same level of accuracy if you remove or rename these commands. Our tests and improvements assume that these commands exist in your system.
* **Potential Maintenance Overheads**
Custom commands require additional testing to ensure they behave consistently across different user inputs. You’ll need to invest in ongoing QA to match the quality of the maintained commands.
* **Possibility of Breaking Changes**
Future updates or improvements to CALM may assume the presence of these default commands. If you’ve drastically modified them, you could need to refactor your assistant for compatibility.
##### How to customize existing commands[](#how-to-customize-existing-commands "Direct link to How to customize existing commands")
If a use case still requires customization of commands, then here is the recommended way:
1. **Override an existing command class**
Identify the existing command you want to change. Define a new Python class inheriting from the corresponding command class. Override the following methods:
* `command` - provides Rasa with the unique identifier of your custom command.
* `from_dict` - handles the deserialization of the command from the JSON object stored in the tracker.
* `from_dsl` - converts the parsed output from the LLM output into a command.
* `to_dsl` - specifies how the command is represented when serialized back into the DSL format.
* `regex_pattern` - used by Rasa to parse and recognize your custom command name from the output generated by the LLM.
* `__eq__` - logic that determines whether two command instances are equal.
All custom commands must inherit from the `Command` abstract class and adhere to the `PromptCommand` protocol.
For example, to customize the name of the `HumanHandoffCommand` class used in your prompt, create the following:
```
from __future__ import annotations
import re
from dataclasses import dataclass
from typing import Any, Dict
from rasa.dialogue_understanding.commands import HumanHandoffCommand
@dataclass
class CustomHumanHandoffCommand(HumanHandoffCommand):
"""A custom human handoff command."""
# Optionally you can define the command arguments
new_command_arg: str
@classmethod
def command(cls) -> str:
"""Returns the command type."""
return "custom human handoff"
@classmethod
def from_dict(cls, data: Dict[str, Any]) -> CustomHumanHandoffCommand:
"""Converts the dictionary to a command.
Returns:
The converted dictionary.
"""
return CustomHumanHandoffCommand(
new_command_arg=data["new_command_arg"]
)
@classmethod
def from_dsl(cls, match: re.Match, **kwargs: Any) -> CustomHumanHandoffCommand:
"""Converts a DSL string to a command."""
# Example extraction: assume `new_command_arg` is captured by the first regex group
new_command_arg = match.group(1)
return CustomHumanHandoffCommand(
new_command_arg=new_command_arg
)
def to_dsl(self) -> str:
"""Converts the command to a DSL string."""
return f"custom human handoff {self.new_command_arg}"
@staticmethod
def regex_pattern() -> str:
"""Returns regular expression used to parse the command from the LLM output"""
return r"""^[\s\W\d]*custom human handoff ['"`]?([a-zA-Z0-9_-]+)['"`]*"""
def __eq__(self, other: object) -> bool:
return isinstance(other, CustomHumanHandoffCommand)
```
2. **Override the existing command behavior**
If you also want to update the command behavior, override the `run_command_on_tracker` method within your class.
```
@dataclass
class CustomHumanHandoffCommand(HumanHandoffCommand):
"""A custom human handoff command."""
new_command_arg: str
...
def run_command_on_tracker(
self,
tracker: DialogueStateTracker,
all_flows: FlowsList,
original_tracker: DialogueStateTracker,
) -> List[Event]:
"""Runs the command on the tracker.
Args:
tracker: The tracker to run the command on.
all_flows: All flows in the assistant.
original_tracker: The tracker before any command was executed.
Returns:
The events to apply to the tracker.
"""
# Get the copy of the current dialogue stack of frames
stack = tracker.stack
# Implement your custom command behavior here
# For example, add a frame related to human handoff logic
stack.push(HumanHandoffPatternFlowStackFrame())
# Generate events reflecting the updated dialogue stack state
events = tracker.create_stack_updated_events(stack)
return events
```
3. **Create custom command generator**
Create a custom command generator class by extending Rasa's default command generator. Override its `parse_commands` method as follows to handle your customized commands:
custom\_command\_generator.py
```
# Import the utility method under a different name to prevent confusion with the
# command generator's `parse_commands`
from rasa.dialogue_understanding.generator.command_parser import (
parse_commands as parse_commands_using_command_parsers,
)
# Define logger
structlogger = structlog.get_logger()
class CustomCommandGenerator(CompactLLMCommandGenerator):
@classmethod
def parse_commands(
cls, actions: Optional[str], tracker: DialogueStateTracker, flows: FlowsList
) -> List[Command]:
commands = parse_commands_using_command_parsers(
actions,
flows,
# Register custom command
additional_commands=[CustomHumanHandoffCommand],
# Exclude replaced default command
default_commands_to_remove=[HumanHandoffCommand]
)
if not commands:
structlogger.warning(
f"{cls.__name__}.parse_commands",
message="No commands were parsed from the LLM actions.",
actions=actions,
)
return commands
```
4. **Update the prompt template**
Create the custom prompt template that uses your new command name explicitly. For example:
custom\_prompt\_template.jinja2
```
...
## Available Actions:
* `start flow flow_name`: Starting a flow. For example, `start flow transfer_money` or `start flow list_contacts`.
* `set slot slot_name slot_value`: Slot setting. For example, `set slot transfer_money_recipient Freddy`. Can be used to correct and change previously set values.
* `cancel flow`: Cancelling the current flow.
* `disambiguate flows flow_name1 flow_name2 ... flow_name_n`: Disambiguate which flow should be started when user input is ambiguous by listing the potential flows as options. For example, `disambiguate flows list_contacts add_contact remove_contact ...` if the user just wrote "contacts".
* `provide info`: Responding to the user's questions by supplying relevant information, such as answering FAQs or explaining services.
* `offtopic reply`: Responding to casual or social user messages that are unrelated to any flows, engaging in friendly conversation and addressing off-topic remarks.
* `custom human handoff new_command_arg`:
...
```
5. **Update the `config.yml` to utilize the custom command generator and the new prompt template**
config.yml
```
pipeline:
- name: path.to.custom_command_generator.CustomCommandGenerator
prompt_template: path/to/custom_prompt_template.jinja2
```
---
#### Customizing Patterns
Rasa assistants use patterns (pre-built flow templates) to handle conversation repair and some system behaviour. By separating patterns from the business-logic flows, you avoid having to weave every possible “what if the user changes their mind” scenario into your main flows. Instead, your flows can stay focused on the high-level steps for accomplishing tasks (booking a flight, transferring money, etc.), while the conversation patterns makes sure your flows are adaptive to how the user wants to accomplish their goal.
By default, every common conversation repair scenario—like corrections, digressions, or incomplete data—has a pre-written pattern in Rasa. However, you can override those defaults to better suit your assistant’s needs.
Digging into patterns
For more information on the concept of patterns, head to the [Home section on Patterns](https://rasa.com/docs/docs/learn/concepts/conversation-patterns/).
For a complete list of patterns and their low-level implementations, head to the [corresponding section in the Reference](https://rasa.com/docs/docs/reference/primitives/patterns/).
#### Why Customise Patterns?[](#why-customise-patterns "Direct link to Why Customise Patterns?")
##### Templated Flows for Repair[](#templated-flows-for-repair "Direct link to Templated Flows for Repair")
Think of a pattern as a **reusable template** for handling a repeatable scenario (cancellation, correction, human handoff, etc.). Because patterns need to work anywhere in your assistant, you typically want to keep them general rather than making them skill-specific.
##### Balancing Consistency and Adaptation[](#balancing-consistency-and-adaptation "Direct link to Balancing Consistency and Adaptation")
Although you want to keep these templated flows broadly applicable, you may still want to:
* **Adapt the language** of responses (e.g., brand or domain-specific wording).
* **Request user confirmation** before updating slots (such as in the correction pattern).
* **Hand over to a live agent** when certain issues arise.
For purely language-level customization (i.e., to keep brand voice consistent), consider using the Response Rephraser to automatically adapt the text in the pattern’s default responses. You can find more information on customizing the tone of your assistant [here](https://rasa.com/docs/docs/pro/customize/assistant-tone/).
#### How to Customise Patterns[](#how-to-customise-patterns "Direct link to How to Customise Patterns")
##### 1. Override a Pattern Flow[](#1-override-a-pattern-flow "Direct link to 1. Override a Pattern Flow")
To customise a pattern, create a flow in your `flows.yml` file **with the same name** as the pattern. For instance, if you want to change how a cancellation is handled, create a flow named `pattern_cancel_flow`:
flows.yml
```
flows:
pattern_cancel_flow:
description: Custom cancellation flow
steps:
- action: action_cancel_flow
- action: utter_flow_cancelled_rasa
```
When your assistant sees a user cancellation, it will **use your new `pattern_cancel_flow`** instead of the default one.
For existing default pattern implementations see to the Reference section on [Patterns](https://rasa.com/docs/docs/reference/primitives/patterns/#reference-default-pattern-configuration).
*Keep pattern overrides concise. Most patterns interrupt an ongoing flow, so it’s best to return the user to the main conversation quickly.*
##### 2. Override Default Actions or Responses[](#2-override-default-actions-or-responses "Direct link to 2. Override Default Actions or Responses")
Some patterns make use of **default actions**, like `action_correct_flow_slot` or `action_trigger_chitchat`. If you need more control over the logic:
1. Create a custom action in your `actions.py`.
2. Reference it in your custom pattern flow and your `domain.yml`.
Likewise, the default text responses are in your domain’s `responses:` section. Override them with your own text or tie them into the Rephraser if needed.
##### 3. Link Patterns to Other Flows[](#3-link-patterns-to-other-flows "Direct link to 3. Link Patterns to Other Flows")
You can also “jump” from a pattern to another flow (for example, if the user clarifies something and you want to start a brand-new flow). To do this, add a **link** step at the end of your pattern:
flows.yml
```
flows:
pattern_clarification:
description: "Clarification pattern"
steps:
- noop: true
next:
- if: context.names
then:
- action: action_clarify_flows
next:
- if: context.names contains "transfer_money"
then:
- link: transfer_money
- else: clarify_options
- else:
- action: utter_clarification_no_options_rasa
next: END
- id: clarify_options
action: utter_clarification_options_rasa
```
When the user clarifies that they want to transfer money, you directly start the `transfer_money` flow.
##### 4. Human Handoff and Other Special Cases[](#4-human-handoff-and-other-special-cases "Direct link to 4. Human Handoff and Other Special Cases")
For certain special patterns like `pattern_human_handoff` or `pattern_chitchat`:
* **Human handoff**: Override `pattern_human_handoff` to add your own logic for connecting to a live agent.
* **Chitchat**: By default, chitchat is turned off, and the assistant responds with the default `utter_cannot_handle` response. You can switch to free-form generation by overriding `pattern_chitchat` and calling an LLM-based response.
For more information on customizing patterns, see to the Reference section on [Patterns](https://rasa.com/docs/docs/reference/primitives/patterns/#common-modifications).
---
#### Enterprise Search
Enterprise Search provides a way to manage informational user queries by integrating your assistant with your information retrieval pipelines. When a user asks a question requiring external knowledge—e.g., product information, support manuals, or FAQs—Enterprise Search enables your assistant to look up relevant documents from a vector store or other data repository.
With Enterprise Search, you can:
* Retrieve relevant content from your own knowledge base or documents.
* Provide the content to a Large Language Model (LLM) for answer generation, or choose an extractive approach (i.e., respond with the exact text from your repository, rather than an LLM-generated rephrasing).
* Integrate advanced retrieval patterns (e.g., slot-based search filters or re-ranking) to handle more complex user queries.
For more information on configuring Enterprise Search and integrating your RAG pipeline, head to the [Build section on Enterprise Search](https://rasa.com/docs/docs/pro/build/configuring-enterprise-search/).
What can you customise in Enterprise Search?
#### Vector Store Integrations[](#vector-store-integrations "Direct link to Vector Store Integrations")
Rasa’s **Enterprise Search** supports out-of-the-box integrations with multiple vector stores. These integrations allow you to set up a pipeline that indexes your documents for semantic search and returns the most relevant chunks when triggered by your assistant.
##### Out-of-the-Box Vector Stores[](#out-of-the-box-vector-stores "Direct link to Out-of-the-Box Vector Stores")
* [Qdrant](https://qdrant.tech/)
* [Milvus](https://github.com/milvus-io/milvus/)
* [Faiss](https://ai.meta.com/tools/faiss/)
You can configure each vector store (e.g., connection parameters, threshold scores) in your `endpoints.yml` and `config.yml` files. Refer to the [Enterprise Search Policy](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/) reference for the exact configuration details and examples.
#### Custom Information Retrieval[](#custom-information-retrieval "Direct link to Custom Information Retrieval")
Enterprise Search can also connect your own custom retrieval logic if you need something beyond the built-in integrations. This is especially useful for:
* **Slot-based retrieval**: Filter your documents based on specific slots in the conversation (e.g., filtering an FAQ or knowledge base by a user’s role or product tier).
* **Proprietary search engines**: If your organization already has a custom search pipeline or advanced ML models you want to reuse, you can integrate them via a custom retriever interface.
* **Different embedding or indexing strategies**: Use your own embeddings or indexing approach to match your domain needs.
For implementation details, such as how to create a custom retriever class and plug it into the retrieval pipeline, see the reference docs on [Custom Information Retrieval](https://rasa.com/docs/docs/reference/config/policies/custom-information-retrievers/).
#### Extractive Search[](#extractive-search "Direct link to Extractive Search")
Extractive Search removes the LLM-based generation step in RAG altogether, allowing your assistant to respond with direct text snippets from your stored FAQ data. This approach can be ideal if you have a well-structured or curated knowledge base and want to reduce costs and hallucination risk by not calling an LLM for generating an answer.
1. **How It Works**
* Each piece of Q\&A content is ingested as a “document” with a question stored in the document text (page content) and the corresponding answer in the document metadata.
* The assistant retrieves the best match from the knowledge base using a vector store or a custom retriever and responds with the metadata’s answer field directly.
2. **Why Use Extractive Search**
* **Lower Latency and Cost**: No calls to an external LLM service are required to rephrase or synthesize an answer.
* **Exact Answers**: Ideal when your domain demands an exact snippet from curated sources.
* **Simplicity**: Fewer moving parts in your pipeline if your answers need not be dynamically generated or summarized.
3. **Configuration**
* In your `config.yml`, set `use_generative_llm: false` under the `EnterpriseSearchPolicy` component.
* Make sure your dataset is loaded into whichever store you’re using (Faiss, Milvus, Qdrant, or a custom retriever) in the Q\&A format.
For more information on Extractive Search see the corresponding [reference page](https://rasa.com/docs/docs/reference/config/policies/extractive-search/).
#### Configuring fallbacks[](#configuring-fallbacks "Direct link to Configuring fallbacks")
Often end users ask questions that cannot be answered from the available content in the knowledge bases. In such scenarios, it is important for the assistant to abstain from responding to the user. `EnterpriseSearchPolicy` can be configured to do so by setting `check_relevancy` to `True` in its config options. By doing so, the assistant assesses whether the user's query has a relevant answer in the knowledge base. If it doesn't find a relevant answer, the control is passed to `pattern_cannot_handle`. The default behaviour of the assistant in this case is to answer with a generic response - `I’m sorry, I can’t help with that`. However, this behaviour is fully [customizable](https://rasa.com/docs/docs/reference/config/policies/generative-search/#relevancy-check) to either respond with a different utterance, fallback to a free-form generative response, fallback to a live agent or any business logic you want the assistant to run in this scenario.
---
#### Fine-Tuning an LLM for Command Generation
New in 3.10
Fine-tuning LLMs is available starting with version `3.10.0` as a **beta** feature. This page provides a walkthrough and in-depth implementation details.
This page explains why you might want to fine-tune a smaller LLM (e.g., Llama-3.1 8B) for command generation in CALM. It outlines Rasa’s fine-tuning recipe at a high level, and shows you how to get started, and where to go next.
#### Why Would You Want to Fine-Tune an LLM for Command Generation?[](#why-would-you-want-to-fine-tune-an-llm-for-command-generation "Direct link to Why Would You Want to Fine-Tune an LLM for Command Generation?")
When starting out with CALM, you might rely on a powerful off-the-shelf LLM (e.g., GPT-4o) via OpenAI or Azure OpenAI. That’s often the quickest path to a functional assistant. However, as your use cases multiply and your traffic grows, you might hit constraints like:
1. **Response Latency:** Third-party LLM services are shared resources and can become slower at peak usage times, leading to a frustrating user experience.
2. **Rate Limits & Availability:** Relying on external providers can mean hitting token usage caps or facing downtime.
3. **High Inference Costs:** Token-based payment and especially provisioned throughput units (PTUs) are costly at scale.
4. **Model Life Cycles:** Third-party services often phase out models quickly
Fine-tuning a smaller LLM locally or on a private cloud helps mitigate these issues. By tailoring an LLM model specifically for *command generation* in your assistant, you can:
* **Boost Performance and Reliability:** A fine-tuned smaller model can respond faster with greater latency guarantees.
* **Cut Costs:** Inference on a smaller, domain-tailored LLM can be significantly cheaper.
* **Retain Control Over Your Data and Processes:** Run the model on your own infrastructure to avoid potential data-sharing, vendor lock-in, or model lifecycle concerns.
#### What Is the Fine-Tuning Recipe?[](#what-is-the-fine-tuning-recipe "Direct link to What Is the Fine-Tuning Recipe?")
Our fine-tuning recipe streamlines the process of gathering training data and fine-tuning an LLM for your domain.
Below is a high-level overview of the fine-tuning process:

1. **Prepare Your Assistant & Tests**
* Make sure your CALM assistant uses an LLM-based command generator (e.g., `CompactLLMCommandGenerator` with an LLM like `gpt-4o-2024-11-20`)
* Check that you have [**comprehensive E2E tests**](https://rasa.com/docs/docs/reference/testing/coverage/) covering your most important conversation flows and that they are passing.
* E2E tests are the basis for generating training data. Failing tests cannot be turned into training data.
2. **Generate Finetuning Training Data**
* Run [`rasa llm finetune prepare-data --num-rephrases 2 --output-format conversational`](https://rasa.com/docs/docs/reference/api/command-line-interface/#rasa-llm-finetune-prepare-data) on your E2E tests.
* This process executes the e2e tests and captures the prompt and the desired commands at each user step.
* Rephrasings increase the linguistic variety of user messages. Each rephrasing is confirmed to produce the same command as the original user message and dropped otherwise.
* By default, the resulting dataset is split into training (80%) and validation (20%).
3. **Fine-Tune Your Model**
* Rasa provides [a jupyter notebook](https://nbviewer.org/github/RasaHQ/notebooks/blob/main/cmd_gen_finetuning.ipynb) that guides you through the process of fine-tuning a smaller LLM for the task of command generation and storing the resulting model.
4. **Test & Deploy**
* [Deploy the fine-tuned LLM model](https://rasa.com/docs/docs/pro/deploy/deploy-fine-tuned-model/) to a test environment.
* Test your fine-tuned LLM by running the original or additional E2E tests.
* If the results meet your quality and performance criteria, you can deploy the new model to your production environment.
We explain each of the steps in more detail in the following sections.
#### Preparing e2e Tests[](#preparing-e2e-tests "Direct link to Preparing e2e Tests")
To fine-tune an LLM effectively, it’s crucial to ensure that your assistant is comprehensively covered by E2E tests. These tests provide the data needed for fine-tuning. If your E2E tests do not sufficiently cover the assistant's functionality, the fine-tuned model may not perform well due to a lack of relevant training examples.
To address this, you can use an [E2E test diagnostic tool](https://rasa.com/docs/docs/reference/testing/coverage/), which is available as part of Rasa’s CLI. This tool helps you evaluate whether your E2E tests adequately cover the system's capabilities. It also identifies areas where existing tests may need to be updated or where new tests should be created before proceeding with fine-tuning.
##### Assessing Test Coverage for Fine-tuning[](#assessing-test-coverage-for-fine-tuning "Direct link to Assessing Test Coverage for Fine-tuning")
When reviewing the results of the diagnostic tool there are two key areas to focus on to ensure your data is suitable for fine-tuning:
1. Representation of [All Commands](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#command-reference): Ensure that all commands your assistant might generate are represented in your tests. If certain commands are not covered, the model may struggle to generate them correctly, having never "seen" these scenarios during training. This can be evaluated by inspecting the [command coverage histograms](https://rasa.com/docs/docs/reference/testing/coverage/#command-coverage)
2. Representation of all flows: Ensure that the flows you want your bot to handle are well-represented in the tests. This ensures the model learns from a variety of examples and scenarios, increasing its robustness and reliability. This can be evaluated by inspecting the [flow coverage report](https://rasa.com/docs/docs/reference/testing/coverage/#flow-coverage)
By carefully analyzing and expanding your test coverage, you can better prepare your model for fine-tuning, resulting in improved performance and a more reliable assistant.
#### Training Data Generation[](#training-data-generation "Direct link to Training Data Generation")
important
If an E2E test is failing on your assistant, you won't be able to use that test for fine-tuning an LLM. Hence, please ensure that the assistant is able to successfully pass the input E2E tests. We also recommend using the [E2E coverage analysis tool](https://rasa.com/docs/docs/reference/testing/coverage/) to understand the coverage your passing tests are providing for the flows of your assistant.
Training data for fine-tuning LLMs consists of prompt and command pairs. These pairs are extracted during execution of e2e tests from the `CompactLLMCommandGenerator` or the `SearchReadyLLMCommandGenerator` components. Only user steps that are processed by these components can generate the needed prompt command pairs. For example, if your tests use [buttons that issue set slot commands](https://rasa.com/docs/docs/reference/primitives/responses/#issuing-set-slot-commands) to bypass the `CompactLLMCommandGenerator` no prompt command pair will be generated for that specific step.
The data generation happens using the currently configured LLM for your command generator component. Make sure to use the most capable LLM available to you for this step, to have as many passing tests as possible and thus as many training data points as possible. In our experience, a few hundred data points are enough to fine-tune an LLM using the recipe.
You can generate training data using the following command:
`rasa llm finetune prepare-data --num-rephrases 2 --output-format conversational`
##### Data Augmentation in Detail[](#data-augmentation-in-detail "Direct link to Data Augmentation in Detail")
During the data generation, you can augment your training data by automatic rephrasing of user utterances. The rephrasing happens using another LLM call. Any generated variant is verified to generate the same commands as the original message. A notable exception are slot sets, where the slot name must be the same, but the value might differ. Only rephrased variants that pass this check are added to the training set.
**Note**: User utterances that come from buttons, e.g. the user clicked on a button instead of typing a response, are not rephrased and skipped by the synthetic data generator.
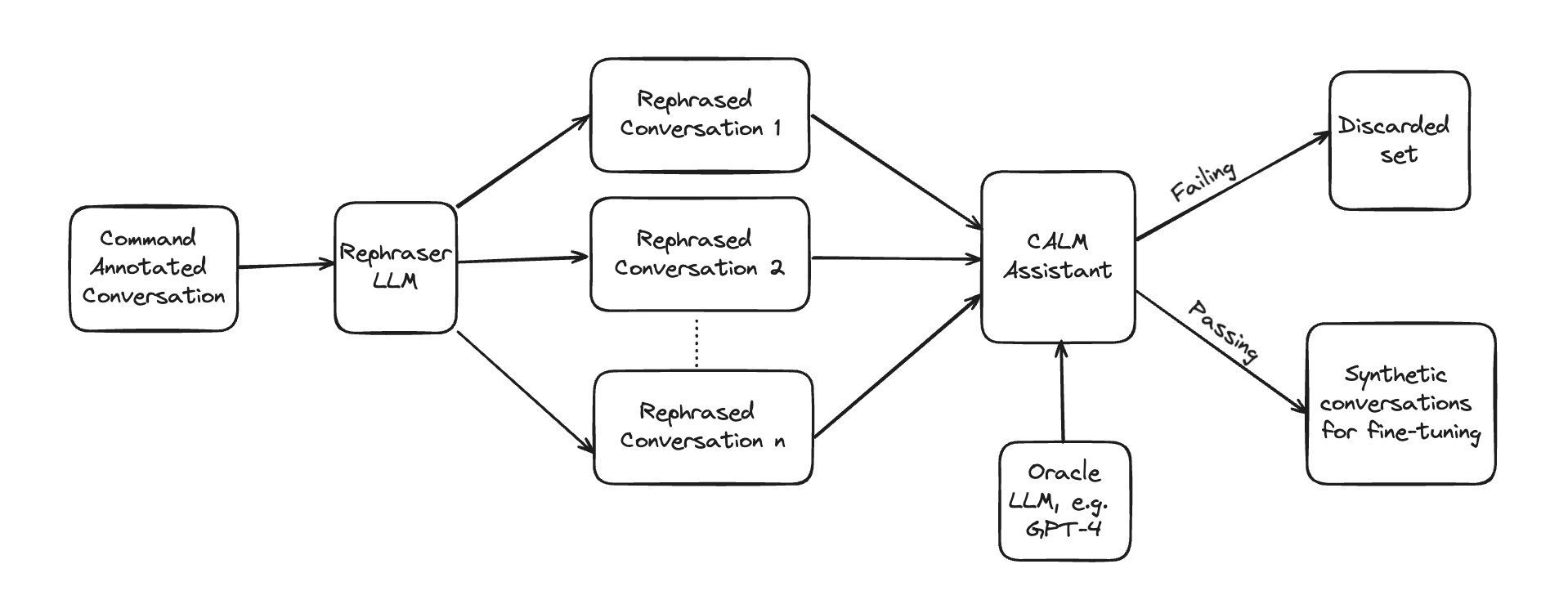
The number of rephrasings to generate and test can be influenced with the `--num-rephrases` parameter. Note that you are not guaranteed to get that specific number of rephrasings for each message. This parameter just controls the number of candidate rephrasings that are then verified to generate the same result as the original message.
If you set `--num-rephrases 0`, the synthetic data generator will be skipped.
###### Rephraser LLM Call[](#rephraser-llm-call "Direct link to Rephraser LLM Call")
By default, the rephraser uses `gpt-4.1-mini-2025-04-14` to paraphrase user steps. The rephraser uses the following prompt to create the rephrasings:
```
Objective:
Create multiple rephrasings of user messages tailored to the "{{ test_case_name }}" conversation scenario.
===
Conversation overview:
{{ transcript or "Not provided." }}
===
Task:
Produce {{ number_of_rephrasings }} rephrasings for each user message that are diverse yet contextually appropriate.
Preserve the intent and content, but vary the structure, formality, and detail.
Only rephrase messages prefixed with "{{ user_prefix }}:".
Guidelines:
- Use a variety of expressions from brief and casual to elaborate and formal.
- Vary sentence structures, vocabularies, and expressions creatively.
- Keep the core message intact with concise and simple modifications.
Format:
- Each original user message should be prefixed with "USER: ".
- Enumerate the rephrasing.
- Separate each user message set with a line break.
===
Example output for 3 rephrasings of 2 user messages:
"""
USER: Show invoices
1. I want to see my bills.
2. I mean bills
3. Yes, I want to see the invoices.
USER: I'd like to book a car
1. I need to reserve a car.
2. Could I arrange for a car rental?
3. I'm interested in hiring a car.
"""
===
Expected output:
{{ number_of_rephrasings }} rephrasings for the following {{ number_of_user_messages }} user messages in the expected
format:
{% for message in user_messages -%}
- {{ message }}
{% endfor %}
```
If you want to modify the prompt or use a different LLM for the Rephraser LLM you can specify a custom config via the argument `--rephrase-config ` on the CLI command [`rasa llm finetune prepare-data`](https://rasa.com/docs/docs/reference/api/command-line-interface/#rasa-llm-finetune-prepare-data). The default config looks like this
```
prompt_template: default_rephrase_prompt_template.jina2
llm:
model: gpt-4.1-mini-2025-04-14
provider: openai
```
###### Validation of Rephrased User Steps[](#validation-of-rephrased-user-steps "Direct link to Validation of Rephrased User Steps")
To validate the rephrased user steps, Rasa takes the prompt of the original user step and replaces the original user utterance with the rephrased one. Then the prompt is sent to the same LLM used to annotate the conversation originally. If the response of the LLM after parsing and processing matches the response of the original user step, the rephrased user utterance passes the test and is added to the synthetic conversation dataset for fine-tuning.
###### Recombination of Rephrased User Steps[](#recombination-of-rephrased-user-steps "Direct link to Recombination of Rephrased User Steps")
Let's take a look at an example to understand how Rasa constructs new conversations using the rephrased messages. Take this original conversation:
```
- user: I'd like to book a car
- bot: in which city?
- user: to Basel
- bot: When would you like to pick up the car?
- user: from may 14th to the 17th
- utter: utter_ask_car_rental_selection
- user: I'll take the luxury one! looks nice
```
and the following rephrasings per user step:
| **original user message** | **passing rephrase 1** | **passing rephrase 2** | **passing rephrase 3** |
| ------------------------------------ | ---------------------------------------------------------- | -------------------------------------------- | ---------------------------------------------------------- |
| I'd like to book a car | I need to reserve a car. | Could I arrange for a car rental? | I'm interested in hiring a car. |
| to Basel | The destination is Basel. | I'd like to go to Basel. | |
| from may 14th to the 17th | The rental period will be May 14th to 17th. | I need the car from May 14th to May 17th. | I'll require the vehicle from the 14th to the 17th of May. |
| I'll take the luxury one! looks nice | I'd like to go with the luxury option; it looks appealing. | I'll choose the luxury model; it seems nice. | I'm opting for the luxury car; it looks great. |
To construct a new conversation, we combine passing rephrases at the same index position to build a new conversation. If some rephrasings have failed to pass, we evenly use the other passing rephrases.
So, the final conversations would look like this:
```
# conversation 1 (original conversation)
- user: I'd like to book a car
- bot: in which city?
- user: to Basel
- bot: When would you like to pick up the car?
- user: from may 14th to the 17th
- utter: utter_ask_car_rental_selection
- user: I'll take the luxury one! looks nice
# conversation 2
- user: I need to reserve a car.
- bot: in which city?
- user: The destination is Basel.
- bot: When would you like to pick up the car?
- user: The rental period will be May 14th to 17th.
- utter: utter_ask_car_rental_selection
- user: I'd like to go with the luxury option; it looks appealing.
# conversation 3
- user: Could I arrange for a car rental?
- bot: in which city?
- user: I'd like to go to Basel.
- bot: When would you like to pick up the car?
- user: I need the car from May 14th to May 17th.
- utter: utter_ask_car_rental_selection
- user: I'll choose the luxury model; it seems nice.
# conversation 4
- user: I'm interested in hiring a car.
- bot: in which city?
- user: The destination is Basel.
- bot: When would you like to pick up the car?
- user: I'll require the vehicle from the 14th to the 17th of May.
- utter: utter_ask_car_rental_selection
- user: I'm opting for the luxury car; it looks great.
```
##### Data Split into Training and Validation[](#data-split-into-training-and-validation "Direct link to Data Split into Training and Validation")
By default, Rasa takes 80% of the fine-tuning data for the training dataset. The remaining data points go to the validation set. During that process, we make certain that all command **types** present in the fine-tuning dataset will end up at least once in the training dataset. This means specifically that Rasa makes sure that even less common command types such as a flow cancellation are at least once in the training set. Rasa does not take into account the arguments to these command types. That means you are currently not guaranteed to have at least one starting command for each flow in your training dataset.
When it comes to rephrasings, we make sure that all variants of a test conversation end up either in train OR in test. This way Rasa does not contaminate the test set with near duplicates of the train set.
You can update the fraction of data that goes into the training dataset by setting the flag `--train-frac ` on the CLI command [`rasa llm finetune prepare-data`](https://rasa.com/docs/docs/reference/api/command-line-interface/#rasa-llm-finetune-prepare-data).
If you would like to have more control over your data split, it makes sense to manually generate a static test train split upfront. Then generate training and test data separately by disabling the automatic splitting using `--train-frac 1.0`.
##### Data Point Format[](#data-point-format "Direct link to Data Point Format")
When you [fine-tune a base model](#model-fine-tuning), the base model expects the data to be in a specific format. By default, the training and validation datasets are in [instruction data format](https://huggingface.co/docs/trl/en/sft_trainer#dataset-format-support).
If you want to use the nowadays more common [conversational data format](https://huggingface.co/docs/trl/en/sft_trainer#dataset-format-support) instead set the flag `--output-format conversational` on the CLI command [`rasa llm finetune prepare-data`](https://rasa.com/docs/docs/reference/api/command-line-interface/#rasa-llm-finetune-prepare-data).
##### Folder Structure of the Results[](#folder-structure-of-the-results "Direct link to Folder Structure of the Results")
After generating the fine-tuning data you will find the result in the `output` folder.
If you want to get straight to the fine-tuning part check out the `.jsonl` files in `output/4_train_test_split/ft_splits`.
Rasa also provides a number of intermediate data structures that can help while debugging the process.
* `output/1_command_annotations` has your original e2e tests annotated with commands.
* `output/2_rephrasings` contains the rephrasings for each conversation.
* `output/3_llm_finetune_data` holds an intermediate data structure after turning conversations and rephrased conversations into individual data points for fine-tuning. It contains the prompt, the desired output, the original test case name, and the original and potentially rephrased message.
* `output/4_train_test_split/e2e_tests` contains the original e2e tests according to the train/test split. This can help you to run e2e testing specifically against those tests that made it into train or those that made it into validation.
* `output/4_train_test_split/ft_splits` contains the data points that can be used for LLM fine-tuning.
#### Model Fine-tuning[](#model-fine-tuning "Direct link to Model Fine-tuning")
Once you have the dataset prepared, you can start fine-tuning an open source LLM to help it excel at the task of command generation.
Rasa provides this example [python notebook](https://nbviewer.org/github/RasaHQ/notebooks/blob/main/cmd_gen_finetuning.ipynb) as a reference for fine-tuning. It has been tested on GCP Vertex AI and AWS SageMaker, it can be easily adapted to work on other cloud platforms. By default, it:
1. Uses the HuggingFace stack for training [LoRA-adapters](https://huggingface.co/docs/peft/en/package_reference/lora) for your model.
2. Downloads a base model from [huggingface hub](https://huggingface.co/models). Using [Llama-3.1 8b Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) model is recommended.
3. Loads the base model with the option for quantization using the [BitsandBytes](https://huggingface.co/docs/transformers/main/en/quantization/bitsandbytes) library for efficient memory usage.
4. Provides default hyperparameters that have worked well in the past.
5. Adds a chat template if the model does not already have one.
6. Runs the fine-tuning and visualizes loss as the metric to monitor across the training and validation set. When testing this step on an NVIDIA A100 with the default hyperparameters, it took around 1 hour to perform fine-tuning with a training dataset containing around 1600 examples. Hence, this step is relatively cheap and quick to run.
7. Allows persisting the model on the cloud.
note
CALM exclusively uses the chat completions endpoint of the model server, so it's essential that the model's tokenizer includes a chat template. Models lacking a chat template will not be compatible with CALM.
#### Deploying your Model[](#deploying-your-model "Direct link to Deploying your Model")
Head over to the [LLM deployment section](https://rasa.com/docs/docs/pro/deploy/deploy-fine-tuned-model/) to learn how to start using your fine-tuned model in CALM.
---
### Deploy and Scale
#### Deploying Fine-Tuned LLMs for Command Generation
New in 3.10
This page relates to the [fine-tuning recipe](https://rasa.com/docs/docs/pro/customize/fine-tuning-llm/), which is a **beta** feature available starting with version `3.10.0`
After you have fine-tuned a base language model for the task of command generation, you can deploy it to be used by a CALM assistant.
The deployed fine-tuned model must be accessible by the assistant via an [litellm compatible API](https://docs.litellm.ai/docs/providers).
It is highly recommended that you use the [vLLM](https://docs.vllm.ai/en/stable/index.html) model serving library, as it provides a number of important features such as batching and prefix caching.
This page gives an overview on the requirements and options for deploying a fine-tuned model in different environments with links to more detailed guides in our reference section. The same instructions can also be used to deploy any language model from [Hugging Face](https://huggingface.co/models), not only ones that you have fine-tuned.
info
After deploying your model, you will have to [update your assistant's config](https://rasa.com/docs/docs/reference/config/components/llm-configuration/#self-hosted-model-server) for it to use the model for command generation.
#### Hardware Requirements[](#hardware-requirements "Direct link to Hardware Requirements")
Hosting large language models requires a GPU to achieve fast inference latency.
If you are using a language model with billions of parameters, such as Llama 3.1, it is highly recommended that you use a GPU with a relatively large amount of memory. For example, an 8 Billion parameter model needs at least 16GB of GPU memory to fit the weights when using 16-bit precision. On top of that, some memory is required for processing one or multiple queries at once, and for caching activations from prior queries (prefix caching) to speed up processing of similar queries. In our experience, a GPU with 40GB of memory provides enough memory to operate a 8B parameter model at scale.
Suitable GPUs for low-latency inference:
* A100 (40GB/80GB)
* L40S (48GB)
* H100 (80GB)
#### Expected Throughput and Latency[](#expected-throughput-and-latency "Direct link to Expected Throughput and Latency")
With one of the recommended GPUs you can process around 5 requests per second for command generation at a median response time below 500ms. Note that requests per second is not equal to the number of users. For example, in a voice bot, a user might only interact with the system every 10 seconds because the interaction loop involves user speaking, processing, system responding, user listening, deciding and speaking again. Thus, 5 requests per second would equate to around 50 concurrent users.
info
The exact latency and throughput numbers will depend on the size of your prompt, which in turn is influenced by things such as the number of flows, their description length, whether you are using flow retrieval, etc.
Also take a look at our [reference section on further optimizations](https://rasa.com/docs/docs/reference/deployment/deploy-fine-tuned-model/#optimizations)
#### Options for deploying the fine-tuned model[](#options-for-deploying-the-fine-tuned-model "Direct link to Options for deploying the fine-tuned model")
The following options show different scenarios for using the [vLLM](https://docs.vllm.ai/en/stable/index.html) model serving library with your fine-tuned model.
* If you like to serve the model for testing purposes right on the machine where you trained it, you can [use vLLM directly](https://rasa.com/docs/docs/reference/deployment/deploy-fine-tuned-model/#using-vllm-directly)
* You can also [use docker to start vLLM on a VM](https://rasa.com/docs/docs/reference/deployment/deploy-fine-tuned-model/#using-vllm-via-docker).
* For production use you can [deploy the LLM to a kubernetes cluster](https://rasa.com/docs/docs/reference/deployment/deploy-fine-tuned-model/#kubernetes-cluster)
* If you are on AWS, [Sagemaker Inference Endpoints](https://docs.aws.amazon.com/sagemaker-unified-studio/latest/userguide/sagemaker-deploy-models.html) are another option for production use. Try them out with our [guide in the reference section](https://rasa.com/docs/docs/reference/deployment/deploy-fine-tuned-model/#sagemaker-inference-endpoints).
---
#### Deploying to Kubernetes
Kubernetes (and OpenShift) provide a reliable way to run containerized applications at scale. With Kubernetes, you can:
* Orchestrate multiple Rasa Pro services (e.g., Rasa core container, Action Server, Rasa Pro Services) on any cloud or on-prem setup.
* Easily scale up or down by adding more replicas.
* Seamlessly manage rolling updates, networking, and load balancing.
* Simplify the deployment of new versions of your assistant.
If you are unfamiliar with Kubernetes or want a fully managed solution, consider [Rasa’s Managed Service](https://rasa.com/product/managed-service/).
#### Deployment Requirements[](#deployment-requirements "Direct link to Deployment Requirements")
Before deploying Rasa Pro on Kubernetes, make sure you have:
1. **A Kubernetes or OpenShift cluster**
* Many providers (AWS EKS, Azure AKS, GCP, DigitalOcean) offer managed clusters.
* Ensure you have `kubectl` (for Kubernetes) or `oc` (for OpenShift) installed and connected to your cluster.
2. **Helm CLI (v3.5 or newer)**
* You’ll need it to install the Rasa Pro Helm chart.
3. **A valid Rasa License**
* You will pass it as a secret or an environment variable in your deployment.
4. **(Optional) A Model Storage Bucket**
* If you plan to store or mount your trained models from cloud storage (AWS S3, GCP Storage, or Azure Blob), set this up in advance.
5. **(Optional) A Kafka cluster and Data Warehouse**
* Required if you plan to deploy Rasa Pro Services for analytics and logging.
If you do not already have the above, see your cloud provider’s documentation for setting up a Kubernetes or OpenShift cluster. For additional details on Rasa Pro environment variables or advanced configuration, refer to the [Reference](https://rasa.com/docs/docs/reference/config/environment-variables/).
#### How to Deploy Rasa[](#how-to-deploy-rasa "Direct link to How to Deploy Rasa")
##### 1. Kubernetes/OpenShift Cluster[](#1-kubernetesopenshift-cluster "Direct link to 1. Kubernetes/OpenShift Cluster")
* **Confirm connectivity**:
```
kubectl version
```
Ensure it shows both client and server versions (for OpenShift, use `oc version`).
* **Create a dedicated namespace** (recommended):
```
kubectl create namespace
kubectl config set-context --current --namespace=
```
This helps isolate your Rasa Pro deployment from other workloads.
##### 2. Rasa Pro Helm Chart[](#2-rasa-pro-helm-chart "Direct link to 2. Rasa Pro Helm Chart")
Rasa provides a Helm chart to simplify deployment. The chart is hosted on a public Artifact Registry.
1. **Download the Helm chart**:
```
helm pull oci://europe-west3-docker.pkg.dev/rasa-releases/helm-charts/rasa
```
This command downloads a file named `rasa-.tgz`.
2. **Check your Helm version**:
```
helm version --short
```
You need v3.5 or newer.
For the complete documentation of the Helm Chart, see [Rasa Pro Helm Chart](https://helm.rasa.com/charts/rasa/).
##### 3. Deploy Rasa Pro[](#3-deploy-rasa-pro "Direct link to 3. Deploy Rasa Pro")
Below is the minimal workflow for deploying Rasa Pro on Kubernetes or OpenShift using the Helm chart.
###### a) Prepare Secrets[](#a-prepare-secrets "Direct link to a) Prepare Secrets")
1. **Create a `secrets.yml` file** (or name it as you wish) with the Rasa license and any other secret values you may need (authentication tokens, etc.). Base64-encode your secret values.
secrets.yml
```
apiVersion: v1
kind: Secret
metadata:
name: rasa-secrets
type: Opaque
data:
rasaProLicense:
authToken:
jwtSecret:
```
2. **Apply the secrets**:
```
kubectl apply -f secrets.yml
```
###### b) Create a `values.yml` for your deployment[](#b-create-a-valuesyml-for-your-deployment "Direct link to b-create-a-valuesyml-for-your-deployment")
1. **Minimal `values.yml`** example:
values.yml
```
# Rasa Pro Container
rasa:
image:
repository: "europe-west3-docker.pkg.dev/rasa-releases/rasa-pro/rasa-pro"
tag: "3.8.0-latest"
# Additional Rasa configuration can go here.
# Disable the Rasa Pro Services container if not needed
rasaProServices:
enabled: false
```
2. **Deploy with Helm**:
```
helm install \
--namespace \
--values values.yml \
\
rasa-.tgz
```
This starts a Rasa Pro pod. If you need to update any configuration:
```
helm upgrade \
--namespace \
--values values.yml \
\
rasa-.tgz
```
To remove:
```
helm delete
```
##### 4. Model Storage Bucket[](#4-model-storage-bucket "Direct link to 4. Model Storage Bucket")
To load a trained model from cloud storage:
1. **Set up a bucket** on AWS S3, Azure Blob, or Google Cloud Storage, and upload your trained model.
2. **Mount or configure** the bucket for your Rasa container.
For example, in Google Cloud:
values.yml
```
rasa:
endpoints:
models:
enabled: false
volumes:
- csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName:
mountOptions: implicit-dirs,only-dir=
name: rasa-models
volumeMounts:
- name: rasa-models
mountPath: /app/models
readOnly: true
serviceAccount:
create: true
annotations:
iam.gke.io/gcp-service-account:
name: "rasa-pro-sa"
podAnnotations:
gke-gcsfuse/volumes: "true"
```
For other cloud platforms or more advanced configurations, see the [Reference](https://rasa.com/docs/docs/reference/config/environment-variables/).
##### 5. Deploy Action Server[](#5-deploy-action-server "Direct link to 5. Deploy Action Server")
If your assistant uses **Custom Actions**, you can build and deploy a separate Action Server container alongside your Rasa Pro container.
1. **Build your custom action image**:
* Place your Python code in `actions/actions.py`.
* Optionally specify any dependencies in `requirements-actions.txt`.
* Create a `Dockerfile` extending the official `rasa/rasa-sdk` image:
```
FROM rasa/rasa-sdk:latest
WORKDIR /app
# (Optional) for custom dependencies
# COPY actions/requirements-actions.txt ./
# RUN pip install -r requirements-actions.txt
COPY ./actions /app/actions
USER 1001
```
* Build & push the image to your container registry (e.g., DockerHub, GCR, ECR).
2. **Reference your Action Server in `values.yml`**:
values.yml
```
rasa:
endpoints:
actionEndpoint:
url: http://action-server:5055/webhook
actionServer:
enabled: true
image:
repository: /
tag:
```
3. **Upgrade the Helm release**:
```
helm upgrade \
--namespace \
--values values.yml \
\
rasa-.tgz
```
##### 6. Deploy Rasa Pro Services[](#6-deploy-rasa-pro-services "Direct link to 6. Deploy Rasa Pro Services")
Rasa Pro Services is an optional container providing analytics, data collection, and other enterprise features. It must connect to:
* A Kafka cluster (production-ready)
* A data warehouse (e.g., PostgreSQL)
New in `rasa-1.3.0` Helm Chart
We have simplified how Rasa Pro Services handle database and Kafka configurations. Previously, these settings were passed as individual environment variables. They are now defined directly in `values.yaml` under structured configuration blocks (database and kafka).
1. **Configure Kafka** for your Rasa Pro container. In your `values.yml`, make sure:
values.yml
```
rasa:
settings:
endpoints:
eventBroker:
enabled: true
type: kafka
# other settings as needed...
```
2. **Enable Rasa Pro Services**:
values.yml
```
rasaProServices:
enabled: true
image:
repository: "europe-west3-docker.pkg.dev/rasa-releases/rasa-pro/rasa-pro-services"
tag: "3.6.1-latest"
loggingLevel: "INFO"
useCloudProviderIam:
# -- useCloudProviderIam.enabled specifies whether to use cloud provider IAM for the Rasa Pro Services container.
enabled: false
# -- useCloudProviderIam.provider specifies the cloud provider for the Rasa Pro Services container. Supported value is aws
provider: "aws"
# -- useCloudProviderIam.region specifies the region for IAM authentication. Required if IAM_CLOUD_PROVIDER is set to aws.
region: "us-east-1"
database:
# -- database.enableAwsRdsIam specifies whether to use AWS RDS IAM authentication for the Rasa Pro Services container.
enableAwsRdsIam: false
# -- database.url specifies the URL of the data lake to store analytics data in. Use `hostname` if you use IAM authentication.
url: ""
# -- database.username specifies the username for the data lake to store analytics data in. Required if enableAwsRdsIam is true.
username: ""
# -- database.hostname specifies the hostname of the data lake to store analytics data in. Required if enableAwsRdsIam is true.
hostname: ""
# -- database.port specifies the port for the data lake to store analytics data in. Required if enableAwsRdsIam is true.
port: "5432"
# -- database.databaseName specifies the database name for the data lake to store analytics data in. Required if enableAwsRdsIam is true.
databaseName: ""
# -- database.sslMode specifies the SSL mode for the data lake to store analytics data in. Required if enableAwsRdsIam is true.
sslMode: ""
# -- database.sslCaLocation specifies the SSL CA location for the data lake to store analytics data in. Required if sslMode is verify-full.
sslCaLocation: ""
kafka:
# -- kafka.enableAwsMskIam specifies whether to use AWS MSK IAM authentication for the Rasa Pro Services container.
enableAwsMskIam: false
# -- kafka.brokerAddress specifies the broker address for the Rasa Pro Services container. Required if enableAwsMskIam is true.
brokerAddress: ""
# -- kafka.topic specifies the topic for the Rasa Pro Services container.
topic: "rasa-core-events"
# -- kafka.dlqTopic specifies the DLQ topic fused to publish events that resulted in a processing failure.
dlqTopic: "rasa-analytics-dlq"
# -- kafka.saslMechanism specifies the SASL mechanism for the Rasa Pro Services container. Leave empty if you are using SSL.
saslMechanism: ""
# -- kafka.securityProtocol specifies the security protocol for the Rasa Pro Services container. Supported mechanisms are PLAINTEXT, SASL_PLAINTEXT, SASL_SSL and SSL
securityProtocol: ""
# -- kafka.sslCaLocation specifies the SSL CA location for the Rasa Pro Services container.
sslCaLocation: ""
# -- kafka.sslCertFileLocation specifies the filepath for SSL client Certificate that will be used to connect with Kafka. Required if securityProtocol is SSL.
sslCertFileLocation: ""
# -- kafka.sslKeyFileLocation specifies the filepath for SSL Keyfile that will be used to connect with Kafka. Required if securityProtocol is SSL.
sslKeyFileLocation: ""
# -- kafka.consumerId specifies the consumer ID for the Rasa Pro Services container.
consumerId: "rasa-analytics-group"
# -- kafka.saslUsername specifies the SASL username for the Rasa Pro Services container. Do not set if enableAwsMskIam is true.
saslUsername: ""
# -- kafka.saslPassword specifies the SASL password for the Rasa Pro Services container. Do not set if enableAwsMskIam is true.
saslPassword:
secretName: "rasa-secrets"
secretKey: "kafkaSslPassword"
```
3. **Upgrade via Helm**:
```
helm upgrade \
--namespace \
--values values.yml \
\
rasa-.tgz
```
You can confirm the Rasa Pro Services pod is running and check the `/healthcheck` endpoint to verify status.
##### 7. Adding Environment Variables[](#7-adding-environment-variables "Direct link to 7. Adding Environment Variables")
You can pass extra environment variables to any container by adding them to `values.yml`. For example, to add environment variables to the Rasa Pro container:
values.yml
```
rasa:
additionalEnv: []
```
If you have sensitive data (e.g., passwords), store them in Kubernetes secrets and reference them in `values.yml`. For example, to add environment variables from a ConfigMap or Secret:
values.yml
```
rasa:
envFrom: []
# - configMapRef:
# name: my-configmap
```
A full list of available environment variables for Rasa Pro, Rasa Pro Services, and the Rasa Action Server can be found in the [Environment Variables reference](https://rasa.com/docs/docs/reference/config/environment-variables/).
---
#### LLM Routing
When building assistants that use Large Language Models (LLMs), it’s often important to distribute or “route” requests across multiple deployments or even multiple providers. For instance, you might deploy the same model in multiple regions to reduce latency, or switch among providers to balance usage and cost. Rasa provides a **multi-LLM router** that does this work for you behind the scenes.
The router can also handle embedding models in the same way. In this guide, you’ll learn how to:
* Define multiple model groups in your `endpoints.yml`
* Select a routing strategy (e.g., `simple-shuffle`, `least-busy`)
* Configure caching or store usage data in Redis
* Use the router for LLM completions and for embeddings
Note
The Multi-LLM router feature requires Rasa Pro 3.11.0 and above.
#### Why Use Multi-LLM Routing?[](#why-use-multi-llm-routing "Direct link to Why Use Multi-LLM Routing?")
Some scenarios where you might want to configure multiple LLM providers or deployments:
* **Load balancing**: Distribute requests across multiple deployments to avoid hitting rate limits or usage caps on a single LLM deployment.
* **Latency optimization**: Direct user requests to the nearest or least busy region to reduce response times.
* **Failover**: If one deployment goes down or fails to respond, seamlessly switch to the next available deployment.
* **Cost optimization**: Route requests based on token usage or cost per token to stay within budget.
#### Basic Configuration[](#basic-configuration "Direct link to Basic Configuration")
All multi-LLM routing happens in your `endpoints.yml` under **model groups**. A model group defines one or more LLM (or embedding) deployments that share the same underlying model. You then specify a `router` block with your chosen routing strategy and any additional parameters.
##### Minimal Example[](#minimal-example "Direct link to Minimal Example")
endpoints.yml
```
model_groups:
- id: azure_llm_deployments
models:
- provider: azure
deployment: rasa-gpt-4
api_base: https://azure-deployment/
api_version: "2024-02-15-preview"
api_key: ${MY_AZURE_API_KEY}
router:
routing_strategy: simple-shuffle
```
1. **`id`:** A unique identifier for this group.
2. **`models`:** One or more LLM deployments to include in the group.
3. **`routing_strategy`:** How requests are distributed across the models.
Recommendation
Add multiple identical deployments (e.g., different regions or hosts) to ensure consistent outputs. Mixing fundamentally different models (e.g., GPT-3.5 vs GPT-4) in the same group may lead to unpredictable behavior.
#### Using Multiple Deployments[](#using-multiple-deployments "Direct link to Using Multiple Deployments")
Below, we define **two** deployments in the same model group and apply a shuffle routing strategy:
endpoints.yml
```
model_groups:
- id: azure_llm_deployments
models:
- provider: azure
deployment: gpt-4-instance-france
api_base: https://azure-deployment-france/
api_version: "2024-02-15-preview"
api_key: ${MY_AZURE_API_KEY_FRANCE}
- provider: azure
deployment: gpt-4-instance-canada
api_base: https://azure-deployment-canada/
api_version: "2024-02-15-preview"
api_key: ${MY_AZURE_API_KEY_CANADA}
router:
routing_strategy: simple-shuffle
```
##### Available Routing Strategies[](#available-routing-strategies "Direct link to Available Routing Strategies")
* **`simple-shuffle`**: Distributes requests by randomly shuffling across deployments.
* **`least-busy`**: Routes to whichever deployment currently has the fewest ongoing requests.
* **`latency-based-routing`**: Routes to the deployment with the lowest measured response time.
* **`cost-based-routing`**: Requires Redis. Routes to whichever deployment so far has the lowest total cost.
* **`usage-based-routing`**: Requires Redis. Routes to the deployment with the lowest total token usage over time.
To learn more or configure advanced strategies, see the **Reference → LLM Configuration** docs.
#### Multiple Model Groups[](#multiple-model-groups "Direct link to Multiple Model Groups")
You can define **separate** model groups for different base models or usage patterns. Each group is configured independently, allowing you to route GPT-4 requests differently from GPT-3.5, for example.
endpoints.yml
```
model_groups:
- id: azure_gpt4_deployments
models:
- provider: azure
deployment: gpt-4-instance-france
...
- provider: azure
deployment: gpt-4-instance-canada
...
router:
routing_strategy: least-busy
- id: azure_gpt35_turbo_deployments
models:
- provider: azure
deployment: gpt-35-instance-france
...
- provider: azure
deployment: gpt-35-instance-canada
...
router:
routing_strategy: simple-shuffle
```
#### Customizing the Router[](#customizing-the-router "Direct link to Customizing the Router")
There are multiple ways to customize router behavior. For instance:
* **`cooldown_time`**: Time in seconds after a deployment fails before the router retries using that deployment.
* **`allowed_fails`**: How many failures are allowed before a deployment is considered unavailable.
* **`num_retries`**: How many times to retry a failed request.
endpoints.yml
```
model_groups:
- id: azure_llm_deployments
models:
- provider: azure
deployment: rasa-gpt-4
...
router:
routing_strategy: simple-shuffle
cooldown_time: 10
allowed_fails: 2
num_retries: 3
```
For the full list of configurable parameters, see the **Reference → LLM Configuration** docs.
#### Embeddings Routing[](#embeddings-routing "Direct link to Embeddings Routing")
You can use **the same** multi-LLM router approach for embedding models. For example:
endpoints.yml
```
model_groups:
- id: azure_embeddings_deployments
models:
- provider: azure
deployment: text-embeddings-instance-france
...
- provider: azure
deployment: text-embeddings-instance-canada
...
router:
routing_strategy: simple-shuffle
```
This is helpful if you maintain multiple region-specific embedding deployments or want to route embeddings based on usage and cost.
#### Self-Hosted Models and Other Providers[](#self-hosted-models-and-other-providers "Direct link to Self-Hosted Models and Other Providers")
The router supports many types of model deployments, including self-hosted LLM endpoints (e.g., vLLM, Llama.cpp, Ollama). Configuration follows the same pattern:
endpoints.yml
```
model_groups:
- id: vllm_deployments
models:
- provider: self-hosted
model: meta-llama/Meta-Llama-3-8B
api_base: "http://localhost:8000/v1"
- provider: self-hosted
model: meta-llama/Meta-Llama-3-8B
api_base: "http://localhost:8001/v1"
router:
routing_strategy: least-busy
# If not using chat-completions endpoint:
use_chat_completions_endpoint: false
```
Note
If you need a proxy or custom connectivity (e.g., via LiteLLM proxy), you can place the proxy URL under `api_base` for each model.
***
#### Caching[](#caching "Direct link to Caching")
By default, the router can cache responses to reduce load and improve performance. To enable caching in production, you must configure a **persistent store** like Redis. In-memory caching is possible, but not recommended in production since it won’t persist across restarts.
endpoints.yml
```
router:
routing_strategy: simple-shuffle
cache_responses: true
```
#### Redis Setup for Advanced Routing[](#redis-setup-for-advanced-routing "Direct link to Redis Setup for Advanced Routing")
If you want to use **cost-based** or **usage-based** routing, configure Redis in your `endpoints.yml`:
endpoints.yml
```
model_groups:
- id: azure_llm_deployments
models:
- provider: azure
deployment: rasa-gpt-4
...
router:
routing_strategy: cost-based-routing
redis_host: localhost
redis_port: 6379
redis_password: ${REDIS_PASSWORD}
```
Alternatively, specify a `redis_url` directly:
endpoints.yml
```
router:
routing_strategy: cost-based-routing
redis_url: "redis://:mypassword@host:port"
```
**That’s it!** You have now set up **multi-LLM routing** in your Rasa (CALM) assistant. If you need more details on advanced configurations or want to dig deeper into how each parameter works under the hood, head over to the [Reference](https://rasa.com/docs/docs/reference/deployment/multi-llm-routing/).
---
#### Load Testing Guidelines
In order to gather metrics on our system's ability to handle increased loads and users, we have performed tests to evaluate the maximum number of concurrent users a Rasa assistant can handle with certain machine configurations. In each test case we spawned the following number of concurrent users at peak concurrency using a [spawn rate](https://docs.locust.io/en/1.5.0/configuration.html#all-available-configuration-options) of 1000 users per second. In our tests we used the Rasa [HTTP-API](https://rasa.com/docs/docs/reference/api/pro/http-api/) and the [Locust](https://locust.io/) open source load testing tool.
| Users | CPU | Memory |
| ------------ | -------------------------------- | ------ |
| Up to 50,000 | 6vCPU | 16 GB |
| Up to 80,000 | 6vCPU, with almost 90% CPU usage | 16 GB |
##### Debugging bot related issues while scaling up[](#debugging-bot-related-issues-while-scaling-up "Direct link to Debugging bot related issues while scaling up")
To test the Rasa [HTTP-API](https://rasa.com/docs/docs/reference/api/pro/http-api/) ability to handle a large number of concurrent user activity we used Rasa's [tracing](https://rasa.com/docs/docs/pro/improve/tracing/) capability along with a tracing backend or collector, such as Jaeger, to collect traces for the bot under test.
note
Our team is currently in the process of running additional performance-related tests. More information will be added here as we progress.
---
#### Quick Deployment with Docker Compose
For small deployments we recommend using this [docker compose template](https://github.com/RasaHQ/developer-edition-docker-compose). This typically takes less than 20 minutes, including the time required to provision a VM.
##### Scalable Deployment[](#scalable-deployment "Direct link to Scalable Deployment")
If you have a commercial (paid) Rasa license, we will help you set up a cluster deployment to handle high traffic volumes across multiple nodes. A full [Rasa Pro deployment](https://rasa.com/docs/docs/reference/architecture/rasa-pro/) includes services for:
* Running multiple Rasa pods to serve high traffic
* Analytics
* Managing models via S3
* Secrets management
* Connection to Rasa Studio
Read on for more details about [deploying with kubernetes](https://rasa.com/docs/docs/pro/deploy/deploy-kubernetes/).
---
#### Setting Up CI/CD
**Continuous Integration (CI)** is the practice of merging code changes frequently and automatically running tests on every commit. **Continuous Deployment (CD)** means automatically deploying integrated changes to a staging or production environment once they pass testing.
For conversational AI projects, this provides several benefits:
* **Frequent Updates**: You can release improvements to your assistant more often, ensuring a shorter feedback loop.
* **Reduced Risk**: Automated tests (e.g., end-to-end tests, unit tests for custom actions) catch errors before they make it to production.
* **Consistent Quality**: By enforcing coding and model training standards in your pipeline, you maintain consistent quality in your assistant’s performance.
* **Faster Iterations**: You can address user feedback quickly and ship updates without waiting on infrequent, manual release cycles.
#### CI/CD Best Practices[](#cicd-best-practices "Direct link to CI/CD Best Practices")
When setting up CI/CD for a Rasa assistant, keep in mind a few best practices:
1. **Use Version Control**
Keep all conversation flows, prompt configurations, and custom actions in version control (e.g., Git). This way, any changes to flows, patterns, or the command generator prompt can be tracked and rolled back if needed.
2. **Automated Testing**
Run [e2e conversation-level tests](https://rasa.com/docs/docs/pro/testing/evaluating-assistant/) to ensure your assistant responds correctly to user messages, triggers the right flows, and properly handles conversation repair patterns.
3. **Environment Parity**
Try to keep development, staging, and production environments as similar as possible. For example, if you’re using Docker, ensure you use the same Docker images for local development and production deployments.
4. **Gradual Deployment**
If you have a large user base, consider rolling out changes to a subset of users first (canary or blue-green deployments) to minimize risk.
5. **Artifact Storage**
Store trained models and compiled assistant configurations in a stable, versioned repository (e.g., a cloud bucket). This allows you to revert to a previous model if something goes wrong.
#### How to Set Up CI/CD[](#how-to-set-up-cicd "Direct link to How to Set Up CI/CD")
Below is an example of how you might configure a CI/CD pipeline using **GitHub Actions**. You can follow similar steps with other CI/CD tools like GitLab CI, Jenkins, or CircleCI.
1. **Train Your Assistant**
* Run [`rasa train`](https://rasa.com/docs/docs/reference/api/command-line-interface/#rasa-train) to compile your flows, patterns, and conversation data into a deployable model.
* In CALM, training compiles your rule-based flows and dialogue stack logic alongside any LLM configuration.
* Make sure your CI environment is aligned with the same Python, Docker image, and Rasa Pro version used in production.
2. **Run Automated Tests**
* Spin up your custom action server.
* Run [end-to-end tests](https://rasa.com/docs/docs/pro/testing/evaluating-assistant/) (`rasa test e2e`) to validate conversation logic (flows, patterns, slot fillings, and repairs).
* If tests fail, the pipeline should stop and avoid deploying a broken model.
3. **Deploy to Your Environment**
* Once your model passes all tests, upload it to a centralized model storage or directly deploy to your staging/production environment.
* Update your orchestrator (e.g., Kubernetes, Docker Compose) to pull the new model and reload the assistant.
Below is a sample **GitHub Actions** workflow illustrating these steps:
workflow.yml
```
name: Rasa Pro CI/CD Pipeline
on:
push:
branches:
- main
paths:
- 'data/**'
- 'domain/**'
jobs:
train_test_deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v3
# Pull the same Rasa Pro version used in TEST/PROD
- name: Pull Rasa Pro image
run: |
docker pull europe-west3-docker.pkg.dev/rasa-releases/rasa-pro/rasa-pro:3.8.0-latest
# Train the assistant model
- name: Train Rasa model
run: |
docker run -v ${GITHUB_WORKSPACE}:/app \
-e OPENAI_API_KEY=${OPENAI_API_KEY} \
-e RASA_LICENSE=${RASA_LICENSE} \
-e RASA_TELEMETRY_ENABLED=false \
europe-west3-docker.pkg.dev/rasa-releases/rasa-pro/rasa-pro:3.8.0-latest \
train --domain /app/domain --data /app/data --out /app/models
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
RASA_LICENSE: ${{ secrets.RASA_LICENSE }}
# Start the action server and run E2E tests
- name: Start Action Server and Test Rasa model
run: |
# Spin up your custom action server
docker run -d -p 5055:5055 --name action_server
# Wait until the action server is ready
echo "Waiting for action server to be ready..."
timeout=60
while ! curl --output /dev/null --silent --fail http://localhost:5055/health; do
printf '.'
sleep 5
timeout=$((timeout-5))
if [ "$timeout" -le 0 ]; then
echo "Action server did not become ready in time."
docker logs action_server
exit 1
fi
done
# Run E2E tests
docker run -v ${GITHUB_WORKSPACE}:/app \
--link action_server:action_server \
-e OPENAI_API_KEY=${OPENAI_API_KEY} \
-e RASA_LICENSE=${RASA_LICENSE} \
-e RASA_TELEMETRY_ENABLED=false \
europe-west3-docker.pkg.dev/rasa-releases/rasa-pro/rasa-pro:3.8.0-latest \
test e2e /app/tests/e2e_test_cases.yml --model /app/models --endpoints /app/endpoints.yml
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
RASA_LICENSE: ${{ secrets.RASA_LICENSE }}
# Authenticate and upload the trained model to your storage
- name: Authenticate to Google Cloud
uses: google-github-actions/auth@v0.4.0
with:
credentials_json: '${{ secrets.GCP_SA_KEY }}'
- name: Configure Google Cloud project
run: |
echo $GCP_SA_KEY | gcloud auth activate-service-account --key-file=-
env:
GCP_SA_KEY: ${{ secrets.GCP_SA_KEY }}
- name: Upload model to Google Cloud Storage
run: |
gsutil cp -r models/* gs://my-model-storage/
```
In this example, the pipeline:
1. **Checks Out** your code.
2. **Pulls** the specified Rasa Pro Docker image.
3. **Trains** the assistant using your domain, data, and flows.
4. **Starts** a custom action server for testing.
5. **Runs** end-to-end tests against the trained model.
6. **Uploads** the successful build to a cloud storage bucket for deployment.
You can adapt this workflow to other CI/CD providers and storage solutions (e.g., S3, Azure Blob Storage, on-prem artifact repositories).a
With a solid CI/CD pipeline, you can rapidly iterate on your CALM-based assistant, ensuring robust, reliable, and up-to-date experiences for your users.
---
### Installation and Set Up
#### Get Started with Rasa
Rasa has different installation options to get you started with building your assistant. Each option serves different needs.
##### Requirements[](#requirements "Direct link to Requirements")
Regardless of the option you pick, there are some prerequisites you will need to get started:
* **Rasa License Key** - you'll need a license key to use Rasa. You can request a Rasa Developer Edition license key [here](https://rasa.com/rasa-pro-developer-edition-license-key-request/) and read more about our licensing [here](https://rasa.com/docs/docs/pro/installation/licensing/).
* **LLM Provider API Key** - you don't need this for the [tutorial](https://rasa.com/docs/docs/pro/tutorial/), but for building your own projects you'll need an API key from one of our [supported LLM providers](https://rasa.com/docs/docs/reference/config/components/llm-configuration/).
##### [GitHub Quickstart](https://rasa.com/docs/docs/learn/quickstart/pro/)[](#github-quickstart "Direct link to github-quickstart")
Our recommended way to get started rapidly and experiment with Rasa. This option provides a fully-managed environment in GitHub Codespaces, no local installation necessary.
##### [Python](https://rasa.com/docs/docs/pro/installation/python/)[](#python "Direct link to python")
Best suited for those who are already familiar with Python development and comfortable with installing packages.
##### [Docker](https://rasa.com/docs/docs/pro/installation/docker/)[](#docker "Direct link to docker")
Best suited for those who prefer a containerised approach to development.
**Ready to deploy?** Pick your path, follow the steps, and get started with building amazing conversational AI experiences.
---
#### Licensing
Rasa offers Enterprise licenses for teams building assistants at scale, with advanced features like enterprise-grade security, scalability, and dedicated support. But if you're just getting started, you can get a free Developer Edition License to try it out.
###### [Developer Edition](https://rasa.com/rasa-pro-developer-edition-license-key-request/)
[If you want to start building assistants with CALM you can get started today with the Rasa Developer Edition.](https://rasa.com/rasa-pro-developer-edition-license-key-request/)
[](https://rasa.com/rasa-pro-developer-edition-license-key-request/)
[](https://rasa.com/rasa-pro-developer-edition-license-key-request/)[Get it here](https://rasa.com/rasa-pro-developer-edition-license-key-request/)
#### How Licensing Works[](#how-licensing-works "Direct link to How Licensing Works")
Rasa will look for your license in the env var `RASA_LICENSE`, which must contain the content of the license key file provided by rasa.
You can set the `RASA_LICENSE` env var temporarily in your terminal, but it is recommended to set it persistently so that you don't have to set it every time you run Rasa.
* Bash
* Windows Powershell
```
## Temporary
export RASA_LICENSE=YOUR_LICENSE_STRING_HERE
## Persistent
echo "export RASA_LICENSE=YOUR_LICENSE_STRING_HERE" >> ~/.bashrc
## If you're using a different flavor of bash e.g. Zsh, replace .bashrc with your shell's initialization script e.g. ~/.zshrc
```
```
## Temporary
$env: RASA_LICENSE=YOUR_LICENSE_STRING_HERE
## Persistent for the current user
[System.Environment]::SetEnvironmentVariable('RASA_LICENSE','YOUR_LICENSE_STRING_HERE','USER')
```
Then you can use the [`rasa` CLI](https://rasa.com/docs/docs/reference/api/command-line-interface/) as usual, for example:
```
rasa init
```
---
#### Quickstart With Codespaces
---
#### Troubleshooting
##### Python 3.10 requirements[](#python-310-requirements "Direct link to Python 3.10 requirements")
*If you are using Linux*, installing `rasa-pro` could result in a failure while installing `tokenizers` and `cryptography`.
In order to resolve it, you must follow these steps to install a Rust compiler:
```
apt install rustc && apt install cargo
```
After initializing the Rust compiler, you should restart the console and check its installation:
```
rustc --version
```
In case the PATH variable had not been automatically setup, run:
```
export PATH="$HOME/.cargo/bin:$PATH"
```
*If you are using macOS*, note that installing `rasa-pro` could result in a failure while installing `tokenizers` (issue described in depth [here](https://github.com/huggingface/tokenizers/issues/1050)).
In order to resolve it, you must follow these steps to install a Rust compiler:
```
brew install rustup
rustup-init
```
After initializing the Rust compiler, you should restart the console and check its installation:
```
rustc --version
```
In case the PATH variable had not been automatically setup, run:
```
export PATH="$HOME/.cargo/bin:$PATH"
```
##### OSError: \[Errno 40] Message too long[](#oserror-errno-40-message-too-long "Direct link to OSError: [Errno 40] Message too long")
If you run `rasa train` or `rasa run` after you’ve enabled tracing using Jaeger as a backend in your local development environment, you might come across this error `OSError: [Errno 40] Message too long`.
This could be caused by the OS of your local development environment restricting UDP packet size. You can find out the current UDP packet size by running `sysctl net.inet.udp.maxdgram` on macOS. You can increase UDP packet size by running `sudo sysctl -w net.inet.udp.maxdgram=65535`.
---
#### Using Docker
The Rasa Pro Docker image is available on [Docker Hub](https://hub.docker.com/r/rasa/rasa-pro/tags) as `rasa/rasa-pro`.
note
In the commands below, replace `RASAVERSION` with your desired version of Rasa Pro. To find the latest version of Rasa Pro, see the [Changelog](https://rasa.com/docs/docs/reference/changelogs/rasa-pro-changelog/).
To pull the image, run:
```
docker pull rasa/rasa-pro:RASAVERSION
```
#### Optional Dependencies (Extras)[](#optional-dependencies-extras "Direct link to Optional Dependencies (Extras)")
Rasa Pro supports optional dependencies through "extras":
* **`nlu`**: Dependencies required for NLU components
* **`channels`**: Dependencies required for channel connectors
* **`full`**: Complete set of all optional dependencies
By default, the Rasa Pro Docker image already contains the `nlu` and `channels` dependencies.
##### Extending the Docker Image[](#extending-the-docker-image "Direct link to Extending the Docker Image")
To extend the Docker image with optional dependencies that are not already included in the default image, create a custom Dockerfile:
```
# Extend the official Rasa Pro image
FROM rasa/rasa-pro:RASAVERSION
# Install all optional dependencies
RUN pip install rasa[full]
# Alternatively, install individual optional packages rather than all optional dependencies comprised in `full`
RUN pip install rasa[spacy]
```
Build and run your custom image:
```
# Build the custom image
docker build -t my-custom-rasa:latest .
# Run the custom image
docker run -v ./:/app \
-e RASA_LICENSE=${RASA_LICENSE} \
-p 5005:5005 \
my-custom-rasa:latest \
run
```
#### Licensing[](#licensing "Direct link to Licensing")
As explained in [Licensing](https://rasa.com/docs/docs/pro/installation/licensing/), at runtime you must provide the license key in the environment variable `RASA_LICENSE`.
After you defined the environment variable on your system, you can pass it into the docker container via the `-e` parameter, for example:
```
# execute `rasa init` via docker
docker run -v ./:/app \
-e RASA_LICENSE=${RASA_LICENSE} \
rasa/rasa-pro:RASAVERSION \
init --no-prompt --template tutorial
```
---
#### Using Python
**Rasa** has a Python package called `rasa-pro` that you can install locally, with `uv` package manager. You can use `pip` but it'll take longer to install.
#### Set Up Your Python Environment[](#set-up-your-python-environment "Direct link to Set Up Your Python Environment")
info
Rasa supports Python `3.10`, `3.11`, `3.12`, and `3.13`. For detailed information about supported Python versions and dependency groups, see our [Python Versions and Dependencies](https://rasa.com/docs/docs/reference/python-versions-and-dependencies/) reference page.
Check if your Python environment is already configured by ensuring you have Python 3.10 or 3.11.
Check Python Version
```
python --version
pip --version
```
If the right packages are already installed, you can skip to the next step.
Otherwise, proceed with the instructions below to install them.
* macOS and Linux
* Windows
Install the package manager uv by executing this command in the Terminal. Other installation methods are documented [in uv documentation](https://docs.astral.sh/uv/getting-started/installation/).
```
curl -LsSf https://astral.sh/uv/install.sh | sh
```
Install the package manager [uv](https://docs.astral.sh/uv/getting-started/installation/) by executing this command in the Windows Powershell.
```
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
In the next step, we will be using uv to install Python.
##### Create Virtual Environment[](#create-virtual-environment "Direct link to Create Virtual Environment")
Python uses [Virtual Environments](https://docs.python.org/3/tutorial/venv.html) to isolate project dependencies. They help avoid conflicts between different projects by creating a clean workspace where you can install specific package versions for each project. We recommend installing rasa-pro within a virtual environment. You can follow the instructions below to set them up,
Each Rasa project should be started in a new directory.
```
mkdir my-rasa-assistant
cd my-rasa-assistant
```
Create a new virtual environment with Python 3.11. uv will install Python if it is not already installed.
```
uv venv --python 3.11
```
Virtual environments only need to be created once for each project, but you must activate them every time you open a new terminal session to work on your project. Activate the virtual environment
* macOS and Linux
* Windows
```
source .venv/bin/activate
```
```
.venv\Scripts\activate
```
This activation step ensures your commands use the project's isolated dependencies rather than your system-wide Python installation.
##### Install Rasa[](#install-rasa "Direct link to Install Rasa")
Now we are ready to install Rasa. To install the latest version of Rasa with uv, run the command:
```
uv pip install rasa-pro
```
Don't forget to obtain your Rasa Developer Edition License from the [license request page](https://rasa.com/rasa-pro-developer-edition-license-key-request/). Export it as an environment variable:
* macOS and Linux
* Windows
```
export RASA_LICENSE=YOUR_LICENSE_KEY
```
```
set RASA_LICENSE=YOUR_LICENSE_KEY
```
Check the Rasa version:
```
rasa --version
```
Create a new template CALM assistant from a template:
```
rasa init --template tutorial
```
That's it - you should now be ready to dive into [building your first bot](https://rasa.com/docs/docs/pro/tutorial/)! For troubleshooting tips or FAQs on install see our [troubleshooting guide](https://rasa.com/docs/docs/pro/installation/troubleshooting/).
---
### Test
#### Evaluating Your Assistant (E2E Testing)
This page covers how to evaluate your CALM assistant comprehensively using end-to-end (E2E) tests. You’ll learn why E2E tests are an essential component of your testing and quality strategy, the difference between qualitative and quantitative assessments, and best practices for writing and running your tests.
You can do 2 types of evaluation in Rasa:
* **Qualitative Evaluation with Inspector**
Tools like the Inspector allow you to explore real or test conversations step by step, seeing exactly how the LLM and flows behave.
* **Quantitative Evaluation with E2E Tests**
End-to-end tests automate entire conversation scenarios, ensuring that your assistant handles them exactly as you expect. E2E tests are an important guardrail to prevent regressions—especially as you iterate on your flows, patterns, or LLM prompts.
#### What Is E2E Testing?[](#what-is-e2e-testing "Direct link to What Is E2E Testing?")
End-to-End testing in Rasa checks your assistant as a *whole* system, from user message to final bot response or action. This includes:
* **Assertions**: Validate that certain events happen in the conversation as expected (e.g., a slot is set, a flow is started, a specific action is triggered, a response is grounded).
* **Custom Actions**: Run or stub out actions to test side effects (e.g., calling an API or setting multiple slots).
* **Generative Responses**: Use specialized assertions (like “generative\_response\_is\_relevant”) to confirm that generative responses from the Response Rephraser or Enterprise Search are sufficiently on-topic or factually accurate.
* **Test Coverage**: Understand which flows or commands have been tested. Some advanced features let you generate coverage reports highlighting gaps in tested flows.
In short, E2E tests act like conversation “blueprints” that must pass unchanged, ensuring your assistant consistently handles the end-to-end user journey.
#### How to Write E2E Tests[](#how-to-write-e2e-tests "Direct link to How to Write E2E Tests")
E2E test cases live in YAML files in your project’s `tests` directory. These can be subdivided for better organization (e.g., `tests/e2e_test_cases.yml`, or `tests/pattern_tests/test_patterns.yml`, etc.).
Below is a condensed guide to writing E2E tests. For a deeper reference on every possible key/value, see the [Test cases reference](https://rasa.com/docs/docs/reference/testing/test-cases/).
##### 1. Step-Based Test Case Format:[](#1-step-based-test-case-format "Direct link to 1. Step-Based Test Case Format:")
Create a file (e.g., `tests/e2e_test_cases.yml`) where you include test cases:
Each `test_case`:
* Has a `name` (e.g., `user books a restaurant`).
* Contains a sequence of `steps` describing the interaction.
##### 2. Writing Steps[](#2-writing-steps "Direct link to 2. Writing Steps")
**`user` step**
Simulates the user’s message. May optionally include metadata to specify additional context (e.g., device info or session data).
**`bot` or `utter` step**
Checks the expected textual response from the bot.
* **`bot:`** matches the exact text of the bot’s last utterance.
* **`utter:`** matches the domain-defined response name (like `utter_welcome`).
**Slot checks**
* **`slot_was_set:`** confirms the assistant sets a slot. If you provide a value, it checks that it’s the correct value.
* **`slot_was_not_set:`** confirms the assistant did *not* set a particular slot or did *not* set it to a specific value.
##### 3. Using Assertions Instead of Steps[](#3-using-assertions-instead-of-steps "Direct link to 3. Using Assertions Instead of Steps")
If you want more detailed checks, you can use *assertions*. For example:
tests/e2e\_test\_cases.yml
```
test_cases:
- test_case: flight_booking
steps:
- user: "I want to book a flight"
assertions:
- flow_started: "flight_booking"
- bot_uttered:
utter_name: "utter_ask_destination"
- user: "New York"
assertions:
- slot_was_set:
- name: "destination"
value: "New York"
```
Assertions allow you to check events like flows starting, or to confirm if a generative response is relevant/grounded, among others.
Important
If a user step contains assertions, the older step types like bot: ... or utter: ... are ignored within that same step. You’ll have to rely on the `bot_uttered` assertion to check the response.
Below is a list of assertion types you can use in your E2E tests. For more details on each assertion with examples, go to the [Reference section](https://rasa.com/docs/docs/reference/testing/assertions/#assertion-types)
* **flow\_started:** Verify a specified flow has begun.
* **flow\_completed:** Confirm a flow (or a specific flow step) has finished.
* **flow\_cancelled:** Ensure a flow (or designated flow step) was cancelled.
* **pattern\_clarification\_contains:** Check that the expected clarification suggestions (flow names) are returned.
* **slot\_was\_set:** Validate that a slot is filled with the expected value.
* **slot\_was\_not\_set:** Confirm that a slot is not set or does not have a specific value.
* **action\_executed:** Assert that a particular action was triggered.
* **bot\_uttered:** Verify the bot’s response (including text, buttons, or domain response name) matches expectations.
* **bot\_did\_not\_utter:** Ensure the bot’s response does not match a specified pattern.
* **generative\_response\_is\_relevant:** Check that the generative response is contextually relevant (using a relevance threshold).
* **generative\_response\_is\_grounded:** Confirm that the generative response is factually accurate against a ground truth.
##### 4. Fixtures for Pre-Filled Slots[](#4-fixtures-for-pre-filled-slots "Direct link to 4. Fixtures for Pre-Filled Slots")
To test scenarios where users already have certain context (e.g., a “premium” user logged in), you can define top-level `fixtures` to set slot values before the test begins:
tests/e2e\_test\_cases.yml
```
fixtures:
- premium:
membership_type: premium
logged_in: true
test_cases:
- test_case: test_premium_booking
fixtures:
- premium
steps:
- user: "Hi!"
- bot: "Welcome back! How can I help you?"
...
```
##### 5. Converting Sample Conversations[](#5-converting-sample-conversations "Direct link to 5. Converting Sample Conversations")
If you have design documents or sample interactions in CSV/XLSX, you can generate initial tests via:
```
rasa data convert e2e -o
```
This automates test creation but always review the generated tests to refine or add extra assertions.
#### How to Run Tests[](#how-to-run-tests "Direct link to How to Run Tests")
Once you have written your E2E tests, you can run them via the CLI using the command: `rasa test e2e`
Head over to the [command reference](https://rasa.com/docs/docs/reference/api/command-line-interface/#rasa-test-e2e) for a full list of arguments.
##### Testing Custom Actions[](#testing-custom-actions "Direct link to Testing Custom Actions")
By default, E2E tests call your action server in the background if your `endpoints.yml` is configured. Make sure the action server is running:
```
rasa run actions &
rasa test e2e
```
Or, if you want to *stub* out custom actions (so they don’t run external API calls), you can define a `stub_custom_actions` section in your test file. Under this key, map custom action names to dictionaries that specify the expected events and responses—mirroring the output of the action server. This avoids calling the actual action server during tests.
For example, stubbing the `check_balance` action might look like:
```
stub_custom_actions:
check_balance:
events:
- event: slot
name: account_balance
value: 1000
responses:
- text: "Your account balance is 1000."
```
If you need multiple stubs for the same action, follow the naming convention `test_case_id::action_name` to differentiate them.
##### Interpreting Results[](#interpreting-results "Direct link to Interpreting Results")
* The CLI will print a summary of passing or failing test cases.
* Any mismatches appear in a diff-like format, showing the expected versus actual events.
Tip
Coverage metrics help you see which flows and commands are not tested. If key flows appear missing, add more E2E tests.
#### Test Results Analysis[](#test-results-analysis "Direct link to Test Results Analysis")
When running test cases with assertions, the test runner provides an accuracy summary for each assertion type in that specific test run. The accuracy is calculated by dividing the number of successful assertions by the total of successful and failed assertions. Note that any assertions skipped due to a prior assertion failing are excluded from the accuracy calculation.
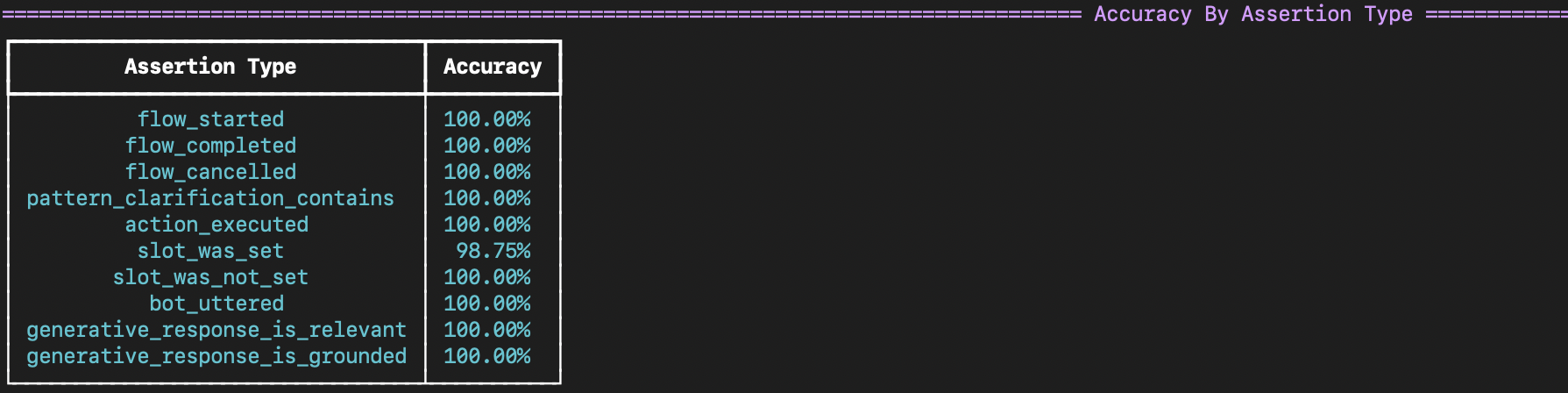
In addition, the test runner will provide a detailed report of the failed assertions, including the assertion itself, the error message, the line number in the test case file, and the transcript of the string representation of the actual events that were recorded in the dialogue up until the failed assertion.
#### To Sum it Up:[](#to-sum-it-up "Direct link to To Sum it Up:")
* **Use Test-Driven Development**: Begin writing E2E tests (or converting real conversations) early.
* **Automate**: Integrate E2E tests into your CI/CD pipeline to catch regressions.
* **Monitor**: Once in production, keep an eye on real user interactions for new edge cases or performance drifts, then add or update tests accordingly.
With a thorough E2E test strategy—plus interactive inspection and continuous monitoring—you’ll build confidence that both your rule-based flows and LLM-driven responses consistently deliver the experience your users expect.
---
#### Trying Your Assistant
Once you’re ready to talk to your newly built flow, train your assistant by running:
```
rasa train
```
After you have trained your assistant successfully, start talking to it in your browser by running:
```
rasa inspect
```
This command opens **Inspector**, a browser-based tool that launches a local version of your assistant, allowing you to chat with it and watch what happens under the hood in real time.
#### Interface Description[](#interface-description "Direct link to Interface Description")
The **`rasa inspect`** command starts an assistant based on the last trained model and opens a new tab in the browser with the following four panes (right-to-left and top-down):
* **Chat Widget**, where you can field-test a conversation with your assistant,
* **Flow View** visualizing the currently active flow and step of the conversation,
* **Stack View** listing bottom-up the activated flows and their latest steps, and
* **Slots, End-2-End Test and Tracker State View** containing details of the data captured during the chat.
##### Chat Widget[](#chat-widget "Direct link to Chat Widget")
Start a free-form chat with your assistant. The three remaining debugging panes will show the intrinsics of the conversation development and allow to check if the correct flows are activated at the right moments and if the conversation is proceeding as planned.
##### Flow View[](#flow-view "Direct link to Flow View")
Visualize the currently active flow in a flowchart and highlight the latest step. By clicking on the rows of the stack table, you can view the specific flows activated at different points in the conversation. At the bottom of the pane you can find a "restart conversation" button, which will discard any previous information and start a new chat. A page reload will cause the same behavior.
##### Stack View[](#stack-view "Direct link to Stack View")
The stack section gives a bottom-up chronological overview of the activated flows and their latest steps. The topmost item in that table represents the currently active flow step that the assistant is trying to complete. The flows listed below are 'paused' and will resume once every flow in a row above them has been complete.
* **ID**: A unique identifier for each stack frame.
* **Flow**: The active flow's identifier, linked to the **`flows.yml`** file.
* **Step ID**: The current step's identifier, also found in the **`flows.yml`** file.
##### Slots, End-2-End Test and Tracker State View[](#slots-end-2-end-test-and-tracker-state-view "Direct link to Slots, End-2-End Test and Tracker State View")
Here you can check details of the data collected so far:
###### Slots[](#slots "Direct link to Slots")
[Slots](https://rasa.com/docs/docs/reference/config/domain/#slots) are dynamic variables where the assistant stores and retrieves information throughout the conversation. They are defined in your **`domain.yml`** file.
###### End-2-End Test[](#end-2-end-test "Direct link to End-2-End Test")
The test conversation carried out in the chat widget is represented here in the [end-to-end test format](https://rasa.com/docs/docs/reference/testing/test-cases/). This helps to quickly transform the conversation into a test case which when added to your end-to-end test set can enhance the robustness of the assistant.
###### Tracker State[](#tracker-state "Direct link to Tracker State")
The tracker state view offers detailed information about past events and the current state of a conversation. It presents the conversation history through a series of recorded events, such as the message sent by the user accompanied by the command predicted by the LLM, slots that are set, conversation repair patterns triggered and actions executed by the bot.
#### Inspecting Voice Assistants[](#inspecting-voice-assistants "Direct link to Inspecting Voice Assistants")
Rasa Inspector can also be used for testing voice conversations. To get started, add the built-in `browser_audio` channel in the `credentials.yml` file of the assistant with the ASR and TTS services of your choice. In this example, we will use Cartesia and Deepgram:
credentials.yml
```
browser_audio:
server_url: localhost
asr:
name: deepgram
tts:
name: cartesia
```
Ensure that the appropriate API keys are added to the environment variables, in this case, `CARTESIA_API_KEY` and `DEEPGRAM_API_KEY`. Checkout the [speech integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/) page for more information.
Launch the Inspector with the `--voice` flag using the command `rasa inspect --voice`.
#### Inspecting Conversations over External Channels[](#inspecting-conversations-over-external-channels "Direct link to Inspecting Conversations over External Channels")
Rasa Inspector can also be used to debug conversations happening on external channels. When you have certain channels defined in `credentials.yml`, you can run Rasa with Inspector using the command `rasa run --inspect`.
Rasa will create Inspector URLs for each channel. You can start a conversation over the external channel and view the conversation on Rasa Inspector along with all the relevant information about the conversation. It can be used to inspect conversations over any external channel including voice channels (like Twilio Media Streams).
For example, to inspect conversations over Rest channel. Ensure that `credentials.yml` contains the channel you would like to inspect:
credentials.yml
```
rest:
```
Lauch Rasa Server with Inspector with the command `rasa run --inspect`. Open the inspector URL mentioned in the logs:
```
Development inspector for channel rest is running.
To inspect conversations, visit http://localhost:5005/webhooks/rest/inspect.html
```
Now, the first conversation started over the REST channel will be visible on the Inspector. You can try it with the following cURL request:
```
curl -X POST \
'http://localhost:5005/webhooks/rest/webhook' \
--header 'Content-Type: application/json' \
--data-raw '{
"sender": "test_user",
"message": "I would like to transfer money"
}'
```
---
## Rasa Studio
### Welcome to Studio
Rasa Studio is a no-code tool that lets you create, refine, and test Rasa assistants visually. It allows anyone on your team to build assistants, review and improve conversational content, and conduct tests all in one place—making collaboration easy and effective, regardless of technical expertise.
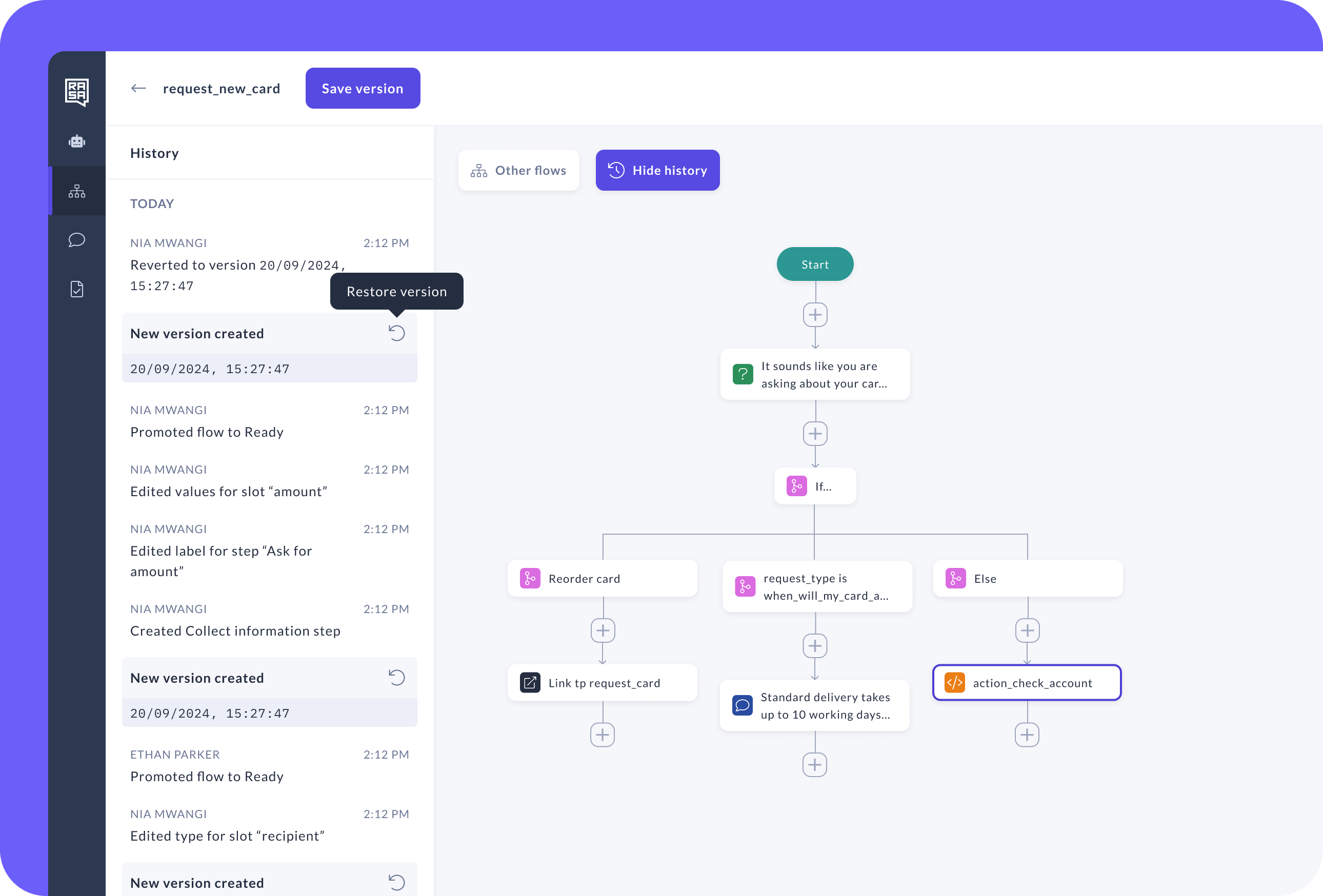
#### **Who is Studio for?**[](#who-is-studio-for "Direct link to who-is-studio-for")
Anyone that prefers a visual approach to building an AI assistant through Rasa. You can think of it as an advanced content management system for conversational AI, letting you work on the same assistant as your development team.
##### For Business Users and Designers[](#for-business-users-and-designers "Direct link to For Business Users and Designers")
Rasa Studio allows you to bring your conversational ideas to life. You can visually craft your business logic, test your changes and fine-tune responses without needing deep technical expertise. It helps you focus on creating a great conversational experience rather than the implementation details.
##### For Technical Teams[](#for-technical-teams "Direct link to For Technical Teams")
Rasa Studio adds a visual layer to your Rasa project, simplifying collaboration and speeding up the feedback loop. Built on the Rasa framework, Studio lets you export assistants as code or import compatible projects—ensuring that you keep full control over integration, customization, and deployment.
---
### Your First Assistant
In this guide, you’ll create a simple assistant that greets users, introduces itself, and helps with money transfers. Don't worry if you're new to Rasa or building assistants, this guide will walk you through each step.
By the end of this tutorial you will have built a [CALM](https://rasa.com/docs/docs/learn/concepts/calm/)-based assistant that greets users, introduces itself, and assists with money transfers.
#### Step 1: Create a new assistant[](#step-1-create-a-new-assistant "Direct link to Step 1: Create a new assistant")
1. **Log In:** Start by logging into Studio with either the `superuser` or `developer` role. [Learn more about the default roles and their permissions](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/).
2. **Create Your Assistant:**
* On the Welcome page, click **Create new project**.
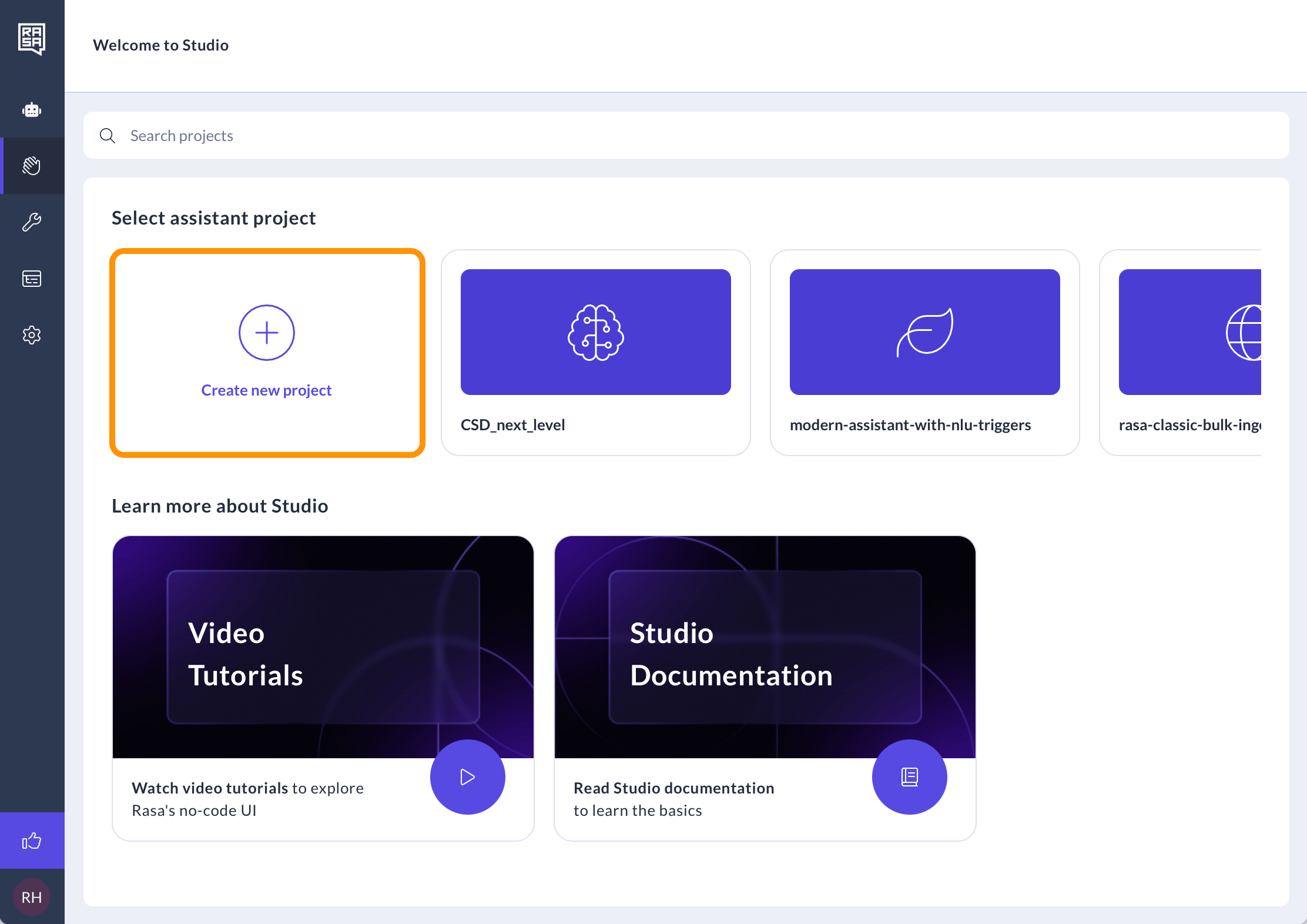
* Give your assistant a name that describes what it will do. Since we're building a bot that transfers money let's name it: `transfer_money_assistant`.
* Keep the **English** selected as a default language, then click **Create assistant**.
#### Step 2: Create your First Conversation[](#step-2-create-your-first-conversation "Direct link to Step 2: Create your First Conversation")
One of the key concepts in Rasa's [CALM](https://rasa.com/docs/docs/learn/concepts/calm/) (Conversational AI with Language Models) is a flow. A flow represents a series of steps that guide the user through a conversation. Think of it as a conversation tree, where each step helps the assistant figure out what to say or do next based on what the user says.
Now, let's create your first flow:
1. **Checkout the Flow Builder**: Navigate to the **Flows** page through the tab in the menu.
2. **Create your first flow**: Click **Create flow** to begin crafting your welcome flow.
3. **Create an ID for your Flow**: Since this flow is going to welcome the user, at the beginning of our conversation let's name it **welcome**.
You can optionally add a flow name, but it’s fine to leave it blank for now.
4. **Write your Flow Description:** Let's describe the flow so your assistant knows when it should be triggered. Ensure you provide specific and unique instructions, in this case: `Greet the user and introduce yourself` is appropriate. Click "Save" to create and open your flow.
note
Flow descriptions are incredibly important for your assistant's ability to know where to take a conversation. Rasa assistants use the flow description to determine when it is appropriate to trigger a specific flow.
[Read more about flows here](https://rasa.com/docs/docs/reference/primitives/flows/).
5. Flows start with the "Start" step, which is where you configure how the flow gets triggered. By default, it will be triggered by CALM based on the description you provided. This works for us, so you can leave it as is for now.
6. Click the "Plus" icon to add a step. From the dropdown menu, select "Send message" to have your assistant send a text message to the user.
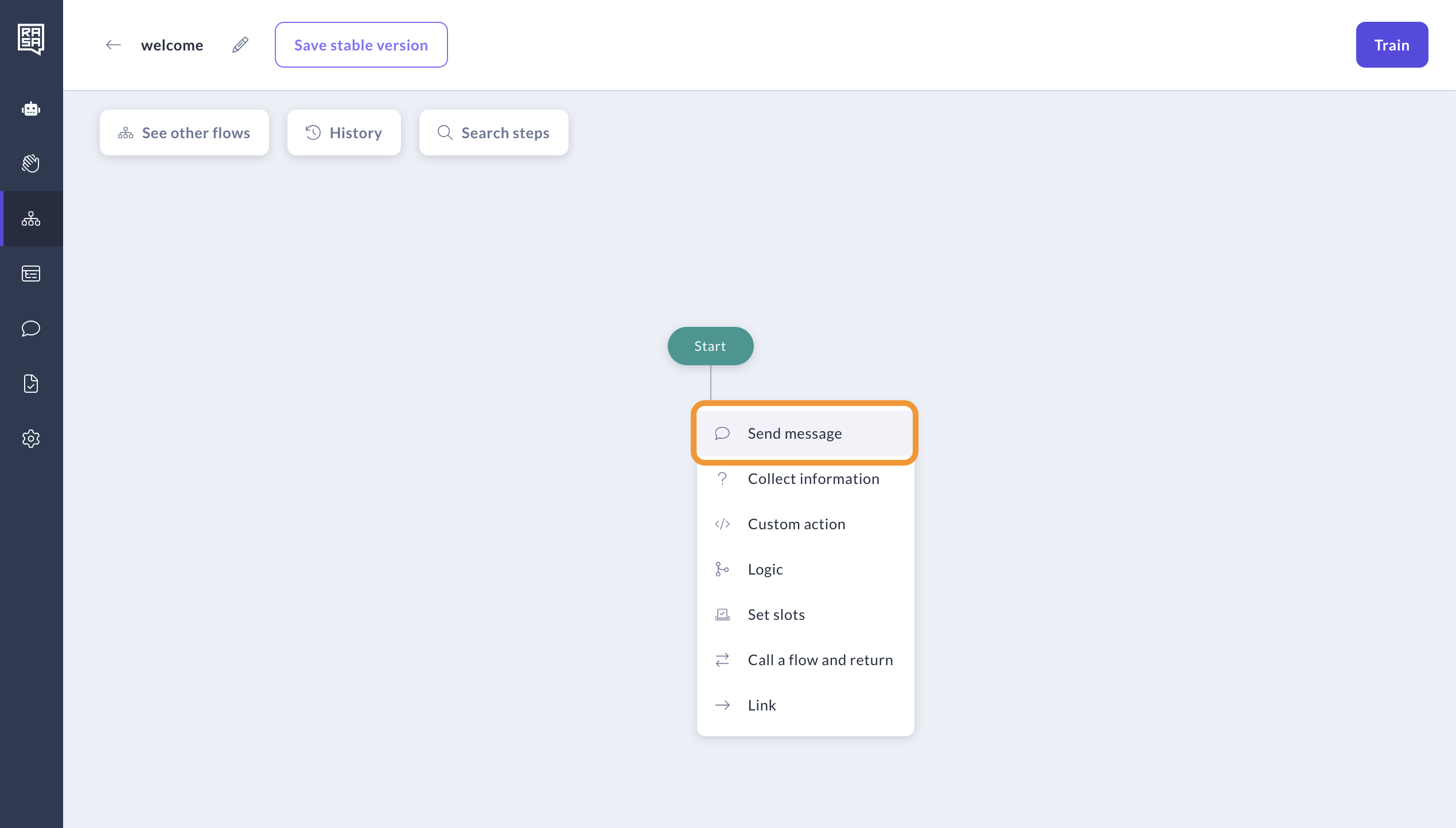
7. Click on "Select or create response" on the side panel. When the pop-up appears, click the "Create new response" button.
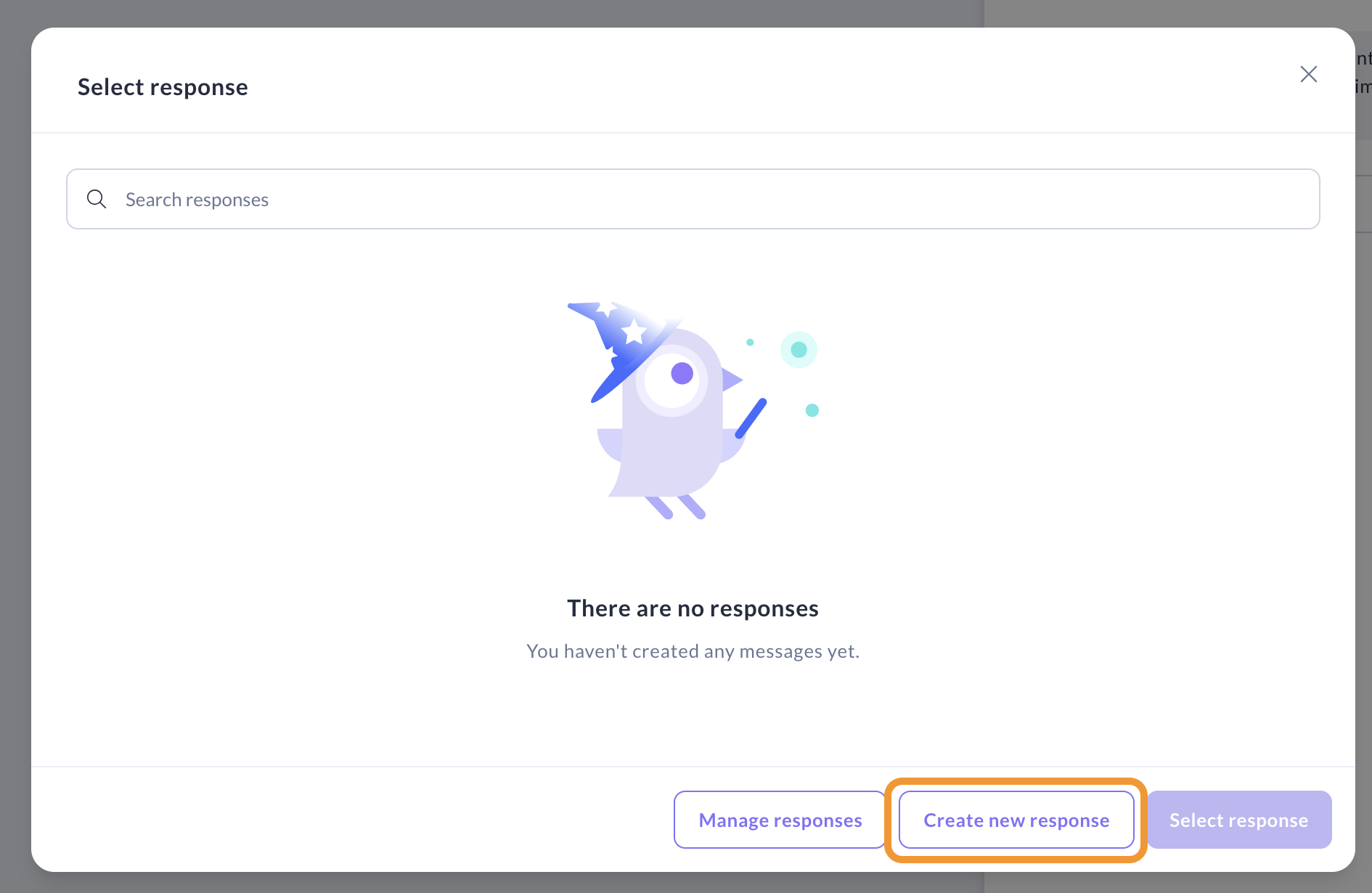
8. Fill in the details:
1. Enter the name, e.g `greet`.
2. Enter the response e.g "Hello! I’m your assistant, created with Rasa Studio. I’m here to help you with money transfers".
3. Select "Use contextual response rephraser" to have the response automatically rephrased based on the conversation’s context.
4. Once you're set, click "Save".
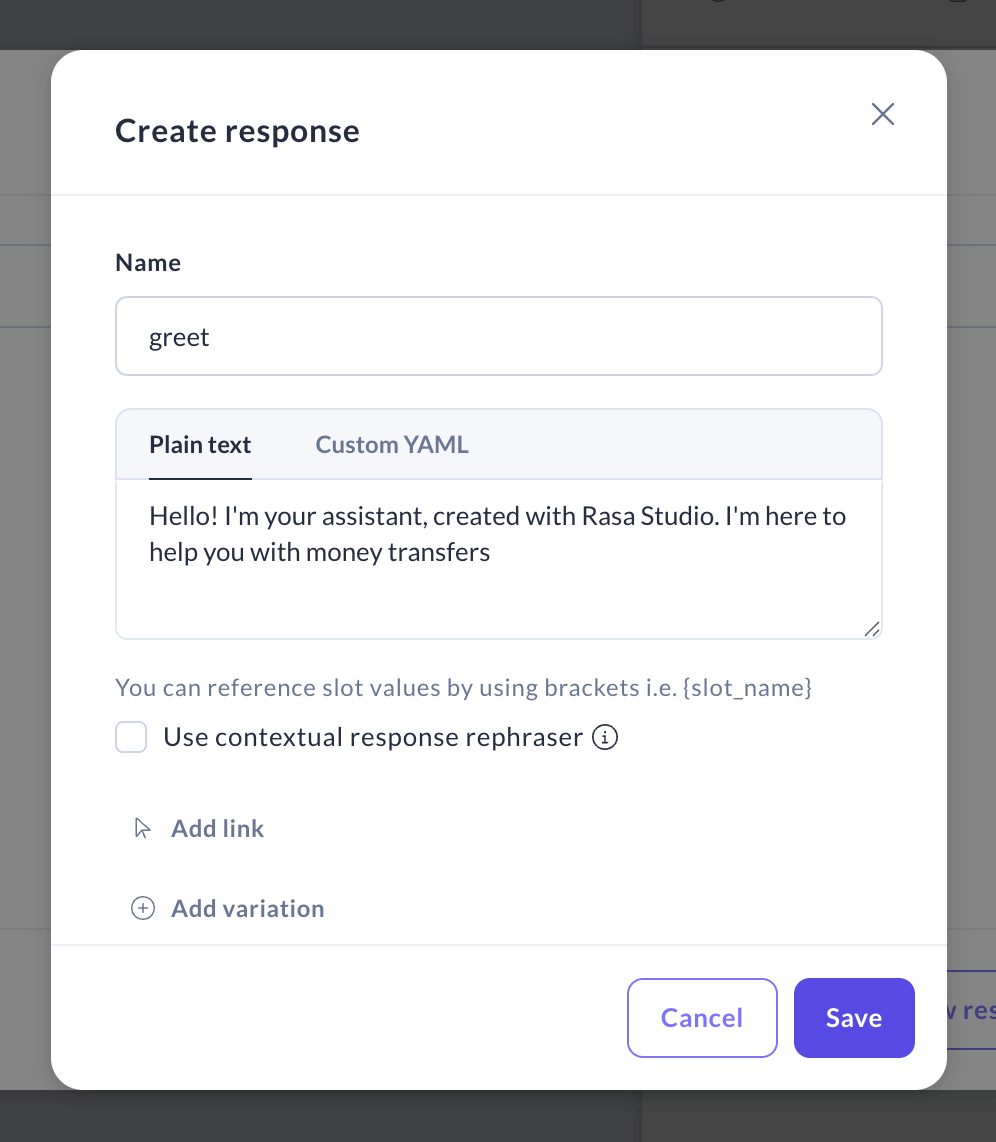
#### Step 3: Creating Money Transfer flow[](#step-3-creating-money-transfer-flow "Direct link to Step 3: Creating Money Transfer flow")
Let’s now build another flow to help users in conducting money transfers, allowing CALM to activate this process when users inquire about sending money. To do it:
1. Return to the flow list and click "Create flow".
2. Name your flow `money_transfer` and add the description: "Ask all the required questions to process a money transfer request from users." Click "Save".
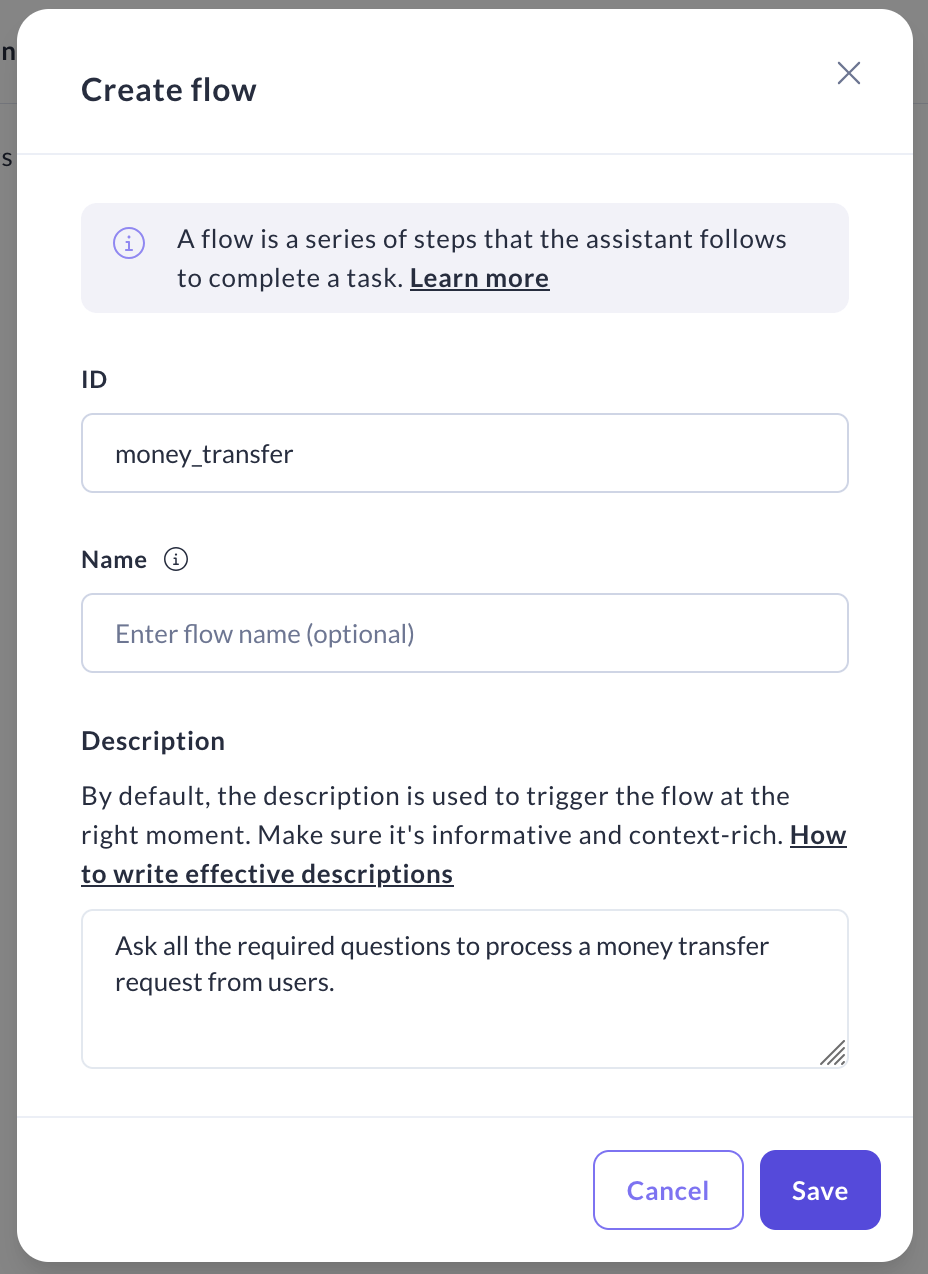
##### Collecting information about the recipient[](#collecting-information-about-the-recipient "Direct link to Collecting information about the recipient")
1. In the newly created flow, add the "Collect Information" step to ask the user who the recipient of the transfer will be.
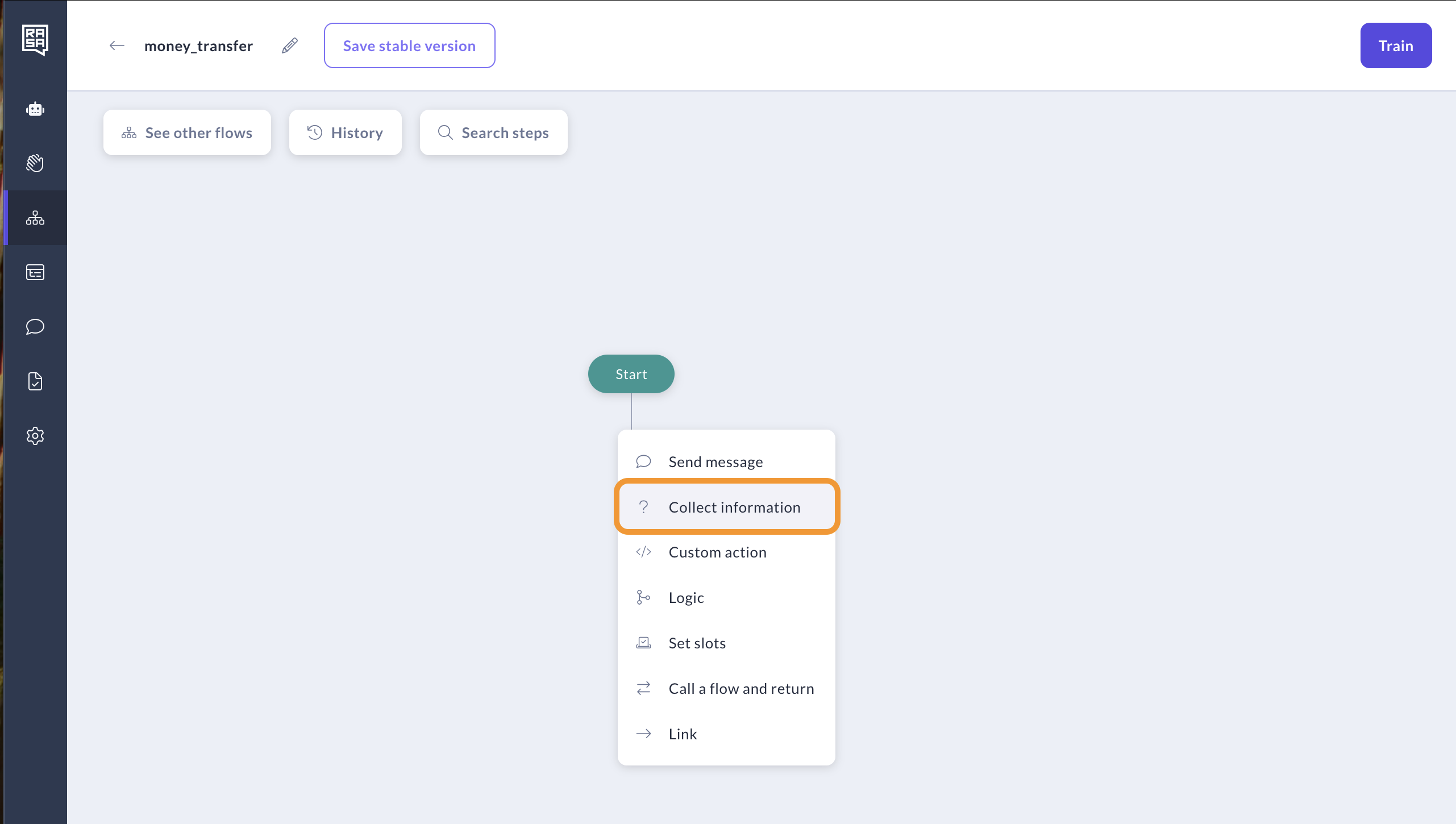
2. Instruct the assistant on what information to collect in this step by filling out the "Description" field. For example, "This step inquires about the recipient of the payment."
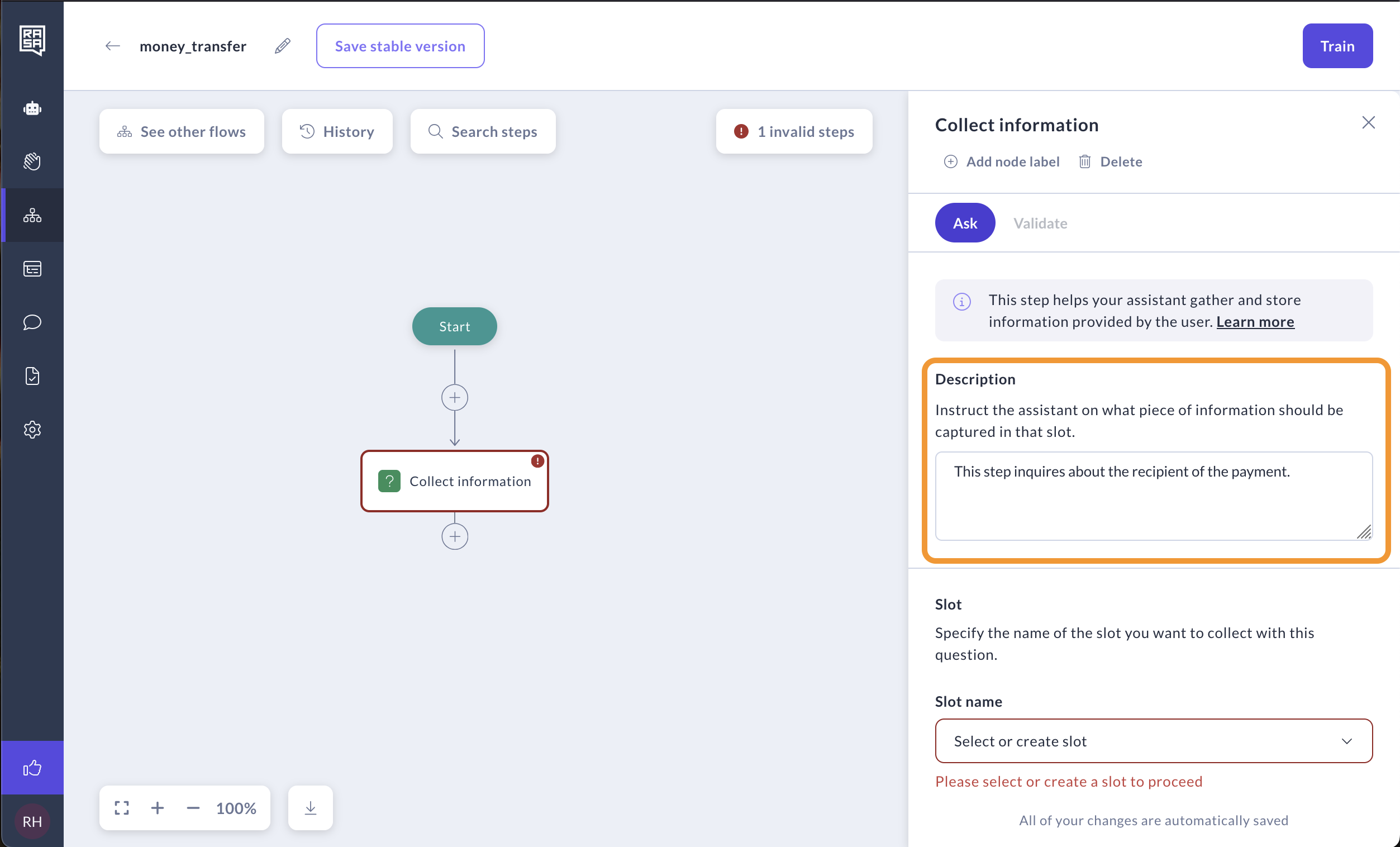
3. To define the specific information the assistant should collect from the user's reply, you'll need to create a [slot](https://rasa.com/docs/docs/reference/primitives/slots/). Slots function as your bot's memory, it will hold the data that the user provides . To create a slot, click on the "Select or create slot" field and choose "Create slot."
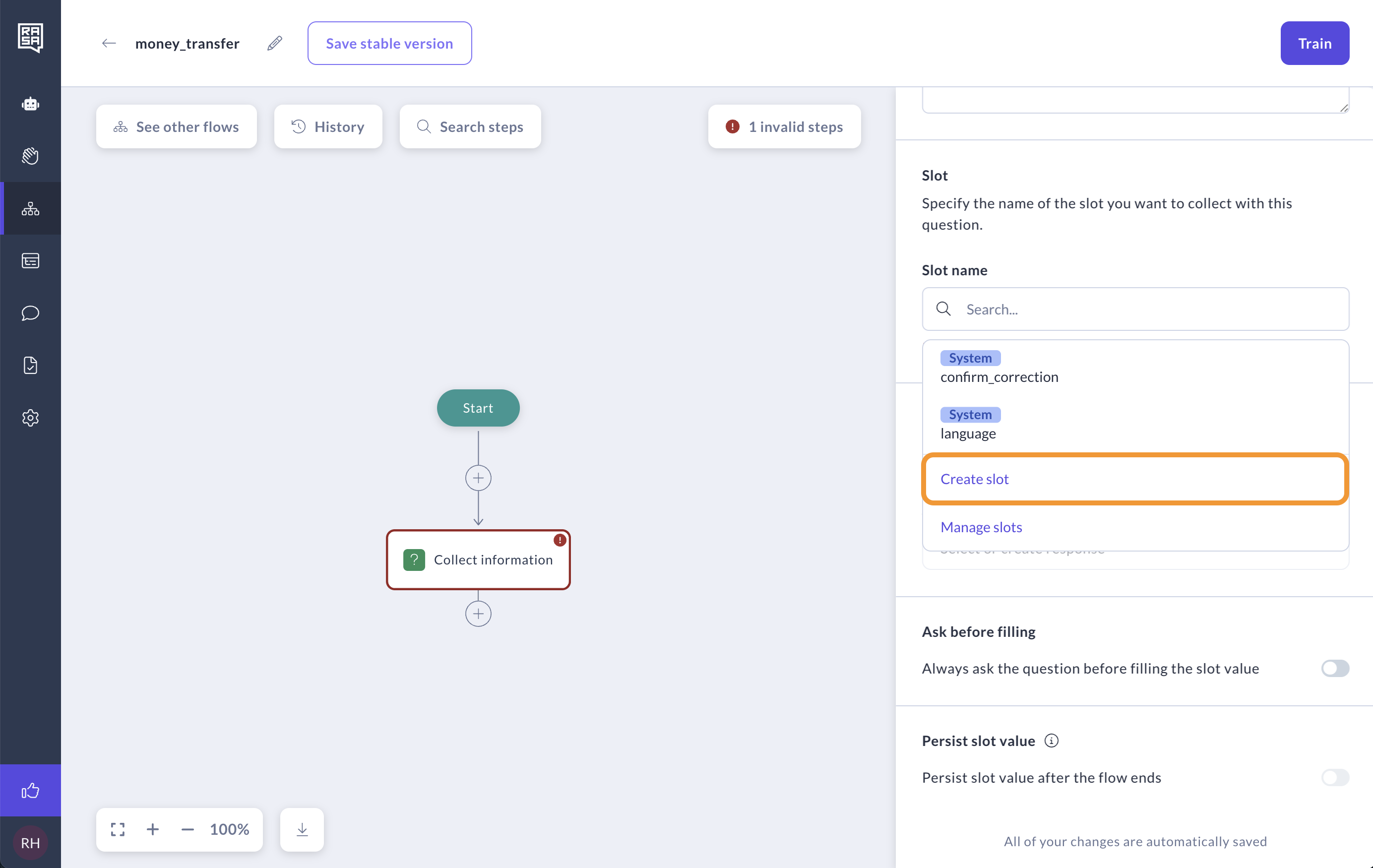
4. Input `recipient` as a slot name. Then select `Text` as type—a text slot stores information like personal names, countries, cities, etc. While you can provide an initial value for any slot, it's not applicable in this scenario. [Learn more about slot types](https://rasa.com/docs/docs/studio/build/flow-building/collect/#slot-types).
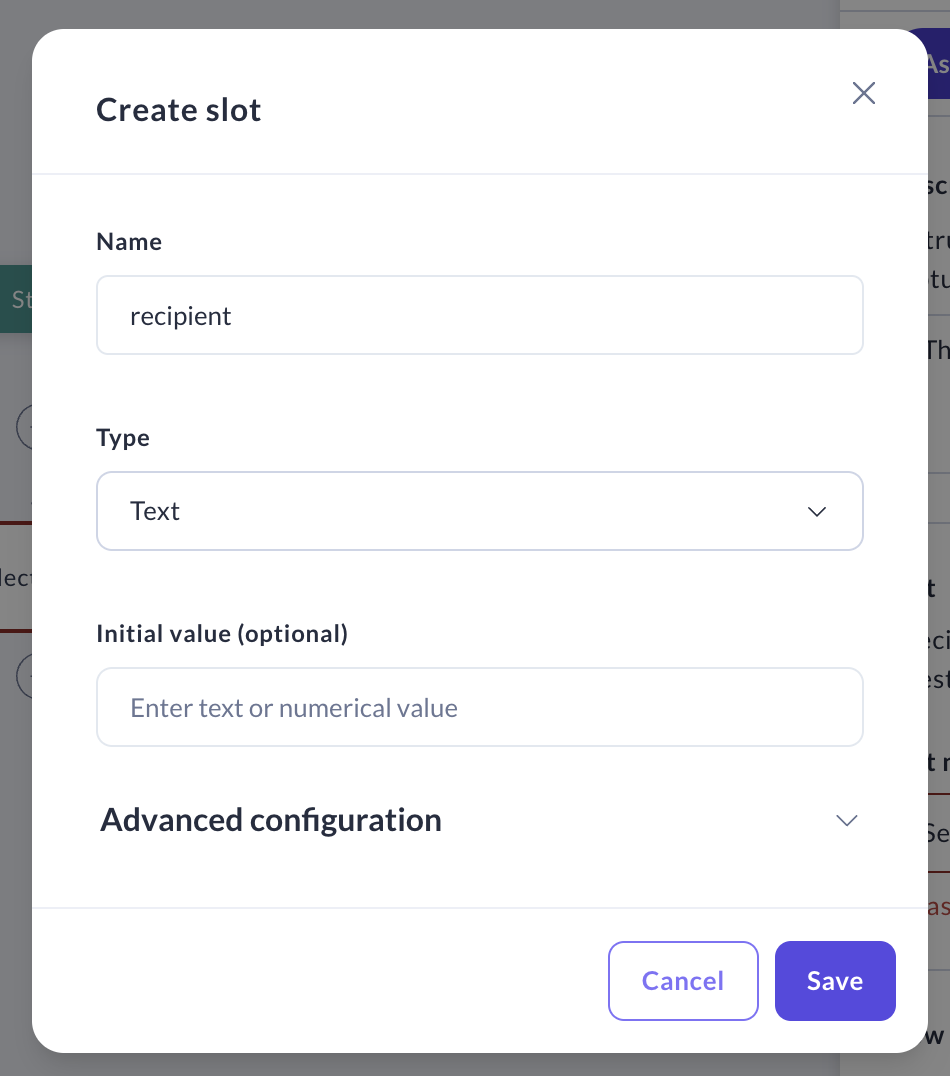
5. Finally, generate a response that the assistant will use to collect this information from the user. To do this, click "Select or create response".
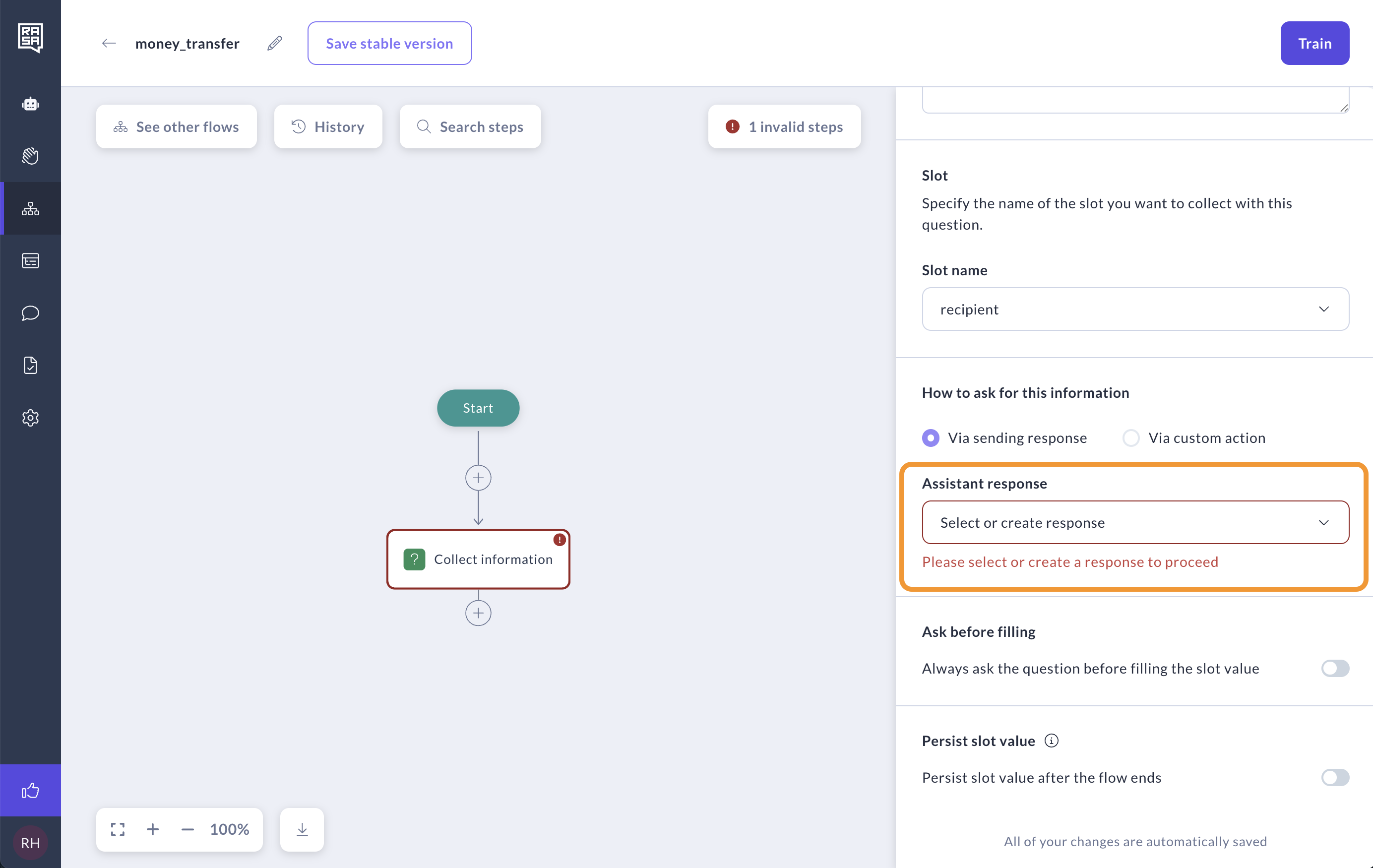
6. The system will automatically fill in the response name by combining the slot name with the prefix `utter_ask`, resulting in `utter_ask_recipient`. Enter the text as "Who would you like to send money to?"

7. Decide whether to check the "Use contextual response rephraser" box. If you leave it unchecked, the assistant will always use the exact same wording. If you check it, the message will vary slightly each time, depending on the conversation context, making it sound more natural. [Learn more](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/).
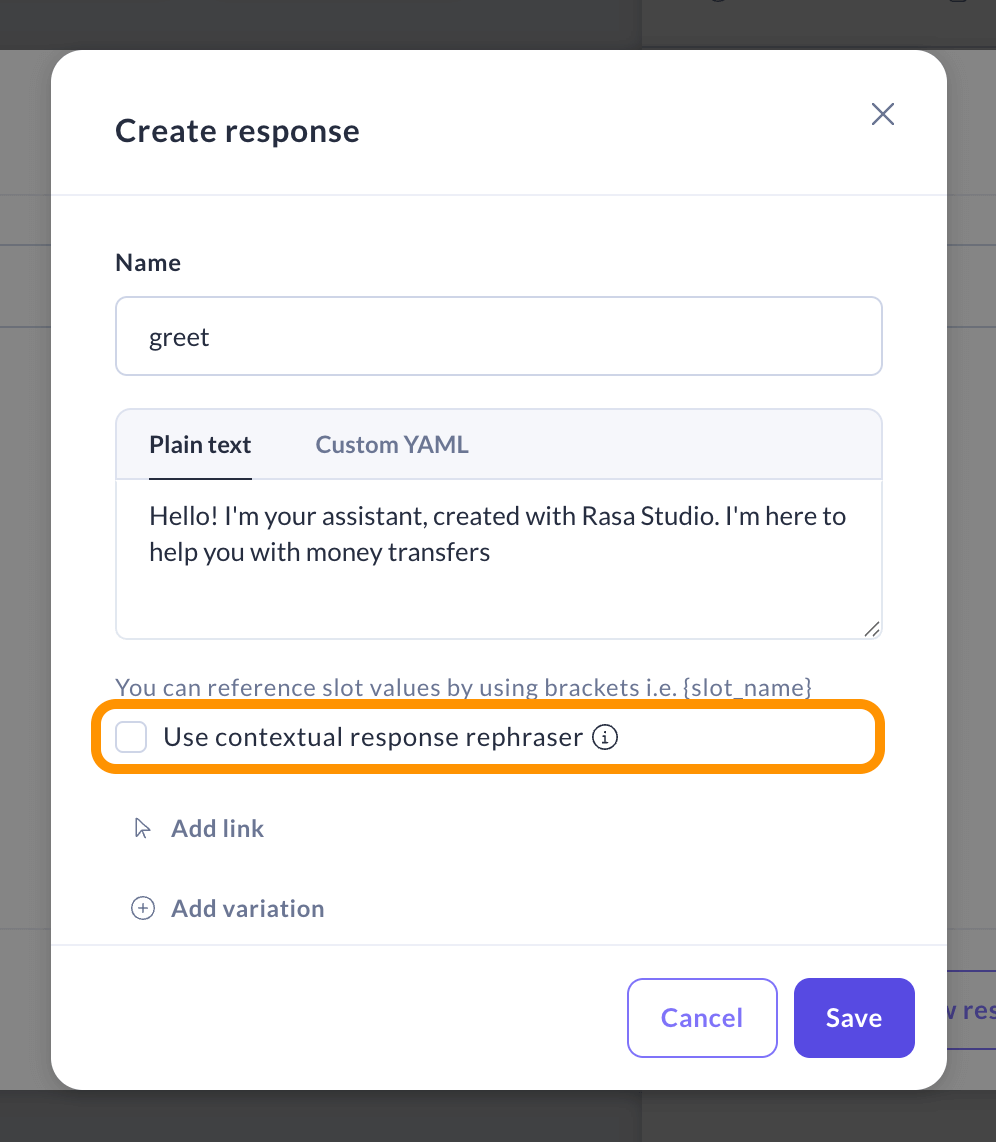
8. If you prefer full control over responses or don’t want to use an LLM, you can manually create response variations by clicking the "Add variation" button. Add as many variations as you'd like. During the conversation, Rasa will randomly pick one of them.
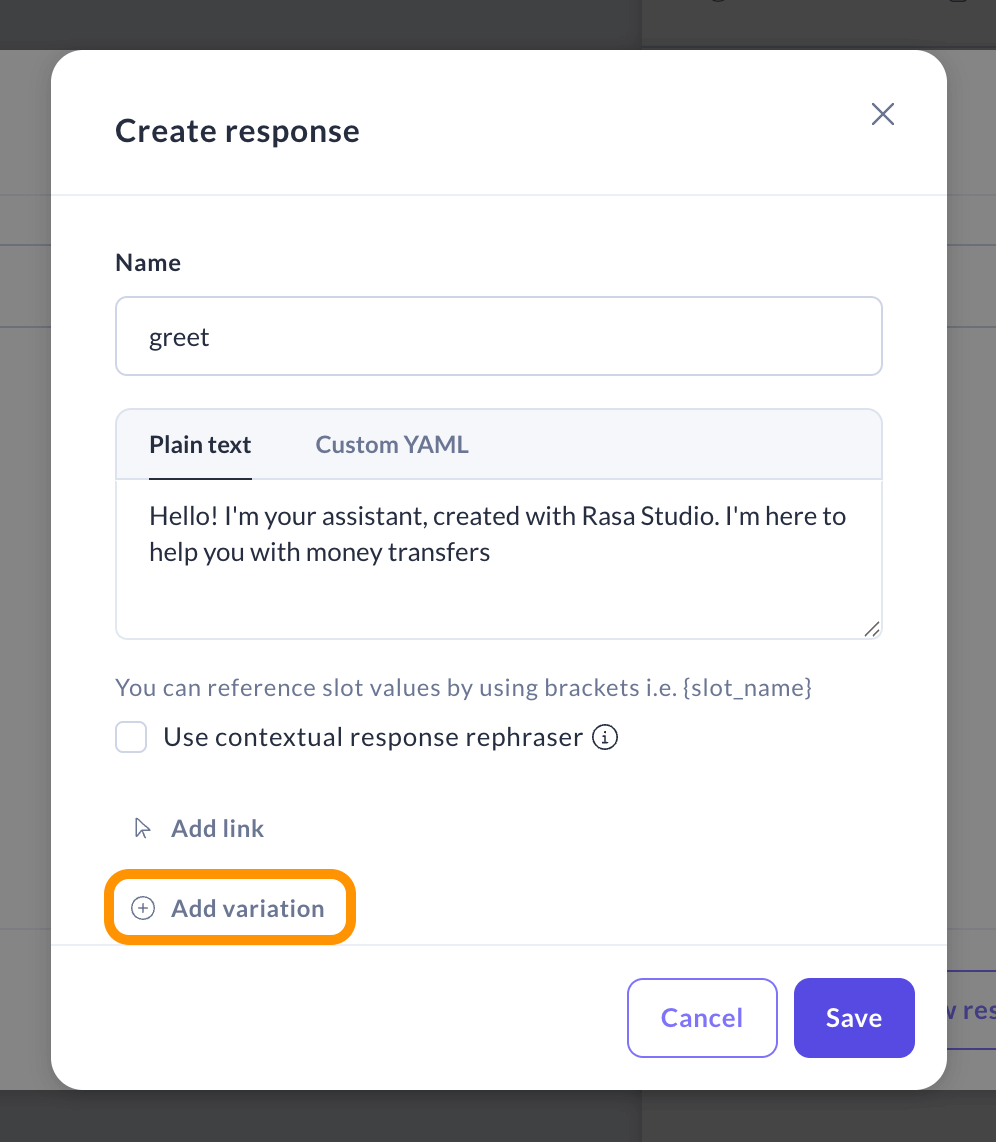
9. By default, a "Collect Information" step can be skipped if the slot is already filled. For example, if a user says, "I want to transfer money to John" at the beginning of the conversation, the assistant will recognize John as the recipient and won't ask for the name again. If you want the assistant to always ask the question, even if the slot is already filled, enable the "Ask before filling" option. In this particular case, we recommend to leave it disabled.
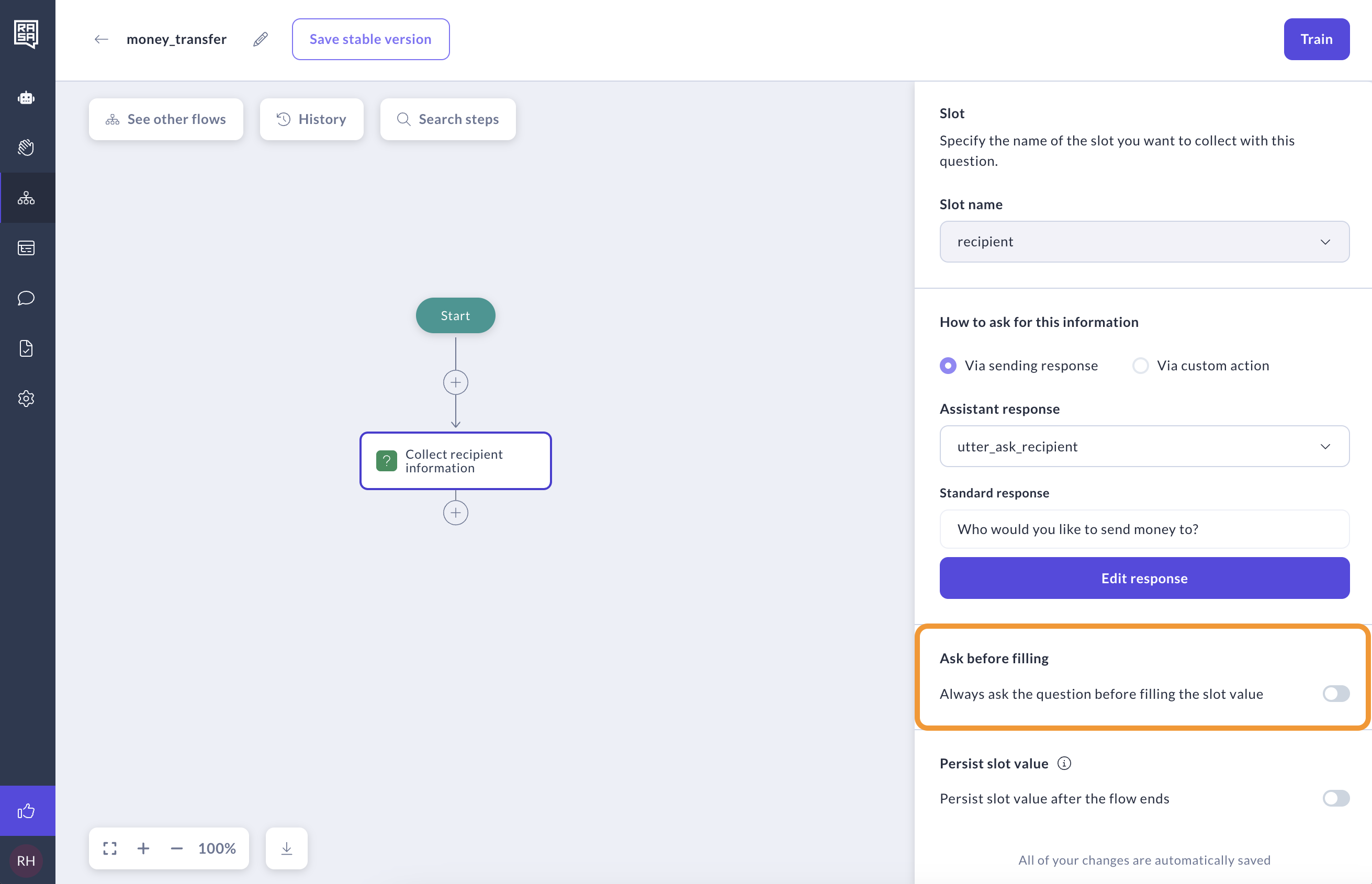
10. When the "Persist slot value" option is disabled, the system will clear the slot after the flow's final steps, prompting the question again in future sessions. This is useful for slots like `transfer_amount` or `recipient_name`, which can change each session. In this particular case, we recommend leaving the "Persist slot value" option disabled.
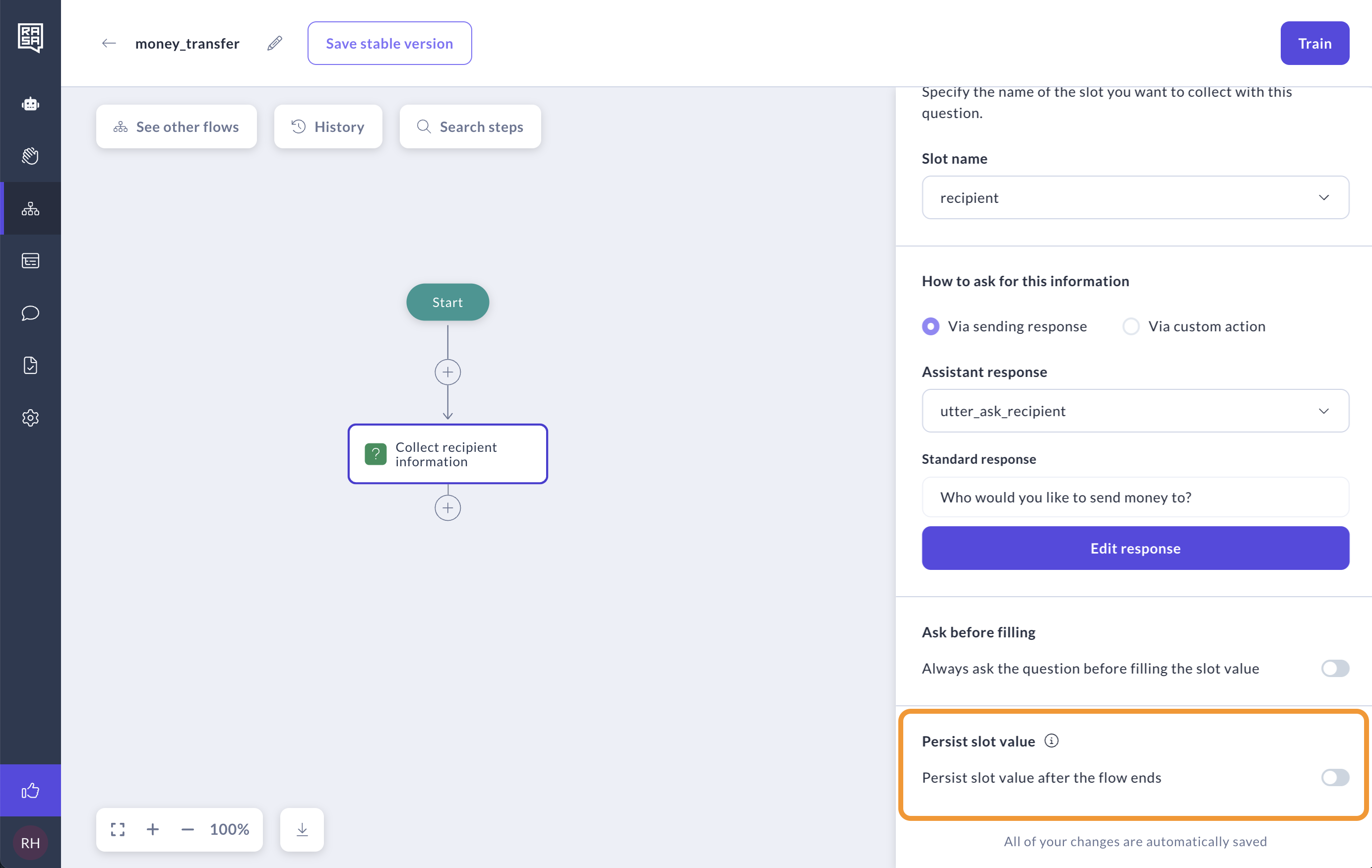
##### Collecting information about the amount[](#collecting-information-about-the-amount "Direct link to Collecting information about the amount")
1. Add one more "Collect information" step to ask the user about the amount of transfer.
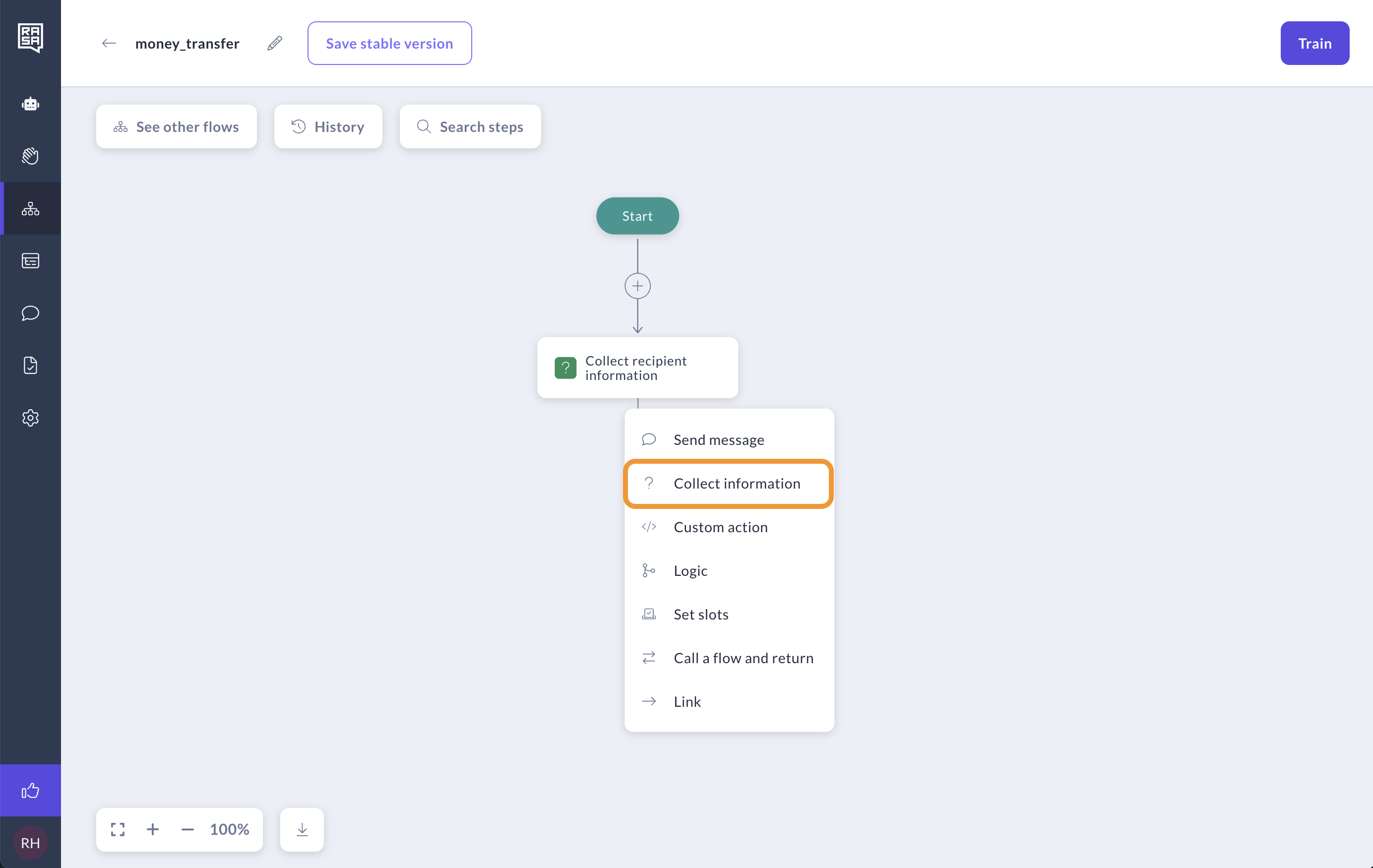
2. Enter the description: "This step inquires about the amount of the payment, in US Dollars."
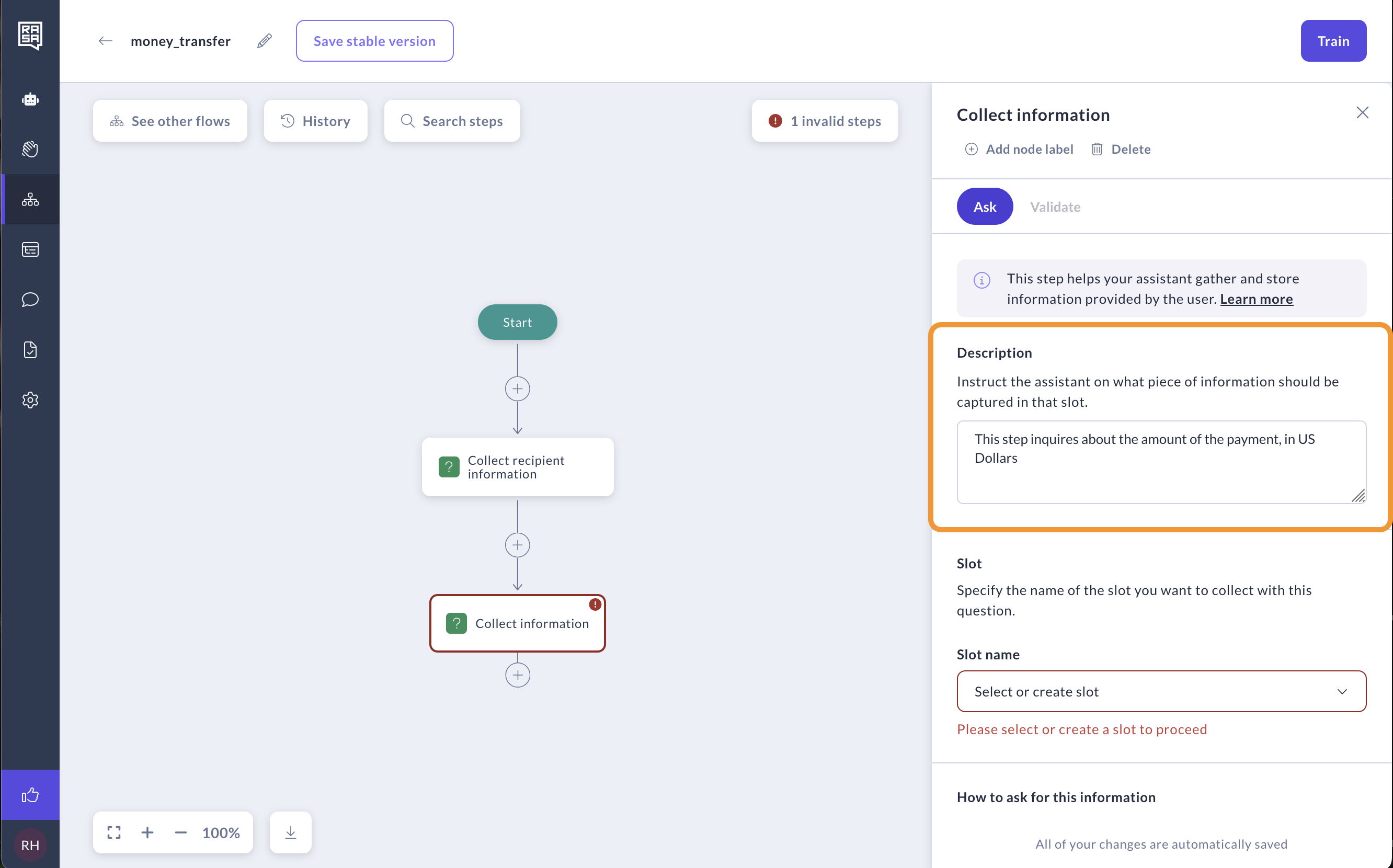
3. Create a new slot.
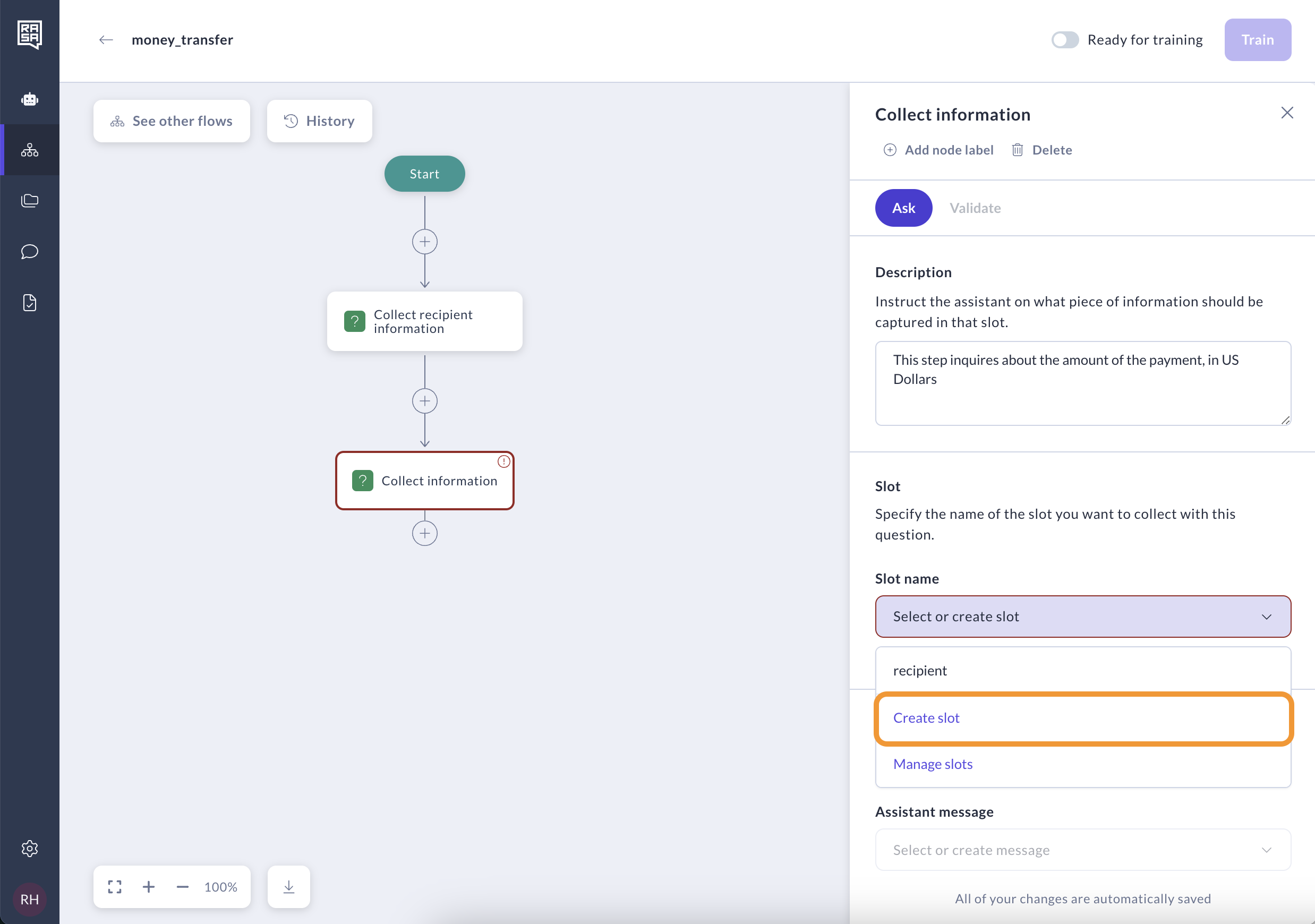
4. Input `amount` as the slot name. Then select `Float` as type — it is employed for storing numerical values that can have decimal points. Click "Save".
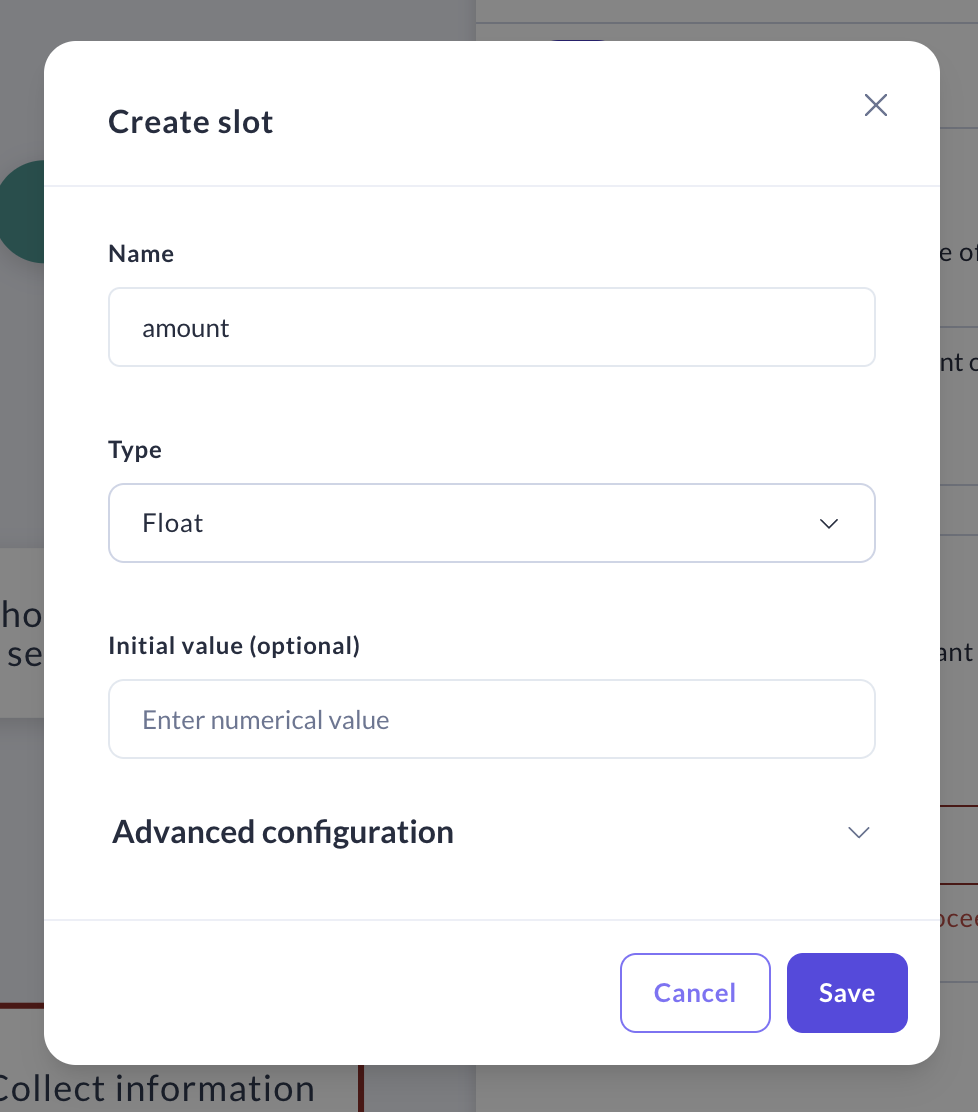
5. Finally, generate a response that the assistant will use to collect this information from the user. To do this, click "Select or create response".
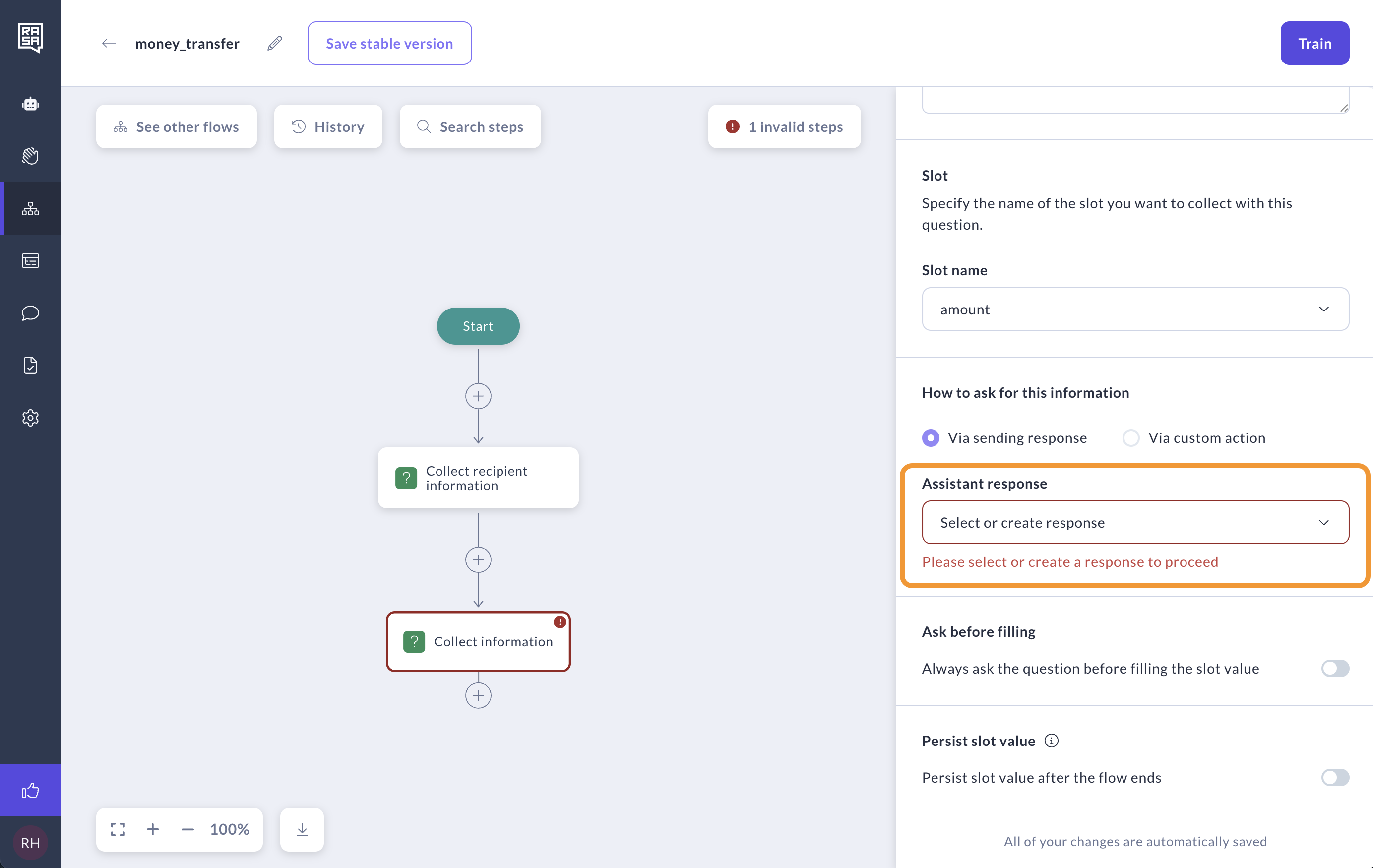
6. Modal to select or create new response will open. Click on "Create new response".
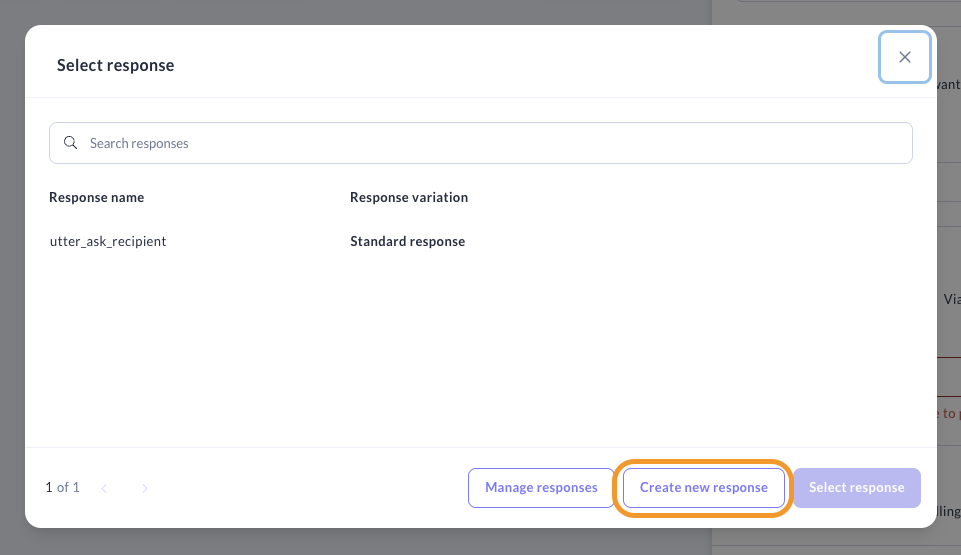
7. The system will automatically fill in the response name with `utter_ask_amount`. For the response content, you might use "How much money would you like to send (in US Dollars)?"
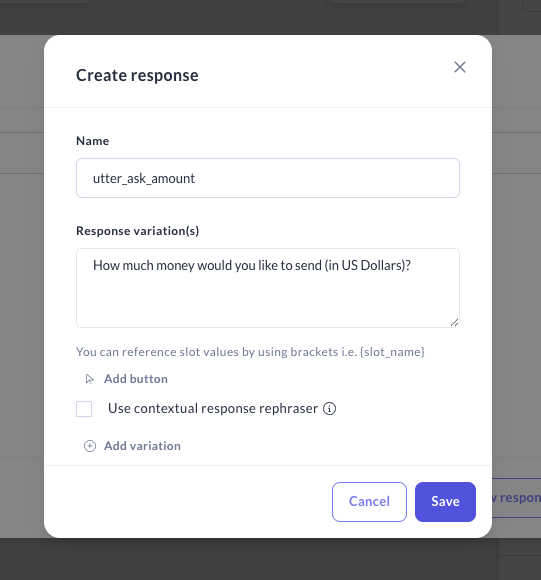
8. You can optionally add buttons to give users structured choices, making it easier for them to quickly select an answer. To do this, click "Add button".

9. In the modal that opens, enter a button title, e.g., "50". You can leave the Payload field empty.
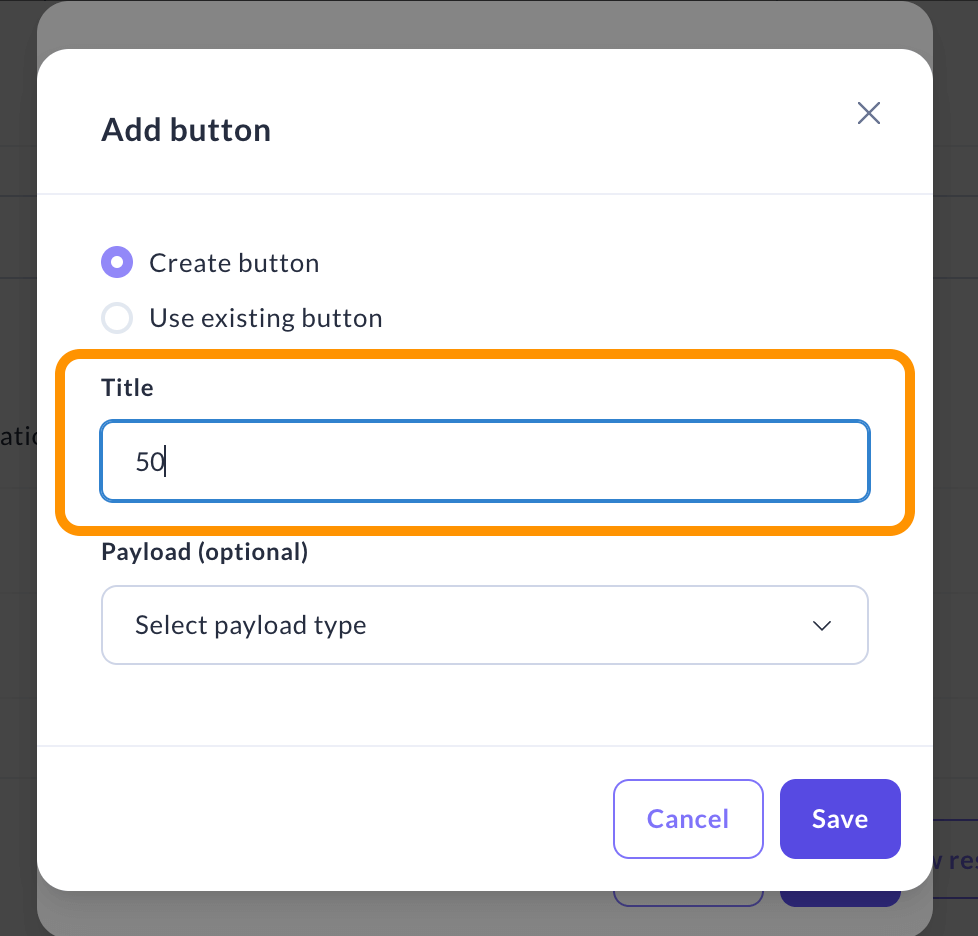
10. Click "Add another button" to add more options, such as `500`, `1000`, `1500`, etc. Don’t forget to save your buttons and the response when you're done.

11. Leave "Ask before filling" option disabled. If a user starts the conversation with "I want to transfer 50 dollars", the assistant will already fill the slot and won't to ask for the amount again. Also leave "Persist slot value" disabled to ensure that the next time a user requests a money transfer, the assistant will ask for the amount again.
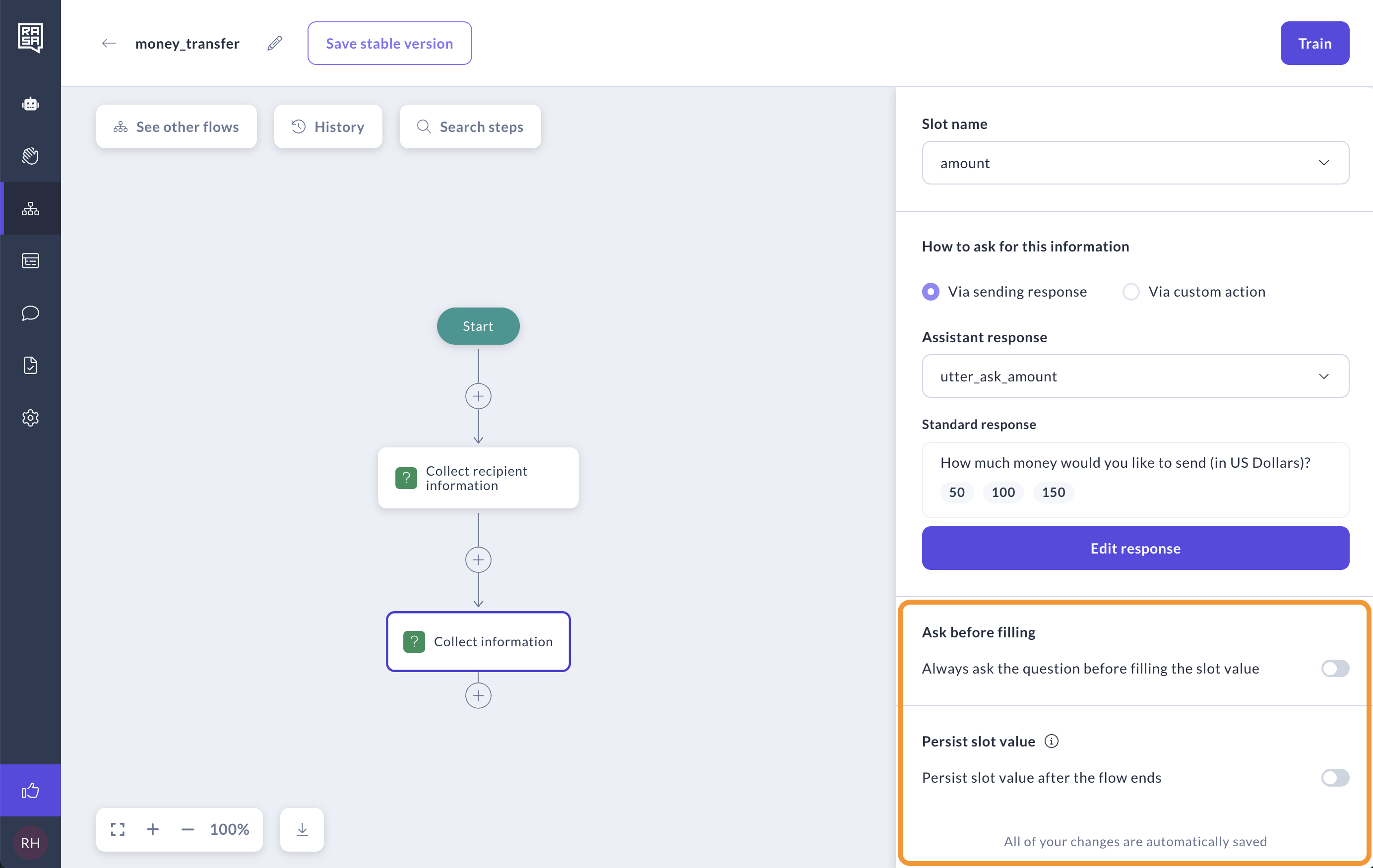
##### Verifying if funds are sufficient[](#verifying-if-funds-are-sufficient "Direct link to Verifying if funds are sufficient")
In this step, we aim to verify whether the user has sufficient funds for the transfer. Ideally, this is done using a custom action (API call) to check the user's balance and return a response. However, for the first part of the tutorial, we'll use Logic to mock the result of this custom action.
1. Add a "Logic" step. This type of step allows you to branch the flow based on a condition.
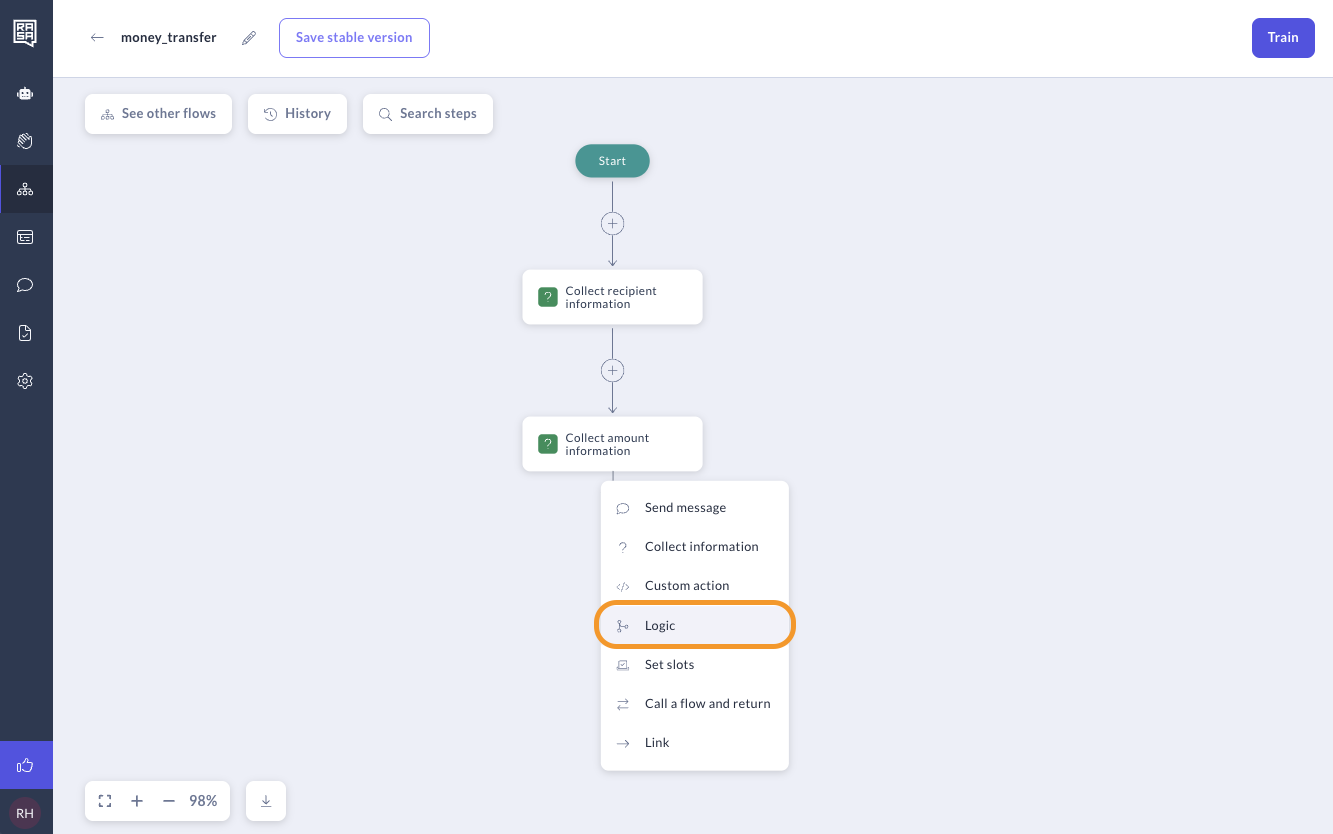
2. Define the condition for sufficient funds. Click on the first logic branch to create a scenario where the transaction amount is less than or equal to $1000. If the transaction amount is less than the available funds, it indicates sufficient funds are available. Select the first condition and set it to `amount` `is less than or equal` `1000`.
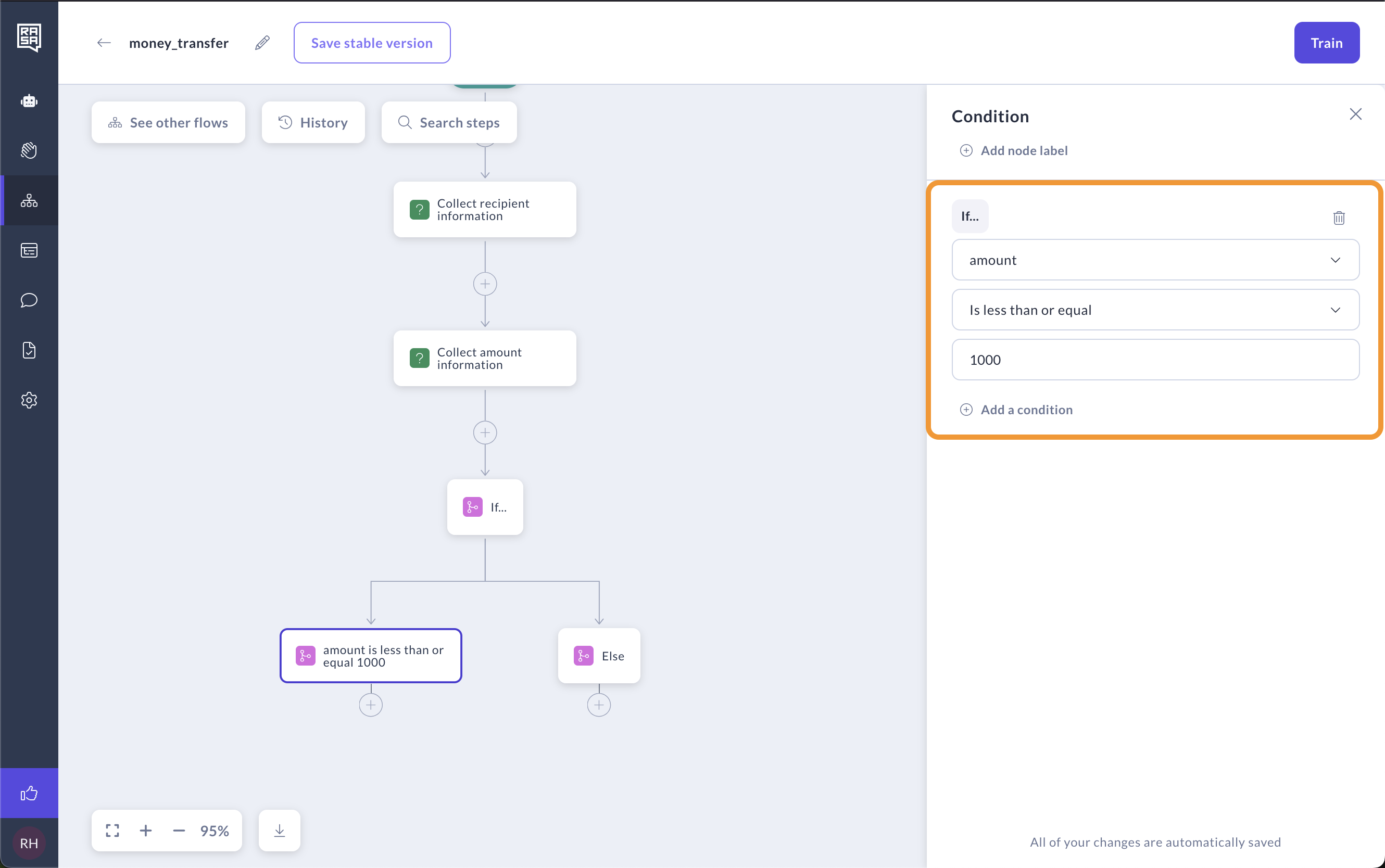
3. For cases where the user does not have enough funds, the "Else" logic branch will be activated. In this case, we need to notify the user that the transfer amount is insufficient. To do so, add a "Send message" step after the "Else" branch.
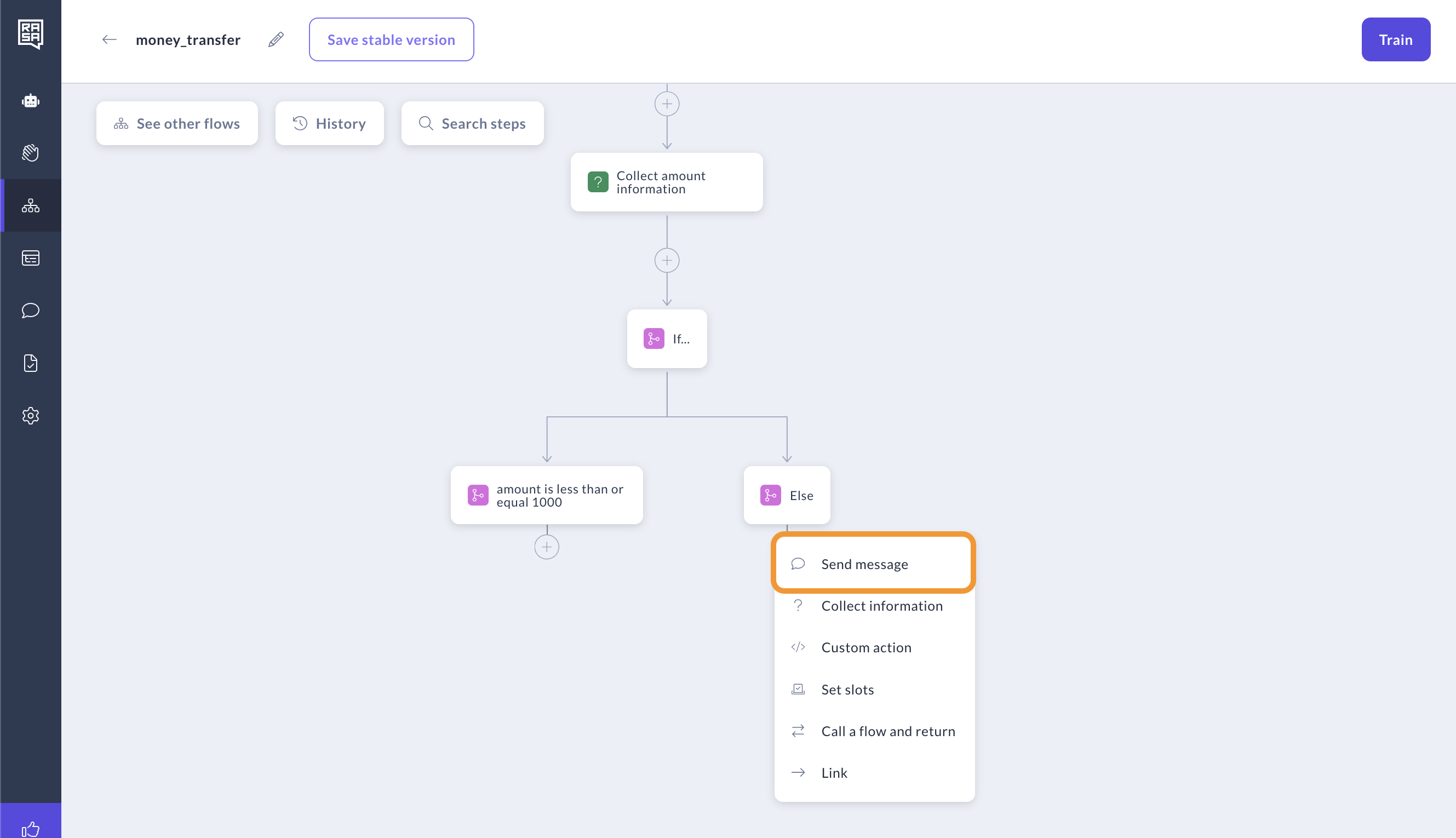
4. Create the response. Name it `insufficient_funds` and add the text "You don't have sufficient funds to complete this transaction." Click "Save."
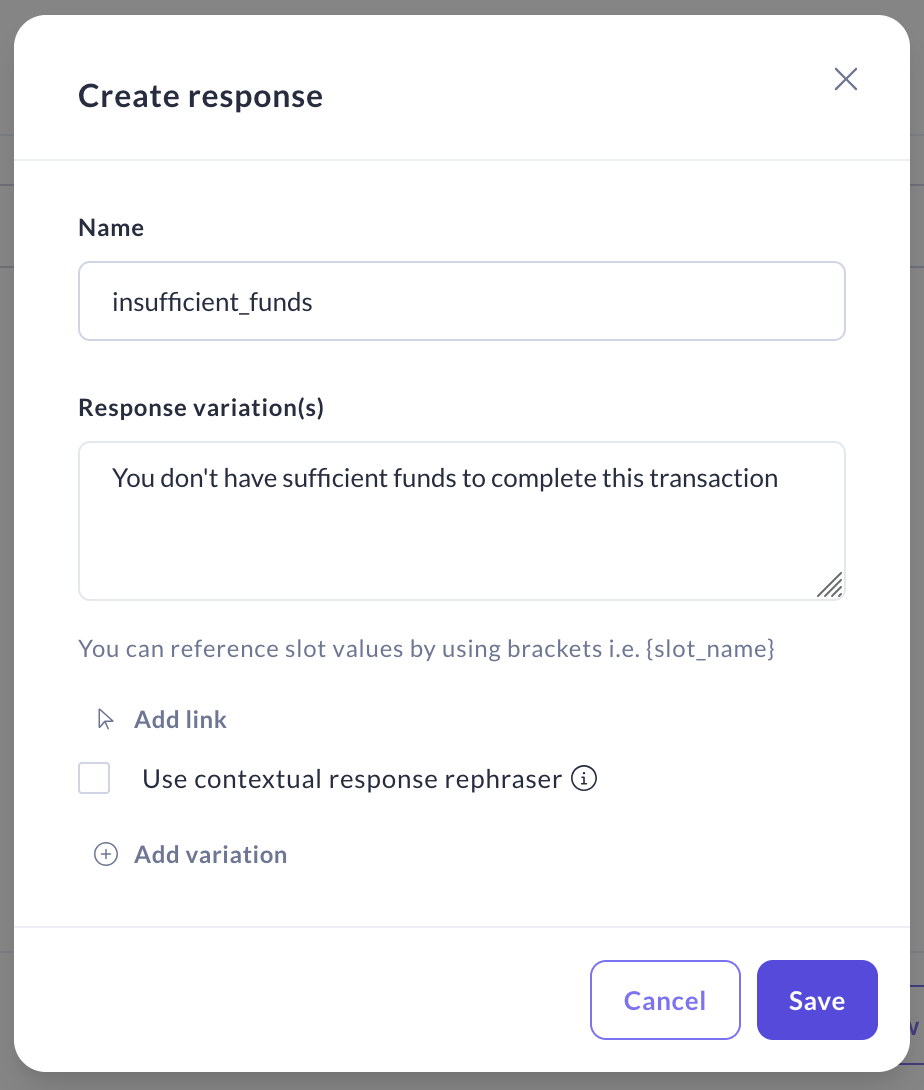
##### Confirming the request[](#confirming-the-request "Direct link to Confirming the request")
If the user has sufficient funds, we can proceed to the next step: verifying the transfer details.
1. After the first condition, add the "Collect information" step.
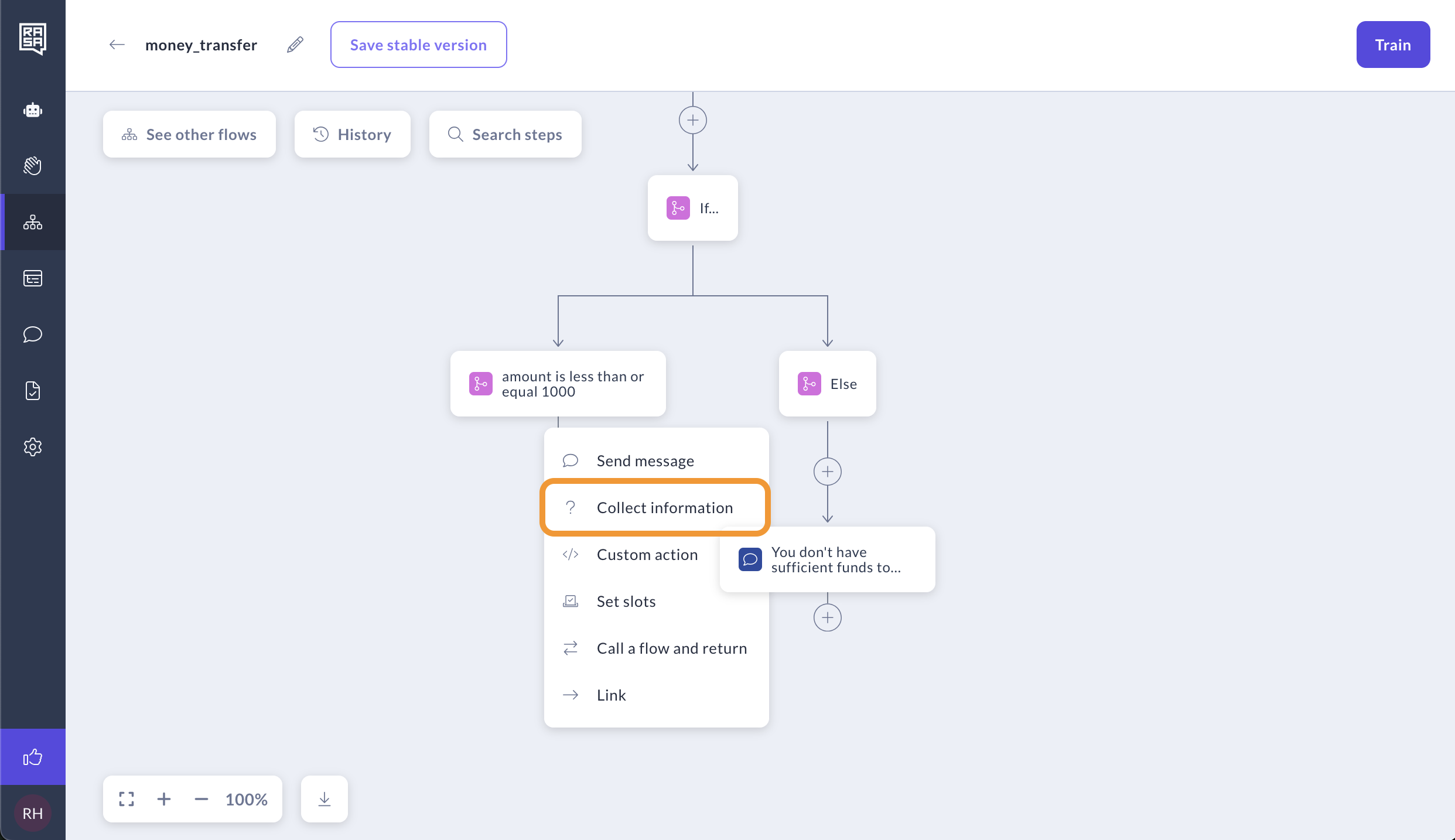
2. Add the description "This step asks the user to confirm the recipient and the transfer amount."
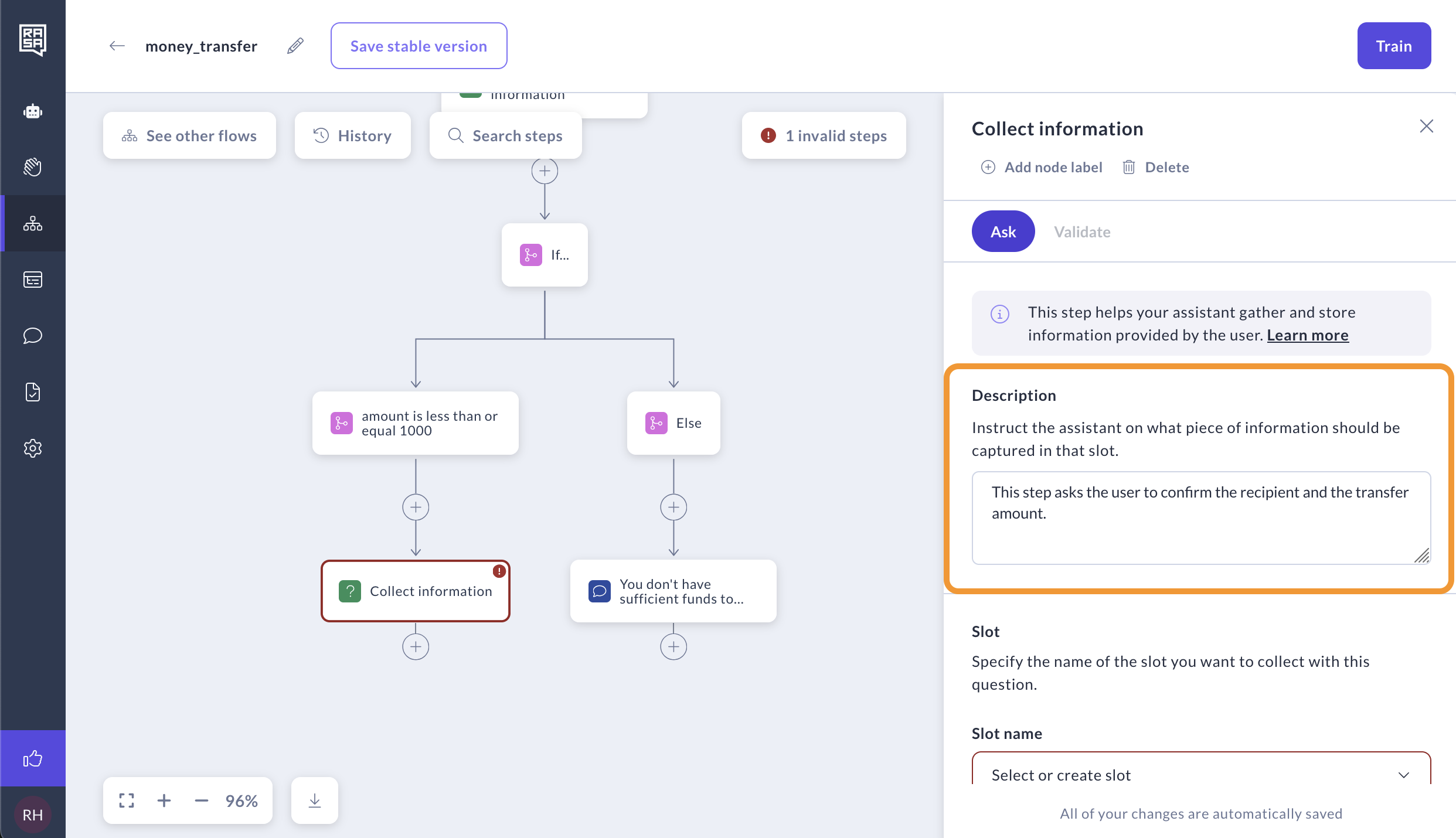
3. Create a slot and call it `final_confirmation`. Since you are asking a Yes or No question, you can store the result as a `Boolean` type. Click "Save".
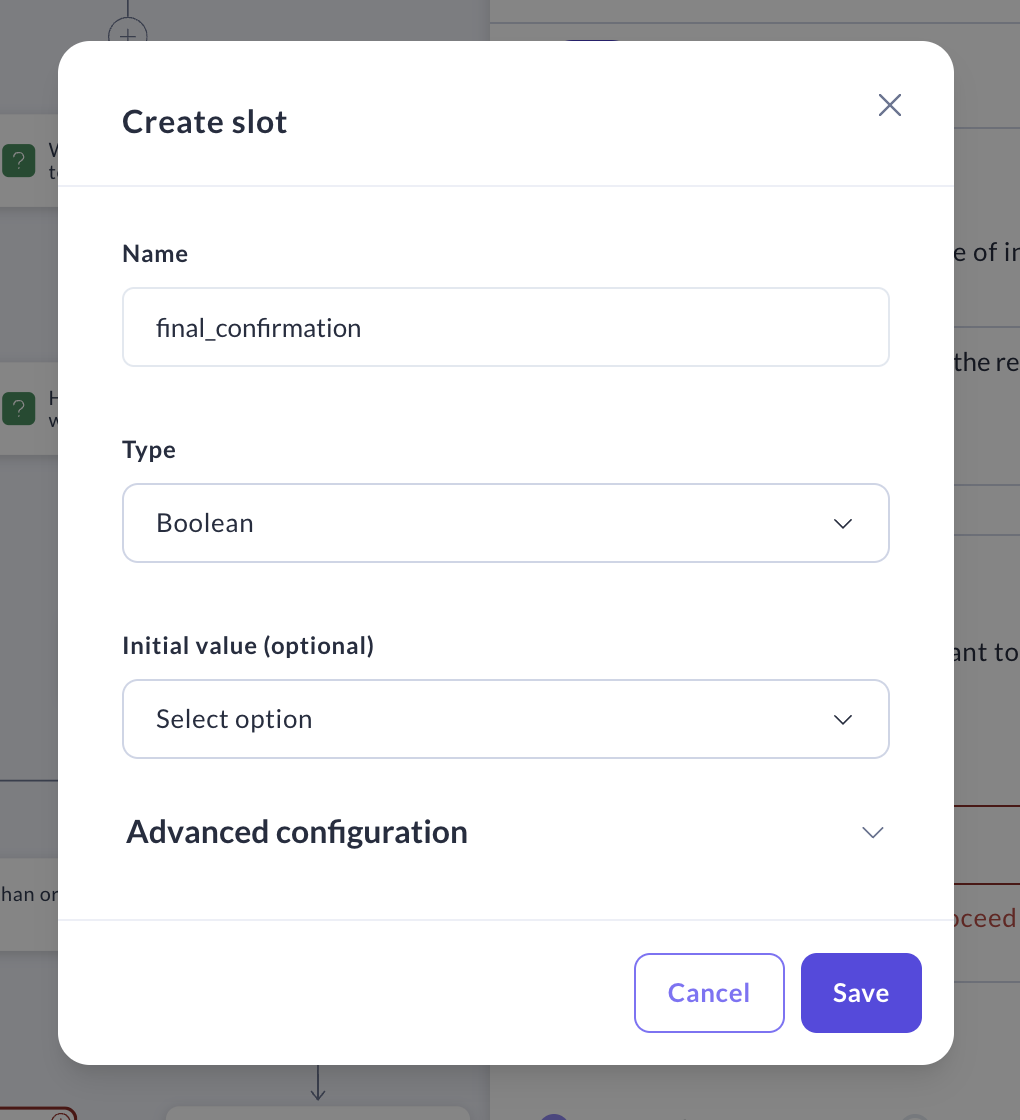
4. Create a new assistant response, which will be automatically named `utter_ask_final_confirmation`. Enter the text "Please confirm that you want to transfer {amount} to {recipient}." We use curly brackets to reference slot values, so the amount and recipient saved from previous questions will be inserted here.
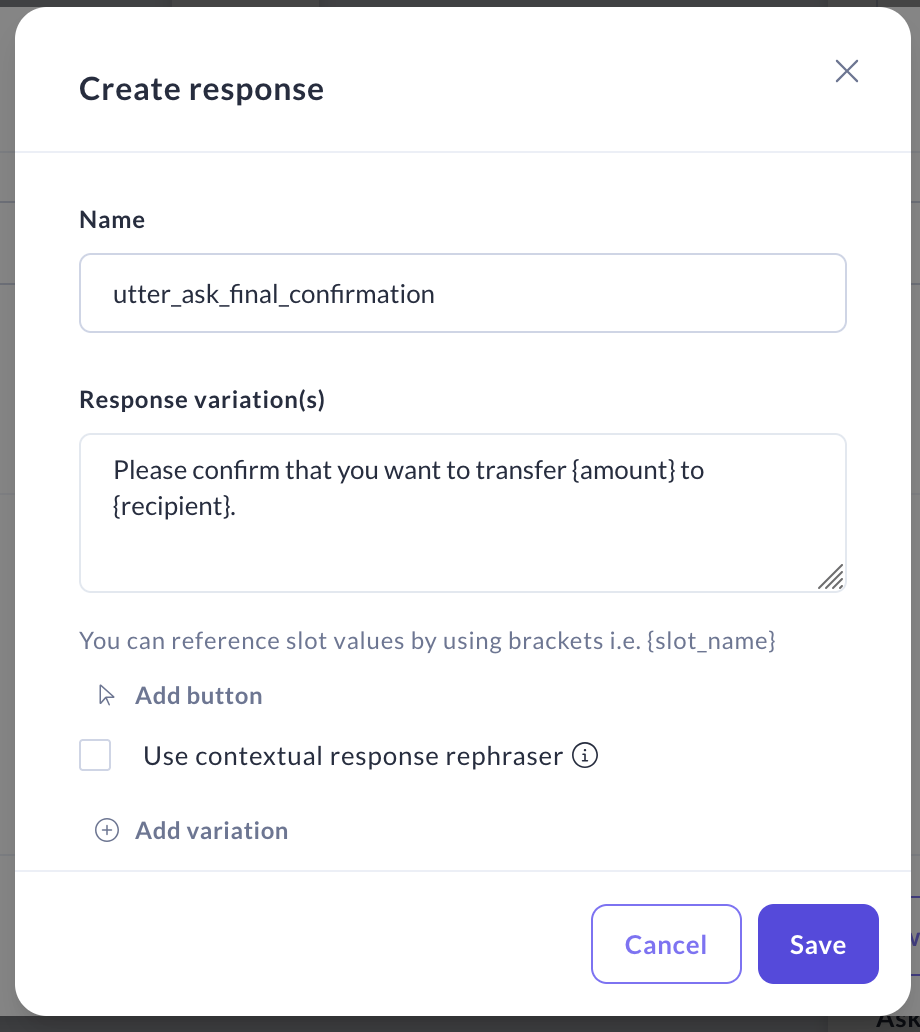
5. Enable "Ask before filling" so that with the next transfer, the assistant will not automatically fill this slot and will ask for confirmation again.
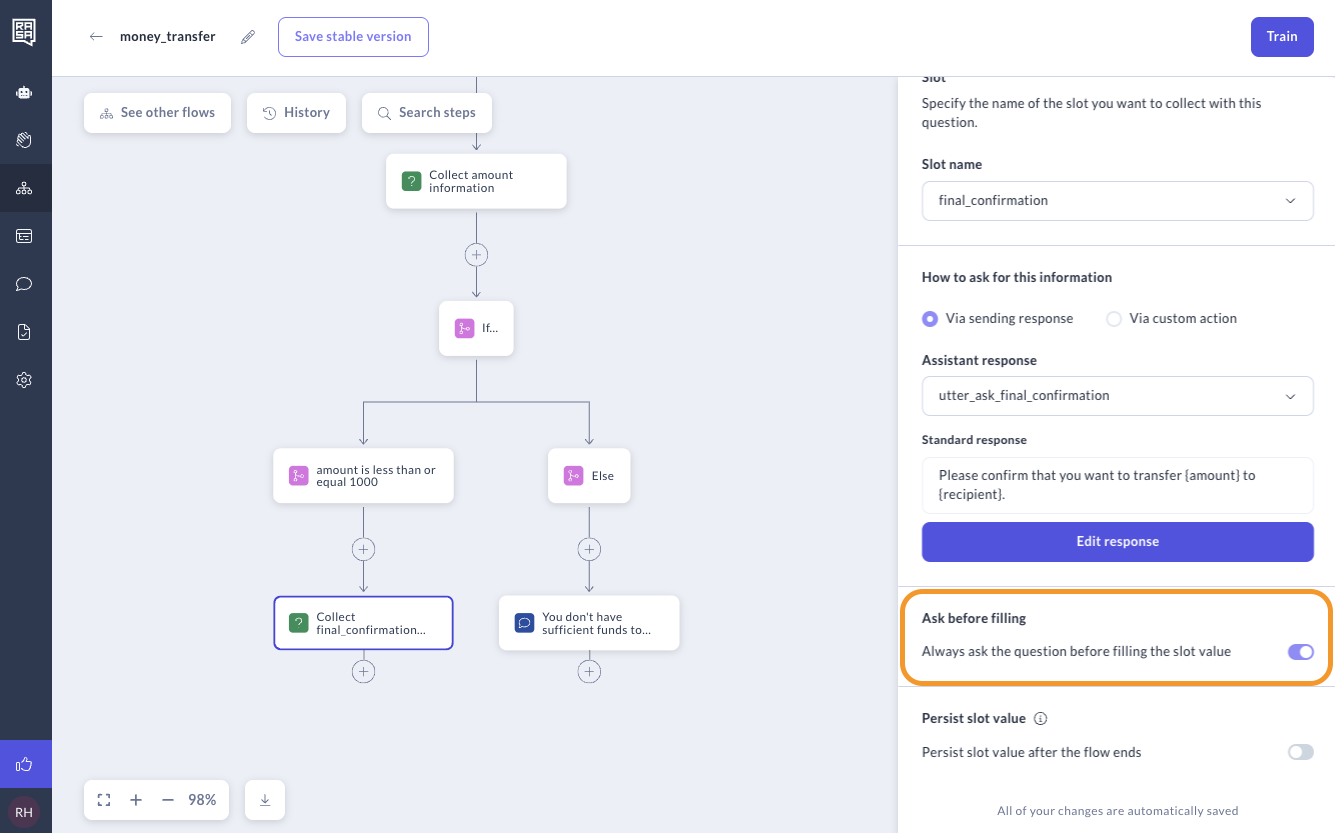
6. After the "Collect information", add the "Logic" step.
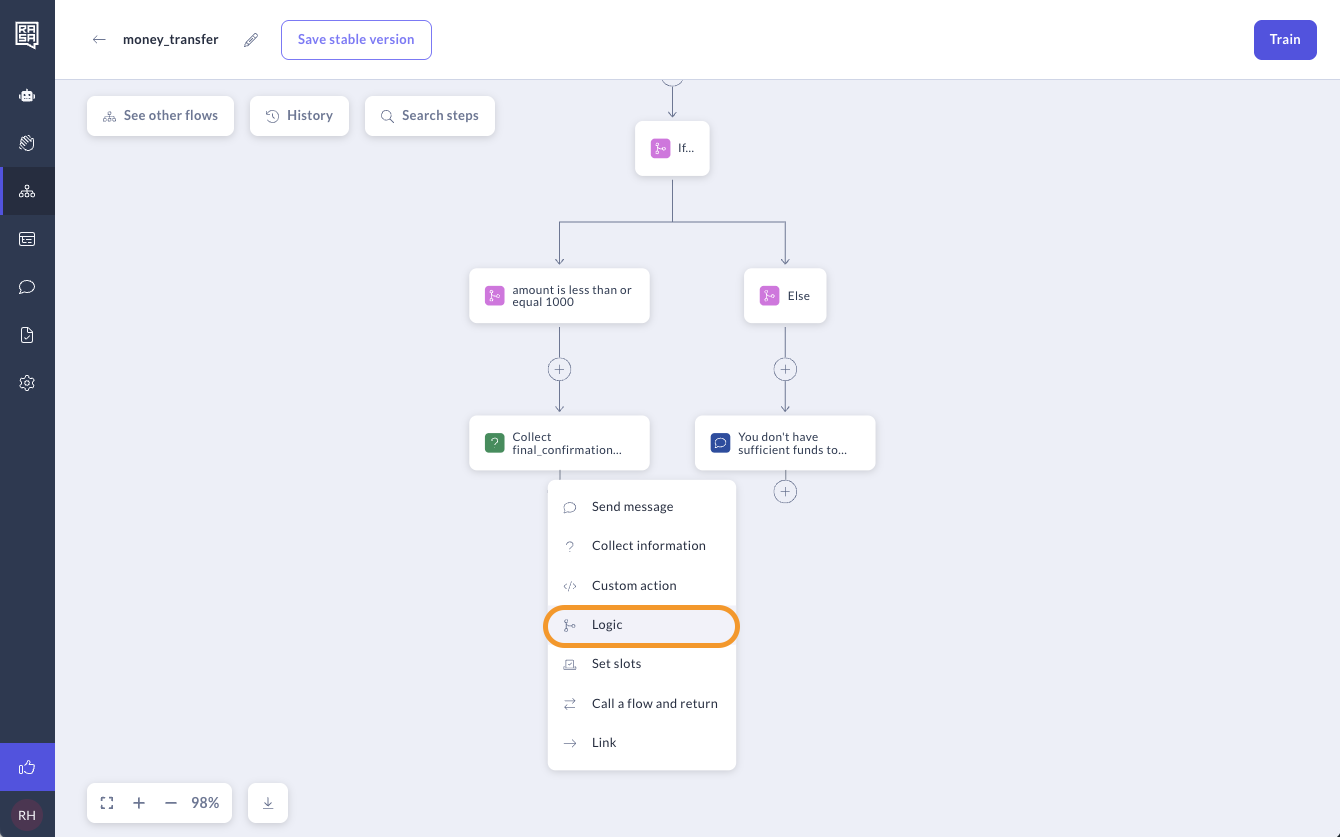
7. For the scenario where the user confirms the request (first logic branch), enter the following details: `final_confirmation` `is` `True`.
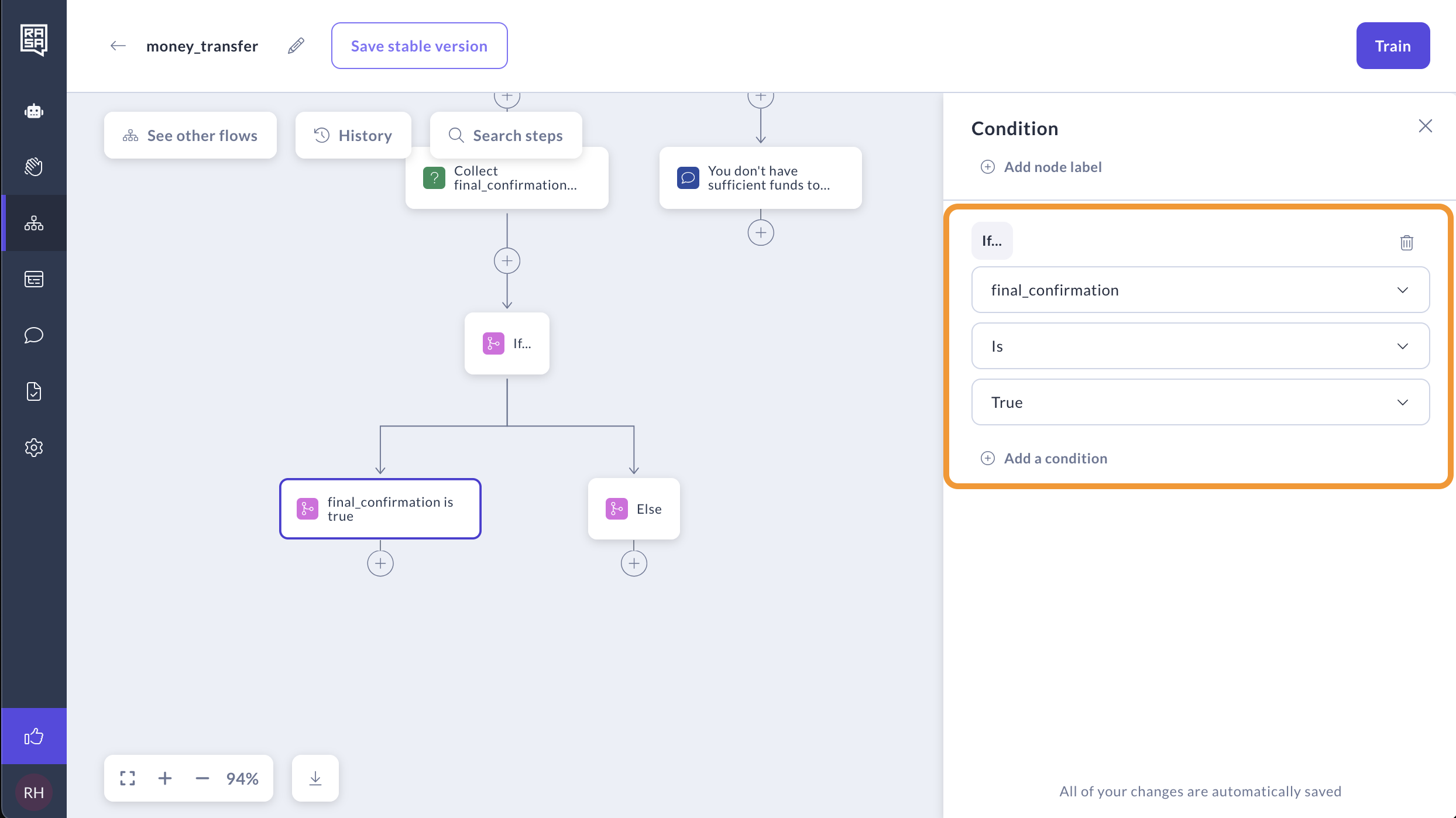
8. The Else branch will automatically cover any other scenarios, such as the user denying the transfer or sending messages outside of the flow's business logic.
##### Displaying success and cancel messages[](#displaying-success-and-cancel-messages "Direct link to Displaying success and cancel messages")
If the user confirms the transaction request, we'll provide a success message.
1. After the `final_confirmation is true` branch, add the "Send message" step.
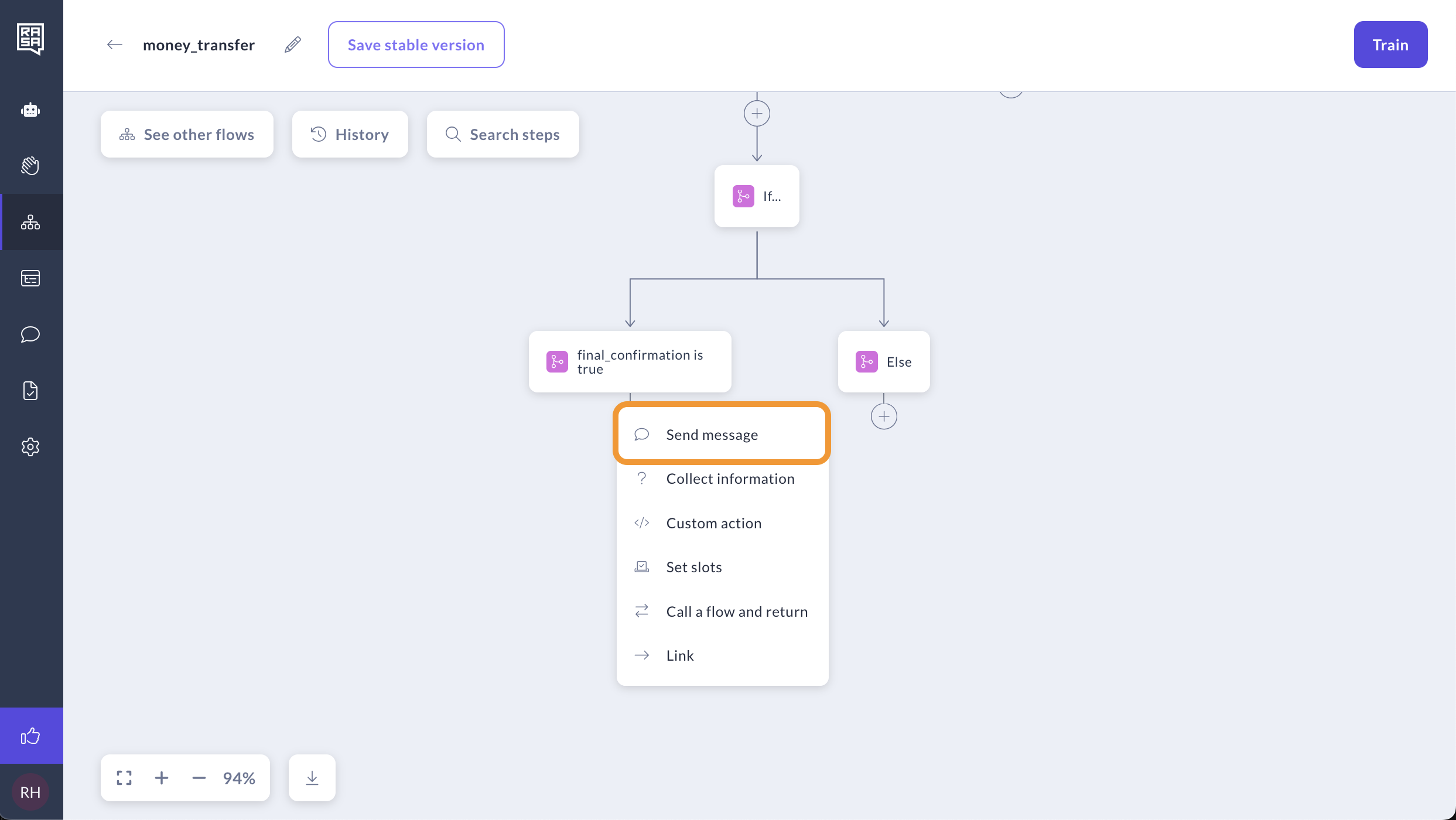
2. Create a new response named `transfer_successful` with the text "All done. {amount} USD has been sent to {recipient}."
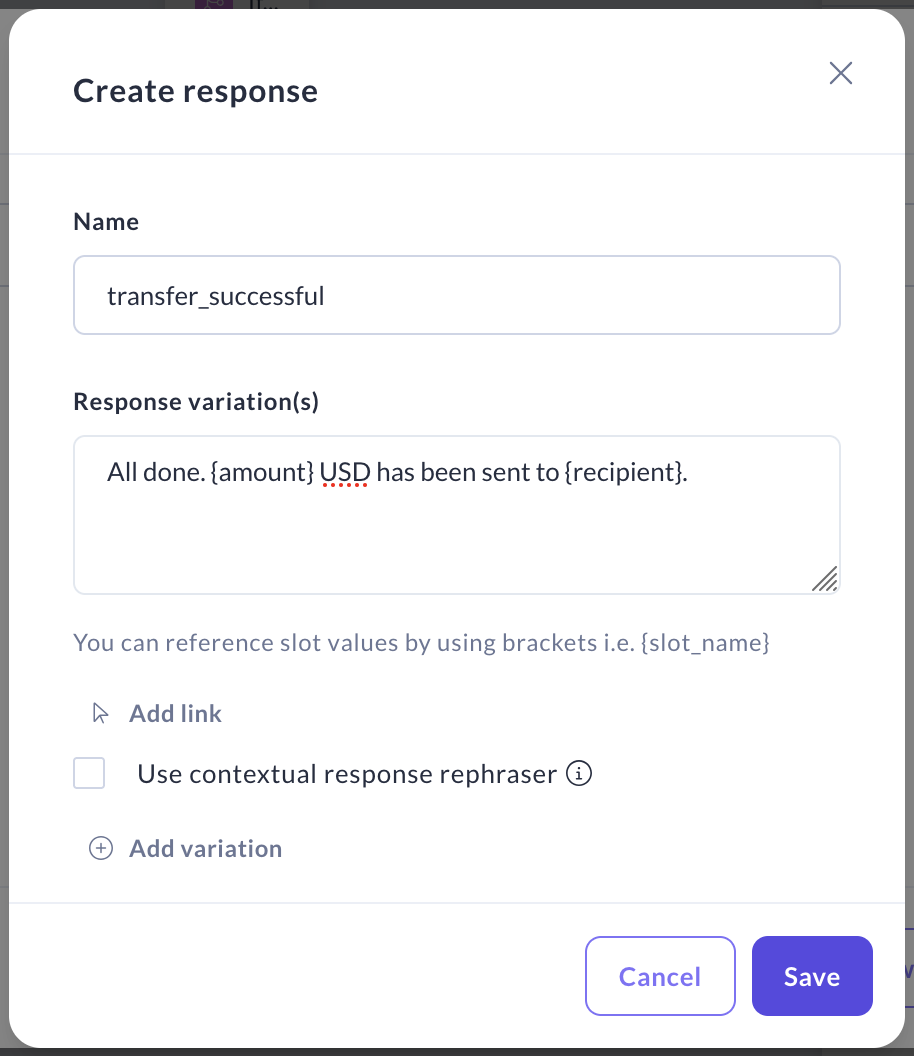
3. For the Else branch, also add the "Send message" step.
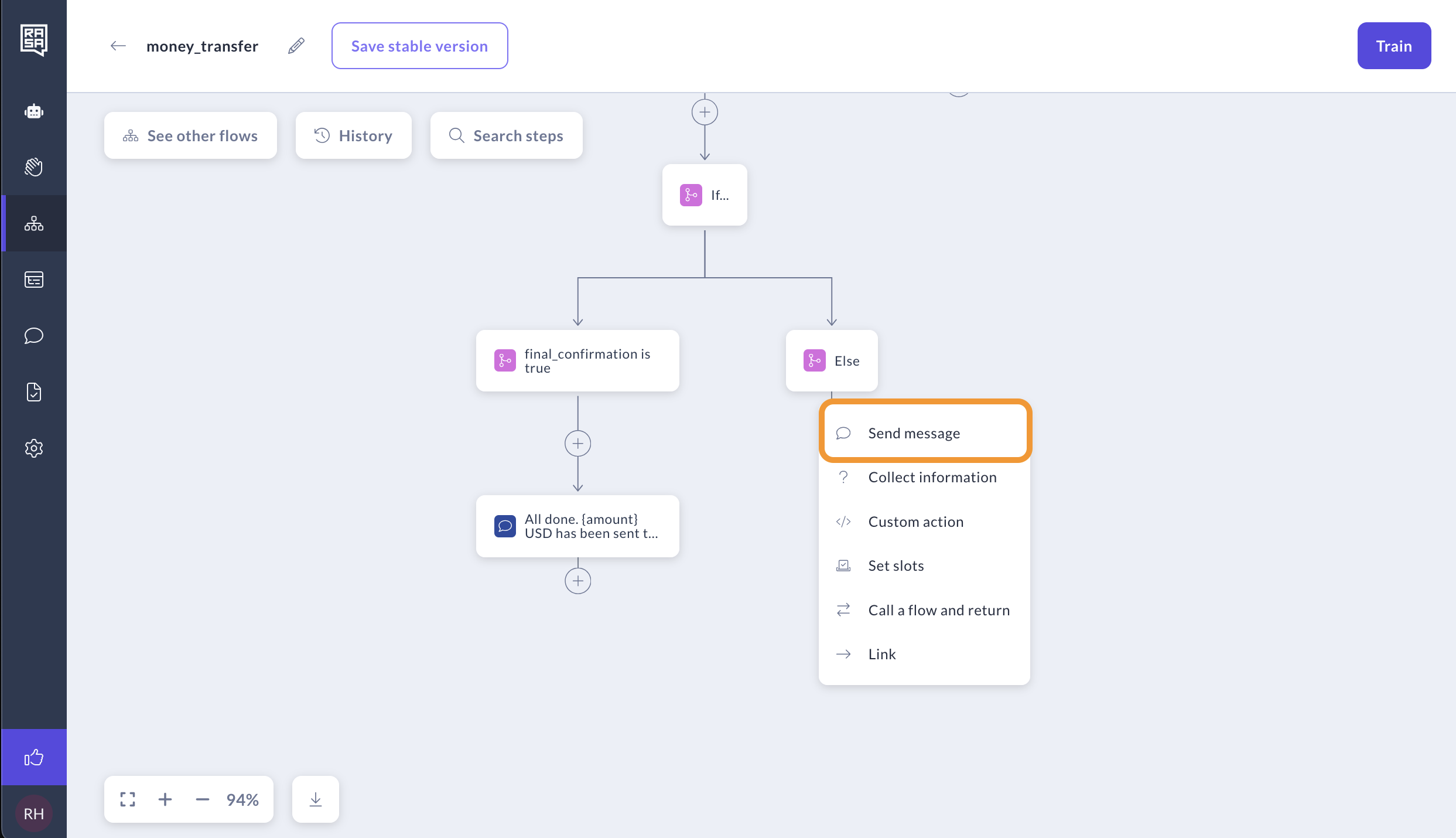
4. Create a new message. Name it `cancel_transfer` and add the text "Transfer canceled". Click "Save".
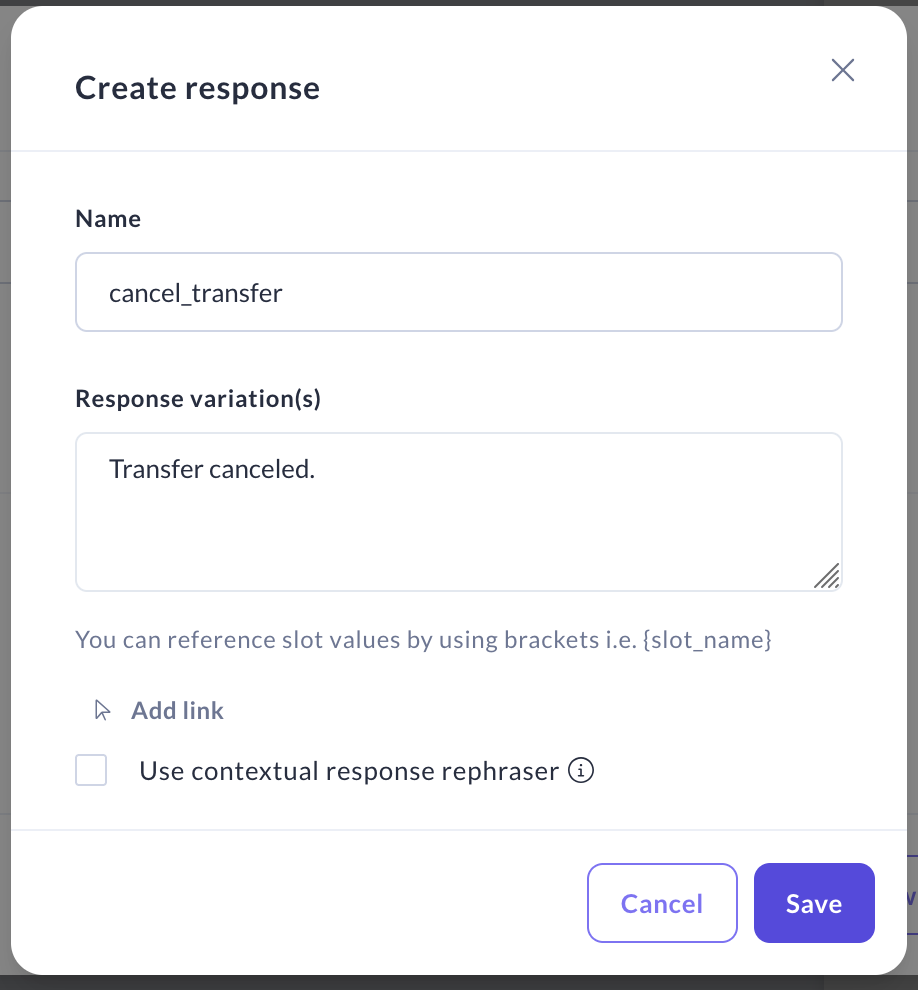
##### Linking to Feedback flow[](#linking-to-feedback-flow "Direct link to Linking to Feedback flow")
Let's now ask users to leave feedback on the assistant's performance. For a complex assistant, this feedback logic can be reused in multiple scenarios, so it makes sense to separate it into a different flow.
1. Add a “Link” step after both “Transfer successful” and “Transfer canceled” messages. This step links flows together by ending the current flow and starting the target one.
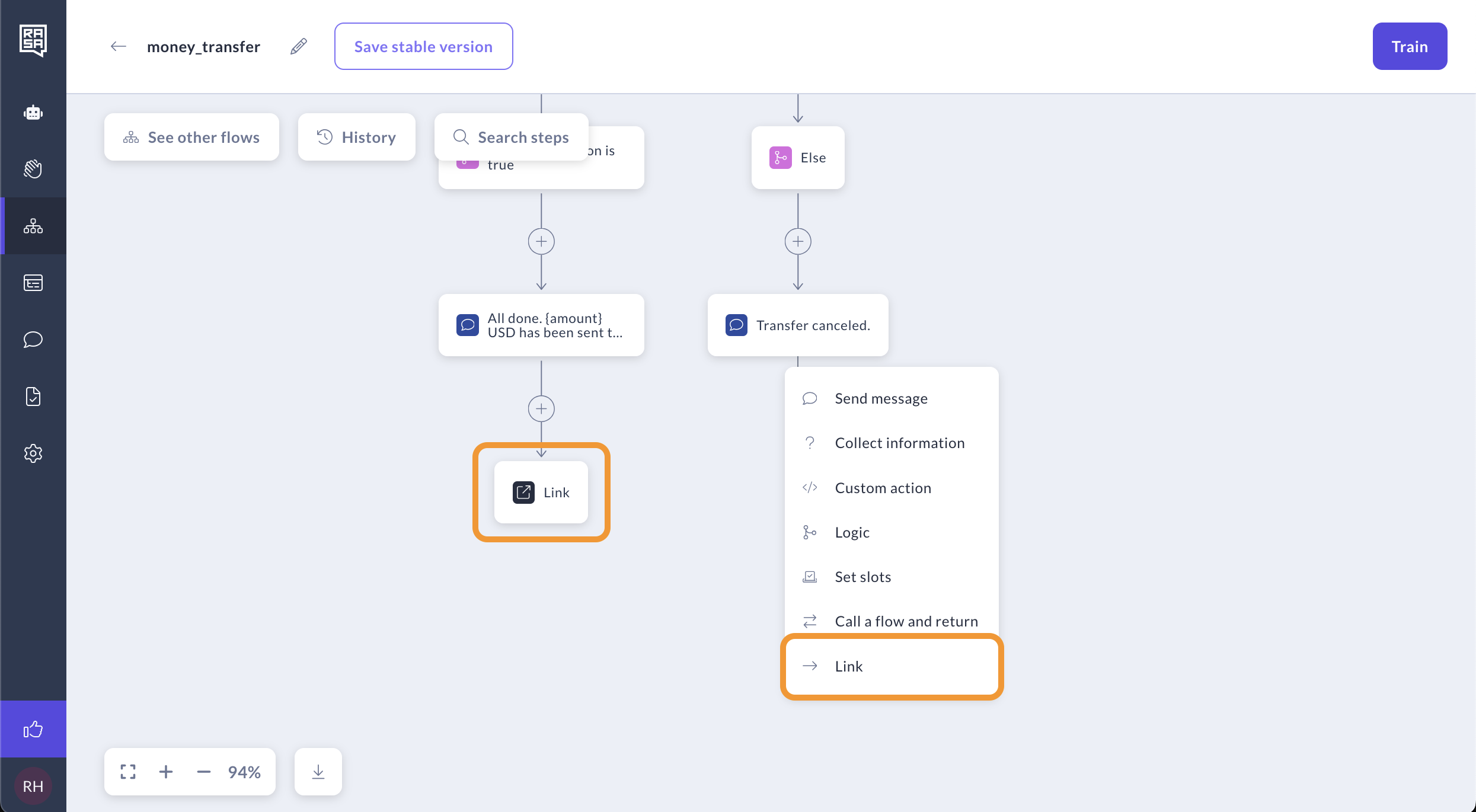
2. In one of those Link steps, select "Create flow" in the dropdown.
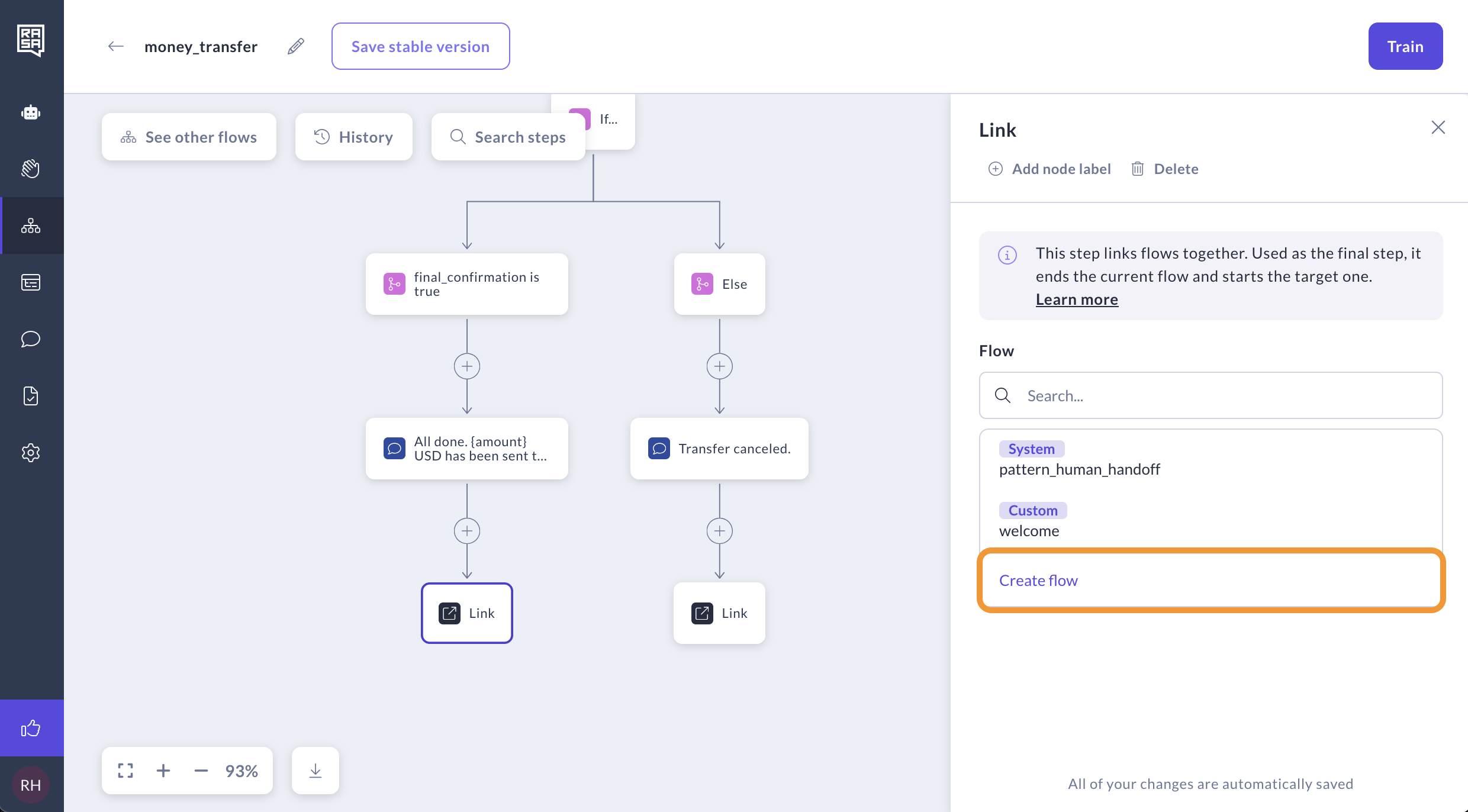
3. Name the new flow `leave_feedback`. Enter the description: "This flow collects user feedback on a scale from 1 to 5."
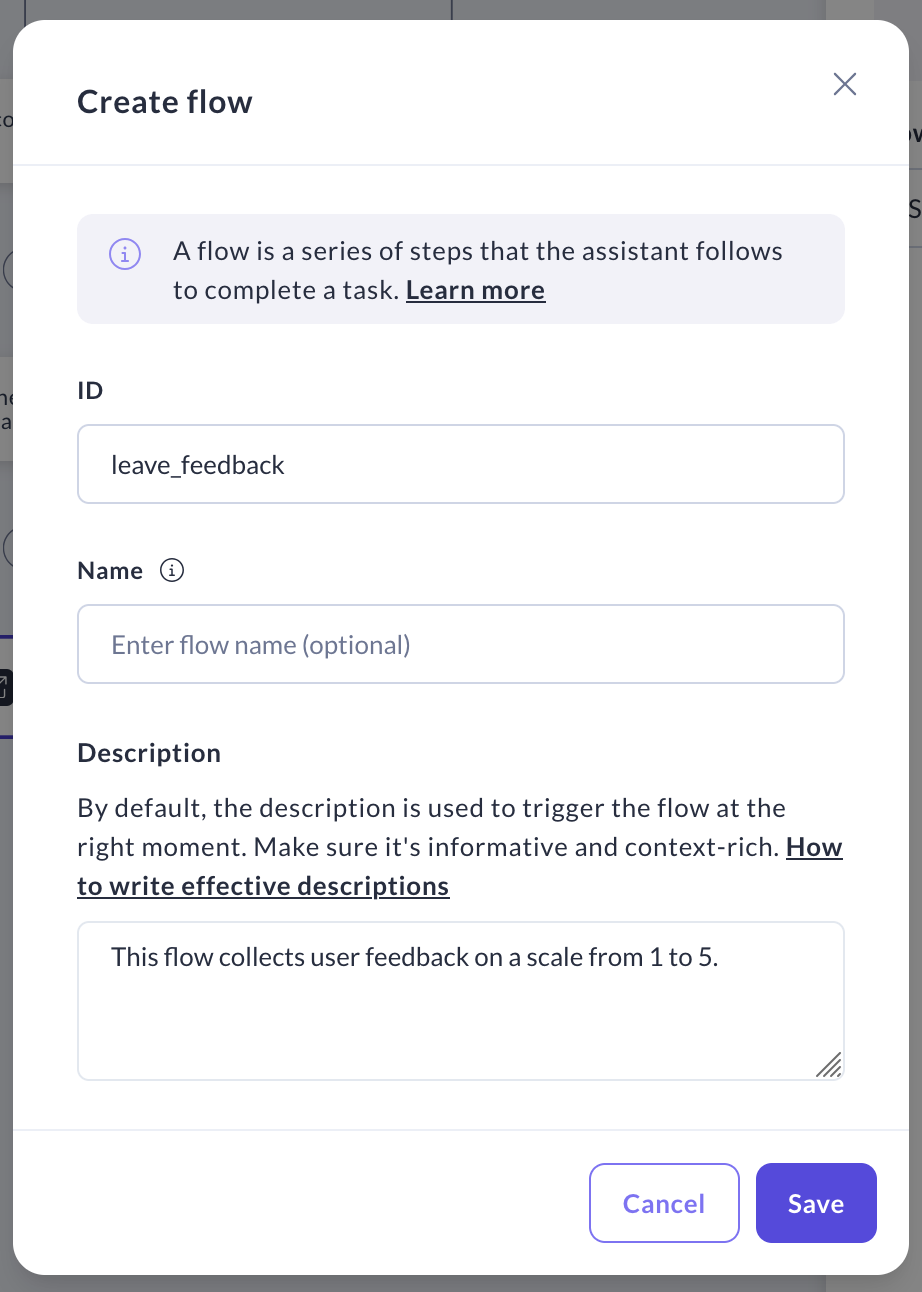
4. Select the same flow in another Link step.
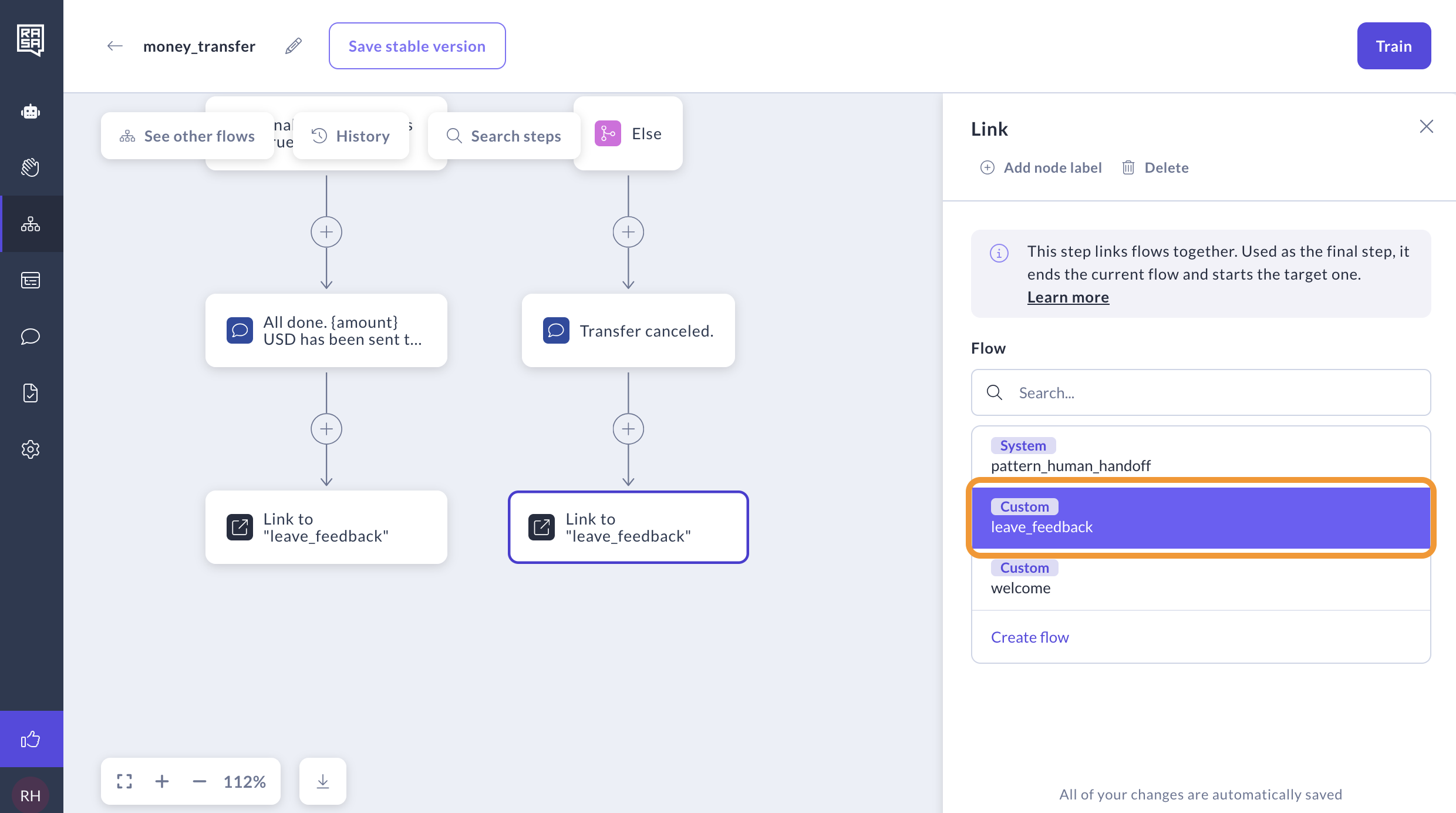
#### Step 4: Building Feedback flow[](#step-4-building-feedback-flow "Direct link to Step 4: Building Feedback flow")
1. Go to the `leave_feedback` flow that you’ve just created. You can do this by clicking on the "Open the flow in a new tab" link.
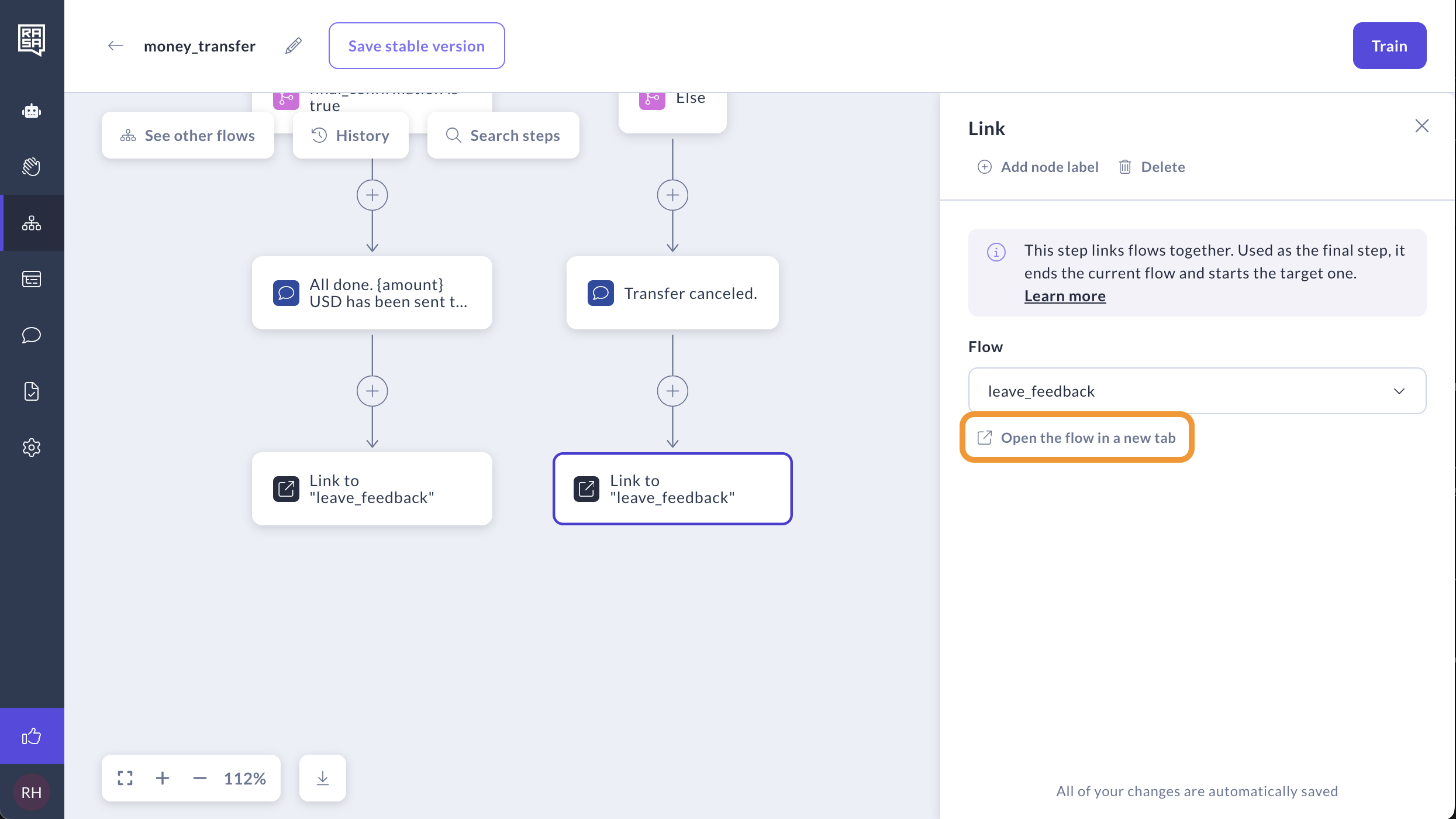
2. We don't want the user to see the feedback flow out of nowhere and want it to only be triggered after particular operations with the assistant. To add this restriction, let's use [Flow guards](https://rasa.com/docs/docs/studio/build/flow-building/trigger-flows/#flow-guards). Flow guards help you start the flow only if specific conditions are met, preventing automatic triggering with CALM or intents. To add a flow guard, select the "Start" step. This is where you configure how the flow can be started. Click on the "Flow guards" section.
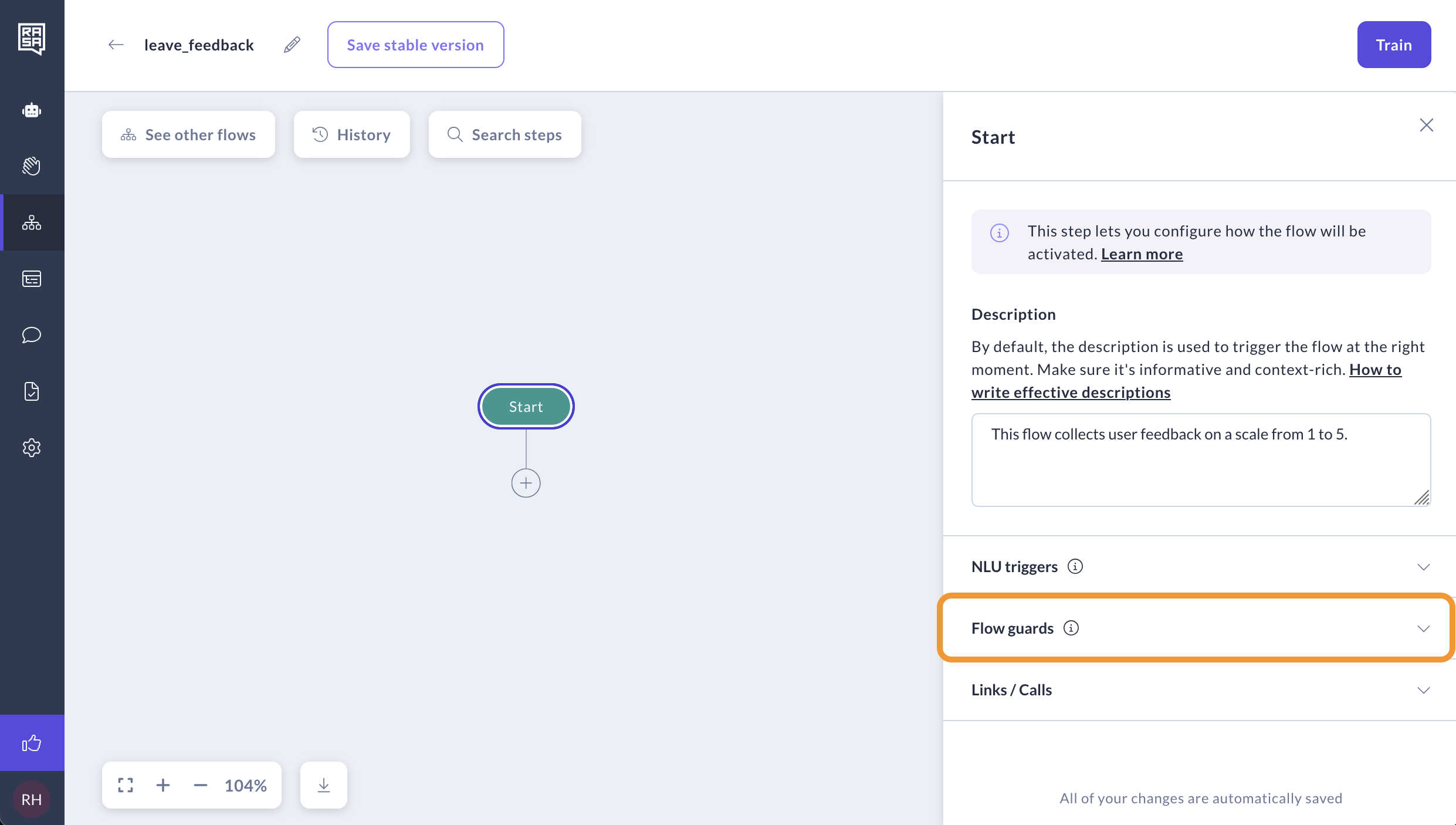
3. Select "Start the flow exclusively via links". This setting will ensure that this flow won't be started automatically by the LLM and will only be initiated after the "Link" step in the `transfer_money` flow.
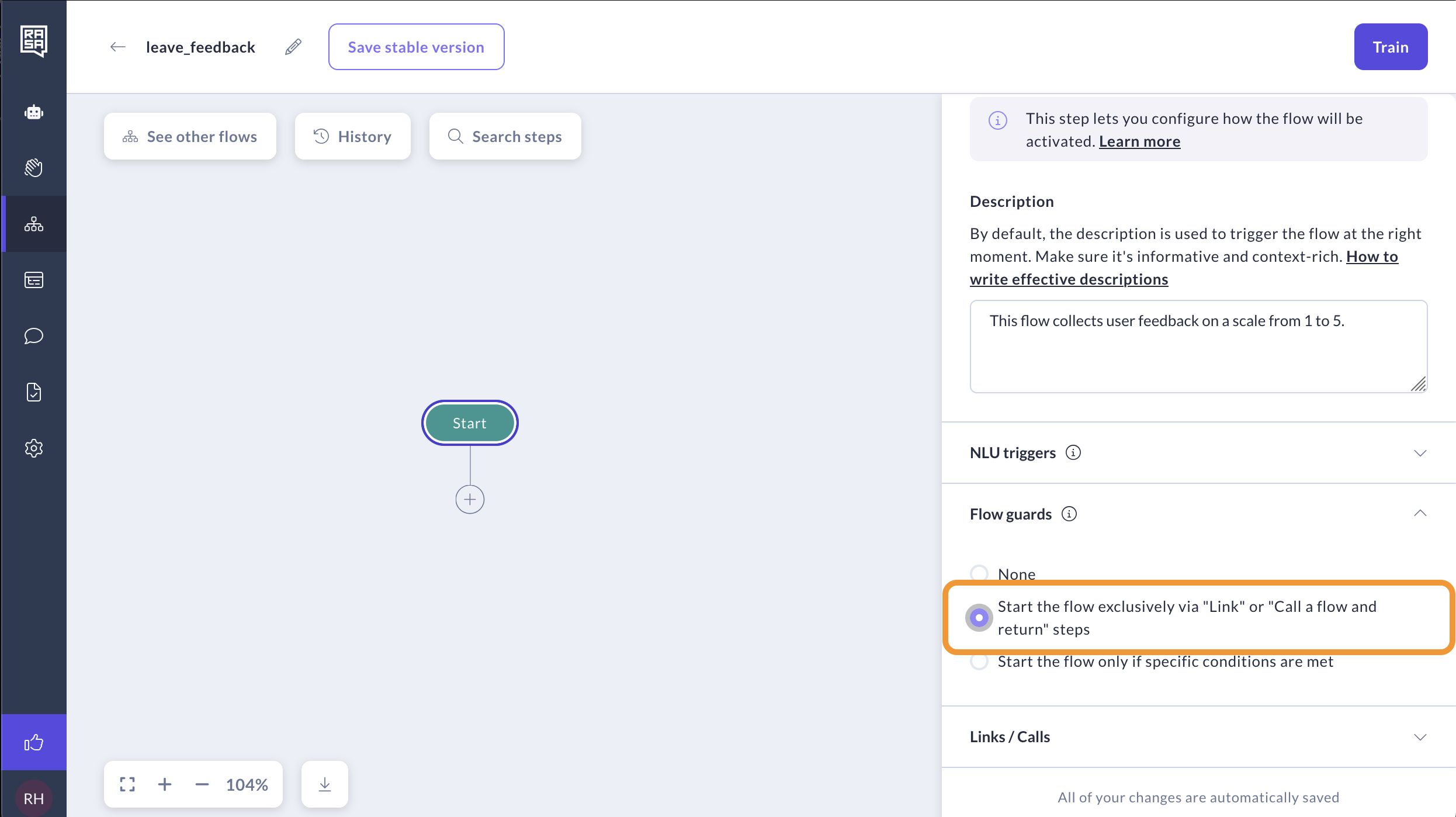
4. Now we can proceed to building the flow. Add the “Collect Information” step to ask the user if they want to leave feedback. Fill it with the following details:
1. Add the step description "Ask user to leave feedback."
2. Create a slot named `feedback` with a `Boolean` type, as it's a yes or No question.
3. Add an assistant's message with the name `utter_ask_feedback` and the text "Do you want to leave feedback?"
4. The result should look like this:
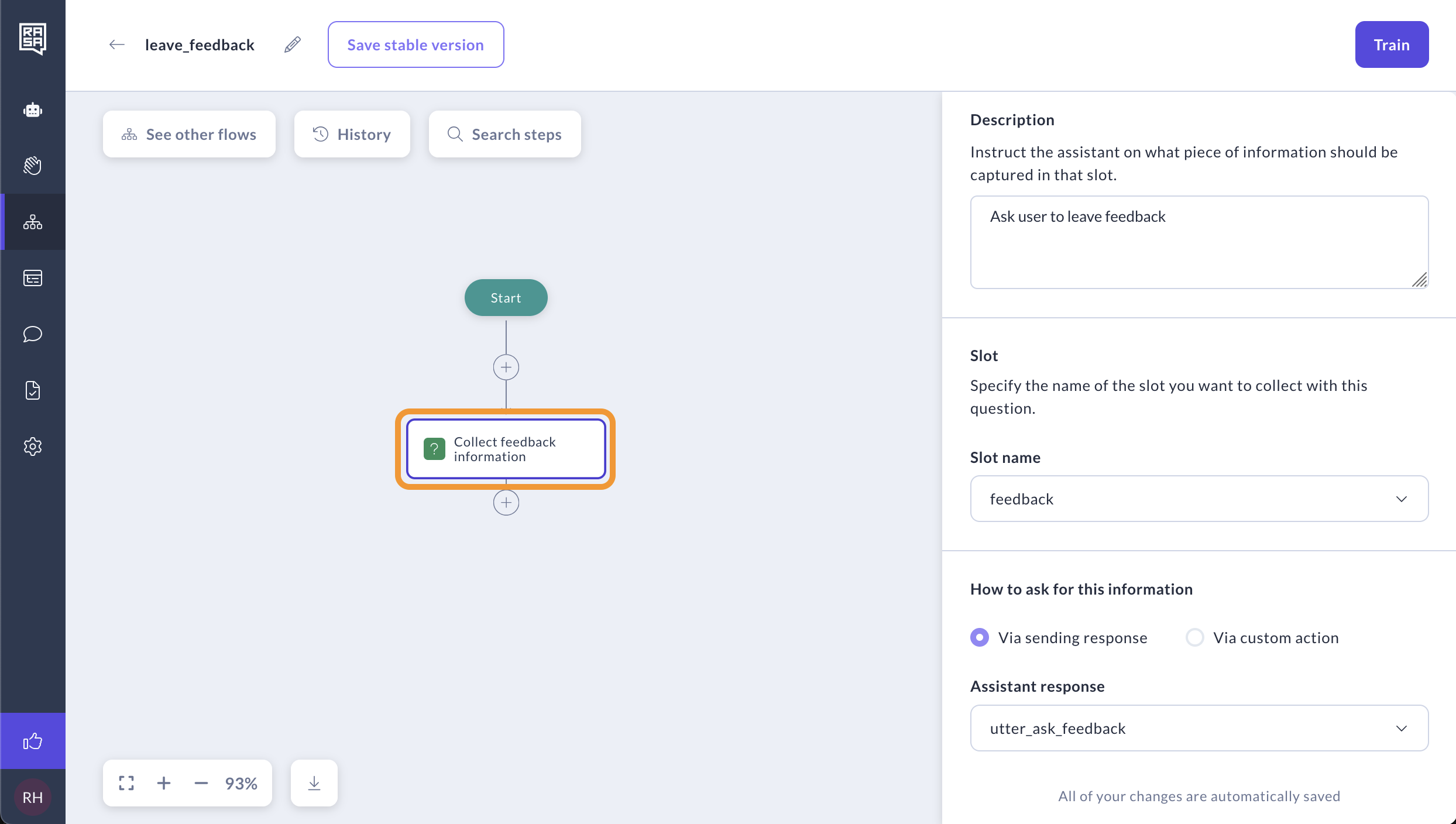
5. Following this question, insert the "Logic" step, and set the first logic branch to `feedback` `is` `true`. If the user is willing to leave feedback, the conversation will follow this branch.
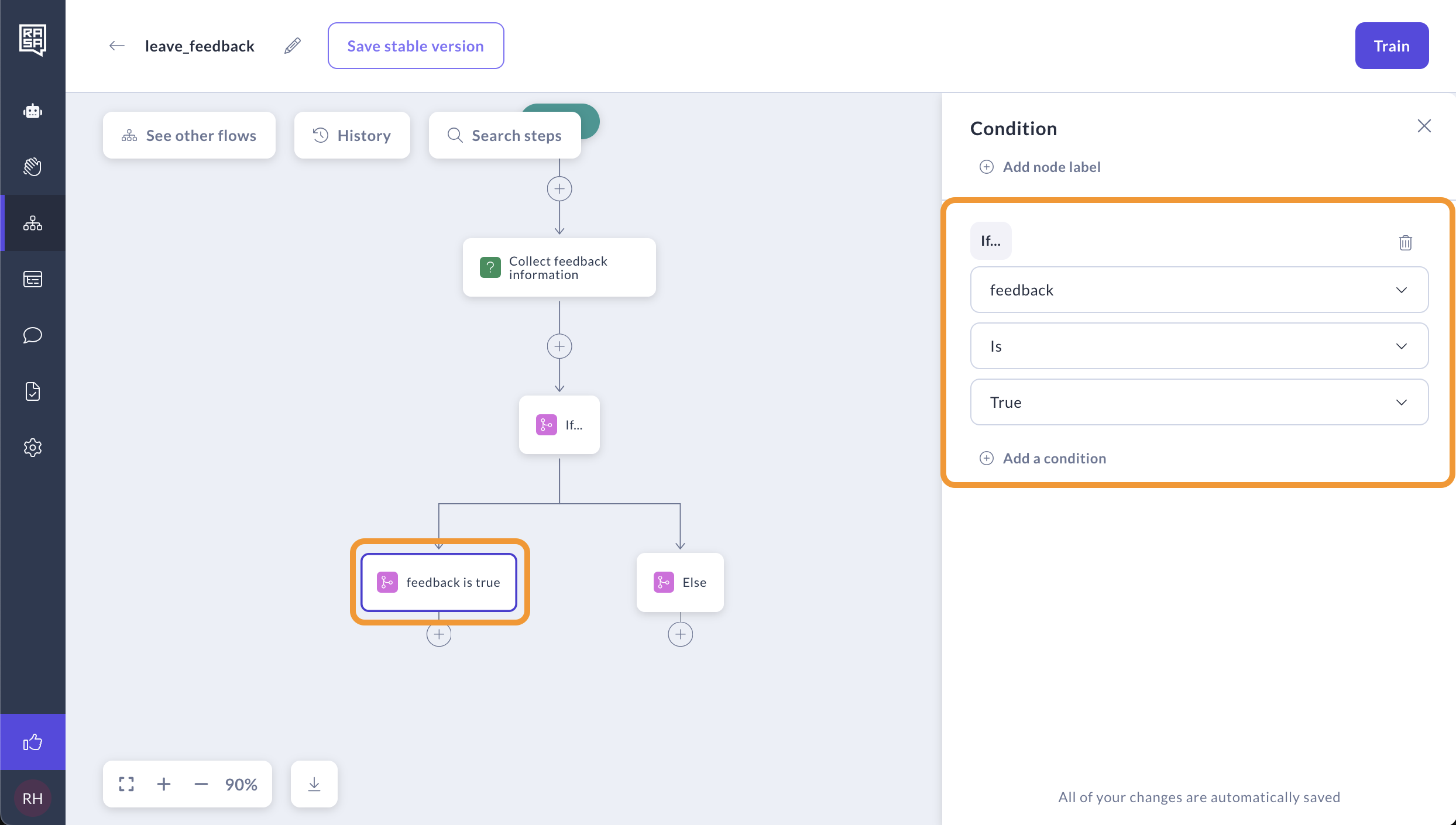
6. After the Else branch — the case when the user doesn’t want to leave feedback — add the "Message" step. Name the new message `goodbye` and add the text "Thank you and have a great day!"
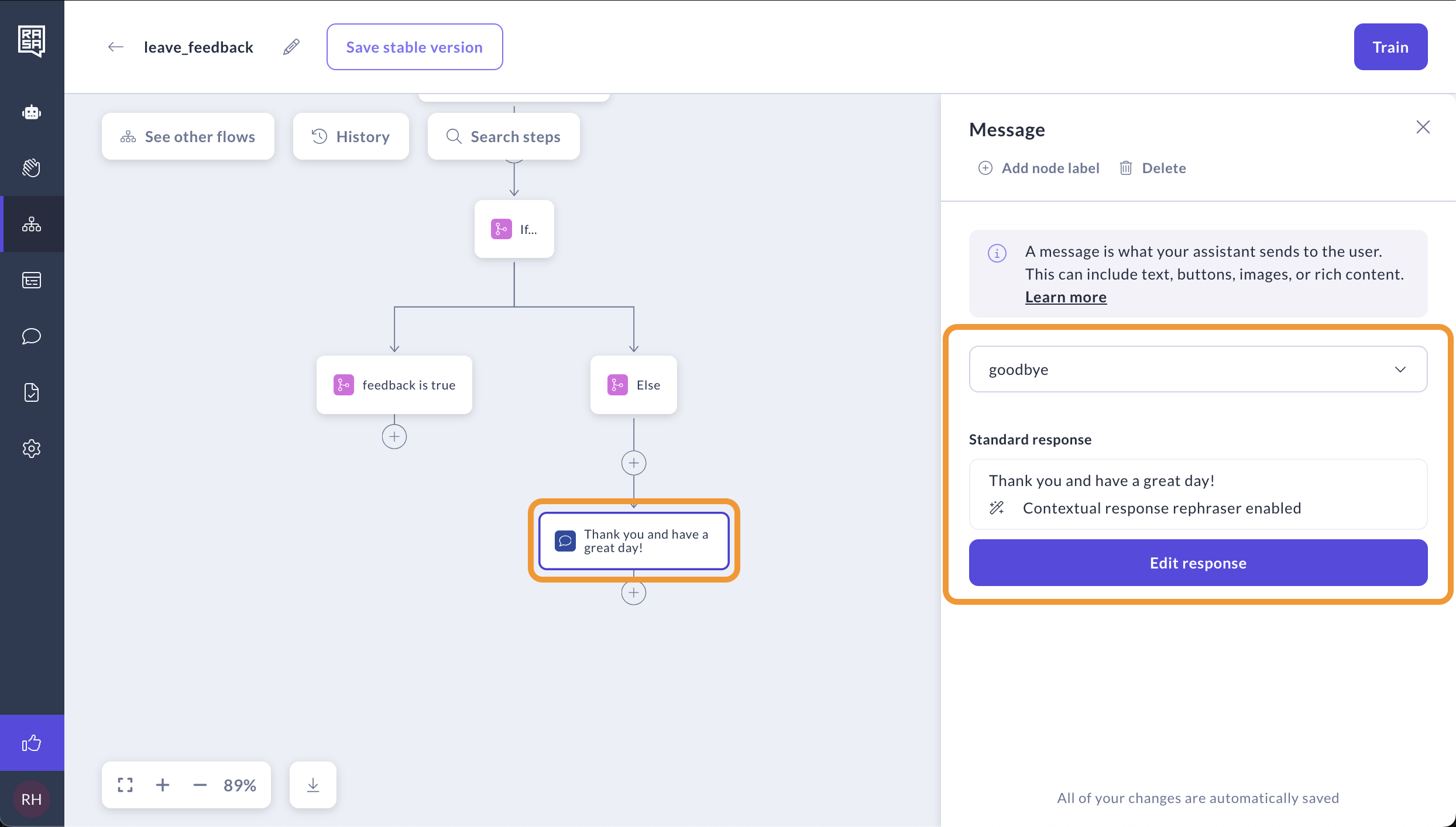
7. After `feedback` `is` `true` branch, add the “Collect information” step to collect feedback from the users. Fill it with the following details:
1. Add the step description "Ask users to rate the assistant's performance."
2. Create a slot named `rating` with a `float` type, as we'll accept the number from 1 to 5.
3. Add an assistant's message with the name `utter_ask_rating` and the text "How would you rate my performance from 1 to 5?" Optionally you can add buttons so user could easily pick the answer.
4. The result should look like this:
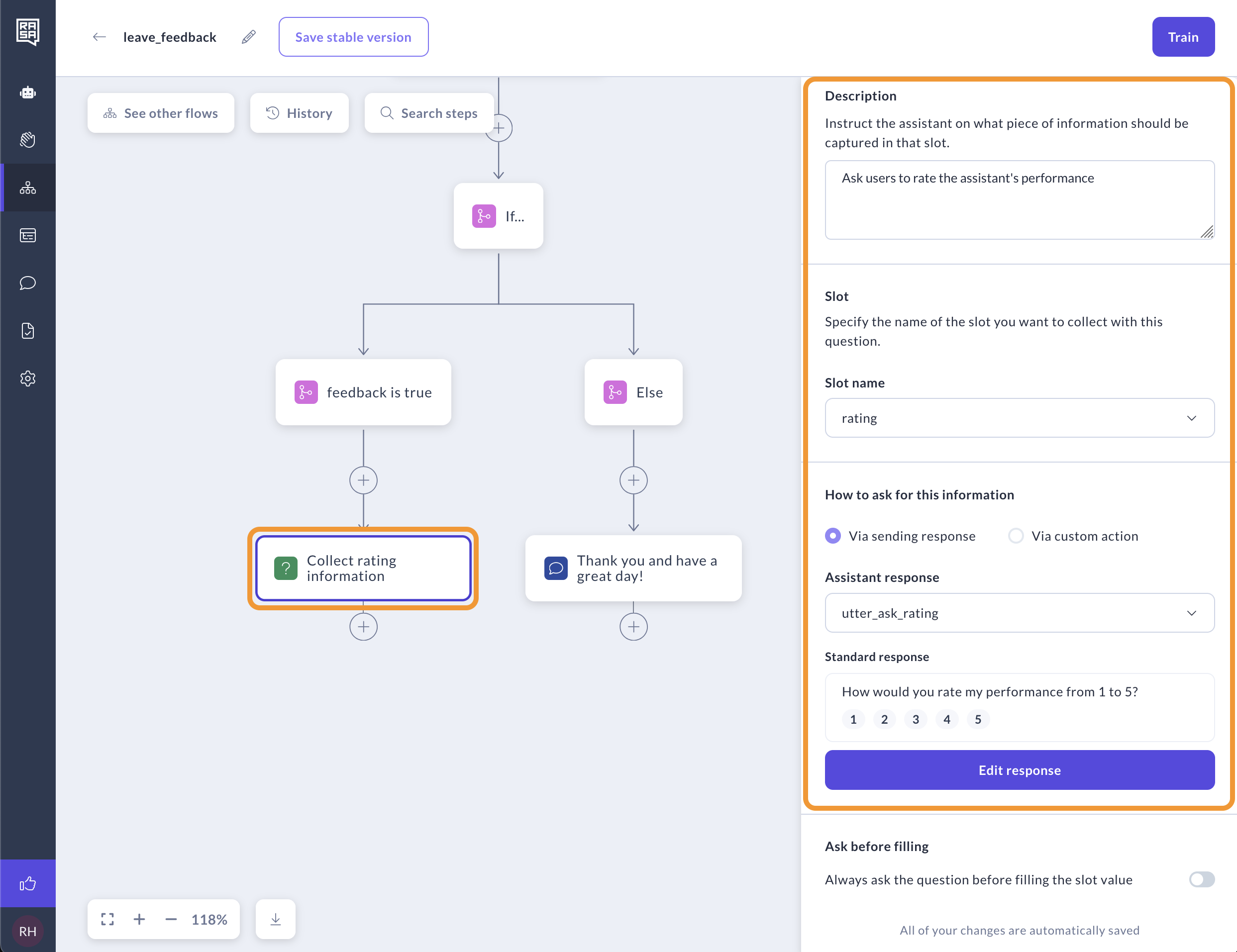
Your simple assistant is ready!
#### Step 5: Training and testing the assistant[](#step-5-training-and-testing-the-assistant "Direct link to Step 5: Training and testing the assistant")
Training and testing a model are fundamental steps in developing an assistant. Studio users can directly train their assistant within the user interface. To train your assistant:
1. Click the "Train" button.
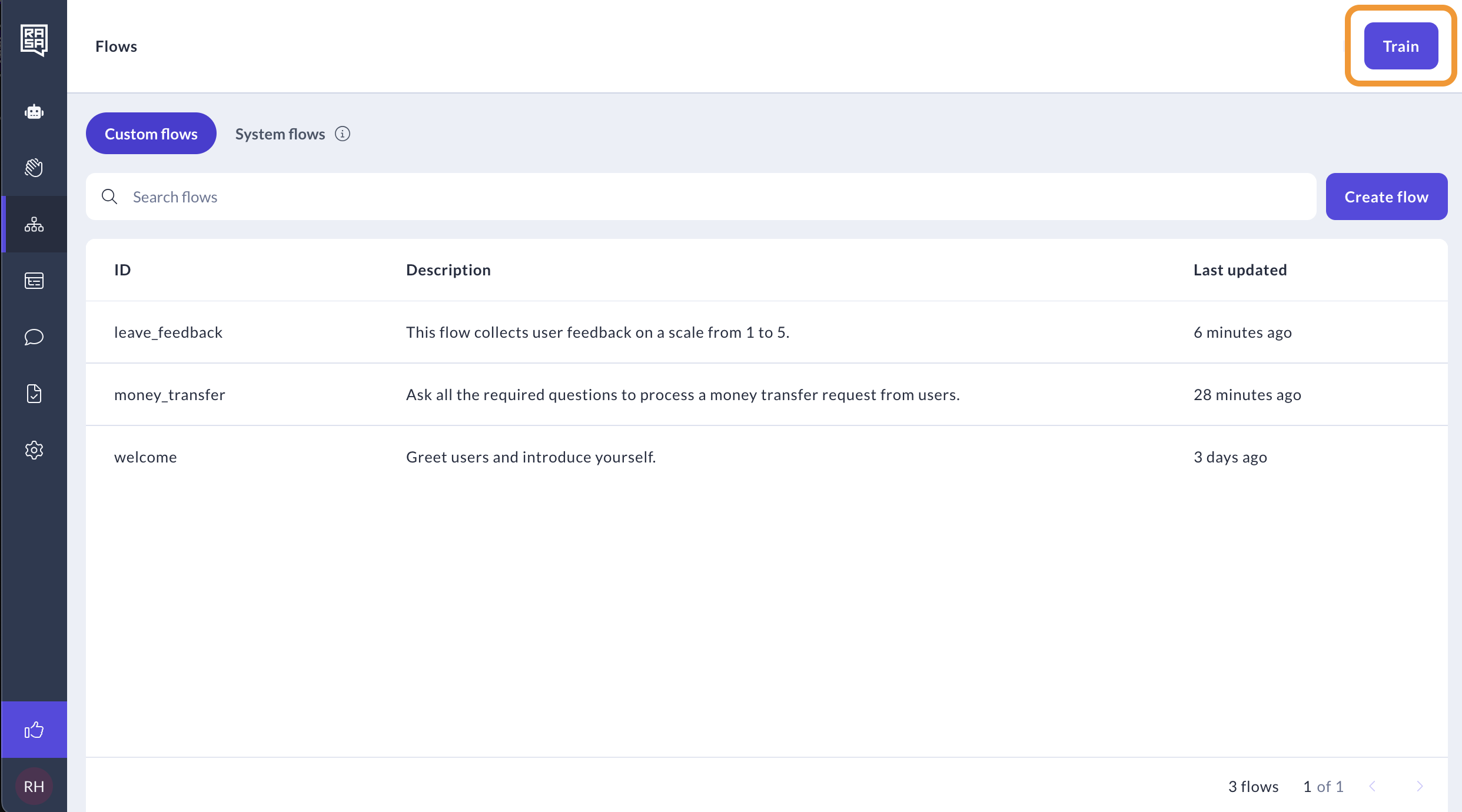
2. In the training panel, select the flows you want to include in the training. Select all flows, then click the "Start training" button.
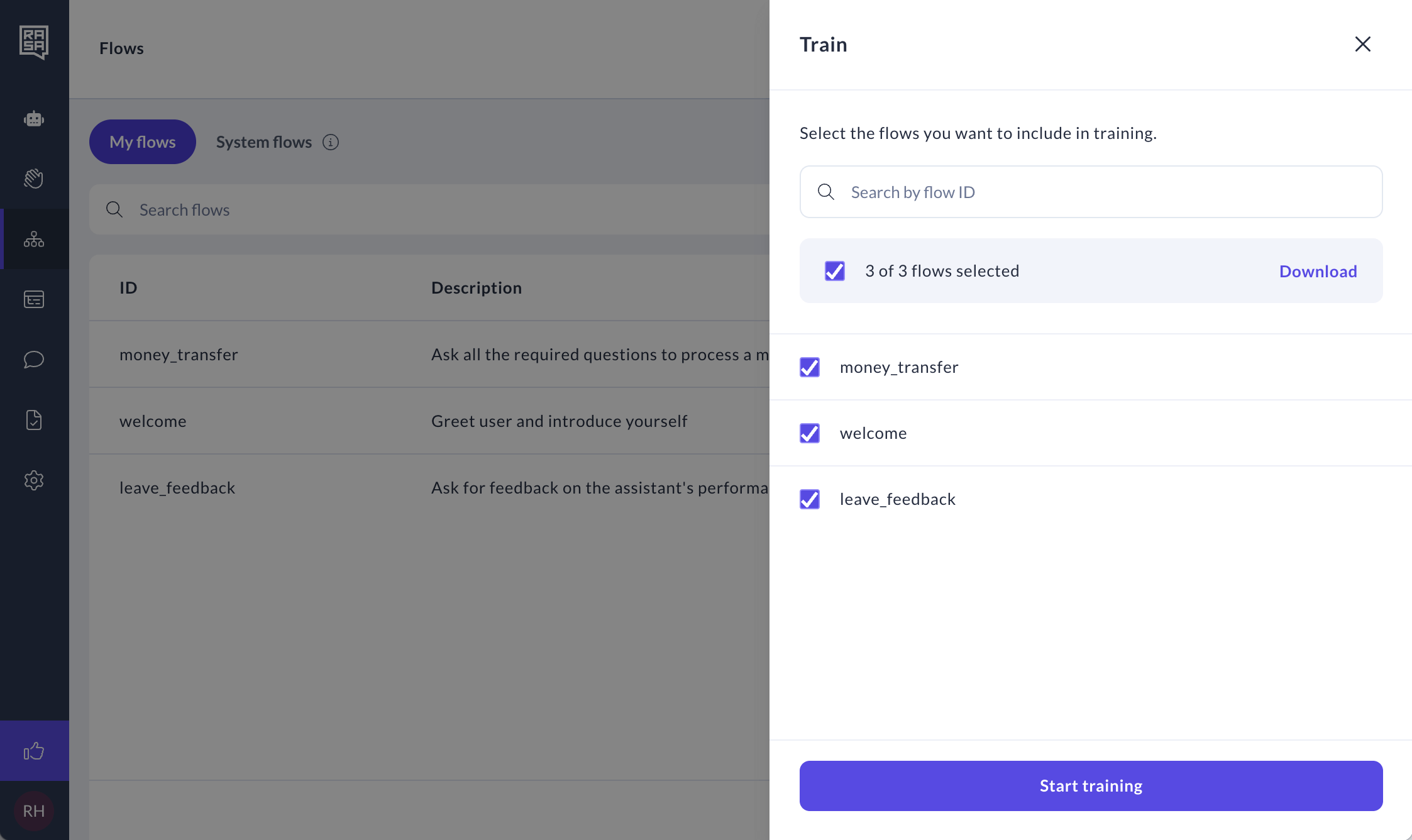
3. First, Studio will validate all your flows. If there are errors that could lead to training failures, you will see the "Unable to train the assistant" message. You can navigate through the list of flows with errors by clicking on their names. Once all errors are corrected, you can try to train the assistant again.
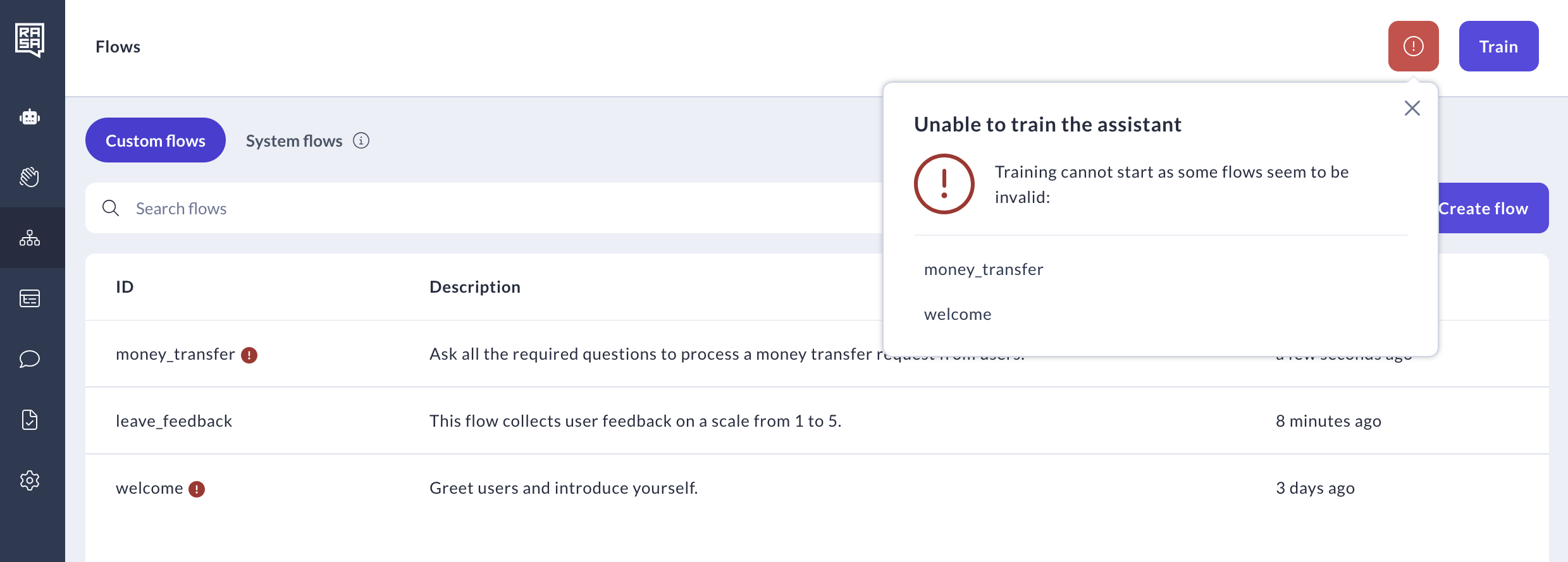
4. Once the training has started, you will see the following message:
5. If the training process encounters an issue or fails, the following message will appear. You can download training log and investigate the reason for the failure.
6. In the event of a successful model training, you will see the green tick and the following message:
7. After successful training, go to "Try your assistant" page to test how well the assistant navigates between your flows and provides the correct answers.
8. Optionally, enable "Inspector mode" to access detailed event information and debugging tools.
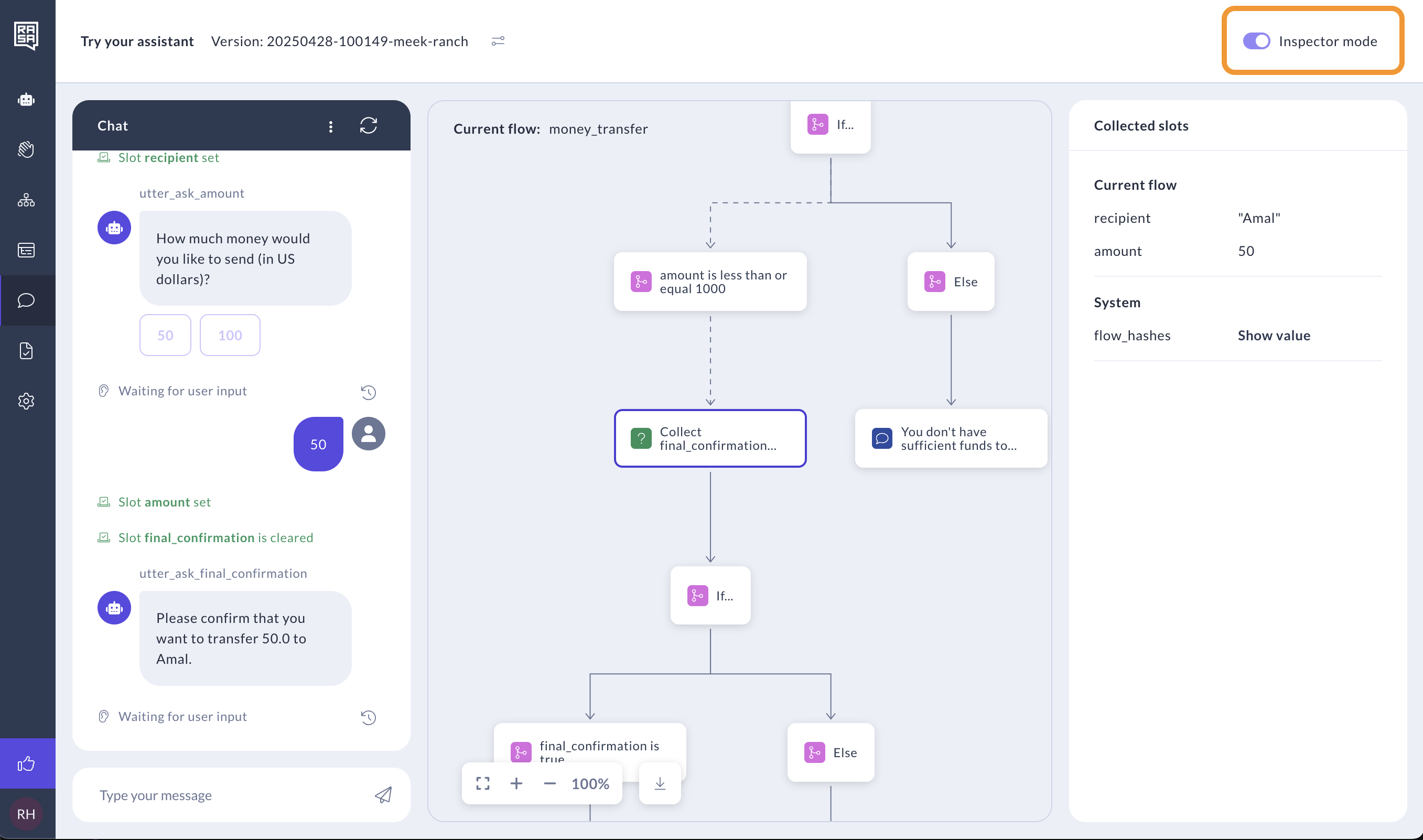
#### Step 6 \[Advanced]: Adding a custom action[](#step-6-advanced-adding-a-custom-action "Direct link to Step 6 [Advanced]: Adding a custom action")
A Custom action step can execute any code you desire, including API calls, database queries, and more. Whether it's turning on the lights, adding an event to a calendar, checking a user's bank balance, or anything else you can imagine, custom actions offer extensive flexibility.
As of now, custom actions can only be implemented outside of Studio. For details on how to implement a custom action, please refer to [the SDK Action Server documentation](https://rasa.com/docs/docs/reference/integrations/action-server/running-action-server/). Any custom action that you want to use in flows should be added into the actions section of your [domain](https://rasa.com/docs/docs/reference/config/domain/).
In this part of the tutorial, we are going to replace the previously created amount validation logic with a custom action.
1. Return to the `money_transfer` flow.
2. After the question about how much money you would like to transfer and before the logic branch, add a "Custom action" step.
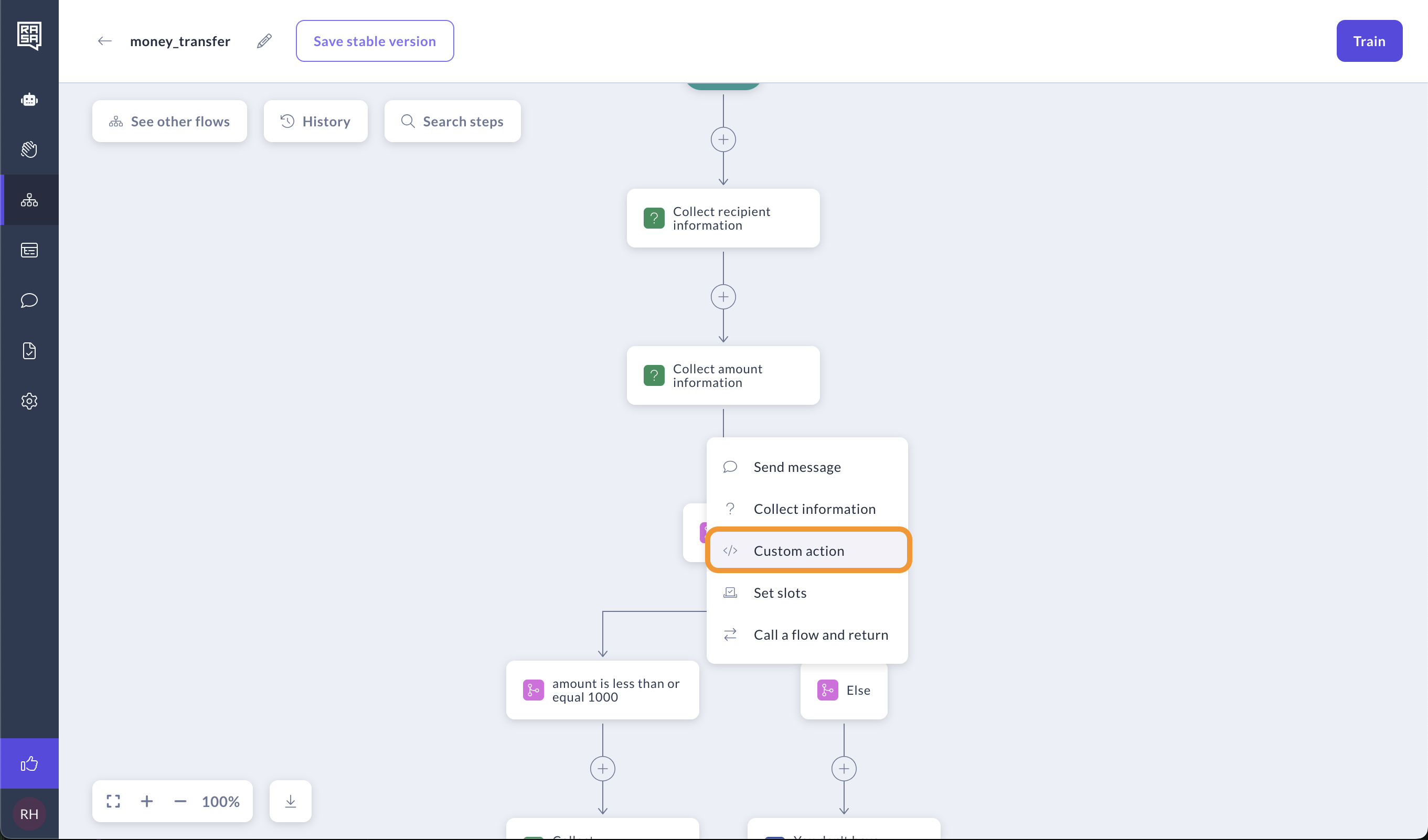
3. Open the custom action dropdown and click "Create custom action."
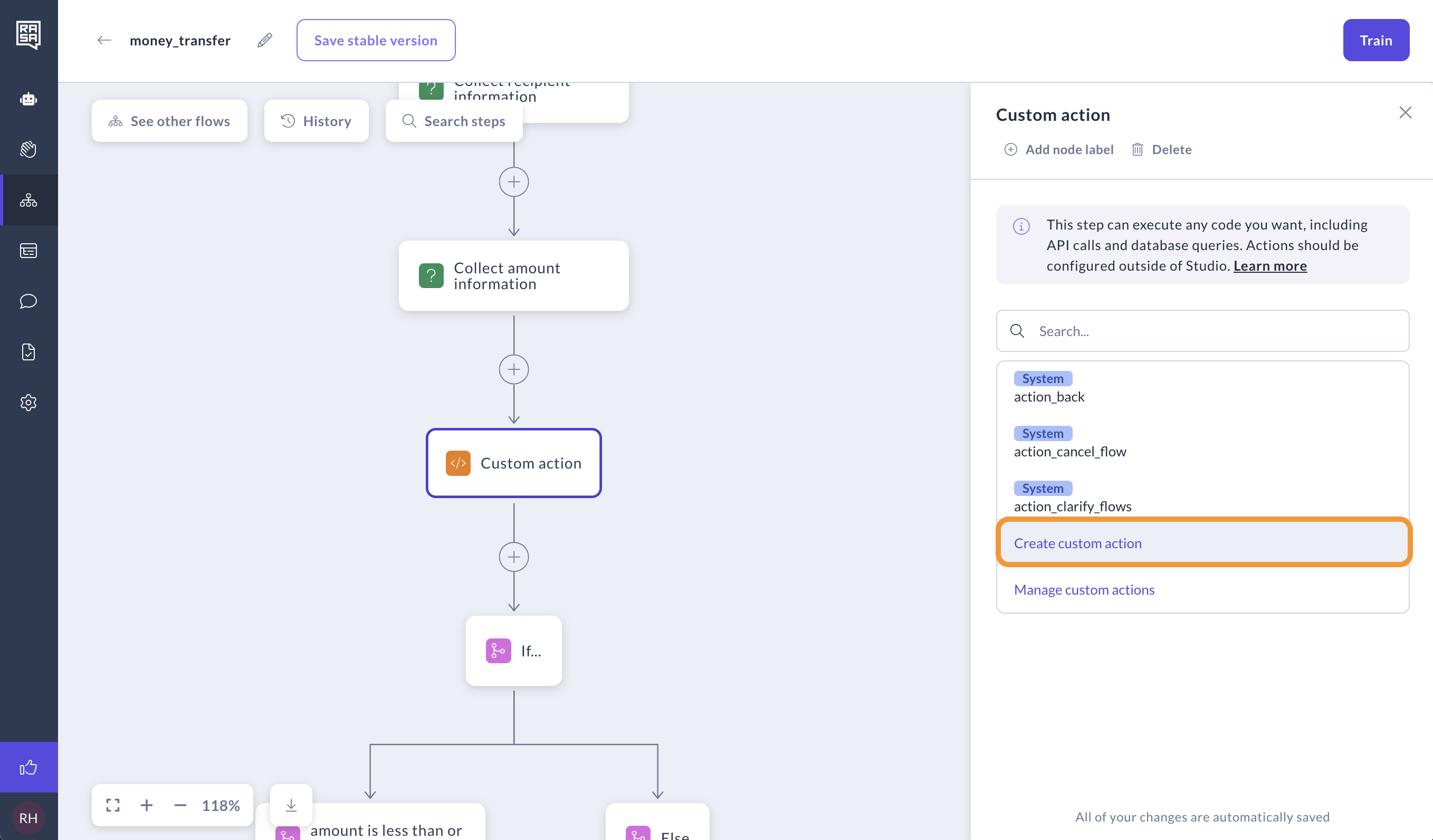
4. Enter the name `action_validate_sufficient_funds` and a description: "Goal: Validate whether the funds are sufficient for the transfer. Requirement: Check if the slot `amount` is greater than 1000. If true, return a `true` value for the slot `has_sufficient_funds`. If false, return a `false` value for the slot `has_sufficient_funds`."
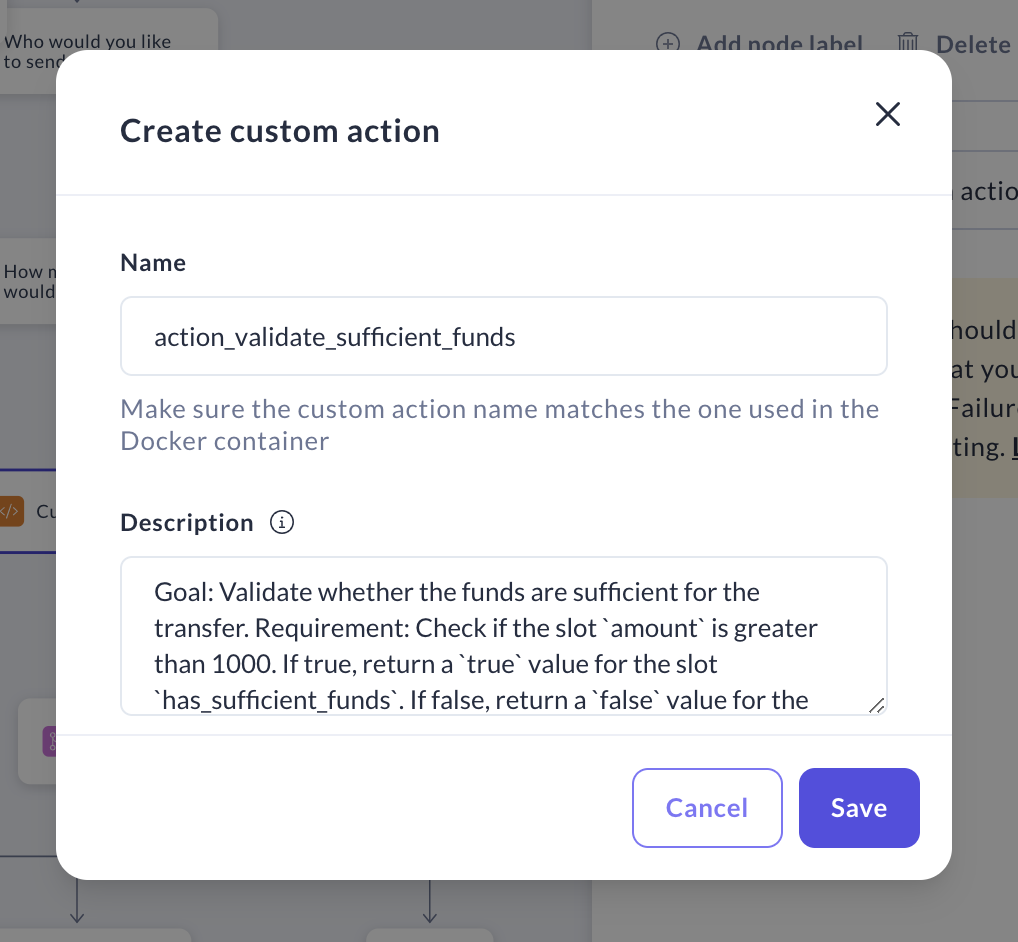
5. Select the first logic branch, the one labeled `amount` `is less_or_equal` `1000`. We’ll need to replace this with validation from the custom action. Instead of `amount`, create a new slot.
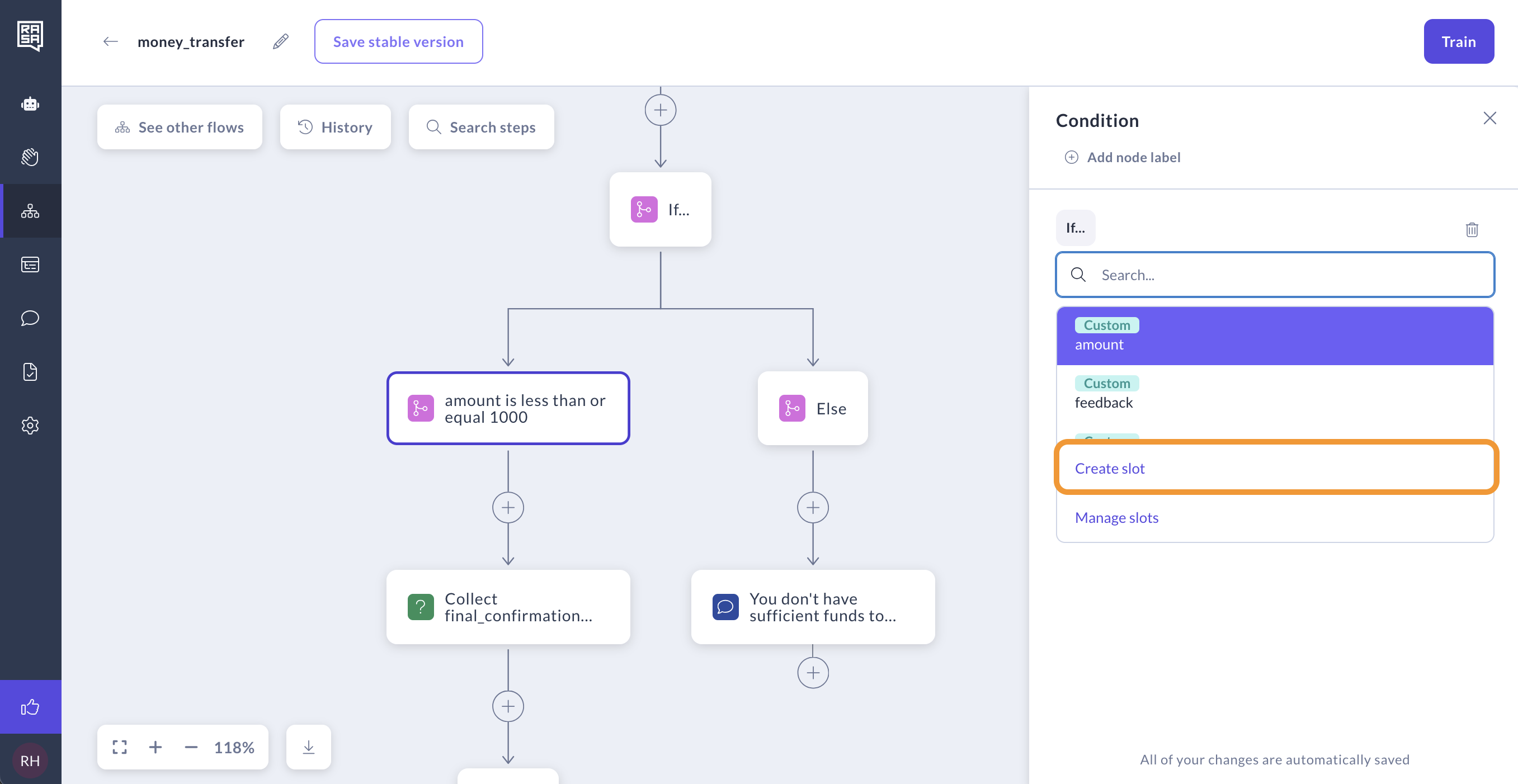
6. Enter slot name `has_sufficient_funds`. Select `Boolean` as a type and click "Save".
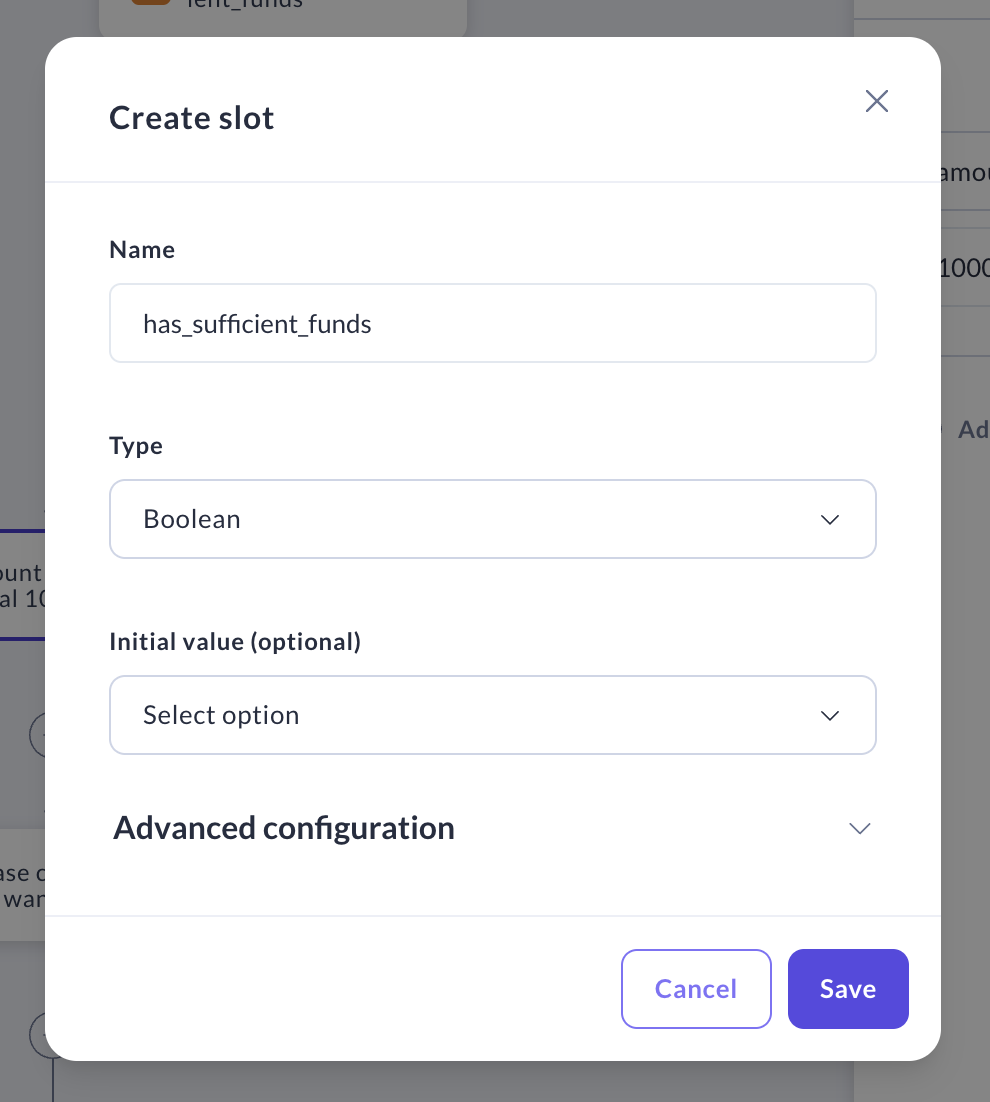
7. Set the condition so that `has_sufficient_funds` `is` `true`.
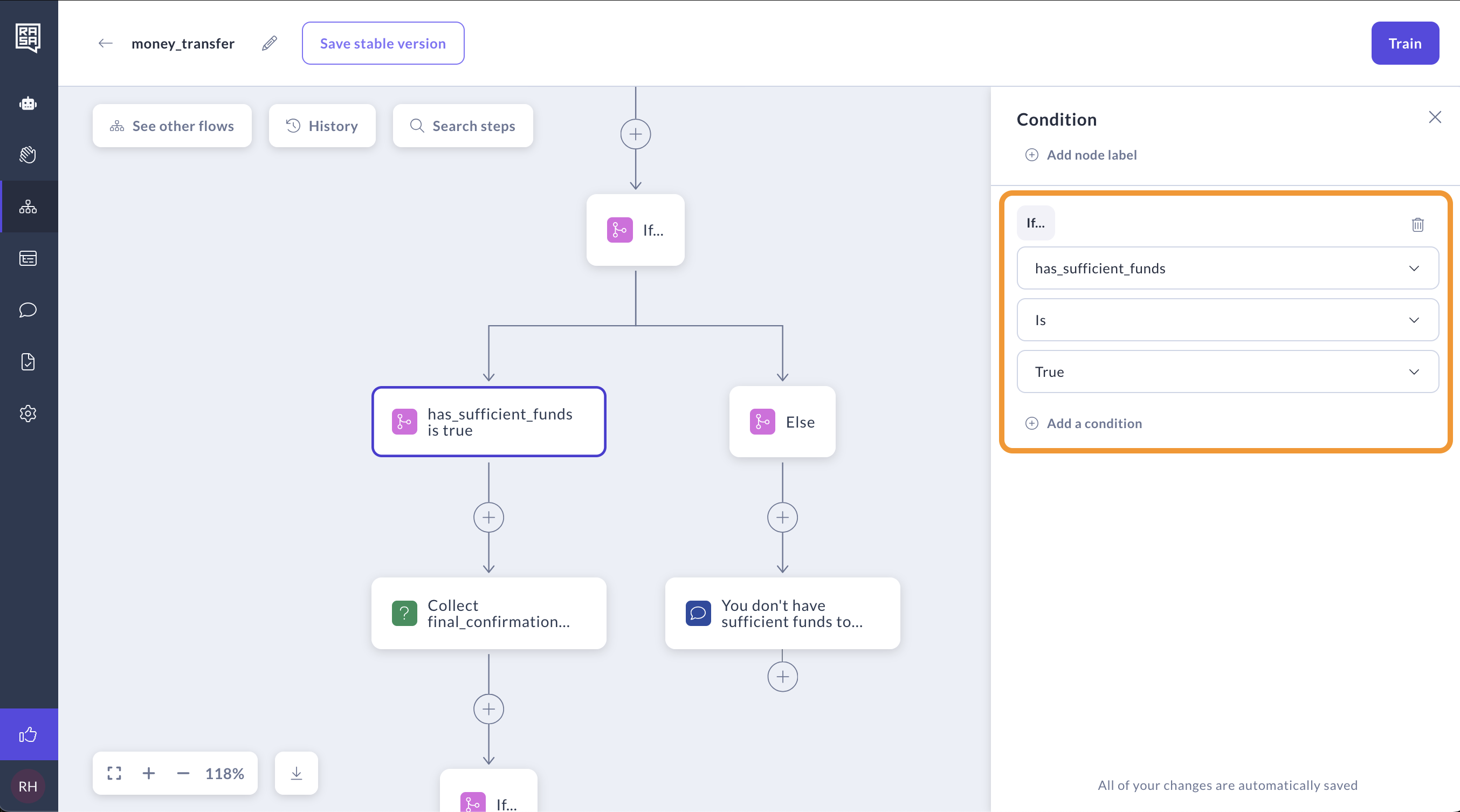
8. Switch to an IDE to set up your own Rasa Action Server.
To do this, you need Rasa Pro 3.7.0 or newer.
**Create a local Rasa project**
```
rasa init --template calm
```
9. Implement the custom action that validates the amount of funds. You can copy/paste the following Python code in `actions/actions.py`:
```
# These files contains your custom actions which can be used to run
# custom Python code.
#
# See this guide on how to implement these action:
# https://rasa.com/docs/reference/primitives/custom-actions
from typing import Any, Text, Dict, List
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
from rasa_sdk.events import SlotSet
class ActionValidateSufficientFunds(Action):
def name(self) -> Text:
return "action_validate_sufficient_funds"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
# hard-coded balance for tutorial purposes. in production this
# would be retrieved from a database or an API
balance = 1000
transfer_amount = tracker.get_slot("amount")
has_sufficient_funds = transfer_amount <= balance
return [SlotSet("has_sufficient_funds", has_sufficient_funds)]
```
10. Run action server using Rasa CLI.
```
rasa run actions
```
11. Use a reverse proxy like `ngrok` to expose the action server running on your local machine to the public internet and pass this to Studio for training. This can help you with quick prototyping & testing. Optionally you can also deploy this action server in your chosen cloud environment and pass the public URL to Studio to connect with your assistant.
```
ngrok http 5055
```
12. You can provide the URL + `/webhook` in **Assistant Settings - Configuration - Action Endpoint**:
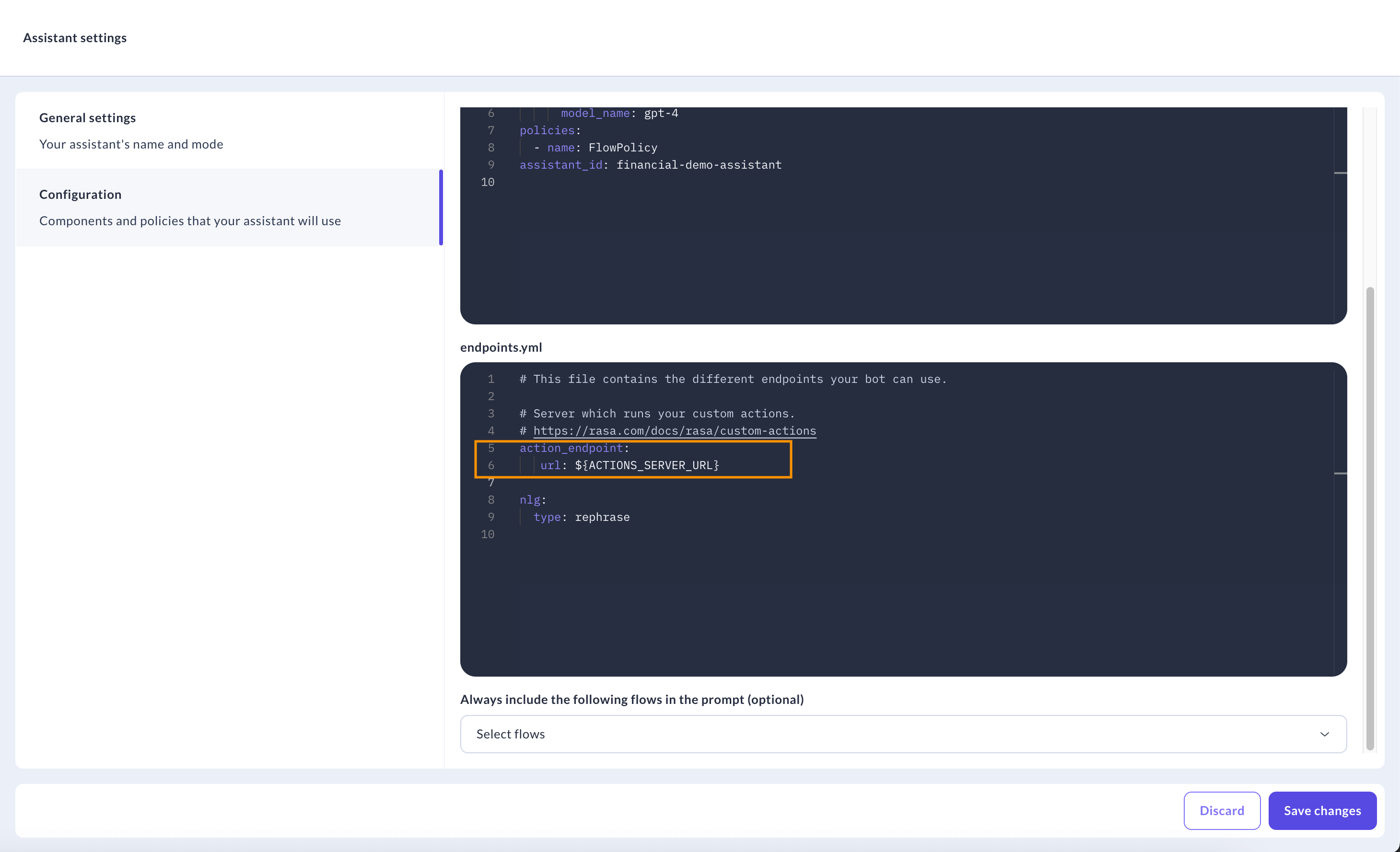
13. Train and test your assistants again, as described in **Step 5**.
#### Step 7: Editing YAML files \[Advanced][](#step-7-editing-yaml-files-advanced "Direct link to Step 7: Editing YAML files [Advanced]")
1. Download YAML files from Studio via Rasa CLI.
To do this, you need Rasa Pro 3.7.0 or newer. We recommend the latest Rasa version in order to use the latest features and improvements. Starting from Rasa Pro 3.9.8, you can download endpoint and config files as well.
**Note:** Make sure you pass the value for `studio-url`, `realm-name` and `client-id` based on variables used during your Studio deployment
**Create a new folder**
```
mkdir my-assistant-name
cd my-assistant-name
```
**Configure CLI to connect to Studio**
```
rasa studio config
```
Provide the Studio URL to configure the connection.
**Log in to Studio as a developer**
```
rasa studio login
```
Provide the credentials of the user belonging to the developer group.
**Download assistant by assistant-name**
Run the below command to download the assistant files.
```
rasa studio download
```
This will download the assistant's files to the current directory. The default directory structure will look like this:
```
|-endpoints.yml
|-config.yml
|-domain.yml
|-data
| |-studio_flows.yml
| |-studio_nlu.yml
```
Run `rasa studio download --help` to see the full list of arguments.
2. Apply changes, you can’t apply in Studio but only in YAML:
* view Tracing (Observability)
* add IVR Channel with AudioCodes
* run End-to-End Test
* use Secrets Management
* use PII Management
* add markers
* use Custom Information Retrieval
* add Conversation Tracking
* add Generation prompt in flow.yml
3. Train the rasa model locally using rasa CLI.
```
rasa train
```
4. Test your assistant with custom action using Rasa Inspector.
```
rasa inspect
```
---
### Analyze
#### Conversation Review
Conversation Review allows you to review conversations users have had with your assistant. It helps you detect patterns in conversations that might explain why certain skills are not working well—whether due to bad design, limited scope, bad routing, or implementation error.
Configure Rasa assistant for Conversation Review
In order for Studio to display conversation data, you need to configure your Rasa assistant to send conversation data to Studio via a Kafka broker. Make sure that your assistant and Studio are both connected to same Kafka instance and are listening to the same topic. You can review the technical reference on [the event broker here](https://rasa.com/docs/docs/reference/integrations/event-brokers/#kafka-event-broker) to know more about Kafka configuration in Rasa Pro. Make sure the that `assistant_id` field in the `config.yml` of your Rasa assistant is set to the same value as the assistant name in Studio.
#### Getting started[](#getting-started "Direct link to Getting started")
Choose an assistant from the dropdown menu in the left navigation bar.
Select Conversation Review in the left navigation bar.
You will now see Conversation Review’s Conversations Table

#### Conversations Table[](#conversations-table "Direct link to Conversations Table")
The Conversations Table lists all conversations your assistant has had with your users. By default, the Conversations Table shows the 100 most recent conversations occurring within the last seven days, sorted by descending start time.
The Conversations Table has the following columns:
| Column Name | Description |
| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Conversation ID | The unique ID associated with a user conversation. Also called a Session or User ID. |
| Session Start | The timestamp for the first event in the conversation session. Note that the session start time in the Conversations Table and the session start time elsewhere may differ: Studio auto-adjusts the default UTC timestamp to reflect the time in your local timezone. |
| Tags | Tags associated with the Conversation ID that you or your teammates have added. |
| Messages | The number of messages the user sent during the conversation. |
| Reviewed | When you or another user has viewed a conversation and marked it as reviewed, a green checkbox will appear in this column. |
##### Filters[](#filters "Direct link to Filters")
Applying filters to the Conversations Table helps you quickly identify conversations that need analysis. To access filters, click the Filters icon in the top left corner of the Conversations Table.
The following filters are available:
| Column Name | Description |
| --------------------------- | --------------------------------------------------------------- |
| Timeframe | The timestamp for the first event in the conversation session |
| Conversation ID | The unique ID associated with a user conversation. |
| Predicted Intent | The intents predicted during the course of the conversation. |
| Flow (CALM assistants only) | The Flows started during the course of the conversation. |
| Tags | Tags associated with the Conversation ID. |
| Response | Assistant responses used during the course of the conversation. |
| Channel | Channel where the conversation occurred. |
#### Conversation Details Panel[](#conversation-details-panel "Direct link to Conversation Details Panel")
The Details panel shows session, user and event data that will help you with conversation evaluation. The panel shows the following session-level data for every conversation:
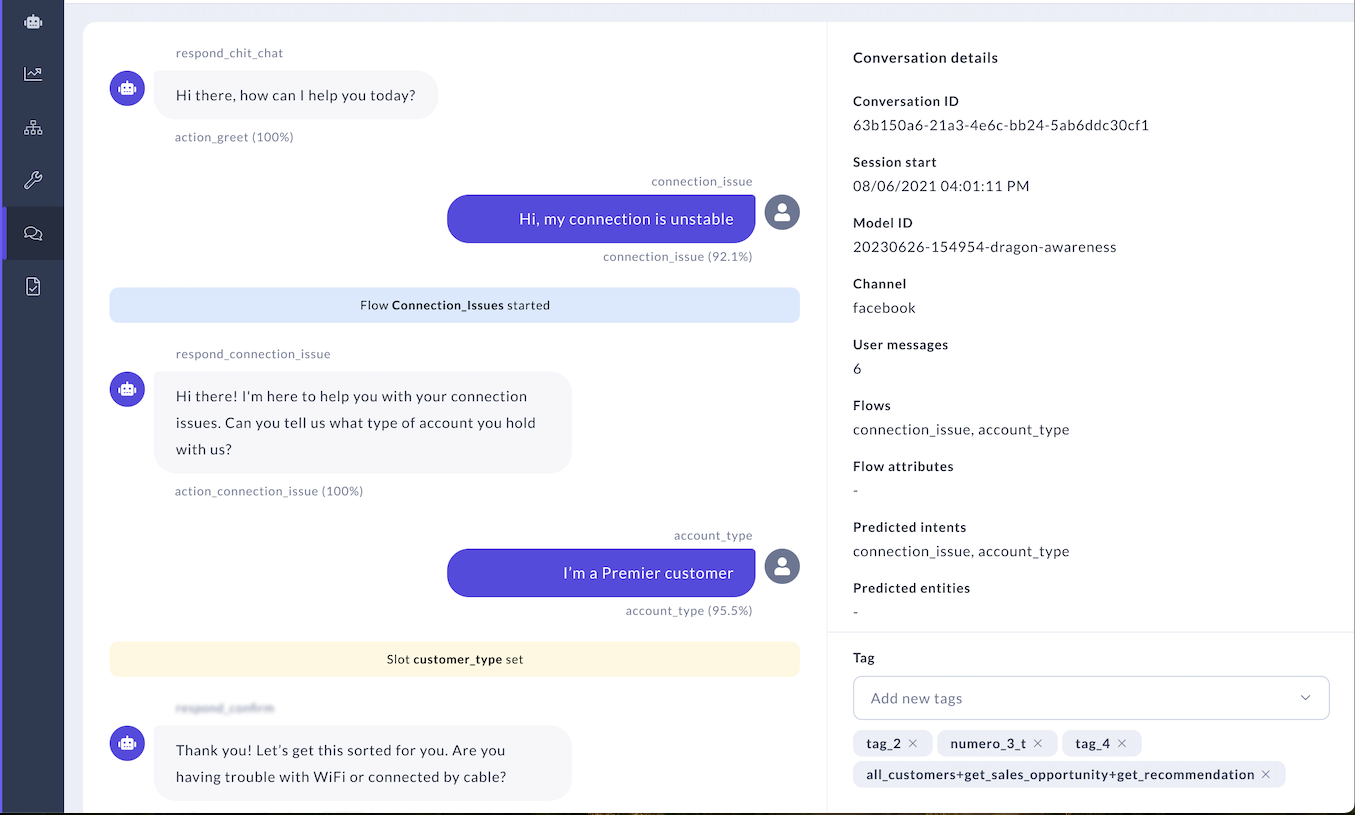
| Column Name | Description |
| ---------------------------------------- | -------------------------------------------------------------- |
| Conversation ID | The unique ID assigned to the conversation you are viewing. |
| Session Start | The timestamp for the first event in the conversation session. |
| Model ID | The unique ID assigned to the model your assistant is using. |
| Channel | The channel where the conversation took place. |
| User Messages | The total number of user messages sent during the session. |
| Flows (CALM assistants only) | The Flows started during the course of the conversation. |
| Flows attributes | The attributes associated with the Flow. |
| Predicted intents (NLU assistants only) | The intents predicted during the course of the conversation. |
| Predicted entities (NLU assistants only) | The entities predicted during the course of the conversation. |
| Tags | Tags associated with the Conversation ID. |
##### Adding Tags[](#adding-tags "Direct link to Adding Tags")
The Details section is also where you can append tags to the conversation you’re reviewing. Scrolling to the bottom of the details panel will allow you to add and delete tags associated with a Conversation.
[Learn more about tags and how to use Tags.](https://rasa.com/docs/docs/studio/analyze/conversation-review/#conversation-tags)
#### Conversation Stream[](#conversation-stream "Direct link to Conversation Stream")
The Conversation Stream is a turn-by-turn breakdown of the conversation you selected for review. Clicking on messages, responses and certain event types will show you more information in the Details panel.
##### User Messages[](#user-messages "Direct link to User Messages")
User messages are shown on the right hand side of the stream. Clicking on a message will show more details about the message in the Details panel:
* **Message timestamp**: The time at which the message was sent.
* **Message ID**: The unique ID of the user message.
* **Message in conversation**: The sequential number of the message in the conversation. 
If you are analyzing an NLU assistant, you will also see:
* Predicted intents with confidence scores
##### Events[](#events "Direct link to Events")
Slot and Flow events are represented with a colored banner. Clicking on the banner reveals additional details about the events.
###### Slot events[](#slot-events "Direct link to Slot events")
Slots are your bot's memory. They store information a user has provided (for example, their name or phone number) or information the assistant can access about the user (for example, their account ID or device in use). The bot can then refer to this information throughout the conversation. When a slot is set during the course of a conversation, you will see a yellow banner. Clicking on the banner will show more details about the set slot in the Details panel:
* **Event timestamp**: The time at which the Slot event took place.
* **Event ID**: The unique ID associated with the event.
* **Event in Conversation**: The sequence of the event in the conversation.
* **Slot Name**: The name of the slot that was set.
* **Slot Value**: The information about the user or conversation that is now stored in the slot. 
###### Flow events (CALM assistants only)[](#flow-events-calm-assistants-only "Direct link to Flow events (CALM assistants only)")
CALM assistants are powered by Flows. Flows are abstract representations of the business processes your assistant completes. If you are analyzing a conversation with a CALM assistant, you will see the following Flow events:
* **Flow started**: The assistant started a Flow in response to a user question.
* **Flow interrupted**: The Flow stopped before completion. It will continue once the interrupted flow is finished.
* **Flow resumed**: The Flow restarted after stopping. Flow restart at the point where it left off.
* **Flow completed**: The Flow was completed within the session window.
* **Flow cancelled**: The user cancelled the Flow during the conversation session.
When a Flow event happens during the course of a conversation, you will see a blue banner. Clicking on the banner will show more details about the Flow event in the Details panel:
* **Timestamp of event**: The time at which the Flow event took place.
* **Event ID**: The unique ID associated with the event.
* **Event in Conversation**: The sequence of the event in the conversation.
* **Flow name**: The name of the Flow.
* **Flow event type**: The type of Flow event triggered. 
#### Conversation Tags[](#conversation-tags "Direct link to Conversation Tags")
Tags are a way for your team to supercharge your review workflows.
Imagine a scenario where you are analyzing a conversation between a user and a weather app assistant. During the conversation, the user requested information on the pollen index for their zip code. However, the assistant was designed to only answer questions directly related to weather events, and so the question triggered the assistant’s fallback behavior. With tags, you could:
* Batch this conversation with similar ones by assigning a tag like `out-of-scope` to denote the user asked a question outside of the assistant’s domain
* Batch this conversation with similar ones by assigning a tag like `topic-pollen-index` to denote the user asked a question related to the pollen index for their location
* Specify what action the team should take next by assigning a tag like `needs-further-analysis`, `implement-behavior`, or a even a knowledgeable teammate’s name.  These conversations can then be easily surfaced in the Conversations Table.
#### Automatic Conversation Deletion[](#automatic-conversation-deletion "Direct link to Automatic Conversation Deletion")
To manage data retention and ensure compliance with data protection regulations, old conversations can be automatically deleted periodically. [Learn more about automatic conversation deletion](https://rasa.com/docs/docs/reference/deployment/automatic-conversation-deletion/)
#### Conversations via API[](#conversations-via-api "Direct link to Conversations via API")
For developers looking to programmatically tag and delete conversations, please refer to our [Conversations API Documentation](https://rasa.com/docs/docs/reference/api/studio/conversation-api/).
---
#### How to Annotate your Conversations
This guide teaches you how to annotate intents and entities in Rasa Studio, helping your assistant better understand user inputs by creating high-quality training data. You’ll learn how to assign, review, and manage annotations effectively to ensure your assistant performs accurately and reliably.
note
This feature requires that you've integrated Live Conversation Review. To enable Studio to visualize conversation data, your Rasa assistant must be configured to transmit this data to Studio using a Kafka broker. Ensure that both your Rasa Pro assistant and Studio are connected to the same Kafka instance and monitoring the same topic.
Additionally, verify that the `assistant_id` field in your Rasa assistant’s `config.yml` file matches the assistant name defined in Studio.
To dive deeper into the event broker, check out [configuring Kafka in Rasa](https://rasa.com/docs/docs/reference/integrations/event-brokers/#kafka-event-broker).
#### What is Annotation in Studio?[](#what-is-annotation-in-studio "Direct link to What is Annotation in Studio?")
Annotation in Rasa Studio allows your team to label user messages with intents and entities. Users that have the [Lead Annotator](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/#roles-overview) role can assign tasks, review annotations, and approve them to build training data or export it for further use.
#### Intro to the Annotation Dashboard[](#intro-to-the-annotation-dashboard "Direct link to Intro to the Annotation Dashboard")
1. Open the **Annotation Dashboard** under **Bot Tuner** in the navigation bar.
2. View key data:
* **Total Utterances**: All user messages sent to the assistant.
* **Total Conversations**: All sessions initiated by users.
#### How to Assign Annotations[](#how-to-assign-annotations "Direct link to How to Assign Annotations")
1. Click **Assign Annotation** in the Annotation Dashboard.
2. Select annotators from the list. You can include yourself.
3. Use filters to define the messages for annotation:
* **Date Range**: Filter by when messages were sent.
* **Channels**: Choose specific communication channels.
* **Keywords**: Filter messages containing specific words.
* **Predicted Intent**: Include messages with specific predicted intents.
* **Confidence Range**: Set a confidence score range for predictions.
* **Sample Size**: Limit the number of messages in the batch.
4. Click the refresh icon to update the message count based on filters.
5. Click **Assign Annotation** to create the batch.
#### How to Annotate Messages[](#how-to-annotate-messages "Direct link to How to Annotate Messages")
##### Accessing Batches[](#accessing-batches "Direct link to Accessing Batches")
1. Go to **Annotation Inbox** under **Bot Tuner** to see batches assigned to you.
2. Click **Annotate** on a batch to begin.
##### Bulk Annotation[](#bulk-annotation "Direct link to Bulk Annotation")
* **View Messages**: See a list of messages with predicted intents and confidence scores.
* **Tabs**:
* **Inbox**: Messages awaiting annotation.
* **Saved**: Annotated and saved messages.
* **Discarded**: Messages excluded from training.
###### Annotating Intents[](#annotating-intents "Direct link to Annotating Intents")
1. Select messages and choose an intent from the dropdown.
2. Save annotations by clicking **Annotate**. Annotated messages move to the "Saved" tab.
3. Discard irrelevant messages to exclude them from training.
###### Annotating Entities[](#annotating-entities "Direct link to Annotating Entities")
1. Highlight words in the message to tag them as entities.
2. Assign an entity type, role, or synonym in the panel below the message.
3. Confirm or discard predicted entities.
##### Single Annotation[](#single-annotation "Direct link to Single Annotation")
* Switch to single annotation mode for detailed review.
* See the full conversation context and annotate messages individually.
#### Reviewing Annotations[](#reviewing-annotations "Direct link to Reviewing Annotations")
1. Open the **Review Inbox** to review batches.
2. Apply filters to focus on specific messages.
3. Approve annotations or make corrections as needed.
4. Mark the batch as reviewed to finalize annotations.
#### Managing Annotation History[](#managing-annotation-history "Direct link to Managing Annotation History")
1. Access **Annotation History** to view approved annotations.
2. Filter by confidence scores, intents, or training data status.
3. Export annotations as a CSV or add them as training data.
4. Train your model to incorporate new training data.
💡 Remember to retrain your model after adding new training data.
#### Linked Features[](#linked-features "Direct link to Linked Features")
##### Creating a New Intent During Annotation[](#creating-a-new-intent-during-annotation "Direct link to Creating a New Intent During Annotation")
1. Click the intent dropdown and select **Create New Intent**.
2. Enter a name for the intent (no spaces or special characters).
3. Save the intent to use it immediately in the batch.
By following these steps, you can streamline the annotation process, ensuring accurate training data for your assistant.
---
### Build
#### Buttons and Links
The buttons and links section of the CMS is a centralised place for content managers and flow builders to create and manage all the buttons and links used in an assistant.
Access from Buttons and Links navigation item under CMS on the navigation menu.
##### How to Create a Button[](#how-to-create-a-button "Direct link to How to Create a Button")
1. Click on the “Create new” button on the top right of the screen, or on the middle of the screen if no buttons or links exist yet.
2. Type in a name and select the button payload type, and then click the save button.
##### How to Create a Link[](#how-to-create-a-link "Direct link to How to Create a Link")
1. Click on the “Create new” button on the top right of the screen.
2. Click the “Create link” radio button, and then type in the link title, fill in the link URL and click the save button.
##### How to Manage Buttons and Links[](#how-to-manage-buttons-and-links "Direct link to How to Manage Buttons and Links")
1. Select the button or link from the list on the left
2. Click the “See responses” button to view which responses are using this button or link. You can also click on the response name to navigate to it on the Response CMS.
3. Click the “Delete” button to delete the button from the assistant.
4. Change any button or link values or types using the fields on the page.
---
#### Conversation Review
Conversation Review allows you to review conversations users have had with your assistant. It helps you detect patterns in conversations that might explain why certain skills are not working well—whether due to bad design, limited scope, bad routing, or implementation error.
Conversation View is available for both CALM and NLU-based assistants.
Configure Rasa assistant for Conversation Review
In order for Studio to display conversation data, you need to configure your Rasa assistant to send conversation data to Studio via a Kafka broker. Make sure that your assistant and Studio are both connected to same Kafka instance and are listening to the same topic. Look [here](https://rasa.com/docs/docs/reference/integrations/event-brokers/#kafka-event-broker) to know more about Kafka configuration in Rasa. Make sure the that `assistant_id` field in the `config.yml` of your Rasa assistant is set to the same value as the assistant name in Studio.
#### Getting started[](#getting-started "Direct link to Getting started")
Choose an assistant from the dropdown menu in the left navigation bar.

Select Conversation Review in the left navigation bar.

You will now see Conversation Review’s Conversations Table

#### Conversations Table[](#conversations-table "Direct link to Conversations Table")
The Conversations Table lists all conversations your assistant has had with your users. By default, the Conversations Table shows the 100 most recent conversations occurring within the last seven days, sorted by descending start time.
The Conversations Table has the following columns:
| Column Name | Description |
| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Conversation ID | The unique ID associated with a user conversation. Also called a Session or User ID. |
| Session Start | The timestamp for the first event in the conversation session. Note that the session start time in the Conversations Table and the session start time elsewhere may differ: Studio auto-adjusts the default UTC timestamp to reflect the time in your local timezone. |
| Tags | Tags associated with the Conversation ID that you or your teammates have added. |
| Messages | The number of messages the user sent during the conversation. |
| Reviewed | When you or another user has viewed a conversation and marked it as reviewed, a green checkbox will appear in this column. |
##### Filters[](#filters "Direct link to Filters")
Applying filters to the Conversations Table helps you quickly identify conversations that need analysis. To access filters, click the Filters icon in the top left corner of the Conversations Table.

The following filters are available:
| Column Name | Description |
| --------------------------- | ------------------------------------------------------------- |
| Timeframe | The timestamp for the first event in the conversation session |
| Conversation ID | The unique ID associated with a user conversation. |
| Predicted Intent | The intents predicted during the course of the conversation. |
| Flow (CALM assistants only) | The Flows started during the course of the conversation. |
| Tags | Tags associated with the Conversation ID. |
| Reviewed conversations | Whether or not a conversation has been reviewed. |
#### Conversation Details Panel[](#conversation-details-panel "Direct link to Conversation Details Panel")
The Details panel shows session, user and event data that will help you with conversation evaluation. The panel shows the following session-level data for every conversation:

| Column Name | Description |
| ---------------------------------------- | -------------------------------------------------------------- |
| Conversation ID | The unique ID assigned to the conversation you are viewing. |
| Session Start | The timestamp for the first event in the conversation session. |
| Model ID | The unique ID assigned to the model your assistant is using. |
| Channel | The channel where the conversation took place. |
| User Messages | The total number of user messages sent during the session. |
| Flows (CALM assistants only) | The Flows started during the course of the conversation. |
| Flows attributes | The attributes associated with the Flow. |
| Predicted intents (NLU assistants only) | The intents predicted during the course of the conversation. |
| Predicted entities (NLU assistants only) | The entities predicted during the course of the conversation. |
| Tags | Tags associated with the Conversation ID. |
##### Adding Tags[](#adding-tags "Direct link to Adding Tags")
The Details section is also where you can append tags to the conversation you’re reviewing. Scrolling to the bottom of the details panel will allow you to add and delete tags associated with a Conversation.
[Learn more about tags and how to use Tags.](https://rasa.com/docs/docs/studio/build/content-management/conversation-review/#conversation-tags)
#### Conversation Stream[](#conversation-stream "Direct link to Conversation Stream")
The Conversation Stream is a turn-by-turn breakdown of the conversation you selected for review. Clicking on messages, responses and certain event types will show you more information in the Details panel.
##### User Messages[](#user-messages "Direct link to User Messages")
User messages are shown on the right hand side of the stream. Clicking on a message will show more details about the message in the Details panel:
* **Message timestamp**: The time at which the message was sent.
* **Message ID**: The unique ID of the user message.
* **Message in conversation**: The sequential number of the message in the conversation. 
If you are analyzing an NLU assistant, you will also see:
* Predicted intents with confidence scores
##### Events[](#events "Direct link to Events")
Slot and Flow events are represented with a colored banner. Clicking on the banner reveals additional details about the events.
###### Slot events[](#slot-events "Direct link to Slot events")
Slots are your bot's memory. They store information a user has provided (for example, their name or phone number) or information the assistant can access about the user (for example, their account ID or device in use). The bot can then refer to this information throughout the conversation. When a slot is set during the course of a conversation, you will see a yellow banner. Clicking on the banner will show more details about the set slot in the Details panel:
* **Event timestamp**: The time at which the Slot event took place.
* **Event ID**: The unique ID associated with the event.
* **Event in Conversation**: The sequence of the event in the conversation.
* **Slot Name**: The name of the slot that was set.
* **Slot Value**: The information about the user or conversation that is now stored in the slot. 
###### Flow events (CALM assistants only)[](#flow-events-calm-assistants-only "Direct link to Flow events (CALM assistants only)")
CALM assistants are powered by Flows. Flows are abstract representations of the business processes your assistant completes. If you are analyzing a conversation with a CALM assistant, you will see the following Flow events:
* **Flow started**: The assistant started a Flow in response to a user question.
* **Flow interrupted**: The Flow stopped before completion. It will continue once the interrupted flow is finished.
* **Flow resumed**: The Flow restarted after stopping. Flow restart at the point where it left off.
* **Flow completed**: The Flow was completed within the session window.
* **Flow cancelled**: The user cancelled the Flow during the conversation session.
When a Flow event happens during the course of a conversation, you will see a blue banner. Clicking on the banner will show more details about the Flow event in the Details panel:
* **Timestamp of event**: The time at which the Flow event took place.
* **Event ID**: The unique ID associated with the event.
* **Event in Conversation**: The sequence of the event in the conversation.
* **Flow name**: The name of the Flow.
* **Flow event type**: The type of Flow event triggered. 
#### Conversation Tags[](#conversation-tags "Direct link to Conversation Tags")
Tags are a way for your team to supercharge your review workflows.
Imagine a scenario where you are analyzing a conversation between a user and a weather app assistant. During the conversation, the user requested information on the pollen index for their zip code. However, the assistant was designed to only answer questions directly related to weather events, and so the question triggered the assistant’s fallback behavior. With tags, you could:
* Batch this conversation with similar ones by assigning a tag like `out-of-scope` to denote the user asked a question outside of the assistant’s domain
* Batch this conversation with similar ones by assigning a tag like `topic-pollen-index` to denote the user asked a question related to the pollen index for their location
* Specify what action the team should take next by assigning a tag like `needs-further-analysis`, `implement-behavior`, or a even a knowledgeable teammate’s name.  These conversations can then be easily surfaced in the Conversations Table.
#### Automatic Conversation Deletion[](#automatic-conversation-deletion "Direct link to Automatic Conversation Deletion")
To manage data retention and ensure compliance with data protection regulations, old conversations can be automatically deleted periodically. [Learn more about automatic conversation deletion](https://rasa.com/docs/docs/reference/deployment/automatic-conversation-deletion/)
#### Conversations via API[](#conversations-via-api "Direct link to Conversations via API")
For developers looking to programmatically tag and delete conversations, please refer to our [Conversations API Documentation](https://rasa.com/docs/docs/reference/api/studio/conversation-api/).
---
#### Flow Builder — Best practices
#### Structure flows[](#structure-flows "Direct link to Structure flows")
Structuring flows effectively can make your chatbot development process smoother and more maintainable.
* **Organise Flows by names:** Use the same prefix the naming flows that are within the same domain/skill to make it easier to locate and work with flows as your assistant grows. i.e Flow 1: open\_account\_eligible, Flow 2: open\_account\_ineligible
* **Prevent Flow Duplications:** Before creating a new flow, check if a similar flow already exists (similar description, similar steps). Duplicating flows can lead to maintenance challenges and confusion. Instead, consider reusing existing flows when applicable.
* **Link Flows Where Possible:** When designing your bot's conversation paths, look for opportunities to link existing flows together. This is also one way to reuse flows and can reduce redundancy and make your bot's logic more streamlined.
* **Continuously** **Review and Test Your Bot:** After structuring your flows, periodically review and test your assistant to ensure that the conversation paths and logic work as intended or if you need to add/remove/rearrange some of the flows.
#### Common conversation elements[](#common-conversation-elements "Direct link to Common conversation elements")
Including in your assistant flows that cover the common conversation elements can help ensure that your chatbot is well-rounded and capable of handling various user interactions. Here's a checklist of essential flows to consider:
1. **Greeting:** Implement a flow with a friendly and context-aware greeting message to welcome users as they initiate a conversation.
2. **Introduction:** Create a flow that provides a brief introduction to the bot's purpose, capabilities, and how it can assist the user.
3. **User Help:** Include a flow or path that can be triggered when users request help or guidance during the conversation.
4. **Exit or Goodbye:** Create an exit flow where you include an exit or goodbye and prompts for feedback when users decide to end the conversation or complete a task.This encourages users to provide feedback on their experience to help improve the bot's performance.
5. **Privacy and Data Handling Information:** Create a flow about privacy and data handling and inform users about how their data is handled and assure them of privacy and security measures. Offer users the option to opt-out of the data procession.
6. **FAQ Handling:** Create series of flows for FAQs and ensure the assistant can provide relevant information.
7. **Human Handoff:** Implement a flow for transferring the conversation to a human agent when the assistant can't handle a user's request effectively.
#### Create human handoff flow[](#create-human-handoff-flow "Direct link to Create human handoff flow")
A human handoff skill is essential for scenarios where your assistant encounters complex or sensitive questions that it can't handle on its own. In this guide, we’ll look at how to add this handoff skill as a backup plan to ensure a smooth transition from assistant to human.
Step 1. **Identify Handoff Trigger Scenarios:** Determine the specific situations in which your assistant should trigger a human handoff as backup plan. These could include questions about sensitive topics, complex issues, or when the user explicitly requests human assistance
Step 2. **Integrate Handoff Logic:** Implement the logic that triggers the human handoff skill. This logic should be based on the scenarios you identified in step 1. For example, you can use specific keywords or phrases as triggers.
Step 3. **Prepare User for Handoff:** Before transferring to a human agent, inform the user that a human is taking over to provide assistance. Set clear expectations about the handoff process and reassure the user.
Step 4. **Integrate with Human Support:** Ensure that your assistant can seamlessly connect with human support agents. This might involve integrating with a helpdesk system, customer support platform, or routing requests to a designated team.
Step 5. **Test and Refine:** Thoroughly test the bot's behavior when triggering the handoff. Make adjustments and refining the handoff triggers as needed to improve the handoff experience.
---
#### How to Collect Information
This guide will teach you how to enable your assistant to gather user data through **Collect** steps. You’ll learn how to set up slots, create prompts, and validate user inputs, enabling your assistant to handle interactions smoothly and accurately.
##### What is a Collect Step?
The collect step helps your assistant gather and store information provided by the user. You define the type of data you want to collect—like a name, email, or date—as a slot, and this step helps you to get the answer you need to set the value.
This guide walks you through setting up a Collect step — from creating slots and designing prompts to advanced validation and slot-filling logic.

#### Create a Collect Step[](#create-a-collect-step "Direct link to Create a Collect Step")
Here's how to define what your assistant should ask and where to store the user's response.
##### 1. Describe What to Collect[](#1-describe-what-to-collect "Direct link to 1. Describe What to Collect")
Add a short description to instruct the assistant on what kind of information it should collect. Use a clear and consistent format.
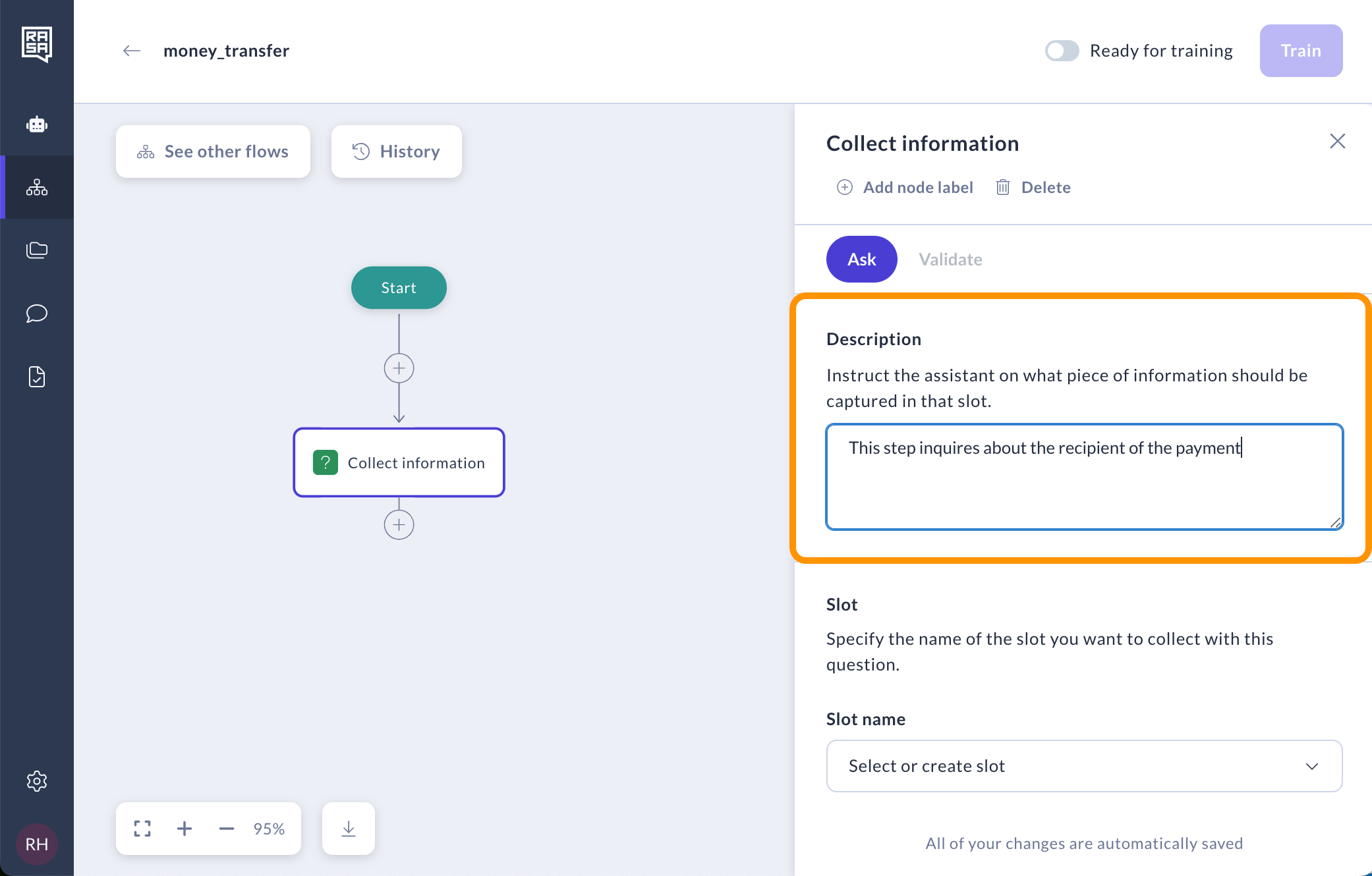
##### 2. Store the Response[](#2-store-the-response "Direct link to 2. Store the Response")
In order to be able to store the user's response, define a new [**slot**](https://rasa.com/docs/docs/studio/build/flow-building/collect/#slots). Use descriptive names that clearly indicate the information you want to gather.
**📌 Tip:** To keep your slots organized - prefix flow-specific slots with the flow name ie. `money_transfer_` and global ones that are shared between flows with `global_`.

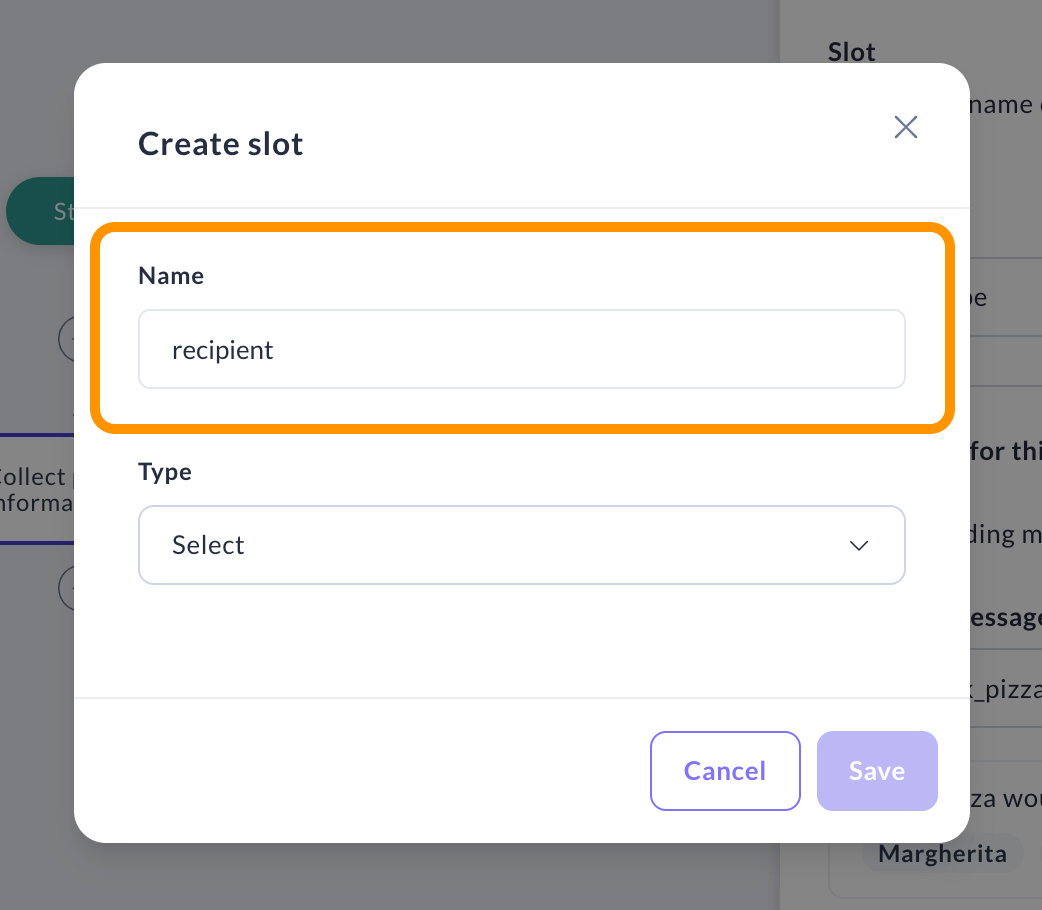
###### Choose the Type of Information[](#choose-the-type-of-information "Direct link to Choose the Type of Information")
Pick the right slot type for the information you're collecting. Read more about the [**different types of slots here**](https://rasa.com/docs/docs/studio/build/flow-building/collect/#slot-types).
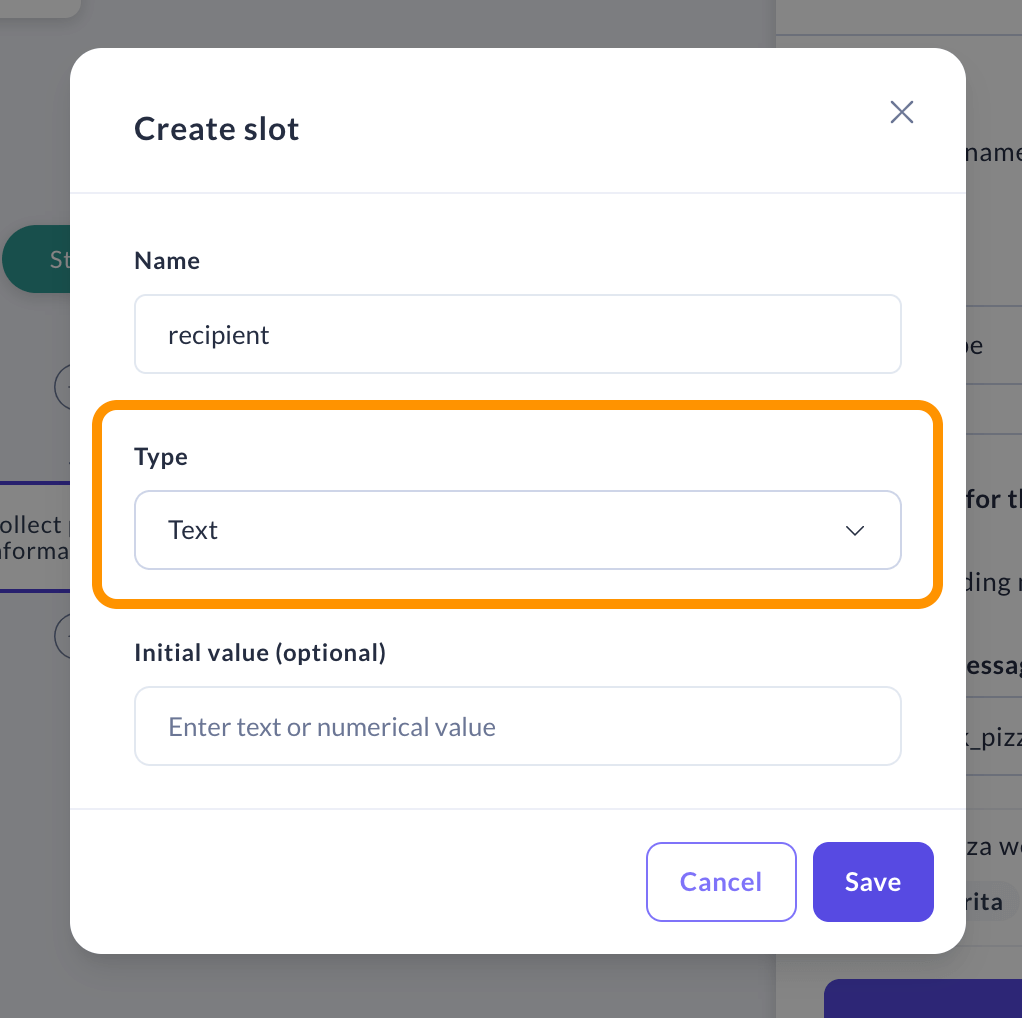
#### Design How to Ask For Information[](#design-how-to-ask-for-information "Direct link to Design How to Ask For Information")
You can tailor how your assistant asks for information or presents options to your user.
##### Option 1: Use a Response[](#option-1-use-a-response "Direct link to Option 1: Use a Response")
Click **Select or create response** and write what you'd like your assistant your assistant to say. The response name will default to `utter_ask_{slot_name}`.



###### Add Buttons (Optional)[](#add-buttons-optional "Direct link to Add Buttons (Optional)")
Optionally, you can add buttons to allow the user to select an answer more quickly and present user with structured choices. This is particularly helpful for complex tasks or when the assistant needs specific information to proceed. [Learn more about buttons](https://rasa.com/docs/docs/studio/build/flow-building/collect/#buttons).

##### Option 2: Use a Custom Action[](#option-2-use-a-custom-action "Direct link to Option 2: Use a Custom Action")
Instead of using a response for the Collect step, you can use a [custom action](https://rasa.com/docs/docs/studio/build/actions/create-a-custom-action/#how-to-create-custom-action). This is useful if, for example, you want to display dynamic data to the user as options.
The custom action must follow a specific naming convention and be called `action_ask_{slot_name}`, which is why the name will be pre-filled. Make sure to add this custom action to your [domain file outside of Studio](https://rasa.com/docs/docs/studio/build/actions/create-a-custom-action/).
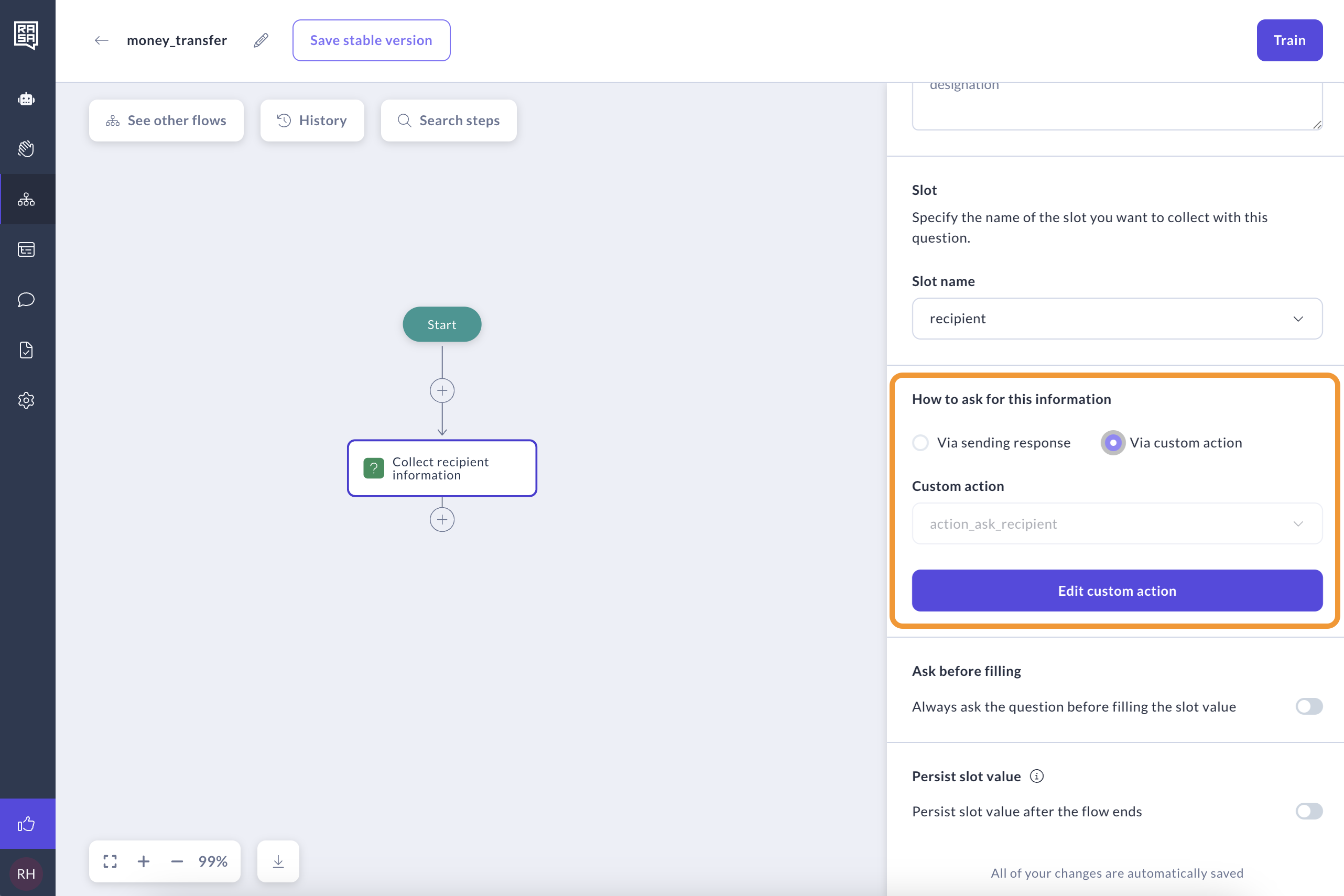
#### Configure Collection Rules[](#configure-collection-rules "Direct link to Configure Collection Rules")
You can fine-tune how your assistant gathers information using the options below. These help ensure the right data is collected — and in the right way for your use case.
##### Ask Before Filling[](#ask-before-filling "Direct link to Ask Before Filling")
Normally, if a slot is already filled earlier in the conversation, the assistant won’t ask again.
But if you want the assistant to *always* ask — even when it already has an answer — switch on **Ask before filling**.
**When to use it:**
Useful when you want to confirm or re-collect something every time or when the value may need to be updated in the context of a flow, like a time slot for a booking.
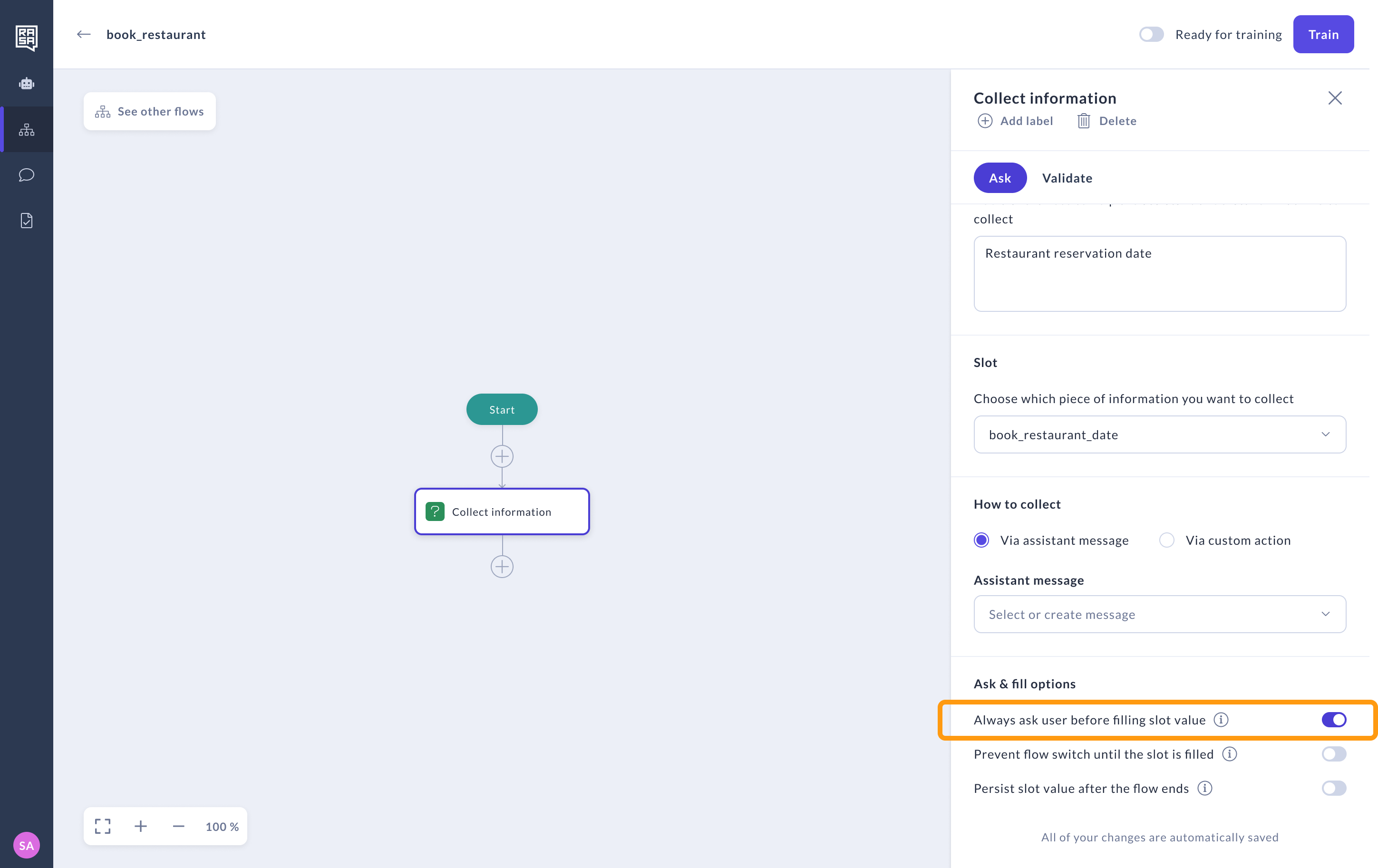
##### Prevent Digressions[](#prevent-digressions "Direct link to Prevent Digressions")
If you want to prevent users jumping topics before giving you a crucial detail, you can ensure that the assistant collects a the slot value before moving to a different flow with this feature.
**When to use it:**
If you have some required data like an email that you need to be able to fill out a support ticket — you can use this feature to ensure your assistant doesn't digress to another topic without it.
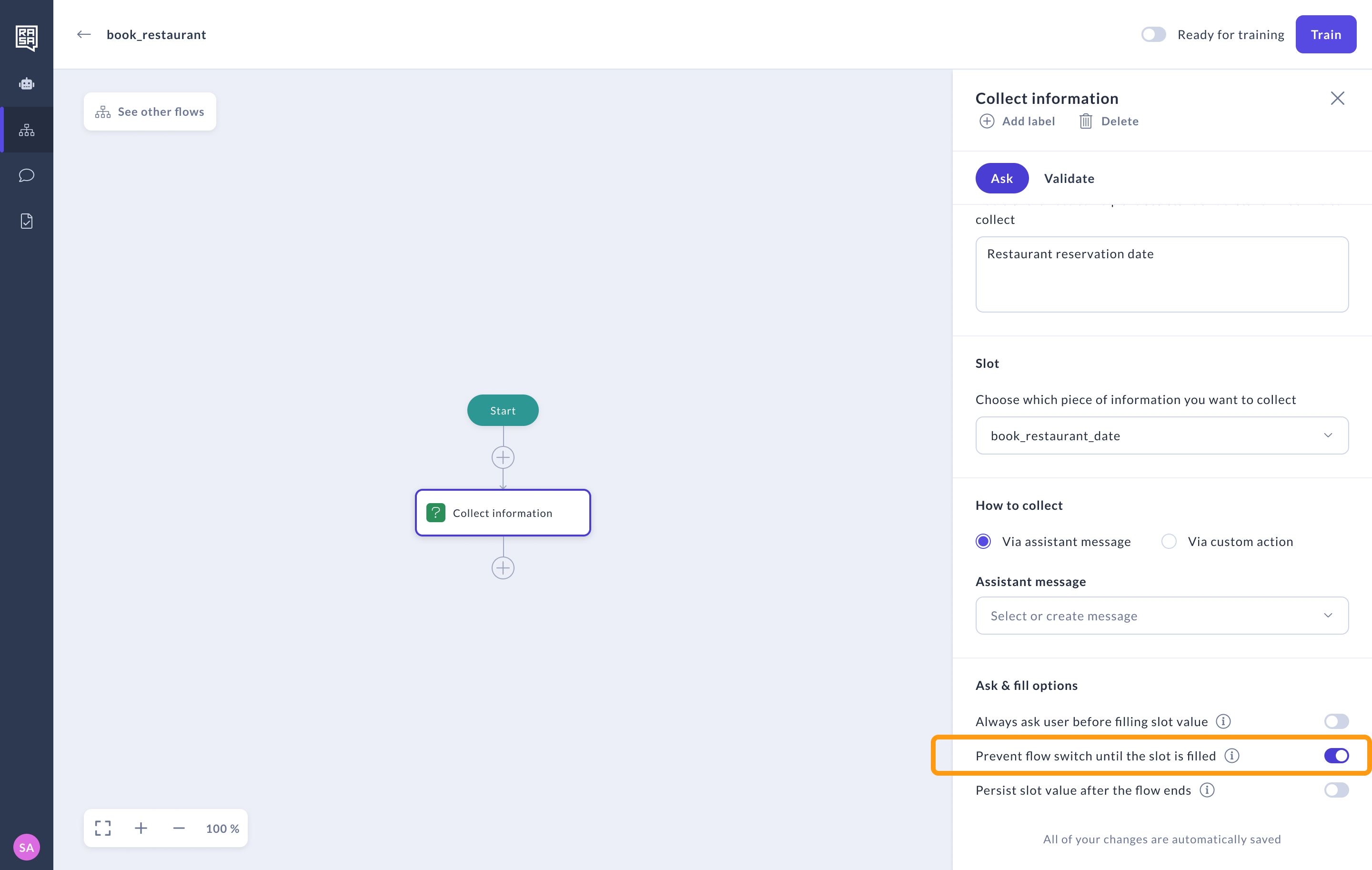
##### Persist Slot Value[](#persist-slot-value "Direct link to Persist Slot Value")
By default slots are stored in the assistant's memory during a given flow but are then reset when you change to a new topic. Switch on **Persist slot value** to have your assistant remember the info for later use in a different flow context.
**When to use it:**
Helpful for things like remembering a user's preferences across a full conversation.
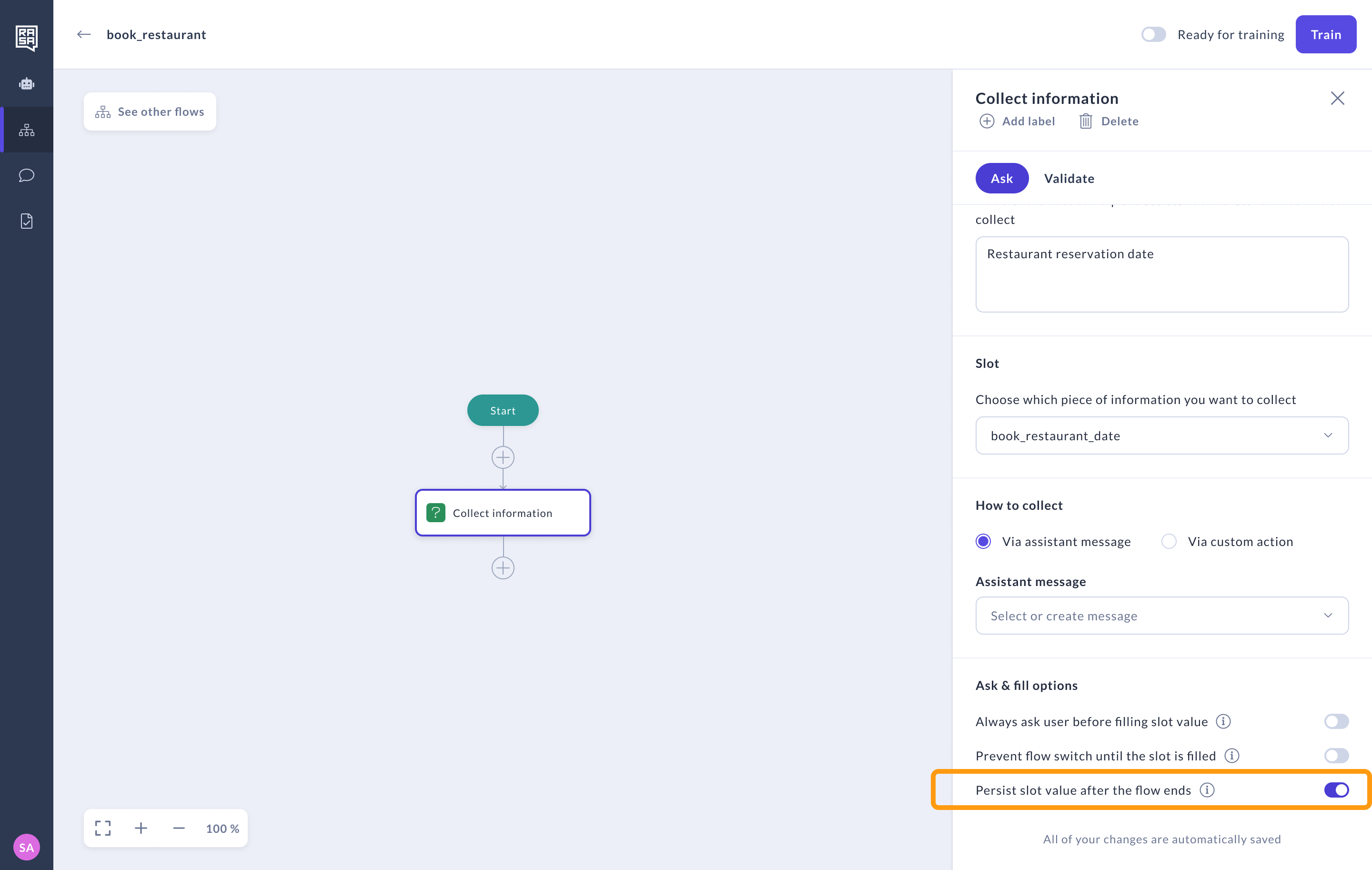
##### Silcence handling[](#silcence-handling "Direct link to Silcence handling")
If your Rasa license includes voice, you’ll see the **Silence handling** option. It sets how long the assistant waits during voice interactions before repeating the question and checking if the user is still there. You can define a global timeout in Assistant settings or override it per Collect step for questions that may need more response time.

#### Validate[](#validate "Direct link to Validate")
Validation is optional but sometimes you may want to validate a slot to ensure the user has provided the correct information before proceeding to the next step in the dialogue.
1. To do this, go to the **Validate** tab of **Collect information** step.
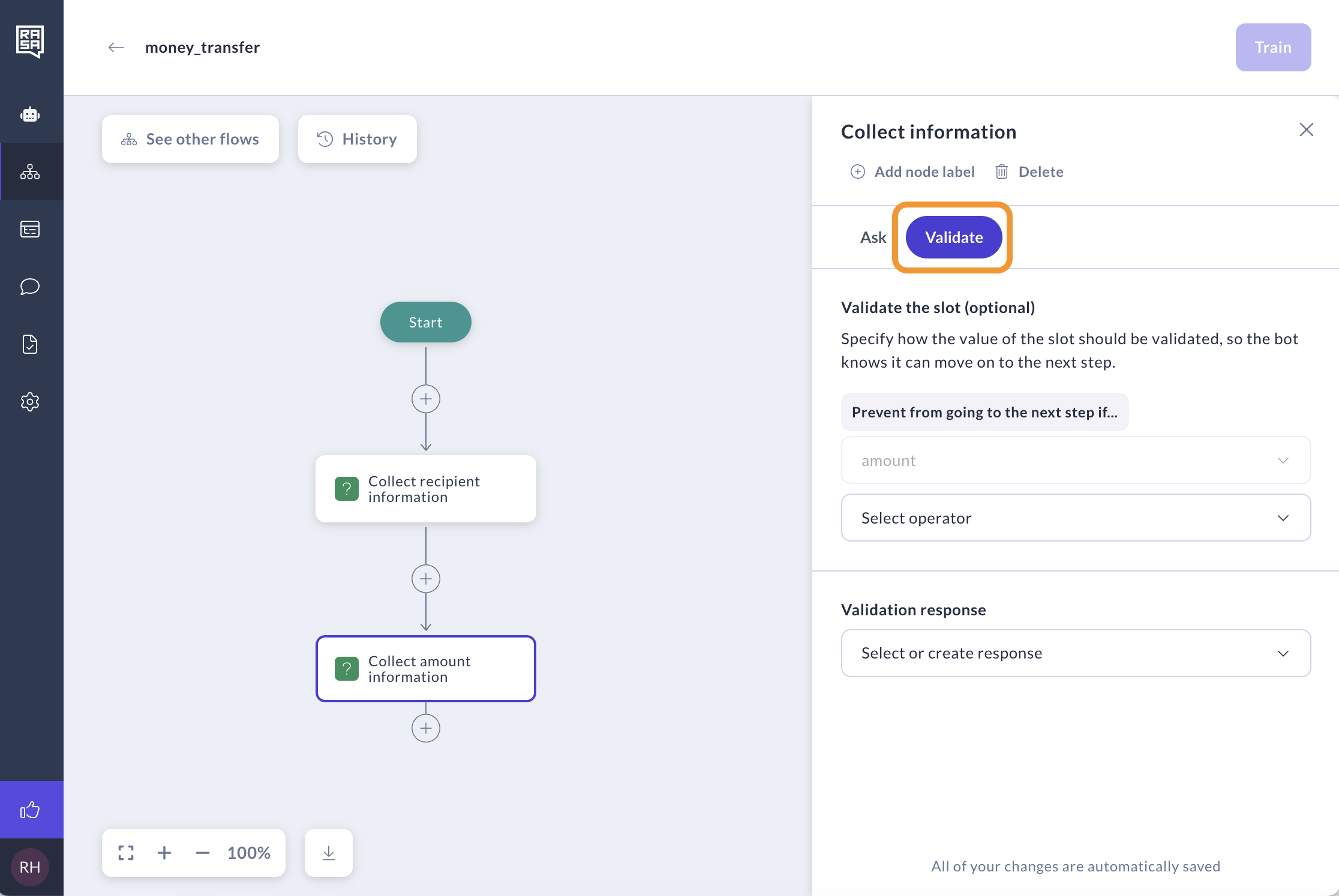
2. Prevent user from going to the next step if certain conditions are not met.
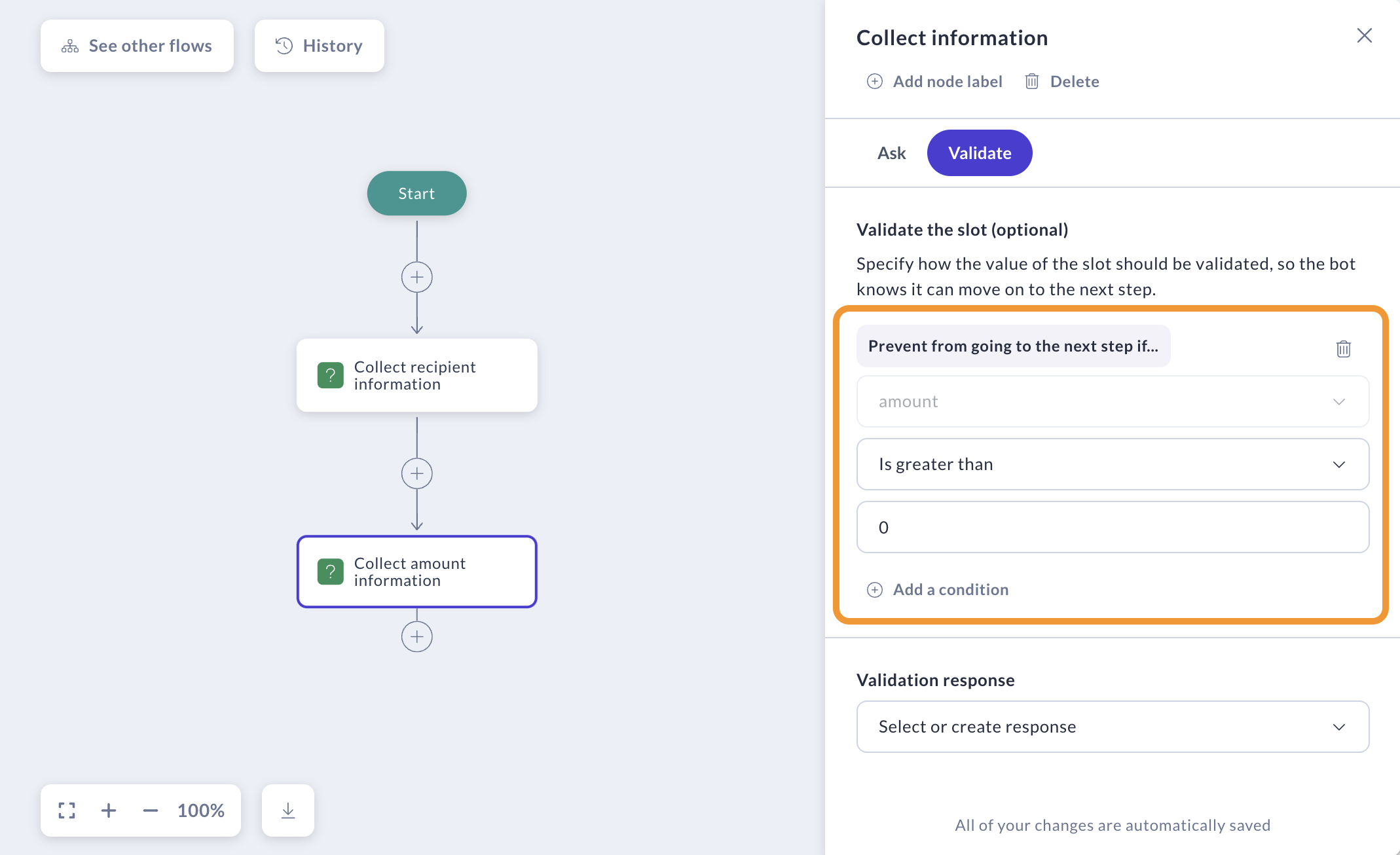
3. Click **Select or create response**. If the user's answer deviates from these values, a validation response will be displayed to them.
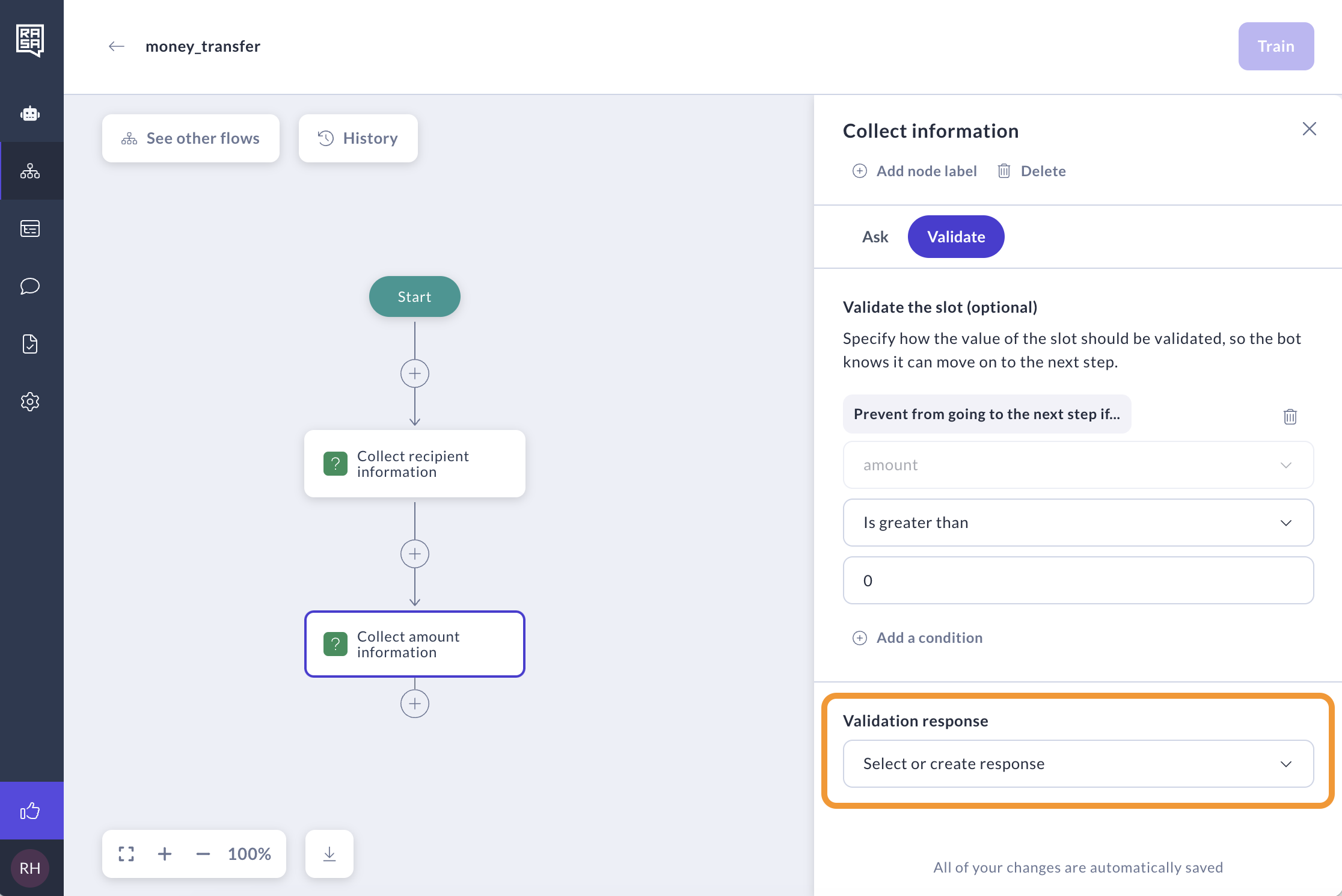
4. Select **Create new response**.

5. In the modal that appears, specify the text for the response, and then click "Save."

6. You can edit or delete previously created validation responses by clicking on the drop-down menu and choosing the **Manage responses** option in the modal that opens.
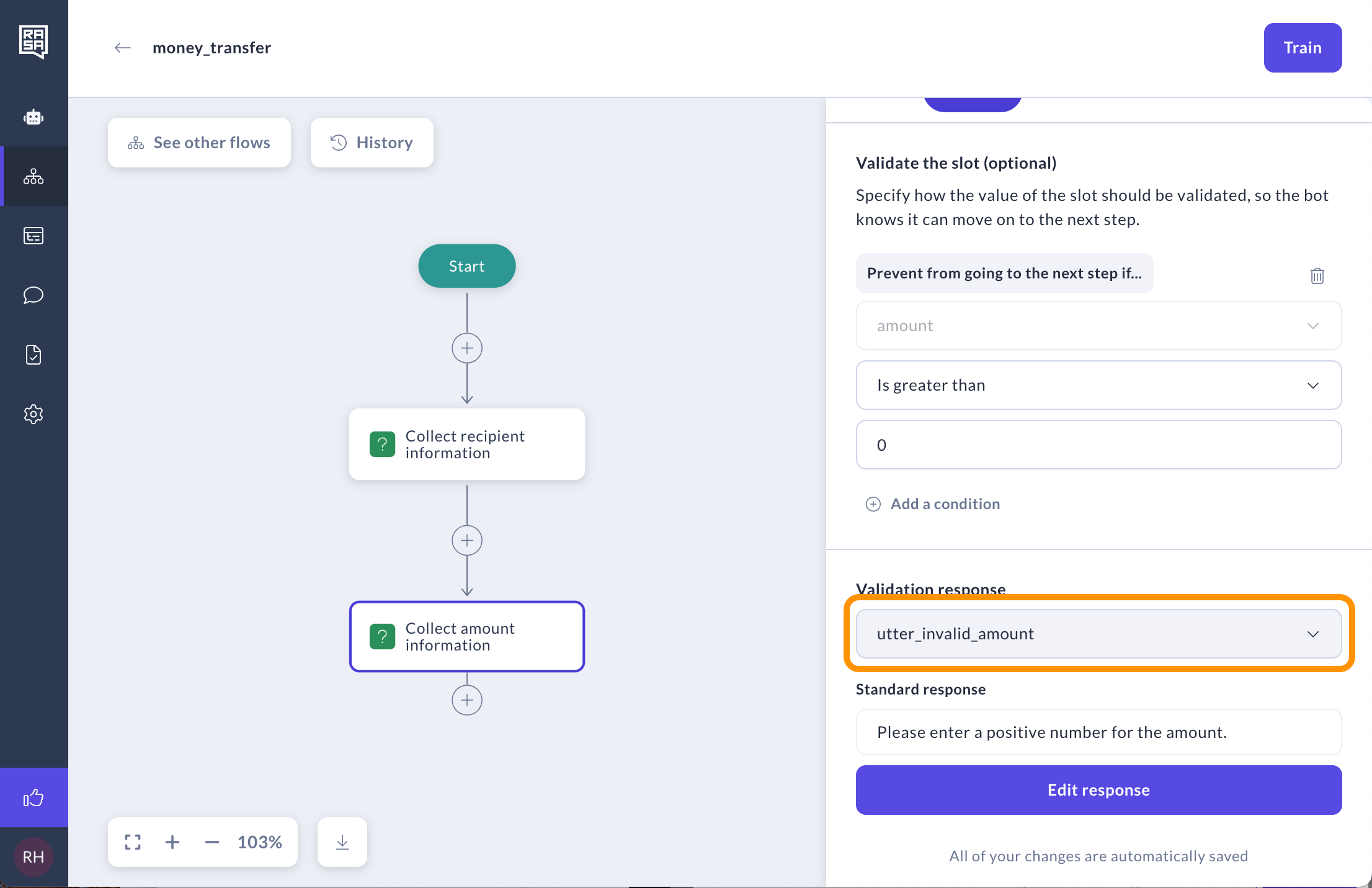 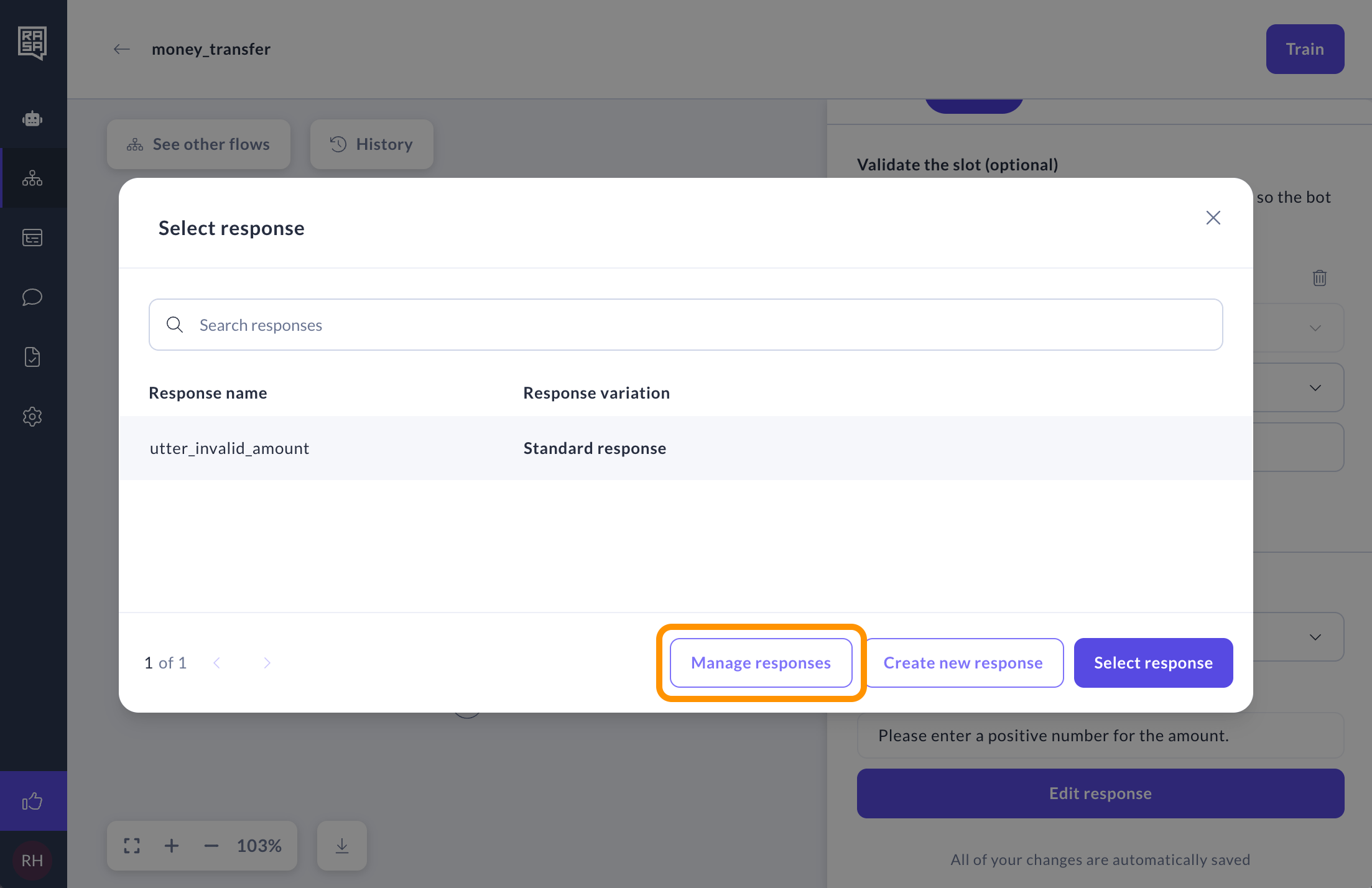
#### Slots[](#slots "Direct link to Slots")
##### What is a Slot?
Think of slots as your assistant’s memory. They store important pieces of information from the conversation, like a user’s name, date, or location, and can be referenced throughout the flow.
##### Slot types[](#slot-types "Direct link to Slot types")
###### Text[](#text "Direct link to Text")
A **text** slot is used to store textual information such as names of countries, cities, or personal names. It's designed to hold various types of alphanumeric characters, making it suitable for a wide range of textual data.
###### Boolean[](#boolean "Direct link to Boolean")
A **boolean** slot is designed to store binary information, representing either a true or false value. It's commonly used for yes/no questions or scenarios where only two opposing options exist, like true/false statements.
###### Categorical[](#categorical "Direct link to Categorical")
A **categorical** slot is used to store data that can take on one of a specific set of values. It's well-suited for scenarios where data can be classified into distinct categories, like labels such as low, medium, or high to describe levels of something.
###### Float[](#float "Direct link to Float")
A **float** slot is employed for storing numerical values that can have decimal points. It's suitable for handling continuous numeric data, such as age, temperature, or monetary amounts involving fractions.
###### Any[](#any "Direct link to Any")
An **any** slot is capable of storing a wide variety of data types without any specific constraints. It's a flexible option for cases where the data type might vary or is not well-defined in advance, allowing you to store arbitrary values with diverse characteristics.
#### Buttons[](#buttons "Direct link to Buttons")
You can make your assistant even more interactive by adding buttons to the responses in the Collect Information step. Instead of making users type, they can simply click on buttons to give their answers.
##### Button properties[](#button-properties "Direct link to Button properties")
A button has two important parts:
* **Title:** This is the text your users will see on the button.
* **Payload:** Think of this as a behind-the-scenes command the assistant uses when the button is clicked. You don’t have to fill it in unless you want to give your assistant extra instructions like skipping LLM calls and going straight to a specific command, intent, or entity.
##### How to add buttons[](#how-to-add-buttons "Direct link to How to add buttons")
1. Click **Add button** in your Collect information response.

2. Choose between reusing an existing button or creating a new one. If you create a new button, enter a title for it. This title will be the text displayed on the button for users to click.

3. Optional: If you want the button to bypass the LLM, choose a payload. Here are the types of things you can set it to do:
* **Intent** — triggers an intent.
* **Intent and entity** — passes entities along with the intent.
* **Set slot** — sends commands to set or reset slot values.
* **Text** — sends a predefined free-form text to the assistant. This should only be used if none of the above options apply.
* If you leave the field empty, it will automatically be pre-filled with the same text as the title.
4. Keep clicking **Add button** and fill in the information for as many buttons as you need.

5. If you want to reuse an existing button, select **Use existing button** and choose the button you'd like to use from the dropdown menu.
6. Use the icons next to the buttons to edit or delete them from the response.

##### Reordering buttons[](#reordering-buttons "Direct link to Reordering buttons")
You can drag and drop buttons directly in the response editor — giving you full control over the order in which options are shown to users.

#### Slot Mappings (Advanced)[](#slot-mappings-advanced "Direct link to Slot Mappings (Advanced)")
Use slot mappings to control how slot values are extracted.
##### From LLM[](#from-llm "Direct link to From LLM")
By default, the slot value is extracted from the user's message using an LLM, which interprets the message and fills the slot accordingly. The prompt includes descriptions and slot definitions from each flow as relevant information. However, if your assistant includes NLU components (intents and entities), you might consider using alternative extraction methods.
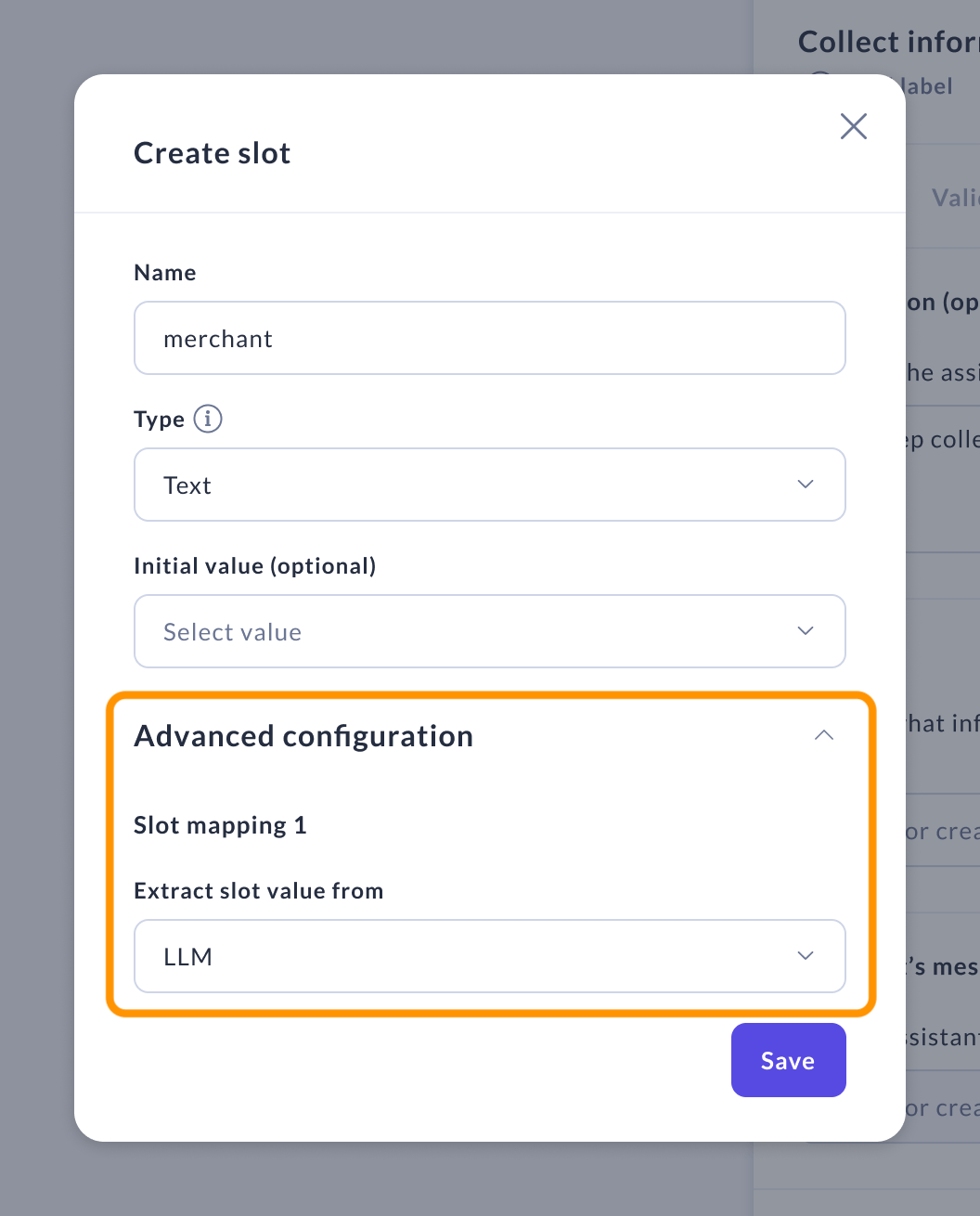
##### From text[](#from-text "Direct link to From text")
This mapping type uses the text of the last user message to fill the slot. Optionally it can be configured with the following parameters:
* **Intent** — Only applies the mapping when this intent is predicted.
* **Intent is not** — Excludes the mapping when this intent is predicted.
* **Active flows** — Restricts the mapping to certain flows, selectable in this field.
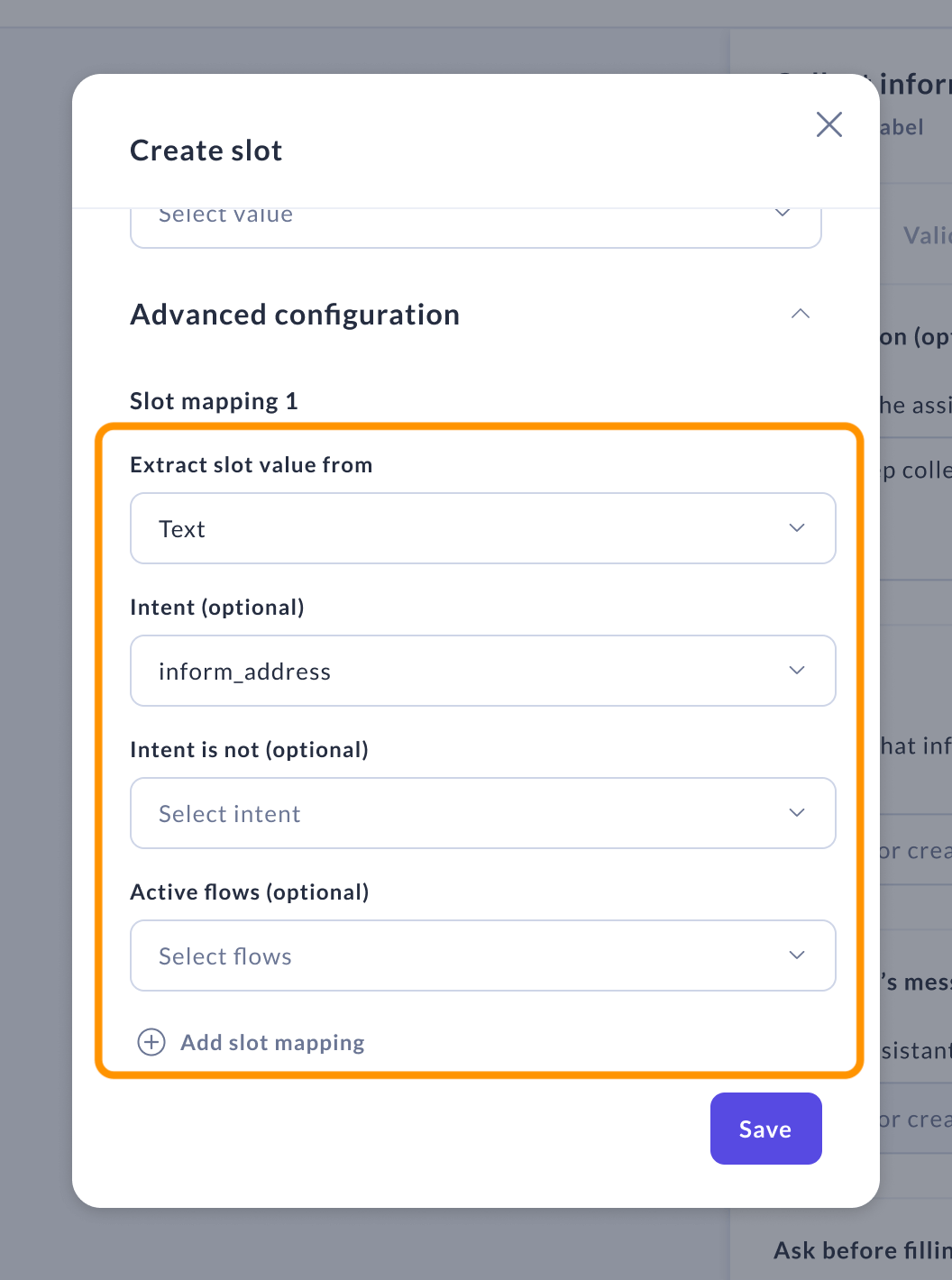
##### From entity[](#from-entity "Direct link to From entity")
This mapping type fills slots based on extracted entities. The following parameters are required:
* **Entity** — The entity used to fill the slot.
Optional parameters to specify the application of the mapping include:
* **Intent** — Applies only when this intent is predicted.
* **Intent is not** — Excludes the mapping when this intent is predicted.
* **Role** — Applies only if the extracted entity has this specified role.
* **Active flows** — Restricts the mapping to certain flows, selectable in this field.
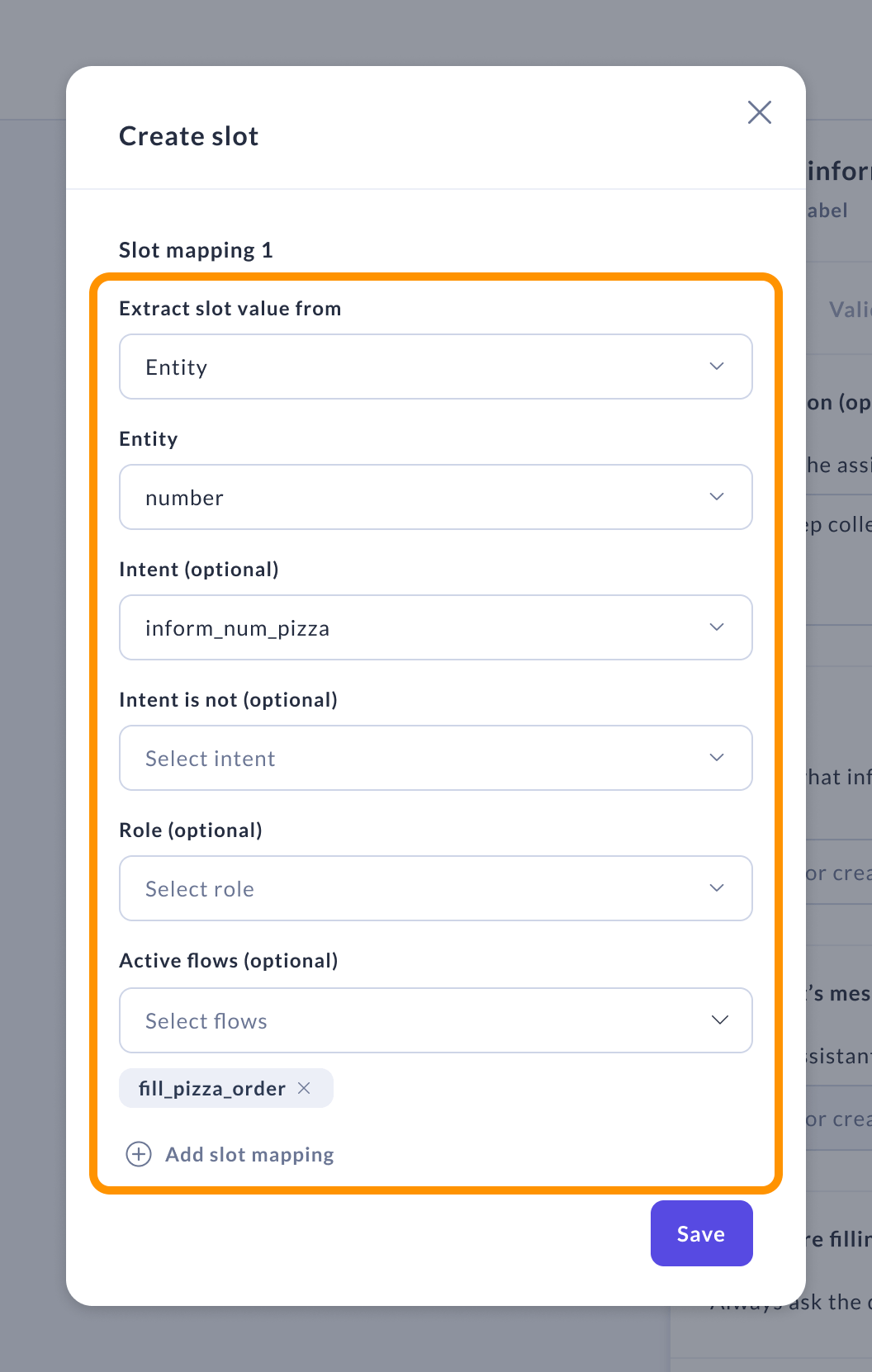
##### From intent[](#from-intent "Direct link to From intent")
This mapping fills a slot with a specified value if the user's intent matches. If no intent is specified, the slot fills regardless, unless the intent matches those listed under "Intent is not."
Required parameter:
* **Value** — The value to fill the slot.
Optional parameters include:
* **Intent** — Applies the mapping only when this intent is predicted.
* **Intent is not** — Excludes the mapping when this intent is predicted.
* **Active flows** — Restricts the mapping to certain flows, selectable in this field.
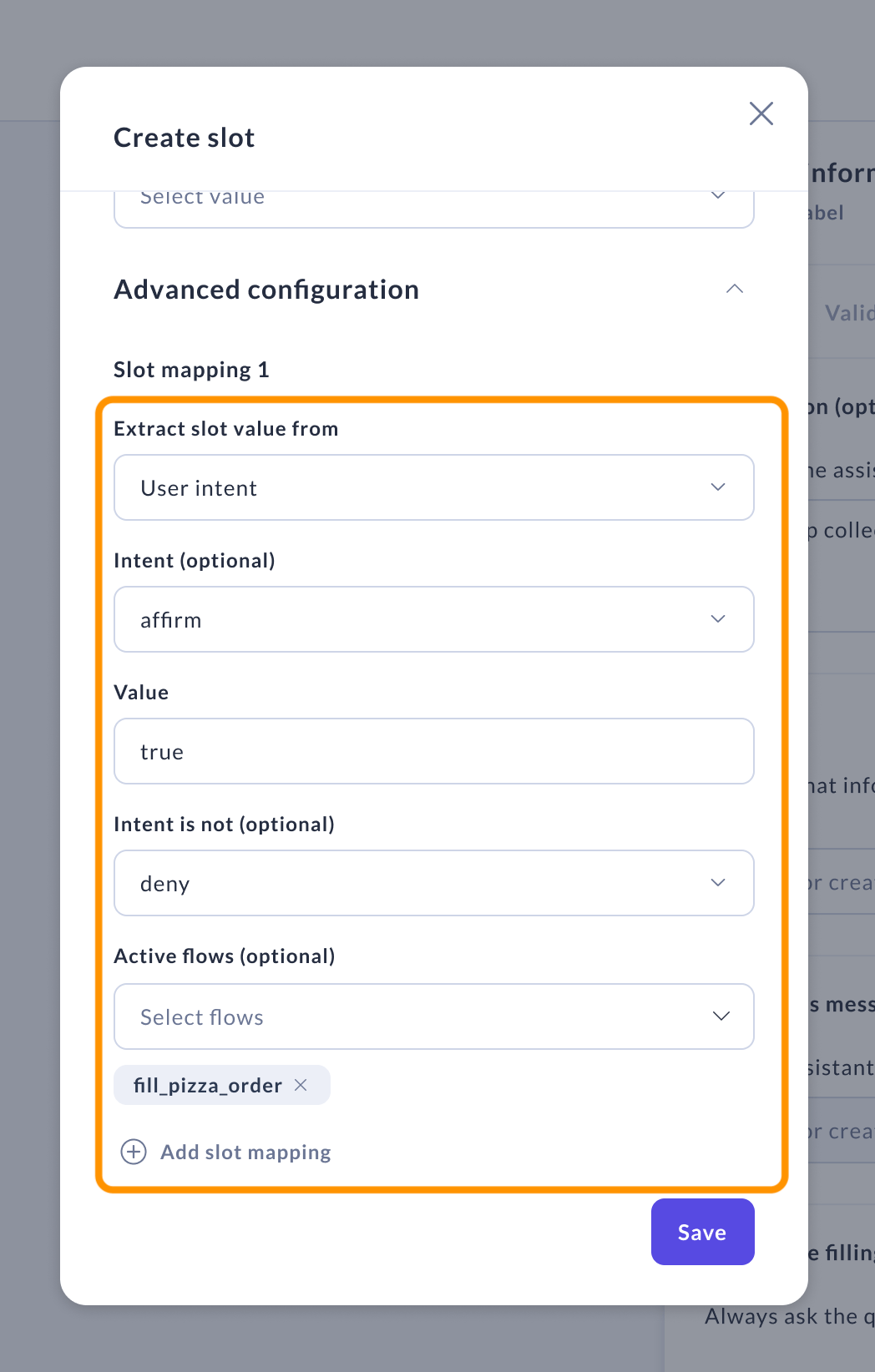
##### From custom action[](#from-custom-action "Direct link to From custom action")
Use the "From custom action" mapping type for slots that need to be filled by a specified [custom action](https://rasa.com/docs/docs/studio/build/actions/create-a-custom-action/). This action must be detailed in the "Custom action" field of the slot mapping.
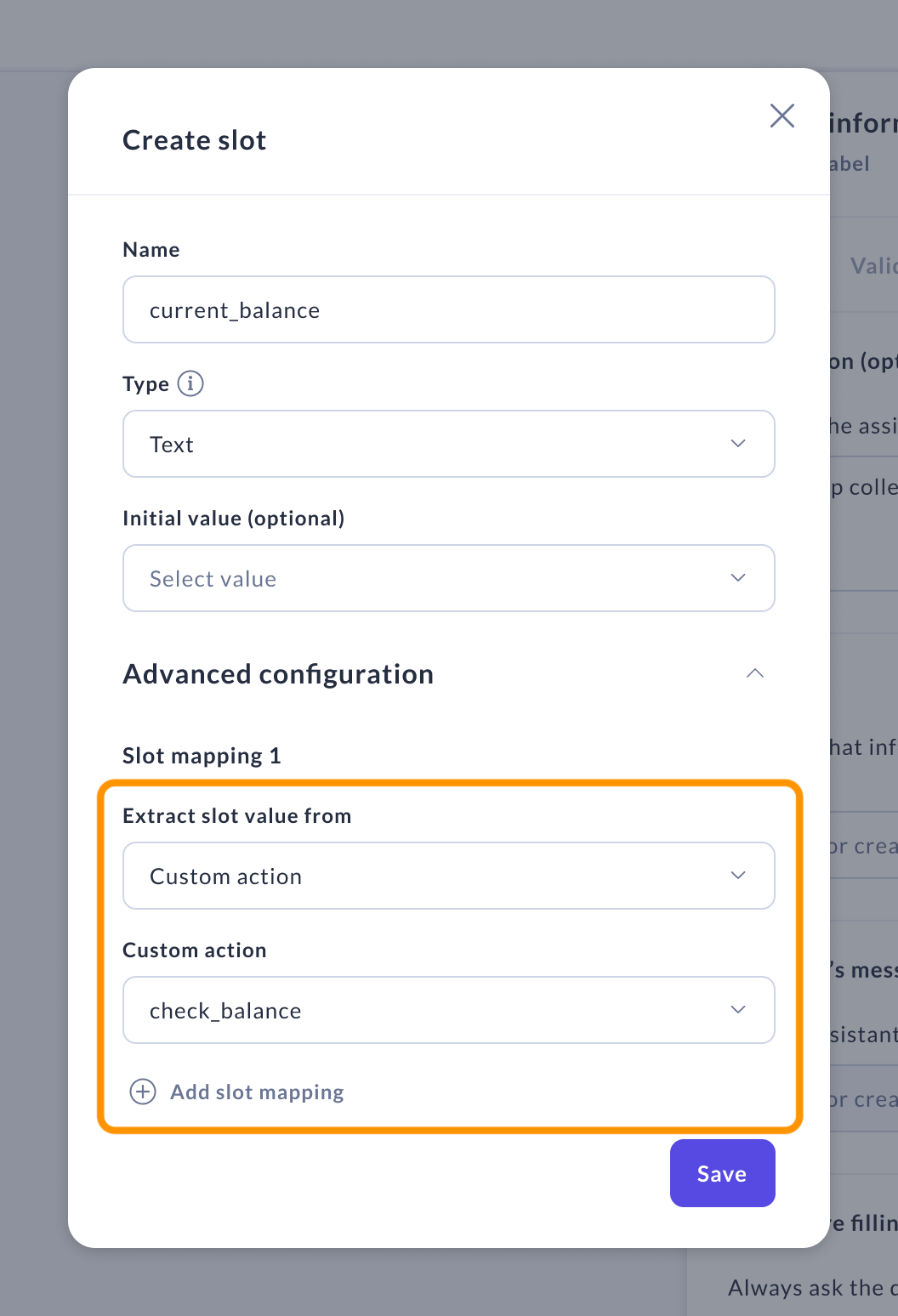
In case you use multiple mappings for one slot, they will be prioritized in the order they are listed. The first slot mapping found to apply will be used to fill the slot.
Recommendation on combining slot mapping types
A slot cannot have both "From LLM" and NLU-based predefined mappings or mappings from custom actions simultaneously. If you set a slot to use the "From LLM" mapping, you must not define any other types of mappings for that slot.
[Learn more about slot mappings](https://rasa.com/docs/docs/reference/config/domain/#slots)
---
#### How to Create a Custom Action
This guide will show you how to use **Custom Actions** in Rasa Studio to integrate data from sources like databases or APIs. Custom actions allow your assistant to fetch information, update records, and connect with external tools, improving the quality and relevance of conversations.
##### What are Custom Actions?
Custom Actions allow your assistant to execute any code you define as part of a flow. This could include tasks like retrieving account details, booking a meeting, or retrieving data from external systems.
#### How to create Custom action[](#how-to-create-custom-action "Direct link to How to create Custom action")
1. Select the "Custom Action" step from the menu. 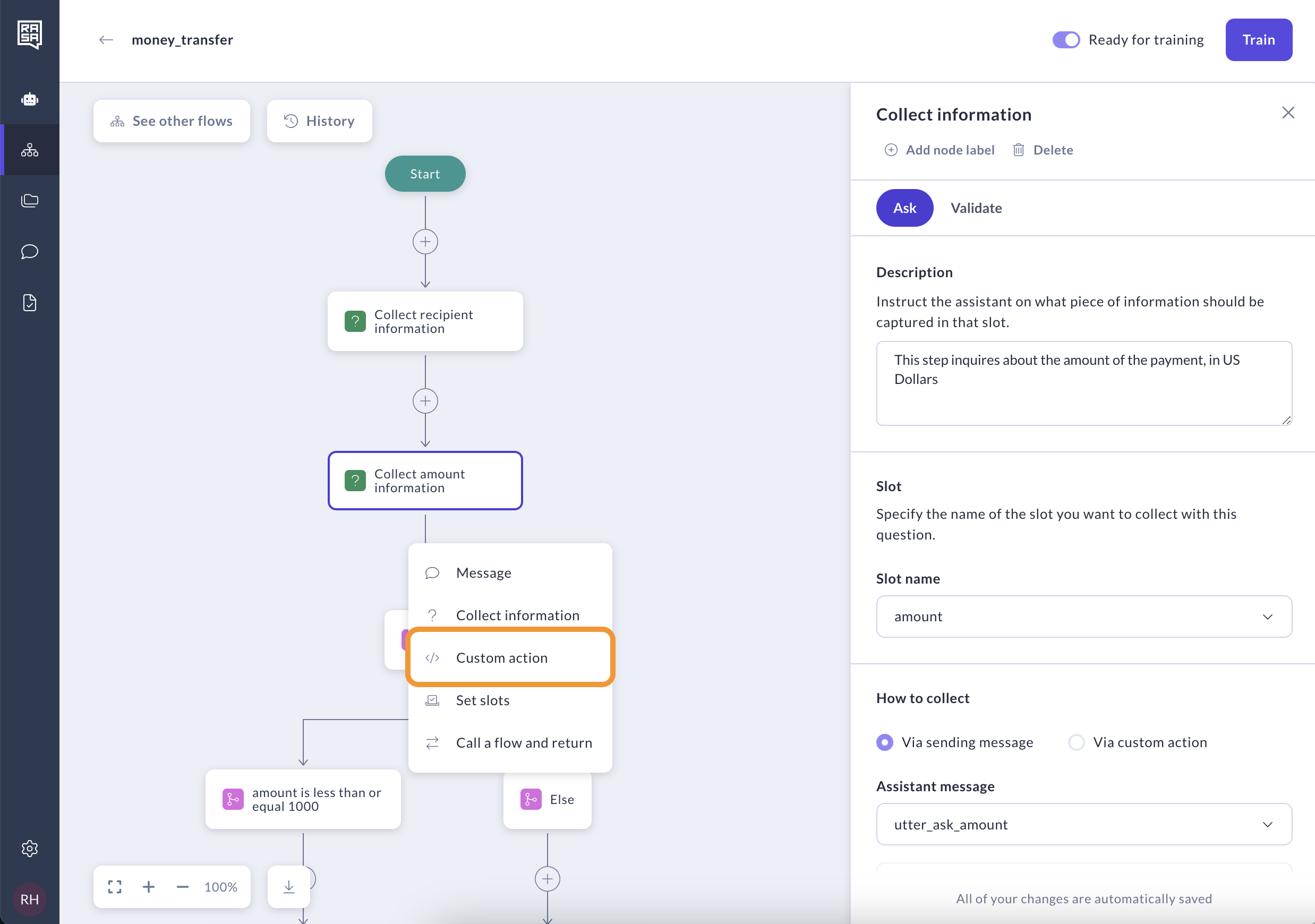
2. Select an existing custom action or click on "Create custom action" to create a new one. 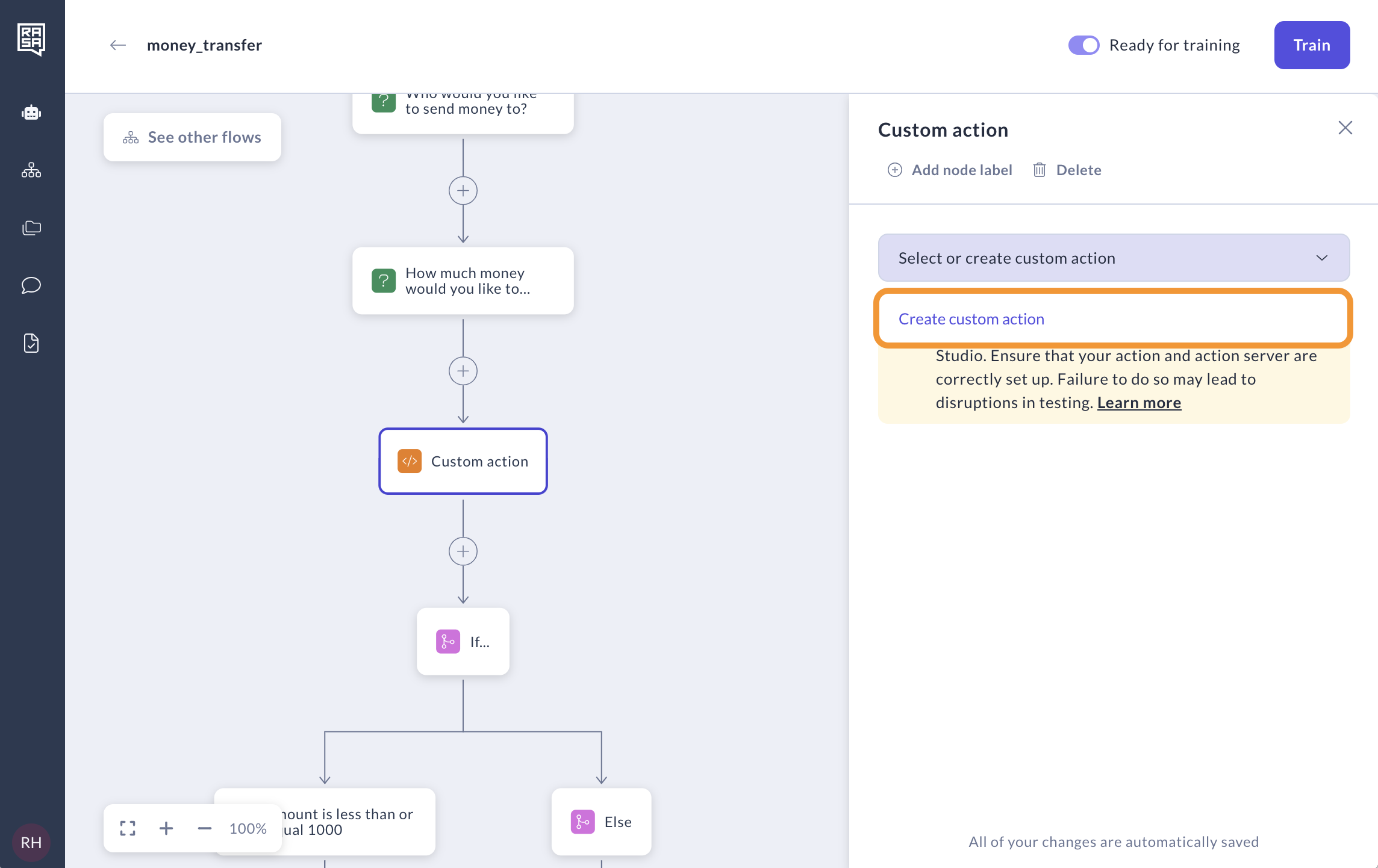
3. In the window that appears, enter the name of the custom action, ensuring it exactly matches the one implemented in your Docker container. In the "Description field "provide a detailed description of what the action does in free form. Note: This description will be read by whoever implements this action so it should describe what this action should achieve, what slot(s) it should use and what slot value to return in which case.

4. You can edit the name or description of a custom action, or delete it, by selecting "Manage custom actions" from the drop-down menu. Note that when you use a custom action in many places, when you edit or delete this action, it will also affect other flows and steps as well. 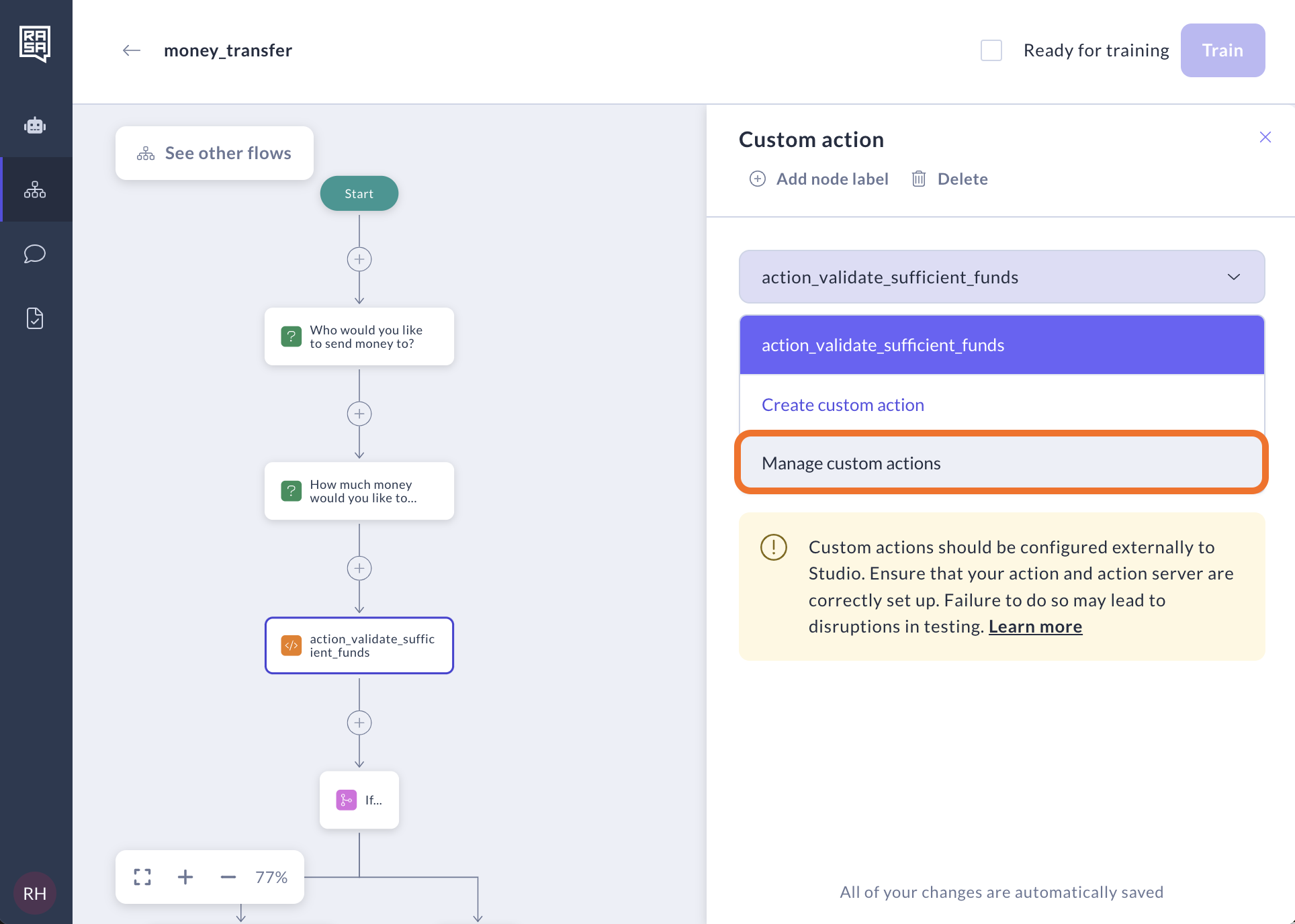
---
#### How to Create a Flow
This guide will teach you to create a flow in Rasa Studio, the foundation of your assistant’s conversational logic. By the end, you’ll know how to name, describe, and build a flow.
#### Get Started[](#get-started "Direct link to Get Started")
1. Go to the Flow builder page
2. Hit the "Create flow" button.

3. For your flow's ID, avoid spaces, +, / or ! symbols. In the "Description" field, provide a detailed summary of the flow's purpose. This description is what will be used by LLM to decide when your flow should be triggered. Once you're set, click "Save".

---
#### How to Edit System Flows
In an ideal conversation, known as the "happy path," the assistant asks for information, and the user provides the correct response, allowing the conversation to flow smoothly. But in reality, conversations don’t always follow that perfect path. This is where system flows, come in.
System Flows in Rasa
It's important to note that there is a **naming difference** in Studio vs the rest of Rasa for this feature.
What is called a **System Flow** in Studio is called a **Pattern** in Rasa. To see a complete list of what patterns are included in Rasa and detailed specs take a look at [the reference](https://rasa.com/docs/docs/reference/primitives/patterns/).
##### A Short Intro to System Flows[](#a-short-intro-to-system-flows "Direct link to A Short Intro to System Flows")
System flows are pre-built flows available out of the box, designed to handle conversations that go off track. For example, they help when:
* The assistant asks for information (like an amount of money), but the user responds with something else.
* The user interrupts the current flow and changes the topic.
* The user changes their mind about something they said earlier.
If you're interested into diving more into detail about system flows and how they work, you can read more in the Learn section on [Conversation Patterns](https://rasa.com/docs/docs/learn/concepts/conversation-patterns/).
##### System Flows in Studio[](#system-flows-in-studio "Direct link to System Flows in Studio")
To find system flows, navigate to the **System Flows** tab of the Flows page.
##### Modifying system flows[](#modifying-system-flows "Direct link to Modifying system flows")
The default version of system flows is always included in your assistant model out of the box. While you can't disable them—since they are essential for the smooth functioning of your assistant—you can fully customize them to suit your specific business needs and conversation design best practices.
##### Editing system flow texts[](#editing-system-flow-texts "Direct link to Editing system flow texts")
To change the default text used in a system flow, you can override the message with a new one. Here's how:
Select the step in a system flow you want to customize.
Click on the message name in the right panel and choose the "Create message" option.
In the modal that opens, specify the new message name and text, then click Save.
The message is now replaced.
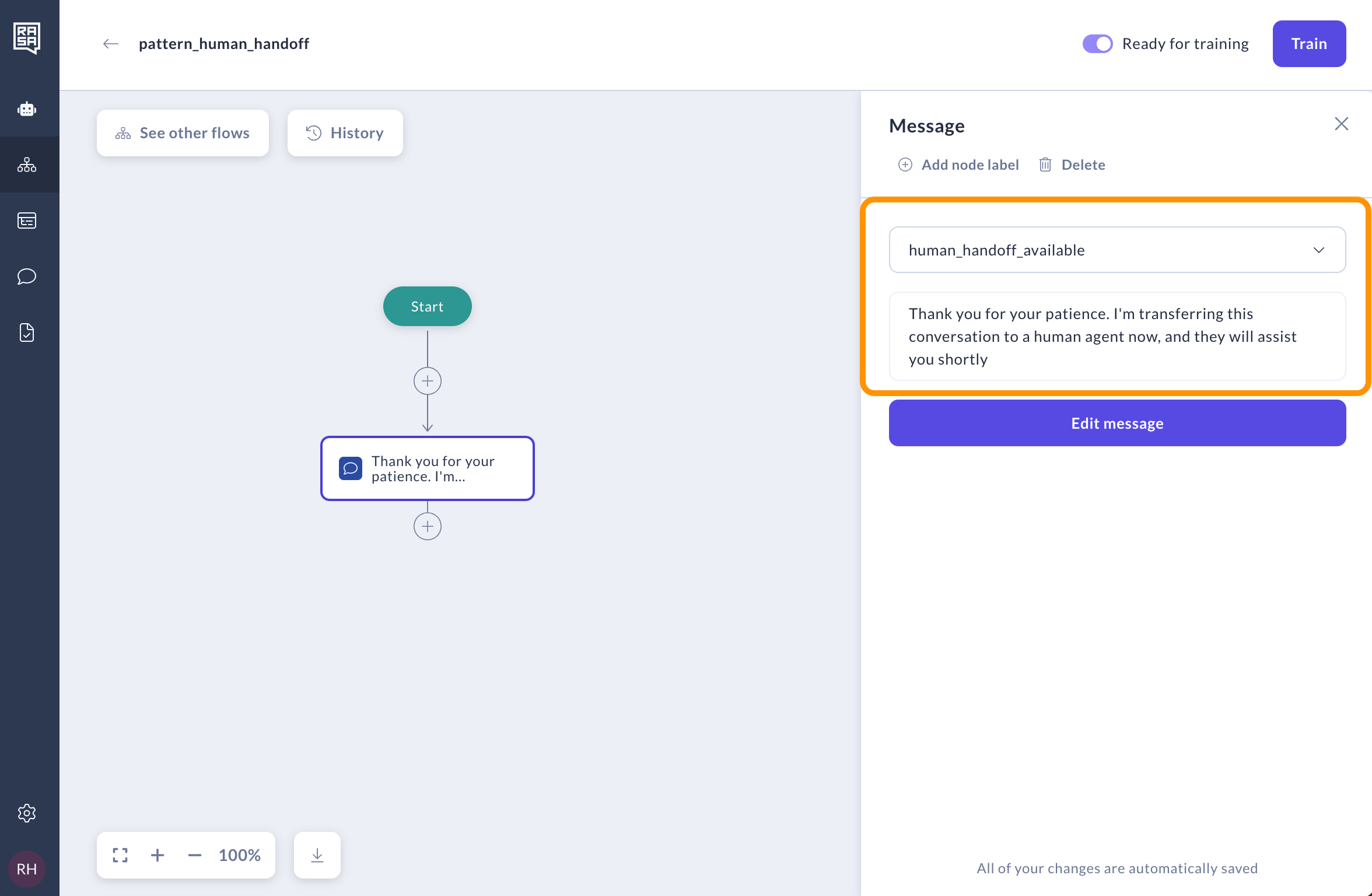
##### Overriding system flow logic[](#overriding-system-flow-logic "Direct link to Overriding system flow logic")
You can modify system flows just like custom ones by adding or removing steps. Let’s walk through an example of modifying the `pattern_completed` system flow that asks if the user needs more help after completing their goals or ending a conversation.
By default, the `pattern_completed` has one step—a message that asks, "What else can I help you with?" This message will be presented to the user after each flow ends unless there are specific links to other flows. However, after some flows, such as a greeting, we may want to skip this question, especially when the assistant hasn't provided any help yet. 
To reconfigure the system flow so that the question is skipped after specific flows, we can add a Logic branch before the message to specify those flows.
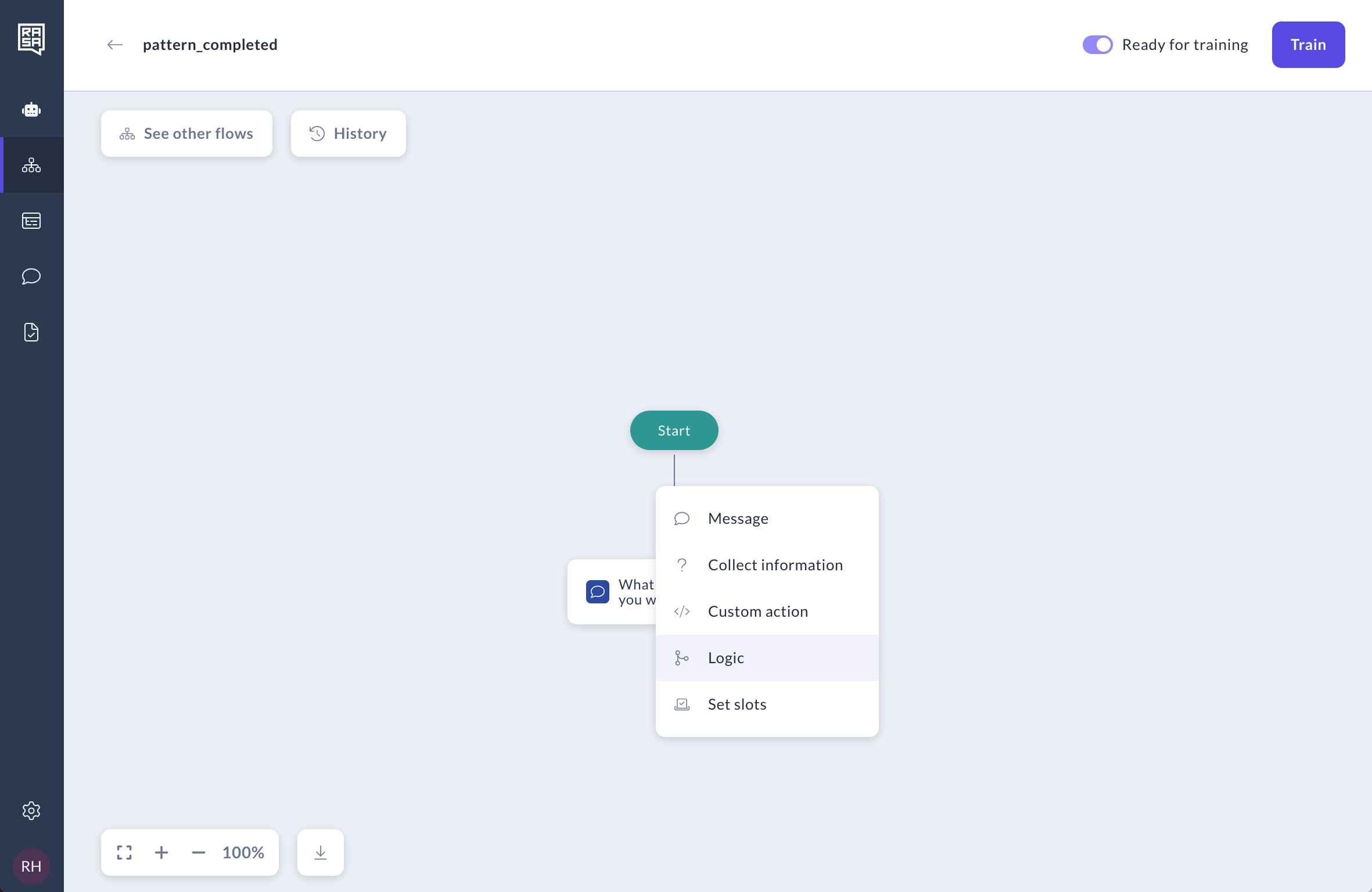
In the first logic branch, select the context "previous flow name" and specify that the previous flow shouldn't be the one that greets the user.
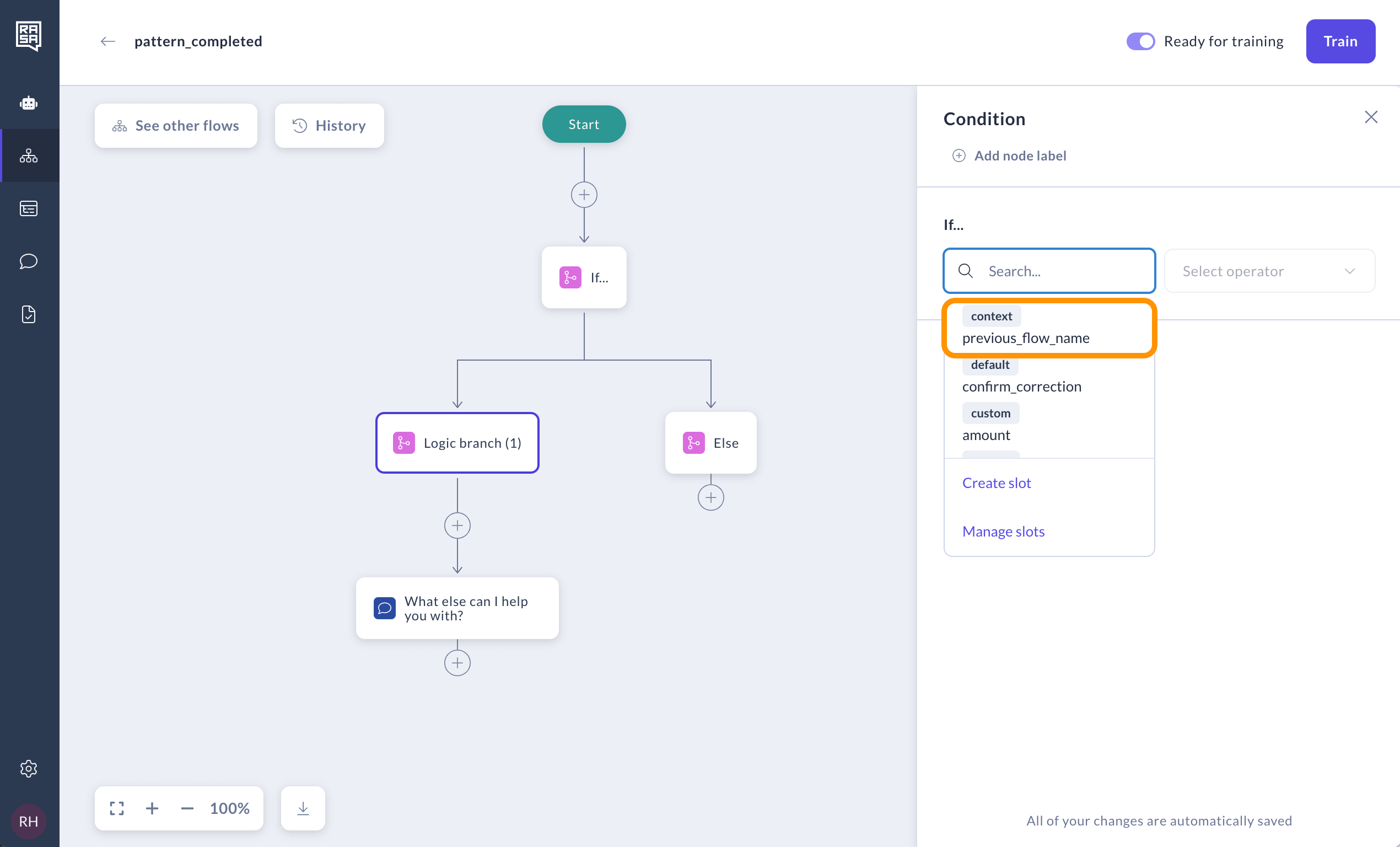
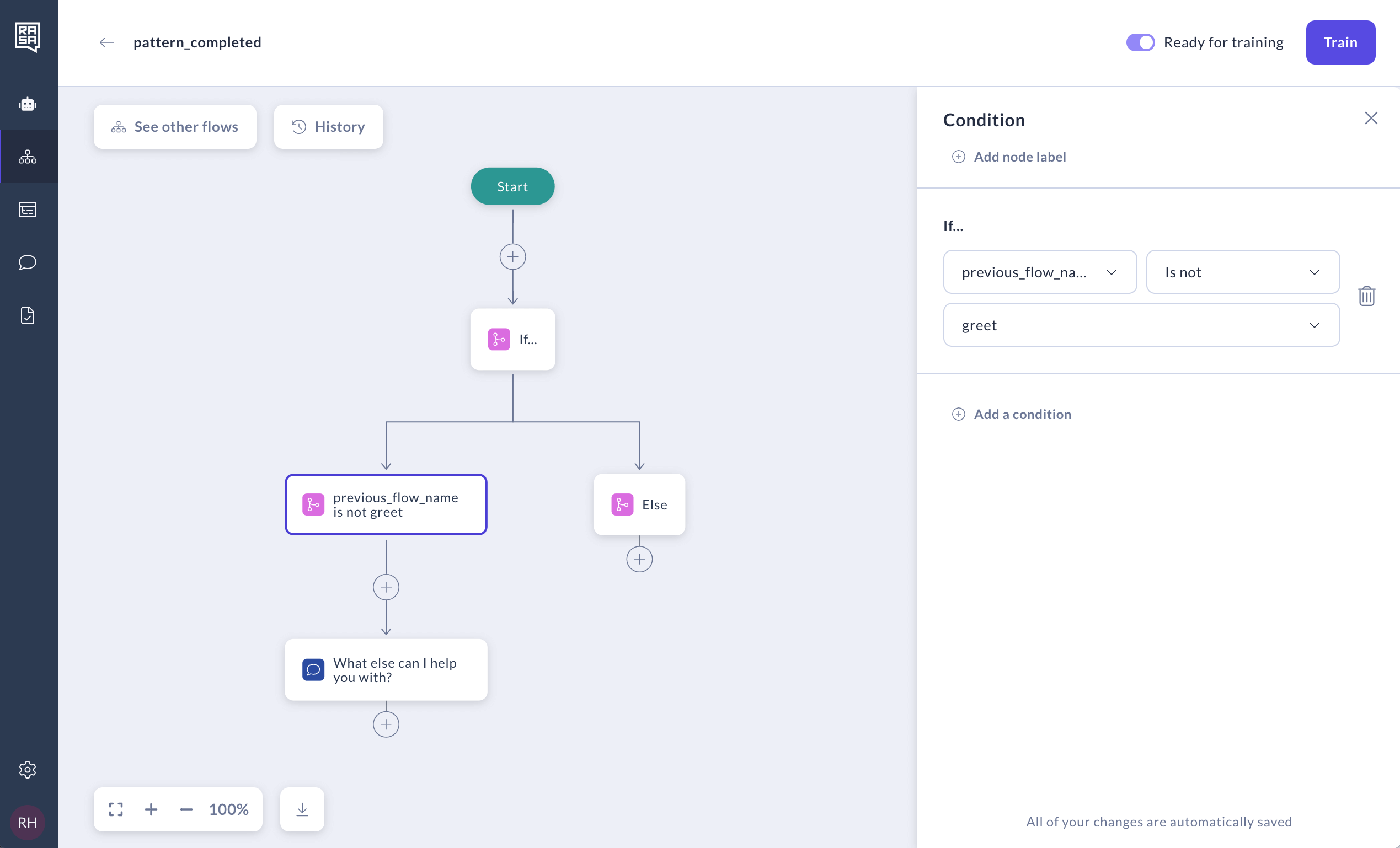
For the **Else** branch, which now handles the case after the "greet" flow, we want the assistant to remain silent and wait for the next question from the user, so we leave it empty.
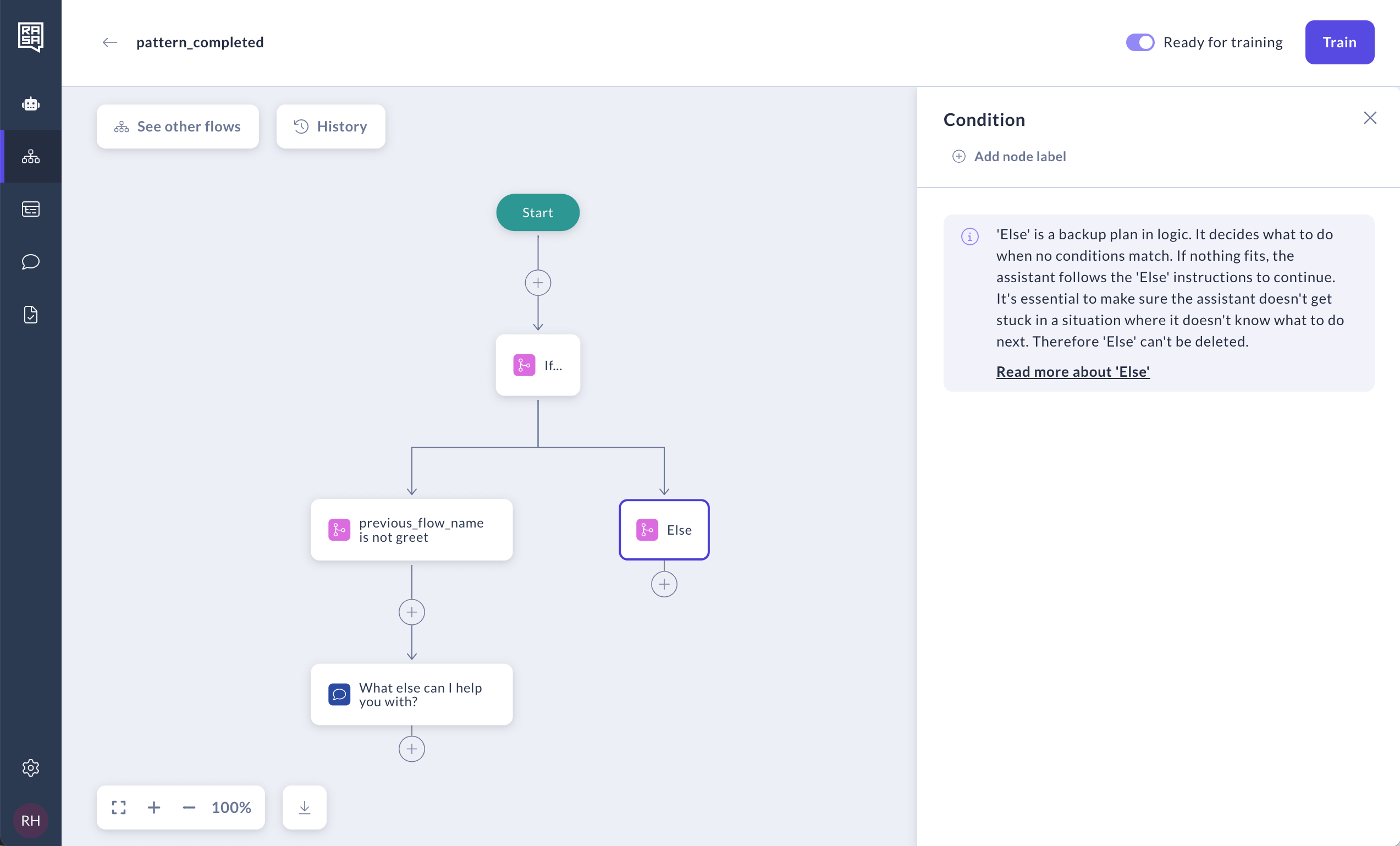
After modifying a system flow, make sure to re-train your assistant and test the changes on the Try your assistant page. Resetting to default
After customizing a system flow, you will see the "Customized" label next to it. If you want to cancel your updates and reset a system flow to its default configuration, simply hover over it in the table and click the "Reset to default" button.
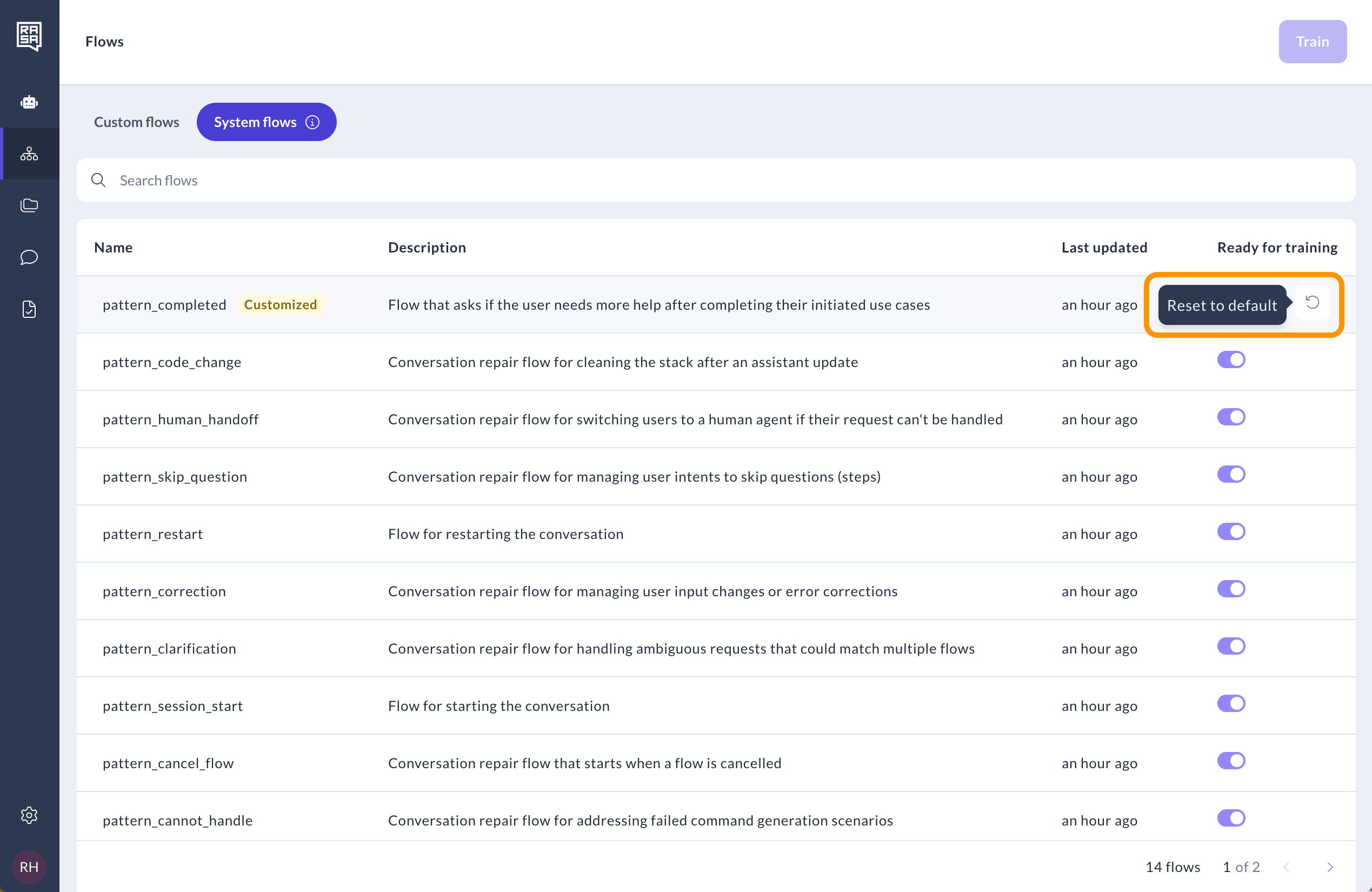
##### Enabling Enterprise search policy via `pattern_search`[](#enabling-enterprise-search-policy-via-pattern_search "Direct link to enabling-enterprise-search-policy-via-pattern_search")
You can enable the Enterprise search policy in Studio and integrate knowledge base document search by modifying assistant configuration and `pattern_search`.
Log in with a `superuser` or `developer` role to access Assistant configuration.
Go to the "System flows" tab and open `pattern_search` to modify it.

Delete the message and add the custom action step instead. In the right panel, select the action named `action_trigger_search`.

Go to the Assistant settings page to modify the configuration.
In the config.yml field, add Enterprise Search Policy and specify the type of your vector store.

In the endpoints.yml, set up the connection to your vector store. Click "Save".

Train your assistant and test it on the Try your assistant page. You will be able to see the answers generated by the Enterprise search.
---
#### How to Link, Call and Connect Flows
This guide will teach you how to **Link**, **Call**, and **Connect Steps** in Rasa Studio to structure and streamline your assistant’s logic.
You’ll learn what each step does, when to use it, and how these tools can help you build clean, modular flows that are easy to scale and maintain.
#### Link Steps[](#link-steps "Direct link to Link Steps")
##### What is a Link?
A link is a mechanism in Rasa that connects flows together, enabling smooth transitions between business logic.
1. **Add a Link Step:** Select the "Link" option from the menu.
2. **Choose a Target Flow:** Select an existing flow or create a new one.
3. **Fill in Details (if creating a new flow):** Enter the necessary information in the modal that opens.
note
A **Link** step hands over control to another flow and does **not** return to the original flow. Use this when the new flow should take over the rest of the conversation.
#### Call Steps[](#call-steps "Direct link to Call Steps")
##### What are Call Steps?
A call step is a mechanism in Rasa that enables one flow to switch to another, complete tasks there, and then return, treating the second flow as a seamless extension of the first.
1. **Add a Call Step:** Select the "Call a flow and return" option from the menu.
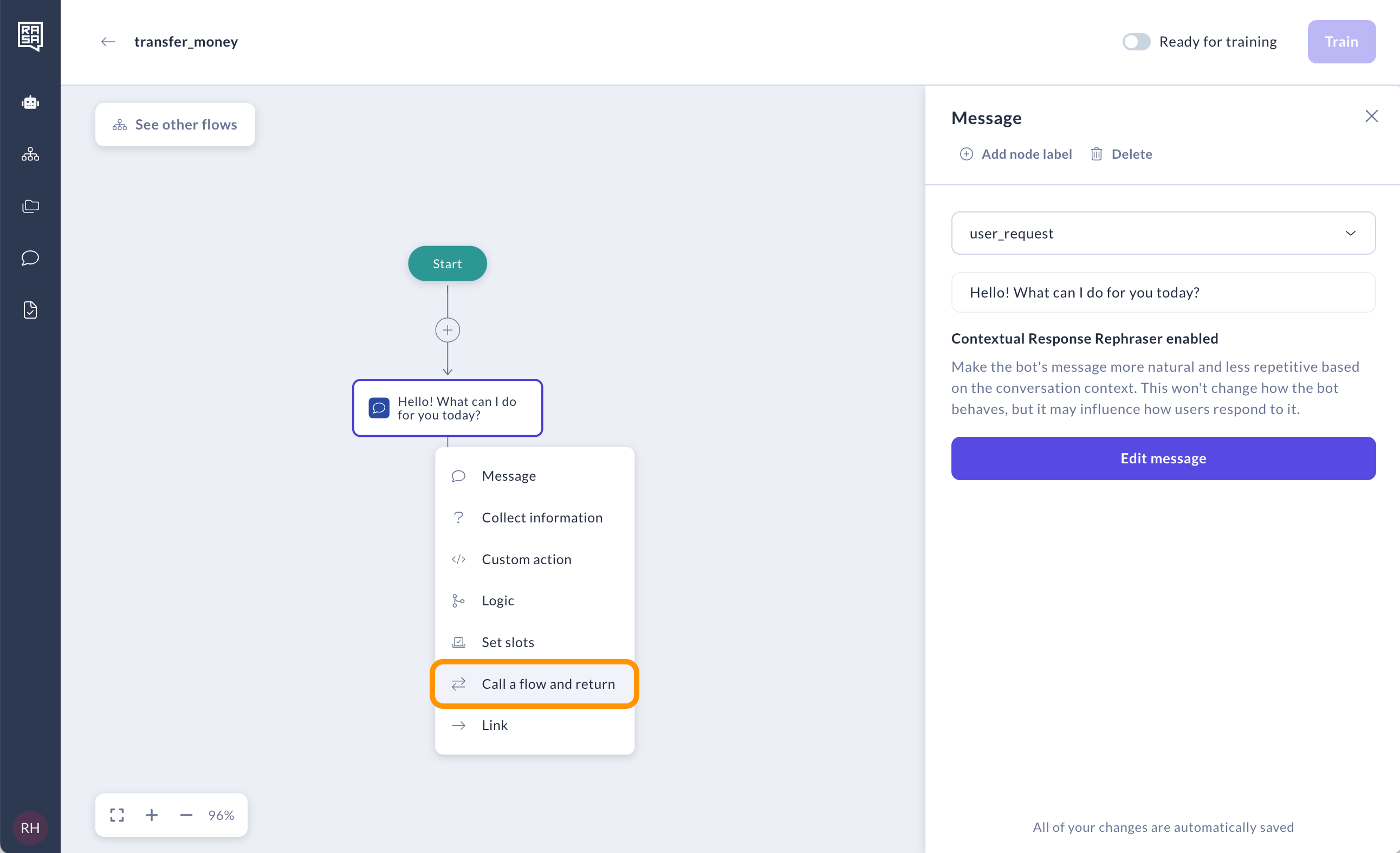
2. **Choose a Target Flow:** Select an existing flow or create a new one.
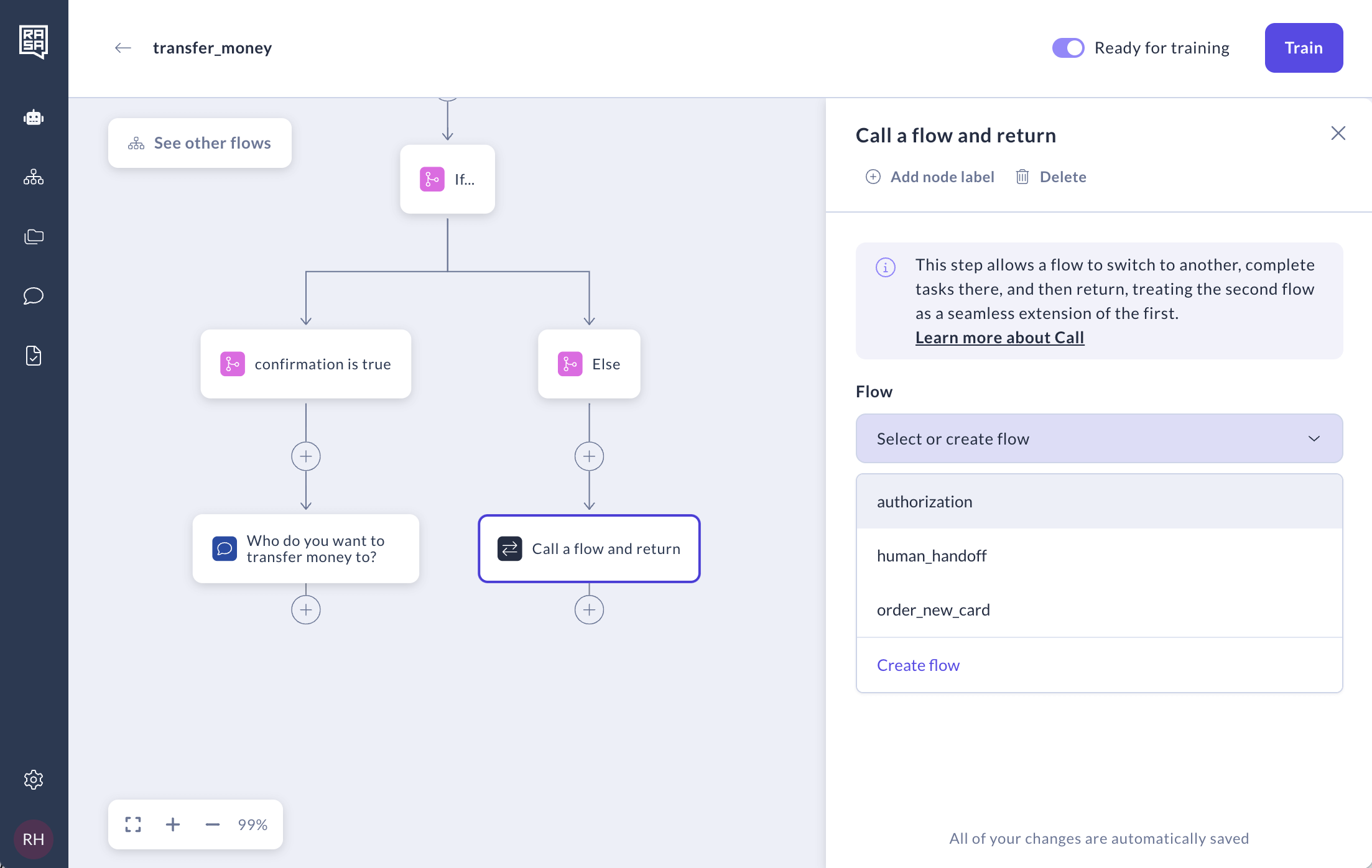
3. **Fill in Details (if creating a new flow):** Enter the necessary information in the modal that opens.
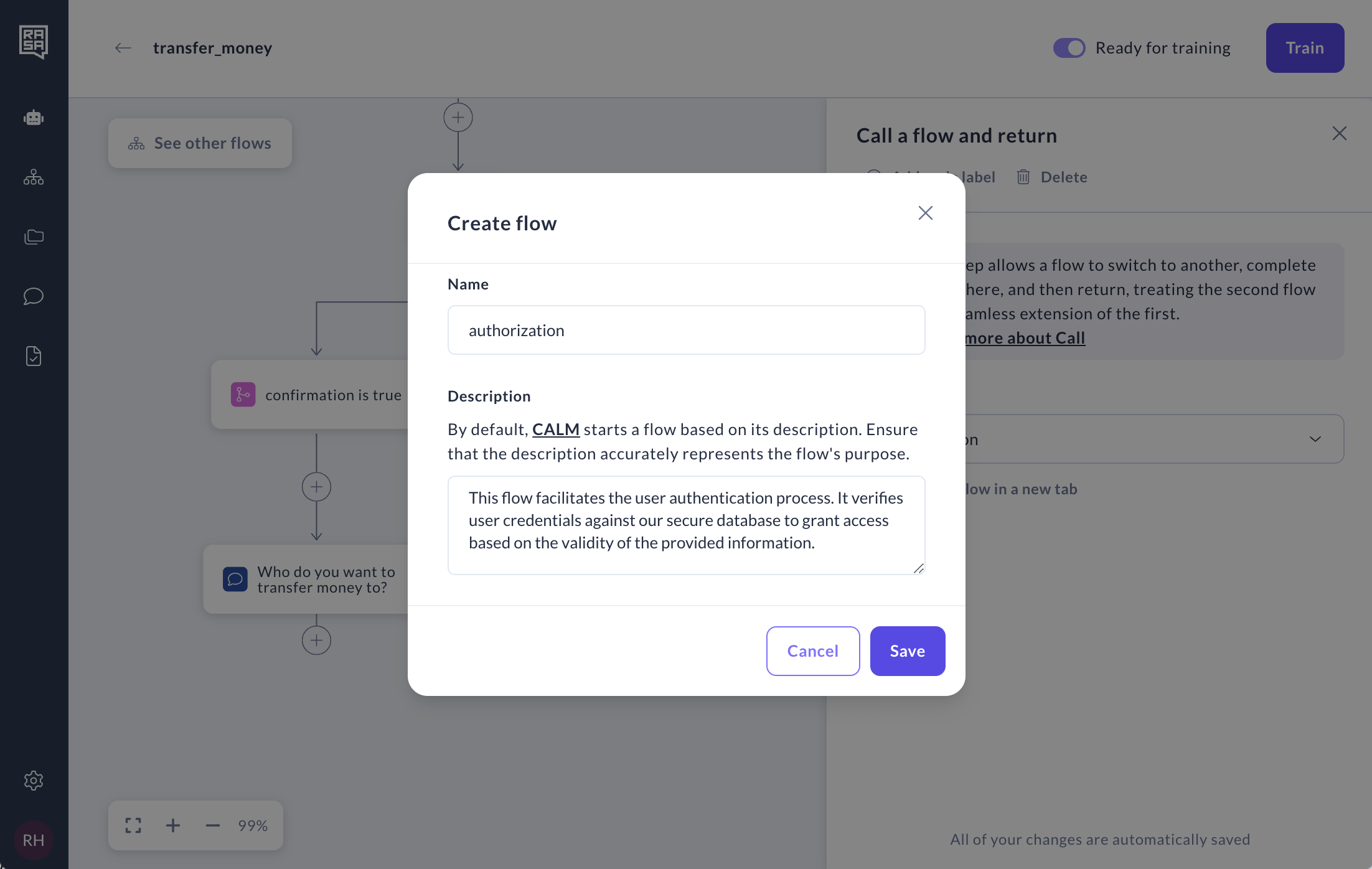
4. **Return to the Original Flow:** After the target flow finishes, control returns to the current flow and the conversation continues from the following step.
note
A **Call** step temporarily moves the conversation to another flow and returns after the target flow finishes. It's useful for handling sub-tasks like gathering user input or performing lookups.
#### Connecting Steps Within a Flow[](#connecting-steps-within-a-flow "Direct link to Connecting Steps Within a Flow")
Use connections to move between steps within the same flow — whether you're progressing, looping back, or merging branches.
To create a new connection:
1. **Open the Action Menu:** Select “Connect to” from the menu. 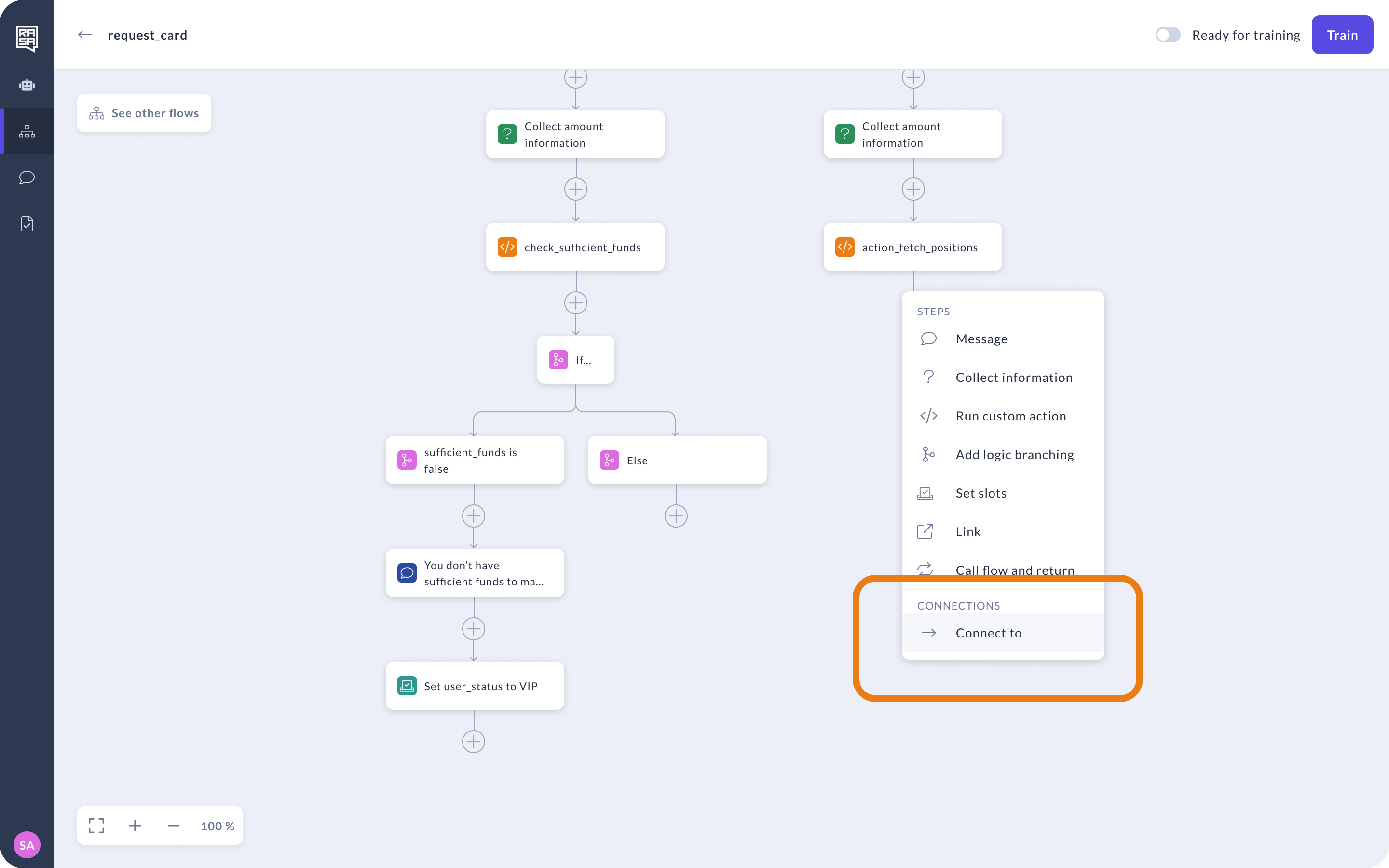
2. **Choose a Target Step:** Select the step that you want to connect to. This can be earlier in the flow (to loop) or later in the flow (to converge).
📌 *You can’t connect directly to a condition. Conditions are part of a step, not standalone steps. To route logic through a condition, connect to the step that contains it.* 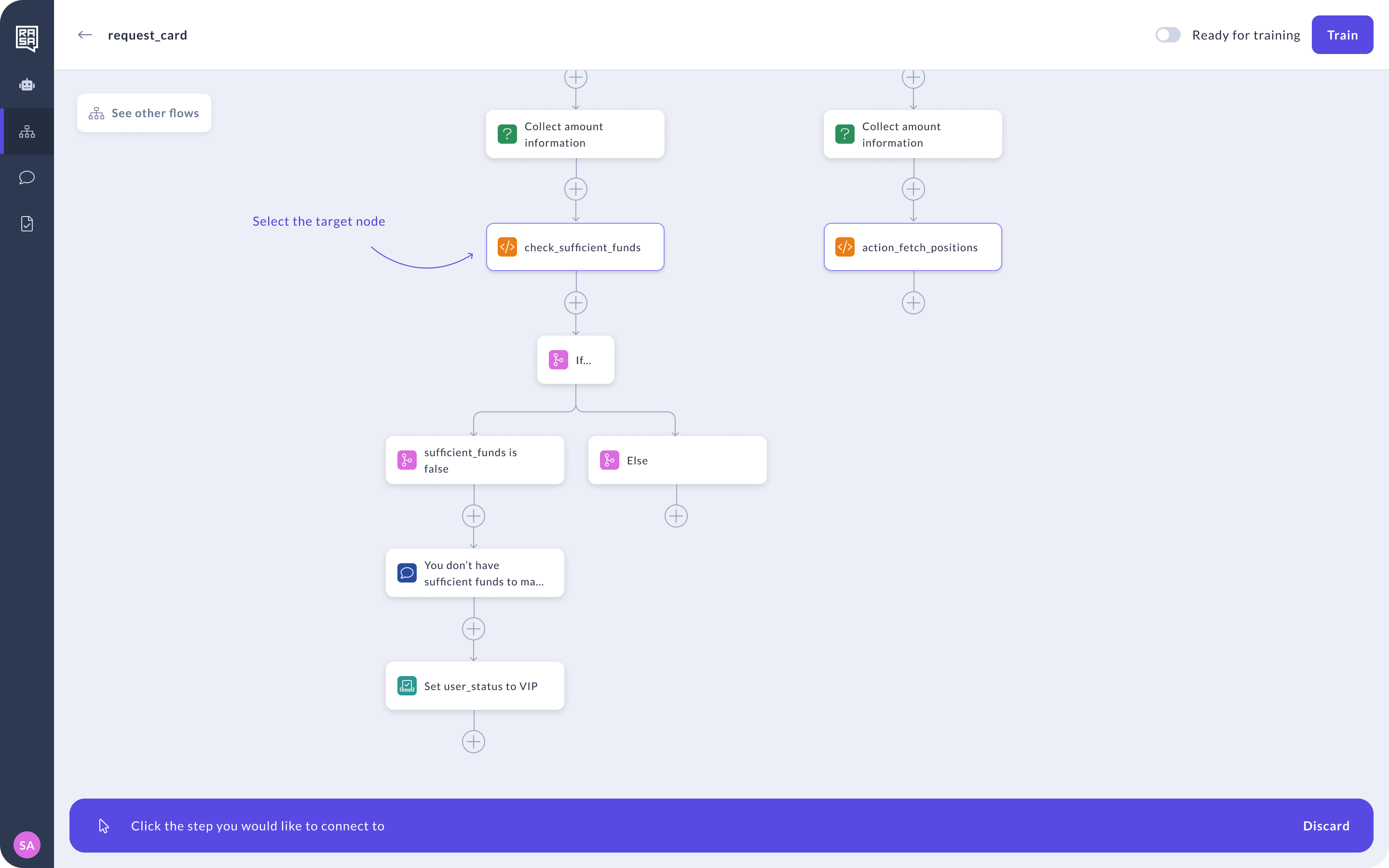
To delete a loop or connection:
1. Hover over the connection.
2. Click the delete icon.
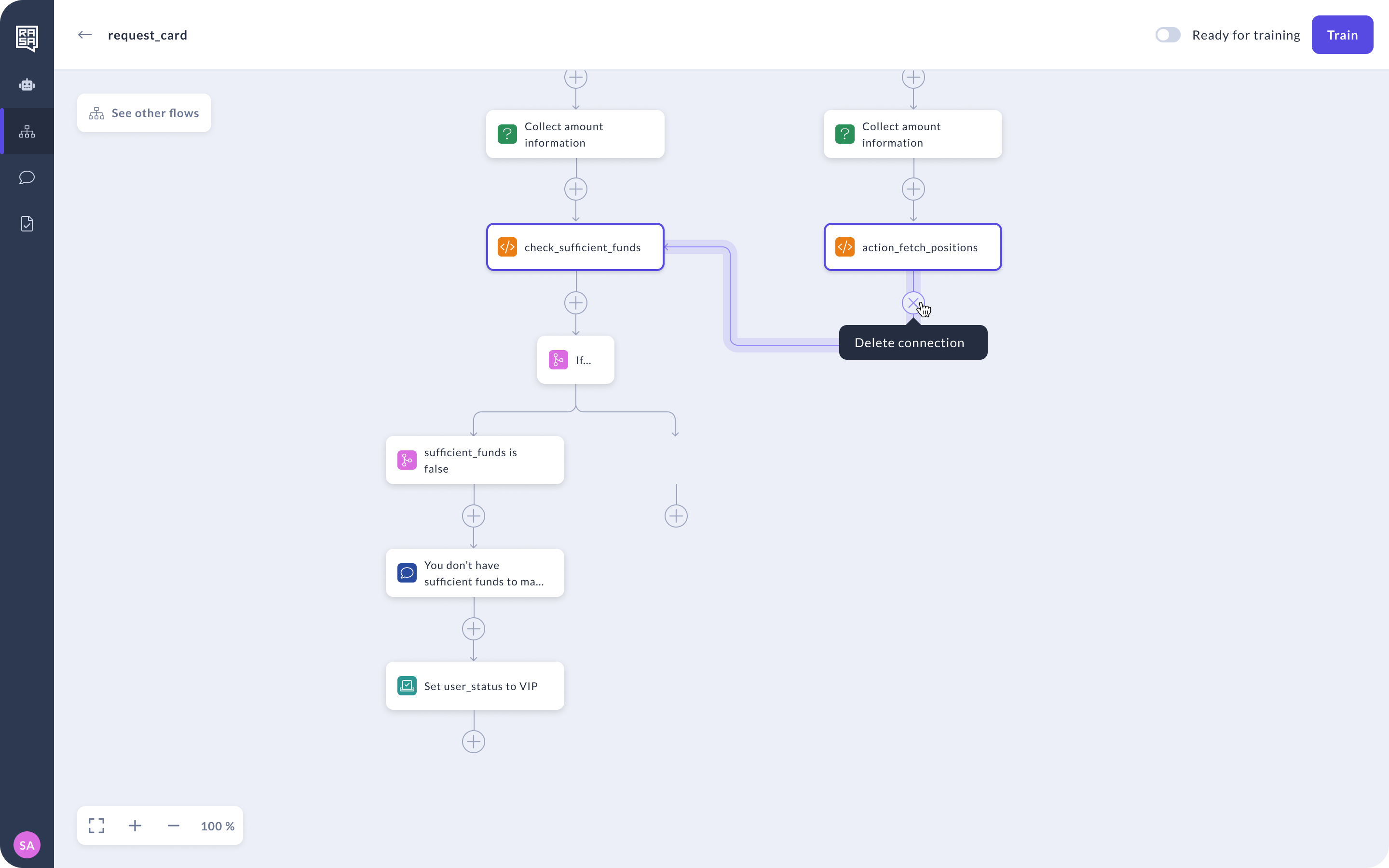
caution
**Avoid Infinite Loops:** Always ensure there's an exit path when connecting back to earlier steps. Unintended loops may cause unexpected behavior during training or runtime.
Loops help keep flows modular and avoid duplication. Just make sure there’s always a way out.
#### When to Use Link, Call, or Connections in Flows[](#when-to-use-link-call-or-connections-in-flows "Direct link to When to Use Link, Call, or Connections in Flows")
##### Use a **Link** when:[](#use-a-link-when "Direct link to use-a-link-when")
*You want to permanently hand over the conversation to another flow.*
The target flow is independent and should handle the rest of the interaction.
##### Use a **Call** when:[](#use-a-call-when "Direct link to use-a-call-when")
*You need to run a reusable flow and then return.*
This is helpful for sub-tasks such as gathering information or checking conditions.
##### Use **Connections** when:[](#use-connections-when "Direct link to use-connections-when")
*You want to control the conversation within the same flow — whether moving forward, looping back, or merging multiple branches.*
This helps reduce duplication and keeps your flows modular and easy to maintain.
By using Link, Call, and Connections intentionally, you can create modular, efficient flows that are easy to test and maintain.
---
#### How to Make Decisions
This guide will teach you how to use **Conditions** in Rasa Studio to make logic branches in your assistant’s conversations. By the end, you’ll know how to set conditions, branch flows, and create fallback options.
##### What is a Condition?
Conditions are logical statements used to decide how a conversation proceeds. For example, you can use a condition to check if a slot is filled before showing the next response.
#### How to create Logic branching[](#how-to-create-logic-branching "Direct link to How to create Logic branching")
1. Select "Logic" from the list to branch your flow.
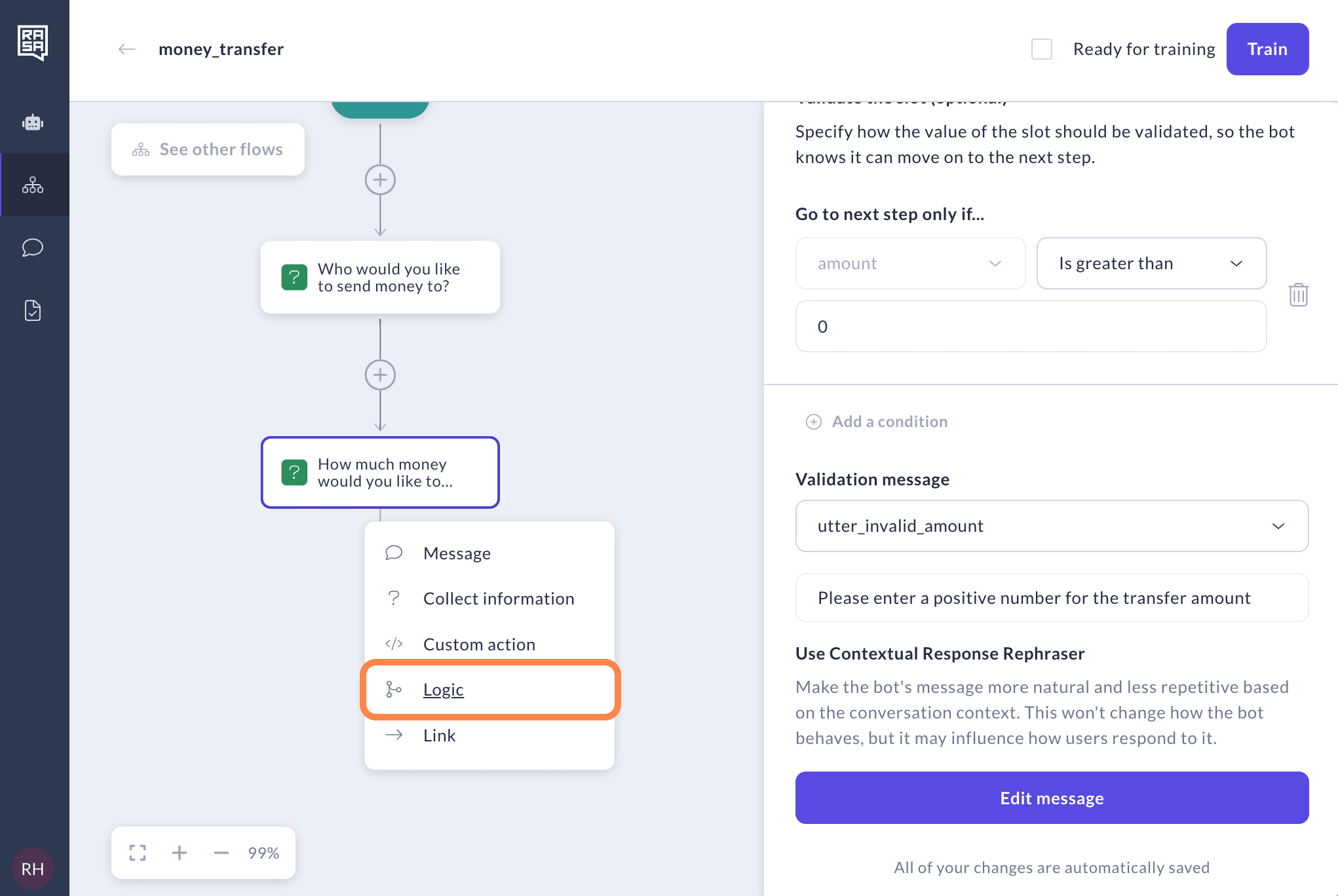
2. The branching structure will be immediately created. By clicking "Add logic branch" button you can add as many logic branches as you need.
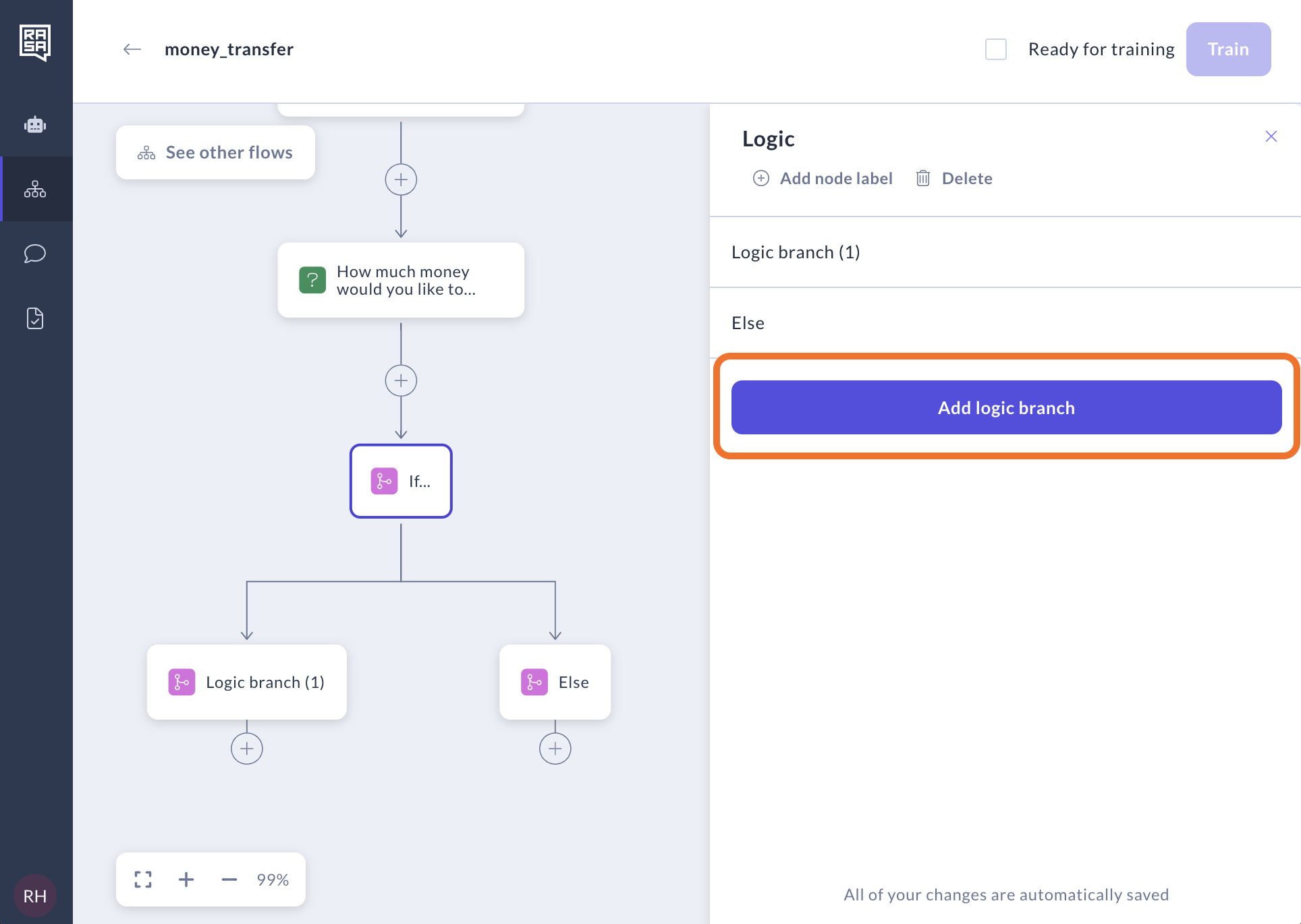
3. Click on one of the branches to begin describing the condition(s).
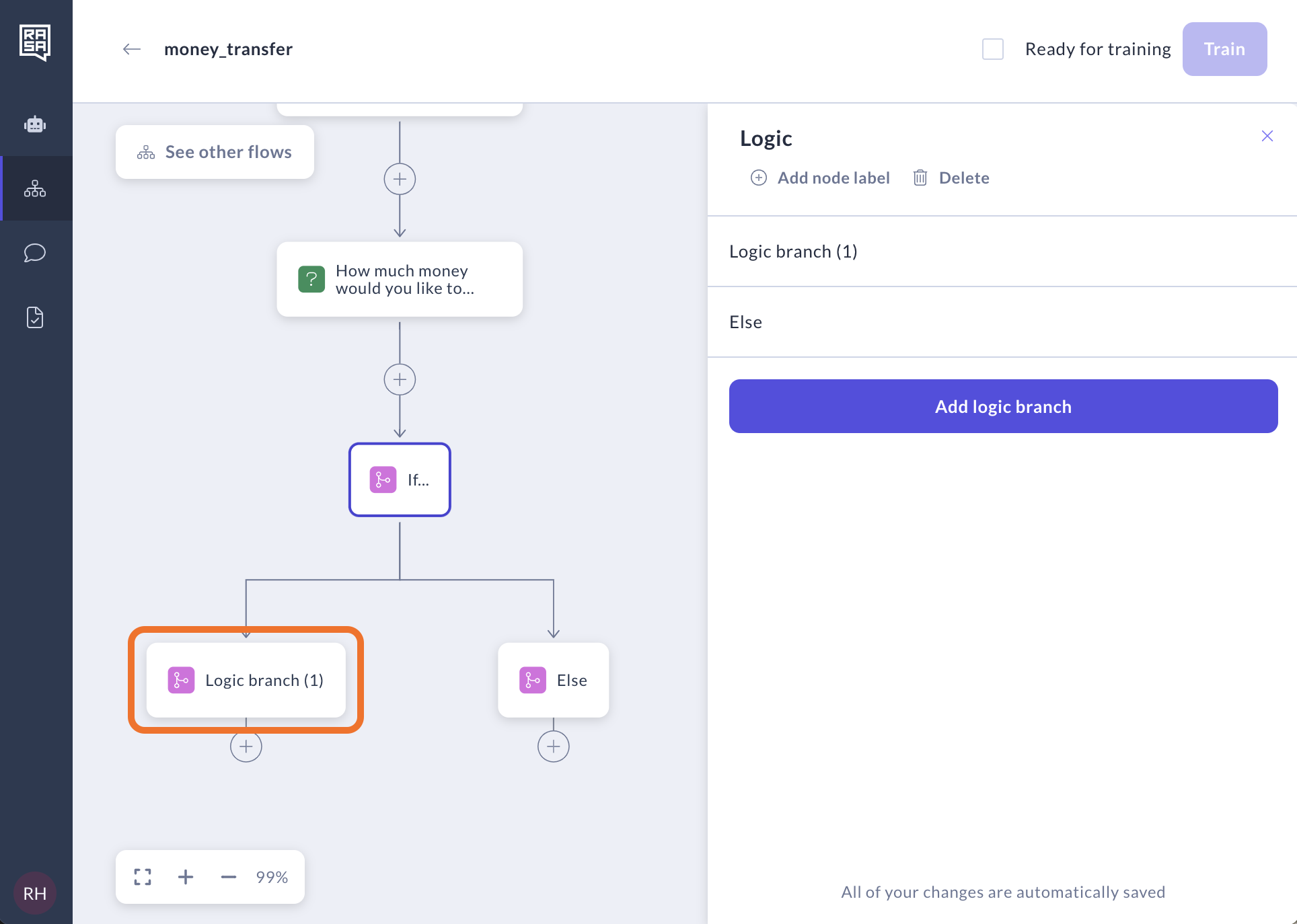
4. Select the [slot](https://rasa.com/docs/docs/studio/build/flow-building/collect/#slots) from the dropdown menu. You can also create new slots here if they have been used in previously created custom actions. In that case, ensure that the custom action uses the exact slot names created here.
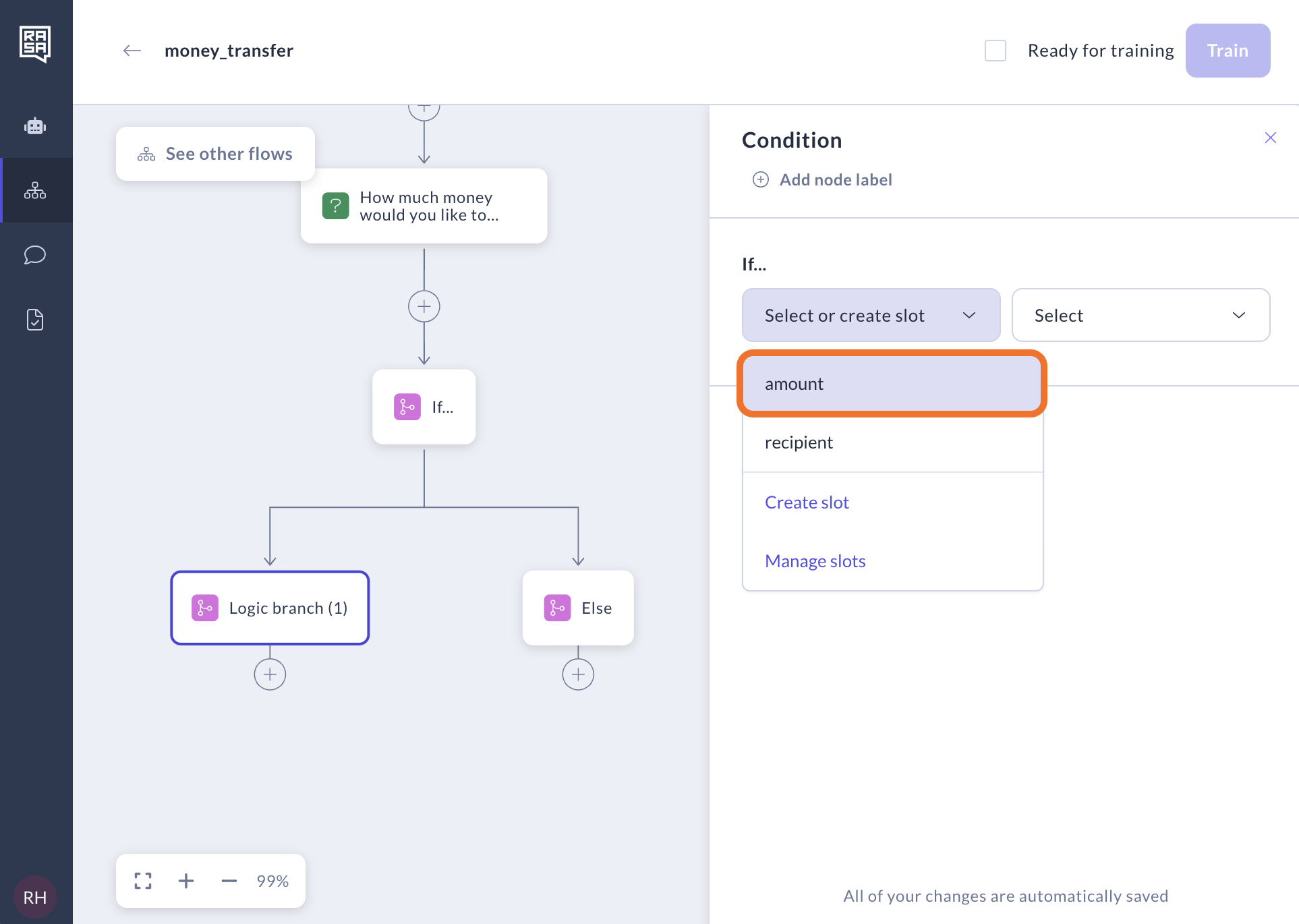
5. Select an operator. Studio supports the following operators:
* `and`: Combines two conditions with logical AND
* `or`: Combines two conditions with logical OR
* `>`: Greater than
* `>=`: Greater than or equal to
* `<`: Less than
* `<=`: Less than or equal to
* `=`: Equal to
* `!=`: Not equal to
* `is`: Checks for identity
* `is not`: Checks for non-identity
* `contains`: Checks if a value is contained within another value
* `matches`: Uses regular expressions to match strings
* `notmaches`: Uses regular expressions to negate strings
* `is set`: Checks if the slot has been assigned a value
* `is empty`: Checks if the slot hasn't been assigned a value
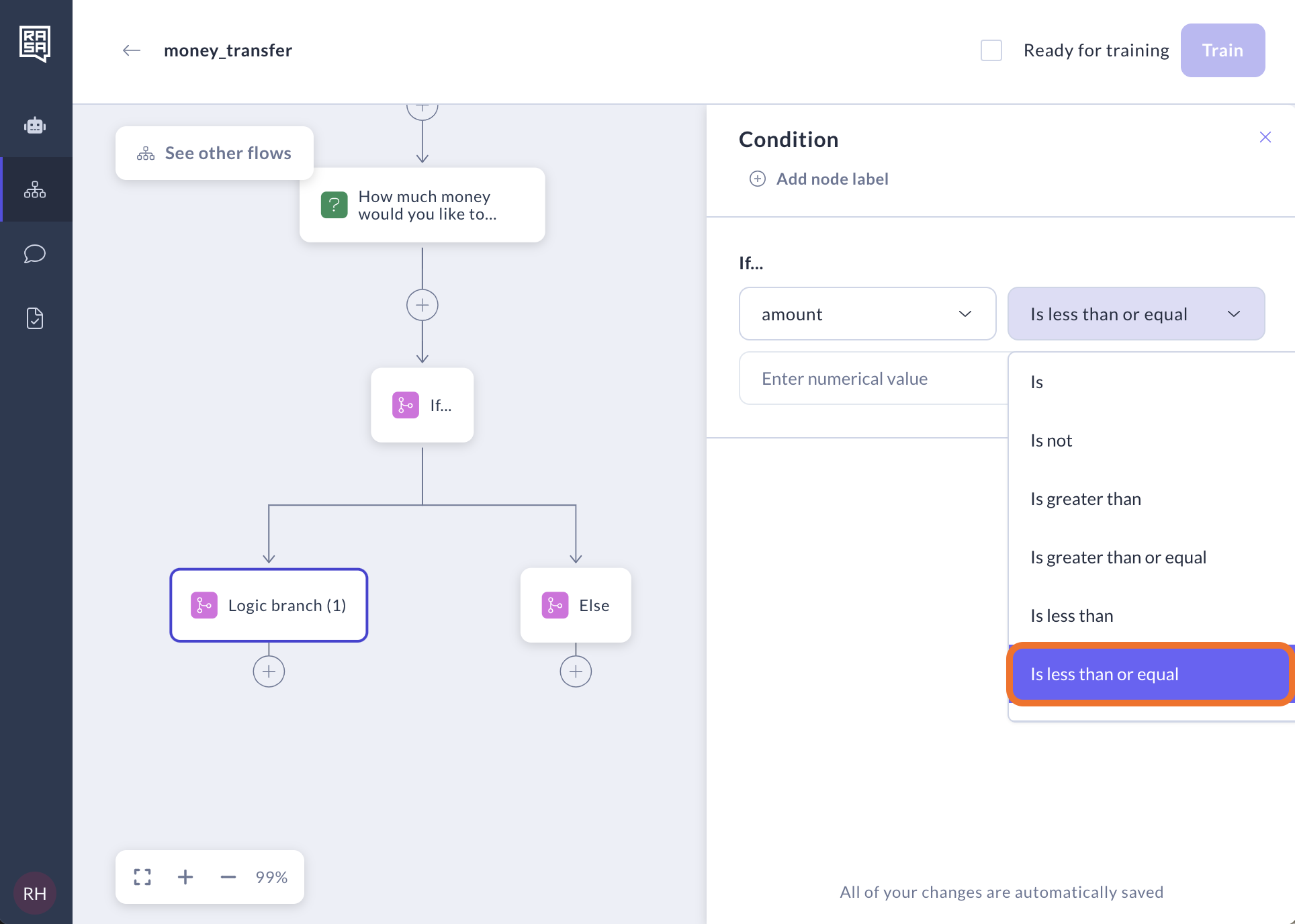
6. Enter the value
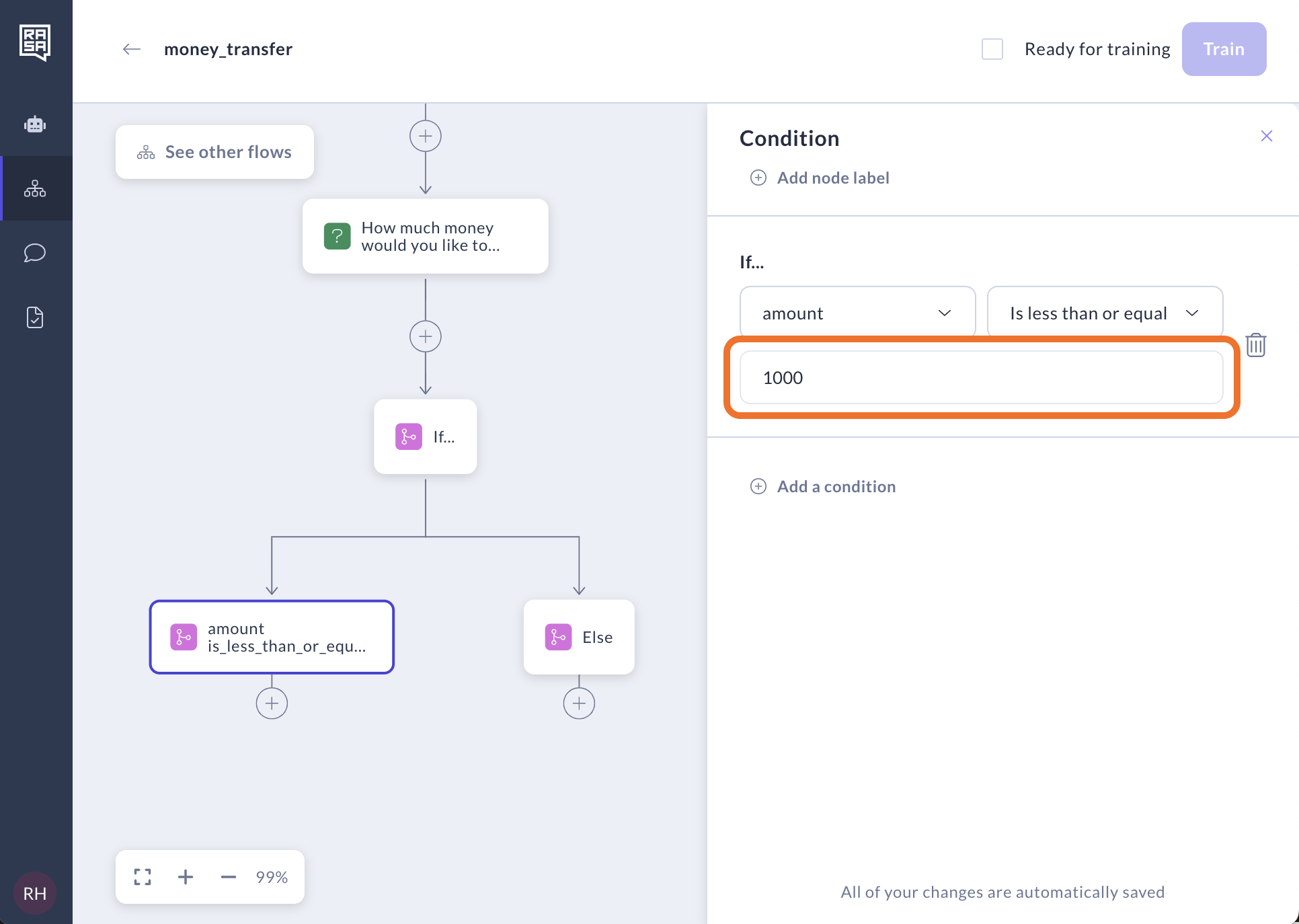
7. If you want to add more conditions into this branch, click "Add condition". The relationships between the condition is "And" meaning all the conditions need to be met for this branch to move forward.
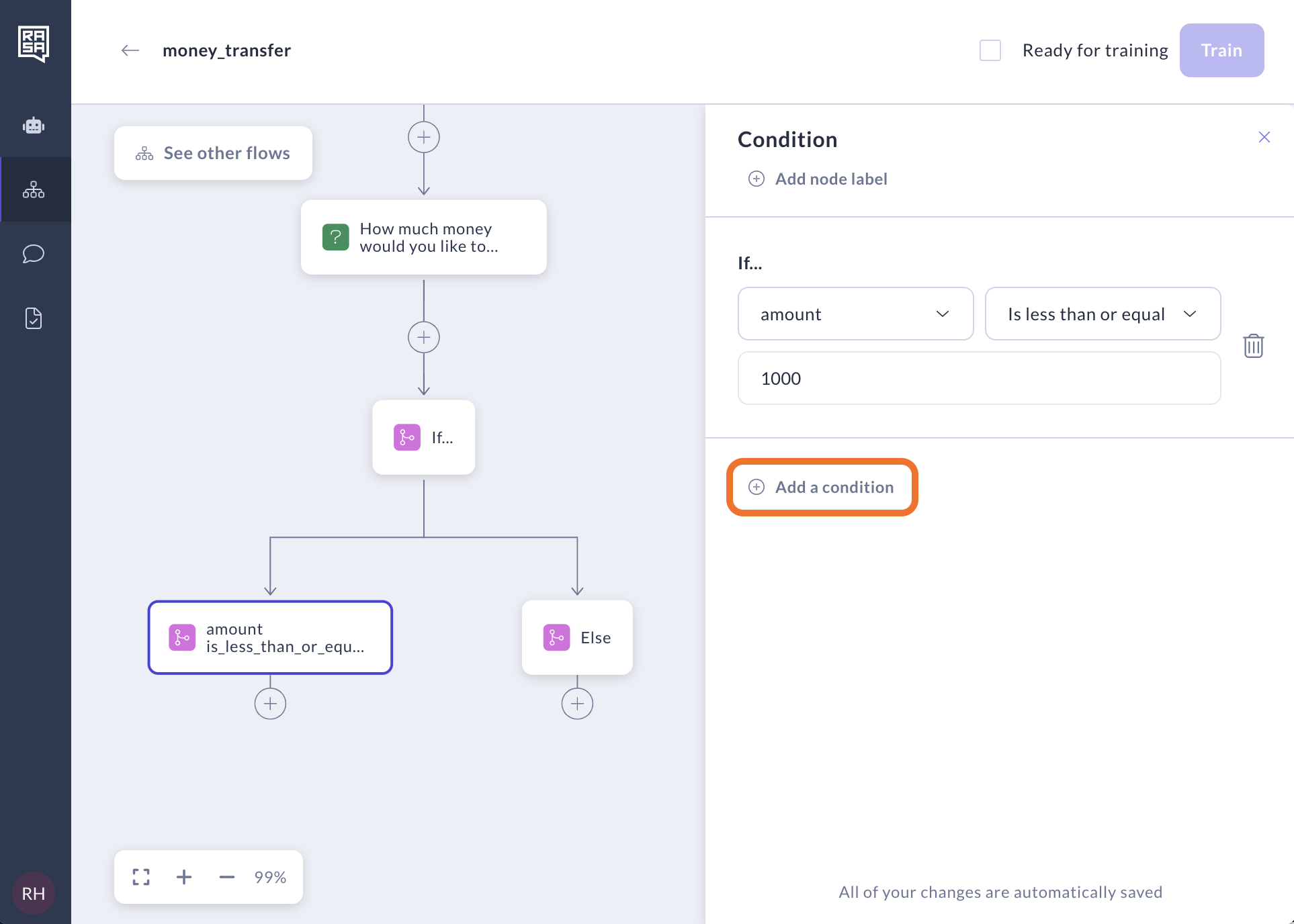
#### Else[](#else "Direct link to Else")
"Else" is the last logic branch and serves as a backup plan in logic. You don’t need to create any conditions for it but you also can’t delete it. It’s there to make sure the assistant always knows what to do even when no condition that you created for this scenarios matches with what happens in the current dialog.
A next step for "Else" is highly dependent on your use case but it could be a human handoff flow or a generic answer to reply to a user’s answer.
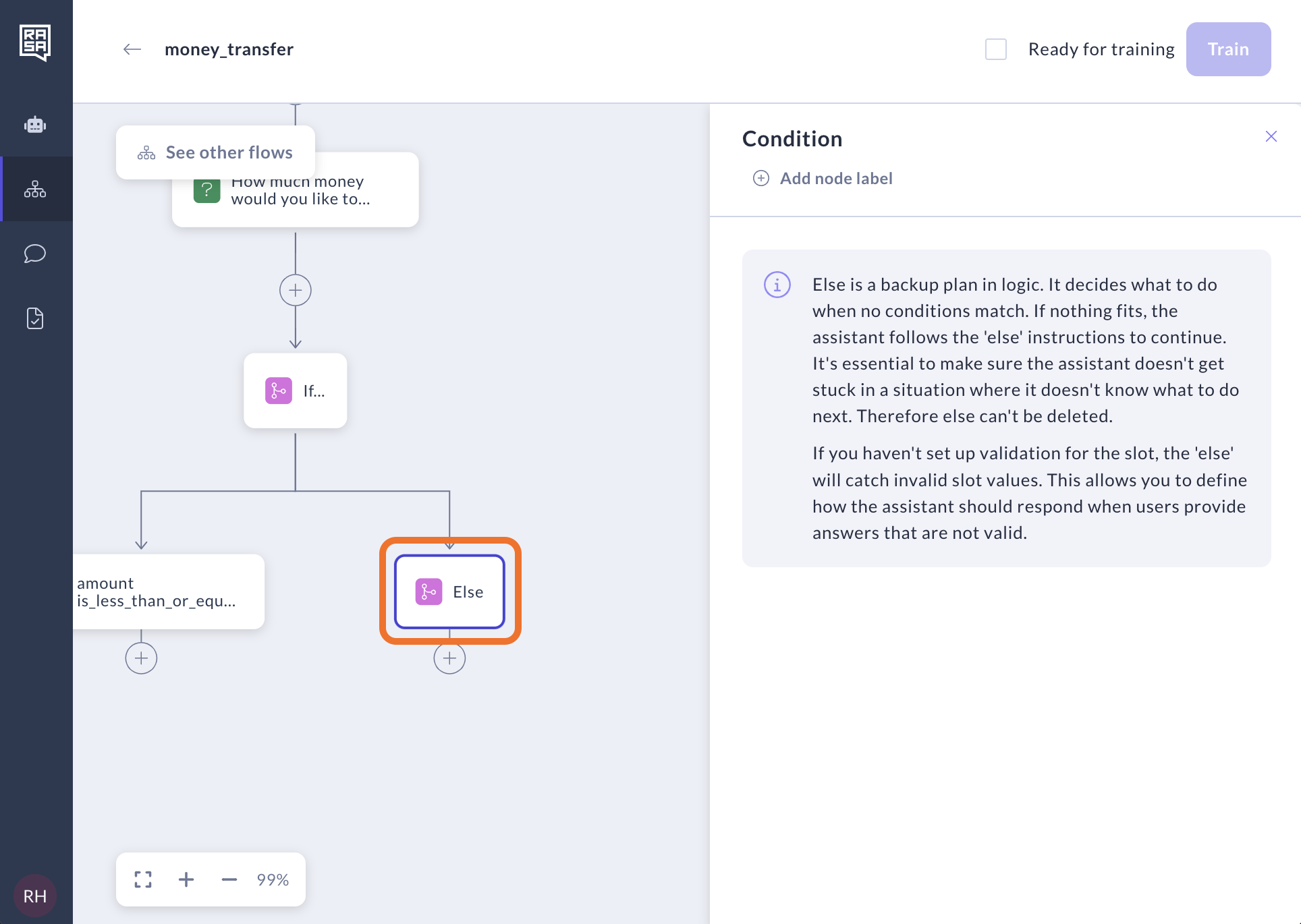
#### Delete conditions[](#delete-conditions "Direct link to Delete conditions")
To delete conditions inside Logic step:
* Click the delete icon next to the condition you want to delete. You can delete all but one.
* Confirm the deletion.
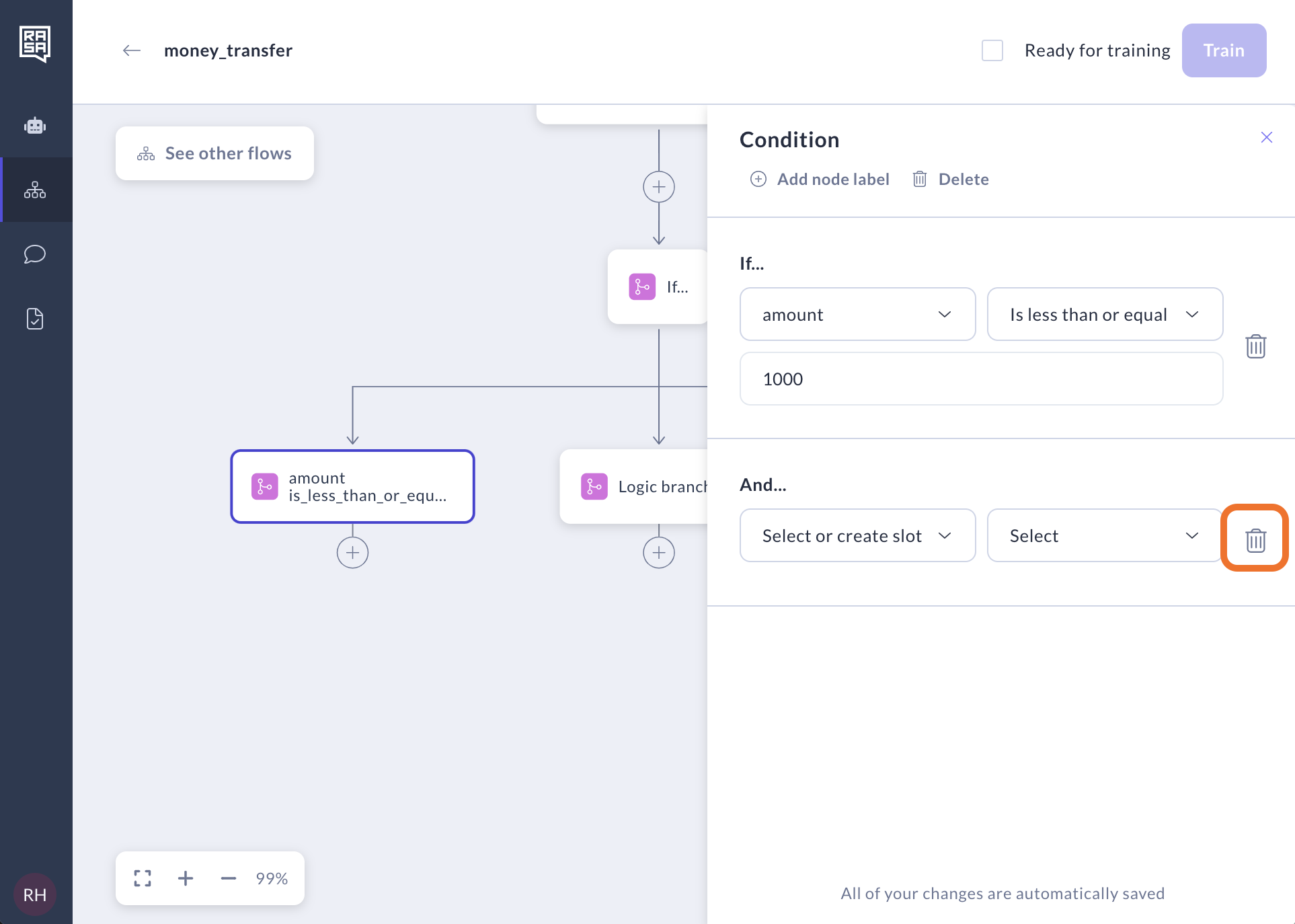
#### Delete logic branches[](#delete-logic-branches "Direct link to Delete logic branches")
To delete a logic branch, select it and click the Delete button. You can delete all branches but one.
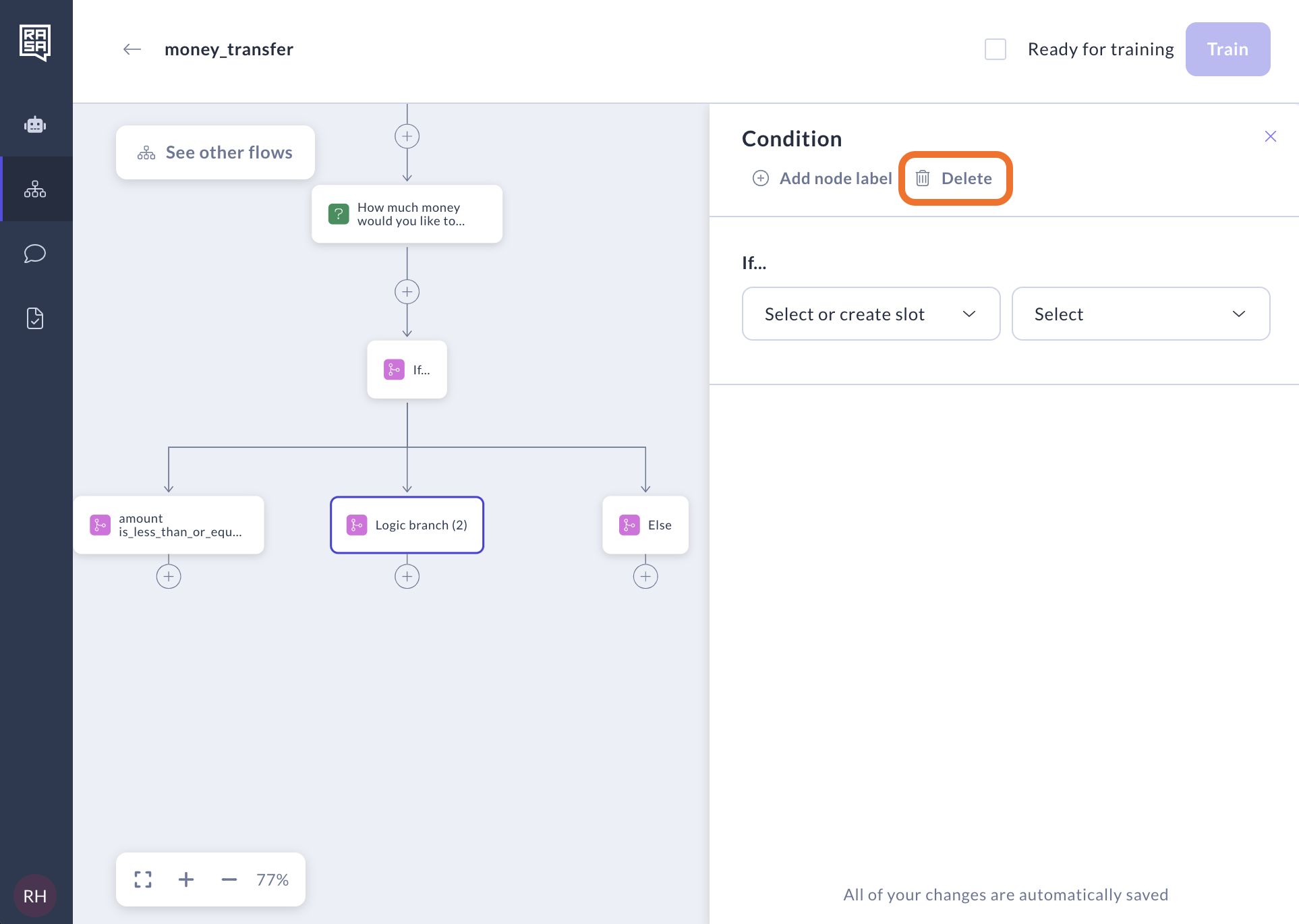
**Warning:** All steps subsequent to this condition will also be deleted. Therefore, we advise you to edit the condition or add new steps before the logic step. Only consider deleting a condition as a last resort.
#### Delete Logic step[](#delete-logic-step "Direct link to Delete Logic step")
You can delete the entire Logic step the same way you delete any other step—by clicking on the Delete icon. However, a warning will appear notifying you that all conditions and subsequent steps will also be deleted, and you will need to confirm your decision to delete everything.
**Note:** Deleting the entire Logic step can have significant repercussions. We advise you to consider updating the existing logic and conditions or adding new steps before the logic step instead of deleting it.
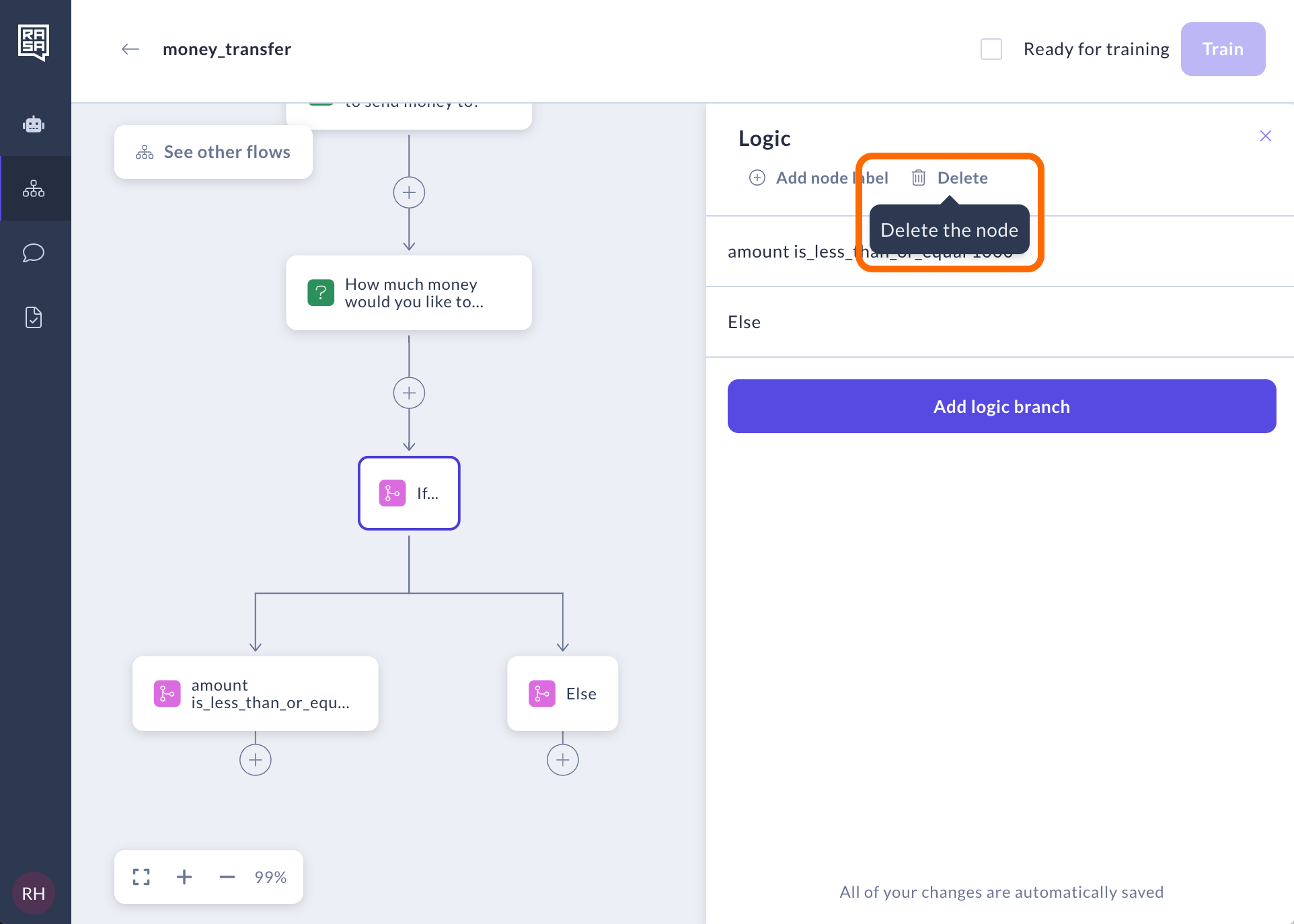
---
#### How to Manage Flows
This guide will show you how to manage flows using Rasa Studio. You’ll learn to navigate, edit, delete, and organize flows, helping you maintain a clean and efficient workspace for your assistant.
#### Finding your flows[](#finding-your-flows "Direct link to Finding your flows")
There are 2 ways to navigate through flows:
1. The flow table: It is the first thing you see when you visit the Flow builder page. Here, you can view the description and state of each flow, sorted by the date of the last edit.
2. The flow list: To access this list, click on the "See flows" button in the upper left corner of the canvas.
#### Editing flows[](#editing-flows "Direct link to Editing flows")
1. To edit a flow’s description, open the flow and select the **Start** step. You can update the description in the side panel on the right.
2. To rename a flow or change its ID, click the pencil icon next to the flow’s ID.
##### (Optional) Translating flow names[](#optional-translating-flow-names "Direct link to (Optional) Translating flow names")
Assistants will sometimes refer to flows in conversation when cancelling or clarifying an action. If you have a multi-language assistant you can provide a user friendly flow name that will be used in this case and localize for your supported languages.
#### Duplicating flows[](#duplicating-flows "Direct link to Duplicating flows")
You can duplicate an existing flow to reuse its logic:
1. Hover over the flow name and click **Duplicate**.
2. A copy of the flow will appear with “Copy” in the name and description — you can rename and adjust it as needed.
#### Deleting flows[](#deleting-flows "Direct link to Deleting flows")
1. To delete a flow, hover over the flow name and click **Delete**.
2. In the modal that opens, confirm deletion by typing the flow name.
#### Searching flows[](#searching-flows "Direct link to Searching flows")
You can search for flows by typing their names into the search bar.
#### Deleting flow steps[](#deleting-flow-steps "Direct link to Deleting flow steps")
Deleting a step other than Logic doesn’t remove the elements used in that step. For example, deleting a reply step only removes it from this section of the flow; the reply used in that step remains intact.

#### Adding step labels[](#adding-step-labels "Direct link to Adding step labels")
When adding a step, its type dictates the displayed information. Details added to the step are used to present it. If the automatic display isn’t helpful, you can add labels to the steps to make them more descriptive and easier to navigate.
#### Navigating flow canvas[](#navigating-flow-canvas "Direct link to Navigating flow canvas")
Here are the navigation options supported in Flow Builder:
* Zoom in using keyboard and mouse
* Zoom out using keyboard and mouse
* Adjust the screen display size
* Move around the canvas using keyboard and mouse
---
#### How to Send Messages
This guide will show you how to create and manage **Message** steps in Rasa Studio. You'll learn to craft clear, engaging responses and refine them to make your assistant’s interactions more natural.
##### What is a Message?
A message is what your assistant sends to the user. This can include text, buttons, images, or rich content like quick replies. Messages can be customized for different conversation scenarios.
#### How to create a Message step[](#how-to-create-a-message-step "Direct link to How to create a Message step")
1. Select the **Send message** step in the menu.
2. Click **Select or create response**.
3. In the modal, select **Create new response**.

4. Enter the response name and the text.

5. The **Use contextual response rephraser** option is off by default. This feature enables the assistant to rephrase its responses by prompting an LLM, based on the conversation's context. It helps make the assistant's responses feel more organic and conversational.
Read More
When you create a new response, there’s an option called "Use Contextual Response Rephraser" that automatically follows a general setting (called `rephrase_all`) defined in the system’s configuration file.
If you leave this option as it is, the system won’t assign a specific rephrasing setting just for that response—it will just use the general setting.
However, if you decide to change this option to something different, the system will remember your choice and apply it specifically to that response.
No matter what you choose, the interface will always show you whether rephrasing is turned on or off, based on either your specific choice (if you made one) or the general setting.

6. If you prefer full control over responses, but still want them to sound more natural and less repetitive, you can manually add as many variations as you want by clicking the **Add variation** button.

7. You can edit or delete previously created responses by clicking on the drop-down menu and selecting the **Manage responses** option.
#### Links[](#links "Direct link to Links")
Within the response, you can provide users with links to extend your assistant's functionality.
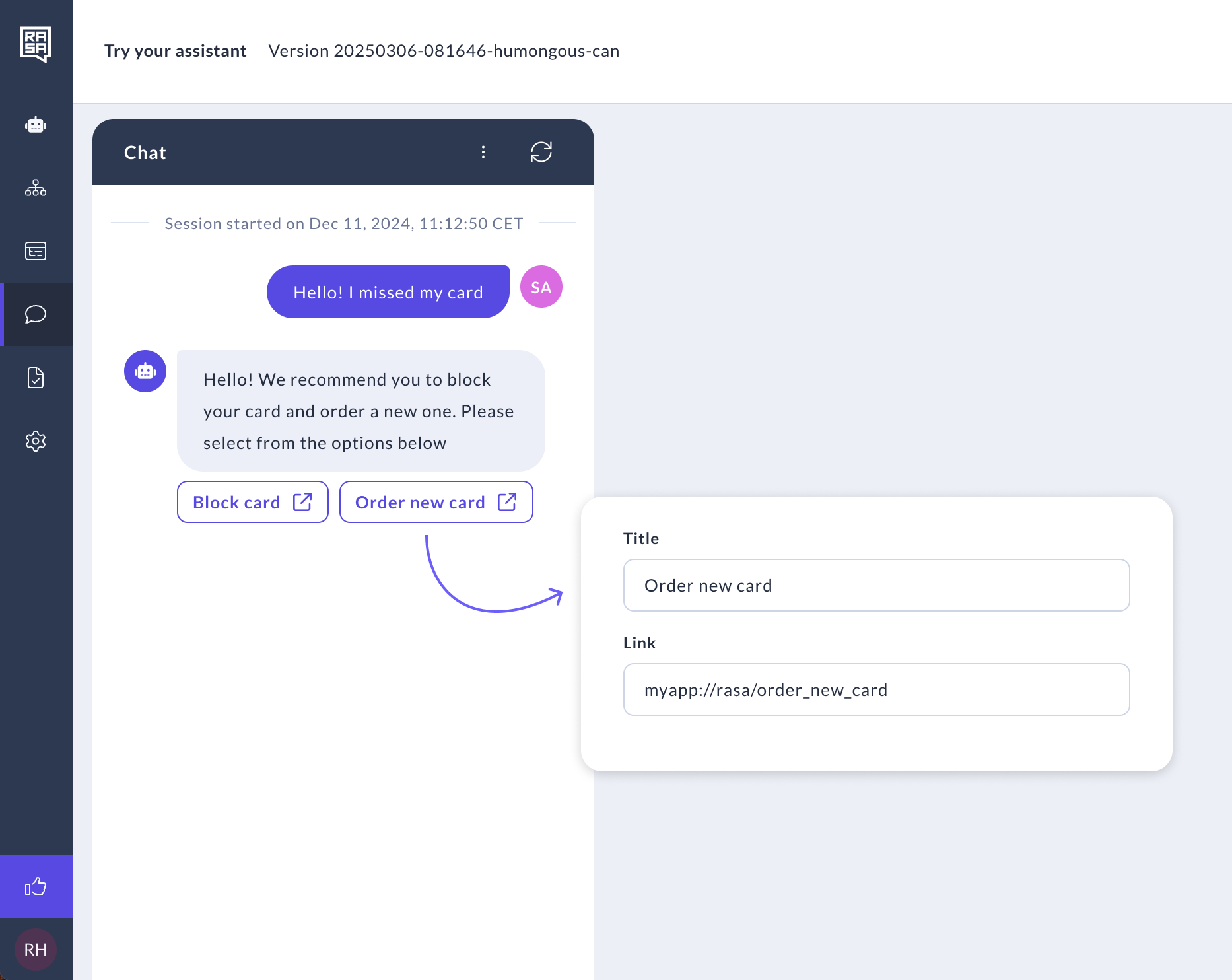
##### How to add links[](#how-to-add-links "Direct link to How to add links")
1. Click **Add link** in your response.
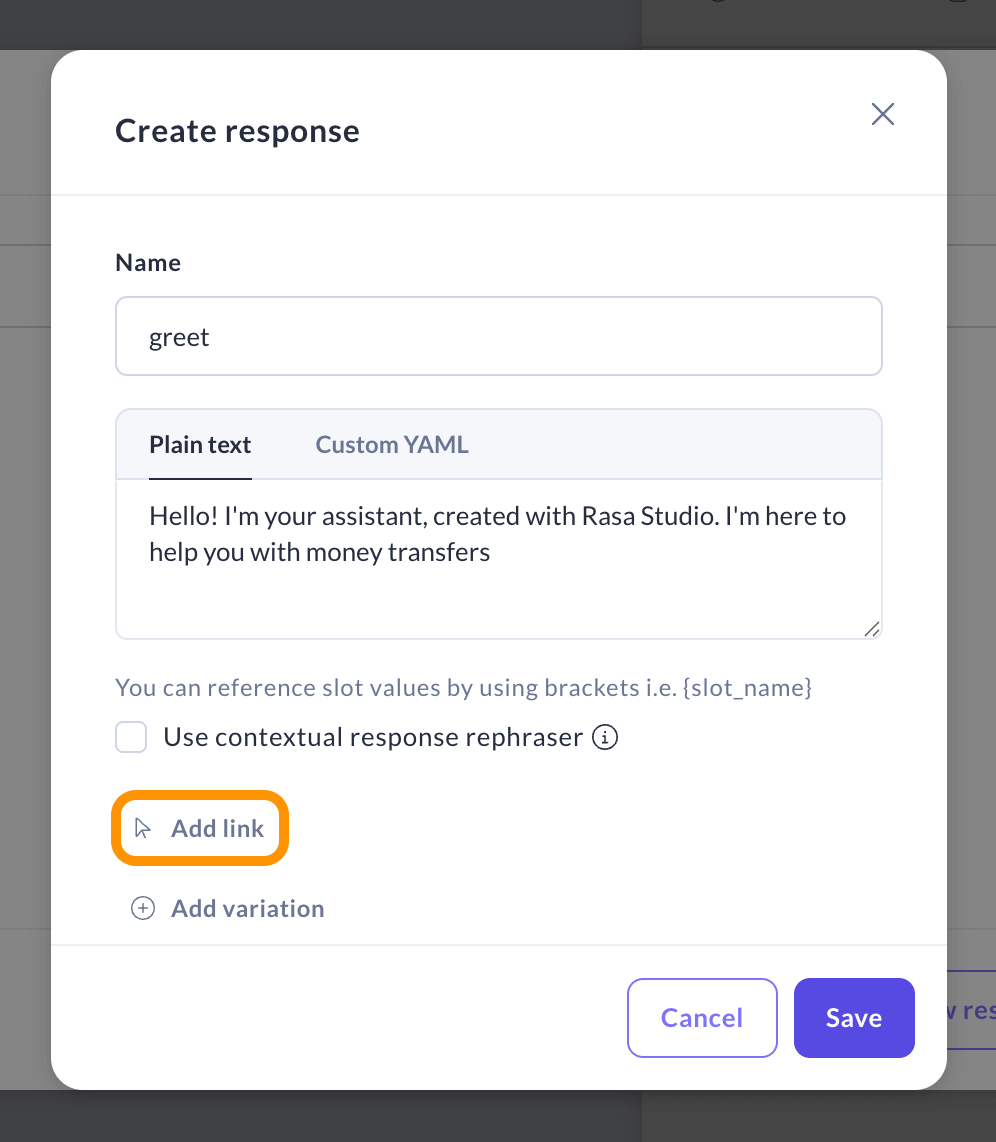
2. Choose between reusing an existing link or creating a new one. If you create a new link, enter a title for it. This title will be the text displayed on the link for users to click.
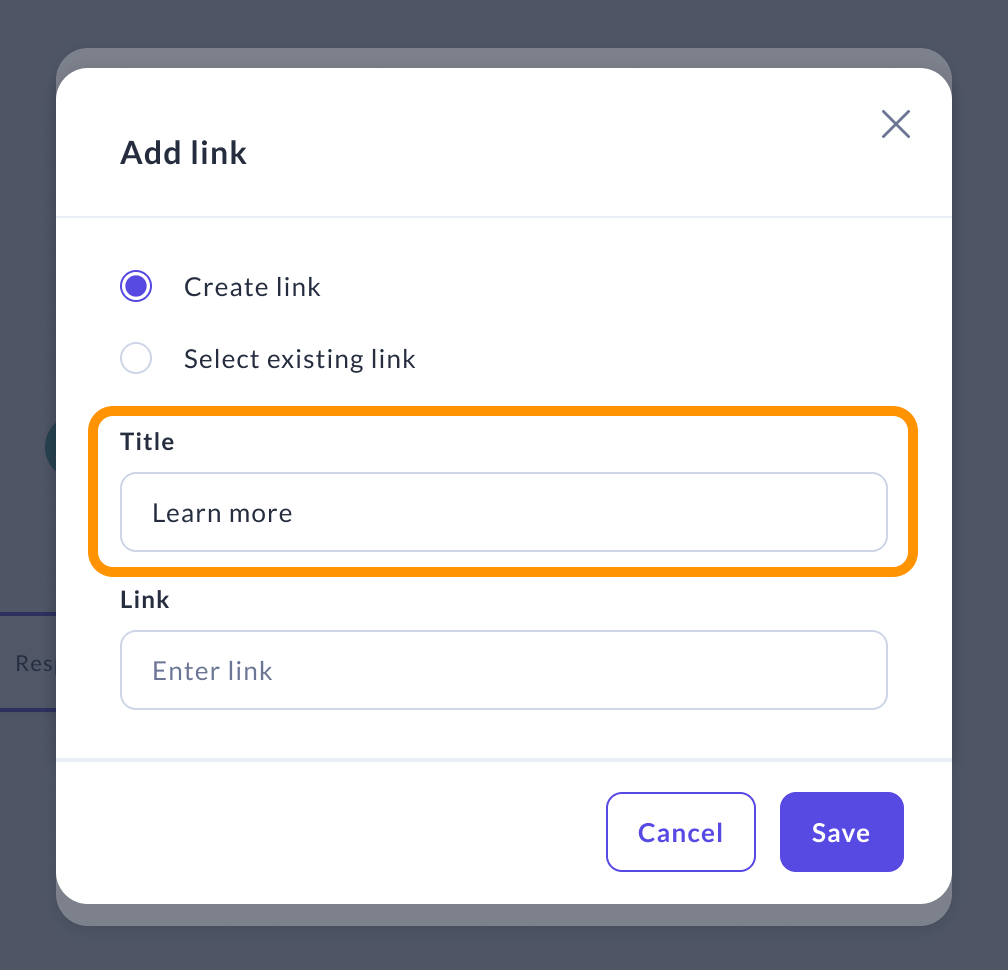
3. Enter the link itself. Links can be of the following types:
* **External URL**, e.g., `https://rasa.com`
* **Internal link** within your application, e.g., `myapp://rasa/account?login`
* **Phone call** or **email link**, e.g., `tel:+11111111111` or `mailto:hi@rasa.com`
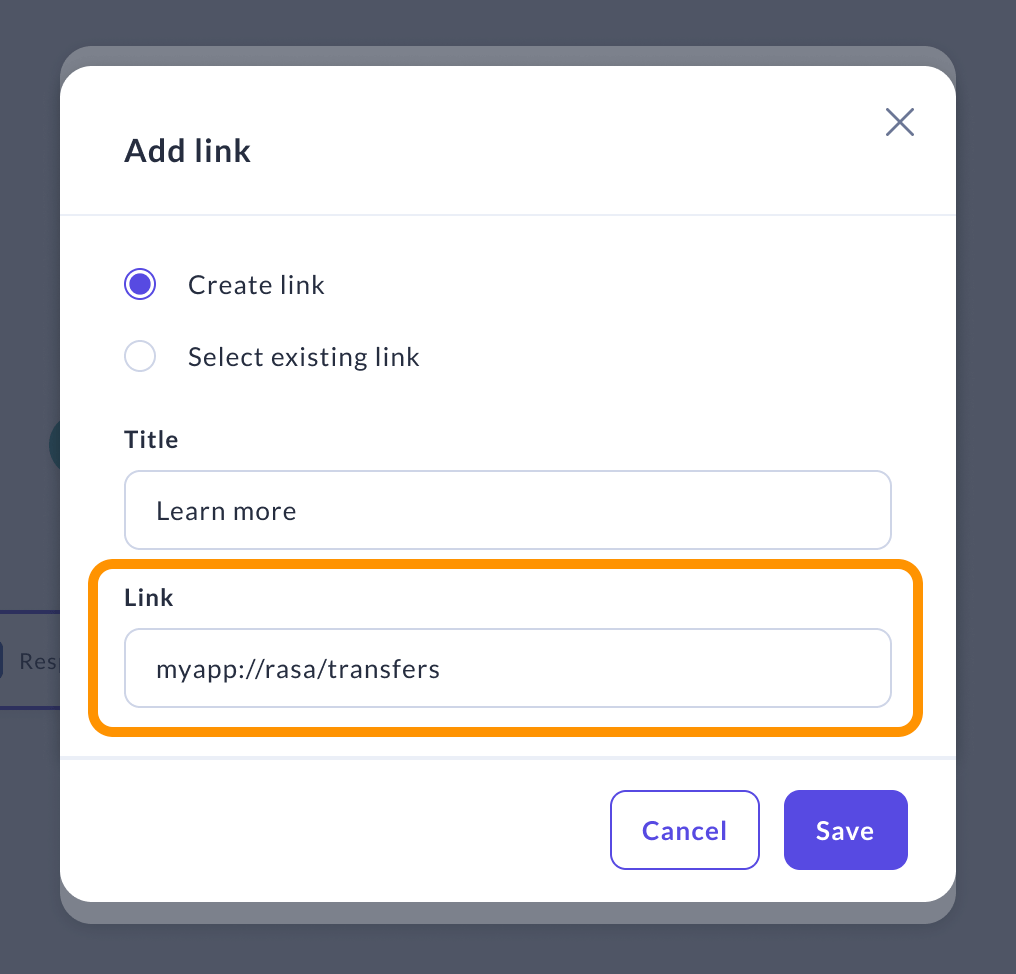
4. Continue clicking **Add link** and fill in the information for as many links as you need.
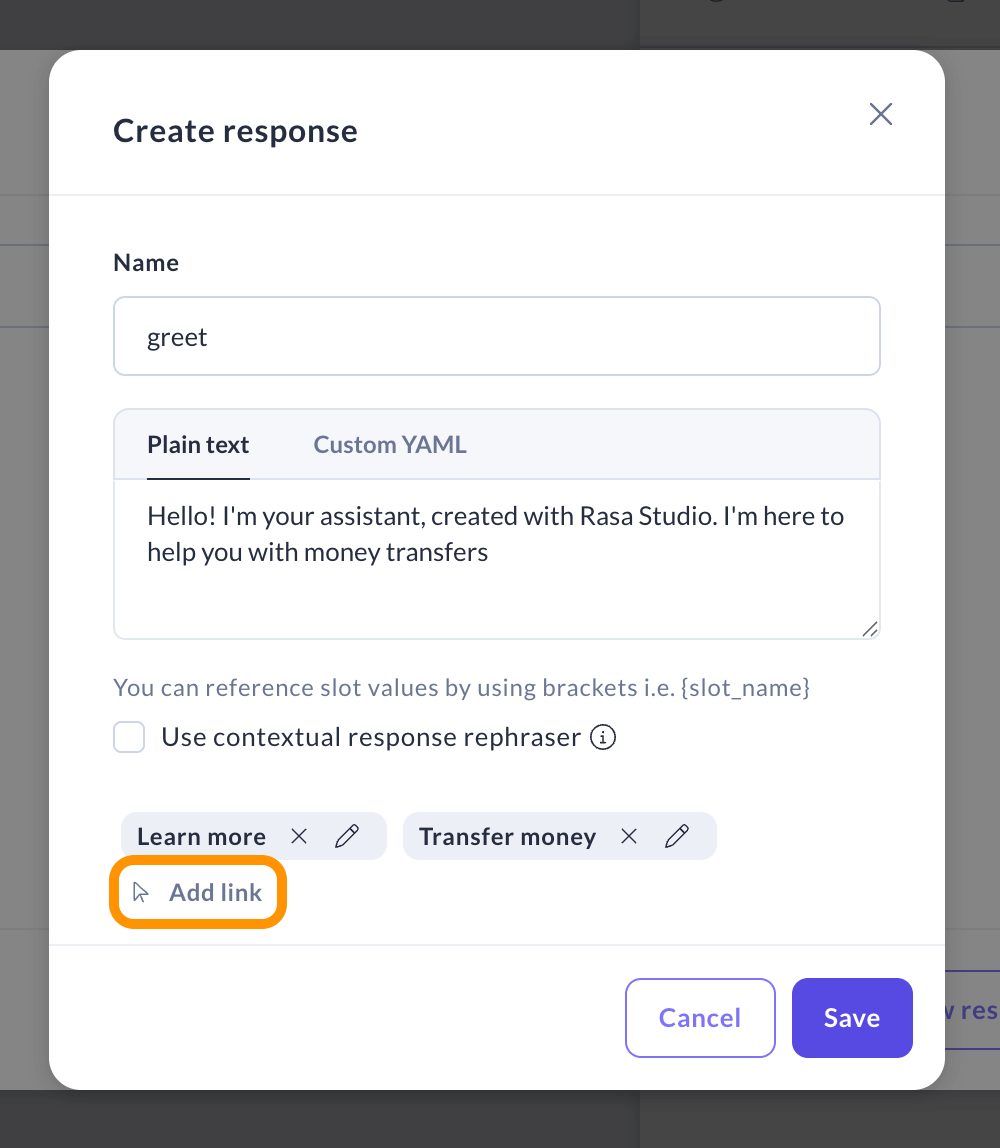
5. To reuse an existing link, choose **Select existing link** and pick the link you'd like to reuse from the dropdown menu.
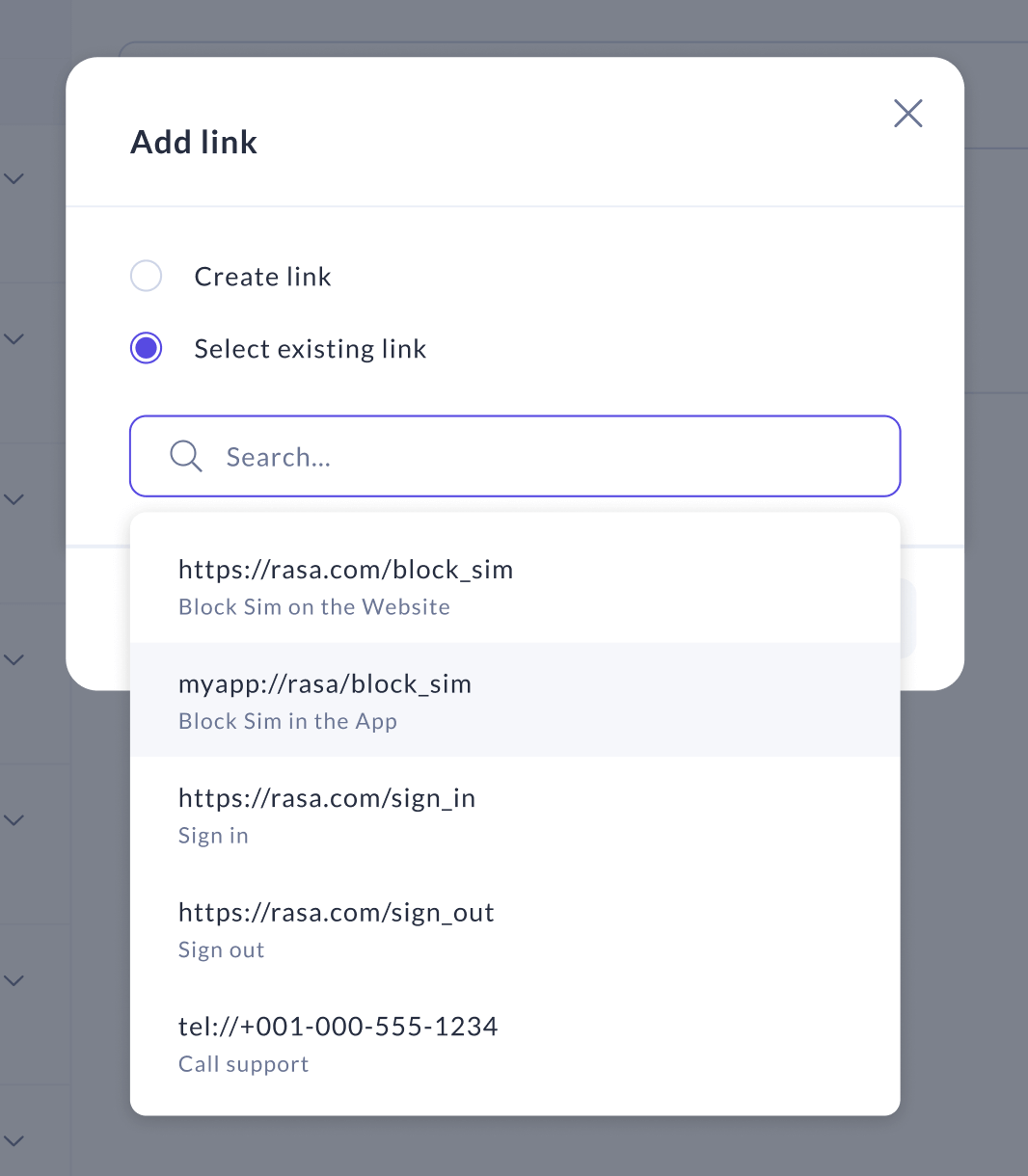
6. Use the icons next to the links to edit or delete them from the response.

##### Reordering links[](#reordering-links "Direct link to Reordering links")
You can drag and drop links directly in the response editor — giving you full control over the order in which options are shown to users.
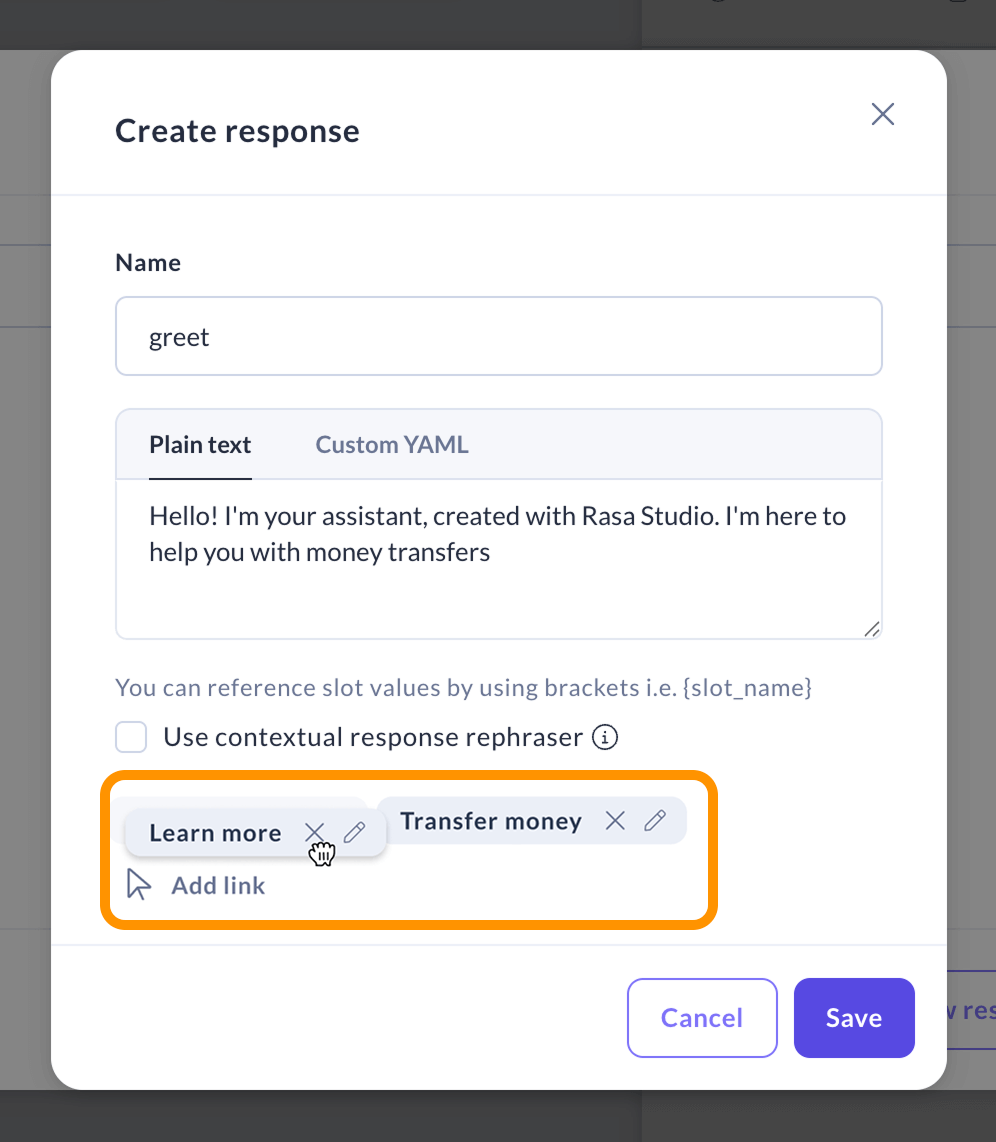
#### Referencing slot values in a response[](#referencing-slot-values-in-a-response "Direct link to Referencing slot values in a response")
This feature enables you to utilize previously collected user information, such as their name or age. It also allows you to confirm user-provided input by incorporating a slot value directly into your response.
1. **Identify the slot**: First, determine which specific [slot](https://rasa.com/docs/docs/studio/build/flow-building/collect/#slots) you want to reference. Understand the flows where this slot is used and the factors that can influence its values. If a slot is utilized across multiple flows, you will see the following alert:

2. **Insert the slot**: To include the slot in your response, enclose the slot name within curly brackets at the desired position. For example, if you have a slot named "user\_name" and you want to greet the user by their name, your response might look like this:
```
Hello, {user_name}! How can I assist you today?
```
3. **Test and improve**: After completing the training, go to the [Try Your Assistant](https://rasa.com/docs/docs/studio/test/try-your-assistant/) page to evaluate how the assistant handles the response. In the assistant’s response, the slot value should dynamically replace the placeholder with the actual value stored. For example, if the user's name is "John" the response should read: "Hello, John! How can I assist you today?
#### Custom responses[](#custom-responses "Direct link to Custom responses")
Custom responses allow you to go beyond simple text and create rich, interactive experiences tailored to your users and channels. You can use any YAML structure to define a custom response — from carousels and cards to events or metadata your frontend channel understands.
1. When editing a response, switch the tab to Custom YAML and add the code of your custom component. You can combine plain text and custom YAML in the same response if needed.
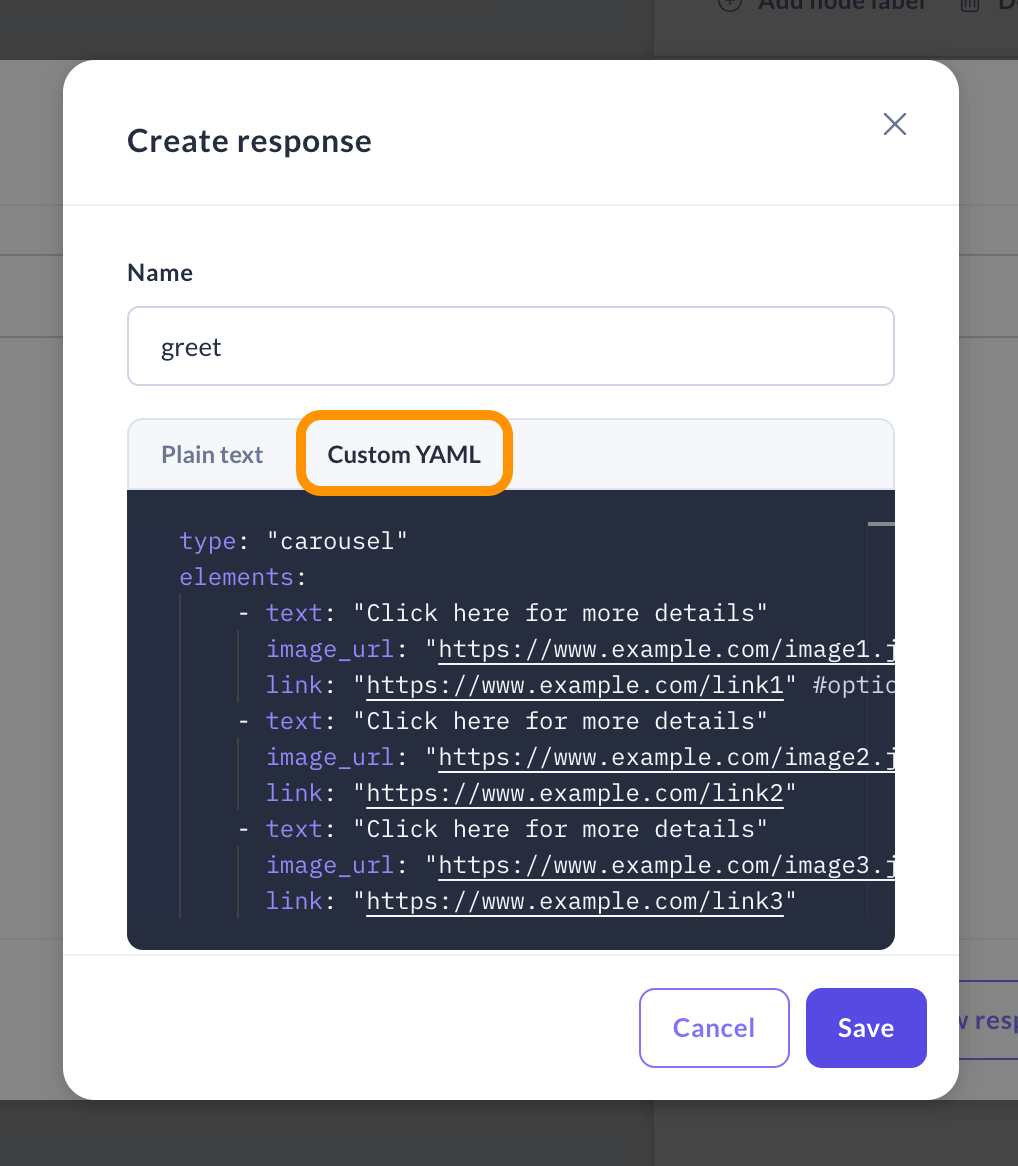
2. When testing in [Try your assistant](https://rasa.com/docs/docs/studio/test/try-your-assistant/), Rasa sends custom components as JSONs. Styling and rendering are handled entirely by your frontend or messaging channel.
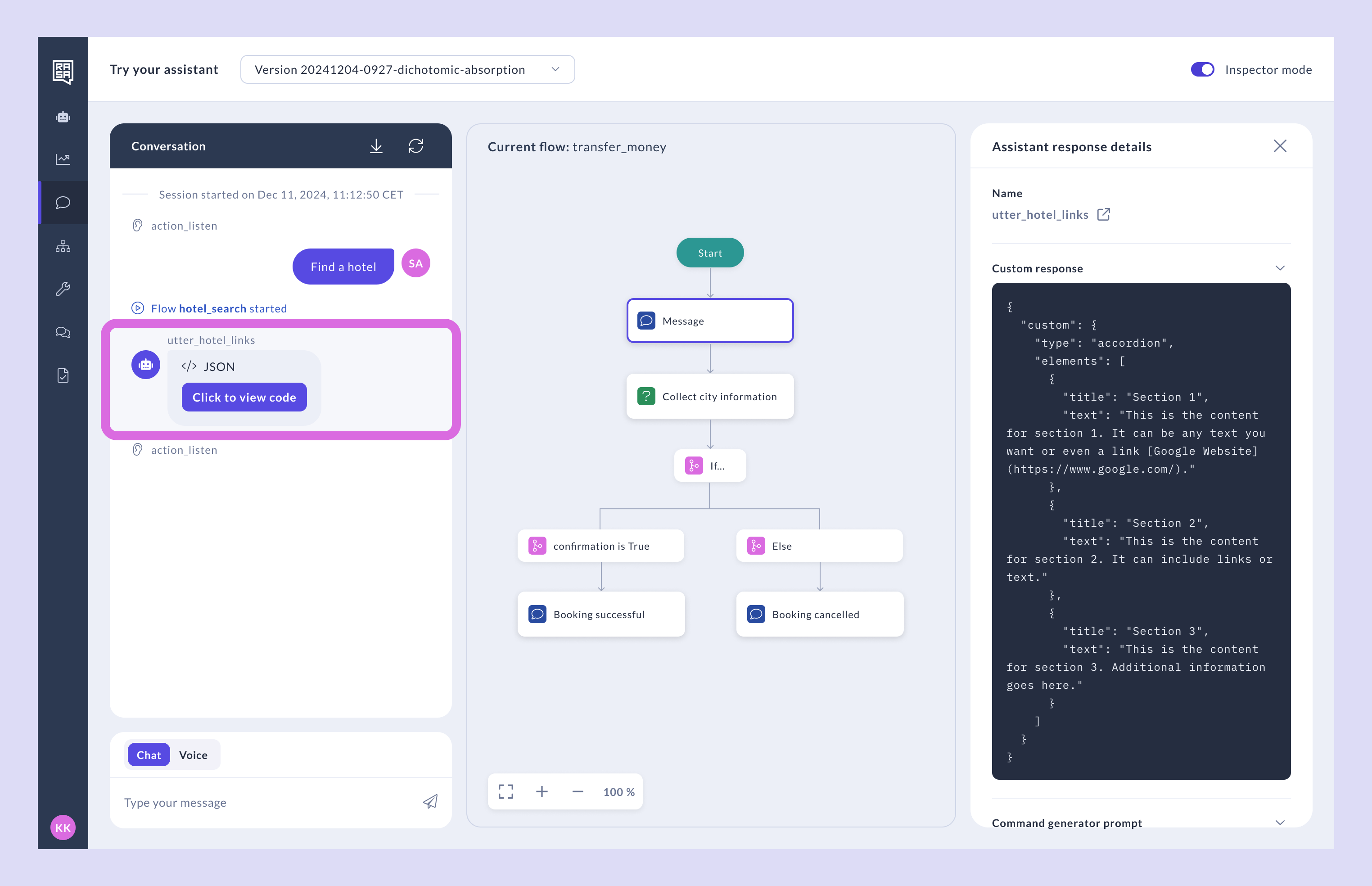
---
#### How to Set Slots
This guide explains how to programmatically assign or clear slot values in your flows. With the **Set Slots** step, you can streamline your conversation logic by managing slot (stored user data) values independently from direct user input.
##### What is a Slot?
Think of slots as your assistant’s memory. They store important pieces of information from the conversation, like a user’s name, date, or location, and can be referenced throughout the flow.
#### Overview[](#overview "Direct link to Overview")
With the Set Slots step, you can:
1. **Assign a value:** Automatically update a slot value (e.g. set the 'age\_category' slot to 'Minor' based on the user's birth year).
2. **Clear a value:** Reset a slot value (e.g. clear the 'amount' slot if the user exceeds the allowed transaction limit to prompt re-entry)
3. **Persist a value:** Persist a slot value (e.g. persist the 'permission\_granted' slot after the flow ends)
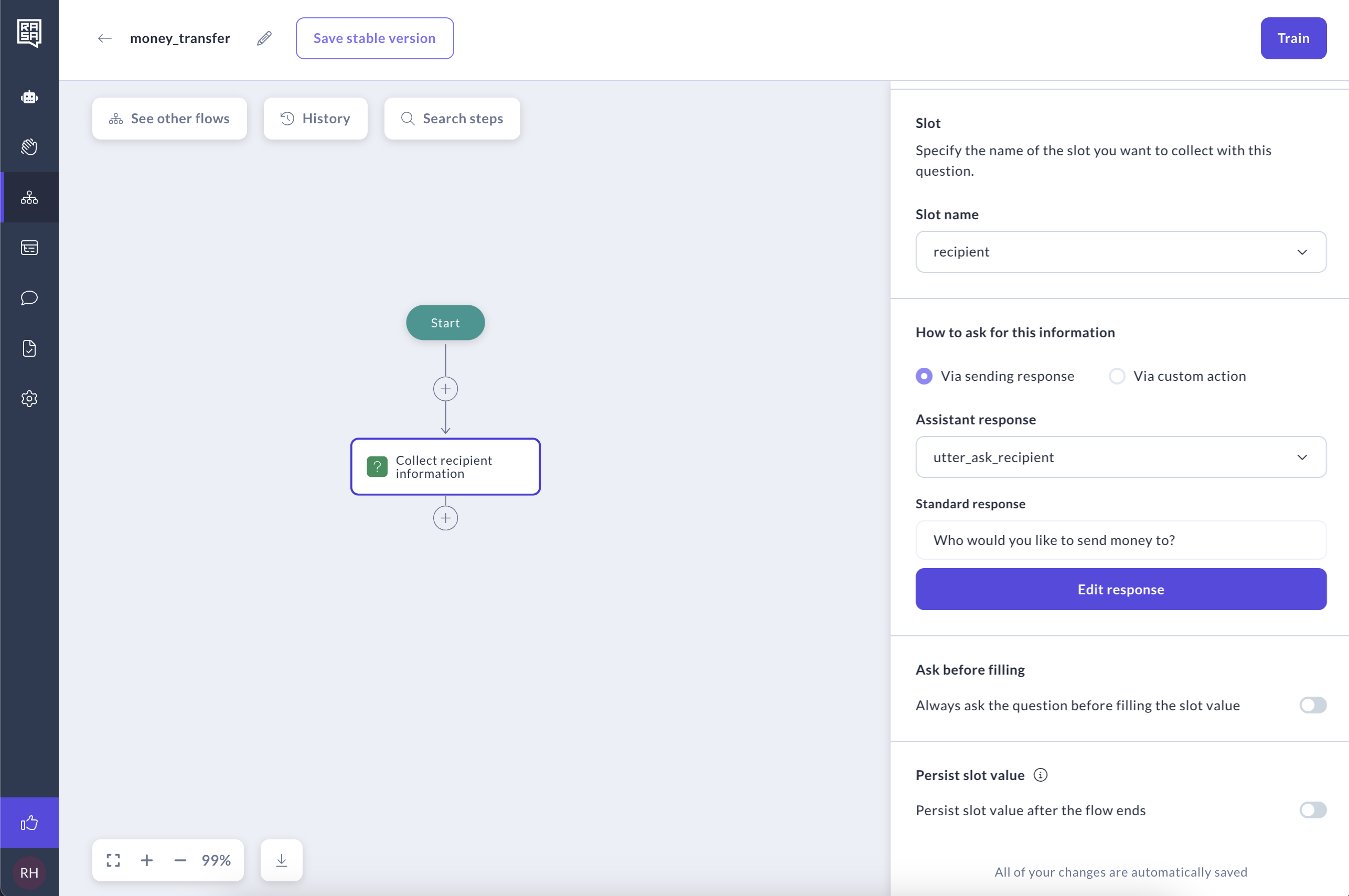
note
This step runs silently in the background without any dialogue. If you need the assistant to prompt the user for input, consider using a [Collect Step](https://rasa.com/docs/docs/studio/build/flow-building/collect/) instead.
##### Setting a Slot Value[](#setting-a-slot-value "Direct link to Setting a Slot Value")
For example, if the user mentions their birth year during a conversation, we can automatically set the `age_category` slot to `Minor` and clear the `permission_granted` slot, streamlining the interaction accordingly.

##### Setting Multiple Slots[](#setting-multiple-slots "Direct link to Setting Multiple Slots")
You can set multiple slots in one step. Simply click on "Set another slot" button to add more. You can see how many slots are set in one step by reading the number on the node.
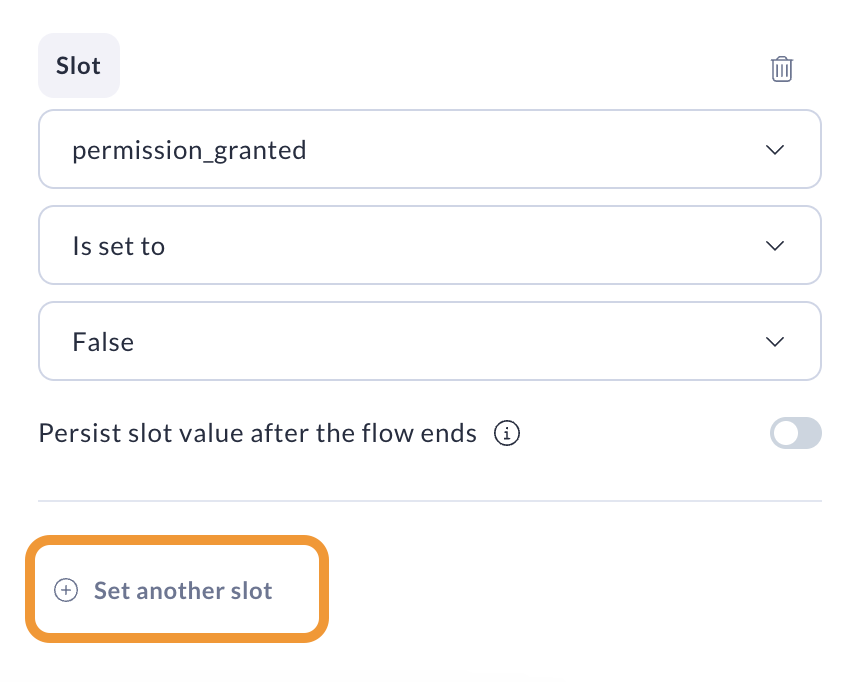
##### Clearing a Slot[](#clearing-a-slot "Direct link to Clearing a Slot")
note
When you choose to clear a slot's value, its current value is reset, and the system will treat it as if it were `null`.
Use this option when a slot’s current value is no longer valid or needed. For example, if a user attempts to transfer more money than available, you can inform them of the issue and then clear the amount slot, prompting them to enter a correct value.
##### Persisting a Slot value[](#persisting-a-slot-value "Direct link to Persisting a Slot value")
note
When you choose to persist a slot's value, that setting applies globally to all its occurrences in the flow.
Use this option when you want to persist slot’s value even after the flow ends.
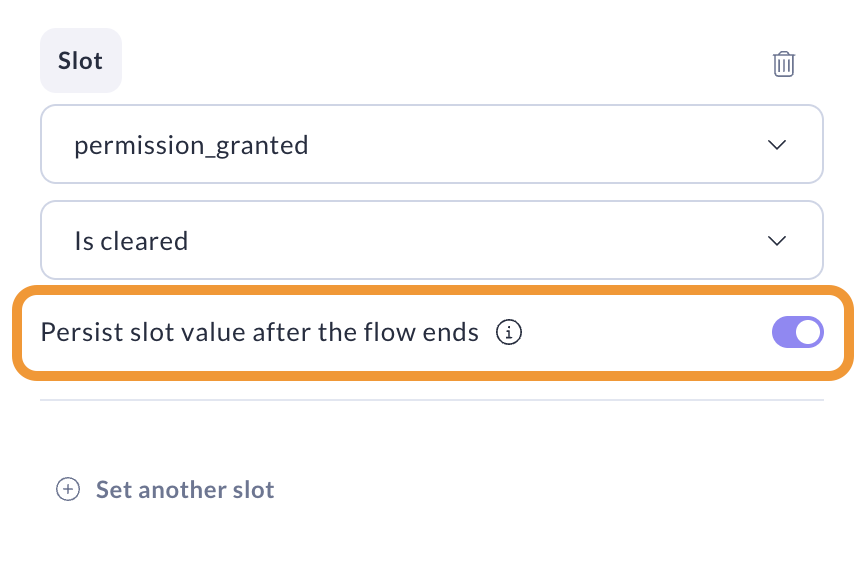
---
#### How to Set Up Your Assistant
This guide will help guide you through some best practices for configuring your assistants in Studio. By the end of it, you'll have configured your assistant and be ready to start building amazing conversational experiences. Let's dive in!
#### Step 1: Log In to Rasa Studio[](#step-1-log-in-to-rasa-studio "Direct link to Step 1: Log In to Rasa Studio")
1. Log in to Rasa Studio as a user with the `superuser` or `developer` role.
For more details on roles and what they can do, check out our [user role guide](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/). 
2. Create or select an assistant you want to configure. 
#### Step 2: Configure Your Assistant[](#step-2-configure-your-assistant "Direct link to Step 2: Configure Your Assistant")
1. Navigate to the "Assistant settings" page. 
2. Click on the "General settings" tab. Here, you will find general information for your assistant like Assistant name and Assistant API ID. These settings aren't editable. 
3. Click on the "Configuration" tab. Here, you will find editors for the default `config.yml` and `endpoints.yml` files." 
Additionally, there is an option to "Always include the following flows in the prompt." This feature ensures that selected flows are always considered by the LLM during dialogue management, regardless of other constraints. This is particularly useful for flows that are crucial to the assistant's functionality and need to be readily available during conversations. For more details on flow retrieval, please refer to the [Retrieving Relevant Flows documentation](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#retrieving-relevant-flows).
##### Configuration Files[](#configuration-files "Direct link to Configuration Files")
You can configure LLMs and their deployments, embeddings, NLU, Core, and Action server in these files.
###### Config[](#config "Direct link to Config")
The `config.yml` file is central to configuring your assistant's behavior. It allows you to customize:
* NLU (Natural Language Understanding) components
* Core model settings
* Training pipeline
* Policies
* LLM (Large Language Model) configurations and deployments
* Embedding settings
###### Endpoints[](#endpoints "Direct link to Endpoints")
The `endpoints.yml` file specifies various service endpoints used by Rasa Studio, including:
* [Tracker store](https://rasa.com/docs/docs/reference/integrations/tracker-stores/)
* [Event broker](https://rasa.com/docs/docs/reference/integrations/event-brokers/)
* [NLG (Natural Language Generation) server](https://rasa.com/docs/docs/reference/integrations/nlg/)
* [Action server](https://rasa.com/docs/docs/action-server/)
#### Optional: Configure Additional Languages[](#optional-configure-additional-languages "Direct link to Optional: Configure Additional Languages")
Configuring additional languages enables your assistant to deliver localized content and offer a better experience for users who speak different languages. It also allows you to manage and translate responses directly in Studio.
1. Navigate to the Assistant Languages tab 
* From the sidebar menu, select “Assistant language.”
* This opens the panel where you can set your assistant’s default and additional languages.
2. Set the Default Language
* You can update your default language from this tab. This language is the primary language your assistant uses and will act as the fallback if translations are missing or errors occur.
🚨 Destructive Action
Be careful when updating the default language—you’ll need to provide a full set of default content for the newly selected language before being able to train.
3. Add Additional Languages
* Select the additional languages you want your assistant to support *(e.g., start typing “Port” to filter Portuguese variants)*.
* Select the appropriate one(s).
* Save your changes.
note
Changes to language settings automatically update your config—no manual changes are needed.
4. (Optional) Add a Custom Language
* If your target language isn’t listed, click “Add custom language” at the bottom of the list.
* This allows you to manually define a language key and name.
###### About Language Codes[](#about-language-codes "Direct link to About Language Codes")
Rasa uses the [BCP 47 standard](https://www.rfc-editor.org/info/bcp47) for encoding languages. This standard supports a wide range of use cases across global markets.
You can find specific language codes in the [IANA Language Subtag Registry](https://www.iana.org/assignments/language-subtag-registry/language-subtag-registry).
###### 📌 Advanced Tips:[](#-advanced-tips "Direct link to 📌 Advanced Tips:")
* **Custom dialects:** Use `x-` for private use (e.g., `x-de-formal` for formal language variants).
* **Regional variants:** We recommend to keep your language codes simple - however, if you have country level localization - use region-prefixed codes like `en-US` 🇺🇸 or `en-UK` 🇬🇧 to support localized behavior.
These formats ensure consistent behavior across Rasa Studio and other parts of the Rasa stack.
#### Further Reading[](#further-reading "Direct link to Further Reading")
For more detailed technical information on `config.yml` and `endpoints.yml` files, refer to the [Rasa documentation on model configuration](https://rasa.com/docs/docs/reference/config/overview/).
---
#### How to Trigger Flows
This guide will teach you the different approaches to triggering flows in Rasa to create flexible and responsive conversations.
#### Starting a Conversation[](#starting-a-conversation "Direct link to Starting a Conversation")
In the "Start" step, you can configure how your flow will be triggered. There are four primary methods for starting the flow:
* Automatically by LLM based on flow description
* Using predicted user intents
* Based on a certain condition
* With links or calls from other flows
#### Flow description[](#flow-description "Direct link to Flow description")
The flow description serves as the default trigger mechanism. The system utilizes the flow description, ongoing conversation, and contextual cues to determine when to start a flow automatically by LLM. For this routing to work properly, it's crucial to write clear and distinct descriptions. Read more about [tips for writing good flow descriptions here](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#best-practices-for-descriptions).
#### NLU triggers[](#nlu-triggers "Direct link to NLU triggers")
NLU triggers allow you to use predicted user intents to start a flow. You can start the flow based on multiple user intents and configure a confidence threshold for each one. We recommend using a confidence threshold calculated by dividing 1 by the total number of intents in the model. However, it's essential to experiment with different confidence thresholds to find the optimal setting for your scenario.
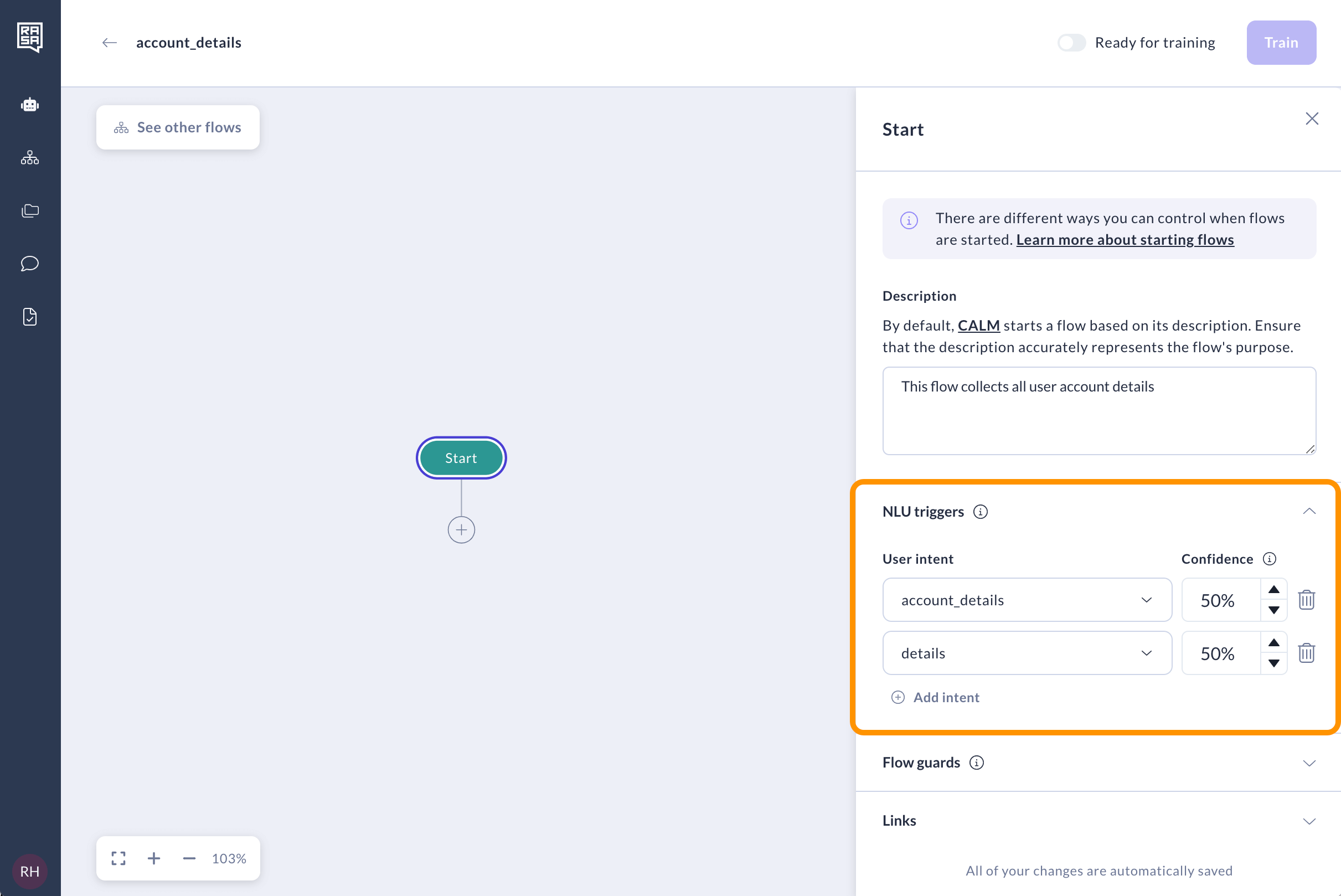
#### Links / Calls[](#links--calls "Direct link to Links / Calls")
This section displays all the flows where your current flow is [linked](https://rasa.com/docs/docs/studio/build/flow-building/linking-flows/#link-steps) or [called](https://rasa.com/docs/docs/studio/build/flow-building/linking-flows/#call-steps) from, so you can see the specific cases in which it will be started. You can go to each of these parent flows to remove those links if needed.
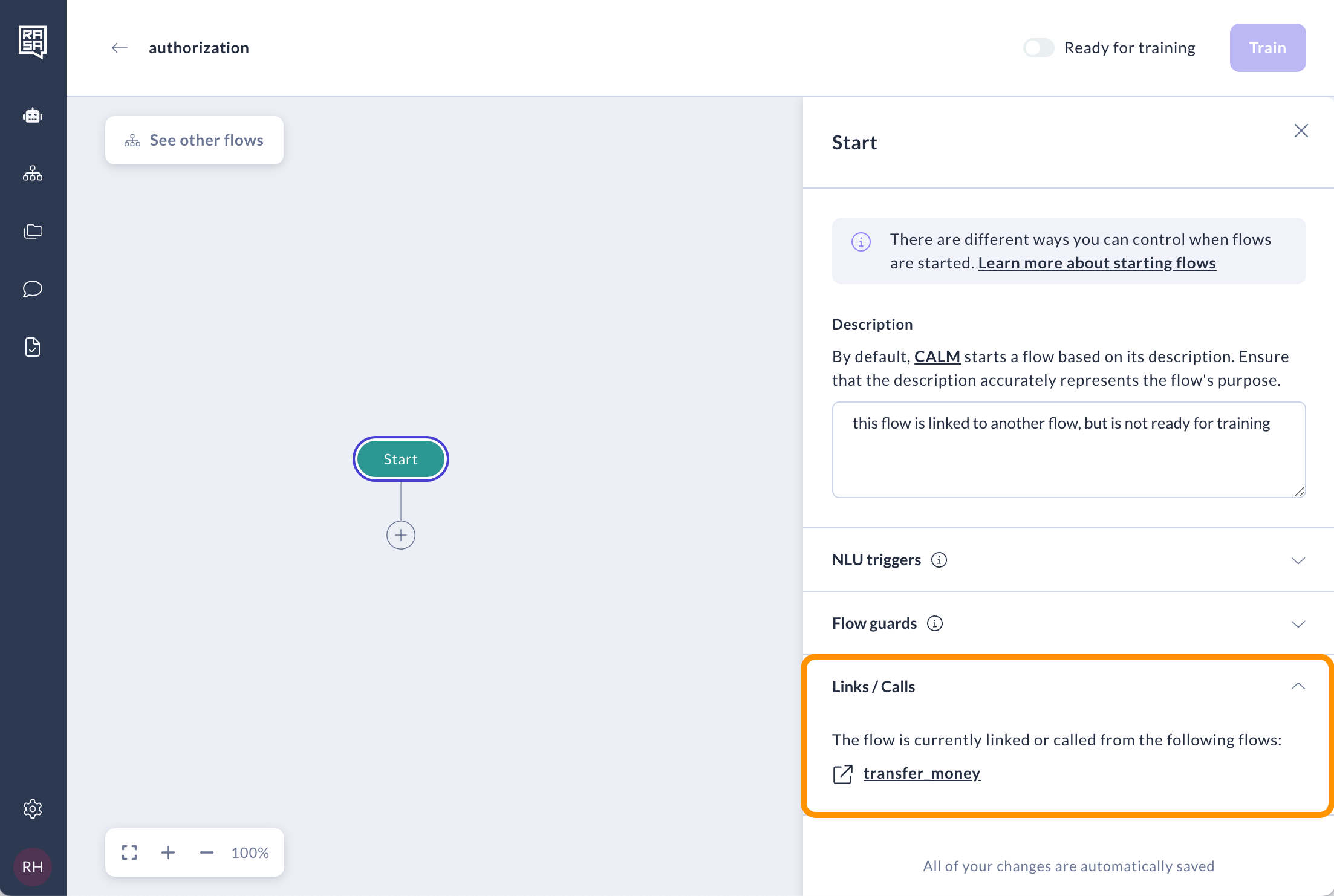
#### Flow guards[](#flow-guards "Direct link to Flow guards")
Flow guards allow you to set certain conditions for starting a flow. By default, there are no flow guards, but you can set either of the following two types:
* When the "Start the flow exclusively via 'Link' or 'Call a flow and return'" setting is enabled, the flow can only be started through linking or calling from other flows.
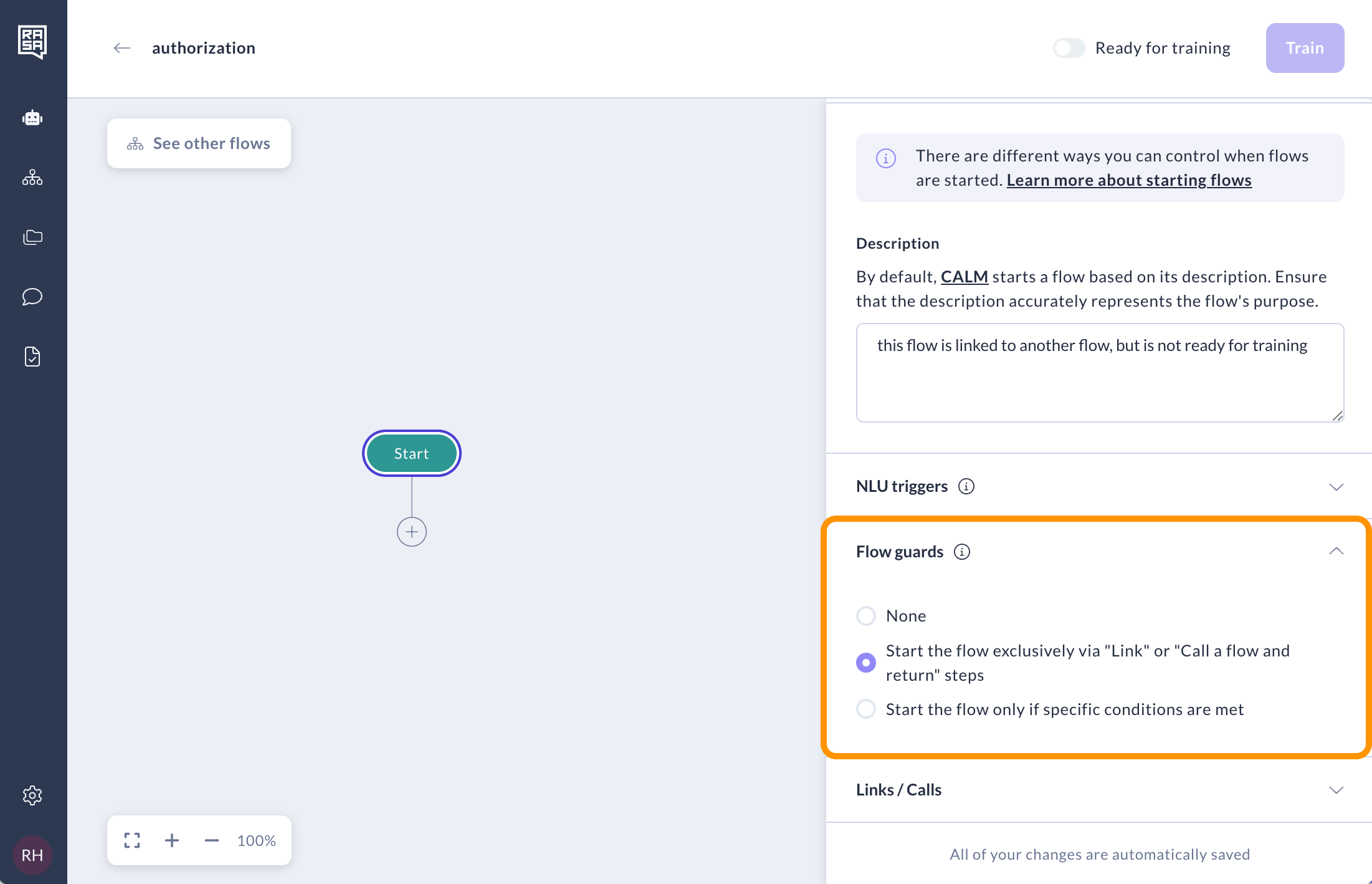
* The "Start the flow only if specific conditions are met" allows you to set specific conditions under which a flow can be started. For example, the flow will only be initiated if the user is authenticated and their email is verified.
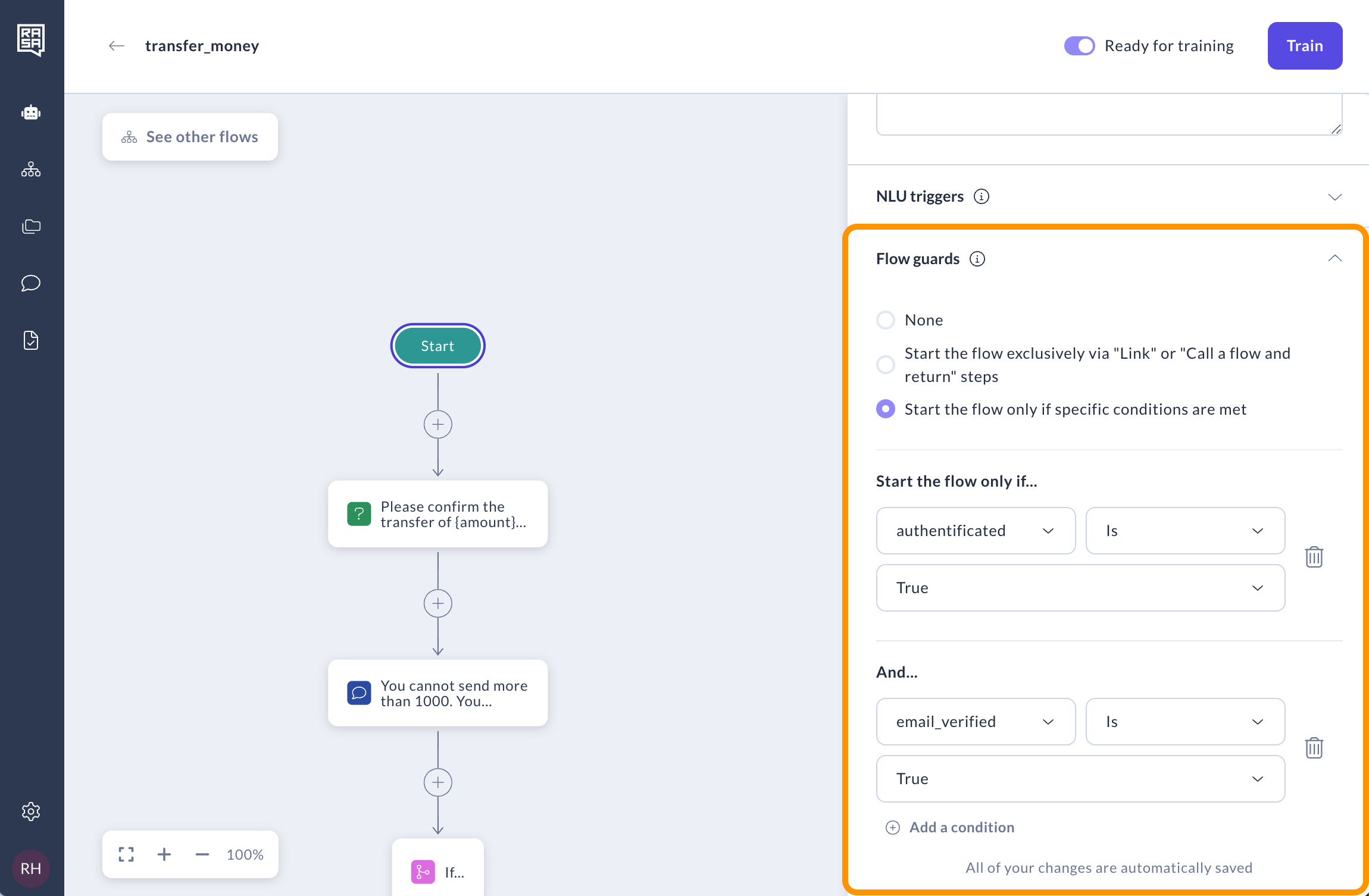
If the flow has active Links/Calls and NLU triggers, the flow guard can only be triggered after these have been executed. The order of execution for flow triggers and guards is as follows:
1. Direct links/calls to the flow are executed first.
2. NLU triggers go next: Specific intent trigger messages, such as `/initialize_conversation`, will "force start" a flow for a targeted intent right after links.
3. Flow guards follow.
4. Flow description is referenced last in the execution order.
---
#### How to use Intents and Entities
You can create your own Intents and Entities to use as triggers in your Rasa Assistant.
Important Note
Using intents in your Rasa assistant is completely optional. The recommended approach for building assistants is to use a [CALM approach](https://rasa.com/docs/docs/learn/concepts/calm/) which leverages Large Language Models (LLMs) to trigger conversation flows dynamically, without relying heavily on pre-defined intents. This approach often leads to more flexible and scalable assistants, especially in complex use cases.
#### Intents in Studio[](#intents-in-studio "Direct link to Intents in Studio")
Managing intents in Studio is an optional way to use NLU within your Rasa assistant. To add a new intent in your assistant:
##### What is a Intent?
An intent represents the goal or purpose behind a user’s message. For example, a user might express the intent to book a ticket, ask for a weather update, or say hello. Intents help the assistant determine what the user wants to achieve.
##### Create an Intent[](#create-an-intent "Direct link to Create an Intent")
1. **Create Intents:** Click the Create intent button at the top right.
2. **Mark Ready for Training:** Toggle the Ready for Training checkbox to remove the `Under Development` label and include the intent in training.
3. **Edit Intents:** Click the Edit button to rename an intent.
4. **Delete Intents:** Click the Delete button to remove an intent. Before deleting, make sure all associated examples and annotations are moved or deleted.
#### Conversation Examples[](#conversation-examples "Direct link to Conversation Examples")
Examples in Rasa Studio are real or simulated user inputs used to train your assistant to recognize and respond to intents.
You can annotate these examples directly within Studio to tag relevant entities or refine intent classification. Additionally, you can upload annotated real conversations to further enhance your assistant's ability to identify intents accurately, ensuring a better match to real-world scenarios.
##### Create a New Example[](#create-a-new-example "Direct link to Create a New Example")
1. **Add Examples**: Use the Add an example text field under the intent.
2. **Delete Examples**: Select examples and click Delete.
3. **Reclassify Examples**: Assign examples to a different intent using Classify to another intent.
4. **Edit Example Text**: Click the edit icon next to an example to update its text.
5. **Annotate Entities**: Highlight words in examples to tag them as entities. Use the to open the annotation panel and specify the entity type, role, or synonym.
##### What is a Entity?
An entity is a specific piece of information extracted from a user’s message. They provide additional context to the intent. For example, in the message "Book a flight to Paris," the intent might be "book\_flight," and the entity would be "Paris" (destination)
#### Best Practices[](#best-practices "Direct link to Best Practices")
1. **Provide Clear Intent Names**: Use descriptive, distinct names for each intent.
2. **Use Diverse Examples**: Provide varied examples for better training.
3. **Be Consistent with Annotation**: Accurately annotate entities to enhance model performance.
4. **Keep your NLU Data Up to Date**: Periodically review and refine your NLU data.
For more details on our recommendations for getting the most out of your assistant, see our [Best Practices for Great Conversations](https://rasa.com/docs/docs/learn/best-practices/conversation-design/).
---
#### Introduction to Actions
**Custom Actions** expand the capabilities of your assistant, enabling it to handle dynamic tasks and interact with real-world systems. With custom actions, your assistant can connect to external services like APIs, databases, or implement custom logic, making it versatile enough to address a wide range of use cases.
#### How to Use Custom Actions in Rasa Studio[](#how-to-use-custom-actions-in-rasa-studio "Direct link to How to Use Custom Actions in Rasa Studio")
Custom actions can be added directly to your assistant’s flow by using the **Custom Action** step. Learn more about how to [create Custom Actions here](https://rasa.com/docs/docs/studio/build/actions/create-a-custom-action/).
If you haven't already, you’ll need to first connect your assistant to an action server. Here’s what you need to know:
###### [Local Testing Guide](https://rasa.com/docs/docs/studio/build/actions/local-testing/)[](#local-testing-guide "Direct link to local-testing-guide")
Ideal for developers quickly testing a new custom action during local development.
###### [Action Server Guide](https://rasa.com/docs/docs/action-server/)[](#action-server-guide "Direct link to action-server-guide")
Best suited for team collaboration for testing deployed custom actions in a shared environment.
Once your action server is configured, you can test your assistant with [**Try Your Assistant**](https://rasa.com/docs/docs/studio/test/try-your-assistant/). This helps ensure your custom actions work as intended before moving to production.
note
Learn more about the role of custom actions and how they fit into the broader assistant architecture in the [Action Server Overview](https://rasa.com/docs/docs/action-server/).
---
#### Introduction to Flows
In Rasa, the business logic of your AI assistant is implemented as a set of **Flows**. Each flow describes the logical steps your AI assistant uses to complete a task. It describes the information you need from the user, data you need to retrieve from an API or a database, and branching logic based on the information collected.
Learn More
If you're **new to flows** or want to dive deeper into the concepts behind **Business Logic** in Rasa you can [read more in our guide](https://rasa.com/docs/docs/learn/concepts/dialogue-management/).
#### Flows in Studio[](#flows-in-studio "Direct link to Flows in Studio")
Studio's **Flow Builder** offers a visual, node-based interface with steps designed to help you quickly iterate on the logic in your assistant.
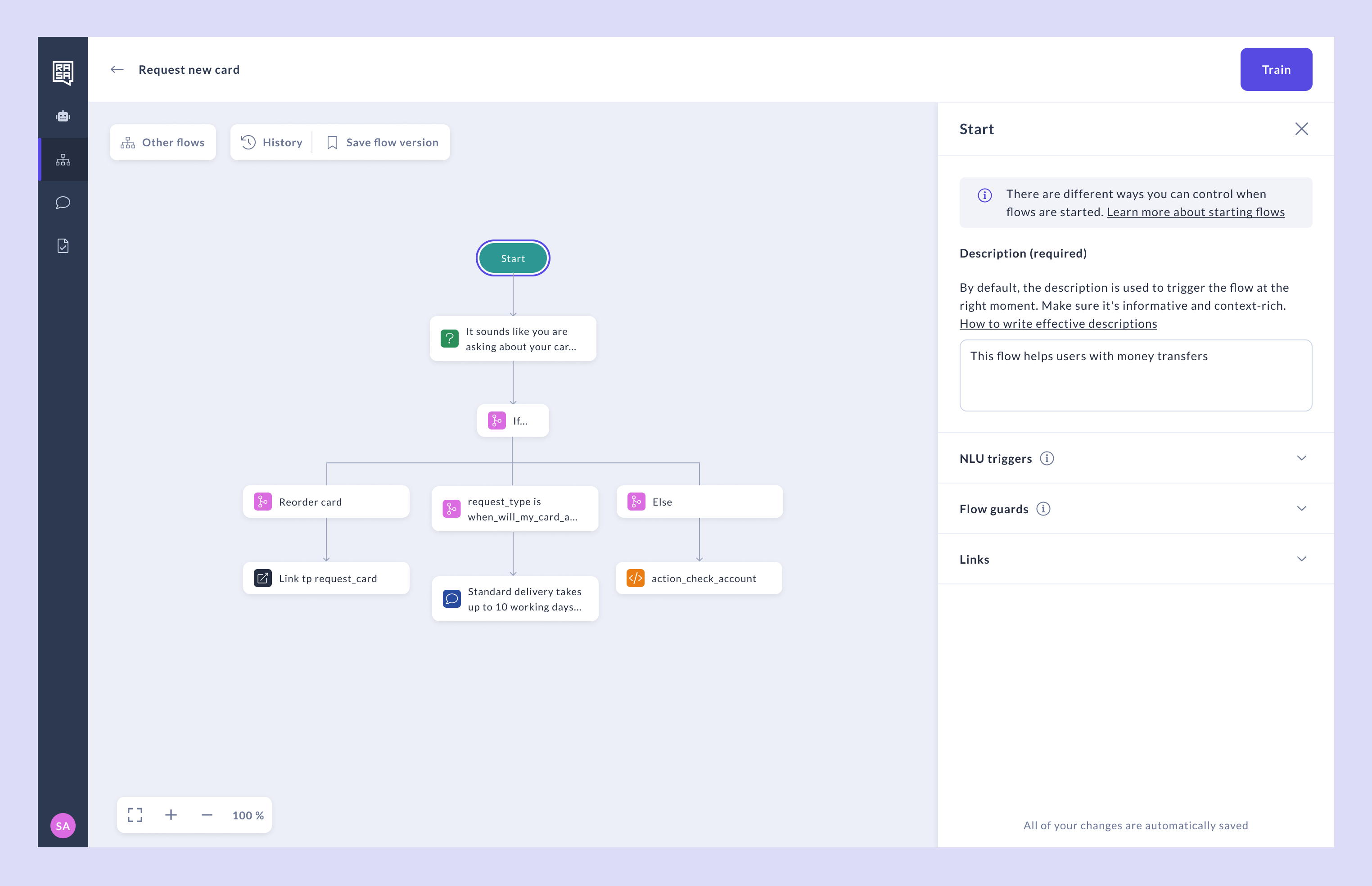
Each flow consists of steps that define the assistant's responses and actions. In the following sections, you'll learn how to use these steps effectively and how they work together to create seamless conversational experiences.
---
#### Local Setup for Custom Actions
This guide is for technical users who want a quick way to test out a new custom action from a local development server.
#### Prerequisites[](#prerequisites "Direct link to Prerequisites")
This workflow requires that you already have a Rasa CALM project initialized. Please see the [Rasa installation guide](https://rasa.com/docs/docs/pro/installation/overview/) for more details.
#### Step 1: Implement Your Custom Action[](#step-1-implement-your-custom-action "Direct link to Step 1: Implement Your Custom Action")
Add your custom action by creating or modifying the actions/actions.py file. Below is an example of a custom action that validates sufficient funds:
actions.py
```
# This file contains your custom actions which can be used to run
# custom Python code.
# See Rasa Tutorial for more details https://rasa.com/docs/pro/tutorial#integrating-an-api-call
from typing import Any, Text, Dict, List
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
from rasa_sdk.events import SlotSet
class ActionValidateSufficientFunds(Action):
def name(self) -> Text:
return "action_validate_sufficient_funds"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
# Hard-coded balance for tutorial purposes. In production,
# this would be retrieved from a database or an API.
balance = 1000
transfer_amount = tracker.get_slot("amount")
has_sufficient_funds = transfer_amount <= balance
return [SlotSet("has_sufficient_funds", has_sufficient_funds)]
```
#### Step 2: Run the Action Server[](#step-2-run-the-action-server "Direct link to Step 2: Run the Action Server")
Start the action server locally using the Rasa CLI:
```
rasa run actions
```
This command launches the action server, which runs on by default.
#### Step 3: Expose the Action Server[](#step-3-expose-the-action-server "Direct link to Step 3: Expose the Action Server")
For Rasa Studio to connect to your custom action server during testing, expose your local server to the public internet. You can use a tool like ngrok for this purpose.
Run the following command:
```
ngrok http 5055
```
##### Optional: Deploy to a Cloud Environment[](#optional-deploy-to-a-cloud-environment "Direct link to Optional: Deploy to a Cloud Environment")
If you want to avoid using ngrok for repeated testing or need a more robust setup, [see more details on the action server reference](https://rasa.com/docs/docs/action-server/) to deploy your development action server to a cloud environment of your choice. Ensure the public URL of your deployed action server is accessible and provide it to Rasa Studio for integration.
#### Step 4: Connect to Studio[](#step-4-connect-to-studio "Direct link to Step 4: Connect to Studio")
1. Open Rasa Studio and load your assistant project.
2. Navigate to the **Settings** section in Rasa Studio.
3. Go to the **Endpoints** tab and locate the **Action Server URL** field.
4. Enter the URL of your action server:
* **Option 1 (Using ngrok)**: Paste the public URL generated by the `ngrok http 5055` command (e.g., `https://.ngrok.io`).
* **Option 2 (Local Server)**: If you are running the action server locally and testing on the same machine, use `http://localhost:5055`.
5. Click **Save** to apply the configuration.
6. Train your assistant by clicking the **Train** button to ensure the new custom action is included in the training process.
7. Use the **Interactive Learning** or **Conversations** tools to test your assistant and confirm that the custom action is executed as expected.
##### Troubleshooting Tips[](#troubleshooting-tips "Direct link to Troubleshooting Tips")
If the assistant cannot connect to the action server:
* Ensure the action server is running (`rasa run actions`).
* If using `ngrok`, verify the public URL is still active and hasn’t expired.
* Confirm the URL matches what is specified in the **Action Server URL** field.
---
#### Managing Content in Studio
It is easy to manage content in Rasa Studio. You cab organize, and refine the data that powers your AI assistant.
#### Overview[](#overview "Direct link to Overview")
[**Flow Management:**](https://rasa.com/docs/docs/studio/build/content-management/manage-flows/) Search and manage your conversational flows efficiently, ensuring a coherent dialogue structure.
[**Version Control:**](https://rasa.com/docs/docs/studio/build/content-management/version-control/) Track changes and maintain different versions of your content, allowing for easy updates and rollbacks.
[**Review Production Conversations:**](https://rasa.com/docs/docs/studio/analyze/conversation-review/) Analyze real user interactions to identify areas for improvement and refine your assistant's performance.
[**Annotate Messages:**](https://rasa.com/docs/docs/studio/analyze/annotation/) Label conversations to enhance your assistant's natural language understanding capabilities.
[**Manage NLU Data:**](https://rasa.com/docs/docs/studio/build/content-management/nlu/) Organize and edit intents, entities, and training examples to improve the accuracy of your assistant's responses.
For more detailed information, refer to the [Rasa Studio documentation](https://rasa.com/docs/studio/).
---
#### Responses
The responses section of the CMS is a centralised place for content managers and flow builders to create and manage all the responses used in an assistant, including adding specific response variations based on one or more slot values, enhancing personalization and flexibility in replies.
This feature allows users to easily build multi-lingual assistants or add segmentation to their assistants based on different criteria.
Access this feature from Responses navigation item under CMS on the navigation menu.
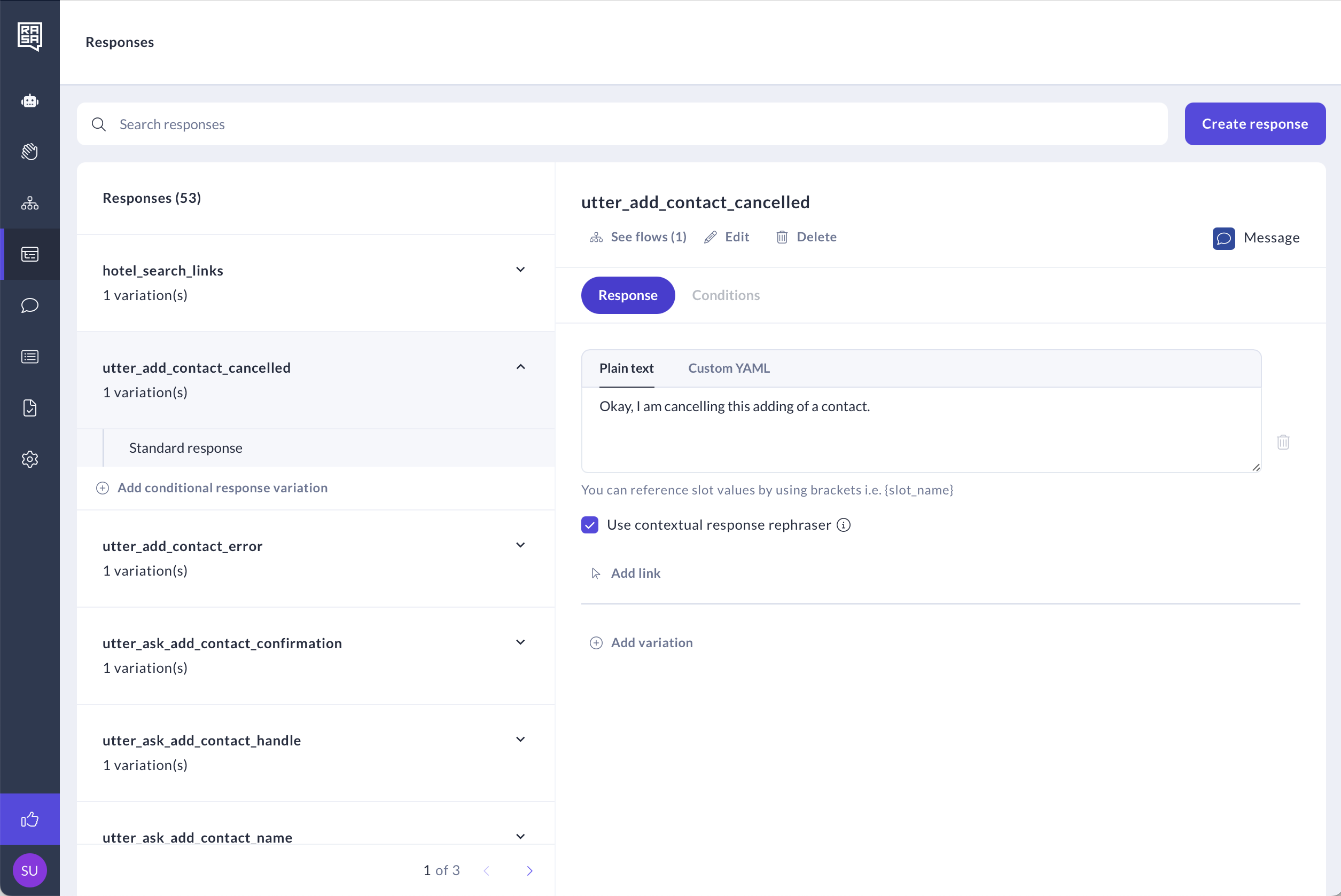
##### How to Create a Response[](#how-to-create-a-response "Direct link to How to Create a Response")
1. Click on the “Create response” button on the top right of the screen.

2. Select the Response type depending on where it will be used. You can choose from Message, Collect information or Invalid input responses types.
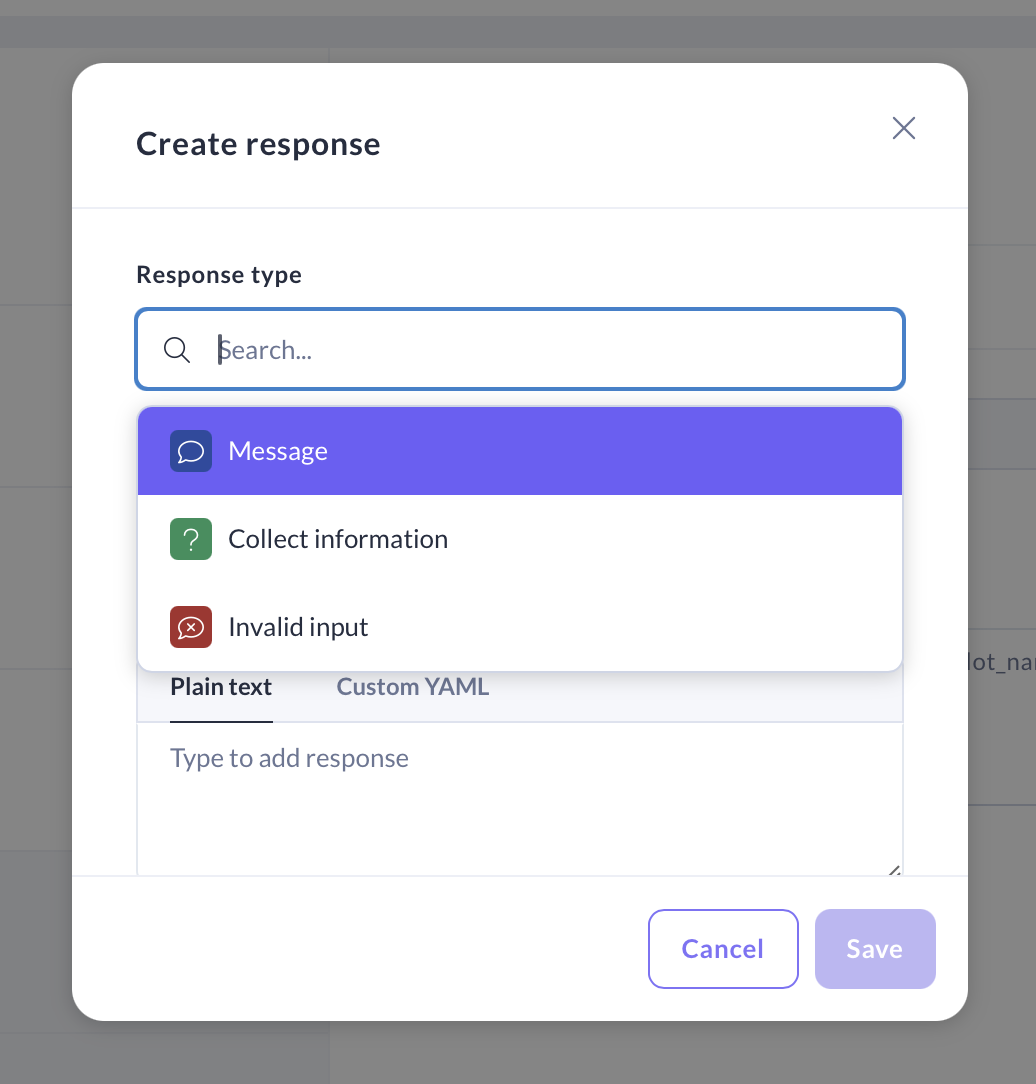
3. Type in a name and the standard response text, and buttons if it's a Collect information response.

4. The "Use Contextual Response Rephraser" option is disabled by default. This feature enables the assistant to rephrase its responses by prompting an LLM, based on the conversation's context. It helps make the assistant's responses feel more organic and conversational.
If you prefer full control over responses, you can uncheck the rephraser and manually add message variations.
Read More
When creating a new response, the "Use Contextual Response Rephraser" option defaults to the global `rephrase_all` value set in the endpoints.yml file.
If you keep this default setting, the per-response rephrasing setting will not be explicitly set for the message.
If you change this option to a different value than the default, the per-response rephrasing setting will be set to your chosen value.
The UI will always display the computed state of rephrasing, taking into account both the per-response setting (if set) and the global `rephrase_all` value.

##### Buttons and Links[](#buttons-and-links "Direct link to Buttons and Links")
Each response can include interactive elements: **buttons** for Collect Information responses and links for **Message** responses. To add them:
1. Click **Add button** or **Add link** in your response.
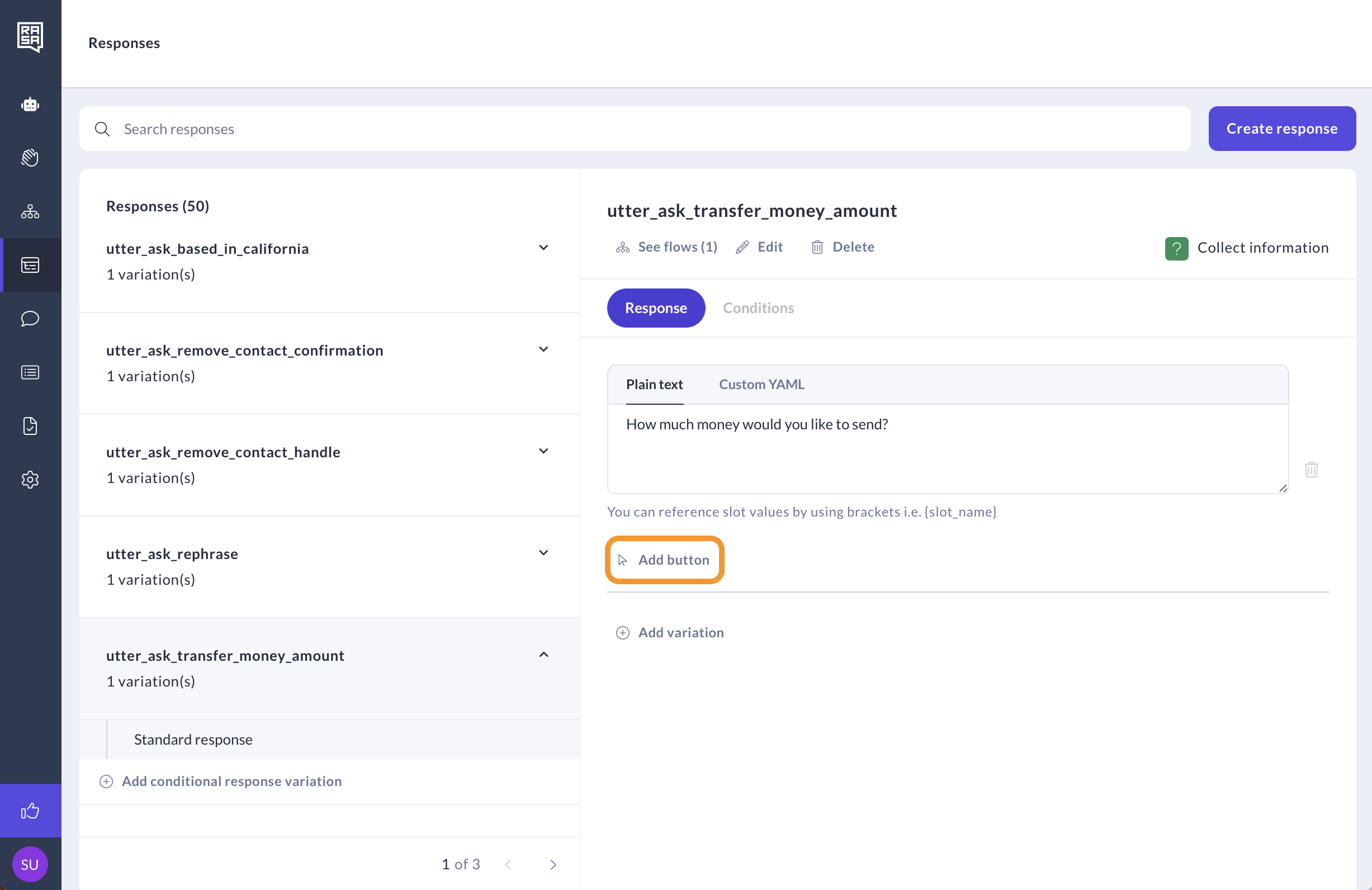
2. In the modal that opens, choose to reuse an existing button or link, or create a new one. Learn more about [buttons](https://rasa.com/docs/docs/studio/build/flow-building/collect/#buttons) and [links](https://rasa.com/docs/docs/studio/build/flow-building/sending-messages/#links).
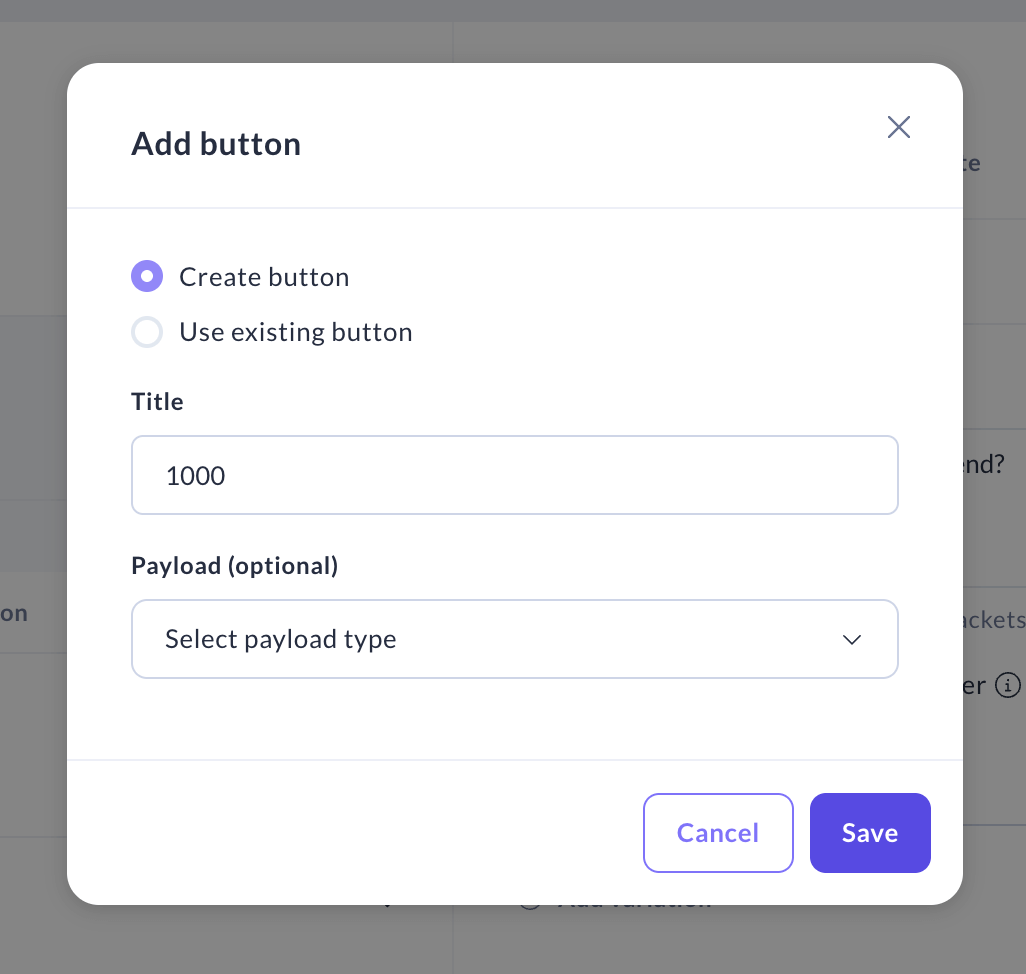
3. Repeat **Add button** or **Add link** and fill in the details for as many options as needed.
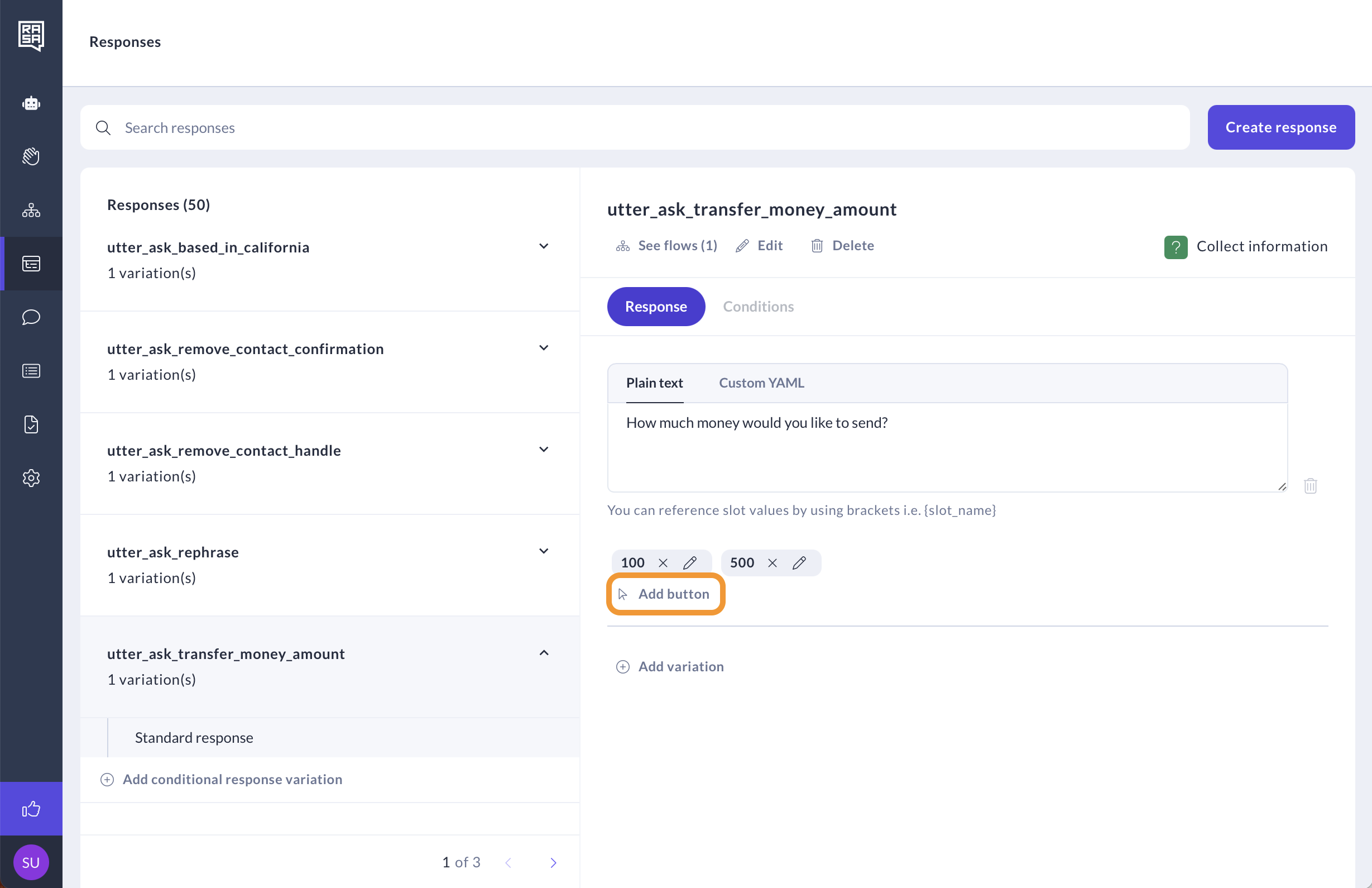
4. To reorder the options shown to the user, drag and drop them directly in the response editor.
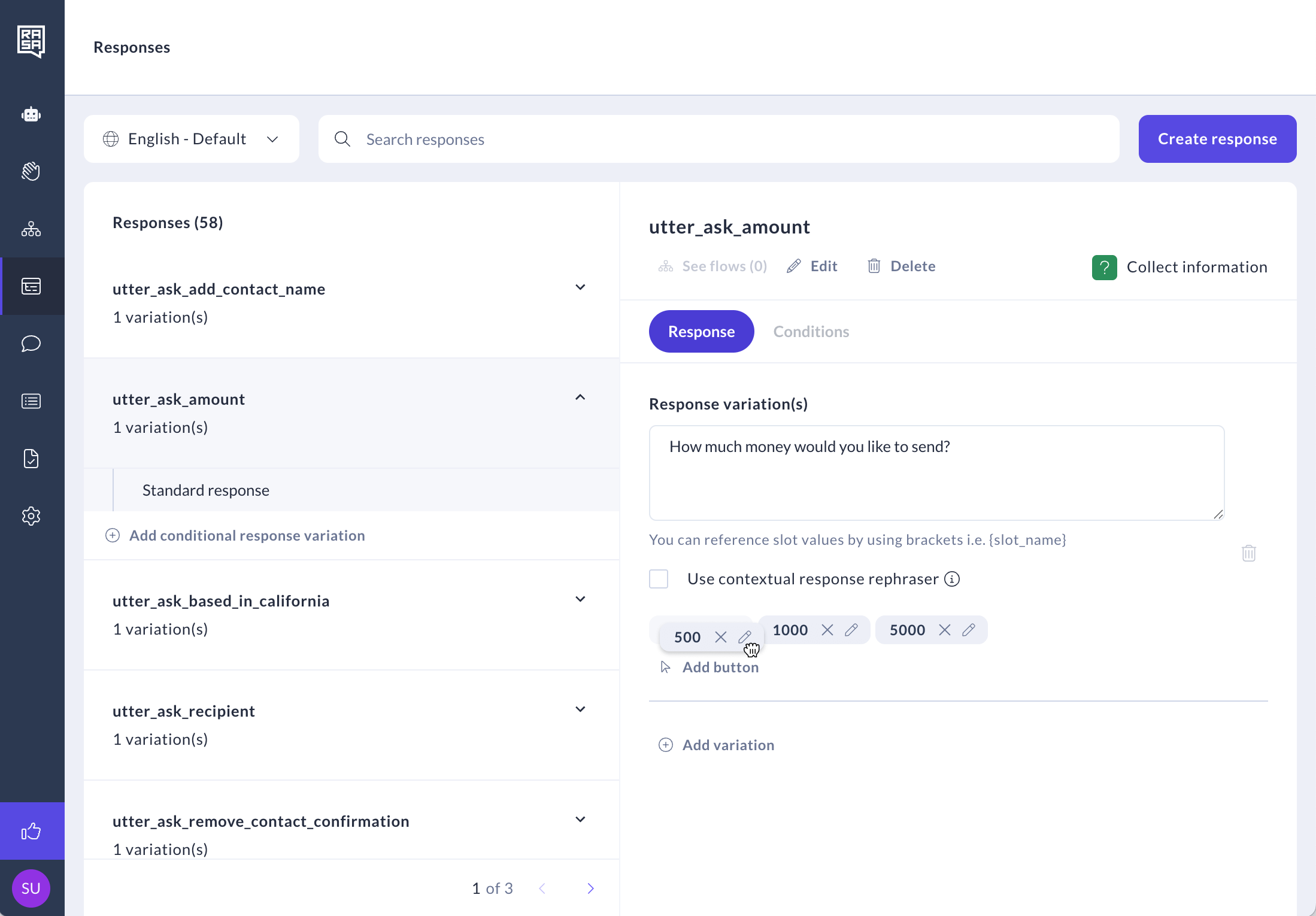
##### Manage Responses[](#manage-responses "Direct link to Manage Responses")
1. Click the **Edit** button under the response name to edit the name and type of the response. Or the **Delete** button to delete the response from the assistant.
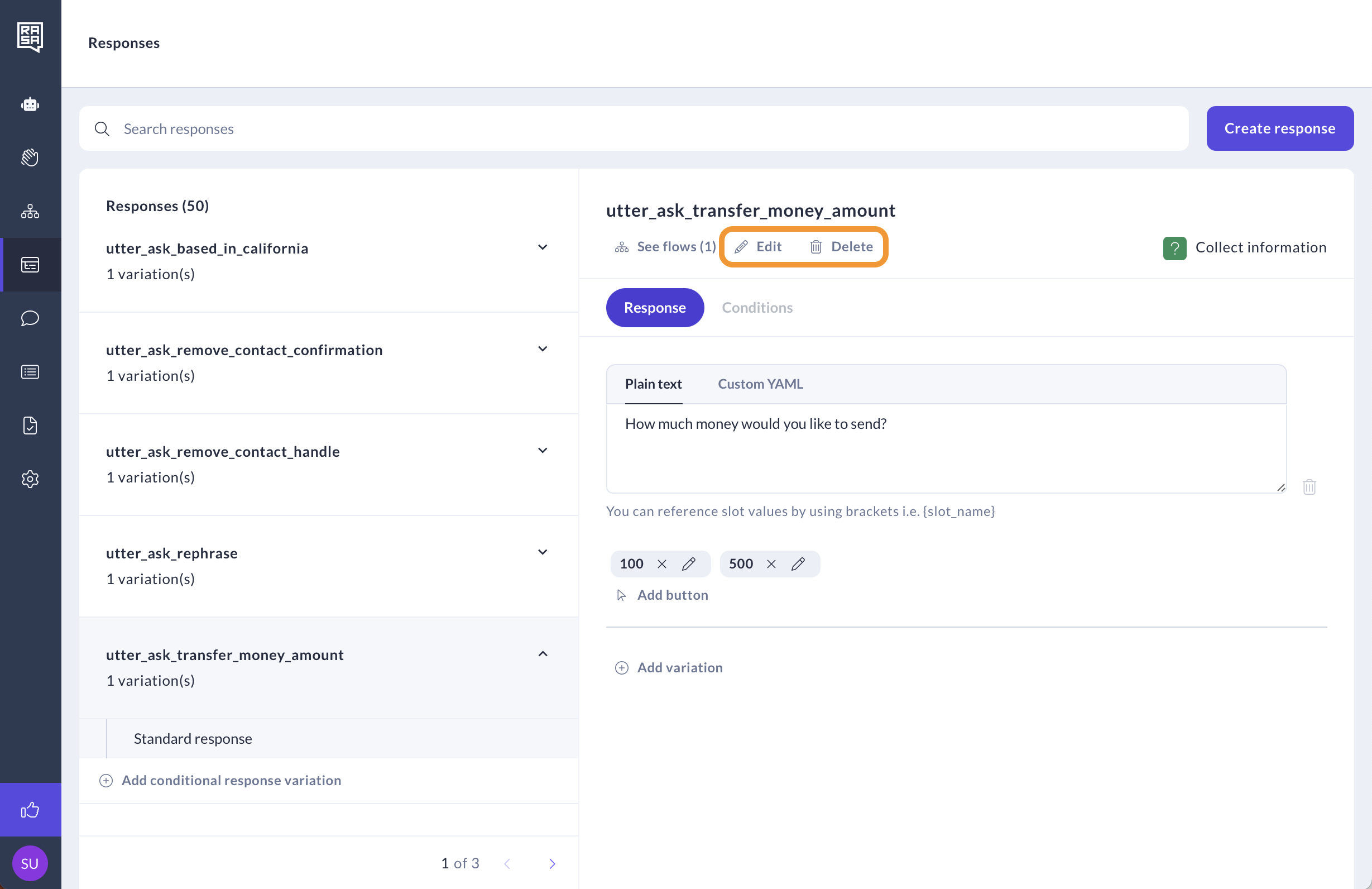
2. Click the **See flows** button to view a list of flows where the response is used.
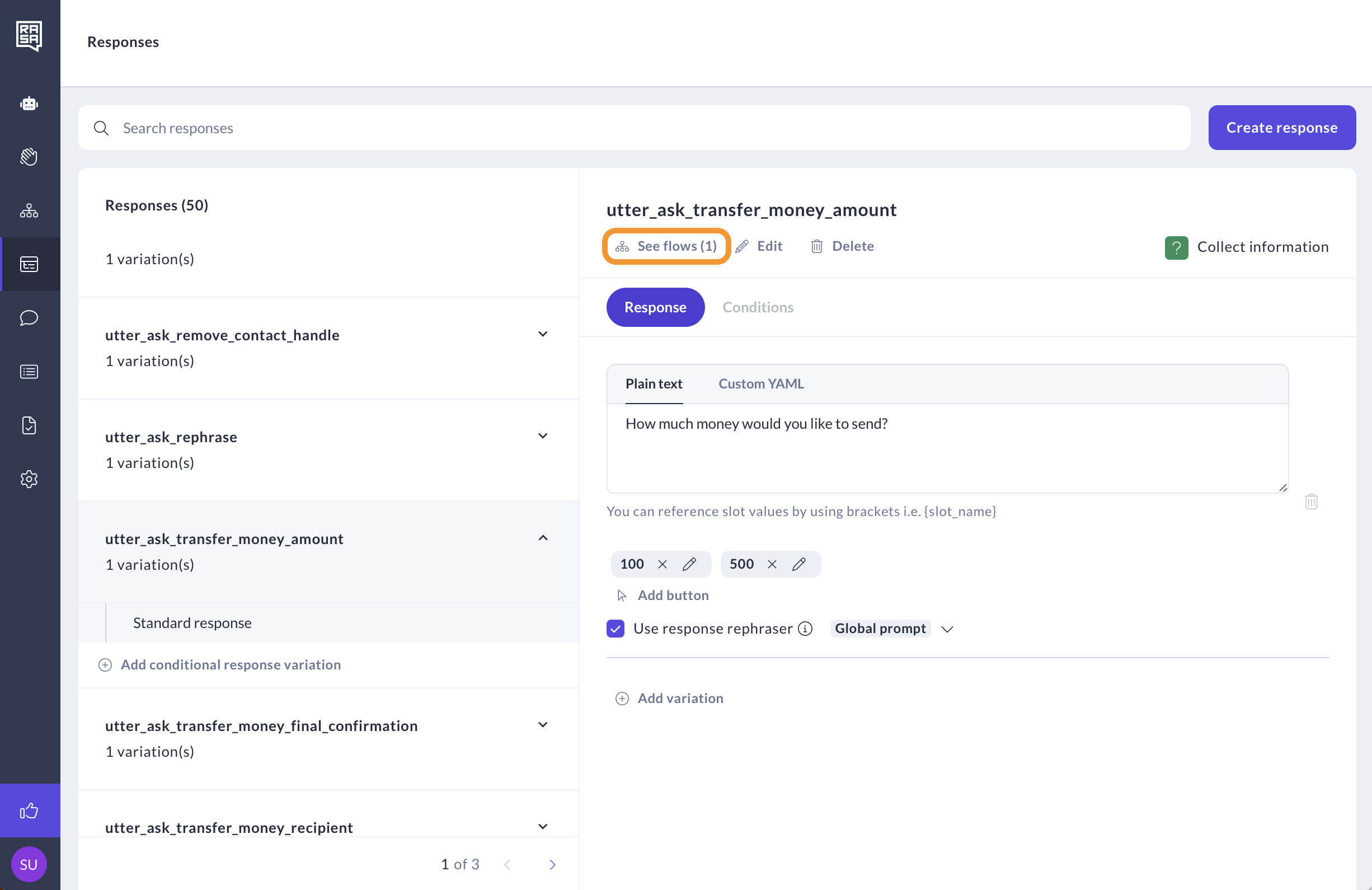
3. From the list, you can navigate to a specific flow to view the context in which the response appears.
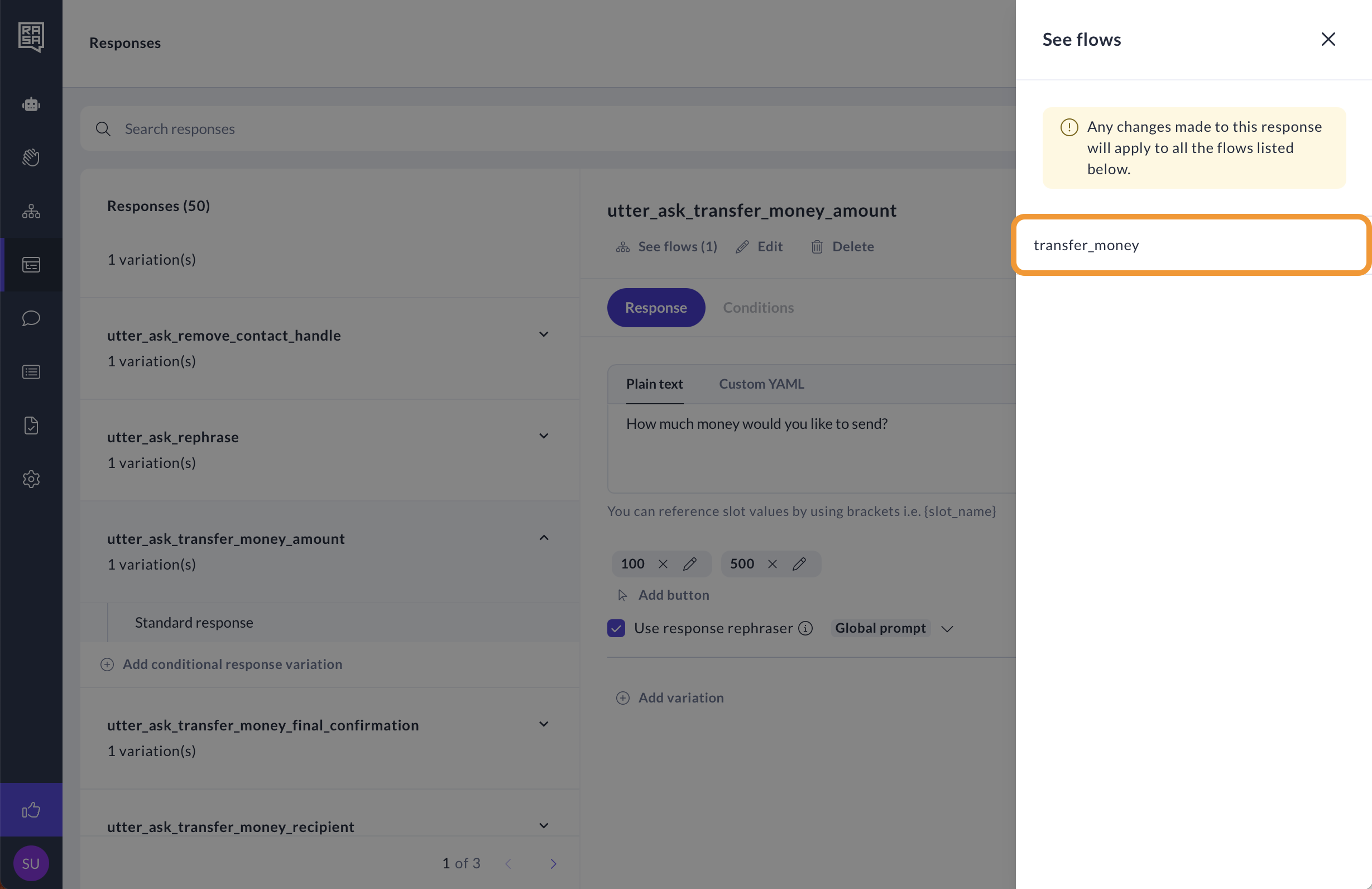
##### Conditional Response Variations[](#conditional-response-variations "Direct link to Conditional Response Variations")
Use conditional response variations to customise your assistant. These conditional response variations will only be shown to the user when they meet the conditions set on the Conditions tab.
You can only create and manage conditional response variations from the Responses section on the CMS.
1. Click the “Add conditional response variation” button under the response in the navigation panel.

2. Add a name for the conditional response variation. You can decide to copy the standard response text to this conditional response variation by checking the checkbox.
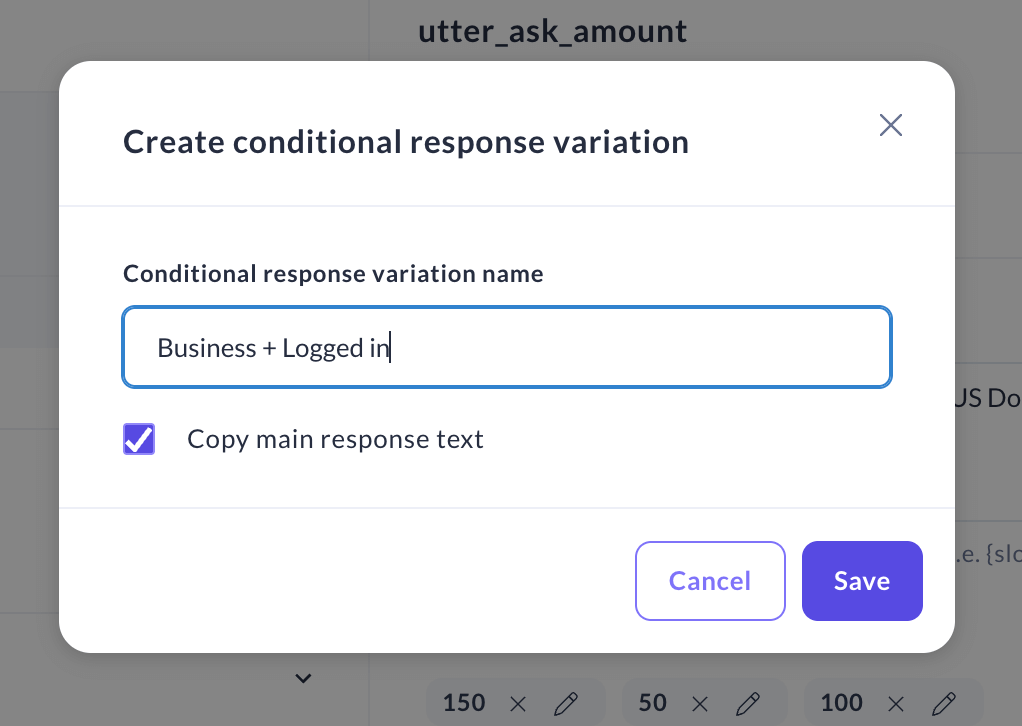
3. You are in the “Response” tab, where you can add the response, buttons and any variations to the response.
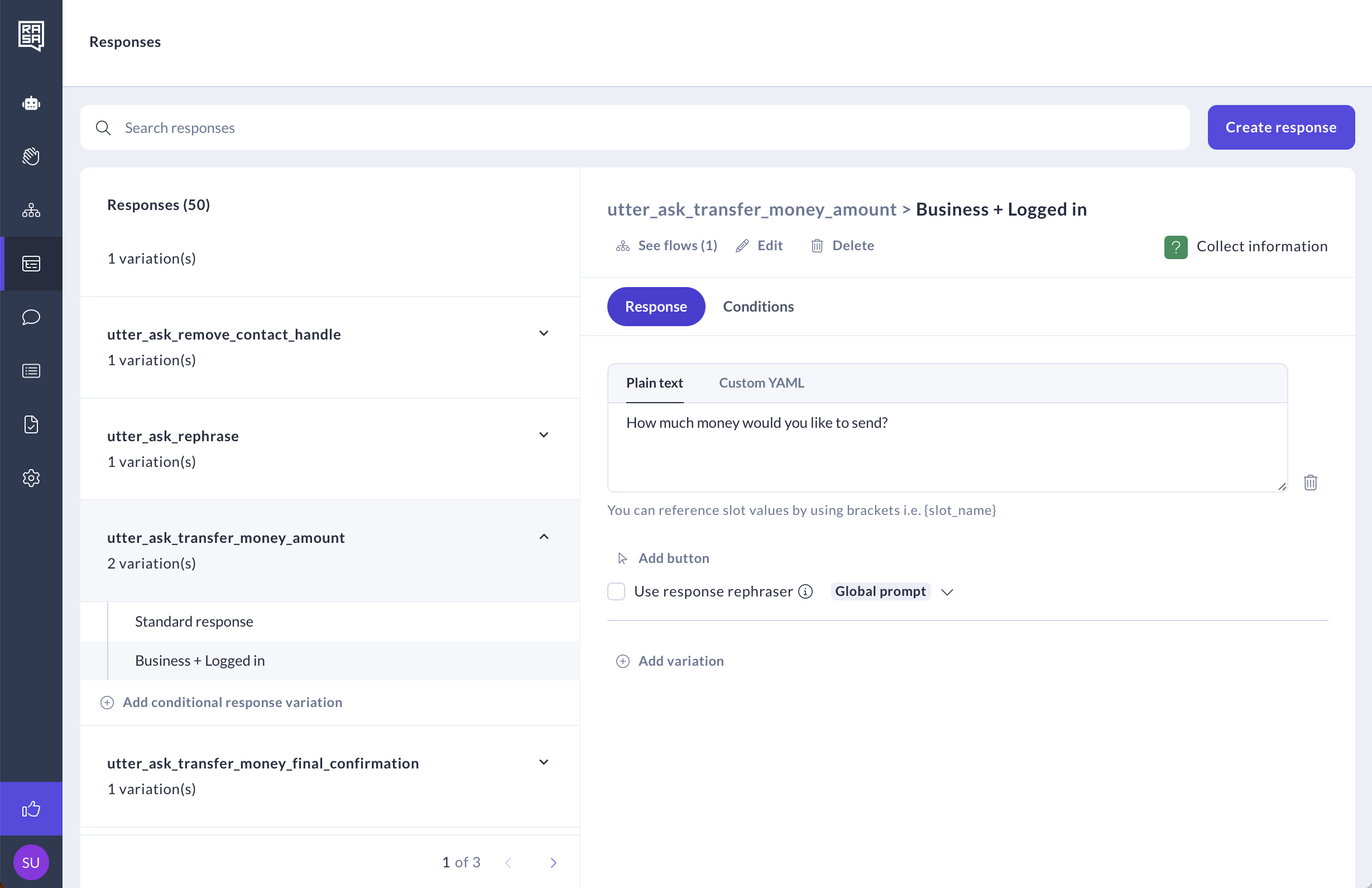
4. Click on the “Conditions” tab, and add as many conditions as you need. Select a slot and the slot value on the dropdowns available.
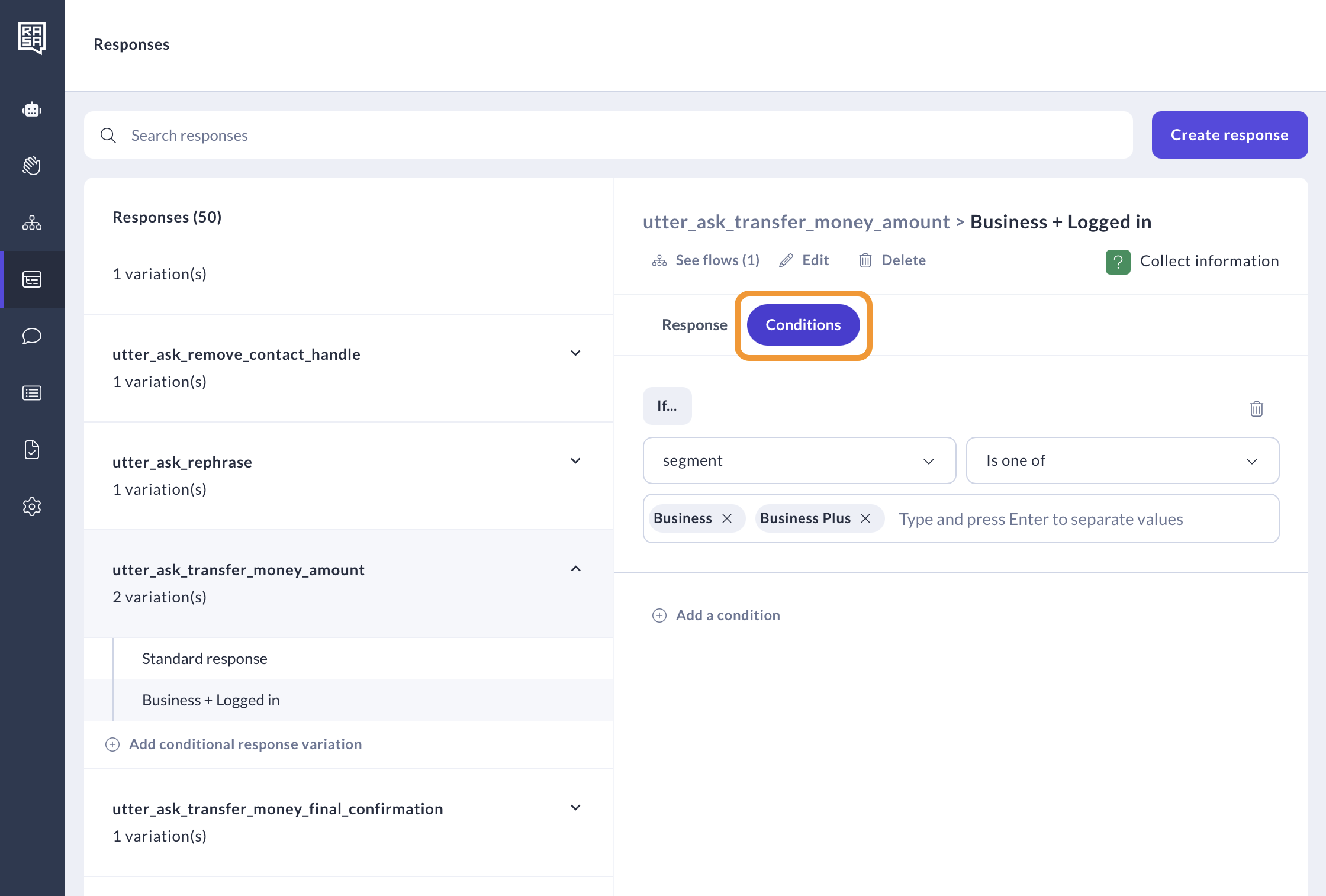
5. Click the “Add condition” button to add more conditions.
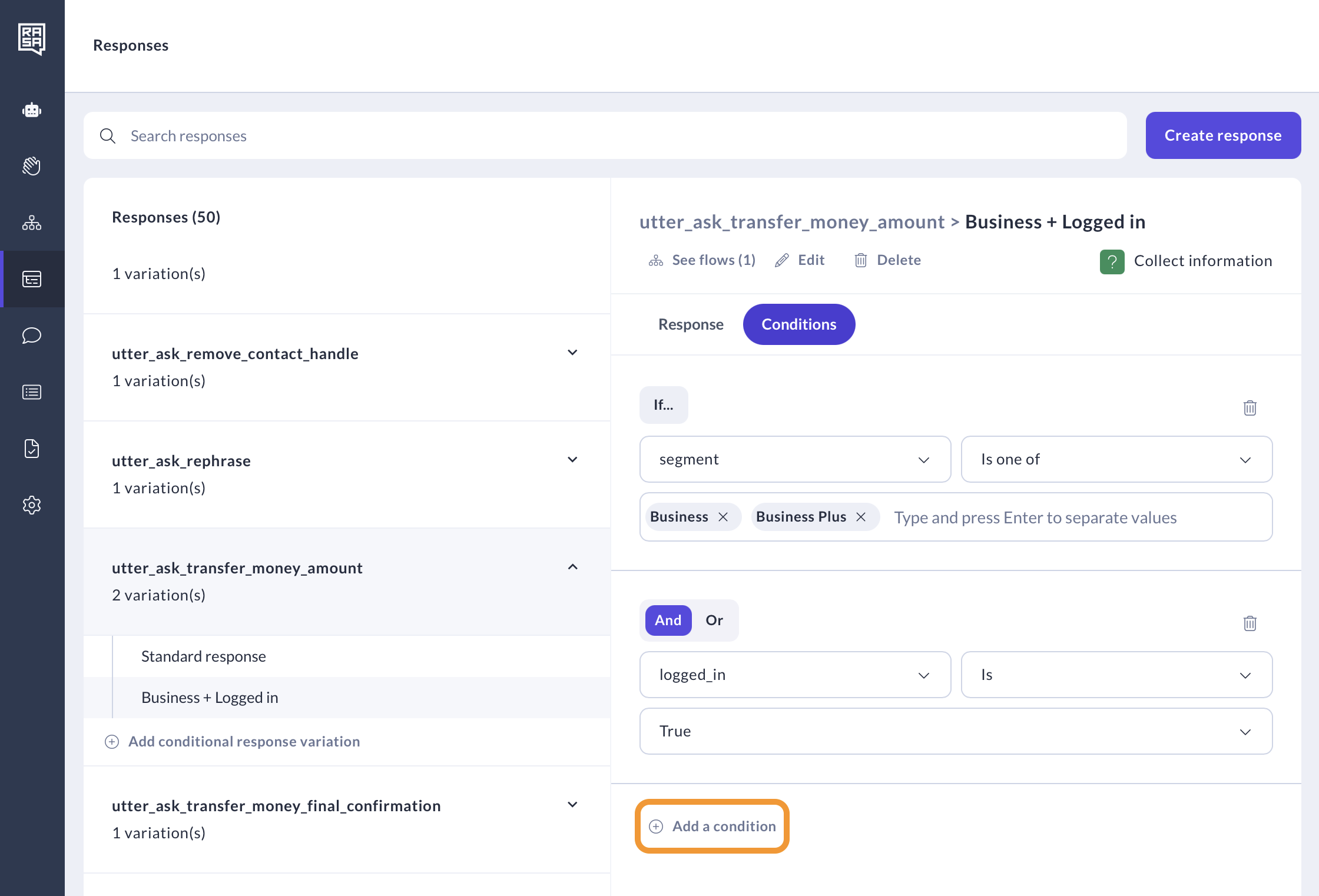
##### Custom Responses[](#custom-responses "Direct link to Custom Responses")
Custom responses allow you to go beyond simple text and create rich, interactive experiences tailored to your users and channels. You can use any YAML structure to define a custom response — from carousels and buttons to event triggers or metadata your channel frontend understands.
1. When editing a response, just switch the tab to Custom YAML and add your custom component in YAML. You can combine plain text and custom YAML in the same response if needed.

2. When testing in [Try your assistant](https://rasa.com/docs/docs/studio/test/try-your-assistant/), Rasa sends custom components as JSONs. Styling and rendering are handled entirely by your frontend or messaging channel.

---
#### Slots
The slots section of the CMS is a centralised place for content managers and flow builders to create and manage all the slots used in an assistant.
Access from Slots navigation item under CMS on the navigation menu.
##### How to Create a Slot[](#how-to-create-a-slot "Direct link to How to Create a Slot")
1. Click on the “Create slot” button on the top right of the screen.
2. Type in a name and select the slot type.
##### How to Manage Slots[](#how-to-manage-slots "Direct link to How to Manage Slots")
1. Select the slot from the list.
2. Click the “Delete” button to delete the response from the assistant.
3. Click the “See nodes” button under the response name to view all the nodes where the slot is being referenced.
 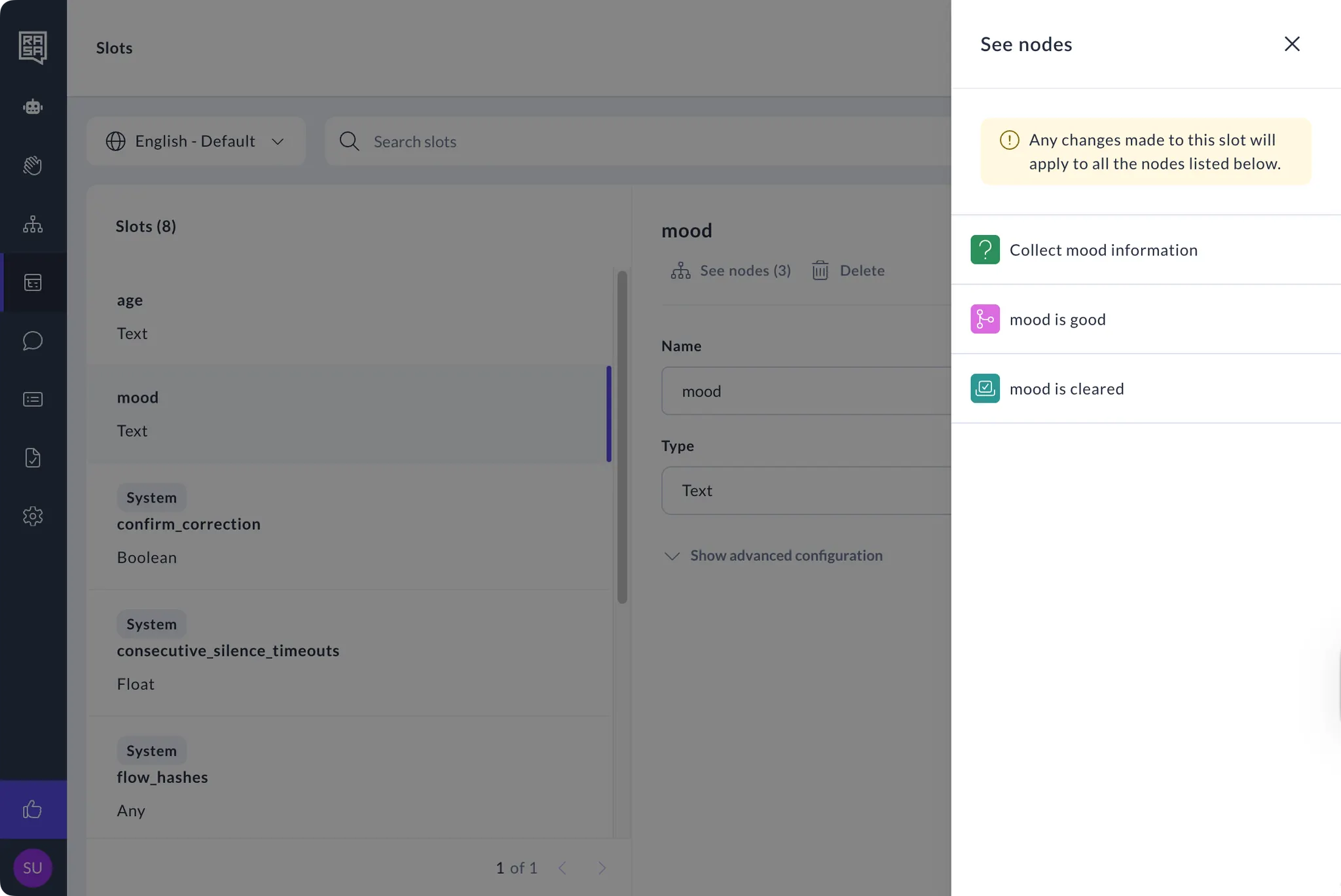
4. Change any slot values or type using the fields on the page, or any other advanced slot configuration by clicking on the “Show advanced configuration” button
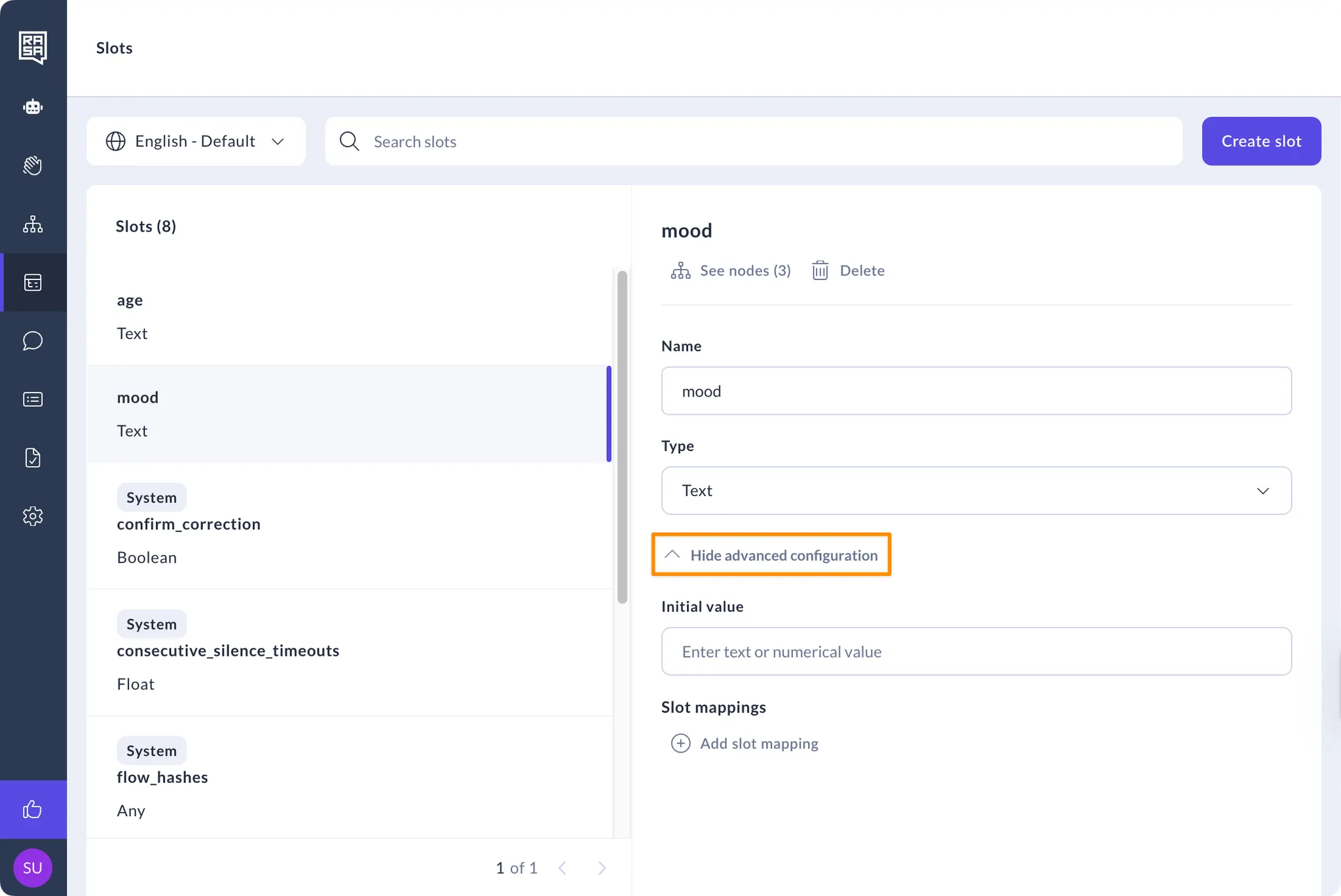
---
#### Translating Your Responses
Once you've [configured your assistant](https://rasa.com/docs/docs/studio/build/set-up-your-assistant/) to support multiple languages, you can translate its content directly in the Studio CMS. Rasa enables you to have fine-grained control over translations for all user facing content including:
* **[Responses](#1-translate-responses)**: Pre-translate or generate translations for all your assistant's responses.
* **[Buttons + Links](#2-translate-buttons-and-links)**: Translate and localize actions and urls in your conversation.
* **[Flow names](https://rasa.com/docs/docs/studio/build/content-management/manage-flows/#optional-translating-flow-names)**: Assistants will sometimes refer to flows in conversation when cancelling or clarifying an action. Translating flow names ensures that this experience is seamless in every language.
##### 1. Translate Responses[](#1-translate-responses "Direct link to 1. Translate Responses")
Use the language dropdown in the top-left corner of the CMS to select the target language for translation.
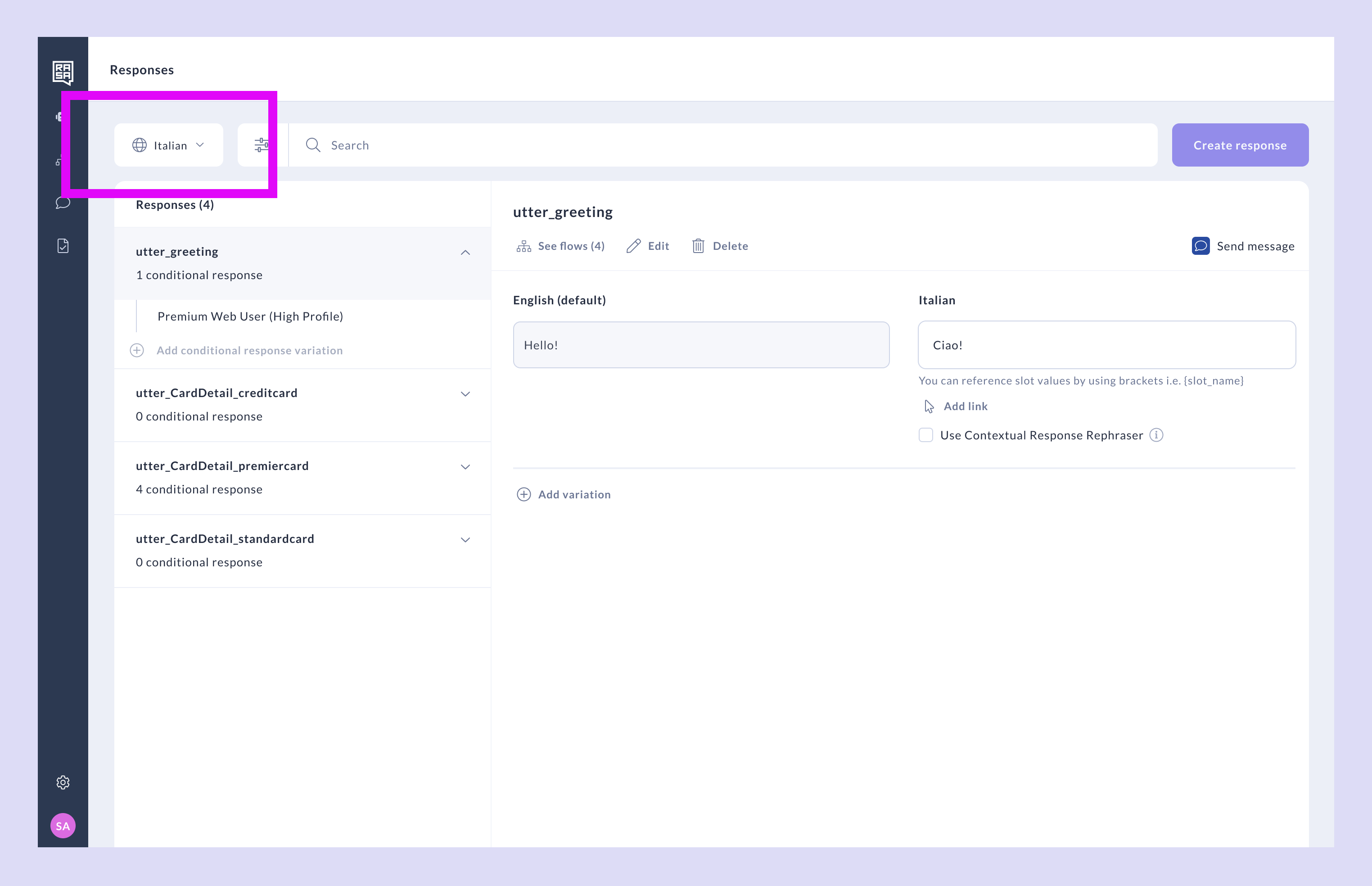
Your default language will appear on the left as a reference. To make changes to it, return to the default view.
note
Before starting translations, ensure your default language response is complete and includes all necessary messages, variants, buttons, and links. All translations will reference this default content.
###### Missing Translation Warnings[](#missing-translation-warnings "Direct link to Missing Translation Warnings")
When opening the translation CMS for the first time, you may notice some translation warning badges in your responses. This means that you are missing pre-translated content for that response in the language you have selected. Once you have providing a translation in that language for the given response the warning will be resolved. You can still train an assistant without resolving these warnings.
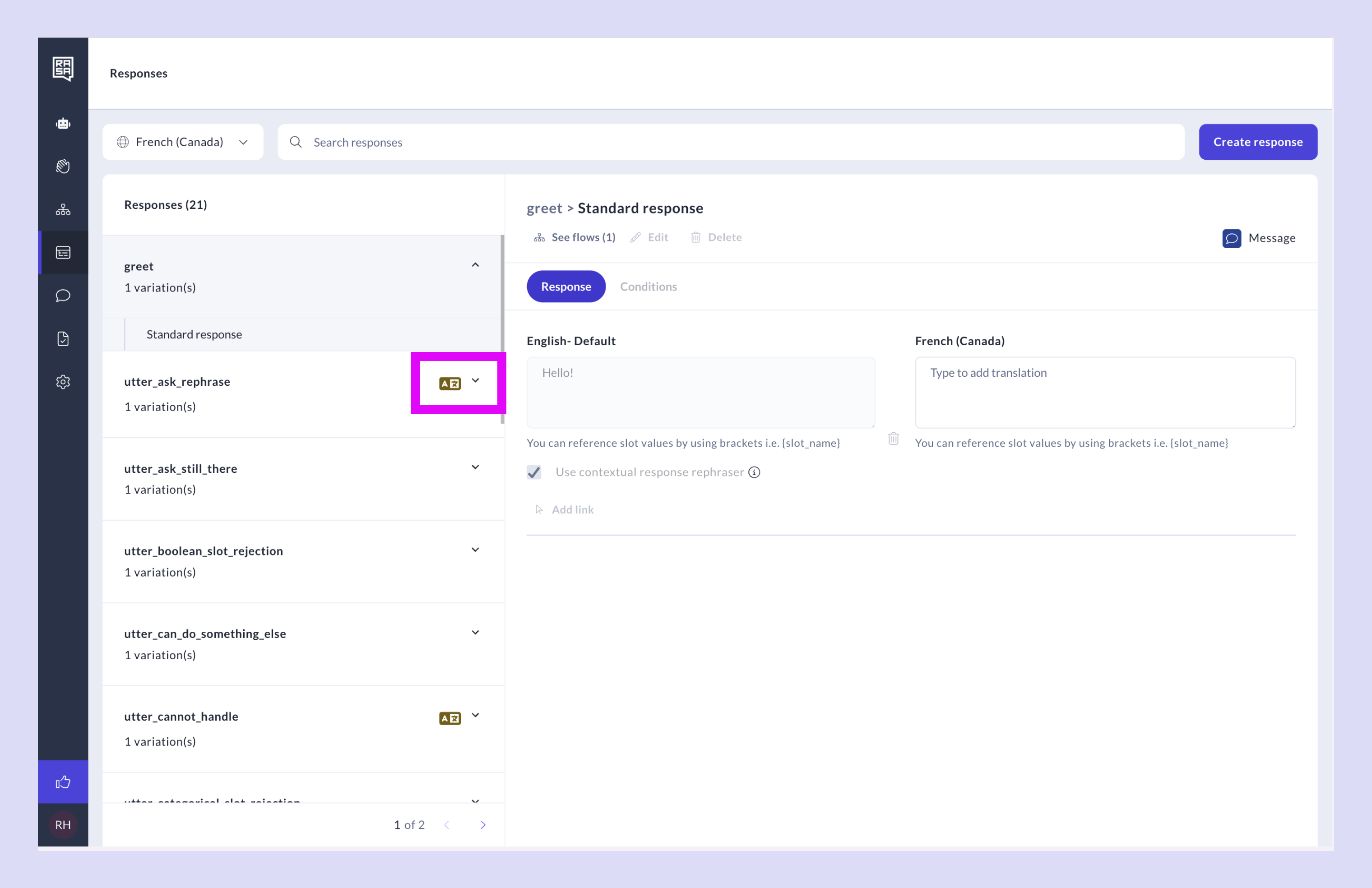
Enter your translations in the corresponding fields for each target language.
* If the Rephraser is **disabled**, ensure you provide translations for all variants to maintain seamless conversations across languages.
* If you use different phrasing for conditional variants, ensure all variants are fully translated.
##### 2. Translate Buttons and Links[](#2-translate-buttons-and-links "Direct link to 2. Translate Buttons and Links")
Buttons and links are listed beneath each response in the CMS.
* Translate the **button text** and **link labels** to reflect the target language.
* Optionally - translate the **button payload** or **link urls** to provide a localized experience.
(ie. `www.yourwebsite.com` -> `www.yourwebsite.com/de`)
##### 3. Using the Rephraser[](#3-using-the-rephraser "Direct link to 3. Using the Rephraser")
If you want to skip writing manual translations, you can enable an LLM to generate translations during the conversation. Learn more about [**Rephraser here**](https://rasa.com/docs/docs/studio/build/set-up-your-assistant/#step-2-configure-your-assistant). To get started quickly - you can enable \[rephraser globally] in your assistant settings or on a per message basis as in the example below. When enabled, your assistant provides a translated generated response in the language of conversation without needing to add any pre-translated content.
* Enable it globally from the Assistant Settings or per individual response.
* When Rephraser is enabled, your assistant automatically generates translations in real-time based on the conversation's language.
* You can still manually overwrite Rephraser output for more control.
> 📌 Tip: Translations are not required to publish your assistant, but missing translations may impact the experience for users in that language. You’ll see a warning if translations are incomplete.
---
#### Version Control in Studio
Studio's new versioning feature is designed to enable multiple users to work on an assistant at the same time. **Flow Version Control** in Studio keeps track of your work as you build and allows you to review your changes, and if necessary, revert to a previous version.
This guide will lead you through Studio's version control features and how to manage your assistant changes with a team.
#### View the Flow History[](#view-the-flow-history "Direct link to View the Flow History")
Flow History lets you view all changes made to a flow by any user.
1. Open your flow in Studio.
2. Click the **“History”** button located in the flow editor.
A panel will slide out from the left side of the screen, showing a detailed timeline of changes. This includes edits made by all users, so you always know who did what. 
#### Save a Stable Version[](#save-a-stable-version "Direct link to Save a Stable Version")
Saving a stable version lets you restore a previous flow if needed. Additionally, it allows you to train your assistant using the last stable version of the flow instead of the current version with the latest changes. This ensures that team members can experiment with updates in the current version without impacting the stability of training and testing for others.
1. Once you have fully tested the flow and confirmed it is working as expected, click the **“Save stable version”** button in the editor.
**✨ Pro Tip ✨** Save a stable version after thoroughly testing your flow so your team can confidently use it for testing. Make sure to save a version before making major changes so you can easily revert to a stable state if needed.
2. Your saved version will appear in the Flow History panel, along with the time, date, and author of the save.
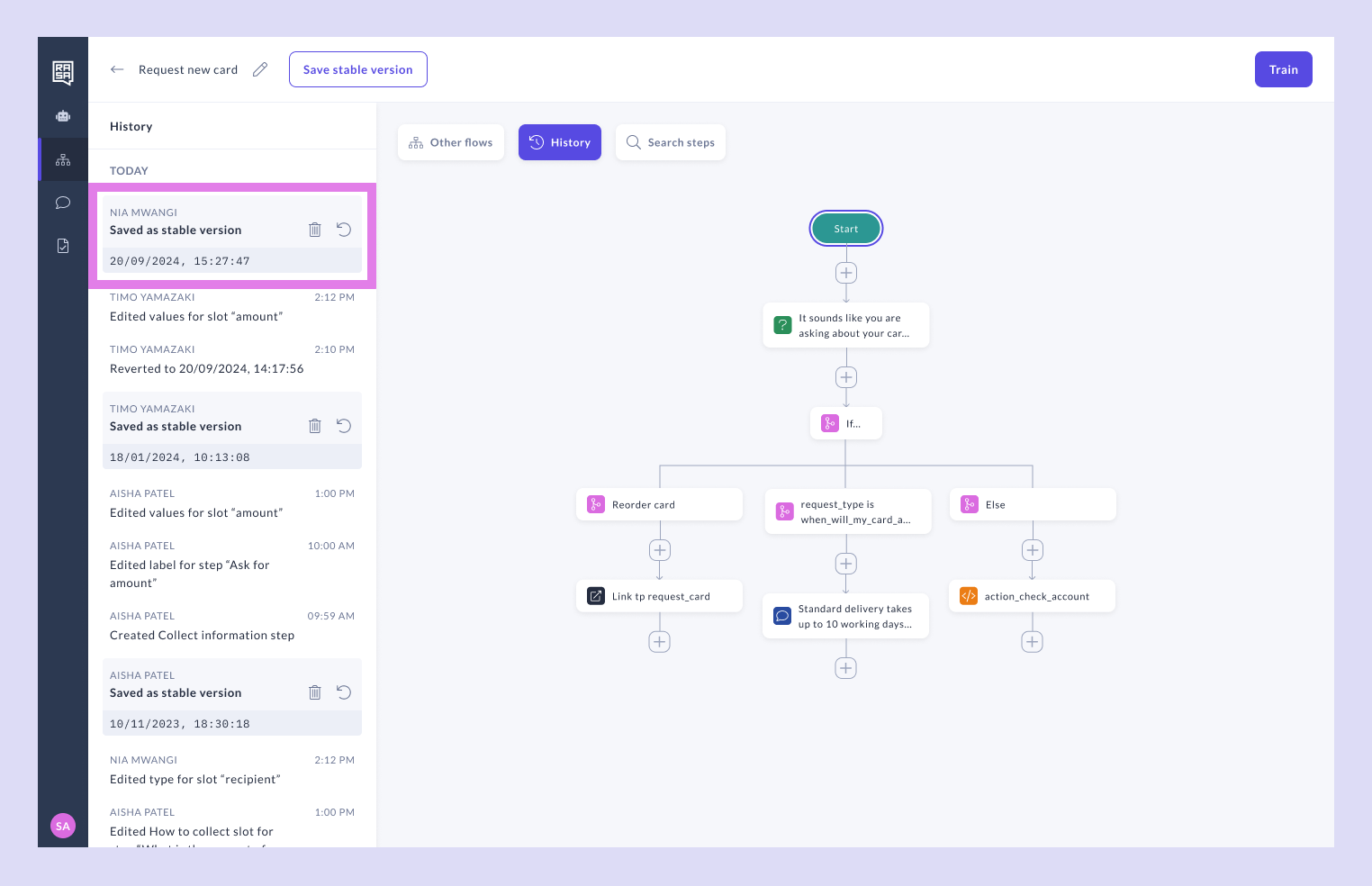
#### Revert to a Previous Version[](#revert-to-a-previous-version "Direct link to Revert to a Previous Version")
If something goes wrong or you want to go back to a previous flow setup, reverting is simple.
1. In the Flow History panel, locate the version you want to restore.
2. Click the **“Revert”** icon next to that version.
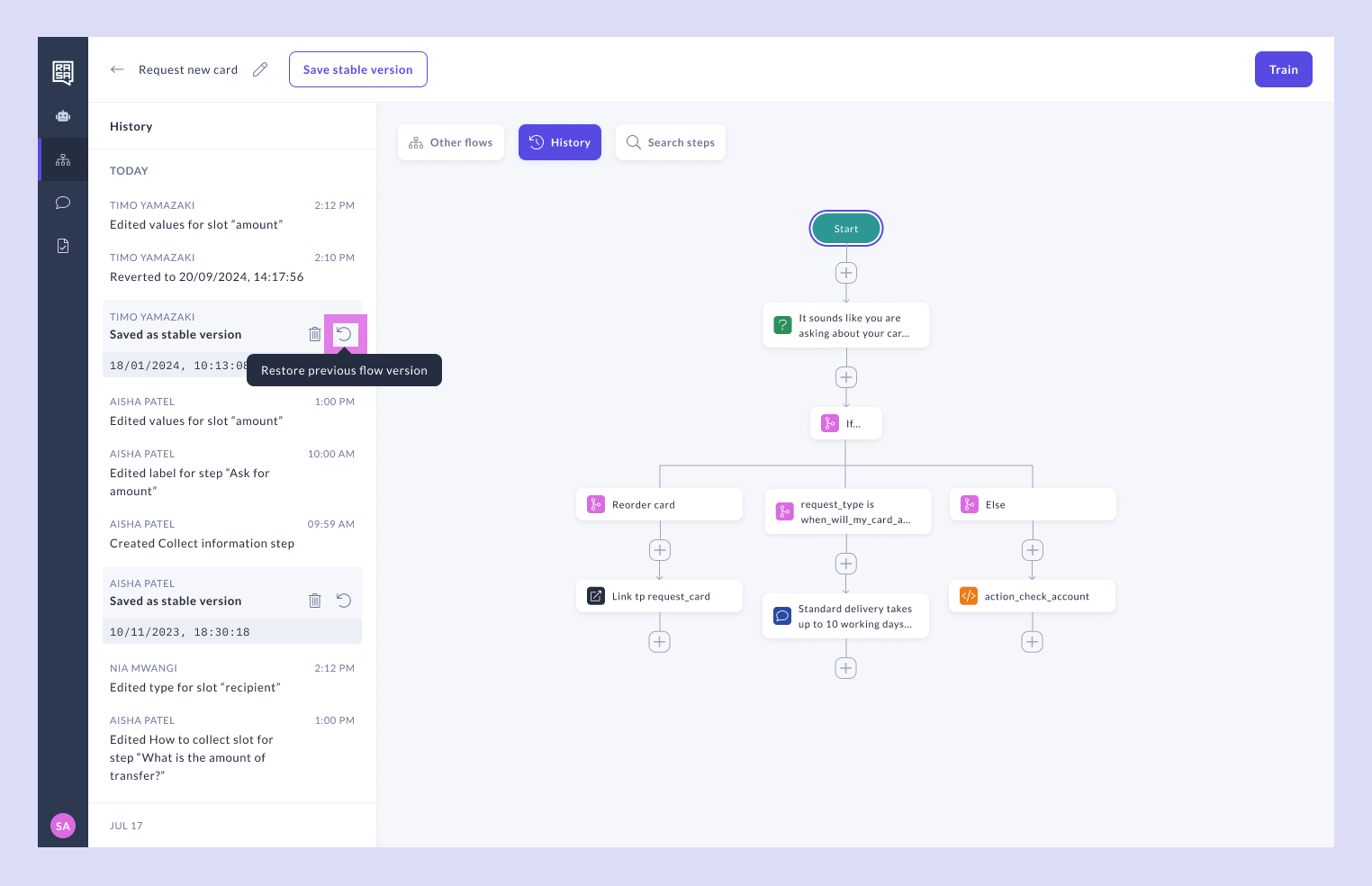
3. Once reverted, the flow will be restored to the selected version, and a note will appear in the Flow History to track the event.
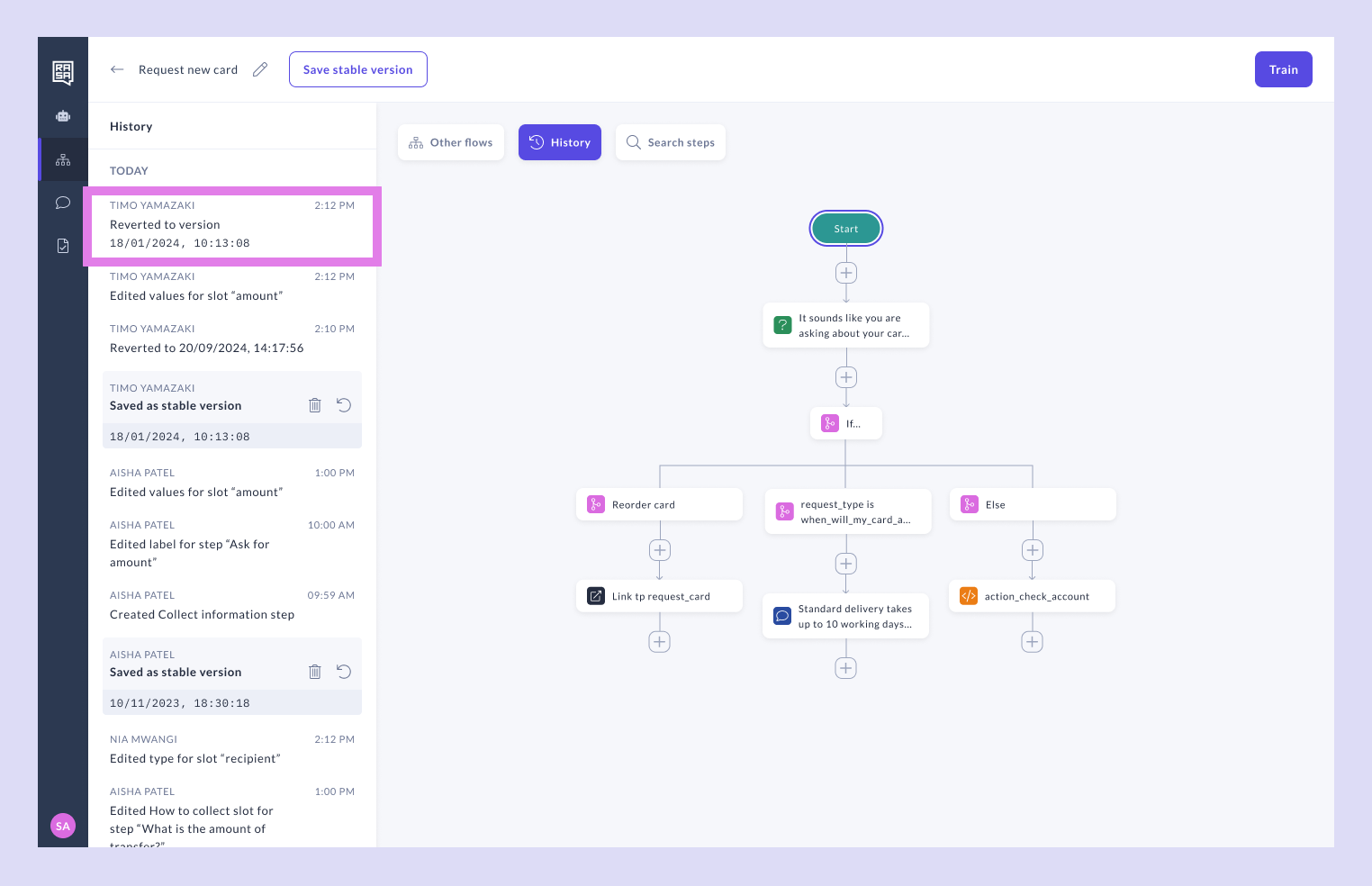
---
### Customize
#### Customize your Assistant's Prompts
This guide will walk you through the process of customizing prompt templates in Rasa Studio.
By the end, you’ll know how to view and edit assistant prompts, adjust responses to better match your assistant’s tone, and manage prompt versions — all directly from the Studio interface.
##### What Are Prompts?[](#what-are-prompts "Direct link to What Are Prompts?")
Prompts are short pieces of text that guide your assistant for specific tasks. Currently in Rasa there are three different types of prompts:
1. **Rephraser Prompts:** Control tone and phrasing for assistant's using LLM-Rephraser.
*For the full reference [Read the Reference](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/#prompt)*.
2. **Enterprise Search Prompt:** Specify how your assistant retrieves and presents information from knowledge sources.
*For the full reference [read here](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/#customization)*.
3. **Command Generator Prompt (Advanced):** Guide how your assistant translates user input and context into actions.
*For more guidance on when to customize [read here](https://rasa.com/docs/docs/pro/customize/command-generator/#customizing-the-prompt-template)*. *For the full reference [read here](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#customizing-the-prompt)*.
##### Who Can Edit Prompts?[](#who-can-edit-prompts "Direct link to Who Can Edit Prompts?")
Users with the **Content Editor** role can edit prompts for individual messages. For editing global prompts you need the **Developer** role assigned.
For more details on roles and how to set them up [see the docs here](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/#roles-overview).
#### How to Edit Prompts in Studio[](#how-to-edit-prompts-in-studio "Direct link to How to Edit Prompts in Studio")
##### Editing a Prompt for a Specific Response[](#editing-a-prompt-for-a-specific-response "Direct link to Editing a Prompt for a Specific Response")
1. Go to any message in the CMS.
2. Make sure that **Rephraser** is enabled for that message.
3. Update the text in the prompt editor.
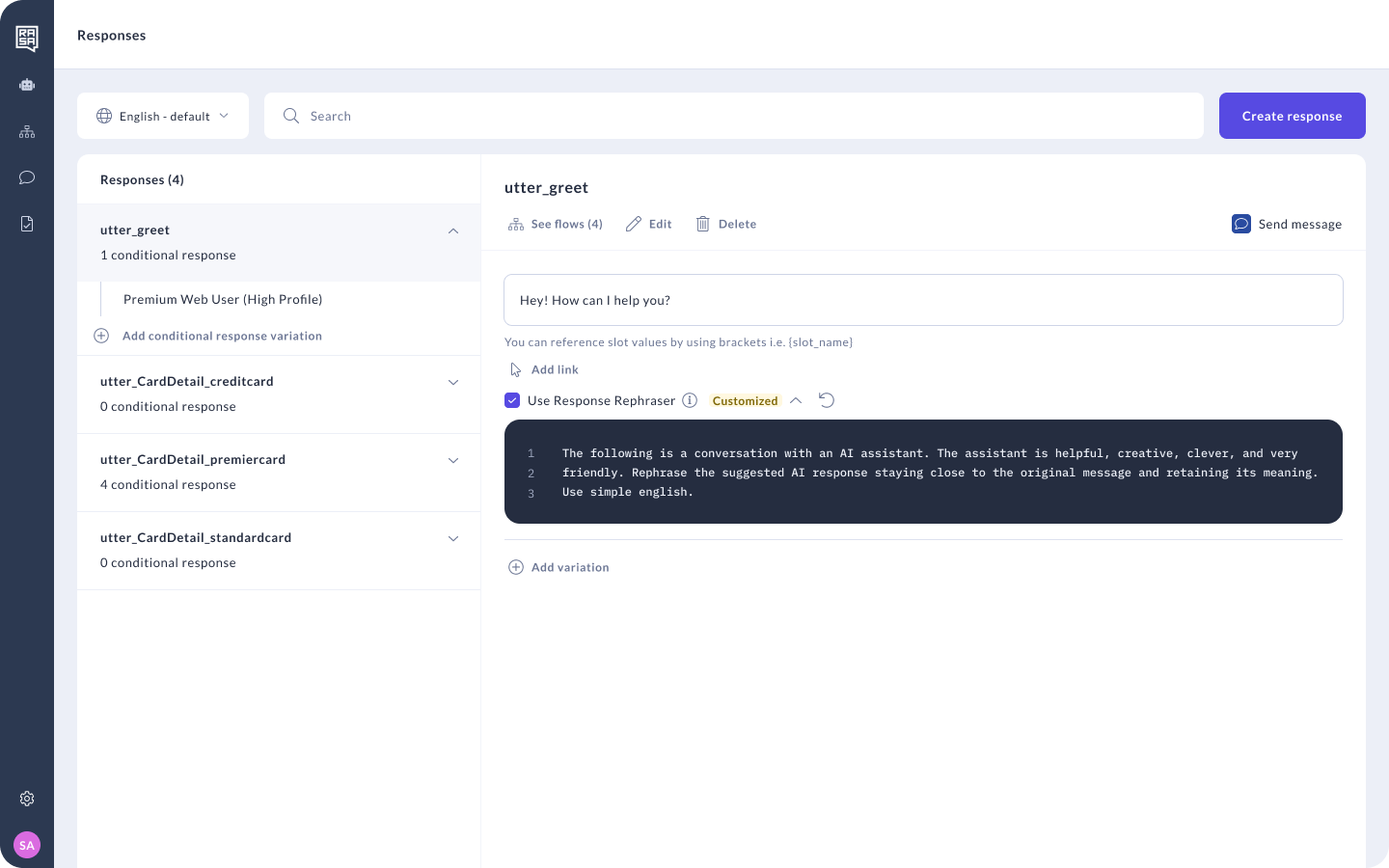
This is helpful when you want to tweak the tone or phrasing for a single message.
##### Editing Global Prompts[](#editing-global-prompts "Direct link to Editing Global Prompts")
1. Open your assistant’s **Settings**.
2. For Command Generator or Enterprise Search go to the **Configuration** tab. 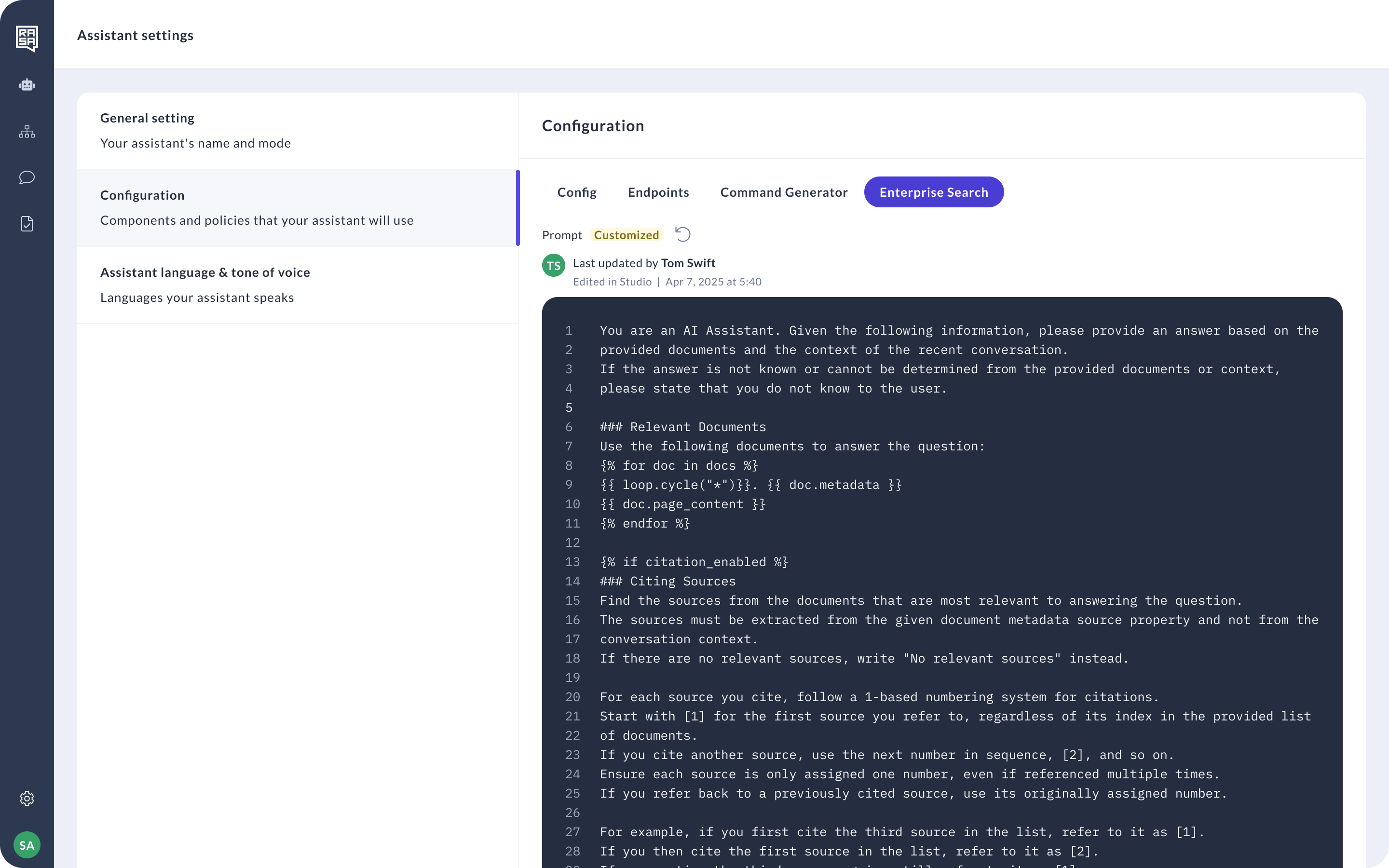
For Rephraser go to **Assistant Language**. 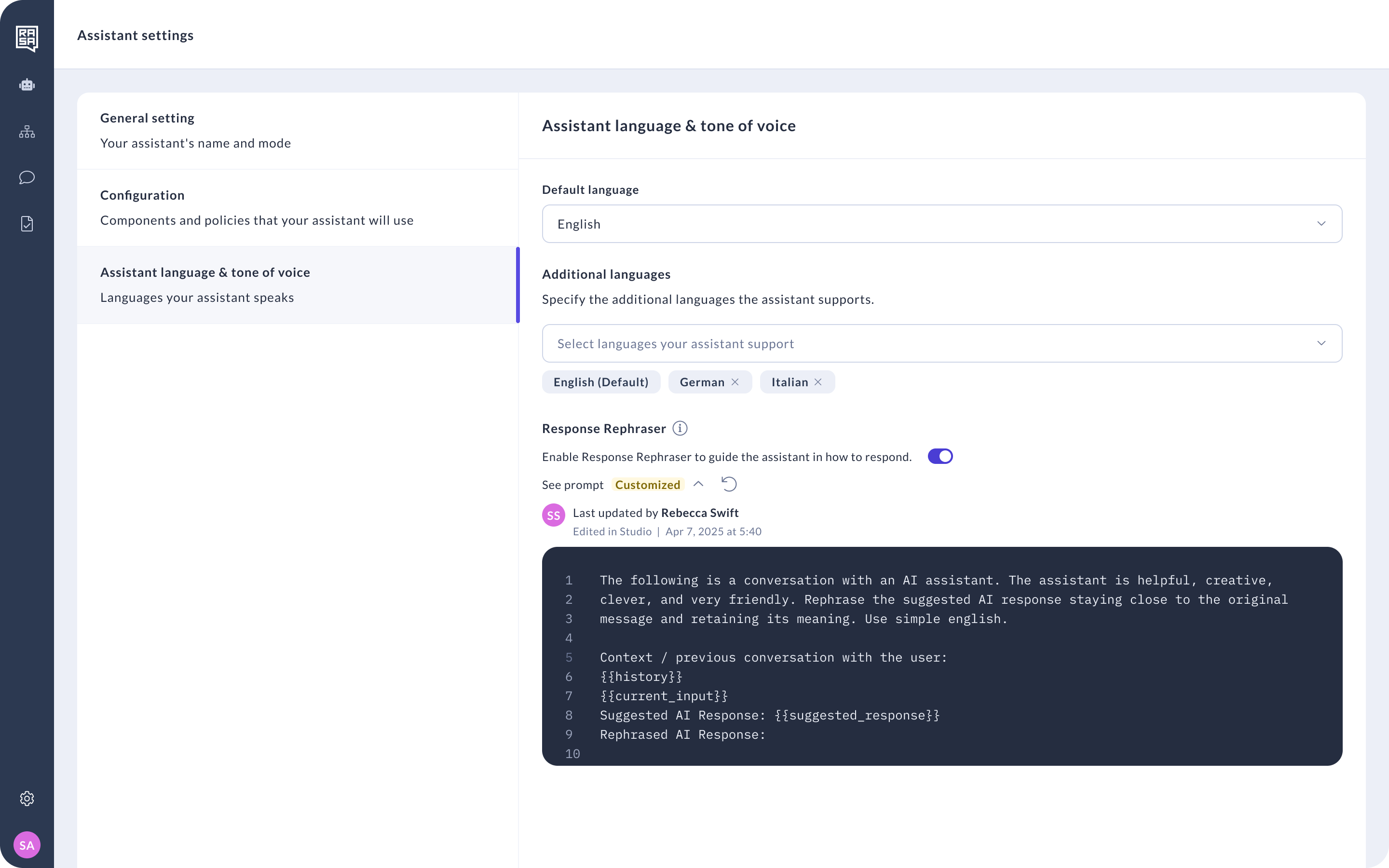
3. Expand the prompt.
4. Make your changes and click **Save**.
✅ You’ll see a small label when the prompt is customized with details about the last editor.
A Note on Editing Command Generator Prompts
Altering your command generator **fundamentally changes your assistant behaviour** and can have unpredictable side effects. We strongly recommend that you ensure that you have [end to end test coverage](https://rasa.com/docs/docs/pro/testing/evaluating-assistant/) in place **before** you make changes to this prompt to ensure that your assistant continues to behave as expected.
##### Resetting a Prompt to Default[](#resetting-a-prompt-to-default "Direct link to Resetting a Prompt to Default")
*To undo your changes:*
1. Go to the customized prompt.
2. Click the **Reset to Default** icon.
3. Confirm that you want to remove the customization.
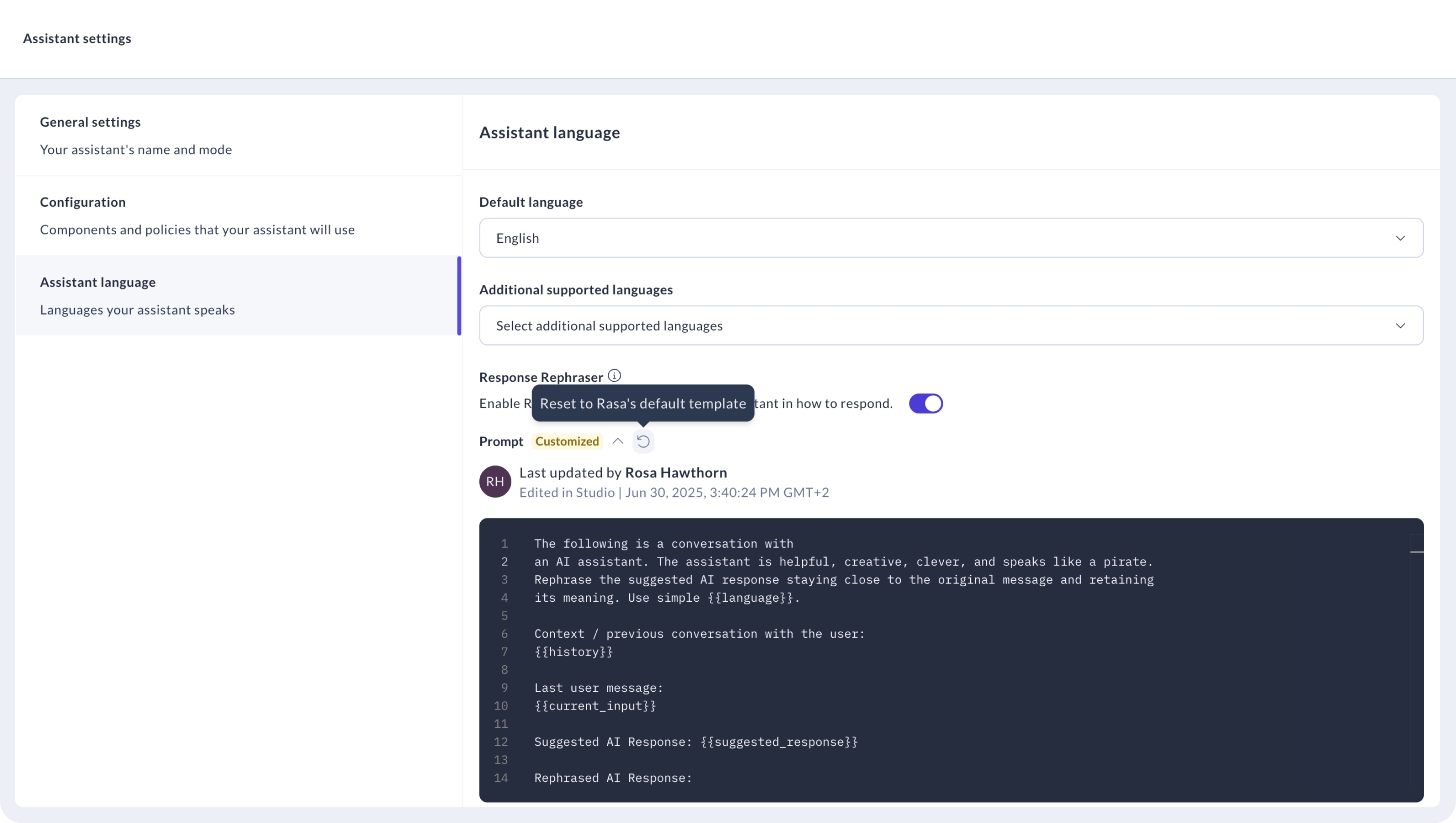
✅ The default prompt will be restored and used moving forward.
#### What's Next?[](#whats-next "Direct link to What's Next?")
Customizing prompts is a powerful way to shape how your assistant communicates and behaves. Once you’ve made changes, we recommend running end to end tests and trying out your assistant behaviour in Inspector.
---
### Installation and Set Up
#### Delete Assistant
Follow these steps to delete your assistant:
1. Go to **Assistant settings**
2. Click on **General settings**
3. Click on the **Delete** button and confirm the action. Note: This action is permanent and cannot be undone.
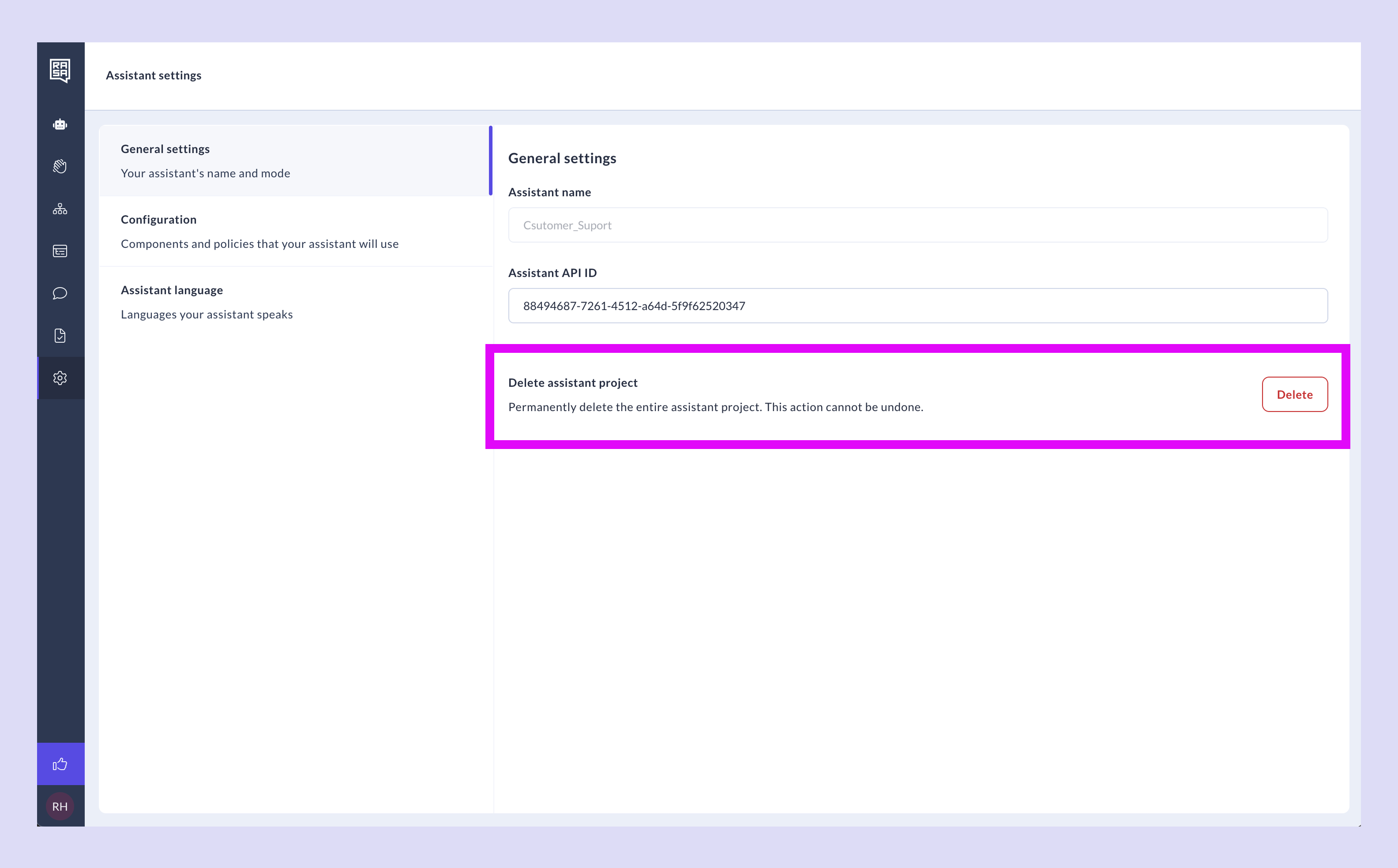
---
#### Docker Compose Installation Guide
#### Requirements[](#requirements "Direct link to Requirements")
To deploy Rasa Studio using Docker Compose, you'll need:
* Docker (version 20.10.0 or higher).
* Docker Compose (version 2.0.0 or higher) (Not required if you have Docker Desktop installed).
* At least 4GB of available RAM.
* A Rasa license key with an entitlement to use Studio.
* An OpenAI API key or credentials for another LLM if you wish to use LLM powered features.
#### Get Started[](#get-started "Direct link to Get Started")
The Docker Compose file to get started with Rasa Studio can be found [here](https://github.com/RasaHQ/studio-docker-compose/). You should clone this repo to your local machine to begin.
1. Rasa Studio requires some environment variables to be set before you can start the application. Open the `.env` file and set the values within. We recommend that you begin with the [latest version](https://www.rasa.com/docs/reference/changelogs/studio-changelog) of Rasa Studio and the [latest compatible version](https://www.rasa.com/docs/reference/changelogs/rasa-pro-changelog) of Rasa Pro. You can check for compatibility using our [Compatibility Matrix](https://www.rasa.com/docs/reference/changelogs/compatibility-matrix#studiopro-versions-compatibility).
2. Start all the services for Rasa Studio by running
```
docker compose up
```
3. The startup process will show logs from all services in your terminal. The application is ready when you see the following message from the startup-helper service:
```
🚀 Rasa Studio is ready!
📱 Studio URL: http://localhost:8080
🔐 Keycloak User Management URL: http://localhost:8081/auth/
```
If you prefer to run the services in the background, you can use:
```
docker compose up -d
```
Then monitor the progress with:
```
docker compose logs -f startup-helper
```
#### Access Rasa Studio[](#access-rasa-studio "Direct link to Access Rasa Studio")
Once the application is ready, the services will be available on different ports and paths:
```
Main Application: http://localhost:8080
Keycloak Admin Console: http://localhost:8081/auth/
Backend API: http://localhost:4000/api
Model Service: http://localhost:8000
```
You can follow our instructions to activate your license and set up users [here](https://www.rasa.com/docs/studio/installation/setup-guides/license-activation).
The Docker Compose setup sets some default credentials for you to use which you can find in our repo's [README file](https://github.com/RasaHQ/studio-docker-compose/?tab=readme-ov-file#credentials-reference). Also documented there are the environment variables you can use to optionally override these default credentials at deployment time by adding the mentioned variables to the `.env` file before you run `docker compose up`.
---
#### Helm Installation Guide
#### Requirements[](#requirements "Direct link to Requirements")
To deploy Studio with Helm you need:
* **Rasa Account:** An enterprise Rasa account as well as Rasa and Rasa Studio license keys.
* **LLM API Key:** OpenAI API key or credentials for another LLM.
* **Helm:** An installed version of [Helm](https://helm.sh/docs/intro/install/#helm) `>=3.8.0`.
* **Kubernetes Cluster:** A running Kubernetes cluster. To create a cluster, see documentation on [Google Cloud Platform](https://cloud.google.com/kubernetes-engine/docs/how-to/creating-a-zonal-cluster), [AWS](https://docs.aws.amazon.com/eks/latest/userguide/create-cluster.html), and [Azure](https://learn.microsoft.com/en-us/azure/aks/tutorial-kubernetes-deploy-cluster?tabs=azure-cli).
* **kubectl:** A working installation to manage your cluster. To install kubectl, see documentation on [Google Cloud Platform](https://cloud.google.com/kubernetes-engine/docs/how-to/cluster-access-for-kubectl#generate_kubeconfig_entry), [AWS](https://docs.aws.amazon.com/eks/latest/userguide/install-kubectl.html), and [Azure](https://learn.microsoft.com/en-us/azure/aks/learn/quick-kubernetes-deploy-cli#connect-to-the-cluster).
#### Get Started[](#get-started "Direct link to Get Started")
##### Step 1: Pull the official Studio helm chart[](#step-1-pull-the-official-studio-helm-chart "Direct link to Step 1: Pull the official Studio helm chart")
You can run the below-mentioned command to pull the latest version chart from Rasa's Google Artifact Registry.
```
helm pull oci://europe-west3-docker.pkg.dev/rasa-releases/helm-charts/studio
```
This will download the chart file (for example `studio-1.0.3.tgz`) to your machine. Extract this file to see the chart templates and `values.yaml` file.
For the complete documentation of the Helm Chart, see [Studio Helm Chart](https://helm.rasa.com/charts/studio/).
##### Step 2: Create a value file[](#step-2-create-a-value-file "Direct link to Step 2: Create a value file")
A value file contains the configuration options and parameters for the Helm chart. You can customize these options based on your requirements. A sample `values.yaml` file is available in the Studio Helm Chart. The file can be seen if you extract the `.tgz` chart file you downloaded from the Google Artifact Registry. Follow these steps to create your value file:
1. Make a copy of `values.yaml` file which can be found inside extracted chart directory. Let us call it `my-values.yaml`. This file will serve as your custom value file.
2. Open `my-values.yaml` in a text editor and modify the configuration options according to your needs. Ensure that you review and update values related to the way your Kubernetes cluster is set up. The chart's readme file will provide you with all the keys that are available with their default values.
3. Save and close the `my-values.yaml` file.
tip
For PostgreSQL database you must [percentage-encode special characters](https://developer.mozilla.org/en-US/docs/Glossary/percent-encoding) in any part of your connection URL - including passwords. For example, `p@$$w0rd` becomes `p%40%24%24w0rd`.
##### Step 3: Create Kubernetes secrets[](#step-3-create-kubernetes-secrets "Direct link to Step 3: Create Kubernetes secrets")
To store sensitive values mentioned in the above section it is recommended to create Kubernetes secrets. To create them
1. Make a copy of the `secrets.yaml` file which can be found inside extracted chart directory. Let us call it `my-secrets.yaml`.
2. Create base64 encoded values of the secrets and update the yaml file with them. You can run `echo -n "my-secret-key" | base64` to quickly create `base64` encoded values of your secrets.
3. Once all the secrets are updated run `kubectl apply -f my-secrets.yaml -n `. This creates the Kubernetes secret in the namespace where you plan to deploy Studio.
4. These secrets are then referenced and passed onto the pods inside the cluster when Studio is deployed with `my-values.yaml` file created in the previous step.
* Helm Chart v2.2.1 and above
* Helm Chart v2.1.9 and below
```
DATABASE_PASSWORD: // Database password for the Studio databases
KAFKA_SASL_PASSWORD: // Kakfa password if you use the SASL mechanism
KEYCLOAK_ADMIN_PASSWORD: // Password to the admin user interface of Keycloak (Studio's user management system). You should use this credential to login to http:///auth
KEYCLOAK_API_PASSWORD: // Password to access Keycloak API. Studio uses this internally to communicate with Keycloak
RASA_LICENSE_SECRET_KEY: // Rasa license key
OPENAI_API_KEY_SECRET_KEY: // OpenAI API key
```
```
DATABASE_URL: // Database URL of the Studio backend database. Format is `postgresql://${DB_USER}:${DB_PASS}@${DB_HOST}:${DB_PORT}/${DB_NAME}?schema=public`
DATABASE_PASSWORD: // Database password for the Studio databases
KAFKA_SASL_PASSWORD: // Kakfa password if you use the SASL mechanism
KEYCLOAK_ADMIN_PASSWORD: // Password to the admin user interface of Keycloak (Studio's user management system). You should use this credential to login to http:///auth
KEYCLOAK_API_PASSWORD: // Password to access Keycloak API. Studio uses this internally to communicate with Keycloak
RASA_LICENSE_SECRET_KEY: // Rasa license key
OPENAI_API_KEY_SECRET_KEY: // OpenAI API key
```
##### Step 4: Deploy Rasa Studio using Helm[](#step-4-deploy-rasa-studio-using-helm "Direct link to Step 4: Deploy Rasa Studio using Helm")
With the Helm chart and value file prepared, you are ready to deploy Rasa Studio in your Kubernetes cluster. Run the following command:
```
helm upgrade -f -n --install
```
``: The name for your Rasa Studio release ie. `rasa-studio`.
``: The path to the extracted folder of the `tgz` file you obtained by downloading the chart from the Google Artifactory registry.
``: The path to your custom value file `my-values.yaml`
``: The Kubernetes namespace you want to deploy to.
Example command:
```
helm upgrade rasa-studio ./studio -f ./my-values.yaml -n studio --install
```
Helm will begin the deployment process, creating the necessary resources and configurations based on the provided values.
##### Step 5: Monitor deployment and access Rasa Studio[](#step-5-monitor-deployment-and-access-rasa-studio "Direct link to Step 5: Monitor deployment and access Rasa Studio")
Once the deployment is complete, you can monitor the deployment status by running:
```
kubectl get pods -n
```
Ensure that all pods are running and ready before accessing Rasa Studio.
You can access Rasa Studio by visiting the URL `https://` in your web browser.
For further information on advanced configuration options and maintenance tasks, refer to the Rasa Studio Helm charts documentation (`README.md` in the downloaded Helm chart and inline comments in `values.yaml` file) and the official [Helm](https://helm.sh/docs/) documentation.
🎉 That's it! You can now proceed to [activate your license](https://rasa.com/docs/docs/studio/installation/setup-guides/license-activation/)
---
#### Installation Overview
Rasa Studio is a self-hosted product designed for collaborative development, requiring deployment within your own environment. Studio offers two deployment options: using Helm or Docker Compose. Each option serves different needs:
##### [Docker Compose](https://rasa.com/docs/docs/studio/installation/installation-guides/docker-compose-guide/)[](#docker-compose "Direct link to docker-compose")
Our recommended getting-started or trial install. Ideal for those who prefer a more straightforward setup without needing Kubernetes.
##### [Helm](https://rasa.com/docs/docs/studio/installation/installation-guides/helm-guide/)[](#helm "Direct link to helm")
Best suited for those who already have a Kubernetes environment and require maximum control and flexibilit for a production deployment.
**Ready to deploy?** Pick your path, follow the steps, and get started with building amazing conversational AI experiences.
note
Read the [System Architecture Guide](https://rasa.com/docs/docs/reference/architecture/studio/) to learn more about the containers, services, and resource requirements for self-hosted deployment instances.
---
#### License Activation
#### Step 1: Upload the license in Studio[](#step-1-upload-the-license-in-studio "Direct link to Step 1: Upload the license in Studio")
In order to activate Studio.
1. Navigate to Studio web client and you will be prompted to upload a license file
2. Hit the `Get Started` button after the license upload to start working with Studio
---
#### Resource Requirements
Below are the recommended CPU and Memory requirements for the individual pods. You can experiment with different values according to your cluster usage metrics and adjust accordingly. These values can be set under the resources section under each component in the values.yaml file
```
resources:
limits:
cpu: 2000m
memory: 2000Mi
requests:
cpu: 1000m
memory: 1000Mi
```
| Pod | CPU | Memory |
| ------------------ | --------------- | --------------- |
| backend | 1000m | 2000Mi |
| keycloak | 1000m | 2000Mi |
| web-client | minimal/default | minimal/default |
| event-ingestion | 500m | 1000Mi |
| Rasa model-service | 2000m | 4000Mi |
info
The resource requirements for the `rasa model-service` pod will depend on the number of trainings and active models that are being run. Training of a model normally requires around 800 MB of RAM and 1000m of CPU units. Allocate higher CPU resources if you anticipate a higher number of parallel trainings.
The resource requirements for the `event-ingestion` will depend on the load the production assistant expects. We recommend you to start with the default values and monitor the resource usage in your cluster.
---
#### Users and Roles Setup Guide
Studio uses [Keycloak](https://www.keycloak.org/) to manage user authentication, roles, and permissions. This guide explains how to set up user roles for your team, including two main authentication options:
1. **[Simple Authentication](#simple-authentication-setup)**: Users log in with a username and password.
2. **[Single Sign On](#sso-setup)**: Centralized login using an identity provider.
#### Roles Overview[](#roles-overview "Direct link to Roles Overview")
Studio includes eight default roles to tailor access levels to your team's needs. You can choose which ones make the most sense for your team and organization:
* **SuperUser**: Oversees all of Studio’s functionality — from configuring settings to building the assistant and reviewing conversations.
* **Lead Annotator**: Oversees and reviews annotations, manages CMS content.
* **Annotator**: Annotates data and creates NLU annotations.
* **Flow Builder**: Designs conversational flows and manages NLU data.
* **NLU Editor**: Creates and edits NLU models for training.
* **Business User**: Tests assistants and interacts with flows for business insights.
* **Developer**: Handles technical tasks like exporting annotations and configuring settings.
* **Conversation Analyst**: Analyzes conversation data and manages tags.
***
#### Simple Authentication Setup[](#simple-authentication-setup "Direct link to Simple Authentication Setup")
Follow these steps to set up users with username/password login:
1. **Log in to Keycloak**: Navigate to `https:///auth` and log in using admin credentials (`KEYCLOAK_ADMIN_USERNAME` and `KEYCLOAK_ADMIN_PASSWORD`).
2. **Select the Realm**: Choose the `rasa-studio` realm from the dropdown menu.
3. **Add a New User**:
* Navigate to `Users` > `Add user`.
* Enter user details and click **Create**.
4. **Assign Roles**:
* Go to the `Groups` tab and add the user to the relevant groups to assign roles. 
5. **Set the Password**:
* Go to `Credentials` and set a password.
* Enable the "Temporary password" toggle if the user needs to reset their password on first login.
#### SSO Setup[](#sso-setup "Direct link to SSO Setup")
To configure SSO for your users:
1. **Log in to Keycloak**: Access the `Administration Console` and select the `rasa-studio` realm.
2. **Configure Identity Providers**:
* Navigate to the `Identity Providers` section.
* Select and configure your desired provider (e.g., Google, Azure AD).
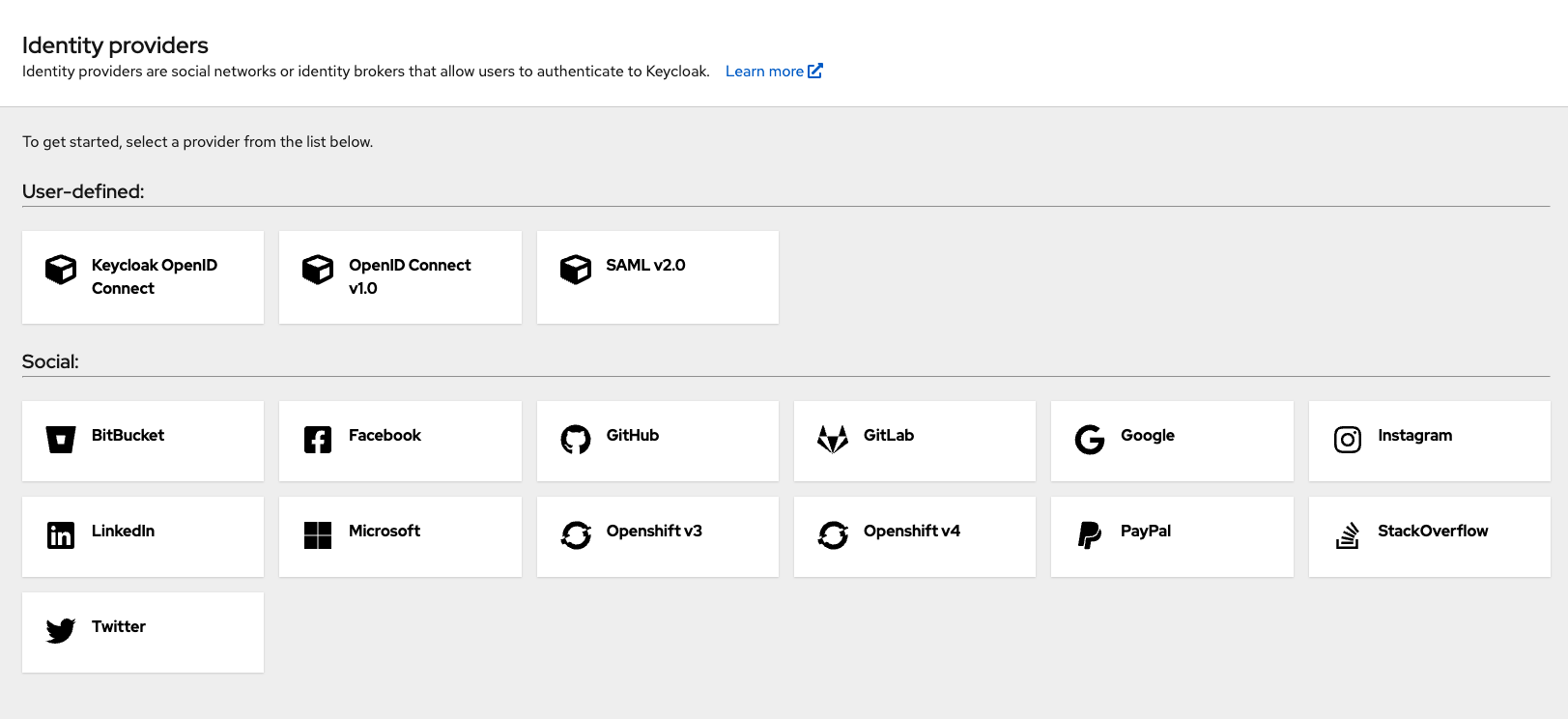
3. **Follow Provider Instructions**: Refer to [Keycloak SSO Documentation](https://www.keycloak.org/docs/latest/server_admin/#sso-protocols) for specific setup steps.
You can read more details on authorization in our [API Authorization Guide](https://rasa.com/docs/docs/studio/security/authorization/) or [Managing Users Guide](https://rasa.com/docs/docs/studio/security/managing-users/).
---
### Security
#### Authorizing Studio Requests
#### Introduction[](#introduction "Direct link to Introduction")
Learn how to obtain the secret and client ID required for authenticating requests to Studio API. API is built using GraphQL, enabling powerful querying and mutations for flexible interaction with Studio API. For authentication, we rely on Keycloak to manage users and secure external communication by using OpenID Connect's "Client Credentials Flow".
##### Studio-External Client Overview[](#studio-external-client-overview "Direct link to Studio-External Client Overview")
The **studio-external** client is a default client in Keycloak for facilitating API integrations with Rasa Studio. This client is pre-configured with roles, ready for use without additional configuration.
Customers can use **studio-external** to:
* Manage conversations via APIs,
* Request urls to artifacts for CI/CD
This flexibility allows for quick integration or custom setups based on specific requirements.
**Note**: The instructions below cover both using the default client and creating a new one. If you decide to use existing **studio-external**, login to Keycloak admin and skip directly to [Obtain Client ID and Secret](#obtaining-client-id-and-secret)
#### Creating a New Client ID[](#creating-a-new-client-id "Direct link to Creating a New Client ID")
To create a new Client ID in Keycloak, follow these steps:
1. Go to Keycloak Admin and log in. **Note**: Ensure the **rasa-studio** realm is selected from the top-left dropdown. 
2. Navigate to the **Clients** tab and click **Create**.
* Set **Client ID** to a name of you choice.
* Set **Client type** to **OpenID Connect**.
* Click **Next**.
##### Client Capability Configuration[](#client-capability-configuration "Direct link to Client Capability Configuration")
1. On the **Capability Config** page, enable:
* **Client Authentication**.
* **Service Account Roles** (for **Client Credentials Flow**).
**Warning**: Keep other settings off.
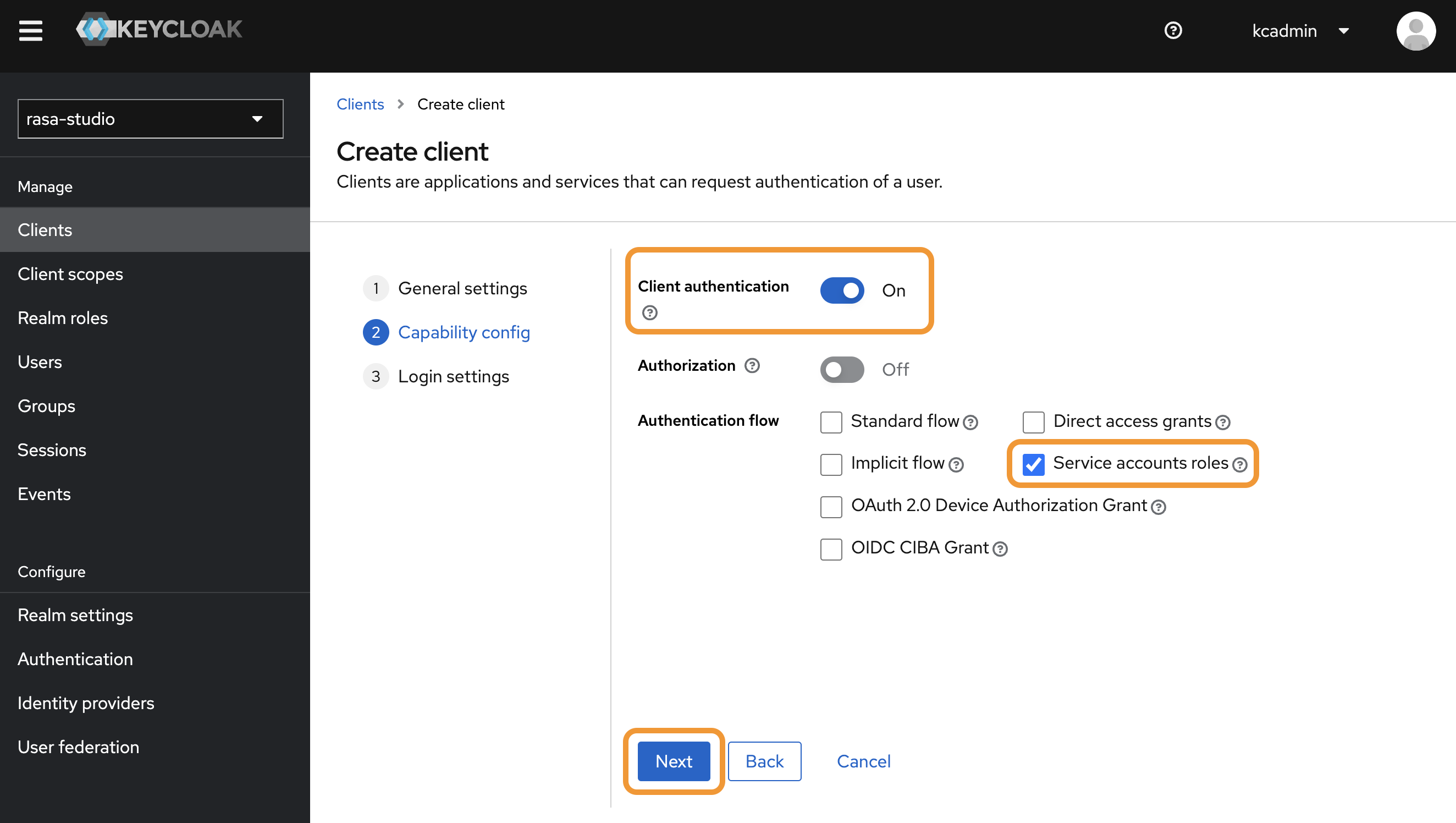
2. Click **Next**.
##### Login Settings[](#login-settings "Direct link to Login Settings")
On this page click **Save** to finish.
##### Assigning a Role to the Client[](#assigning-a-role-to-the-client "Direct link to Assigning a Role to the Client")
1. Go to **Service Accounts Roles** and click on `service-account-studio-external`. **Note:** This service account user may have a different name depending on how you name your client. 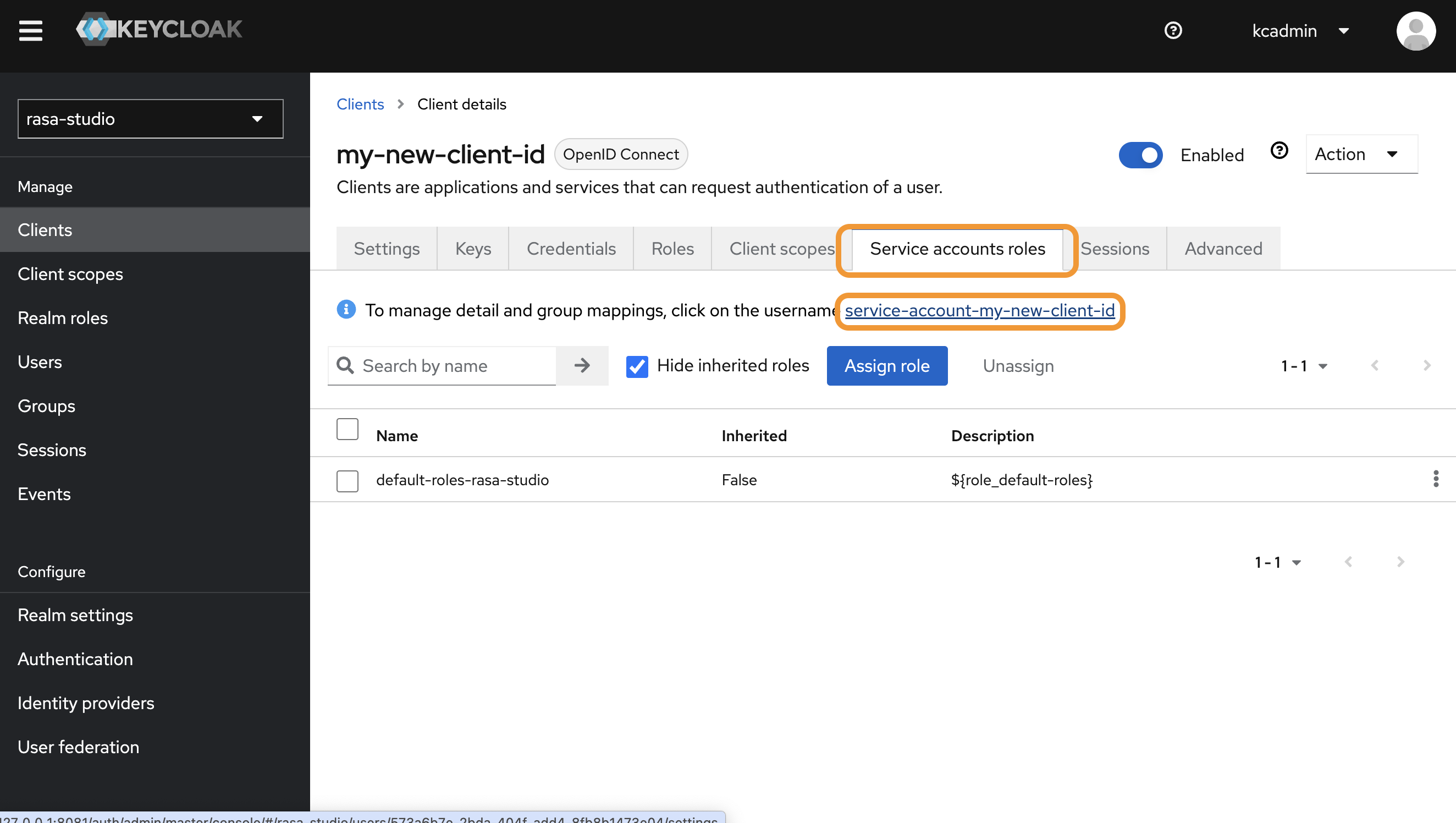
2. In the **Role Mapping** tab, assign a role to your Client, e.g. **Manage conversations** to enable managing conversations via the API.
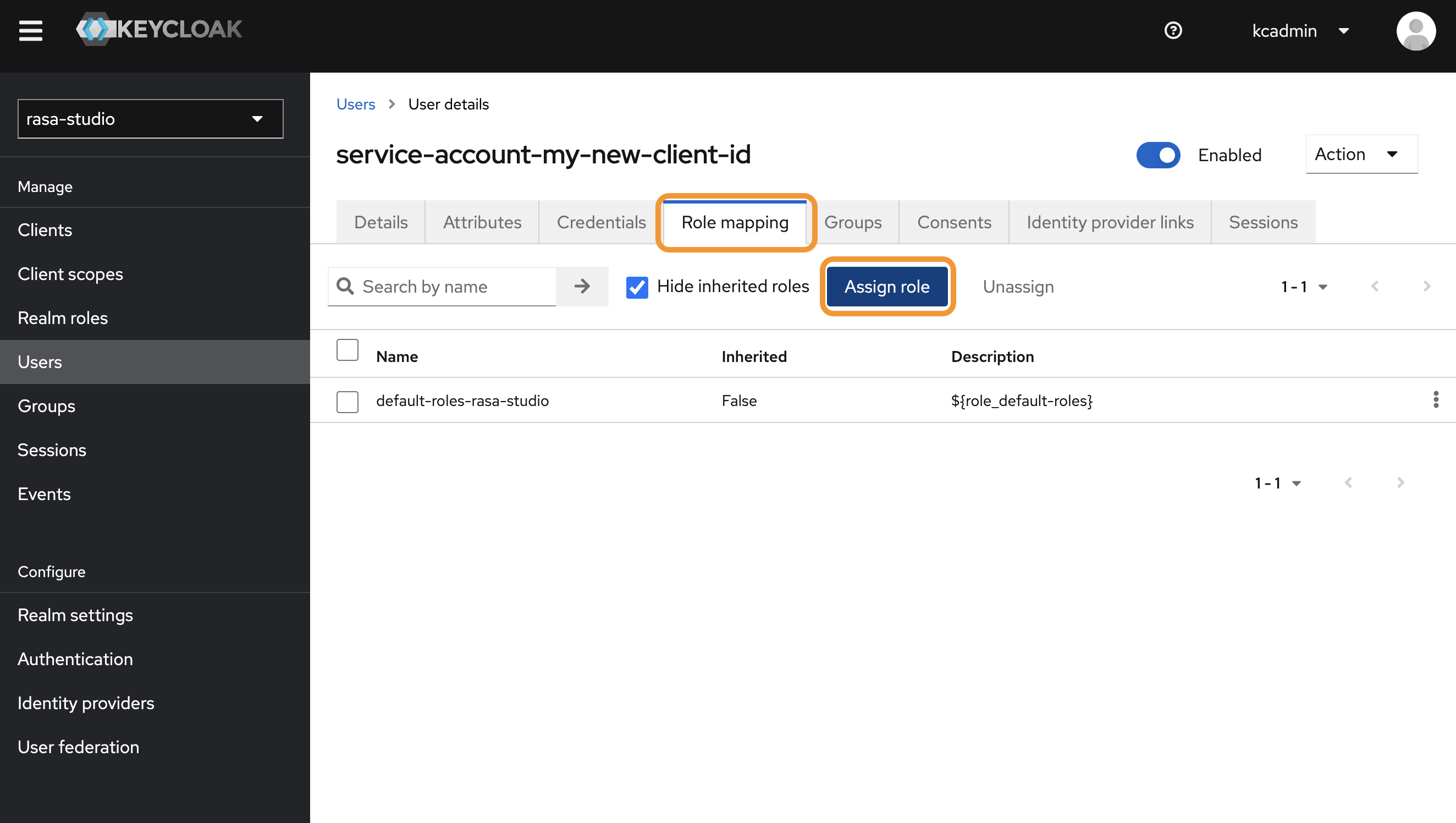 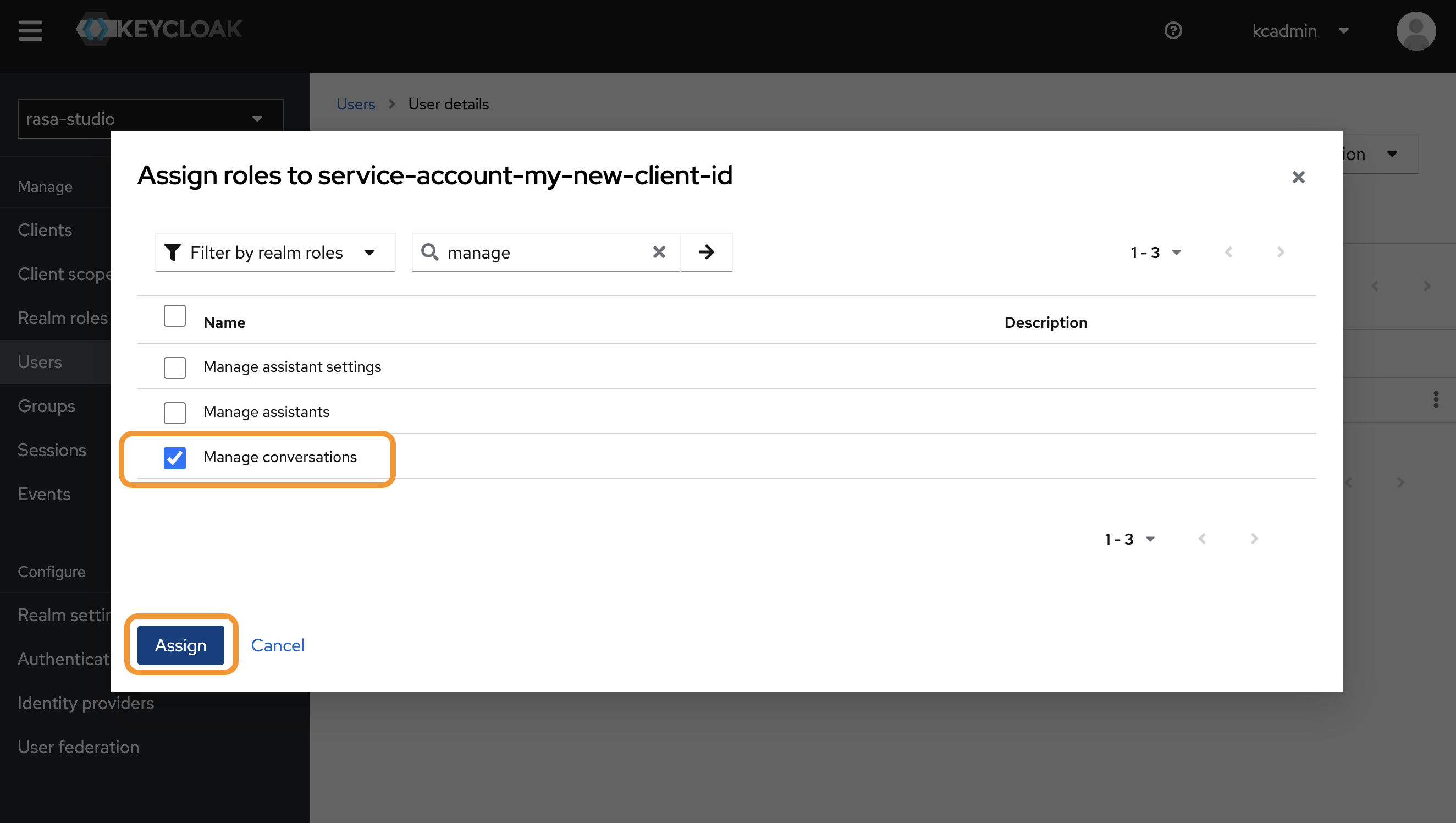
##### Obtaining Client ID and Secret[](#obtaining-client-id-and-secret "Direct link to Obtaining Client ID and Secret")
1. Return to the **Clients** tab, make sure the **rasa-studio** realm is selected, select your client, and go to the **Credentials** tab.
2. Click on Regenerate next to the Client Secret field to enhance security.
3. Make sure to note down the new **Client ID** and **Client Secret** for future use.
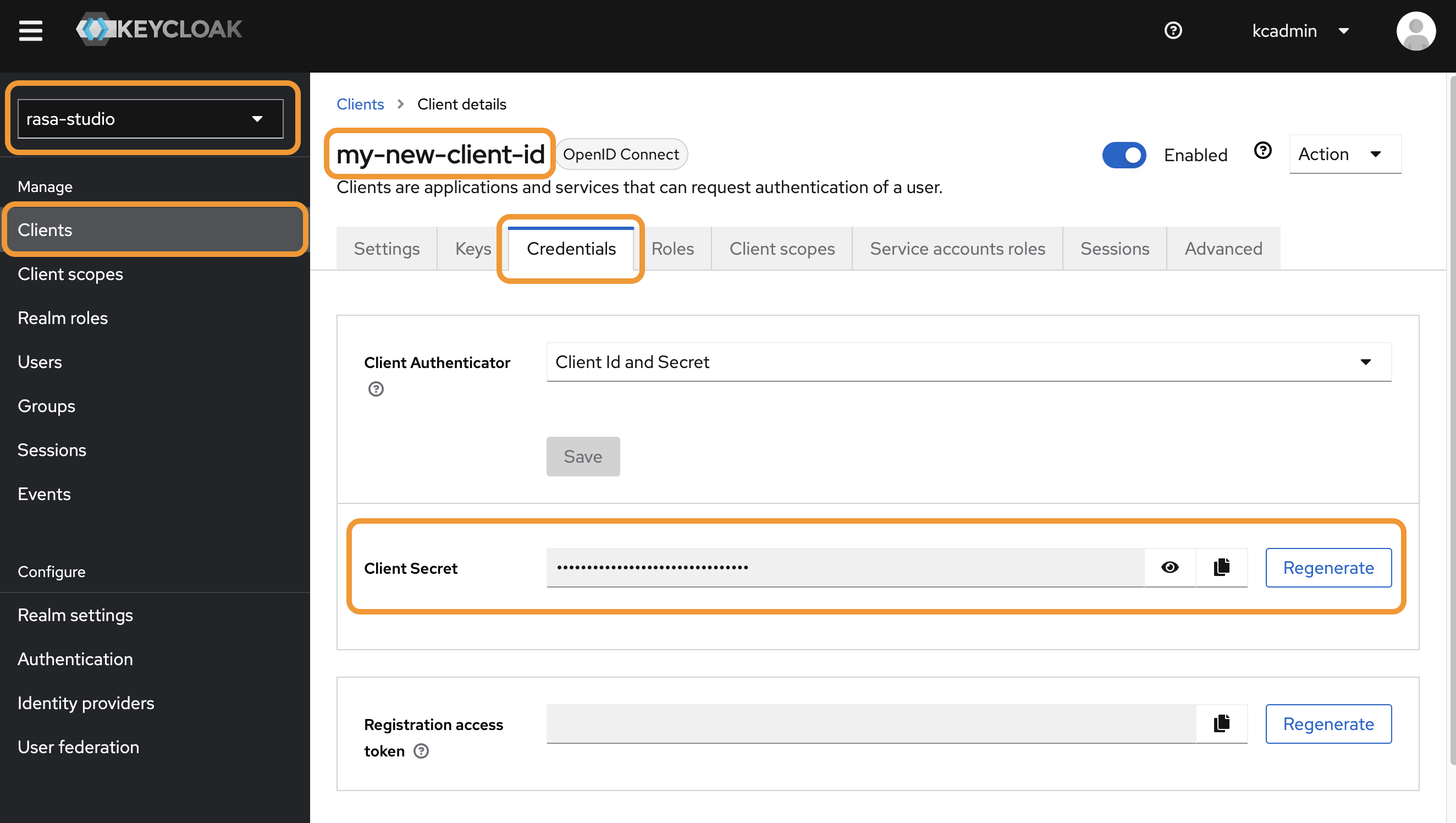
##### Obtain access token[](#obtain-access-token "Direct link to Obtain access token")
To perform API requests, you must first obtain an access token using a **POST** request.
1. Create a **POST** request to:
```
```
https://{your-keycloak-address}/auth/realms/rasa-studio/protocol/openid-connect/token
````
For example in local environment, the URL is:
```plaintext
https://localhost:8081/auth/realms/rasa-studio/protocol/openid-connect/token
````
2. Set **x-www-form-urlencoded** body parameters:
* `grant_type`:\*\* client\_credentials\*\*,
* `client_id`: your new Client ID name,
* `client_secret`: the secret obtained from [Obtain Client ID and Secret](#obtaining-client-id-and-secret)
###### Example curl Request[](#example-curl-request "Direct link to Example curl Request")
```
curl -X POST https://localhost:8081/auth/realms/rasa-studio/protocol/openid-connect/token \
-H "Content-Type: application/x-www-form-urlencoded" \
-d 'grant_type=client_credentials&client_id=&client_secret='
```
You should receive an *access\_token*.
Now, using this token as the **Authorization: Bearer *retrieved\_token*** header, you can send your API requests.
---
#### How to Manage Studio Users
#### Guides for Managing Users[](#guides-for-managing-users "Direct link to Guides for Managing Users")
Admins can manage users at any time by performing the following actions:
##### Delete a User[](#delete-a-user "Direct link to Delete a User")
tip
Do not modify or delete the `realmadmin` user, as it is required for Studio to interact with Keycloak APIs.
1. Go to `Users` and locate the user to delete.
2. Open the kebab menu (three dots) and select **Delete**. 
3. Confirm the deletion.
##### Update User Permissions[](#update-user-permissions "Direct link to Update User Permissions")
1. Select the user in the `Users` list.
2. Go to the `Groups` tab and update their group memberships.
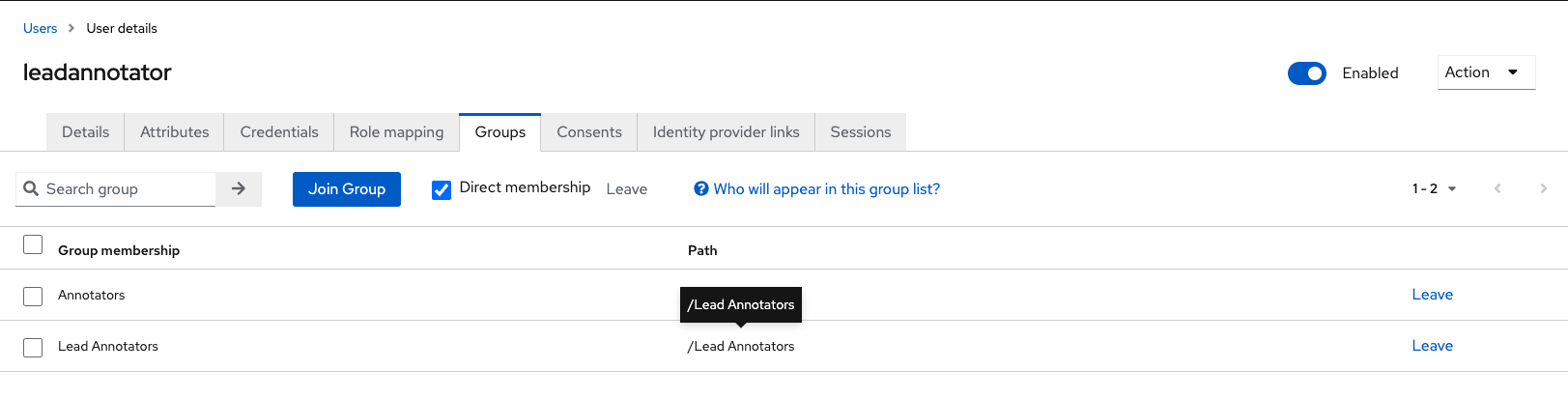
##### Log Out a User[](#log-out-a-user "Direct link to Log Out a User")
1. Navigate to the `Sessions` tab for a selected user.
2. Select **Sign out** from the session menu.
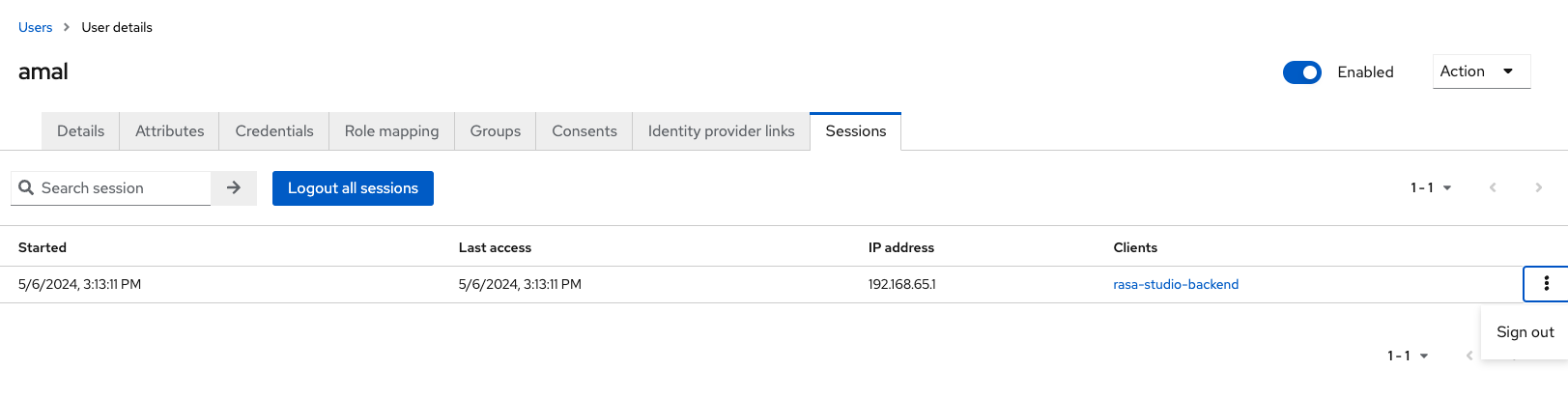
#### Optional: Configure Email Notifications[](#optional-configure-email-notifications "Direct link to Optional: Configure Email Notifications")
Keycloak can send emails for tasks like password resets and account verification. To enable email:
1. Go to `Realm Settings` > `Email`.
2. Enter your SMTP server settings and save changes.
For detailed setup, refer to [Keycloak Email Configuration](https://www.keycloak.org/docs/latest/server_admin/#_email).
---
### Test
#### introduction
---
#### Train your Assistant
This guide will walk you through the process of training your assistant in Rasa Studio. By the end, you'll understand how to initiate training, monitor its progress, resolve common errors, and debug issues.
#### Before You Start[](#before-you-start "Direct link to Before You Start")
Training a model requires specific permissions that are not available to every Studio role. Ensure your role has the [right access](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/) before continuing.
#### About Training[](#about-training "Direct link to About Training")
Training compiles your flows, NLU data, and other inputs into a functional model, that you can use for testing or deploy to production.
Rasa Studio provides two ways to train your assistant:
**[⭐️ Training in Studio (Recommended)](#training-in-studio)**:
For rapid iteration and testing your assistant within the Studio UI.
**[Training your assistant locally with Rasa](#training-your-assistant-locally-using-rasa-pro)**:
Useful for technical users who have additional custom components or advanced integration steps that they want incorporated before training.
note
If you're interested in diving into technical details of how training works see more in our [Training Architecture Reference](https://rasa.com/docs/docs/reference/architecture/studio/#studio-model-service-container).
#### Training in Studio[](#training-in-studio "Direct link to Training in Studio")
##### Get Started[](#get-started "Direct link to Get Started")
1. **Access Training**
Navigate to the **Flow builder**. You should be able to see the **"Train"** button:
2. **Select Flows**
In the **Train** panel, make sure all the flows you want to include in training are selected. Note that NLU, responses and all other primitives saved in Studio are always included in training.
3. **Select Flow Version** (optional)
If you're using flow versioning and have saved some flows as "Stable," you’ll also see a switch to select between the "Draft" and "Stable" versions. Choose either the latest stable version or the current draft to include in training. Select the "Stable" version if you don’t want to include the latest changes made to the flow. [Learn more about creating a stable version of flows](https://rasa.com/docs/docs/studio/build/content-management/version-control/#save-a-stable-version).
4. **Train**
Once your flows are ready, click the **"Start training"** button. Studio will validate your flows before beginning the training process. When the training is completed successfully, test the newly created assistant version on [Try your assistant](https://rasa.com/docs/docs/studio/test/try-your-assistant/).
##### Validate and Improve[](#validate-and-improve "Direct link to Validate and Improve")
Rasa Studio validates your flows before the training process begins. This step helps you catch common issues—like missing intents or invalid syntax—early in the process, saving time and effort.
1. **Resolve Validation Errors**
If errors are found during validation, you’ll see an **"Unable to train"** message.
* Click on the flow names in the error list to locate and fix issues.
* Examples of errors include missing intents, invalid syntax, or unsupported actions.

2. **Monitor Progress**
After validation, Studio will display a training progress message. Other users can view the status but cannot stop or restart training until it’s complete.

##### How to Manage Training Outcomes[](#how-to-manage-training-outcomes "Direct link to How to Manage Training Outcomes")
Once validation is complete, training begins automatically. Studio provides details on the outcomes as well as logs to help you debug any issues that might come up.
1. **Handle Training Outcomes**
* **Successful Training**: A green checkmark and success message indicate the model is ready.

* **Training Failure**: If training fails, download the logs from the **Versions** page to investigate. Typical causes include invalid training data or conflicting rules.
2. **Stop Training (Optional)**
If necessary, the user who initiated training can stop it. This will terminate the process and display a status update.
##### Troubleshooting Tips[](#troubleshooting-tips "Direct link to Troubleshooting Tips")
1. **Access Logs and Versions**
Go to the **Versions** page to view trained versions of your assistant. Use the ellipsis (three dots) next to a version to download the model or training logs for further analysis.

2. **Reproduce Errors Locally**
* Download the model input files from Studio.
* Set up a matching local Rasa Pro environment.
* Run:
```
rasa train --debug
```
This will provide detailed error messages to help identify the issue.
#### Training Your Assistant Locally using Rasa Pro[](#training-your-assistant-locally-using-rasa-pro "Direct link to Training Your Assistant Locally using Rasa Pro")
##### Step One: Download your Assistant Files[](#step-one-download-your-assistant-files "Direct link to Step One: Download your Assistant Files")
**Option 1:** Downloading via the Studio UI
* Navigate to the **Versions** page in Studio, locate the version you want to train, and click the ellipsis (three dots) to download the assistant files.

**Option 2:** Downloading via the Rasa Pro CLI
Replace `[assistant-name]` with the name of your assistant.
```
rasa studio download [assistant-name]
```
##### Step Two: Train Your Assistant[](#step-two-train-your-assistant "Direct link to Step Two: Train Your Assistant")
Place your assistant files in the working directory and run the following command to start training:
```
rasa train
```
For more detailed local training steps using the Rasa Pro you can take a look at the technical reference to [train your assistant locally](https://rasa.com/docs/docs/reference/api/command-line-interface/#rasa-train).
---
#### Try your Assistant
**Try your assistant** in Rasa Studio provides powerful tools to test and inspect how your trained assistant behaves. Whether you're reviewing the logic behind a conversation or converting an interaction into a test, this feature helps ensure everything works as expected.
#### Before You Start[](#before-you-start "Direct link to Before You Start")
Make sure your assistant has been trained at least once.
> Need help? [See the training guide](https://rasa.com/docs/docs/studio/test/train-your-assistant/) for more information on how to train your assistant.
#### Starting a Conversation[](#starting-a-conversation "Direct link to Starting a Conversation")
To access the **Try your assistant** page:
1. Click **Try your assistant** in the left-hand navigation of Rasa Studio.
2. If your assistant supports multiple languages, choose one from the dropdown.
3. Ensure the correct assistant version is selected.
Want to switch versions? Go to **Assistant Versions** and click the chat icon next to the version you want to test.
Once ready, start the conversation by sending a message.
#### Switching Between Chat and Voice[](#switching-between-chat-and-voice "Direct link to Switching Between Chat and Voice")
If your license includes voice capabilities, you can switch between chat and voice modes:
1. Use the toggle above the message input to switch to voice. Then click "Call".
2. Allow microphone access, speak to your assistant, and view real-time transcripts in the chat panel. Currently, voice input is limited to English.
3. By default, Studio uses Deepgram for speech-to-text (STT) and Cartesia for text-to-speech (TTS). You can customize this setup and choose a different provider outside of Studio. [Learn more about building voice assistants](https://rasa.com/docs/docs/pro/build/voice-assistants/)
#### Activate Assistant Version[](#activate-assistant-version "Direct link to Activate Assistant Version")
The assistant version will be inactive after one hour or when the maximum number of active assistants is reached. To reactivate and test it, go to **Assistant versions** and click the arrow icon. Once reactivated, you can test the version again.
#### Basic Mode: Live Flow Preview[](#basic-mode-live-flow-preview "Direct link to Basic Mode: Live Flow Preview")
Basic Mode is the default mode when testing. It provides:
* A live chat interface
* A **Live Flow Preview** panel that shows your assistant moving through different conversation paths
Use this mode to quickly check if your assistant follows the correct logic.
#### Inspector Mode: Debugging and Insights[](#inspector-mode-debugging-and-insights "Direct link to Inspector Mode: Debugging and Insights")
Toggle **Inspector Mode** (top right corner) to unlock deeper insights:
###### 1. View Events[](#1-view-events "Direct link to 1. View Events")
Click on any user or assistant message to view slots set, flows triggered, and other key events.
###### 2. Predicted Commands[](#2-predicted-commands "Direct link to 2. Predicted Commands")
Select a user message to view the predicted command and understand why a specific path was taken.
###### 3. Model Details[](#3-model-details "Direct link to 3. Model Details")
Click on an assistant message to see the prompt, input, and token usage — useful for understanding performance and API costs.
#### Speed Up Testing[](#speed-up-testing "Direct link to Speed Up Testing")
Beyond analysis, Inspector also provides tools to speed up your conversation testing workflow.
###### Conversation Replay[](#conversation-replay "Direct link to Conversation Replay")
1. Select the **Replay** icon next to a "Waiting for user input" event. This will trigger the conversation to replay back that point.
2. Try out different inputs for testing different outcomes of the conversation.
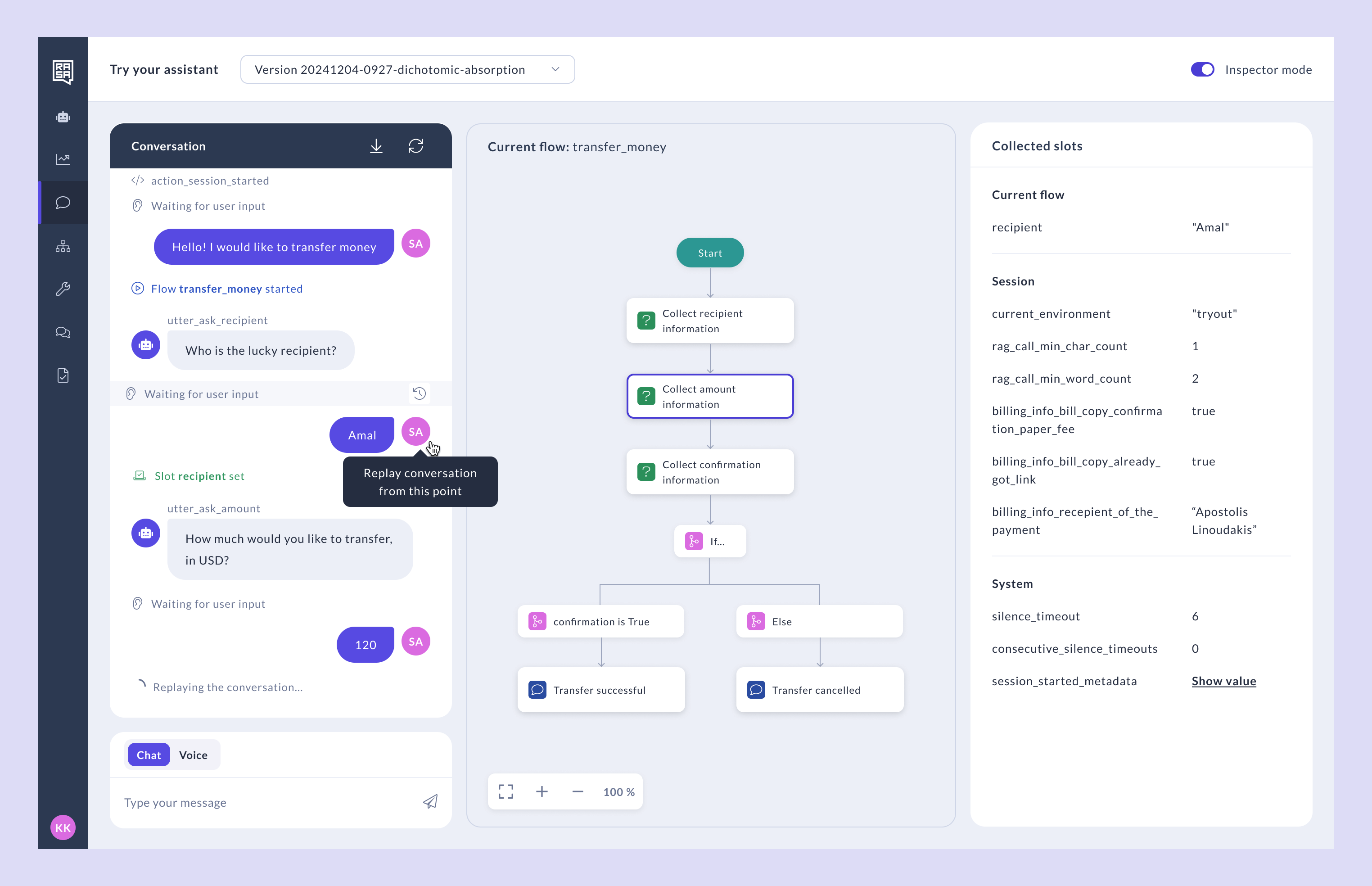
###### Generate Tests from Chat[](#generate-tests-from-chat "Direct link to Generate Tests from Chat")
Once you're happy with a conversation, you can export it to **share with your team**, or **generate a test case** for your assistant.
Select the menu icon in the top right of your conversation panel.
* **Download logs** if you'd like to review the full deployment logs of your running assistant.
* **Download conversation** If you'd like save your conversation in a shareable transcript.
* **Download E2E Tests** If you'd like to save your conversation and use it as an **end-to-end (E2E) test** to validate assistant behavior.
For more details on the testing format and how to run E2E tests as part of your workflow see the [Pro guides for testing](https://rasa.com/docs/docs/pro/testing/evaluating-assistant/).
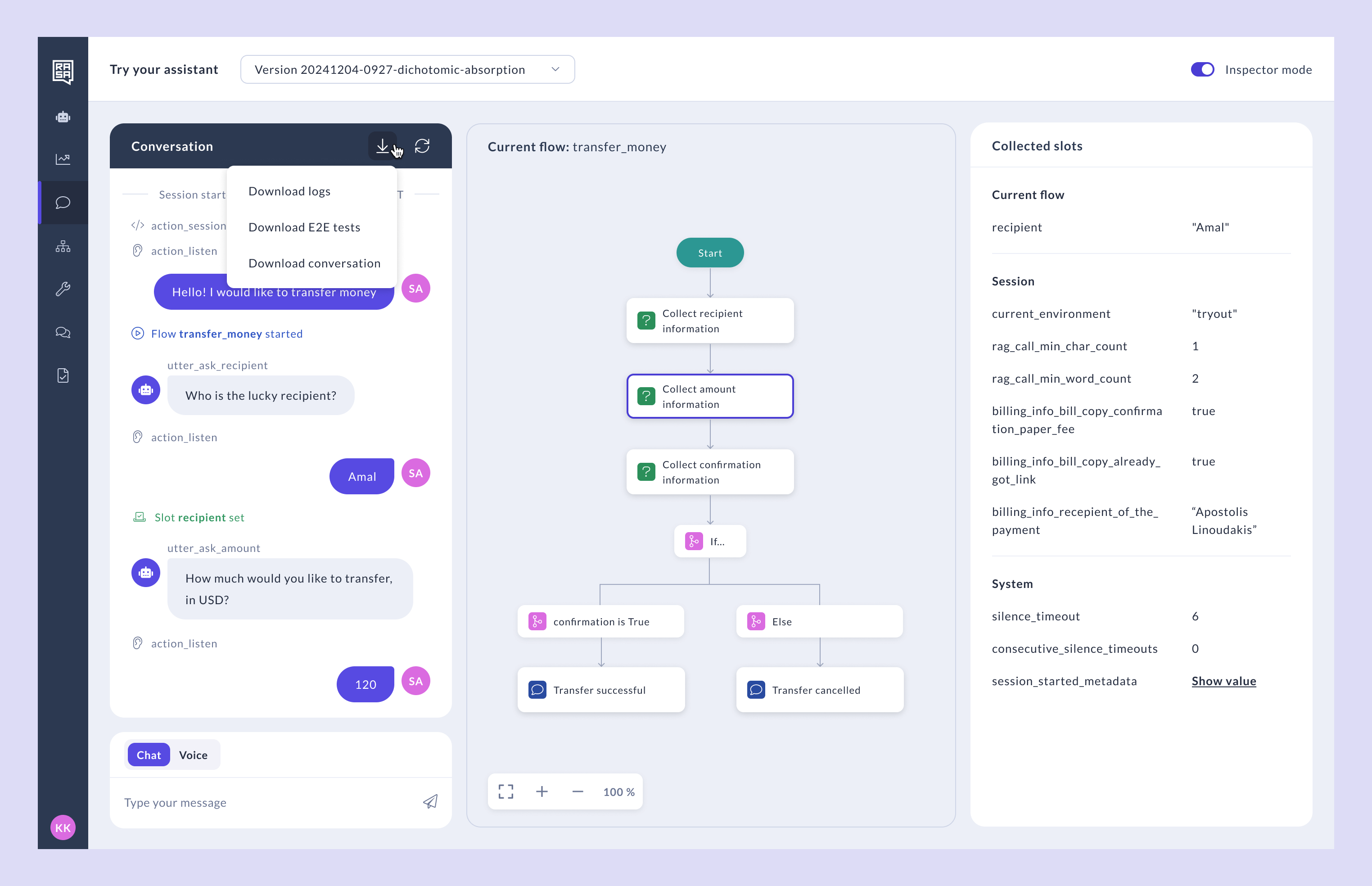
---
## Reference
### Python Versions and Dependencies
This page provides a comprehensive overview of the Python versions and dependency groups supported by Rasa Pro.
#### Supported Python Versions[](#supported-python-versions "Direct link to Supported Python Versions")
Rasa Pro supports the following Python versions:
| Python Version | Support Status | Notes |
| -------------- | -------------- | -------------------------------------------------- |
| 3.10 | ✅ Supported | Full support |
| 3.11 | ✅ Supported | Full support |
| 3.12 | ✅ Supported | Limited support (see TensorFlow limitations below) |
| 3.13 | ✅ Supported | Limited support (see TensorFlow limitations below) |
TensorFlow Limitations
TensorFlow and related dependencies are only supported for Python < 3.12. This means that components requiring TensorFlow are not available for Python >= 3.12:
* `DIETClassifier`
* `TEDPolicy`
* `UnexpecTEDIntentPolicy`
* `ResponseSelector`
* `ConveRTFeaturizer`
* `LanguageModelFeaturizer`
If you need these components, use Python 3.10 or 3.11.
#### Dependency Groups[](#dependency-groups "Direct link to Dependency Groups")
Rasa Pro uses optional dependency groups to allow you to install only the dependencies you need for your specific use case. This helps reduce installation time and keeps your environment lean.
##### Available Dependency Groups[](#available-dependency-groups "Direct link to Available Dependency Groups")
| Dependency Group | Description | Installation Command |
| ---------------- | ----------------------------------- | ---------------------------------- |
| `nlu` | Dependencies for NLU components | `pip install 'rasa-pro[nlu]'` |
| `channels` | Dependencies for channel connectors | `pip install 'rasa-pro[channels]'` |
##### NLU Dependency Group[](#nlu-dependency-group "Direct link to NLU Dependency Group")
The `nlu` dependency group includes dependencies required for NLU components.
These include:
* `spacy` (`^3.5.4`)
* `skops` (`~0.13.0`)
* `mitie` (`^0.7.36`)
* `jieba` (`>=0.42.1, <0.43`)
* `sklearn-crfsuite` (`~0.5.0`)
* `transformers` (`~4.38.2`)
Plus the following dependencies, which are only available for Python < 3.12:
* `tensorflow` (`^2.19.0`)
* `tensorflow-text` (`^2.19.0`)
* `tensorflow-hub` (`^0.13.0`)
* `tensorflow-metal` (`^1.2.0`)
* `tf-keras` (`^2.15.0`)
* `sentencepiece` (`~0.1.99`)
* `tensorflow-io-gcs-filesystem` (`0.31` for sys\_platform == 'win32', `0.34` for sys\_platform == 'linux', `0.34` for sys\_platform == 'linux' for "sys\_platform == 'darwin' and platform\_machine != 'arm64')
##### Channels Dependency Group[](#channels-dependency-group "Direct link to Channels Dependency Group")
The `channels` dependency group includes dependencies required for channel connectors:
* `fbmessenger` (`~6.0.0`)
* `twilio` (`~9.7.2`)
* `webexteamssdk` (`>=1.6.1,<1.7.0`)
* `mattermostwrapper` (`~2.2`)
* `rocketchat_API` (`>=1.32.0,<1.33.0`)
* `aiogram` (`~3.22.0`)
* `slack-sdk` (`~3.36.0`)
* `cvg-python-sdk` (`^0.5.1`)
Channel Dependencies Not Included
The following channels do not require additional dependencies and are included in the main installation:
* `browser_audio`
* `studio_chat`
* `socketIO`
* `rest`
#### Installation Examples[](#installation-examples "Direct link to Installation Examples")
##### Basic Installation[](#basic-installation "Direct link to Basic Installation")
```
# Install Rasa Pro with default dependencies
pip install rasa-pro
```
##### With NLU Components[](#with-nlu-components "Direct link to With NLU Components")
```
# Install Rasa Pro with NLU dependencies
pip install 'rasa-pro[nlu]'
```
##### With Channel Connectors[](#with-channel-connectors "Direct link to With Channel Connectors")
```
# Install Rasa Pro with channel dependencies
pip install 'rasa-pro[channels]'
```
##### With Both NLU and Channels[](#with-both-nlu-and-channels "Direct link to With Both NLU and Channels")
```
# Install Rasa Pro with both NLU and channel dependencies
pip install 'rasa-pro[nlu,channels]'
```
##### Using uv[](#using-uv "Direct link to Using uv")
```
# Using uv package manager (recommended for faster installation)
uv pip install 'rasa-pro[nlu,channels]'
```
#### When to Use Which Dependency Group[](#when-to-use-which-dependency-group "Direct link to When to Use Which Dependency Group")
**Use the `nlu` group when:**
* You are using NLU components in your pipeline (see [NLU Components](https://rasa.com/docs/docs/reference/config/components/nlu-components/) for a full list of all NLU components)
* You need intent classification or entity extraction capabilities
* You're using components like `DIETClassifier`, `TEDPolicy`, or `ResponseSelector`
* You're building assistants that require traditional NLU capabilities
* You need to process user input for intent recognition and entity extraction
**Use the `channels` group when:**
* You're connecting to external messaging platforms (Slack, Telegram, Facebook Messenger, etc.)
* You need voice channel connectors (Jambonz, Audiocodes, Twilio Voice, etc.)
* You're deploying to platforms like Microsoft Bot Framework, Cisco Webex Teams, or RocketChat
* You're building voice assistants that require real-time audio processing
* You need to integrate with customer support platforms or communication systems
##### Use both groups when:[](#use-both-groups-when "Direct link to Use both groups when:")
* You're building a comprehensive assistant that uses both NLU components and external channel integrations
* You need the full feature set of Rasa Pro with traditional NLU capabilities and multi-platform deployment
---
### Rasa Platform Reference
This section provides comprehensive technical documentation and reference materials for building with the Rasa platform. Whether you're developing conversational AI applications or looking to understand specific platform capabilities, you'll find detailed information about Rasa's components, APIs, configuration options, and technical specifications.
The reference documentation covers everything from core concepts to advanced implementation details. Use this reference as your go-to resource when you want to dive deep into Rasa's capabilities. Each subsection is designed to provide clear, accurate, and detailed information to support your development process.
---
### API
#### Analytics Pipeline: Data structure reference
The data structure is created by the Analytics pipeline and treated as a public API. The versioning of the API follows the [Rasa Product Release and Maintenance Policy](https://rasa.com/rasa-product-release-and-maintenance-policy/). All [Internal Tables](#internal-tables) should be considered private and may change without notice.
#### Database Table Overview[](#database-table-overview "Direct link to Database Table Overview")

#### Common Terms[](#common-terms "Direct link to Common Terms")
* **a sender** is a user who is talking to the assistant through a channel. A user might have multiple senders if they use multiple channels, e.g. communicating with the assistant through a website and through a channel integrated into a mobile app.
* **a session** is a conversation between a sender and the assistant. A session is started when a sender sends a message to the assistant and ends when the session either has been timed out or explicitly ended. If a session is interrupted by a longer period of inactivity new activity will trigger a new session to be created ([configurable through the session timeout](https://rasa.com/docs/docs/reference/config/domain/#session-configuration)).
* **a turn** always starts with a message from a sender and ends right before the next message from the sender. A turn can also end with a session being timed out or explicitly ended. A turn will usually contain at least one bot response.
* **a dialogue stack frame** represents the state of a CALM assistant at a certain point in time. The stack frame contains the active flow and step of the assistant. The stack frame is created as the assistant advances through flow(s) and is updated with every event that is sent to the assistant. The stack frame is stored in the [`rasa_dialogue_stack_frame`](#rasa_dialogue_stack_frame) table.
#### Tables[](#tables "Direct link to Tables")
##### rasa\_sender[](#rasa_sender "Direct link to rasa_sender")
A sender is a user who interacts with the assistant through a Rasa Channel. If the assistant supports more than one channel, a user might have multiple senders. For example, a user might have a sender for the Facebook channel and a sender for the Slack channel.

###### `id` sender identifier[](#id-sender-identifier "Direct link to id-sender-identifier")
The unique identifier of the sender is generated by Analytics. Sender gets a different, generated id assigned. The `id` differs from the `sender_id` used by the Rasa channels, the `sender_id` in Rasa is the `sender_key` in Analytics.
* Type: `varchar(36)`
* Example: `a78783c4-bef7-4e55-9ec7-5afb4420f19a`
###### `sender_key` Rasa channel sender identifier[](#sender_key-rasa-channel-sender-identifier "Direct link to sender_key-rasa-channel-sender-identifier")
The unique identifier used by the Rasa channel to identify this sender. The `sender_key` is specific to the channel implementation in Rasa and the format depends on the channel.
* Type: `varchar(255)`
* Example: `fb26ba0a9d8b4bd99e2b8716acb19e4b`
###### `channel` Rasa channel name[](#channel-rasa-channel-name "Direct link to channel-rasa-channel-name")
Name of the channel that is used for this sender. The channel names are defined in the implementation of the respective Rasa channel.
* Type: `varchar(255)`
* Example: `socket.io`
###### `first_seen` first contact with this sender[](#first_seen-first-contact-with-this-sender "Direct link to first_seen-first-contact-with-this-sender")
The date and time of the first contact with this sender. Corresponds to the time of the first event of the first session created for this sender.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `last_seen` latest contact with this sender[](#last_seen-latest-contact-with-this-sender "Direct link to last_seen-latest-contact-with-this-sender")
The date and time of the last contact with this sender. Corresponds to the time of the latest event of the latest session created for this sender.
* Type: `DateTime`
* Example: `2022-10-28 02:15:49.326936`
***
##### rasa\_session[](#rasa_session "Direct link to rasa_session")
The `rasa_session` table contains information about all conversation sessions that users started with the assistant. New sessions are created for every new user and for users who return to the assistant. The conditions that trigger a new session to start can be configured in the [Rasa Domain](https://rasa.com/docs/docs/reference/config/domain/#session-configuration).

###### `id` session identifier[](#id-session-identifier "Direct link to id-session-identifier")
The unique identifier of the session. Every session gets a different, generated id assigned.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `sender_id` sender who started the session[](#sender_id-sender-who-started-the-session "Direct link to sender_id-sender-who-started-the-session")
The unique identifier of the sender who started the session. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `timestamp` creation date time[](#timestamp-creation-date-time "Direct link to timestamp-creation-date-time")
The timestamp when the session was created. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `start_sequence_number` start of the session[](#start_sequence_number-start-of-the-session "Direct link to start_sequence_number-start-of-the-session")
The sequence number of the first event in this session. All events belong to exactly one session. The start sequence number is always smaller or equal to the `end_sequence_number`. The difference between start and end sequence numbers does not equal the number of events in this session since sequence numbers are incremented across multiple conversations.
* Type: `Integer`
* Example: `78`
###### `end_sequence_number` end of the session[](#end_sequence_number-end-of-the-session "Direct link to end_sequence_number-end-of-the-session")
The sequence number of the last event in the session.
* Type: `Integer`
* Example: `91`
***
##### rasa\_turn[](#rasa_turn "Direct link to rasa_turn")
The `rasa_turn` table contains information about all conversation turns. A turn is one interaction between a user and an assistant. A turn always starts with a user message. It ends with the last event before the next user message or with the end of a session. A turn will usually be one user message followed by one or multiple assistant responses. All events between the user message and the end of the turn belong to the same turn.

###### `id` session identifier[](#id-session-identifier-1 "Direct link to id-session-identifier-1")
The unique identifier of the turn. Every turn gets a different generated id assigned.
* Type: `varchar(36)`
* Example: `ffa5d0cd-f5a6-45a4-9506-ba7ffd76edf1`
###### `sender_id` sender who started the turn[](#sender_id-sender-who-started-the-turn "Direct link to sender_id-sender-who-started-the-turn")
The unique identifier of the sender who started the turn. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier "Direct link to session_id-session-identifier")
The unique identifier of the session this turn is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `start_sequence_number` start of the turn[](#start_sequence_number-start-of-the-turn "Direct link to start_sequence_number-start-of-the-turn")
The sequence number of the first event in this turn. All events belong to exactly one session. The start sequence number is always smaller or equal to the `end_sequence_number`. The difference between start and end sequence numbers does not equal the number of events in this session since sequence numbers are incremented across multiple conversations.
* Type: `Integer`
* Example: `79`
###### `end_sequence_number` end of the turn[](#end_sequence_number-end-of-the-turn "Direct link to end_sequence_number-end-of-the-turn")
The sequence number of the last event in this turn.
* Type: `Integer`
* Example: `82`
***
##### rasa\_dialogue\_stack\_frame[](#rasa_dialogue_stack_frame "Direct link to rasa_dialogue_stack_frame")
The `rasa_dialogue_stack_frame` table contains information about the active flow identifier and flow step id of the topmost dialogue stack frame. The CALM assistant adds and removes stack frames to the dialogue stack as it advances through the flow and across flows. When a new `DialogueStackUpdated` event is received, the table is updated with the new stack frame information.
The end sequence number of the stack frame record is updated with the sequence number property of every [rasa event](#rasa_event) that is sent by the assistant after emitting a `DialogueStackUpdated` event. This indicates that the events taking place after this stack update event are associated with the saved stack frame record. The end sequence number is no longer updated when the next `DialogueStackUpdated` event is received.

###### `id` stack frame identifier[](#id-stack-frame-identifier "Direct link to id-stack-frame-identifier")
The unique identifier of the stack frame. Every stack frame record gets a different generated id assigned.
###### `sender_id` sender who started the stack frame[](#sender_id-sender-who-started-the-stack-frame "Direct link to sender_id-sender-who-started-the-stack-frame")
The unique identifier of the sender who started the stack frame. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-1 "Direct link to session_id-session-identifier-1")
The unique identifier of the session this stack frame is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `active_flow_identifier` active flow identifier[](#active_flow_identifier-active-flow-identifier "Direct link to active_flow_identifier-active-flow-identifier")
The identifier of the active flow in the stack frame. The flow identifier is the flow id in the flows yaml file. When the assistant is not in a flow, the active flow identifier is `null`.
* Type: `varchar(255)`
* Example: `book_restaurant`
###### `flow_step_id` step identifier[](#flow_step_id-step-identifier "Direct link to flow_step_id-step-identifier")
The identifier of the current step in the stack frame. The step identifier is the step id in the flows yaml file. When the assistant is not in a flow, the current step is `null`.
* Type: `varchar(255)`
* Example: `2_ask_amount`
###### `inserted_at` creation timestamp[](#inserted_at-creation-timestamp "Direct link to inserted_at-creation-timestamp")
The timestamp when the stack frame was created. The timestamp is in UTC. The timestamp corresponds to the first event timestamp in the stack frame.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `start_sequence_number` start of the stack frame[](#start_sequence_number-start-of-the-stack-frame "Direct link to start_sequence_number-start-of-the-stack-frame")
The sequence number of the first event in this stack frame. All events belong to exactly one session. The start sequence number is always smaller or equal to the `end_sequence_number`. The difference between start and end sequence numbers does not equal the number of events in this session since sequence numbers are incremented across multiple conversations.
* Type: `Integer`
* Example: `79`
###### `end_sequence_number` end of the stack frame[](#end_sequence_number-end-of-the-stack-frame "Direct link to end_sequence_number-end-of-the-stack-frame")
The sequence number of the last event in this stack frame.
* Type: `Integer`
* Example: `82`
***
##### rasa\_flow\_status[](#rasa_flow_status "Direct link to rasa_flow_status")
The `rasa_flow_status` table contains information about the active flow, status of the flow and flow step id in any given session.

###### `id` flow status identifier[](#id-flow-status-identifier "Direct link to id-flow-status-identifier")
The unique identifier of the flow status record. Every flow status record gets a different generated id assigned.
###### `sender_id` sender who started the flow status[](#sender_id-sender-who-started-the-flow-status "Direct link to sender_id-sender-who-started-the-flow-status")
The unique identifier of the sender who started the flow event. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-2 "Direct link to session_id-session-identifier-2")
The unique identifier of the session this stack frame is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `flow_identifier` flow identifier[](#flow_identifier-flow-identifier "Direct link to flow_identifier-flow-identifier")
The identifier of the active flow in the stack frame. The flow identifier is the flow id in the flows yaml file.
* Type: `varchar(255)`
* Example: `book_restaurant`
###### `flow_status` flow status[](#flow_status-flow-status "Direct link to flow_status-flow-status")
The status of the flow. The flow status can be one of the following: The flow status can be one of the following:
* `started`: The flow is started and the assistant is in the flow.
* `completed`: The flow is completed and the assistant is not in the flow.
* `interrupted`: The flow is interrupted and the assistant is not in the flow.
* `resumed`: The flow is resumed and the assistant is in the flow.
* `cancelled`: The flow is aborted and the assistant is not in the flow.
* Type: `varchar(255)`
* Example: `started`
###### `step_id` step identifier[](#step_id-step-identifier "Direct link to step_id-step-identifier")
The identifier of the current step in the stack frame. The step identifier is the step id in the flows yaml file.
* Type: `varchar(255)`
* Example: `0_ask_amount`
###### `inserted_at` creation timestamp[](#inserted_at-creation-timestamp-1 "Direct link to inserted_at-creation-timestamp-1")
The timestamp when the flow status was created. The timestamp is in UTC.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
***
##### rasa\_event[](#rasa_event "Direct link to rasa_event")
The `rasa_event` table contains all events that an assistant created. Events are created for every user message, bot response, and action that is executed as well as for a lot of internal changes to a conversation session. [Overview of all Rasa Events](https://rasa.com/docs/docs/reference/integrations/action-server/events/).

###### `id` event identifier[](#id-event-identifier "Direct link to id-event-identifier")
The unique identifier of the event. Every event gets different, generated id assigned.
* Type: `varchar(36)`
* Example: `f5adcd16-b18d-4c5c-95f0-1747b20cb0e6`
###### `sender_id` sender whose conversation the event belongs to[](#sender_id-sender-whose-conversation-the-event-belongs-to "Direct link to sender_id-sender-whose-conversation-the-event-belongs-to")
The unique identifier of the sender whose conversation this event is part of. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-3 "Direct link to session_id-session-identifier-3")
The unique identifier of the session this event is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `timestamp` creation date time[](#timestamp-creation-date-time-1 "Direct link to timestamp-creation-date-time-1")
The timestamp when the event was created. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `event_type` kind of event[](#event_type-kind-of-event "Direct link to event_type-kind-of-event")
The type of the event. The event type is a string and can be one of the following:
* `user`: The user sent a message to the assistant.
* `bot`: The assistant sent a message to the user.
* `action`: The assistant executed an action.
* `session_started`: A new session was started.
* `action_execution_rejected`: An action failed to execute.
* `active_loop`: The assistant is currently in a loop.
* `slot`: A slot was set.
* `followup`: A follow-up action was triggered.
* `loop_interrupted`: A loop was interrupted.
* `pause`: A session is paused, e.g. because the session was handed over to a human agent.
* `restart`: A session was restarted. This will trigger a new session to be started. The state of the assistant will be reset.
* `rewind`: The assistant rewinds to a previous state.
* `user_featurization`: The assistant featurized the user input.
The event type defines how the event is interpreted and how the event affects the conversation. For example, the `user` event type will be interpreted as a user message and the `bot` event type will be interpreted as a bot response.
* Type: `varchar(255)`
* Example: `action`
###### `model_id` model identifier[](#model_id-model-identifier "Direct link to model_id-model-identifier")
The identifier of the Rasa model that was running as part of the assistant when this event was created.
* Type: `varchar(255)`
* Example: `75a985b7b86d442ca013d61ea4781b22`
###### `environment` name of the assistant environment[](#environment-name-of-the-assistant-environment "Direct link to environment-name-of-the-assistant-environment")
The name of the environment of the assistant that created this event. The environment is a string that is set up during the start of the assistant,
* Type: `varchar(255)`
* Example: `production`
###### `sequence_number` start of the event[](#sequence_number-start-of-the-event "Direct link to sequence_number-start-of-the-event")
The sequence number of the event. The events of a session always have increasing sequence numbers. Sequence numbers are not guaranteed to be sequential for events following one another. But sequence numbers can be used to order the events of a session.
* Type: `Integer`
* Example: `78`
***
##### rasa\_bot\_message[](#rasa_bot_message "Direct link to rasa_bot_message")
A message sent by the assistant to a user will be tracked in the `rasa_bot_message` table. The table contains information about the sent message.

###### `id` bot message identifier[](#id-bot-message-identifier "Direct link to id-bot-message-identifier")
The unique identifier of the bot message is generated by Analytics.
* Type: `varchar(36)`
* Example: `2f2e5384-1bfa-4b53-90a7-c75e5f20b117`
###### `event_id` id of the event of this message[](#event_id-id-of-the-event-of-this-message "Direct link to event_id-id-of-the-event-of-this-message")
The unique identifier of the event that created this bot message. It is a foreign key to the [`rasa_event.id`](#rasa_event) column.
* Type: `varchar(36)`
* Example: `f5adcd16-b18d-4c5c-95f0-1747b20cb0e6`
###### `sender_id` sender whose conversation the message belongs to[](#sender_id-sender-whose-conversation-the-message-belongs-to "Direct link to sender_id-sender-whose-conversation-the-message-belongs-to")
The unique identifier of the sender whose conversation this message is part of. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-4 "Direct link to session_id-session-identifier-4")
The unique identifier of the session this message is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `timestamp` creation date time[](#timestamp-creation-date-time-2 "Direct link to timestamp-creation-date-time-2")
The timestamp when the message was created. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `template_name` name of the template used to generate the message[](#template_name-name-of-the-template-used-to-generate-the-message "Direct link to template_name-name-of-the-template-used-to-generate-the-message")
The name of the template that Rasa used to generate the bot message. Might be empty if the message was not generated from a template but a custom action.
* Type: `varchar(255)`
* Example: `utter_greet`
###### `text` message content[](#text-message-content "Direct link to text-message-content")
The text of the bot message.
* Type: `varchar(65535)`
* Example: `Ok, what can I help you with?`
###### `model_id` model identifier[](#model_id-model-identifier-1 "Direct link to model_id-model-identifier-1")
The identifier of the Rasa model that was running as part of the assistant when this message was created.
* Type: `varchar(255)`
* Example: `75a985b7b86d442ca013d61ea4781b22`
###### `sequence_number` start of the event[](#sequence_number-start-of-the-event-1 "Direct link to sequence_number-start-of-the-event-1")
The sequence number of the message. The events of a session always have increasing sequence numbers. The sequence number of this message is the same as the one of the underlying event.
* Type: `Integer`
* Example: `78`
***
##### rasa\_user\_message[](#rasa_user_message "Direct link to rasa_user_message")
A message sent by a user to the assistant will be tracked in the `rasa_user_message` table. The table contains information about the sent message.

###### `id` user message identifier[](#id-user-message-identifier "Direct link to id-user-message-identifier")
The unique identifier of the user message is generated by Analytics.
* Type: `varchar(36)`
* Example: `49fdd79e-976b-47c2-ab27-a4c3d743a1c9`
###### `event_id` id of the event of this message[](#event_id-id-of-the-event-of-this-message-1 "Direct link to event_id-id-of-the-event-of-this-message-1")
The unique identifier of the event that created this user message. It is a foreign key to the [`rasa_event.id`](#rasa_event) column.
* Type: `varchar(36)`
* Example: `f5adcd16-b18d-4c5c-95f0-1747b20cb0e6`
###### `sender_id` sender whose conversation the message belongs to[](#sender_id-sender-whose-conversation-the-message-belongs-to-1 "Direct link to sender_id-sender-whose-conversation-the-message-belongs-to-1")
The unique identifier of the sender whose conversation this message is part of. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-5 "Direct link to session_id-session-identifier-5")
The unique identifier of the session this message is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `intent` classification of the text[](#intent-classification-of-the-text "Direct link to intent-classification-of-the-text")
The name of the intent that Rasa classified the text as. One of the intents in the domain used to train the model.
* Type: `varchar(255)`
* Example: `book_flight`
###### `retrieval_intent` classification of the text[](#retrieval_intent-classification-of-the-text "Direct link to retrieval_intent-classification-of-the-text")
The name of the retrieval intent that Rasa classified the text as. Only populated if there is a configured retrieval intent.
* Type: `varchar(255)`
* Example: `book_flight/faq`
###### `confidence` certainty the model predicted for classifications[](#confidence-certainty-the-model-predicted-for-classifications "Direct link to confidence-certainty-the-model-predicted-for-classifications")
The confidence of the ML model's intent prediction. The confidence is a value between 0 and 1. The higher the value, the more certain the model is that the intent is correct.
* Type: `Float`
* Example: `0.8798527419567108`
###### `text` message content[](#text-message-content-1 "Direct link to text-message-content-1")
The text of the user message.
* Type: `varchar(65535)`
* Example: `I want to book a flight.`
###### `timestamp` creation date time[](#timestamp-creation-date-time-3 "Direct link to timestamp-creation-date-time-3")
The timestamp when the message was created. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `model_id` model identifier[](#model_id-model-identifier-2 "Direct link to model_id-model-identifier-2")
The identifier of the Rasa model that was running as part of the assistant when this message was created.
* Type: `varchar(255)`
* Example: `75a985b7b86d442ca013d61ea4781b22`
###### `sequence_number` start of the event[](#sequence_number-start-of-the-event-2 "Direct link to sequence_number-start-of-the-event-2")
The sequence number of the message. The events of a session always have increasing sequence numbers. The sequence number of this message is the same as the one of the underlying event.
* Type: `Integer`
* Example: `78`
###### `message_id` unique id for the message text[](#message_id-unique-id-for-the-message-text "Direct link to message_id-unique-id-for-the-message-text")
A unique id that identifies the text of the message.
* Type: `varchar(255)`
* Example: `7cdb5700ac9c493aa46987b77d91c363`
***
##### rasa\_llm\_command[](#rasa_llm_command "Direct link to rasa_llm_command")
Commands sent by [`LLMCommandGenerator`](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/) will be tracked in the `rasa_llm_command` table. The table contains information about the commands issued in response to each user message.

###### `id` llm command identifier[](#id-llm-command-identifier "Direct link to id-llm-command-identifier")
The unique identifier of the LLM command is generated by Analytics.
* Type: `varchar(36)`
* Example: `49fdd79e-976b-47c2-ab27-a4c3d743a1c9`
###### `sender_id` sender whose conversation the command belongs to[](#sender_id-sender-whose-conversation-the-command-belongs-to "Direct link to sender_id-sender-whose-conversation-the-command-belongs-to")
The unique identifier of the sender whose conversation this command is part of. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-6 "Direct link to session_id-session-identifier-6")
The unique identifier of the session this command is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `user_message_id` unique id for the user message text[](#user_message_id-unique-id-for-the-user-message-text "Direct link to user_message_id-unique-id-for-the-user-message-text")
A unique id that identifies the text of the message. Represents a foreign key to the [`rasa_user_message.message_id`](#rasa_user_message) column.
* Type: `varchar(255)`
* Example: `7cdb5700ac9c493aa46987b77d91c363`
###### `command` command name[](#command-command-name "Direct link to command-command-name")
The name of the [command](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#command-reference) issued.
* Type: `varchar(255)`
* Example: `set slot`
###### `inserted_at` creation timestamp[](#inserted_at-creation-timestamp-2 "Direct link to inserted_at-creation-timestamp-2")
The timestamp when the user message was received. The timestamp is in UTC.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `flow_identifier` flow identifier[](#flow_identifier-flow-identifier-1 "Direct link to flow_identifier-flow-identifier-1")
The identifier of the active flow in the stack frame. The flow identifier is the flow id in the flows yaml file. This is only populated for `start flow` commands.
* Type: `varchar(255)`
* Example: `book_restaurant`
###### `set_slot_name` slot name[](#set_slot_name-slot-name "Direct link to set_slot_name-slot-name")
The name of the slot that was set. This is only populated for `set slot` commands.
* Type: `varchar(255)`
* Example: `restaurant_name`
###### `clarification_options` list of flow identifiers[](#clarification_options-list-of-flow-identifiers "Direct link to clarification_options-list-of-flow-identifiers")
The list of flow identifiers that the user can choose from. This is only populated for `clarify` commands.
* Type: `varchar(65535)`
* Example: `'["add_contact", "remove_contact"]'`
***
##### rasa\_action[](#rasa_action "Direct link to rasa_action")
An action executed by the assistant. All actions the bot executes are tracked in the `rasa_action` table. The table contains information about the executed action and its prediction.

###### `id` action identifier[](#id-action-identifier "Direct link to id-action-identifier")
The unique identifier of the action execution is generated by Analytics.
* Type: `varchar(36)`
* Example: `bd074dc7-e745-4db6-86d0-75b0af7bc067`
###### `event_id` id of the event of this action execution[](#event_id-id-of-the-event-of-this-action-execution "Direct link to event_id-id-of-the-event-of-this-action-execution")
The unique identifier of the event that created this action execution. It is a foreign key to the [`rasa_event.id`](#rasa_event) column.
* Type: `varchar(36)`
* Example: `f5adcd16-b18d-4c5c-95f0-1747b20cb0e6`
###### `sender_id` sender whose conversation triggered this action execution[](#sender_id-sender-whose-conversation-triggered-this-action-execution "Direct link to sender_id-sender-whose-conversation-triggered-this-action-execution")
The unique identifier of the sender whose conversation triggered this action execution. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-7 "Direct link to session_id-session-identifier-7")
The unique identifier of the session this action execution is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `name` name of the executed action[](#name-name-of-the-executed-action "Direct link to name-name-of-the-executed-action")
The name of the action that Rasa has predicted and executed. One of the actions in the domain used to train the model.
* Type: `varchar(255)`
* Example: `action_book_flight`
###### `confidence` ML models certainty of the predicted action[](#confidence-ml-models-certainty-of-the-predicted-action "Direct link to confidence-ml-models-certainty-of-the-predicted-action")
The confidence of ML model's action prediction. The confidence is a value between 0 and 1. The higher the value, the more certain the model is that the action is correct.
* Type: `Float`
* Example: `0.9398527419567108`
###### `policy` name of the policy that predicted the action[](#policy-name-of-the-policy-that-predicted-the-action "Direct link to policy-name-of-the-policy-that-predicted-the-action")
The name of the policy that predicted this action. The policy is a component in the Rasa assistant that makes a prediction. The policy can be a rule policy, a memoization policy, or an ML policy.
* Type: `varchar(255)`
* Example: `policy_2_TEDPolicy`
###### `timestamp` creation date time[](#timestamp-creation-date-time-4 "Direct link to timestamp-creation-date-time-4")
The timestamp when the action was executed. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `model_id` model identifier[](#model_id-model-identifier-3 "Direct link to model_id-model-identifier-3")
The identifier of the Rasa model that was running as part of the assistant when this action was executed.
* Type: `varchar(255)`
* Example: `75a985b7b86d442ca013d61ea4781b22`
###### `sequence_number` start of the event[](#sequence_number-start-of-the-event-3 "Direct link to sequence_number-start-of-the-event-3")
The sequence number of the executed action. The events of a session always have increasing sequence numbers. The sequence number of this executed action is the same as the one of the underlying event.
* Type: `Integer`
* Example: `78`
***
##### rasa\_slot[](#rasa_slot "Direct link to rasa_slot")
A slot that has been set for a session. All changes to slot values are tracked in the `rasa_slot` table. The table contains information about the change in the value of the slot.

###### `id` slot change identifier[](#id-slot-change-identifier "Direct link to id-slot-change-identifier")
The unique identifier of this change in slot values is generated by Analytics.
* Type: `varchar(36)`
* Example: `a793d284-b5b9-4cef-be8a-bc0f58c70c28`
###### `event_id` id of the event that triggered this slot change[](#event_id-id-of-the-event-that-triggered-this-slot-change "Direct link to event_id-id-of-the-event-that-triggered-this-slot-change")
The unique identifier of the event that triggered this change in the slot value. It is a foreign key to the [`rasa_event.id`](#rasa_event) column.
* Type: `varchar(36)`
* Example: `f5adcd16-b18d-4c5c-95f0-1747b20cb0e6`
###### `sender_id` sender whose conversation triggered this slot change[](#sender_id-sender-whose-conversation-triggered-this-slot-change "Direct link to sender_id-sender-whose-conversation-triggered-this-slot-change")
The unique identifier of the sender whose conversation triggered this slot change. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-8 "Direct link to session_id-session-identifier-8")
The unique identifier of the session this slot change is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `slot_path` path of the slot[](#slot_path-path-of-the-slot "Direct link to slot_path-path-of-the-slot")
A path to the slot that was changed. The path identifies the slot by its name, the sender and the session. The path is a string that looks like `//`.
* Type: `varchar(255)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53/63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1/email`
###### `name` name of the slot[](#name-name-of-the-slot "Direct link to name-name-of-the-slot")
The name of the changed slot. The name of the slot is the same as the name of the slot in the domain.
* Type: `varchar(255)`
* Example: `email`
###### `value` new slot value[](#value-new-slot-value "Direct link to value-new-slot-value")
The new value of the slot for the session. The value is a dumped JSON object.
* Type: `varchar(65535)`
* Example: `john@example.com`
###### `timestamp` creation date time[](#timestamp-creation-date-time-5 "Direct link to timestamp-creation-date-time-5")
The timestamp when the slot value was changed. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-28 02:15:49.326936`
###### `sequence_number` start of the event[](#sequence_number-start-of-the-event-4 "Direct link to sequence_number-start-of-the-event-4")
The sequence number of the slot change. The events of a session always have increasing sequence numbers. The sequence number of the slot change is the same as the one of the underlying event.
* Type: `Integer`
* Example: `78`
***
##### rasa\_session\_slot\_state[](#rasa_session_slot_state "Direct link to rasa_session_slot_state")
The state of a slot at the end of a session. The state of a slot is the value of the slot at the end of a session. The state of a slot is stored in the `rasa_session_slot_state` table.

###### `id` path of the slot[](#id-path-of-the-slot "Direct link to id-path-of-the-slot")
A path to the slot. The path identifies the slot by its name, the sender and the session. The path is a string that looks like `//`.
* Type: `varchar(255)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53/63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1/email`
###### `sender_id` sender whose conversation this slot is part of[](#sender_id-sender-whose-conversation-this-slot-is-part-of "Direct link to sender_id-sender-whose-conversation-this-slot-is-part-of")
The unique identifier of the sender whose conversation this slot is part of. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-9 "Direct link to session_id-session-identifier-9")
The unique identifier of the session this slot is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `name` name of the slot[](#name-name-of-the-slot-1 "Direct link to name-name-of-the-slot-1")
The name of the slot. The name of the slot is the same as the name of the slot in the domain.
* Type: `varchar(255)`
* Example: `email`
###### `value` last value of the slot in the session[](#value-last-value-of-the-slot-in-the-session "Direct link to value-last-value-of-the-slot-in-the-session")
The value of the slot at the end of the session. The value is a dumped JSON object. If a slot is changed multiple times during a session, the value is set to the last change.
* Type: `varchar(65535)`
* Example: `john@example.com`
###### `timestamp` creation date time[](#timestamp-creation-date-time-6 "Direct link to timestamp-creation-date-time-6")
Time of the last update of the slot in this session. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-21 02:15:49.326936`
##### rasa\_pattern[](#rasa_pattern "Direct link to rasa_pattern")
Patterns are marker definitions that have been received from Rasa. This table is called `rasa_pattern` to distinguish them from extracted markers which are stored in `rasa_marker` table. It stores the configuration of markers (which can be thought of as a pattern of conversational events) along with their metadata.

###### `id` pattern identifier[](#id-pattern-identifier "Direct link to id-pattern-identifier")
The unique identifier of the rasa pattern is generated by Analytics.
* Type: `varchar(36)`
* Example: `bd074dc7-e745-4db6-86d0-75b0af7bc067`
###### `name` pattern name[](#name-pattern-name "Direct link to name-pattern-name")
Name of the pattern
* Type: `varchar()`
* Example: `registration success`
###### `description` pattern description[](#description-pattern-description "Direct link to description-pattern-description")
Description of the pattern
* Type: `varchar()`
* Example: `This marker identifies successful account registration in the chat`
###### `config` pattern configuration[](#config-pattern-configuration "Direct link to config-pattern-configuration")
Pattern configuration dictionary stored as an escaped string
* Type: `varchar()`
* Example: `"{'or': [{'intent': 'mood_unhappy'},{'intent': 'mood_great'}]}"`
###### `is_active` soft-delete flag[](#is_active-soft-delete-flag "Direct link to is_active-soft-delete-flag")
Only patterns with `is_active==True` are processed during real-time analysis
* Type: `boolean`
###### `created_at` creation date time[](#created_at-creation-date-time "Direct link to created_at-creation-date-time")
Time of creation of this pattern. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-21 02:15:49.326936`
###### `updated_at` update date time[](#updated_at-update-date-time "Direct link to updated_at-update-date-time")
Time of the last update of the pattern in this session. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-21 02:15:49.326936`
##### rasa\_marker[](#rasa_marker "Direct link to rasa_marker")
Extracted markers from the conversations. Each row in this table corresponds to a marker along with details of the pattern, sender, session and the last event where it was extracted.

###### `id` marker identifier[](#id-marker-identifier "Direct link to id-marker-identifier")
The unique identifier of the extracted rasa marker is generated by Analytics.
* Type: `varchar(36)`
* Example: `bd074dc7-e745-4db6-86d0-75b0af7bc067`
###### `pattern_id` pattern which was applied in this marker[](#pattern_id-pattern-which-was-applied-in-this-marker "Direct link to pattern_id-pattern-which-was-applied-in-this-marker")
The unique identifier of the pattern which was applied in this marker. It is a foreign key to the [`rasa_pattern.id`](#rasa_pattern) column
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `sender_id` sender identifier[](#sender_id-sender-identifier "Direct link to sender_id-sender-identifier")
The unique identifier of the sender whose conversation this marker is part of. It is a foreign key to the [`rasa_sender.id`](#rasa_sender) column.
* Type: `varchar(36)`
* Example: `9e4ebded-f232-4cc5-af78-d98daa0c1a53`
###### `session_id` session identifier[](#session_id-session-identifier-10 "Direct link to session_id-session-identifier-10")
The unique identifier of the session this marker is part of. It is a foreign key to the [`rasa_session.id`](#rasa_session) column.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `event_id` event identifier[](#event_id-event-identifier "Direct link to event_id-event-identifier")
The unique identifier of the event from event broker where this marker was applied. Note that a marker can be applied across multiple events, this is the ID of the last event in the sequence.
* Type: `varchar(36)`
* Example: `63b150a6-21a3-4e6c-bb24-5ab6ddc30cf1`
###### `num_preceding_user_turns` Number of Proeeding User turns[](#num_preceding_user_turns-number-of-proeeding-user-turns "Direct link to num_preceding_user_turns-number-of-proeeding-user-turns")
an integer indicating the number of user turns preceding the event at which the marker applied.
* Type: `integer`
* Example: `4`
###### `created_at` creation date time[](#created_at-creation-date-time-1 "Direct link to created_at-creation-date-time-1")
Time of creation of this marker. The timestamp is a UTC.
* Type: `DateTime`
* Example: `2022-06-21 02:15:49.326936`
#### Internal Tables[](#internal-tables "Direct link to Internal Tables")
Internal tables are used to store information about the assistant and the events that are sent to the assistant. They are not meant to be queried directly but are required for the functioning of Analytics. They are a private API that is used by the Analytics service internally and might change without notice.
Internal tables:
* `_rasa_raw_event`
* `alembic_version`
---
#### Authorization
#### Introduction[](#introduction "Direct link to Introduction")
Learn how to obtain the secret and client ID required for authenticating requests to Studio API. API is built using GraphQL, enabling powerful querying and mutations for flexible interaction with Studio API. For authentication, we rely on Keycloak to manage users and secure external communication by using OpenID Connect's "Client Credentials Flow".
##### Studio-External Client Overview[](#studio-external-client-overview "Direct link to Studio-External Client Overview")
The **studio-external** client is a default client in Keycloak for facilitating API integrations with Rasa Studio. This client is pre-configured with roles, ready for use without additional configuration.
Customers can use **studio-external** to:
* Manage conversations via APIs,
* Request urls to artifacts for CI/CD
This flexibility allows for quick integration or custom setups based on specific requirements.
**Note**: The instructions below cover both using the default client and creating a new one. If you decide to use existing **studio-external**, login to Keycloak admin and skip directly to [Obtain Client ID and Secret](#obtaining-client-id-and-secret)
#### Creating a New Client ID[](#creating-a-new-client-id "Direct link to Creating a New Client ID")
To create a new Client ID in Keycloak, follow these steps:
1. Go to Keycloak Admin and log in. **Note**: Ensure the **rasa-studio** realm is selected from the top-left dropdown. 
2. Navigate to the **Clients** tab and click **Create**.
* Set **Client ID** to a name of you choice.
* Set **Client type** to **OpenID Connect**.
* Click **Next**.
 
##### Client Capability Configuration[](#client-capability-configuration "Direct link to Client Capability Configuration")
1. On the **Capability Config** page, enable:
* **Client Authentication**.
* **Service Account Roles** (for **Client Credentials Flow**).
**Warning**: Keep other settings off.

2. Click **Next**.
##### Login Settings[](#login-settings "Direct link to Login Settings")
On this page click **Save** to finish.
##### Assigning a Role to the Client[](#assigning-a-role-to-the-client "Direct link to Assigning a Role to the Client")
1. Go to **Service Accounts Roles** and click on `service-account-studio-external`. **Note:** This service account user may have a different name depending on how you name your client.

2. In the **Role Mapping** tab, assign a role to your Client, e.g. **Manage conversations** to enable managing conversations via the API.
 
##### Obtaining Client ID and Secret[](#obtaining-client-id-and-secret "Direct link to Obtaining Client ID and Secret")
1. Return to the **Clients** tab, make sure the **rasa-studio** realm is selected, select your client, and go to the **Credentials** tab.
2. Click on Regenerate next to the Client Secret field to enhance security.
3. Make sure to note down the new **Client ID** and **Client Secret** for future use.

##### Obtain access token[](#obtain-access-token "Direct link to Obtain access token")
To perform API requests, you must first obtain an access token using a **POST** request.
1. Create a **POST** request to:
```
https://your-keycloak-address/auth/realms/rasa-studio/protocol/openid-connect/token
```
For example in local environment, the URL is:
```
https://localhost:8081/auth/realms/rasa-studio/protocol/openid-connect/token
```
2. Set **x-www-form-urlencoded** body parameters:
* `grant_type`: **client\_credentials**,
* `client_id`: your new Client ID name,
* `client_secret`: the secret obtained from [Obtain Client ID and Secret](#obtaining-client-id-and-secret)
###### Example curl Request[](#example-curl-request "Direct link to Example curl Request")
```
curl -X POST https://localhost:8081/auth/realms/rasa-studio/protocol/openid-connect/token \
-H "Content-Type: application/x-www-form-urlencoded" \
-d 'grant_type=client_credentials&client_id=&client_secret='
```
You should receive an *access\_token*.
Now, using this token as the **Authorization: Bearer *retrieved\_token*** header, you can send your API requests.
---
#### Command Line Interface
#### Cheat Sheet[](#cheat-sheet "Direct link to Cheat Sheet")
##### Pro specific[](#pro-specific "Direct link to Pro specific")
The following commands are relevant to all assistants built with Rasa.
| Command | Effect |
| -------------------------------- | -------------------------------------------------------------------------------------------------- |
| `rasa init` | Creates a new project with example training data, actions, and config files. |
| `rasa train` | Trains a model using your NLU data and stories, saves trained model in `./models`. |
| `rasa shell` | Loads your trained model and lets you talk to your assistant on the command line. |
| `rasa run` | Starts a server with your trained model. |
| `rasa run actions` | Starts an action server using the Rasa SDK. |
| `rasa test e2e` | Runs end-to-end testing fully integrated with the action server that serves as acceptance testing. |
| `rasa data convert e2e` | Converts sample conversation data into end-to-end test cases. |
| `rasa llm finetune prepare-data` | Prepares data to fine-tune a base model for the task of command generator. |
| `rasa inspect` | Opens Rasa Inspector. |
| `rasa data validate` | Checks the domain, NLU, flows and conversation data for inconsistencies. |
| `rasa export` | Exports conversations from a tracker store to an event broker. |
| `rasa marker upload` | Upload marker configurations to Analytics Data Pipeline |
| `rasa license` | Display licensing information. |
| `rasa -h` | Shows all available commands. |
| `rasa --version` | Shows version information about Rasa, Python and the expiration date for Rasa License |
##### Studio specific[](#studio-specific "Direct link to Studio specific")
If your team is using **Rasa Studio**, these CLI commands let you manage and sync your assistant between your local environment and your Studio deployment:
| Command | Description |
| --------------------------------------- | ----------------------------------------------------------------------------------- |
| `rasa studio config` | Sets up local configuration to connect to your Rasa Studio deployment. |
| `rasa studio login` | Authenticates and retrieves credentials from your Rasa Studio instance. |
| `rasa studio upload` | Uploads your local assistant as a new project in Rasa Studio. |
| `rasa studio download ` | Downloads the full assistant from Rasa Studio into your current directory. |
| `rasa studio link ` | Links your local project to a specific assistant in Rasa Studio. |
| `rasa studio push` | Pushes your local changes to Studio. |
| `rasa studio pull` | Pulls the latest changes from Studio and merges them into your local project. |
| `rasa studio train` | Trains a model combining local + Studio data and saves trained model in `./models`. |
#### Rasa Pro Commands[](#rasa-pro-commands "Direct link to Rasa Pro Commands")
##### Logging[](#logging "Direct link to Logging")
note
If you run into character encoding issues on Windows like: `UnicodeEncodeError: 'charmap' codec can't encode character ...` or the terminal is not displaying colored messages properly, prepend `winpty` to the command you would like to run. For example `winpty rasa init` instead of `rasa init`
###### Setting log levels[](#setting-log-levels "Direct link to Setting log levels")
Rasa produces log messages at several different levels (eg. warning, info, error and so on). You can control which level of logs you would like to see with `--verbose` (same as `-v`) or `--debug` (same as `-vv`) as optional command line arguments. See each command below for more explanation on what these arguments mean.
In addition to CLI arguments, several environment variables allow you to control log output in a more granular way. With these environment variables, you can configure log levels for messages created by external libraries such as Matplotlib, Pika, and Kafka. These variables follow [standard logging level in Python](https://docs.python.org/3/library/logging.html#logging-levels). Currently, following environment variables are supported:
1. LOG\_LEVEL\_LIBRARIES: This is the general environment variable to configure log level for the main libraries Rasa uses. It covers Tensorflow, `asyncio`, APScheduler, SocketIO, Matplotlib, RabbitMQ, Kafka.
2. LOG\_LEVEL\_MATPLOTLIB: This is the specialized environment variable to configure log level only for Matplotlib.
3. LOG\_LEVEL\_RABBITMQ: This is the specialized environment variable to configure log level only for AMQP libraries, at the moment it handles log levels from `aio_pika` and `aiormq`.
4. LOG\_LEVEL\_KAFKA: This is the specialized environment variable to configure log level only for kafka.
5. LOG\_LEVEL\_PRESIDIO: This is the specialized environment variable to configure log level only for Presidio, at the moment it handles log levels from `presidio_analyzer` and `presidio_anonymizer`.
6. LOG\_LEVEL\_FAKER: This is the specialized environment variable to configure log level only for Faker.
7. LOG\_LEVEL\_MLFLOW: This is the specialized environment variable to configure log level only for MLFlow.
8. LOG\_LEVEL\_PYMONGO: This is the specialized environment variable to configure log level only for PyMongo.
General configuration (`LOG_LEVEL_LIBRARIES`) has less priority than library level specific configuration (`LOG_LEVEL_MATPLOTLIB`, `LOG_LEVEL_RABBITMQ` etc); and CLI parameter sets the lowest level log messages which will be handled. This means variables can be used together with a predictable result. As an example:
```
LOG_LEVEL_LIBRARIES=ERROR LOG_LEVEL_MATPLOTLIB=WARNING LOG_LEVEL_KAFKA=DEBUG rasa shell --debug
```
The above command run will result in showing:
* messages with `DEBUG` level and higher by default (due to `--debug`)
* messages with `WARNING` level and higher for Matplotlib
* messages with `DEBUG` level and higher for kafka
* messages with `ERROR` level and higher for other libraries not configured
Note that CLI config sets the lowest level log messages to be handled, hence the following command will set the log level to `INFO` (due to `--verbose`) and no debug messages will be seen (library level configuration will not have any effect):
```
LOG_LEVEL_LIBRARIES=DEBUG LOG_LEVEL_MATPLOTLIB=DEBUG rasa shell --verbose
```
As an aside, CLI log level sets the level at the root logger (which has the important handler - `coloredlogs` handler); this means even if an environment variable sets a library logger to a lower level, the root logger will reject messages from that library. If not specified, the CLI log level is set to `INFO`.
###### Log Level LLM Components[](#log-level-llm-components "Direct link to Log Level LLM Components")
Rasa provides enhanced control over the debugging process of LLM-driven components via a fine-grained, customizable logging specified through environment variables.
For example, set the `LOG_LEVEL_LLM` environment variable to enable detailed logging at the desired level for all the LLM components or specify the component you are debugging by setting for example the `LOG_LEVEL_LLM_ENTERPRISE_SEARCH` environment variable:
```
export LOG_LEVEL_LLM=INFO
export LOG_LEVEL_LLM_COMMAND_GENERATOR=INFO
export LOG_LEVEL_LLM_ENTERPRISE_SEARCH=DEBUG
export LOG_LEVEL_LLM_INTENTLESS_POLICY=INFO
export LOG_LEVEL_LLM_REPHRASER=INFO
export LOG_LEVEL_NLU_COMMAND_ADAPTER=INFO
export LOG_LEVEL_LLM_BASED_ROUTER=INFO
```
These settings override logging level for the specified components.
The `LOG_LEVEL_LLM_COMMAND_GENERATOR` variable applies to all types of [LLM-based command generators](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/).
##### Custom logging configuration[](#custom-logging-configuration "Direct link to Custom logging configuration")
v3.4
info
The Rasa CLI now includes a new argument `--logging-config-file` which accepts a YAML file as value.
You can now configure any logging formatters or handlers in a separate YAML file. The logging config YAML file must follow the [Python built-in dictionary schema](https://docs.python.org/3/library/logging.config.html#dictionary-schema-details), otherwise it will fail validation. You can pass this file as argument to the `--logging-config-file` CLI option and use it with any of the rasa commands.
###### Custom logging configuration example[](#custom-logging-configuration-example "Direct link to Custom logging configuration example")
The following example illustrates how to customize the logging configuration using a YAML file. Here we define a custom formatter, a stream handler for the root logger and a file handler for the rasa logger.
```
version: 1
disable_existing_loggers: false
formatters:
customFormatter:
format: "{\"time\": \"%(asctime)s\", \"name\": \"[%(name)s]\", \"levelname\": \"%(levelname)s\", \"message\": \"%(message)s\"}"
handlers:
console:
class: logging.StreamHandler
level: INFO
formatter: customFormatter
stream: ext://sys.stdout
file:
class: logging.FileHandler
filename: "rasa_debug.log"
level: DEBUG
formatter: customFormatter
loggers:
root:
handlers: [console]
rasa:
handlers: [file]
propagate: 0
```
info
In Rasa Pro 3.9, running `rasa shell` or `rasa interactive` in debug mode could result in `BlockingIOError` when using the default logging configuration. This issue is resolved by using a custom logging configuration file. If you encounter this issue, you can use the above example to create a custom logging configuration file and pass it to the `--logging-config-file` argument.
##### rasa init[](#rasa-init "Direct link to rasa init")
This command sets up a complete assistant for you with some example training data:
```
rasa init
```
With no arguments, `rasa init` creates the following files:
```
.
├── actions
│ ├── __init__.py
│ └── actions.py
├── config.yml
├── credentials.yml
├── data
│ ├── nlu.yml
│ └── stories.yml
├── domain.yml
├── endpoints.yml
├── models
│ └── .tar.gz
└── tests
└── test_stories.yml
```
It will ask you if you want to train an initial model using this data. If you answer no, the `models` directory will be empty.
This is the best way to get started writing an NLU assistant. You can run `rasa train`, `rasa shell` and `rasa test` without any additional configuration.
Rasa supplies two other templates in addition to the default NLU template described above. Both of these are great ways to get started building your own CALM bots:
* `rasa init --template calm` generates a CALM assistant with [flows](https://rasa.com/docs/docs/reference/primitives/flows/) and a [custom action](https://rasa.com/docs/docs/reference/primitives/custom-actions/) to manage a simple contact list.
* `rasa init --template tutorial` generates the codebase used in the [CALM Tutorial](https://rasa.com/docs/docs/pro/tutorial/).
##### rasa train[](#rasa-train "Direct link to rasa train")
The following command trains a Rasa model:
```
rasa train
```
If you have existing models in your directory (under `models/` by default), only the parts of your model that have changed will be re-trained. For example, if you edit your NLU training data and nothing else, only the NLU part will be trained.
If you want to train an NLU or dialogue model individually, you can run `rasa train nlu` or `rasa train core`. If you provide training data only for one one of these, `rasa train` will fall back to one of these commands by default.
`rasa train` will store the trained model in the directory defined by `--out`, `models/` by default. The name of the model by default is `.tar.gz`. If you want to name your model differently, you can specify the name using the `--fixed-model-name` flag.
By default validation is run before training the model. If you want to skip validation, you can use the `--skip-validation` flag. If you want to fail on validation warnings, you can use the `--fail-on-validation-warnings` flag. The `--validation-max-history` is analogous to the `--max-history` argument of `rasa data validate`.
Run `rasa train --help` to see the full list of arguments.
##### rasa shell[](#rasa-shell "Direct link to rasa shell")
You can start a chat session by running:
```
rasa shell
```
By default, this will load up the latest trained model. You can specify a different model to be loaded by using the `--model` flag.
If you start the shell with an NLU-only model, `rasa shell` will output the intents and entities predicted for any message you enter.
If you have trained a combined Rasa model but only want to see what your model extracts as intents and entities from text, you can use the command `rasa shell nlu`.
To increase the logging level for debugging, run:
```
rasa shell --debug
```
note
In order to see the typical greetings and/or session start behavior you might see in an external channel, you will need to explicitly send `/session_start` as the first message. Otherwise, the session start behavior will begin as described in [Session configuration](https://rasa.com/docs/docs/reference/config/domain/#session-configuration).
The following arguments can be used to configure the command. Most arguments overlap with `rasa run`; see the [following section](#rasa-run) for more info on those arguments.
Note that the `--connector` argument will always be set to `cmdline` when running `rasa shell`. This means all credentials in your credentials file will be ignored, and if you provide your own value for the `--connector` argument it will also be ignored.
Run `rasa shell --help` to see the full list of arguments.
##### rasa run[](#rasa-run "Direct link to rasa run")
To start a server running your trained model, run:
```
rasa run
```
By default the Rasa server uses HTTP for its communication. To secure the communication with SSL and run the server on HTTPS, you need to provide a valid certificate and the corresponding private key file. You can specify these files as part of the `rasa run` command. If you encrypted your keyfile with a password during creation, you need to add the `--ssl-password` as well.
```
rasa run --ssl-certificate myssl.crt --ssl-keyfile myssl.key --ssl-password mypassword
```
Rasa by default listens on each available network interface. You can limit this to a specific network interface using the `-i` command line option.
```
rasa run -i 192.168.69.150
```
Rasa will by default connect to all channels specified in your credentials file. To connect to a single channel and ignore all other channels in your credentials file, specify the name of the channel in the `--connector` argument.
```
rasa run --connector rest
```
The name of the channel should match the name you specify in your credentials file. For supported channels see [the page about messaging and voice channels](https://rasa.com/docs/docs/reference/channels/messaging-and-voice-channels/).
Run `rasa run --help` to see the full list of arguments.
For more information on important additional parameters, see [Model Storage](https://rasa.com/docs/docs/reference/integrations/model-storage/)
See the Rasa [REST API](https://rasa.com/docs/docs/reference/api/pro/rasa-pro-rest-api/) page for detailed documentation of all the endpoints.
##### rasa run actions[](#rasa-run-actions "Direct link to rasa run actions")
To start an action server with the Rasa SDK, run:
```
rasa run actions
```
Run `rasa run actions --help` to see the full list of arguments.
##### rasa visualize[](#rasa-visualize "Direct link to rasa visualize")
To generate a graph of your stories in the browser, run:
```
rasa visualize
```
If your stories are located somewhere other than the default location `data/`, you can specify their location with the `--stories` flag.
Run `rasa visualize --help` to see the full list of arguments.
##### rasa test e2e[](#rasa-test-e2e "Direct link to rasa test e2e")
v3.5
info
You can now use end-to-end testing to test your assistant as a whole, including dialogue management and custom actions.
To run [end-to-end testing](https://rasa.com/docs/docs/pro/testing/evaluating-assistant/) on your trained model, run:
```
rasa test e2e
```
This will test your latest trained model on any end-to-end test cases you have. If you want to use a different model, you can specify it using the `--model` flag.
info
By adding the `--coverage-report` flag you obtain a report describing how well your end-to-end tests cover the assistant's flows in terms of share of steps tested per flow. The report includes a histogram of tested commands and allows you to specify the output path with the `--coverage-output-path` flag.
This feature is currently released in a beta version. The feature might change in the future. If you want to enable this beta feature, set the environment variable `RASA_PRO_BETA_FINE_TUNING_RECIPE=true`.
New in 3.15.0
* You can now specify a custom output path for the end-to-end test results using the `-o` or `--e2e-results` flag.
* You can also now export failed end-to-end tests using the `-f` or `--e2e-failed-tests` flag. This also accepts an optional output path for the failed tests file. This file can then be used to re-run only the failed tests by passing it as an argument to the `rasa test e2e` command.
Here are some of the arguments available:
* positional argument for the path to the test cases file or directory containing the test cases: `rasa test e2e ` If unspecified, the default path is `tests/e2e_test_cases.yml`.
* optional argument for the trained model: `-model `
* optional argument for retrieving the trained model from [**remote storage**](https://rasa.com/docs/docs/reference/integrations/model-storage/#load-model-from-cloud): `-remote-storage `
* optional argument for the `endpoints.yml` file: `-endpoints `
* optional argument for stopping the test run at first failure: `rasa test e2e --fail-fast`
* optional argument for exporting the test results to `e2e_results.yml` file: `rasa test e2e -o` or `rasa test e2e -o `. When you specify the `-o` flag without an output path, the passed and failed test results yml files will be saved to the `tests/` subdirectory in the current working directory.
* optional argument for exporting failed tests to `e2e_failed_tests_{timestamp}.yml` file: `rasa test e2e -f` or `rasa test e2e -f `. When you specify the `-f` flag without an output path, the failed test file will be saved to the `tests/` subdirectory in the current working directory.
* optional argument for creating a coverage report: `rasa test e2e --coverage-report`
* optional argument for specifying the output directory for the coverage report: `rasa test e2e --coverage-output-path`
* you can optionally dump results to `stdout` or to a file (`o`), plus coverage details with `--coverage-report`.
Run `rasa test e2e --help` to see the full list of arguments.
##### rasa llm finetune prepare-data[](#rasa-llm-finetune-prepare-data "Direct link to rasa llm finetune prepare-data")
v3.10
info
This command is part of the [fine-tuning recipe](https://rasa.com/docs/docs/pro/customize/fine-tuning-llm/) available starting with version `3.10.0`. As this feature is a **beta** feature, please set the environment variable `RASA_PRO_BETA_FINETUNING_RECIPE` to `true` to enable it.
This command creates a dataset of prompt to commands pairs from E2E tests that can be used to [fine-tune a base model](https://rasa.com/docs/docs/pro/customize/fine-tuning-llm/) for the task of command generation. To execute the command run
```
rasa llm finetune prepare-data
```
Here are some of the arguments available:
```
positional arguments:
path-to-e2e-test-cases
Input file or folder containing end-to-end test cases. (default: e2e_tests)
options:
-o OUT, --out OUT The output folder to store the data to. (default: output)
-m MODEL, --model MODEL
Path to a trained Rasa model. If a directory is specified, it will use the latest model in this directory. (default: models)
Rephrasing Module:
--num-rephrases {0, ..., 49}
Number of rephrases to be generated per user utterance. (default: 10)
--rephrase-config REPHRASE_CONFIG
Path to config file that contains the configuration of the rephrasing module. (default: None)
Train/Test Split Module:
--train-frac TRAIN_FRAC
The amount of data that should go into the training dataset. The value should be >0.0 and <=1.0. (default: 0.8)
--output-format [{instruction,conversational}]
Format of the output file. (default: instruction)
```
Run `rasa finetune prepare-data --help` to see all available arguments.
##### Resulting file structure[](#resulting-file-structure "Direct link to Resulting file structure")
```
output/
├── 1_command_annotations/ # conversations extracted from your E2E tests
├── 2_rephrasings/ # same conversations + generated rephrasings
├── 3_llm_finetune_data/
│ └── llm_ft_data.jsonl # single JSONL file consumed by the fine-tuner
├── 4_train_test_split/
│ ├── e2e_tests/ # subsets of the original tests
│ │ ├── train.yaml # test cases that fall into the training split
│ │ └── validation.yaml # test cases that fall into the validation split
│ └── ft_splits/
│ ├── train.jsonl # training data for the LLM
│ └── test.jsonl # held-out evaluation data
├── params.yaml # run parameters
└── result_summary.yaml # short report of what was generated
```
##### rasa inspect[](#rasa-inspect "Direct link to rasa inspect")
v3.7
info
This command is part of Rasa's new Conversational AI with Language Models (CALM) approach and available starting with version `3.7.0`.
Opens the [Rasa Inspector](https://rasa.com/docs/docs/pro/testing/trying-assistant/), a debugging tool that offers developers an in-depth look into the conversational mechanics of their Rasa assistant.
Run `rasa inspect --help` to see the full list of arguments.
##### rasa data validate[](#rasa-data-validate "Direct link to rasa data validate")
You can check your domain, NLU data, flows or story data for mistakes and inconsistencies. To validate your data, run this command:
```
rasa data validate
```
The validator searches for errors in the data, e.g. two intents that have some identical training examples. The validator also checks if you have any stories where different assistant actions follow from the same dialogue history. Conflicts between stories will prevent a model from learning the correct pattern for a dialogue. To learn more about the checks performed by the validator on flows, continue reading in the [next section](https://rasa.com/docs/docs/reference/api/command-line-interface/#validate-flows).
Searching for the `assistant_id` key introduced in 3.5
The validator will check whether the `assistant_id` key is present in the config file and will issue a warning if this key is missing or if the default value has not been changed.
If you pass a `max_history` value to one or more policies in your `config.yml` file, provide the smallest of those values in the validator command using the `--max-history ` flag.
###### Validate flows[](#validate-flows "Direct link to Validate flows")
The validator will perform the following checks on flows:
* determine whether flow names or descriptions are unique after stripping punctuation
* verify whether logical expressions in [conditions](https://rasa.com/docs/docs/reference/primitives/conditions/) or `collect` step [rejections](https://rasa.com/docs/docs/reference/primitives/flow-steps/#slot-validation) are valid `pypred` expressions
* determine whether slots used in flows are defined in the domain
* disallow `list` slots from being used in flows `collect` steps: CALM supports only filling slots with values of type `int`, `string` or `bool` in flows.
* disallow `dialogue_stack` internal slot from being used in flows
* ensure that `bool` and `categorical` slots are validated against acceptable values in conditions
For every failure, the validator will log an error and exit the command with exit code 1.
You can validate flows only by running this command:
```
rasa data validate flows
```
##### rasa export[](#rasa-export "Direct link to rasa export")
To export events from a tracker store using an event broker, run:
```
rasa export
```
You can specify the location of the environments file, the minimum and maximum timestamps of events that should be published, as well as the conversation IDs that should be published. Run `rasa export --help` to see the full list of arguments.
##### rasa license[](#rasa-license "Direct link to rasa license")
v3.3
Use `rasa license` to display information about licensing in Rasa, especially information about 3rd party dependencies licenses.
Run `rasa license --help` to see the full list of arguments.
#### Rasa Studio Commands[](#rasa-studio-commands "Direct link to Rasa Studio Commands")
The CLI commands for Rasa Studio enable you to manage updates between your local project and changes made by your team in Studio.
1. Connect to a Studio Deployment: `rasa studio config`
2. Login and authenticate: `rasa studio login`
3. Upload or Download a full project: `rasa studio upload/download`
4. Link a specific assistant project: `rasa studio link `
5. Push and pull updates between Studio and your local project: `rasa studio push/pull`

##### rasa studio config[](#rasa-studio-config "Direct link to rasa studio config")
v3.7
info
This command is available from Rasa Pro 3.7.0 and requires Rasa Studio
This command prompts for parameters of Rasa Studio installation and configures rasa to target that Rasa Studio instance when executing `rasa studio` commands. Configuration is saved to: `$HOME/.config/rasa/global.yml`
The command will use default arguments for the configuration of the authentication server (realm name, client id and authentication url). If you want to use a different configuration, you can specify the parameters by running the command with `rasa studio config --advanced`.
The command will overwrite the existing configuration file with the new configuration.
Example:
```
rasa studio config
```
The command will use SSL strict verification by default to verify the connection to the Rasa Studio authentication server. If you want to skip the strict verification of this connection, you can use the `--disable-verify` or `-x` flag:
```
rasa studio config --disable-verify
```
Run `rasa studio config --help` to see the full list of arguments.
##### rasa studio login[](#rasa-studio-login "Direct link to rasa studio login")
v3.7
This command is used to retrieve the access token from Rasa Studio. All other studio commands use this token to authenticate with Rasa Studio. The token is saved to: `$HOME/.config/rasa/studio_token.yaml`
Example:
```
rasa studio login --username my_user_name --password my_password
```
Run `rasa studio login --help` to see the full list of arguments.
##### rasa studio upload[](#rasa-studio-upload "Direct link to rasa studio upload")
v3.13
new in 3.13
You can now upload and download a full project using the Rasa CLI as well as link a Studio project to a local project for easier syncing.
Uploads an assistant from local files to Rasa Studio.
###### Import of NLU-based assistants[](#import-of-nlu-based-assistants "Direct link to Import of NLU-based assistants")
For NLU-based assistants, it will upload the intent and entity definitions to Rasa Studio to an existing assistant in Rasa Studio. When arguments for specifying which intents or entities to upload are not given, all intents and entities get uploaded. When uploading an intent, all entities used in annotations of that intent's utterance examples are uploaded as well.
tip
At the moment, only some intents and entities can be uploaded to Studio. The following can't be uploaded:
* Retrieval intents
* Entities that have `entity_group`
* Intents with `use_entities` and `ignore_entities`
* Entities with `influence_conversation`
Example:
```
rasa studio upload
```
Run `rasa studio upload --help` to see the full list of arguments.
###### Possible errors[](#possible-errors "Direct link to Possible errors")
###### Assistant name errors[](#assistant-name-errors "Direct link to Assistant name errors")
These include the following:
* `Assistant with name already exists`
* ` is not a valid name`
A valid assistant name will not exceed the length of 128 characters and will not contain spaces.
###### Invalid YAML errors[](#invalid-yaml-errors "Direct link to Invalid YAML errors")
If something is wrong with the YAML files structure, a specific error will be logged. You will see these errors when, for example, a required field is missing for an action, slot, response, config or flow.
Examples:
```
Invalid domain: responses.utter_greeting.0.text: Required
Invalid flows: flows.transfer_money.description: Required
```
###### Reference errors[](#reference-errors "Direct link to Reference errors")
If a flow references a response, slot, action or another flow (with a `link` step), the following errors will be logged:
```
Can't find utter_ask_add_contact_handle in domain
Can't find flow in flows
```
###### Unsupported feature errors[](#unsupported-feature-errors "Direct link to Unsupported feature errors")
Not all the features available in Rasa Pro are supported by Rasa Studio. Trying to import an assistant with unsupported features will result in an error. To find out which versions of Studio support the version of Rasa Pro you are using, check the [compatibility matrix](https://rasa.com/docs/docs/reference/changelogs/compatibility-matrix/).
Examples:
```
Flows with cycles are not supported, flow:
Comparing two slots is not supported. Condition: slots.recurrent_payment_end_date < slots.recurrent_payment_start_date
Having multiple rejections on one slot is not supported, collect:
```
###### Authentication errors[](#authentication-errors "Direct link to Authentication errors")
User needs to be logged into Rasa Studio before uploading. Use the [`rasa studio login`](#rasa-studio-login) command.
##### rasa studio download[](#rasa-studio-download "Direct link to rasa studio download")
v3.13
This command downloads a specified assistant project from Rasa Studio and creates a folder using the assistant name.
The following data is supported:
* configuration
* endpoints
* custom prompts
* flows (for CALM assistants)
* responses
* slots
* custom action declarations
* intents
* entities
Example:
```
rasa studio download my_awesome_assistant
```
Creates a folder at `./my_awesome_assistant`
Run `rasa studio download --help` to see the full list of arguments.
##### rasa studio link[](#rasa-studio-link "Direct link to rasa studio link")
v3.13
Links your local assistant to a project in Rasa Studio. You can specify the assistant name as an argument:
```
rasa studio link my_assistant_name
```
Once linked, all subsequent commands (like `download`, `upload`, `pull`, and `push`) will refer to this assistant.
##### rasa studio pull[](#rasa-studio-pull "Direct link to rasa studio pull")
v3.13
Pulls the latest changes from your Rasa Studio assistant into your local project.
You can either pull the entire assistant:
```
rasa studio pull
```
Or pull a specific section (e.g., just the configuration or endpoints):
```
rasa studio pull config
```
Current supported sections include: `config`, `endpoints`.
##### rasa studio push[](#rasa-studio-push "Direct link to rasa studio push")
v3.13
Pushes the latest changes from your local project to your Rasa Studio assistant.
You can either push everything:
```
rasa studio upload
```
Or push a specific section:
```
rasa studio push config
```
Supported sections include: `config`, `endpoints`.
#### Legacy commands[](#legacy-commands "Direct link to Legacy commands")
##### rasa studio upload[](#rasa-studio-upload-1 "Direct link to rasa studio upload")
v3.7
Uploads an assistant from local files to Rasa Studio.
###### Import of NLU-based assistants[](#import-of-nlu-based-assistants-1 "Direct link to Import of NLU-based assistants")
For NLU-based assistants, it will upload the intent and entity definitions to Rasa Studio to an existing assistant in Rasa Studio. When arguments for specifying which intents or entities to upload are not given, all intents and entities get uploaded. When uploading an intent, all entities used in annotations of that intent's utterance examples are uploaded as well.
tip
At the moment, only some intents and entities can be uploaded to Studio. The following can't be uploaded:
* Retrieval intents
* Entities that have `entity_group`
* Intents with `use_entities` and `ignore_entities`
* Entities with `influence_conversation`
Example:
```
rasa studio upload
```
Run `rasa studio upload --help` to see the full list of arguments.
###### Import of CALM assistants[](#import-of-calm-assistants "Direct link to Import of CALM assistants")
To upload a CALM assistant to Rasa Studio, run this command with `--calm` flag.
Important!
* When uploading a CALM assistant, a new Rasa Studio assistant with specified name will be created. This is different from the NLU-based assistant upload, which will reuse an existing Rasa Studio assistant.
* During CALM upload, we also upload `config` and `endpoints` that can be edited in the UI.
Example:
```
rasa studio upload --calm
```
##### rasa studio download[](#rasa-studio-download-1 "Direct link to rasa studio download")
v3.7
This command downloads the data from Rasa Studio and saves it to files inside `data` folder. If local files use a single domain file, it is updated accordingly. If there is a domain folder instead, domain changes are written to `/studio_domain.yml`.
The command downloads Studio data that is available in Studio but not in local files. The following data is supported:
* configuration
* endpoints
* custom prompts
* flows (for CALM assistants)
* responses
* slots
* custom action declarations
* intents
* entities
The `--overwrite` flag can be used to overwrite the existing data in the existing files when a primitive has the same ID as the one downloaded from Rasa Studio. Special cases:
* If an intent exists in local files, but Studio has examples missing locally, they will be downloaded.
* If local `config` and `endpoints` files exist during the download of a CALM assistant, the user needs to confirm their intent to overwrite them, even when the `--overwrite` flag is provided.
Example:
```
rasa studio download my_awesome_assistant -d my_domain_folder
```
Run `rasa studio download --help` to see the full list of arguments.
##### rasa studio train[](#rasa-studio-train "Direct link to rasa studio train")
v3.7
This command is analogous to `rasa train`. This command combines data from local files and Rasa Studio to train a model. In case both Studio and local files have a primitive]\(../primitives/index.mdx) with the same ID, local one is used for training.
Example:
```
rasa studio train my_awesome_assistant -d my_domain_folder
```
Run `rasa studio train --help` to see the full list of arguments.
##### Other[](#other "Direct link to Other")
For a full list of legacy commands, please head over to [this reference](https://legacy-docs-oss.rasa.com/docs/rasa/command-line-interface/).
---
#### Conversation API
#### Introduction[](#introduction "Direct link to Introduction")
The Conversation API allows external access to delete and tag conversations within Rasa Studio.
#### Requirements[](#requirements "Direct link to Requirements")
* Required API Role `Manage Conversations`. See [Authorization page](https://rasa.com/docs/docs/studio/security/authorization/#creating-a-new-client-id) to learn how to access configuration.
* Assistant API ID. See [guide for user configuration](https://rasa.com/docs/docs/studio/build/set-up-your-assistant/) for more details.
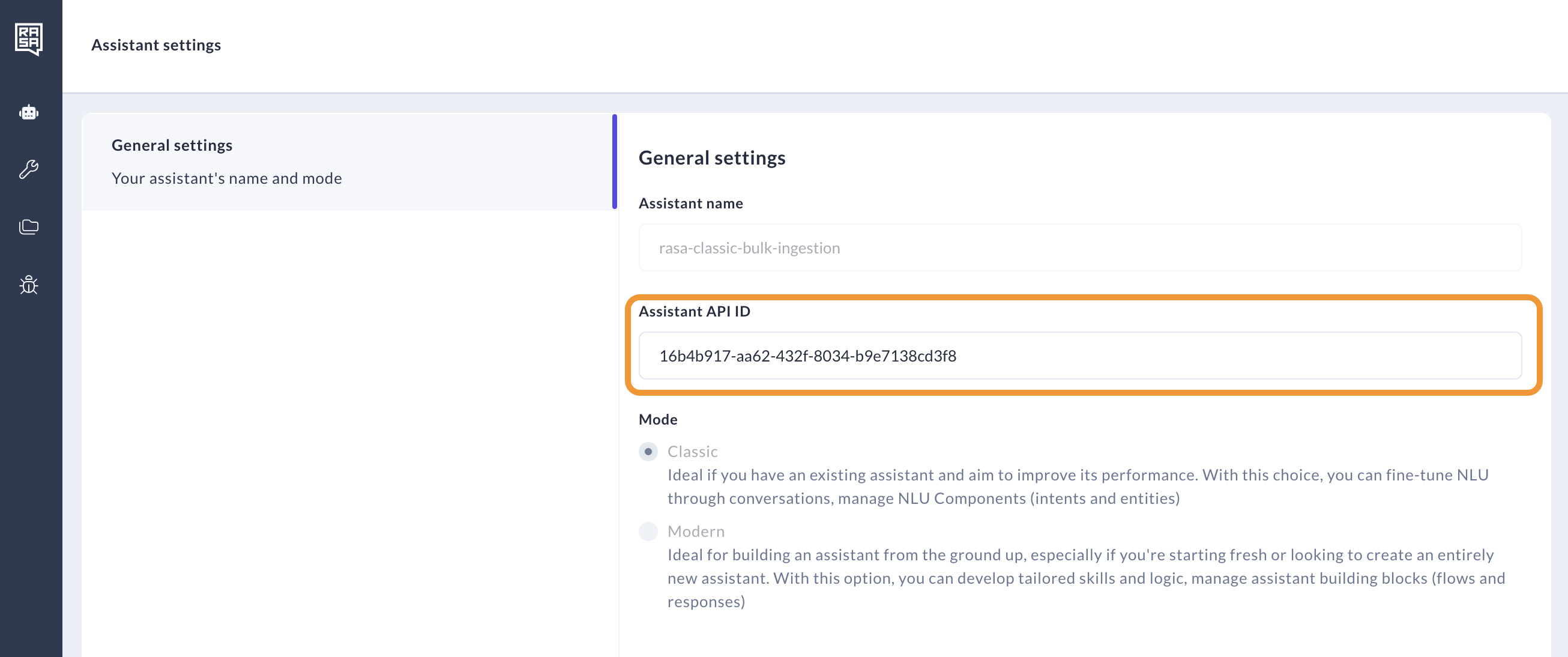
* Tag IDs. To see how to access page from screenshot see [guide for conversation review](https://rasa.com/docs/docs/studio/analyze/conversation-review/).
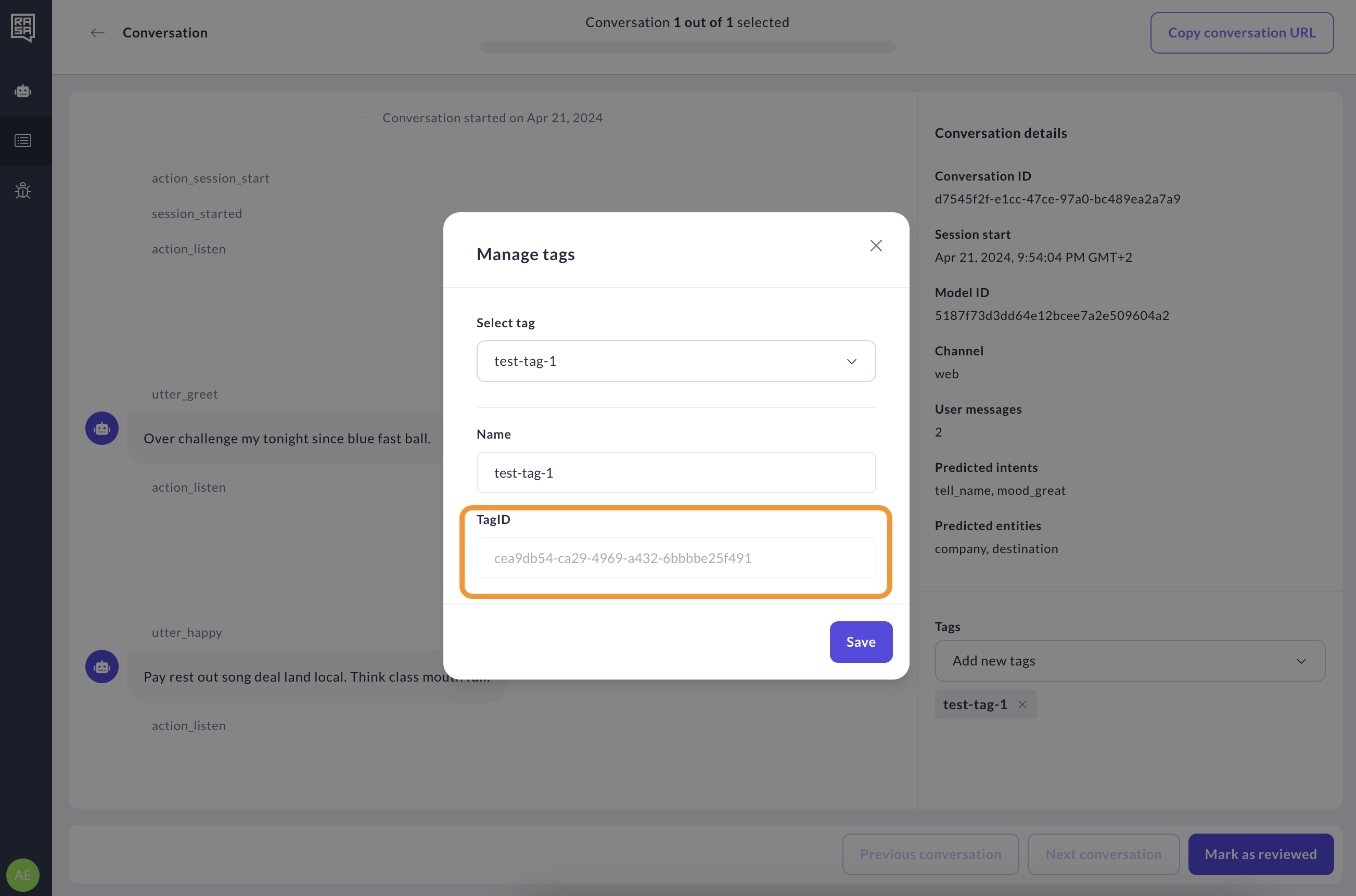
#### Available APIs[](#available-apis "Direct link to Available APIs")
##### Query: `rawConversations`[](#query-rawconversations "Direct link to query-rawconversations")
**Schema:**
```
type Query {
rawConversations(input: RawConversationsInput!): RawConversationsOutput!
}
input RawConversationsInput {
assistantId: ID!
fromTime: String
toTime: String
limit: Int
offset: Int
}
type RawConversation {
id: ID!
conversationEvents: [JSON!]!
}
type RawConversationsOutput {
conversations: [RawConversation!]!
count: Int!
}
```
###### Input: `RawConversationsInput`[](#input-rawconversationsinput "Direct link to input-rawconversationsinput")
| Field | Description |
| ------------- | -------------------------------------------------------------------------------------------------------------- |
| `assistantId` | The unique identifier of the assistant. |
| `fromTime` | Optional start time filter for the conversation retrieval in ISO 8601 UTC format (`YYYY-MM-DDTHH:MM:SS.sssZ`). |
| `toTime` | Optional end time filter for the conversation retrieval in ISO 8601 UTC format (`YYYY-MM-DDTHH:MM:SS.sssZ`). |
| `limit` | Limits the number of conversations returned. Default is `10`. |
| `offset` | Skips a specified number of conversations for pagination. Default is `0`. |
###### Output: `RawConversationsOutput`[](#output-rawconversationsoutput "Direct link to output-rawconversationsoutput")
| Field | Description |
| --------------- | ------------------------------------------------------------------------------------------------------------------------- |
| `conversations` | A list of raw conversation objects. Each conversation contains an `id` and a list of `conversationEvents` in JSON format. |
| `count` | Total count of conversations matching the query criteria. Count is not affected by paging arguments `limit` and `offset`. |
##### JSON Structure for `conversationEvents`[](#json-structure-for-conversationevents "Direct link to json-structure-for-conversationevents")
The `conversationEvents` field contains a list of events that occur within a conversation. These events follow a specific structure that can vary depending on the type of event. For a full description of all possible events, please refer to the [Rasa Events Documentation](https://rasa.com/docs/docs/reference/primitives/events/).
Here are a few examples:
###### Example 1: User Uttered Event[](#example-1-user-uttered-event "Direct link to Example 1: User Uttered Event")
```
{
"sender_id": "f9e5db46255c42e8aefd7fce720d192f",
"event": "user",
"timestamp": 1692186822.4774666,
"metadata": {
"model_id": "003d55f2a67147a597cec7e1df3e96e9",
"assistant_id": "rich-response-rasa"
},
"text": "/mood_great",
"parse_data": {
"intent": {
"name": "mood_great",
"confidence": 1
},
"entities": [],
"text": "/mood_great",
"message_id": "7457d2d8174243409e39b165164c79c7",
"metadata": {},
"intent_ranking": [
{
"name": "mood_great",
"confidence": 1
}
]
},
"input_channel": "cmdline",
"message_id": "7457d2d8174243409e39b165164c79c7"
}
```
###### Example 2: Bot Uttered Event[](#example-2-bot-uttered-event "Direct link to Example 2: Bot Uttered Event")
```
{
"sender_id": "f9e5db46255c42e8aefd7fce720d192f",
"event": "bot",
"timestamp": 1692186813.6298656,
"metadata": {
"utter_action": "utter_greet",
"model_id": "003d55f2a67147a597cec7e1df3e96e9",
"assistant_id": "rich-response-rasa"
},
"text": "Hey! How are you?",
"data": {
"elements": null,
"quick_replies": [
{
"title": "great",
"payload": "/mood_great"
},
{
"title": "super sad",
"payload": "/mood_unhappy",
"image_url": "https://i.imgur.com/l4pF9Fb.jpg"
}
],
"buttons": [
{
"title": "great",
"payload": "/mood_great"
},
{
"title": "super sad",
"payload": "/mood_unhappy",
"image_url": "https://i.imgur.com/l4pF9Fb.jpg"
}
],
"attachment": null,
"image": null,
"custom": null
}
}
```
###### Example 3: Action Executed Event[](#example-3-action-executed-event "Direct link to Example 3: Action Executed Event")
```
{
"sender_id": "f9e5db46255c42e8aefd7fce720d192f",
"event": "action",
"timestamp": 1692186813.2051082,
"metadata": {
"model_id": "003d55f2a67147a597cec7e1df3e96e9",
"assistant_id": "rich-response-rasa"
},
"name": "action_session_start",
"policy": null,
"confidence": 1,
"action_text": null,
"hide_rule_turn": false
}
```
##### Example `curl` Request[](#example-curl-request "Direct link to example-curl-request")
Here's an example cURL request to the `rawConversations` endpoint:
```
curl -X POST https:///api/graphql \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d '{"query": "query rawConversations($input: RawConversationsInput!) { rawConversations(input: $input) { conversations { id, conversationEvents }, count } }", "variables": { "input": { "assistantId": "12345", "fromTime": "2024-01-01T00:00:00Z", "toTime": "2024-01-31T23:59:59Z", "limit": 10, "offset": 0 } }}'
```
##### Mutation: `addConversationTagToConversation`[](#mutation-addconversationtagtoconversation "Direct link to mutation-addconversationtagtoconversation")
**Schema:**
```
type Mutation {
addConversationTagToConversation(
input: AddConversationTagToConversationInput!
): Boolean!
}
input AddConversationTagToConversationInput {
conversationId: ID!
tagId: ID!
}
```
###### Input: `AddConversationTagToConversationInput`[](#input-addconversationtagtoconversationinput "Direct link to input-addconversationtagtoconversationinput")
| Field | Description |
| ---------------- | ------------------------------------------------------------------------- |
| `conversationId` | The unique identifier of the conversation to which the tag will be added. |
| `tagId` | The unique identifier of the tag to be added to the conversation. |
###### Output[](#output "Direct link to Output")
Returns `true` if the tag was successfully added.
**Note**: If the tag already exists, the endpoint will also return true. If a non-existent conversation, tag, or resource mismatch occurs, a descriptive error message with an appropriate error code is returned.
##### Example `curl` Request[](#example-curl-request-1 "Direct link to example-curl-request-1")
```
curl -X POST https:///api/graphql \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d '{"query": "mutation addConversationTagToConversation($input: AddConversationTagToConversationInput!) { addConversationTagToConversation(input: $input) }", "variables": { "input": { "conversationId": "12345", "tagId": "67890" } }}'
```
##### Mutation: `removeConversationTagFromConversation`[](#mutation-removeconversationtagfromconversation "Direct link to mutation-removeconversationtagfromconversation")
**Schema:**
```
type Mutation {
removeConversationTagFromConversation(
input: RemoveConversationTagFromConversationInput!
): Boolean!
}
input RemoveConversationTagFromConversationInput {
conversationId: ID!
tagId: ID!
}
```
###### Input: `RemoveConversationTagFromConversationInput`[](#input-removeconversationtagfromconversationinput "Direct link to input-removeconversationtagfromconversationinput")
| Field | Description |
| ---------------- | --------------------------------------------------------------------------- |
| `conversationId` | Unique identifier of the conversation from which the tag should be removed. |
| `tagId` | Unique identifier of the tag to be removed from the conversation. |
###### Output[](#output-1 "Direct link to Output")
Returns `true` if the tag was successfully removed.
**Note**: If the provided `tagId` is not linked to the `conversationId`, or if the provided `conversationId` or `tagId` is not present in the system, the endpoint will still return `true`.
##### Example `curl` Request[](#example-curl-request-2 "Direct link to example-curl-request-2")
```
curl -X POST https:///api/graphql \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d '{"query": "mutation removeConversationTagFromConversation($input: RemoveConversationTagFromConversationInput!) { removeConversationTagFromConversation(input: $input) }", "variables": { "input": { "conversationId": "12345", "tagId": "67890" } }}'
```
##### Mutation: `deleteConversations`[](#mutation-deleteconversations "Direct link to mutation-deleteconversations")
**Schema:**
```
type Mutation {
deleteConversations(input: DeleteConversationsInput!): Int!
}
input DeleteConversationsInput {
conversationIds: [ID!]!
}
```
###### Input: `DeleteConversationsInput`[](#input-deleteconversationsinput "Direct link to input-deleteconversationsinput")
| Field | Description |
| ----------------- | --------------------------------------- |
| `conversationIds` | List of conversation IDs to be deleted. |
###### Output[](#output-2 "Direct link to Output")
Returns the count of deleted conversations.
**Note**: `Count` only counts conversations that were actually deleted. If all IDs passed to API were invalid `count` will be zero.
##### Example `curl` Request[](#example-curl-request-3 "Direct link to example-curl-request-3")
```
curl -X POST https:///api/graphql \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d '{"query": "mutation deleteConversations($input: DeleteConversationsInput!) { deleteConversations(input: $input) }", "variables": { "input": { "conversationIds": ["12345"] } }}'
```
---
#### Enabling the Rasa REST API
Looking for API endpoints?
Check out the [API Spec](https://rasa.com/docs/docs/reference/api/pro/http-api/) for all of the available endpoints as well as their request and response formats.
#### Enabling the REST API[](#enabling-the-rest-api "Direct link to Enabling the REST API")
By default, running a Rasa server does not enable the API endpoints. Interactions with the bot can happen over the exposed `webhooks//webhook` endpoints.
To enable the API for direct interaction with conversation trackers and other bot endpoints, add the `--enable-api` parameter to your run command:
```
rasa run --enable-api
```
Note that you start the server with an NLU-only model, not all the available endpoints can be called. Some endpoints will return a 409 status code, as a trained dialogue model is needed to process the request.
caution
Make sure to secure your server, either by restricting access to the server (e.g. using firewalls), or by enabling an authentication method. See [Security Considerations](#security-considerations).
By default, the HTTP server runs as a single process. You can change the number of worker processes using the `SANIC_WORKERS` environment variable. It is recommended that you set the number of workers to the number of available CPU cores (check out the [Sanic docs](https://sanicframework.org/en/guide/deployment/running.html#workers) for more details). This will only work in combination with the `RedisLockStore` (see [Lock Stores](https://rasa.com/docs/docs/reference/integrations/lock-stores/).
caution
The [SocketIO channel](https://rasa.com/docs/docs/reference/channels/your-own-website/#socketio-channel) does not support multiple worker processes.
#### Security Considerations[](#security-considerations "Direct link to Security Considerations")
We recommend that you don't expose the Rasa Server to the outside world directly, but rather connect to it via e.g. Nginx.
Nevertheless, there are two authentication methods built in:
##### Token Based Auth[](#token-based-auth "Direct link to Token Based Auth")
To use a plaintext token to secure your server, specify the token in the argument `--auth-token thisismysecret` when starting the server:
```
rasa run \
--enable-api \
--auth-token thisismysecret
```
You can also use environment variable `AUTH_TOKEN` to set the auth token:
```
AUTH_TOKEN=thisismysecret
```
Security best practice
We recommend that you use environment variables to store and share sensitive information such as tokens and secrets when deploying Rasa as Docker container as they will not be stored in your shell history.
Any clients sending requests to the server must pass the token as a query parameter, or the request will be rejected. For example, to fetch a tracker from the server:
```
curl -XGET localhost:5005/conversations/default/tracker?token=thisismysecret
```
##### JWT Based Auth[](#jwt-based-auth "Direct link to JWT Based Auth")
To use JWT based authentication, specify the JWT secret in the argument `--jwt-secret thisismysecret` on startup of the server:
```
rasa run \
--enable-api \
--jwt-secret thisismysecret
```
You can also use environment variable `JWT_SECRET` to set the JWT secret:
```
JWT_SECRET=thisismysecret
```
Security best practice
We recommend that you use environment variables to store and share sensitive information such as tokens and secrets when deploying Rasa as Docker container as they will not be stored in your shell history.
If you want to sign a JWT token with asymmetric algorithms, you can specify the JWT private key to the `--jwt-private-key` CLI argument. You must pass the public key to the `--jwt-secret` argument, and also specify the algorithm to the `--jwt-method` argument:
```
rasa run \
--enable-api \
--jwt-secret \
--jwt-private-key \
--jwt-method RS512
```
You can also use environment variables to configure JWT:
```
JWT_SECRET=
JWT_PRIVATE_KEY=
JWT_METHOD=RS512
```
Security best practice
We recommend that you use environment variables to store and share sensitive information such as tokens and secrets when deploying Rasa as Docker container as they will not be stored in your shell history.
Client requests to the server will need to contain a valid JWT token in the `Authorization` header that is signed using this secret and the `HS256` algorithm e.g.
```
"Authorization": "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ"
"zdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIi"
"wiaWF0IjoxNTE2MjM5MDIyfQ.qdrr2_a7Sd80gmCWjnDomO"
"Gl8eZFVfKXA6jhncgRn-I"
```
The token's payload must contain an object under the `user` key, which in turn must contain the `username` and `role` attributes. The following is an example payload for a JWT token:
```
{
"user": {
"username": "",
"role": "user"
}
}
```
If the `role` is `admin`, all endpoints are accessible. If the `role` is `user`, endpoints with a `sender_id` parameter are only accessible if the `sender_id` matches the payload's `username` property.
```
rasa run \
-m models \
--enable-api \
--jwt-secret thisismysecret
```
To create and encode the token, you can use tools such as the [JWT Debugger](https://jwt.io/), or a Python module such as [PyJWT](https://pyjwt.readthedocs.io/en/latest/).
---
#### Model Download API for CI Integration
#### Introduction[](#introduction "Direct link to Introduction")
The Model Download API provides external access to retrieve download URLs for artifacts generated in Rasa Studio, facilitating CI/CD integration. Built with GraphQL, this API allows queries to request trained assistant models and associated input data in YAML format.
#### Requirements[](#requirements "Direct link to Requirements")
* Required API Role `Model download urls`. See [Authorization](https://rasa.com/docs/docs/reference/api/studio/api-authorization/) to learn how to get an access token.
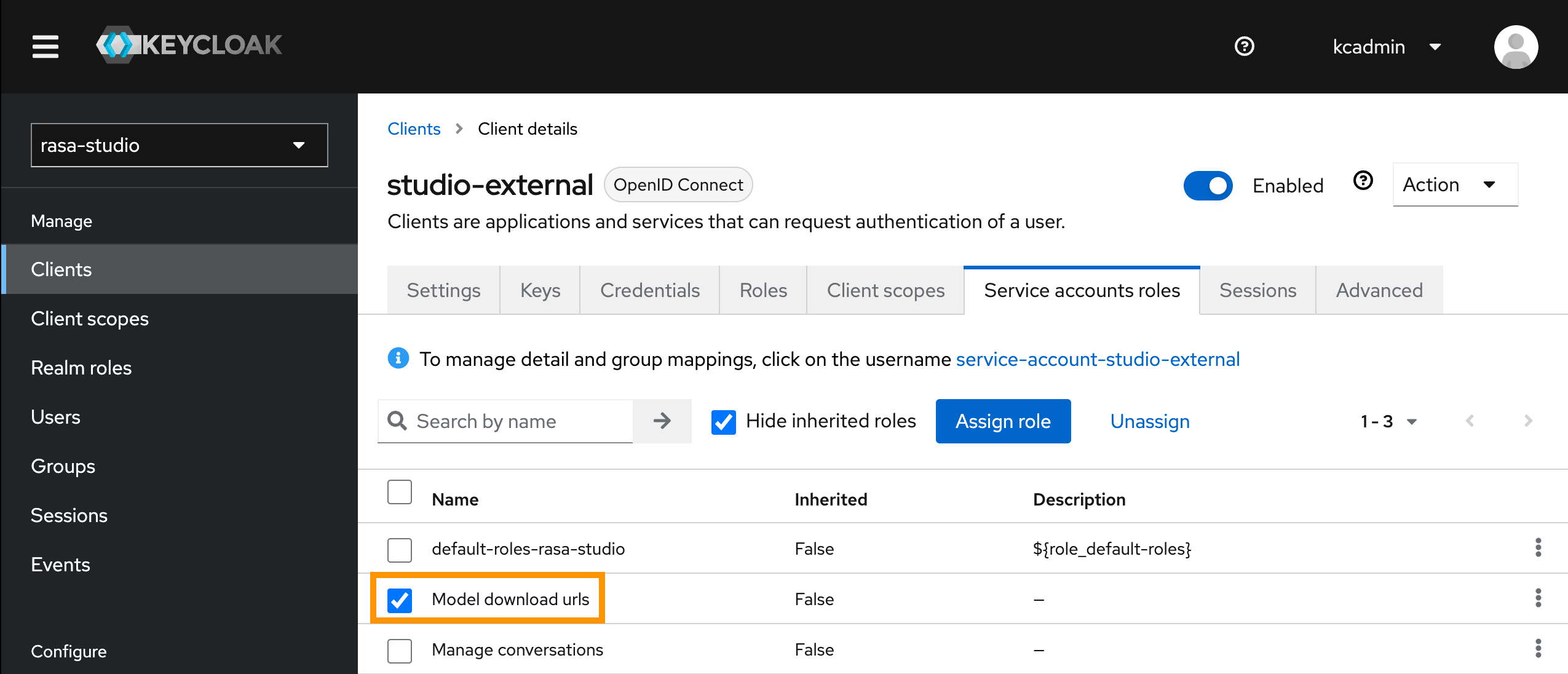
* Assistant API ID. See [authorization guide for configuration](https://rasa.com/docs/docs/studio/installation/setup-guides/authorization-guide/) for more details.
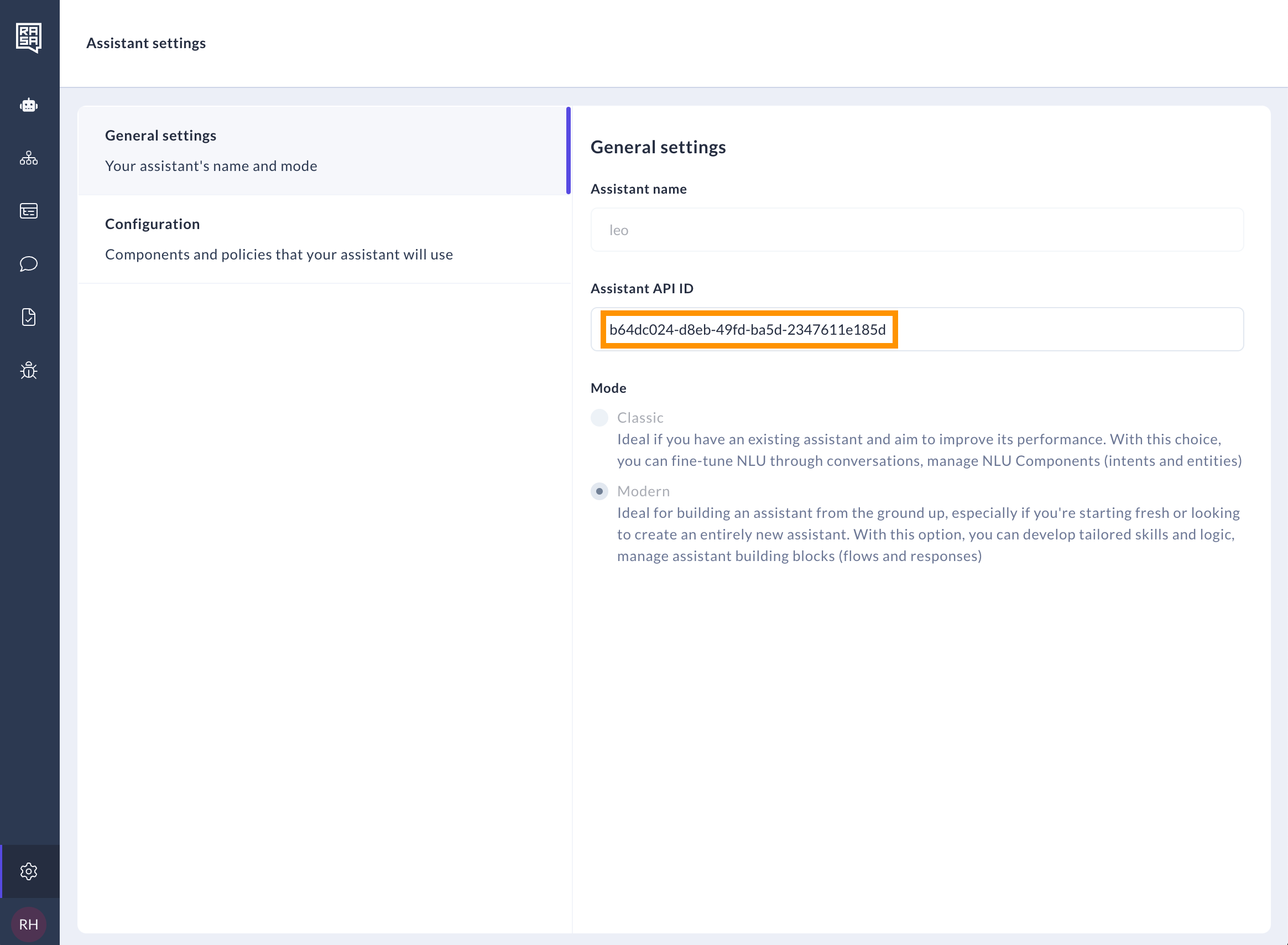
* Assistant Version Name. See [user guide for training](https://rasa.com/docs/docs/studio/test/train-your-assistant/) for more details.
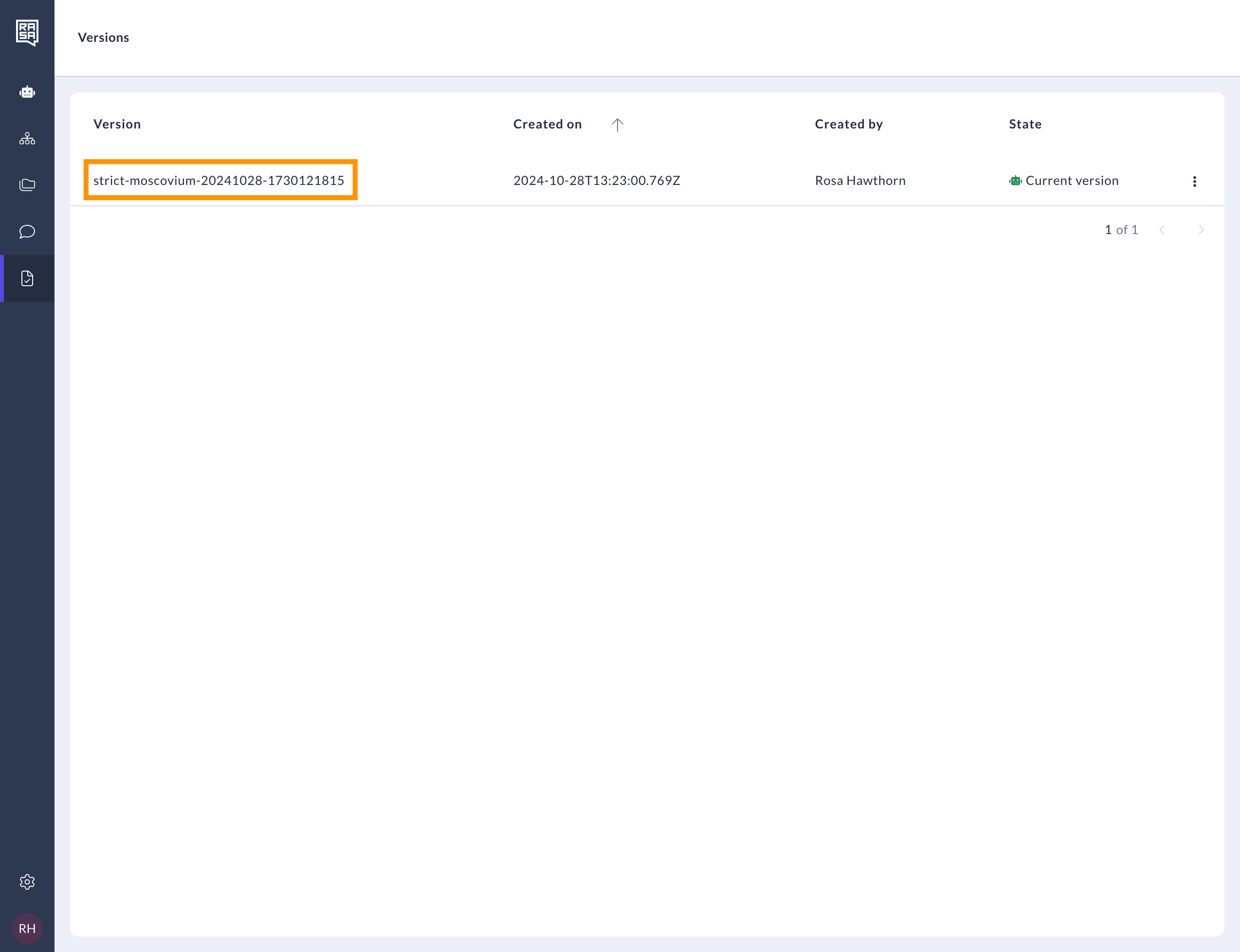
#### Available APIs[](#available-apis "Direct link to Available APIs")
##### Query: `ModelDownloadUrls`[](#query-modeldownloadurls "Direct link to query-modeldownloadurls")
**Schema:**
```
type Query {
modelDownloadUrls(input: ModelDownloadUrlsInput!): ModelDownloadUrlsOutput!
}
input ModelDownloadUrlsInput {
assistantId: ID!
assistantVersionName: ID
}
type ModelDownloadUrlsOutput {
modelFileUrl: String!
modelInputUrl: String!
}
```
###### Input: `ModelDownloadUrlsInput`[](#input-modeldownloadurlsinput "Direct link to input-modeldownloadurlsinput")
| Field | Description |
| ---------------------- | --------------------------------------------------------------- |
| `assistantId` | Unique identifier of the assistant. |
| `assistantVersionName` | Optional version of the trained assistant. Default is `latest`. |
###### Output: `ModelDownloadUrlsOutput`[](#output-modeldownloadurlsoutput "Direct link to output-modeldownloadurlsoutput")
| Field | Description |
| --------------- | ----------------------------------------------------------------- |
| `modelFileUrl` | Url to download the model file `.tar.gz`. |
| `modelInputUrl` | Url to download the model input data in YAML format. |
#### Usage[](#usage "Direct link to Usage")
The query can be used to fetch the download URLs for the trained model and the input data in YAML format for a assistant.
##### Example `curl` Request[](#example-curl-request "Direct link to example-curl-request")
Request the Model Download API using e.g. `curl`:
```
curl -X POST https:///api/graphql \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d '{
"query": "query ModelDownloadUrls($input: ModelDownloadUrlsInput!) { modelDownloadUrls(input: $input) { modelFileUrl modelInputUrl } }",
"variables": {
"input": {
"assistantId": "",
"assistantVersionName": ""
}
}
}'
```
##### Example Response[](#example-response "Direct link to Example Response")
The response will contain the download URLs for the trained model and the model input data.
```
{"data":
{"modelDownloadUrls":
{
"modelFileUrl":"https:///api/v1/download/model-file/",
"modelInputUrl":"https:///api/v1/download/model-input/"
}
}
}
```
##### Download model file[](#download-model-file "Direct link to Download model file")
To download the model file, request the `modelFileUrl` with authorization header.
```
curl "https:///api/v1/download/model-file/" \
-H "Authorization: Bearer " \
-O -J
```
The downloaded model file `.tar.gz` can be used to deploy the trained model.
##### Download model input data[](#download-model-input-data "Direct link to Download model input data")
To download the model input YAML files, request the `modelInputUrl` with authorization header.
```
curl "https:///api/v1/download/model-input/" \
-H "Authorization: Bearer " \
-O -J
```
The downloaded model input zipped directory `_model-input.tar.gz` contains the model input data in YAML format:
* `data/flows.yaml`
* `data/nlu.yaml`
* `config.yaml`
* `credentials.yaml`
* `domain.yaml`
* `endpoints.yaml`
---
#### Rasa Action Server HTTP API
Search...
* postCore request to execute a custom action
[API docs by Redocly](https://redocly.com/redoc/)
### Rasa SDK - Action Server Endpoint (0.0.0)
Download OpenAPI specification:[Download](https://rasa.com/docs/redocusaurus/action-server.yaml)
HTTP API of the action server which is used by Rasa to execute custom actions.
#### [](#operation/call_action)Core request to execute a custom action
Rasa Core sends a request to the action server to execute a certain custom action. As a response to the action call from Core, you can modify the tracker, e.g. by setting slots and send responses back to the user.
###### Request Body schema: application/jsonrequired
Describes the action to be called and provides information on the current state of the conversation.
| | |
| ------------ | ----------------------------------------------------------------------------------------- |
| next\_action | stringThe name of the action which should be executed. |
| sender\_id | stringUnique id of the user who is having the current conversation. |
| tracker | object (Tracker)Conversation tracker which stores the conversation state. |
| domain | object (Domain)The bot's domain. |
##### Responses
**200**
Action was executed succesfully.
**400**
Action execution was rejected. This is the same as returning an `ActionExecutionRejected` event.
**500**
The action server encountered an exception while running the action.
post/
Local development action server
http://localhost:5055/webhook/
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"next_action": "string",
"sender_id": "string",
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
},
"domain": {
"config": {
"store_entities_as_slots": false
},
"intents": [
{
"property1": {
"use_entities": true
},
"property2": {
"use_entities": true
}
}
],
"entities": [
"person",
"location"
],
"slots": {
"property1": {
"auto_fill": true,
"initial_value": "string",
"type": "string",
"values": [
"string"
]
},
"property2": {
"auto_fill": true,
"initial_value": "string",
"type": "string",
"values": [
"string"
]
}
},
"responses": {
"property1": {
"text": "string"
},
"property2": {
"text": "string"
}
},
"actions": [
"action_greet",
"action_goodbye",
"action_listen"
]
}
}`
##### Response samples
* 200
* 400
Content type
application/json
Copy
Expand all Collapse all
`{
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"responses": [
{
"text": "string"
}
]
}`
---
#### Rasa Pro REST API
Search...
* Server Information
* getHealth endpoint of Rasa Server
* getInformation about your Rasa Pro License
* getVersion of Rasa
* getStatus of the Rasa server
* Tracker
* getRetrieve a conversations tracker
* delDelete tracker for a specific conversation
* postAppend events to a tracker
* putReplace a trackers events
* getRetrieve an end-to-end story corresponding to a conversation
* postRun an action in a conversation
* postInject an intent into a conversation
* postPredict the next action
* postAdd a message to a tracker
* Model
* postTrain a Rasa model
* postEvaluate stories
* postPerform an intent evaluation
* postPredict an action on a temporary state
* postParse a message using the Rasa model
* putReplace the currently loaded model
* delUnload the trained model
* Flows
* getRetrieve the flows of the assistant
* Domain
* getRetrieve the loaded domain
* Channel Webhooks
* postPost user message from a REST channel
* postPost user message from a custom channel
[API docs by Redocly](https://redocly.com/redoc/)
### Rasa - Server Endpoints (1.0.0)
Download OpenAPI specification:[Download](https://rasa.com/docs/redocusaurus/pro.yaml)
The Rasa server provides endpoints to retrieve trackers of conversations as well as endpoints to modify them. Additionally, endpoints for training and testing models are provided.
#### [](#tag/Server-Information)Server Information
#### [](#tag/Server-Information/operation/getHealth)Health endpoint of Rasa Server
This URL can be used as an endpoint to run health checks against. When the server is running this will return 200.
##### Responses
**200**
Up and running
get/
Local development server
http://localhost:5005/
##### Response samples
* 200
Content type
text/plain
Copy
```
Hello from Rasa: 1.0.0
```
#### [](#tag/Server-Information/operation/getLicense)Information about your Rasa Pro License
Returns the license information about your Rasa Pro License
##### Responses
**200**
Rasa Pro License Information
get/license
Local development server
http://localhost:5005/license
##### Response samples
* 200
Content type
application/json
Copy
`{
"id": "u5fn8888-e213-4c12-9542-0baslfdkjas",
"company": "acme",
"scope": "rasa:pro rasa:voice",
"email": "acme@email.com",
"expires": "2026-01-01T00:00:00+00:00"
}`
#### [](#tag/Server-Information/operation/getVersion)Version of Rasa
Returns the version of Rasa.
##### Responses
**200**
Version of Rasa
get/version
Local development server
http://localhost:5005/version
##### Response samples
* 200
Content type
application/json
Copy
`{
"version": "1.0.0",
"minimum_compatible_version": "1.0.0"
}`
#### [](#tag/Server-Information/operation/getStatus)Status of the Rasa server
Information about the server and the currently loaded Rasa model.
###### Authorizations:
*TokenAuth\*\*JWT*
##### Responses
**200**
Success
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
get/status
Local development server
http://localhost:5005/status
##### Response samples
* 200
* 401
* 403
* 409
Content type
application/json
Copy
`{
"model_id": "75a985b7b86d442ca013d61ea4781b22",
"model_file": "20190429-103105.tar.gz",
"num_active_training_jobs": 2
}`
#### [](#tag/Tracker)Tracker
#### [](#tag/Tracker/operation/getConversationTracker)Retrieve a conversations tracker
The tracker represents the state of the conversation. The state of the tracker is created by applying a sequence of events, which modify the state. These events can optionally be included in the response.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
| until | numberDefault:"None"Example:until=1559744410All events previous to the passed timestamp will be replayed. Events that occur exactly at the target time will be included. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
get/conversations/{conversation\_id}/tracker
Local development server
http://localhost:5005/conversations/{conversation\_id}/tracker
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}`
#### [](#tag/Tracker/operation/deleteConversationTracker)Delete tracker for a specific conversation
Deletes the tracker of a conversation.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
##### Responses
**204**
Tracker successfully deleted.
**401**
User is not authenticated.
**403**
User has insufficient permission.
**404**
Conversation not found.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
delete/conversations/{conversation\_id}/tracker
Local development server
http://localhost:5005/conversations/{conversation\_id}/tracker
##### Response samples
* 401
* 403
* 409
* 500
Content type
application/json
Copy
`{
"version": "1.0.0",
"status": "failure",
"reason": "NotAuthenticated",
"message": "User is not authenticated to access resource.",
"code": 401
}`
#### [](#tag/Tracker/operation/addConversationTrackerEvents)Append events to a tracker
Appends one or multiple new events to the tracker state of the conversation. Any existing events will be kept and the new events will be appended, updating the existing state. If events are appended to a new conversation ID, the tracker will be initialised with a new session.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| ---------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
| output\_channel | stringEnum: "latest" "slack" "callback" "facebook" "rocketchat" "telegram" "twilio" "webexteams" "socketio"Example:output\_channel=slackThe bot's utterances will be forwarded to this channel. It uses the credentials listed in `credentials.yml` to connect. In case the channel does not support this, the utterances will be returned in the response body. Use `latest` to try to send the messages to the latest channel the user used. Currently supported channels are listed in the permitted values for the parameter. |
| execute\_side\_effects | booleanDefault:falseIf `true`, any `BotUttered` event will be forwarded to the channel specified in the `output_channel` parameter. Any `ReminderScheduled` or `ReminderCancelled` event will also be processed. |
###### Request Body schema: application/jsonrequired
One of
EventEventList
Any of
UserEventBotEventSessionStartedEventActionEventSlotEventResetSlotsEventRestartEventReminderEventCancelReminderEventPauseEventResumeEventFollowupEventExportEventUndoEventRewindEventAgentEventEntitiesAddedEventUserFeaturizationEventActionExecutionRejectedEventFormValidationEventLoopInterruptedEventFormEventActiveLoopEvent
| | |
| -------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| eventrequired | stringValue: "user"Event name |
| timestamp | integerTime of application |
| metadata | object |
| text | string or nullText of user message. |
| input\_channel | string or null |
| message\_id | string or null |
| parse\_data | object (ParseResult)NLU parser information. If set, message will not be passed through NLU, but instead this parsing information will be used. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/tracker/events
Local development server
http://localhost:5005/conversations/{conversation\_id}/tracker/events
##### Request samples
* Payload
Content type
application/json
Example
EventEvent
Copy
Expand all Collapse all
`{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}`
#### [](#tag/Tracker/operation/replaceConversationTrackerEvents)Replace a trackers events
Replaces all events of a tracker with the passed list of events. This endpoint should not be used to modify trackers in a production setup, but rather for creating training data.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
###### Request Body schema: application/jsonrequired
Array
Any of
UserEventBotEventSessionStartedEventActionEventSlotEventResetSlotsEventRestartEventReminderEventCancelReminderEventPauseEventResumeEventFollowupEventExportEventUndoEventRewindEventAgentEventEntitiesAddedEventUserFeaturizationEventActionExecutionRejectedEventFormValidationEventLoopInterruptedEventFormEventActiveLoopEvent
| | |
| -------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| eventrequired | stringValue: "user"Event name |
| timestamp | integerTime of application |
| metadata | object |
| text | string or nullText of user message. |
| input\_channel | string or null |
| message\_id | string or null |
| parse\_data | object (ParseResult)NLU parser information. If set, message will not be passed through NLU, but instead this parsing information will be used. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
put/conversations/{conversation\_id}/tracker/events
Local development server
http://localhost:5005/conversations/{conversation\_id}/tracker/events
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`[
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
]`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}`
#### [](#tag/Tracker/operation/getConversationStory)Retrieve an end-to-end story corresponding to a conversation
The story represents the whole conversation in end-to-end format. This can be posted to the '/test/stories' endpoint and used as a test.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| ------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| until | numberDefault:"None"Example:until=1559744410All events previous to the passed timestamp will be replayed. Events that occur exactly at the target time will be included. |
| all\_sessions | booleanDefault:falseWhether to fetch all sessions in a conversation, or only the latest session- `true` - fetch all conversation sessions.
- `false` - \[default] fetch only the latest conversation session. |
##### Responses
**200**
Success
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
get/conversations/{conversation\_id}/story
Local development server
http://localhost:5005/conversations/{conversation\_id}/story
##### Response samples
* 200
* 401
* 403
* 409
* 500
Content type
text/yml
Copy
```
- story: story_00055028
steps:
- user: |
hello
intent: greet
- action: utter_ask_howcanhelp
- user: |
I'm looking for a [moderately priced]{"entity": "price", "value": "moderate"} [Indian]{"entity": "cuisine"} restaurant for [two]({"entity": "people"}) people
intent: inform
- action: utter_on_it
- action: utter_ask_location
```
#### [](#tag/Tracker/operation/executeConversationAction)Run an action in a conversation Deprecated
DEPRECATED. Runs the action, calling the action server if necessary. Any responses sent by the executed action will be forwarded to the channel specified in the output\_channel parameter. If no output channel is specified, any messages that should be sent to the user will be included in the response of this endpoint.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
| output\_channel | stringEnum: "latest" "slack" "callback" "facebook" "rocketchat" "telegram" "twilio" "webexteams" "socketio"Example:output\_channel=slackThe bot's utterances will be forwarded to this channel. It uses the credentials listed in `credentials.yml` to connect. In case the channel does not support this, the utterances will be returned in the response body. Use `latest` to try to send the messages to the latest channel the user used. Currently supported channels are listed in the permitted values for the parameter. |
###### Request Body schema: application/jsonrequired
| | |
| ------------ | ----------------------------------------------------------- |
| namerequired | stringName of the action to be executed. |
| policy | string or nullName of the policy that predicted the action. |
| confidence | number or nullConfidence of the prediction. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/execute
Local development server
http://localhost:5005/conversations/{conversation\_id}/execute
##### Request samples
* Payload
Content type
application/json
Copy
`{
"name": "utter_greet",
"policy": "string",
"confidence": 0.987232
}`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
},
"messages": [
{
"recipient_id": "string",
"text": "string",
"image": "string",
"buttons": [
{
"title": "string",
"payload": "string"
}
],
"attachement": [
{
"title": "string",
"payload": "string"
}
]
}
]
}`
#### [](#tag/Tracker/operation/triggerConversationIntent)Inject an intent into a conversation
Sends a specified intent and list of entities in place of a user message. The bot then predicts and executes a response action. Any responses sent by the executed action will be forwarded to the channel specified in the `output_channel` parameter. If no output channel is specified, any messages that should be sent to the user will be included in the response of this endpoint.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
| output\_channel | stringEnum: "latest" "slack" "callback" "facebook" "rocketchat" "telegram" "twilio" "webexteams" "socketio"Example:output\_channel=slackThe bot's utterances will be forwarded to this channel. It uses the credentials listed in `credentials.yml` to connect. In case the channel does not support this, the utterances will be returned in the response body. Use `latest` to try to send the messages to the latest channel the user used. Currently supported channels are listed in the permitted values for the parameter. |
###### Request Body schema: application/jsonrequired
| | |
| ------------ | ---------------------------------------- |
| namerequired | stringName of the intent to be executed. |
| entities | object or nullEntities to be passed on. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/trigger\_intent
Local development server
http://localhost:5005/conversations/{conversation\_id}/trigger\_intent
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"name": "greet",
"entities": {
"temperature": "high"
}
}`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
},
"messages": [
{
"recipient_id": "string",
"text": "string",
"image": "string",
"buttons": [
{
"title": "string",
"payload": "string"
}
],
"attachement": [
{
"title": "string",
"payload": "string"
}
]
}
]
}`
#### [](#tag/Tracker/operation/predictConversationAction)Predict the next action
Runs the conversations tracker through the model's policies to predict the scores of all actions present in the model's domain. Actions are returned in the 'scores' array, sorted on their 'score' values. The state of the tracker is not modified.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/predict
Local development server
http://localhost:5005/conversations/{conversation\_id}/predict
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"scores": [
{
"action": "utter_greet",
"score": 1
}
],
"policy": "policy_2_TEDPolicy",
"confidence": 0.057,
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}
}`
#### [](#tag/Tracker/operation/addConversationMessage)Add a message to a tracker
Adds a message to a tracker. This doesn't trigger the prediction loop. It will log the message on the tracker and return, no actions will be predicted or run. This is often used together with the predict endpoint.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ------------------------ | ----------------------------------------------------------- |
| conversation\_idrequired | stringExample:defaultId of the conversation |
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
###### Request Body schema: application/jsonrequired
| | |
| -------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| textrequired | stringMessage text |
| senderrequired | stringValue: "user"Origin of the message - who sent it |
| parse\_data | object (ParseResult)NLU parser information. If set, message will not be passed through NLU, but instead this parsing information will be used. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/conversations/{conversation\_id}/messages
Local development server
http://localhost:5005/conversations/{conversation\_id}/messages
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"text": "Hello!",
"sender": "user",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}`
#### [](#tag/Model)Model
#### [](#tag/Model/operation/trainModel)Train a Rasa model
Trains a new Rasa model. Depending on the data given only a dialogue model, only a NLU model, or a model combining a trained dialogue model with an NLU model will be trained. The new model is not loaded by default.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| ----------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| save\_to\_default\_model\_directory | booleanDefault:trueIf `true` (default) the trained model will be saved in the default model directory, if `false` it will be saved in a temporary directory |
| force\_training | booleanDefault:falseForce a model training even if the data has not changed |
| augmentation | stringDefault:50How much data augmentation to use during training |
| num\_threads | stringDefault:1Maximum amount of threads to use when training |
| callback\_url | stringDefault:"None"Example:callback\_url=https://example.com/rasa\_evaluationsIf specified the call will return immediately with an empty response and status code 204. The actual result or any errors will be sent to the given callback URL as the body of a post request. |
###### Request Body schema: application/yamlrequired
The training data should be in YAML format.
| | |
| ----------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| pipeline | Array of arraysPipeline list |
| policies | Array of arraysPolicies list |
| entities | Array of arraysEntity list |
| slots | Array of arraysSlots list |
| actions | Array of arraysAction list |
| forms | Array of arraysForms list |
| e2e\_actions | Array of arraysE2E Action list |
| responses | objectBot response templates |
| session\_config | objectSession configuration options |
| nlu | Array of arraysRasa NLU data, array of intents |
| rules | Array of arraysRule list |
| stories | Array of arraysRasa Core stories in YAML format |
| flows | objectRasa Pro flows in YAML format |
| force | booleanDeprecatedForce a model training even if the data has not changed |
| save\_to\_default\_model\_directory | booleanDeprecatedIf `true` (default) the trained model will be saved in the default model directory, if `false` it will be saved in a temporary directory |
##### Responses
**200**
Zipped Rasa model
**204**
The incoming request specified a `callback_url` and hence the request will return immediately with an empty response. The actual response will be sent to the provided `callback_url` via POST request.
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**500**
An unexpected error occurred.
post/model/train
Local development server
http://localhost:5005/model/train
##### Request samples
* Payload
Content type
application/yaml
Copy
```
pipeline: []
policies: []
intents:
- greet
- goodbye
entities: []
slots:
contacts_list:
type: text
mappings:
- type: custom
action: list_contacts
actions:
- list_contacts
forms: {}
e2e_actions: []
responses:
utter_greet:
- text: "Hey! How are you?"
utter_goodbye:
- text: "Bye"
utter_list_contacts:
- text: "You currently have the following contacts:\n{contacts_list}"
utter_no_contacts:
- text: "You have no contacts in your list."
session_config:
session_expiration_time: 60
carry_over_slots_to_new_session: true
nlu:
- intent: greet
examples: |
- hey
- hello
- intent: goodbye
examples: |
- bye
- goodbye
rules:
- rule: Say goodbye anytime the user says goodbye
steps:
- intent: goodbye
- action: utter_goodbye
stories:
- story: happy path
steps:
- intent: greet
- action: utter_greet
- intent: goodbye
- action: utter_goodbye
flows:
list_contacts:
name: list your contacts
description: show your contact list
steps:
- action: list_contacts
next:
- if: "slots.contacts_list"
then:
- action: utter_list_contacts
next: END
- else:
- action: utter_no_contacts
next: END
```
##### Response samples
* 400
* 401
* 403
* 500
Content type
application/json
Copy
`{
"version": "1.0.0",
"status": "failure",
"reason": "BadRequest",
"code": 400
}`
#### [](#tag/Model/operation/testModelStories)Evaluate stories
Evaluates one or multiple stories against the currently loaded Rasa model.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| --- | ------------------------------------------------------------------------------------------- |
| e2e | booleanDefault:falsePerform an end-to-end evaluation on the posted stories. |
###### Request Body schema: text/ymlrequired
string (
StoriesTrainingData
)
Rasa Core stories in YAML format
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/model/test/stories
Local development server
http://localhost:5005/model/test/stories
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"actions": [
{
"action": "utter_ask_howcanhelp",
"predicted": "utter_ask_howcanhelp",
"policy": "policy_0_MemoizationPolicy",
"confidence": 1
}
],
"is_end_to_end_evaluation": true,
"precision": 1,
"f1": 0.9333333333333333,
"accuracy": 0.9,
"in_training_data_fraction": 0.8571428571428571,
"report": {
"conversation_accuracy": {
"accuracy": 0.19047619047619047,
"correct": 18,
"with_warnings": 1,
"total": 20
},
"property1": {
"intent_name": "string",
"classification_report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
}
},
"property2": {
"intent_name": "string",
"classification_report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
}
}
}
}`
#### [](#tag/Model/operation/testModelIntent)Perform an intent evaluation
Evaluates NLU model against a model or using cross-validation.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| ------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| model | stringExample:model=rasa-model.tar.gzModel that should be used for evaluation. If the parameter is set, the model will be fetched with the currently loaded configuration setup. However, the currently loaded model will not be updated. The state of the server will not change. If the parameter is not set, the currently loaded model will be used for the evaluation. |
| callback\_url | stringDefault:"None"Example:callback\_url=https://example.com/rasa\_evaluationsIf specified the call will return immediately with an empty response and status code 204. The actual result or any errors will be sent to the given callback URL as the body of a post request. |
| cross\_validation\_folds | integerDefault:nullNumber of cross validation folds. If this parameter is specified the given training data will be used for a cross-validation instead of using it as test set for the specified model. Note that this is only supported for YAML data. |
###### Request Body schema:application/x-yamlapplication/x-yamlrequired
string
NLU training data and model configuration. The model configuration is only required if cross-validation is used.
##### Responses
**200**
NLU evaluation result
**204**
The incoming request specified a `callback_url` and hence the request will return immediately with an empty response. The actual response will be sent to the provided `callback_url` via POST request.
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/model/test/intents
Local development server
http://localhost:5005/model/test/intents
##### Request samples
* Payload
Content type
application/x-yamlapplication/x-yaml
No sample
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"intent_evaluation": {
"report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
},
"accuracy": 0.19047619047619047,
"f1_score": 0.06095238095238095,
"precision": 0.036281179138321996,
"predictions": [
{
"intent": "greet",
"predicted": "greet",
"text": "hey",
"confidence": 0.9973567
}
],
"errors": [
{
"text": "are you alright?",
"intent_response_key_target": "string",
"intent_response_key_prediction": {
"confidence": 0.6323,
"name": "greet"
}
}
]
},
"response_selection_evaluation": {
"report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
},
"accuracy": 0.19047619047619047,
"f1_score": 0.06095238095238095,
"precision": 0.036281179138321996,
"predictions": [
{
"intent": "greet",
"predicted": "greet",
"text": "hey",
"confidence": 0.9973567
}
],
"errors": [
{
"text": "are you alright?",
"intent_response_key_target": "string",
"intent_response_key_prediction": {
"confidence": 0.6323,
"name": "greet"
}
}
]
},
"entity_evaluation": {
"property1": {
"report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
},
"accuracy": 0.19047619047619047,
"f1_score": 0.06095238095238095,
"precision": 0.036281179138321996,
"predictions": [
{
"intent": "greet",
"predicted": "greet",
"text": "hey",
"confidence": 0.9973567
}
],
"errors": [
{
"text": "are you alright?",
"intent_response_key_target": "string",
"intent_response_key_prediction": {
"confidence": 0.6323,
"name": "greet"
}
}
]
},
"property2": {
"report": {
"greet": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100,
"confused_with": {
"chitchat": 3,
"nlu_fallback": 5
}
},
"micro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"macro avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
},
"weightedq avg": {
"precision": 0.123,
"recall": 0.456,
"f1-score": 0.12,
"support": 100
}
},
"accuracy": 0.19047619047619047,
"f1_score": 0.06095238095238095,
"precision": 0.036281179138321996,
"predictions": [
{
"intent": "greet",
"predicted": "greet",
"text": "hey",
"confidence": 0.9973567
}
],
"errors": [
{
"text": "are you alright?",
"intent_response_key_target": "string",
"intent_response_key_prediction": {
"confidence": 0.6323,
"name": "greet"
}
}
]
}
}
}`
#### [](#tag/Model/operation/predictModelAction)Predict an action on a temporary state
Predicts the next action on the tracker state as it is posted to this endpoint. Rasa will create a temporary tracker from the provided events and will use it to predict an action. No messages will be sent and no action will be run.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| include\_events | stringDefault:"AFTER\_RESTART"Enum: "ALL" "APPLIED" "AFTER\_RESTART" "NONE"Example:include\_events=AFTER\_RESTARTSpecify which events of the tracker the response should contain.-`ALL` - every logged event.
-`APPLIED` - only events that contribute to the trackers state. This excludes reverted utterances and actions that got undone.
-`AFTER_RESTART` - all events since the last `restarted` event. This includes utterances that got reverted and actions that got undone.
-`NONE` - no events. |
###### Request Body schema: application/jsonrequired
Array
Any of
UserEventBotEventSessionStartedEventActionEventSlotEventResetSlotsEventRestartEventReminderEventCancelReminderEventPauseEventResumeEventFollowupEventExportEventUndoEventRewindEventAgentEventEntitiesAddedEventUserFeaturizationEventActionExecutionRejectedEventFormValidationEventLoopInterruptedEventFormEventActiveLoopEvent
| | |
| -------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| eventrequired | stringValue: "user"Event name |
| timestamp | integerTime of application |
| metadata | object |
| text | string or nullText of user message. |
| input\_channel | string or null |
| message\_id | string or null |
| parse\_data | object (ParseResult)NLU parser information. If set, message will not be passed through NLU, but instead this parsing information will be used. |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**409**
The request conflicts with the currently loaded model.
**500**
An unexpected error occurred.
post/model/predict
Local development server
http://localhost:5005/model/predict
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`[
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
]`
##### Response samples
* 200
* 400
* 401
* 403
* 409
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"scores": [
{
"action": "utter_greet",
"score": 1
}
],
"policy": "policy_2_TEDPolicy",
"confidence": 0.057,
"tracker": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}
}`
#### [](#tag/Model/operation/parseModelMessage)Parse a message using the Rasa model
Predicts the intent and entities of the message posted to this endpoint. No messages will be stored to a conversation and no action will be run. This will just retrieve the NLU parse results.
###### Authorizations:
*TokenAuth\*\*JWT*
###### query Parameters
| | |
| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| emulation\_mode | stringEnum: "WIT" "LUIS" "DIALOGFLOW"Example:emulation\_mode=LUISSpecify the emulation mode to use. Emulation mode transforms the response JSON to the format expected by the service specified as the emulation\_mode. Requests must still be sent in the regular Rasa format. |
###### Request Body schema: application/jsonrequired
| | |
| ----------- | ------------------------------------------ |
| text | stringMessage to be parsed |
| message\_id | stringOptional ID for message to be parsed |
##### Responses
**200**
Success
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**500**
An unexpected error occurred.
post/model/parse
Local development server
http://localhost:5005/model/parse
##### Request samples
* Payload
Content type
application/json
Copy
`{
"text": "Hello, I am Rasa!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a"
}`
##### Response samples
* 200
* 400
* 401
* 403
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"text": "Hello!",
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
]
}`
#### [](#tag/Model/operation/replaceModel)Replace the currently loaded model
Updates the currently loaded model. First, tries to load the model from the local (note: local to Rasa server) storage system. Secondly, tries to load the model from the provided model server configuration. Last, tries to load the model from the provided remote storage.
###### Authorizations:
*TokenAuth\*\*JWT*
###### Request Body schema: application/jsonrequired
| | |
| --------------- | ---------------------------------------------------------------------------- |
| model\_file | stringPath to model file |
| model\_server | object (EndpointConfig) |
| remote\_storage | stringEnum: "aws" "gcs" "azure"Name of remote storage system |
##### Responses
**204**
Model was successfully replaced.
**400**
Bad Request
**401**
User is not authenticated.
**403**
User has insufficient permission.
**500**
An unexpected error occurred.
put/model
Local development server
http://localhost:5005/model
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"model_file": "/absolute-path-to-models-directory/models/20190512.tar.gz",
"model_server": {
"url": "string",
"params": { },
"headers": { },
"basic_auth": { },
"token": "string",
"token_name": "string",
"wait_time_between_pulls": 0
},
"remote_storage": "aws"
}`
##### Response samples
* 400
* 401
* 403
* 500
Content type
application/json
Copy
`{
"version": "1.0.0",
"status": "failure",
"reason": "BadRequest",
"code": 400
}`
#### [](#tag/Model/operation/unloadModel)Unload the trained model
Unloads the currently loaded trained model from the server.
###### Authorizations:
*TokenAuth\*\*JWT*
##### Responses
**204**
Model was sucessfully unloaded.
**401**
User is not authenticated.
**403**
User has insufficient permission.
delete/model
Local development server
http://localhost:5005/model
##### Response samples
* 401
* 403
Content type
application/json
Copy
`{
"version": "1.0.0",
"status": "failure",
"reason": "NotAuthenticated",
"message": "User is not authenticated to access resource.",
"code": 401
}`
#### [](#tag/Flows)Flows
#### [](#tag/Flows/operation/getFlows)Retrieve the flows of the assistant
Returns the assistant was trained on.
###### Authorizations:
*TokenAuth\*\*JWT*
##### Responses
**200**
Flows were successfully retrieved.
**401**
User is not authenticated.
**403**
User has insufficient permission.
**406**
Invalid header provided.
**500**
An unexpected error occurred.
get/flows
Local development server
http://localhost:5005/flows
##### Response samples
* 200
* 401
* 403
* 406
* 500
Content type
application/json
Copy
Expand all Collapse all
`[
{
"id": "check_balance",
"name": "check balance",
"description": "check the user's account balance",
"steps": [
{ }
]
}
]`
#### [](#tag/Domain)Domain
#### [](#tag/Domain/operation/getDomain)Retrieve the loaded domain
Returns the domain specification the currently loaded model is using.
###### Authorizations:
*TokenAuth\*\*JWT*
##### Responses
**200**
Domain was successfully retrieved.
**401**
User is not authenticated.
**403**
User has insufficient permission.
**406**
Invalid header provided.
**500**
An unexpected error occurred.
get/domain
Local development server
http://localhost:5005/domain
##### Response samples
* 200
* 401
* 403
* 406
* 500
Content type
application/jsonapplication/json
Copy
Expand all Collapse all
`{
"config": {
"store_entities_as_slots": false
},
"intents": [
{
"property1": {
"use_entities": true
},
"property2": {
"use_entities": true
}
}
],
"entities": [
"person",
"location"
],
"slots": {
"property1": {
"auto_fill": true,
"initial_value": "string",
"type": "string",
"values": [
"string"
]
},
"property2": {
"auto_fill": true,
"initial_value": "string",
"type": "string",
"values": [
"string"
]
}
},
"responses": {
"property1": {
"text": "string"
},
"property2": {
"text": "string"
}
},
"actions": [
"action_greet",
"action_goodbye",
"action_listen"
]
}`
#### [](#tag/Channel-Webhooks)Channel Webhooks
#### [](#tag/Channel-Webhooks/operation/postMessageRestChannel)Post user message from a REST channel
Post a message from the user and forward it to the assistant. Return the message of the assistant to the user.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| --------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| rest\_channelrequired | stringEnum: "rest" "callback"The REST channel used for custom integrations. They provide a URL where you can post messages and either receive response messages directly, or asynchronously via a webhook. |
###### Request Body schema: application/jsonrequired
The user message payload
| | |
| ------- | ---------------------- |
| sender | stringThe sender ID |
| message | stringThe message text |
##### Responses
**200**
The message was processed successfully
**401**
User is not authenticated.
**403**
User has insufficient permission.
**406**
Invalid header provided.
**500**
An unexpected error occurred.
post/webhooks/{rest\_channel}/webhook
Local development server
http://localhost:5005/webhooks/{rest\_channel}/webhook
##### Request samples
* Payload
Content type
application/json
Copy
`{
"sender": "default",
"message": "Hello!"
}`
##### Response samples
* 200
* 401
* 403
* 406
* 500
Content type
application/json
Copy
Expand all Collapse all
`[
{
"recipient_id": "default",
"text": "Hello!"
}
]`
#### [](#tag/Channel-Webhooks/operation/postMessageCustomChannel)Post user message from a custom channel
Post a message from the user and forward it to the assistant. Return the message of the assistant to the user. This is from a custom channel.
###### Authorizations:
*TokenAuth\*\*JWT*
###### path Parameters
| | |
| ----------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| custom\_channelrequired | stringExample:my\_custom\_channelThe custom channel connector used for integration. They provide a URL where you can post and receive messages. |
###### Request Body schema: application/jsonrequired
The user message payload
| | |
| -------------- | ---------------------------------------- |
| sender | stringThe sender ID |
| message | stringThe message text |
| stream | booleanWhether to use streaming response |
| input\_channel | stringInput channel name |
| metadata | objectAdditional metadata |
##### Responses
**200**
The message was processed successfully
**401**
User is not authenticated.
**403**
User has insufficient permission.
**406**
Invalid header provided.
**500**
An unexpected error occurred.
post/webhooks/{custom\_channel}/webhook
Local development server
http://localhost:5005/webhooks/{custom\_channel}/webhook
##### Request samples
* Payload
Content type
application/json
Copy
Expand all Collapse all
`{
"sender": "string",
"message": "string",
"stream": true,
"input_channel": "string",
"metadata": { }
}`
##### Response samples
* 200
* 401
* 403
* 406
* 500
Content type
application/json
Copy
Expand all Collapse all
`{
"messages": [
{
"recipient_id": "string",
"text": "string",
"image": "string",
"buttons": [
{
"title": "string",
"payload": "string"
}
],
"attachement": [
{
"title": "string",
"payload": "string"
}
]
}
],
"metadata": { },
"conversation_id": "string",
"tracker_state": {
"sender_id": "default",
"slots": [
{
"slot_name": "slot_value"
}
],
"latest_message": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
},
"latest_event_time": 1537645578.314389,
"followup_action": "string",
"paused": false,
"stack": [
{
"frame_id": "8UJPHH5C",
"flow_id": "transfer_money",
"step_id": "START",
"frame_type": "regular",
"type": "flow"
}
],
"events": [
{
"event": "user",
"timestamp": null,
"metadata": {
"arbitrary_metadata_key": "some string",
"more_metadata": 1
},
"text": "string",
"input_channel": "string",
"message_id": "string",
"parse_data": {
"entities": [
{
"start": 0,
"end": 0,
"value": "string",
"entity": "string",
"confidence": 0
}
],
"intent": {
"confidence": 0.6323,
"name": "greet"
},
"intent_ranking": [
{
"confidence": 0.6323,
"name": "greet"
}
],
"text": "Hello!",
"message_id": "b2831e73-1407-4ba0-a861-0f30a42a2a5a",
"metadata": { },
"commands": [
{
"command": "start flow",
"flow": "transfer_money"
}
],
"flows_from_semantic_search": [ [
"transfer_money",
0.9035494923591614
]
],
"flows_in_prompt": [
"transfer_money"
]
}
}
],
"latest_input_channel": "rest",
"latest_action_name": "action_listen",
"latest_action": {
"action_name": "string",
"action_text": "string"
},
"active_loop": {
"name": "restaurant_form"
}
}
}`
---
### Architecture
#### Rasa Architecture
The diagram below provides an overview of the Rasa Architecture.
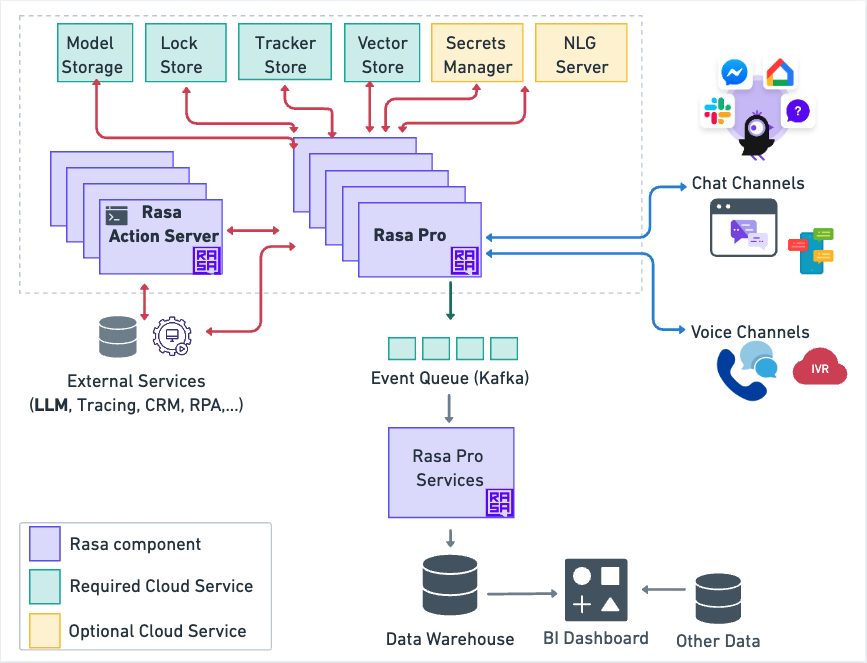
#### Action Server (custom actions)[](#action-server-custom-actions "Direct link to Action Server (custom actions)")
Custom actions are used to implement business logic that cannot be handled by the Rasa bot. They include things like fetching customer information from a database, querying an API, or calling an external service.
Custom actions can be invoked via HTTP or gRPC. Rasa provides the Rasa SDK - a Python SDK to build custom actions. More details can be found at the [rasa action server documentation](https://rasa.com/docs/docs/action-server/).
#### Cloud Services[](#cloud-services "Direct link to Cloud Services")
Your deployed assistant depends on a number of prerequisite cloud services that you need to provision.
Some of these prerequisite cloud services are required (green color), while others are optional (yellow color).
You are highly advised to use **managed cloud services** for their stability, performance and backup. There are many options available at each cloud provider, and the table below lists just a few of the available choices.
| What | AWS | Azure | Google |
| ------------------- | ----------------------------------------------- | ----------------------------- | ---------------------------------------- |
| Model Storage | Amazon S3 | Azure Blob Storage | Google Cloud Storage |
| Lock Store | Amazon ElastiCache for Redis | Azure Cache for Redis | Memorystore for Redis |
| Tracker Store | Amazon RDS for PostgreSQL | Azure Database for PostgreSQL | Google Cloud SQL for PostgreSQL |
| Event Queue (Kafka) | Amazon Managed Streaming for Apache Kafka (MSK) | Azure Kafka Service | Confluent Cloud on Google Cloud Platform |
| Secrets Manager | HashiCorp Vault on AWS | HashiCorp Vault on Azure | HashiCorp Vault with Google Cloud |
Note that the NLG Server is an optional cloud service that you have to create and deploy yourself.
Next you will find a short description of the function of each cloud service.
##### [Model Storage](https://rasa.com/docs/docs/reference/integrations/model-storage/)[](#model-storage "Direct link to model-storage")
The Model storage is a cloud service where the trained model is stored. Upon initialization or restart, Rasa will download that trained model and read it into memory.
##### [Lock Store](https://rasa.com/docs/docs/reference/integrations/lock-stores/)[](#lock-store "Direct link to lock-store")
The Lock Store is needed when you have a high-load scenario that requires the Rasa server to be replicated across multiple instances. It ensures that even with multiple servers, the messages for each conversation are handled in the correct sequence without any loss or overlap.
##### [Tracker Store](https://rasa.com/docs/docs/reference/integrations/tracker-stores/)[](#tracker-store "Direct link to tracker-store")
Your assistant's conversations are stored within a tracker store.
##### [Secrets Manager](https://rasa.com/docs/docs/reference/integrations/secrets-managers/)[](#secrets-manager "Direct link to secrets-manager")
The HashiCorp Vault Secrets Manager is integrated with Rasa to securely store and manage sensitive credentials.
##### [NLG Server](https://rasa.com/docs/docs/reference/integrations/nlg/)[](#nlg-server "Direct link to nlg-server")
The NLG Server in Rasa is used to outsource the response generation and separate it from the dialogue learning process. The benefit of using an NLG Server is that it allows for the dynamic generation of responses without the need to retrain the bot, optimizing workflows by decoupling response text from training data.
##### [Event Queue (Kafka)](https://rasa.com/docs/docs/reference/integrations/event-brokers/)[](#event-queue-kafka "Direct link to event-queue-kafka")
The Kafka Event Broker in Rasa is used to stream all events from the Rasa server to a Kafka topic for robust, scalable message handling and further processing.
---
#### Studio Architecture
#### High Level Architecture[](#high-level-architecture "Direct link to High Level Architecture")
Below is a high level architecture diagram of Rasa Studio. The diagram shows the main components of Rasa Studio and how they interact with each other.
*Please click on the image to view it in full size.*

#### Containers[](#containers "Direct link to Containers")
The below image shows the different containers that make up Rasa Studio. The containers are deployed on a Kubernetes cluster.
*Please click on the image to view it in full size.*

The following container images are part of the Studio deployment:
1. **Studio Web Client Container:** This container hosts the frontend service of Rasa Studio. It provides a user-friendly web interface that allows users to interact with and manage their conversational AI projects.
2. **Studio Backend Server Container:** The Studio backend server container hosts the backend service of Rasa Studio. It processes incoming requests, executes application logic and manages data. The backend server exposes APIs that the web client interacts with to perform various actions in the UI. It also exposes APIs for a developer user to use `Rasa Pro Studio` [CLI commands](https://rasa.com/docs/docs/reference/api/command-line-interface/#rasa-studio-download) to pull/push data from/to Studio.
3. **Studio Database Migration Server Container:** This container is used specifically for running database migrations during deployment or upgrades of Rasa Studio. It ensures that the database schema is up to date and compatible with the latest version of Rasa Studio. This container runs as a Kubernetes job during deployment.
4. **Studio Keycloak Container:** Studio uses [Keycloak](https://www.keycloak.org/) as its user management system. The Keycloak container provides authentication, authorization, and user management capabilities for Rasa Studio. It handles user registration, login, password management, and access control to ensure secure access to Studio's features and functionalities.
5. **Studio Ingestion Service Container:** The Studio Ingestion Service container is responsible for ingesting conversation events from Rasa assistant via the Kafka broker. It listens to the specified Kafka topic, receives bot events, and processes them for storage and analysis within Rasa Studio.
6. **Studio Model Service Container:** This is a service native to Rasa that takes care of training and running an assistant model in Studio. This powers the `try your assistant` feature where a user can try the CALM assistant that they created and trained. The container that runs this service is based off the Rasa Pro container image version >= `3.11.0`.
##### Studio Model Service Container[](#studio-model-service-container "Direct link to Studio Model Service Container")
note
Once you have upgraded to Studio >= v`1.10.0`, you should run a new training request with the new model service to be able to test this model with the `try your assistant` feature.
###### Training[](#training "Direct link to Training")
When training is triggered from the UI, Studio sends a training request to the Rasa Pro model service API. This training request spawns a new subprocess in Rasa that runs the `rasa train` command.
The following diagram depicts the process flow of the training request:

The training process involves the following steps:
* The model service retrieves the training data from the Studio request.
* The model service creates a new directory on the local disk to store the training data.
* The model service writes the training data to the directory.
* The model service runs the `rasa train` command in the subprocess.
The model service allows for multiple trainings to be run concurrently, currently set by default to **10**. This limit is set to prevent the system resources from being overloaded with too many training processes.
If you want to update this limit, you can configure the `MAX_PARALLEL_TRAININGS` environment variable in Studio's Model Service Rasa Pro container. Make sure that the memory and CPU resources set for the Model Service container are sufficient to handle the number of parallel trainings you set. We have outlined the [resource usage recommendations](#resource-usage-recommendations) for the Model Service container below.
When the model service container receives more requests than the defined limit, the training request fails and the user can retry at a later point in time. If the limit is reached, the model service API will return a `429 Too Many Requests` response to the Studio backend server. This response is then sent back to the Studio UI to inform the user that the training request has been rejected due to the limit being reached. If this happens regularly, we recommend to both increase the hardware resources of the Rasa Pro container and increase the limit of parallel trainings.
Once the training process is complete, Studio sends the model service API a request to run the assistant. This request involves the following steps:
* retrieves the model from the local disk or cloud storage
* spawns a new subprocess that runs the `rasa run` command
The model service allows for multiple assistants to be run concurrently, currently set by default to **10**. This limit is set to prevent the system resources from being overloaded with too many assistant processes.
If you want to update this limit, you can configure the `MAX_PARALLEL_BOT_RUNS` environment variable in Studio's Model Service Rasa Pro container. Make sure that the memory and CPU resources set for the Model Service container are sufficient to handle the number of parallel bot runs you set. We have outlined the [resource usage recommendations](#resource-usage-recommendations) for the Model Service container below.
When the model service container receives more requests than the limit set by `MAX_PARALLEL_BOT_RUNS`, it does not queue the requests which is a limitation of the current iteration. If the limit is reached, the model service API will return a `429 Too Many Requests` response to the Studio backend server. This response is then sent back to the Studio UI to inform the user that the assistant run request has been rejected due to the limit being reached. If this happens regularly, we recommend to both increase the hardware resources of the Rasa Pro container and increase the limit of parallel bot runs.
Once the assistant is up and running, the Studio UI notifies the user that the training was successful.
###### Model Storage[](#model-storage "Direct link to Model Storage")
If the training is successful, the trained model is saved to local disk by default.
If you also prefer to have the trained model uploaded to cloud storage, you should configure the `RASA_REMOTE_STORAGE` environment variable in the Studio deployment. This environment variable should be set to one of the Rasa [supported cloud storage options](https://rasa.com/docs/docs/reference/integrations/model-storage/#load-model-from-cloud) - `aws`, `gcs`, `azure`.
Note that if the model is saved to local disk and the container is deployed on Kubernetes or Docker, you should ensure that you specify a persistent volume mounted to the following path: `/app/working-data`, where `working-data` is the default base working directory name for the model service. You can configure the working directory name by setting the `RASA_MODEL_SERVER_BASE_DIRECTORY` environment variable in the Rasa Pro container deployment.
Studio default Helm charts take care of this for you directly.
###### Try Your Assistant[](#try-your-assistant "Direct link to Try Your Assistant")
When a user wants to use the `try your assistant` feature in Studio, the model service API fulfills the following tasks:
* authenticates the Studio user with the Rasa backend server to ensure that the user has the necessary permissions to chat with the assistant.
* creates a socketIO bridge between the Studio socketIO session and the running assistant. This bridge enables the Studio user to send messages to the running bot and to receive back the bot responses.
###### Environment Variables[](#environment-variables "Direct link to Environment Variables")
The following environment variables can be configured on the Studio Model Service Rasa Pro container:
* `MAX_PARALLEL_TRAININGS`: The maximum number of parallel trainings that can be run by the model service. Default is `10`.
* `MAX_PARALLEL_BOT_RUNS`: The maximum number of parallel bot runs that can be run by the model service. Default is `10`.
* `RASA_REMOTE_STORAGE`: The cloud storage option where the trained model should be uploaded. Default is `None`.
###### Resource Usage Recommendations[](#resource-usage-recommendations "Direct link to Resource Usage Recommendations")
Our load tests on a standard CALM assistant show that the Studio Model Service Rasa Pro container requires:
* a minimum of `1 vCPU core` per training, the resource is released once the training is completed.
* `500 Mi/0.5 Gi` of memory per every running assistant.
---
### Changelogs
#### Compatibility Matrix for the Rasa Platform
#### Platform Feature Availability[](#platform-feature-availability "Direct link to Platform Feature Availability")
This table describes the ability of features across the platform.
| **Features** | **Studio** | **Pro** | **Comment** |
| ------------------------------------------------------ | ---------- | ------- | -------------------------------------------- |
| Flow: slot persistence | ✅ | ✅ | |
| Flow: NLU trigger | ✅ | ✅ | |
| Flow: flow guard | ✅ | ✅ | |
| Flow: flow guard context namespace | ❌ | ✅ | |
| Flow: call step | ✅ | ✅ | |
| Flow: set slots | ✅ | ✅ | |
| Flow: button payload | ✅ | ✅ | |
| Flow: Next | ✅ | ✅ | |
| Flow: Noop | ❌ | ✅ | |
| Flow: Slot comparisons | ❌ | ✅ | |
| Flow: Nested logics | ✅ | ✅ | |
| Flow: action trigger search | ❌ | ✅ | |
| System flow/ Repair patterns: pattern\_user\_silence | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_collect\_info | ❌ | ✅ | |
| System flow/ Repair patterns: pattern\_continue | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_correction | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_cancel\_flow | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_skip\_question | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_chitchat | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_completed | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_clarification | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_internal\_error | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_cannot\_handle | ✅ | ✅ | |
| System flow/ Repair patterns: pattern\_human\_handoff | ✅ | ✅ | |
| System flow response editing | ✅ | ✅ | |
| Multi-LLM Routing | ✅ | ✅ | |
| Slot Custom | ❌ | ✅ | |
| Slot List | ❌ | ✅ | |
| Slot Boolean | ✅ | ✅ | |
| Slot Categorical | ✅ | ✅ | |
| Slot Float | ✅ | ✅ | |
| Slot Any | ✅ | ✅ | |
| Slot mapping | ✅ | ✅ | |
| **Advanced Slot mapping** | ❌ | ✅ | |
| Conditional responses variations | ✅ | ✅ | |
| Custom responses | ✅ | ✅ | |
| Images support in responses | ❌ | ✅ | |
| Assistant Domain | ✅ | ✅ | |
| Assistant Endpoints | ✅ | ✅ | |
| Assistant Credentials | ❌ | ✅ | |
| Assistant Configuration | ✅ | ✅ | |
| Assistant Language settings | ✅ | ✅ | |
| Inspector | ✅ | ✅ | |
| Inspector: model metadata (token, consumption) | ✅ | ❌ | |
| Inspector: Replay | ✅ | ❌ | |
| Inspector: Restart | ✅ | ✅ | |
| Mock custom actions | ❌ | ✅ | |
| E2E testing: generate | ✅ | ✅ | |
| E2E testing: Run | ❌ | ✅ | |
| Custom Action | ✅ | ✅ | Studio can read but not create Custom Action |
| Enterprise Search (RAG) config | ✅ | ✅ | |
| Enterprise Search (RAG): Custom Info Retrievers | ❌ | ✅ | |
| Enterprise Search (RAG): Vector Store Connectors | ❌ | ✅ | |
| Enterprise Search (RAG): Extractive Search | ❌ | ✅ | |
| Custom Components | ❌ | ✅ | |
| Command generator prompt editing | ✅ | ✅ | |
| Rephraser prompt editing | ✅ | ✅ | |
| Rephraser prompt editing per response | ✅ | ✅ | |
| Enterprise Search (RAG) prompt adjust | ✅ | ✅ | |
| Consistent project folder structure | ❌ | ✅ | |
| Conversation review tagging API | ✅ | ❌ | |
| Flow builder | ✅ | ✅ | Pro users use IDE |
| Conversation review | ✅ | ❌ | |
| State management | ✅ | ✅ | Pro users use Git |
| Flow history | ✅ | ✅ | Pro users use Git |
| Model management | ✅ | ✅ | Pro users use Git |
| CMS: Intents | ✅ | ✅ | Pro users use IDE |
| CMS: Entities | ✅ | ✅ | Pro users use IDE |
| CMS: Responses | ✅ | ✅ | Pro users use IDE |
| CMS: Slots | ✅ | ✅ | Pro users use IDE |
| CMS: Buttons & Links | ✅ | ✅ | Pro users use IDE |
| Fine tune recipe | ❌ | ✅ | |
| Custom Information Retrievers | ❌ | ✅ | |
| Channel connectors | ❌ | ✅ | |
#### Rasa Pro Services compatibility[](#rasa-pro-services-compatibility "Direct link to Rasa Pro Services compatibility")
When choosing a version of Rasa Pro Services to deploy, you can refer to the table below to see which one is compatible with your installation of Rasa Pro.
Rasa Pro Services version is independent of Rasa Pro version, except that they share the same major version number.
| Rasa Pro Services | Rasa Pro |
| ----------------- | ------------------------------------------------------------ |
| 3.0.x | 3.3.x, 3.4.x, 3.5.x |
| 3.1.x | 3.6.x |
| 3.2.x | 3.7.x, 3.8.x |
| 3.3.x | 3.8.x, 3.9.x, 3.10.x |
| 3.4.x | 3.8.x, 3.9.x, 3.10.x, 3.11.x, 3.12.x |
| 3.5.x | 3.8.x, 3.9.x, 3.10.x, 3.11.x, 3.12.x, 3.13.x |
| 3.6.x | 3.8.x, 3.9.x, 3.10.x, 3.11.x, 3.12.x, 3.13.x, 3.14.x |
| 3.7.x | 3.8.x, 3.9.x, 3.10.x, 3.11.x, 3.12.x, 3.13.x, 3.14.x, 3.15.x |
#### Studio/Pro Versions Compatibility[](#studiopro-versions-compatibility "Direct link to Studio/Pro Versions Compatibility")
Rasa Studio uses Rasa Pro to train and run models. The following table shows the compatibility between Rasa Studio and Rasa Pro.
| Rasa Studio | Rasa Pro |
| ---------------------- | -------- |
| 1.0.x, 1.1.x | 3.7.x |
| 1.2.x | 3.8.x |
| 1.3.0 | 3.8.4 |
| 1.3.1, 1.4.x, 1.5.x | 3.8.7 |
| 1.6.x | 3.9.9 |
| 1.7.x, 1.8.x, 1.9.x | 3.10.x |
| 1.10.x | 3.11.x |
| 1.11.x | 3.11.x |
| 1.12.x | 3.12.x |
| 1.13.x | 3.13.x |
| 1.14.1, 1.14.2, 1.14.3 | 3.13.x |
| 1.14.4 & above | 3.14.x |
| 1.15.x | 3.15.x |
---
#### Rasa Pro Change Log
All notable changes to Rasa Pro will be documented in this page. This product adheres to [Semantic Versioning](https://semver.org/) starting with version 3.3 (initial version).
Rasa Pro consists of two deployable artifacts: Rasa Pro and Rasa Pro Services. You can read the change log for both artifacts below.
#### \[3.15.12] - 2026-02-23[](#31512---2026-02-23 "Direct link to [3.15.12] - 2026-02-23")
Rasa Pro 3.15.12 (2026-02-23)
##### Bugfixes[](#bugfixes "Direct link to Bugfixes")
* **E2E fixture resolution and conftest hierarchy:**
Fixture resolution now uses a conftest-style hierarchy, with local overrides taking precedence over global fixtures. This is a change from the previous behavior where all fixtures were merged into a single list, which could lead to silent data loss if duplicate fixture names were used. Now, every test case has its own resolved set of fixtures, and duplicate fixture names are allowed when the intent is "override".
Details:
* **Conftest-style hierarchy:** Fixtures can be defined at root or folder level (e.g. `conftest.yml` / `conftest.yaml`); all e2e tests under that path see them.
* **Single-file run parity:** Running one test file resolves fixtures the same way as when that file is run as part of the full suite (global/conftest fixtures are loaded for that file’s path).
* **Runtime namespace:** Each test case has its own resolved set of fixtures; there is no shared mutable fixture state between tests. Duplicate fixture names in **different** files are allowed when the intent is “override” (no need to remove or rename for full-suite runs).
* **Override semantics:** Local (file-level) fixtures override folder-level; folder-level overrides root. Within a single file, duplicate fixture names remain an error.
* Update cryptography dependency to 46.0.5 to address CVE-2026-26007. Update pillow dependency to 12.1.1 to address CVE-2026-25990. Update pyasn1 dependency to 0.6.2 to address CVE-2026-23490. Update python-multipart dependency to 0.0.22 to address CVE-2026-24486.
#### \[3.15.11] - 2026-02-18[](#31511---2026-02-18 "Direct link to [3.15.11] - 2026-02-18")
Rasa Pro 3.15.11 (2026-02-18)
##### Bugfixes[](#bugfixes-1 "Direct link to Bugfixes")
* Upgrade `litellm` to 1.80.0.
* Remove config file content from endpoint read success logs to prevent sensitive data exposure.
* Update `protobuf` to v5.29.6 to address CVE-2026-0994. Update `wheel` to v0.46.3 to address CVE-2026-24049.
#### \[3.15.10] - 2026-02-10[](#31510---2026-02-10 "Direct link to [3.15.10] - 2026-02-10")
Rasa Pro 3.15.10 (2026-02-10)
##### Improvements[](#improvements "Direct link to Improvements")
* Flows can now link to `pattern_search` (e.g. to trigger RAG or branch on knowledge-based search).
##### Bugfixes[](#bugfixes-2 "Direct link to Bugfixes")
* Added interruption handling for final transcripts. Moved interruption check to eliminate interruption handling delay.
* Fix Enterprise Search Policy triggering `utter_ask_rephrase` instead of `utter_no_relevant_answer_found` when the vector store search returns no matching documents. The `pattern_cannot_handle` now correctly receives the `cannot_handle_no_relevant_answer` as a `context.reason` in all cases where no relevant answer is found, not only when the optional relevancy check rejects the answer.
#### \[3.15.9] - 2026-02-05[](#3159---2026-02-05 "Direct link to [3.15.9] - 2026-02-05")
Rasa Pro 3.15.9 (2026-02-05)
##### Bugfixes[](#bugfixes-3 "Direct link to Bugfixes")
* Upgrade Keras to 3.12.1 to address CVE-2026-0897.
* Fixed `language` parameter in RimeTTS configuration to be passed correctly to the Rime API. Temporarily changed RimeTTS to non-streaming input mode as a workaround for a Rime API bug that impacts conversation experience; audio is now generated from the complete response at once.
#### \[3.15.8] - 2026-01-26[](#3158---2026-01-26 "Direct link to [3.15.8] - 2026-01-26")
Rasa Pro 3.15.8 (2026-01-26)
##### Bugfixes[](#bugfixes-4 "Direct link to Bugfixes")
* Update azure-core to 1.38.0 to address CVE-2026-21226.
#### \[3.15.7] - 2026-01-21[](#3157---2026-01-21 "Direct link to [3.15.7] - 2026-01-21")
Rasa Pro 3.15.7 (2026-01-21)
##### Bugfixes[](#bugfixes-5 "Direct link to Bugfixes")
* Fixed e2e test coverage report to correctly track coverage per flow. Each flow now appears as a separate entry with accurate coverage percentages. Additionally, `call`/`link` steps and `collect` steps with prefilled slots are now properly marked as visited.
* Fix OAuth2AuthStrategy to use URL-encoded parameters with Basic Authentication to fetch access token
#### \[3.15.6] - 2026-01-15[](#3156---2026-01-15 "Direct link to [3.15.6] - 2026-01-15")
Rasa Pro 3.15.6 (2026-01-15)
##### Bugfixes[](#bugfixes-6 "Direct link to Bugfixes")
* Fixed an issue where storing documents in FAISS individually could hit the token limit. Now, documents are stored in batches to avoid exceeding the token limit.
* Throw error when duplicate fixtures are found in the same file or across files.
* `SessionEnded` does not reset the tracker anymore.
* Updated `werkzeug`, `aiohttp`, `filelock`, `fonttools`, `marshmallow`, `urllib3` and `langchain-core`to resolve security vulnerabilities.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.15.5] - 2025-12-29[](#3155---2025-12-29 "Direct link to [3.15.5] - 2025-12-29")
Rasa Pro 3.15.5 (2025-12-29)
##### Bugfixes[](#bugfixes-7 "Direct link to Bugfixes")
* Include response button titles in conversation history in prompts of LLM based components.
* Fix OpenTelemetry exporter `Invalid type of value None` error when recording the request duration metric for requests made from Rasa server to the custom action server. This error occurred because the url parameter was not being passed to the method that records the request duration metric, resulting in a NoneType value.
* Fix DUT fails with AttributeError when running with custom CommandGenerator
#### \[3.15.4] - 2025-12-19[](#3154---2025-12-19 "Direct link to [3.15.4] - 2025-12-19")
Rasa Pro 3.15.4 (2025-12-19)
##### Bugfixes[](#bugfixes-8 "Direct link to Bugfixes")
* Fixed token expiration validation failing on servers running in non-UTC timezones. Token expiration checks now use timezone-aware UTC datetimes consistently, preventing premature "access token expired" errors on systems in timezones like UTC+8.
#### \[3.15.3] - 2025-12-11[](#3153---2025-12-11 "Direct link to [3.15.3] - 2025-12-11")
Rasa Pro 3.15.3 (2025-12-11)
##### Bugfixes[](#bugfixes-9 "Direct link to Bugfixes")
* Fix potential Tensor shape mismatch error in `TEDPolicy` and `DIETClassifier`.
* Update `mcp` version to `~1.23.0` to address security vulnerability CVE-2025-66416.
* Fix bug in `CommandPayloadReader` where regex matching did not account for list slots, leading to incorrect parsing of slot keys and values. Now, slot names and values are correctly extracted even if a list is provided.
* Previously, `DialogueStateTracker.has_coexistence_routing_slot` could incorrectly return `True` when the tracker was created without domain slots (i.e., using `AnySlotDict`), because `AnySlotDict` pretends all slots exist. Now, the property returns False in that case, so the routing slot is only considered present if it is actually defined in the domain.
* Fix LLM prompt template loading to raise an error instead of just printing a warning when a custom prompt file is missing or cannot be read.
* Fix `AttributeError: 'str' object has no attribute 'pop'` when using `KnowledgeAnswerCommand` with tracing enabled.
* Fix `UnboundLocalError` in `E2ETestRunner._handle_fail_diff` that caused e2e tests to crash when processing `slot_was_not_set` assertion failures.
* Fixed button payloads with nested parentheses (e.g., `/SetSlots(slot=value)`) not being parsed correctly in `rasa shell`. The payload was incorrectly stripped of its `/SetSlots` prefix, causing it to be treated as text instead of a slot-setting command.
* Add missing deprecation warning for legacy `RASA_PRO_LICENSE` environment variable. Update license validation error messages to reference the actual environment variable used.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-1 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.15.2] - 2025-12-04[](#3152---2025-12-04 "Direct link to [3.15.2] - 2025-12-04")
Rasa Pro 3.15.2 (2025-12-04)
##### Bugfixes[](#bugfixes-10 "Direct link to Bugfixes")
* Fix agentic prompt template to access slots directly.
* Disable LLM health check for Enterprise Search Policy when generative search is disabled (i.e. use\_generative\_llm is False).
* Fix deduplication of collect steps in cases where the same slot was called in different flows.
* Cancel active flow before triggering internal pattern error during a custom action failure.
* Fix bug with the missing `language_data` module by installing `langcodes` with the `data` extra dependency.
#### \[3.15.1] - 2025-12-02[](#3151---2025-12-02 "Direct link to [3.15.1] - 2025-12-02")
Rasa Pro 3.15.1 (2025-12-02)
##### Bugfixes[](#bugfixes-11 "Direct link to Bugfixes")
* Raise validation error when duplicate slot definitions are found across domains.
* Raise validation error when a slot with an initial value set is collected by a flow collect step which sets `asks_before_filling` to `true` without having a corresponding collect utterance or custom action.
* Update `pip` to fix security vulnerability.
* Fix AgentToolSchema.\_ensure\_property\_types() correctly preserves structural keywords ($ref, anyOf, oneOf, etc.)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-2 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.15.0] - 2025-11-26[](#3150---2025-11-26 "Direct link to [3.15.0] - 2025-11-26")
Rasa Pro 3.15.0 (2025-11-26)
##### Features[](#features "Direct link to Features")
* Added Langfuse integration for tracing LLM and embedding calls. All LLM-based components (Command Generators, Rephraser, Enterprise Search Policy, ReAct Sub Agent) and embedding operations are automatically traced when Langfuse is configured. Each trace includes, among other things, input/output, latency, token usage, cost, session ID, and component name.
To get started, configure Langfuse by adding a `langfuse` entry to the `tracing` section in `endpoints.yml`.
Example:
```
tracing:
- type: langfuse
public_key: ${LANGFUSE_PUBLIC_KEY}
private_key: ${LANGFUSE_PRIVATE_KEY}
host: https://cloud.langfuse.com
```
Custom components can override `get_llm_tracing_metadata()` to customize metadata.
* Added support for triggering clarification when multiple `StartFlow` commands are generated with no active flow. To enable this feature, set the `CLARIFY_ON_MULTIPLE_START_FLOWS` environment variable to `True`.
* Adds DTMF (Dual-Tone Multi-Frequency) input support for collect steps in flows. Voice channels can now configure DTMF collection with options for digit length, finish key, and audio input control. The feature gracefully handles non-voice channels by skipping DTMF configuration when call\_state is not initialized.
* Added new CLI option `-f, --e2e-failed-tests` to export failed e2e tests to a file that can be directly used to re-run only those tests. It accepts an optional filename or directory path, with automatic timestamping to prevent overwriting previous test runs.
* Added support for including current datetime information by default in LLM prompts. This feature enables LLM-based components to include date and time context in their prompts, helping the model understand temporal references and provide time-aware responses.
**Components Updated:**
* `CompactLLMCommandGenerator`
* `SearchReadyLLMCommandGenerator`
* `EnterpriseSearchPolicy`
* `MCPOpenAgent` (with timezone support)
* `MCPTaskAgent` (with timezone support)
**Prompt Template Updates:** When `include_date_time` is enabled, prompts include a "Date & Time Context" section showing:
* Current date (formatted as "DD Month, YYYY")
* Current time (formatted as "HH:MM
:SS
" with timezone)
* Current day of the week
**E2E Testing Support:** For deterministic testing, you can mock the datetime using the `mocked_datetime` slot in e2e test fixtures. The mocked datetime value must be provided in ISO 8601 format (e.g., `"2024-01-15T10:30:00+00:00"`). The e2e test runner validates the format and raises a `ValidationError` if the value is invalid.
##### Improvements[](#improvements-1 "Direct link to Improvements")
* Updated `pattern_completed` to check wether the user wants to continue the conversation or not by adding a `collect` step to the pattern.
* The `OutputChannel` is now provided to policies through the graph inputs. This enables any policy to access the output channel and send messages directly to the user, which is particularly useful for sending intermediate or filler messages.
* Allow LLM responses to be streamed to the output channel for any generative responses. This currently only applies to Enterprise Search Policy and Rephraser. Output channels that support streaming should handle duplicate message prevention when a response has already been streamed. Voice output channels (Browser Audio, Genesys, Audiocodes Stream, and Jambonz Stream) have been updated to use the streaming tokens to prepare the Text-to-Speech audio stream instead of waiting for the complete response to be generated. These changes are backward compatible; any existing channel does NOT need any additional changes. However, it can add new methods to make use of the streaming responses whenever they are available.
* Enhanced the clarification pattern with a configurable limit on the number of flows in the clarification options. Added a new slot `max_clarification_options` to the `default_flows_for_patterns.yml` with an initial value of `3` which can be changed by overriding the `initial_value` of the slot `max_clarification_options` to customize the maximum number of flows displayed during clarification.
* Enhanced the clarification pattern to handle empty clarification options. Added `utter_clarification_no_options_rasa` response to `default_flows_for_patterns.yml`, triggered when `pattern_clarification` receives a `ClarifyCommand` with no options.
* Allow e2e test results CLI flag `-o`, `--e2e-results` to be specified with a custom path. If the flag is used without a path, the default path `tests/` is used.
* Enable generative responses dispatched by custom actions to be evaluated by `generative_response_is_grounded` and `generative_response_is_relevant` assertions in E2E testing. In order for the E2E testing framework to evaluate generative responses dispatched by custom actions, you must add the custom action dispatching the generative bot response to the `utter_source` key of the appopriate assertion in the E2E test case. For example, if you have a custom action `action_generate_summary` that generates a summary using a generative model, you can add the following assertion to your E2E test case:
```
test_cases:
- test_case: Generate summary for user query
steps:
- user: |
Can you provide a summary of the latest news on climate change?
assertions:
- generative_response_is_grounded:
threshold: 0.8
utter_source: action_generate_summary
ground_truth:
- generative_response_is_relevant:
threshold: 0.9
utter_source: action_generate_summary
```
* Allow `flow_started` and `pattern_clarification_contains` E2E testing assertions to define the operator i.e. `all`, `any`, for matching multiple flow\_id values. Previously, `flow_started` only supported a single flow\_id value, while `pattern_clarification_contains` defaulted to `all`. Introduce new format to specify the operator explicitly:
```
test_cases:
- test_case: user is asked to clarify contact-related message
steps:
- user: contacts
assertions:
- pattern_clarification_contains:
operator: "any"
flow_ids:
- remove_contact
- list_contacts
- add_contact
- update_contact
- test_case: user removes a missing contact
steps:
- user: i want to remove a contact
assertions:
- flow_started:
operator: "any"
flow_ids:
- remove_contact
- update_contact
```
The `operator` field can take values `all` or `any`, determining whether all specified flow\_ids must match or if any one of them is sufficient.
The previous format for these two assertions remains unchanged for backward compatibility, however it has been deprecated and will be removed in a future major release.
* Updated the default model and voice of Cartesia TTS, using `sonic-3` and voice ID American English Katie.
* Move commit messages to top of the SSE
* Allow trigerring empty `Clarify Command` without flow options.
##### Bugfixes[](#bugfixes-12 "Direct link to Bugfixes")
* Run action\_session\_start if tracker ends with SessionEnded event.
* Fixed PostgreSQL `UniqueViolation` error when running an assistant with multiple Sanic workers.
* Fix Kafka producer creation failing when SASL mechanism is specified in lowercase. The SASL mechanism is now case-insensitive in the Kafka producer configuration.
* Fix issue where the validation of the assistant files continued even when the provided domain was invalid and was being loaded as empty. The training or validation command didn't exit because the final merged domain contained only the default implementations for patterns, slots and responses and therefore passed the check for being non-empty.
* Trigger pattern\_internal\_error in a CALM assistant when a custom action fails during execution.
* Create AWS Bedrock / Sagemaker client only if the LLM healthcheck environment variable is set. If the environment variable is not set, validate that required credentials are present.
* Update `langchain-core` version to `~0.3.80` to address security vulnerability CVE-2025-65106.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-3 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.14.15] - 2026-02-23[](#31415---2026-02-23 "Direct link to [3.14.15] - 2026-02-23")
Rasa Pro 3.14.15 (2026-02-23)
##### Bugfixes[](#bugfixes-13 "Direct link to Bugfixes")
* Remove config file content from endpoint read success logs to prevent sensitive data exposure.
* Update `protobuf` to v5.29.6 to address CVE-2026-0994. Update `wheel` to v0.46.3 to address CVE-2026-24049.
* **E2E fixture resolution and conftest hierarchy:**
Fixture resolution now uses a conftest-style hierarchy, with local overrides taking precedence over global fixtures. This is a change from the previous behavior where all fixtures were merged into a single list, which could lead to silent data loss if duplicate fixture names were used. Now, every test case has its own resolved set of fixtures, and duplicate fixture names are allowed when the intent is "override".
Details:
* **Conftest-style hierarchy:** Fixtures can be defined at root or folder level (e.g. `conftest.yml` / `conftest.yaml`); all e2e tests under that path see them.
* **Single-file run parity:** Running one test file resolves fixtures the same way as when that file is run as part of the full suite (global/conftest fixtures are loaded for that file’s path).
* **Runtime namespace:** Each test case has its own resolved set of fixtures; there is no shared mutable fixture state between tests. Duplicate fixture names in **different** files are allowed when the intent is “override” (no need to remove or rename for full-suite runs).
* **Override semantics:** Local (file-level) fixtures override folder-level; folder-level overrides root. Within a single file, duplicate fixture names remain an error.
#### \[3.14.14] - 2026-02-12[](#31414---2026-02-12 "Direct link to [3.14.14] - 2026-02-12")
Rasa Pro 3.14.14 (2026-02-12)
* Upgrade `litellm` to 1.80.0.
* Fix Enterprise Search Policy triggering `utter_ask_rephrase` instead of `utter_no_relevant_answer_found` when the vector store search returns no matching documents. The `pattern_cannot_handle` now correctly receives the `cannot_handle_no_relevant_answer` as a `context.reason` in all cases where no relevant answer is found, not only when the optional relevancy check rejects the answer.
#### \[3.14.13] - 2026-02-05[](#31413---2026-02-05 "Direct link to [3.14.13] - 2026-02-05")
Rasa Pro 3.14.13 (2026-02-05)
##### Bugfixes[](#bugfixes-14 "Direct link to Bugfixes")
* Upgrade Keras to 3.12.1 to address CVE-2026-0897.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-4 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.14.12] - 2026-01-26[](#31412---2026-01-26 "Direct link to [3.14.12] - 2026-01-26")
Rasa Pro 3.14.12 (2026-01-26)
##### Bugfixes[](#bugfixes-15 "Direct link to Bugfixes")
* Update azure-core to 1.38.0 to address CVE-2026-21226.
#### \[3.14.11] - 2026-01-21[](#31411---2026-01-21 "Direct link to [3.14.11] - 2026-01-21")
Rasa Pro 3.14.11 (2026-01-21)
##### Bugfixes[](#bugfixes-16 "Direct link to Bugfixes")
* Fixed e2e test coverage report to correctly track coverage per flow. Each flow now appears as a separate entry with accurate coverage percentages. Additionally, `call`/`link` steps and `collect` steps with prefilled slots are now properly marked as visited.
* Throw error when duplicate fixtures are found in the same file or across files.
* Fix OAuth2AuthStrategy to use URL-encoded parameters with Basic Authentication to fetch access token
#### \[3.14.10] - 2026-01-15[](#31410---2026-01-15 "Direct link to [3.14.10] - 2026-01-15")
Rasa Pro 3.14.10 (2026-01-15)
##### Bugfixes[](#bugfixes-17 "Direct link to Bugfixes")
* Fixed an issue where storing documents in FAISS individually could hit the token limit. Now, documents are stored in batches to avoid exceeding the token limit.
* `SessionEnded` does not reset the tracker anymore.
* Updated `werkzeug`, `aiohttp`, `filelock`, `fonttools`, `marshmallow`, `urllib3` and `langchain-core`to resolve security vulnerabilities.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-5 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.14.9] - 2025-12-29[](#3149---2025-12-29 "Direct link to [3.14.9] - 2025-12-29")
Rasa Pro 3.14.9 (2025-12-29)
##### Bugfixes[](#bugfixes-18 "Direct link to Bugfixes")
* Include response button titles in conversation history in prompts of LLM based components.
* Fix OpenTelemetry exporter `Invalid type of value None` error when recording the request duration metric for requests made from Rasa server to the custom action server. This error occurred because the url parameter was not being passed to the method that records the request duration metric, resulting in a NoneType value.
* Fix DUT fails with AttributeError when running with custom CommandGenerator
#### \[3.14.8] - 2025-12-19[](#3148---2025-12-19 "Direct link to [3.14.8] - 2025-12-19")
Rasa Pro 3.14.8 (2025-12-19)
##### Bugfixes[](#bugfixes-19 "Direct link to Bugfixes")
* Fixed token expiration validation failing on servers running in non-UTC timezones. Token expiration checks now use timezone-aware UTC datetimes consistently, preventing premature "access token expired" errors on systems in timezones like UTC+8.
#### \[3.14.7] - 2025-12-11[](#3147---2025-12-11 "Direct link to [3.14.7] - 2025-12-11")
Rasa Pro 3.14.7 (2025-12-11)
##### Bugfixes[](#bugfixes-20 "Direct link to Bugfixes")
* Fix potential Tensor shape mismatch error in `TEDPolicy` and `DIETClassifier`.
* Update `mcp` version to `~1.23.0` to address security vulnerability CVE-2025-66416.
* Fix bug in `CommandPayloadReader` where regex matching did not account for list slots, leading to incorrect parsing of slot keys and values. Now, slot names and values are correctly extracted even if a list is provided.
* Previously, `DialogueStateTracker.has_coexistence_routing_slot` could incorrectly return `True` when the tracker was created without domain slots (i.e., using `AnySlotDict`), because `AnySlotDict` pretends all slots exist. Now, the property returns False in that case, so the routing slot is only considered present if it is actually defined in the domain.
* Fix LLM prompt template loading to raise an error instead of just printing a warning when a custom prompt file is missing or cannot be read.
* Fix `AttributeError: 'str' object has no attribute 'pop'` when using `KnowledgeAnswerCommand` with tracing enabled.
* Fix `UnboundLocalError` in `E2ETestRunner._handle_fail_diff` that caused e2e tests to crash when processing `slot_was_not_set` assertion failures.
* Fixed button payloads with nested parentheses (e.g., `/SetSlots(slot=value)`) not being parsed correctly in `rasa shell`. The payload was incorrectly stripped of its `/SetSlots` prefix, causing it to be treated as text instead of a slot-setting command.
* Add missing deprecation warning for legacy `RASA_PRO_LICENSE` environment variable. Update license validation error messages to reference the actual environment variable used.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-6 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.14.6] - 2025-12-05[](#3146---2025-12-05 "Direct link to [3.14.6] - 2025-12-05")
Rasa Pro 3.14.6 (2025-12-05)
##### Bugfixes[](#bugfixes-21 "Direct link to Bugfixes")
* Fix agentic prompt template to access slots directly.
* Disable LLM health check for Enterprise Search Policy when generative search is disabled (i.e. use\_generative\_llm is False).
* Fix deduplication of collect steps in cases where the same slot was called in different flows.
* Cancel active flow before triggering internal pattern error during a custom action failure.
* Fix bug with the missing `language_data` module by installing `langcodes` with the `data` extra dependency.
#### \[3.14.5] - 2025-12-02[](#3145---2025-12-02 "Direct link to [3.14.5] - 2025-12-02")
Rasa Pro 3.14.5 (2025-12-02)
##### Bugfixes[](#bugfixes-22 "Direct link to Bugfixes")
* Update `pip` to fix security vulnerability.
* Fix AgentToolSchema.\_ensure\_property\_types() correctly preserves structural keywords ($ref, anyOf, oneOf, etc.)
#### \[3.14.4] - 2025-11-27[](#3144---2025-11-27 "Direct link to [3.14.4] - 2025-11-27")
Rasa Pro 3.14.4 (2025-11-27)
##### Bugfixes[](#bugfixes-23 "Direct link to Bugfixes")
* Fixed `patten-continue-interrupted` running out of order before linked flows.
* Fix `rasa studio upload` timeouts by enabling TCP keep-alive with platform-specific socket options to maintain stable connections.
* Remove `action_metadata` tracing span attribute from `EnterpriseSearchPolicy` instrumentation to prevent PII leakages. Add new environment variable `RASA_TRACING_DEBUGGING_ENABLED` to enable adding `action_metadata` to `EnterpriseSearchPolicy` spans for debugging purposes. By default, this variable is set to `false` to ensure PII is not logged in production environments.
* Fixed PostgreSQL `UniqueViolation` error when running an assistant with multiple Sanic workers.
* Fix Kafka producer creation failing when SASL mechanism is specified in lowercase. The SASL mechanism is now case-insensitive in the Kafka producer configuration.
* Fix issue where the validation of the assistant files continued even when the provided domain was invalid and was being loaded as empty. The training or validation command didn't exit because the final merged domain contained only the default implementations for patterns, slots and responses and therefore passed the check for being non-empty.
* Trigger pattern\_internal\_error in a CALM assistant when a custom action fails during execution.
* Create AWS Bedrock / Sagemaker client only if the LLM healthcheck environment variable is set. If the environment variable is not set, validate that required credentials are present.
* Update `langchain-core` version to `~0.3.80` to address security vulnerability CVE-2025-65106.
* Raise validation error when duplicate slot definitions are found across domains.
* Raise validation error when a slot with an initial value set is collected by a flow collect step which sets `asks_before_filling` to `true` without having a corresponding collect utterance or custom action.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-7 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.14.3] - 2025-11-13[](#3143---2025-11-13 "Direct link to [3.14.3] - 2025-11-13")
Rasa Pro 3.14.3 (2025-11-13)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-8 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.14.2] - 2025-10-30[](#3142---2025-10-30 "Direct link to [3.14.2] - 2025-10-30")
Rasa Pro 3.14.2 (2025-10-30)
##### Improvements[](#improvements-2 "Direct link to Improvements")
* Add new environment variable `LOG_LEVEL_PYMONGO` to control the logging level of PyMongo dependency of Rasa. This can be useful to reduce the verbosity of logs. Default value is `INFO`.
The logging level of PyMongo can also be set via the `LOG_LEVEL_LIBRARIES` environment variable, which provides the default logging level for a selection of third-party libraries used by Rasa. If both variables are set, `LOG_LEVEL_PYMONGO` takes precedence.
##### Bugfixes[](#bugfixes-24 "Direct link to Bugfixes")
* Clean up duplicated `ChitChatAnswerCommands` in command processor.
Ensure that one `CannotHandleCommand` remains if only multiple `CannotHandleCommands` were present.
* LLM request timeouts are now enforced at the event loop level using `asyncio.wait_for`.
Previously, timeout values configured in `endpoints.yml` could be overridden by the HTTP client's internal timeout behavior. This fix ensures that when a specific timeout value is configured for LLM requests, the request respects that exact timing regardless of the underlying HTTP client implementation.
* Fixed an issue where duplicate collect steps in a flow could cause rendering problems, such as exceeding token limits. This occurred when a flow called another flow multiple times. Now, each collect step is listed only once when retrieving all collect steps for a flow.
* If a FloatSlot does not have min and max values set in the domain, the slot will not be validated against any range. If the slot defines an initial value, as well as min and max values, the initial value will be validated against the range and an error will be raised if the initial value is out of range. Enhance run-time validation for new values assigned to FloatSlot instances, ensuring they fall within the defined min and max range if these are set. If min and max are not set, no range validation is performed.
* Fixed bug preventing `deployment` parameter from being used in generative response LLM judge configuration.
* Fixed bug where `persisted_slots` defined in called flows were incorrectly reset when the parent flow ended, unless they were also explicitly defined in the parent flow. Persisted slots now only need to be defined in the called flow to remain persisted after the parent flow ends.
* Fixes the prompt template resolution logic in the CompactLLMCommandGenerator and SearchReadyLLMCommandGenerator classes.
* When `action_clean_stack` is used in a user flow, allow `pattern_completed` to be triggered even if there are pattern flows at the bottom of the dialogue stack below the top user flow frame. Previously, `pattern_completed` would only trigger if there were no other frames below the top user flow frame. This assumes that the `action_clean_stack` is the last action called in the user flow.
* Update `pip` version used in Dockerfile to `23.*` to address security vulnerability CVE-2023-5752. Update `python-socketio` version to `5.14.0` to address security vulnerability CVE-2025-61765.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-9 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.14.1] - 2025-10-10[](#3141---2025-10-10 "Direct link to [3.14.1] - 2025-10-10")
Rasa Pro 3.14.1 (2025-10-10)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-10 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.14.0] - 2025-10-09[](#3140---2025-10-09 "Direct link to [3.14.0] - 2025-10-09")
Rasa Pro 3.14.0 (2025-10-09)
##### Features[](#features-1 "Direct link to Features")
* Added the possibility to call an agent from within a flow via a `call` step. We support two types of ReAct style agents:
1. An open ended exploratory agent - Here the user’s goal is loosely defined, for example researching about stocks to invest in. There is no pre-defined criteria which can be used to know when the goal is reached. Hence the agent itself needs to figure out when it has helped the user to the best of its capabilities.
```
flows:
stock_investment_research:
description: helps research and analyze stock investment options
steps:
- call: stock_explorer # runs until agent signals completion
```
2. A task specific agent - Here we can come up with conditions, which when true, signals the completion of a user goal. For example, helping the user find an appointment slot based on their preferences - you know the agent can exit once all user’s preferences have been met and they have agreed to a slot.
```
flows:
book_appointment:
description: helps users book appointments
steps:
- call: ticket_agent
exit_if:
- slots.chosen_appointment is not null
- slots.booking_completed is True**
- collect: user_confirmation
```
To configure the agents you need to create a folder structure like this:
```
your_project/
├── config.yml
├── domain/
├── data/flows/
└── sub_agents/
└── stock_explorer/
├── config.yml # mandatory
└── prompt_template.jinja2 # optional
```
The `config.yml` file for each agent is mandatory and should look, for example, like this:
```
# Basic agent information
agent:
name: stock_explorer # name of the agent
protocol: RASA # protocol for its connections either RASA or A2A
description: "Agent that helps users research and analyze stock options" # a brief description used by the command generator to continue / stop the agent and the agent during its execution
# Core configuration
configuration:
llm: # (optional) Same format as other Rasa LLM configs
type: openai
model: gpt-4
prompt_template: sub_agents/stock_explorer/prompt_template.jinja2 # (optional) prompt template file containing a customized prompt
timeout: 30 # (optional) seconds before timing out
max_retries: 3 # (optional) connection retry attempts
# MCP server connections
connections:
mcp_servers:
- name: trade_server
include_tools: # optional: specify which tools to include
- find_symbol
- get_company_news
- apply_technical_analysis
- fetch_live_price
exclude_tools: # optional: tools to exclude; helpful to not allow the agent to execute critical tools.
- place_buy_order
- view_positions
```
* Added the possibility to call an MCP tool directly from a flow step via a `call` step.
Example:
```
- call: place_buy_order # MCP tool name
mcp_server: trade_server # MCP server where tool is available
mapping:
input:
- param: ticker_symbol # tool parameter name
slot: stock_name # slot to send as value
- param: quantity
slot: order_quantity
output:
- slot: order_status # slot to store results
result_key: result.structuredContent.order_status.success
```
The MCP server needs to be defined in the `endpoints.yml` file
```
mcp_servers:
- name: trade_server
url: http://localhost:8080
type: http
```
* We updated the inspector
* to highlight when a call step is calling an agent or an MCP tool using a little icon in the flow view.
* and added an additional agent widget that shows the available agents and their corresponding status in the conversation.
* Whenever agents are configured, the `SearchReadyLLMCommandGenerator` and the `CompactLLMCommandGenerator` will use new default prompt templates that contain new agent specific commands (`RestartAgent` and `ContinueAgent`) and instructions.
* Adds Interruption Handling Support (beta) in Voice Stream Channels, namely Browser Audio, Twilio Media Streams and Jambonz Stream. Interruptions are identified from partial transcripts sent by the Automatic Speech Recogintion (ASR) Engine. Interruption Handling is disabled by defaulat and can be configured using the optional `interruptions` key in `credentials.yml`.
```
browser_audio:
server_url: localhost
interruptions:
enabled: True
min_words: 3
asr:
name: "deepgram"
tts:
name: cartesia
```
The configuration property `min_words` (default 3) requires the partial transcript to have at least 3 words to interrupt the bot. This is a rudimentary way to filter backchannels (brief responses like "hmm", "yeah", "ok").
Interruptions can be disabled for certain responses using the domain response property `allow_interruptions` (default true). Example,
```
responses:
utter_current_balance:
- text: You still have {current_balance} in your account.
allow_interruptions: false
```
* Added the following new events to capture the state of any agent used within a conversation:
* `AgentStarted`
* `AgentCompleted`
* `AgentCancelled`
* `AgentResumed`
* `AgentInterrupted`
* Added support for Redis Cluster mode in the tracker store for horizontal scaling and cloud compatibility.
Added support for Redis Sentinel mode in the tracker store for high availability with automatic failover.
Added 3 new configuration parameters to `RedisTrackerStore`:
* `deployment_mode`: String value specifying Redis deployment type ("standard", "cluster", or "sentinel"). Defaults to "standard".
* `endpoints`: List of strings in "host
:port
" format defining cluster nodes or sentinel instances.
* `sentinel_service`: String value specifying the sentinel service name to connect to. Only used in sentinel mode, defaults to "mymaster".
* Add support for IAM authentication to AWS RDS SQL tracker store. To enable this feature:
* set the `IAM_CLOUD_PROVIDER` environment variable to `aws`.
* set the `AWS_DEFAULT_REGION` environment variable to your desired AWS region.
* if you want to enforce SSL verification, you can set the `SQL_TRACKER_STORE_SSL_MODE` environment variable (for example, to `verify-full` or `verify-ca`) and provide the path to the CA certificate using the `SQL_TRACKER_STORE_SSL_ROOT_CERTIFICATE` environment variable.
* Add support for IAM authentication to AWS Managed Streaming for Kafka event broker. This allows secure authentication to an AWS MSK cluster without the need for static credentials. To enable this feature:
* set the `IAM_CLOUD_PROVIDER` environment variable to `aws`.
* set the `AWS_DEFAULT_REGION` environment variable to your desired AWS region.
* ensure that your application has the necessary IAM permissions to access the AWS Managed Service Kafka cluster.
* ensure the topic is created on the MSK cluster.
* use the `SASL_SSL` security protocol and `OAUTHBEARER` SASL mechanism in your Kafka configuration in `endpoints.yml`.
* download the root certificate from Amazon Trust Services: and provide its path to the `ssl_cafile` event broker yaml property.
* Added support for Redis Cluster mode in `RedisLockStore` for horizontal scaling and cloud compatibility.
Added support for Redis Sentinel mode in `RedisLockStore` for high availability with automatic failover.
Added 3 new configuration parameters to `RedisLockStore`:
* `deployment_mode`: String value specifying Redis deployment type ("standard", "cluster", or "sentinel"). Defaults to "standard".
* `endpoints`: List of strings in "host
:port
" format defining cluster nodes or sentinel instances.
* `sentinel_service`: String value specifying the sentinel service name to connect to. Only used in sentinel mode, defaults to "mymaster".
* Added support for Redis Cluster mode in `ConcurrentRedisLockStore` for horizontal scaling and cloud compatibility.
Added support for Redis Sentinel mode in `ConcurrentRedisLockStore` for high availability with automatic failover.
Added 3 new configuration parameters to `ConcurrentRedisLockStore`:
* `deployment_mode`: String value specifying Redis deployment type ("standard", "cluster", or "sentinel"). Defaults to "standard".
* `endpoints`: List of strings in "host
:port
" format defining cluster nodes or sentinel instances.
* `sentinel_service`: String value specifying the sentinel service name to connect to. Only used in sentinel mode, defaults to "mymaster".
* Add support for IAM authentication to AWS ElastiCache for Redis lock store. This allows secure authentication to an AWS ElastiCache without the need for static credentials. To enable this feature:
* set the `IAM_CLOUD_PROVIDER` environment variable to `aws`.
* set the `AWS_DEFAULT_REGION` environment variable to your desired AWS region.
* download the root certificate from Amazon Trust Services and provide its path to the `ssl_ca_certs` lock store yaml property.
* if enabling cluster mode, set the `AWS_ELASTICACHE_CLUSTER_NAME` environment variable to your ElastiCache cluster name.
* ensure that your application has the necessary IAM permissions to access the AWS ElastiCache for Redis cluster.
* Default silence timeout is now configurable per channel. Default silence timeout is read from channel configuration in credentials file. Example:
```
audiocodes_stream:
server_url: "humble-arguably-stork.ngrok-free.app"
asr:
name: deepgram
tts:
name: cartesia
silence_timeout: 5
```
Silence timeout at collect step is also configurable per channel:
```
flows:
- name: example_flow
steps:
- collect:
silence_timeout:
- audiocodes_stream: 5
```
If not configured, default silence timeout is 7 seconds for each channel.
* Adds support for Deepgram TTS Adds `browser_audio` channel to the credentials.yml in `tutorial` template
##### Improvements[](#improvements-3 "Direct link to Improvements")
* In case a `StartFlowCommand` for a flow, that is already on the stack, is predicted, we now resume the flow and interrupt the current active flow instead of ignoring the `StartFlowCommand`.
* Updated `pattern_continue_interrupted` to ask the user if they want to proceed with any of the interrupted flows before resuming that particular flow.
* We have isolated the dependencies that are only required for NLU components. These include:
* `transformers` (version: `"~4.38.2"`)
* `tensorflow` (version: `"^2.19.0`, only available for `"python_version < '3.12'`)
* `tensorflow-text` (version `"^2.19.0"`, only available for `"python_version < '3.12'`)
* `tensorflow-hub` (version: `"^0.13.0"`, only available for `"python_version < '3.12'`)
* `tensorflow-io-gcs-filesystem` (version: `"==0.31"` for `sys_platform == 'win32'`, version: `"==0.34"` for `sys_platform == 'linux'`, version: `"==0.34"` for `sys_platform == 'linux'` for `"sys_platform == 'darwin' and platform_machine != 'arm64'`; all only available for `"python_version < '3.12'`)
* `tensorflow-metal` (version: `"^1.2.0"`, only available for `"python_version < '3.12'`)
* `tf-keras` (version: `"^2.15.0"`, only available for `"python_version < '3.12'`)
* `spacy` (version: `"^3.5.4"`)
* `sentencepiece` (version: `"~0.1.99"`, only available for `"python_version < '3.12'`)
* `skops` (version: `"~0.13.0"`)
* `mitie` (version: `"^0.7.36"`, added for consistency)
* `jieba` (version: `">=0.42.1, <0.43"`)
* `sklearn-crfsuite` (version: `"~0.5.0"`)
The dependencies for those components are now in their own extra, called `nlu` and can be installed via: `poetry install --extras nlu`, `pip install 'rasa-pro[nlu]'` or `uv pip install 'rasa-pro[nlu]'`.
* We added dependencies for agent orchestration, `mcp` (`"~1.12.0"`) and `a2a-sdk` (`"~0.3.4"`), to the list of default dependencies. As a result, they get installed via: `poetry install`, `pip install 'rasa-pro'` or `uv pip install 'rasa-pro'`.
To ensure compatibility between `a2a-sdk` and `tensorflow`, `tensorflow` and its related dependencies were updated. These include:
* `tensorflow` (from `"2.14.1"` to `"^2.19.0"`)
* `tensorflow-text` (from `"2.14.0"` to `^2.19.0`)
* `tensorflow-metal` (from `"1.1.0"` to `"^1.2.0"`)
* instead of `keras` (`"2.14.0"`), we now use `tf-keras` (`"^2.15.0"`)
Additionally, tensorflow dependencies that are incompatible with the upgraded `tensorflow` version were removed. These include: `tensorflow-intel`, `tensorflow-cpu-aws`, `tensorflow-macos`.
Because tensorflow and related packages were upgraded, tensorflow code was also updated. As a consequence, the incremental training feature is not supported anymore. This is because `tf-keras` (`"^2.15.0"`) does not allow a compiled model to be updated.
* We updated the supported Python versions:
* Dropped support for Python 3.9.
* Added support for Python 3.12 and Python 3.13. So, whilst we previously supported `python = ">=3.9.2,<3.12"`, we now support `python = ">=3.10.0,<3.14"`.
To ensure compatibility with the newly supported Python versions, existing dependencies had to be updated. These include:
* `protobuf` (from `"~4.25.8"` to `"~5.29.5"`)
* `importlib-resources` (from `"6.1.3"` to `"^6.5.2"`)
* `opentelemetry-sdk` (from `"~1.16.0"` to `"~1.33.0"`)
* `opentelemetry-exporter-jaeger` (`"~1.16.0"`) - has been removed
* `opentelemetry-exporter-otlp` (from `"~1.16.0"` to `"~1.33.0"`)
* `opentelemetry-api` (from `"~1.16.0"` to `"~1.33.0"`)
* `pep440-version-utils` - only available for `"python_version < '3.13'"`
* `pymilvus` (from `">=2.4.1,<2.4.2"` to `"^2.6.1"`)
* `numpy` (from `"~1.26.4"` to `"~2.1.3"`)
* `scipy` (`"~1.13.1"` for `"python_version < '3.12'"`; `"~1.14.0"` for `"python_version >= '3.12'"`)
* `tensorflow` (version: `"^2.19.0`, only available for `"python_version < '3.12'`)
* `tensorflow-text` (version `"^2.19.0"`, only available for `"python_version < '3.12'`)
* `tensorflow-hub` (version: `"^0.13.0"`, only available for `"python_version < '3.12'`)
* `tensorflow-io-gcs-filesystem` (version: `"==0.31"` for `sys_platform == 'win32'`, version: `"==0.34"` for `sys_platform == 'linux'`, version: `"==0.34"` for `sys_platform == 'linux'` for `"sys_platform == 'darwin' and platform_machine != 'arm64'`; all only available for `"python_version < '3.12'`)
* `tensorflow-metal` (version: `"^1.2.0"`, only available for `"python_version < '3.12'`)
* `tf-keras` (version: `"^2.15.0"`, only available for `"python_version < '3.12'`)
* `sentencepiece` (version: `"~0.1.99"`, only available for `"python_version < '3.12'`)
Note that `tensorflow` and related dependencies are only supported for Python < 3.12. As a result, components requiring those dependencies are not available for Python >= 3.12. These are: `DIETClassifier` , `TEDPolicy` , `UnexpecTEDIntentPolicy` , `ResponseSelector` , `ConveRTFeaturizer` and `LanguageModelFeaturizer` .
* We have isolated the dependencies required for channel connectors. These include:
* `fbmessenger` (version: `"~6.0.0"`)
* `twilio` (version: `"~9.7.2"`)
* `webexteamssdk` (version: `">=1.6.1,<1.7.0"`)
* `mattermostwrapper` (version: `"~2.2"`)
* `rocketchat_API` (version: `">=1.32.0,<1.33.0"`)
* `aiogram` (version: `"~3.22.0"`)
* `slack-sdk` (version: `"~3.36.0"`)
* `cvg-python-sdk` (version: `"^0.5.1"`)
The dependencies for those channels are now in their own extra, called `channels` and can be installed via: `poetry install --extras channels`, `pip install 'rasa-pro[channels]'` or `uv pip install 'rasa-pro[channels]'`. Note that the dependencies for the channels `browser_audio`, `studio_chat`, `socketIO` and `rest` are not included and remain in the main list of dependencies.
* Validation errors now raise meaningful exceptions instead of calling sys.exit(1), producing clearer and more actionable log messages while allowing custom error handling.
* Engine-related modules now raise structured exceptions instead of calling `sys.exit(1)` or `print_error_and_exit`, providing clearer, more actionable log messages and enabling custom error handling.
* Enable connection to AWS services for LLMs (e.g. Bedrock, Sagemaker) via multiple additional methods to environment variables, for example by using IAM roles or AWS credentials file.
* Relocate `latency display` in Inspector
* Implement Redis connection factory class to handle different Redis deployment modes. This class abstracts Redis connection creation and automatically selects the appropriate redis-py client (Redis, RedisCluster, or Sentinel) based on configuration.
* In `standard` mode, connects to a single Redis instance.
* In `cluster` mode, connects to a Redis Cluster using the provided endpoints.
* In `sentinel` mode, connects to a Redis Sentinel setup for high availability.
* Metadata of `action_listen` event in the tracker contains the execution times for Command Processor and Prediction Loop for the previous turn. This information is present in the key `execution_times` in the metadata and the times are in milliseconds.
* Rasa Voice Inspector (browser\_audio channel) used to require a Rasa License with a specific voice scope. This scope requirement has been dropped.
* Add new environment variables for each AWS service integration (RDS, ElastiCache for Redis, MSK) that indicates whether to use IAM authentication when connecting to the service:
* `KAFKA_MSK_AWS_IAM_ENABLED` - set to `true` to enable IAM authentication for MSK connections.
* `RDS_SQL_DB_AWS_IAM_ENABLED` - set to `true` to enable IAM authentication for RDS connections.
* `ELASTICACHE_REDIS_AWS_IAM_ENABLED` - set to `true` to enable IAM authentication for ElastiCache for Redis connections.
##### Bugfixes[](#bugfixes-25 "Direct link to Bugfixes")
* Pass all flows to `find_updated_flows` to avoid creating a `HandleCodeChangeCommand` in situations where flows were not updated.
* The .devcontainer docker-compose file now uses the new `docker.io/bitnamilegacy` repository for images, rather than the old `docker.io/bitnami`. This change was made in response to Bitnami's announcement that they will be putting all of their public Helm Chart container images behind a paywall starting August 28th, 2025. Existing public images are moved to the new legacy repository - `bitnamilegacy` - which is only intended for short-term migration purposes.
* In case an agents fails with an fatal error or returns an unkown state, we now cancel the current active flow next to triggering `pattern_internal_error`.
* Bugfix for Jambonz Stream channel Websocket URL path which resulted in failed Websocket Connections
* Fixed the contextual response rephraser to use and update the correct translated response text for the current language, instead of falling back to the default response.
* Refactored `validate_argument_paths` to accept list values and aggregate all missing paths before exiting.
* Fix expansion of referenced environment variables in `endpoints.yml` during Bedrock model config validation.
* Enabled the data argument to support both string and list inputs, normalizing to a list for consistent handling.
* Fixed model loading failures on Windows systems running recent Python versions (3.9.23+, 3.10.18+, 3.11.13+) due to tarfile security fix incompatibility with Windows long path prefix.
* Fixes the silence handling bug in Audiocodes Stream Channel where consecutive bot responses could trip silence timeout pattern while the bot is speaking. Audiocodes Stream channel now forecefully cancels the silence timeout watcher whenever it sends the bot response audio.
* Use correct formatting method for messages in `completion` and `acompletion` functions of `LiteLLMRouterLLMClient`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-11 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.13.24] - 2026-02-23[](#31324---2026-02-23 "Direct link to [3.13.24] - 2026-02-23")
Rasa Pro 3.13.24 (2026-02-23)
##### Bugfixes[](#bugfixes-26 "Direct link to Bugfixes")
* **E2E fixture resolution and conftest hierarchy:**
Fixture resolution now uses a conftest-style hierarchy, with local overrides taking precedence over global fixtures. This is a change from the previous behavior where all fixtures were merged into a single list, which could lead to silent data loss if duplicate fixture names were used. Now, every test case has its own resolved set of fixtures, and duplicate fixture names are allowed when the intent is "override".
Details:
* **Conftest-style hierarchy:** Fixtures can be defined at root or folder level (e.g. `conftest.yml` / `conftest.yaml`); all e2e tests under that path see them.
* **Single-file run parity:** Running one test file resolves fixtures the same way as when that file is run as part of the full suite (global/conftest fixtures are loaded for that file’s path).
* **Runtime namespace:** Each test case has its own resolved set of fixtures; there is no shared mutable fixture state between tests. Duplicate fixture names in **different** files are allowed when the intent is “override” (no need to remove or rename for full-suite runs).
* **Override semantics:** Local (file-level) fixtures override folder-level; folder-level overrides root. Within a single file, duplicate fixture names remain an error.
#### \[3.13.23] - 2026-02-12[](#31323---2026-02-12 "Direct link to [3.13.23] - 2026-02-12")
Rasa Pro 3.13.23 (2026-02-12)
##### Improvements[](#improvements-4 "Direct link to Improvements")
* Flows can now link to `pattern_search` (e.g. to trigger RAG or branch on knowledge-based search).
##### Bugfixes[](#bugfixes-27 "Direct link to Bugfixes")
* Fixed e2e test coverage report to correctly track coverage per flow. Each flow now appears as a separate entry with accurate coverage percentages. Additionally, `call`/`link` steps and `collect` steps with prefilled slots are now properly marked as visited.
* Upgrade `litellm` to 1.80.0.
* Fix Enterprise Search Policy triggering `utter_ask_rephrase` instead of `utter_no_relevant_answer_found` when the vector store search returns no matching documents. The `pattern_cannot_handle` now correctly receives the `cannot_handle_no_relevant_answer` as a `context.reason` in all cases where no relevant answer is found, not only when the optional relevancy check rejects the answer.
#### \[3.13.22] - 2026-01-15[](#31322---2026-01-15 "Direct link to [3.13.22] - 2026-01-15")
Rasa Pro 3.13.22 (2026-01-15)
##### Bugfixes[](#bugfixes-28 "Direct link to Bugfixes")
* Fixed an issue where storing documents in FAISS individually could hit the token limit. Now, documents are stored in batches to avoid exceeding the token limit.
* Throw error when duplicate fixtures are found in the same file or across files.
* `SessionEnded` does not reset the tracker anymore.
* Updated `werkzeug`, `filelock`, `fonttools`, `marshmallow`, `urllib3` and `langchain-core`to resolve security vulnerabilities.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-12 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.13.21] - 2025-12-29[](#31321---2025-12-29 "Direct link to [3.13.21] - 2025-12-29")
Rasa Pro 3.13.21 (2025-12-29)
##### Bugfixes[](#bugfixes-29 "Direct link to Bugfixes")
* Include response button titles in conversation history in prompts of LLM based components.
* Fix OpenTelemetry exporter `Invalid type of value None` error when recording the request duration metric for requests made from Rasa server to the custom action server. This error occurred because the url parameter was not being passed to the method that records the request duration metric, resulting in a NoneType value.
* Fix DUT fails with AttributeError when running with custom CommandGenerator
#### \[3.13.20] - 2025-12-19[](#31320---2025-12-19 "Direct link to [3.13.20] - 2025-12-19")
Rasa Pro 3.13.20 (2025-12-19)
##### Bugfixes[](#bugfixes-30 "Direct link to Bugfixes")
* Fixed token expiration validation failing on servers running in non-UTC timezones. Token expiration checks now use timezone-aware UTC datetimes consistently, preventing premature "access token expired" errors on systems in timezones like UTC+8.
#### \[3.13.19] - 2025-12-11[](#31319---2025-12-11 "Direct link to [3.13.19] - 2025-12-11")
Rasa Pro 3.13.19 (2025-12-11)
##### Bugfixes[](#bugfixes-31 "Direct link to Bugfixes")
* Fix bug in `CommandPayloadReader` where regex matching did not account for list slots, leading to incorrect parsing of slot keys and values. Now, slot names and values are correctly extracted even if a list is provided.
* Previously, `DialogueStateTracker.has_coexistence_routing_slot` could incorrectly return `True` when the tracker was created without domain slots (i.e., using `AnySlotDict`), because `AnySlotDict` pretends all slots exist. Now, the property returns False in that case, so the routing slot is only considered present if it is actually defined in the domain.
* Fix LLM prompt template loading to raise an error instead of just printing a warning when a custom prompt file is missing or cannot be read.
* Fix `AttributeError: 'str' object has no attribute 'pop'` when using `KnowledgeAnswerCommand` with tracing enabled.
* Fix `UnboundLocalError` in `E2ETestRunner._handle_fail_diff` that caused e2e tests to crash when processing `slot_was_not_set` assertion failures.
* Fixed button payloads with nested parentheses (e.g., `/SetSlots(slot=value)`) not being parsed correctly in `rasa shell`. The payload was incorrectly stripped of its `/SetSlots` prefix, causing it to be treated as text instead of a slot-setting command.
* Add missing deprecation warning for legacy `RASA_PRO_LICENSE` environment variable. Update license validation error messages to reference the actual environment variable used.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-13 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.13.18] - 2025-12-04[](#31318---2025-12-04 "Direct link to [3.13.18] - 2025-12-04")
Rasa Pro 3.13.18 (2025-12-04)
##### Bugfixes[](#bugfixes-32 "Direct link to Bugfixes")
* Update `pip` to fix security vulnerability.
* Disable LLM health check for Enterprise Search Policy when generative search is disabled (i.e. use\_generative\_llm is False).
* Fix deduplication of collect steps in cases where the same slot was called in different flows.
* Cancel active flow before triggering internal pattern error during a custom action failure.
* Fix bug with the missing `language_data` module by installing `langcodes` with the `data` extra dependency.
#### \[3.13.17] - 2025-11-27[](#31317---2025-11-27 "Direct link to [3.13.17] - 2025-11-27")
Rasa Pro 3.13.17 (2025-11-27)
##### Bugfixes[](#bugfixes-33 "Direct link to Bugfixes")
* Fixed PostgreSQL `UniqueViolation` error when running an assistant with multiple Sanic workers.
* Fix Kafka producer creation failing when SASL mechanism is specified in lowercase. The SASL mechanism is now case-insensitive in the Kafka producer configuration.
* Fix issue where the validation of the assistant files continued even when the provided domain was invalid and was being loaded as empty. The training or validation command didn't exit because the final merged domain contained only the default implementations for patterns, slots and responses and therefore passed the check for being non-empty.
* Trigger pattern\_internal\_error in a CALM assistant when a custom action fails during execution.
* Create AWS Bedrock / Sagemaker client only if the LLM healthcheck environment variable is set. If the environment variable is not set, validate that required credentials are present.
* Update `langchain-core` version to `~0.3.80` to address security vulnerability CVE-2025-65106.
* Raise validation error when duplicate slot definitions are found across domains.
* Raise validation error when a slot with an initial value set is collected by a flow collect step which sets `asks_before_filling` to `true` without having a corresponding collect utterance or custom action.
#### \[3.13.16] - 2025-11-21[](#31316---2025-11-21 "Direct link to [3.13.16] - 2025-11-21")
Rasa Pro 3.13.16 (2025-11-21)
##### Bugfixes[](#bugfixes-34 "Direct link to Bugfixes")
* Fixed `patten-continue-interrupted` running out of order before linked flows.
* Fix `rasa studio upload` timeouts by enabling TCP keep-alive with platform-specific socket options to maintain stable connections.
* Remove `action_metadata` tracing span attribute from `EnterpriseSearchPolicy` instrumentation to prevent PII leakages. Add new environment variable `RASA_TRACING_DEBUGGING_ENABLED` to enable adding `action_metadata` to `EnterpriseSearchPolicy` spans for debugging purposes. By default, this variable is set to `false` to ensure PII is not logged in production environments.
#### \[3.13.15] - 2025-11-13[](#31315---2025-11-13 "Direct link to [3.13.15] - 2025-11-13")
Rasa Pro 3.13.15 (2025-11-13)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-14 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.13.14] - 2025-10-30[](#31314---2025-10-30 "Direct link to [3.13.14] - 2025-10-30")
Rasa Pro 3.13.14 (2025-10-30)
##### Improvements[](#improvements-5 "Direct link to Improvements")
* Add new environment variable `LOG_LEVEL_PYMONGO` to control the logging level of PyMongo dependency of Rasa. This can be useful to reduce the verbosity of logs. Default value is `INFO`.
The logging level of PyMongo can also be set via the `LOG_LEVEL_LIBRARIES` environment variable, which provides the default logging level for a selection of third-party libraries used by Rasa. If both variables are set, `LOG_LEVEL_PYMONGO` takes precedence.
##### Bugfixes[](#bugfixes-35 "Direct link to Bugfixes")
* Clean up duplicated `ChitChatAnswerCommands` in command processor.
Ensure that one `CannotHandleCommand` remains if only multiple `CannotHandleCommands` were present.
* LLM request timeouts are now enforced at the event loop level using `asyncio.wait_for`.
Previously, timeout values configured in `endpoints.yml` could be overridden by the HTTP client's internal timeout behavior. This fix ensures that when a specific timeout value is configured for LLM requests, the request respects that exact timing regardless of the underlying HTTP client implementation.
* Fixed an issue where duplicate collect steps in a flow could cause rendering problems, such as exceeding token limits. This occurred when a flow called another flow multiple times. Now, each collect step is listed only once when retrieving all collect steps for a flow.
* If a FloatSlot does not have min and max values set in the domain, the slot will not be validated against any range. If the slot defines an initial value, as well as min and max values, the initial value will be validated against the range and an error will be raised if the initial value is out of range. Enhance run-time validation for new values assigned to FloatSlot instances, ensuring they fall within the defined min and max range if these are set. If min and max are not set, no range validation is performed.
* Fixed bug preventing `deployment` parameter from being used in generative response LLM judge configuration.
* Fixed bug where `persisted_slots` defined in called flows were incorrectly reset when the parent flow ended, unless they were also explicitly defined in the parent flow. Persisted slots now only need to be defined in the called flow to remain persisted after the parent flow ends.
* Fixes the prompt template resolution logic in the CompactLLMCommandGenerator and SearchReadyLLMCommandGenerator classes.
* When `action_clean_stack` is used in a user flow, allow `pattern_completed` to be triggered even if there are pattern flows at the bottom of the dialogue stack below the top user flow frame. Previously, `pattern_completed` would only trigger if there were no other frames below the top user flow frame. This assumes that the `action_clean_stack` is the last action called in the user flow.
* Update `pip` version used in Dockerfile to `23.*` to address security vulnerability CVE-2023-5752. Update `python-socketio` version to `5.14.0` to address security vulnerability CVE-2025-61765.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-15 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.13.13] - 2025-10-13[](#31313---2025-10-13 "Direct link to [3.13.13] - 2025-10-13")
Rasa Pro 3.13.13 (2025-10-13)
##### Bugfixes[](#bugfixes-36 "Direct link to Bugfixes")
* Use correct formatting method for messages in `completion` and `acompletion` functions of `LiteLLMRouterLLMClient`.
#### \[3.13.12] - 2025-09-17[](#31312---2025-09-17 "Direct link to [3.13.12] - 2025-09-17")
Rasa Pro 3.13.12 (2025-09-17)
##### Improvements[](#improvements-6 "Direct link to Improvements")
* Accept either `RASA_PRO_LICENSE` or `RASA_LICENSE` as a valid Environment Variable for providing the Rasa License. Also deprecates `RASA_PRO_LICENSE` Environment Variable.
##### Bugfixes[](#bugfixes-37 "Direct link to Bugfixes")
* Fixed conversation hanging when using direct action execution with invalid actions module by deferring module validation until action execution time, allowing proper exception handling in the processor.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-16 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.13.11] - 2025-09-15[](#31311---2025-09-15 "Direct link to [3.13.11] - 2025-09-15")
Rasa Pro 3.13.11 (2025-09-15)
No significant changes.
#### \[3.13.10] - 2025-09-12[](#31310---2025-09-12 "Direct link to [3.13.10] - 2025-09-12")
Rasa Pro 3.13.10 (2025-09-12)
##### Bugfixes[](#bugfixes-38 "Direct link to Bugfixes")
* Fixes the silence handling bug in Audiocodes Stream Channel where consecutive bot responses could trip silence timeout pattern while the bot is speaking. Audiocodes Stream channel now forcefully cancels the silence timeout watcher whenever it sends the bot response audio.
* Update `langchain` to `0.3.27` and `langchain-community` to `0.3.29` to fix CVE-2025-6984 vulnerability in `langchain-community` version `0.2.19`.
#### \[3.13.9] - 2025-09-03[](#3139---2025-09-03 "Direct link to [3.13.9] - 2025-09-03")
Rasa Pro 3.13.9 (2025-09-03)
##### Bugfixes[](#bugfixes-39 "Direct link to Bugfixes")
* Upgrade `skops` to version `0.13.0` and `requests` to version `2.32.5` to fix vulnerabilities.
* Fixed flow retrieval to skip vector store population when there are no flows to embed.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-17 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.13.8] - 2025-08-26[](#3138---2025-08-26 "Direct link to [3.13.8] - 2025-08-26")
Rasa Pro 3.13.8 (2025-08-26)
##### Improvements[](#improvements-7 "Direct link to Improvements")
* Validation errors now raise meaningful exceptions instead of calling sys.exit(1), producing clearer and more actionable log messages while allowing custom error handling.
* Enable connection to AWS services for LLMs (e.g. Bedrock, Sagemaker) via multiple additional methods to environment variables, for example by using IAM roles or AWS credentials file.
##### Bugfixes[](#bugfixes-40 "Direct link to Bugfixes")
* The .devcontainer docker-compose file now uses the new `docker.io/bitnamilegacy` repository for images, rather than the old `docker.io/bitnami`. This change was made in response to Bitnami's announcement that they will be putting all of their public Helm Chart container images behind a paywall starting August 28th, 2025. Existing public images are moved to the new legacy repository - `bitnamilegacy` - which is only intended for short-term migration purposes.
* Fix expansion of referenced environment variables in `endpoints.yml` during Bedrock model config validation.
* Fixed model loading failures on Windows systems running recent Python versions (3.9.23+, 3.10.18+, 3.11.13+) due to tarfile security fix incompatibility with Windows long path prefix.
#### \[3.13.7] - 2025-08-15[](#3137---2025-08-15 "Direct link to [3.13.7] - 2025-08-15")
Rasa Pro 3.13.7 (2025-08-15)
##### Bugfixes[](#bugfixes-41 "Direct link to Bugfixes")
* Don't tigger a slot correction for slots that are currently set to `None` as `None` counts as empty value.
* Enabled the data argument to support both string and list inputs, normalizing to a list for consistent handling.
#### \[3.13.6] - 2025-08-08[](#3136---2025-08-08 "Direct link to [3.13.6] - 2025-08-08")
Rasa Pro 3.13.6 (2025-08-08)
##### Bugfixes[](#bugfixes-42 "Direct link to Bugfixes")
* Fixed the contextual response rephraser to use and update the correct translated response text for the current language, instead of falling back to the default response.
* Refactored `validate_argument_paths` to accept list values and aggregate all missing paths before exiting.
#### \[3.13.5] - 2025-07-31[](#3135---2025-07-31 "Direct link to [3.13.5] - 2025-07-31")
Rasa Pro 3.13.5 (2025-07-31)
##### Bugfixes[](#bugfixes-43 "Direct link to Bugfixes")
* Fix correction of slots:
* Slots can only be corrected in case they belong to any flow on the stack and the slot to be corrected is part of a collect step in any of those flows.
* A correction of a slot should be applied if the flow that is about to start is using this slot.
* Upgrade `axios` to fix security vulnerability.
* Fix issue where called flows could not set slots of their parent flow.
#### \[3.13.4] - 2025-07-23[](#3134---2025-07-23 "Direct link to [3.13.4] - 2025-07-23")
Rasa Pro 3.13.4 (2025-07-23)
##### Improvements[](#improvements-8 "Direct link to Improvements")
* Engine-related modules now raise structured exceptions instead of calling `sys.exit(1)` or `print_error_and_exit`, providing clearer, more actionable log messages and enabling custom error handling.
##### Bugfixes[](#bugfixes-44 "Direct link to Bugfixes")
* Fix validation of the FAISS documents folder to ensure it correctly discovers files in a recursive directory structure.
* Updated `Inspector` dependent packages (`vite`, and `@adobe/css-tools`) to address security vulnerabilities.
* Fixed bug preventing `model_group` from being used with `embeddings` in generative response LLM judge configuration.
#### \[3.13.3] - 2025-07-17[](#3133---2025-07-17 "Direct link to [3.13.3] - 2025-07-17")
Rasa Pro 3.13.3 (2025-07-17)
##### Bugfixes[](#bugfixes-45 "Direct link to Bugfixes")
* Allowed NLG servers to return None for the text property and ensured custom response data is properly retained.
#### \[3.13.2] - 2025-07-16[](#3132---2025-07-16 "Direct link to [3.13.2] - 2025-07-16")
Rasa Pro 3.13.2 (2025-07-16)
##### Bugfixes[](#bugfixes-46 "Direct link to Bugfixes")
* Pass all flows to `find_updated_flows` to avoid creating a `HandleCodeChangeCommand` in situations where flows were not updated.
* Bugfix for Jambonz Stream channel Websocket URL path which resulted in failed Websocket Connections
#### \[3.13.1] - 2025-07-14[](#3131---2025-07-14 "Direct link to [3.13.1] - 2025-07-14")
Rasa Pro 3.13.1 (2025-07-14)
##### Bugfixes[](#bugfixes-47 "Direct link to Bugfixes")
* Fix issues with bot not giving feedback for slot corrections.
* Fixed bot speaking state management in Audiocodes Stream channel. This made the assistant unable to handle user silences Added periodic keepAlive messages to deepgram, this interval can be configured with `keep_alive_interval` parameter
#### \[3.13.0] - 2025-07-07[](#3130---2025-07-07 "Direct link to [3.13.0] - 2025-07-07")
Rasa Pro 3.13.0 (2025-07-07)
##### Deprecations and Removals[](#deprecations-and-removals "Direct link to Deprecations and Removals")
* Deprecate IntentlessPolicy and schedule for removal in Rasa `4.0.0`.
* Removed `monitor_silence` parameter from Voice Channel configuration. Silence Monitoring is now enabled by default. It can be configured by changing the value of Global Silence Timeout
* Remove pre-CALM PII management capability originally released in Rasa Plus 3.6.0. Remove `presidio`, `faker` and `pycountry` dependencies from Rasa Pro.
##### Features[](#features-2 "Direct link to Features")
* Introducing the `SearchReadyLLMCommandGenerator` component, an enhancement over the `CompactLLMCommandGenerator`. This new component improves the triggering accuracy of `KnowledgeAnswerCommand` and should be used when the `EnterpriseSearchPolicy` is added to the pipeline. By default, this new component does not trigger the `ChitChatAnswerCommand` and `HumanHandoffCommand`. Handling small talk and chit-chat conversations is now delegated to the `EnterpriseSearchPolicy`.
To incorporate the `SearchReadyLLMCommandGenerator` into your pipeline, simply add the following:
pipeline:
```
...
- name: SearchReadyLLMCommandGenerator
...
```
* Implement Privacy Filter capability to detect PII in 3 supported events (SlotSet, BotUttered, and UserUttered) and anonymise PII from the event data.
The PII detection takes a tiered approach:
* the first tier represents a slot-based approach: the sensitive data is stored in a slot whose name is defined in the privacy YAML configuration.
* the second optional tier uses a default GliNer model to detect PII that is not captured by the slot-based approach.
The anonymisation of PII is done by redacting or replacing the sensitive data with a placeholder. These anonymisation rules are also defined in the privacy YAML configuration.
* `EnterpriseSearchPolicy` can now assess the relevancy of the generated answer. By default, the policy does not check the relevancy of the generated answer. But you enable the relevancy check by setting `check_relevancy` to `true` in the policy configuration.
```
policies:
- name: FlowPolicy
- name: EnterpriseSearchPolicy
...
check_relevancy: true # by default this is false
```
If the relevancy check is enabled, the policy will evaluate the generated answer and determine if it is relevant to the user's query. In case the answer is relevant, the generated answer will be returned to the user. If the answer is not relevant, the policy will fallback to `pattern_cannot_handle` to handle the situation.
```
pattern_cannot_handle:
description: |
Conversation repair flow for addressing failed command generation scenarios
name: pattern cannot handle
steps:
- noop: true
next:
... # other cases
# Fallback to handle cases where the generated answer is not relevant
- if: "'{{context.reason}}' = 'cannot_handle_no_relevant_answer'"
then:
- action: utter_no_relevant_answer_found
next: "END"
```
* Implement privacy manager class which manages privacy-related tasks in the background.
This class handles the anonymization and deletion of sensitive information in dialogue state trackers stored in the tracker store, as well as the streaming of anonymized events to event brokers. It uses background schedulers to periodically run these tasks and processes trackers from a queue to ensure that sensitive information is handled in a timely manner.
* Add support for `jambonz_stream` voice-stream channel. Log level of `websockets` library is set to `ERROR` by default, it can be changed by the environment variable `LOG_LEVEL_LIBRARIES`.
* Remove the beta feature flag check from the `RepeatBotMessagesCommand`. The `RASA_PRO_BETA_REPEAT_COMMAND` environment variable is no longer needed as the feature is GA in 3.13.0.
##### Improvements[](#improvements-9 "Direct link to Improvements")
* Coverage report feature can now be used independently of RASA\_PRO\_BETA\_FINE\_TUNING\_RECIPE feature flag.
* Update default Embedding model from `text-embedding-ada-002` to `text-embedding-3-large`. Update `LLMBasedRouter`, `IntentlessPolicy` and `ContextualResponseRephraser` default models to use `gpt-4o-2024-11-20` instead of `gpt-3.5-turbo`. Update the `EnterpriseSearchPolicy` to use `gpt-4.1-mini-2025-04-14` instead of `gpt-3.5-turbo`.
* Update `MultistepCommandGenerator` to use `gpt-4o`, specifically `gpt-4o-2024-11-20`, instead of `gpt-3.5-turbo` as `gpt-3.5-turbo` will be deprecated on July 16, 2025. Add deprecation warning for `SingleStepCommandGenerator`; leave current default model as `gpt-4-0613`. Adapt tests for CommandGenerators to use `gpt-4o` instead of `gpt-3.5-turbo` due to upcoming model deprecation. Update `LLMJudgeModel` and `Fine tuning Conversation Rephraser` to use `gpt-4.1-mini`, specifically `gpt-4.1-mini-2025-04-14`, instead of `gpt-4o-mini`, as `gpt-4o-mini` will be deprecated on September 15, 2025.
* Make `CALM` template the default for `rasa init`.
* Redis lock store now accepts `host` property from endpoints config. Property `url` is marked as deprecated for Redis lock store.
* Added support for basic authentication in Twilio channels (Voice Ready and Voice Streaming). This allows users to authenticate their Twilio channels using basic authentication credentials, enhancing security and access control for voice communication. To use this feature, set `username` and `password` in the Twilio channel configuration.
credentials.yaml
```
twilio_voice:
username: your_username
password: your_password
...
twilio_media_streams:
username: your_username
password: your_password
...
```
At Twilio, configure the webhook URL to include the basic authentication credentials:
```
# twilio voice webhook
https://:@yourdomain.com/webhooks/twilio_voice/webhook
# twilio media streams webhook
https://:@yourdomain.com/webhooks/twilio_media_streams/webhook
```
* Added two endpoints to the model service for retrieving the assistant’s default configuration and the default project template used by the assistant.
* All conversations on Twilio Media Streams, Audiocodes Stream, Genesys channel ends with the message `/session_end`. This applies to both the conversation ended by user and the assistant.
* Refactor Voice Inspector to use AudioWorklet Web API
* Added new CLI commands to support project-level linking and granular push/pull workflows for Rasa Studio assistants:
* Introduced `rasa studio link` to associate a local project with a specific Studio assistant.
* Added `rasa studio pull` and `rasa studio push`, with subcommands for granular resource updates (`config`, `endpoints`) between local and Studio assistants.
* Implement `delete` method for `InMemoryTrackerStore`,`AuthRetryTrackerStore`, `AwaitableTrackerStore` and `FailSafeTrackerStore` subclasses.
* Implement `delete` method for `MongoTrackerStore`.
* Implement `delete` method for SQLTrackerStore: this method accepts sender\_id and deletes the corresponding tracker from the store if it exists.
* Implement `delete` method for DynamoTrackerStore: this method accepts sender\_id and deletes the corresponding tracker from the store if it exists.
* Implement `delete` method for `RedisTrackerStore`.
* Update `KafkaEventBroker` YAML config to accept 2 new parameters:
* `stream_pii`: boolean (default: true). If set to `false`, the broker will not publish un-anonymised events to the configured topic.
* `anonymization_topics`: list of strings (default: \[]). If set, the broker will publish anonymised events to the configured topics when the PII management capability is enabled.
* Add 2 new PII configuration parameters to `PikaEventBroker`:
* `stream_pii`: Boolean flag to control whether or not to publish un-anonymised events to the configured `queues`. If set to False, un-anonymised events won't be published to RabbitMQ. Defaults to `True` for backwards compatibility.
* `anonymization_queues`: List of queue names that should receive anonymized events with PII removed. Defaults to an empty list (`[]`).
* Add a new `anonymized_at` timestamp field to the Rasa Pro events supported by the PII management capability:
* `user`
* `slot`
* `bot` This field indicates when the PII data in the event was anonymized. The field is set to `null` if the PII data has not been anonymized.
* Add support for reading `privacy` configuration key from endpoints file to enable PII management capability.
* Add new `DELETE /conversations//tracker` endpoint that allows deletion of tracker data for a specific conversation.
* Cleaned up potential sources of PII from `info`, `exception` and `error` logs.
* Allow default patterns to link to `pattern_chitchat`.
* Cleaned up potential sources of PII from `warning` logs.
* Add a warning log to alert users when exporting tracker data that contains unanonymized events.
* Remove beta feature flag for pypred predicate usage in conditional response variations. Mark this functionality for general availability (GA).
* Updated the default behavior of `pattern_chitchat`. With the deprecation of `IntentlessPolicy`, `pattern_chitchat` now defaults to responding with `utter_cannot_handle` instead of triggering `action_trigger_chitchat`.
* PII deletion job now performs a single database transaction in the case of trackers with multiple sessions, where only some sessions are eligible for deletion. The deletion job overwrites the serialized tracker record with the retained events only. This ensures that the tracker store is updated atomically, preventing any potential tracker data loss in case of Rasa Pro server crashes or other issues during the deletion job execution.
##### Bugfixes[](#bugfixes-48 "Direct link to Bugfixes")
* Fixes a bug where fine-tuning data generation raises a FineTuningDataPreparationException for test cases without assertions that end with one/multiple user utterance/s, as opposed to one/multiple bot utterance/s.
For these types of test cases, the fine-tuning data generation transcript now contains all test case utterances up to but excluding the last user utterance(s) as the test case does not specify the corresponding, expected bot response(s).
* allowed for usage of litellm model prefixes that do not end in '\/'
* Fixes a bug in Inspector that raised a TypeError when serialising `numpy.float64` from Tracker
* * Fixes an issue with prompt rendering where minified JSON structures were displayed without properly escaping newlines, tabs, and quotes.
* Introduced a new Jinja `filter to_json_encoded_string` that escapes newlines (`\n`), tabs (`\t`), and quotes (`\"`) for safe JSON rendering. `to_json_encoded_string` filter preserves other special characters (e.g., umlauts) without encoding them.
* Updated the default prompts for `gpt-4o` and `claude-sonnet-3.5`
* Fix intermittent crashes on Inspector app when Enterprise Search or Chitchat Policies were triggered
* Add channel name to UserMessage created by the Audiocodes channel.
* Reduced redundant log entries when reading prompt templates by contextualizing them. Added source component and method metadata to logs, and changed prompt-loading logs triggered from `fingerprint_addon` to use `DEBUG` level.
* Prompts for rephrased messages and conversations are now rendered using agent, eliminating errors that occurred when string replacements broke after prompt updates.
* Fix retrieval of latest tracker session from DynamoTrackerStore.
* Files generated by the finetuning data generation pipeline are now encoded in UTF-8, allowing characters such as German umlauts (ä, ö, ü) to render correctly.
* Fix an issue where the SetSlot and Clarify command value was parsed incorrectly if a newline character immediately followed the value argument in the LLM output.
* Fixed the repeat action to include all messages of the last turn in collect steps.
* * Fix an issue where running `rasa inspect` would always set the `route_session_to_calm` slot to `True`, even when no user-triggered commands were present. This caused incorrect routing to CALM, bypassing the logic of the router.
* Fix a regression in non-sticky routing where sessions intended for the NLU were incorrectly routed to CALM when the router predicted `NoopCommand()`.
* Fix validation and improve error messages for the documents source directory when FAISS vector store is configured for the Enterprise Search Policy.
* Prevent slot correction when the slot is already set to the desired value.
* Fallback to `CannotHandle` command when the slot predicted by the LLM is not defined in the domain.
* Fix tracker store PII background jobs not updating the `InMemoryTrackerStore` reference stored by the Agent.
* Fix potential `KeyError` in `EnterpriseSearchPolicy` citation post-processing when the source does not have the correct citation. Improve the citation post-processing logic to handle additional edge cases.
* Fix issue with PrivacyManager unable to retrieve trackers from Redis tracker store during its deletion background job, because the Redis tracker store prefix was added twice during retrieval.
* Fixed anonymization failing for `FloatSlots` when user-provided integer values don't match the stored float representation during text replacement.
* Fix Redis tracker store saving tracker with prefix added twice during the anonymization background job.
* Fix DynamoDB tracker store overwriting tracker with the latest session in case of multiple sessions saved prior.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-18 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.42] - 2025-12-11[](#31242---2025-12-11 "Direct link to [3.12.42] - 2025-12-11")
Rasa Pro 3.12.42 (2025-12-11)
##### Bugfixes[](#bugfixes-49 "Direct link to Bugfixes")
* Fix bug in `CommandPayloadReader` where regex matching did not account for list slots, leading to incorrect parsing of slot keys and values. Now, slot names and values are correctly extracted even if a list is provided.
* Previously, `DialogueStateTracker.has_coexistence_routing_slot` could incorrectly return `True` when the tracker was created without domain slots (i.e., using `AnySlotDict`), because `AnySlotDict` pretends all slots exist. Now, the property returns False in that case, so the routing slot is only considered present if it is actually defined in the domain.
* Fix LLM prompt template loading to raise an error instead of just printing a warning when a custom prompt file is missing or cannot be read.
* Fix `AttributeError: 'str' object has no attribute 'pop'` when using `KnowledgeAnswerCommand` with tracing enabled.
* Fix `UnboundLocalError` in `E2ETestRunner._handle_fail_diff` that caused e2e tests to crash when processing `slot_was_not_set` assertion failures.
* Fixed button payloads with nested parentheses (e.g., `/SetSlots(slot=value)`) not being parsed correctly in `rasa shell`. The payload was incorrectly stripped of its `/SetSlots` prefix, causing it to be treated as text instead of a slot-setting command.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-19 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.41] - 2025-12-04[](#31241---2025-12-04 "Direct link to [3.12.41] - 2025-12-04")
Rasa Pro 3.12.41 (2025-12-04)
##### Bugfixes[](#bugfixes-50 "Direct link to Bugfixes")
* Update `pip` to fix security vulnerability.
* Disable LLM health check for Enterprise Search Policy when generative search is disabled (i.e. use\_generative\_llm is False).
* Fix deduplication of collect steps in cases where the same slot was called in different flows.
* Cancel active flow before triggering internal pattern error during a custom action failure.
* Fix bug with the missing `language_data` module by installing `langcodes` with the `data` extra dependency.
#### \[3.12.40] - 2025-11-27[](#31240---2025-11-27 "Direct link to [3.12.40] - 2025-11-27")
Rasa Pro 3.12.40 (2025-11-27)
##### Bugfixes[](#bugfixes-51 "Direct link to Bugfixes")
* Fixed PostgreSQL `UniqueViolation` error when running an assistant with multiple Sanic workers.
* Fix issue where the validation of the assistant files continued even when the provided domain was invalid and was being loaded as empty. The training or validation command didn't exit because the final merged domain contained only the default implementations for patterns, slots and responses and therefore passed the check for being non-empty.
* Trigger pattern\_internal\_error in a CALM assistant when a custom action fails during execution.
* Update `langchain-core` version to `~0.3.80` to address security vulnerability CVE-2025-65106.
* Raise validation error when duplicate slot definitions are found across domains.
* Raise validation error when a slot with an initial value set is collected by a flow collect step which sets `asks_before_filling` to `true` without having a corresponding collect utterance or custom action.
#### \[3.12.39] - 2025-11-21[](#31239---2025-11-21 "Direct link to [3.12.39] - 2025-11-21")
Rasa Pro 3.12.39 (2025-11-21)
##### Bugfixes[](#bugfixes-52 "Direct link to Bugfixes")
* Fixed `patten-continue-interrupted` running out of order before linked flows.
* Remove `action_metadata` tracing span attribute from `EnterpriseSearchPolicy` instrumentation to prevent PII leakages. Add new environment variable `RASA_TRACING_DEBUGGING_ENABLED` to enable adding `action_metadata` to `EnterpriseSearchPolicy` spans for debugging purposes. By default, this variable is set to `false` to ensure PII is not logged in production environments.
* Fix Kafka producer creation failing when SASL mechanism is specified in lowercase. The SASL mechanism is now case-insensitive in the Kafka producer configuration.
#### \[3.12.38] - 2025-11-13[](#31238---2025-11-13 "Direct link to [3.12.38] - 2025-11-13")
Rasa Pro 3.12.38 (2025-11-13)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-20 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.37] - 2025-10-30[](#31237---2025-10-30 "Direct link to [3.12.37] - 2025-10-30")
Rasa Pro 3.12.37 (2025-10-30)
##### Bugfixes[](#bugfixes-53 "Direct link to Bugfixes")
* Clean up duplicated `ChitChatAnswerCommands` in command processor.
Ensure that one `CannotHandleCommand` remains if only multiple `CannotHandleCommands` were present.
* LLM request timeouts are now enforced at the event loop level using `asyncio.wait_for`.
Previously, timeout values configured in `endpoints.yml` could be overridden by the HTTP client's internal timeout behavior. This fix ensures that when a specific timeout value is configured for LLM requests, the request respects that exact timing regardless of the underlying HTTP client implementation.
* Fixed an issue where duplicate collect steps in a flow could cause rendering problems, such as exceeding token limits. This occurred when a flow called another flow multiple times. Now, each collect step is listed only once when retrieving all collect steps for a flow.
* Fixes the prompt template resolution logic in the CompactLLMCommandGenerator.
* When `action_clean_stack` is used in a user flow, allow `pattern_completed` to be triggered even if there are pattern flows at the bottom of the dialogue stack below the top user flow frame. Previously, `pattern_completed` would only trigger if there were no other frames below the top user flow frame. This assumes that the `action_clean_stack` is the last action called in the user flow.
* Update `pip` version used in Dockerfile to `23.*` to address security vulnerability CVE-2023-5752.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-21 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.36] - 2025-10-27[](#31236---2025-10-27 "Direct link to [3.12.36] - 2025-10-27")
Rasa Pro 3.12.36 (2025-10-27)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-22 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.35] - 2025-10-21[](#31235---2025-10-21 "Direct link to [3.12.35] - 2025-10-21")
Rasa Pro 3.12.35 (2025-10-21)
##### Improvements[](#improvements-10 "Direct link to Improvements")
* Add new environment variable `LOG_LEVEL_PYMONGO` to control the logging level of PyMongo dependency of Rasa. This can be useful to reduce the verbosity of logs. Default value is `INFO`.
The logging level of PyMongo can also be set via the `LOG_LEVEL_LIBRARIES` environment variable, which provides the default logging level for a selection of third-party libraries used by Rasa. If both variables are set, `LOG_LEVEL_PYMONGO` takes precedence.
##### Bugfixes[](#bugfixes-54 "Direct link to Bugfixes")
* If a FloatSlot does not have min and max values set in the domain, the slot will not be validated against any range. If the slot defines an initial value, as well as min and max values, the initial value will be validated against the range and an error will be raised if the initial value is out of range. Enhance run-time validation for new values assigned to FloatSlot instances, ensuring they fall within the defined min and max range if these are set. If min and max are not set, no range validation is performed.
* Fixed bug preventing `deployment` parameter from being used in generative response LLM judge configuration.
* Fixed bug where `persisted_slots` defined in called flows were incorrectly reset when the parent flow ended, unless they were also explicitly defined in the parent flow. Persisted slots now only need to be defined in the called flow to remain persisted after the parent flow ends.
#### \[3.12.34] - 2025-10-13[](#31234---2025-10-13 "Direct link to [3.12.34] - 2025-10-13")
Rasa Pro 3.12.34 (2025-10-13)
##### Bugfixes[](#bugfixes-55 "Direct link to Bugfixes")
* Fixed conversation hanging when using direct action execution with invalid actions module by deferring module validation until action execution time, allowing proper exception handling in the processor.
* Use correct formatting method for messages in `completion` and `acompletion` functions of `LiteLLMRouterLLMClient`.
#### \[3.12.33] - 2025-09-12[](#31233---2025-09-12 "Direct link to [3.12.33] - 2025-09-12")
Rasa Pro 3.12.33 (2025-09-12)
##### Bugfixes[](#bugfixes-56 "Direct link to Bugfixes")
* Fixes the silence handling bug in Audiocodes Stream Channel where consecutive bot responses could trip silence timeout pattern while the bot is speaking. Audiocodes Stream channel now forcefully cancels the silence timeout watcher whenever it sends the bot response audio.
* Fixed flow retrieval to skip vector store population when there are no flows to embed.
#### \[3.12.32] - 2025-09-03[](#31232---2025-09-03 "Direct link to [3.12.32] - 2025-09-03")
Rasa Pro 3.12.32 (2025-09-03)
##### Bugfixes[](#bugfixes-57 "Direct link to Bugfixes")
* Upgrade `skops` to version `0.13.0` and `requests` to version `2.32.5` to fix vulnerabilities.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-23 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.31] - 2025-08-26[](#31231---2025-08-26 "Direct link to [3.12.31] - 2025-08-26")
Rasa Pro 3.12.31 (2025-08-26)
##### Bugfixes[](#bugfixes-58 "Direct link to Bugfixes")
* The .devcontainer docker-compose file now uses the new `docker.io/bitnamilegacy` repository for images, rather than the old `docker.io/bitnami`. This change was made in response to Bitnami's announcement that they will be putting all of their public Helm Chart container images behind a paywall starting August 28th, 2025. Existing public images are moved to the new legacy repository - `bitnamilegacy` - which is only intended for short-term migration purposes.
* Fixed model loading failures on Windows systems running recent Python versions (3.9.23+, 3.10.18+, 3.11.13+) due to tarfile security fix incompatibility with Windows long path prefix.
#### \[3.12.30] - 2025-08-19[](#31230---2025-08-19 "Direct link to [3.12.30] - 2025-08-19")
Rasa Pro 3.12.30 (2025-08-19)
##### Bugfixes[](#bugfixes-59 "Direct link to Bugfixes")
* Don't tigger a slot correction for slots that are currently set to `None` as `None` counts as empty value.
#### \[3.12.29] - 2025-07-31[](#31229---2025-07-31 "Direct link to [3.12.29] - 2025-07-31")
Rasa Pro 3.12.29 (2025-07-31)
##### Bugfixes[](#bugfixes-60 "Direct link to Bugfixes")
* Fix correction of slots:
* Slots can only be corrected in case they belong to any flow on the stack and the slot to be corrected is part of a collect step in any of those flows.
* A correction of a slot should be applied if the flow that is about to start is using this slot.
#### \[3.12.28] - 2025-07-29[](#31228---2025-07-29 "Direct link to [3.12.28] - 2025-07-29")
Rasa Pro 3.12.28 (2025-07-29)
##### Bugfixes[](#bugfixes-61 "Direct link to Bugfixes")
* Upgrade `axios` to fix security vulnerability.
* Fix issue where called flows could not set slots of their parent flow.
#### \[3.12.27] - 2025-07-23[](#31227---2025-07-23 "Direct link to [3.12.27] - 2025-07-23")
Rasa Pro 3.12.27 (2025-07-23)
##### Bugfixes[](#bugfixes-62 "Direct link to Bugfixes")
* Fix validation of the FAISS documents folder to ensure it correctly discovers files in a recursive directory structure.
* Updated `Inspector` dependent packages (`vite`, and `@adobe/css-tools`) to address security vulnerabilities.
* Fixed bug preventing `model_group` from being used with `embeddings` in generative response LLM judge configuration.
#### \[3.12.26] - 2025-07-17[](#31226---2025-07-17 "Direct link to [3.12.26] - 2025-07-17")
Rasa Pro 3.12.26 (2025-07-17)
##### Bugfixes[](#bugfixes-63 "Direct link to Bugfixes")
* Allowed NLG servers to return None for the text property and ensured custom response data is properly retained.
#### \[3.12.25] - 2025-07-16[](#31225---2025-07-16 "Direct link to [3.12.25] - 2025-07-16")
Rasa Pro 3.12.25 (2025-07-16)
##### Bugfixes[](#bugfixes-64 "Direct link to Bugfixes")
* Pass all flows to `find_updated_flows` to avoid creating a `HandleCodeChangeCommand` in situations where flows were not updated.
#### \[3.12.24] - 2025-07-14[](#31224---2025-07-14 "Direct link to [3.12.24] - 2025-07-14")
Rasa Pro 3.12.24 (2025-07-14)
##### Bugfixes[](#bugfixes-65 "Direct link to Bugfixes")
* Fixed the repeat action to include all messages of the last turn in collect steps.
* Fix issues with bot not giving feedback for slot corrections.
* Fixed bot speaking state management in Audiocodes Stream channel. This made the assistant unable to handle user silences Added periodic keepAlive messages to deepgram, this interval can be configured with `keep_alive_interval` parameter
#### \[3.12.23] - 2025-07-08[](#31223---2025-07-08 "Direct link to [3.12.23] - 2025-07-08")
Rasa Pro 3.12.23 (2025-07-08)
##### Bugfixes[](#bugfixes-66 "Direct link to Bugfixes")
* Reverted fix for custom multilingual output payloads being overwritten.
#### \[3.12.22] - 2025-07-07[](#31222---2025-07-07 "Direct link to [3.12.22] - 2025-07-07")
Rasa Pro 3.12.22 (2025-07-07)
No significant changes.
#### \[3.12.21] - 2025-07-03[](#31221---2025-07-03 "Direct link to [3.12.21] - 2025-07-03")
Rasa Pro 3.12.21 (2025-07-03)
##### Bugfixes[](#bugfixes-67 "Direct link to Bugfixes")
* Fixes a bug where fine-tuning data generation raises a FineTuningDataPreparationException for test cases without assertions that end with one/multiple user utterance/s, as opposed to one/multiple bot utterance/s.
For these types of test cases, the fine-tuning data generation transcript now contains all test case utterances up to but excluding the last user utterance(s) as the test case does not specify the corresponding, expected bot response(s).
* Fix validation and improve error messages for the documents source directory when FAISS vector store is configured for the Enterprise Search Policy.
* Prevent slot correction when the slot is already set to the desired value.
* Fallback to `CannotHandle` command when the slot predicted by the LLM is not defined in the domain.
* Fix potential `KeyError` in `EnterpriseSearchPolicy` citation post-processing when the source does not have the correct citation. Improve the citation post-processing logic to handle additional edge cases.
#### \[3.12.20] - 2025-06-24[](#31220---2025-06-24 "Direct link to [3.12.20] - 2025-06-24")
Rasa Pro 3.12.20 (2025-06-24)
##### Bugfixes[](#bugfixes-68 "Direct link to Bugfixes")
* Flows now traverse called and linked flows, including nested and branching called / linked flows. As a result, E2E coverage reports include any linked and called flows triggered by the flow being tested.
* Fixed a bug in Genesys and Audiocodes Stream channels where conversations used a placeholder value `default` as the Sender ID. Added a new method `VoiceInputChannel.get_sender_id(call_parameters)` that returns the platform's `call_id` as the Sender ID. This ensures each conversation has a unique identifier based on the call ID from the respective platform. Channels can override this method to customize Sender ID generation.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-24 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.19] - 2025-06-18[](#31219---2025-06-18 "Direct link to [3.12.19] - 2025-06-18")
Rasa Pro 3.12.19 (2025-06-18)
##### Bugfixes[](#bugfixes-69 "Direct link to Bugfixes")
* Fix issues where linked flows could not be cancelled and slots collected within linked flows could not be prefilled.
* Fix `InvalidFlowStepIdException` thrown when a bot is restarted with a retrained model which contains an update to the step order in a given active flow. Once retrained and restarted, the bot will now correctly handle the updated step order by triggering `pattern_code_change`.
#### \[3.12.18] - 2025-06-12[](#31218---2025-06-12 "Direct link to [3.12.18] - 2025-06-12")
Rasa Pro 3.12.18 (2025-06-12)
##### Bugfixes[](#bugfixes-70 "Direct link to Bugfixes")
* Ensure that old step ID formats (without the flow ID prefix) can be loaded without raising an `InvalidFlowStepIdException` in newer Rasa versions that expect the flow ID prefix.
* * Fix an issue where running `rasa inspect` would always set the `route_session_to_calm` slot to `True`, even when no user-triggered commands were present. This caused incorrect routing to CALM, bypassing the logic of the router.
* Fix a regression in non-sticky routing where sessions intended for the NLU were incorrectly routed to CALM when the router predicted `NoopCommand()`.
* Enable slot prefilling in patterns.
#### \[3.12.17] - 2025-06-05[](#31217---2025-06-05 "Direct link to [3.12.17] - 2025-06-05")
Rasa Pro 3.12.17 (2025-06-05)
##### Bugfixes[](#bugfixes-71 "Direct link to Bugfixes")
* Fix an issue where the SetSlot and Clarify command value was parsed incorrectly if a newline character immediately followed the value argument in the LLM output.
#### \[3.12.16] - 2025-06-03[](#31216---2025-06-03 "Direct link to [3.12.16] - 2025-06-03")
Rasa Pro 3.12.16 (2025-06-03)
##### Bugfixes[](#bugfixes-72 "Direct link to Bugfixes")
* Make `domain` an optional argument in `CommandProcessorComponent`. This change addresses a potential `TypeError` that could occur when loading a model trained without providing domain as a required argument. By making domain optional, models trained with older configurations or without a domain component will now load correctly without errors.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-25 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.15] - 2025-06-02[](#31215---2025-06-02 "Direct link to [3.12.15] - 2025-06-02")
Rasa Pro 3.12.15 (2025-06-02)
##### Improvements[](#improvements-11 "Direct link to Improvements")
:
##### Bugfixes[](#bugfixes-73 "Direct link to Bugfixes")
* Add turn\_wrapper to count multiple utterances by bot/user as single turn rather than individual turns. Always include last user utterance in rephraser prompt's conversation history.
* Remove `StoryGraphProvider` from the prediction graph in case `IntentlessPolicy` is not present to reduce the loading time of the bot in cases where the `IntentlessPolicy` is not used and a lot of stories are present.
#### \[3.12.14] - 2025-05-28[](#31214---2025-05-28 "Direct link to [3.12.14] - 2025-05-28")
Rasa Pro 3.12.14 (2025-05-28)
##### Improvements[](#improvements-12 "Direct link to Improvements")
* * Updates the parameter name from `max_tokens`, which is deprecated by OpenAI, to `max_completion_tokens`. The old `max_tokens` is not supported for the `o` models.
* Exposes LiteLLM's `drop_params` parameter for LLM configurations.
##### Bugfixes[](#bugfixes-74 "Direct link to Bugfixes")
* * Fixes default config initialization for the `IntentlessPolicy`.
* Prompts for rephrased messages and conversations are now rendered using agent, eliminating errors that occurred when string replacements broke after prompt updates.
* Fix parsing of escape characters in translation of LLM prediction to SetSlotCommand.
* Files generated by the finetuning data generation pipeline are now encoded in UTF-8, allowing characters such as German umlauts (ä, ö, ü) to render correctly.
#### \[3.12.13] - 2025-05-19[](#31213---2025-05-19 "Direct link to [3.12.13] - 2025-05-19")
Rasa Pro 3.12.13 (2025-05-19)
##### Bugfixes[](#bugfixes-75 "Direct link to Bugfixes")
* The `Clarify` (syntax used by `SingleStepLLMCommandGenerator`) / `disambiguate flows` (syntax used by `CompactLLMCommandGenerator`) command will now parse flow names with dashes.
* Fix remote model download when models are stored in a path, not in the root of the remote storage. Add new training CLI param `--remote-root-only` that can be used by the model service to store the model in the root of the remote storage. Propagate this parameter to the persistor's `persist` method. Simplify persistor code when retrieving models by downloading the model to the target path directly rather than copying the downloaded model to the target path. This also improved testability.
* When inspector is not used, root server path should output: `Hello from Rasa: .`. When inspector is used, root server path should output HTML page with a link to the path on which inspector can be reached.
* Change the default value of `minimize_num_calls` in the config of LLM-based command generators to `True`.
#### \[3.12.12] - 2025-05-15[](#31212---2025-05-15 "Direct link to [3.12.12] - 2025-05-15")
Rasa Pro 3.12.12 (2025-05-15)
##### Improvements[](#improvements-13 "Direct link to Improvements")
* Improved `CRFEntityExtractor` persistence and loading methods to improve model loading times.
##### Bugfixes[](#bugfixes-76 "Direct link to Bugfixes")
* Bumps aiohttp to 3.10.x, sentry-sdk to 2.8.x. Also bumps the locked versions for urllib3 and h11
#### \[3.12.11] - 2025-05-14[](#31211---2025-05-14 "Direct link to [3.12.11] - 2025-05-14")
Rasa Pro 3.12.11 (2025-05-14)
No significant changes.
#### \[3.12.10] - 2025-05-08[](#31210---2025-05-08 "Direct link to [3.12.10] - 2025-05-08")
Rasa Pro 3.12.10 (2025-05-08)
##### Bugfixes[](#bugfixes-77 "Direct link to Bugfixes")
* Fix issues in Audiocodes Channel Connector. The values in `user_phone` and `bot_phone` available in session\_started\_metadata are swapped to correctly map to `calller` and `callee` respectively. Fixed evening handling where events without the key "parameters" raised an exception.
* Filtered out only `None` values from the response payload to avoid removing valid empty values.
#### \[3.12.9] - 2025-05-06[](#3129---2025-05-06 "Direct link to [3.12.9] - 2025-05-06")
Rasa Pro 3.12.9 (2025-05-06)
##### Bugfixes[](#bugfixes-78 "Direct link to Bugfixes")
* Implemented backtracking and corrected the recursion logic in the all-paths generation for a flow. Removed the need to deepcopy the `step_ids_visited` set on each branch within `_handle_links`, which prevents the coverage report from freezing due to hitting the recursion limit.
* Upgrade openai and litellm dependencies to fix found vulnerabilities in litellm.
#### \[3.12.8] - 2025-04-30[](#3128---2025-04-30 "Direct link to [3.12.8] - 2025-04-30")
Rasa Pro 3.12.8 (2025-04-30)
##### Bugfixes[](#bugfixes-79 "Direct link to Bugfixes")
* Reduced redundant log entries when reading prompt templates by contextualizing them. Added source component and method metadata to logs, and changed prompt-loading logs triggered from `fingerprint_addon` to use `DEBUG` level.
* Add support for `auth_token` to Rasa Inspector.
* Fixed issue where a slot mapping referencing a form in the `active_loop` slot mapping conditions that wouldn't list this slot in the form's `required_slots` caused training to fail. Now, this is only logged as a validation warning without causing the training to fail.
#### \[3.12.7] - 2025-04-28[](#3127---2025-04-28 "Direct link to [3.12.7] - 2025-04-28")
Rasa Pro 3.12.7 (2025-04-28)
##### Improvements[](#improvements-14 "Direct link to Improvements")
* Adds two optional properties on Jambonz channel connector, `username` and `password` which can be used to enable Basic Access Authentication
* Added support for basic authentication in Twilio channels (Voice Ready and Voice Streaming). This allows users to authenticate their Twilio channels using basic authentication credentials, enhancing security and access control for voice communication. To use this feature, set `username` and `password` in the Twilio channel configuration.
credentials.yaml
```
twilio_voice:
username: your_username
password: your_password
...
twilio_media_streams:
username: your_username
password: your_password
...
```
At Twilio, configure the webhook URL to include the basic authentication credentials:
```
# twilio voice webhook
https://:@yourdomain.com/webhooks/twilio_voice/webhook
# twilio media streams webhook
https://:@yourdomain.com/webhooks/twilio_media_streams/webhook
```
##### Bugfixes[](#bugfixes-80 "Direct link to Bugfixes")
* Fail rasa commands (`rasa run`, `rasa inspect`, `rasa shell`) when model file path doesn't exist instead of defaulting to the latest model file from the default directory `/models`.
* Fix the behaviour of `action_hangup` on Voice Inspector (browser\_audio channel). Display that the session has ended
* Display a helpful error message in case of invalid API Key with Azure TTS
* Fixes Audiocodes Channel's event to intent mapping. All audiocode events are now mapped to an intent in the format `vaig_event_`. That is, if Audiocodes sends an event `noUserInput`, the assistant will receive the intent `/vaig_event_noUserInput`
#### \[3.12.6] - 2025-04-15[](#3126---2025-04-15 "Direct link to [3.12.6] - 2025-04-15")
Rasa Pro 3.12.6 (2025-04-15)
##### Deprecations and Removals[](#deprecations-and-removals-1 "Direct link to Deprecations and Removals")
* Remove the behaviour handling digressions as eligible flows that can be started while handling an active collect step. These properties have been removed from the flow and collect step:
* `ask_confirm_digressions`
* `block_digressions` Remove the new pattern `pattern_handle_digressions`.
##### Features[](#features-3 "Direct link to Features")
* Introduce a new boolean property `force_slot_filling` for the `collect` flow step. This property allows you to suppress incorrect predictions of the command generator or user digressions that are not relevant to the current slot filling. To enable this behavior, you should set the `force_slot_filling` property to `True` in the `collect` step of your flow configuration.
```
flows:
order_pizza:
name: order pizza
description: user asks for a pizza
steps:
- collect: pizza_type
- collect: quantity
- collect: address
force_slot_filling: true
```
When `force_slot_filling` is set to `True`, the command generator will only process the `SetSlot` command for the specified slot. By default, the property is set to `False`.
##### Bugfixes[](#bugfixes-81 "Direct link to Bugfixes")
* Security patch for Audiocodes and Genesys Channel connector Adds `api_key` (required) and `client_secret` (optional) properties to Genesys channel configuration Adds `token` (optional) property to Audiocodes-Stream channel
* Fix execution of custom validation action `action_validate_slot_mappings` by passing the extracted slot events to the tracker used when running this action.
* Make sure training always fail when domain is invalid.
* Add channel name to UserMessage created by the Audiocodes channel.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-26 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.5] - 2025-04-07[](#3125---2025-04-07 "Direct link to [3.12.5] - 2025-04-07")
Rasa Pro 3.12.5 (2025-04-07)
##### Bugfixes[](#bugfixes-82 "Direct link to Bugfixes")
* Fix `ChitChatAnswerCommand` command replaced with `CannotHandleCommand` if there are no e2e stories defined. Improve validation that `IntentlessPolicy` has applicable responses: either responses in the domain that are not part of any flow, or if there are e2e stories. This validation performed during the training time and during cleanup of the `ChitChatAnswerCommand` command.
* * Fixes an issue with prompt rendering where minified JSON structures were displayed without properly escaping newlines, tabs, and quotes.
* Introduced a new Jinja `filter to_json_encoded_string` that escapes newlines (`\n`), tabs (`\t`), and quotes (`\"`) for safe JSON rendering. `to_json_encoded_string` filter preserves other special characters (e.g., umlauts) without encoding them.
* Updated the default prompts for `gpt-4o` and `claude-sonnet-3.5`
#### \[3.12.4] - 2025-04-01[](#3124---2025-04-01 "Direct link to [3.12.4] - 2025-04-01")
Rasa Pro 3.12.4 (2025-04-01)
##### Bugfixes[](#bugfixes-83 "Direct link to Bugfixes")
* Send error event to the Kafka broker, when the original message size is too large, above the configured broker limit. This error handling mechanism was added to prevent Rasa-Pro server crashes.
* Update the following dependencies to versions that contain the latest patches for security vulnerabilities:
* `jinja2`
* `werkzeug`
* `cryptography`
* `pyarrow`
* `langchain`
* `langchain-community`
* Fix intermittent crashes on Inspector app when Enterprise Search or Chitchat Policies were triggered
#### \[3.12.3] - 2025-03-26[](#3123---2025-03-26 "Direct link to [3.12.3] - 2025-03-26")
Rasa Pro 3.12.3 (2025-03-26)
##### Bugfixes[](#bugfixes-84 "Direct link to Bugfixes")
* Fixes a bug in Inspector that raised a TypeError when serialising `numpy.float64` from Tracker
#### \[3.12.2] - 2025-03-25[](#3122---2025-03-25 "Direct link to [3.12.2] - 2025-03-25")
Rasa Pro 3.12.2 (2025-03-25)
No significant changes.
#### \[3.12.1] - 2025-03-21[](#3121---2025-03-21 "Direct link to [3.12.1] - 2025-03-21")
Rasa Pro 3.12.1 (2025-03-21)
##### Bugfixes[](#bugfixes-85 "Direct link to Bugfixes")
* Fix filtering of StartFlow commands from LLM-based command generators during the overlap check with prior commands. When prior commands do not contain any StartFlow or HandleDigression commands, we should not filter out the StartFlow command from the LLM-based command generator.
* Remove:
* cancel command when digression handling is defined
* duplicate digression handling commands during command processing
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-27 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.12.0] - 2025-03-19[](#3120---2025-03-19 "Direct link to [3.12.0] - 2025-03-19")
Rasa Pro 3.12.0 (2025-03-19)
##### Deprecations and Removals[](#deprecations-and-removals-2 "Direct link to Deprecations and Removals")
* Deprecate MultiStepLLMCommandGenerator and schedule for removal in Rasa `4.0.0`.
* Remove the beta feature flag check from the e2e testing with assertions feature. The `RASA_PRO_BETA_E2E_ASSERTIONS` environment variable is no longer needed as the feature is GA in 3.12.0.
* Deprecate the `custom` slot mapping type and its `action` slot mapping property which has been replaced with `run_action_every_turn` property name to retain backwards-compatible behavior.
* Deprecate the former list of dictionaries format for the `condition` key in a conditional response variation.
##### Features[](#features-4 "Direct link to Features")
* Add capability to use OAuth over Azure Entra ID for OpenAI instances deployed on Azure.
* Added Voice Stream Channel Connector for Genesys Cloud (AudioConnector Integration)
* Prevent unwanted digressions at collect flow steps by using one of the following new attributes available at both flow and collect step level:
* `ask_confirm_digressions`: Asks the user to confirm if to continue with the current flow. Can be set to `true` or to a list of flow ids for which this behaviour should be activated.
* `block_digressions`: Blocks any digression from the current flow and informs the user that they will return to the digression once the current flow is completed. Can be set to `true` or to a list of flow ids for which this behaviour should be activated.
The above-mentioned behaviour is governed by a new pattern `pattern_handle_digressions` which is triggered only when the above attributes are used.
* Implement real-time validation of slot values.
Add an optional property `validation` to slots to configure validations that should be run immediately. This property expects a list of `rejections` and a `refill_utter` which will be used to prompt users to provide a new value when validation fails.
These validations are limited to common, reusable and universal checks that work independently of conversation context. For more complex validations that depend on conversation state, business logic, or external data, implement them in your flow definitions or custom actions instead.
* Introducing the `CompactLLMCommandGenerator` component, an enhancement over the `SingleStepLLMCommandGenerator`. This new component utilizes the highest-performing prompts for the models `gpt-4o-2024-11-20` and `claude-3-5-sonnet-20240620`.
To incorporate the `CompactLLMCommandGenerator` into your pipeline, simply add the following:
```
pipeline:
...
- name: CompactLLMCommandGenerator
...
```
* Multi-language support was implemented to enable the assistant to deliver localized responses and flow names that dynamically adjust to the user's language preference. In particular:
* The default language is defined using the `language` key in `config.yml`, while additional supported languages are specified under `additional_languages`.
* A `translation` section was introduced for responses to provide language-specific versions of the response text.
* A `translation` section was added for flows to define localized flow names.
* The rephraser prompt now accommodates the selected language.
* Validation mechanisms were implemented to ensure proper use of translations; the CLI command `rasa validate data translations` is available for verification.
* A new slot type, `StrictCategoricalSlot`, was developed to restrict its values to a predefined set.
* A built-in `language` slot of the `StrictCategoricalSlot` type was added for managing translations effectively.
* \[beta] Added Voice Stream channel connector to Audiocodes (audiocodes\_stream)
##### Improvements[](#improvements-15 "Direct link to Improvements")
* Added validation to issue warnings for non-existent fixture/metadata names referenced in end-to-end tests.
* Implemented a fail fast mechanism that fails the end-to-end test case on the first failure, whether in user/bot turns or while using the assertions, to provide faster feedback.
* Added `utterance_end_ms` configuration to deepgram asr to handle noisy environments better
* Replace the optional dependency `mlflow` leveraged in the beta release of E2E testing with assertions when evaluating generative answers with custom prompts for each of the two generative metrics: `generative_response_is_relevant` and `generative_response_is_grounded`. This change now enables the usage of different LLM model providers and allows for a more flexible evaluation of generative components.
Additionally, these generative assertions can make use of a new property `utter_source` (i.e. Enterprise Search, Contextual Rephraser or Intentless). This enables the assertion to be applied to a specific bot message source. It also for example prevents phrases such as `Is there anything else i can help you with?` triggered by `pattern_completed` to be checked for groundedness when the assertion should not be applied to it. Remove applying the same generative assertion to multiple bot messages in the same turn, however one bot message can be evaluated by multiple generative assertions in the same turn.
* Remove unnecessary deepcopy to improve performance in `undo_fallback_prediction` method of `FallbackClassifier`
* Add capability to control whether `pattern_completed` should execute when flow completes its execution. To control this behavior, a new parameter `run_pattern_completed` is added to the flow definition. By default this parameter is set to `True` which means `pattern_completed` will be executed when flow completes its execution (backward compatible). If this parameter is set to `False`, `pattern_completed` will not be executed when flow completes its execution.
* Allow slots to be filled by different slot extraction mechanisms (e.g. from\_llm, predefined NLU-based mappings, custom actions etc.). Add new `from_llm` slot mapping boolean property `allow_nlu_correction`(by default set to `False`), which gives permission for LLM-issued SetSlot commands to correct slots previously filled via NLU-based mechanisms.
Allow LLM-based command generators to issue other commands after `NLUCommandAdapter` has issued commands. Introduce a new LLM-based command generator config property `minimize_num_calls` (by default set to `False`) which maintains backwards compatibility with previous behaviour where LLM-based command generators were blocked from invoking the LLM after `NLUCommandAdapter` had issued commands.
Update the default utterance `utter_corrected_previous_input` to use a new context property `new_slot_values`.
* Set the default priority for StartFlow commands issued by different command generator types i.e. NLUCommandAdapter or LLM-based command generator: When the different command generators issue StartFlow commands for different flows in the same user turn, the NLUCommandAdapter will always take priority while the LLM-based start flow command will be discarded.
Remove the limitation that the NLUCommandAdapter must always precede the LLM-based command generator in the config pipeline.
* Introduce a new slot mapping type `controlled` that can be assigned to slots that are set via button payloads, `set_slots` flow steps or custom actions.
Slots that solely use the new `controlled` slot mapping will not be available to be filled probabilistically by the NLU or LLM components. Note that this slot mapping can still be used alongside the other slot mapping types, however this comes with the risk of the slot being filled by the NLU or LLM components in a probabilistic manner.
* Slots with mappings of type `controlled` (formerly the now deprecated `custom` mapping type) can be set at every turn without its custom action having to be called explicitly by the user flow.
If you are building a coexistence assistant where different `controlled` slots are set by custom actions in different subsystems, you must indicate which coexistence system is allowed to fill the slot. This is done by setting the `coexistence_system` property in the slot mapping configuration. This property is a string that must match one of the available categorical values: `NLU`, `CALM`, `SHARED` (when either system can set the slot).
* Support user to send a preformatted message to the `invoke_llm` method. This let's the user switch between the `user` and `system` roles when invoking the LLM model.
* Add support for [`pypred`](https://github.com/armon/pypred) predicates in conditional response variations, similar to the usage of predicates in flows. The `condition` key in a response variation can now also be a string predicate that supports only the `slots` namespace. One of many logical operators supported is `not`.
* Make current slot type and its allowed values available for the prompt template rendering in `SingleStepLLMCommandGenerator` and `CompactLLMCommandGenerator` classes. Now you can use `{{ current_slot_type }}` and `{{ current_slot_allowed_values }}` placeholders in your custom prompt template.
* Made azure ASR `endpoint` and `host`, azure tts `endpoint` and cartesia tts `endpoint` configurable.
* Support usage of custom commands in the fine-tuning recipe.
* add support for `mstts` markups on azure TTS for improved SSML usage
##### Bugfixes[](#bugfixes-86 "Direct link to Bugfixes")
* Add the possibility to pass a `transform` callable parameter when writing yaml. This allows passing a custom function to transform endpoints before uploading to Studio. This was required to fix the issue where yaml wraps in quotes any string that doesn't start with an alphabetic character such as unexpanded environment variables in the endpoints yml file.
* Fixed the accuracy calculation to prevent 100% assertion reporting when a test case fails before any assertions are reached.
* Fixed regression on training time for projects with a lot of YAML files.
* Fix AvailableEndpoints to read from the default `endpoints.yaml`, if no endpoint is specified.
* Update domain yaml schema for conditional response condition `type` key to specify valid enum type as `slot` only.
* * Fixed an issue where the `pattern_continue_interrupted` was not correctly triggered when the flow digressed to a step containing a link.
* Add the flow ID as a prefix to step ID to ensure uniqueness. This resolves a rare bug where steps in a child flow with a structure similar to those in a parent flow (using a "call" step) could result in duplicate step IDs. In this case duplicates previously caused incorrect next step selection.
* Enable default action `action_extract_slots` to set slots that should be shared for coexistence in a NLU-based system, when the same slot can be requested and filled by a flow in the CALM system too.
* Fixed conversation stalling in AudioCodes channel by handling activities in background tasks. Previously, activities were processed synchronously which blocked responses to AudioCodes, causing request timeouts and activity retries. These retries would cancel ongoing processing and get rejected as duplicates. Now activities are processed asynchronously while responding immediately to AudioCodes requests.
* Improved error handling for Deepgram and Cartesia connection failures to display more meaningful error messages when authentication fails or other connection issues occur.
* Modify Enterprise Search Citation Prompt Template to use `doc.text`
* Fixes ClarifyCommand syntax in the fine-tuning recipe.
* Fixed a bug that lead to the response to silence timeouts being cut off
* Fixed a bug in Voice Inspector where the tracker (hence the conversation transcript) was only updated after the prediction loop was complete. The bug resulted in a perceived delay in case of slow custom actions where transcript was rendered after processing the complete conversation turn. Now the tracker is sent to the Inspector app after every iteration of prediction loop, which conveys a more accurate conversation state and transcript on the inspector app
* Fix passing the incorrect input type (user question text instead of bot answer text) to the prompt used by the `generative_response_is_relevant` assertion. Add instructions to both relevance and groundedness prompts to not add any more explanations to the LLM output apart from the expected json output to prevent parsing errors.
* Make real-time validation work with all slot types. Fixes bug where the same `ValidateSlotPatternFlowStackFrame` was being triggered multiple times.
* Handle multiple duplicate digressing flows occurring within the same flow:
* if `action_block_digressions` runs for a found duplicate digressing flow already on the stack, it will not add it again
* if `action_continue_digressions` runs for a found duplicate digressing flow already on the stack, it first removes it from the stack before pushing it to the top of the stack.
* Do not push the clarification pattern when the top user frame is an interruption frame.
* Consider linked and called flows as active flows when processing `StartFlow` commands.
* Fixed slot value injection in translated responses by updating response keys to interpolate.
* Updated language code parsing to enforce BCP 47 standard.
* Fix validation check that ensures that the slot used in the response condition is defined in the domain file.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-28 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.11.19] - 2025-08-19[](#31119---2025-08-19 "Direct link to [3.11.19] - 2025-08-19")
Rasa Pro 3.11.19 (2025-08-19)
##### Bugfixes[](#bugfixes-87 "Direct link to Bugfixes")
* Fix correction of slots:
* Slots can only be corrected in case they belong to any flow on the stack and the slot to be corrected is part of a collect step in any of those flows.
* A correction of a slot should be applied if the flow that is about to start is using this slot.
* Don't tigger a slot correction for slots that are currently set to `None` as `None` counts as empty value.
* Fix issue where called flows could not set slots of their parent flow.
#### \[3.11.18] - 2025-07-24[](#31118---2025-07-24 "Direct link to [3.11.18] - 2025-07-24")
Rasa Pro 3.11.18 (2025-07-24)
##### Bugfixes[](#bugfixes-88 "Direct link to Bugfixes")
* Fix issues with bot not giving feedback for slot corrections.
* Fix validation of the FAISS documents folder to ensure it correctly discovers files in a recursive directory structure.
* Updated `Inspector` dependent packages (`vite`, and `@adobe/css-tools`) to address security vulnerabilities.
* Upgrade `axios` to fix security vulnerability.
* Upgrade `litellm` to fix security vulnerability.
#### \[3.11.17] - 2025-07-03[](#31117---2025-07-03 "Direct link to [3.11.17] - 2025-07-03")
Rasa Pro 3.11.17 (2025-07-03)
##### Bugfixes[](#bugfixes-89 "Direct link to Bugfixes")
* Flows now traverse called and linked flows, including nested and branching called / linked flows. As a result, E2E coverage reports include any linked and called flows triggered by the flow being tested.
* Fix issues where linked flows could not be cancelled and slots collected within linked flows could not be prefilled.
* Fix validation and improve error messages for the documents source directory when FAISS vector store is configured for the Enterprise Search Policy.
* Prevent slot correction when the slot is already set to the desired value.
* Fallback to `CannotHandle` command when the slot predicted by the LLM is not defined in the domain.
* Fix potential `KeyError` in `EnterpriseSearchPolicy` citation post-processing when the source does not have the correct citation. Improve the citation post-processing logic to handle additional edge cases.
#### \[3.11.16] - 2025-06-12[](#31116---2025-06-12 "Direct link to [3.11.16] - 2025-06-12")
Rasa Pro 3.11.16 (2025-06-12)
##### Bugfixes[](#bugfixes-90 "Direct link to Bugfixes")
* Ensure that old step ID formats (without the flow ID prefix) can be loaded without raising an `InvalidFlowStepIdException` in newer Rasa versions that expect the flow ID prefix.
* Fix an issue where running `rasa inspect` would always set the `route_session_to_calm` slot to `True`, even when no user-triggered commands were present. This caused incorrect routing to CALM, bypassing the logic of the router.
* Enable slot prefilling in patterns.
#### \[3.11.15] - 2025-06-03[](#31115---2025-06-03 "Direct link to [3.11.15] - 2025-06-03")
Rasa Pro 3.11.15 (2025-06-03)
##### Bugfixes[](#bugfixes-91 "Direct link to Bugfixes")
* Make `domain` an optional argument in `CommandProcessorComponent`. This change addresses a potential `TypeError` that could occur when loading a model trained without providing domain as a required argument. By making domain optional, models trained with older configurations or without a domain component will now load correctly without errors.
#### \[3.11.14] - 2025-06-02[](#31114---2025-06-02 "Direct link to [3.11.14] - 2025-06-02")
Rasa Pro 3.11.14 (2025-06-02)
##### Improvements[](#improvements-16 "Direct link to Improvements")
* * Updates the parameter name from `max_tokens`, which is deprecated by OpenAI, to `max_completion_tokens`. The old `max_tokens` is not supported for the `o` models.
* Exposes LiteLLM's `drop_params` parameter for LLM configurations. :
##### Bugfixes[](#bugfixes-92 "Direct link to Bugfixes")
* The `Clarify` command now parses flow names with dashes.
* Add turn\_wrapper to count multiple utterances by bot/user as single turn rather than individual turns. Always include last user utterance in rephraser prompt's conversation history.
* Remove `StoryGraphProvider` from the prediction graph in case `IntentlessPolicy` is not present to reduce the loading time of the bot in cases where the `IntentlessPolicy` is not used and a lot of stories are present.
* * Fixes default config initialization for the `IntentlessPolicy`.
* Fix remote model download when models are stored in a path, not in the root of the remote storage. Add new training CLI param `--remote-root-only` that can be used by the model service to store the model in the root of the remote storage. Propagate this parameter to the persistor's `persist` method. Simplify persistor code when retrieving models by downloading the model to the target path directly rather than copying the downloaded model to the target path. This also improved testability.
* When inspector is not used, root server path should output: `Hello from Rasa: .`. When inspector is used, root server path should output HTML page with a link to the path on which inspector can be reached.
#### \[3.11.13] - 2025-05-15[](#31113---2025-05-15 "Direct link to [3.11.13] - 2025-05-15")
Rasa Pro 3.11.13 (2025-05-15)
##### Improvements[](#improvements-17 "Direct link to Improvements")
* Improved `CRFEntityExtractor` persistence and loading methods to improve model loading times.
##### Bugfixes[](#bugfixes-93 "Direct link to Bugfixes")
* Bumps aiohttp to 3.10.x, sentry-sdk to 2.8.x. Also bumps the locked versions for urllib3 and h11
#### \[3.11.12] - 2025-05-14[](#31112---2025-05-14 "Direct link to [3.11.12] - 2025-05-14")
Rasa Pro 3.11.12 (2025-05-14)
No significant changes.
#### \[3.11.11] - 2025-05-08[](#31111---2025-05-08 "Direct link to [3.11.11] - 2025-05-08")
Rasa Pro 3.11.11 (2025-05-08)
##### Bugfixes[](#bugfixes-94 "Direct link to Bugfixes")
* Fix issues in Audiocodes Channel Connector. The values in `user_phone` and `bot_phone` available in session\_started\_metadata are swapped to correctly map to `calller` and `callee` respectively. Fixed evening handling where events without the key "parameters" raised an exception.
#### \[3.11.10] - 2025-05-06[](#31110---2025-05-06 "Direct link to [3.11.10] - 2025-05-06")
Rasa Pro 3.11.10 (2025-05-06)
##### Bugfixes[](#bugfixes-95 "Direct link to Bugfixes")
* Implemented backtracking and corrected the recursion logic in the all-paths generation for a flow. Removed the need to deepcopy the `step_ids_visited` set on each branch within `_handle_links`, which prevents the coverage report from freezing due to hitting the recursion limit.
#### \[3.11.9] - 2025-04-30[](#3119---2025-04-30 "Direct link to [3.11.9] - 2025-04-30")
Rasa Pro 3.11.9 (2025-04-30)
##### Bugfixes[](#bugfixes-96 "Direct link to Bugfixes")
* Upgrade openai and litellm dependencies to fix found vulnerabilities in litellm.
* Add support for `auth_token` to Rasa Inspector.
* Fixed issue where a slot mapping referencing a form in the `active_loop` slot mapping conditions that wouldn't list this slot in the form's `required_slots` caused training to fail. Now, this is only logged as a validation warning without causing the training to fail.
#### \[3.11.8] - 2025-04-28[](#3118---2025-04-28 "Direct link to [3.11.8] - 2025-04-28")
Rasa Pro 3.11.8 (2025-04-28)
##### Improvements[](#improvements-18 "Direct link to Improvements")
* Adds two optional properties on Jambonz channel connector, `username` and `password` which can be used to enable Basic Access Authentication
* Added support for basic authentication in Twilio channels (Voice Ready and Voice Streaming). This allows users to authenticate their Twilio channels using basic authentication credentials, enhancing security and access control for voice communication. To use this feature, set `username` and `password` in the Twilio channel configuration.
credentials.yaml
```
twilio_voice:
username: your_username
password: your_password
...
twilio_media_streams:
username: your_username
password: your_password
...
```
At Twilio, configure the webhook URL to include the basic authentication credentials:
```
# twilio voice webhook
https://:@yourdomain.com/webhooks/twilio_voice/webhook
# twilio media streams webhook
https://:@yourdomain.com/webhooks/twilio_media_streams/webhook
```
##### Bugfixes[](#bugfixes-97 "Direct link to Bugfixes")
* Fixed a bug that lead to the response to silence timeouts being cut off
* Fail rasa commands (`rasa run`, `rasa inspect`, `rasa shell`) when model file path doesn't exist instead of defaulting to the latest model file from the default directory `/models`.
* Fix the behaviour of `action_hangup` on Voice Inspector (browser\_audio channel). Display that the session has ended
* Display a helpful error message in case of invalid API Key with Azure TTS
* Fixes Audiocodes Channel's event to intent mapping. All audiocode events are now mapped to an intent in the format `vaig_event_`. That is, if Audiocodes sends an event `noUserInput`, the assistant will receive the intent `/vaig_event_noUserInput`
#### \[3.11.7] - 2025-04-14[](#3117---2025-04-14 "Direct link to [3.11.7] - 2025-04-14")
Rasa Pro 3.11.7 (2025-04-14)
##### Bugfixes[](#bugfixes-98 "Direct link to Bugfixes")
* Fix `ChitChatAnswerCommand` command replaced with `CannotHandleCommand` if there are no e2e stories defined. Improve validation that `IntentlessPolicy` has applicable responses: either responses in the domain that are not part of any flow, or if there are e2e stories. This validation performed during the training time and during cleanup of the `ChitChatAnswerCommand` command.
* Security patch for Audiocodes channel connector. Audiocodes channel was only checking for the existence of authentication token. It now does a constant-time string comparison of the authentication token in connection request with that provided in channel configruation.
* Make sure training always fail when domain is invalid.
* Add channel name to UserMessage created by the Audiocodes channel.
#### \[3.11.6] - 2025-04-02[](#3116---2025-04-02 "Direct link to [3.11.6] - 2025-04-02")
Rasa Pro 3.11.6 (2025-04-02)
##### Bugfixes[](#bugfixes-99 "Direct link to Bugfixes")
* Improved error handling for Deepgram and Cartesia connection failures to display more meaningful error messages when authentication fails or other connection issues occur.
* Modify Enterprise Search Citation Prompt Template to use `doc.text`
* Fixes ClarifyCommand syntax in the fine-tuning recipe.
* Send error event to the Kafka broker, when the original message size is too large, above the configured broker limit. This error handling mechanism was added to prevent Rasa-Pro server crashes.
* Update the following dependencies to versions that contain the latest patches for security vulnerabilities:
* `jinja2`
* `werkzeug`
* `requests`
* `cryptography`
* `pyarrow`
* `langchain`
* `langchain-community`
#### \[3.11.5] - 2025-02-18[](#3115---2025-02-18 "Direct link to [3.11.5] - 2025-02-18")
Rasa Pro 3.11.5 (2025-02-18)
##### Bugfixes[](#bugfixes-100 "Direct link to Bugfixes")
* Updated `Inspector` dependent packages (cross-spawn, mermaid, dom-purify, vite, braces, ws, axios and rollup) to address security vulnerabilities.
* Enable default action `action_extract_slots` to set slots that should be shared for coexistence in a NLU-based system, when the same slot can be requested and filled by a flow in the CALM system too.
* Fixed conversation stalling in AudioCodes channel by handling activities in background tasks. Previously, activities were processed synchronously which blocked responses to AudioCodes, causing request timeouts and activity retries. These retries would cancel ongoing processing and get rejected as duplicates. Now activities are processed asynchronously while responding immediately to AudioCodes requests.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-29 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.11.4] - 2025-01-30[](#3114---2025-01-30 "Direct link to [3.11.4] - 2025-01-30")
Rasa Pro 3.11.4 (2025-01-30)
##### Improvements[](#improvements-19 "Direct link to Improvements")
* Remove unnecessary deepcopy to improve performance in `undo_fallback_prediction` method of `FallbackClassifier`
##### Bugfixes[](#bugfixes-101 "Direct link to Bugfixes")
* * Fixed an issue where the `pattern_continue_interrupted` was not correctly triggered when the flow digressed to a step containing a link.
* Add the flow ID as a prefix to step ID to ensure uniqueness. This resolves a rare bug where steps in a child flow with a structure similar to those in a parent flow (using a "call" step) could result in duplicate step IDs. In this case duplicates previously caused incorrect next step selection.
* Optimized the `DirectCustomActionExecutor` by registering custom actions only once.
* Updated `cryptography` and `anyio` to resolve security vulnerabilities.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-30 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.11.3] - 2025-01-14[](#3113---2025-01-14 "Direct link to [3.11.3] - 2025-01-14")
Rasa Pro 3.11.3 (2025-01-14)
##### Improvements[](#improvements-20 "Direct link to Improvements")
* Enhances YAML parser to validate environment variable resolution for sensitive keys.
##### Bugfixes[](#bugfixes-102 "Direct link to Bugfixes")
* Add flow yaml validation when using the HTTP API `/model/train` endpoint. An invalid flow yaml will return a 400 response status code with a message describing the error.
* Make `pattern_session_start` work with `rasa inspector` to allow the assistant proactively start the conversation with a user.
* Fix writing the test cases obtained via the e2e test case conversion command to file, where `test_cases` key was written as a list item, instead of a dict key. This caused running the test cases to fail because it didn't comply with the e2e test schema. This PR fixes the issue by writing the test cases as a dict key.
* Fixed Inspector's Tracker State view not updating in real-time by moving story fetch logic into WebSocket message handler. Previously, story updates were only triggered on session ID changes, causing stale tracker state after the first conversation turn.
* Add pre-training custom validation to the domain responses that would raise a Rasa Pro validation error when a domain response is an empty sequence.
* Fixes a critical security vulnerability with `jsonpickle` dependency by upgrading to the patched version.
* Updated `pymilvus` and `minio` to address security vulnerability.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-31 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.11.2] - 2024-12-19[](#3112---2024-12-19 "Direct link to [3.11.2] - 2024-12-19")
Rasa Pro 3.11.2 (2024-12-19)
##### Bugfixes[](#bugfixes-103 "Direct link to Bugfixes")
* Validate that `api_type` key is only used for supported providers (Azure and OpenAI).
* Enable asserting events returned by `action_session_start` when running end-to-end testing with assertions format. The following assertions can be used:
* `slot_was_set`
* `slot_was_not_set`
* `bot_uttered`
* `bot_did_not_utter`
* `action_executed`
* Fixed voice inspector to work with any URL by dynamically constructing WebSocket URL from current domain. This enables voice testing in GitHub Codespaces and other remote environments.
* * Fixed an error in `rasa llm finetune prepare-data` when using a subclass of `SingleStepLLMCommandGenerator`.
* Resolved an issue where `rasa llm finetune prepare-data` did not support model groups.
* Fix AvailableEndpoints to read from the default `endpoints.yaml`, if no endpoint is specified.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-32 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.11.1] - 2024-12-13[](#3111---2024-12-13 "Direct link to [3.11.1] - 2024-12-13")
Rasa Pro 3.11.1 (2024-12-13)
##### Bugfixes[](#bugfixes-104 "Direct link to Bugfixes")
* Add the possibility to pass a `transform` callable parameter when writing yaml. This allows passing a custom function to transform endpoints before uploading to Studio. This was required to fix the issue where yaml wraps in quotes any string that doesn't start with an alphabetic character such as unexpanded environment variables in the endpoints yml file.
* Pass flow human-readable name instead of flow id when the cancel pattern stack frame is pushed during flow policy validation checks of collect steps.
* Fixed the accuracy calculation to prevent 100% assertion reporting when a test case fails before any assertions are reached.
* Fixed regression on training time for projects with a lot of YAML files.
#### \[3.11.0] - 2024-12-11[](#3110---2024-12-11 "Direct link to [3.11.0] - 2024-12-11")
Rasa Pro 3.11.0 (2024-12-11)
##### Deprecations and Removals[](#deprecations-and-removals-3 "Direct link to Deprecations and Removals")
* Removed `UnexpecTEDIntentPolicy` from the default config.yml. It is an experimental policy and not suitable for default configuration
* The `reset_after_flow_ends` property of collect steps is now deprecated and will be removed in Rasa Pro 4.0.0. Please use the `persisted_slots` property at the flow level instead.
##### Features[](#features-5 "Direct link to Features")
* Added Twilio Media Streams channel which can be configured to use arbitrary Text-To-Speech and Speech-To-Text services. Added Voice Stream Channel Interface which makes it easier to add voice channels that directly integrate with audio streams. Added support for Deepgram Speech-To-Text and Azure Text-To-Speech in Voice Stream Channels.
* Added default action `action_hangup` it can be used to hang up a phone call from a flow. Added `SessionEnded` event and `SessionEndCommand` command Updated Audiocodes, Jambonz and Twilio Voice channels to send `/session_end` if the phone call is disconnected by user.
* Added support for Cartesia Text-To-Speech in Voice Stream Channels.
* Implement Rasa Pro native model service that takes care of training and running an assistant model in Studio. To find out more about this service, read more in the Studio [documentation](https://rasa.com/docs/studio/deployment/architecture#studio-model-service-container).
* Added a feature to be able to use voice to interact with the bot in the inspector.
* Multi-LLM Routing:
1. **Decoupled LLM Configuration from Components**
* The previous integration of LLMs within CALM is closely tied to the components where they are used. However, this is no longer necessary, as we no longer perform training within the individual components that interact with external LLM endpoints.
* As a result, LLM and embedding client configurations have been moved to `endpoints.yml`. To define LLM configurations in `endpoints.yml`, use the `model_groups` as shown below:
```
model_groups:
- id: gpt-4-direct
models:
- provider: openai
model: gpt-4
timeout: 7
temperature: 0.0
- id: text-embedding-3-small-direct
models:
- provider: openai
model: text-embedding-3-small
```
* These `model_groups` can then be referenced in `config.yml` as follows:
```
pipeline:
...
- name: SingleStepLLMCommandGenerator
llm:
model_group: gpt-4-direct
flow_retrieval:
embeddings:
model_group: text-embedding-3-smal-direct
...
```
2. **Support for Multiple Subscription Deployments**
* Allows customers to use deployments from different subscriptions for the same provider.
* Resolved the limitation of API key configuration being tied exclusively to a single environment variable.
Example configuration in `endpoints.yml` for Azure deployments:
```
model_groups:
- id: azure-gpt-model-eu
models:
- provider: azure
deployment: azure-eu-deployment
api_base: https://api.azure-europe.example.com
api_version: 2024-08-01-preview
api_key: ${AZURE_API_KEY_EU}
timeout: 7
temperature: 0.0
...
- id: azure-gpt-model-us
models:
- provider: azure
deployment: azure-us-deployment
api_base: https://api.azure-us.example.com
api_version: 2024-08-01-preview
api_key: ${AZURE_API_KEY_US}
timeout: 7
temperature: 0.0
...
...
```
3. **Seamless Model Configuration Across Environments Without Retraining**
* Added support for using different model configurations in different environments, such as `dev`, `staging`, and `prod`, without requiring the bot to be retrained for each environment.
* Extended the `${...}` syntax to `deployment`, `api_base`, and `api_version` in `model_groups`, allowing these values to change dynamically based on the environment.
```
model_groups:
- id: azure-gpt-4
models:
- provider: azure
deployment: ${AZURE_DEPLOYMENT_GPT4}
api_base: ${AZURE_API_BASE_GPT4}
api_key: ${AZURE_API_KEY_GPT4}
...
- id: azure-text-embeddings-3-small
models:
- provider: azure
deployment: ${AZURE_DEPLOYMENT_EMBEDDINGS_3_SMALL}
api_base: ${AZURE_API_BASE_EMBEDDINGS_3_SMALL}
api_key: ${AZURE_API_EMBEDDINGS_3_SMALL}
...
```
4. **Supporting Multiple Deployments for Load Balancing**
* Enabled targeting of multiple LLM deployments for a single Rasa component.
* Implemented the routing feature that supports load balancing to handle rate limits and improve scalability. When multiple models are defined within a model group, you can specify the `router` key with a `routing_strategy` to control how requests are distributed among the models.
Example configuration in `endpoints.yml` for Azure deployments with load balancing:
```
model_groups:
- id: azure-gpt-models
models:
- provider: azure
deployment: azure-eu-deployment
api_base: https://api.azure-europe.example.com
api_version: 2024-08-01-preview
api_key: ${AZURE_API_KEY_EU}
timeout: 7
temperature: 0.0
...
- provider: azure
deployment: azure-us-deployment
api_base: https://api.azure-us.example.com
api_version: 2024-08-01-preview
api_key: ${AZURE_API_KEY_US}
timeout: 7
temperature: 0.0
...
router:
routing_strategy: least-busy
...
```
Example of usage in `config.yml`:
```
pipeline:
...
- name: SingleStepLLMCommandGenerator
llm:
model_group: azure-gpt-models
...
```
5. **Backward Compatibility**
* Existing configurations that couple LLMs to specific Rasa components remain unaffected by this change.
* However, this configuration method is now deprecated and scheduled for removal in version 4.0.0.
* Added support for Azure Speech-To-Text in Voice Stream Channels.
* Added `UserSilenceCommand` and `pattern_user_silence` which is triggered by Voice Stream channels when the user is silent for more than a silence timeout. These values are configurable with the newly added slots `silence_timeout` and `consecutive_silence_timeouts`. Silence Monitoring is disabled by default and can be enabled using the configuration `monitor_silence: true` in the relevant Voice Stream Channel configuration.
* The inspector is not its own input / output channel anymore. Rather, it can be attached to other channels. This way, it isn't limited to conversations going through the socketio channel anymore, but can be used with other text channels or voice channels.
You can attach it to any channel(s) configured in your credentials.yml by adding a flag to rasa run: rasa run --inspect.
In addition to that, the conenience cli command rasa inspect is retained, which starts the inspector with the socketio channel as usual.
##### Improvements[](#improvements-21 "Direct link to Improvements")
* In Audiocodes channel, `/vaig_event_start` is replaced by `/session_start`. This intent marks the beginning of conversation and it is sent when the phone call is connected.
* Introduced the environment variable `MAX_NUMBER_OF_PREDICTIONS_CALM` to configure the CALM-specific limit for the number of predictions. This variable defaults to 1000, providing a higher prediction limit compared to the default value of 10 for nlu-based assistants.
* In Audiocodes and Twilio Voice channel connector, the call metadata received from the providers can be accessed in the slot `session_started_metadata`. The call metadata parameter names have been standardised with CallParameters dataclass Twilio Voice Channel Connector sends `/session_start` intent at the beginning of conversation and the channel parameter `initial_prompt` has been removed
* Enable configurability of Vault secret manager's mount point property in the endpoints yaml file or as an environment variable.
* In Twilio Media Streams channel connector, call metadata is availble in `session_start_metadata` slot. It also supports default action `action_hangup`
* Catch API connection errors, and validate the correctness of the values present in model configuration at model training time by making a test API request. This feature is enabled by default and can be disabled by setting the environment variable `LLM_API_HEALTH_CHECK` to `False`.
* `Socketio` channel connector now sends the websocket messages `tracker_state` and `rasa_events` with each bot response. `tracker_state` contains the tracker store state at that point in conversation and includes slots, events, stack, latest message and latest action. `rasa_events` contains a list of new events that have happened since the last message.
* Speech-To-Text and Text-To-Speech Services can be configured for Voice Stream Channel Connectors Added tests for voice components and redefined code structure
* Add support for Python 3.11
* Removed JSON response validation except when HTTP protocol and E2E Stub is used for Custom Action execution.
* Optimized JSON response validation by initializing the `Draft202012Validator` once and caching it.
* Add an optional property `persisted_slots` at the flow level. This property configures whether slots collected or set across any of the flow steps should be persisted after the flow ends. This property expects a list of slot names.
* Added support for custom Automatic Speech Recognition (ASR) or Text To Speech (TTS) providers to a Rasa Assistant. This allows developers to bring their own speech providers to Rasa by subclassing classes `ASREngine` and `TTSEngine`
* If flow retrieval is disabled, a warning is raised only if the number of user flows exceed 20.
* Added validation to the `TestCase` class to issue a warning when duplicate user messages lack metadata or have incorrect metadata. This enhancement provides clear guidance to users on the issue and how to resolve it.
* Fixed global `should-hangup` variable in Voice Stream Channels by moving to a context variable CallState that stores the session variables
* Run Rasa Pro data validation before uploading to Studio. This is to avoid uploading invalid assistant data that would raise errors during Rasa Pro model training in Studio.
* Added `vector_name` to Qdrant's configuration to enable customization of the vector field name for storing embeddings.
* Enhanced `YamlValidationException` error messages to include the line number and a relevant YAML snippet showing where the validation error occurred. Line numbers start from 1 (1-based indexing).
The error-handling behavior has been modified so that only one validation error is displayed. This exception is raised when the YAML content does not comply with the defined YAML schema.
* Added a new assertion type `bot_did_not_utter` to allow testing that the bot does not utter specific messages or include certain buttons during conversations.
* Ensure that the model service fails properly if the minimum disk space requirement is not met.
* Do not expand environment variables when reading yaml files during `rasa studio upload` execution.
* Stream model files to Studio rather than providing full files. Provide a HEAD endpoint for Studio to check if a model is available and what its size is. Add an environment variable to set the port of the model service. This makes the development with Studio easier, previously the port was hard coded making it harder to use a separately deployed model service now that Studio includes that in its development deployment.
* Add flag `--skip-yaml-validation` to skip YAML validation during Rasa run. User can use it to skip domain YAML validation during Rasa run. Do not instantiate multiple instances of TrainingDataImporter class for validation and training.
* Introduced a `summarize_history` flag for the contextual response rephraser, defaulting to `True`. When set to `False`, the conversation transcript instead of the summary is included in the prompt of the contextual response rephraser. This saves a separate summarization call to an LLM. The number of conversation turns to be used when `summarize_history` is set to `False` can be set via `max_historical_turns`. By default this value is set to 5.
Example:
```
nlg:
- type: rephrase
summarize_history: False
max_historical_turns: 5
```
##### Bugfixes[](#bugfixes-105 "Direct link to Bugfixes")
* Fix OpenAI LLM client ignoring API base and API version arguments if set.
* Fix `AttributeError` with the instrumentation of the `run` method of the `CustomActionExecutor` class.
* Throw DuplicatedFlowIdException during `rasa data validate` and `rasa train` if there are duplicate flows defined.
* Replace `pickle` and `joblib` with safer alternatives, e.g. `json`, `safetensors`, and `skops`, for serializing components.
**Note**: This is a model breaking change. Please retrain your model.
If you have a custom component that inherits from one of the components listed below and modified the `persist` or `load` method, make sure to update your code. Please contact us in case you encounter any problems.
Affected components:
* `CountVectorFeaturizer`
* `LexicalSyntacticFeaturizer`
* `LogisticRegressionClassifier`
* `SklearnIntentClassifier`
* `DIETClassifier`
* `CRFEntityExtractor`
* `TrackerFeaturizer`
* `TEDPolicy`
* `UnexpectedIntentTEDPolicy`
* Avoid filling slots that have `ask_before_filling = True` and utilize a `from_text` slot mapping during other steps in the flow. Ensure that the `NLUCommandAdapter` only fills these types of slots when the flow reaches the designated collection step.
* Check for the metadata's `step_id` and `active_flow` keys when adding the `ActionExecuted` event to the flows paths stack.
* Fixed a bug on Windows where flow files with names starting with 'u' would fail to load due to improper path escaping in YAML content processing
* Fixes OpenAIException - AsyncClient.**init**() got an unexpected keyword argument 'proxies'
* Fix retrieval of model file stored in the cloud storage by the model service. This change consisted in uploading only the model file instead of the full model path during training when `--remote-storage` CLI flag is used.
* Fix issue in e2e testing when customising `action_session_start` would lead to AttributeError, because the `output_channel` was not set. This is now fixed by setting the `output_channel` to `CollectingOutputChannel()`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-33 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.10.27] - 2025-06-03[](#31027---2025-06-03 "Direct link to [3.10.27] - 2025-06-03")
Rasa Pro 3.10.27 (2025-06-03)
##### Bugfixes[](#bugfixes-106 "Direct link to Bugfixes")
* Make `domain` an optional argument in `CommandProcessorComponent`. This change addresses a potential `TypeError` that could occur when loading a model trained without providing domain as a required argument. By making domain optional, models trained with older configurations or without a domain component will now load correctly without errors.
#### \[3.10.26] - 2025-06-02[](#31026---2025-06-02 "Direct link to [3.10.26] - 2025-06-02")
Rasa Pro 3.10.26 (2025-06-02)
##### Improvements[](#improvements-22 "Direct link to Improvements")
* * Updates the parameter name from `max_tokens`, which is deprecated by OpenAI, to `max_completion_tokens`. The old `max_tokens` is not supported for the `o` models.
* Exposes LiteLLM's `drop_params` parameter for LLM configurations.
##### Bugfixes[](#bugfixes-107 "Direct link to Bugfixes")
* The `Clarify` command now parses flow names with dashes.
* Add turn\_wrapper to count multiple utterances by bot/user as single turn rather than individual turns. Always include last user utterance in rephraser prompt's conversation history.
* Remove `StoryGraphProvider` from the prediction graph in case `IntentlessPolicy` is not present to reduce the loading time of the bot in cases where the `IntentlessPolicy` is not used and a lot of stories are present.
* * Fixes default config initialization for the `IntentlessPolicy`.
#### \[3.10.25] - 2025-05-15[](#31025---2025-05-15 "Direct link to [3.10.25] - 2025-05-15")
Rasa Pro 3.10.25 (2025-05-15)
##### Improvements[](#improvements-23 "Direct link to Improvements")
* Improved `CRFEntityExtractor` persistence and loading methods to improve model loading times.
##### Bugfixes[](#bugfixes-108 "Direct link to Bugfixes")
* Bumps aiohttp to 3.10.x, sentry-sdk to 2.8.x. Also bumps the locked versions for urllib3 and h11
#### \[3.10.24] - 2025-05-14[](#31024---2025-05-14 "Direct link to [3.10.24] - 2025-05-14")
Rasa Pro 3.10.24 (2025-05-14)
No significant changes.
#### \[3.10.23] - 2025-05-06[](#31023---2025-05-06 "Direct link to [3.10.23] - 2025-05-06")
Rasa Pro 3.10.23 (2025-05-06)
##### Bugfixes[](#bugfixes-109 "Direct link to Bugfixes")
* Implemented backtracking and corrected the recursion logic in the all-paths generation for a flow. Removed the need to deepcopy the `step_ids_visited` set on each branch within `_handle_links`, which prevents the coverage report from freezing due to hitting the recursion limit.
#### \[3.10.22] - 2025-04-30[](#31022---2025-04-30 "Direct link to [3.10.22] - 2025-04-30")
Rasa Pro 3.10.22 (2025-04-30)
##### Bugfixes[](#bugfixes-110 "Direct link to Bugfixes")
* Add support for `auth_token` to Rasa Inspector.
#### \[3.10.21] - 2025-04-29[](#31021---2025-04-29 "Direct link to [3.10.21] - 2025-04-29")
Rasa Pro 3.10.21 (2025-04-29)
##### Bugfixes[](#bugfixes-111 "Direct link to Bugfixes")
* Fixed issue where a slot mapping referencing a form in the `active_loop` slot mapping conditions that wouldn't list this slot in the form's `required_slots` caused training to fail. Now, this is only logged as a validation warning without causing the training to fail.
#### \[3.10.20] - 2025-04-28[](#31020---2025-04-28 "Direct link to [3.10.20] - 2025-04-28")
Rasa Pro 3.10.20 (2025-04-28)
##### Improvements[](#improvements-24 "Direct link to Improvements")
* Added support for basic authentication in Twilio voice channel. This allows users to authenticate their Twilio voice channel using basic authentication credentials, enhancing security and access control for voice communication. To use this feature, set `username` and `password` in the Twilio channel configuration.
credentials.yaml
```
twilio_voice:
username: your_username
password: your_password
...
```
At Twilio, configure the webhook URL to include the basic authentication credentials:
```
# twilio voice webhook
https://:@yourdomain.com/webhooks/twilio_voice/webhook
```
##### Bugfixes[](#bugfixes-112 "Direct link to Bugfixes")
* Fail rasa commands (`rasa run`, `rasa inspect`, `rasa shell`) when model file path doesn't exist instead of defaulting to the latest model file from the default directory `/models`.
* Upgrade openai and litellm dependencies to fix found vulnerabilities in litellm.
#### \[3.10.19] - 2025-04-15[](#31019---2025-04-15 "Direct link to [3.10.19] - 2025-04-15")
Rasa Pro 3.10.19 (2025-04-15)
##### Bugfixes[](#bugfixes-113 "Direct link to Bugfixes")
* Fix `ChitChatAnswerCommand` command replaced with `CannotHandleCommand` if there are no e2e stories defined. Improve validation that `IntentlessPolicy` has applicable responses: either responses in the domain that are not part of any flow, or if there are e2e stories. This validation performed during the training time and during cleanup of the `ChitChatAnswerCommand` command.
* Security patch for Audiocodes channel connector. Audiocodes channel was only checking for the existence of authentication token. It now does a constant-time string comparison of the authentication token in connection request with that provided in channel configruation.
* Make sure training always fail when domain is invalid.
* Add channel name to UserMessage created by the Audiocodes channel.
#### \[3.10.18] - 2025-04-02[](#31018---2025-04-02 "Direct link to [3.10.18] - 2025-04-02")
Rasa Pro 3.10.18 (2025-04-02)
##### Bugfixes[](#bugfixes-114 "Direct link to Bugfixes")
* Updated `Inspector` dependent packages (cross-spawn, mermaid, dom-purify, vite, braces, ws, axios and rollup) to address security vulnerabilities.
* Modify Enterprise Search Citation Prompt Template to use `doc.text`
* Fixes ClarifyCommand syntax in the fine-tuning recipe.
* Send error event to the Kafka broker, when the original message size is too large, above the configured broker limit. This error handling mechanism was added to prevent Rasa-Pro server crashes.
* Update the following dependencies to versions that contain the latest patches for security vulnerabilities:
* `jinja2`
* `werkzeug`
* `requests`
* `cryptography`
* `pyarrow`
* `langchain`
* `langchain-community`
#### \[3.10.17] - 2025-01-30[](#31017---2025-01-30 "Direct link to [3.10.17] - 2025-01-30")
Rasa Pro 3.10.17 (2025-01-30)
##### Improvements[](#improvements-25 "Direct link to Improvements")
* Remove unnecessary deepcopy to improve performance in `undo_fallback_prediction` method of `FallbackClassifier`
##### Bugfixes[](#bugfixes-115 "Direct link to Bugfixes")
* * Fixed an issue where the `pattern_continue_interrupted` was not correctly triggered when the flow digressed to a step containing a link.
* Add the flow ID as a prefix to step ID to ensure uniqueness. This resolves a rare bug where steps in a child flow with a structure similar to those in a parent flow (using a "call" step) could result in duplicate step IDs. In this case duplicates previously caused incorrect next step selection.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-34 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.10.16] - 2025-01-15[](#31016---2025-01-15 "Direct link to [3.10.16] - 2025-01-15")
Rasa Pro 3.10.16 (2025-01-15)
##### Bugfixes[](#bugfixes-116 "Direct link to Bugfixes")
* * Fixed an error in `rasa llm finetune prepare-data` when using a subclass of `SingleStepLLMCommandGenerator`.
* Make `pattern_session_start` work with `rasa inspector` to allow the assistant proactively start the conversation with a user.
* Fix writing the test cases obtained via the e2e test case conversion command to file, where `test_cases` key was written as a list item, instead of a dict key. This caused running the test cases to fail because it didn't comply with the e2e test schema. This PR fixes the issue by writing the test cases as a dict key.
* Add pre-training custom validation to the domain responses that would raise a Rasa Pro validation error when a domain response is an empty sequence.
* Fixes a critical security vulnerability with `jsonpickle` dependency by upgrading to the patched version.
* Updated `pymilvus` and `minio` to address security vulnerability.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-35 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.10.15] - 2024-12-18[](#31015---2024-12-18 "Direct link to [3.10.15] - 2024-12-18")
Rasa Pro 3.10.15 (2024-12-18)
##### Bugfixes[](#bugfixes-117 "Direct link to Bugfixes")
* Validate that `api_type` key is only used for supported providers (Azure and OpenAI).
* Fix issue in e2e testing when customising `action_session_start` would lead to AttributeError, because the `output_channel` was not set. This is now fixed by setting the `output_channel` to `CollectingOutputChannel()`.
* Fixed the accuracy calculation to prevent 100% assertion reporting when a test case fails before any assertions are reached.
* Pass flow human-readable name instead of flow id when the cancel pattern stack frame is pushed during flow policy validation checks of collect steps.
* Try to instantiate LLM/embeddings client when loading component to validate environment variables.
* Enable asserting events returned by `action_session_start` when running end-to-end testing with assertions format. The following assertions can be used:
* `slot_was_set`
* `slot_was_not_set`
* `bot_uttered`
* `action_executed`
#### \[3.10.14] - 2024-12-04[](#31014---2024-12-04 "Direct link to [3.10.14] - 2024-12-04")
Rasa Pro 3.10.14 (2024-12-04)
##### Bugfixes[](#bugfixes-118 "Direct link to Bugfixes")
* Avoid filling slots that have `ask_before_filling = True` and utilize a `from_text` slot mapping during other steps in the flow. Ensure that the `NLUCommandAdapter` only fills these types of slots when the flow reaches the designated collection step.
* Fixes OpenAIException - AsyncClient.**init**() got an unexpected keyword argument 'proxies'
* Fix validation for LLM/Embedding clients when the api\_base is configured in the config itself but not as an environment variable.
#### \[3.10.13] - 2024-11-29[](#31013---2024-11-29 "Direct link to [3.10.13] - 2024-11-29")
Rasa Pro 3.10.13 (2024-11-29)
##### Bugfixes[](#bugfixes-119 "Direct link to Bugfixes")
* Implement `eq` and `hash` functions for `ChangeFlowCommand` to fix `error=unhashable type: 'ChangeFlowCommand'` error in `MultiStepCommandGenerator`.
* Fixed an issue on Windows where flow files with names starting with 'u' would fail to load due to improper path escaping in YAML content processing
* Store the value of the `--disable-verify` CLI flag in the `disable_verify` attribute of the `StudioConfig` object, so it can be reused across other studio commands.
#### \[3.10.12] - 2024-11-25[](#31012---2024-11-25 "Direct link to [3.10.12] - 2024-11-25")
Rasa Pro 3.10.12 (2024-11-25)
##### Bugfixes[](#bugfixes-120 "Direct link to Bugfixes")
* Replace `pickle` and `joblib` with safer alternatives, e.g. `json`, `safetensors`, and `skops`, for serializing components.
**Note**: This is a model breaking change. Please retrain your model.
If you have a custom component that inherits from one of the components listed below and modified the `persist` or `load` method, make sure to update your code. Please contact us in case you encounter any problems.
Affected components:
* `CountVectorFeaturizer`
* `LexicalSyntacticFeaturizer`
* `LogisticRegressionClassifier`
* `SklearnIntentClassifier`
* `DIETClassifier`
* `CRFEntityExtractor`
* `TrackerFeaturizer`
* `TEDPolicy`
* `UnexpectedIntentTEDPolicy`
#### \[3.10.11] - 2024-11-20[](#31011---2024-11-20 "Direct link to [3.10.11] - 2024-11-20")
Rasa Pro 3.10.11 (2024-11-20)
##### Bugfixes[](#bugfixes-121 "Direct link to Bugfixes")
* Fix parsing of commands in case the LLM response surrounds flow names, slot names, or slot values with single or double quotes.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-36 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.10.10] - 2024-11-14[](#31010---2024-11-14 "Direct link to [3.10.10] - 2024-11-14")
Rasa Pro 3.10.10 (2024-11-14)
##### Bugfixes[](#bugfixes-122 "Direct link to Bugfixes")
* Check for the metadata's `step_id` and `active_flow` keys when adding the `ActionExecuted` event to the flows paths stack.
#### \[3.10.9] - 2024-11-13[](#3109---2024-11-13 "Direct link to [3.10.9] - 2024-11-13")
Rasa Pro 3.10.9 (2024-11-13)
##### Bugfixes[](#bugfixes-123 "Direct link to Bugfixes")
* Introduced the environment variable `MAX_NUMBER_OF_PREDICTIONS_CALM` to configure the CALM-specific limit for the number of predictions. This variable defaults to 1000, providing a higher prediction limit compared to the default value of 10 for nlu-based assistants.
* Filter out comments from e2e test input files when writing e2e results to file.
* Specified UTF-8 encoding to correctly read test cases on Windows.
#### \[3.10.8] - 2024-10-24[](#3108---2024-10-24 "Direct link to [3.10.8] - 2024-10-24")
Rasa Pro 3.10.8 (2024-10-24)
##### Bugfixes[](#bugfixes-124 "Direct link to Bugfixes")
* The user message "/restart" is now restarting the session again after adding a proper implementation (stack frame and command) for `pattern_restart`.
* Only infer and set the provider to `azure` for our LLM clients in case NO `provider` is specified, but the `deployment` key is set.
* Fix OPENAI\_API\_KEY authentication error when using self-hosted provider.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-37 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.10.7] - 2024-10-17[](#3107---2024-10-17 "Direct link to [3.10.7] - 2024-10-17")
Rasa Pro 3.10.7 (2024-10-17)
##### Improvements[](#improvements-26 "Direct link to Improvements")
* Change default response of `utter_free_chitchat_response` from `"placeholder_this_utterance_needs_the_rephraser"` to `"Sorry, I'm not able to answer that right now."`.
##### Bugfixes[](#bugfixes-125 "Direct link to Bugfixes")
* Disallow using the command payload syntax to set slots not filled by any of the active or startable flow(s) `collect` steps.
* Add flow name to error message `validator.verify_flows_steps_against_domain.collect_step`.
* Update e2e test results output files on each test run so that, for example, when all tests pass on subsequent runs after failing previously, the failed results output file is emptied.
* Disable strict SSL verification to the Rasa Studio authentication server via the `--disable-verify` or `-x` CLI argument added to the `rasa studio config` command.
* Upgrade `zipp` dependency version to fix a security vulnerability: [CVE-2024-5569](https://github.com/advisories/GHSA-jfmj-5v4g-7637).
#### \[3.10.6] - 2024-10-04[](#3106---2024-10-04 "Direct link to [3.10.6] - 2024-10-04")
Rasa Pro 3.10.6 (2024-10-04)
##### Bugfixes[](#bugfixes-126 "Direct link to Bugfixes")
* Fix cleanup of `SetSlot` commands issued by the LLM-based command generator for slots that define a slot mapping other than the `from_llm` slot mapping. The command processor now correctly removes the SetSlot command in these scenarios and instead adds a `CannotHandleCommand`.
* Fix `UnicodeDecodeError` while reading Windows path from yaml files.
* Fix model loading from remote storage by correcting the handling of remote storage enum during the creation of the persistor object.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-38 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.10.5] - 2024-10-01[](#3105---2024-10-01 "Direct link to [3.10.5] - 2024-10-01")
Rasa Pro 3.10.5 (2024-10-01)
##### Bugfixes[](#bugfixes-127 "Direct link to Bugfixes")
* Fix the case where IntentlessPolicy is triggered while no e2e stories were written to guide it. In this situation a CannotHandleCommand will be issued.
* Update litellm to version 1.45.0 to fix security vulnerability (CVE-2024-6587). Update gitpython to version 3.1.41 to fix security vulnerability (CVE-2024-22190). Update certifi to version 2024.07.04 to fix security vulnerability (CVE-2024-39689).
* Prevent invalid domain with incorrectly defined intent from throwing stack trace. Throw InvalidDomain exception and send message to the user instead. The message looks like this:
```
Detected invalid intent definition: {'intent': 'ask_help'}.
Please make sure all intent definitions are valid.
```
* Support text completions endpoint when using self hosted models.
The `use_chat_completions_endpoint` parameter is now supported when using self-hosted models. This parameter is used to enable the use of the chat completions endpoint when using a self-hosted model. This parameter is set to `True` by default. To use the text completions endpoint, set `use_chat_completions_endpoint` to `False` in the `llm` section of the component.
Usage:
```
llm:
provider: self-hosted
model: meta-llama/Meta-Llama-3-8B
api_base: "https://my-endpoint/v1"
use_chat_completions_endpoint: false
```
* Fixes an issue where the `CountVectorsFeaturizer` and `LogisticRegressionClassifier` would throw error during inference when no NLU training data is provided.
* Added tracing explicitly to `GRPCCustomActionExecutor.run` in order to pass the tracing context to the action server.
#### \[3.10.4] - 2024-09-25[](#3104---2024-09-25 "Direct link to [3.10.4] - 2024-09-25")
Rasa Pro 3.10.4 (2024-09-25)
##### Bugfixes[](#bugfixes-128 "Direct link to Bugfixes")
* Fix failing validation of categorical slots when slot values contain Apostrophe.
#### \[3.10.3] - 2024-09-20[](#3103---2024-09-20 "Direct link to [3.10.3] - 2024-09-20")
Rasa Pro 3.10.3 (2024-09-20)
No significant changes.
#### \[3.10.2] - 2024-09-19[](#3102---2024-09-19 "Direct link to [3.10.2] - 2024-09-19")
Rasa Pro 3.10.2 (2024-09-19)
##### Deprecations and Removals[](#deprecations-and-removals-4 "Direct link to Deprecations and Removals")
* Dropped support for Python 3.8 ahead of [Python 3.8 End of Life in October 2024](https://devguide.python.org/versions/#supported-versions). In Rasa Pro versions 3.10.0, 3.9.11 and 3.8.13, we needed to pin the TensorFlow library version to 2.13.0rc1 in order to remove critical vulnerabilities; this resulted in poor user experience when installing these versions of Rasa Pro with `uv pip`. Removing support for Python 3.8 will make it possible to upgrade to a stabler version of TensorFlow.
##### Improvements[](#improvements-27 "Direct link to Improvements")
* Update Keras and Tensorflow to version 2.14. This will eliminate the need to use the `--prerelease allow` flag when installing Rasa Pro using `uv pip` tool.
##### Bugfixes[](#bugfixes-129 "Direct link to Bugfixes")
* Revert the old behavior when loading trained model by supplying a path to the model on the remote storage by using the model path (`-m`) argument when `REMOTE_STORAGE_PATH` environment variable is not set. Resulting path on the remote storage will be the same as the model path (`-m`) argument.
Additionally, entire model path (`-m`) argument wil be used when trained model is being uploaded to the remote storage with `REMOTE_STORAGE_PATH` environment variable not set. Resulting path on the remote storage will be the same as the model path (`-m`) argument.
If `REMOTE_STORAGE_PATH` environment variable is set, only the file name part of the model path (`-m`) argument is used in both loading and storage from/to the remote storage. Resulting path on the remote storage will be: `REMOTE_STORAGE_PATH` + file name part of the model path (`-m`) argument.
* Fixed UnexpecTEDIntentlessPolicy training errors that resulted from a change to batching behavior. Changed the batching behavior back to the original for all components. Made the changed batching behavior accessible in DietClassifier using `drop_small_last_batch: True`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-39 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.10.1] - 2024-09-11[](#3101---2024-09-11 "Direct link to [3.10.1] - 2024-09-11")
Rasa Pro 3.10.1 (2024-09-11)
##### Bugfixes[](#bugfixes-130 "Direct link to Bugfixes")
* Fix OpenAI LLM client ignoring API base and API version arguments if set.
* Fix `FileNotFound` error when running `rasa studio` commands and no pre-existing local assistant project exists.
* Fixed telemetry collection for the components Rephraser, LLM Intent Classifier, Intentless Policy and Enterprise Search Policy to ensure that the telemetry data is only collected when it is enabled
* Update the default config for E2E test conversion to use the `provider` key instead of `api_type`.
* Fix inconsistent recording of telemetry events for llm-based command generators.
* Throw deprecation warning when REQUESTS\_CA\_BUNDLE env var is used.
#### \[3.10.0] - 2024-09-04[](#3100---2024-09-04 "Direct link to [3.10.0] - 2024-09-04")
Rasa Pro 3.10.0 (2024-09-04)
##### Deprecations and Removals[](#deprecations-and-removals-5 "Direct link to Deprecations and Removals")
* Remove experimental `LLMIntentClassifier`. Use Rasa CALM instead.
##### Features[](#features-6 "Direct link to Features")
* Implement the shell output of [accuracy rate by assertion type](https://rasa.com/docs/rasa-pro/testing/e2e-testing-assertions/assertions-how-to-guide#test-results-analysis) as a table when running end-to-end testing with assertions.
* Implement E2E testing assertions that measure metrics such as grounded-ness and answer relevance of generative responses issued by either Enterprise Search or the Contextual Response Rephraser.
You must specify a threshold which must be reached for the generative evaluation assertion to pass. In addition, you can also specify `ground_truth` if you prefer providing this in the E2E test rather than relying on the retrieved context from the vector store (in the case of Enterprise Search) or from the domain (in the case of Contextual Response Rephraser) that is stored in the bot utterance event metadata. For rephrased answers, you must specify `utter_name` to run the assertion.
These assertions can be specified for user steps only and cannot be used alongside the former E2E test format. You can learn more about this new feature in the documentation sections for [grounded](https://rasa.com/docs/rasa-pro/testing/e2e-testing-assertions/assertions-fundamentals#generative-response-is-grounded-assertion) and [relevant](https://rasa.com/docs/rasa-pro/testing/e2e-testing-assertions/assertions-fundamentals#generative-response-is-relevant-assertion) assertion types.
To enable this feature, please set the environment variable `RASA_PRO_BETA_E2E_ASSERTIONS` to `true`.
```
export RASA_PRO_BETA_E2E_ASSERTIONS=true
```
* You can now produce a coverage report of your e2e tests via the following command:
```
rasa test e2e --coverage-report [--coverage-output-path ]
```
The coverage report contains the number of steps and the number of tested steps per flow. Untested steps are referenced by line numbers.
```
Flow Name Coverage Num Steps Missing Steps Line Numbers
flow_1 0.00% 1 1 [10-10]
flow_2 100.00% 4 0 []
Total 80.00% 5 1
```
Additionally, we also create a histogram of command coverage showing how many and what commands are produced in your e2e tests.
To enable this feature, please set the environment variable `RASA_PRO_BETA_FINETUNING_RECIPE` to `true`.
```
export RASA_PRO_BETA_FINETUNING_RECIPE=true
```
More information can be found on the [documentation](https://rasa.com/docs/rasa-pro/production/testing-your-assistant#e2e-test-coverage-report) of the feature.
* Create a self-hosted LLM client compatible with OpenAI format. Users can connect to their own self-hosted LLM server that is compatible with OpenAI format.
Sample basic usage:
```
llm:
provider: self-hosted
model:
api_base:
api_type: openai [Optional]
```
* Add a new [CLI command](https://rasa.com/docs/rasa-pro/command-line-interface#rasa-llm-finetune-prepare-data) `rasa llm finetune prepare-data` to create a dataset from e2e tests that can be used to fine-tune a base model for the task of command generation.
To enable this feature, please set the environment variable `RASA_PRO_BETA_FINETUNING_RECIPE` to `true`.
```
export RASA_PRO_BETA_FINETUNING_RECIPE=true
```
* It is now allowed to link to `pattern_human_handoff` from any pattern and user flow.
* Allow links from all patterns to user flows except for `pattern_internal_error`.
* * **LiteLLM Integration & Reduced LangChain Reliance:**
* Introduced `LLMClient` and `EmbeddingClient` protocols for standardized client interfaces.
* Created lightweight client wrappers for LiteLLM to streamline model instantiation, management, and inference.
* Updated `llm_factory` and `embedder_factory` to utilize these LiteLLM client wrappers.
* Added dedicated clients for Azure OpenAI and OpenAI to support both LLMs and embedding models.
* Added a HuggingFace client to compute embeddings using locally stored transformer models via the `sentence-transformers` package.
* **LangChain Update:** Upgraded to the latest version (0.2.x) for improved compatibility and features. To understand the implications on your assistant, please refer to the [feature documentation](https://rasa.com/docs/rasa-pro/concepts/components/llm-configuration) and the [migration guide](https://rasa.com/docs/rasa-pro/migration-guide#rasa-pro-39-to-rasa-pro-310).
* Implement as part of E2E testing a new type of evaluation specifically designed to increase confidence in CALM. This evaluation runs assertions on the assistant's actual events and generative responses. New assertions include the ability to check for the presence of specific events, such as:
* flow started, flow completed or flow cancelled events
* whether `pattern_clarification` was triggered for specific flows
* whether buttons rendered well as part of the bot uttered event
* whether slots were set correctly or not
* whether the bot text response matches a provided regex pattern
* whether the bot response matches a provided domain response name
These assertions can be specified for user steps only and cannot be used alongside the former E2E test format. You can learn more about this new feature in the [documentation](https://rasa.com/docs/rasa-pro/testing/e2e-testing-assertions/assertions-introduction).
To enable this feature, please set the environment variable `RASA_PRO_BETA_E2E_ASSERTIONS` to `true`.
```
export RASA_PRO_BETA_E2E_ASSERTIONS=true
```
* Configure [LLM-as-Judge settings](https://rasa.com/docs/rasa-pro/testing/e2e-testing-assertions/assertions-installation#generative-response-llm-judge-configuration) in the `llm_as_judge` section of the `conftest.yml` file. These settings will be used to evaluate the groundedness and relevance of generated bot responses. The `conftest.yml` is discoverable as long as it is in the root directory of the assistant project, at the same level as the `config.yml` file.
If the `conftest.yml` file is not present in the root directory, the default LLM judge settings will be used.
* Implement automatic E2E test case conversion from sample conversation data.
This feature includes:
* A CLI command to convert sample conversation data (CSV, XLSX) into executable E2E test cases.
* Conversion of sample data using an LLM to generate YAML formatted test cases.
* Export of generated test cases into a specified YAML file.
Usage:
```
rasa data convert e2e
```
To enable this feature, please set the environment variable `RASA_PRO_BETA_E2E_CONVERSION` to `true`.
```
export RASA_PRO_BETA_E2E_CONVERSION=true
```
For more details, please refer to this [documentation page](https://rasa.com/docs/rasa-pro/testing/e2e-test-conversion).
##### Improvements[](#improvements-28 "Direct link to Improvements")
* Implemented custom action stubbing for E2E test cases. To define custom action stubs, add `stub_custom_actions` to the test case file.
Stubs can be defined in two ways:
* Test file level: Define each action by its name (`action_name`).
* Test case level: Define the stub using the test case ID as a prefix (`test_case_id::action_name`).
To learn more about this feature, please refer to the [documentation](https://rasa.com/docs/rasa-pro/production/testing-your-assistant#stubbing-custom-actions).
To enable this feature, set the environment variable `RASA_PRO_BETA_STUB_CUSTOM_ACTION` to `true`:
```
export RASA_PRO_BETA_STUB_CUSTOM_ACTION=true
```
* Add `max_messages_in_query` parameter to Enterprise Search Policy, it allows controlling the number of past messages that are used in the search query for retrieval
* Configure [LLM E2E test converter settings](https://rasa.com/docs/rasa-pro/testing/e2e-test-conversion#llm-configuration) in the `llm_e2e_test_conversion` section of the `conftest.yml` file.
These settings will be used to configure the LLM used to convert sample conversation data into E2E test cases.
The `conftest.yml` is discoverable as long as it is in the root directory of the tests output path.
If the `conftest.yml` file is not present in the root directory, the default LLM settings will be used.
* Add the datetime of Rasa Pro license expiry to `rasa --version` command Add `/license` API endpoint that also returns the same information
* Suppress LiteLLM info and debug log messages in the console.
* Cache llm\_factory and embedder\_factory methods to avoid client instantiation and validation for every user utterance.
* Added E2E Test Conversion Completed telemetry event with file type and test case count properties.
* Separate writing of failed and passed e2e test results to distinct file paths.
* Implement support for evaluating IntentlessPolicy responses with generative response assertions.
* Use direct custom action execution in tutorial and CALM templates. Skip action server health check in e2e testing if direct custom action execution is configured.
* Modified the type of flows which are included into the import CLI (previously only user flows were enabled, now patterns are included). Use case: This is needed for Studio 1.7, since that release is enabling modification and management of patterns inside Studio, and needs the ability to import patterns from yaml files.
* Improve events and responses sub-schemas used by the `stub_custom_actions` sub-schema of end-to-end testing. The events sub-schema only allows the usage of events which are supported by the `rasa-sdk`. These are documented in the [action server API documentation](https://rasa.com/docs/docs/reference/api/pro/action-server-api/).
* Change default model of conversation rephraser to 'gpt-4o-mini'.
* Add `file_path` to `Flow` so that we can show the full name, e.g. `path/to/flow.py::flow name` in the e2e test coverage report.
* Introduced remote storage to upload trained model to persistors(AWS, GCP, Azure)
* Add ability to download training data from remote storage(gcs, aws, azure)
* Allow saving models to and retrieving from sub folders in cloud storage.
* Introduced `DirectCustomActionExecutor` for executing custom actions directly through the assistant.
Introduced `actions_module` variable under `action_endpoint` in `endpoints.yml` to explicitly specify the path to custom actions module.
If `actions_module` is set, custom actions will be executed directly through the assistant.
* Add validation for the values against which categorical and boolean slots are checked in the if conditional steps. An error will be thrown when a slot is compared to an invalid/non-existent value for boolean and categorical slots.
* Add user query and retrieved document results to the metadata of `action_send_text` predicted by EnterpriseSearchPolicy. In addition, add domain ground truth responses to the `BotUttered` event metadata when rephrasing is enabled. These changes were required to allow evaluations of generative responses against the ground truth stored in the metadata of `BotUttered` events.
##### Bugfixes[](#bugfixes-131 "Direct link to Bugfixes")
* Fix problem with custom action invocation when model is loaded from remote storage.
* Ensure certificates for openai based clients.
* Mark the first slot event as seen when the user turn in a E2E test case contains multiple slot events for the same slot. This fixes the issue when the `assertion_order_enabled` is set to `true` and the user step in a test case contained multiple `slot_was_set` assertions for the same slot, the last slot event was marked as seen when the first assertion was running. This caused the test to fail for subsequent `slot_was_set` assertions for the same slot with error `Slot was not set`.
* Validate the LLM configuration during training for the following components:
* `Contextual Response Rephraser`
* `Enterprise Search Policy`
* `Intentless Policy`
* `LLM Based Command Generator`
* `LLM Based Router`
Additionally, update the `get_provider_from_config` method to retrieve the provider using both the `model` and `model_name` configuration parameters.
* Fixes throwing the deprecation warning if the setting for Azure OpenAI Embedding Client was not set through the deprecated environment variable.
* Fix execution of stub custom actions when they contain test case name and the separator in its provided stub name. Test runner will now correctly execute the correct stub implementation for the same custom action dependent on the test name.
* Add validation to conversation rephraser.
* Ensure YAML files with datetime-formatted strings are read as plain strings instead of being converted to datetime objects.
* Deprecate 'request\_timeout' for OpenAI and Azure OpenAI clients in favor of 'timeout'
* Forbid `stream` and `n` parameters for clients. Having these parameters within `llm` and `embeddings` configuration will result in error.
* Raise deprecation warning if `api_type` is set to `huggingface` instead of `huggingface_local` for HuggingFace local embeddings.
* Fix resolving aliases for deprecated keys when instantiating LLM and embedding clients.
* Fix detection of conftest file which contained custom LLM judge configuration.
* Fix issue with Rasa Pro Studio download command exporting default flows which had not been customized by the Studio user. Rasa Pro Studio download command only exports user defined flows, customized patterns and user defined domain locally from the Studio instance.
Similarly, fix issue with Rasa Pro Studio upload command importing default flows which had not been customized to Studio. Rasa Pro Studio upload command only imports user defined flows, customized patterns and user defined domain to the Studio instance.
* Disable auto-inferring provider from the config. Ensure the provider is explicitly read from the `provider` key.
* Fix writing e2e test cases to disk. `slot_was_set` and `slot_was_not_set` are now written down correctly.
* The rephraser of the `rasa llm finetune data-prepare` command now compares the original user message and the user message returned in the LLM output case-insensitive.
* \[rasa llm finetune prepare-data] Do not rephrase user messages that come from a button payload.
* Separate commands in the expected LLM output by newlines.
* Fix TypeError in PatternClarificationContainsAssertion hash function by converting sets to lists for successful JSON serialization.
* Fix validation in case a link to `pattern_human_handoff` is used.
* \[`rasa llm finetune prepare-data`] Skip paraphrasing module in case `num-rephrases` is set to 0.
* Update the handling of incorrect use of slash syntax. Messages with undefined intents do not automatically trigger `pattern_cannot_handle`; instead, they are sanitized (prepended slash(es) are removed) and passed through the graph.
* Allow suitable patterns to be properly started using nlu triggers
* Fix API connection error for bedrock embedding endpoint.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-40 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.9.20] - 2025-04-14[](#3920---2025-04-14 "Direct link to [3.9.20] - 2025-04-14")
Rasa Pro 3.9.20 (2025-04-14)
##### Bugfixes[](#bugfixes-132 "Direct link to Bugfixes")
* Updated `Inspector` dependent packages (cross-spawn, mermaid, dom-purify, vite, braces, ws, axios and rollup) to address security vulnerabilities.
* Modify Enterprise Search Citation Prompt Template to use `doc.text`
* Security patch for Audiocodes channel connector. Audiocodes channel was only checking for the existence of authentication token. It now does a constant-time string comparison of the authentication token in connection request with that provided in channel configruation.
#### \[3.9.19] - 2025-01-30[](#3919---2025-01-30 "Direct link to [3.9.19] - 2025-01-30")
Rasa Pro 3.9.19 (2025-01-30)
##### Improvements[](#improvements-29 "Direct link to Improvements")
* Remove unnecessary deepcopy to improve performance in `undo_fallback_prediction` method of `FallbackClassifier`
##### Bugfixes[](#bugfixes-133 "Direct link to Bugfixes")
* * Fixed an issue where the `pattern_continue_interrupted` was not correctly triggered when the flow digressed to a step containing a link.
* Add the flow ID as a prefix to step ID to ensure uniqueness. This resolves a rare bug where steps in a child flow with a structure similar to those in a parent flow (using a "call" step) could result in duplicate step IDs. In this case duplicates previously caused incorrect next step selection.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-41 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.9.18] - 2025-01-15[](#3918---2025-01-15 "Direct link to [3.9.18] - 2025-01-15")
Rasa Pro 3.9.18 (2025-01-15)
##### Bugfixes[](#bugfixes-134 "Direct link to Bugfixes")
* Fix issue in e2e testing when customising `action_session_start` would lead to AttributeError, because the `output_channel` was not set. This is now fixed by setting the `output_channel` to `CollectingOutputChannel()`.
* Pass flow human-readable name instead of flow id when the cancel pattern stack frame is pushed during flow policy validation checks of collect steps.
* Make `pattern_session_start` work with `rasa inspector` to allow the assistant proactively start the conversation with a user.
* Fixes a critical security vulnerability with `jsonpickle` dependency by upgrading to the patched version.
* Updated `minio` to address security vulnerability.
#### \[3.9.17] - 2024-12-05[](#3917---2024-12-05 "Direct link to [3.9.17] - 2024-12-05")
Rasa Pro 3.9.17 (2024-12-05)
##### Bugfixes[](#bugfixes-135 "Direct link to Bugfixes")
* Implement `eq` and `hash` functions for `ChangeFlowCommand` to fix `error=unhashable type: 'ChangeFlowCommand'` error in `MultiStepCommandGenerator`.
#### \[3.9.16] - 2024-11-26[](#3916---2024-11-26 "Direct link to [3.9.16] - 2024-11-26")
Rasa Pro 3.9.16 (2024-11-26)
##### Bugfixes[](#bugfixes-136 "Direct link to Bugfixes")
* Replace `pickle` and `joblib` with safer alternatives, e.g. `json`, `safetensors`, and `skops`, for serializing components.
**Note**: This is a model breaking change. Please retrain your model.
If you have a custom component that inherits from one of the components listed below and modified the `persist` or `load` method, make sure to update your code. Please contact us in case you encounter any problems.
Affected components:
* `CountVectorFeaturizer`
* `LexicalSyntacticFeaturizer`
* `LogisticRegressionClassifier`
* `SklearnIntentClassifier`
* `DIETClassifier`
* `CRFEntityExtractor`
* `TrackerFeaturizer`
* `TEDPolicy`
* `UnexpectedIntentTEDPolicy`
#### \[3.9.15] - 2024-10-18[](#3915---2024-10-18 "Direct link to [3.9.15] - 2024-10-18")
Rasa Pro 3.9.15 (2024-10-18)
##### Improvements[](#improvements-30 "Direct link to Improvements")
* Change default response of `utter_free_chitchat_response` from `"placeholder_this_utterance_needs_the_rephraser"` to `"Sorry, I'm not able to answer that right now."`.
##### Bugfixes[](#bugfixes-137 "Direct link to Bugfixes")
* Fix cleanup of `SetSlot` commands issued by the LLM-based command generator for slots that define a slot mapping other than the `from_llm` slot mapping. The command processor now correctly removes the SetSlot command in these scenarios and instead adds a `CannotHandleCommand`.
* Disallow using the command payload syntax to set slots not filled by any of the active or startable flow(s) `collect` steps.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-42 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.9.14] - 2024-10-02[](#3914---2024-10-02 "Direct link to [3.9.14] - 2024-10-02")
Rasa Pro 3.9.14 (2024-10-02)
No significant changes.
#### \[3.9.13] - 2024-10-01[](#3913---2024-10-01 "Direct link to [3.9.13] - 2024-10-01")
Rasa Pro 3.9.13 (2024-10-01)
##### Bugfixes[](#bugfixes-138 "Direct link to Bugfixes")
* Fix inconsistent recording of telemetry events for llm-based command generators.
* Added tracing explicitly to `GRPCCustomActionExecutor.run` in order to pass the tracing context to the action server.
* Fixes an issue where the `CountVectorsFeaturizer` and `LogisticRegressionClassifier` would throw error during inference when no NLU training data is provided.
#### \[3.9.12] - 2024-09-20[](#3912---2024-09-20 "Direct link to [3.9.12] - 2024-09-20")
Rasa Pro 3.9.12 (2024-09-20)
##### Deprecations and Removals[](#deprecations-and-removals-6 "Direct link to Deprecations and Removals")
* Dropped support for Python 3.8 ahead of [Python 3.8 End of Life in October 2024](https://devguide.python.org/versions/#supported-versions). In Rasa Pro versions 3.10.0, 3.9.11 and 3.8.13, we needed to pin the TensorFlow library version to 2.13.0rc1 in order to remove critical vulnerabilities; this resulted in poor user experience when installing these versions of Rasa Pro with `uv pip`. Removing support for Python 3.8 will make it possible to upgrade to a stabler version of TensorFlow.
##### Improvements[](#improvements-31 "Direct link to Improvements")
* Update Keras and Tensorflow to version 2.14. This will eliminate the need to use the `--prerelease allow` flag when installing Rasa Pro using `uv pip` tool.
##### Bugfixes[](#bugfixes-139 "Direct link to Bugfixes")
* Fix `AttributeError` with the instrumentation of the `run` method of the `CustomActionExecutor` class.
* Fixed UnexpecTEDIntentlessPolicy training errors that resulted from a change to batching behavior. Changed the batching behavior back to the original for all components. Made the changed batching behavior accessible in DietClassifier using `drop_small_last_batch: True`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-43 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.9.11] - 2024-09-13[](#3911---2024-09-13 "Direct link to [3.9.11] - 2024-09-13")
Rasa Pro 3.9.11 (2024-09-13)
##### Bugfixes[](#bugfixes-140 "Direct link to Bugfixes")
* Update Keras to 2.13.1 and Tensorflow to 2.13.0rc0 to fix critical vulnerability (CVE-2024-3660).
#### \[3.9.10] - 2024-09-12[](#3910---2024-09-12 "Direct link to [3.9.10] - 2024-09-12")
Rasa Pro 3.9.10 (2024-09-12)
##### Bugfixes[](#bugfixes-141 "Direct link to Bugfixes")
* Fix `FileNotFound` error when running `rasa studio` commands and no pre-existing local assistant project exists.
* Fixed telemetry collection for the components Rephraser, LLM Intent Classifier, Intentless Policy and Enterprise Search Policy to ensure that the telemetry data is only collected when it is enabled
#### \[3.9.9] - 2024-08-23[](#399---2024-08-23 "Direct link to [3.9.9] - 2024-08-23")
Rasa Pro 3.9.9 (2024-08-23)
##### Bugfixes[](#bugfixes-142 "Direct link to Bugfixes")
* Updated behaviour of policies in coexistence:
* CALM policies run in case the routing slot is set to `True` (routing to CALM).
* Policies of the nlu-based system run in case the routing slot is set to `False` (routing to NLU-based system) or `None` (non-sticky routing).
* Don't create an instance of `FlowRetrieval` in the command generators in case no flows exists.
* Patterns do not count as active flows in `MultiStepLLMCommandGenerator` anymore.
* Make sure that all e2e test cases in rasa inspector are valid.
* Downloading of CALM Assistants from Studio improved:
* Downloading CALM assistants from Studio now includes `config` and `endpoints` files
* Downloading CALM assistants from Studio now doesn't require `config.yml` and `data` folder to exist
#### \[3.9.8] - 2024-08-21[](#398---2024-08-21 "Direct link to [3.9.8] - 2024-08-21")
Rasa Pro 3.9.8 (2024-08-21)
##### Bugfixes[](#bugfixes-143 "Direct link to Bugfixes")
* Fix problem with custom action invocation when model is loaded from remote storage.
#### \[3.9.7] - 2024-08-15[](#397---2024-08-15 "Direct link to [3.9.7] - 2024-08-15")
Rasa Pro 3.9.7 (2024-08-15)
##### Bugfixes[](#bugfixes-144 "Direct link to Bugfixes")
* Fix extraction of tracing context from the request headers and injection into the Rasa server tracing context.
* `YamlValidationException` will correctly return line number of the element where the error occurred when line number of that element is not returned by `ruamel.yaml` (for elements of primitive types, e.g. `str`, `int`, etc.), instead of returning the line number of the parent element.
* Updated `setuptools` to fix security vulnerability.
* Fix tracing context propagation to work for all external service calls.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-44 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.9.6] - 2024-08-07[](#396---2024-08-07 "Direct link to [3.9.6] - 2024-08-07")
Rasa Pro 3.9.6 (2024-08-07)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-45 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.9.5] - 2024-08-01[](#395---2024-08-01 "Direct link to [3.9.5] - 2024-08-01")
Rasa Pro 3.9.5 (2024-08-01)
##### Improvements[](#improvements-32 "Direct link to Improvements")
* Enabled generative chitchat in the `tutorial` template with instructions on how to turn it off added to the documentation.
##### Bugfixes[](#bugfixes-145 "Direct link to Bugfixes")
* Update the usage of `time.process_time_ns` with `time.perf_counter_ns` to fix the inconsistencies between duration metrics and trace spans duration.
#### \[3.9.4] - 2024-07-25[](#394---2024-07-25 "Direct link to [3.9.4] - 2024-07-25")
Rasa Pro 3.9.4 (2024-07-25)
##### Bugfixes[](#bugfixes-146 "Direct link to Bugfixes")
* Fix instrumentation not accounting for `kwargs` that are passed to `NLUCommandAdapter.predict_commands`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-46 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.9.3] - 2024-07-18[](#393---2024-07-18 "Direct link to [3.9.3] - 2024-07-18")
Rasa Pro 3.9.3 (2024-07-18)
##### Bugfixes[](#bugfixes-147 "Direct link to Bugfixes")
* Refactor the supported remote storage (AWS, GCS, Azure) verification check before downloading Rasa model by fixing the initial implementation which attempted to create the object storage to check existence.
* Fix `TypeError: InformationRetrieval.search() got an unexpected keyword argument` when tracing is enabled with `EnterpriseSearchPolicy`.
* Change `warning` log level to `error` log level for `Validator` methods that verify that forms and actions used in stories and rules are present in the domain.
#### \[3.9.2] - 2024-07-09[](#392---2024-07-09 "Direct link to [3.9.2] - 2024-07-09")
Rasa Pro 3.9.2 (2024-07-09)
##### Bugfixes[](#bugfixes-148 "Direct link to Bugfixes")
* Add key-word arguments in the predict\_commands method of LLM-based CommandGenerator class to ensure custom components are not impacted by changes to the signature of the base classes.
#### \[3.9.1] - 2024-07-04[](#391---2024-07-04 "Direct link to [3.9.1] - 2024-07-04")
Rasa Pro 3.9.1 (2024-07-04)
##### Bugfixes[](#bugfixes-149 "Direct link to Bugfixes")
* Modify the validation to throw an error for a missing associated action/utterance in a collect step only if the slot does not have a defined initial value.
* Modify the collect step validation in flow executor to trigger `pattern_internal_error` for a missing associated action/utterance in a collect step only if the slot does not have a defined initial value.
#### \[3.9.0] - 2024-07-03[](#390---2024-07-03 "Direct link to [3.9.0] - 2024-07-03")
Rasa Pro 3.9.0 (2024-07-03)
##### Features[](#features-7 "Direct link to Features")
* Introduce a new response [button payload format](https://rasa.com/docs/rasa-pro/concepts/responses#payload-syntax) that runs set slot CALM commands directly by skipping the user message processing pipeline.
* Added support for Information Retrieval custom components. It allows Enterprise Search Policy to be used with arbitrary search systems. Custom Information Retrievals can be implemented as a subclass of `rasa.core.information_retrieval.InformationRetrieval`
* Enable slot filling in a CALM assistant to be configurable:
* either use NLU-based predefined slot mappings that instructs `NLUCommandAdapter` to issue SetSlot commands with values extracted from the user input via an entity extractor or intent classifier
* or use the new predefined slot mapping `from_llm` which enables LLM-based command generators to issue SetSlot commands If no slot mapping is defined, the default behavior is to use the `from_llm` slot mapping.
In case you had been using `custom` slot mapping type for slots set with the prediction of the LLM-based command generator, you need to update your assistant configuration to use the new `from_llm` slot mapping type. Note that even if you have written custom slot validation actions (following the `validate_` convention) for slots set by the LLM-based command generator, you need to update your assistant configuration to use the new `from_llm` slot mapping type.
For [slots that are set only via the custom action](https://rasa.com/docs/docs/reference/primitives/slots/#custom-slot-mappings) e.g. slots set by external sources only, you need to add the action name to the slot mapping:
```
slots:
slot_name:
type: text
mappings:
- type: custom
action: custom_action_name
```
* Skip `SetSlot` commands issued by LLM based command generators for slots with NLU-based predefined slot mappings. Instead, the command processor component will issue `CannotHandle` command to trigger `pattern_cannot_handle` if no other valid command is found.
* Rasa now supports gRPC protocol for custom actions. This allows users to use gRPC to invoke custom actions. To connect to the action server using gRPC, specify:
endpoints.yml
```
action_endpoint:
url: "grpc://:"
```
Users can use secure (TLS) and insecure connections to communicate over gRPC. To use TLS specify the following in `endpoints.yml`:
endpoints.yml
```
action_endpoint:
url: "grpc://:"
cafile: ""
```
* Add `MultiStepLLMCommandGenerator` as an alternative LLM based command generator. `MultiStepLLMCommandGenerator` breaks down the task of dialogue understanding into two steps: handling the flows and filling the slots. The component was designed to enable cheaper and smaller LLMs, such as `gpt-3.5-turbo`, as viable alternatives to costlier but more powerful models such as `gpt-4`. To use the `MultiStepLLMCommandGenerator` add it to your pipeline:
```
pipeline:
...
- name: MultiStepLLMCommandGenerator
...
```
##### Improvements[](#improvements-33 "Direct link to Improvements")
* Improve diagram display in the inspector by adding an horizontal scroll and an auto scroll to the active step.
* Create a separate default prompt for Enterprise Search with source citation enabled and revert the default Enterprise Search prompt to that of `3.7.x`.
* Refactored `RemoteAction` to utilize a new `CustomActionExecutor` interface by implementing `HTTPCustomActionExecutor` to handle HTTP requests for custom actions.
* Implemented an optimization to reduce payload size by ensuring the Assistant sends the domain dictionary to the Action Server only once, which the server then stores. If the Action Server responds with a 449 status code indicating a missing domain context, the Assistant will repeat the API request including the domain dictionary in the payload, ensuring the server properly saves this data.
* Integrate the capability of testing scenarios that reflect actual operational environments where conversations can be influenced by real-time external data. This is done by injecting metadata when running end-to-end tests.
* Introduced LRU caching for reading and parsing YAML files to enhance performance by avoiding multiple reads of the same file. Added `READ_YAML_FILE_CACHE_MAXSIZE` environment variable with a default value of 256 to configure the cache size.
* Add validations for flow ID to allow only alphanumeric characters, underscores, and hyphens except for the first character.
* The `LLMCommandGenerator` component has been renamed to `SingleStepLLMCommandGenerator`. There is no change to the functionality.
Using the `LLMCommandGenerator` as the name of the component results in a deprecation warning as it will be permanently renamed to `SingleStepLLMCommandGenerator` in 4.0.0. Please modify the assistant’s configuration to use the `SingleStepLLMCommandGenerator` instead of the `LLMCommandGenerator` to avoid seeing the deprecation warning.
* Make improvements to `rasa data validate` that check if the usage of slot mappings in a CALM assistant is valid:
* a slot cannot have both a `from_llm` mapping and either a nlu-predefined mapping or a custom slot mapping
* a slot collected in a flow by a custom action has an associated `action_ask_` defined in the domain
* a CALM assistant with slots that have nlu-based predefined mappings include `NLUCommandAdapter` in the config pipeline
* a NLU-based assistant cannot have slots that have a `from_llm` mapping
* Modify post processing of commands - Clarify command with single option is converted into a StartFlow command.
* Improve debug logging for predicate evaluation.
##### Bugfixes[](#bugfixes-150 "Direct link to Bugfixes")
* Properly handle projects where `rasa studio download` is run in a project with no NLU data.
* Tracing is supported for actions called over gRPC protocol.
* Fix the hash function of ClarifyCommand to return a hashed list of options.
* Raise an error if action\_reset\_routing is used without the defined ROUTE\_TO\_CALM\_SLOT / router.
* Add a few bugfixes to the CALM slot mappings feature:
* Coexistence bot should ignore `NoOpCommand` when checking if the processed message contains commands.
* Update condition under which FlowPolicy triggers `pattern_internal_error` for slots with custom slot mappings.
* Remove invalid warnings during collect step.
* * Fixed issue where messages with invalid intent triggers ('/\') were not handled correctly. Now triggering the `pattern_cannot_handle`.
* Introduced a new reason `cannot_handle_invalid_intent` for use in the pattern\_cannot\_handle switch mechanism to improve error handling.
* Validates that a collect step in a flow either has an action or an utterance defined in the domain to avoid the bot being silent.
* Slots that are set via response buttons should not trigger `pattern_cannot_handle` regardless of the slots' mapping type.
* Coerce "None", "null" or "undefined" slot values set via response buttons to be of type `NoneType` instead of `str`.
* Avoid raising a `UserWarning` during validation of response buttons which contain double curly braces.
* Do not run NLUCommandAdapter during message parsing when receiving a `/SetSlots` button payload. This is because the NLUCommandAdapter run during message parsing (when the graph is skipped) is meant to handle intent button payloads only.
* Exclude slots that are not collected in any flow from being set by the NLUCommandAdapter in a coexistence assistant.
* Default action `action_extract_slots` should not run custom actions specified in custom slot mappings for slots that are set by custom actions in the flows/CALM system of a coexistence assistant.
* Fix pattern flows being unavailable during input preparation and template rendering in `MultiStepLLMCommandGenerator`.
* Skip command cleaning when no commands are present in NLUCommandAdapter. Fix get active flows to return the correct active flows, including all the nested parent flows if present.
* If FlowPolicy tries to collect a slot with a custom slot mapping without the `action` key or `action_ask` specified in the domain, it will trigger `pattern_cancel_flow` first, then `pattern_internal_error`.
* Cancel user flow in progress and invoke pattern\_internal\_error if the flow reached a collect step which does not have an associated utter\_ask response or action\_ask action defined in the domain.
* IntentlessPolicy abstains from making a prediction during coexistence when it's the turn of the NLU-based system.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-47 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.8.17] - 2024-10-18[](#3817---2024-10-18 "Direct link to [3.8.17] - 2024-10-18")
Rasa Pro 3.8.17 (2024-10-18)
##### Improvements[](#improvements-34 "Direct link to Improvements")
* Change default response of `utter_free_chitchat_response` from `"placeholder_this_utterance_needs_the_rephraser"` to `"Sorry, I'm not able to answer that right now."`.
#### \[3.8.16] - 2024-10-02[](#3816---2024-10-02 "Direct link to [3.8.16] - 2024-10-02")
Rasa Pro 3.8.16 (2024-10-02)
No significant changes.
#### \[3.8.15] - 2024-10-01[](#3815---2024-10-01 "Direct link to [3.8.15] - 2024-10-01")
Rasa Pro 3.8.15 (2024-10-01)
##### Bugfixes[](#bugfixes-151 "Direct link to Bugfixes")
* Fixes an issue where the `CountVectorsFeaturizer` and `LogisticRegressionClassifier` would throw error during inference when no NLU training data is provided.
#### \[3.8.14] - 2024-09-20[](#3814---2024-09-20 "Direct link to [3.8.14] - 2024-09-20")
Rasa Pro 3.8.14 (2024-09-20)
##### Deprecations and Removals[](#deprecations-and-removals-7 "Direct link to Deprecations and Removals")
* Dropped support for Python 3.8 ahead of [Python 3.8 End of Life in October 2024](https://devguide.python.org/versions/#supported-versions). In Rasa Pro versions 3.10.0, 3.9.11 and 3.8.13, we needed to pin the TensorFlow library version to 2.13.0rc1 in order to remove critical vulnerabilities; this resulted in poor user experience when installing these versions of Rasa Pro with `uv pip`. Removing support for Python 3.8 will make it possible to upgrade to a stabler version of TensorFlow.
##### Improvements[](#improvements-35 "Direct link to Improvements")
* Update Keras and Tensorflow to version 2.14. This will eliminate the need to use the `--prerelease allow` flag when installing Rasa Pro using `uv pip` tool.
##### Bugfixes[](#bugfixes-152 "Direct link to Bugfixes")
* Fixed UnexpecTEDIntentlessPolicy training errors that resulted from a change to batching behavior. Changed the batching behavior back to the original for all components. Made the changed batching behavior accessible in DietClassifier using `drop_small_last_batch: True`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-48 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.8.13] - 2024-09-12[](#3813---2024-09-12 "Direct link to [3.8.13] - 2024-09-12")
Rasa Pro 3.8.13 (2024-09-12)
##### Bugfixes[](#bugfixes-153 "Direct link to Bugfixes")
* Fixed telemetry collection for the components Rephraser, LLM Intent Classifier, Intentless Policy and Enterprise Search Policy to ensure that the telemetry data is only collected when it is enabled
* Update Keras to 2.13.1 and Tensorflow to 2.13.0rc0 to fix critical vulnerability (CVE-2024-3660).
#### \[3.8.12] - 2024-08-12[](#3812---2024-08-12 "Direct link to [3.8.12] - 2024-08-12")
Rasa Pro 3.8.12 (2024-08-12)
##### Bugfixes[](#bugfixes-154 "Direct link to Bugfixes")
* Fix `TypeError: InformationRetrieval.search() got an unexpected keyword argument` when tracing is enabled with `EnterpriseSearchPolicy`.
* Fix extraction of tracing context from the request headers and injection into the Rasa server tracing context.
* Update the usage of `time.process_time_ns` with `time.perf_counter_ns` to fix the inconsistencies between duration metrics and trace spans duration.
* `YamlValidationException` will correctly return line number of the element where the error occurred when line number of that element is not returned by `ruamel.yaml` (for elements of primitive types, e.g. `str`, `int`, etc.), instead of returning the line number of the parent element.
* Updated `setuptools` to fix security vulnerability.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-49 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.8.11] - 2024-07-04[](#3811---2024-07-04 "Direct link to [3.8.11] - 2024-07-04")
Rasa Pro 3.8.11 (2024-07-04)
##### Improvements[](#improvements-36 "Direct link to Improvements")
* Improve debug logging for predicate evaluation.
##### Bugfixes[](#bugfixes-155 "Direct link to Bugfixes")
* Raise an error if action\_reset\_routing is used without the defined ROUTE\_TO\_CALM\_SLOT / router.
* Remove invalid warnings during collect step.
* * Fixed issue where messages with invalid intent triggers ("/intent\_name") were not handled correctly. Now triggering the `pattern_cannot_handle`.
* Introduced a new reason `cannot_handle_invalid_intent` for use in the pattern\_cannot\_handle switch mechanism to improve error handling.
* Validates that a collect step in a flow either has an action or an utterance defined in the domain to avoid the bot being silent.
* Skip command cleaning when no commands are present in NLUCommandAdapter. Fix get active flows to return the correct active flows, including all the nested parent flows if present.
* Update the handling of incorrect use of slash syntax. Messages with undefined intents do not automatically trigger `pattern_cannot_handle`; instead, they are sanitized (prepended slash(es) are removed) and passed through the graph.
* Modify the validation to throw an error for a missing associated action/utterance in a collect step only if the slot does not have a defined initial value.
#### \[3.8.10] - 2024-06-19[](#3810---2024-06-19 "Direct link to [3.8.10] - 2024-06-19")
Rasa Pro 3.8.10 (2024-06-19)
##### Improvements[](#improvements-37 "Direct link to Improvements")
* Added NLG validation to the rasa model training process.
##### Bugfixes[](#bugfixes-156 "Direct link to Bugfixes")
* Fixes Clarify command being dropped by command processor due to presence of coexistence slot - `route_session_to_calm`
* Fix validation for LLMBasedRouter to check only for calm\_entry.sticky
#### \[3.8.9] - 2024-06-14[](#389---2024-06-14 "Direct link to [3.8.9] - 2024-06-14")
Rasa Pro 3.8.9 (2024-06-14)
##### Improvements[](#improvements-38 "Direct link to Improvements")
* Add validations for flow ID to allow only alphanumeric characters, underscores, and hyphens except for the first character.
#### \[3.8.8] - 2024-06-07[](#388---2024-06-07 "Direct link to [3.8.8] - 2024-06-07")
Rasa Pro 3.8.8 (2024-06-07)
##### Bugfixes[](#bugfixes-157 "Direct link to Bugfixes")
* Add wrappers around openai clients that can set the self-signed certs via `REQUESTS_CA_BUNDLE` env variable.
#### \[3.8.7] - 2024-05-29[](#387---2024-05-29 "Direct link to [3.8.7] - 2024-05-29")
Rasa Pro 3.8.7 (2024-05-29)
##### Bugfixes[](#bugfixes-158 "Direct link to Bugfixes")
* Add support for domain entities in CALM import
* Download NLU data when running `rasa studio download` for a modern assistant with NLU triggers. Previously, this data was not downloaded, leading to a partial assistant.
#### \[3.8.6] - 2024-05-27[](#386---2024-05-27 "Direct link to [3.8.6] - 2024-05-27")
Rasa Pro 3.8.6 (2024-05-27)
##### Improvements[](#improvements-39 "Direct link to Improvements")
* Adds `tracker_state` attribute to `OutputChannel`. It simplifies the access of tracker state for custom channel connector with `CollectingOutputChannel.tracker_state`.
##### Bugfixes[](#bugfixes-159 "Direct link to Bugfixes")
* If a button in a response does not have a payload, socketio channel will use the title as payload by default rather than throwing an exception.
#### \[3.8.5] - 2024-05-03[](#385---2024-05-03 "Direct link to [3.8.5] - 2024-05-03")
Rasa Pro 3.8.5 (2024-05-03)
##### Bugfixes[](#bugfixes-160 "Direct link to Bugfixes")
* Trigger `pattern_internal_error` if collection does not exist in a Qdrant vector store.
#### \[3.8.4] - 2024-04-30[](#384---2024-04-30 "Direct link to [3.8.4] - 2024-04-30")
Rasa Pro 3.8.4 (2024-04-30)
##### Improvements[](#improvements-40 "Direct link to Improvements")
* Added support for NLU Triggers by supporting uploading the NLU files for CALM Assistants
#### \[3.8.3] - 2024-04-26[](#383---2024-04-26 "Direct link to [3.8.3] - 2024-04-26")
Rasa Pro 3.8.3 (2024-04-26)
##### Improvements[](#improvements-41 "Direct link to Improvements")
* * Throw validation error and exit when duplicate responses are found across domains. This is a breaking change, as it will cause training to fail if duplicate responses are found. If you have duplicate responses in your training data, you will need to remove them before training.
* Update domain importing to ignore the warnings about duplicates when merging with the default flow domain
##### Bugfixes[](#bugfixes-161 "Direct link to Bugfixes")
* Use AzureChatOpenAI class instead of AzureOpenAI class to instantiate openai models deployed in Azure. This fixes the usage of gpt-3.5-turbo model in Azure.
* Fixes validation to catch empty placeholders in response that dumps entire context.
* Fix security vulnerabilities by updating poetry environment: fonttools, CVE-2023-45139, from 4.40.0 to 4.43.0 aiohttp, CVE-2024-27306, from 3.9.3 to 3.9.4 dnspython, CVE-2023-29483, from 2.3.0 to 2.6.1 pymongo, CVE-2024-21506, from 4.3.3 to 4.6.3
* Numbers that are part of the body of the LLM answer in EnterpriseSearch should not be matched as citation references in the postprocessing method.
* Errors from the Flow Retrieval API are now both logged and thrown. When such errors occur, an ErrorCommand is emitted by the Command Generator.
#### \[3.8.2] - 2024-04-25[](#382---2024-04-25 "Direct link to [3.8.2] - 2024-04-25")
Rasa Pro 3.8.2 (2024-04-25)
##### Bugfixes[](#bugfixes-162 "Direct link to Bugfixes")
* Add the currently active flow as well as the called flow (if present) to the list of available flows for the `LLMCommandGenerator`.
* Fix custom prompt not read from the model resource path for LLMCommandGenerator.
#### \[3.8.1] - 2024-04-17[](#381---2024-04-17 "Direct link to [3.8.1] - 2024-04-17")
Rasa Pro 3.8.1 (2024-04-17)
##### Improvements[](#improvements-42 "Direct link to Improvements")
* Adjusted chat widget behavior to remain open when clicking outside the chat box area.
* Improve debug logs to include information about evaluation of `if-else` conditions in flows at runtime.
* Remove the `ContextualResponseRephraser` from the tutorial template to keep it simple as it is not needed anymore.
* Update poetry package manager version to `1.8.2`. Check the [migration guide](https://rasa.com/docs/rasa-pro/migration-guide#rasa-pro-380-to-rasa-pro-381) for instructions on how to update your environment.
##### Bugfixes[](#bugfixes-163 "Direct link to Bugfixes")
* Introduced support for numbered Markdown lists.
* Added support for uploading assistants with default domain directory.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-50 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.8.0] - 2024-04-03[](#380---2024-04-03 "Direct link to [3.8.0] - 2024-04-03")
Rasa Pro 3.8.0 (2024-04-03)
##### Features[](#features-8 "Direct link to Features")
* Introduces **semantic retrieval of flows** at runtime to reduce the size of the prompt sent to the LLM by utilizing similarity between vector embeddings. It enables the assistant to scale to a large number of flows.
Flow retrieval is **enabled by default**. To configure it, you can modify the settings under the `flow_retrieval` property of `LLMCommandGenerator` component. For detailed configuration options, refer to our [documentation](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#customizing-flow-retrieval).
Introduces `always_include_in_prompt` field to the [flow definition](https://rasa.com/docs/rasa-pro/concepts/flows/#flow-properties). If field is set to `true` and the [flow guard](https://rasa.com/docs/rasa-pro/concepts/starting-flows/#flow-guards) defined in the `if` field evaluates to `true`, the flow will be included in the prompt.
* Introduction of coexistence between CALM and NLU-based assistants. Coexistence allows you to use policies from both CALM and NLU-based assistants in a single assistant. This allows migrating from NLU-based paradigm to CALM in an iterative fashion.
* Introduction of `call` step. You can use a `call` step to embed another flow. When the execution reaches a `call` step, Rasa starts the called flow. Once the called flow is complete, the execution continues with the calling flow.
##### Improvements[](#improvements-43 "Direct link to Improvements")
* Instrument the `command_processor` module, in particular the following functions:
* `execute_commands`
* `clean_up_commands`
* `validate_state_of_commands`
* `remove_duplicated_set_slots`
* Improve the instrumentation of `LLMCommandGenerator`:
* extract more LLM configuration parameters, e.g. `type`, `temperature`, `request-timeout`, `engine` and `deployment` (the latter 2 being only for the Azure OpenAI service).
* instrument the private method `_check_commands_against_startable_flows` to track the commands with which the LLM responded, as well as the startable flow ids.
* Instrument `flow_executor.py` module, in particular these functions:
* `advance_flows()`: extract `available_actions` tracing tag
* `advance_flows_until_next_action()`: extract action name and score, metadata and prediction events as tracing tags from the returned prediction value
* `run_step()`: extract step custom id, description and current flow id.
* Instrument `Policy._prediction()` method for each of the policy subclasses.
* Instrument `IntentlessPolicy` methods such as:
* `find_closest_response`: extract the `response` and `score` from the returned tuple;
* `select_response_examples`: extract the `ai_response_examples` from returned value;
* `select_few_shot_conversations`: extract the `conversation_samples` from returned value;
* `extract_ai_responses`: extract the `ai_responses` from returned value;
* `generate_answer`: extract the `llm_response` from returned value.
* 1. Instrument `InformationRetrieval.search` method for supported vector stores: extract query and document metadata tracing attributes.
2. Instrument `EnterpriseSearchPolicy._generate_llm_answer` method: extract LLM config tracing attributes.
3. Extract dialogue stack current context in the following functions:
* `rasa.dialogue_understanding.processor.command_processor.clean_up_commands`
* `rasa.core.policies.flows.flow_executor.advance_flows`
* `rasa.core.policies.flows.flow_executor.run_step`
* 1. Instrument `NLUCommandAdapter.predict_commands` method and extract the `commands` from the returned value, as well as the user message `intent`.
2. Improve LLM config tracing attribute extraction for `ContextualResponseRephraser`.
* Add new config boolean property `trace_prompt_tokens` that would enable the tracing of the length of the prompt tokens for the following components:
* `LLMCommandGenerator`
* `EnterpriseSearchPolicy`
* `IntentlessPolicy`
* `ContextualResponseRephraser`
* Enable execution of single E2E tests by including the test case name in the path to test cases, like so: `path/to/test_cases.yml::test_case_name` or `path/to/folder_containing_test_cases::test_case_name`.
* Implement `MetricInstrumentProvider` interface whose role is to:
* register instruments during metrics configuration
* retrieve the appropriate instrument to record measurements in the relevant instrumentation code section
* Enabled the setting of a minimum similarity score threshold for retrieved documents in Enterprise Search's `vector_store` with the addition of the `threshold` property. If no documents are retrieved, it triggers Pattern Cannot Handle. This feature is supported in Milvus and Qdrant vector stores.
* Record measurements for the following metrics in the instrumentation code:
* CPU usage of the `LLMCommandGenerator`
* memory usage of `LLMCommandGenerator`
* prompt token usage of `LLMCommandGenerator`
* method call duration for LLM specific calls (in `LLMCommandGenerator`, `EnterpriseSearchPolicy`, `IntentlessPolicy`, `ContextualResponseRephraser`)
* rasa client request duration
* rasa client request body size
Instrument `EndpointConfig.request()` method call in order to measure the client request metrics.
* Improvements around default behaviour of `ChitChatAnswerCommand()`:
* The command processor will issue `CannotHandleCommand()` instead of the `ChitChatCommand()` when `pattern_chitchat` uses an action step `action_trigger_chitchat` without the `IntentlessPolicy` being configured. During training a warning is raised.
* Changed the default pattern\_chitchat to:
```
pattern_chitchat:
description: handle interactions with the user that are not task-oriented
name: pattern chitchat
steps:
- action: action_trigger_chitchat
```
* Default rasa init template for CALM comes with `IntentlessPolicy` added to pipeline.
* Add support for OTLP Collector as metrics receiver which can forward metrics to the chosen metrics backend, e.g. Prometheus.
* Enable document source citation for Enterprise Search knowledge answers by setting the boolean `citation_enabled: true` property in the `config.yml` file:
```
policies:
- name: EnterpriseSearchPolicy
citation_enabled: true
```
* Add telemetry events for flow retrieval and call step
* Tighten python dependency constraints in `pyproject.toml`, hence reducing the installation time to around 20 minutes with `pip` (and no caching enabled).
* Improved tracing clarity of the Contextual Response Rephraser by adding the `_create_history` method span, including its LLM configuration attributes.
* Users now have enhanced control over the debugging process of LLM-driven components. This update introduces a fine-grained, customizable logging that can be controlled through specific environment variables.
For example, set the `LOG_LEVEL_LLM` environment variable to enable detailed logging at the desired level for all the LLM components or specify the component you are debugging:
#### Example configuration[](#example-configuration "Direct link to Example configuration")
```
export LOG_LEVEL_LLM=DEBUG
export LOG_LEVEL_LLM_COMMAND_GENERATOR=INFO
export LOG_LEVEL_LLM_ENTERPRISE_SEARCH=INFO
export LOG_LEVEL_LLM_INTENTLESS_POLICY=DEBUG
export LOG_LEVEL_LLM_REPHRASER=DEBUG
```
* If the user wants to chat with the assistant at the end of `rasa init`, we are now calling `rasa inspect` instead of `rasa shell`.
* A slot can now be collected via an action `action_ask_` instead of the utterance `utter_ask_` in a collect step. You can either define an utterance or an action for the collect step in your flow. Make sure to add your custom action `action_ask_` to the domain file.
* Validate the configuration of the coexistence router before the actual training starts.
* Improved error handling in Enterprise Search Policy, changed the prompt to improve formatting of documents and ensured empty slots are not added to the prompt.
* Implement asynchronous graph execution. CALM assistants rely on a lot of I/O calls (e.g. to a LLM service), which impaired performances. With this change, we've improved the response time performance by 10x. All policies and components now support async calling.
* Merge `rasa` and `rasa-plus` packages into one. As a result, we renamed the Python package to `rasa-pro` and the Docker image to `rasa-pro`. Please head over to the migration guide [here](https://rasa.com/docs/rasa-pro/migration-guide#installation) for installation, and [here](https://rasa.com/docs/rasa-pro/migration-guide#component-yaml-configuration-changes) for the necessary configuration updates.
##### Bugfixes[](#bugfixes-164 "Direct link to Bugfixes")
* Updated pillow and jinja2 packages to address security vulnerabilities.
* Fix OpenTelemetry `Invalid type NoneType for attribute value` warning.
* Add support for `metadata_payload_key` for Qdrant Vector Store with an error message if `content_payload_key` or `metadata_payload_key` are incorrect
* Changed the ordering of returned events to order by ID (previously timestamp) in SQL Tracker Store
* Improved the end-to-end test comparison mechanism to accurately handle and strip trailing newline characters from expected bot responses, preventing false negatives due to formatting mismatches.
* Fixed a bug that caused inaccurate search results in Enterprise Search when a bot message appeared before the last user message.
* Fixes flow guards pypredicate evaluatation bug: pypredicate was evaluated with `Slot` instances instead of slot values
* Post-process source citations in Enterprise Search Policy responses so that they are enumerated in the correct order.
* Resolves issue causing the `FlowRetrieval.populate` to always use default embeddings.
* Fix the bug with the validation of routing setup crashing when the pipeline is not specified (null)
* Remove conversation turns prior to a restart when creating a conversation transcript for an LLM call.
This helps in cases where the prior conversation is not relevant for the current session. Information which should be carried to the next session should explicitly be stored in slots.
* Add tracker back to the LLMCommandGenerator.parse\_command to ensure compatibility with custom command generator built with 3.7.
* Move coexistence routing setup validation from `rasa.validator.Validator` to `rasa.engine.validation`. This gave access to graph schema which allowed for validation checks of subclassed routers.
* Fixes a bug in determining the name of the model based on provided parameters.
* `LogisticRegressionClassifier` checks if training examples are present during training and logs a warning in case no training examples are provided.
* Fixes the bug that resulted in an infinite loop on a collect step in a flow with a flow guard set to `if: False`.
* Fix training the enterprise search policy multiple times with a different source folder name than the default name "docs".
* Log message `llm_command_generator.predict_commands.finished` is set to debug log by default. To enable logging of the `LLMCommandGenerator` set `LOG_LEVEL_LLM_COMMAND_GENERATOR` to `INFO`.
* Improvements and fixes to cleaning up commands:
* Clean up predicted `StartFlow` commands from the `LLMCommandGenerator` if the flow, that should be started, is already active.
* Clean up predicted SetSlot commands from the `LLMCommandGenerator` if the value of the slot is already set on the tracker.
* Use string comparison for slot values to make sure to capture cases when the `LLMCommandGenerator` predicted a string value but the value set on the tracker is, for example, an integer value.
* Remove `context` from list of `restricted` slots
* Improved handling of categorical slots with text values when using CALM.
Slot values extracted by the command generator (LLM) will be stored in the same casing as the casing used to define the categorical slot values in the domain. E.g. A categorical slot defined to store the values \["A", "B"] will store "A" if the LLM predicts the slot to be filled with "a". Previously, this would have stored "a".
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-51 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.7.9] - 2024-03-26[](#379---2024-03-26 "Direct link to [3.7.9] - 2024-03-26")
Rasa Pro 3.7.9 (2024-03-26)
##### Improvements[](#improvements-44 "Direct link to Improvements")
* Add validations for flow ID to allow only alphanumeric characters, underscores, and hyphens except for the first character.
##### Bugfixes[](#bugfixes-165 "Direct link to Bugfixes")
* Changed the ordering of returned events to order by ID (previously timestamp) in SQL Tracker Store
* Fixes flow guards pypredicate evaluatation bug: pypredicate was evaluated with `Slot` instances instead of slot values
* Improved handling of categorical slots with text values when using CALM.
Slot values extracted by the command generator (LLM) will be stored in the same casing as the casing used to define the categorical slot values in the domain. E.g. A categorical slot defined to store the values \["A", "B"] will store "A" if the LLM predicts the slot to be filled with "a". Previously, this would have stored "a".
* Log message `llm_command_generator.predict_commands.finished` is set to debug log by default. To enable logging of the `LLMCommandGenerator` set `LOG_LEVEL_LLM_COMMAND_GENERATOR` to `INFO`.
* Improvements and fixes to cleaning up commands:
* Clean up predicted `StartFlow` commands from the `LLMCommandGenerator` if the flow, that should be started, is already active.
* Clean up predicted SetSlot commands from the `LLMCommandGenerator` if the value of the slot is already set on the tracker.
* Use string comparison for slot values to make sure to capture cases when the `LLMCommandGenerator` predicted a string value but the value set on the tracker is, for example, an integer value.
#### \[3.7.8] - 2024-02-28[](#378---2024-02-28 "Direct link to [3.7.8] - 2024-02-28")
Rasa Pro 3.7.8 (2024-02-28)
##### Improvements[](#improvements-45 "Direct link to Improvements")
* Improved UX around ClarifyCommand by checking options for existence and ordering them. Also, now dropping Clarify commands if there are any other commands to prevent two questions or statements to be uttered at the same time.
* LLMCommandGenerator returns CannotHandle() command when is encountered with scenarios where it is unable to predict a valid command.
##### Bugfixes[](#bugfixes-166 "Direct link to Bugfixes")
* Replace categorical slot values in a predicate with lower case replacements. This fixes the case sensitive slot comparisons in flow guards, branches in flows and slot rejections.
* Modify flows YAML schema to make next step mandatory to noop step.
* Flush messages when Kafka producer is closed. This is to ensure that all messages in the producer's internal queue are sent to the broker. Ensure to import all pattern stack frame subclasses of `DialogueStackFrame` when retrieving tracker from the tracker store, a required step during `rasa export`.
* Add support for `metadata_payload_key` for Qdrant Vector Store with an error message if `content_payload_key` or `metadata_payload_key` are incorrect
#### \[3.7.7] - 2024-02-06[](#377---2024-02-06 "Direct link to [3.7.7] - 2024-02-06")
Rasa Pro 3.7.7 (2024-02-06)
##### Bugfixes[](#bugfixes-167 "Direct link to Bugfixes")
* Updated pillow and jinja2 packages to address security vulnerabilities.
#### \[3.7.6] - 2024-02-01[](#376---2024-02-01 "Direct link to [3.7.6] - 2024-02-01")
Rasa Pro 3.7.6 (2024-02-01)
##### Bugfixes[](#bugfixes-168 "Direct link to Bugfixes")
* Fix reported issue, e.g. in Rasa Pro: Do not unpack json payload if `data` key is not present in the response custom output payloads when using socketio channel. This allows assistants which use custom output payloads to work with the Rasa Inspector debugging tool.
* Make flow description a required property in the flow json schema.
* Fix training the enterprise search policy multiple times with a different source folder name than the default name "docs".
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-52 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.7.5] - 2024-01-24[](#375---2024-01-24 "Direct link to [3.7.5] - 2024-01-24")
Rasa Pro 3.7.5 (2024-01-24)
##### Improvements[](#improvements-46 "Direct link to Improvements")
* Add new embedding types: `huggingface` and `huggingface_bge`. These new types import the `HuggingFaceEmbeddings` and `HuggingFaceBgeEmbeddings` embedding classes from Langchain.
##### Bugfixes[](#bugfixes-169 "Direct link to Bugfixes")
* Fixes a bug that caused the `full_retrieval_intent_name` key to be missing in the published event. Rasa Analytics makes use of this key to get the Retrieval Intent Name
* Pin `grpcio` indirect dependency to `1.56.2` to address [CVE-2023-33953](https://www.cve.org/CVERecord?id=CVE-2023-33953) Pin `aiohttp` to version `3.9.0` to address [CVE-2023-49081](https://www.cve.org/CVERecord?id=CVE-2023-49081)
* Fixes the bug that resulted in an infinite loop on a collect step in a flow with a flow guard set to `if: False`.
* Changed the parameters request timeout to 10 seconds and maximum number of retries to 1 for the default LLM used by Enterprise Search Policy. Any error during vector search or LLM API calls should now trigger the pattern `pattern_internal_error`. Updated the default enterprise search policy prompt to respond more succinctly to queries.
#### \[3.7.4] - 2024-01-03[](#374---2024-01-03 "Direct link to [3.7.4] - 2024-01-03")
Rasa Pro 3.7.4 (2024-01-03)
##### Improvements[](#improvements-47 "Direct link to Improvements")
* Add embeddings type `azure` to simplify azure configurations, particularly when using Enterprise Search Policy
##### Bugfixes[](#bugfixes-170 "Direct link to Bugfixes")
* Add a validation in `rasa data validate` to check the LinkFlowStep refers to a valid flow ID
#### \[3.7.3] - 2023-12-21[](#373---2023-12-21 "Direct link to [3.7.3] - 2023-12-21")
Rasa Pro 3.7.3 (2023-12-21)
##### Improvements[](#improvements-48 "Direct link to Improvements")
* Persist prompt as part of the model and reread prompt from the model storage instead of original file path during loading. Impacts LLMCommandGenerator.
* Replaced soon to be depracted text-davinci-003 model with gpt-3.5-turbo. Affects components - LLM Intent Classifier and Contextual Response Rephraser.
##### Bugfixes[](#bugfixes-171 "Direct link to Bugfixes")
* Fix stale cache of local knowledge base used by EnterpriseSearchPolicy by implementing the `fingerprint_addon` class method.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-53 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.7.2] - 2023-12-07[](#372---2023-12-07 "Direct link to [3.7.2] - 2023-12-07")
Rasa Pro 3.7.2 (2023-12-07)
##### Bugfixes[](#bugfixes-172 "Direct link to Bugfixes")
* Fix propagation of context across rasa spans when running `rasa run --enable-api` in the case when no additional tracing context is passed to rasa.
* Fixed a bug in policy invocation that made Enterprise Search Policy and `action_trigger_search` behaved strangely when used with rules and stories
* Updated aiohttp, cryptography and langchain to address security vulnerabilities.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-54 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.7.1] - 2023-12-01[](#371---2023-12-01 "Direct link to [3.7.1] - 2023-12-01")
Rasa Pro 3.7.1 (2023-12-01)
##### Improvements[](#improvements-49 "Direct link to Improvements")
* Improved error handling in Enterprise Search Policy, changed the prompt to improve formatting of documents and ensured empty slots are not added to the prompt
#### \[3.7.0] - 2023-11-22[](#370---2023-11-22 "Direct link to [3.7.0] - 2023-11-22")
Rasa Pro 3.7.0 (2023-11-22)
##### Features[](#features-9 "Direct link to Features")
* Added Enterprise Search Policy that uses an LLM with conversation context and relevant knowledge base documents to generate rephrased responses. The LLM is prompted to answer the user questions given the chat transcript, documents retrived from a document search and the slot values so far. This policy supports an in-memory Faiss vector store and connecting to instances of Milvus or Qdrant vector store.
##### Improvements[](#improvements-50 "Direct link to Improvements")
* Skip executing the pipeline when the user message is of the form /intent or /intent + entities.
* Remove tensorflow-addons from dependencies as it is now deprecated.
* Add building multi-platform Docker image (amd64/arm64)
* Switch struct log to `FilteringBoundLogger` in order to retain log level set in the config.
* Added metadata as an additional argument as an additional parameter to an `Action`s `run` method.
Added an additional default action called `action_send_text` which allows a policy to respond with a text. The text is passed to the action using the metadata, e.g. `metadata={"message": {"text": "Hello"}}`.
Added LLM utility functions.
* Passed request headers from REST channel.
* Added additional method `fingerprint_addon` to the `GraphComponent` interface to allow inclusion of external data into the fingerprint calculation of a component
* Added Schema file and schema validation for flows.
* Added environment variables to configure JWT and auth token. For JWT the following environment variables are available:
* JWT\_SECRET
* JWT\_METHOD
* JWT\_PRIVATE\_KEY
For auth token the following environment variable is available:
* AUTH\_TOKEN
* Add skip question command
* Update the CALM starter template by:
* adding the following flows from the financial chatbot:
* add\_contact.yml
* remove\_contact.yml
* list\_contacts.yml
* using multiple modules (in the form of yml files) to segregate the flows (a good model to be followed)
* adding e2e tests:
* happy paths
* cancelations
* corrections
* * Enhanced the Rasa error pattern for accommodating various error types.
* Upgraded the LLMCommandGenerator for processing the new 'user\_input' configuration section. This update includes handling of messages that surpass the defined character limit.
**Configuration Update:**
The LLMCommandGenerator now supports a user-defined character limit via the 'user\_input' configuration:
```
- name: LLMCommandGenerator
llm:
...
user_input:
max_characters: 500
```
**Default Behavior:**
In the absence of a specified limit, it defaults to a 420-character cap. To bypass the limit entirely, set the 'max\_characters' value to -1.
* * Bot now returns a default message in response to an empty user message. This improves user experience by providing feedback even when no input is detected.
* `LLMCommandGenerator` behavior updated. It now returns an `ErrorCommand` for empty user messages.
* Updated default error pattern and added the default utterance in `default_flows_for_patterns.yml`
* Add support for Vault namespaces. To use namespace set either:
* `VAULT_NAMESPACE` environment variable
* `namespace` property in `secrets_manager` section at `endpoints.yaml`
* Added Rasa Labs LLM components. Added components are:
* `LLMIntentClassifier`
* `IntentlessPolicy`
* `ContextualResponseRephraser`
* Made it possible for the Rasa REST channel to accept OpenTelemetry tracing context.
* Improved the naming of trace spans and added more trace tags.
* Add `slot_was_not_set` to E2E testing for asserting that a slot was not set and that a slot was not set with a specific value.
* Introduced the rasa studio download command, enabling data retrieval from the studio. Implemented the option to refresh the Keycloak token. Expanded the functionality of RasaPrimitiveStorageMapper with the addition of flows. Added flows support to `rasa studio train`.
* Instrument `LLMCommandGenerator._generate_action_list_using_llm` and `Command.run_command_on_tracker` methods.
* Added the default values for the number of tokens generated by the LLM (`max_tokens`)
* Make the instrumentation of `Command.run_command_on_tracker` method applicable to all subclasses of the `Command` class\`
* Instrument `ContextualResponseRephraser._generate_llm_response` and `ContextualResponseRephraser.generate` methods.
* Extract commands as tracing attributes from message input when previous node was the `LLMCommandGenerator`.
* Rename `rasa chat` command to `rasa inspect` and rename channel name to `inspector`.
* Extract `events` and `optional_events` when `GraphNode` is `FlowPolicy`.
##### Bugfixes[](#bugfixes-173 "Direct link to Bugfixes")
* uvloop is disabled by default on apple silicon machines
* Add `rasa_events` to the list of anonymizable structlog keys and rename structlog keys.
* Introduce a validation step in `rasa data validate` and `rasa train` commands to identify non-existent paths and empty domains.
* Rich responses containing buttons with parentheses characters are now correctly parsed. Previously any characters found between the first identified pair of `()` in response button took precedence.
* Resolve dependency incompatibility: Pin version of `dnspython` to ==2.3.0.
* Fixed `KeyError` which resulted when `domain_responses` doesn't exist as a keyword argument while using a custom action dispatcher with nlg server.
* Fixed incompatibility with latest python-socketio release.
The python-socketio released a backwards incompatible change on their minor release. This fix addresses this and makes the code compatible with prior and the new python-socketio version.
* Fixed the `404 Not Found` Github actions error while removing packages.
* Corrected E2E diff behavior to prevent it from going out of sync when more than one turn difference exists between actual and expected events. Fixed E2E tests from propagating errors when events and test steps did not have the same length. Fixed the issue where E2E tests couldn't locate slot events that were not arranged chronologically. Resolved the problem where E2E tests were incorrectly diffing user utter events when they were not in the correct order.
* Fixed E2E runner wrongly selecting the first available bot utterance when generating the test fail diff.
* Updated werkzeug and urllib3 to address security vulnerabilities.
* Fix cases when E2E test runner crashes when there is no response from the bot.
##### Improved Documentation[](#improved-documentation "Direct link to Improved Documentation")
* Update wording in Rasa Pro installation page.
* Updated docs on sending Conversation Events to Multiple DBs.
* Corrected [action server api](https://rasa.com/docs/docs/reference/api/pro/action-server-api/) sample in docs.
* Document support for Vault namespaces.
* Updated tracing documentation to include tracing in the action server and the REST Channel.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-55 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.6.13] - 2023-10-23[](#3613---2023-10-23 "Direct link to [3.6.13] - 2023-10-23")
Rasa Pro 3.6.13 (2023-10-23)
##### Bugfixes[](#bugfixes-174 "Direct link to Bugfixes")
* Fix wrong conflicts that occur when rasa validate stories is run with slots that have active\_loop set to null in mapping conditions.
#### \[3.6.12] - 2023-10-10[](#3612---2023-10-10 "Direct link to [3.6.12] - 2023-10-10")
Rasa Pro 3.6.12 (2023-10-10)
##### Improvements[](#improvements-51 "Direct link to Improvements")
* Added `username` to the connection parameters for `ConcurrentRedisLockStore`.
##### Bugfixes[](#bugfixes-175 "Direct link to Bugfixes")
* Refresh headers used in requests (e.g. action server requests) made by `EndpointConfig` using its `headers` attribute.
* Upgrade `pillow` to `10.0.1` to address security vulnerability CVE-2023-4863 found in `10.0.0` version.
* Fix setuptools security vulnerability CVE-2022-40897 in Docker build by updating setuptools in poetry's environment.
#### \[3.6.11] - 2023-10-05[](#3611---2023-10-05 "Direct link to [3.6.11] - 2023-10-05")
Rasa Pro 3.6.11 (2023-10-05)
##### Bugfixes[](#bugfixes-176 "Direct link to Bugfixes")
* Intent names will not be falsely abbreviated in interactive training (fixes OSS-413).
This will also fix a bug where forced user utterances (using the regex matcher) will be reverted even though they are present in the domain.
* Cache `EndpointConfig` session object using `cached_property` decorator instead of recreating this object on every request. Initialize these connection pools for action server and model server endpoints as part of the Sanic `after_server_start` listener. Also close connection pools during Sanic `after_server_stop` listener.
#### \[3.6.10] - 2023-09-26[](#3610---2023-09-26 "Direct link to [3.6.10] - 2023-09-26")
Rasa Pro 3.6.10 (2023-09-26)
##### Improvements[](#improvements-52 "Direct link to Improvements")
* Improved handling of last batch during DIET and TED training. The last batch is discarded if it contains less than half a batch size of data.
* Added `username` to the connection parameters for `RedisLockStore` and `RedisTrackerStore`
* Telemetry data is only send for licensed users.
##### Improved Documentation[](#improved-documentation-1 "Direct link to Improved Documentation")
* Remove the Playground from docs.
#### \[3.6.9] - 2023-09-15[](#369---2023-09-15 "Direct link to [3.6.9] - 2023-09-15")
Rasa Pro 3.6.9 (2023-09-15)
##### Improvements[](#improvements-53 "Direct link to Improvements")
* Added additional method `fingerprint_addon` to the `GraphComponent` interface to allow inclusion of external data into the fingerprint calculation of a component
##### Bugfixes[](#bugfixes-177 "Direct link to Bugfixes")
* Fixed `KeyError` which resulted when `domain_responses` doesn't exist as a keyword argument while using a custom action dispatcher with nlg server.
#### \[3.6.8] - 2023-08-30[](#368---2023-08-30 "Direct link to [3.6.8] - 2023-08-30")
Rasa Pro 3.6.8 (2023-08-30)
##### Bugfixes[](#bugfixes-178 "Direct link to Bugfixes")
* Fix E2E testing diff algorithm to support the following use cases:
* asserting a slot was not set under a `slot_was_set` block
* asserting multiple slot names and/or values under a `slot_was_set` block Additionally, the diff algorithm has been improved to show a higher fidelity result.
#### \[3.6.7] - 2023-08-29[](#367---2023-08-29 "Direct link to [3.6.7] - 2023-08-29")
Rasa Pro 3.6.7 (2023-08-29)
##### Bugfixes[](#bugfixes-179 "Direct link to Bugfixes")
* Updated certifi, cryptography, and scipy packages to address security vulnerabilities.
* Updated setuptools and wheel to address security vulnerabilities.
#### \[3.6.6] - 2023-08-23[](#366---2023-08-23 "Direct link to [3.6.6] - 2023-08-23")
Rasa Pro 3.6.6 (2023-08-23)
##### Bugfixes[](#bugfixes-180 "Direct link to Bugfixes")
* Updated setuptools and wheel to address security vulnerabilities.
#### \[3.6.5] - 2023-08-17[](#365---2023-08-17 "Direct link to [3.6.5] - 2023-08-17")
Rasa Pro 3.6.5 (2023-08-17)
##### Improvements[](#improvements-54 "Direct link to Improvements")
* Use the same session across requests in `RasaNLUHttpInterpreter`
##### Bugfixes[](#bugfixes-181 "Direct link to Bugfixes")
* Resolve dependency incompatibility: Pin version of `dnspython` to ==2.3.0.
* Fix the issue in `rasa test e2e` where test diff inaccurately displayed actual event transcripts, leading to the duplication of `BotUtter`` or `UserUtter`` events. This occurred specifically when `SetSlot`` events took place that were not explicitly defined in the Test Cases.
##### Improved Documentation[](#improved-documentation-2 "Direct link to Improved Documentation")
* Updated PII docs with new section on how to use Rasa X/Enterprise with PII management solution, and a new note on debug logs being displayed after the bot message with `rasa shell`.
#### \[3.6.4] - 2023-07-21[](#364---2023-07-21 "Direct link to [3.6.4] - 2023-07-21")
Rasa Pro 3.6.4 (2023-07-21)
##### Bugfixes[](#bugfixes-182 "Direct link to Bugfixes")
* Extract conditional response variation and channel variation filtering logic into a separate component. Enable usage of this component in the NaturalLanguageGenerator subclasses (e.g. CallbackNaturalLanguageGenerator, TemplatedNaturalLanguageGenerator). Amend nlg\_request\_format to include a single response ID string field, instead of a list of IDs.
* Added details to the logs of successful and failed cases of running the markers upload command.
##### Improved Documentation[](#improved-documentation-3 "Direct link to Improved Documentation")
* Updated commands with square brackets e.g (`pip install rasa[spacy]`) to use quotes (`pip install 'rasa[spacy]'`) for compatibility with zsh in docs.
#### \[3.6.3] - 2023-07-20[](#363---2023-07-20 "Direct link to [3.6.3] - 2023-07-20")
Rasa Pro 3.6.3 (2023-07-20)
##### Improvements[](#improvements-55 "Direct link to Improvements")
* Added a human readable component to structlog using the `event_info` key and made it the default rendered key if present.
##### Bugfixes[](#bugfixes-183 "Direct link to Bugfixes")
* Fix the issue with the most recent model not being selected if the owner or permissions where modified on the model file.
* Fixed `BlockingIOError` which occured as a result of too large data passed to strulogs.
* Fixed the error handling mechanism in `rasa test e2e` to quickly detect and communicate errors when the action server, defined in endpoints.yaml, is not available.
* Allow hyphens `-` to be present in e2e test slot names.
* Resolved issues in `rasa test e2e` where errors occurred when the bot concluded the conversation with `SetSlot` events while there were remaining steps in the test case. Corrected the misleading error message '- No slot set' to '- Slot types do not match' in `rasa test e2e` when a type mismatch occurred during testing.
##### Improved Documentation[](#improved-documentation-4 "Direct link to Improved Documentation")
* Update action server documentation with new capability to extend Sanic features by using plugins. Update rasa-sdk dependency to version 3.6.1.
* Updated commands with square brackets e.g (`pip install rasa[spacy]`) to use quotes (`pip install 'rasa[spacy]'`) for compatibility with zsh in docs.
#### \[3.6.2] - 2023-07-06[](#362---2023-07-06 "Direct link to [3.6.2] - 2023-07-06")
Rasa Pro 3.6.2 (2023-07-06)
##### Improvements[](#improvements-56 "Direct link to Improvements")
* Add building Docker container for arm64 (e.g. to allow running Rasa inside docker on M1/M2).
Bumped the version of OpenTelemetry to meet the requirement of protobuf 4.x.
##### Bugfixes[](#bugfixes-184 "Direct link to Bugfixes")
* Resolves the issue of importing TensorFlow on Docker for ARM64 architecture.
#### \[3.6.1] - 2023-07-03[](#361---2023-07-03 "Direct link to [3.6.1] - 2023-07-03")
Rasa Pro 3.6.1 (2023-07-03)
##### Improvements[](#improvements-57 "Direct link to Improvements")
* Add building multi-platform Docker image (amd64/arm64)
* Switch struct log to `FilteringBoundLogger` in order to retain log level set in the config.
* Add new anonymizable structlog keys.
##### Bugfixes[](#bugfixes-185 "Direct link to Bugfixes")
* Add `rasa_events` to the list of anonymizable structlog keys and rename structlog keys.
* Introduce a validation step in `rasa data validate` and `rasa train` commands to identify non-existent paths and empty domains.
* Rich responses containing buttons with parentheses characters are now correctly parsed. Previously any characters found between the first identified pair of `()` in response button took precedence.
* Add PII bugfixes (e.g. handling None values and casting data types to string before being passed to the anonymizer) after testing manually with Audiocodes channel.
##### Improved Documentation[](#improved-documentation-5 "Direct link to Improved Documentation")
* Update wording in Rasa Pro installation page.
* Document new PII Management section.
* Added Documentation for Realtime Markers Section.
* Add "Rasa Pro Change Log" to documentation.
* Document new Load Testing Guidelines section.
* Changes the formatting of realtime markers documentation page
#### \[3.6.0] - 2023-06-14[](#360---2023-06-14 "Direct link to [3.6.0] - 2023-06-14")
Rasa Pro 3.6.0 (2023-06-14)
##### Deprecations and Removals[](#deprecations-and-removals-8 "Direct link to Deprecations and Removals")
* Removed Python 3.7 support as [it reaches its end of life in June 2023](https://devguide.python.org/versions/)
##### Features[](#features-10 "Direct link to Features")
* Implemented PII (Personally Idenfiable Information) management using Microsoft Presidio as the entity analyzer and anonymization engine. The feature covers the following:
* anonymization of Rasa events (`UserUttered`, `BotUttered`, `SlotSet`, `EntitiesAdded`) before they are streamed to Kafka event broker anonymization topics specified in `endpoints.yml`.
* anonymization of Rasa logs that expose PII data
The main components of the feature are:
* anonymization rules that define in `endpoints.yml` the PII entities to be anonymized and the anonymization method to be used
* anonymization executor that executes the anonymization rules on a given text
* anonymization orchestrator that orchestrates the execution of the anonymization rules and publishes the anonymized event to the matched Kafka topic.
* anonymization pipeline that contains a list of orchestrators and is registered to a singleton provider component, which gets invoked in hook calls in Rasa Pro when the pipeline must be retrieved for anonymizing events and logs.
Please read through the PII Management section in the official documentation to learn how to get started.
* Implemented support for real time evaluation of Markers with the Analytics Data Pipeline, enabling you to gain valuable insights and enhance the performance of your Rasa Assistant.
For this feature, we've added support for `rasa markers upload` command. Running this command validates the marker configuration file against the domain file and uploads the configuration to Analytics Data Pipeline.
##### Improvements[](#improvements-58 "Direct link to Improvements")
* Add optional property `ids` to the nlg server request body. IDs will be transmitted to the NLG server and can be used to identify the response variation that should be used.
* Add building Docker container for arm64 (e.g. to allow running Rasa inside docker on M1/M2).
* Add support for Location data from Whatsapp on Twilio Channel
* Add validation to `rasa train` to align validation expectations with `rasa data validate`. Add `--skip-validation` flag to disable validation and `--fail-on-validation-warnings`, `--validation-max-history` to `rasa train` to have the same options as `rasa data validate`.
* Updated tensorflow to version 2.11.1 for all platforms except Apple Silicon which stays on 2.11.0 as 2.11.1 is not available yet
* Slot mapping conditions accept `active_loop` specified as `null` in those cases when slots with this mapping condition should be filled only outside form contexts.
* Add an optional `description` key to the Markers Configuration format. This can be used to add documentation and context about marker's usage. For example, a `markers.yml` can look like
```
marker_name_provided:
description: “Name slot has been set”
slot_was_set: name
marker_mood_expressed:
description: “Unhappy or Great Mood was expressed”
or:
- intent: mood_unhappy
- intent: mood_great
```
* Add `rasa marker upload` command to upload markers to the Rasa Pro Services. Usage: `rasa marker upload --config= -d= -rasa-pro-services-url=`.
* Enhance the validation of the `anonymization` key in `endpoints.yaml` by introducing checks for required fields and duplicate IDs.
##### Bugfixes[](#bugfixes-186 "Direct link to Bugfixes")
* Fix running custom form validation to update required slots at form activation when prefilled slots consist only of slots that are not requested by the form.
* Anonymize `rasa_events` structlog key.
* Fixes issue with uploading locally trained model to a cloud rasa-plus instance where the conversation does not go as expected because slots don't get set correctly, e.g. an error is logged `Tried to set non existent slot 'placeholder_slot_name'. Make sure you added all your slots to your domain file.`. This is because the updated domain during the cloud upload did not get passed to the wrapped tracker store of the `AuthRetryTrackerStore` rasa-plus component. The fix was to add domain property and setter methods to the `AuthRetryTrackerStore` component.
* When using `rasa studio upload`, if no specific `intents` or `entities` are specified by the user, the update will now include all available `intents` or `entities`.
##### Improved Documentation[](#improved-documentation-6 "Direct link to Improved Documentation")
* Explicitly set Node.js version to 12.x in order to run Docusaurus.
* Update obselete commands in docs README.
* Correct docker image name for `deploy-rasa-pro-services` in docs.
* Update Compatibility Matrix.
* Implement `rasa data split stories` to split stories data into train/test parts.
* Updated [knowledge base action docs](https://rasa.com/docs/rasa-pro/action-server/knowledge-bases) to reflect the improvements made in `knowledge base actions` in Rasa Pro 3.6 version. This enhancement now allows users to query for the `object` attribute without the need for users to request a list of `objects` of a particular `object type` beforehand. The docs update mentions this under `:::info New in 3.6` section.
* Fix dead link in Analytics documentation.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-56 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.5.12] - 2023-06-23[](#3512---2023-06-23 "Direct link to [3.5.12] - 2023-06-23")
Rasa Pro 3.5.12 (2023-06-23)
##### Bugfixes[](#bugfixes-187 "Direct link to Bugfixes")
* Rich responses containing buttons with parentheses characters are now correctly parsed. Previously any characters found between the first identified pair of `()` in response button took precedence.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-57 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.5.11] - 2023-06-08[](#3511---2023-06-08 "Direct link to [3.5.11] - 2023-06-08")
Rasa Pro 3.5.11 (2023-06-08)
##### Bugfixes[](#bugfixes-188 "Direct link to Bugfixes")
* Fix running custom form validation to update required slots at form activation when prefilled slots consist only of slots that are not requested by the form.
#### \[3.5.10] - 2023-05-23[](#3510---2023-05-23 "Direct link to [3.5.10] - 2023-05-23")
Rasa Pro 3.5.10 (2023-05-23)
##### Improved Documentation[](#improved-documentation-7 "Direct link to Improved Documentation")
* Added documentation for spaces alpha
#### \[3.5.9] - 2023-05-19[](#359---2023-05-19 "Direct link to [3.5.9] - 2023-05-19")
Rasa Pro 3.5.9 (2023-05-19)
No significant changes.
#### \[3.5.8] - 2023-05-12[](#358---2023-05-12 "Direct link to [3.5.8] - 2023-05-12")
Rasa Pro 3.5.8 (2023-05-12)
##### Bugfixes[](#bugfixes-189 "Direct link to Bugfixes")
* Explicitly handled `BufferError exception - Local: Queue full` in Kafka producer.
#### \[3.5.7] - 2023-05-09[](#357---2023-05-09 "Direct link to [3.5.7] - 2023-05-09")
Rasa Pro 3.5.7 (2023-05-09)
##### Bugfixes[](#bugfixes-190 "Direct link to Bugfixes")
* `SlotSet` events will be emitted when the value set by the custom action is the same as the existing value of the slot. This was fixed for `AugmentedMemoizationPolicy` to work properly with truncated trackers.
To restore the previous behaviour, the custom action can return a SlotSet only if the slot value has changed. For example,
```
class CustomAction(Action):
def name(self) -> Text:
return "custom_action"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
# current value of the slot
slot_value = tracker.get_slot('my_slot')
# value of the entity
# this is parsed from the user utterance
entity_value = next(tracker.get_latest_entity_values("entity_name"), None)
if slot_value != entity_value:
return[SlotSet("my_slot", entity_value)]
```
#### \[3.5.6] - 2023-04-28[](#356---2023-04-28 "Direct link to [3.5.6] - 2023-04-28")
Rasa Pro 3.5.6 (2023-04-28)
##### Bugfixes[](#bugfixes-191 "Direct link to Bugfixes")
* Addresses Regular Expression Denial of Service vulnerability in slack connector ()
* Fix parsing of RabbitMQ URL provided in `endpoints.yml` file to include vhost path and query parameters. Re-allows inclusion of credentials in the URL as a regression fix (this was supported in 2.x).
#### \[3.5.5] - 2023-04-20[](#355---2023-04-20 "Direct link to [3.5.5] - 2023-04-20")
Rasa Pro 3.5.5 (2023-04-20)
##### Bugfixes[](#bugfixes-192 "Direct link to Bugfixes")
* Allow slot mapping parameter `intent` to accept a list of intent names (as strings), in addition to accepting an intent name as a single string.
* Fix `BlockingIOError` when running `rasa shell` on utterances with more than 5KB of text.
* Use `ruamel.yaml` round-trip loader in order to preserve all comments after appending `assistant_id` to `config.yml`.
* Fix `AttributeError: 'NoneType' object has no attribute 'send_response'` caused by retrieving tracker via `GET /conversations/\{conversation_id\}/tracker` endpoint when `action_session_start` is customized in a custom action. This was addressed by passing an instance of `CollectingOutputChannel` to the method retrieving the tracker from the `MessageProcessor`.
##### Improved Documentation[](#improved-documentation-8 "Direct link to Improved Documentation")
* Updated AWS model loading documentation to indicate what should `AWS_ENDPOINT_URL` environment variable be set to. Added integration test for AWS model loading.
* Updated Rasa Pro Services documentation to add `KAFKA_SSL_CA_LOCATION` environment variable. Allows connections over SSL to Kafka
* Added note to CLI documentation to address encoding and color issues on certain Windows terminals
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-58 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.5.4] - 2023-04-05[](#354---2023-04-05 "Direct link to [3.5.4] - 2023-04-05")
Rasa Pro 3.5.4 (2023-04-05)
##### Bugfixes[](#bugfixes-193 "Direct link to Bugfixes")
* Fix issue with failures while publishing events to RabbitMQ after a RabbitMQ restart. The fix consists of pinning `aio-pika` dependency to `8.2.3`, since this issue was introduced in `aio-pika` v`8.2.4`.
* Patch redis Race Conditiion vulnerability.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-59 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.5.3] - 2023-03-30[](#353---2023-03-30 "Direct link to [3.5.3] - 2023-03-30")
Rasa Pro 3.5.3 (2023-03-30)
##### Improved Documentation[](#improved-documentation-9 "Direct link to Improved Documentation")
* Add new Rasa Pro page in docs, together with minimal content changes.
#### \[3.5.2] - 2023-03-30[](#352---2023-03-30 "Direct link to [3.5.2] - 2023-03-30")
Rasa Pro 3.5.2 (2023-03-30)
##### Improvements[](#improvements-59 "Direct link to Improvements")
* Add a self-reference of the synonym in the EntitySynonymMapper to handle entities extracted in a casing different to synonym case. (For example if a synonym `austria` is added, entities extracted with any alternate casing of the synonym will also be mapped to `austria`). It addresses ATO-616
##### Bugfixes[](#bugfixes-194 "Direct link to Bugfixes")
* Make custom actions inheriting from rasa-sdk `FormValidationAction` parent class an exception of the `selective_domain` rule and always send them domain.
* Fix 2 issues detected with the HTTP API:
* The `GET /conversations/\{conversation_id\}/tracker` endpoint was not returning the tracker with all sessions when `include_events` query parameter was set to `ALL`. The fix constituted in using `TrackerStore.retrieve_full_tracker` method instead of `TrackerStore.retrieve` method in the function handling the `GET /conversations/\{conversation_id\}/tracker` endpoint. Implemented or updated this method across all tracker store subclasses.
* The `GET /conversations/\{conversation_id\}/story` endpoint was not returning all the stories for all sessions when `all_sessions` query parameter was set to `true`. The fix constituted in using all events of the tracker to be converted in stories instead of only the `applied_events`.
##### Improved Documentation[](#improved-documentation-10 "Direct link to Improved Documentation")
* Add documentation for secrets managers.
#### \[3.5.1] - 2023-03-24[](#351---2023-03-24 "Direct link to [3.5.1] - 2023-03-24")
Rasa Pro 3.5.1 (2023-03-24)
##### Bugfixes[](#bugfixes-195 "Direct link to Bugfixes")
* Fixes training `DIETCLassifier` on the GPU.
A deterministic GPU implementation of SparseTensorDenseMatmulOp is not currently available
##### Improved Documentation[](#improved-documentation-11 "Direct link to Improved Documentation")
* Updated `Test your assistant` section to describe the new end-to-end testing feature. Also updated CLI and telemetry reference docs.
* Update Compatibility Matrix.
#### \[3.5.0] - 2023-03-21[](#350---2023-03-21 "Direct link to [3.5.0] - 2023-03-21")
Rasa Pro 3.5.0 (2023-03-21)
##### Features[](#features-11 "Direct link to Features")
* Add a new required key (`assistant_id`) to `config.yml` to uniquely identify assistants in deployment. The assistant identifier is extracted from the model metadata and added to the metadata of all dialogue events. Re-training will be required to include the assistant id in the event metadata.
If the assistant identifier is missing from the `config.yml` or the default identifier value is not replaced, a random identifier is generated during each training.
An assistant running without an identifier will issue a warning that dialogue events without identifier metadata will be streamed to the event broker.
* End-to-end testing is an enhanced and comprehensive CLI-based testing tool that allows you to test conversation scenarios with different pre-configured contexts, execute custom actions, verify response texts or names, and assert when slots are filled. It is available ysing the new `rasa test e2e` command.
* You can now store your assistant's secrets in an external credentials manager. In this release, Rasa Pro currently supports credentials manager for the Tracker Store with HashiCorp Vault.
##### Improvements[](#improvements-60 "Direct link to Improvements")
* Add capability to send compressed body in HTTP request to action server. Use COMPRESS\_ACTION\_SERVER\_REQUEST=True to turn the feature on.
##### Bugfixes[](#bugfixes-196 "Direct link to Bugfixes")
* Address potentially missing events with Pika consumer due to weak references on asynchronous tasks, as specifcied in [Python official documentation](https://docs.python.org/3/library/asyncio-task.html#asyncio.create_task).
* Sets a global seed for numpy, TensorFlow, keras, Python and CuDNN, to ensure consistent random number generation.
##### Improved Documentation[](#improved-documentation-12 "Direct link to Improved Documentation")
* Clarify in the docs, how rules are designed and how to use this behaviour to abort a rule
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-60 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.4.14] - 2023-06-08[](#3414---2023-06-08 "Direct link to [3.4.14] - 2023-06-08")
Rasa Pro 3.4.14 (2023-06-08)
##### Bugfixes[](#bugfixes-197 "Direct link to Bugfixes")
* Fix running custom form validation to update required slots at form activation when prefilled slots consist only of slots that are not requested by the form.
#### \[3.4.13] - 2023-05-19[](#3413---2023-05-19 "Direct link to [3.4.13] - 2023-05-19")
Rasa Pro 3.4.13 (2023-05-19)
No significant changes.
#### \[3.4.12] - 2023-05-12[](#3412---2023-05-12 "Direct link to [3.4.12] - 2023-05-12")
Rasa Pro 3.4.12 (2023-05-12)
##### Bugfixes[](#bugfixes-198 "Direct link to Bugfixes")
* Explicitly handled `BufferError exception - Local: Queue full` in Kafka producer.
#### \[3.4.11] - 2023-05-09[](#3411---2023-05-09 "Direct link to [3.4.11] - 2023-05-09")
Rasa Pro 3.4.11 (2023-05-09)
##### Bugfixes[](#bugfixes-199 "Direct link to Bugfixes")
* Fix parsing of RabbitMQ URL provided in `endpoints.yml` file to include vhost path and query parameters. Re-allows inclusion of credentials in the URL as a regression fix (this was supported in 2.x).
* `SlotSet` events will be emitted when the value set by the custom action is the same as the existing value of the slot. This was fixed for `AugmentedMemoizationPolicy` to work properly with truncated trackers.
To restore the previous behaviour, the custom action can return a SlotSet only if the slot value has changed. For example,
```
class CustomAction(Action):
def name(self) -> Text:
return "custom_action"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
# current value of the slot
slot_value = tracker.get_slot('my_slot')
# value of the entity
# this is parsed from the user utterance
entity_value = next(tracker.get_latest_entity_values("entity_name"), None)
if slot_value != entity_value:
return[SlotSet("my_slot", entity_value)]
```
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-61 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.4.10] - 2023-04-17[](#3410---2023-04-17 "Direct link to [3.4.10] - 2023-04-17")
Rasa Pro 3.4.10 (2023-04-17)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-62 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.4.9] - 2023-04-05[](#349---2023-04-05 "Direct link to [3.4.9] - 2023-04-05")
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-63 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.4.8] - 2023-04-03[](#348---2023-04-03 "Direct link to [3.4.8] - 2023-04-03")
Rasa Pro 3.4.8 (2023-04-03)
##### Bugfixes[](#bugfixes-200 "Direct link to Bugfixes")
* Fix issue with failures while publishing events to RabbitMQ after a RabbitMQ restart. The fix consists of pinning `aio-pika` dependency to `8.2.3`, since this issue was introduced in `aio-pika` v`8.2.4`.
#### \[3.4.7] - 2023-03-30[](#347---2023-03-30 "Direct link to [3.4.7] - 2023-03-30")
Rasa Pro 3.4.7 (2023-03-30)
##### Improvements[](#improvements-61 "Direct link to Improvements")
* Add a self-reference of the synonym in the EntitySynonymMapper to handle entities extracted in a casing different to synonym case. (For example if a synonym `austria` is added, entities extracted with any alternate casing of the synonym will also be mapped to `austria`). It addresses ATO-616
##### Bugfixes[](#bugfixes-201 "Direct link to Bugfixes")
* Fix 2 issues detected with the HTTP API:
* The `GET /conversations/\{conversation_id\}/tracker` endpoint was not returning the tracker with all sessions when `include_events` query parameter was set to `ALL`. The fix constituted in using `TrackerStore.retrieve_full_tracker` method instead of `TrackerStore.retrieve` method in the function handling the `GET /conversations/\{conversation_id\}/tracker` endpoint. Implemented or updated this method across all tracker store subclasses.
* The `GET /conversations/\{conversation_id\}/story` endpoint was not returning all the stories for all sessions when `all_sessions` query parameter was set to `true`. The fix constituted in using all events of the tracker to be converted in stories instead of only the `applied_events`.
* Make custom actions inheriting from rasa-sdk `FormValidationAction` parent class an exception of the `selective_domain` rule and always send them domain.
#### \[3.4.6] - 2023-03-16[](#346---2023-03-16 "Direct link to [3.4.6] - 2023-03-16")
Rasa Pro 3.4.6 (2023-03-16)
##### Bugfixes[](#bugfixes-202 "Direct link to Bugfixes")
* Fixes CountVectorFeaturizer to train when min\_df != 1.
#### \[3.4.5] - 2023-03-09[](#345---2023-03-09 "Direct link to [3.4.5] - 2023-03-09")
Rasa Pro 3.4.5 (2023-03-09)
##### Bugfixes[](#bugfixes-203 "Direct link to Bugfixes")
* Check unresolved slots before initiating model training.
* Fixes the bug when a slot (with `from_intent` mapping which contains no input for `intent` parameter) will no longer fill for any intent that is not under the `not_intent` parameter.
* Fix validation metrics calculation when batch\_size is dynamic.
##### Improved Documentation[](#improved-documentation-13 "Direct link to Improved Documentation")
* Add a link to an existing docs section on how to test the audio channel on `localhost`.
#### \[3.4.4] - 2023-02-17[](#344---2023-02-17 "Direct link to [3.4.4] - 2023-02-17")
Rasa Pro 3.4.4 (2023-02-17)
##### Improvements[](#improvements-62 "Direct link to Improvements")
* Add capability to send compressed body in HTTP request to action server. Use COMPRESS\_ACTION\_SERVER\_REQUEST=True to turn the feature on.
##### Bugfixes[](#bugfixes-204 "Direct link to Bugfixes")
* Fix the error which resulted during merging multiple domain files where at least one of them contains custom actions that explicitly need `send_domain` set as True in the domain.
#### \[3.4.3] - 2023-02-14[](#343---2023-02-14 "Direct link to [3.4.3] - 2023-02-14")
Rasa Pro 3.4.3 (2023-02-14)
##### Improvements[](#improvements-63 "Direct link to Improvements")
* Add support for custom RulePolicy.
* Add capability to select which custom actions should receive domain when they are invoked.
##### Bugfixes[](#bugfixes-205 "Direct link to Bugfixes")
* Fix calling the form validation action twice for the same user message triggering a form.
* Fix conditional response does not check other conditions if first condition matches.
##### Improved Documentation[](#improved-documentation-14 "Direct link to Improved Documentation")
* Add section in tracker store docs to document the fallback tracker store mechanism.
#### \[3.4.2] - 2023-01-27[](#342---2023-01-27 "Direct link to [3.4.2] - 2023-01-27")
Rasa Pro 3.4.2 (2023-01-27)
##### Bugfixes[](#bugfixes-206 "Direct link to Bugfixes")
* Decision to publish docs should not consider next major and minor alpha release versions.
* Exit training/running Rasa model when SpaCy runtime version is not compatible with the specified SpaCy model version.
* The new custom logging feature was not working due to small syntax issue in the argparse level.
Previously, the file name passed using the argument --logging-config-file was never retrieved so it never creates the new custom config file with the desired formatting.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-64 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.4.1] - 2023-01-19[](#341---2023-01-19 "Direct link to [3.4.1] - 2023-01-19")
Rasa Pro 3.4.1 (2023-01-19)
##### Bugfixes[](#bugfixes-207 "Direct link to Bugfixes")
* Changed categorical slot comparison to be case insensitive.
* Exit training when transformer\_size is not divisible by the number\_of\_attention\_heads parameter and update the transformer documentations.
##### Improved Documentation[](#improved-documentation-15 "Direct link to Improved Documentation")
* Update compatibility matrix between Rasa-plus and Rasa Pro services.
#### \[3.4.0] - 2022-12-14[](#340---2022-12-14 "Direct link to [3.4.0] - 2022-12-14")
Rasa Pro 3.4.0 (2022-12-14)
##### Features[](#features-12 "Direct link to Features")
* Add metadata to Websocket channel. Messages can now include a `metadata` object which will be included as metadata to Rasa. The metadata can be supplied on a user configurable key with the `metadata_key` setting in the `socketio` section of the `credentials.yml`.
* Use a new IVR Channel to connect your assistant to AudioCodes VoiceAI Connect.
##### Improvements[](#improvements-64 "Direct link to Improvements")
* Added `./docker/Dockerfile_pretrained_embeddings_spacy_it` to include Spacy's Italian pre-trained model `it_core_news_md`.
* Replace `kafka-python` dependency with `confluent-kafka` async Producer API.
* Add support for Python 3.10 version.
* Added CLI option `--logging-config-file` to enable configuration of custom logs formatting.
##### Bugfixes[](#bugfixes-208 "Direct link to Bugfixes")
* Implements a new CLI option `--jwt-private-key` required to have complete support for asymmetric algorithms as specified originally in the docs.
##### Improved Documentation[](#improved-documentation-16 "Direct link to Improved Documentation")
* Clarify in the documentation how to write testing stories if a user presses a button with payload.
* Clarify prioritisation of used slot asking option in forms in documentation.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-65 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.3.8] - 2023-04-06[](#338---2023-04-06 "Direct link to [3.3.8] - 2023-04-06")
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-66 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.3.7] - 2023-03-31[](#337---2023-03-31 "Direct link to [3.3.7] - 2023-03-31")
##### Improvements[](#improvements-65 "Direct link to Improvements")
* Add a self-reference of the synonym in the EntitySynonymMapper to handle entities extracted in a casing different to synonym case. (For example if a synonym `austria` is added, entities extracted with any alternate casing of the synonym will also be mapped to `austria`). It addresses ATO-616
##### Bugfixes[](#bugfixes-209 "Direct link to Bugfixes")
* Fix issue with failures while publishing events to RabbitMQ after a RabbitMQ restart. The fix consists of pinning `aio-pika` dependency to `8.2.3`, since this issue was introduced in `aio-pika` v`8.2.4`.
* Fix 2 issues detected with the HTTP API:
* The `GET /conversations/\{conversation_id\}/tracker` endpoint was not returning the tracker with all sessions when `include_events` query parameter was set to `ALL`. The fix constituted in using `TrackerStore.retrieve_full_tracker` method instead of `TrackerStore.retrieve` method in the function handling the `GET /conversations/\{conversation_id\}/tracker` endpoint. Implemented or updated this method across all tracker store subclasses.
* The `GET /conversations/\{conversation_id\}/story` endpoint was not returning all the stories for all sessions when `all_sessions` query parameter was set to `true`. The fix constituted in using all events of the tracker to be converted in stories instead of only the `applied_events`.
#### \[3.3.6] - 2023-03-09[](#336---2023-03-09 "Direct link to [3.3.6] - 2023-03-09")
Rasa Pro 3.3.6 (2023-03-09)
##### Bugfixes[](#bugfixes-210 "Direct link to Bugfixes")
* Fixes the bug when a slot (with `from_intent` mapping which contains no input for `intent` parameter) will no longer fill for any intent that is not under the `not_intent` parameter.
* Fix validation metrics calculation when batch\_size is dynamic.
#### \[3.3.5] - 2023-02-21[](#335---2023-02-21 "Direct link to [3.3.5] - 2023-02-21")
No significant changes.
#### \[3.3.4] - 2023-02-14[](#334---2023-02-14 "Direct link to [3.3.4] - 2023-02-14")
Rasa Pro 3.3.4 (2023-02-14)
##### Improvements[](#improvements-66 "Direct link to Improvements")
* Add capability to send compressed body in HTTP request to action server. Use COMPRESS\_ACTION\_SERVER\_REQUEST=True to turn the feature on.
* Add support for custom RulePolicy.
#### \[3.3.3] - 2022-12-01[](#333---2022-12-01 "Direct link to [3.3.3] - 2022-12-01")
##### Bugfixes[](#bugfixes-211 "Direct link to Bugfixes")
* Bypass Windows path length restrictions upon saving and reading a model archive in `rasa.engine.storage.LocalModelStorage`.
##### Improvements[](#improvements-67 "Direct link to Improvements")
* Updated tensorflow to 2.8.4.
#### \[3.3.2] - 2022-11-30[](#332---2022-11-30 "Direct link to [3.3.2] - 2022-11-30")
##### Improvements[](#improvements-68 "Direct link to Improvements")
* Added support for camembert french bert model
##### Bugfixes[](#bugfixes-212 "Direct link to Bugfixes")
* Fixes `RuntimeWarning: coroutine 'Bot.set_webhook' was never awaited` issue encountered when starting the rasa server, which caused the Telegram bot to be unresponsive.
##### Improved Documentation[](#improved-documentation-17 "Direct link to Improved Documentation")
* The documentation was updated for Buttons using messages that start with '/'. Previously, it wrongly stated that messages with '/' bypass NLU, which is not the case.
* Add documentation for Rasa Pro Services upgrades.
#### \[3.3.1] - 2022-11-09[](#331---2022-11-09 "Direct link to [3.3.1] - 2022-11-09")
##### Improved Documentation[](#improved-documentation-18 "Direct link to Improved Documentation")
* Add docs on how to set up additional data lakes for Rasa Pro analytics pipeline.
* Update migration guide and form docs with prescriptive recommendation on how to implement dynamic forms with custom slot mappings.
##### Improvements[](#improvements-69 "Direct link to Improvements")
* Updated numpy and scikit learn version to fix vulnerabilities of those dependencies
#### \[3.3.0] - 2022-10-24[](#330---2022-10-24 "Direct link to [3.3.0] - 2022-10-24")
##### Features[](#features-13 "Direct link to Features")
* Tracing capabilities for your Rasa Pro assistant. Distributed tracing tracks requests as they flow through a distributed system (in this case: a Rasa assistant), sending data about the requests to a tracing backend which collects all trace data and enables inspecting it. With this version of the Tracing feature, Rasa Pro supports OpenTelemetry.
* `ConcurrentRedisLockStore` is a new lock store that uses Redis as a persistence layer and is safe for use with multiple Rasa server replicas.
##### Improvements[](#improvements-70 "Direct link to Improvements")
* Added option `--offset-timestamps-by-seconds` to offset the timestamp of events when using `rasa export`
* Rasa supports native installations on Apple Silicon (M1 / M2). Please follow the installation instructions and take a look at the limitations.
* Caching `Message` and `Features` fingerprints unless they are altered, saving up to 2/3 of fingerprinting time in our tests.
* Added package versions of component dependencies as an additional part of fingerprinting calculation. Upgrading an dependency will thus lead to a retraining of the component in the future. Also, by changing fingerprint calculation, the next training after this change will be a complete retraining.
* Export events continuously rather than loading all events in memory first when using `rasa export`. Events will be streamed right from the start rather than loading all events first and pushing them to the broker afterwards.
* Adds new dependency pluggy, with which it was possible to implement new plugin functionality. This plugin manager enables the extension and/or enhancement of the Rasa command line interface with functionality made available in the rasa-plus package.
##### Bugfixes[](#bugfixes-213 "Direct link to Bugfixes")
* Fix `BlockingIOError` when running `rasa interactive`, after the upgrade of `prompt-toolkit` dependency.
* Fixes a bug that lead to initial slot values being incorporated into all rules by default, thus breaking most rules when the slot value changed from its initial value
* Made logistic regression classifier output a proper intent ranking and made ranking length configurable
##### Deprecations and Removals[](#deprecations-and-removals-9 "Direct link to Deprecations and Removals")
* Remove code related to Rasa X local mode as it is deprecated and scheduled for removal.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-67 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.2.13] - 2023-03-09[](#3213---2023-03-09 "Direct link to [3.2.13] - 2023-03-09")
Rasa 3.2.13 (2023-03-09)
##### Bugfixes[](#bugfixes-214 "Direct link to Bugfixes")
* Fix validation metrics calculation when batch\_size is dynamic.
* Fixes the bug when a slot (with `from_intent` mapping which contains no input for `intent` parameter) will no longer fill for any intent that is not under the `not_intent` parameter.
#### \[3.2.12] - 2023-02-21[](#3212---2023-02-21 "Direct link to [3.2.12] - 2023-02-21")
##### Features[](#features-14 "Direct link to Features")
* Add metadata to Websocket channel. Messages can now include a `metadata` object which will be included as metadata to Rasa. The metadata can be supplied on a user configurable key with the `metadata_key` setting in the `socketio` section of the `credentials.yml`.
##### Improvements[](#improvements-71 "Direct link to Improvements")
* Add capability to send compressed body in HTTP request to action server. Use COMPRESS\_ACTION\_SERVER\_REQUEST=True to turn the feature on.
##### Bugfixes[](#bugfixes-215 "Direct link to Bugfixes")
* Decision to publish docs should not consider next major and minor alpha release versions.
#### \[3.2.11] - 2022-12-05[](#3211---2022-12-05 "Direct link to [3.2.11] - 2022-12-05")
##### Improvements[](#improvements-72 "Direct link to Improvements")
* Caching `Message` and `Features` fingerprints unless they are altered, saving up to 2/3 of fingerprinting time in our tests.
##### Bugfixes[](#bugfixes-216 "Direct link to Bugfixes")
* Implements a new CLI option `--jwt-private-key` required to have complete support for asymmetric algorithms as specified originally in the docs.
#### \[3.2.10] - 2022-09-29[](#3210---2022-09-29 "Direct link to [3.2.10] - 2022-09-29")
##### Bugfixes[](#bugfixes-217 "Direct link to Bugfixes")
* Fixes scenarios in which a slot with `from_trigger_intent` mapping that specifies an `active_loop` condition was being filled despite that `active_loop` not being activated. In addition, fixes scenario in which a slot with `from_trigger_intent` mapping without a specified `active_loop` mapping condition is only filled if the form gets activated. Removes unnecessary validation warning that a slot with `from_trigger_intent` and a mapping condition should be included in the form's required\_slots.
* Fixed a bug where `DIETClassier` crashed during training when both masked language modelling and evaluation during training were used.
##### Improved Documentation[](#improved-documentation-19 "Direct link to Improved Documentation")
* Rasa SDK documentation lives now in Rasa Open Source documentation under the *Rasa SDK* category.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-68 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.2.9] - 2022-09-09[](#329---2022-09-09 "Direct link to [3.2.9] - 2022-09-09")
Yanked.
#### \[3.2.8] - 2022-09-08[](#328---2022-09-08 "Direct link to [3.2.8] - 2022-09-08")
##### Bugfixes[](#bugfixes-218 "Direct link to Bugfixes")
* Fix bug where `KeywordIntentClassifier` overrides preceding intent classifiers' predictions although the `KeyWordIntentClassifier` was not matching any keywords.
#### \[3.2.7] - 2022-08-31[](#327---2022-08-31 "Direct link to [3.2.7] - 2022-08-31")
##### Improvements[](#improvements-73 "Direct link to Improvements")
* Improve `rasa data validate` command so that it uses custom importers when they are defined in config file.
##### Bugfixes[](#bugfixes-219 "Direct link to Bugfixes")
* Re-instates the REST channel metadata feature. Metadata can be provided on the `metadata` key.
#### \[3.2.6] - 2022-08-12[](#326---2022-08-12 "Direct link to [3.2.6] - 2022-08-12")
##### Bugfixes[](#bugfixes-220 "Direct link to Bugfixes")
* This fix makes sure that when a Domain object is loaded from multiple files where one file specifies a custom session config and the rest do not, the default session configuration does not override the custom session config.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-69 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.2.5] - 2022-08-05[](#325---2022-08-05 "Direct link to [3.2.5] - 2022-08-05")
##### Bugfixes[](#bugfixes-221 "Direct link to Bugfixes")
* Fix `KeyError` which resulted when `action_two_stage_fallback` got executed in a project whose domain contained slot mappings.
* Fixes regression in which slot mappings were prioritized according to reverse order as they were listed in the domain, instead of in order from first to last, as was implicitly expected in `2.x`. Clarifies this implicit priority order in the docs.
* Enables the dispatching of bot messages returned as events by slot validation actions.
#### \[3.2.4] - 2022-07-21[](#324---2022-07-21 "Direct link to [3.2.4] - 2022-07-21")
##### Bugfixes[](#bugfixes-222 "Direct link to Bugfixes")
* Added session\_config key as valid domain key during domain loading from directory containing a separate domain file with session configuration.
* Run default action `action_extract_slots` after a custom action returns a `UserUttered` event to fill any applicable slots.
* Handle the case when an `EndpointConfig` object is given as parameter to the `AwaitableTrackerStore.create()` method.
#### \[3.2.3] - 2022-07-18[](#323---2022-07-18 "Direct link to [3.2.3] - 2022-07-18")
##### Bugfixes[](#bugfixes-223 "Direct link to Bugfixes")
* * Fixed error in creating response when slack sends retry messages. Assigning `None` to `response.text` caused `TypeError: Bad body type. Expected str, got NoneType`.
* Fixed Slack triggering timeout after 3 seconds if the action execution is too slow. Running `on_new_message` as an asyncio background task instead of a blocking await fixes this by immediately returning a response with code 200.
* Revert change in #10295 that removed running the form validation action on activation of the form before the loop is active.
* `SlotSet` events will be emitted when the value set by the current user turn is the same as the existing value.
Previously, `ActionExtractSlots` would not emit any `SlotSet` events if the new value was the same as the existing one. This caused the augmented memoization policy to lose these slot values when truncating the tracker.
#### \[3.2.2] - 2022-07-05[](#322---2022-07-05 "Direct link to [3.2.2] - 2022-07-05")
##### Improved Documentation[](#improved-documentation-20 "Direct link to Improved Documentation")
* Update documentation for customizable classes such as tracker stores, event brokers and lock stores.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-70 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.2.1] - 2022-06-17[](#321---2022-06-17 "Direct link to [3.2.1] - 2022-06-17")
##### Bugfixes[](#bugfixes-224 "Direct link to Bugfixes")
* Fix failed check in `rasa data validate` that verifies forms in rules or stories are consistent with the domain when the rule or story contains a default action as `active_loop` step.
#### \[3.2.0] - 2022-06-14[](#320---2022-06-14 "Direct link to [3.2.0] - 2022-06-14")
##### Deprecations and Removals[](#deprecations-and-removals-10 "Direct link to Deprecations and Removals")
* [NLU training data](https://legacy-docs-oss.rasa.com/docs/rasa/nlu-training-data) in JSON format is deprecated and will be removed in Rasa Open Source 4.0. Please use `rasa data convert nlu -f yaml --data ` to convert your NLU JSON data to YAML format before support for NLU JSON data is removed.
##### Improvements[](#improvements-74 "Direct link to Improvements")
* Make `TrackerStore` interface methods asynchronous and supply an `AwaitableTrackerstore` wrapper for custom tracker stores which do not implement the methods as asynchronous.
* Added flag `use_gpu` to `TEDPolicy` and `UnexpecTEDIntentPolicy` that can be used to enable training on CPU even when a GPU is available.
* Add `--endpoints` command line parameter to `rasa train` parser.
##### Bugfixes[](#bugfixes-225 "Direct link to Bugfixes")
* The azure botframework channel now validates the incoming JSON Web Tokens (including signature).
Previously, JWTs were not validated at all.
* `rasa shell` now outputs custom json unicode characters instead of `\uxxxx` codes
##### Improved Documentation[](#improved-documentation-21 "Direct link to Improved Documentation")
* Clarify aspects of the API spec GET /status endpoint: Correct response schema for model\_id - a string, not an object.
GET /conversations/{conversation\_id}/tracker: Describe each of the enum options for include\_events query parameter
POST & PUT /conversations/{conversation\_id}/tracker/eventss: Events schema added for each event type
GET /conversations/{conversation\_id}/story: Clarified the all\_sessions query parameter and default behaviour.
POST /model/test/intents : Remove JSON payload option since it is not supported
POST /model/parse: Explain what emulation\_mode is and how it affects response results
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-71 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.1.7] - 2022-08-30[](#317---2022-08-30 "Direct link to [3.1.7] - 2022-08-30")
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-72 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.1.6] - 2022-07-20[](#316---2022-07-20 "Direct link to [3.1.6] - 2022-07-20")
##### Bugfixes[](#bugfixes-226 "Direct link to Bugfixes")
* Run default action `action_extract_slots` after a custom action returns a `UserUttered` event to fill any applicable slots.
#### \[3.1.5] - 2022-07-15[](#315---2022-07-15 "Direct link to [3.1.5] - 2022-07-15")
##### Bugfixes[](#bugfixes-227 "Direct link to Bugfixes")
* `SlotSet` events will be emitted when the value set by the current user turn is the same as the existing value.
Previously, `ActionExtractSlots` would not emit any `SlotSet` events if the new value was the same as the existing one. This caused the augmented memoization policy to lose these slot values when truncating the tracker.
#### \[3.1.4] - 2022-06-21 No significant changes.[](#314---2022-06-21--------------------------no-significant-changes "Direct link to [3.1.4] - 2022-06-21 No significant changes.")
Upgrade dependent libraries with security vulnerabilities (Pillow, TensorFlow, ujson).
#### \[3.1.3] - 2022-06-17[](#313---2022-06-17 "Direct link to [3.1.3] - 2022-06-17")
##### Bugfixes[](#bugfixes-228 "Direct link to Bugfixes")
* The azure botframework channel now validates the incoming JSON Web Tokens (including signature).
Previously, JWTs were not validated at all.
* Backports fix for failed check in `rasa data validate` that verifies forms in rules or stories are consistent with the domain when the rule or story contains a default action as `active_loop` step.
#### \[3.1.2] - 2022-06-08[](#312---2022-06-08 "Direct link to [3.1.2] - 2022-06-08")
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-73 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.1.1] - 2022-06-03[](#311---2022-06-03 "Direct link to [3.1.1] - 2022-06-03")
##### Bugfixes[](#bugfixes-229 "Direct link to Bugfixes")
* Remove warning for Rasa X localmode not being supported when the `--production` flag is present.
* Pin requirement for `scipy<1.8.0` since `scipy>=1.8.0` is not backward compatible with `scipy<1.8.0` and additionally requires Python>=3.8, while Rasa supports Python 3.7 as well.
* Fix the extraction of values for slots with mapping conditions from trigger intents that activate a form, which was possible in `2.x`.
#### \[3.1.0] - 2022-03-25[](#310---2022-03-25 "Direct link to [3.1.0] - 2022-03-25")
##### Features[](#features-15 "Direct link to Features")
* Add configuration options (via env variables) for library logging.
* Support other recipe types.
This pull request also adds support for graph recipes, see details at and check Graph Recipe page.
Graph recipe is a raw format for specifying executed graph directly. This is useful if you need a more powerful way to specify your model creation.
* Added optional `ssl_keyfile`, `ssl_certfile`, and `ssl_ca_certs` parameters to the Redis tracker store.
* Added `LogisticRegressionClassifier` to the NLU classifiers.
This model is lightweight and might help in early prototyping. The training times typically decrease substantially, but the accuracy might be a bit lower too.
* Added support for Python 3.9.
##### Improvements[](#improvements-75 "Direct link to Improvements")
* Bump TensorFlow version to 2.7.
caution
We can't guarantee the exact same output and hence model performance if your configuration uses `LanguageModelFeaturizer`. This applies to the case where the model is re-trained with the new rasa open source version without changing the configuration, random seeds, and data as well as to the case where a model trained with a previous version of rasa open source is loaded with this new version for inference.
We suggest training a new model if you are upgrading to this version of Rasa Open Source.
* Make `rasa data validate` check for duplicated intents, forms, responses and slots when using domains split between multiple files.
* Add an `influence_conversation` flag to entites to provide a shorthand for ignoring an entity for all intents.
* Add `--request-timeout` command line argument to `rasa shell`, allowing users to configure the time a request can take before it's terminated.
##### Bugfixes[](#bugfixes-230 "Direct link to Bugfixes")
* Validate regular expressions in nlu training data configuration.
* Unset the default values for `num_threads` and `finetuning_epoch_fraction` to `None` in order to fix cases when CLI defaults override the data from config.
* Update `rasa data validate` to not fail when `active_loop` is `null`
* Fixes Domain loading when domain config uses multiple yml files.
Previously not all configures attributes were necessarily known when merging Domains, and in the case of `entities` were not being properly assigned to `intents`.
* Fix `max_history` truncation in `AugmentedMemoizationPolicy` to preserve the most recent `UserUttered` event. Previously, `AugmentedMemoizationPolicy` failed to predict next action after long sequences of actions (longer than `max_history`) because the policy did not have access to the most recent user message.
* Add `RASA_ENVIRONMENT` header in Kafka only if the environmental variable is set.
* Merge domain entities as lists of dicts, not lists of lists to support entity roles and groups across multiple domains.
* Add an option to specify `--domain` for `rasa test nlu` CLI command.
##### Improved Documentation[](#improved-documentation-22 "Direct link to Improved Documentation")
* Fixed an over-indent in the Tokenizers section of the Components page of the docs.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-74 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.0.10] - 2022-03-15## \[3.0.10] - 2022-03-15[](#3010---2022-03-15-3010---2022-03-15 "Direct link to [3.0.10] - 2022-03-15## [3.0.10] - 2022-03-15")
##### Bugfixes[](#bugfixes-231 "Direct link to Bugfixes")
* Fix broken conversion from Rasa JSON NLU data to Rasa YAML NLU data.
#### \[3.0.9] - 2022-03-11[](#309---2022-03-11 "Direct link to [3.0.9] - 2022-03-11")
##### Bugfixes[](#bugfixes-232 "Direct link to Bugfixes")
* Fix Socket IO connection issues by upgrading sanic to v21.12.
The bug is caused by [an invalid function signature](https://github.com/sanic-org/sanic/issues/2272) and is fixed in [v21.12](https://sanic.readthedocs.io/en/v21.12.1/sanic/changelog.html#version-21-12-0).
This update brings some deprecations in `sanic`:
* Sanic and Blueprint may no longer have arbitrary properties attached to them
* Fixed this by moving user defined properties to the `instance.ctx` object
* Sanic and Blueprint forced to have compliant names
* Fixed this by using string literal names instead of the module's name via \_\_name\_\_
* `sanic.exceptions.abort` is Deprecated
* Fixed by replacing it with `sanic.exceptions.SanicException`
* `sanic.response.StreamingHTTPResponse` is deprecated
* Fixed by replacing it with sanic.response.ResponseStream
* Update `rasa data validate` to not fail when `active_loop` is `null`
##### Improved Documentation[](#improved-documentation-23 "Direct link to Improved Documentation")
* Updated the `model_confidence` parameter in `TEDPolicy` and `DIETClassifier`. The `linear_norm` is removed as it is no longer supported.
* Added an additional step to `Receiving Messages` section in slack.mdx documentation. After a slack update this additional step is needed to allow direct messages to the bot.
* Backport the updated deployment docs to 3.0.x.
#### \[3.0.8] - 2022-02-11[](#308---2022-02-11 "Direct link to [3.0.8] - 2022-02-11")
##### Improvements[](#improvements-76 "Direct link to Improvements")
* Allow single tokens in rasa end-to-end test files to be annotated with multiple entities.
Some entity extractors (s.a. `RegexEntityExtractor`) can generate multiple entities from a single expression. Before this change, `rasa test` would fail in this case, because test stories could not be annotated correctly. New annotation option is
```
stories:
- story: Some story
steps:
- user: |
cancel my [iphone][{"entity":"iphone", "value":"iphone"},{"entity":"smartphone", "value":"true"}{"entity":"mobile_service", "value":"true"}]
intent: cancel_contract
```
##### Bugfixes[](#bugfixes-233 "Direct link to Bugfixes")
* Fixed a bug where the `POST /conversations//tracker/events` endpoint repeated session start events when appending events to a new tracker.
#### \[3.0.7] - 2022-02-09[](#307---2022-02-09 "Direct link to [3.0.7] - 2022-02-09")
##### Bugfixes[](#bugfixes-234 "Direct link to Bugfixes")
* Checkpoint weights were never loaded before. Implements overwriting checkpoint weights to the final model weights after training of `DIETClassifier`, `ResponseSelector` and `TEDPolicy`.
* Allow arbitrary keys under each slot in the domain to allow for custom slot types.
* Fix issue with missing running event loop in `MainThread` when starting Rasa Open Source for Rasa X with JWT secrets.
#### \[3.0.6] - 2022-01-28[](#306---2022-01-28 "Direct link to [3.0.6] - 2022-01-28")
##### Deprecations and Removals[](#deprecations-and-removals-11 "Direct link to Deprecations and Removals")
* Removed CompositionView.
##### Bugfixes[](#bugfixes-235 "Direct link to Bugfixes")
* Fixes a bug which was caused by `DIETClassifier` (`ResponseSelector`, `SklearnIntentClassifier` and `CRFEntityExtractor` have the same issue) trying to process message which didn't have required features. Implements removing unfeaturized messages for the above-mentioned components before training and prediction.
* Enable slots with `from_entity` mapping that are not part of a form's required slots to be set during active loop.
* Catch `ValueError` for any port values that cannot be cast to integer and re-raise as `RasaException` during the initialisation of `SQLTrackerStore`.
* Use `tf.function` for model prediction to improve inference speed.
* Tie prompt-toolkit to ^2.0 to fix `rasa-shell`.
##### Improved Documentation[](#improved-documentation-24 "Direct link to Improved Documentation")
* Update dynamic form behaviour docs section with an example on how to override `required_slots` in case of removal of a form required slot.
#### \[3.0.5] - 2022-01-19[](#305---2022-01-19 "Direct link to [3.0.5] - 2022-01-19")
##### Bugfixes[](#bugfixes-236 "Direct link to Bugfixes")
* Corrects `transformer_size` parameter value (`None` by default) with a default size during loading in case `ResponseSelector` contains transformer layers.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-75 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.0.4] - 2021-12-22[](#304---2021-12-22 "Direct link to [3.0.4] - 2021-12-22")
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-76 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.0.3] - 2021-12-16[](#303---2021-12-16 "Direct link to [3.0.3] - 2021-12-16")
##### Bugfixes[](#bugfixes-237 "Direct link to Bugfixes")
* Copy lookup tables to train and test folds in cross validation. Before, the generated folds did not have a copy of the lookup tables from the original NLU data, so that `RegexEntityExtractor` could not recognize any entities during the evaluation.
* Do not print warning when subintent actions have response.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-77 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.0.2] - 2021-12-09[](#302---2021-12-09 "Direct link to [3.0.2] - 2021-12-09")
##### Bugfixes[](#bugfixes-238 "Direct link to Bugfixes")
* Update SQLAlchemy version to a compatible one in case other dependencies force a lower version.
* Fix overriding of default config with custom config containing nested dictionaries. Before, the keys of a nested dictionary in the default config that were not specified in the custom config got lost.
* Add `UserWarning` to alert users trying to run `rasa x` CLI command with rasa version 3.0 or higher that rasa-x currently doesn't support rasa 3.x.
##### Improved Documentation[](#improved-documentation-25 "Direct link to Improved Documentation")
* Added note to the slot mappings section of the migration guide to recommend checking dynamic form behavior on migrated assistants.
#### \[3.0.1] - 2021-12-02[](#301---2021-12-02 "Direct link to [3.0.1] - 2021-12-02")
##### Bugfixes[](#bugfixes-239 "Direct link to Bugfixes")
* Fix previous slots getting filled after a restart. Previously events were searched from oldest to newest which meant we would find first occurrence of a message and use slots from thereafter. Now we use the last utterance or the restart event.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-78 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.0.0] - 2021-11-23[](#300---2021-11-23 "Direct link to [3.0.0] - 2021-11-23")
##### Deprecations and Removals[](#deprecations-and-removals-12 "Direct link to Deprecations and Removals")
* Remove backwards compatibility code with Rasa Open Source 1.x, Rasa Enterprise 0.35, and other outdated backwards compatibility code in `rasa.cli.x`, `rasa.core.utils`, `rasa.model_testing`, `rasa.model_training` and `rasa.shared.core.events`.
* Removed Python 3.6 support as [it reaches its end of life in December 2021](https://www.python.org/dev/peps/pep-0494/#lifespan).
* Follow through on removing deprecation warnings for synchronous `EventBroker` methods.
* Follow through on deprecation warnings for policies and policy ensembles.
* Follow through on deprecation warnings for `rasa.shared.data`.
* Follow through on deprecation warnings for the `Domain`. Most importantly this will enforce the schema of the [`forms` section](https://legacy-docs-oss.rasa.com/docs/rasa/forms) in the domain file. This further includes the removal of the `UnfeaturizedSlot` type.
* Remove deprecated `change_form_to` and `set_form_validation` methods from `DialogueStateTracker`.
* Remove the support of Markdown training data format. This includes:
* reading and writing of story files in Markdown format
* reading and writing of NLU data in Markdown format
* reading and writing of retrieval intent data in Markdown format
* all the Markdown examples and tests that use Markdown
* Removed automatic renaming of deprecated action `action_deactivate_form` to `action_deactivate_loop`. `action_deactivate_form` will just be treated like other non-existing actions from now on.
* Remove deprecated `sorted_intent_examples` method from `TrainingData`.
* Raising `RasaException` instead of deprecation warning when using `class_from_module_path` for loading types other than classes.
* Specifying the `retrieve_events_from_previous_conversation_sessions` kwarg for the any `TrackerStore` was deprecated and has now been removed. Please use the `retrieve_full_tracker()` method instead.
Deserialization of pickled trackers was deprecated and has now been removed. Rasa will perform any future save operations of trackers using json serialisation.
Removed catch for missing (deprecated) `session_date` when saving trackers in `DynamoTrackerStore`.
* Removed the deprecated dialogue policy state featurizers: `BinarySingleStateFeature` and `LabelTokenizerSingleStateFeaturizer`.
Removed the deprecated method `encode_all_actions` of `SingleStateFeaturizer`. Use `encode_all_labels` instead.
* Follow through with removing deprecated policies: `FormPolicy`, `MappingPolicy`, `FallbackPolicy`, `TwoStageFallbackPolicy`, and `SklearnPolicy`.
Remove warning about default value of `max_history` in MemoizationPolicy. The default value is now `None`.
* Follow through on deprecation warnings and remove code, tests, and docs for `ConveRTTokenizer`, `LanguageModelTokenizer` and `HFTransformersNLP`.
* `rasa.shared.nlu.training_data.message.Message` method `get_combined_intent_response_key` has been removed. `get_full_intent` should now be used in its place.
* Intent IDs sent with events (to kafka and elsewhere) have been removed, intent names can be used instead (or if numerical values are needed for backwards compatibility, one can also hash the names to get previous ID values, ie. `hash(intent_name)` is the old ID values). Intent IDs have been removed because they were providing no extra value and integers that large were problematic for some event broker implementations.
* Remove `loop` argument from `train` method in `rasa`. This argument became redundant when Python 3.6 support was dropped as `asyncio.run` became available in Python 3.7.
* Remove `template_variables` and `e2e` arguments from `get_stories` method of `TrainingDataImporter`. This argument was used in Markdown data format and became redundant once Markdown was removed.
* `weight_sparsity` has been removed. Developers should replace it with `connection_density` in the following way: `connection_density` = 1-`weight_sparsity`.
`softmax` is not available as a `loss_type` anymore.
The `linear_norm` option has been removed as possible value for `model_confidence`. Please, use `softmax` instead.
`minibatch` has been removed as a value for `tensorboard_log_level`, use `batch` instead.
Removed deprecation warnings related to the removed component config values.
* Follow through on removing deprecation warnings raised in these modules:
* `rasa/server.py`
* `rasa/core/agent.py`
* `rasa/core/actions/action.py`
* `rasa/core/channels/mattermost.py`
* `rasa/core/nlg/generator.py`
* `rasa/nlu/registry.py`
* Remove deprecation warnings associated with the `"number_additional_patterns"` parameter of `rasa.nlu.featurizers.sparse_featurizer.regex_featurizer.RegexFeaturizer`. This parameter is no longer needed for incremental training.
Remove deprecation warnings associated with the `"additional_vocabulary_size"` parameter of `rasa.nlu.featurizers.sparse_featurizer.count_vectors_featurizer.CountVectorsFeaturizer`. This parameter is no longer needed for incremental training.
Remove deprecated functions `training_states_actions_and_entities` and `training_states_and_actions` from `rasa.core.featurizers.tracker_featurizers.TrackerFeaturizer`. Use `training_states_labels_and_entities` and `training_states_and_labels` instead.
* Follow through on deprecation warning for `NGramFeaturizer`
* The CLI commands `rasa data convert config` and `rasa data convert responses` which converted from the Rasa Open Source 1 to the Rasa Open Source 2 formats were removed. Please use a Rasa Open Source 2 installation to convert your training data before moving to Rasa Open Source 3.
* `rasa.core.agent.Agent.visualize` was removed. Please use `rasa visualize` or `rasa.core.visualize.visualize` instead.
* Removed slot auto-fill functionality, making the key invalid to use in the domain file. The `auto_fill` parameter was also removed from the constructor of the `Slot` class. In order to continue filling slots with entities of the same name, you now have to define a `from_entity` mapping in the `slots` section of the domain. To learn more about how to migrate your 2.0 assistant, please read the migration guide.
##### Features[](#features-16 "Direct link to Features")
* Training data version upgraded from `2.0` to `3.0` due to breaking changes to format in Rasa Open Source 3.0
* A new experimental feature called `Markers` has been added. `Markers` allow you to define points of interest in conversations as a set of conditions that need to be met. A new command `rasa evaluate markers` allows you to apply these conditions to your existing tracker stores and outputs the points at which the conditions were satisfied.
* Rasa Open Source now uses the [model configuration](https://legacy-docs-oss.rasa.com/docs/rasa/model-configuration) to build a
[directed acyclic graph](https://en.wikipedia.org/wiki/Directed_acyclic_graph). This graph describes the dependencies between the items in your model configuration and how data flows between them. This has two major benefits:
* Rasa Open Source can use the computational graph to optimize the execution of your model. Examples for this are efficient caching of training steps or executing independent steps in parallel.
* Rasa Open Source can represent different model architectures flexibly. As long as the graph remains acyclic Rasa Open Source can in theory pass any data to any graph component based on the model configuration without having to tie the underlying software architecture to the used model architecture.
This change required changes to custom policies and custom NLU components. See the documentation for a detailed [migration guide](https://legacy-docs-oss.rasa.com/docs/rasa/migration-guide#custom-policies-and-custom-components).
* Added explicit mechanism for slot filling that allows slots to be set and/or updated throughout the conversation. This mechanism is enabled by defining global slot mappings in the `slots` section of the domain file.
In order to support this new functionality, implemented a new default action: `action_extract_slots`. This new action runs after each user turn and checks if any slots can be filled with information extracted from the last user message based on defined slot mappings.
Since slot mappings were moved away from the `forms` section of the domain file, converted the form's `required_slots` to a list of slot names. In order to restrict certain mappings to a form, you can now use the `conditions` key in the mapping to define the applicable `active_loop`, like so:
```
slots:
location:
type: text
influence_conversation: false
mappings:
- type: from_entity
entity: city
conditions:
- active_loop: booking_form
```
To learn more about how to migrate your 2.0 assistant, please read the migration guide.
##### Improvements[](#improvements-77 "Direct link to Improvements")
* Updated the `/status` endpoint response payload, and relevant documentation, to return/reflect the updated 3.0 keys/values.
* Bump TensorFlow version to 2.6.
This update brings some security benefits (see TensorFlow [release notes](https://github.com/tensorflow/tensorflow/releases/tag/v2.6.0) for details). However, internal experiments suggest that it is also associated with increased train and inference time, as well as increased memory usage.
You can read more about why we decided to update TensorFlow, and what the expected impact is [here](https://rasa.com/blog/let-s-talk-about-tensorflow-2-6/).
If you experience a significant increase in train time, inference time, and/or memory usage, please let us know in the [forum](https://forum.rasa.com/t/feedback-upgrading-to-tensorflow-2-6/48331).
Users can no longer set `TF_DETERMINISTIC_OPS=1` if they are using GPU(s) because a `tf.errors.UnimplementedError` will be thrown by TensorFlow (read more [here](https://github.com/tensorflow/tensorflow/releases/tag/v2.6.0)).
caution
This **breaks backward compatibility of previously trained models**. It is not possible to load models trained with previous versions of Rasa Open Source. Please re-train your assistant before trying to use this version.
* Added authentication support for connecting to external RabbitMQ servers. Currently user has to hardcode a username and a password in a URL in order to connect to an external RabbitMQ server.
* 1. Failed test stories will display full retrieval intents.
2. Retrieval intents will be extracted during action prediction in test stories so that we won't have unnecessary mismatches anymore.
Let's take this example story:
```
- story: test story
steps:
- user: |
what is your name?
intent: chitchat/ask_name
- action: utter_chitchat/ask_name
- intent: bye
- action: utter_bye
```
Before:
```
steps:
- intent: chitchat # 1) intent is not displayed in it's original form
- action: utter_chitchat/ask_name # predicted: utter_chitchat
# 2) retrieval intent is not extracted during action prediction and we have a mismatch
- intent: bye # some other fail
- action: utter_bye # some other fail
```
Both 1) and 2) problems are solved.
Now:
```
steps:
- intent: chitchat/ask_name
- action: utter_chitchat/ask_name
- intent: bye # some other fail
- action: utter_bye # some other fail
```
* Added `-i` command line option to make RASA listen on a specific ip-address instead of any network interface
* `rasa data validate` now checks that forms referenced in `active_loop` directives are defined in the domain
* Every conversation event now includes in its metadata the ID of the model which loaded at the time it was created.
* Send indices of user message tokens along with the `UserUttered` event through the event broker to Rasa X.
* Added optional flag to convert intent ID hashes from integer to string in the `KafkaEventBroker`.
* Make it possible to use `or` functionality for `slot_was_set` events.
* Upgraded the spaCy dependency from version 3.0 to 3.1.
* Implemented `fingerprint` methods in these classes:
* `Event`
* `Slot`
* `DialogueStateTracker`
* Added debug message that logs when a response condition is used.
* The naming scheme for trained models was changed. Unless you provide a `--fixed-model-name` to `rasa train`, Rasa Open Source will now generate a new model name using the schema `-.tar.gz`, e.g.
* `20211018-094821-composite-pita.tar.gz` (for a model containing a trained NLU and dialogue model)
* `nlu-20211018-094821-composite-pita.tar.gz` (for a model containing only a trained NLU model but not a dialogue model)
* `core-20211018-094821-composite-pita.tar.gz` (for a model containing only a trained dialogue model but no NLU model)
* Due to changes in the model architecture the behavior of `rasa train --dry-run` changed. The exit codes now have the following meaning:
* `0` means that the model does not require an expensive retraining. However, the responses might still require updating by running `rasa train`
* `1` means that one or multiple components require to be retrained.
* `8` means that the `--force` flag was used and hence any cached results are ignored and the entire model is retrained.
* Machine learning components like `DIETClassifier`, `ResponseSelector` and `TEDPolicy` using a `ranking_length` parameter will no longer report renormalised confidences for the top predictions by default.
A new parameter `renormalize_confidences` is added to these components which if set to `True`, renormalizes the confidences of top `ranking_length` number of predictions to sum up to 1. The default value is `False`, which means no renormalization will be applied by default. It is advised to leave it to `False` but if you are trying to reproduce the results from previous versions of Rasa Open Source, you can set it to `True`.
Renormalization will only be applied if `model_confidence=softmax` is used.
##### Bugfixes[](#bugfixes-240 "Direct link to Bugfixes")
* Fixed validation behavior and logging output around unused intents and utterances.
* `rasa test nlu --cross-validation` uses autoconfiguration when no pipeline is defined instead of failing
* Update DynamoDb tracker store to correctly retrieve all `sender_ids` from a DynamoDb table.
* Fix for `failed_test_stories.yml` not printing the correct message when the extracted entity specified in a test story is incorrect.
* Fix CVE-2021-41127
##### Improved Documentation[](#improved-documentation-26 "Direct link to Improved Documentation")
* Added new docs for Markers.
* Update pip in same command which installs rasa and clarify supported version in docs.
* Update `pika` consumer code in Event Brokers documentation.
* Adds documentation on how to use `CRFEntityExtractor` with features from a dense featurizer (e.g. `LanguageModelFeaturizer`).
* Updated docs (Domain, Forms, Default Actions, Migration Guide, CLI) to provide more detail over the new slot mappings changes.
* Updated documentation publishing mechanisms to build one version of [the documentation](https://rasa.com/docs/rasa) for each major version of Rasa Open Source, starting from 2.x upwards. Previously, we were building one version of the documentation for each minor version of Rasa Open Source, resulting in a poor user experience and high maintenance costs.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-79 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.8.16] - 2021-12-09[](#2816---2021-12-09 "Direct link to [2.8.16] - 2021-12-09")
##### Improvements[](#improvements-78 "Direct link to Improvements")
* The value of the `RASA_ENVIRONMENT` environmental variable is sent as a header in messages logged by `KafkaEventBroker`. This value was previously only made available by `PikaEventConsumer`.
##### Bugfixes[](#bugfixes-241 "Direct link to Bugfixes")
* Make `action_metadata` json serializable and make it available on the tracker. This is a backport of a fix in 3.0.0.
#### \[2.8.15] - 2021-11-25[](#2815---2021-11-25 "Direct link to [2.8.15] - 2021-11-25")
##### Bugfixes[](#bugfixes-242 "Direct link to Bugfixes")
* Validate regular expressions in nlu training data configuration.
#### \[2.8.14] - 2021-11-18[](#2814---2021-11-18 "Direct link to [2.8.14] - 2021-11-18")
##### Bugfixes[](#bugfixes-243 "Direct link to Bugfixes")
* Bump TensorFlow version to 2.6.2. *We have plans to port this change to 3.x (see [this issue](https://github.com/RasaHQ/rasa/issues/10378))*.
* Downgrade google-auth to <2.
#### \[2.8.13] - 2021-11-11[](#2813---2021-11-11 "Direct link to [2.8.13] - 2021-11-11")
##### Bugfixes[](#bugfixes-244 "Direct link to Bugfixes")
* Fixed new intent creation in `rasa interactive` command. Previously, this failed with 500 from the server due to `UnexpecTEDIntentPolicy` trying to predict with the new intent not in domain.
* Install mitie library when preparing test runs. This step was missing before and tests were thus failing as we have many tests which rely on mitie library. Previously, `make install-full` was required.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-80 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.8.12] - 2021-10-21[](#2812---2021-10-21 "Direct link to [2.8.12] - 2021-10-21")
##### Bugfixes[](#bugfixes-245 "Direct link to Bugfixes")
* Fixed a bug where `rasa test --fail-on-prediction-errors` would raise a `WrongPredictionException` for entities which were actually predicted correctly.
This happened in two ways:
1. if for a user message some entities were extracted multiple times (by multiple entity extractors) but listed only once in the test story,
2. if the order in which entities from a message were extracted didn't match the order in which they were listed in the test story.
##### Improved Documentation[](#improved-documentation-27 "Direct link to Improved Documentation")
* Improve the documentation for training `TEDPolicy` with data augmentation.
#### \[2.8.11] - 2021-10-20[](#2811---2021-10-20 "Direct link to [2.8.11] - 2021-10-20")
##### Bugfixes[](#bugfixes-246 "Direct link to Bugfixes")
* Updates dependency on `sanic-jwt` (1.5.0 -> ">=1.6.0, <1.7.0")
This removes the need to pin the version of `pyjwt` as the newer version of `sanic-jwt` manages this properly.
#### \[2.8.10] - 2021-10-14[](#2810---2021-10-14 "Direct link to [2.8.10] - 2021-10-14")
##### Bugfixes[](#bugfixes-247 "Direct link to Bugfixes")
* Add List handling in the `send_custom_json` method on `channels/facebook.py`. Bellow are some examples that could cause en error before.
Example 1: when the whole json is a List
```
[
{
"blocks": {
"type": "progression_bar",
"text": {"text": "progression 1", "level": "1"},
}
},
{"sender": {"id": "example_id"}},
]
```
Example 2: instead of being a Dict, *blocks* is a List when there are 2 *type* keys under it
```
{
"blocks": [
{"type": "title", "text": {"text": "Conversation progress"}},
{
"type": "progression_bar",
"text": {"text": "Look how far we are...", "level": "1"},
},
]
}
```
* Fixed bug when using wit.ai training data to train. Training failed with an error similarly to this:
```
File "./venv/lib/python3.8/site-packages/rasa/nlu/classifiers/diet_classifier.py", line 803, in train
self.check_correct_entity_annotations(training_data)
File "./venv/lib/python3.8/site-packages/rasa/nlu/extractors/extractor.py", line 418, in check_correct_entity_annotations
entities_repr = [
File "./venv/lib/python3.8/site-packages/rasa/nlu/extractors/extractor.py", line 422, in \
entity[ENTITY_ATTRIBUTE_VALUE],
KeyError: 'value'
```
* Fix CVE-2021-41127
#### \[2.8.9] - 2021-10-08[](#289---2021-10-08 "Direct link to [2.8.9] - 2021-10-08")
##### Improvements[](#improvements-79 "Direct link to Improvements")
* Bump TensorFlow version to 2.6.
This update brings some security benefits (see TensorFlow [release notes](https://github.com/tensorflow/tensorflow/releases/tag/v2.6.0) for details). However, internal experiments suggest that it is also associated with increased train and inference time, as well as increased memory usage.
You can read more about why we decided to update TensorFlow, and what the expected impact is [here](https://rasa.com/blog/let-s-talk-about-tensorflow-2-6/).
If you experience a significant increase in train time, inference time, and/or memory usage, please let us know in the [forum](https://forum.rasa.com/t/feedback-upgrading-to-tensorflow-2-6/48331).
Users can no longer set `TF_DETERMINISTIC_OPS=1` if they are using GPU(s) because a `tf.errors.UnimplementedError` will be thrown by TensorFlow (read more [here](https://github.com/tensorflow/tensorflow/releases/tag/v2.6.0)).
caution
This **breaks backward compatibility of previously trained models**. It is not possible to load models trained with previous versions of Rasa Open Source. Please re-train your assistant before trying to use this version.
#### \[2.8.8] - 2021-10-06[](#288---2021-10-06 "Direct link to [2.8.8] - 2021-10-06")
##### Improvements[](#improvements-80 "Direct link to Improvements")
* Added a function to display the actual text of a Token when inspecting a Message in a pipeline, making it easier to debug.
##### Improved Documentation[](#improved-documentation-28 "Direct link to Improved Documentation")
* Removing the experimental feature warning for `conditional response variations` from the Rasa docs. The behaviour of the feature remains unchanged.
* Updates [quick install documentation](https://rasa.com/docs/rasa-pro/installation/python/installation) with optional venv step, better pip install instructions, & M1 warning
#### \[2.8.7] - 2021-09-20[](#287---2021-09-20 "Direct link to [2.8.7] - 2021-09-20")
##### Bugfixes[](#bugfixes-248 "Direct link to Bugfixes")
* Explicitly set the upper limit for currently compatible TensorFlow versions.
#### \[2.8.6] - 2021-09-09[](#286---2021-09-09 "Direct link to [2.8.6] - 2021-09-09")
##### Bugfixes[](#bugfixes-249 "Direct link to Bugfixes")
* Fix rules not being applied when a featurised categorical slot has as one of its allowed values `none`, `NoNe`, `None` or a similar value.
#### \[2.8.5] - 2021-09-06[](#285---2021-09-06 "Direct link to [2.8.5] - 2021-09-06")
##### Bugfixes[](#bugfixes-250 "Direct link to Bugfixes")
* AugmentedMemoizationPolicy is accelerated for large trackers
* Bump tensorflow to 2.3.4 to address security vulnerabilities
#### \[2.8.4] - 2021-09-02[](#284---2021-09-02 "Direct link to [2.8.4] - 2021-09-02")
##### Improvements[](#improvements-81 "Direct link to Improvements")
* Increase speed of augmented lookup for `AugmentedMemoizationPolicy`
##### Bugfixes[](#bugfixes-251 "Direct link to Bugfixes")
* Fix `--data` being treated as if non-optional on sub-commands of `rasa data convert`
* Fixes bug where `hide_rule_turn` was defaulting to `None` when ActionExecuted was deserialised.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-81 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.8.3] - 2021-08-19[](#283---2021-08-19 "Direct link to [2.8.3] - 2021-08-19")
##### Bugfixes[](#bugfixes-252 "Direct link to Bugfixes")
* Ignore checking that intent is in domain for E2E story utterances when running `rasa data validate`. Previously data validation would fail on E2E stories.
#### \[2.8.2] - 2021-08-04[](#282---2021-08-04 "Direct link to [2.8.2] - 2021-08-04")
##### Bugfixes[](#bugfixes-253 "Direct link to Bugfixes")
* Fixes a bug which caused training of `UnexpecTEDIntentPolicy` to crash when end-to-end training stories were included in the training data.
Stories with end-to-end training data will now be skipped for the training of `UnexpecTEDIntentPolicy`.
##### Improved Documentation[](#improved-documentation-29 "Direct link to Improved Documentation")
* Removing the experimental feature warning for the `story validation` tool from the rasa docs. The behaviour of the feature remains unchanged.
* Removing the experimental feature warning for `entity roles and groups` from the rasa docs, and from the code where it previously appeared as a print statement. The behaviour of the feature remains otherwise unchanged.
#### \[2.8.1] - 2021-07-22[](#281---2021-07-22 "Direct link to [2.8.1] - 2021-07-22")
##### Improvements[](#improvements-82 "Direct link to Improvements")
* Add support for `cafile` parameter in `endpoints.yaml`. This will load a custom local certificate file and use it when making requests to that endpoint.
For example:
```
action_endpoint:
url: https://localhost:5055/webhook
cafile: ./cert.pem
```
This means that requests to the action server `localhost:5055` will use the certificate `cert.pem` located in the current working directory.
##### Bugfixes[](#bugfixes-254 "Direct link to Bugfixes")
* Fixes wrong overriding of `epochs` parameter when `TEDPolicy` or `UnexpecTEDIntentPolicy` is not loaded in finetune mode.
#### \[2.8.0] - 2021-07-12[](#280---2021-07-12 "Direct link to [2.8.0] - 2021-07-12")
##### Deprecations and Removals[](#deprecations-and-removals-13 "Direct link to Deprecations and Removals")
* The option `model_confidence=linear_norm` is deprecated and will be removed in Rasa Open Source `3.0.0`.
Rasa Open Source `2.3.0` introduced `linear_norm` as a possible value for `model_confidence` parameter in machine learning components such as `DIETClassifier`, `ResponseSelector` and `TEDPolicy`. Based on user feedback, we have identified multiple problems with this option. Therefore, `model_confidence=linear_norm` is now deprecated and will be removed in Rasa Open Source `3.0.0`. If you were using `model_confidence=linear_norm` for any of the mentioned components, we recommend to revert it back to `model_confidence=softmax` and re-train the assistant. After re-training, we also recommend to [re-tune the thresholds for fallback components](https://legacy-docs-oss.rasa.com/docs/rasa/fallback-handoff/#fallbacks).
* The fallback mechanism for spaCy models has now been removed in Rasa `3.0.0`.
Rasa Open Source `2.5.0` introduced support for spaCy 3.0. This introduced a breaking feature because models would no longer be manually linked. To make the transition smooth Rasa would rely on the `language` parameter in the `config.yml` to fallback to a medium spaCy model if no model was configured for the `SpacyNLP` component. In Rasa Open Source `3.0.0` and onwards the `SpacyNLP` component will require the model name (like `"en_core_web_md"`) to be passed explicitly.
##### Features[](#features-17 "Direct link to Features")
* Added `sasl_mechanism` as an optional configurable parameters for the [Kafka Producer](https://rasa.com/docs/rasa-pro/production/event-brokers#kafka-event-broker).
* Introduces a new policy called [`UnexpecTEDIntentPolicy`](https://legacy-docs-oss.rasa.com/docs/rasa/policies#unexpected-intent-policy).
`UnexpecTEDIntentPolicy` helps you review conversations and also allows your bot to react to unexpected user turns in conversations. It is an auxiliary policy that should only be used in conjunction with at least one other policy, as the only action that it can trigger is the special and newly introduced [`action_unlikely_intent`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/default-actions#action_unlikely_intent) action.
The auto-configuration will include `UnexpecTEDIntentPolicy` in your configuration automatically, but you can also include it yourself in the `policies` section of the configuration:
```
policies:
- name: UnexpecTEDIntentPolicy
epochs: 200
max_history: 5
```
As part of the feature, it also introduces:
* [`IntentMaxHistoryTrackerFeaturizer`](https://legacy-docs-oss.rasa.com/docs/rasa/policies#3-intent-max-history) to featurize the trackers for `UnexpecTEDIntentPolicy`.
* `MultiLabelDotProductLoss` to support `UnexpecTEDIntentPolicy`'s multi-label training objective.
* A new default action called [`action_unlikely_intent`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/default-actions#action_unlikely_intent).
`rasa test` command has also been adapted to `UnexpecTEDIntentPolicy`:
* If a test story contains `action_unlikely_intent` and the policy ensemble does not trigger it, this leads to a test error (wrongly predicted action) and the corresponding story will be logged in `failed_test_stories.yml`.
* If the story does not contain `action_unlikely_intent` and Rasa Open Source does predict it then the prediction of `action_unlikely_intent` will be ignored for the evaluation (and hence not lead to a prediction error) but the story will be logged in a file called `stories_with_warnings.yml`.
The `rasa data validate` command will warn if `action_unlikely_intent` is included in the training stories. Accordingly, `YAMLStoryWriter` and `MarkdownStoryWriter` have been updated to not dump `action_unlikely_intent` when writing stories to a file.
caution
The introduction of a new default action **breaks backward compatibility of previously trained models**. It is not possible to load models trained with previous versions of Rasa Open Source. Please re-train your assistant before trying to use this version.
##### Improvements[](#improvements-83 "Direct link to Improvements")
* Added detailed json schema validation for `UserUttered`, `SlotSet`, `ActionExecuted` and `EntitiesAdded` events both sent and received from the action server, as well as covered at high-level the validation of the rest of the 20 events. In case the events are invalid, a `ValidationError` will be raised.
* Users don't need to specify an additional buffer size for sparse featurizers anymore during incremental training.
Space for new sparse features are created dynamically inside the downstream machine learning models - `DIETClassifier`, `ResponseSelector`. In other words, no extra buffer is created in advance for additional vocabulary items and space will be dynamically allocated for them inside the model.
This means there's no need to specify `additional_vocabulary_size` for [`CountVectorsFeaturizer`](https://legacy-docs-oss.rasa.com/docs/rasa/components#countvectorsfeaturizer) or `number_additional_patterns` for [`RegexFeaturizer`](https://legacy-docs-oss.rasa.com/docs/rasa/components#regexfeaturizer). These parameters are now deprecated.
**Before**
```
pipeline:
- name: "WhitespaceTokenizer"
- name: "RegexFeaturizer"
number_additional_patterns: 100
- name: "CountVectorsFeaturizer"
additional_vocabulary_size: {text: 100, response: 20}
```
**Now**
```
pipeline:
- name: "WhitespaceTokenizer"
- name: "RegexFeaturizer"
- name: "CountVectorsFeaturizer"
```
Also, all custom layers specifically built for machine learning models - `RasaSequenceLayer`, `RasaFeatureCombiningLayer` and `ConcatenateSparseDenseFeatures` now inherit from `RasaCustomLayer` so that they support flexible incremental training out of the box.
* Speed up the contradiction check of the [`RulePolicy`](https://legacy-docs-oss.rasa.com/docs/rasa/policies#rule-policy) by a factor of 3.
* Change the confidence score assigned by [`FallbackClassifier`](https://legacy-docs-oss.rasa.com/docs/rasa/components#fallbackclassifier) to fallback intent to be the same as the fallback threshold.
* Issue a UserWarning if a specified **domain folder** contains files that look like YML files but cannot be parsed successfully. Only invoked if user specifies a folder path in `--domain` paramater. Previously those invalid files in the specified folder were silently ignored. **Does not apply** to individually specified domain YAML files, e.g. `--domain /some/path/domain.yml`, those being invalid will still raise an exception.
##### Bugfixes[](#bugfixes-255 "Direct link to Bugfixes")
* Fix for unnecessary retrain and duplication of folders in the model
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-82 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.7.2] - 2021-08-09[](#272---2021-08-09 "Direct link to [2.7.2] - 2021-08-09")
##### Bugfixes[](#bugfixes-256 "Direct link to Bugfixes")
* Ignore checking that intent is in domain for E2E story utterances when running `rasa data validate`. Previously data validation would fail on E2E stories.
* Fix for unnecessary retrain and duplication of folders in the model
#### \[2.7.1] - 2021-06-16[](#271---2021-06-16 "Direct link to [2.7.1] - 2021-06-16")
##### Bugfixes[](#bugfixes-257 "Direct link to Bugfixes")
* Best model checkpoint allows for metrics to be equal to previous best if at least one metric improves, rather than strict improvement for each metric.
* Fixes a bug where multiple plots overlap each other and are rendered incorrectly when comparing performance across multiple NLU pipelines.
* Don't evaluate entities if no entities present in test data.
Also, catch exception in `plot_paired_histogram` when data is empty.
#### \[2.7.0] - 2021-06-03[](#270---2021-06-03 "Direct link to [2.7.0] - 2021-06-03")
##### Improvements[](#improvements-84 "Direct link to Improvements")
* Changed the default config to train the `RulePolicy` before the `TEDPolicy`. This means that conflicting rule/stories will be identified before a potentially slow training of the `TEDPolicy`.
* Updated validator used by `rasa data validate` to verify that actions used in stories and rules are present in the domain and that form slots match domain slots.
* Rename `plot_histogram` to `plot_paired_histogram` and fix missing bars in the plot.
* Changed --data option type in the \`\`rasa data validate\`\`\` command to allow more than one path to be passed.
##### Bugfixes[](#bugfixes-258 "Direct link to Bugfixes")
* The file `failed_test_stories.yml` (generated by `rasa test`) now also includes the wrongly predicted entity as a comment next to the entity of a user utterance. Additionally, the comment printed next to the intent of a user utterance is printed only if the intent was wrongly predicted (irrelevantly if there was a wrongly predicted entity or not in the specific user utterance).
* Added check in PikaEventBroker constructor: if port cannot be cast to integer, raise RasaException
* Fixed bug where missing intent warnings appear when running `rasa test`
* Update `should_retrain` function to return the correct fingerprint comparison result even when there is a problem with model unpacking.
* Handle correctly Telegram edited message.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-83 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.6.3] - 2021-05-28[](#263---2021-05-28 "Direct link to [2.6.3] - 2021-05-28")
##### Bugfixes[](#bugfixes-259 "Direct link to Bugfixes")
* `ResponseSelector` can now be trained with the transformer enabled (i.e. when a positive `number_of_transformer_layers` is provided) even if one doesn't specify the transformer's size. Previously, not specifying `transformer_size` led to an error.
* Return `EntityEvaluationResult` during evaluation of test stories only if `parsed_message` is not `None`.
* Ignore `OSError` in Sentry reporting.
* Replaced `ValueError` with `RasaException` in TED model `_check_data` method.
* Changed import to fix agent creation in Jupyter.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-84 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.6.2] - 2021-05-18[](#262---2021-05-18 "Direct link to [2.6.2] - 2021-05-18")
##### Bugfixes[](#bugfixes-260 "Direct link to Bugfixes")
* Fixed a bug where [`ListSlot`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#list-slot)s were filled with single items in case only one matching entity was extracted for this slot.
Values applied to [`ListSlot`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#list-slot)s will be converted to a `List` in case they aren't one.
* Fix bug with false rule conflicts
This essentially reverts [PR 8446](https://github.com/RasaHQ/rasa/pull/8446/files), except for the tests. The PR is redundant due to [PR 8646](https://github.com/RasaHQ/rasa/pull/8646/files).
* Handle `AttributeError `thrown by empty slot mappings in domain form through refactoring.
* Fixed incorrect `The action 'utter_\' is used in the stories, but is not a valid utterance action` error when running `rasa data validate` with response selector responses in the domain file.
##### Improved Documentation[](#improved-documentation-30 "Direct link to Improved Documentation")
* Added a note to clarify best practice for resetting all slots after form deactivation.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-85 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.6.1] - 2021-05-11[](#261---2021-05-11 "Direct link to [2.6.1] - 2021-05-11")
##### Bugfixes[](#bugfixes-261 "Direct link to Bugfixes")
* Made `SchemaError` message available to validator so that the reason why reason schema validation fails during `rasa data validate` is displayed when response `text` value is `null`. Added warning message when deprecated MappingPolicy format is used in the domain.
* When there are multiple entities in a user message, they will get sorted when creating a representation of the current dialogue state.
Previously, the ordering was random, leading to inconsistent state representations. This would sometimes lead to memoization policies failing to recall a memorised action.
#### \[2.6.0] - 2021-05-06[](#260---2021-05-06 "Direct link to [2.6.0] - 2021-05-06")
##### Deprecations and Removals[](#deprecations-and-removals-14 "Direct link to Deprecations and Removals")
* In forms, the keyword `required_slots` should always precede the definition of slot mappings and the lack of it is deprecated. Please see the [migration guide](https://rasa.com/docs/rasa-pro/migration-guide) for more information.
* `rasa.data.get_test_directory`, `rasa.data.get_core_nlu_directories`, and `rasa.shared.nlu.training_data.training_data.TrainingData::get_core_nlu_directories` are deprecated and will be removed in Rasa Open Source 3.0.0.
* Update the minimum compatible model version to "2.6.0". This means all models trained with an earlier version will have to be retrained.
##### Features[](#features-18 "Direct link to Features")
* Feature enhancement enabling JWT authentication for the Socket.IO channel. Users can define `jwt_key` and `jwt_method` as parameters in their credentials file for authentication.
* Allows a Rasa bot to be connected to a Twilio Voice channel. More details in the [Twilio Voice docs](https://rasa.com/docs/rasa-pro/connectors/twilio-voice)
* Conditional response variations are supported in the `domain.yml` without requiring users to write custom actions code.
A condition can be a list of slot-value mapping constraints.
##### Improvements[](#improvements-85 "Direct link to Improvements")
* Added an optional `ignored_intents` parameter in forms.
* To use it, add the `ignored_intents` parameter in your `domain.yml` file after the forms name and provide a list of intents to ignore. Please see [Forms](https://legacy-docs-oss.rasa.com/docs/rasa/forms) for more information.
* This can be used in case the user never wants to fill any slots of a form with the specified intent, e.g. chitchat.
* Add function to carry `max_history` to featurizer
* Improved the machine learning models' codebase by factoring out shared feature-processing logic into three custom layer classes:
* `ConcatenateSparseDenseFeatures` combines multiple sparse and dense feature tensors into one.
* `RasaFeatureCombiningLayer` additionally combines sequence-level and sentence-level features.
* `RasaSequenceLayer` is used for attributes with sequence-level features; it additionally embeds the combined features with a transformer and facilitates masked language modeling.
* Added the following usability improvements with respect to entities getting extracted multiple times:
* Added warnings for competing entity extractors at training time and for overlapping entities at inference time
* Improved docs to help users handle overlapping entity problems.
* Replace `weight_sparsity` with `connection_density` in all transformer-based models and add guarantees about internal layers.
We rename `DenseWithSparseWeights` into `RandomlyConnectedDense`, and guarantee that even at density zero the output is dense and every input is connected to at least one output. The former `weight_sparsity` parameter of DIET, TED, and the ResponseSelector, is now roughly equivalent to `1 - connection_density`, except at very low densities (high sparsities).
All layers and components that used to have a `sparsity` argument (`Ffnn`, `TransformerRasaModel`, `MultiHeadAttention`, `TransformerEncoderLayer`, `TransformerEncoder`) now have a `density` argument instead.
* Rasa test now prints a warning if the test stories contain bot utterances that are not part of the domain.
* Updated `asyncio.Task.all_tasks` to `asyncio.all_tasks`, with a fallback for python 3.6, which raises an AttributeError for `asyncio.all_tasks`. This removes the deprecation warning for the `Task.all_tasks` usage.
* Change variable name from `i` to `array_2D`
* Implement a new interface `run_inference` inside `RasaModel` which performs batch inferencing through tensorflow models.
`rasa_predict` inside `RasaModel` has been made a private method now by changing it to `_rasa_predict`.
##### Bugfixes[](#bugfixes-262 "Direct link to Bugfixes")
* Fixed a bug for plotting trackers with non-ascii texts during interactive training by enforcing utf-8 encoding
* Fix masked language modeling in DIET to only apply masking to token-level (sequence-level) features. Previously, masking was applied to both token-level and sentence-level features.
* Make it possible to use `null` entities in stories.
* Introduce a `skip_validation` flag in order to speed up reading YAML files that were already validated.
* Fixed a bug in interactive training that lead to crashes for long Chinese, Japanese, or Korean user or bot utterances.
#### \[2.5.2] - 2021-06-16[](#252---2021-06-16 "Direct link to [2.5.2] - 2021-06-16")
##### Features[](#features-19 "Direct link to Features")
* Added `sasl_mechanism` as an optional configurable parameters for the [Kafka Producer](https://rasa.com/docs/rasa-pro/production/event-brokers#kafka-event-broker).
#### \[2.5.1] - 2021-04-28[](#251---2021-04-28 "Direct link to [2.5.1] - 2021-04-28")
##### Bugfixes[](#bugfixes-263 "Direct link to Bugfixes")
* Fixed prediction for rules with multiple entities.
* Mitigated Matplotlib backend issue using lazy configuration and added a more explicit error message to guide users.
#### \[2.5.0] - 2021-04-12[](#250---2021-04-12 "Direct link to [2.5.0] - 2021-04-12")
##### Deprecations and Removals[](#deprecations-and-removals-15 "Direct link to Deprecations and Removals")
* The following import abbreviations were removed:
* `rasa.core.train`: Please use `rasa.core.train.train` instead.
* `rasa.core.visualize`: Please use `rasa.core.visualize.visualize` instead.
* `rasa.nlu.train`: Please use `rasa.nlu.train.train` instead.
* `rasa.nlu.test`: Please use `rasa.nlu.test.run_evaluation` instead.
* `rasa.nlu.cross_validate`: Please use `rasa.nlu.test.cross_validate` instead.
##### Features[](#features-20 "Direct link to Features")
* Upgraded Rasa to be compatible with spaCy 3.0.
This means that we can support more features for more languages but there are also a few changes.
SpaCy 3.0 deprecated the `spacy link \` command so that means that from now on [the full model name](https://spacy.io/models) needs to be used in the `config.yml` file.
**Before**
Before you could run `spacy link en en_core_web_md` and then we would be able to pick up the correct model from the `language` parameter.
```
language: en
pipeline:
- name: SpacyNLP
```
**Now**
This behavior will be deprecated and instead you'll want to be explicit in `config.yml`.
```
language: en
pipeline:
- name: SpacyNLP
model: en_core_web_md
```
**Fallback**
To make the transition easier, Rasa will try to fall back to a medium spaCy model when-ever a compatible language is configured for the entire pipeline in `config.yml` even if you don't specify a `model`. This fallback behavior is temporary and will be deprecated in Rasa 3.0.0.
We've updated our docs to reflect these changes. All examples now show a direct link to the correct spaCy model. We've also added a warning to the [SpaCyNLP](https://legacy-docs-oss.rasa.com/docs/rasa/components#spacynlp) docs that explains the fallback behavior.
##### Improvements[](#improvements-86 "Direct link to Improvements")
* Improved CLI startup time.
* Add `augmentation` and `num_threads` arguments to API `POST /model/train`
Fix boolean casting issue for `force_training` and `save_to_default_model_directory` arguments
* Add minimum compatible version to --version command
* Updated warning for unexpected slot events during prediction time to Rasa Open Source 2.0 YAML training data format.
* Hide dialogue turns predicted by `RulePolicy` in the tracker states for ML-only policies like `TEDPolicy` if those dialogue turns only appear as rules in the training data and do not appear in stories.
Add `set_shared_policy_states(...)` method to all policies. This method sets `_rule_only_data` dict with keys:
* `rule_only_slots`: Slot names, which only occur in rules but not in stories.
* `rule_only_loops`: Loop names, which only occur in rules but not in stories.
This information is needed for correct featurization to hide dialogue turns that appear only in rules.
* Faster reading of YAML NLU training data files.
* Added partition\_by\_sender flag to [Kafka Producer](https://rasa.com/docs/rasa-pro/production/event-brokers#kafka-event-broker) to optionally associate events with Kafka partition based on sender\_id.
##### Bugfixes[](#bugfixes-264 "Direct link to Bugfixes")
* Fixed the 'loading model' message which was logged twice when using `rasa run`.
* Change training data validation to only count nlu training examples.
* Rule tracker states no longer include the initial value of slots. Rules now only require slot values when explicitly stated in the rule.
* `rasa test`, `rasa test core` and `rasa test nlu` no longer show temporary paths in case there are issues in the test files.
* Resolved memory problems with dense features and `CRFEntityExtractor`
* Handle empty intent and entity mapping in the `domain`.
There is now an InvalidDomain exception raised if in the `domain.yml` file there are empty intent or entity mappings. An example of empty intent and entity mappings is the following :
```
intents:
- greet:
- goodbye:
entities:
- cuisine:
- number:
```
* Fixed a bug in a form where slot mapping doesn't work if the predicted intent name is substring for another intent name.
* Fixes bug where stories could not be retrieved if entities had no start or end.
* Catch ChannelNotFoundEntity exception coming from the pika broker and raise as ConnectionException.
* Fix bug with NoReturn throwing an exception in Python 3.7.0 when running `rasa train`
* Throw `RasaException` instead of `ValueError` in situations when environment variables specified in YAML cannot be expanded.
* Updated python-engineio version for compatibility with python-socketio
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-86 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.4.3] - 2021-03-26[](#243---2021-03-26 "Direct link to [2.4.3] - 2021-03-26")
##### Bugfixes[](#bugfixes-265 "Direct link to Bugfixes")
* Fixes bug where stories could not be retrieved if entities had no start or end.
#### \[2.4.2] - 2021-03-25[](#242---2021-03-25 "Direct link to [2.4.2] - 2021-03-25")
##### Bugfixes[](#bugfixes-266 "Direct link to Bugfixes")
* Fix `UnicodeException` in `is_key_in_yaml`.
* Fixed the bug that events from previous conversation sessions would be re-saved in the [`SQLTrackerStore`](https://rasa.com/docs/rasa-pro/production/tracker-stores#sqltrackerstore) or [`MongoTrackerStore`](https://rasa.com/docs/rasa-pro/production/tracker-stores#mongotrackerstore) when `retrieve_events_from_previous_conversation_sessions` was true.
#### \[2.4.1] - 2021-03-23[](#241---2021-03-23 "Direct link to [2.4.1] - 2021-03-23")
##### Bugfixes[](#bugfixes-267 "Direct link to Bugfixes")
* Fix `TEDPolicy` training e2e entities when no entities are present in the stories but there are entities in the domain.
* Fixed missing model configuration file validation.
* In Rasa 2.4.0, support for using `template` in `utter_message` when handling a custom action was wrongly deprecated. Both `template` and `response` are now supported, though note that `template` will be deprecated at Rasa 3.0.0.
#### \[2.4.0] - 2021-03-11[](#240---2021-03-11 "Direct link to [2.4.0] - 2021-03-11")
##### Deprecations and Removals[](#deprecations-and-removals-16 "Direct link to Deprecations and Removals")
* NLG Server
* Changed request format to send `response` as well as `template` as a field. The `template` field will be removed in Rasa Open Source 3.0.0.
`rasa.core.agent`
* The terminology `template` is deprecated and replaced by `response`. Support for `template` from the NLG response will be removed in Rasa Open Source 3.0.0. Please see [here](https://rasa.com/docs/rasa-pro/production/nlg) for more details.
`rasa.core.nlg.generator`
* `generate()` now takes in `utter_action` as a parameter.
* The terminology `template` is deprecated and replaced by `response`. Support for `template` in the `NaturalLanguageGenerator` will be removed in Rasa Open Source 3.0.0.
`rasa.shared.core.domain`
* The property `templates` is deprecated. Use `responses` instead. It will be removed in Rasa Open Source 3.0.0.
* `retrieval_intent_templates` will be removed in Rasa Open Source 3.0.0. Please use `retrieval_intent_responses` instead.
* `is_retrieval_intent_template` will be removed in Rasa Open Source 3.0.0. Please use `is_retrieval_intent_response` instead.
* `check_missing_templates` will be removed in Rasa Open Source 3.0.0. Please use `check_missing_responses` instead.
Response Selector
* The field `template_name` will be deprecated in Rasa Open Source 3.0.0. Please use `utter_action` instead. Please see [here](https://legacy-docs-oss.rasa.com/docs/rasa/components#selectors) for more details.
* The field `response_templates` will be deprecated in Rasa Open Source 3.0.0. Please use `responses` instead. Please see [here](https://legacy-docs-oss.rasa.com/docs/rasa/components#selectors) for more details.
##### Improvements[](#improvements-87 "Direct link to Improvements")
* The following endpoints now require the existence of the conversation for the specified conversation ID, raising an exception and returning a 404 status code.
* `GET /conversations/\/story`
* `POST /conversations/\/execute`
* `POST /conversations/\/predict`
* Simplify our training by overwriting `train_step` instead of `fit` for our custom models.
This allows us to use the build-in callbacks from Keras, such as the [Tensorboard Callback](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/TensorBoard), which offers more functionality compared to what we had before.
warning
If you want to use Tensorboard for `DIETClassifier`, `ResponseSelector`, or `TEDPolicy` and log metrics after every (mini)batch, please use 'batch' instead of 'minibatch' as 'tensorboard\_log\_level'.
* When `TED` is configured to extract entities `rasa test` now evaluates them against the labels in the test stories. Results are saved in `/results` along with the results for the NLU components that extract entities.
* We're now running integration tests for Rasa Open Source, with initial coverage for `SQLTrackerStore` (with PostgreSQL), `RedisLockStore` (with Redis) and `PikaEventBroker` (with RabbitMQ). The integration tests are now part of our CI, and can also be ran locally using `make test-integration` (see [Rasa Open Source README](https://github.com/RasaHQ/rasa#running-the-integration-tests) for more information).
* Allow tests to be located anywhere, not just in `tests` directory.
* Model configuration files are now validated whether they match the expected schema.
* Speed up `YAMLStoryReader.is_key_in_yaml` function by making it to check if key is in YAML without actually parsing the text file.
* Speed up YAML parsing by reusing parsers, making the process of environment variable interpolation optional, and by not adding duplicating implicit resolvers and YAML constructors to `ruamel.yaml`
* Drastically improved finger printing time for large story graphs
* Remove console logging of conversation level F1-score and precision since these calculations were not meaningful.
Add conversation level accuracy to core policy results logged to file in `story_report.json` after running `rasa test core` or `rasa test`.
* Improved the [lock store](https://rasa.com/docs/rasa-pro/production/lock-stores) debug log message when the process has to queue because other messages have to be processed before this item.
##### Bugfixes[](#bugfixes-268 "Direct link to Bugfixes")
* Fixed the bug that OR statements in stories would break the check whether a model needs to be retrained
* Update the spec of `POST /model/test/intents` and add tests for cases when JSON is provided.
Fix the incorrect temporary file extension for the data that gets extracted from the payload provided in the body of `POST /model/test/intents` request.
* Fix for the cli command `rasa data convert config` when migrating Mapping Policy and no rules.
Making `rasa data convert config` migrate correctly the Mapping Policy when no rules are available. It updates the `config.yml` file by removing the `MappingPolicy` and adding the `RulePolicy` instead. Also, it creates the `data/rules.yml` file even if empty in the case of no available rules.
* Allow to have slots with values that result to a dictionary under the key `slot_was_set` (in `stories.yml` file).
An example would be to have the following story step in `stories.yml`:
```
- slot_was_set:
- some_slot:
some_key: 'some_value'
other_key: 'other_value'
```
This would be allowed if the `some_slot` is also set accordingly in the `domain.yml` with type `any`.
* Update the fingerprinting function to recognize changes in lookup files.
* Fixed a bug when interpolating environment variables in YAML files which included `$` in their value. This led to the following stack trace:
```
ValueError: Error when trying to expand the environment variables in '${PASSWORD}'. Please make sure to also set these environment variables: '['$qwerty']'.
(13 additional frame(s) were not displayed)
...
File "rasa/utils/endpoints.py", line 26, in read_endpoint_config
content = rasa.shared.utils.io.read_config_file(filename)
File "rasa/shared/utils/io.py", line 527, in read_config_file
content = read_yaml_file(filename)
File "rasa/shared/utils/io.py", line 368, in read_yaml_file
return read_yaml(read_file(filename, DEFAULT_ENCODING))
File "rasa/shared/utils/io.py", line 349, in read_yaml
return yaml_parser.load(content) or {}
File "rasa/shared/utils/io.py", line 314, in env_var_constructor
" variables: '{}'.".format(value, not_expanded)
```
* The REQUESTED\_SLOT always belongs to the currently active form.
Previously it was possible that after form switching, the REQUESTED\_SLOT was for the previous form.
* Update the `LanguageModelFeaturizer` tests to reflect new default model weights for `bert`, and skip all `bert` tests with default model weights on CI, run `bert` tests with `bert-base-uncased` on CI instead.
##### Improved Documentation[](#improved-documentation-31 "Direct link to Improved Documentation")
* Update links to Sanic docs in the documentation.
* Update Rasa Playground to correctly use `tracking_id` when calling API methods.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-87 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.3.5] - 2021-06-16[](#235---2021-06-16 "Direct link to [2.3.5] - 2021-06-16")
##### Features[](#features-21 "Direct link to Features")
* Added `sasl_mechanism` as an optional configurable parameters for the [Kafka Producer](https://rasa.com/docs/rasa-pro/production/event-brokers#kafka-event-broker).
##### Improvements[](#improvements-88 "Direct link to Improvements")
* Drastically improved finger printing time for large story graphs
* Improved the [lock store](https://rasa.com/docs/rasa-pro/production/lock-stores) debug log message when the process has to queue because other messages have to be processed before this item.
##### Bugfixes[](#bugfixes-269 "Direct link to Bugfixes")
* Fixed the bug that OR statements in stories would break the check whether a model needs to be retrained
* Updated `python-engineio` dependency version for compatibility with `python-socketio`.
##### Improved Documentation[](#improved-documentation-32 "Direct link to Improved Documentation")
* Update links to Sanic docs in the documentation.
#### \[2.3.4] - 2021-02-26[](#234---2021-02-26 "Direct link to [2.3.4] - 2021-02-26")
##### Bugfixes[](#bugfixes-270 "Direct link to Bugfixes")
* Setting `model_confidence=cosine` in `DIETClassifier`, `ResponseSelector` and `TEDPolicy` is deprecated and will no longer be available. This was introduced in Rasa Open Source version `2.3.0` but post-release experiments suggest that using cosine similarity as model's confidences can change the ranking of predicted labels which is wrong.
`model_confidence=inner` is deprecated and is replaced by `model_confidence=linear_norm` as the former produced an unbounded range of confidences which broke the logic of assistants in various other places.
We encourage you to try `model_confidence=linear_norm` which will produce a linearly normalized version of dot product similarities with each value in the range `[0,1]`. This can be done with the following config:
```
- name: DIETClassifier
model_confidence: linear_norm
constrain_similarities: True
```
This should ease up [tuning fallback thresholds](https://legacy-docs-oss.rasa.com/docs/rasa/fallback-handoff/#fallbacks) as confidences for wrong predictions are better distributed across the range `[0, 1]`.
If you trained a model with `model_confidence=cosine` or `model_confidence=inner` setting using previous versions of Rasa Open Source, please re-train by either removing the `model_confidence` option from the configuration or setting it to `linear_norm`.
`model_confidence=cosine` is removed from the configuration generated by [auto-configuration](https://legacy-docs-oss.rasa.com/docs/rasa/model-configuration#suggested-config).
#### \[2.3.3] - 2021-02-25[](#233---2021-02-25 "Direct link to [2.3.3] - 2021-02-25")
##### Bugfixes[](#bugfixes-271 "Direct link to Bugfixes")
* Fixed bug where the conversation does not lock before handling a reminder event.
#### \[2.3.2] - 2021-02-22[](#232---2021-02-22 "Direct link to [2.3.2] - 2021-02-22")
##### Bugfixes[](#bugfixes-272 "Direct link to Bugfixes")
* Fix a bug where, if a user injects an intent using the HTTP API, slot auto-filling is not performed on the entities provided.
#### \[2.3.1] - 2021-02-17[](#231---2021-02-17 "Direct link to [2.3.1] - 2021-02-17")
##### Bugfixes[](#bugfixes-273 "Direct link to Bugfixes")
* Fixed a YAML validation error which happened when executing multiple validations concurrently. This could e.g. happen when sending concurrent requests to server endpoints which process YAML training data.
#### \[2.3.0] - 2021-02-11[](#230---2021-02-11 "Direct link to [2.3.0] - 2021-02-11")
##### Improvements[](#improvements-89 "Direct link to Improvements")
* Expose diagnostic data for action and NLU predictions.
Add `diagnostic_data` field to the Message and Prediction objects, which contain information about attention weights and other intermediate results of the inference computation. This information can be used for debugging and fine-tuning, e.g. with [RasaLit](https://github.com/RasaHQ/rasalit).
For examples of how to access the diagnostic data, see [here](https://gist.github.com/JEM-Mosig/c6e15b81ee70561cb72e361aff310d7e).
* Using the `TrainingDataImporter` interface to load the data in `rasa test core`.
Failed test stories are now referenced by their absolute path instead of the relative path.
* Improve error handling and Sentry tracking:
* Raise `MarkdownException` when training data in Markdown format cannot be read.
* Raise `InvalidEntityFormatException` error instead of `json.JSONDecodeError` when entity format is in valid in training data.
* Gracefully handle empty sections in endpoint config files.
* Introduce `ConnectionException` error and raise it when `TrackerStore` and `EventBroker` cannot connect to 3rd party services, instead of raising exceptions from 3rd party libraries.
* Improve `rasa.shared.utils.common.class_from_module_path` function by making sure it always returns a class. The function currently raises a deprecation warning if it detects an anomaly.
* Ignore `MemoryError` and `asyncio.CancelledError` in Sentry.
* `rasa.shared.utils.validation.validate_training_data` now raises a `SchemaValidationError` when validation fails (this error inherits `jsonschema.ValidationError`, ensuring backwards compatibility).
* Allow `PolicyEnsemble` in cases where calling individual policy's `load` method returns `None`.
* User message metadata can now be accessed via the default slot `session_started_metadata` during the execution of a [custom `action_session_start`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/default-actions#customization).
```
from typing import Any, Text, Dict, List
from rasa_sdk import Action, Tracker
from rasa_sdk.events import SlotSet, SessionStarted, ActionExecuted, EventType
class ActionSessionStart(Action):
def name(self) -> Text:
return "action_session_start"
async def run(
self, dispatcher, tracker: Tracker, domain: Dict[Text, Any]
) -> List[Dict[Text, Any]]:
metadata = tracker.get_slot("session_started_metadata")
# Do something with the metadata
print(metadata)
# the session should begin with a `session_started` event and an `action_listen`
# as a user message follows
return [SessionStarted(), ActionExecuted("action_listen")]
```
* Add BILOU tagging schema for entity extraction in end-to-end TEDPolicy.
* Added two new parameters `constrain_similarities` and `model_confidence` to machine learning (ML) components - [DIETClassifier](https://legacy-docs-oss.rasa.com/docs/rasa/components#dietclassifier), [ResponseSelector](https://legacy-docs-oss.rasa.com/docs/rasa/components#dietclassifier) and [TEDPolicy](https://legacy-docs-oss.rasa.com/docs/rasa/policies#ted-policy).
Setting `constrain_similarities=True` adds a sigmoid cross-entropy loss on all similarity values to restrict them to an approximate range in `DotProductLoss`. This should help the models to perform better on real world test sets. By default, the parameter is set to `False` to preserve the old behaviour, but users are encouraged to set it to `True` and re-train their assistants as it will be set to `True` by default from Rasa Open Source 3.0.0 onwards.
Parameter `model_confidence` affects how model's confidence for each label is computed during inference. It can take three values:
1. `softmax` - Similarities between input and label embeddings are post-processed with a softmax function, as a result of which confidence for all labels sum up to 1.
2. `cosine` - Cosine similarity between input label embeddings. Confidence for each label will be in the range `[-1,1]`.
3. `inner` - Dot product similarity between input and label embeddings. Confidence for each label will be in an unbounded range.
Setting `model_confidence=cosine` should help users tune the fallback thresholds of their assistant better. The default value is `softmax` to preserve the old behaviour, but we recommend using `cosine` as that will be the new default value from Rasa Open Source 3.0.0 onwards. The value of this option does not affect how confidences are computed for entity predictions in `DIETClassifier` and `TEDPolicy`.
With both the above recommendations, users should configure their ML component, e.g. `DIETClassifier`, as
```
- name: DIETClassifier
model_confidence: cosine
constrain_similarities: True
...
```
Once the assistant is re-trained with the above configuration, users should also tune fallback confidence thresholds.
Configuration option `loss_type=softmax` is now deprecated and will be removed in Rasa Open Source 3.0.0 . Use `loss_type=cross_entropy` instead.
The default [auto-configuration](https://legacy-docs-oss.rasa.com/docs/rasa/model-configuration#suggested-config) is changed to use `constrain_similarities=True` and `model_confidence=cosine` in ML components so that new users start with the recommended configuration.
**EDIT**: Some post-release experiments revealed that using `model_confidence=cosine` is wrong as it can change the order of predicted labels. That's why this option was removed in Rasa Open Source version `2.3.3`. `model_confidence=inner` is deprecated as it produces an unbounded range of confidences which can break the logic of assistants in various other places. Please use `model_confidence=linear_norm` which will produce a linearly normalized version of dot product similarities with each value in the range `[0,1]`. Please read more about this change under the notes for release `2.3.4`.
* Use simple random uniform distribution of integers in negative sampling, because negative sampling with `tf.while_loop` and random shuffle inside creates a memory leak.
* Added support to configure `exchange_name` for [pika event broker](https://rasa.com/docs/rasa-pro/production/event-brokers#pika-event-broker).
* If `MaxHistoryTrackerFeaturizer` is used, invert the dialogue sequence before passing it to the transformer so that the last dialogue input becomes the first one and therefore always have the same positional encoding.
##### Bugfixes[](#bugfixes-274 "Direct link to Bugfixes")
* Fixed an error when using the endpoint `GET /conversations/\/story` with a tracker which contained slots.
* Add the option to configure whether extracted entities should be split by comma (`","`) or not to TEDPolicy. Fixes crash when this parameter is accessed during extraction.
* When switching forms, the next form will always correctly ask for the first required slot.
Before, the next form did not ask for the slot if it was the same slot as the requested slot of the previous form.
* Fix the bug when `RulePolicy` handling loop predictions are overwritten by e2e `TEDPolicy`.
* When switching forms, the next form is cleanly activated.
Before, the next form was correctly activated, but the previous form had wrongly uttered the response that asked for the requested slot when slot validation for that slot had failed.
* Fix a bug in incremental training when passing a specific model path with the `--finetune` argument.
* Fix the role of `unidirectional_encoder` in TED. This parameter is only applied to transformers for `text`, `action_text` and `label_action_text`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-88 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.2.10] - 2021-02-08[](#2210---2021-02-08 "Direct link to [2.2.10] - 2021-02-08")
##### Improvements[](#improvements-90 "Direct link to Improvements")
* Updated error message when using incompatible model versions.
##### Bugfixes[](#bugfixes-275 "Direct link to Bugfixes")
* Limit `numpy` version to `< 1.2` as `tensorflow` is not compatible with `numpy` versions `>= 1.2`. `pip` versions `<= 20.2` don't resolve dependencies conflicts correctly which could result in an incompatible `numpy` version and the following error:
```
NotImplementedError: Cannot convert a symbolic Tensor (strided_slice_6:0) to a numpy array. This error may indicate that you're trying to pass a Tensor to a NumPy call, which is not supported
```
#### \[2.2.9] - 2021-02-02[](#229---2021-02-02 "Direct link to [2.2.9] - 2021-02-02")
##### Bugfixes[](#bugfixes-276 "Direct link to Bugfixes")
* Correctly include the `confused_with` field in the test report for the [`POST /model/test/intents`](https://rasa.com/docs/docs/reference/api/pro/http-api/) endpoint.
#### \[2.2.8] - 2021-01-28[](#228---2021-01-28 "Direct link to [2.2.8] - 2021-01-28")
##### Bugfixes[](#bugfixes-277 "Direct link to Bugfixes")
* Fixes a bug in [forms](https://legacy-docs-oss.rasa.com/docs/rasa/forms) where the next slot asked was not consistent after returning to a form from an unhappy path.
#### \[2.2.7] - 2021-01-25[](#227---2021-01-25 "Direct link to [2.2.7] - 2021-01-25")
##### Improvements[](#improvements-91 "Direct link to Improvements")
* Add support for in `RasaYAMLWriter` for writing intent and example metadata back into NLU YAML files.
##### Bugfixes[](#bugfixes-278 "Direct link to Bugfixes")
* Fixed a bug with `Domain.is_domain_file()` that could raise an Exception in case the potential domain file is not a valid YAML.
#### \[2.2.6] - 2021-01-21[](#226---2021-01-21 "Direct link to [2.2.6] - 2021-01-21")
##### Bugfixes[](#bugfixes-279 "Direct link to Bugfixes")
* Fix wrong warning `The method 'EventBroker.close' was changed to be asynchronous` when the `EventBroker.close` was actually asynchronous.
* Fix incremental training for cases when training data does not contain entities but `DIETClassifier` is configured to perform entity recognition also.
Now, the instance of `RasaModelData` inside `DIETClassifier` does not contain `entities` as a feature for training if there is no training data present for entity recognition.
#### \[2.2.5] - 2021-01-12[](#225---2021-01-12 "Direct link to [2.2.5] - 2021-01-12")
##### Bugfixes[](#bugfixes-280 "Direct link to Bugfixes")
* Fixed key-error bug on `rasa data validate stories`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-89 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.2.4] - 2021-01-08[](#224---2021-01-08 "Direct link to [2.2.4] - 2021-01-08")
##### Improvements[](#improvements-92 "Direct link to Improvements")
* Improve the warning in case the [RulePolicy](https://legacy-docs-oss.rasa.com/docs/rasa/policies#rule-policy) or the deprecated [MappingPolicy](https://rasa.com/docs/rasa/2.x/policies#mapping-policy) are missing from the model's `policies` configuration. Changed the info log to a warning as one of this policies should be added to the model configuration.
##### Bugfixes[](#bugfixes-281 "Direct link to Bugfixes")
* Explicitly specify the `crypto` extra dependency of `pyjwt` to ensure that the `cryptography` dependency is installed. `cryptography` is strictly required to be able to be able to verify JWT tokens.
#### \[2.2.3] - 2021-01-06[](#223---2021-01-06 "Direct link to [2.2.3] - 2021-01-06")
##### Bugfixes[](#bugfixes-282 "Direct link to Bugfixes")
* Correctly retrieve intent ranking from `UserUttered` even during default affirmation action implementation.
* Fixed a problem when using the `POST /model/test/intents` endpoint together with a [model server](https://rasa.com/docs/rasa-pro/production/model-storage#load-model-from-server). The error looked as follows:
```
ERROR rasa.core.agent:agent.py:327 Could not load model due to Detected inconsistent loop usage. Trying to schedule a task on a new event loop, but scheduler was created with a different event loop. Make sure there is only one event loop in use and that the scheduler is running on that one.
```
This also fixes a problem where testing a model from a model server would change the production model.
#### \[2.2.2] - 2020-12-21[](#222---2020-12-21 "Direct link to [2.2.2] - 2020-12-21")
##### Bugfixes[](#bugfixes-283 "Direct link to Bugfixes")
* Fixed incompatibility between Rasa Open Source 2.2.x and Rasa X < 0.35.
#### \[2.2.1] - 2020-12-17[](#221---2020-12-17 "Direct link to [2.2.1] - 2020-12-17")
##### Bugfixes[](#bugfixes-284 "Direct link to Bugfixes")
* Fixed a problem where a [form](https://legacy-docs-oss.rasa.com/docs/rasa/forms) wouldn't reject when the `FormValidationAction` re-implemented `required_slots`.
* Fixed an error when using the [SQLTrackerStore](https://rasa.com/docs/rasa-pro/production/tracker-stores#sqltrackerstore) with a Postgres database and the parameter `login_db` specified.
The error was:
```
psycopg2.errors.SyntaxError: syntax error at end of input
rasa-production_1 | LINE 1: SELECT 1 FROM pg_catalog.pg_database WHERE datname = ?
```
#### \[2.2.0] - 2020-12-16[](#220---2020-12-16 "Direct link to [2.2.0] - 2020-12-16")
##### Deprecations and Removals[](#deprecations-and-removals-17 "Direct link to Deprecations and Removals")
* `Domain.random_template_for` is deprecated and will be removed in Rasa Open Source 3.0.0. You can alternatively use the `TemplatedNaturalLanguageGenerator`.
`Domain.action_names` is deprecated and will be removed in Rasa Open Source 3.0.0. Please use `Domain.action_names_or_texts` instead.
* Interfaces for `Policy.__init__` and `Policy.load` have changed. See [migration guide](https://legacy-docs-oss.rasa.com/docs/rasa/migration-guide/#rasa-21-to-rasa-22) for details.
* Deprecate training and test data in Markdown format. This includes:
* reading and writing of story files in Markdown format
* reading and writing of NLU data in Markdown format
* reading and writing of retrieval intent data in Markdown format
Support for Markdown data will be removed entirely in Rasa Open Source 3.0.0.
Please convert your existing Markdown data by using the commands from the [migration guide](https://legacy-docs-oss.rasa.com/docs/rasa/migration-guide/#rasa-21-to-rasa-22):
```
rasa data convert nlu -f yaml --data={SOURCE_DIR} --out={TARGET_DIR}
rasa data convert nlg -f yaml --data={SOURCE_DIR} --out={TARGET_DIR}
rasa data convert core -f yaml --data={SOURCE_DIR} --out={TARGET_DIR}
```
* `Domain.add_categorical_slot_default_value`, `Domain.add_requested_slot` and `Domain.add_knowledge_base_slots` are deprecated and will be removed in Rasa Open Source 3.0.0. Their internal versions are now called during the Domain creation. Calling them manually is no longer required.
##### Features[](#features-22 "Direct link to Features")
* Incremental training of models in a pipeline is now supported.
If you have added new NLU training examples or new stories/rules for dialogue manager, you don't need to train the pipeline from scratch. Instead, you can initialize the pipeline with a previously trained model and continue finetuning the model on the complete dataset consisting of new training examples. To do so, use `rasa train --finetune`. For more detailed explanation of the command, check out the docs on [incremental training](https://legacy-docs-oss.rasa.com/docs/rasa/command-line-interface/#incremental-training).
Added a configuration parameter `additional_vocabulary_size` to [`CountVectorsFeaturizer`](https://legacy-docs-oss.rasa.com/docs/rasa/components#countvectorsfeaturizer) and `number_additional_patterns` to [`RegexFeaturizer`](https://legacy-docs-oss.rasa.com/docs/rasa/components#regexfeaturizer). These parameters are useful to configure when using incremental training for your pipelines.
* Add the option to use cross-validation to the [`POST /model/test/intents`](https://rasa.com/docs/docs/reference/api/pro/http-api/) endpoint. To use cross-validation specify the query parameter `cross_validation_folds` in addition to the training data in YAML format.
Add option to run NLU evaluation ([`POST /model/test/intents`](https://rasa.com/docs/docs/reference/api/pro/http-api/)) and model training ([`POST /model/train`](https://rasa.com/docs/docs/reference/api/pro/http-api/)) asynchronously. To trigger asynchronous processing specify a callback URL in the query parameter `callback_url` which Rasa Open Source should send the results to. This URL will also be called in case of errors.
* Make [TED Policy](https://legacy-docs-oss.rasa.com/docs/rasa/policies#ted-policy) an end-to-end policy. Namely, make it possible to train TED on stories that contain intent and entities or user text and bot actions or bot text. If you don't have text in your stories, TED will behave the same way as before. Add possibility to predict entities using TED.
Here's an example of a dialogue in the Rasa story format:
```
stories:
- story: collect restaurant booking info # name of the story - just for debugging
steps:
- intent: greet # user message with no entities
- action: utter_ask_howcanhelp # action that the bot should execute
- intent: inform # user message with entities
entities:
- location: "rome"
- price: "cheap"
- bot: On it # actual text that bot can output
- action: utter_ask_cuisine
- user: I would like [spanish](cuisine). # actual text that user input
- action: utter_ask_num_people
```
Some model options for `TEDPolicy` got renamed. Please update your configuration files using the following mapping:
| Old model option | New model option |
| ------------------------------- | ----------------------------------------------------------- |
| transformer\_size | dictionary “transformer\_size” with keys |
| | “text”, “action\_text”, “label\_action\_text”, “dialogue” |
| number\_of\_transformer\_layers | dictionary “number\_of\_transformer\_layers” with keys |
| | “text”, “action\_text”, “label\_action\_text”, “dialogue” |
| dense\_dimension | dictionary “dense\_dimension” with keys |
| | “text”, “action\_text”, “label\_action\_text”, “intent”, |
| | “action\_name”, “label\_action\_name”, “entities”, “slots”, |
| | “active\_loop” |
##### Improvements[](#improvements-93 "Direct link to Improvements")
* Added a message showing the location where the failed stories file was saved.
* Add support for the top-level response keys `quick_replies`, `attachment` and `elements` refered to in `rasa.core.channels.OutputChannel.send_reponse`, as well as `metadata`.
* Changed the format of the histogram of confidence values for both correct and incorrect predictions produced by running `rasa test`.
* Run [`bandit`](https://bandit.readthedocs.io/en/latest/) checks on pull requests. Introduce `make static-checks` command to run all static checks locally.
* Add `rasa train --dry-run` command that allows to check if training needs to be performed and what exactly needs to be retrained.
* [`POST /model/test/intents`](https://rasa.com/docs/docs/reference/api/pro/http-api/) now returns the `report` field for `intent_evaluation`, `entity_evaluation` and `response_selection_evaluation` as machine-readable JSON payload instead of string.
* Make `rasa data validate stories` work for end-to-end.
The `rasa data validate stories` function now considers the tokenized user text instead of the plain text that is part of a state. This is closer to what Rasa Core actually uses to distinguish states and thus captures more story structure problems.
##### Bugfixes[](#bugfixes-285 "Direct link to Bugfixes")
* Rename `language_list` to `supported_language_list` for `JiebaTokenizer`.
* A `float` slot returns unambiguous values - `[1.0, ]` if successfully converted, `[0.0, 0.0]` if not. This makes it possible to distinguish an empty float slot from a slot set to `0.0`.
caution
This change is model-breaking. Please retrain your models.
* Fix an erroneous attribute for Redis key prefix in `rasa.core.tracker_store.RedisTrackerStore`: 'RedisTrackerStore' object has no attribute 'prefix'.
* Remove token when its text (for example, whitespace) can't be tokenized by LM tokenizer (from `LanguageModelFeaturizer`).
* Temporary directories which were created during requests to the [HTTP API](https://rasa.com/docs/rasa-pro/production/http-api) are now cleaned up correctly once the request was processed.
* Add option `use_word_boundaries` for `RegexFeaturizer` and `RegexEntityExtractor`. To correctly process languages such as Chinese that don't use whitespace for word separation, the user needs to add the `use_word_boundaries: False` option to those two components.
* Correctly fingerprint the default domain slots. Previously this led to the issue that `rasa train core` would always retrain the model even if the training data hasn't changed.
##### Improved Documentation[](#improved-documentation-33 "Direct link to Improved Documentation")
* Return the "Migrate from" entry to the docs sidebar.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-90 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.1.3] - 2020-12-04[](#213---2020-12-04 "Direct link to [2.1.3] - 2020-12-04")
##### Improvements[](#improvements-94 "Direct link to Improvements")
* Removed `multidict` from the project dependencies. `multidict` continues to be a second order dependency of Rasa Open Source but will be determined by the dependencies which use it instead of by Rasa Open Source directly.
This resolves issues like the following:
```
sanic 20.9.1 has requirement multidict==5.0.0, but you'll have multidict 4.6.0 which is incompatible.
```
##### Bugfixes[](#bugfixes-286 "Direct link to Bugfixes")
* `SingleStateFeaturizer` checks whether it was trained with `RegexInterpreter` as nlu interpreter. If that is the case, `RegexInterpreter` is used during prediction.
* Make sure the `responses` are synced between NLU training data and the Domain even if there're no retrieval intents in the NLU training data.
* Categorical slots will have a default value set when just updating nlg data in the domain.
Previously this resulted in `InvalidDomain` being thrown.
* * Preserve `domain` slot ordering while dumping it back to the file.
* Preserve multiline `text` examples of `responses` defined in `domain` and `NLU` training data.
#### \[2.1.2] - 2020-11-27[](#212---2020-11-27 "Direct link to [2.1.2] - 2020-11-27")
##### Bugfixes[](#bugfixes-287 "Direct link to Bugfixes")
* Slots that use `initial_value` won't cause rule contradiction errors when `conversation_start: true` is used. Previously, two rules that differed only in their use of `conversation_start` would be flagged as contradicting when a slot used `initial_value`.
In checking for incomplete rules, an action will be required to have set *only* those slots that the same action has set in another rule. Previously, an action was expected to have set also slots which, despite being present after this action in another rule, were not actually set by this action.
* Fixed Rasa Open Source not being able to fetch models from certain URLs.
#### \[2.1.1] - 2020-11-23[](#211---2020-11-23 "Direct link to [2.1.1] - 2020-11-23")
##### Bugfixes[](#bugfixes-288 "Direct link to Bugfixes")
* Sender ID is correctly set when copying the tracker and sending it to the action server (instead of sending the `default` value). This fixes a problem where the action server would only retrieve trackers with a `sender_id` `default`.
#### \[2.1.0] - 2020-11-17[](#210---2020-11-17 "Direct link to [2.1.0] - 2020-11-17")
##### Deprecations and Removals[](#deprecations-and-removals-18 "Direct link to Deprecations and Removals")
* The [`Policy`](https://legacy-docs-oss.rasa.com/docs/rasa/policies) interface was changed to return a `PolicyPrediction` object when `predict_action_probabilities` is called. Returning a list of probabilities directly is deprecated and support for this will be removed in Rasa Open Source 3.0.
You can adapt your custom policy by wrapping your probabilities in a `PolicyPrediction` object:
```
from rasa.core.policies.policy import Policy, PolicyPrediction
# ... other imports
def predict_action_probabilities(
self,
tracker: DialogueStateTracker,
domain: Domain,
interpreter: NaturalLanguageInterpreter,
**kwargs: Any,
) -> PolicyPrediction:
probabilities = ... # an action prediction of your policy
return PolicyPrediction(probabilities, "policy_name", policy_priority=self.priority)
```
The same change was applied to the `PolicyEnsemble` interface. Instead of returning a tuple of action probabilities and policy name, it is now returning a `PolicyPrediction` object. Support for the old `PolicyEnsemble` interface will be removed in Rasa Open Source 3.0.
caution
This change is model-breaking. Please retrain your models.
* The [Pika Event Broker](https://rasa.com/docs/rasa-pro/production/event-brokers#pika-event-broker) no longer supports the environment variables `RABBITMQ_SSL_CA_FILE` and `RABBITMQ_SSL_KEY_PASSWORD`. You can alternatively specify `RABBITMQ_SSL_CA_FILE` in the RabbitMQ connection URL as described in the [RabbitMQ documentation](https://www.rabbitmq.com/uri-query-parameters.html).
```
event_broker:
type: pika
url: "amqps://user:password@host?cacertfile=path_to_ca_cert&password=private_key_password"
queues:
- my_queue
```
Support for `RABBITMQ_SSL_KEY_PASSWORD` was removed entirely.
The method [`Event Broker.close`](https://rasa.com/docs/rasa-pro/production/event-brokers) was changed to be asynchronous. Support for synchronous implementations will be removed in Rasa Open Source 3.0.0. To adapt your implementation add the `async` keyword:
```
from rasa.core.brokers.broker import EventBroker
class MyEventBroker(EventBroker):
async def close(self) -> None:
# clean up event broker resources
```
##### Features[](#features-23 "Direct link to Features")
* [Policies](https://legacy-docs-oss.rasa.com/docs/rasa/policies) can now return obligatory and optional events as part of their prediction. Obligatory events are always applied to the current conversation tracker. Optional events are only applied to the conversation tracker in case the policy wins.
##### Improvements[](#improvements-95 "Direct link to Improvements")
* Changed `Agent.load` method to support `pathlib` paths.
* If you are using the feature [Entity Roles and Groups](https://legacy-docs-oss.rasa.com/docs/rasa/nlu-training-data#entities-roles-and-groups), you should now also list the roles and groups in your domain file if you want roles and groups to influence your conversations. For example:
```
entities:
- city:
roles:
- from
- to
- name
- topping:
groups:
- 1
- 2
- size:
groups:
- 1
- 2
```
Entity roles and groups can now influence dialogue predictions. For more information see the section [Entity Roles and Groups influencing dialogue predictions](https://legacy-docs-oss.rasa.com/docs/rasa/nlu-training-data#entity-roles-and-groups-influencing-dialogue-predictions).
* Predictions of the [`FallbackClassifier`](https://legacy-docs-oss.rasa.com/docs/rasa/components#fallbackclassifier) are ignored when [evaluating the NLU model](https://rasa.com/docs/rasa-pro/nlu-based-assistants/testing-your-assistant#evaluating-an-nlu-model) Note that the `FallbackClassifier` predictions still apply to [test stories](https://rasa.com/docs/rasa-pro/nlu-based-assistants/testing-your-assistant#writing-test-stories).
* Adapt the training data reader and emulator for wit.ai to their latest format. Update the instructions in the migrate from wit.ai documentation to run Rasa Open Source in wit.ai emulation mode.
* Adding configurable prefixes to Redis [Tracker](https://rasa.com/docs/rasa-pro/production/tracker-stores) and [Lock Stores](https://rasa.com/docs/rasa-pro/production/lock-stores) so that a single Redis instance (and logical DB) can support multiple conversation trackers and locks. By default, conversations will be prefixed with `tracker:...` and all locks prefixed with `lock:...`. Additionally, you can add an alphanumeric-only `prefix: value` in `endpoints.yml` such that keys in redis will take the form `value:tracker:...` and `value:lock:...` respectively.
* Log the model's relative path when using CLI commands.
* Adds the option to configure whether extracted entities should be split by comma (`","`) or not. The default behaviour is `True` - i.e. split any list of extracted entities by comma. This makes sense for a list of ingredients in a recipie, for example `"avocado, tofu, cauliflower"`, however doesn't make sense for an address such as `"Schönhauser Allee 175, 10119 Berlin, Germany"`.
In the latter case, add a new option to your config, e.g. if you are using the `DIETClassifier` this becomes:
```
...
- name: DIETClassifier
split_entities_by_comma: False
...
```
in which case, none of the extracted entities will be split by comma. To switch it on/off for specific entity types you can use:
```
...
- name: DIETClassifier
split_entities_by_comma:
address: True
ingredient: False
...
```
where both `address` and `ingredient` are two entity types.
This feature is also available for `CRFEntityExtractor`.
* Fetching test stories from the HTTP API endpoint `GET /conversations//story` no longer triggers an update of the [conversation session](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#session-configuration).
Added a new boolean query parameter `all_sessions` (default: `false`) to the [HTTP API](https://rasa.com/docs/rasa-pro/production/http-api) endpoint for fetching test stories (`GET /conversations//story`).
When setting `?all_sessions=true`, the endpoint returns test stories for all conversation sessions for `conversation_id`. When setting `?all_sessions=all_sessions`, or when omitting the `all_sessions` parameter, a single test story is returned for `conversation_id`. In cases where multiple conversation sessions exist, only the last story is returned.
Specifying the `retrieve_events_from_previous_conversation_sessions` kwarg for the [Tracker Store](https://rasa.com/docs/rasa-pro/production/tracker-stores) class is deprecated and will be removed in Rasa Open Source 3.0. Please use the `retrieve_full_tracker()` method instead.
* Improve the `rasa data convert nlg` command and introduce the `rasa data convert responses` command to simplify the migration from pre-2.0 response selector format to the new format.
* Added warning for when an option is provided for a [component](https://legacy-docs-oss.rasa.com/docs/rasa/components) that is not listed as a key in the defaults for that component.
* [Forms](https://legacy-docs-oss.rasa.com/docs/rasa/forms) no longer reject their execution before a potential custom action for validating / extracting slots was executed. Forms continue to reject in two cases automatically:
* A slot was requested to be filled, but no slot mapping applied to the latest user message and there was no custom action for potentially extracting other slots.
* A slot was requested to be filled, but the custom action for validating / extracting slots didn't return any slot event.
Additionally you can also reject the form execution manually by returning a `ActionExecutionRejected` event within your custom action for validating / extracting slots.
* Remove dependency between `ConveRTTokenizer` and `ConveRTFeaturizer`. The `ConveRTTokenizer` is now deprecated, and the `ConveRTFeaturizer` can be used with any other `Tokenizer`.
Remove dependency between `HFTransformersNLP`, `LanguageModelTokenizer`, and `LanguageModelFeaturizer`. Both `HFTransformersNLP` and `LanguageModelTokenizer` are now deprecated. `LanguageModelFeaturizer` implements the behavior of the stack and can be used with any other `Tokenizer`.
* Gray out "Download" button in Rasa Playground when the project is not yet ready to be downloaded.
* Slot mappings for [Forms](https://legacy-docs-oss.rasa.com/docs/rasa/forms) in the domain are now optional. If you do not provide any slot mappings as part of the domain, you need to provide [custom slot mappings](https://legacy-docs-oss.rasa.com/docs/rasa/forms#custom-slot-mappings) through a custom action. A form without slot mappings is specified as follows:
```
forms:
my_form:
# no mappings
```
The action for [forms](https://legacy-docs-oss.rasa.com/docs/rasa/forms) can now be overridden by defining a custom action with the same name as the form. This can be used to keep using the deprecated Rasa Open Source `FormAction` which is implemented within the Rasa SDK. Note that it is **not** recommended to override the form action for anything else than using the deprecated Rasa SDK `FormAction`.
* Changed the default model weights loaded for `HFTransformersNLP` component.
Use a [language agnostic sentence embedding model](https://tfhub.dev/google/LaBSE/1) as the default model. These model weights should help improve performance on intent classification and response selection.
* Add validations for [slot mappings](https://legacy-docs-oss.rasa.com/docs/rasa/forms#slot-mappings). If a slot mapping is not valid, an `InvalidDomain` error is raised.
* Adapt the training data reader and emulator for LUIS to their v3 format and add support for roles. Update the instructions in the "Migrate from LUIS" documentation page to reflect the recent changes made to the UI of LUIS.
* Adapt the training data reader and emulator for DialogFlow to [their latest format](https://cloud.google.com/dialogflow/es/docs/reference/rest/v2/DetectIntentResponse) and add support for regex entities.
* The [Pika Event Broker](https://rasa.com/docs/rasa-pro/production/event-brokers#pika-event-broker) was reimplemented with the `[aio-pika` library\[(). Messages will now be published to RabbitMQ asynchronously which improves the prediction performance.
* The confidence of the [`FallbackClassifier`](https://legacy-docs-oss.rasa.com/docs/rasa/components#fallbackclassifier) predictions is set to `1 - top intent confidence`.
##### Bugfixes[](#bugfixes-289 "Direct link to Bugfixes")
* `ActionRestart` will now trigger `ActionSessionStart` as a followup action.
* Fixed a bug with `rasa data split nlu` which caused the resulting train / test ratio to sometimes differ from the ratio specified by the user or by default.
The splitting algorithm ensures that every intent and response class appears in both the training and the test set. This means that each split must contain at least as many examples as there are classes, which for small datasets can contradict the requested training fraction. When this happens, the command issues a warning to the user that the requested training fraction can't be satisfied.
* Fixed bug where slots with `influence_conversation=false` affected the action prediction if they were set manually using the `POST /conversations/
```
* Update example formbot to use `FormValidationAction` for slot validation
#### \[2.0.2] - 2020-10-22[](#202---2020-10-22 "Direct link to [2.0.2] - 2020-10-22")
##### Bugfixes[](#bugfixes-296 "Direct link to Bugfixes")
* Fix description of previous event in output of `rasa data validate stories`
* Fixed command line coloring for windows command lines running an encoding other than `utf-8`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-92 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[2.0.1] - 2020-10-20[](#201---2020-10-20 "Direct link to [2.0.1] - 2020-10-20")
##### Bugfixes[](#bugfixes-297 "Direct link to Bugfixes")
* Create correct `KafkaProducer` for `PLAINTEXT` and `SASL_SSL` security protocols.
* * Fix `YAMLStoryReader` not being able to represent [`OR` statements](https://legacy-docs-oss.rasa.com/docs/rasa/stories#or-statements) in conversion mode.
* Fix `MarkdownStoryWriter` not being able to write stories with `OR` statements (when loaded in conversion mode).
#### \[2.0.0] - 2020-10-07[](#200---2020-10-07 "Direct link to [2.0.0] - 2020-10-07")
##### Deprecations and Removals[](#deprecations-and-removals-19 "Direct link to Deprecations and Removals")
* Removed previously deprecated packages `rasa_nlu` and `rasa_core`.
Use imports from `rasa.core` and `rasa.nlu` instead.
* Removed previously deprecated classes:
* event brokers (`EventChannel` and `FileProducer`, `KafkaProducer`, `PikaProducer`, `SQLProducer`)
* intent classifier `EmbeddingIntentClassifier`
* policy `KerasPolicy`
Removed previously deprecated methods:
* `Agent.handle_channels`
* `TrackerStore.create_tracker_store`
Removed support for pipeline templates in `config.yml`
Removed deprecated training data keys `entity_examples` and `intent_examples` from json training data format.
* Removed `restaurantbot` example as it was confusing and not a great way to build a bot.
* `LabelTokenizerSingleStateFeaturizer` is deprecated. To replicate `LabelTokenizerSingleStateFeaturizer` functionality, add a `Tokenizer` with `intent_tokenization_flag: True` and `CountVectorsFeaturizer` to the NLU pipeline. An example of elements to be added to the pipeline is shown in the improvement changelog 6296\`.
`BinarySingleStateFeaturizer` is deprecated and will be removed in the future. We recommend to switch to `SingleStateFeaturizer`.
* Specifying the parameters `force` and `save_to_default_model_directory` as part of the JSON payload when training a model using `POST /model/train` is now deprecated. Please use the query parameters `force_training` and `save_to_default_model_directory` instead. See the [API documentation](https://rasa.com/docs/docs/reference/api/pro/http-api/) for more information.
* The conversation event `form` was renamed to `active_loop`. Rasa Open Source will continue to be able to read and process old `form` events. Note that serialized trackers will no longer have the `active_form` field. Instead the `active_loop` field will contain the same information. Story representations in Markdown and YAML will use `active_loop` instead of `form` to represent the event.
* Removed support for `queue` argument in `PikaEventBroker` (use `queues` instead).
Domain file:
* Removed support for `templates` key (use `responses` instead).
* Removed support for string `responses` (use dictionaries instead).
NLU `Component`:
* Removed support for `provides` attribute, it's not needed anymore.
* Removed support for `requires` attribute (use `required_components()` instead).
Removed `_guess_format()` utils method from `rasa.nlu.training_data.loading` (use `guess_format` instead).
Removed several config options for [TED Policy](https://legacy-docs-oss.rasa.com/docs/rasa/policies#ted-policy), [DIETClassifier](https://legacy-docs-oss.rasa.com/docs/rasa/components#dietclassifier) and [ResponseSelector](https://legacy-docs-oss.rasa.com/docs/rasa/components#responseselector):
* `hidden_layers_sizes_pre_dial`
* `hidden_layers_sizes_bot`
* `droprate`
* `droprate_a`
* `droprate_b`
* `hidden_layers_sizes_a`
* `hidden_layers_sizes_b`
* `num_transformer_layers`
* `num_heads`
* `dense_dim`
* `embed_dim`
* `num_neg`
* `mu_pos`
* `mu_neg`
* `use_max_sim_neg`
* `C2`
* `C_emb`
* `evaluate_every_num_epochs`
* `evaluate_on_num_examples`
Please check the documentation for more information.
* The conversation event `form_validation` was renamed to `loop_interrupted`. Rasa Open Source will continue to be able to read and process old `form_validation` events.
* `SklearnPolicy` was deprecated. `TEDPolicy` is the preferred machine-learning policy for dialogue models.
* [Slots](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#slots) of type `unfeaturized` are now deprecated and will be removed in Rasa Open Source 3.0. Instead you should use the property `influence_conversation: false` for every slot type as described in the [migration guide](https://legacy-docs-oss.rasa.com/docs/rasa/migration-guide/#unfeaturized-slots).
* [Conversation sessions](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#session-configuration) are now enabled by default if your [Domain](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain) does not contain a session configuration. Previously a missing session configuration was treated as if conversation sessions were disabled. You can explicitly disable conversation sessions using the following snippet:
domain.yml
```
session_config:
# A session expiration time of `0`
# disables conversation sessions
session_expiration_time: 0
```
* Using the [default action](https://rasa.com/docs/rasa-pro/nlu-based-assistants/default-actions) `action_deactivate_form` to deactivate the currently active loop / [Form](https://legacy-docs-oss.rasa.com/docs/rasa/forms) is deprecated. Please use `action_deactivate_loop` instead.
##### Features[](#features-24 "Direct link to Features")
* Added template name to the metadata of bot utterance events.
`BotUttered` event contains a `template_name` property in its metadata for any new bot message.
* Added a `--num-threads` CLI argument that can be passed to `rasa train` and will be used to train NLU components.
* You can now define what kind of features should be used by what component (see [Choosing a Pipeline](https://legacy-docs-oss.rasa.com/docs/rasa/tuning-your-model/)).
You can set an alias via the option `alias` for every featurizer in your pipeline. The `alias` can be anything, by default it is set to the full featurizer class name. You can then specify, for example, on the [DIETClassifier](https://legacy-docs-oss.rasa.com/docs/rasa/components#dietclassifier) what features from which featurizers should be used. If you don't set the option `featurizers` all available features will be used. This is also the default behavior. Check components to see what components have the option `featurizers` available.
Here is an example pipeline that shows the new option. We define an alias for all featurizers in the pipeline. All features will be used in the `DIETClassifier`. However, the `ResponseSelector` only takes the features from the `ConveRTFeaturizer` and the `CountVectorsFeaturizer` (word level).
```
pipeline:
- name: ConveRTTokenizer
- name: ConveRTFeaturizer
alias: "convert"
- name: CountVectorsFeaturizer
alias: "cvf_word"
- name: CountVectorsFeaturizer
alias: "cvf_char"
analyzer: char_wb
min_ngram: 1
max_ngram: 4
- name: RegexFeaturizer
alias: "regex"
- name: LexicalSyntacticFeaturizer
alias: "lsf"
- name: DIETClassifier:
- name: ResponseSelector
epochs: 50
featurizers: ["convert", "cvf_word"]
- name: EntitySynonymMapper
```
caution
This change is model-breaking. Please retrain your models.
* Added `--port` commandline argument to the interactive learning mode to allow changing the port for the Rasa server running in the background.
* Add new entity extractor `RegexEntityExtractor`. The entity extractor extracts entities using the lookup tables and regexes defined in the training data. For more information see [RegexEntityExtractor](https://legacy-docs-oss.rasa.com/docs/rasa/components#regexentityextractor).
* Introduced a new `YAML` format for Core training data and implemented a parser for it. Rasa Open Source can now read stories in both `Markdown` and `YAML` format.
* You can now enable threaded message responses from Rasa through the Slack connector. This option is enabled using an optional configuration in the credentials.yml file
```
slack:
slack_token:
slack_channel:
use_threads: True
```
Button support has also been added in the Slack connector.
* Add support for [rules](https://legacy-docs-oss.rasa.com/docs/rasa/rules) data and [forms](https://legacy-docs-oss.rasa.com/docs/rasa/forms) in YAML format.
* The NLU `interpreter` is now passed to the [Policies](https://legacy-docs-oss.rasa.com/docs/rasa/policies) during training and inference time. Note that this requires an additional parameter `interpreter` in the method `predict_action_probabilities` of the `Policy` interface. In case a custom `Policy` implementation doesn't provide this parameter Rasa Open Source will print a warning and omit passing the `interpreter`.
* Added the new dialogue policy RulePolicy which will replace the old “rule-like” policies [Mapping Policy](https://rasa.com/docs/rasa/2.x/policies#mapping-policy), [Fallback Policy](https://rasa.com/docs/rasa/2.x/policies#fallback-policy), [Two-Stage Fallback Policy](https://rasa.com/docs/rasa/2.x/policies#two-stage-fallback-policy), and [Form Policy](https://rasa.com/docs/rasa/2.x/policies#form-policy). These policies are now deprecated and will be removed in the future. Please see the [rules documentation](https://legacy-docs-oss.rasa.com/docs/rasa/rules) for more information.
Added new NLU component [FallbackClassifier](https://legacy-docs-oss.rasa.com/docs/rasa/components#fallbackclassifier) which predicts an intent `nlu_fallback` in case the confidence was below a given threshold. The intent `nlu_fallback` may then be used to write stories / rules to handle the fallback in case of low NLU confidence.
```
pipeline:
- # Other NLU components ...
- name: FallbackClassifier
# If the highest ranked intent has a confidence lower than the threshold then
# the NLU pipeline predicts an intent `nlu_fallback` which you can then be used in
# stories / rules to implement an appropriate fallback.
threshold: 0.5
```
* Added possibility to split the domain into separate files. All YAML files under the path specified with `--domain` will be scanned for domain information (e.g. intents, actions, etc) and then combined into a single domain.
The default value for `--domain` is still `domain.yml`.
* Add optional metadata argument to `NaturalLanguageInterpreter`'s parse method.
* The Rasa Open Source API endpoint `POST /model/train` now supports training data in YAML format. Please specify the header `Content-Type: application/yaml` when training a model using YAML training data. See the [API documentation](https://rasa.com/docs/docs/reference/api/pro/http-api/) for more information.
* Added a YAML schema and a writer for 2.0 Training Core data.
* Users can now use the `rasa data convert {nlu|core} -f yaml` command to convert training data from Markdown format to YAML format.
* Add option `use_lemma` to `CountVectorsFeaturizer`. By default it is set to `True`.
`use_lemma` indicates whether the featurizer should use the lemma of a word for counting (if available) or not. If this option is set to `False` it will use the word as it is.
##### Improvements[](#improvements-96 "Direct link to Improvements")
* Add support for Python 3.8.
* Changed the project structure for Rasa projects initialized with the [CLI](https://rasa.com/docs/rasa-pro/command-line-interface) (using the `rasa init` command): `actions.py` -> `actions/actions.py`. `actions` is now a Python package (it contains a file `actions/__init__.py`). In addition, the `__init__.py` at the root of the project has been removed.
* `DIETClassifier` now also assigns a confidence value to entity predictions.
* Added behavior to the `rasa --version` command. It will now also list information about the operating system, python version and `rasa-sdk`. This will make it easier for users to file bug reports.
* Support for additional training metadata.
Training data messages now to support kwargs and the Rasa JSON data reader includes all fields when instantiating a training data instance.
* Standardize testing output. The following test output can be produced for intents, responses, entities and stories:
* report: a detailed report with testing metrics per label (e.g. precision, recall, accuracy, etc.)
* errors: a file that contains incorrect predictions
* successes: a file that contains correct predictions
* confusion matrix: plot of confusion matrix
* histogram: plot of confidence distribution (not available for stories)
* To avoid the problem of our entity extractors predicting entity labels for just a part of the words, we introduced a cleaning method after the prediction was done. We should avoid the incorrect prediction in the first place. To achieve this we will not tokenize words into sub-words anymore. We take the mean feature vectors of the sub-words as the feature vector of the word.
caution
This change is model breaking. Please, retrain your models.
* Move option `case_sensitive` from the tokenizers to the featurizers.
* Remove the option from the `WhitespaceTokenizer` and `ConveRTTokenizer`.
* Add option `case_sensitive` to the `RegexFeaturizer`.
* If a user sends a voice message to the bot using Facebook, users messages was set to the attachments URL. The same is now also done for the rest of attachment types (image, video, and file).
* Creating a `Domain` using `Domain.fromDict` can no longer alter the input dictionary. Previously, there could be problems when the input dictionary was re-used for other things after creating the `Domain` from it.
* The debug-level logs when instantiating an [SQLTrackerStore](https://rasa.com/docs/rasa-pro/production/tracker-stores#sqltrackerstore) no longer show the password in plain text. Now, the URL is displayed with the password hidden, e.g. `postgresql://username:***@localhost:5432`.
* Shorten the information in tqdm during training ML algorithms based on the log level. If you train your model in debug mode, all available metrics will be shown during training, otherwise, the information is shorten.
* Ignore conversation test directory `tests/` when importing a project using `MultiProjectImporter` and `use_e2e` is `False`. Previously, any story data found in a project subdirectory would be imported as training data.
* Implemented model checkpointing for DIET (including the response selector) and TED. The best model during training will be stored instead of just the last model. The model is evaluated on the basis of `evaluate_every_number_of_epochs` and `evaluate_on_number_of_examples`.
Checkpointing is enabled iff the following is set for the models in the `config.yml` file:
* `checkpoint_model: True`
* `evaluate_on_number_of_examples > 0`
The model is stored to whatever location has been specified with the `--out` parameter when calling `rasa train nlu/core ...`.
* `rasa data split nlu` now makes sure that there is at least one example per intent and response in the test data.
* The method `ensure_consistent_bilou_tagging` now also considers the confidence values of the predicted tags when updating the BILOU tags.
* We updated the way how we save and use features in our NLU pipeline.
The message object now has a dedicated field, called `features`, to store the features that are generated in the NLU pipeline. We adapted all our featurizers in a way that sequence and sentence features are stored independently. This allows us to keep different kind of features for the sequence and the sentence. For example, the `LexicalSyntacticFeaturizer` does not produce any sentence features anymore as our experiments showed that those did not bring any performance gain just quite a lot of additional values to store.
We also modified the DIET architecture to process the sequence and sentence features independently at first. The features are concatenated just before the transformer.
We also removed the `__CLS__` token again. Our Tokenizers will not add this token anymore.
caution
This change is model-breaking. Please retrain your models.
* Add endpoint kwarg to `rasa.jupyter.chat` to enable using a custom action server while chatting with a model in a jupyter notebook.
* Support for rasa conversation id with special characters on the server side - necessary for some channels (e.g. Viber)
* Add support for proxy use in [slack](https://rasa.com/docs/rasa-pro/connectors/slack) input channel.
* Log the number of examples per intent during training. Logging can be enabled using `rasa train --debug`.
* Support for other remote storages can be achieved by using an external library.
* Add `output_channel` query param to `/conversations//tracker/events` route, along with boolean `execute_side_effects` to optionally schedule/cancel reminders, and forward bot messages to output channel.
* Allow Rasa to boot when model loading exception occurs. Forward HTTP Error responses to standard log output.
* Rename `DucklingHTTPExtractor` to `DucklingEntityExtractor`.
* * Modified functionality of `SingleStateFeaturizer`.
`SingleStateFeaturizer` uses trained NLU `Interpreter` to featurize intents and action names. This modified `SingleStateFeaturizer` can replicate `LabelTokenizerSingleStateFeaturizer` functionality. This component is deprecated from now on. To replicate `LabelTokenizerSingleStateFeaturizer` functionality, add a `Tokenizer` with `intent_tokenization_flag: True` and `CountVectorsFeaturizer` to the NLU pipeline. Please update your configuration file.
For example:
```
language: en
pipeline:
- name: WhitespaceTokenizer
intent_tokenization_flag: True
- name: CountVectorsFeaturizer
```
Please train both NLU and Core (using `rasa train`) to use a trained tokenizer and featurizer for core featurization.
The new `SingleStateFeaturizer` stores slots, entities and forms in sparse features for more lightweight storage.
`BinarySingleStateFeaturizer` is deprecated and will be removed in the future. We recommend to switch to `SingleStateFeaturizer`.
* Modified `TEDPolicy` to handle sparse features. As a result, `TEDPolicy` may require more epochs than before to converge.
* Default TEDPolicy featurizer changed to `MaxHistoryTrackerFeaturizer` with infinite max history (takes all dialogue turns into account).
* Default batch size for TED increased from \[8,32] to \[64, 256]
* [Response selector templates](https://legacy-docs-oss.rasa.com/docs/rasa/components#responseselector) now support all features that domain utterances do. They use the yaml format instead of markdown now. This means you can now use buttons, images, ... in your FAQ or chitchat responses (assuming they are using the response selector).
As a consequence, training data form in markdown has to have the file suffix `.md` from now on to allow proper file type detection-
* Support for test stories written in yaml format.
* [Response Selectors](https://legacy-docs-oss.rasa.com/docs/rasa/components#responseselector) are now trained on retrieval intent labels by default instead of the actual response text. For most models, this should improve training time and accuracy of the `ResponseSelector`.
If you want to revert to the pre-2.0 default behavior, add the `use_text_as_label=true` parameter to your `ResponseSelector` component.
You can now also have multiple response templates for a single sub-intent of a retrieval intent. The first response template containing the text attribute is picked for training(if `use_text_as_label=True`) and a random template is picked for bot's utterance just as how other `utter_` templates are picked.
All response selector related evaluation artifacts - `report.json, successes.json, errors.json, confusion_matrix.png` now use the sub-intent of the retrieval intent as the target and predicted labels instead of the actual response text.
The output schema of `ResponseSelector` has changed - `full_retrieval_intent` and `name` have been deprecated in favour of `intent_response_key` and `response_templates` respectively. Additionally a key `all_retrieval_intents` is added to the response selector output which will hold a list of all retrieval intents(faq,chitchat, etc.) that are present in the training data.An example output looks like this -
```
"response_selector": {
"all_retrieval_intents": ["faq"],
"default": {
"response": {
"id": 1388783286124361986, "confidence": 1.0, "intent_response_key": "faq/is_legit",
"response_templates": [
{
"text": "absolutely",
"image": "https://i.imgur.com/nGF1K8f.jpg"
},
{
"text": "I think so."
}
],
},
"ranking": [
{
"id": 1388783286124361986,
"confidence": 1.0,
"intent_response_key": "faq/is_legit"
},
]
```
An example bot demonstrating how to use the `ResponseSelector` is added to the `examples` folder.
* Do not modify conversation tracker's `latest_input_channel` property when using `POST /trigger_intent` or `ReminderScheduled`.
* Do not set the output dimension of the `sparse-to-dense` layers to the same dimension as the dense features.
Update default value of `dense_dimension` and `concat_dimension` for `text` in `DIETClassifier` to 128.
* Retrieval actions with `respond_` prefix are now replaced with usual utterance actions with `utter_` prefix.
If you were using retrieval actions before, rename all of them to start with `utter_` prefix. For example, `respond_chitchat` becomes `utter_chitchat`. Also, in order to keep the response templates more consistent, you should now add the `utter_` prefix to all response templates defined for retrieval intents. For example, a response template `chitchat/ask_name` becomes `utter_chitchat/ask_name`. Note that the NLU examples for this will still be under `chitchat/ask_name` intent. The example `responseselectorbot` should help clarify these changes further.
* Added telemetry reporting. Rasa uses telemetry to report anonymous usage information. This information is essential to help improve Rasa Open Source for all users. Reporting will be opt-out. More information can be found in our [telemetry documentation](https://rasa.com/docs/rasa-pro/telemetry/telemetry).
* Update `extract_other_slots` method inside `FormAction` to fill a slot from an entity with a different name if corresponding slot mapping of `from_entity` type is unique.
* [Slots](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#slots) of any type can now be ignored during a conversation. To do so, specify the property `influence_conversation: false` for the slot.
```
slot:
a_slot:
type: text
influence_conversation: false
```
The property `influence_conversation` is set to `true` by default. See the [documentation for slots](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#slots) for more information.
A new slot type [`any`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#any-slot) was added. Slots of this type can store any value. Slots of type `any` are always ignored during conversations.
* Improved exception handling within Rasa Open Source.
All exceptions that are somewhat expected (e.g. errors in file formats like configurations or training data) will share a common base class `RasaException`.
::warning Backwards Incompatibility Base class for the exception raised when an action can not be found has been changed from a `NameError` to a `ValueError`. ::
Some other exceptions have also slightly changed:
* raise `YamlSyntaxException` instead of YAMLError (from ruamel) when failing to load a yaml file with information about the line where loading failed
* introduced `MissingDependencyException` as an exception raised if packages need to be installed
* Debug logs from `matplotlib` libraries are now hidden by default and are configurable with the `LOG_LEVEL_LIBRARIES` environment variable.
* Update `KafkaEventBroker` to support `SASL_SSL` and `PLAINTEXT` protocols.
##### Bugfixes[](#bugfixes-298 "Direct link to Bugfixes")
* Fixed issue where temporary model directories were not removed after pulling from a model server.
If the model pulled from the server was invalid, this could lead to large amounts of local storage usage.
* Fixed a bug in the `CountVectorsFeaturizer` which resulted in the very first message after loading a model to be processed incorrectly due to the vocabulary not being loaded yet.
* Fixed Rasa shell skipping button messages if buttons are attached to a message previous to the latest.
* Stack level for `FutureWarning` updated to level 2.
* If custom utter message contains no value or integer value, then it fails returning custom utter message. Fixed by converting the template to type string.
* Don't create TensorBoard log files during prediction.
* Fixed DIET breaking with empty spaCy model.
* Pinned the library version for the Azure [Cloud Storage](https://rasa.com/docs/rasa-pro/production/model-storage#load-model-from-cloud) to 2.1.0 since the persistor is currently not compatible with later versions of the azure-storage-blob library.
* Remove `clean_up_entities` from extractors that extract pre-defined entities. Just keep the clean up method for entity extractors that extract custom entities.
* Fixed issue where the `DucklingHTTPExtractor` component would not work if its `url` contained a trailing slash.
* Changed to variable `CERT_URI` in `hangouts.py` to a string type
* Slots will be correctly interpolated for `button` responses.
Previously this resulted in no interpolation due to a bug.
* Remove option `token_pattern` from `CountVectorsFeaturizer`. Instead all tokenizers now have the option `token_pattern`. If a regular expression is set, the tokenizer will apply the token pattern.
* Allow user to retry failed file exports in interactive training.
* Fixed a bug when custom metadata passed with the utterance always restarted the session.
* `WhitespaceTokenizer` does not remove vowel signs in Hindi anymore.
* Convert entity values coming from `DucklingHTTPExtractor` to string during evaluation to avoid mismatches due to different types.
* Update `FeatureSignature` to store just the feature dimension instead of the complete shape. This change fixes the usage of the option `share_hidden_layers` in the `DIETClassifier`.
* Unescape the `\n, \t, \r, \f, \b` tokens on reading nlu data from markdown files.
On converting json files into markdown, the tokens mentioned above are espaced. These tokens need to be unescaped on loading the data from markdown to ensure that the data is treated in the same way.
* Fix the way training data is generated in rasa test nlu when using the `-P` flag. Each percentage of the training dataset used to be formed as a part of the last sampled training dataset and not as a sample from the original training dataset.
* Prevent `WhitespaceTokenizer` from outputting empty list of tokens.
* Add `EntityExtractor` as a required component for `EntitySynonymMapper` in a pipeline.
* Better handling of input sequences longer than the maximum sequence length that the `HFTransformersNLP` models can handle.
During training, messages with longer sequence length should result in an error, whereas during inference they are gracefully handled but a debug message is logged. Ideally, passing messages longer than the acceptable maximum sequence lengths of each model should be avoided.
* When using the `DynamoTrackerStore`, if there are more than 100 DynamoDB tables, the tracker could attempt to re-create an existing table if that table was not among the first 100 listed by the dynamo API.
* Fixed a deprication warning that pops up due to changes in numpy
* Update `rasabaster` to fix an issue with syntax highlighting on "Prototype an Assistant" page.
Update default stories and rules on "Prototype an Assistant" page.
* Fixed a bug in the `serialise` method of the `EvaluationStore` class which resulted in a wrong end-to-end evaluation of the predicted entities.
* [Forms](https://legacy-docs-oss.rasa.com/docs/rasa/forms) with slot mappings defined in `domain.yml` must now be a dictionary (with form names as keys). The previous syntax where `forms` was simply a list of form names is still supported.
* Remove BILOU tag prefix from role and group labels when creating entities.
* Fixed a bug in the featurization of the boolean slot type. Previously, to set a slot value to "true", you had to set it to "1", which is in conflict with the documentation. In older versions `true` (without quotes) was also possible, but now raised an error during yaml validation.
* Fixed a bug in rasa interactive. Now it exports the stories and nlu training data as yml file.
* Fixed slots not being featurized before first user utterance.
Fixed AugmentedMemoizationPolicy to forget the first action on the first going back
* Fixed the remote URL of ConveRT model as it was recently updated by its authors.
* Treat the length of OOV token as 1 to fix token align issue when OOV occurred.
* Fixed the bug when entity was extracted even if it had a role or group but roles or groups were not expected.
* Fixed the bug that caused `supported_language_list` of `Component` to not work correctly.
To avoid confusion, only one of `supported_language_list` and `not_supported_language_list` can be set to not `None` now
* Fixed issue where responses including `text: ""` and no `custom` key would incorrectly fail domain validation.
* Fixed issue where extra keys other than `title` and `payload` inside of `buttons` made a response fail domain validation.
* Do not filter training data in model.py but on component side.
* Check if a model was provided when executing `rasa test core`. If not, print a useful error message and stop.
* Transfer only response templates for retrieval intents from domain to NLU Training Data.
This avoids retraining the NLU model if one of the non retrieval intent response templates are edited.
##### Improved Documentation[](#improved-documentation-35 "Direct link to Improved Documentation")
* Added documentation on `ambiguity_threshold` parameter in Fallback Actions page.
* Remove outdated whitespace tokenizer warning in Testing Your Assistant documentation.
* Updated Facebook Messenger channel docs with supported attachment information
* Update `rasa shell` documentation to explain how to recreate external channel session behavior.
* Event brokers documentation should say `url` instead of `host`.
* Update `rasa init` documentation to include `tests/conversation_tests.md` in the resulting directory tree.
* Update ["Validating Form Input" section](https://legacy-docs-oss.rasa.com/docs/rasa/forms#validating-form-input) to include details about how `FormValidationAction` class makes it easier to validate form slots in custom actions and how to use it.
* Update the examples in the API docs to use YAML instead of Markdown
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-93 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[1.10.26] - 2021-06-17[](#11026---2021-06-17 "Direct link to [1.10.26] - 2021-06-17")
##### Features[](#features-25 "Direct link to Features")
* Added `sasl_mechanism` as an optional configurable parameter for the [Kafka Producer](https://rasa.com/docs/rasa-pro/production/event-brokers#kafka-event-broker).
#### \[1.10.25] - 2021-04-14[](#11025---2021-04-14 "Direct link to [1.10.25] - 2021-04-14")
##### Features[](#features-26 "Direct link to Features")
* Added `partition_by_sender` flag to Kafka Producer to optionally associate events with Kafka partition based on sender\_id.
##### Improvements[](#improvements-97 "Direct link to Improvements")
* Improved the [lock store](https://rasa.com/docs/rasa-pro/production/lock-stores) debug log message when the process has to queue because other messages have to be processed before this item.
#### \[1.10.24] - 2021-03-29[](#11024---2021-03-29 "Direct link to [1.10.24] - 2021-03-29")
##### Bugfixes[](#bugfixes-299 "Direct link to Bugfixes")
* Added `group_id` parameter back to `KafkaEventBroker` to fix error when instantiating event broker with a config containing the `group_id` parameter which is only relevant to the event consumer
#### \[1.10.23] - 2021-02-22[](#11023---2021-02-22 "Direct link to [1.10.23] - 2021-02-22")
##### Bugfixes[](#bugfixes-300 "Direct link to Bugfixes")
* Fixed bug where the conversation does not lock before handling a reminder event.
#### \[1.10.22] - 2021-02-05[](#11022---2021-02-05 "Direct link to [1.10.22] - 2021-02-05")
##### Bugfixes[](#bugfixes-301 "Direct link to Bugfixes")
* Backported the Rasa Open Source 2 `PikaEventBroker` implementation to address problems when using it with multiple Sanic workers.
#### \[1.10.21] - 2021-02-01[](#11021---2021-02-01 "Direct link to [1.10.21] - 2021-02-01")
##### Improvements[](#improvements-98 "Direct link to Improvements")
* The `url` option now supports a list of servers `url: ['10.0.0.158:32803','10.0.0.158:32804']`. Removed `group_id` because it is not a valid Kafka producer parameter.
##### Bugfixes[](#bugfixes-302 "Direct link to Bugfixes")
* Fixed a bug that occurred when setting multiple Sanic workers in combination with a custom [Lock Store](https://rasa.com/docs/rasa-pro/production/lock-stores). Previously, if the number was set higher than 1 and you were using a custom lock store, it would reject because of a strict check to use a [Redis Lock Store](https://rasa.com/docs/rasa-pro/production/lock-stores#redislockstore).
* Fix a bug where, if a user injects an intent using the HTTP API, slot auto-filling is not performed on the entities provided.
#### \[1.10.20] - 2020-12-18[](#11020---2020-12-18 "Direct link to [1.10.20] - 2020-12-18")
##### Bugfixes[](#bugfixes-303 "Direct link to Bugfixes")
* Fix scikit-learn crashing during evaluation of `ResponseSelector` predictions.
#### \[1.10.19] - 2020-12-17[](#11019---2020-12-17 "Direct link to [1.10.19] - 2020-12-17")
##### Improvements[](#improvements-99 "Direct link to Improvements")
* Kafka Producer connection now remains active across sends. Added support for group and client id. The Kafka producer also adds support for the `PLAINTEXT` and `SASL_SSL` protocols.
DynamoDB table exists check fixed bug when more than 100 tables exist.
* Replace use of `python-telegram-bot` package with `pyTelegramBotAPI`
* Use response selector keys (sub-intents) as labels for plotting the confusion matrix during NLU evaluation to improve readability.
#### \[1.10.18] - 2020-11-26[](#11018---2020-11-26 "Direct link to [1.10.18] - 2020-11-26")
##### Bugfixes[](#bugfixes-304 "Direct link to Bugfixes")
* [#7340](https://github.com/rasahq/rasa/issues/7340%3E): Fixed an issues with the DynamoDB TrackerStore creating a new table entry/object for each TrackerStore update. The column `session_date` has been deprecated and should be removed manually in existing DynamoDB tables.
#### \[1.10.17] - 2020-11-12[](#11017---2020-11-12 "Direct link to [1.10.17] - 2020-11-12")
##### Bugfixes[](#bugfixes-305 "Direct link to Bugfixes")
* Prevent the message handling process in `PikaEventBroker` from being terminated.
#### \[1.10.16] - 2020-10-15[](#11016---2020-10-15 "Direct link to [1.10.16] - 2020-10-15")
##### Bugfixes[](#bugfixes-306 "Direct link to Bugfixes")
* Update Pika event broker to be a separate process and make it use a `multiprocessing.Queue` to send and process messages. This change should help avoid situations when events stop being sent after a while.
#### \[1.10.15] - 2020-10-09[](#11015---2020-10-09 "Direct link to [1.10.15] - 2020-10-09")
##### Bugfixes[](#bugfixes-307 "Direct link to Bugfixes")
* Fixed issue where temporary model directories were not removed after pulling from a model server. If the model pulled from the server was invalid, this could lead to large amounts of local storage usage.
* Treat the length of OOV token as 1 to fix token align issue when OOV occurred.
* Fixed `MappingPolicy` not predicting `action_listen` after the mapped action while running `rasa test`.
##### Improvements[](#improvements-100 "Direct link to Improvements")
* Debug logs from `matplotlib` libraries are now hidden by default and are configurable with the `LOG_LEVEL_LIBRARIES` environment variable.
#### \[1.10.14] - 2020-09-23[](#11014---2020-09-23 "Direct link to [1.10.14] - 2020-09-23")
##### Bugfixes[](#bugfixes-308 "Direct link to Bugfixes")
* Fixed the remote URL of ConveRT model as it was recently updated by its authors. Also made the remote URL configurable at runtime in the corresponding tokenizer's and featurizer's configuration.
#### \[1.10.13] - 2020-09-22[](#11013---2020-09-22 "Direct link to [1.10.13] - 2020-09-22")
##### Bugfixes[](#bugfixes-309 "Direct link to Bugfixes")
* Remove BILOU tag prefix from role and group labels when creating entities.
#### \[1.10.12] - 2020-09-03[](#11012---2020-09-03 "Direct link to [1.10.12] - 2020-09-03")
##### Bugfixes[](#bugfixes-310 "Direct link to Bugfixes")
* Fix slow training of `CRFEntityExtractor` when using Entity Roles and Groups.
#### \[1.10.11] - 2020-08-21[](#11011---2020-08-21 "Direct link to [1.10.11] - 2020-08-21")
##### Improvements[](#improvements-101 "Direct link to Improvements")
* Do not deepcopy slots when instantiating trackers. This leads to a significant speedup when training on domains with a large number of slots.
* Added more debugging logs to the [Lock Stores](https://rasa.com/docs/rasa-pro/production/lock-stores) to simplify debugging in case of
connection problems.
Added a new parameter `socket_timeout` to the `RedisLockStore`. If Redis doesn't answer within `socket_timeout` seconds to requests from Rasa Open Source, an error is raised. This avoids seemingly infinitely blocking connections and exposes connection problems early.
##### Bugfixes[](#bugfixes-311 "Direct link to Bugfixes")
* Fixed a bug where domain fields such as `store_entities_as_slots` were overridden with defaults and therefore ignored.
* If two entities are separated by a comma (or any other symbol), extract them as two separate entities.
* If two entities are separated by a single space and uses BILOU tagging, extract them as two separate entities based on their BILOU tags.
#### \[1.10.10] - 2020-08-04[](#11010---2020-08-04 "Direct link to [1.10.10] - 2020-08-04")
##### Bugfixes[](#bugfixes-312 "Direct link to Bugfixes")
* Fixed `TypeError: expected string or bytes-like object` issue caused by integer, boolean, and null values in templates.
#### \[1.10.9] - 2020-07-29[](#1109---2020-07-29 "Direct link to [1.10.9] - 2020-07-29")
##### Improvements[](#improvements-102 "Direct link to Improvements")
* Rasa Open Source will no longer add `responses` to the `actions` section of the domain when persisting the domain as a file. This addresses related problems in Rasa X when Integrated Version Control introduced big diffs due to the added utterances in the `actions` section.
##### Bugfixes[](#bugfixes-313 "Direct link to Bugfixes")
* Consider entity roles/groups during interactive learning.
#### \[1.10.8] - 2020-07-15[](#1108---2020-07-15 "Direct link to [1.10.8] - 2020-07-15")
##### Bugfixes[](#bugfixes-314 "Direct link to Bugfixes")
* Add 'Access-Control-Expose-Headers' for 'filename' header
* Fixed a bug where an invalid language variable prevents rasa from finding training examples when importing Dialogflow data.
#### \[1.10.7] - 2020-07-07[](#1107---2020-07-07 "Direct link to [1.10.7] - 2020-07-07")
##### Features[](#features-27 "Direct link to Features")
* Add `not_supported_language_list` to component to be able to define languages that a component can NOT handle.
`WhitespaceTokenizer` is not able to process languages which are not separated by whitespace. `WhitespaceTokenizer` will throw an error if it is used with Chinese, Japanese, and Thai.
##### Bugfixes[](#bugfixes-315 "Direct link to Bugfixes")
* `WhitespaceTokenizer` only removes emoji if complete token matches emoji regex.
#### \[1.10.6] - 2020-07-06[](#1106---2020-07-06 "Direct link to [1.10.6] - 2020-07-06")
##### Bugfixes[](#bugfixes-316 "Direct link to Bugfixes")
* Prevent `WhitespaceTokenizer` from outputting empty list of tokens.
#### \[1.10.5] - 2020-07-02[](#1105---2020-07-02 "Direct link to [1.10.5] - 2020-07-02")
##### Bugfixes[](#bugfixes-317 "Direct link to Bugfixes")
* Explicitly remove all emojis which appear as unicode characters from the output of `regex.sub` inside `WhitespaceTokenizer`.
#### \[1.10.4] - 2020-07-01[](#1104---2020-07-01 "Direct link to [1.10.4] - 2020-07-01")
##### Bugfixes[](#bugfixes-318 "Direct link to Bugfixes")
* `WhitespaceTokenizer` does not remove vowel signs in Hindi anymore.
* Previously, specifying a lock store in the endpoint configuration with a type other than `redis` or `in_memory` would lead to an `AttributeError: 'str' object has no attribute 'type'`. This bug is fixed now.
* Fix `Interpreter parsed an intent ...` warning when using the `/model/parse` endpoint with an NLU-only model.
* Convert entity values coming from any entity extractor to string during evaluation to avoid mismatches due to different types.
* The assistant will respond through the webex channel to any user (room) communicating to it. Before the bot responded only to a fixed `roomId` set in the `credentials.yml` config file.
#### \[1.10.3] - 2020-06-12[](#1103---2020-06-12 "Direct link to [1.10.3] - 2020-06-12")
##### Improvements[](#improvements-103 "Direct link to Improvements")
* Reduced duplicate logs and warnings when running `rasa train`.
##### Bugfixes[](#bugfixes-319 "Direct link to Bugfixes")
* Remove the `clean_up_entities` method from the `DIETClassifier` and `CRFEntityExtractor` as it let to incorrect entity predictions.
* Fix server crashes that occurred when Rasa Open Source pulls a model from a [model server](https://rasa.com/docs/rasa-pro/production/model-storage#load-model-from-server) and an exception was thrown during model loading (such as a domain with invalid YAML).
#### \[1.10.2] - 2020-06-03[](#1102---2020-06-03 "Direct link to [1.10.2] - 2020-06-03")
##### Bugfixes[](#bugfixes-320 "Direct link to Bugfixes")
* Responses used in ResponseSelector now support new lines with explicitly adding `\\n` between them.
* Fixed a bug in [`rasa export`](https://rasa.com/docs/rasa-pro/command-line-interface#rasa-export)) which caused Rasa Open Source to only migrate conversation events from the last [Session configuration](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#session-configuration).
#### \[1.10.1] - 2020-05-15[](#1101---2020-05-15 "Direct link to [1.10.1] - 2020-05-15")
##### Improvements[](#improvements-104 "Direct link to Improvements")
* Creating a `Domain` using `Domain.fromDict` can no longer alter the input dictionary. Previously, there could be problems when the input dictionary was re-used for other things after creating the `Domain` from it.
##### Bugfixes[](#bugfixes-321 "Direct link to Bugfixes")
* Don't create TensorBoard log files during prediction.
* Fix: DIET breaks with empty spaCy model
* Remove `clean_up_entities` from extractors that extract pre-defined entities. Just keep the clean up method for entity extractors that extract custom entities.
* Fixed issue where the `DucklingHTTPExtractor` component would not work if its url contained a trailing slash.
* Fix list index out of range error in `ensure_consistent_bilou_tagging`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-94 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[1.10.0] - 2020-04-28[](#1100---2020-04-28 "Direct link to [1.10.0] - 2020-04-28")
##### Features[](#features-28 "Direct link to Features")
* Add support for entities with roles and grouping of entities in Rasa NLU.
You can now define a role and/or group label in addition to the entity type for entities. Use the role label if an entity can play different roles in your assistant. For example, a city can be a destination or a departure city. The group label can be used to group multiple entities together. For example, you could group different pizza orders, so that you know what toppings goes with which pizza and what size which pizza has. For more details see [Entities Roles and Groups](https://legacy-docs-oss.rasa.com/docs/rasa/nlu-training-data#entities-roles-and-groups).
To fill slots from entities with a specific role/group, you need to either use forms or use a custom action. We updated the tracker method `get_latest_entity_values` to take an optional role/group label. If you want to use a form, you can add the specific role/group label of interest to the slot mapping function `from_entity` (see [Forms](https://legacy-docs-oss.rasa.com/docs/rasa/forms)).
note
Composite entities are currently just supported by the [DIETClassifier](https://legacy-docs-oss.rasa.com/docs/rasa/components#dietclassifier) and [CRFEntityExtractor](https://legacy-docs-oss.rasa.com/docs/rasa/components#crfentityextractor).
* Update training data format for NLU to support entities with a role or group label.
You can now specify synonyms, roles, and groups of entities using the following data format: Markdown:
```
[LA]{"entity": "location", "role": "city", "group": "CA", "value": "Los Angeles"}
```
JSON:
```
"entities": [
{
"start": 10,
"end": 12,
"value": "Los Angeles",
"entity": "location",
"role": "city",
"group": "CA",
}
]
```
The markdown format `[LA](location:Los Angeles)` is deprecated. To update your training data file just execute the following command on the terminal of your choice: `sed -i -E 's/\\[([^)]+)\\]\\(([^)]+):([^)]+)\\)/[\\1]{"entity": "\\2", "value": "\\3"}/g' nlu.md`
For more information about the new data format see [Training Data Format](https://legacy-docs-oss.rasa.com/docs/rasa/training-data-format).
##### Improvements[](#improvements-105 "Direct link to Improvements")
* Suppressed `pika` logs when establishing the connection. These log messages mostly happened when Rasa X and RabbitMQ were started at the same time. Since RabbitMQ can take a few seconds to initialize, Rasa X has to re-try until the connection is established. In case you suspect a different problem (such as failing authentication) you can re-enable the `pika` logs by setting the log level to `DEBUG`. To run Rasa Open Source in debug mode, use the `--debug` flag. To run Rasa X in debug mode, set the environment variable `DEBUG_MODE` to `true`.
* Include the source filename of a story in the failed stories
Include the source filename of a story in the failed stories to make it easier to identify the file which contains the failed story.
* Add confusion matrix and “confused\_with” to response selection evaluation
If you are using ResponseSelectors, they now produce similiar outputs during NLU evaluation. Misclassfied responses are listed in a “confused\_with” attribute in the evaluation report. Similiarily, a confusion matrix of all responses is plotted.
* Added `socketio` to the compatible channels for [Reminders and External Events](https://legacy-docs-oss.rasa.com/docs/rasa/reaching-out-to-user).
* Update `POST /model/train` endpoint to accept retrieval action responses at the `responses` key of the JSON payload.
* All Rasa Open Source images are now using Python 3.7 instead of Python 3.6.
* Update dependencies based on the `dependabot` check.
* Add dropout between `FFNN` and `DenseForSparse` layers in `DIETClassifier`, `ResponseSelector` and `EmbeddingIntentClassifier` controlled by `use_dense_input_dropout` config parameter.
* `DIETClassifier` only counts as extractor in `rasa test` if it was actually trained for entity recognition.
* Remove regularization gradient for variables that don't have prediction gradient.
* Raise a warning in `CRFEntityExtractor` and `DIETClassifier` if entities are not correctly annotated in the training data, e.g. their start and end values do not match any start and end values of tokens.
* Add `full_retrieval_intent` property to `ResponseSelector` rankings
* Change default values for hyper-parameters in `EmbeddingIntentClassifier` and `DIETClassifier`
Use `scale_loss=False` in `DIETClassifier`. Reduce the number of dense dimensions for sparse features of text from 512 to 256 in `EmbeddingIntentClassifier`.
##### Bugfixes[](#bugfixes-322 "Direct link to Bugfixes")
* Fixed issue where posting to certain callback channel URLs would return a 500 error on successful posts due to invalid response format.
* One word can just have one entity label.
If you are using, for example, `ConveRTTokenizer` words can be split into multiple tokens. Our entity extractors assign entity labels per token. So, it might happen, that a word, that was split into two tokens, got assigned two different entity labels. This is now fixed. One word can just have one entity label at a time.
* An entity label should always cover a complete word.
If you are using, for example, `ConveRTTokenizer` words can be split into multiple tokens. Our entity extractors assign entity labels per token. So, it might happen, that just a part of a word has an entity label. This is now fixed. An entity label always covers a complete word.
* Fixed an issue that happened when metadata is passed in a new session.
Now the metadata is correctly passed to the ActionSessionStart.
* Updated Python dependency `ruamel.yaml` to `>=0.16`. We recommend to use at least `0.16.10` due to the security issue [CVE-2019-20478](https://nvd.nist.gov/vuln/detail/CVE-2019-20478) which is present in in prior versions.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-95 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[1.9.7] - 2020-04-23[](#197---2020-04-23 "Direct link to [1.9.7] - 2020-04-23")
##### Improvements[](#improvements-106 "Direct link to Improvements")
* The stream reading timeout for `rasa shell\` is now configurable by using the environment variable \`\`RASA\_SHELL\_STREAM\_READING\_TIMEOUT\_IN\_SECONDS`. This can help to fix problems when using `rasa shell\` with custom actions which run 10 seconds or longer.
##### Bugfixes[](#bugfixes-323 "Direct link to Bugfixes")
* Reverted changes in 1.9.6 that led to model incompatibility. Upgrade to 1.9.7 to fix `self.sequence_lengths_for(tf_batch_data[TEXT_SEQ_LENGTH][0]) IndexError: list index out of range` error without needing to retrain earlier 1.9 models.
Therefore, all 1.9 models except for 1.9.6 will be compatible; a model trained on 1.9.6 will need to be retrained on 1.9.7.
#### \[1.9.6] - 2020-04-15[](#196---2020-04-15 "Direct link to [1.9.6] - 2020-04-15")
##### Bugfixes[](#bugfixes-324 "Direct link to Bugfixes")
* Fix rasa test nlu plotting when using multiple runs.
* Fixed issue where `max_number_of_predictions` was not considered when running end-to-end testing.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-96 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[1.9.5] - 2020-04-01[](#195---2020-04-01 "Direct link to [1.9.5] - 2020-04-01")
##### Improvements[](#improvements-107 "Direct link to Improvements")
* Support for [PostgreSQL schemas](https://www.postgresql.org/docs/11/ddl-schemas.html) in [SQLTrackerStore](https://rasa.com/docs/rasa-pro/production/tracker-stores#sqltrackerstore). The `SQLTrackerStore` accesses schemas defined by the `POSTGRESQL_SCHEMA` environment variable if connected to a PostgreSQL database.
The schema is added to the connection string option's `-csearch_path` key, e.g. `-options=-csearch_path=` (see the [PostgreSQL docs](https://www.postgresql.org/docs/11/contrib-dblink-connect.html) for more details). As before, if no `POSTGRESQL_SCHEMA` is defined, Rasa uses the database's default schema (`public`).
The schema has to exist in the database before connecting, i.e. it needs to have been created with
```
CREATE SCHEMA schema_name;
```
##### Bugfixes[](#bugfixes-325 "Direct link to Bugfixes")
* Fixed ambiguous logging in `DIETClassifier` by adding the name of the calling class to the log message.
#### \[1.9.4] - 2020-03-30[](#194---2020-03-30 "Direct link to [1.9.4] - 2020-03-30")
##### Bugfixes[](#bugfixes-326 "Direct link to Bugfixes")
* Fix memory leak problem on increasing number of calls to `/model/parse` endpoint.
#### \[1.9.3] - 2020-03-27[](#193---2020-03-27 "Direct link to [1.9.3] - 2020-03-27")
##### Bugfixes[](#bugfixes-327 "Direct link to Bugfixes")
* Set default value for `weight_sparsity` in `ResponseSelector` to `0`. This fixes a bug in the default behavior of `ResponseSelector` which was accidentally introduced in `rasa==1.8.0`. Users should update to this version and re-train their models if `ResponseSelector` was used in their pipeline.
#### \[1.9.2] - 2020-03-26[](#192---2020-03-26 "Direct link to [1.9.2] - 2020-03-26")
##### Improved Documentation[](#improved-documentation-36 "Direct link to Improved Documentation")
* Fix documentation to bring back Sara.
#### \[1.9.1] - 2020-03-25[](#191---2020-03-25 "Direct link to [1.9.1] - 2020-03-25")
##### Bugfixes[](#bugfixes-328 "Direct link to Bugfixes")
* Fix an issue where the deprecated `queue` parameter for the [Pika Event Broker](https://rasa.com/docs/rasa-pro/production/event-brokers#pika-event-broker) was ignored and Rasa Open Source published the events to the `rasa_core_events` queue instead. Note that this does not change the fact that the `queue` argument is deprecated in favor of the `queues` argument.
#### \[1.9.0] - 2020-03-24[](#190---2020-03-24 "Direct link to [1.9.0] - 2020-03-24")
##### Features[](#features-29 "Direct link to Features")
* Channel `hangouts` for Rasa integration with Google Hangouts Chat is now supported out-of-the-box.
* Add an optional path to a specific directory to download and cache the pre-trained model weights for [HFTransformersNLP](https://rasa.com/docs/rasa/2.x/components#hftransformersnlp).
* Add options `tensorboard_log_directory` and `tensorboard_log_level` to `EmbeddingIntentClassifier`, `DIETClasifier`, `ResponseSelector`, `EmbeddingPolicy` and `TEDPolicy`.
By default `tensorboard_log_directory` is `None`. If a valid directory is provided, metrics are written during training. After the model is trained you can take a look at the training metrics in tensorboard. Execute `tensorboard --logdir `.
Metrics can either be written after every epoch (default) or for every training step. You can specify when to write metrics using the variable `tensorboard_log_level`. Valid values are 'epoch' and 'minibatch'.
We also write down a model summary, i.e. layers with inputs and types, to the given directory.
##### Improvements[](#improvements-108 "Direct link to Improvements")
* Make response timeout configurable. `rasa run`, `rasa shell` and `rasa x` can now be started with `--response-timeout ` to configure a response timeout of `` seconds.
* Add full retrieval intent name to message data `ResponseSelector` will now add the full retrieval intent name e.g. `faq/which_version` to the prediction, making it accessible from the tracker.
* Added `PikaEventBroker` ([Pika Event Broker](https://rasa.com/docs/rasa-pro/production/event-brokers#pika-event-broker)) support for publishing to multiple queues. Messages are now published to a `fanout` exchange with name `rasa-exchange` (see [exchange-fanout](https://www.rabbitmq.com/tutorials/amqp-concepts.html#exchange-fanout) for more information on `fanout` exchanges).
The former `queue` key is deprecated. Queues should now be specified as a list in the `endpoints.yml` event broker config under a new key `queues`. Example config:
```
event_broker:
type: pika
url: localhost
username: username
password: password
queues:
- queue-1
- queue-2
- queue-3
```
* Change `rasa init` to include `tests/conversation_tests.md` file by default.
* The endpoint `PUT /conversations//tracker/events` no longer adds session start events (to learn more about conversation sessions, please see [Session configuration](https://rasa.com/docs/rasa-pro/nlu-based-assistants/domain#session-configuration)) in addition to the events which were sent in the request payload. To achieve the old behavior send a `GET /conversations//tracker` request before appending events.
* Make `scale_loss` for intents behave the same way as in versions below `1.8`, but only scale if some of the examples in a batch has probability of the golden label more than `0.5`. Introduce `scale_loss` for entities in `DIETClassifier`.
##### Bugfixes[](#bugfixes-329 "Direct link to Bugfixes")
* Fixed the bug when FormPolicy was overwriting MappingPolicy prediction (e.g. `/restart`). Priorities for [Mapping Policy](https://rasa.com/docs/rasa/2.x/policies#mapping-policy) and [Form Policy](https://rasa.com/docs/rasa/2.x/policies#form-policy) are no longer linear: `FormPolicy` priority is 5, but its prediction is ignored if `MappingPolicy` is used for prediction.
* Fixed issue related to storing Python `float` values as `decimal.Decimal` objects in DynamoDB tracker stores. All `decimal.Decimal` objects are now converted to `float` on tracker retrieval.
Added a new docs section on [DynamoTrackerStore](https://rasa.com/docs/rasa-pro/production/tracker-stores#dynamotrackerstore).
* Fixed bug where `FallbackPolicy` would always fall back if the fallback action is `action_listen`.
* Fixed bug where starting or ending a response with `\\n\\n` led to one of the responses returned being empty.
* Fixes issue where model always gets retrained if multiple NLU/story files are in a directory, by sorting the list of files.
* Fixed ambiguous logging in DIETClassifier by adding the name of the calling class to the log message.
##### Improved Documentation[](#improved-documentation-37 "Direct link to Improved Documentation")
* Restructure the “Evaluating models” documentation page and rename this page to [Testing Your Assistant](https://rasa.com/docs/rasa-pro/nlu-based-assistants/testing-your-assistant).
* Improved documentation on how to build and deploy an action server image for use on other servers such as Rasa X deployments.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-97 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[1.8.3] - 2020-03-27[](#183---2020-03-27 "Direct link to [1.8.3] - 2020-03-27")
##### Bugfixes[](#bugfixes-330 "Direct link to Bugfixes")
* Fixes issue where model always gets retrained if multiple NLU/story files are in a directory, by sorting the list of files.
* Fixed ambiguous logging in DIETClassifier by adding the name of the calling class to the log message.
* Set default value for `weight_sparsity` in `ResponseSelector` to `0`. This fixes a bug in the default behavior of `ResponseSelector` which was accidentally introduced in `rasa==1.8.0`. Users should update to this version or `rasa>=1.9.3` and re-train their models if `ResponseSelector` was used in their pipeline.
##### Improved Documentation[](#improved-documentation-38 "Direct link to Improved Documentation")
* Improved documentation on how to build and deploy an action server image for use on other servers such as Rasa X deployments.
#### \[1.8.2] - 2020-03-19[](#182---2020-03-19 "Direct link to [1.8.2] - 2020-03-19")
##### Bugfixes[](#bugfixes-331 "Direct link to Bugfixes")
* Fixed bug when installing rasa with `poetry`.
* Fixed bug with `EmbeddingIntentClassifier`, where results weren't the same as in 1.7.x. Fixed by setting weight sparsity to 0.
##### Improved Documentation[](#improved-documentation-39 "Direct link to Improved Documentation")
* Explain how to run commands as `root` user in Rasa SDK Docker images since version `1.8.0`. Since version `1.8.0` the Rasa SDK Docker images does not longer run as `root` user by default. For commands which require `root` user usage, you have to switch back to the `root` user in your Docker image as described in [Building an Action Server Image](https://legacy-docs-oss.rasa.com/docs/rasa/action-server/deploy-action-server#building-an-action-server-image).
* Made improvements to Building Assistants tutorial
#### \[1.8.1] - 2020-03-06[](#181---2020-03-06 "Direct link to [1.8.1] - 2020-03-06")
##### Bugfixes[](#bugfixes-332 "Direct link to Bugfixes")
* Fixed issue with using language models like `xlnet` along with `entity_recognition` set to `True` inside `DIETClassifier`.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-98 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[1.8.0] - 2020-02-26[](#180---2020-02-26 "Direct link to [1.8.0] - 2020-02-26")
##### Deprecations and Removals[](#deprecations-and-removals-20 "Direct link to Deprecations and Removals")
* Removed `Agent.continue_training` and the `dump_flattened_stories` parameter from `Agent.persist`.
* Properties `Component.provides` and `Component.requires` are deprecated. Use `Component.required_components()` instead.
##### Features[](#features-30 "Direct link to Features")
* Add default value `__other__` to `values` of a `CategoricalSlot`.
All values not mentioned in the list of values of a `CategoricalSlot` will be mapped to `__other__` for featurization.
* Add story structure validation functionality (e.g. rasa data validate stories –max-history 5).
* Add [LexicalSyntacticFeaturizer](https://legacy-docs-oss.rasa.com/docs/rasa/components#lexicalsyntacticfeaturizer) to sparse featurizers.
`LexicalSyntacticFeaturizer` does the same featurization as the `CRFEntityExtractor`. We extracted the featurization into a separate component so that the features can be reused and featurization is independent from the entity extraction.
* Integrate language models from HuggingFace's [Transformers](https://github.com/huggingface/transformers) Library.
Add a new NLP component [HFTransformersNLP](https://rasa.com/docs/rasa/2.x/components#hftransformersnlp) which tokenizes and featurizes incoming messages using a specified pre-trained model with the Transformers library as the backend. Add [LanguageModelTokenizer](https://rasa.com/docs/rasa/2.x/components#languagemodeltokenizer) and [LanguageModelFeaturizer](https://legacy-docs-oss.rasa.com/docs/rasa/components#languagemodelfeaturizer) which use the information from [HFTransformersNLP](https://rasa.com/docs/rasa/2.x/components#hftransformersnlp) and sets them correctly for message object. Language models currently supported: BERT, OpenAIGPT, GPT-2, XLNet, DistilBert, RoBERTa.
* Added a new CLI command `rasa export` to publish tracker events from a persistent tracker store using an event broker. See [Export Conversations to an Event Broker](https://rasa.com/docs/rasa-pro/command-line-interface#rasa-export), [Tracker Stores](https://rasa.com/docs/rasa-pro/production/tracker-stores) and [Event Brokers](https://rasa.com/docs/rasa-pro/production/event-brokers) for more details.
* Refactor how GPU and CPU environments are configured for TensorFlow 2.0.
Please refer to the documentation on [Configuring TensorFlow](https://legacy-docs-oss.rasa.com/docs/rasa/tuning-your-model/#configuring-tensorflow) to understand which environment variables to set in what scenarios. A couple of examples are shown below as well:
```
# This specifies to use 1024 MB of memory from GPU with logical ID 0 and 2048 MB of memory from GPU with logical ID 1
TF_GPU_MEMORY_ALLOC="0:1024, 1:2048"
# Specifies that at most 3 CPU threads can be used to parallelize multiple non-blocking operations
TF_INTER_OP_PARALLELISM_THREADS="3"
# Specifies that at most 2 CPU threads can be used to parallelize a particular operation.
TF_INTRA_OP_PARALLELISM_THREADS="2"
```
* Added a new NLU component [DIETClassifier](https://legacy-docs-oss.rasa.com/docs/rasa/components#dietclassifier) and a new policy [TEDPolicy](https://legacy-docs-oss.rasa.com/docs/rasa/policies#ted-policy).
DIET (Dual Intent and Entity Transformer) is a multi-task architecture for intent classification and entity recognition. You can read more about this component in the [DIETClassifier](https://legacy-docs-oss.rasa.com/docs/rasa/components#dietclassifier) documentation. The new component will replace the `EmbeddingIntentClassifier` and the [CRFEntityExtractor](https://legacy-docs-oss.rasa.com/docs/rasa/components#crfentityextractor) in the future. Those two components are deprecated from now on. See [migration guide](https://legacy-docs-oss.rasa.com/docs/rasa/migration-guide/#rasa-17-to-rasa-18) for details on how to switch to the new component.
[TEDPolicy](https://legacy-docs-oss.rasa.com/docs/rasa/policies#ted-policy) is the new name for EmbeddingPolicy. `EmbeddingPolicy` is deprecated from now on. The functionality of `TEDPolicy` and `EmbeddingPolicy` is the same. Please update your configuration file to use the new name for the policy.
* The sentence vector of the `SpacyFeaturizer` and `MitieFeaturizer` can be calculated using max or mean pooling.
To specify the pooling operation, set the option `pooling` for the `SpacyFeaturizer` or the `MitieFeaturizer` in your configuration file. The default pooling operation is `mean`. The mean pooling operation also does not take into account words, that do not have a word vector.
##### Improvements[](#improvements-109 "Direct link to Improvements")
* Added command line argument `--conversation-id` to `rasa interactive`. If the argument is not given, `conversation_id` defaults to a random uuid.
* Added a new command-line argument `--init-dir` to command `rasa init` to specify the directory in which the project is initialised.
* Added support to send images with the twilio output channel.
* Part of Slack sanitization: Multiple garbled URL's in a string coming from slack will be converted into actual strings. `Example: health check of and to health check of eemdb.net and eemdb1.net`
* New command-line argument –conversation-id will be added and wiil give the ability to set specific conversation ID for each shell session, if not passed will be random.
* Messages sent to the [Pika Event Broker](https://rasa.com/docs/rasa-pro/production/event-brokers#pika-event-broker) are now persisted. This guarantees the RabbitMQ will re-send previously received messages after a crash. Note that this does not help for the case where messages are sent to an unavailable RabbitMQ instance.
* Added support for mattermost connector to use bot accounts.
* We updated our code to TensorFlow 2.
* Events exported using `rasa export` receive a message header if published through a `PikaEventBroker`. The header is added to the message's `BasicProperties.headers` under the `rasa-export-process-id` key (`rasa.core.constants.RASA_EXPORT_PROCESS_ID_HEADER_NAME`). The value is a UUID4 generated at each call of `rasa export`. The resulting header is a key-value pair that looks as follows:
```
'rasa-export-process-id': 'd3b3d3ffe2bd4f379ccf21214ccfb261'
```
* Added `followlinks=True` to os.walk calls, to allow the use of symlinks in training, NLU and domain data.
* Support invoking a `SlackBot` by direct messaging or `@` mentions.
##### Bugfixes[](#bugfixes-333 "Direct link to Bugfixes")
* Fixed timestamp parsing warning when using DucklingHTTPExtractor
* Fixed issue with `action_restart` getting overridden by `action_listen` when the [Mapping Policy](https://rasa.com/docs/rasa/2.x/policies#mapping-policy) and the [Two-Stage Fallback Policy](https://rasa.com/docs/rasa/2.x/policies#two-stage-fallback-policy) are used together.
* Fixed incorrectly raised Error encountered in pipelines with a `ResponseSelector` and NLG.
When NLU training data is split before NLU pipeline comparison, NLG responses were not also persisted and therefore training for a pipeline including the `ResponseSelector` would fail.
NLG responses are now persisted along with NLU data to a `/train` directory in the `run_x/xx%_exclusion` folder.
* Fixed sending custom json with Twilio channel
##### Improved Documentation[](#improved-documentation-40 "Direct link to Improved Documentation")
* Updated the documentation to properly suggest not to explicitly add utterance actions to the domain.
* Added user guide for reminders and external events, including `reminderbot` demo.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-99 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[1.7.4] - 2020-02-24[](#174---2020-02-24 "Direct link to [1.7.4] - 2020-02-24")
##### Bugfixes[](#bugfixes-334 "Direct link to Bugfixes")
* Tracker stores supporting conversation sessions (`SQLTrackerStore` and `MongoTrackerStore`) do not save the tracker state to database immediately after starting a new conversation session. This leads to the number of events being saved in addition to the already-existing ones to be calculated correctly.
This fixes `action_listen` events being saved twice at the beginning of conversation sessions.
#### \[1.7.3] - 2020-02-21[](#173---2020-02-21 "Direct link to [1.7.3] - 2020-02-21")
##### Bugfixes[](#bugfixes-335 "Direct link to Bugfixes")
* Fix segmentation fault when running `rasa train` or `rasa shell`.
##### Improved Documentation[](#improved-documentation-41 "Direct link to Improved Documentation")
* Fix doc links on “Deploying your Assistant” page
#### \[1.7.2] - 2020-02-13[](#172---2020-02-13 "Direct link to [1.7.2] - 2020-02-13")
##### Bugfixes[](#bugfixes-336 "Direct link to Bugfixes")
* Fixed incompatibility of Oracle with the [SQLTrackerStore](https://rasa.com/docs/rasa-pro/production/tracker-stores#sqltrackerstore), by using a `Sequence` for the primary key columns. This does not change anything for SQL databases other than Oracle. If you are using Oracle, please create a sequence with the instructions in the [SQLTrackerStore](https://rasa.com/docs/rasa-pro/production/tracker-stores#sqltrackerstore) docs.
##### Improved Documentation[](#improved-documentation-42 "Direct link to Improved Documentation")
* Added section on setting up the SQLTrackerStore with Oracle
* Renamed “Running the Server” page to “Configuring the HTTP API”
#### \[1.7.1] - 2020-02-11[](#171---2020-02-11 "Direct link to [1.7.1] - 2020-02-11")
##### Bugfixes[](#bugfixes-337 "Direct link to Bugfixes")
* Fixed file loading of non proper UTF-8 story files, failing properly when checking for story files.
* Fix problem with multi-intents. Training with multi-intents using the `CountVectorsFeaturizer` together with `EmbeddingIntentClassifier` is working again.
* Fix bug `ValueError: Cannot concatenate sparse features as sequence dimension does not match`.
When training a Rasa model that contains responses for just some of the intents, training was failing. Fixed the featurizers to return a consistent feature vector in case no response was given for a specific message.
* If no text features are present in `EmbeddingIntentClassifier` return the intent `None`.
* Resolve version conflicts: Pin version of cloudpickle to ~=1.2.0.
#### \[1.7.0] - 2020-01-29[](#170---2020-01-29 "Direct link to [1.7.0] - 2020-01-29")
##### Deprecations and Removals[](#deprecations-and-removals-21 "Direct link to Deprecations and Removals")
* The endpoint `/conversations//execute` is now deprecated. Instead, users should use the `/conversations//trigger_intent` endpoint and thus trigger intents instead of actions.
* Remove option `use_cls_token` from tokenizers and option `return_sequence` from featurizers.
By default all tokenizer add a special token (`__CLS__`) to the end of the list of tokens. This token will be used to capture the features of the whole utterance.
The featurizers will return a matrix of size (number-of-tokens x feature-dimension) by default. This allows to train sequence models. However, the feature vector of the `__CLS__` token can be used to train non-sequence models. The corresponding classifier can decide what kind of features to use.
##### Features[](#features-31 "Direct link to Features")
* Rename `templates` key in domain to `responses`.
`templates` key will still work for backwards compatibility but will raise a future warning.
* Added a new configuration parameter, `ranking_length` to the `EmbeddingPolicy`, `EmbeddingIntentClassifier`, and `ResponseSelector` classes.
* External events and reminders now trigger intents (and entities) instead of actions.
Add new endpoint `/conversations//trigger_intent`, which lets the user specify an intent and a list of entities that is injected into the conversation in place of a user message. The bot then predicts and executes a response action.
* Add `ConveRTTokenizer`.
The tokenizer should be used whenever the `ConveRTFeaturizer` is used.
Every tokenizer now supports the following configuration options: `intent_tokenization_flag`: Flag to check whether to split intents (default `False`). `intent_split_symbol`: Symbol on which intent should be split (default `_`)
##### Improvements[](#improvements-110 "Direct link to Improvements")
* Remove the need of specifying utter actions in the `actions` section explicitly if these actions are already listed in the `templates` section.
* Entity examples that have been extracted using an external extractor are excluded from Markdown dumping in `MarkdownWriter.dumps()`. The excluded external extractors are `DucklingHTTPExtractor` and `SpacyEntityExtractor`.
* The `EmbeddingPolicy`, `EmbeddingIntentClassifier`, and `ResponseSelector` now by default normalize confidence levels over the top 10 results. See [Rasa 1.6 to Rasa 1.7](https://legacy-docs-oss.rasa.com/docs/rasa/migration-guide/#rasa-16-to-rasa-17) for more details.
* `ReminderCancelled` can now cancel multiple reminders if no name is given. It still cancels a single reminder if the reminder's name is specified.
##### Bugfixes[](#bugfixes-338 "Direct link to Bugfixes")
* Requests to `/model/train` do not longer block other requests to the Rasa server.
* Fixed default behavior of `rasa test core --evaluate-model-directory` when called without `--model`. Previously, the latest model file was used as `--model`. Now the default model directory is used instead.
New behavior of `rasa test core --evaluate-model-directory` when given an existing file as argument for `--model`: Previously, this led to an error. Now a warning is displayed and the directory containing the given file is used as `--model`.
* Updated the dependency `networkx` from 2.3.0 to 2.4.0. The old version created incompatibilities when using pip.
There is an imcompatibility between Rasa dependecy requests 2.22.0 and the own depedency from Rasa for networkx raising errors upon pip install. There is also a bug corrected in `requirements.txt` which used `~=` instead of `==`. All of these are fixed using networkx 2.4.0.
* Fixed compatibility issue with Microsoft Bot Framework Emulator if `service_url` lacked a trailing `/`.
* DynamoDB tracker store decimal values will now be rounded on save. Previously values exceeding 38 digits caused an unhandled error.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-100 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[1.6.2] - 2020-01-28[](#162---2020-01-28 "Direct link to [1.6.2] - 2020-01-28")
##### Improvements[](#improvements-111 "Direct link to Improvements")
* Switching back to a TensorFlow release which only includes CPU support to reduce the size of the dependencies. If you want to use the TensorFlow package with GPU support, please run `pip install tensorflow-gpu==1.15.0`.
##### Bugfixes[](#bugfixes-339 "Direct link to Bugfixes")
* Fixes `Exception 'Loop' object has no attribute '_ready'` error when running `rasa init`.
* Updated the end-to-end ValueError you recieve when you have a invalid story format to point to the updated doc link.
#### \[1.6.1] - 2020-01-07[](#161---2020-01-07 "Direct link to [1.6.1] - 2020-01-07")
##### Bugfixes[](#bugfixes-340 "Direct link to Bugfixes")
* Use an empty domain in case a model is loaded which has no domain (avoids errors when accessing `agent.doman.`).
* Replace error message with warning in tokenizers and featurizers if default parameter not set.
* Pin sanic patch version instead of minor version. Fixes sanic `_run_request_middleware()` error.
* Fix wrong calculation of additional conversation events when saving the conversation. This led to conversation events not being saved.
* Fix wrong order of conversation events when pushing events to conversations via `POST /conversations//tracker/events`.
#### \[1.6.0] - 2019-12-18[](#160---2019-12-18 "Direct link to [1.6.0] - 2019-12-18")
##### Deprecations and Removals[](#deprecations-and-removals-22 "Direct link to Deprecations and Removals")
* Removed `ner_features` as a feature name from `CRFEntityExtractor`, use `text_dense_features` instead.
The following settings match the previous `NGramFeaturizer`:
```
pipeline:
- name: 'CountVectorsFeaturizer'
analyzer: 'char_wb'
min_ngram: 3
max_ngram: 17
max_features: 10
min_df: 5
```
* To [use custom features in the `CRFEntityExtractor`](https://legacy-docs-oss.rasa.com/docs/rasa/components#crfentityextractor) use `text_dense_features` instead of `ner_features`. If `text_dense_features` are present in the feature set, the `CRFEntityExtractor` will automatically make use of them. Just make sure to add a dense featurizer in front of the `CRFEntityExtractor` in your pipeline and set the flag `return_sequence` to `True` for that featurizer.
* Deprecated `Agent.continue_training`. Instead, a model should be retrained.
* Specifying lookup tables directly in the NLU file is now deprecated. Please specify them in an external file.
##### Features[](#features-32 "Direct link to Features")
* Replaced the warnings about missing templates, intents etc. in validator.py by debug messages.
* Added conversation sessions to trackers.
A conversation session represents the dialog between the assistant and a user. Conversation sessions can begin in three ways: 1. the user begins the conversation with the assistant, 2. the user sends their first message after a configurable period of inactivity, or 3. a manual session start is triggered with the `/session_start` intent message. The period of inactivity after which a new conversation session is triggered is defined in the domain using the `session_expiration_time` key in the `session_config` section. The introduction of conversation sessions comprises the following changes:
* Added a new event `SessionStarted` that marks the beginning of a new conversation session.
* Added a new default action `ActionSessionStart`. This action takes all `SlotSet` events from the previous session and applies it to the next session.
* Added a new default intent `session_start` which triggers the start of a new conversation session.
* `SQLTrackerStore` and `MongoTrackerStore` only retrieve events from the last session from the database.
note
The session behavior is disabled for existing projects, i.e. existing domains without session config section.
* Preparation for an upcoming change in the `EmbeddingIntentClassifier`:
Add option `use_cls_token` to all tokenizers. If it is set to `True`, the token `__CLS__` will be added to the end of the list of tokens. Default is set to `False`. No need to change the default value for now.
Add option `return_sequence` to all featurizers. By default all featurizers return a matrix of size (1 x feature-dimension). If the option `return_sequence` is set to `True`, the corresponding featurizer will return a matrix of size (token-length x feature-dimension). See [Text Featurizers](https://legacy-docs-oss.rasa.com/docs/rasa/components#featurizers). Default value is set to `False`. However, you might want to set it to `True` if you want to use custom features in the `CRFEntityExtractor`. See [passing custom features to the `CRFEntityExtractor`](https://legacy-docs-oss.rasa.com/docs/rasa/components#crfentityextractor)
Changed some featurizers to use sparse features, which should reduce memory usage with large amounts of training data significantly. Read more: [Text Featurizers](https://legacy-docs-oss.rasa.com/docs/rasa/components#featurizers) .
caution
These changes break model compatibility. You will need to retrain your old models!
##### Improvements[](#improvements-112 "Direct link to Improvements")
* Added `--no-plot` option for `rasa test` command, which disables rendering of confusion matrix and histogram. By default plots will be rendered.
* If matplotlib couldn't set up a default backend, it will be set automatically to TkAgg/Agg one
* Add the option `\`random\_seed\``to the`\`rasa data split nlu\`\` command to generate reproducible train/test splits.
* Changed `url` `__init__()` arguments for custom tracker stores to `host` to reflect the `__init__` arguments of currently supported tracker stores. Note that in `endpoints.yml`, these are still declared as `url`.
* The `kafka-python` dependency has become as an “extra” dependency. To use the `KafkaEventConsumer`, `rasa` has to be installed with the `[kafka]` option, i.e.
```
$ pip install rasa[kafka]
```
* Allow creation of natural language interpreter and generator by classname reference in `endpoints.yml`.
* Made it explicit that interactive learning does not work with NLU-only models.
Interactive learning no longer trains NLU-only models if no model is provided and no core data is provided.
* The `intent_report.json` created by `rasa test` now creates an extra field `confused_with` for each intent. This is a dictionary containing the names of the most common false positives when this intent should be predicted, and the number of such false positives.
* `rasa test nlu --cross-validation` now also includes an evaluation of the response selector. As a result, the train and test F1-score, accuracy and precision is logged for the response selector. A report is also generated in the `results` folder by the name `response_selection_report.json`
##### Bugfixes[](#bugfixes-341 "Direct link to Bugfixes")
* If a `wait_time_between_pulls` is configured for the model server in `endpoints.yml`, this will be used instead of the default one when running Rasa X.
* Training Luis data with `luis_schema_version` higher than 4.x.x will show a warning instead of throwing an exception.
* Running `rasa interactive` with no NLU data now works, with the functionality of `rasa interactive core`.
* When loading models from S3, namespaces (folders within a bucket) are now respected. Previously, this would result in an error upon loading the model.
* “rasa init” will ask if user wants to train a model
* Pin `multidict` dependency to 4.6.1 to prevent sanic from breaking, see [the Sanic GitHub issue](https://github.com/huge-success/sanic/issues/1729 "Sanic Github Issue #1729 about Multidict update breaking Sanic") for more info.
* Fix errors during training and testing of `ResponseSelector`.
#### \[1.5.3] - 2019-12-11[](#153---2019-12-11 "Direct link to [1.5.3] - 2019-12-11")
##### Improvements[](#improvements-113 "Direct link to Improvements")
* Improved error message that appears when an incorrect parameter is passed to a policy.
##### Bugfixes[](#bugfixes-342 "Direct link to Bugfixes")
* Added `rasa/nlu/schemas/config.yml` to wheel package
* Pin `multidict` dependency to 4.6.1 to prevent sanic from breaking, see [the Sanic GitHub issue](https://github.com/huge-success/sanic/issues/1729 "Sanic Github Issue #1729 about Multidict update breaking Sanic")
#### \[1.5.2] - 2019-12-09[](#152---2019-12-09 "Direct link to [1.5.2] - 2019-12-09")
##### Improvements[](#improvements-114 "Direct link to Improvements")
* `rasa interactive` will skip the story visualization of training stories in case there are more than 200 stories. Stories created during interactive learning will be visualized as before.
* The log level for SocketIO loggers, including `websockets.protocol`, `engineio.server`, and `socketio.server`, is now handled by the `LOG_LEVEL_LIBRARIES` environment variable, where the default log level is `ERROR`.
* Updated all example bots and documentation to use the updated `dispatcher.utter_message()` method from rasa-sdk==1.5.0.
##### Bugfixes[](#bugfixes-343 "Direct link to Bugfixes")
* `rasa interactive` will not load training stories in case the visualization is skipped.
* Fixed error where spacy models where not found in the docker images.
* Fixed unnecessary `kwargs` unpacking in `rasa.test.test_core` call in `rasa.test.test` function.
* Training data files now get loaded in the same order (especially relevant to subdirectories) each time to ensure training consistency when using a random seed.
* Locks for tickets in `LockStore` are immediately issued without a redundant check for their availability.
##### Improved Documentation[](#improved-documentation-43 "Direct link to Improved Documentation")
* Added `towncrier` to automatically collect changelog entries.
* Document the pipeline for `pretrained_embeddings_convert` in the pre-configured pipelines section.
* `Proactively Reaching Out to the User Using Actions` now correctly links to the endpoint specification.
#### \[1.5.1] - 2019-11-27[](#151---2019-11-27 "Direct link to [1.5.1] - 2019-11-27")
##### Improvements[](#improvements-115 "Direct link to Improvements")
* When NLU training data is dumped as Markdown file the intents are not longer ordered alphabetically, but in the original order of given training data
##### Bugfixes[](#bugfixes-344 "Direct link to Bugfixes")
* End to end stories now support literal payloads which specify entities, e.g. `greet: /greet{"name": "John"}`
* Slots will be correctly interpolated if there are lists in custom response templates.
* Fixed compatibility issues with `rasa-sdk` `1.5`
* Updated `/status` endpoint to show correct path to model archive
#### \[1.5.0] - 2019-11-26[](#150---2019-11-26 "Direct link to [1.5.0] - 2019-11-26")
##### Features[](#features-33 "Direct link to Features")
* Added data validator that checks if domain object returned is empty. If so, exit early from the command `rasa data validate`.
* Added the KeywordIntentClassifier.
* Added documentation for `AugmentedMemoizationPolicy`.
* Fall back to `InMemoryTrackerStore` in case there is any problem with the current tracker store.
* Arbitrary metadata can now be attached to any `Event` subclass. The data must be stored under the `metadata` key when reading the event from a JSON object or dictionary.
* Add command line argument `rasa x --config CONFIG`, to specify path to the policy and NLU pipeline configuration of your bot (default: `config.yml`).
* Added a new NLU featurizer - `ConveRTFeaturizer` based on [ConveRT](https://github.com/PolyAI-LDN/polyai-models) model released by PolyAI.
* Added a new preconfigured pipeline - `pretrained_embeddings_convert`.
##### Improvements[](#improvements-116 "Direct link to Improvements")
* Do not retrain the entire Core model if only the `templates` section of the domain is changed.
* Upgraded `jsonschema` version.
##### Deprecations and Removals[](#deprecations-and-removals-23 "Direct link to Deprecations and Removals")
* Remove duplicate messages when creating training data (issues/1446).
##### Bugfixes[](#bugfixes-345 "Direct link to Bugfixes")
* `MultiProjectImporter` now imports files in the order of the import statements
* Fixed server hanging forever on leaving `rasa shell` before first message
* Fixed rasa init showing traceback error when user does Keyboard Interrupt before choosing a project path
* `CountVectorsFeaturizer` featurizes intents only if its analyzer is set to `word`
* Fixed bug where facebooks generic template was not rendered when buttons were `None`
* Fixed default intents unnecessarily raising undefined parsing error
#### \[1.4.6] - 2019-11-22[](#146---2019-11-22 "Direct link to [1.4.6] - 2019-11-22")
##### Bugfixes[](#bugfixes-346 "Direct link to Bugfixes")
* Fixed Rasa X not working when any tracker store was configured for Rasa.
* Use the matplotlib backend `agg` in case the `tkinter` package is not installed.
#### \[1.4.5] - 2019-11-14[](#145---2019-11-14 "Direct link to [1.4.5] - 2019-11-14")
##### Bugfixes[](#bugfixes-347 "Direct link to Bugfixes")
* NLU-only models no longer throw warnings about parsing features not defined in the domain
* Fixed bug that stopped Dockerfiles from building version 1.4.4.
* Fixed format guessing for e2e stories with intent restated as `/intent`
#### \[1.4.4] - 2019-11-13[](#144---2019-11-13 "Direct link to [1.4.4] - 2019-11-13")
##### Features[](#features-34 "Direct link to Features")
* `PikaEventProducer` adds the RabbitMQ `App ID` message property to published messages with the value of the `RASA_ENVIRONMENT` environment variable. The message property will not be assigned if this environment variable isn't set.
##### Improvements[](#improvements-117 "Direct link to Improvements")
* Updated Mattermost connector documentation to be more clear.
* Updated format strings to f-strings where appropriate.
* Updated tensorflow requirement to `1.15.0`
* Dump domain using UTF-8 (to avoid `\\UXXXX` sequences in the dumped files)
##### Bugfixes[](#bugfixes-348 "Direct link to Bugfixes")
* Fixed exporting NLU training data in `json` format from `rasa interactive`
* Fixed numpy deprecation warnings
#### \[1.4.3] - 2019-10-29[](#143---2019-10-29 "Direct link to [1.4.3] - 2019-10-29")
##### Bugfixes[](#bugfixes-349 "Direct link to Bugfixes")
* Fixed `Connection reset by peer` errors and bot response delays when using the RabbitMQ event broker.
#### \[1.4.2] - 2019-10-28[](#142---2019-10-28 "Direct link to [1.4.2] - 2019-10-28")
##### Deprecations and Removals[](#deprecations-and-removals-24 "Direct link to Deprecations and Removals")
* TensorFlow deprecation warnings are no longer shown when running `rasa x`
##### Bugfixes[](#bugfixes-350 "Direct link to Bugfixes")
* Fixed `'Namespace' object has no attribute 'persist_nlu_data'` error during interactive learning
* Pinned networkx~=2.3.0 to fix visualization in rasa interactive and Rasa X
* Fixed `No model found` error when using `rasa run actions` with “actions” as a directory.
#### \[1.4.1] - 2019-10-22[](#141---2019-10-22 "Direct link to [1.4.1] - 2019-10-22")
Regression: changes from `1.2.12` were missing from `1.4.0`, readded them
#### \[1.4.0] - 2019-10-19[](#140---2019-10-19 "Direct link to [1.4.0] - 2019-10-19")
##### Features[](#features-35 "Direct link to Features")
* add flag to CLI to persist NLU training data if needed
* log a warning if the `Interpreter` picks up an intent or an entity that does not exist in the domain file.
* added `DynamoTrackerStore` to support persistence of agents running on AWS
* added docstrings for `TrackerStore` classes
* added buttons and images to mattermost.
* `CRFEntityExtractor` updated to accept arbitrary token-level features like word vectors (issues/4214)
* `SpacyFeaturizer` updated to add `ner_features` for `CRFEntityExtractor`
* Sanitizing incoming messages from slack to remove slack formatting like `` or `` and substitute it with original content
* Added the ability to configure the number of Sanic worker processes in the HTTP server (`rasa.server`) and input channel server (`rasa.core.agent.handle_channels()`). The number of workers can be set using the environment variable `SANIC_WORKERS` (default: 1). A value of >1 is allowed only in combination with `RedisLockStore` as the lock store.
* Botframework channel can handle uploaded files in `UserMessage` metadata.
* Added data validator that checks there is no duplicated example data across multiples intents
##### Improvements[](#improvements-118 "Direct link to Improvements")
* Unknown sections in markdown format (NLU data) are not ignored anymore, but instead an error is raised.
* It is now easier to add metadata to a `UserMessage` in existing channels. You can do so by overwriting the method `get_metadata`. The return value of this method will be passed to the `UserMessage` object.
* Tests can now be run in parallel
* Serialise `DialogueStateTracker` as json instead of pickle. **DEPRECATION warning**: Deserialisation of pickled trackers will be deprecated in version 2.0. For now, trackers are still loaded from pickle but will be dumped as json in any subsequent save operations.
* Event brokers are now also passed to custom tracker stores (using the `event_broker` parameter)
* Don't run the Rasa Docker image as `root`.
* Use multi-stage builds to reduce the size of the Rasa Docker image.
* Updated the `/status` api route to use the actual model file location instead of the `tmp` location.
##### Deprecations and Removals[](#deprecations-and-removals-25 "Direct link to Deprecations and Removals")
* **Removed Python 3.5 support**
##### Bugfixes[](#bugfixes-351 "Direct link to Bugfixes")
* fixed missing `tkinter` dependency for running tests on Ubuntu
* fixed issue with `conversation` JSON serialization
* fixed the hanging HTTP call with `ner_duckling_http` pipeline
* fixed Interactive Learning intent payload messages saving in nlu files
* fixed DucklingHTTPExtractor dimensions by actually applying to the request
#### \[1.3.10] - 2019-10-18[](#1310---2019-10-18 "Direct link to [1.3.10] - 2019-10-18")
##### Features[](#features-36 "Direct link to Features")
* Can now pass a package as an argument to the `--actions` parameter of the `rasa run actions` command.
##### Bugfixes[](#bugfixes-352 "Direct link to Bugfixes")
* Fixed visualization of stories with entities which led to a failing visualization in Rasa X
#### \[1.3.9] - 2019-10-10[](#139---2019-10-10 "Direct link to [1.3.9] - 2019-10-10")
##### Features[](#features-37 "Direct link to Features")
* Port of 1.2.10 (support for RabbitMQ TLS authentication and `port` key in event broker endpoint config).
* Port of 1.2.11 (support for passing a CA file for SSL certificate verification via the –ssl-ca-file flag).
##### Bugfixes[](#bugfixes-353 "Direct link to Bugfixes")
* Fixed the hanging HTTP call with `ner_duckling_http` pipeline.
* Fixed text processing of `intent` attribute inside `CountVectorFeaturizer`.
* Fixed `argument of type 'NoneType' is not iterable` when using `rasa shell`, `rasa interactive` / `rasa run`
#### \[1.3.8] - 2019-10-08[](#138---2019-10-08 "Direct link to [1.3.8] - 2019-10-08")
##### Improvements[](#improvements-119 "Direct link to Improvements")
* Policies now only get imported if they are actually used. This removes TensorFlow warnings when starting Rasa X
##### Bugfixes[](#bugfixes-354 "Direct link to Bugfixes")
* Fixed error `Object of type 'MaxHistoryTrackerFeaturizer' is not JSON serializable` when running `rasa train core`
* Default channel `send_` methods no longer support kwargs as they caused issues in incompatible channels
#### \[1.3.7] - 2019-09-27[](#137---2019-09-27 "Direct link to [1.3.7] - 2019-09-27")
##### Bugfixes[](#bugfixes-355 "Direct link to Bugfixes")
* re-added TLS, SRV dependencies for PyMongo
* socketio can now be run without turning on the `--enable-api` flag
* MappingPolicy no longer fails when the latest action doesn't have a policy
#### \[1.3.6] - 2019-09-21[](#136---2019-09-21 "Direct link to [1.3.6] - 2019-09-21")
##### Features[](#features-38 "Direct link to Features")
* Added the ability for users to specify a conversation id to send a message to when using the `RasaChat` input channel.
#### \[1.3.5] - 2019-09-20[](#135---2019-09-20 "Direct link to [1.3.5] - 2019-09-20")
##### Bugfixes[](#bugfixes-356 "Direct link to Bugfixes")
* Fixed issue where `rasa init` would fail without spaCy being installed
#### \[1.3.4] - 2019-09-20[](#134---2019-09-20 "Direct link to [1.3.4] - 2019-09-20")
##### Features[](#features-39 "Direct link to Features")
* Added the ability to set the `backlog` parameter in Sanics `run()` method using the `SANIC_BACKLOG` environment variable. This parameter sets the number of unaccepted connections the server allows before refusing new connections. A default value of 100 is used if the variable is not set.
* Status endpoint (`/status`) now also returns the number of training processes currently running
##### Bugfixes[](#bugfixes-357 "Direct link to Bugfixes")
* Added the ability to properly deal with spaCy `Doc`-objects created on empty strings as discussed in [issue #4445](https://github.com/RasaHQ/rasa/issues/4445 "Rasa issue #4445: Handling spaCy objects on empty strings"). Only training samples that actually bear content are sent to `self.nlp.pipe` for every given attribute. Non-content-bearing samples are converted to empty `Doc`-objects. The resulting lists are merged with their preserved order and properly returned.
* asyncio warnings are now only printed if the callback takes more than 100ms (up from 1ms).
* `agent.load_model_from_server` no longer affects logging.
##### Improvements[](#improvements-120 "Direct link to Improvements")
* The endpoint `POST /model/train` no longer supports specifying an output directory for the trained model using the field `out`. Instead you can choose whether you want to save the trained model in the default model directory (`models`) (default behavior) or in a temporary directory by specifying the `save_to_default_model_directory` field in the training request.
#### \[1.3.3] - 2019-09-13[](#133---2019-09-13 "Direct link to [1.3.3] - 2019-09-13")
##### Bugfixes[](#bugfixes-358 "Direct link to Bugfixes")
* Added a check to avoid training `CountVectorizer` for a particular attribute of a message if no text is provided for that attribute across the training data.
* Default one-hot representation for label featurization inside `EmbeddingIntentClassifier` if label features don't exist.
* Policy ensemble no longer incorrectly wrings “missing mapping policy” when mapping policy is present.
* “text” from `utter_custom_json` now correctly saved to tracker when using telegram channel
##### Deprecations and Removals[](#deprecations-and-removals-26 "Direct link to Deprecations and Removals")
* Removed computation of `intent_spacy_doc`. As a result, none of the spacy components process intents now.
#### \[1.3.2] - 2019-09-10[](#132---2019-09-10 "Direct link to [1.3.2] - 2019-09-10")
##### Bugfixes[](#bugfixes-359 "Direct link to Bugfixes")
* SQL tracker events are retrieved ordered by timestamps. This fixes interactive learning events being shown in the wrong order.
#### \[1.3.1] - 2019-09-09[](#131---2019-09-09 "Direct link to [1.3.1] - 2019-09-09")
##### Improvements[](#improvements-121 "Direct link to Improvements")
* Pin gast to == 0.2.2
#### \[1.3.0] - 2019-09-05[](#130---2019-09-05 "Direct link to [1.3.0] - 2019-09-05")
##### Features[](#features-40 "Direct link to Features")
* Added option to persist nlu training data (default: False)
* option to save stories in e2e format for interactive learning
* bot messages contain the `timestamp` of the `BotUttered` event, which can be used in channels
* `FallbackPolicy` can now be configured to trigger when the difference between confidences of two predicted intents is too narrow
* experimental training data importer which supports training with data of multiple sub bots. Please see the docs for more information.
* throw error during training when triggers are defined in the domain without `MappingPolicy` being present in the policy ensemble
* The tracker is now available within the interpreter's `parse` method, giving the ability to create interpreter classes that use the tracker state (eg. slot values) during the parsing of the message. More details on motivation of this change see issues/3015.
* add example bot `knowledgebasebot` to showcase the usage of `ActionQueryKnowledgeBase`
* `softmax` starspace loss for both `EmbeddingPolicy` and `EmbeddingIntentClassifier`
* `balanced` batching strategy for both `EmbeddingPolicy` and `EmbeddingIntentClassifier`
* `max_history` parameter for `EmbeddingPolicy`
* Successful predictions of the NER are written to a file if `--successes` is set when running `rasa test nlu`
* Incorrect predictions of the NER are written to a file by default. You can disable it via `--no-errors`.
* New NLU component `ResponseSelector` added for the task of response selection
* Message data attribute can contain two more keys - `response_key`, `response` depending on the training data
* New action type implemented by `ActionRetrieveResponse` class and identified with `response_` prefix
* Vocabulary sharing inside `CountVectorsFeaturizer` with `use_shared_vocab` flag. If set to True, vocabulary of corpus is shared between text, intent and response attributes of message
* Added an option to share the hidden layer weights of text input and label input inside `EmbeddingIntentClassifier` using the flag `share_hidden_layers`
* New type of training data file in NLU which stores response phrases for response selection task.
* Add flag `intent_split_symbol` and `intent_tokenization_flag` to all `WhitespaceTokenizer`, `JiebaTokenizer` and `SpacyTokenizer`
* Added evaluation for response selector. Creates a report `response_selection_report.json` inside `--out` directory.
* argument `--config-endpoint` to specify the URL from which `rasa x` pulls the runtime configuration (endpoints and credentials)
* `LockStore` class storing instances of `TicketLock` for every `conversation_id`
* environment variables `SQL_POOL_SIZE` (default: 50) and `SQL_MAX_OVERFLOW` (default: 100) can be set to control the pool size and maximum pool overflow for `SQLTrackerStore` when used with the `postgresql` dialect
* Add a bot\_challenge intent and a utter\_iamabot action to all example projects and the rasa init bot.
* Allow sending attachments when using the socketio channel
* `rasa data validate` will fail with a non-zero exit code if validation fails
##### Improvements[](#improvements-122 "Direct link to Improvements")
* added character-level `CountVectorsFeaturizer` with empirically found parameters into the `supervised_embeddings` NLU pipeline template
* NLU evaluations now also stores its output in the output directory like the core evaluation
* show warning in case a default path is used instead of a provided, invalid path
* compare mode of `rasa train core` allows the whole core config comparison, naming style of models trained for comparison is changed (this is a breaking change)
* pika keeps a single connection open, instead of open and closing on each incoming event
* `RasaChatInput` fetches the public key from the Rasa X API. The key is used to decode the bearer token containing the conversation ID. This requires `rasa-x>=0.20.2`.
* more specific exception message when loading custom components depending on whether component's path or class name is invalid or can't be found in the global namespace
* change priorities so that the `MemoizationPolicy` has higher priority than the `MappingPolicy`
* substitute LSTM with Transformer in `EmbeddingPolicy`
* `EmbeddingPolicy` can now use `MaxHistoryTrackerFeaturizer`
* non zero `evaluate_on_num_examples` in `EmbeddingPolicy` and `EmbeddingIntentClassifier` is the size of hold out validation set that is excluded from training data
* defaults parameters and architectures for both `EmbeddingPolicy` and `EmbeddingIntentClassifier` are changed (this is a breaking change)
* evaluation of NER does not include 'no-entity' anymore
* `--successes` for `rasa test nlu` is now boolean values. If set incorrect/successful predictions are saved in a file.
* `--errors` is renamed to `--no-errors` and is now a boolean value. By default incorrect predictions are saved in a file. If `--no-errors` is set predictions are not written to a file.
* Remove `label_tokenization_flag` and `label_split_symbol` from `EmbeddingIntentClassifier`. Instead move these parameters to `Tokenizers`.
* Process features of all attributes of a message, i.e. - text, intent and response inside the respective component itself. For e.g. - intent of a message is now tokenized inside the tokenizer itself.
* Deprecate `as_markdown` and `as_json` in favour of `nlu_as_markdown` and `nlu_as_json` respectively.
* pin python-engineio >= 3.9.3
* update python-socketio req to >= 4.3.1
##### Bugfixes[](#bugfixes-360 "Direct link to Bugfixes")
* `rasa test nlu` with a folder of configuration files
* `MappingPolicy` standard featurizer is set to `None`
* Removed `text` parameter from send\_attachment function in slack.py to avoid duplication of text output to slackbot
* server `/status` endpoint reports status when an NLU-only model is loaded
##### Deprecations and Removals[](#deprecations-and-removals-27 "Direct link to Deprecations and Removals")
* Removed `--report` argument from `rasa test nlu`. All output files are stored in the `--out` directory.
#### \[1.2.12] - 2019-10-16[](#1212---2019-10-16 "Direct link to [1.2.12] - 2019-10-16")
##### Features[](#features-41 "Direct link to Features")
* Support for transit encryption with Redis via `use_ssl: True` in the tracker store config in endpoints.yml
#### \[1.2.11] - 2019-10-09[](#1211---2019-10-09 "Direct link to [1.2.11] - 2019-10-09")
##### Features[](#features-42 "Direct link to Features")
* Support for passing a CA file for SSL certificate verification via the –ssl-ca-file flag
#### \[1.2.10] - 2019-10-08[](#1210---2019-10-08 "Direct link to [1.2.10] - 2019-10-08")
##### Features[](#features-43 "Direct link to Features")
* Added support for RabbitMQ TLS authentication. The following environment variables need to be set: `RABBITMQ_SSL_CLIENT_CERTIFICATE` - path to the SSL client certificate (required) `RABBITMQ_SSL_CLIENT_KEY` - path to the SSL client key (required) `RABBITMQ_SSL_CA_FILE` - path to the SSL CA file (optional, for certificate verification) `RABBITMQ_SSL_KEY_PASSWORD` - SSL private key password (optional)
* Added ability to define the RabbitMQ port using the `port` key in the `event_broker` endpoint config.
#### \[1.2.9] - 2019-09-17[](#129---2019-09-17 "Direct link to [1.2.9] - 2019-09-17")
##### Bugfixes[](#bugfixes-361 "Direct link to Bugfixes")
* Correctly pass SSL flag values to x CLI command (backport of
#### \[1.2.8] - 2019-09-10[](#128---2019-09-10 "Direct link to [1.2.8] - 2019-09-10")
##### Bugfixes[](#bugfixes-362 "Direct link to Bugfixes")
* SQL tracker events are retrieved ordered by timestamps. This fixes interactive learning events being shown in the wrong order. Backport of `1.3.2` patch (PR #4427).
#### \[1.2.7] - 2019-09-02[](#127---2019-09-02 "Direct link to [1.2.7] - 2019-09-02")
##### Bugfixes[](#bugfixes-363 "Direct link to Bugfixes")
* Added `query` dictionary argument to `SQLTrackerStore` which will be appended to the SQL connection URL as query parameters.
#### \[1.2.6] - 2019-09-02[](#126---2019-09-02 "Direct link to [1.2.6] - 2019-09-02")
##### Bugfixes[](#bugfixes-364 "Direct link to Bugfixes")
* fixed bug that occurred when sending template `elements` through a channel that doesn't support them
#### \[1.2.5] - 2019-08-26[](#125---2019-08-26 "Direct link to [1.2.5] - 2019-08-26")
##### Features[](#features-44 "Direct link to Features")
* SSL support for `rasa run` command. Certificate can be specified using `--ssl-certificate` and `--ssl-keyfile`.
##### Bugfixes[](#bugfixes-365 "Direct link to Bugfixes")
* made default augmentation value consistent across repo
* `'/restart'` will now also restart the bot if the tracker is paused
#### \[1.2.4] - 2019-08-23[](#124---2019-08-23 "Direct link to [1.2.4] - 2019-08-23")
##### Bugfixes[](#bugfixes-366 "Direct link to Bugfixes")
* the `SocketIO` input channel now allows accesses from other origins (fixes `SocketIO` channel on Rasa X)
#### \[1.2.3] - 2019-08-15[](#123---2019-08-15 "Direct link to [1.2.3] - 2019-08-15")
##### Improvements[](#improvements-123 "Direct link to Improvements")
* messages with multiple entities are now handled properly with e2e evaluation
* `data/test_evaluations/end_to_end_story.md` was re-written in the restaurantbot domain
#### \[1.2.3] - 2019-08-15[](#123---2019-08-15-1 "Direct link to [1.2.3] - 2019-08-15")
##### Improvements[](#improvements-124 "Direct link to Improvements")
* messages with multiple entities are now handled properly with e2e evaluation
* `data/test_evaluations/end_to_end_story.md` was re-written in the restaurantbot domain
##### Bugfixes[](#bugfixes-367 "Direct link to Bugfixes")
* Free text input was not allowed in the Rasa shell when the response template contained buttons, which has now been fixed.
#### \[1.2.2] - 2019-08-07[](#122---2019-08-07 "Direct link to [1.2.2] - 2019-08-07")
##### Bugfixes[](#bugfixes-368 "Direct link to Bugfixes")
* `UserUttered` events always got the same timestamp
#### \[1.2.1] - 2019-08-06[](#121---2019-08-06 "Direct link to [1.2.1] - 2019-08-06")
##### Features[](#features-45 "Direct link to Features")
* Docs now have an `EDIT THIS PAGE` button
##### Bugfixes[](#bugfixes-369 "Direct link to Bugfixes")
* `Flood control exceeded` error in Telegram connector which happened because the webhook was set twice
#### \[1.2.0] - 2019-08-01[](#120---2019-08-01 "Direct link to [1.2.0] - 2019-08-01")
##### Features[](#features-46 "Direct link to Features")
* add root route to server started without `--enable-api` parameter
* add `--evaluate-model-directory` to `rasa test core` to evaluate models from `rasa train core -c `
* option to send messages to the user by calling `POST /conversations/\{conversation_id\}/execute`
##### Improvements[](#improvements-125 "Direct link to Improvements")
* `Agent.update_model()` and `Agent.handle_message()` now work without needing to set a domain or a policy ensemble
* Update pytype to `2019.7.11`
* new event broker class: `SQLProducer`. This event broker is now used when running locally with Rasa X
* API requests are not longer logged to `rasa_core.log` by default in order to avoid problems when running on OpenShift (use `--log-file rasa_core.log` to retain the old behavior)
* `metadata` attribute added to `UserMessage`
##### Bugfixes[](#bugfixes-370 "Direct link to Bugfixes")
* `rasa test core` can handle compressed model files
* rasa can handle story files containing multi line comments
* template will retain { if escaped with {. e.g. {{“foo”: {bar}}} will result in {“foo”: “replaced value”}
#### \[1.1.8] - 2019-07-25[](#118---2019-07-25 "Direct link to [1.1.8] - 2019-07-25")
##### Features[](#features-47 "Direct link to Features")
* `TrainingFileImporter` interface to support customizing the process of loading training data
* fill slots for custom templates
##### Improvements[](#improvements-126 "Direct link to Improvements")
* `Agent.update_model()` and `Agent.handle_message()` now work without needing to set a domain or a policy ensemble
* update pytype to `2019.7.11`
##### Bugfixes[](#bugfixes-371 "Direct link to Bugfixes")
* interactive learning bug where reverted user utterances were dumped to training data
* added timeout to terminal input channel to avoid freezing input in case of server errors
* fill slots for image, buttons, quick\_replies and attachments in templates
* `rasa train core` in comparison mode stores the model files compressed (`tar.gz` files)
* slot setting in interactive learning with the TwoStageFallbackPolicy
#### \[1.1.7] - 2019-07-18[](#117---2019-07-18 "Direct link to [1.1.7] - 2019-07-18")
##### Features[](#features-48 "Direct link to Features")
* added optional pymongo dependencies `[tls, srv]` to `requirements.txt` for better mongodb support
* `case_sensitive` option added to `WhiteSpaceTokenizer` with `true` as default.
##### Bugfixes[](#bugfixes-372 "Direct link to Bugfixes")
* validation no longer throws an error during interactive learning
* fixed wrong cleaning of `use_entities` in case it was a list and not `True`
* updated the server endpoint `/model/parse` to handle also messages with the intent prefix
* fixed bug where “No model found” message appeared after successfully running the bot
* debug logs now print to `rasa_core.log` when running `rasa x -vv` or `rasa run -vv`
#### \[1.1.6] - 2019-07-12[](#116---2019-07-12 "Direct link to [1.1.6] - 2019-07-12")
##### Features[](#features-49 "Direct link to Features")
* rest channel supports setting a message's input\_channel through a field `input_channel` in the request body
##### Improvements[](#improvements-127 "Direct link to Improvements")
* recommended syntax for empty `use_entities` and `ignore_entities` in the domain file has been updated from `False` or `None` to an empty list (`[]`)
##### Bugfixes[](#bugfixes-373 "Direct link to Bugfixes")
* `rasa run` without `--enable-api` does not require a local model anymore
* using `rasa run` with `--enable-api` to run a server now prints “running Rasa server” instead of “running Rasa Core server”
* actions, intents, and utterances created in `rasa interactive` can no longer be empty
#### \[1.1.5] - 2019-07-10[](#115---2019-07-10 "Direct link to [1.1.5] - 2019-07-10")
##### Features[](#features-50 "Direct link to Features")
* debug logging now tells you which tracker store is connected
* the response of `/model/train` now includes a response header for the trained model filename
* `Validator` class to help developing by checking if the files have any errors
* project's code is now linted using flake8
* `info` log when credentials were provided for multiple channels and channel in `--connector` argument was specified at the same time
* validate export paths in interactive learning
##### Improvements[](#improvements-128 "Direct link to Improvements")
* deprecate `rasa.core.agent.handle_channels(...)\`. Please use \`\`rasa.run(...)`or`rasa.core.run.configure\_app\` instead.
* `Agent.load()` also accepts `tar.gz` model file
##### Deprecations and Removals[](#deprecations-and-removals-28 "Direct link to Deprecations and Removals")
* revert the stripping of trailing slashes in endpoint URLs since this can lead to problems in case the trailing slash is actually wanted
* starter packs were removed from Github and are therefore no longer tested by Travis script
##### Bugfixes[](#bugfixes-374 "Direct link to Bugfixes")
* all temporal model files are now deleted after stopping the Rasa server
* `rasa shell nlu` now outputs unicode characters instead of `\\uxxxx` codes
* fixed PUT /model with model\_server by deserializing the model\_server to EndpointConfig.
* `x in AnySlotDict` is now `True` for any `x`, which fixes empty slot warnings in interactive learning
* `rasa train` now also includes NLU files in other formats than the Rasa format
* `rasa train core` no longer crashes without a `--domain` arg
* `rasa interactive` now looks for endpoints in `endpoints.yml` if no `--endpoints` arg is passed
* custom files, e.g. custom components and channels, load correctly when using the command line interface
* `MappingPolicy` now works correctly when used as part of a PolicyEnsemble
#### \[1.1.4] - 2019-06-18[](#114---2019-06-18 "Direct link to [1.1.4] - 2019-06-18")
##### Features[](#features-51 "Direct link to Features")
* unfeaturize single entities
* added agent readiness check to the `/status` resource
##### Improvements[](#improvements-129 "Direct link to Improvements")
* removed leading underscore from name of '\_create\_initial\_project' function.
##### Bugfixes[](#bugfixes-375 "Direct link to Bugfixes")
* fixed bug where facebook quick replies were not rendering
* take FB quick reply payload rather than text as input
* fixed bug where training\_data path in metadata.json was an absolute path
#### \[1.1.3] - 2019-06-14[](#113---2019-06-14 "Direct link to [1.1.3] - 2019-06-14")
##### Bugfixes[](#bugfixes-376 "Direct link to Bugfixes")
* fixed any inconsistent type annotations in code and some bugs revealed by type checker
#### \[1.1.2] - 2019-06-13[](#112---2019-06-13 "Direct link to [1.1.2] - 2019-06-13")
##### Bugfixes[](#bugfixes-377 "Direct link to Bugfixes")
* fixed duplicate events appearing in tracker when using a PostgreSQL tracker store
#### \[1.1.1] - 2019-06-13[](#111---2019-06-13 "Direct link to [1.1.1] - 2019-06-13")
##### Bugfixes[](#bugfixes-378 "Direct link to Bugfixes")
* fixed compatibility with Rasa SDK
* bot responses can contain `custom` messages besides other message types
#### \[1.1.0] - 2019-06-13[](#110---2019-06-13 "Direct link to [1.1.0] - 2019-06-13")
##### Features[](#features-52 "Direct link to Features")
* nlu configs can now be directly compared for performance on a dataset in `rasa test nlu`
##### Improvements[](#improvements-130 "Direct link to Improvements")
* update the tracker in interactive learning through reverting and appending events instead of replacing the tracker
* `POST /conversations/\{conversation_id\}/tracker/events` supports a list of events
##### Bugfixes[](#bugfixes-379 "Direct link to Bugfixes")
* fixed creation of `RasaNLUHttpInterpreter`
* form actions are included in domain warnings
* default actions, which are overriden by custom actions and are listed in the domain are excluded from domain warnings
* SQL `data` column type to `Text` for compatibility with MySQL
* non-featurizer training parameters don't break SklearnPolicy anymore
#### \[1.0.9] - 2019-06-10[](#109---2019-06-10 "Direct link to [1.0.9] - 2019-06-10")
##### Improvements[](#improvements-131 "Direct link to Improvements")
* revert PR #3739 (as this is a breaking change): set `PikaProducer` and `KafkaProducer` default queues back to `rasa_core_events`
#### \[1.0.8] - 2019-06-10[](#108---2019-06-10 "Direct link to [1.0.8] - 2019-06-10")
##### Features[](#features-53 "Direct link to Features")
* support for specifying full database urls in the `SQLTrackerStore` configuration
* maximum number of predictions can be set via the environment variable `MAX_NUMBER_OF_PREDICTIONS` (default is 10)
##### Improvements[](#improvements-132 "Direct link to Improvements")
* default `PikaProducer` and `KafkaProducer` queues to `rasa_production_events`
* exclude unfeaturized slots from domain warnings
##### Bugfixes[](#bugfixes-380 "Direct link to Bugfixes")
* loading of additional training data with the `SkillSelector`
* strip trailing slashes in endpoint URLs
#### \[1.0.7] - 2019-06-06[](#107---2019-06-06 "Direct link to [1.0.7] - 2019-06-06")
##### Features[](#features-54 "Direct link to Features")
* added argument `--rasa-x-port` to specify the port of Rasa X when running Rasa X locally via `rasa x`
##### Bugfixes[](#bugfixes-381 "Direct link to Bugfixes")
* slack notifications from bots correctly render text
* fixed usage of `--log-file` argument for `rasa run` and `rasa shell`
* check if correct tracker store is configured in local mode
#### \[1.0.6] - 2019-06-03[](#106---2019-06-03 "Direct link to [1.0.6] - 2019-06-03")
##### Bugfixes[](#bugfixes-382 "Direct link to Bugfixes")
* fixed backwards incompatible utils changes
#### \[1.0.5] - 2019-06-03[](#105---2019-06-03 "Direct link to [1.0.5] - 2019-06-03")
##### Bugfixes[](#bugfixes-383 "Direct link to Bugfixes")
* fixed spacy being a required dependency (regression)
#### \[1.0.4] - 2019-06-03[](#104---2019-06-03 "Direct link to [1.0.4] - 2019-06-03")
##### Features[](#features-55 "Direct link to Features")
* automatic creation of index on the `sender_id` column when using an SQL tracker store. If you have an existing data and you are running into performance issues, please make sure to add an index manually using `CREATE INDEX event_idx_sender_id ON events (sender_id);`.
##### Improvements[](#improvements-133 "Direct link to Improvements")
* NLU evaluation in cross-validation mode now also provides intent/entity reports, confusion matrix, etc.
#### \[1.0.3] - 2019-05-30[](#103---2019-05-30 "Direct link to [1.0.3] - 2019-05-30")
##### Bugfixes[](#bugfixes-384 "Direct link to Bugfixes")
* non-ascii characters render correctly in stories generated from interactive learning
* validate domain file before usage, e.g. print proper error messages if domain file is invalid instead of raising errors
#### \[1.0.2] - 2019-05-29[](#102---2019-05-29 "Direct link to [1.0.2] - 2019-05-29")
##### Features[](#features-56 "Direct link to Features")
* added `domain_warnings()` method to `Domain` which returns a dict containing the diff between supplied `actions`, `intents`, `entities`, `slots` and what's contained in the domain
##### Bugfixes[](#bugfixes-385 "Direct link to Bugfixes")
* fix lookup table files failed to load issues/3622
* buttons can now be properly selected during cmdline chat or when in interactive learning
* set slots correctly when events are added through the API
* mapping policy no longer ignores NLU threshold
* mapping policy priority is correctly persisted
#### \[1.0.1] - 2019-05-21[](#101---2019-05-21 "Direct link to [1.0.1] - 2019-05-21")
##### Bugfixes[](#bugfixes-386 "Direct link to Bugfixes")
* updated installation command in docs for Rasa X
#### \[1.0.0] - 2019-05-21[](#100---2019-05-21 "Direct link to [1.0.0] - 2019-05-21")
##### Features[](#features-57 "Direct link to Features")
* added arguments to set the file paths for interactive training
* added quick reply representation for command-line output
* added option to specify custom button type for Facebook buttons
* added tracker store persisting trackers into a SQL database (`SQLTrackerStore`)
* added rasa command line interface and API
* Rasa HTTP training endpoint at `POST /jobs`. This endpoint will train a combined Rasa Core and NLU model
* `ReminderCancelled(action_name)` event to cancel given action\_name reminder for current user
* Rasa HTTP intent evaluation endpoint at `POST /intentEvaluation`. This endpoints performs an intent evaluation of a Rasa model
* option to create template for new utterance action in `interactive learning`
* you can now choose actions previously created in the same session in `interactive learning`
* add formatter 'black'
* channel-specific utterances via the `- "channel":` key in utterance templates
* arbitrary json messages via the `- "custom":` key in utterance templates and via `utter_custom_json()` method in custom actions
* support to load sub skills (domain, stories, nlu data)
* support to select which sub skills to load through `import` section in `config.yml`
* support for spaCy 2.1
* a model for an agent can now also be loaded from a remote storage
* log level can be set via environment variable `LOG_LEVEL`
* add `--store-uncompressed` to train command to not compress Rasa model
* log level of libraries, such as tensorflow, can be set via environment variable `LOG_LEVEL_LIBRARIES`
* if no spaCy model is linked upon building a spaCy pipeline, an appropriate error message is now raised with instructions for linking one
##### Improvements[](#improvements-134 "Direct link to Improvements")
* renamed all CLI parameters containing any `_` to use dashes `-` instead (GNU standard)
* renamed `rasa_core` package to `rasa.core`
* for interactive learning only include manually annotated and ner\_crf entities in nlu export
* made `message_id` an additional argument to `interpreter.parse`
* changed removing punctuation logic in `WhitespaceTokenizer`
* `training_processes` in the Rasa NLU data router have been renamed to `worker_processes`
* created a common utils package `rasa.utils` for nlu and core, common methods like `read_yaml` moved there
* removed `--num_threads` from run command (server will be asynchronous but running in a single thread)
* the `_check_token()` method in `RasaChat` now authenticates against `/auth/verify` instead of `/user`
* removed `--pre_load` from run command (Rasa NLU server will just have a maximum of one model and that model will be loaded by default)
* changed file format of a stored trained model from the Rasa NLU server to `tar.gz`
* train command uses fallback config if an invalid config is given
* test command now compares multiple models if a list of model files is provided for the argument `--model`
* Merged rasa.core and rasa.nlu server into a single server. See swagger file in `docs/_static/spec/server.yaml` for available endpoints.
* `utter_custom_message()` method in rasa\_core\_sdk has been renamed to `utter_elements()`
* updated dependencies. as part of this, models for spacy need to be reinstalled for 2.1 (from 2.0)
* make sure all command line arguments for `rasa test` and `rasa interactive` are actually used, removed arguments that were not used at all (e.g. `--core` for `rasa test`)
##### Deprecations and Removals[](#deprecations-and-removals-29 "Direct link to Deprecations and Removals")
* removed possibility to execute `python -m rasa_core.train` etc. (e.g. scripts in `rasa.core` and `rasa.nlu`). Use the CLI for rasa instead, e.g. `rasa train core`.
* removed `_sklearn_numpy_warning_fix` from the `SklearnIntentClassifier`
* removed `Dispatcher` class from core
* removed projects: the Rasa NLU server now has a maximum of one model at a time loaded.
##### Bugfixes[](#bugfixes-387 "Direct link to Bugfixes")
* evaluating core stories with two stage fallback gave an error, trying to handle None for a policy
* the `/evaluate` route for the Rasa NLU server now runs evaluation in a parallel process, which prevents the currently loaded model unloading
* added missing implementation of the `keys()` function for the Redis Tracker Store
* in interactive learning: only updates entity values if user changes annotation
* log options from the command line interface are applied (they overwrite the environment variable)
* all message arguments (kwargs in dispatcher.utter methods, as well as template args) are now sent through to output channels
* utterance templates defined in actions are checked for existence upon training a new agent, and a warning is thrown before training if one is missing
---
#### Rasa Pro Services Change Log
All notable changes to Rasa Pro Services will be documented in this page. This product adheres to [Semantic Versioning](https://semver.org/) starting with version 3.3 (initial version).
#### \[3.7.0] - 2025-11-26[](#370---2025-11-26 "Direct link to [3.7.0] - 2025-11-26")
Rasa Pro Services 3.7.0 (2025-11-26)
##### Improvements[](#improvements "Direct link to Improvements")
* Add the original Rasa event message offset to the header of the message being sent to the Kafka dead-letter-queue. This allows easier tracing of the original message in case of errors. The offset header is named `original_offset`.
* Allow skipping of db migration run when starting the Analytics service by setting the environment variable RUN\_ANALYTICS\_DB\_MIGRATIONS to "false". This can be useful in scenarios where migrations have already been applied or when managing migrations separately.
* Add database indexes to analytics tables to improve query performance. The following indexes were added to speed up analytics throughput and reduce query execution time during event processing and transformation:
* `idx_rasa_dialogue_stack_frame_sender_session_seq` on `rasa_dialogue_stack_frame` table
* `idx_rasa_event_pattern_query` on `rasa_event` table
* `idx_rasa_event_stack_query` on `rasa_event` table
* `idx_rasa_event_was_processed` on `rasa_event` table
* `idx_rasa_sender_sender_key` on `rasa_sender` table
* `idx_rasa_session_sender_seq` on `rasa_session` table
* `idx_rasa_turn_sender_session_seq` on `rasa_turn` table
#### \[3.6.2] - 2025-11-25[](#362---2025-11-25 "Direct link to [3.6.2] - 2025-11-25")
Rasa Pro Services 3.6.2 (2025-11-25)
##### Bugfixes[](#bugfixes "Direct link to Bugfixes")
* Implement custom timestamp type inheriting from `sqlalchemy.types.TypeDecorator`. This custom type normalizes and denormalizes timestamp columns across all db tables to ensure consistent timezone handling during inserting and querying.
#### \[3.6.1] - 2025-10-29[](#361---2025-10-29 "Direct link to [3.6.1] - 2025-10-29")
Rasa Pro Services 3.6.1 (2025-10-29)
##### Bugfixes[](#bugfixes-1 "Direct link to Bugfixes")
* Catch all exceptions raised during DialogueStackUpdated event processing and skip the event if an exception occurs. Add the skipped events to the DLQ topic, while allowing other events in the batch to be processed normally.
* Update `urllib3` version to `2.5.0` to address security vulnerabilities CVE-2024-37891 & CVE-2025-50181.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.6.0] - 2025-10-10[](#360---2025-10-10 "Direct link to [3.6.0] - 2025-10-10")
Rasa Pro Services 3.6.0 (2025-10-10)
##### Features[](#features "Direct link to Features")
* Add support for IAM authentication for AWS RDS database in the analytics service. To enable this feature, set the following environment variables:
* `IAM_CLOUD_PROVIDER`: set to `aws` to enable IAM authentication for AWS RDS
* `RASA_ANALYTICS_DB_HOST_NAME`: `` the hostname of the RDS instance
* `RASA_ANALYTICS_DB_PORT`: `` the port of the RDS instance
* `RASA_ANALYTICS_DB_NAME`: `` the name of the database
* `RASA_ANALYTICS_DB_USERNAME`: `` the username to connect to the database
* `AWS_DEFAULT_REGION`: `` the AWS region where the RDS instance is hosted
Additionally, you can also set the following optional environment variables:
* `RASA_ANALYTICS_DB_SSL_MODE`: the SSL mode to use when connecting to the database, e.g. `verify-full` or `verify-ca`
* `RASA_ANALYTICS_DB_SSL_CA_LOCATION`: the path to the SSL root certificate to use when connecting to the database
When these environment variables are set, the analytics service will use IAM authentication to connect to the AWS RDS database.
* Add support for IAM authentication for AWS Managed Streaming for Apache Kafka in the analytics service. To enable this feature, set the following environment variables:
* `IAM_CLOUD_PROVIDER`: set to `aws` to enable IAM authentication for AWS MSK
* `AWS_DEFAULT_REGION`: `` the AWS region where the MSK instance is hosted
* `KAFKA_SECURITY_PROTOCOL`: set to `SASL_SSL` to use SASL over SSL
* `KAFKA_SASL_MECHANISM`: set to `OAUTHBEARER` to use OAuth Bearer token authentication
* `KAFKA_SSL_CA_LOCATION`: the path to the SSL root certificate to use when connecting to the MSK cluster, this can be downloaded from Amazon Trust Services.
When these environment variables are set, the analytics service will use IAM authentication to generate temporary credentials to connect to AWS MSK.
* Configure Analytics service to connect to Kafka broker using mTLS. To enable this feature, set the following environment variables:
* `KAFKA_SSL_CERTFILE_LOCATION`: Path to the client certificate file.
* `KAFKA_SSL_KEYFILE_LOCATION`: Path to the client private key file.
##### Improvements[](#improvements-1 "Direct link to Improvements")
* Add new environment variables for each AWS service integration (RDS, MSK) that indicates whether to use IAM authentication when connecting to the service:
* `KAFKA_MSK_AWS_IAM_ENABLED` - set to `true` to enable IAM authentication for MSK connections.
* `RDS_SQL_DB_AWS_IAM_ENABLED` - set to `true` to enable IAM authentication for RDS connections.
##### Bugfixes[](#bugfixes-2 "Direct link to Bugfixes")
* Refactor the logic for creating new sessions. It now gets the previous event context directly from the database which makes the logic more robust against cases where the in-memory event stream might not have the previous event.
#### \[3.5.10] - 2025-11-25[](#3510---2025-11-25 "Direct link to [3.5.10] - 2025-11-25")
Rasa Pro Services 3.5.10 (2025-11-25)
##### Bugfixes[](#bugfixes-3 "Direct link to Bugfixes")
* Implement custom timestamp type inheriting from `sqlalchemy.types.TypeDecorator`. This custom type normalizes and denormalizes timestamp columns across all db tables to ensure consistent timezone handling during inserting and querying.
#### \[3.5.9] - 2025-10-29[](#359---2025-10-29 "Direct link to [3.5.9] - 2025-10-29")
Rasa Pro Services 3.5.9 (2025-10-29)
##### Bugfixes[](#bugfixes-4 "Direct link to Bugfixes")
* Catch all exceptions raised during DialogueStackUpdated event processing and skip the event if an exception occurs. Add the skipped events to the DLQ topic, while allowing other events in the batch to be processed normally.
* Update `urllib3` version to `2.5.0` to address security vulnerabilities CVE-2024-37891 & CVE-2025-50181.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-1 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.5.8] - 2025-10-10[](#358---2025-10-10 "Direct link to [3.5.8] - 2025-10-10")
Rasa Pro Services 3.5.8 (2025-10-10)
##### Bugfixes[](#bugfixes-5 "Direct link to Bugfixes")
* Refactor the logic for creating new sessions. It now gets the previous event context directly from the database which makes the logic more robust against cases where the in-memory event stream might not have the previous event.
#### \[3.5.7] - 2025-10-06[](#357---2025-10-06 "Direct link to [3.5.7] - 2025-10-06")
Rasa Pro Services 3.5.7 (2025-10-06)
##### Bugfixes[](#bugfixes-6 "Direct link to Bugfixes")
* Add the installation of `zlib` OS dependency to Analytics Dockerfile to fix build issues when running the service.
#### \[3.5.6] - 2025-09-11[](#356---2025-09-11 "Direct link to [3.5.6] - 2025-09-11")
Rasa Pro Services 3.5.6 (2025-09-11)
##### Bugfixes[](#bugfixes-7 "Direct link to Bugfixes")
* Upgrade alpine base image to 3.19 in order to a security vulnerability in alpine:3.17
#### \[3.5.5] - 2025-09-03[](#355---2025-09-03 "Direct link to [3.5.5] - 2025-09-03")
Rasa Pro Services 3.5.5 (2025-09-03)
##### Bugfixes[](#bugfixes-8 "Direct link to Bugfixes")
* Upgrade vulnerabilities:
* `requests` to version `2.32.5`
* `cryptography` to version `43.0.3`
* Fix vulnerabilities in outdated `setuptools` and `pip` installed via the `python:3.9-slim` original base image used by the Analytics Docker image build. Replace `python:3.9-slim` base image with `alpine:3.17` which installs python 3.10. Drop python 3.9 support which has reached its EOL.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-2 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.5.4] - 2025-07-29[](#354---2025-07-29 "Direct link to [3.5.4] - 2025-07-29")
Rasa Pro Services 3.5.4 (2025-07-29)
##### Bugfixes[](#bugfixes-9 "Direct link to Bugfixes")
* Upgrade the following dependencies to fix security vulnerabilities in the analytics service:
* `setuptools` to version 78.1.1
* `gunicorn` to version 23.0.0
* `redshift-connector` to version 2.1.8
* Check if the message has already been processed before processing it. Commit message offset only after it was processed successfully. If message processing fails retry the transaction. If the message offset commit fails, retry the command.
Added environment variables:
* `RETRY_CONNECTION_COUNT` - how many times the connection to the Kafka broker is retried when it fails, Confluent Kafka producer and consumer are recreated on each retry
* `RETRY_DB_TRANSACTION_COUNT` - how many times the DB transaction is retried when it fails
* `KAFKA_SOCKET_KEEP_ALIVE_ENABLED` - whether the socket keep alive is enabled for the Kafka connection. Corresponds to `socket.keepalive.enable` in librdkafka.
* `KAFKA_METADATA_MAX_AGE_MS` - the maximum age of the Kafka metadata in milliseconds. Corresponds to `metadata.max.age.ms` in librdkafka.
* `KAFKA_PRODUCER_RETRIES` - how many times the librdkafka producer retries sending a message when it fails. Corresponds to `retries` in librdkafka.
* `KAFKA_PRODUCER_TIMEOUT_MS` - the timeout for the librdkafka Kafka producer in milliseconds. Corresponds to `request.timeout.ms` in librdkafka.
* `KAFKA_PRODUCER_PARTITIONER` - the partitioner used by the librdkafka Kafka producer. Corresponds to `partitioner` in librdkafka.
* `KAFKA_COMPRESSION_CODEC` - the compression codec used by the librdkafka Kafka producer. Corresponds to `compression.codec` in librdkafka.
* `KAFKA_CONSUMER_HEARTBEAT_INTERVAL_MS` - the heartbeat interval for the librdkafka Kafka consumer in milliseconds. Corresponds to `heartbeat.interval.ms` in librdkafka.
* `KAFKA_CONSUMER_SESSION_TIMEOUT_MS` - the session timeout for the librdkafka Kafka consumer in milliseconds. Corresponds to `session.timeout.ms` in librdkafka.
* `KAFKA_CONSUMER_MAX_POLL_INTERVAL_MS` - the maximum poll interval for the librdkafka Kafka consumer in milliseconds. Corresponds to `max.poll.interval.ms` in librdkafka.
* `MAX_MESSAGES_TO_FETCH` - how many messages are fetched from the queue at once, default is 10
For more info about the librdkafka configuration options see .
#### \[3.5.3] - 2025-06-27[](#353---2025-06-27 "Direct link to [3.5.3] - 2025-06-27")
Rasa Pro Services 3.5.3 (2025-06-27)
##### Bugfixes[](#bugfixes-10 "Direct link to Bugfixes")
* Handle `JsonPatchConflict` exceptions gracefully when loading pre-existing dialogue stack events or when applying current event patches. This prevents the Analytics service from crashing due to conflicts in the JSON patch operations.
#### \[3.5.2] - 2025-05-21[](#352---2025-05-21 "Direct link to [3.5.2] - 2025-05-21")
Rasa Pro Services 3.5.2 (2025-05-21)
##### Bugfixes[](#bugfixes-11 "Direct link to Bugfixes")
* Fixed a bug in Rasa Analytics for Session Creation Logic. A session can be created by events `slot` event with the slot `session_started_metadata` followed by `action` event for `action_session_start` OR just the event `action` for `action_session_start` alone.
#### \[3.5.1] - 2025-05-12[](#351---2025-05-12 "Direct link to [3.5.1] - 2025-05-12")
Rasa Pro Services 3.5.1 (2025-05-12)
##### Bugfixes[](#bugfixes-12 "Direct link to Bugfixes")
* Fix the processing of stack events by the analytics service in the case of multiple parallel conversations whose events are split across several batches consumed by the service.
* Replace sqlalchemy's `DateTime` type with postgresql dialect specific `TIMESTAMP` type in columns that record date and time. This is required to keep fractional seconds precision which is essential when retrieving `stack` events from the database to reconstruct the dialogue stack for each different conversation id.
#### \[3.5.0] - 2025-03-20[](#350---2025-03-20 "Direct link to [3.5.0] - 2025-03-20")
Rasa Pro Services 3.5.0 (2025-03-20)
##### Improvements[](#improvements-2 "Direct link to Improvements")
* MTS: Update MTS to train without the need for NFS.
* MRS: Update MRS to run with bot config and model trained from remote storage instead of using NFS.
##### Bugfixes[](#bugfixes-13 "Direct link to Bugfixes")
* Updated `jinja2`, `werkzeug`, `idna`, `requests`, `zipp` and `urllib3` to address security vulnerabilities.
#### \[3.4.1] - 2025-05-12[](#341---2025-05-12 "Direct link to [3.4.1] - 2025-05-12")
Rasa Pro Services 3.4.1 (2025-05-12)
##### Bugfixes[](#bugfixes-14 "Direct link to Bugfixes")
* Updated `jinja2`, `werkzeug`, `idna`, `requests`, `zipp` and `urllib3` to address security vulnerabilities.
* Fix the processing of stack events by the analytics service in the case of multiple parallel conversations whose events are split across several batches consumed by the service.
* Replace sqlalchemy's `DateTime` type with postgresql dialect specific `TIMESTAMP` type in columns that record date and time. This is required to keep fractional seconds precision which is essential when retrieving `stack` events from the database to reconstruct the dialogue stack for each different conversation id.
#### \[3.4.0] - 2024-12-12[](#340---2024-12-12 "Direct link to [3.4.0] - 2024-12-12")
Rasa Pro Services 3.4.0 (2024-12-12)
##### Improvements[](#improvements-3 "Direct link to Improvements")
* Added Python 3.10 and Python 3.11 support to Rasa Analytics
##### Bugfixes[](#bugfixes-15 "Direct link to Bugfixes")
* MTS and MRS: Add retry capability to Kubernetes API calls on `5xx` errors.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-3 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.3.5] - 2024-10-29[](#335---2024-10-29 "Direct link to [3.3.5] - 2024-10-29")
Rasa Pro Services 3.3.5 (2024-10-29)
##### Bugfixes[](#bugfixes-16 "Direct link to Bugfixes")
* MTS and MRS: Add retry capability to Kubernetes API calls on `5xx` errors.
#### \[3.3.4] - 2024-10-02[](#334---2024-10-02 "Direct link to [3.3.4] - 2024-10-02")
Rasa Pro Services 3.3.4 (2024-10-02)
##### Bugfixes[](#bugfixes-17 "Direct link to Bugfixes")
* Return status code 503 when the Analytics service is unavailable during a healthcheck request. This allows the user to implement liveness probes that could automatically restart the service upon failure.
#### \[3.3.3] - 2024-09-25[](#333---2024-09-25 "Direct link to [3.3.3] - 2024-09-25")
Rasa Pro Services 3.3.3 (2024-09-25)
##### Bugfixes[](#bugfixes-18 "Direct link to Bugfixes")
* MTS: Fix bug (ATO-2257) when training pod's status is not caught when MTS consumer job restarts.
* \[MTS] Update certifi to 2023.7.22 to resolve vulnerability CVE-2023-37920.
#### \[3.3.2] - 2024-05-28[](#332---2024-05-28 "Direct link to [3.3.2] - 2024-05-28")
Rasa Pro Services 3.3.2 (2024-05-28)
##### Improvements[](#improvements-4 "Direct link to Improvements")
* MRS: Upload rasa pod logs to remote storage for user-friendly access to logs in case the running of the assistant fails.
#### \[3.3.1] - 2024-05-27[](#331---2024-05-27 "Direct link to [3.3.1] - 2024-05-27")
Rasa Pro Services 3.3.1 (2024-05-27)
##### Bugfixes[](#bugfixes-19 "Direct link to Bugfixes")
* Allow users to specify image pull secrets for MTS / MRS
#### \[3.3.0] - 2024-04-03[](#330---2024-04-03 "Direct link to [3.3.0] - 2024-04-03")
Rasa Pro Services 3.3.0 (2024-04-03)
##### Improvements[](#improvements-5 "Direct link to Improvements")
* Align column names representing the `flow_id` as defined in the yaml file across `rasa_flow_status`, `rasa_llm_command` and `rasa_dialogue_stack_frame` tables:
* `rasa_llm_command` table: `flow_name` column has been renamed to `flow_identifier`.
* `rasa_dialogue_stack_frame` table: `active_flow` column has been renamed to `active_flow_identifier`.
* MTS: Handle MTS Job Consumer restarts when rasa training pod continues to run. If the `TrainingManager` finds a running training job when it restarts, it will check the status of the pod:
* If the pod is pending or running, it will watch the pod until training is complete.
* If the pod has completed, it will upload the logs and trained model (only if it is present).
* MTS: Accept `nlu` in the config data of CALM assistants in order to use `nlu_triggers`.
* MTS and MRS: Support debug logs in rasa pods.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-4 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.2.3] - 2023-12-20[](#323---2023-12-20 "Direct link to [3.2.3] - 2023-12-20")
Rasa Pro Services 3.2.3 (2023-12-20)
##### Improvements[](#improvements-6 "Direct link to Improvements")
* MTS: Setup alembic schema migration mechanism for the database of the model training orchestrator. Add initial table creation migration file.
* \[MTS] Add capability to configure log level for MTS orchestrator. Log level can be configured through `LOG_LEVEL` environment variable. Default log level is `INFO`.
##### Bugfixes[](#bugfixes-20 "Direct link to Bugfixes")
* Fix telemetry reporting in shipped Docker images.
#### \[3.2.2] - 2023-12-05[](#322---2023-12-05 "Direct link to [3.2.2] - 2023-12-05")
Rasa Pro Services 3.2.2 (2023-12-05)
##### Bugfixes[](#bugfixes-21 "Direct link to Bugfixes")
* Remove obsolete component RemoteGCSFetcher from MTS orchestrator.
#### \[3.2.1] - 2023-12-01[](#321---2023-12-01 "Direct link to [3.2.1] - 2023-12-01")
Rasa Pro Services 3.2.1 (2023-12-01)
##### Improvements[](#improvements-7 "Direct link to Improvements")
* Align column names representing the `flow_id` as defined in the yaml file across `rasa_flow_status`, `rasa_llm_command` and `rasa_dialogue_stack_frame` tables:
* `rasa_llm_command` table: `flow_name` column has been renamed to `flow_identifier`.
* `rasa_dialogue_stack_frame` table: `active_flow` column has been renamed to `active_flow_identifier`.
* Add environment variables to control resource requirements and limits for Rasa pod. MTS and MRS job consumers can now be configured to use specify resource requirements and limits for the Rasa pod. This can be done by setting the following environment variables in the Rasa pod:
* RASA\_REQUESTS\_CPU
* RASA\_REQUESTS\_MEMORY
* RASA\_LIMITS\_CPU
* RASA\_LIMITS\_MEMORY
#### \[3.2.0] - 2023-11-22[](#320---2023-11-22 "Direct link to [3.2.0] - 2023-11-22")
Rasa Pro Services 3.2.0 (2023-11-22)
##### Features[](#features-1 "Direct link to Features")
* Added new table `rasa_dialogue_stack_frame` to store active flow names and steps for each event sequence in the conversation.
* Add new table `rasa_llm_command` to store LLM generated commands for each user message. Add new column in the `_rasa_raw_event` table to store the serialized LLM generated commands.
* Add new table `rasa_flow_status` to store the transformations of rasa flow events. Add new columns in the `_rasa_raw_event` table to store the flow\_id and step\_id of these events where applicable.
#### \[3.1.1] - 2023-07-17[](#311---2023-07-17 "Direct link to [3.1.1] - 2023-07-17")
Rasa Pro Services 3.1.1 (2023-07-17)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-5 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.1.0] - 2023-07-03[](#310---2023-07-03 "Direct link to [3.1.0] - 2023-07-03")
Rasa Pro Services 3.1.0 (2023-07-03)
##### Features[](#features-2 "Direct link to Features")
* Added Real Time Processing of Markers. Markers can now be evaluated real time by the Analytics Data Pipeline. We've added event handlers for evaluation all events from Kafka to extract markers. The extracted markers are saved into `rasa_marker` database table. These markers are evaluated with the patterns stored in `rasa_pattern` table.
Added API endpoints to create patterns in `rasa_pattern` table. This endpoint is used by Rasa Plus for `rasa markers upload` command.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-6 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.0.2] - 2023-06-13[](#302---2023-06-13 "Direct link to [3.0.2] - 2023-06-13")
Rasa Pro Services 3.0.2 (2023-06-13)
##### Improvements[](#improvements-8 "Direct link to Improvements")
* Adds an environment variable to control logging level of the application.
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-7 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.0.1] - 2022-10-26[](#301---2022-10-26 "Direct link to [3.0.1] - 2022-10-26")
Rasa Pro Services 3.0.1 (2023-10-26)
##### Miscellaneous internal changes[](#miscellaneous-internal-changes-8 "Direct link to Miscellaneous internal changes")
*Miscellaneous internal changes.*
#### \[3.0.0] - 2022-10-24[](#300---2022-10-24 "Direct link to [3.0.0] - 2022-10-24")
Rasa Pro Services 3.0.0 (2023-10-24)
##### Features[](#features-3 "Direct link to Features")
* Analytics Data Pipeline helps visualize and process Rasa assistant metrics in the tooling (BI tools, data warehouses) of your choice. Visualizations and analysis of the production assistant and its conversations allow you to assess ROI and improve the performance of the assistant over time.
---
#### Rasa Pro Version Migration Guide
This page contains information about changes between major versions and how you can migrate from one version to another.
#### Rasa Pro 3.14 to Rasa Pro 3.15[](#rasa-pro-314-to-rasa-pro-315 "Direct link to Rasa Pro 3.14 to Rasa Pro 3.15")
##### Changes to `invoke_llm` Method Signature[](#changes-to-invoke_llm-method-signature "Direct link to changes-to-invoke_llm-method-signature")
As part of the Langfuse integration for tracing LLM calls, the `invoke_llm` method signature has been updated to use `LLMInput` instead of a plain prompt string. This change enables passing metadata (such as session ID, component name, and model ID) to LLM calls for better observability.
This breaking change affects any custom components that override the `invoke_llm` method in the following components:
* `CompactLLMCommandGenerator`
* `SearchReadyLLMCommandGenerator`
* `ContextualResponseRephraser`
* `EnterpriseSearchPolicy`
* `IntentlessPolicy`
* `LLMBasedRouter`
###### Migration Guide[](#migration-guide "Direct link to Migration Guide")
If you have custom components that override `invoke_llm`, you need to update the method signature and how you call the LLM:
* Rasa Pro 3.14
* Rasa Pro 3.15
```
from rasa.shared.utils.llm import llm_factory, DEFAULT_LLM_CONFIG
from rasa.shared.constants import LLM_CONFIG_KEY
async def invoke_llm(self, prompt: str) -> Optional[str]:
"""Use LLM to generate a response.
Args:
prompt: The prompt to send to the LLM.
Returns:
The generated text.
"""
llm = llm_factory(self.config.get(LLM_CONFIG_KEY), DEFAULT_LLM_CONFIG)
try:
llm_response = await llm.acompletion(prompt)
return llm_response.choices[0]
except Exception as e:
structlogger.error("component.llm.error", error=e)
raise ProviderClientAPIException(
message="LLM call exception", original_exception=e
)
```
```
from rasa.shared.utils.llm import llm_factory, DEFAULT_LLM_CONFIG, LLMInput
from rasa.shared.providers.llm.llm_response import LLMResponse
from rasa.shared.constants import LLM_CONFIG_KEY
async def invoke_llm(self, llm_input: LLMInput) -> Optional[LLMResponse]:
"""Use LLM to generate a response.
Args:
llm_input: The LLM input containing the prompt and metadata.
Returns:
The LLM response object.
"""
llm = llm_factory(self.config.get(LLM_CONFIG_KEY), DEFAULT_LLM_CONFIG)
try:
llm_response = await llm.acompletion(
llm_input.prompt, metadata=llm_input.metadata
)
return llm_response
except Exception as e:
structlogger.error("component.llm.error", error=e)
raise ProviderClientAPIException(
message="LLM call exception", original_exception=e
)
```
###### Creating LLMInput[](#creating-llminput "Direct link to Creating LLMInput")
When calling `invoke_llm`, you now need to create an `LLMInput` object that includes both the prompt and metadata:
```
from rasa.shared.utils.llm import LLMInput
# Create LLMInput with prompt and metadata
llm_input = LLMInput(
prompt=your_prompt,
metadata=self.get_llm_tracing_metadata(tracker)
)
# Call invoke_llm with LLMInput
response = await self.invoke_llm(llm_input)
```
The `get_llm_tracing_metadata()` method is available in all LLM-based components and returns a dictionary with session ID, tags, and custom metadata.
##### Changes to Pattern Clarification[](#changes-to-pattern-clarification "Direct link to Changes to Pattern Clarification")
We modified the `pattern_clarification` to handle empty clarification options. Here is a comparison between the old and new implementations:
* Rasa Pro 3.14
* Rasa Pro 3.15
```
pattern_clarification:
description: Conversation repair flow for handling ambiguous requests that could match multiple flows
name: pattern clarification
steps:
- action: action_clarify_flows
- action: utter_clarification_options_rasa
```
```
pattern_clarification:
description: Conversation repair flow for handling ambiguous requests that could match multiple flows
name: pattern clarification
steps:
- noop: true
next:
- if: context.names
then: action_clarify_flows
- else:
- action: utter_clarification_no_options_rasa
next: END
- id: action_clarify_flows
action: action_clarify_flows
- action: utter_clarification_options_rasa
```
##### Changes to `AgentInput` and `AgentOutput`[](#changes-to-agentinput-and-agentoutput "Direct link to changes-to-agentinput-and-agentoutput")
**Migration Impact**: These changes enable intermediate message support for sub agents. If you have custom agent implementations, you may need to update your code to handle the new fields.
To enable sending intermediate messages from sub agents, we updated the `AgentInput` and `AgentOutput` schemas:
**`AgentInput` Changes:**
* Added `recipient_id: Optional[str] = None` field to ensure intermediate messages are sent to the correct recipient
**`AgentOutput` Changes:**
* Changed the `events` field from `Optional[List[SlotSet]]` to `Optional[List[Event]]` to support bot uttered events for intermediate messages sent to users
##### Changes to Agent Protocol[](#changes-to-agent-protocol "Direct link to Changes to Agent Protocol")
**Migration Impact**: If you have custom agent protocol implementations, you need to update the `run` method signature to accept the optional `output_channel` parameter.
We added an `output_channel` parameter to the agent protocol's `run` method signature to allow sending intermediate messages directly to users via the output channel:
```
async def run(
self, input: "AgentInput", output_channel: Optional[OutputChannel] = None
) -> "AgentOutput":
"""Send a message to Agent/server and return response.
Args:
input: The agent input containing user message and context
output_channel: Optional output channel for sending intermediate messages
Returns:
The agent output containing response and status
"""
```
##### Updated Default Prompts to Support Current Date Time in Prompts[](#updated-default-prompts-to-support-current-date-time-in-prompts "Direct link to Updated Default Prompts to Support Current Date Time in Prompts")
The default prompt templates for all components that support including current date and time information have been updated to include a "Date & Time Context" section. By default, `include_date_time` is enabled, so prompts will automatically include date and time context unless explicitly disabled. This change affects the following components:
* `CompactLLMCommandGenerator`
* `SearchReadyLLMCommandGenerator`
* `EnterpriseSearchPolicy`
* `MCPOpenAgent` (with timezone support)
* `MCPTaskAgent` (with timezone support)
###### What Changed[](#what-changed "Direct link to What Changed")
By default, the prompts now automatically include a "Date & Time Context" section that displays:
* Current date (formatted as "DD Month, YYYY")
* Current time (formatted as "HH:MM
:SS
" with timezone)
* Current day of the week
This context is added to help LLMs understand temporal references and provide time-aware responses.
###### Impact[](#impact "Direct link to Impact")
If you have custom prompt templates that override the default templates, you may want to review them to ensure they are compatible with the new DateTime context format. The DateTime context is conditionally included using Jinja2 template syntax:
```
{% if current_datetime %}
---
### Date & Time Context
- Current date: {{ current_datetime.strftime("%d %B, %Y") }} (DD Month, YYYY)
- Current time: {{ current_datetime.strftime("%H:%M:%S") }} ({{ current_datetime.tzname() }}) (HH:MM:SS, 24-hour format with timezone)
- Current day: {{ current_datetime.strftime("%A") }} (Day of week)
{% endif %}
```
###### Migration Steps[](#migration-steps "Direct link to Migration Steps")
1. **Review your custom prompt templates** (if any) to ensure they work with the new DateTime context format. The DateTime context is included by default, so your templates should handle the `current_datetime` variable.
2. **Test your components** to verify the prompts render correctly with the date and time context included.
3. **If you want to disable date/time context**, you can set `include_date_time: false` in your component configuration:
config.yml
```
pipeline:
- name: CompactLLMCommandGenerator
include_date_time: false
```
If you're using the default prompt templates, no action is required, the DateTime context will be automatically included by default.
#### Rasa Pro 3.13 to Rasa Pro 3.14[](#rasa-pro-313-to-rasa-pro-314 "Direct link to Rasa Pro 3.13 to Rasa Pro 3.14")
##### Dependencies[](#dependencies "Direct link to Dependencies")
info
To avoid any conflicts we strongly recommend using a fresh environment when installing Rasa >=3.14.0.
The default `pip` package for `rasa-pro` now supports Python versions `3.12` and `3.13`, and drops support for Python version `3.9`.
The package will exclude the following dependency categories:
1. **`nlu`** - All dependencies required to run NLU/coexistence bots, including: `transformers`, `tensorflow` (and related packages: `tensorflow-text`, `tensorflow-hub`, `tensorflow-gcs-filesystem`, `tensorflow-metal`, `tf-keras`), `spacy`, `sentencepiece`, `skops`, `mitie`, `jieba`, `sklearn-crfsuite`.
2. **`channels`** - All dependencies required to connect to channel connectors, including: `fbmessenger`, `twilio`, `webexteamssdk`, `mattermostwrapper`, `rocketchat_API`, `aiogram`, `slack-sdk`, `cvg-python-sdk`. *Note*: The following channels are **NOT** included in the channels extra: `browser_audio`, `studio_chat`, `socketIO`, and `rest` (used by inspector for text and voice).
Optional dependency categories are available to install the relevant packages. Use `pip install rasa-pro[nlu]` if you have an agent with NLU components. Similarly use `pip install rasa-pro[channels]` if you have an agent making use of channel connectors.
Docker images will continue to have the same dependencies as previously, except for the additional packages `mcp` and `a2a-sdk` which now form part of the core dependencies.
**Important**: `tensorflow` and its related dependencies are only supported for `"python_version < '3.12'"`, so components requiring TensorFlow are not available for Python ≥ 3.12. These components are: `DIETClassifier`, `TEDPolicy`, `UnexpecTEDIntentPolicy`, `ResponseSelector`, `ConveRTFeaturizer`, and `LanguageModelFeaturizer`.
##### Pattern Continue Interrupted[](#pattern-continue-interrupted "Direct link to Pattern Continue Interrupted")
We modified the `pattern_continue_interrupted` to ask for confirmation before returning to an interrupted flow. Here is an example conversation comparing the old and new implementations:
* Old
* New
```
user: I want to transfer money
bot: how much do you want to transfer?
user: wait what's my balance?
bot: you have 4200 in your account
bot: how much do you want to transfer? # immediately returns to the interrupted flow
```
```
user: I want to transfer money
bot: how much do you want to transfer?
user: wait what's my balance?
bot: you have 4200 in your account
bot: Would you like to go back to transferring money? # asks for confirmation before continuing
```
**Rationale for this change:**
1. **Improved UX**: Immediately returning to interrupted flows often creates an unnatural conversational experience.
2. **Error Correction**: Sometimes the command generator incorrectly identifies a cancellation + start flow as a digression. This change allows users to guide the assistant in correcting these mistakes.
3. **Agent Integration**: Sub agents sometimes don't have a reliable way to signal completion. When these agents are wrapped in flows and a digression occurs, we need user input to determine if the agent's task is complete.
Here is the comparison between the old and the new `pattern_continue_interrupted`.
* Old
* New
```
pattern_continue_interrupted:
description: Conversation repair flow for managing when users switch between different flows
name: pattern continue interrupted
steps:
- action: utter_flow_continue_interrupted
```
```
pattern_continue_interrupted:
description: Conversation repair flow for managing when users switch between different flows
name: pattern continue interrupted
steps:
- noop: true
next:
- if: context.multiple_flows_interrupted
then: collect_interrupted_flow_to_continue
- else: collect_continue_interrupted_flow_confirmation
- id: collect_interrupted_flow_to_continue
collect: interrupted_flow_to_continue
description: "Fill this slot with the name of the flow the user wants to continue. If the user does not want to continue any of the interrupted flows, fill this slot with 'none'."
next:
- if: slots.interrupted_flow_to_continue is not "none"
then:
- action: action_continue_interrupted_flow
next: END
- else:
- action: action_cancel_interrupted_flows
next: END
- id: collect_continue_interrupted_flow_confirmation
collect: continue_interrupted_flow_confirmation
description: "If the user wants to continue the interrupted flow, fill this slot with true. If the user does not want to continue the interrupted flow, fill this slot with false."
next:
- if: slots.continue_interrupted_flow_confirmation
then:
- action: action_continue_interrupted_flow
next: END
- else:
- action: action_cancel_interrupted_flows
next: END
```
##### Command Generator[](#command-generator "Direct link to Command Generator")
###### Prompt Template[](#prompt-template "Direct link to Prompt Template")
**No Action Required**: If you don't use sub agents, your prompt templates remain unchanged.
**Migration Required**: When sub agents are used, Rasa automatically switches to new default prompts that include agent support. If you have customized prompt templates for the `CompactLLMCommandGenerator` or `SearchReadyLLMCommandGenerator`, you must update your custom prompts to include the new agent-related commands and functionality.
**Prompt Templates of the `CompactLLMCommandGenerator`**
* GPT-4o with Agent Support
* Claude 3.5 Sonnet with Agent Support
The prompt template for the `gpt-4o-2024-11-20` model with agent support is as follows:
````
## Task Description
Your task is to analyze the current conversation context and generate a list of actions to start new business processes that we call flows, to extract slots, or respond to small talk and knowledge requests.
---
## Available Flows and Slots
Use the following structured data:
```json
{"flows":[{% for flow in available_flows %}{"name":"{{ flow.name }}","description":{{ flow.description | to_json_escaped_string }}{% if flow.agent_info %},"sub-agents":[{% for agent in flow.agent_info %}{"name":"{{ agent.name }}","description":{{ agent.description | to_json_escaped_string }}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}{% if flow.slots %},"slots":[{% for slot in flow.slots %}{"name":"{{ slot.name }}"{% if slot.description %},"description":{{ slot.description | to_json_escaped_string }}{% endif %}{% if slot.allowed_values %},"allowed_values":{{ slot.allowed_values }}{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]}
```
---
## Available Actions:
* `start flow flow_name`: Starting a flow. For example, `start flow transfer_money` or `start flow list_contacts`.
* `set slot slot_name slot_value`: Slot setting. For example, `set slot transfer_money_recipient Freddy`. Can be used to correct and change previously set values. ONLY use slots that are explicitly defined in the flow's slot list.
* `cancel flow`: Cancelling the current flow.
* `disambiguate flows flow_name1 flow_name2 ... flow_name_n`: Disambiguate which flow should be started when user input is ambiguous by listing the potential flows as options. For example, `disambiguate flows list_contacts add_contact remove_contact ...` if the user just wrote "contacts".
* `provide info`: Responding to the user's questions by supplying relevant information, such as answering FAQs or explaining services.
* `offtopic reply`: Responding to casual or social user messages that are unrelated to any flows, engaging in friendly conversation and addressing off-topic remarks.
* `hand over`: Handing over to a human, in case the user seems frustrated or explicitly asks to speak to one.
* `repeat message`: Repeating the last bot message.{% if active_agent %}
* `continue agent`: Continue the currently active agent {{ active_agent.name }}. This has HIGHEST PRIORITY when an agent is active and the user is responding to agent questions.{% endif %}{% if completed_agents %}
* `restart agent agent_name`: Restart the agent with the given name, in case the user wants to change some answer to a previous question asked by the agent. For example, `restart agent car_research_agent` if the user changed his mind about the car he wants to buy. ONLY use agents that are listed in the `completed_agents` section.{% endif %}
---
## General Tips
* Do not fill slots with abstract values or placeholders.
* For categorical slots try to match the user message with allowed slot values. Use "other" if you cannot match it.
* Set the boolean slots based on the user response. Map positive responses to `True`, and negative to `False`.
* Extract text slot values exactly as provided by the user. Avoid assumptions, format changes, or partial extractions.
* ONLY use `set slot` with slots that are explicitly defined in the current flow's slot list. Do NOT create or assume slots that don't exist.
* Only use information provided by the user.
* Use clarification in ambiguous cases.
* Multiple flows can be started. If a user wants to digress into a second flow, you do not need to cancel the current flow.
* Do not cancel the flow unless the user explicitly requests it.
* Strictly adhere to the provided action format.
* ONLY use the exact actions listed above. Do NOT invent new actions like "respond " or any other variations.
* Focus on the last message and take it one step at a time.
* Use the previous conversation steps only to aid understanding.{% if active_agent %}
* When an agent is active, ALWAYS prioritize `continue agent` over `provide info` or `offtopic reply` unless the user is clearly asking something unrelated to the agent's task.{% endif %}{% if completed_agents %}
* ONLY use `restart agent` with agents that are listed in the `completed_agents` section. Do NOT restart non-existent agents.{% endif %}{% if active_agent or completed_agents %}
* If you're unsure about agent names, refer to the structured data provided in the `Current State` section.{% endif %}
---
## Current State
{% if current_flow != None %}
Use the following structured data:
```json
{"active_flow":{"name":"{{ current_flow }}","current_step":{"requested_slot":"{{ current_slot }}","requested_slot_description":{{ current_slot_description | to_json_escaped_string }}},"slots":[{% for slot in flow_slots %}{"name":"{{ slot.name }}","value":"{{ slot.value }}","type":"{{ slot.type }}"{% if slot.description %},"description":{{ slot.description | to_json_escaped_string }}{% endif %}{% if slot.allowed_values %},"allowed_values":"{{ slot.allowed_values }}"{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]}{% if active_agent %},"active_agent":{"name":"{{ active_agent.name }}","description":{{ active_agent.description | to_json_escaped_string }}}{% endif %}{% if completed_agents %},"completed_agents":[{% for agent in completed_agents %}{"name":"{{ agent.name }}","description":{{ agent.description | to_json_escaped_string }}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}}
```{% else %}
You are currently not inside any flow.{% endif %}
---
## Conversation History
{{ current_conversation }}
---
## Task
Create an action list with one action per line in response to the user's last message: """{{ user_message }}""".
Your action list:
````
The prompt template for the `claude-3-5-sonnet-20240620` / `anthropic.claude-3-5-sonnet-20240620-v1:0` model with agent support is as follows:
````
## Task Description
Your task is to analyze the current conversation context and generate a list of actions to start new business processes that we call flows, to extract slots, or respond to small talk and knowledge requests.
--
## Available Actions:
* `start flow flow_name`: Starting a flow. For example, `start flow transfer_money` or `start flow list_contacts`.
* `set slot slot_name slot_value`: Slot setting. For example, `set slot transfer_money_recipient Freddy`. Can be used to correct and change previously set values. ONLY use slots that are explicitly defined in the flow's slot list.
* `cancel flow`: Cancelling the current flow.
* `disambiguate flows flow_name1 flow_name2 ... flow_name_n`: Disambiguate which flow should be started when user input is ambiguous by listing the potential flows as options. For example, `disambiguate flows list_contacts add_contact remove_contact ...` if the user just wrote "contacts".
* `provide info`: Responding to the user's questions by supplying relevant information, such as answering FAQs or explaining services.
* `offtopic reply`: Responding to casual or social user messages that are unrelated to any flows, engaging in friendly conversation and addressing off-topic remarks.
* `hand over`: Handing over to a human, in case the user seems frustrated or explicitly asks to speak to one.
* `repeat message`: Repeating the last bot message.{% if active_agent %}
* `continue agent`: Continue the currently active agent {{ active_agent.name }}. This has HIGHEST PRIORITY when an agent is active and the user is responding to agent questions.{% endif %}{% if completed_agents %}
* `restart agent agent_name`: Restart the agent with the given name, in case the user wants to change some answer to a previous question asked by the agent. For example, `restart agent car_research_agent` if the user changed his mind about the car he wants to buy. ONLY use agents that are listed in the `completed_agents` section.{% endif %}
--
## General Tips
* Do not fill slots with abstract values or placeholders.
* For categorical slots try to match the user message with allowed slot values. Use "other" if you cannot match it.
* Set the boolean slots based on the user response. Map positive responses to `True`, and negative to `False`.
* Always refer to the slot description to determine what information should be extracted and how it should be formatted.
* For text slots, extract values exactly as provided by the user unless the slot description specifies otherwise. Preserve formatting and avoid rewording, truncation, or making assumptions.
* ONLY use `set slot` with slots that are explicitly defined in the current flow's slot list. Do NOT create or assume slots that don't exist.
* Only use information provided by the user.
* Use clarification in ambiguous cases.
* Multiple flows can be started. If a user wants to digress into a second flow, you do not need to cancel the current flow.
* Do not cancel the flow unless the user explicitly requests it.
* Strictly adhere to the provided action format.
* ONLY use the exact actions listed above. Do NOT invent new actions like "respond " or any other variations.
* Focus on the last message and take it one step at a time.
* Use the previous conversation steps only to aid understanding.{% if active_agent %}
* When an agent is active, ALWAYS prioritize `continue agent` over `provide info` or `offtopic reply` unless the user is clearly asking something unrelated to the agent's task.{% endif %}{% if completed_agents %}
* ONLY use `restart agent` with agents that are listed in the `completed_agents` section. Do NOT restart non-existent agents.{% endif %}{% if active_agent or completed_agents %}
* If you're unsure about agent names, refer to the structured data provided in the `Current State` section.{% endif %}
--
## Available Flows and Slots
Use the following structured data:
```json
{"flows":[{% for flow in available_flows %}{"name":"{{ flow.name }}","description":{{ flow.description | to_json_escaped_string }}{% if flow.agent_info %},"sub-agents":[{% for agent in flow.agent_info %}{"name":"{{ agent.name }}","description":{{ agent.description | to_json_escaped_string }}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}{% if flow.slots %},"slots":[{% for slot in flow.slots %}{"name":"{{ slot.name }}"{% if slot.description %},"description":{{ slot.description | to_json_escaped_string }}{% endif %}{% if slot.allowed_values %},"allowed_values":{{ slot.allowed_values }}{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]}
```
--
## Current State
{% if current_flow != None %}Use the following structured data:
```json
{"active_flow":{"name":"{{ current_flow }}","current_step":{"requested_slot":"{{ current_slot }}","requested_slot_description":{{ current_slot_description | to_json_escaped_string }}},"slots":[{% for slot in flow_slots %}{"name":"{{ slot.name }}","value":"{{ slot.value }}","type":"{{ slot.type }}"{% if slot.description %},"description":{{ slot.description | to_json_escaped_string }}{% endif %}{% if slot.allowed_values %},"allowed_values":"{{ slot.allowed_values }}"{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]}{% if active_agent %},"active_agent":{"name":"{{ active_agent.name }}","description":{{ active_agent.description | to_json_escaped_string }}}{% endif %}{% if completed_agents %},"completed_agents":[{% for agent in completed_agents %}{"name":"{{ agent.name }}","description":{{ agent.description | to_json_escaped_string }}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}}
```{% else %}
You are currently not inside any flow.{% endif %}
---
## Conversation History
{{ current_conversation }}
---
## Task
Create an action list with one action per line in response to the user's last message: """{{ user_message }}""".
Your action list:
````
**Prompt Templates of the `SearchReadyLLMCommandGenerator`**
* GPT-4o with Agent Support
* Claude 3.5 Sonnet with Agent Support
The prompt template for the `gpt-4o-2024-11-20` model with agent support is as follows:
````
## Task Description
Your task is to analyze the current conversation context and generate a list of actions to start new business processes that we call flows, to extract slots, or respond to off-topic and knowledge requests.
---
## Available Flows and Slots
Use the following structured data:
```json
{"flows":[{% for flow in available_flows %}{"name":"{{ flow.name }}","description":{{ flow.description | to_json_escaped_string }}{% if flow.agent_info %},"sub-agents":[{% for agent in flow.agent_info %}{"name":"{{ agent.name }}","description":{{ agent.description | to_json_escaped_string }}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}{% if flow.slots %},"slots":[{% for slot in flow.slots %}{"name":"{{ slot.name }}"{% if slot.description %},"description":{{ slot.description | to_json_escaped_string }}{% endif %}{% if slot.allowed_values %},"allowed_values":{{ slot.allowed_values }}{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]}
```
---
## Available Actions:
* `start flow flow_name`: Start a flow. For example, `start flow transfer_money` or `start flow list_contacts`.
* `set slot slot_name slot_value`: Set a slot for the active flow. For example, `set slot transfer_money_recipient Freddy`. Can be used to correct and change previously set values. ONLY use slots that are explicitly defined in the flow's slot list.
* `disambiguate flows flow_name1 flow_name2 ... flow_name_n`: When a message could refer to multiple flows, list the possible flows as options to clarify. Example: `disambiguate flows list_contacts add_contact remove_contact`.
* `search and reply`: Provide a response from the knowledge base to address the user’s inquiry when no flows fit, including domain knowledge, FAQs, and all off-topic or social messages.
* `cancel flow`: Cancel the current flow if the user requests it.
* `repeat message`: Repeat the last bot message.{% if active_agent %}
* `continue agent`: Continue the currently active agent {{ active_agent.name }}. This has HIGHEST PRIORITY when an agent is active and the user is responding to agent questions.{% endif %}{% if completed_agents %}
* `restart agent agent_name`: Restart the agent with the given name, in case the user wants to change some answer to a previous question asked by the agent. For example, `restart agent car_research_agent` if the user changed his mind about the car he wants to buy. ONLY use agents that are listed in the `completed_agents` section.{% endif %}
---
## General Instructions
### Start Flow
* Only start a flow if the user's message is clear and fully addressed by that flow's description and purpose.
* Pay close attention to exact wording and scope in the flow description — do not assume or “stretch” the intended use of a flow.
### Set Slot
* Do not fill slots with abstract values or placeholders.
* For categorical slots try to match the user message with allowed slot values. Use "other" if you cannot match it.
* Set the boolean slots based on the user response. Map positive responses to `True`, and negative to `False`.
* Extract text slot values exactly as provided by the user. Avoid assumptions, format changes, or partial extractions.
* ONLY use `set slot` with slots that are explicitly defined in the current flow's slot list. Do NOT create or assume slots that don't exist.
### Disambiguate Flows
* Use `disambiguate flows` when the user's message matches multiple flows and you cannot decide which flow is most appropriate.
* If the user message is short and not precise enough to start a flow or `search and reply`, disambiguate.
* If a single flow is a strong/plausible fit, prefer starting that flow directly.
* If a user's message unambiguously and distinctly matches multiple flows, start all relevant flows at once (rather than disambiguating).
### Search and Reply
* Only start `search and reply` if the user intent is clear.
* Flow Priority: If you are unsure between starting a flow or `search and reply`, always prioritize starting a flow.
### Cancel Flow
* Do not cancel any flow unless the user explicitly requests it.
* Multiple flows can be started without cancelling the previous, if the user wants to pursue multiple processes.{% if active_agent or completed_agents %}
### Agents{% if active_agent %}
* When an agent is active, ALWAYS prioritize `continue agent` over `search and reply` unless the user is clearly asking something unrelated to the agent's task.{% endif %}{% if completed_agents %}
* ONLY use `restart agent` with agents that are listed in the `completed_agents` section. Do NOT restart non-existent agents.{% endif %}
* If you're unsure about agent names, refer to the structured data provided in the `Current State` section.
{% endif %}### General Tips
* Only use information provided by the user.
* Strictly adhere to the provided action format.
* ONLY use the exact actions listed above. Do NOT invent new actions like "respond " or any other variations.
* Focus on the last message and take it one step at a time.
* Use the previous conversation steps only to aid understanding.
---
## Decision Rule Table
| Condition | Action |
|---------------------------------------------------------------|--------------------|{% if active_agent %}
| Agent is active and the user is responding to agent questions | continue agent |{% endif %}
| Flow perfectly matches user's message | start flow |
| Multiple flows are equally strong, relevant matches | disambiguate flows |
| User's message is unclear or imprecise | disambiguate flows |
| No flow fits at all, but knowledge base may help | search and reply |
---
## Current State
{% if current_flow != None %}Use the following structured data:
```json
{"active_flow":{"name":"{{ current_flow }}","current_step":{"requested_slot":"{{ current_slot }}","requested_slot_description":{{ current_slot_description | to_json_escaped_string }}},"slots":[{% for slot in flow_slots %}{"name":"{{ slot.name }}","value":"{{ slot.value }}","type":"{{ slot.type }}"{% if slot.description %},"description":{{ slot.description | to_json_escaped_string }}{% endif %}{% if slot.allowed_values %},"allowed_values":"{{ slot.allowed_values }}"{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]}{% if active_agent %},"active_agent":{"name":"{{ active_agent.name }}","description":{{ active_agent.description | to_json_escaped_string }}}{% endif %}{% if completed_agents %},"completed_agents":[{% for agent in completed_agents %}{"name":"{{ agent.name }}","description":{{ agent.description | to_json_escaped_string }}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}}
```{% else %}
You are currently not inside any flow.{% endif %}
---
## Conversation History
{{ current_conversation }}
---
## Task
Create an action list with one action per line in response to the user's last message: """{{ user_message }}""".
Your action list:
````
The prompt template for the `claude-3-5-sonnet-20240620` / `anthropic.claude-3-5-sonnet-20240620-v1:0` model with agent support is as follows:
````
## Task Description
Your task is to analyze the current conversation context and generate a list of actions to start new business processes that we call flows, to extract slots, or respond to off-topic and knowledge requests.
---
## Available Actions:
* `start flow flow_name`: Start a flow. For example, `start flow transfer_money` or `start flow list_contacts`.
* `set slot slot_name slot_value`: Set a slot for the active flow. For example, `set slot transfer_money_recipient Freddy`. Can be used to correct and change previously set values. ONLY use slots that are explicitly defined in the flow's slot list.
* `disambiguate flows flow_name1 flow_name2 ... flow_name_n`: When a message could refer to multiple flows, list the possible flows as options to clarify. Example: `disambiguate flows list_contacts add_contact remove_contact`.
* `search and reply`: Provide a response from the knowledge base to address the user's inquiry when no flows fit, including domain knowledge, FAQs, and all off-topic or social messages.
* `cancel flow`: Cancel the current flow if the user requests it.
* `repeat message`: Repeat the last bot message.{% if active_agent %}
* `continue agent`: Continue the currently active agent {{ active_agent.name }}. This has HIGHEST PRIORITY when an agent is active and the user is responding to agent questions.{% endif %}{% if completed_agents %}
* `restart agent agent_name`: Restart the agent with the given name, in case the user wants to change some answer to a previous question asked by the agent. For example, `restart agent car_research_agent` if the user changed his mind about the car he wants to buy. ONLY use agents that are listed in the `completed_agents` section.{% endif %}
---
## General Instructions
### Start Flow
* Only start a flow if the user's message is clear and fully addressed by that flow's description and purpose.
* Pay close attention to exact wording and scope in the flow description — do not assume or “stretch” the intended use of a flow.
### Set Slot
* Do not fill slots with abstract values or placeholders.
* For categorical slots, try to match the user message with allowed slot values. Use "other" if you cannot match it.
* Set the boolean slots based on the user's response. Map positive responses to `True`, and negative to `False`.
* Extract text slot values exactly as provided by the user. Avoid assumptions, format changes, or partial extractions.
* ONLY use `set slot` with slots that are explicitly defined in the current flow's slot list. Do NOT create or assume slots that don't exist.
### Disambiguate Flows
* Use `disambiguate flows` when the user's message matches multiple flows and you cannot decide which flow is most appropriate.
* If the user message is short and not precise enough to start a flow or `search and reply`, disambiguate.
* If a single flow is a strong/plausible fit, prefer starting that flow directly.
* If a user's message unambiguously and distinctly matches multiple flows, start all relevant flows at once (rather than disambiguating).
### Search and Reply
* Only start `search and reply` if the user intent is clear.
* Flow Priority: If you are unsure between starting a flow or `search and reply`, always prioritize starting a flow.
### Cancel Flow
* Do not cancel any flow unless the user explicitly requests it.
* Multiple flows can be started without cancelling the previous, if the user wants to pursue multiple processes.{% if active_agent or completed_agents %}
### Agents{% if active_agent %}
* When an agent is active, ALWAYS prioritize `continue agent` over `search and reply` unless the user is clearly asking something unrelated to the agent's task.{% endif %}{% if completed_agents %}
* ONLY use `restart agent` with agents that are listed in the `completed_agents` section. Do NOT restart non-existent agents.{% endif %}
* If you're unsure about agent names, refer to the structured data provided in the `Current State` section.
{% endif %}### General Tips
* Only use information provided by the user.
* Strictly adhere to the provided action format.
* ONLY use the exact actions listed above. Do NOT invent new actions like "respond " or any other variations.
* Focus on the last message and take it one step at a time.
* Use the previous conversation steps only to aid understanding.
---
## Decision Rule Table
| Condition | Action |
|---------------------------------------------------------------|--------------------|{% if active_agent %}
| Agent is active and the user is responding to agent questions | continue agent |{% endif %}
| Flow perfectly matches user's message | start flow |
| Multiple flows are equally strong, relevant matches | disambiguate flows |
| User's message is unclear or imprecise | disambiguate flows |
| No flow fits at all, but knowledge base may help | search and reply |
---
## Available Flows and Slots
Use the following structured data:
```json
{"flows":[{% for flow in available_flows %}{"name":"{{ flow.name }}","description":{{ flow.description | to_json_escaped_string }}{% if flow.agent_info %},"sub-agents":[{% for agent in flow.agent_info %}{"name":"{{ agent.name }}","description":{{ agent.description | to_json_escaped_string }}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}{% if flow.slots %},"slots":[{% for slot in flow.slots %}{"name":"{{ slot.name }}"{% if slot.description %},"description":{{ slot.description | to_json_escaped_string }}{% endif %}{% if slot.allowed_values %},"allowed_values":{{ slot.allowed_values }}{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]}
```
---
## Current State
{% if current_flow != None %}Use the following structured data:
```json
{"active_flow":{"name":"{{ current_flow }}","current_step":{"requested_slot":"{{ current_slot }}","requested_slot_description":{{ current_slot_description | to_json_escaped_string }}},"slots":[{% for slot in flow_slots %}{"name":"{{ slot.name }}","value":"{{ slot.value }}","type":"{{ slot.type }}"{% if slot.description %},"description":{{ slot.description | to_json_escaped_string }}{% endif %}{% if slot.allowed_values %},"allowed_values":"{{ slot.allowed_values }}"{% endif %}}{% if not loop.last %},{% endif %}{% endfor %}]}{% if active_agent %},"active_agent":{"name":"{{ active_agent.name }}","description":{{ active_agent.description | to_json_escaped_string }}}{% endif %}{% if completed_agents %},"completed_agents":[{% for agent in completed_agents %}{"name":"{{ agent.name }}","description":{{ agent.description | to_json_escaped_string }}}{% if not loop.last %},{% endif %}{% endfor %}]{% endif %}}
```{% else %}
You are currently not inside any flow.{% endif %}
---
## Conversation History
{{ current_conversation }}
---
## Task
Create an action list with one action per line in response to the user's last message: """{{ user_message }}""".
Your action list:
````
###### Template Rendering[](#template-rendering "Direct link to Template Rendering")
We updated the `render_template` method to include sub agent information.
If you customized the rendering method, add the new sub agent information to your implementation. The key changes to the function are highlighted below.
```
def render_template(
self,
message: Message,
tracker: DialogueStateTracker,
startable_flows: FlowsList,
all_flows: FlowsList,
) -> str:
"""Render the jinja template to create the prompt for the LLM.
Args:
message: The current message from the user.
tracker: The tracker containing the current state of the conversation.
startable_flows: The flows startable at this point in time by the user.
all_flows: all flows present in the assistant
Returns:
The rendered prompt template.
"""
# need to make this distinction here because current step of the
# top_calling_frame would be the call step, but we need the collect step from
# the called frame. If no call is active calling and called frame are the same.
top_calling_frame = top_flow_frame(tracker.stack)
top_called_frame = top_flow_frame(tracker.stack, ignore_call_frames=False)
top_flow = top_calling_frame.flow(all_flows) if top_calling_frame else None
current_step = top_called_frame.step(all_flows) if top_called_frame else None
flow_slots = self.prepare_current_flow_slots_for_template(
top_flow, current_step, tracker
)
current_slot, current_slot_description = self.prepare_current_slot_for_template(
current_step
)
current_slot_type = None
current_slot_allowed_values = None
if current_slot:
current_slot_type = (
slot.type_name
if (slot := tracker.slots.get(current_slot)) is not None
else None
)
current_slot_allowed_values = allowed_values_for_slot(
tracker.slots.get(current_slot)
)
has_agents = Configuration.get_instance().available_agents.has_agents()
current_conversation = tracker_as_readable_transcript(
tracker, highlight_agent_turns=has_agents
)
latest_user_message = sanitize_message_for_prompt(message.get(TEXT))
current_conversation += f"\nUSER: {latest_user_message}"
inputs: Dict[str, Any] = {
"available_flows": self.prepare_flows_for_template(
startable_flows,
tracker,
add_agent_info=has_agents,
),
"current_conversation": current_conversation,
"flow_slots": flow_slots,
"current_flow": top_flow.id if top_flow is not None else None,
"current_slot": current_slot,
"current_slot_description": current_slot_description,
"current_slot_type": current_slot_type,
"current_slot_allowed_values": current_slot_allowed_values,
"user_message": latest_user_message,
}
if has_agents:
inputs["active_agent"] = (
get_active_agent_info(tracker, top_flow.id) if top_flow else None
)
inputs["completed_agents"] = get_completed_agents_info(tracker)
return self.compile_template(self.prompt_template).render(**inputs)
```
##### LLM Clients[](#llm-clients "Direct link to LLM Clients")
We updated the signature of the `completion` and `acompletion` functions in our `LLMClient` protocol to support LLM calls with tools:
```
def completion(
self, messages: Union[List[dict], List[str], str], **kwargs: Any
) -> LLMResponse:
```
```
async def acompletion(
self, messages: Union[List[dict], List[str], str], **kwargs: Any
) -> LLMResponse:
```
The `**kwargs` are passed through to the underlying `LiteLLM` completion functions.
**Migration Required**: If you have modified any existing LLM clients or implemented custom clients, update your `completion` and `acompletion` methods to match the new signature.
Here are a code snippets of the updated implementations in `_BaseLiteLLMClient`:
* Synchronous
* Asynchronous
```
def completion(
self, messages: Union[List[dict], List[str], str], **kwargs: Any
) -> LLMResponse:
"""Synchronously generate completions for given list of messages.
Args:
messages: The message can be,
- a list of preformatted messages. Each message should be a dictionary
with the following keys:
- content: The message content.
- role: The role of the message (e.g. user or system).
- a list of messages. Each message is a string and will be formatted
as a user message.
- a single message as a string which will be formatted as user message.
**kwargs: Additional parameters to pass to the completion call.
Returns:
List of message completions.
Raises:
ProviderClientAPIException: If the API request fails.
"""
...
response = litellm.completion(
messages=formatted_messages, **{**arguments, **kwargs}
)
...
```
```
async def acompletion(
self, messages: Union[List[dict], List[str], str], **kwargs: Any
) -> LLMResponse:
"""Asynchronously generate completions for given list of messages.
Args:
messages: The message can be,
- a list of preformatted messages. Each message should be a dictionary
with the following keys:
- content: The message content.
- role: The role of the message (e.g. user or system).
- a list of messages. Each message is a string and will be formatted
as a user message.
- a single message as a string which will be formatted as user message.
**kwargs: Additional parameters to pass to the completion call.
Returns:
List of message completions.
Raises:
ProviderClientAPIException: If the API request fails.
"""
...
response = await litellm.acompletion(
messages=formatted_messages, **{**arguments, **kwargs}
)
...
```
###### Add `tool_calls` to `LLMResponse`[](#add-tool_calls-to-llmresponse "Direct link to add-tool_calls-to-llmresponse")
We added a `tool_calls` field to the `LLMResponse` class to capture tool calls from LLM responses. The `_format_response` function was updated to extract tool calls from the LiteLLM response.
**Migration Impact**: If you have custom code that processes `LLMResponse` objects, you may need to handle the new `tool_calls` field.
```
@dataclass
class LLMResponse:
id: str
"""A unique identifier for the completion."""
choices: List[str]
"""The list of completion choices the model generated for the input prompt."""
created: int
"""The Unix timestamp (in seconds) of when the completion was created."""
model: Optional[str] = None
"""The model used for completion."""
usage: Optional[LLMUsage] = None
"""An optional details about the token usage for the API call."""
additional_info: Optional[Dict] = None
"""Optional dictionary for storing additional information related to the
completion that may not be covered by other fields."""
latency: Optional[float] = None
"""Optional field to store the latency of the LLM API call."""
tool_calls: Optional[List[LLMToolCall]] = None
"""The list of tool calls the model generated for the input prompt."""
```
```
class LLMToolCall(BaseModel):
"""A class representing a response from an LLM tool call."""
id: str
"""The ID of the tool call."""
tool_name: str
"""The name of the tool that was called."""
tool_args: Dict[str, Any]
"""The arguments passed to the tool call."""
type: str = "function"
"""The type of the tool call."""
```
##### Command[](#command "Direct link to Command")
**Migration Impact**: The changes mentioned below improve conversation flow handling and agent state management. No action required unless you have custom command implementations.
###### StartFlow Command[](#startflow-command "Direct link to StartFlow Command")
We updated the `run_command_on_tracker` method to handle `StartFlow` commands when users are in `pattern_continue_interrupted` state, ensuring smooth conversation flow by cleaning up the pattern. We also added proper agent state management to handle agent interruptions.
*Flow Resumption*: Previously, `StartFlow` commands for flows already on the stack (but not active) were ignored. This behavior was updated to resume the flow instead.
```
def run_command_on_tracker(
self,
tracker: DialogueStateTracker,
all_flows: FlowsList,
original_tracker: DialogueStateTracker,
) -> List[Event]:
"""Runs the command on the tracker.
Args:
tracker: The tracker to run the command on.
all_flows: All flows in the assistant.
original_tracker: The tracker before any command was executed.
Returns:
The events to apply to the tracker.
"""
stack = tracker.stack
original_stack = original_tracker.stack
applied_events: List[Event] = []
if self.flow not in all_flows.flow_ids:
structlogger.debug(
"start_flow_command.skip_command.start_invalid_flow_id", command=self
)
return []
original_user_frame = top_user_flow_frame(original_stack)
original_top_flow = (
original_user_frame.flow(all_flows) if original_user_frame else None
)
# if the original top flow is the same as the flow to start, the flow is
# already active, do nothing
if original_top_flow is not None and original_top_flow.id == self.flow:
# in case continue_interrupted is not active, skip the already active start
# flow command
if not is_continue_interrupted_flow_active(stack):
return []
# if the continue interrupted flow is active, and the command generator
# predicted a start flow command for the flow which is on top of the stack,
# we just need to remove the pattern_continue_interrupted frame(s) from the
# stack
stack, flow_completed_events = remove_pattern_continue_interrupted_frames(
stack
)
applied_events.extend(flow_completed_events)
return applied_events + tracker.create_stack_updated_events(stack)
# if the flow is already on the stack, resume it
if (
self.flow in user_flows_on_the_stack(stack)
and original_user_frame is not None
):
# if pattern_continue_interrupted is active, we need to remove it
# from the stack before resuming the flow
stack, flow_completed_events = remove_pattern_continue_interrupted_frames(
stack
)
applied_events.extend(flow_completed_events)
applied_events.extend(resume_flow(self.flow, tracker, stack))
# the current active flow is interrupted
applied_events.append(
FlowInterrupted(
original_user_frame.flow_id, original_user_frame.step_id
)
)
return applied_events
frame_type = FlowStackFrameType.REGULAR
# remove the pattern_continue_interrupted frames from the stack
# if it is currently active but the user digressed from the pattern
stack, flow_completed_events = remove_pattern_continue_interrupted_frames(stack)
applied_events.extend(flow_completed_events)
if original_top_flow:
# if the original top flow is not the same as the flow to start,
# interrupt the current active flow
frame_type = FlowStackFrameType.INTERRUPT
if original_user_frame is not None:
applied_events.append(
FlowInterrupted(
original_user_frame.flow_id, original_user_frame.step_id
)
)
# If there is an active agent frame, interrupt it
active_agent_stack_frame = stack.find_active_agent_frame()
if active_agent_stack_frame:
structlogger.debug(
"start_flow_command.interrupt_agent",
command=self,
agent_id=active_agent_stack_frame.agent_id,
frame_id=active_agent_stack_frame.frame_id,
flow_id=active_agent_stack_frame.flow_id,
)
active_agent_stack_frame.state = AgentState.INTERRUPTED
applied_events.append(
AgentInterrupted(
active_agent_stack_frame.agent_id,
active_agent_stack_frame.flow_id,
)
)
structlogger.debug("start_flow_command.start_flow", command=self)
stack.push(UserFlowStackFrame(flow_id=self.flow, frame_type=frame_type))
return applied_events + tracker.create_stack_updated_events(stack)
```
###### Cancel Command[](#cancel-command "Direct link to Cancel Command")
We updated the `run_command_on_tracker` method to properly handle agent cancellation when flows are canceled, ensuring active agent stack frames are removed and agents are properly canceled.
```
def run_command_on_tracker(
self,
tracker: DialogueStateTracker,
all_flows: FlowsList,
original_tracker: DialogueStateTracker,
) -> List[Event]:
"""Runs the command on the tracker.
Args:
tracker: The tracker to run the command on.
all_flows: All flows in the assistant.
original_tracker: The tracker before any command was executed.
Returns:
The events to apply to the tracker.
"""
stack = tracker.stack
original_stack = original_tracker.stack
applied_events: List[Event] = []
user_frame = top_user_flow_frame(
original_stack, ignore_call_and_link_frames=False
)
current_flow = user_frame.flow(all_flows) if user_frame else None
if not current_flow:
structlogger.debug(
"cancel_command.skip_cancel_flow.no_active_flow", command=self
)
return []
if agent_frame := original_tracker.stack.find_active_agent_stack_frame_for_flow(
current_flow.id
):
structlogger.debug(
"cancel_command.remove_agent_stack_frame",
command=self,
frame=agent_frame,
)
remove_agent_stack_frame(stack, agent_frame.agent_id)
applied_events.append(
AgentCancelled(agent_id=agent_frame.agent_id, flow_id=current_flow.id)
)
# we pass in the original dialogue stack (before any of the currently
# predicted commands were applied) to make sure we don't cancel any
# frames that were added by the currently predicted commands.
canceled_frames = self.select_canceled_frames(original_stack)
stack.push(
CancelPatternFlowStackFrame(
canceled_name=current_flow.readable_name(
language=tracker.current_language
),
canceled_frames=canceled_frames,
)
)
if user_frame:
applied_events.append(FlowCancelled(user_frame.flow_id, user_frame.step_id))
return applied_events + tracker.create_stack_updated_events(stack)
```
###### Clarify Command[](#clarify-command "Direct link to Clarify Command")
We updated the `run_command_on_tracker` method to properly signal agent interruption when clarification is needed.
```
def run_command_on_tracker(
self,
tracker: DialogueStateTracker,
all_flows: FlowsList,
original_tracker: DialogueStateTracker,
) -> List[Event]:
"""Runs the command on the tracker.
Args:
tracker: The tracker to run the command on.
all_flows: All flows in the assistant.
original_tracker: The tracker before any command was executed.
Returns:
The events to apply to the tracker.
"""
flows = [all_flows.flow_by_id(opt) for opt in self.options]
clean_options = [flow.id for flow in flows if flow is not None]
if len(clean_options) != len(self.options):
structlogger.debug(
"clarify_command.altered_command.dropped_clarification_options",
command=self,
original_options=self.options,
cleaned_options=clean_options,
)
if len(clean_options) == 0:
structlogger.debug(
"clarify_command.skip_command.empty_clarification", command=self
)
return []
stack = tracker.stack
relevant_flows = [all_flows.flow_by_id(opt) for opt in clean_options]
names = [
flow.readable_name(language=tracker.current_language)
for flow in relevant_flows
if flow is not None
]
applied_events: List[Event] = []
# if the top stack frame is an agent stack frame, we need to
# update the state to INTERRUPTED and add an AgentInterrupted event
if top_stack_frame := stack.top():
if isinstance(top_stack_frame, AgentStackFrame):
applied_events.append(
AgentInterrupted(
top_stack_frame.agent_id,
top_stack_frame.flow_id,
)
)
top_stack_frame.state = AgentState.INTERRUPTED
stack.push(ClarifyPatternFlowStackFrame(names=names))
return applied_events + tracker.create_stack_updated_events(stack)
```
###### ChitChat Command[](#chitchat-command "Direct link to ChitChat Command")
We updated the `run_command_on_tracker` method to properly signal agent interruption when handling chitchat.
```
def run_command_on_tracker(
self,
tracker: DialogueStateTracker,
all_flows: FlowsList,
original_tracker: DialogueStateTracker,
) -> List[Event]:
"""Runs the command on the tracker.
Args:
tracker: The tracker to run the command on.
all_flows: All flows in the assistant.
original_tracker: The tracker before any command was executed.
Returns:
The events to apply to the tracker.
"""
stack = tracker.stack
applied_events: List[Event] = []
# if the top stack frame is an agent stack frame, we need to
# update the state to INTERRUPTED and add an AgentInterrupted event
if top_stack_frame := stack.top():
if isinstance(top_stack_frame, AgentStackFrame):
applied_events.append(
AgentInterrupted(
top_stack_frame.agent_id,
top_stack_frame.flow_id,
)
)
top_stack_frame.state = AgentState.INTERRUPTED
stack.push(ChitchatPatternFlowStackFrame())
return applied_events + tracker.create_stack_updated_events(stack)
```
###### KnowledgeAnswer Command[](#knowledgeanswer-command "Direct link to KnowledgeAnswer Command")
We updated the `run_command_on_tracker` method to properly signal agent interruption when handling knowledge requests.
```
def run_command_on_tracker(
self,
tracker: DialogueStateTracker,
all_flows: FlowsList,
original_tracker: DialogueStateTracker,
) -> List[Event]:
"""Runs the command on the tracker.
Args:
tracker: The tracker to run the command on.
all_flows: All flows in the assistant.
original_tracker: The tracker before any command was executed.
Returns:
The events to apply to the tracker.
"""
stack = tracker.stack
applied_events: List[Event] = []
# if the top stack frame is an agent stack frame, we need to
# update the state to INTERRUPTED and add an AgentInterrupted event
if top_stack_frame := stack.top():
if isinstance(top_stack_frame, AgentStackFrame):
applied_events.append(
AgentInterrupted(
top_stack_frame.agent_id,
top_stack_frame.flow_id,
)
)
top_stack_frame.state = AgentState.INTERRUPTED
stack.push(SearchPatternFlowStackFrame())
return applied_events + tracker.create_stack_updated_events(stack)
```
##### Tracing for Jaeger[](#tracing-for-jaeger "Direct link to Tracing for Jaeger")
We updated the port configuration for Jaeger tracing collection.
**Migration Required**: Update your Jaeger configuration to use the new port settings.
**Updated Docker Command**:
```
docker run --rm --name jaeger \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
-p 5778:5778 \
-p 9411:9411 \
cr.jaegertracing.io/jaegertracing/jaeger:2.10.0
```
**Updated Configuration**:
Update your `endpoints.yml` file with the new port configuration:
```
tracing:
type: jaeger
host: 0.0.0.0
port: 4317
service_name: rasa
sync_export: ~
```
The Jaeger UI is now accessible at [`http://localhost:16686/search`](http://localhost:16686/search).
#### Rasa Pro 3.12 to Rasa Pro 3.13[](#rasa-pro-312-to-rasa-pro-313 "Direct link to Rasa Pro 3.12 to Rasa Pro 3.13")
##### LLM Judge Model Change in E2E Testing[](#llm-judge-model-change-in-e2e-testing "Direct link to LLM Judge Model Change in E2E Testing")
Starting with Rasa Pro v3.13.x, the default model for the LLM Judge in E2E tests has changed from `gpt-4o-mini` to `gpt-4.1-mini`, see [Generative Response LLM Judge Configuration](https://rasa.com/docs/docs/reference/testing/assertions/#generative-response-llm-judge-configuration). The new model may produce lower scores for the `generative_response_is_relevant` and `generative_response_is_grounded` assertions, which can cause previously passing responses to be incorrectly marked as failures (false negatives).
Action Required:
* Lower the thresholds for `generative_response_is_relevant` and `generative_response_is_grounded` in your E2E test configuration to reduce the risk of false negatives.
* Alternatively, if you prefer not to lower the thresholds, configure the LLM Judge to use a more performant model (note: this may increase costs). For details on configuring the LLM Judge, see the [E2E testing documentation](https://rasa.com/docs/docs/pro/testing/evaluating-assistant/).
#### Rasa Pro 3.11 to Rasa Pro 3.12[](#rasa-pro-311-to-rasa-pro-312 "Direct link to Rasa Pro 3.11 to Rasa Pro 3.12")
##### Custom LLM-based Command Generators[](#custom-llm-based-command-generators "Direct link to Custom LLM-based Command Generators")
In order to improve [slot filling in CALM](https://rasa.com/docs/docs/reference/primitives/slots/#calm-slot-mappings) and allow all types of command generators to [issue commands at every conversation turn](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#interaction-with-other-types-of-command-generators), we have made the following changes which you should consider to benefit from the new CALM slot filling improvements:
* added a new method `_check_commands_overlap` to the base class `CommandGenerator`. This method checks if the commands issued by the current command generator overlap with the commands issued by other command generators. This method returns the final deduplicated commands. This method is called by the `predict_commands` method of the `CommandGenerator` children classes.
* added two new methods `_check_start_flow_command_overlap` and `_filter_slot_commands` to the base class `CommandGenerator` that will raise `NotImplementedError` if not implemented by the child class. These methods are already implemented by the `LLMBasedCommandGenerator` and `NLUCommandAdapter` classes to uphold the [prioritization system of the commands](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#prioritization-of-commands).
* added a new method `_get_prior_commands` to the base class `CommandGenerator`. This method returns a list of commands that have been issued by other command generators prior to the one currently running. This method is called by the `predict_commands` method of any command generators that inherit from the `CommandGenerator` class. This prior commands can be either returned in case of an empty tracker or flows, or included to the newly issued commands. For example:
```
prior_commands = self._get_prior_commands(tracker)
if tracker is None or flows.is_empty():
return prior_commands
# custom command generation logic block
return self._check_commands_overlap(prior_commands, commands)
```
* added a new method `_should_skip_llm_call` to the `LLMBasedCommandGenerator`. This method returns `True` only if `minimize_num_calls` is set to True and either prior commands contain a `StartFlow` command or a `SetSlot` command for the slot that is requested by an active `collect` flow step. This method is called by the `predict_commands` method of the `LLMBasedCommandGenerator` children classes. If the method returns `True`, the LLM call is skipped and the method returns the prior commands.
* moved the `_check_commands_against_slot_mappings` static method from the `CommandGenerator` to the `LLMBasedCommandGenerator` class. This method is used to check if the issued LLM commands are relevant to the slot mappings. The method is called by the `predict_commands` method of the `LLMBasedCommandGenerator` children classes.
##### Migration from `SingleStepLLMCommandGenerator`s to the `CompactLLMCommandGenerator`s[](#migration-from-singlestepllmcommandgenerators-to-the-compactllmcommandgenerators "Direct link to migration-from-singlestepllmcommandgenerators-to-the-compactllmcommandgenerators")
It is recommended to use the new `CompactLLMCommandGenerator` with optimized prompts for the `gpt-4o-2024-11-20` and `claude-sonnet-3.5-20240620` models. Using the `CompactLLMCommandGenerator` can significantly reduce costs - approximately 10 times, according to our tests.
If you've built a custom command generator that extends `SingleStepLLMCommandGenerator`, we recommend migrating to the new command generator by inheriting the class from `CompactLLMCommandGenerator`.
```
# Old class definition:
from rasa.dialogue_understanding.generators import SingleStepLLMCommandGenerator
class MyCommandGenerator(SingleStepLLMCommandGenerator):
...
# New class definition:
from rasa.dialogue_understanding.generators import CompactLLMCommandGenerator
class MyCommandGenerator(CompactLLMCommandGenerator):
...
```
##### Migration from `SingleStepLLMCommandGenerator`s to the `CompactLLMCommandGenerator`s with the custom commands[](#migration-from-singlestepllmcommandgenerators-to-the-compactllmcommandgenerators-with-the-custom-commands "Direct link to migration-from-singlestepllmcommandgenerators-to-the-compactllmcommandgenerators-with-the-custom-commands")
If yo've built a custom command generator that extends `SingleStepLLMCommandGenerator` and you've defined new commands or overridden Rasa's default commands, you should:
* Update the `parse_commands` method to reflect the changes in the command parsing logic.
* Update the custom command classes so they are compatible with the latest command interface. For details on updating and implementing custom command classes, please refer to [How to customize existing commands](https://rasa.com/docs/docs/pro/customize/command-generator/#how-to-customize-existing-commands) section.
In the new implementation, command parsing has been delegated to a dedicated parsing utility method `parse_commands` which can be imported from `rasa.dialogue_understanding.generator.command_parser` This method handles the parsing of the predicted LLM output into commands more effectively and flexibly, especially when using customized or newly introduced command types.
Here is the new recommended pattern for your command generator's `parse_commands` method:
```
# Import the utility method under a different name to prevent confusion with the
# command generator's `parse_commands`
from rasa.dialogue_understanding.generator.command_parser import (
parse_commands
as parse_commands_using_command_parsers,
)
class CustomCommandGenerator(CompactLLMCommandGenerator):
"""Custom implementation of the LLM command generator."""
...
@classmethod
def parse_commands(
cls, actions: Optional[str], tracker: DialogueStateTracker, flows: FlowsList
) -> List[Command]:
"""Parse the actions returned by the LLM into intents and entities as commands.
Args:
actions: The actions returned by the LLM.
tracker: The tracker containing the current state of the conversation.
flows: The current list of active flows.
Returns:
The parsed commands.
"""
commands = parse_commands_using_command_parsers(
actions,
flows,
# Register any custom command classes you have created here
additional_commands=[CustomCommandClass1, CustomCommandClass2, ...],
# If your custom command classes replaces or extends default commands,
# specify the defaults commands for removal here
default_commands_to_remove=[HumandHandoffCommand, ...]
)
if not commands:
structlogger.warning(
f"{cls.__name__}.parse_commands",
message="No commands were parsed from the LLM actions.",
actions=actions,
)
return commands
```
##### Migration of the custom prompt from `SingleStepLLMCommandGenerator`s to the `CompactLLMCommandGenerator`s[](#migration-of-the-custom-prompt-from-singlestepllmcommandgenerators-to-the-compactllmcommandgenerators "Direct link to migration-of-the-custom-prompt-from-singlestepllmcommandgenerators-to-the-compactllmcommandgenerators")
If you've customized the default prompt template previously used with the `SingleStepLLMCommandGenerator` and are now migrating to the `CompactLLMCommandGenerator`, you must update this template to use the new prompt commands syntax. This updated command syntax is specifically optimized for the capabilities of the new `CompactLLMCommandGenerator`.
For more details on the new prompt, refer to the documentation [here](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#prompt-template)
##### Update to `utter_corrected_previous_input` default utterance[](#update-to-utter_corrected_previous_input-default-utterance "Direct link to update-to-utter_corrected_previous_input-default-utterance")
The text of the default `utter_corrected_previous_input` utterance has been updated to use a new correction frame context property `context.new_slot_values` instead of `context.corrected_slots.values`. The new utterance is:
```
"Ok, I am updating {{ context.corrected_slots.keys()|join(', ') }} to {{ context.new_slot_values | join(', ') }} respectively."
```
##### LLM Judge Config Format Change in E2E Testing[](#llm-judge-config-format-change-in-e2e-testing "Direct link to LLM Judge Config Format Change in E2E Testing")
The custom configuration of the LLM Judge used by E2E testing with assertions has been updated to use the `llm_judge` key which follows the same structure as other generative components in Rasa. This can either use [model groups](https://rasa.com/docs/docs/reference/config/components/llm-configuration/#model-groups) configuration or the individual model configuration option. The `llm_judge` key can be used in the `conftest.yml` file as shown below:
```
llm_judge:
llm:
provider: "openai"
model: "gpt-4-0613"
embeddings:
provider: "openai"
model: "text-embedding-ada-002"
```
##### `action` property in custom slot mapping replaced with `run_action_every_turn`[](#action-property-in-custom-slot-mapping-replaced-with-run_action_every_turn "Direct link to action-property-in-custom-slot-mapping-replaced-with-run_action_every_turn")
With the deprecation of the [custom slot mapping](https://rasa.com/docs/docs/reference/primitives/slots/#custom-slot-mappings) in favor of the new [controlled mapping](https://rasa.com/docs/docs/reference/primitives/slots/#controlled-slot-mappings) type, the `action` property associated with the custom slot mapping has been replaced with the `run_action_every_turn` [property](https://rasa.com/docs/docs/reference/primitives/slots/#run_action_every_turn). For this reason, if you prefer not to run these custom actions at every turn, it is recommended you remove the `action` property from your slot mappings.
#### Rasa Pro 3.9 to Rasa Pro 3.10[](#rasa-pro-39-to-rasa-pro-310 "Direct link to Rasa Pro 3.9 to Rasa Pro 3.10")
##### LLM/Embedding Configuration[](#llmembedding-configuration "Direct link to LLM/Embedding Configuration")
The LLM and embedding configurations have been updated to use the `provider` key instead of the `type` key. These changes apply to all providers, with some examples provided for reference.
**Cohere**
```
llm:
provider: "cohere" # instead of "type: cohere"
model: "command-r"
```
**Vertex AI**
```
llm:
provider: "vertex_ai" # instead of "type: vertexai"
model: "gemini-pro"
```
**Hugging Face Hub**
```
llm:
provider: "huggingface" # instead of "type: huggingface_hub"
model: "HuggingFaceH4/zephyr-7b-beta" # instead of "repo_id: HuggingFaceH4/zephyr-7b-beta"
```
**llama.cpp**
The support for loading models directly have been removed. You need to deploy the model to a server and use the server URL to load the model. For instance a llama.cpp server can be run using the following command, `./llama-server -m your_model.gguf --port 8080`.
For more information on llama.cpp server, refer to the [llama.cpp documentation](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#web-server) The assistant can be configured as:
```
llm:
provider: "self-hosted" # instead of "type: llamacpp"
api_base: "http://localhost:8000/v1" # instead of "model_path: "/path/to/model.bin""
model: "ggml-org/Meta-Llama-3.1-8B-Instruct-Q4_0-GGUF"
```
**vLLM**
The model can be deployed and served through `vLLM==0.6.0`. For instance a vLLM server can be run using the following command, `vllm serve your_model`
For more information on vLLM server, refer to the [vLLM documentation](https://docs.vllm.ai/en/stable/serving/openai_compatible_server.html#openai-compatible-server) The assistant can be configured as:
```
llm:
provider: "self-hosted" # instead of "type: vllm_openai"
api_base: "http://localhost:8000/v1"
model: "NousResearch/Meta-Llama-3-8B-Instruct" # the name of the model you have deployed
```
note
CALM exclusively utilizes the chat completions endpoint of the model server, so it's essential that the model's tokenizer includes a chat template. Models lacking a chat template will not be compatible with CALM anymore.
Backward compatibility has been maintained for `OpenAI` and `Azure` configurations. For all other providers, ensure the use of the `provider` key and review the configuration against the [documentation](https://rasa.com/docs/docs/reference/config/components/llm-configuration-before-3-10/).
###### Disabling the cache[](#disabling-the-cache "Direct link to Disabling the cache")
For Rasa Pro versions `<= 3.9.x`, the correct way to disable the cache was:
```
llm:
model: ...
cache: false
```
Rasa Pro `3.10.0` onwards, this has changed since we rely on LiteLLM to manage caching. To avoid errors, change your configuration to -
```
llm:
model: ...
cache:
no-cache: true
```
##### Custom Components using an LLM[](#custom-components-using-an-llm "Direct link to Custom Components using an LLM")
As of Rasa Pro 3.10, the backend for sending LLM and Embedding API requests has undergone a significant change. The previous LangChain version `0.0.329` has been replaced with [LiteLLM](https://www.litellm.ai/).
This shift can potentially break custom implementations of components that configure and send API requests to chat completion and embedding endpoints. Specifically, the following components are impacted:
* [SingleStepLLMCommandGenerator](https://rasa.com/docs/docs/reference/config/components/deprecated-components/#singlestepllmcommandgenerator)
* [MultiStepLLMCommandGenerator](https://rasa.com/docs/docs/reference/config/components/deprecated-components/#multistepllmcommandgenerator)
* [ContextualResponseRephraser](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/)
* [EnterpriseSearchPolicy](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/)
* [IntentlessPolicy](https://rasa.com/docs/docs/reference/config/policies/intentless-policy/)
* [FlowRetrieval](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#retrieving-relevant-flows)
* [LLMBasedRouter](https://rasa.com/docs/docs/reference/config/components/coexistence-routers/#llmbasedrouter)
If your project contains custom components based on any of the affected components listed above, you will need to verify and possibly refactor your code to ensure compatibility with LiteLLM.
###### Changes to `llm_factory`[](#changes-to-llm_factory "Direct link to changes-to-llm_factory")
The `llm_factory` is used across all components that configure and send API requests to an LLM. Previously, the `llm_factory` relied on LangChain's [mapping](https://github.com/langchain-ai/langchain/blob/ecee4d6e9268d71322bbf31fd16c228be304d45d/langchain/llms/__init__.py#L110) to instantiate LangChain clients.
Rasa Pro 3.10 onwards, the `llm_factory` returns clients that conform to the new `LLMClient` protocol. This impacts any custom component that was previously relying on `LangChain` types.
If you have overridden components, such as a command generator, you will need to update your code to handle the new return type of `LLMClient`. This includes adjusting method calls and ensuring compatibility with the new protocol.
The following method calls will need to be adjusted if you have overridden them:
* `SingleStepLLMCommandGenerator.invoke_llm`
* `MultiStepLLMCommandGenerator.invoke_llm`
* `ContextualResponseRephraser.rephrase`
* `EnterpriseSearchPolicy.predict_action_probabilities`
* `IntentlessPolicy.generate_answer`
* `LLMBasedRouter.predict_commands`
Here's an example of how to update your code:
* Rasa 3.9 - LangChain
* Rasa 3.10 - LiteLLM
```
from rasa.shared.utils.llm import llm_factory
# get the llm client via factory
llm = llm_factory(config, default_config)
# get the llm response synchronously
sync_completion: str = llm.predict(prompt)
# get the llm response asynchronously
async_completion: str = await llm.apredict(prompt)
```
```
from rasa.shared.utils.llm import llm_factory
from rasa.shared.providers.llm.llm_client import LLMClient
from rasa.shared.providers.llm.llm_response import LLMResponse
# get the llm client via factory
llm: LLMClient = llm_factory(config, default_config)
# get the llm response synchronously
sync_response: LLMResponse = llm.completion(prompt) # or llm.completion([prompt_1, prompt_2,..., prompt_n])
sync_completion: str = sync_response.choices[0]
# get the llm response asynchronously
async_response: LLMResponse = await llm.acompletion(prompt) # or llm.acompletion([prompt_1, prompt_2,..., prompt_n])
async_completion: str = async_response.choices[0]
```
###### Changes to `embedder_factory`[](#changes-to-embedder_factory "Direct link to changes-to-embedder_factory")
The `embedder_factory` is used across all components that configure and send API requests to an embedding model. Previously, the `embedder_factory` returned LangChain's embedding clients of [Embeddings](https://github.com/langchain-ai/langchain/blob/ecee4d6e9268d71322bbf31fd16c228be304d45d/langchain/embeddings/base.py#L6) type.
Rasa Pro 3.10 onwards, the `embedder_factory` returns clients that conform to the new `EmbeddingClient` protocol. This change is part of the move to LiteLLM, and it impacts any custom components that were previously relying on LangChain types.
If you have overridden components that rely on instantiating clients with `embedder_factory` you will need to update your code to handle the new return type of `EmbeddingClient`. This includes adjusting method calls and ensuring compatibility with the new protocol.
The following method calls will need to be adjusted if you have overridden them:
* `FlowRetrieval.load`
* `FlowRetrieval.populate`
* `EnterpriseSearchPolicy.load`
* `EnterpriseSearchPolicy.train`
* `IntentlessPolicy.load`
* Or if you have overridden the `IntentlessPolicy.embedder` attribute.
Here's an example of how to update your code:
* Rasa 3.9 - LangChain
* Rasa 3.10 - LiteLLM
```
from rasa.shared.utils.llm import embedder_factory
# get the embedding client via factory
embedder = embedder_factory(config, default_config)
# get the embedding response synchronously
vectors: List[List[float]] = embedder.embed_documents([doc_1, doc_2])
# get the embedding response asynchronously
vectors: List[List[float]] = await embedder.aembed_documents([doc_1, doc_2])
```
```
from rasa.shared.utils.llm import embedder_factory
from rasa.shared.providers.embedding.embedding_client import EmbeddingClient
from rasa.shared.providers.embedding.embedding_response import EmbeddingResponse
# get the embedding client via factory
embedder: EmbeddingClient = embedder_factory(config, default_config)
# get the embedding response synchronously
sync_response: EmbeddingResponse = embedder.embed([doc_1, doc_2])
vectors: List[List[float]] = sync_response.data
# get the embedding response asynchronously
async_response: EmbeddingResponse = await embedder.aembed([doc_1, doc_2])
vectors: List[List[float]] = async_response.data
```
###### Changes to `invoke_llm`[](#changes-to-invoke_llm "Direct link to changes-to-invoke_llm")
The previous implementation of `invoke_llm` method in `SingleStepLLMCommandGenerator`, `MultiStepLLMCommandGenerator`, and the deprecated `LLMCommandGenerator` used `llm_factory` to instantiate LangChain clients. Since the factory now returns clients that conform to the new `LLMClient` protocol, any custom overrides of the `invoke_llm` method will need to be updated to accommodate the new return type.
Below you can find the `invoke_llm` method from Rasa Pro 3.9 and its updated version in Rasa Pro 3.10:
* Rasa 3.9
* Rasa 3.10
```
async def invoke_llm(self, prompt: Text) -> Optional[Text]:
"""Use LLM to generate a response.
Args:
prompt: The prompt to send to the LLM.
Returns:
The generated text.
Raises:
ProviderClientAPIException if an error during API call.
"""
llm = llm_factory(self.config.get(LLM_CONFIG_KEY), DEFAULT_LLM_CONFIG)
try:
return await llm.apredict(prompt)
except Exception as e:
structlogger.error("llm_based_command_generator.llm.error", error=e)
raise ProviderClientAPIException(
message="LLM call exception", original_exception=e
)
```
```
async def invoke_llm(self, prompt: Text) -> Optional[Text]:
"""Use LLM to generate a response.
Args:
prompt: The prompt to send to the LLM.
Returns:
The generated text.
Raises:
ProviderClientAPIException if an error during API call.
"""
llm = llm_factory(self.config.get(LLM_CONFIG_KEY), DEFAULT_LLM_CONFIG)
try:
llm_response = await llm.acompletion(prompt)
return llm_response.choices[0]
except Exception as e:
structlogger.error("llm_based_command_generator.llm.error", error=e)
raise ProviderClientAPIException(
message="LLM call exception", original_exception=e
)
```
###### Changes to `SingleStepLLMCommandGenerator.predict_commands`[](#changes-to-singlestepllmcommandgeneratorpredict_commands "Direct link to changes-to-singlestepllmcommandgeneratorpredict_commands")
For `SingleStepLLMCommandGenerator`, the `predict_commands` method now includes a call to `self._update_message_parse_data_for_fine_tuning(message, commands, flow_prompt)`. This function is essential for enabling the [fine-tuning recipe](https://rasa.com/docs/docs/pro/customize/fine-tuning-llm/).
If you have overridden the `predict_commands` method, you need to manually add this call to ensure proper functionality:
```
async def predict_commands(
self,
message: Message,
flows: FlowsList,
tracker: Optional[DialogueStateTracker] = None,
**kwargs: Any,
) -> List[Command]:
...
action_list = await self.invoke_llm(flow_prompt)
commands = self.parse_commands(action_list, tracker, flows)
self._update_message_parse_data_for_fine_tuning(message, commands, flow_prompt)
return commands
```
###### Changes to the default configuration dictionary[](#changes-to-the-default-configuration-dictionary "Direct link to Changes to the default configuration dictionary")
The default configurations for the following components have been updated:
* [SingleStepLLMCommandGenerator](https://rasa.com/docs/docs/reference/config/components/deprecated-components/#singlestepllmcommandgenerator)
* [MultiStepLLMCommandGenerator](https://rasa.com/docs/docs/reference/config/components/deprecated-components/#multistepllmcommandgenerator)
* [ContextualResponseRephraser](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/)
* [EnterpriseSearchPolicy](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/)
* [IntentlessPolicy](https://rasa.com/docs/docs/reference/config/policies/intentless-policy/)
* [FlowRetrieval](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#retrieving-relevant-flows)
* [LLMBasedRouter](https://rasa.com/docs/docs/reference/config/components/coexistence-routers/#llmbasedrouter)
If you have custom implementations based on the default configurations for any of these components, ensure that your configuration dictionary aligns with the updates shown in the tables below, as the defaults have changed.
Default **LLM configuration** keys have been updated from:
```
DEFAULT_LLM_CONFIG = {
"_type": "openai",
"model_name": ...,
"request_timeout": ...,
"temperature": ...,
"max_tokens": ...,
}
```
to:
```
DEFAULT_LLM_CONFIG = {
"provider": "openai",
"model": ...,
"temperature": ...,
"max_tokens": ...,
"timeout": ...,
}
```
Similarly, default **embedding configuration** keys have been updated from:
```
DEFAULT_EMBEDDINGS_CONFIG = {
"_type": "openai",
"model": ...,
}
```
to:
```
DEFAULT_EMBEDDINGS_CONFIG = {
"provider": "openai",
"model": ...,
}
```
Be sure to update your custom configurations to reflect these changes in order to ensure continued functionality.
##### Dropped support for Python 3.8[](#dropped-support-for-python-38 "Direct link to Dropped support for Python 3.8")
Dropped support for Python 3.8 ahead of [Python 3.8 End of Life in October 2024](https://devguide.python.org/versions/#supported-versions).
In Rasa Pro versions `3.10.0`, `3.9.11` and `3.8.13`, we needed to pin the TensorFlow library version to 2.13.0rc1 in order to remove critical vulnerabilities; this resulted in poor user experience when installing these versions of Rasa Pro with `uv pip`. Removing support for Python 3.8 will make it possible to upgrade to a stabler version of TensorFlow.
#### Rasa Pro 3.8 to Rasa Pro 3.9[](#rasa-pro-38-to-rasa-pro-39 "Direct link to Rasa Pro 3.8 to Rasa Pro 3.9")
##### LLMCommandGenerator[](#llmcommandgenerator "Direct link to LLMCommandGenerator")
Starting from Rasa Pro 3.9 the former `LLMCommandGenerator` is replaced by `SingleStepLLMCommandGenerator`. The `LLMCommandGenerator` is now deprecated and will be removed in version `4.0.0`.
The `SingleStepLLMCommandGenerator` differs from the `LLMCommandGenerator` in how it handles failures of the `invoke_llm` method. Specifically, if the `invoke_llm` method call fails in `SingleStepLLMCommandGenerator`, it raises a `ProviderClientAPIException`. In contrast, the `LLMCommandGenerator` simply returns `None` when the method call fails.
##### Slot Mappings[](#slot-mappings "Direct link to Slot Mappings")
In case you had been using `custom` slot mapping type for slots set with the prediction of the LLM-based command generator, you need to update your assistant's slot configuration to use the new [`from_llm`](https://rasa.com/docs/docs/reference/primitives/slots/#from_llm) slot mapping type. Note that even if you have written custom slot validation actions (following the `validate_` convention) for slots set by the LLM-based command generator, you need to update your assistant's slot configuration to use the new `from_llm` slot mapping type.
For [slots that are set only via a custom action](https://rasa.com/docs/docs/reference/primitives/slots/#custom-slot-mappings) e.g. slots set by external sources only, you must add the action name to the slot mapping:
```
slots:
slot_name:
type: text
mappings:
- type: custom
action: custom_action_name
```
#### Rasa Pro 3.8.0 to Rasa Pro 3.8.1[](#rasa-pro-380-to-rasa-pro-381 "Direct link to Rasa Pro 3.8.0 to Rasa Pro 3.8.1")
##### Poetry Installation[](#poetry-installation "Direct link to Poetry Installation")
Starting from Rasa Pro 3.8.1 in the `3.8.x` minor series, we have upgraded the version Poetry for managing dependencies in the Rasa Pro Python package to `1.8.2`. To install the latest micro versions of Rasa Pro in your project, you must first [upgrade Poetry](https://python-poetry.org/docs/cli/#self-update) to version `1.8.2`:
```
poetry self update 1.8.2
```
#### Rasa Pro 3.7 to 3.8[](#rasa-pro-37-to-38 "Direct link to Rasa Pro 3.7 to 3.8")
info
Starting from `3.8.0`, Rasa and Rasa Plus have been merged into a single artifact, named Rasa Pro.
##### Installation[](#installation "Direct link to Installation")
Following the merge we renamed the resulting python package and Docker image to `rasa-pro`.
###### Python package[](#python-package "Direct link to Python package")
Rasa Pro python package, for `3.8.0` and onward, is located at:
```
https://europe-west3-python.pkg.dev/rasa-releases/rasa-pro-python
```
Name of the package is `rasa-pro`.
Example of how to install the package:
```
pip install --extra-index-url=https://europe-west3-python.pkg.dev/rasa-releases/rasa-pro-python/simple rasa-pro==3.8.0
```
While python package name was changed, the import process remains the same:
```
import rasa.core
from rasa import train
```
For more information on how to install Rasa Pro, please refer to the [Python installation guide](https://rasa.com/docs/docs/pro/installation/python/).
###### Helm Chart / Docker Image[](#helm-chart--docker-image "Direct link to Helm Chart / Docker Image")
Rasa Pro docker image, for `3.8.0` and onward, is located at:
```
europe-west3-docker.pkg.dev/rasa-releases/rasa-pro/rasa-pro
```
Example how to pull the image:
```
docker pull europe-west3-docker.pkg.dev/rasa-releases/rasa-pro/rasa-pro:3.8.0
```
For more information on how to install Rasa Pro Docker image, please refer to the [Docker installation guide](https://rasa.com/docs/docs/pro/installation/docker/).
##### Component Yaml Configuration Changes[](#component-yaml-configuration-changes "Direct link to Component Yaml Configuration Changes")
Follow the below instructions to update the configuration of Rasa Pro components in the 3.8 version:
* [`ConcurrentRedisLockStore`](https://rasa.com/docs/docs/reference/integrations/lock-stores/#concurrentredislockstore) - update `endpoints.yml` to `type: concurrent_redis`:
```
lock_store:
type: concurrent_redis
```
* [`ContextualResponseRephraser`](https://rasa.com/docs/docs/reference/primitives/contextual-response-rephraser/)- update `endpoints.yml` to either `type: rephrase` or `type: rasa.core.ContextualResponseRephraser`:
```
nlg:
type: rephrase
```
* [Audiocodes](https://rasa.com/docs/docs/reference/channels/audiocodes-voiceai-connect/) and Vier CVG channels can be specified in `credentials.yml` using directly their channel name:
```
audiocodes:
token: "sample_token"
vier_cvg:
...
```
* [`EnterpriseSearchPolicy`](https://rasa.com/docs/docs/reference/config/policies/enterprise-search-policy/) and [`IntentlessPolicy`](https://rasa.com/docs/docs/reference/config/policies/intentless-policy/) - update `config.yml` to only use the policy class name:
```
policies:
- name: EnterpriseSearchPolicy
- name: IntentlessPolicy
```
##### Changes to default behaviour[](#changes-to-default-behaviour "Direct link to Changes to default behaviour")
info
With Rasa Pro 3.8, we introduced a couple of changes that rectifies the default behaviour of certain components. We believe these changes align better with the principles of CALM. If you are migrating an assistant built with Rasa Pro 3.7, please ensure you have checked if these changes affect your assistant.
###### Prompt Rendering[](#prompt-rendering "Direct link to Prompt Rendering")
Rasa Pro 3.8 introduces a new feature [flow-retrieval](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#retrieving-relevant-flows) which ensures that only the flows that are relevant to the conversation context are included in the prompt sent to the LLM in the `LLMCommandGenerator`. This helps the assistant scale to a higher number of flows and also reduces the LLM costs.
This feature is **enabled by default** and we recommend to use it if the assistant has more than 40 flows. By default, the feature uses embedding models from OpenAI, but if you are using a different provider (for e.g. Azure), please ensure -
1. An embedding model is configured with the provider.
2. `LLMCommandGenerator` has been configured correctly to connect to the embedding provider. For example, see the section on [configuration required to connect to Azure OpenAI service](https://rasa.com/docs/docs/reference/config/components/llm-configuration-before-3-10/#azure-openai-service)
If you wish to disable the feature you can configure the `LLMCommandGenerator` as:
config.yml
```
pipeline:
- name: SingleStepLLMCommandGenerator
...
flow_retrieval:
active: false
...
```
###### Processing Chitchat[](#processing-chitchat "Direct link to Processing Chitchat")
The default behaviour in Rasa Pro 3.7 to handle chitchat utterances was to rely on free form generative responses. This can lead to the assistant sending unwanted responses or responding to out of scope user utterances. The new default behaviour in Rasa Pro 3.8 is to rely on [`IntentlessPolicy`](https://rasa.com/docs/docs/reference/config/policies/intentless-policy/) to respond to chitchat utterances using pre-defined responses only.
If you were relying on free form generative responses to handle chitchat in Rasa Pro 3.7, you will now see a warning message when you train the same assistant with Rasa Pro 3.8 - " `pattern_chitchat` has an action step with `action_trigger_chitchat`, but `IntentlessPolicy` is not configured". This appears because the default definition of `pattern_chitchat` has been modified in Rasa Pro 3.8 to:
```
pattern_chitchat:
description: handle interactions with the user that are not task-oriented
name: pattern chitchat
steps:
- action: action_trigger_chitchat
```
For the assistant to be able to handle chitchat utterances, you have two options:
1. If you are happy with free-form generative responses for such user utterances, then you can override `pattern_chitchat` to:
```
pattern_chitchat:
description: handle interactions with the user that are not task-oriented
name: pattern chitchat
steps:
- action: utter_free_chitchat_response
```
2. If you want to switch to using pre-defined responses, you should first add `IntentlessPolicy` to the `policies` section of the config -
```
policies:
- name: IntentlessPolicy
```
Next, you should add response templates for the pre-defined responses you want the assistant to consider when [responding to a chitchat user utterance](https://rasa.com/docs/docs/reference/config/policies/intentless-policy/#chitchat).
###### Handling of categorical slots[](#handling-of-categorical-slots "Direct link to Handling of categorical slots")
Rasa Pro versions `<= 3.7.8` used to store the value of a categorical slot in the same casing as it was either specified in the user message or predicted by the LLM in a `SetSlot` command. This wasn't necessarily same as the casing used in the corresponding possible value defined for that slot in the domain. For e.g, if the categorical slot was defined to have `[A, B, C]` as the possible values and the prediction was to set it to `a` then the slot would be set to `a`. This lead to problems downstream when that slot had to be used in other primitives i.e. flows or custom action.
Rasa Pro `3.7.9` fixes this by always storing the slot value in the same casing as defined in the domain. So, in the above example, the slot would now be stored as `A` instead of `a`. This ensures that the user is writing business logic for slot comparisons, for e.g. `if` conditions in flows, using the same casing as defined by them in the domain.
If you are migrating from Rasa pro versions `<= 3.7.8`, please double check your flows and custom actions to make sure none of them break because of this change.
###### Update default signature of LLM calls[](#update-default-signature-of-llm-calls "Direct link to Update default signature of LLM calls")
In Rasa Pro `>= 3.8` we switched from doing synchronous LLM calls to asynchronous calls. We updated all components that use an LLM, e.g.
* `LLMCommandGenerator`
* `ContextualResponseRephraser`
* `EnterpriseSearchPolicy`
* `IntentlessPolicy`
This can potentially break assistants migrating to 3.8 that have sub-classed one of these components in their own custom components.
For example, the method `predict_commands` in the `LLMCommandGenerator` is now `async` and needs to `await` the methods `_generate_action_list_using_llm` and `flow_retrieval.filter_flows` as these methods are also async. For more information on asyncio please check their [documentation](https://docs.python.org/3/library/asyncio.html).
##### Dependency Upgrades[](#dependency-upgrades "Direct link to Dependency Upgrades")
We've updated our core dependencies to enhance functionality and performance across our platform.
###### Spacy 3.7.x[](#spacy-37x "Direct link to Spacy 3.7.x")
Upgraded from `>=3.6` to `>=3.7`.
We have transitioned to using Spacy version 3.7.x to benefit from the latest enhancements in natural language processing. If you're using any spacy models with your assistant, please update them to Spacy 3.7.x compatible models.
###### Pydantic 2.x[](#pydantic-2x "Direct link to Pydantic 2.x")
Upgraded from `>=1.10.9,<1.10.10` to `^2.0`.
Along with the Spacy upgrade, we have moved to Pydantic version 2.x, which necessitates updates to Pydantic models. For assistance with updating your models, please refer to the [Pydantic Migration Guide](https://docs.pydantic.dev/latest/migration/#install-pydantic-v2). This ensures compatibility with the latest improvements in data validation and settings management.
#### Rasa Pro 3.7.9 to Rasa Pro 3.7.10[](#rasa-pro-379-to-rasa-pro-3710 "Direct link to Rasa Pro 3.7.9 to Rasa Pro 3.7.10")
##### Poetry Installation[](#poetry-installation-1 "Direct link to Poetry Installation")
Starting from Rasa Pro 3.7.10 in the `3.7.x` minor series, we have upgraded the version Poetry for managing dependencies in the Rasa Pro Python package to `1.8.2`. To install Rasa Pro in your project, you must first [upgrade Poetry](https://python-poetry.org/docs/cli/#self-update) to version `1.8.2`:
```
poetry self update 1.8.2
```
#### Rasa Pro 3.7.8 to Rasa Pro 3.7.9[](#rasa-pro-378-to-rasa-pro-379 "Direct link to Rasa Pro 3.7.8 to Rasa Pro 3.7.9")
##### Changes to default behaviour[](#changes-to-default-behaviour-1 "Direct link to Changes to default behaviour")
###### Handling of categorical slots[](#handling-of-categorical-slots-1 "Direct link to Handling of categorical slots")
Rasa Pro versions `<= 3.7.8` used to store the value of a categorical slot in the same casing as it was either specified in the user message or predicted by the LLM in a `SetSlot` command. This wasn't necessarily same as the casing used in the corresponding possible value defined for that slot in the domain. For e.g, if the categorical slot was defined to have `[A, B, C]` as the possible values and the prediction was to set it to `a` then the slot would be set to `a`. This lead to problems downstream when that slot had to be used in other primitives i.e. flows or custom action.
Rasa Pro `3.7.9` fixes this by always storing the slot value in the same casing as defined in the domain. So, in the above example, the slot would now be stored as `A` instead of `a`. This ensures that the user is writing business logic for slot comparisons, for e.g. `if` conditions in flows, using the same casing as defined by them in the domain.
If you are migrating from Rasa pro versions `<= 3.7.8`, please double check your flows and custom actions to make sure none of them break because of this change.
#### Rasa 3.6 to Rasa Pro 3.7[](#rasa-36-to-rasa-pro-37 "Direct link to Rasa 3.6 to Rasa Pro 3.7")
##### Installation[](#installation-1 "Direct link to Installation")
info
Starting from Rasa 3.7.0, Rasa has moved to a new package registry and Docker registry. You will need to update your package registry to install Rasa 3.7.0 and later versions. If you are a Rasa customer, please reach out to your Rasa account manager or support obtain a [license](https://rasa.com/docs/docs/pro/installation/licensing/).
###### Python package[](#python-package-1 "Direct link to Python package")
Rasa python package for `3.7.0` has been moved to python package registry.
```
https://europe-west3-python.pkg.dev/rasa-releases/rasa-plus-py
```
Name of the package is `rasa`.
Example of how to install the package:
```
pip install --extra-index-url=https://europe-west3-python.pkg.dev/rasa-releases/rasa-plus-py/simple rasa==3.7.0
```
For more information on how to install Rasa Pro, please refer to the [Python installation guide](https://rasa.com/docs/docs/pro/installation/python/).
###### Helm Chart / Docker Image[](#helm-chart--docker-image-1 "Direct link to Helm Chart / Docker Image")
Rasa docker image for `3.7.0` is located at:
```
europe-west3-docker.pkg.dev/rasa-releases/rasa-docker/rasa
```
Example how to pull the image:
```
docker pull europe-west3-docker.pkg.dev/rasa-releases/rasa-docker/rasa:3.7.0
```
For more information on how to install Rasa Pro Docker image, please refer to the [Docker installation guide](https://rasa.com/docs/docs/pro/installation/docker/).
#### Migrating from older versions[](#migrating-from-older-versions "Direct link to Migrating from older versions")
For migrating from Rasa Open Source versions, please refer to the [migration guide](https://legacy-docs-oss.rasa.com/docs/rasa/migration-guide).
---
#### Rasa SDK Change Log
The Rasa SDK changelog can be found in the [Rasa SDK repository](https://github.com/RasaHQ/rasa-sdk/blob/main/CHANGELOG.mdx)
---
#### Studio Change Log
All notable changes to Rasa Studio will be documented in this page.
#### Important Notice: Database Migration Changes in Studio v1.13.x+[](#important-notice-database-migration-changes-in-studio-v113x "Direct link to Important Notice: Database Migration Changes in Studio v1.13.x+")
caution
Starting with version `1.13.x`, Studio supports deployments using non-superuser database roles. If you're upgrading from an earlier version, manual steps are required before the upgrade can be completed successfully. Please refer to [Rasa Studio 1.12.x to Rasa Studio 1.13.x](https://rasa.com/docs/docs/reference/changelogs/rasa-pro-migration-guide/#rasa-pro-311-to-rasa-pro-312) for full instructions. Skipping these steps will cause migration issues during deployment.
#### \[1.15.2] - 2026-01-13[](#1152---2026-01-13 "Direct link to [1.15.2] - 2026-01-13")
##### Bugfixes[](#bugfixes "Direct link to Bugfixes")
* Fixed collision errors during Studio upload when default custom actions in `domain.yml` were defined.
#### \[1.15.0] - 2025-12-09[](#1150---2025-12-09 "Direct link to [1.15.0] - 2025-12-09")
##### Features[](#features "Direct link to Features")
* **Slots CMS:** Studio users can now create and manage their assistant slots from a centralised CMS. [Learn more about Slots here](https://rasa.com/docs/docs/studio/build/content-management/slots/)
* **Buttons & Links CMS:** Studio users can now create and manage the buttons and links used on their assistant responses from a centralised CMS. [Learn more about Buttons & Links here](https://rasa.com/docs/docs/studio/build/content-management/buttons-and-links/)
##### Improvements[](#improvements "Direct link to Improvements")
* **Conversation Review Improvements:** Studio users can now filter conversations on Conversation Review by channel and assistant response.
#### \[1.14.6] - 2026-01-13[](#1146---2026-01-13 "Direct link to [1.14.6] - 2026-01-13")
##### Bugfixes[](#bugfixes-1 "Direct link to Bugfixes")
* Fixed collision errors during Studio upload when default custom actions in `domain.yml` were defined.
#### \[1.14.4] - 2025-11-27[](#1144---2025-11-27 "Direct link to [1.14.4] - 2025-11-27")
##### Improvements[](#improvements-1 "Direct link to Improvements")
* Add support for Rasa Pro 3.14.1
#### \[1.14.3] - 2025-11-24[](#1143---2025-11-24 "Direct link to [1.14.3] - 2025-11-24")
##### Bugfixes[](#bugfixes-2 "Direct link to Bugfixes")
* Fixed an issue where user messages with date/time entities (Duckling) were failing to process correctly, causing errors in conversation handling.
#### \[1.14.2] - 2025-11-13[](#1142---2025-11-13 "Direct link to [1.14.2] - 2025-11-13")
##### Improvements[](#improvements-2 "Direct link to Improvements")
* Improve the assistant upload time.
#### \[1.14.1] - 2025-10-28[](#1141---2025-10-28 "Direct link to [1.14.1] - 2025-10-28")
##### Features[](#features-1 "Direct link to Features")
* **Supporting Controlled Slots:** Studio now supports controlled slots; these can be used to define slots that should be filled by a custom action, [response button payload](https://rasa.com/docs/docs/reference/primitives/responses/#payload-syntax), or a [`set_slots` flow step](https://rasa.com/docs/docs/reference/primitives/flow-steps/#set-slots).
* **Response latency:** Response latency per turn on text and on voice with color coding with Rasa latency and TTS.
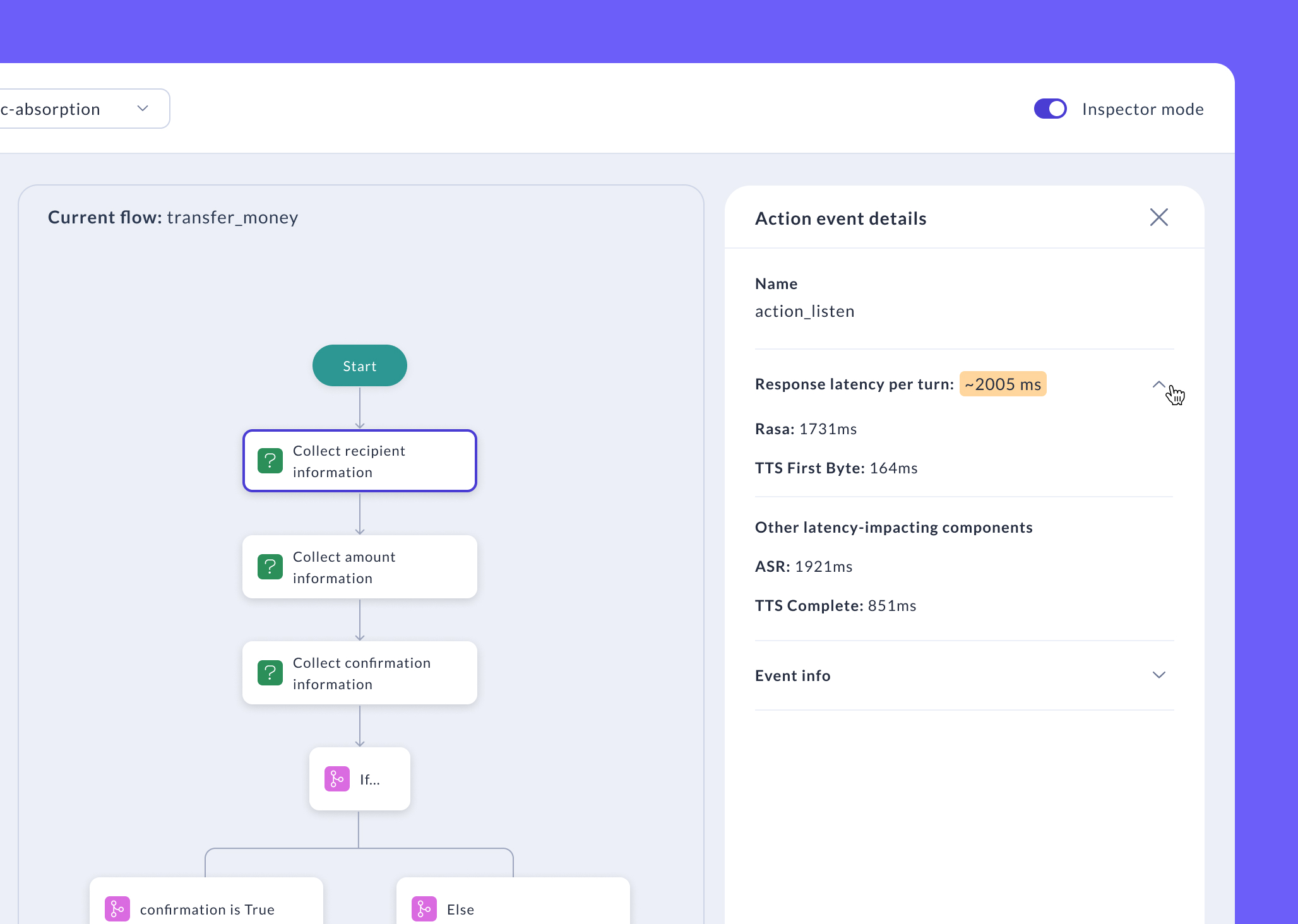
* **Support for IAM auth in AWS:** Studio now supports AWS IAM database authentication for enhanced security and simplified credential management.
More details on how to set it up and impacts can be found [here](https://rasa.com/docs/docs/reference/changelogs/studio-version-migration-guide/#rasa-studio-v113x--v114x)
##### Improvements[](#improvements-3 "Direct link to Improvements")
* **Deployment improvements:** The Rasa Studio deployment experience has undergone drastic improvements. We have released new Rasa Studio Deployment Playbooks, reducing the time and effort required to deploy Rasa Studio.
* **Upload license:** You can now upload your extended license from Studio.
#### \[1.14.0.edge1] - 2025-08-29[](#1140edge1---2025-08-29 "Direct link to [1.14.0.edge1] - 2025-08-29")
##### Features[](#features-2 "Direct link to Features")
* **Streamlined UX for flow versioning:**
* Flows can now be marked as Draft or Published to clearly communicate their status to your team.
* You can add comments to flow versions to describe changes, making it easier to track progress and revert to a specific version.
* The history log is now streamlined to highlight key changes and who made them, with the option to view a detailed breakdown when needed.
* **Editing system responses:** You can now directly edit responses in Rasa system flows, making it easy to adjust how your assistant handles unexpected turns and to align the tone of voice with your brand.
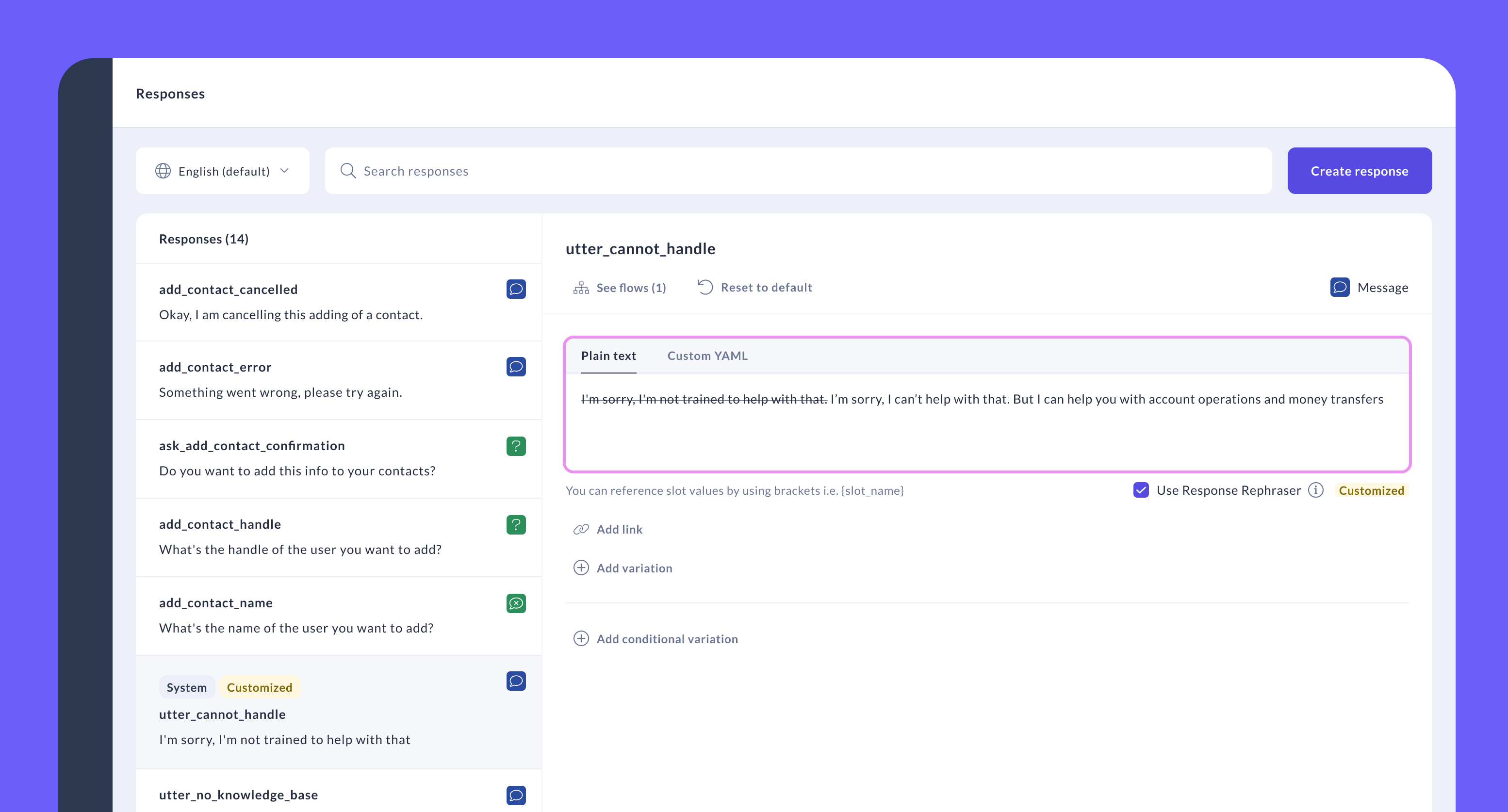
* **Keycloak upgrade:**
* The Keycloak Docker image has been upgraded from version `23` to `26.3.2`
* This update includes security patches, performance improvements, and API updates from the upstream release
##### Improvements[](#improvements-4 "Direct link to Improvements")
* **Vulnerability fixes**
* All Docker images are now upgraded from node `v20.11.0` to node `v.22.18.0`
* Update all package dependencies to fix security vulnerabilities
##### Bugfixes[](#bugfixes-3 "Direct link to Bugfixes")
* Silence timeout in Collect step shows an inaccurate value in the UI
* Voice Inspector does not hang up the call after executing the silence pattern
#### \[1.13.8] - 2025-12-09[](#1138---2025-12-09 "Direct link to [1.13.8] - 2025-12-09")
##### Bugfixes[](#bugfixes-4 "Direct link to Bugfixes")
* Fix validation so Studio no longer blocks assistant uploads on incorrect persisted-slot warnings when training succeeds.
#### \[1.13.7] - 2025-11-24[](#1137---2025-11-24 "Direct link to [1.13.7] - 2025-11-24")
##### Improvement[](#improvement "Direct link to Improvement")
* Introduce enhanced debug logging across the backend and Keycloak.
#### \[1.13.6] - 2025-10-31[](#1136---2025-10-31 "Direct link to [1.13.6] - 2025-10-31")
##### Bugfixes[](#bugfixes-5 "Direct link to Bugfixes")
* Fixed event ingestion issue which prevented entities from `DucklingEntityExtractor` to be ingested
#### \[1.13.5] - 2025-10-16[](#1135---2025-10-16 "Direct link to [1.13.5] - 2025-10-16")
##### Bugfixes[](#bugfixes-6 "Direct link to Bugfixes")
* Fixed a Prisma transaction handling issue that prevented assistants from being downloaded in Studio.
#### \[1.13.4] - 2025-09-25[](#1134---2025-09-25 "Direct link to [1.13.4] - 2025-09-25")
##### Bugfixes[](#bugfixes-7 "Direct link to Bugfixes")
* Improved the previous flow node validation fix to ensure it continues working correctly after multiple training runs.
#### \[1.13.3] - 2025-09-15[](#1133---2025-09-15 "Direct link to [1.13.3] - 2025-09-15")
##### Bugfixes[](#bugfixes-8 "Direct link to Bugfixes")
* Fixed an issue where training in Studio failed with an “invalid step” error unless the condition value was manually re-selected.
#### \[1.13.2] - 2025-08-25[](#1132---2025-08-25 "Direct link to [1.13.2] - 2025-08-25")
##### Bugfixes[](#bugfixes-9 "Direct link to Bugfixes")
* Fixed all npm vulnerabilities
#### \[1.13.1] - 2025-07-28[](#1131---2025-07-28 "Direct link to [1.13.1] - 2025-07-28")
##### Bugfixes[](#bugfixes-10 "Direct link to Bugfixes")
* Fixed prisma dependency installation script
* Fixes a timeout issue in viewing conversation in Studio with bigger datasets
#### \[1.13.0] - 2025-07-14[](#1130---2025-07-14 "Direct link to [1.13.0] - 2025-07-14")
##### Features[](#features-3 "Direct link to Features")
* **Supporting Loops in Flows:** Studio now supports looping flows, making it easier to build conversations with more natural and flexible control. You can now:
* **Loop back** to earlier steps in the same flow — useful for retries, clarifications, or repeated prompts.
* **Loop forward** by connecting multiple branches to the same ending, simplifying flows that converge to a common result.
[Learn more](https://rasa.com/docs/docs/studio/build/flow-building/linking-flows/#connecting-steps-within-a-flow)
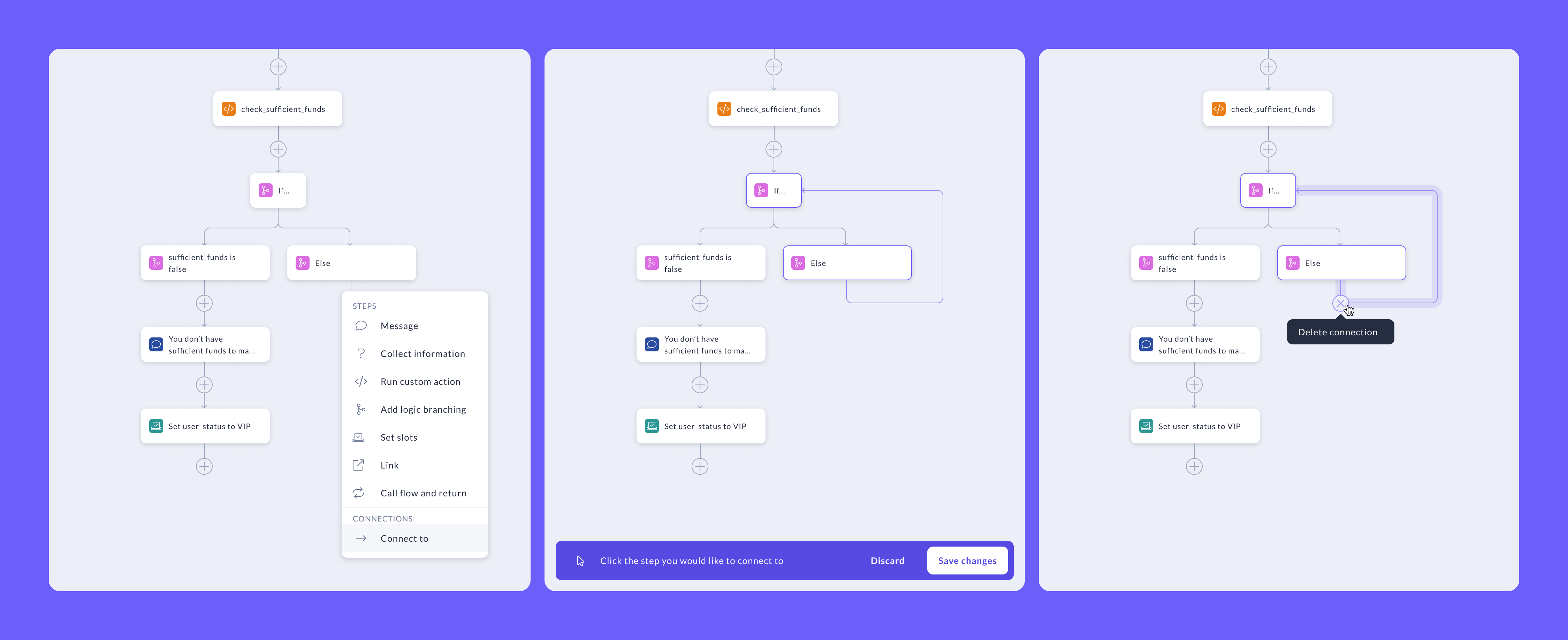
* **Custom Responses:** You can now add and edit any custom response components — carousels, cards, date pickers, or anything else your chat widget supports — directly in Studio using the inline YAML editor.
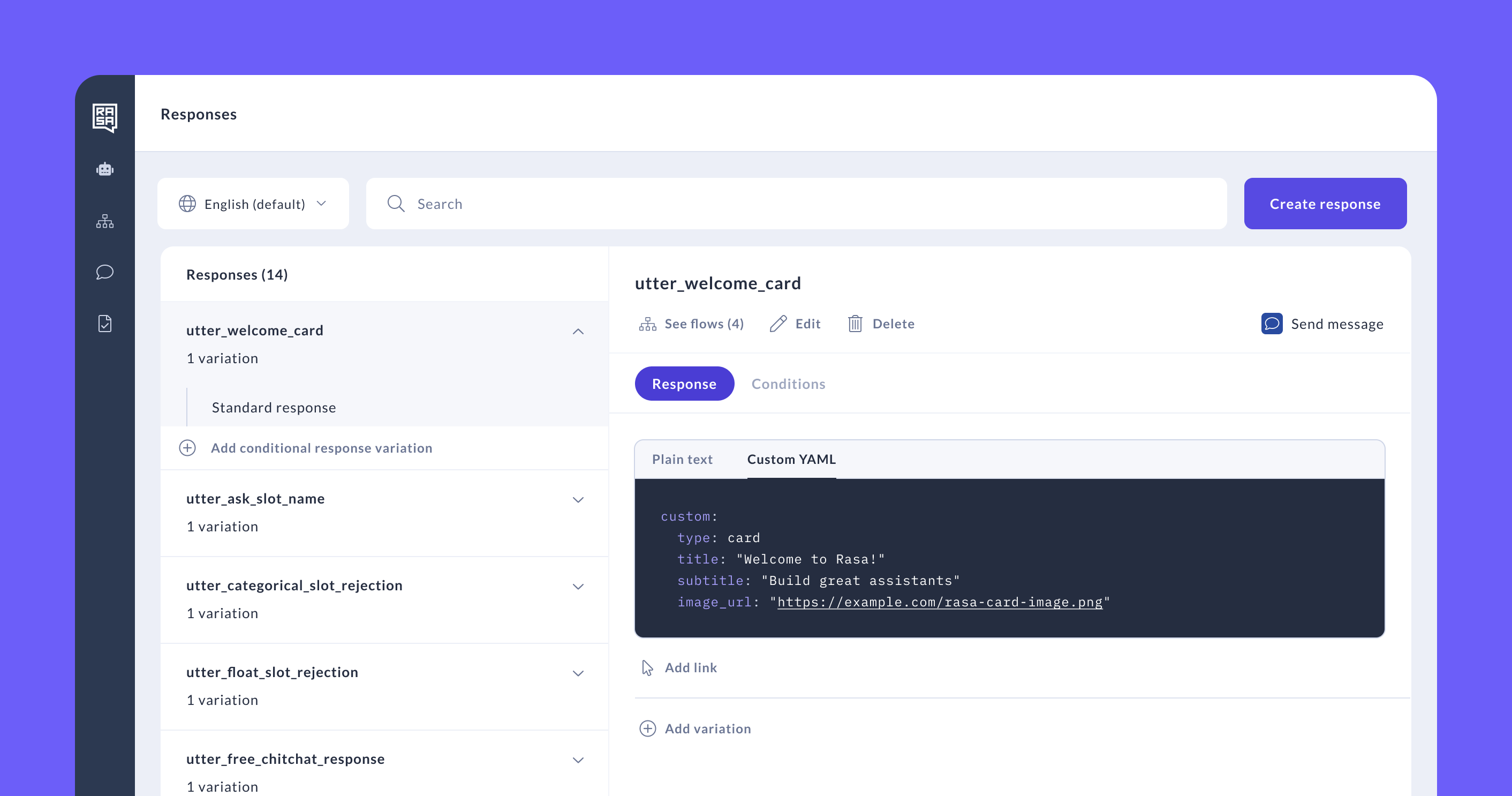
Custom response code will also be visible in the Inspector during testing, so you can review exactly what was sent during conversations.
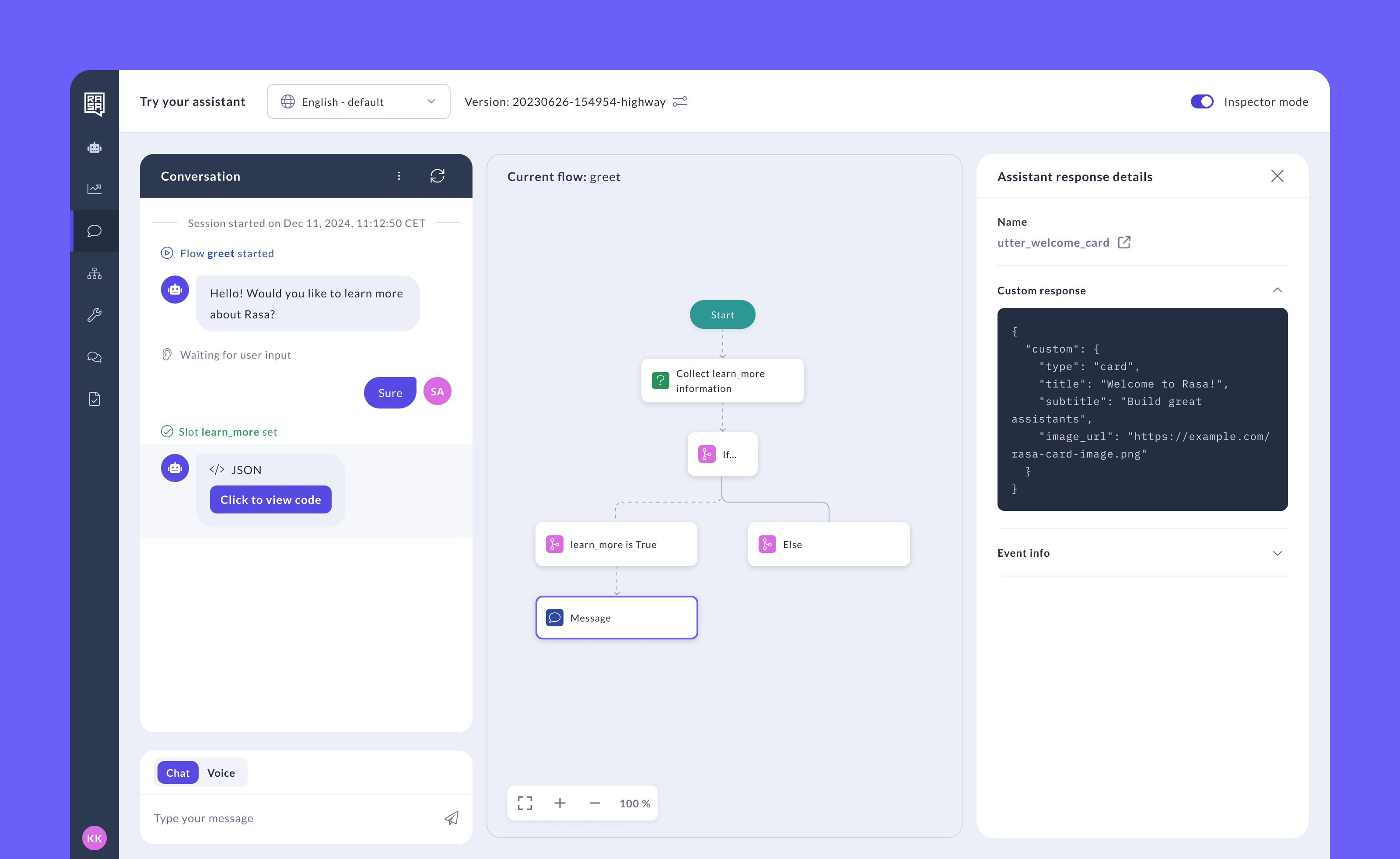
* **Custom Prompts:** This release introduces the ability to edit assistant prompts directly in the UI:
* Fine-tune your assistant’s tone of voice by editing the global rephraser prompt and individual response prompts directly in Studio.
* For more low-level control over your assistant’s behaviour, you can now edit Command Generator and Enterprise Search prompts.
***⚠️ Note:** Modifying the command generator prompt can significantly impact assistant behavior. We recommend validating changes with end-to-end testing before deploying to production.*

* **Testing in Voice:** You can now test your assistant not just in chat, but also in voice — directly in Studio **using the Inspector view:**
* Choose whether you want to test with chat or voice
* Start a call with your assistant, grant microphone access, and begin speaking
* All events and responses are transcribed and visible in the Inspector, just like with chat
* It uses Rasa’s default voice setup (STT from Deepgram and TTS from Cartesia), so there’s nothing to configure — defaults work out of the box.
* For now, voice input is limited to English.
⚠️ Only available if voice is included in your Rasa license
[Learn more](https://rasa.com/docs/docs/studio/test/try-your-assistant/#switching-between-chat-and-voice)
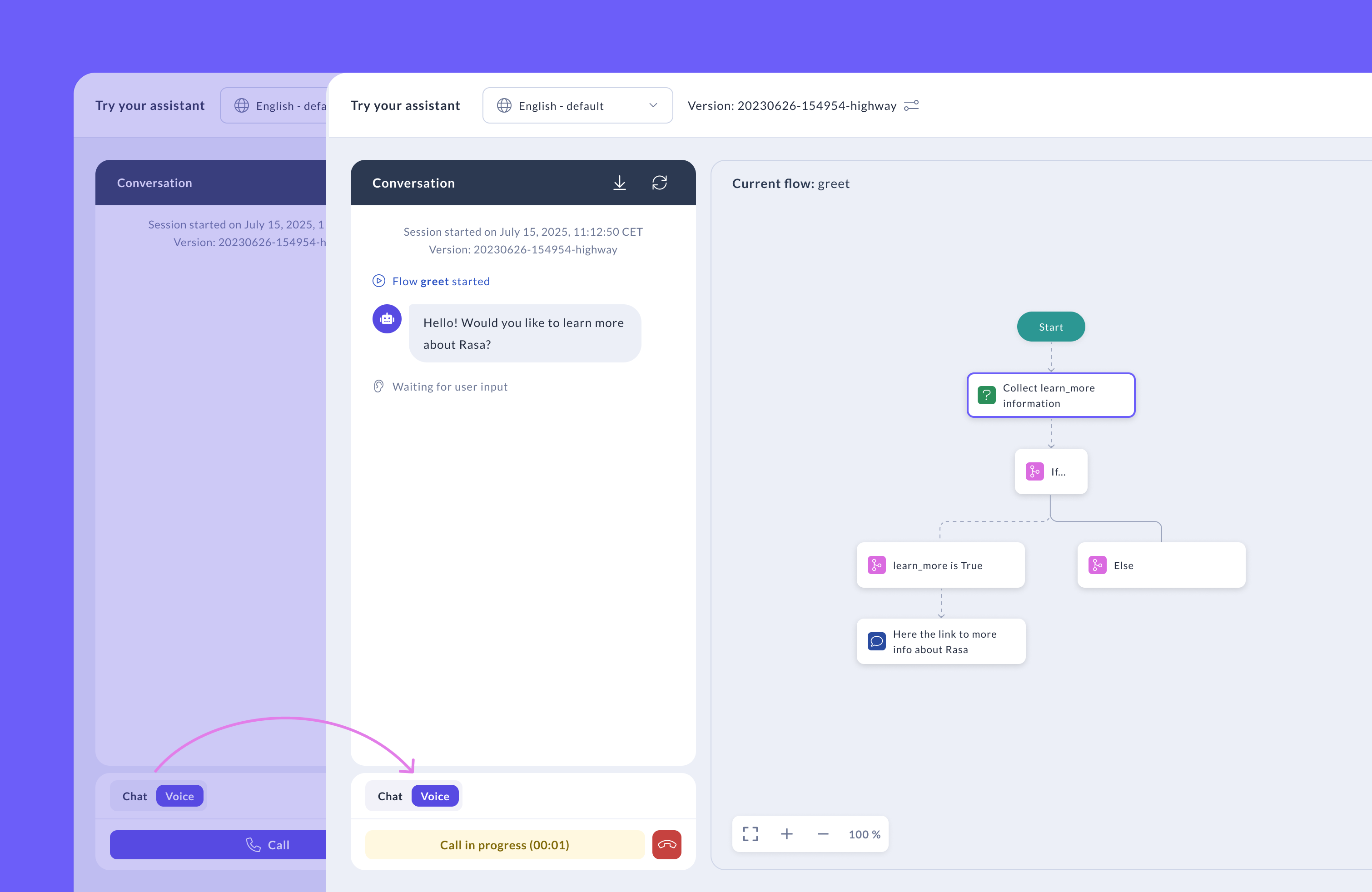
* **Silence Handling for Voice Interactions:** You can now configure how long your assistant should wait for a user response during voice interactions before treating it as silence. Default is 7 seconds, you can change it in endpoints.yml:
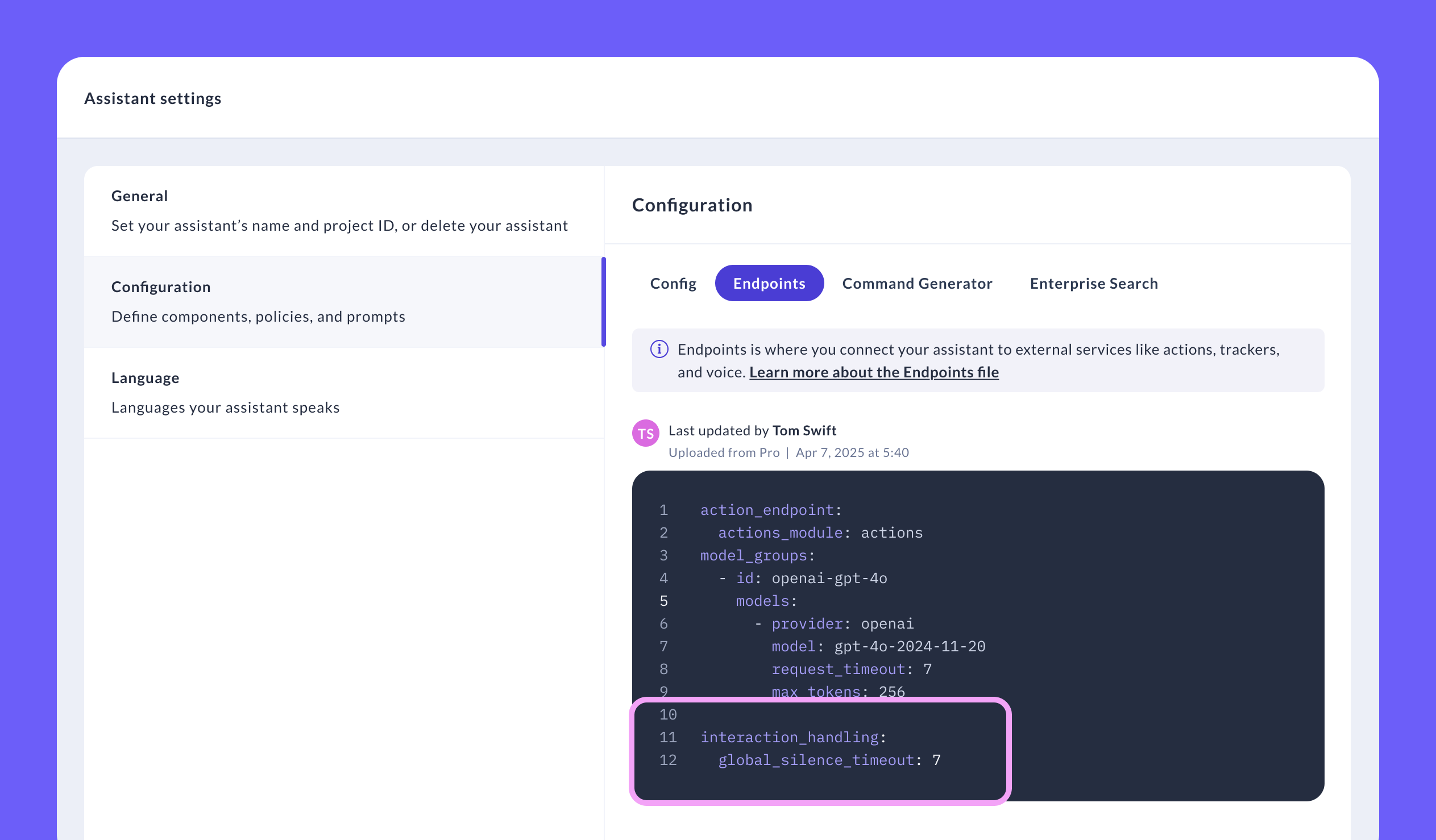
Or override it per Collect step to fine-tune behavior for specific questions:
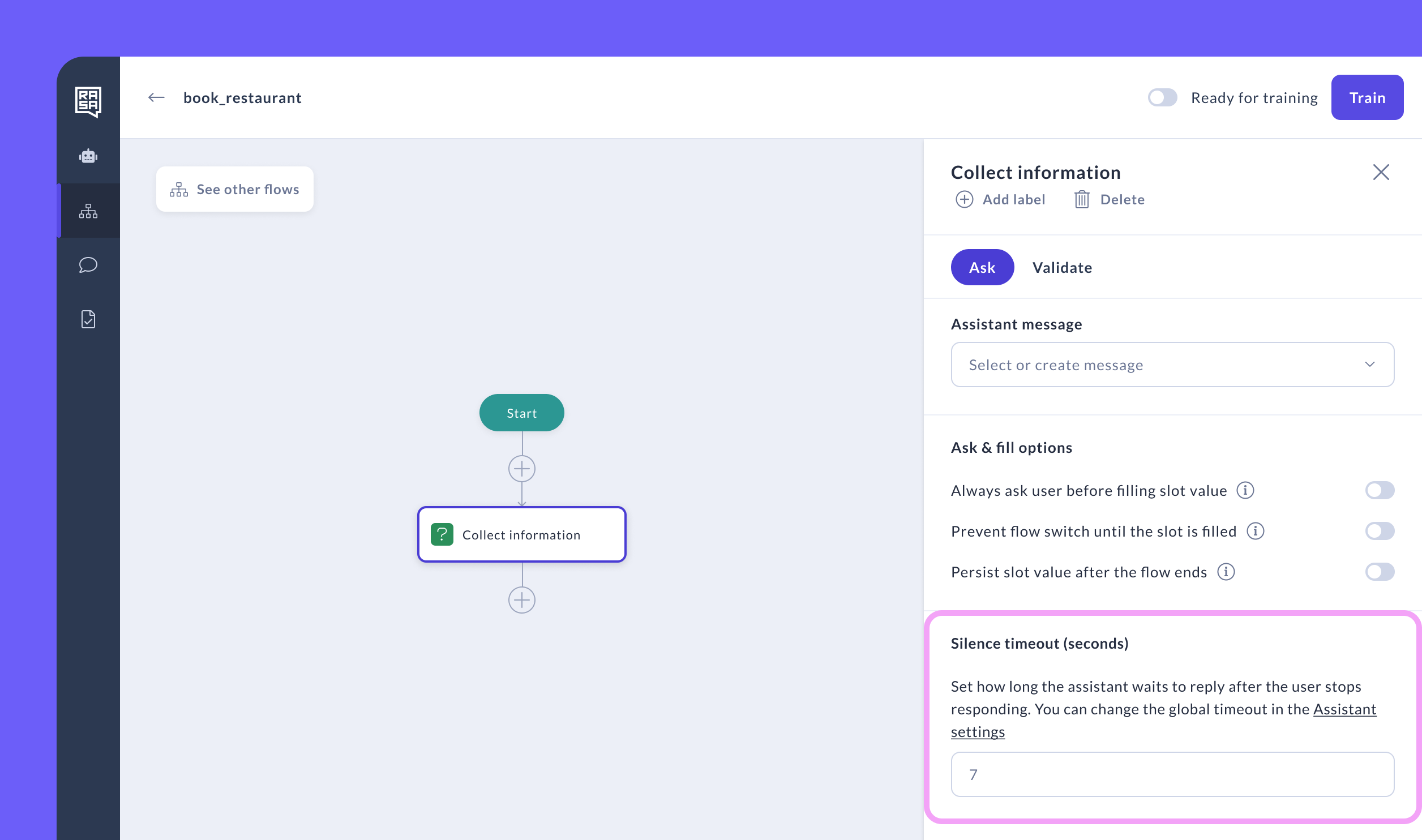
When the timeout is reached, the assistant triggers the `pattern_user_silence`, allowing you to define how it should respond to user silence — for example, by repeating the question or offering help.
⚠️ Only available if voice is included in your Rasa license
* **Supporting All Logical Operators and OR in Conditional Responses:** Studio now supports both AND and OR operators in conditional response variations, along with all comparison operators available in the Rasa Framework (e.g. `==`, `!=`, `>`, `<`). This brings more flexibility when defining when a response should be shown.
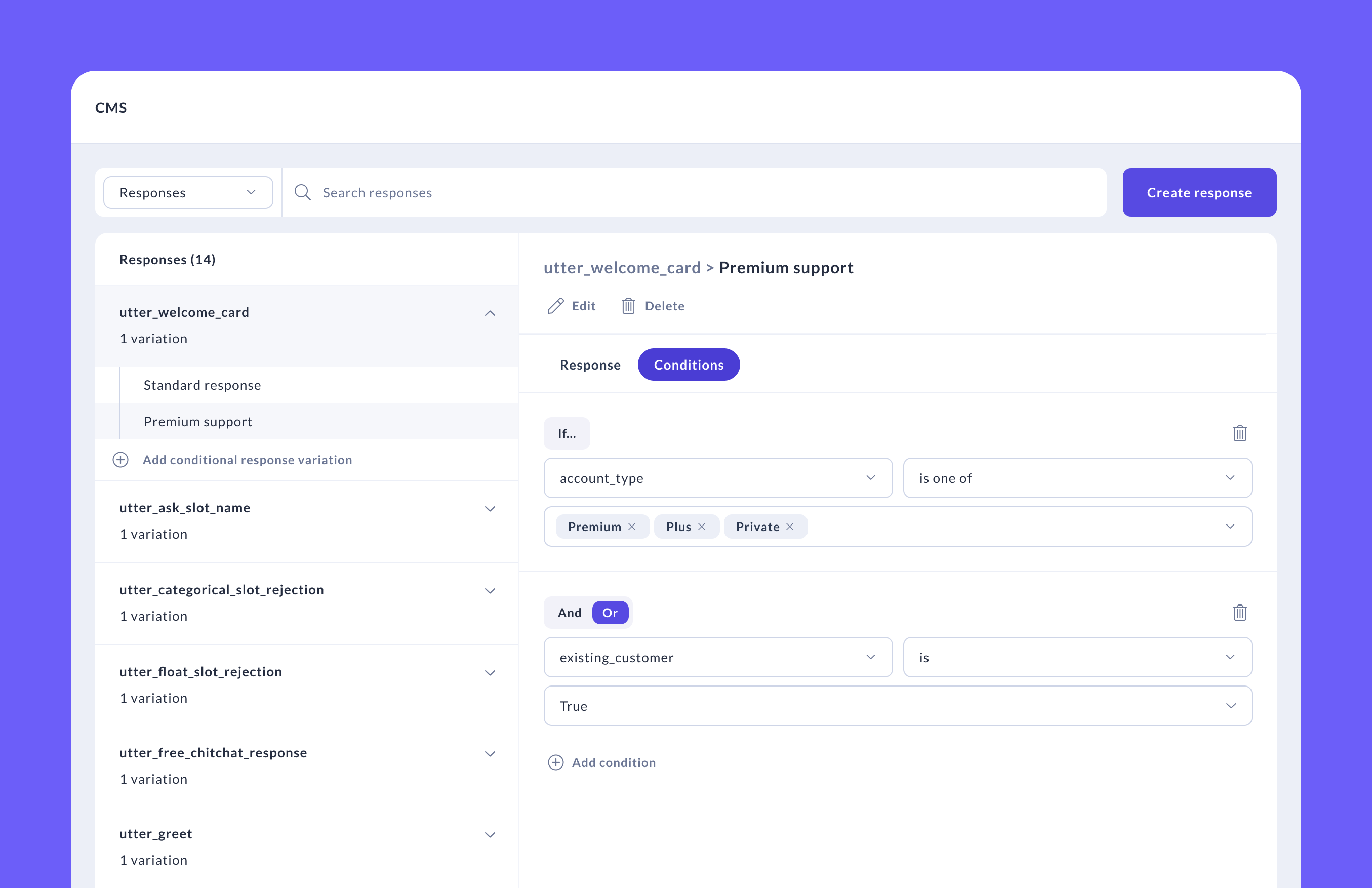
* **Preventing Digressions:** You can now keep conversations on track while collecting multiple pieces of user input by turning on a setting that prevents users from switching flows until specific required slots are filled.
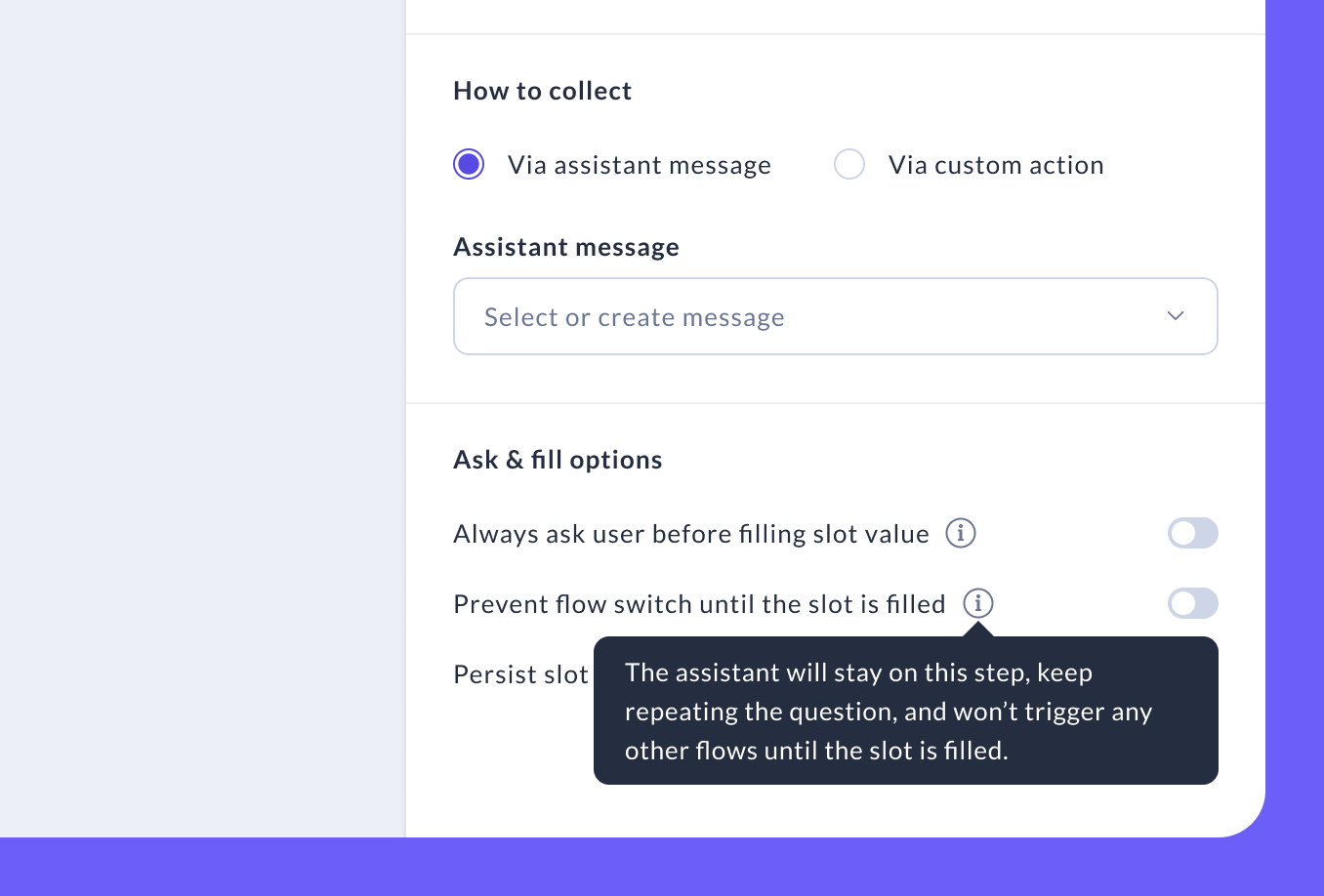
##### Improvements[](#improvements-5 "Direct link to Improvements")
* Allow deleting primitives and flows used in old assistant versions
* Allow nested Logic steps in flows
* Automatically open a flow on creation
#### \[1.13.0.edge1] - 2025-05-19[](#1130edge1---2025-05-19 "Direct link to [1.13.0.edge1] - 2025-05-19")
##### Features[](#features-4 "Direct link to Features")
* **Duplicating flows:** Need to reuse existing flow logic? Now you can duplicate any flow in one click — no need to rebuild from scratch. A simple way to speed up editing and keep things consistent. [Learn more](https://rasa.com/docs/docs/studio/build/content-management/manage-flows/#duplicating-flows)
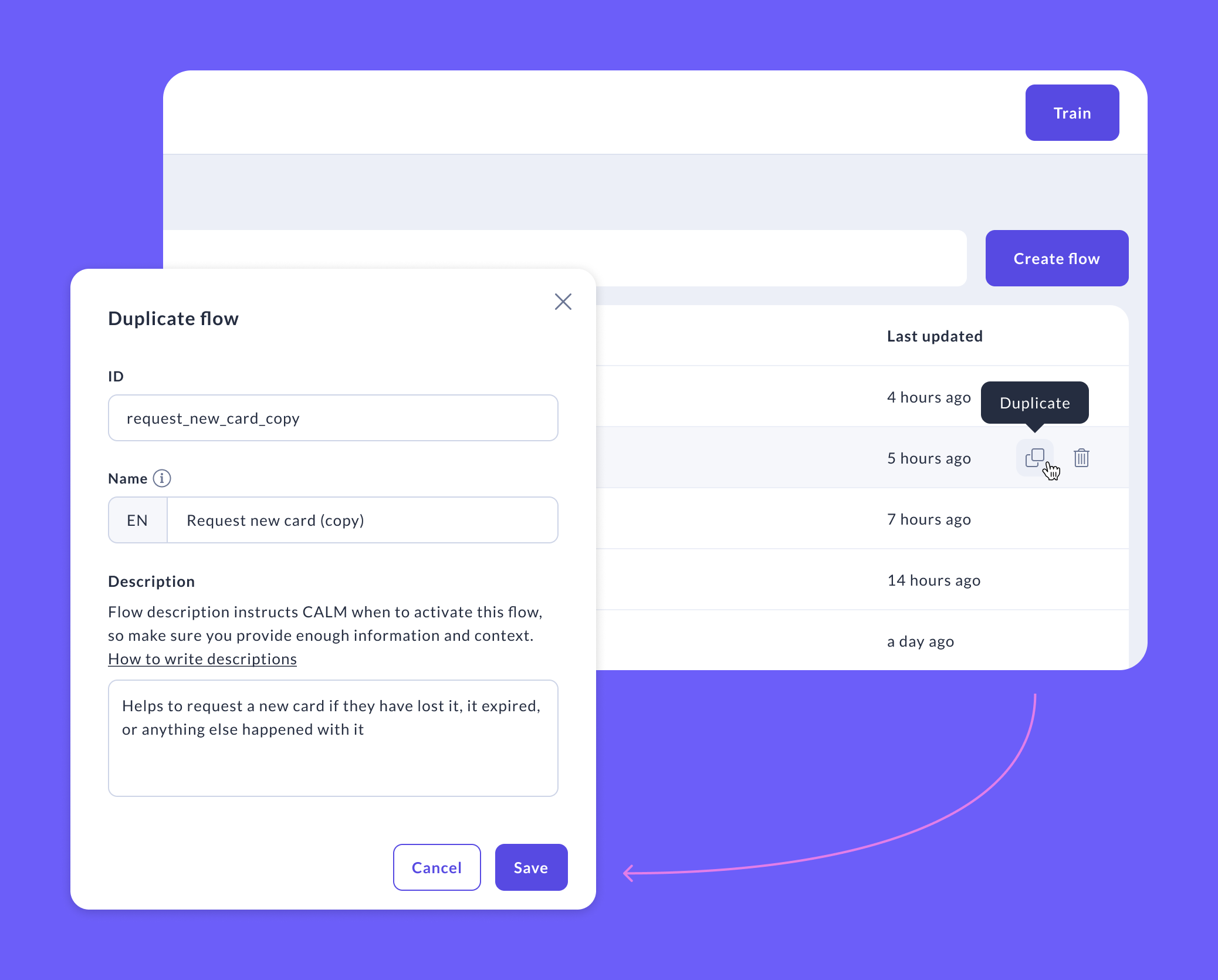
* **Reordering buttons and links in responses:** You can now drag and drop buttons and links directly in the response editor — giving you full control over the order in which options are shown to users. Learn more about [buttons](https://rasa.com/docs/docs/studio/build/flow-building/collect/#reordering-buttons) and [links](https://rasa.com/docs/docs/studio/build/flow-building/sending-messages/#reordering-links)
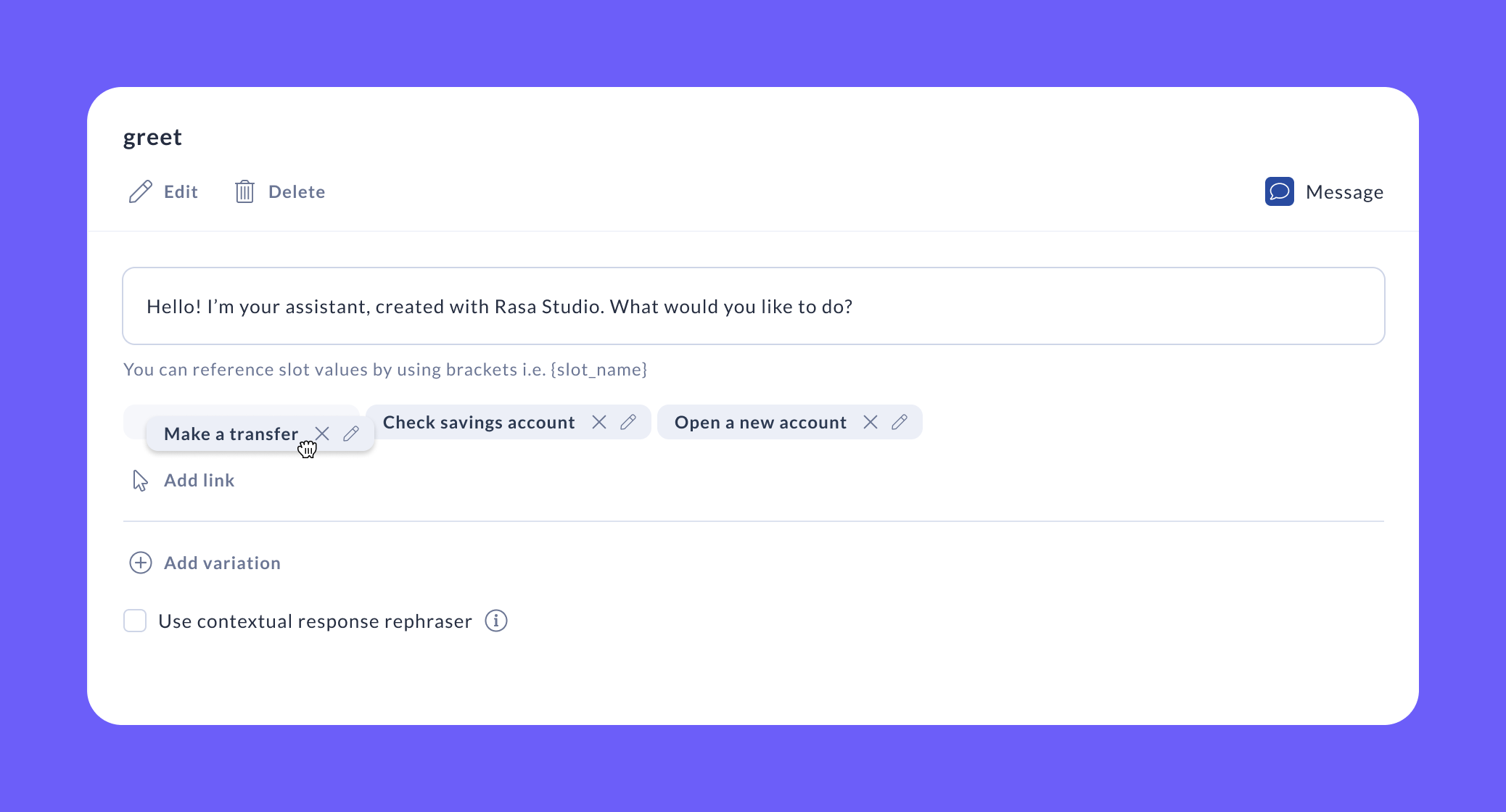
* **Upload & download improvements:** Granular upload and download of Assistant Settings is now available, enabling users to maintain consistent and synchronized `config.yml` and `endpoints.yaml` files across Studio and Pro.
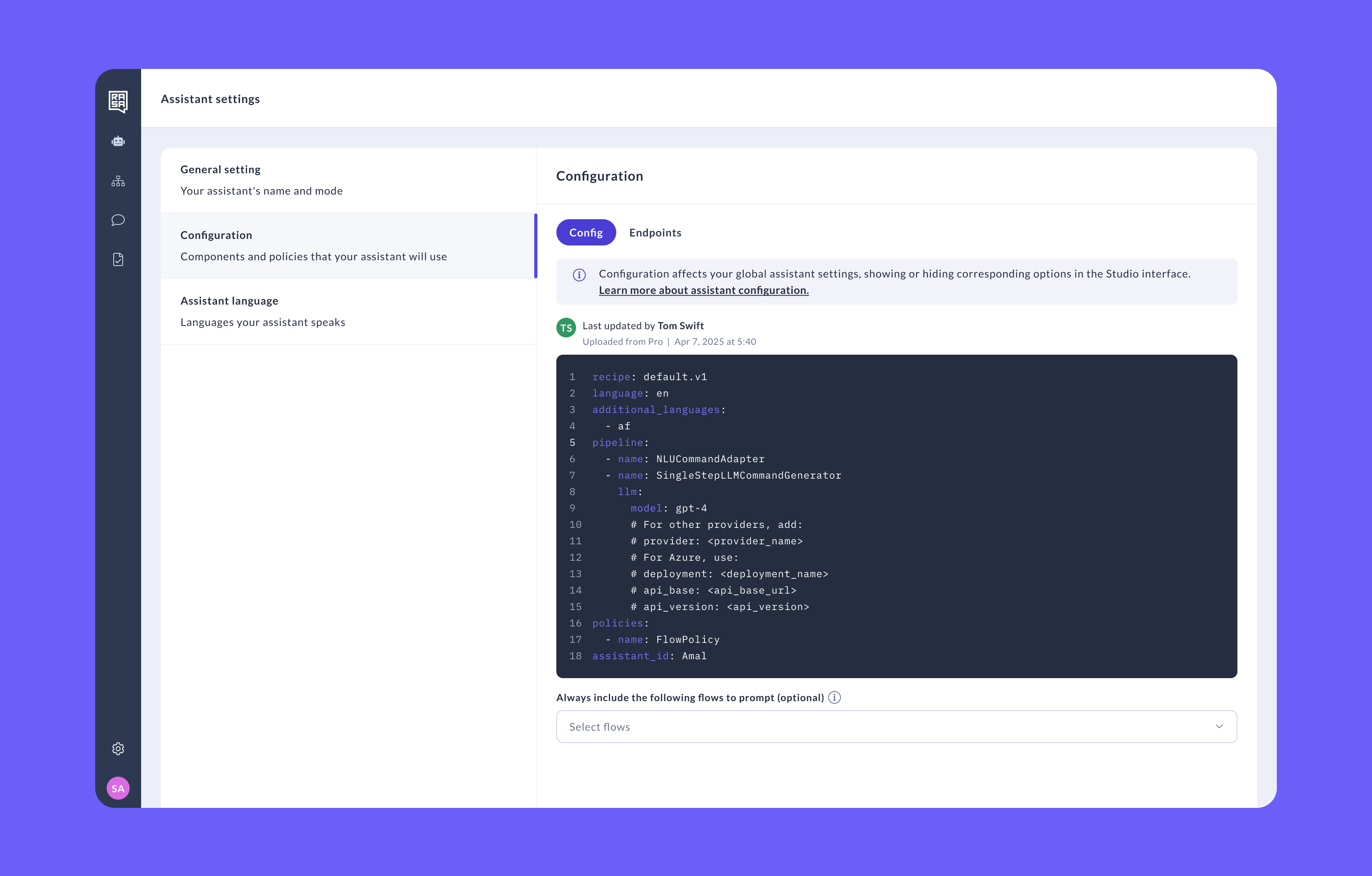
##### Improvements[](#improvements-6 "Direct link to Improvements")
* **Training panel Improvements:** Managing training just got easier
1. Newly created flows are selected for training by default. If you adjust the selection, the assistant will remember your choice.
2. Along with your flows, the panel now shows only *customized* system flows — keeping things cleaner.
3. Selecting a version is only required if you’re using flow versioning. [Learn More](https://rasa.com/docs/docs/studio/test/train-your-assistant/#training-in-studio)
##### Bugfixes[](#bugfixes-11 "Direct link to Bugfixes")
* Fixed incorrect error message shown when deleting intents with examples but no annotations.
* Fixed unexpected navigation from “Try your assistant” when clicking empty canvas areas in inspector mode.
* Fixed hidden initial values for boolean slots in slot configuration modal.
* Fixed issue where intent and entity dropdowns were empty when editing slot mappings.
* Other minor fixes for Studio trial improvement
#### \[1.12.13] - 2025-08-25[](#11213---2025-08-25 "Direct link to [1.12.13] - 2025-08-25")
##### Bugfixes[](#bugfixes-12 "Direct link to Bugfixes")
* Fixed all dependency vulnerabilities
#### \[1.12.12] - 2025-07-29[](#11212---2025-07-29 "Direct link to [1.12.12] - 2025-07-29")
##### Bugfixes[](#bugfixes-13 "Direct link to Bugfixes")
* Fixes a timeout issue in viewing conversation in Studio with bigger datasets
#### \[1.12.10] - 2025-06-27[](#11210---2025-06-27 "Direct link to [1.12.10] - 2025-06-27")
##### Bugfixes[](#bugfixes-14 "Direct link to Bugfixes")
* Fixed a bug on uploading condition on many categorical values
#### \[1.12.9] - 2025-06-17[](#1129---2025-06-17 "Direct link to [1.12.9] - 2025-06-17")
##### Improvements[](#improvements-7 "Direct link to Improvements")
* Updated latest Rasa-pro version
* Other minor bugfixes
#### \[1.12.8] - 2025-06-03[](#1128---2025-06-03 "Direct link to [1.12.8] - 2025-06-03")
##### Bugfixes[](#bugfixes-15 "Direct link to Bugfixes")
* Defaulted new assistants to use `CompactLLMCommandGenerator` and `gpt-4o-2024-11-20` model since the older gpt-4 model will soon be deprecated.
* Added selected language to test case metadata to ensure that the generated e2e tests can be run for specific language configuration.
#### \[1.12.7] - 2025-05-23[](#1127---2025-05-23 "Direct link to [1.12.7] - 2025-05-23")
##### Bugfixes[](#bugfixes-16 "Direct link to Bugfixes")
* Fixed a bug where re-adding a language caused duplicates and broken translations.
#### \[1.12.5] - 2025-05-15[](#1125---2025-05-15 "Direct link to [1.12.5] - 2025-05-15")
##### Bugfixes[](#bugfixes-17 "Direct link to Bugfixes")
* Fixed a crash on the Versions page caused by a Rust-to-NAPI string conversion error.
* Fixed an issue causing the Flows page to render blank due to unexpected local storage state.
#### \[1.12.4] - 2025-05-08[](#1124---2025-05-08 "Direct link to [1.12.4] - 2025-05-08")
##### Bugfixes[](#bugfixes-18 "Direct link to Bugfixes")
* Fixed an issue due to duplication of button translations during import.
* Fixed an issue related to incorrect parsing of slot conditions during import.
* Removed unwanted validation of model names during import.
* `pattern completed` and `session start` system flows are now displayed in `Inspector mode`.
* Other minor bug fixes.
#### \[1.12.3] - 2025-04-29[](#1123---2025-04-29 "Direct link to [1.12.3] - 2025-04-29")
##### Improvements[](#improvements-8 "Direct link to Improvements")
* Users can download selected flows from the Flows page.
* New non-empty flows are automatically selected for training.
* Users are directed to the `Try your assistant` page when selecting an assistant project from the welcome page.
* Users can edit custom languages in the assistant settings.
* Multiple UX improvements to the CMS page.
* Renamed `Custom Flows` to `My Flows`.
* Updated T\&C links.
#### \[1.12.2] - 2025-04-14[](#1122---2025-04-14 "Direct link to [1.12.2] - 2025-04-14")
##### Bugfixes[](#bugfixes-19 "Direct link to Bugfixes")
* Fixed CVE-2025-32812
* Fixed an issue where duplicate links could be added in the 'Create response' modal.
* Fixed a bug where localized button payload settings were not saved correctly.
#### \[1.12.1] - 2025-04-08[](#1121---2025-04-08 "Direct link to [1.12.1] - 2025-04-08")
##### Bugfixes[](#bugfixes-20 "Direct link to Bugfixes")
* Fixed an issue where the Flows page rendered blank due to stale data in local storage.
#### \[1.12.0] - 2025-04-08[](#1120---2025-04-08 "Direct link to [1.12.0] - 2025-04-08")
##### Features[](#features-5 "Direct link to Features")
* **Reusable Links and Buttons in Responses:**
1. Native link support is now available within responses. You can add links to external URLs, within your application, or phone/email links.
[Learn More about links in responses](https://rasa.com/docs/docs/studio/build/flow-building/sending-messages/#links)
2. Links and buttons can now be reused within a project. Create a button or link once, and simply select it in another response for reuse. 
* **Integrated Multi-Language Support:** This release introduces multi-language support natively in Rasa to make multilingual assistants easier to manage and scale. With this update, you can now configure multiple languages directly within your assistant’s settings. This means you can pre-translate responses, buttons, links, and even flow names, ensuring a consistent and brand-aligned experience across different languages.
**Language Configuration:** Define your assistant’s default language and add additional languages in the `config.yml` file or through the Assistant Settings in Studio. 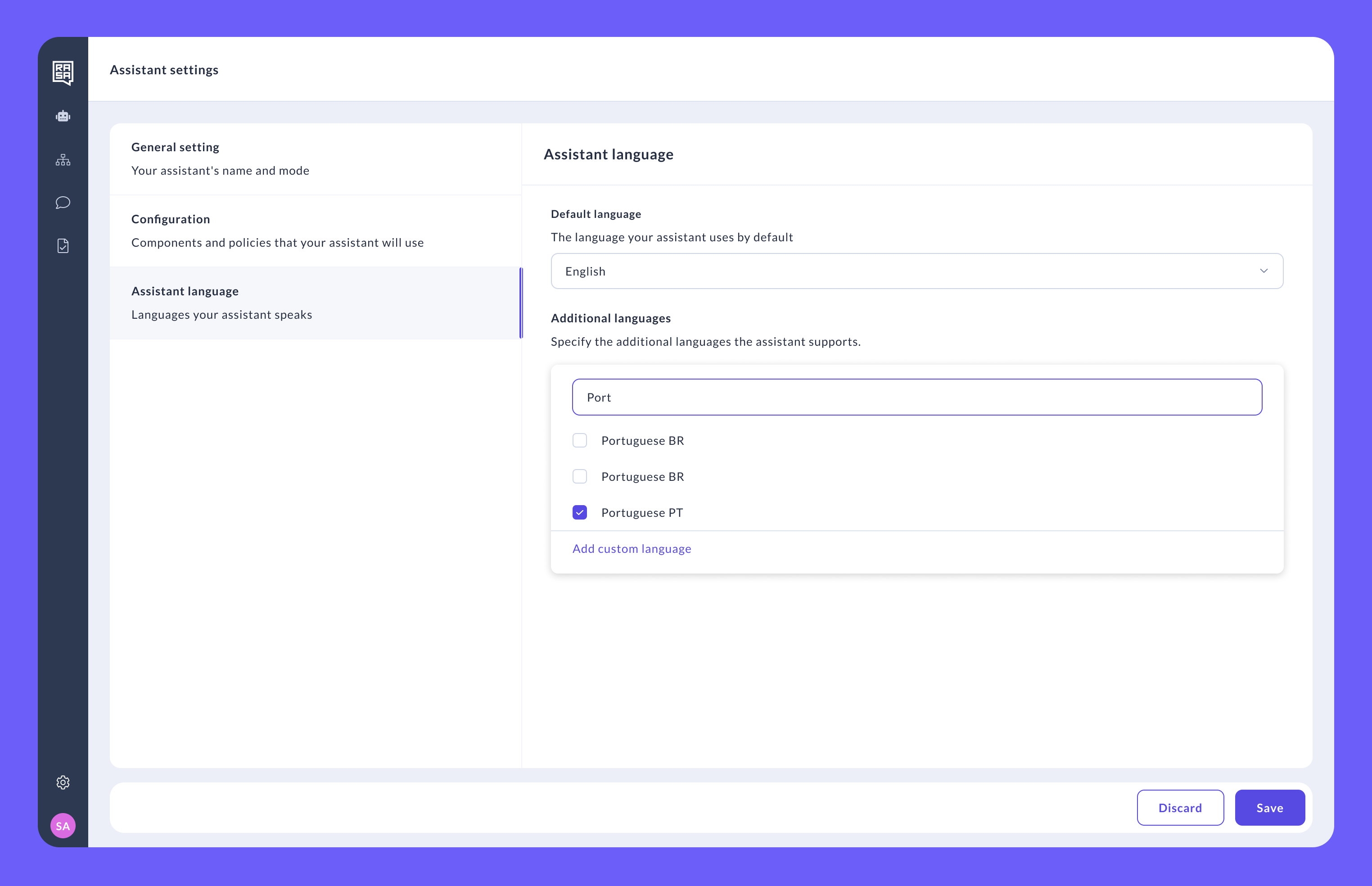
**Content Translation:** Manage your translations for responses, buttons, links, and flow names. 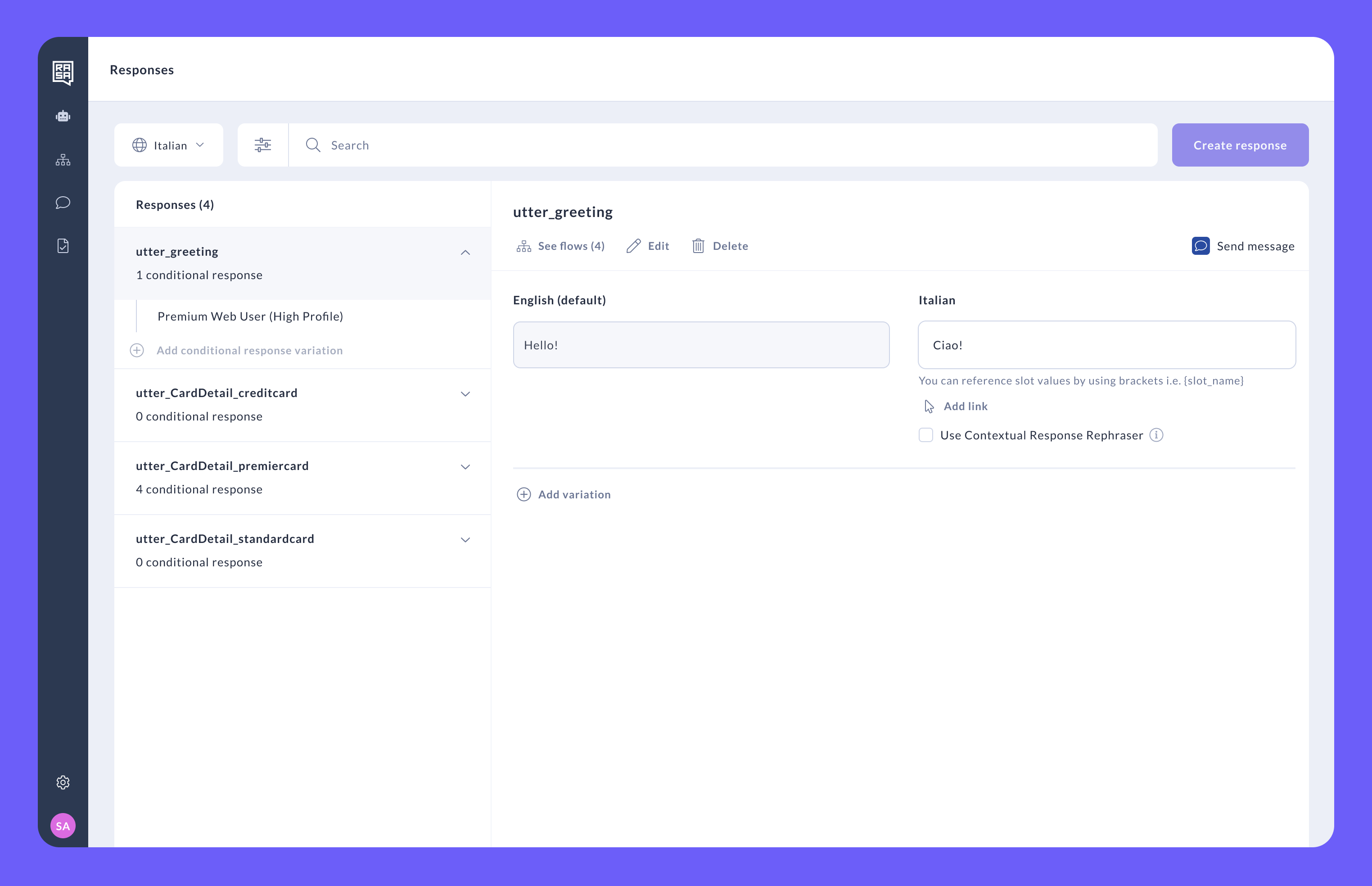
**Try your assistant in all your supported languages:** Test out your assistant in different languages to ensure that your user experience is seamless for any market. 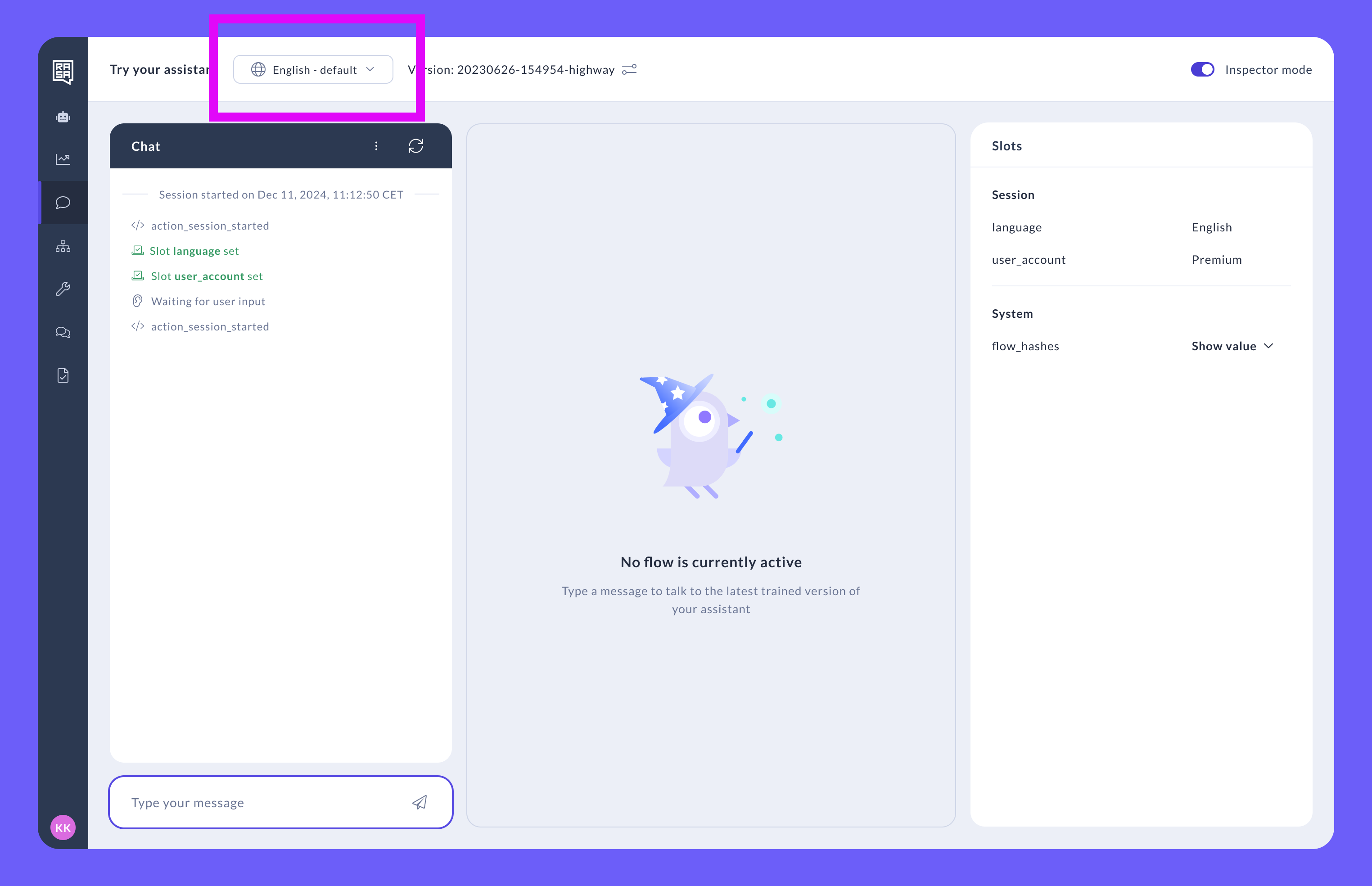
* **Train & Test in Isolation :** With this release, customers can create and include different versions of flows in training, allowing them to test the model in isolation without disrupting others' work.
1. **Save stable flow versions for training :** store reliable versions of flows that teams can use consistently for training and testing. 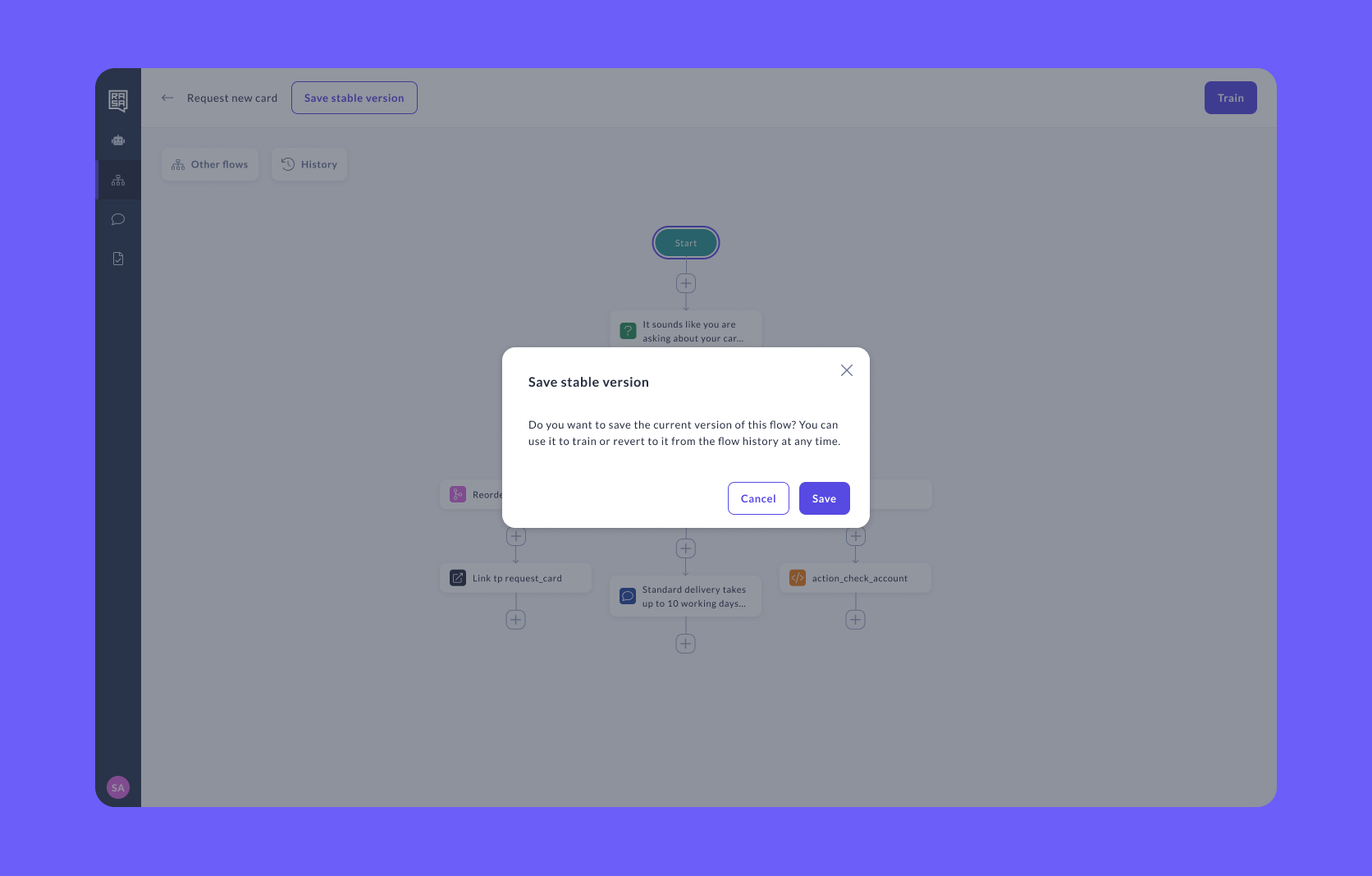
2. **Train assistant with specific flow versions :** choose between stable or current versions of a flow when training a model, and create a dedicated model version. 
3. **Test in isolation :** test newly created assistant versions without affecting others’ testing. 
4. **Assistant version management :** manage multiple assistant versions, test them anytime, and update their name and description as needed. 
* **Persisted Slot Values :** You now have more control over the bot’s memory. Choose whether to persist or clear a specific slot value after the flow ends. 
* **Welcome Page for Improved Studio Navigation :** Studio now has a homepage, so you could navigate between projects and explore educational materials. 
##### Improvements[](#improvements-9 "Direct link to Improvements")
* **Form to Leave Feedback About the Product** You can now share your thoughts and insights about Studio using a dedicated Feedback button in the menu.
* **Documentation Links for Contextual Help** Rasa now has new documentation! To make it easier to discover, we’ve added contextual links to it in various places across the UI where help might be needed.

* **Navigation Enhancements**
1. In-Flow Search: Quickly find and jump to specific nodes within your flow, reducing time spent scrolling and faster editing of complex assistants. 
2. View Linked Flows in CMS: You can now preview which flows are using a response and jump to the response in the flow builder directly from the CMS 
* **Enable Delete Assistant :** Users can now delete an assistant.
##### Bugfixes[](#bugfixes-21 "Direct link to Bugfixes")
* Other minor bugfixes
#### \[1.12.0.dev2] - 2025-02-20[](#1120dev2---2025-02-20 "Direct link to [1.12.0.dev2] - 2025-02-20")
##### Bugfixes[](#bugfixes-22 "Direct link to Bugfixes")
* Fixed an issue around flow version validation where conditions linked to a slot now apply only to draft flows, preventing validation issues caused by historical flow versions.
#### \[1.12.0.dev1] - 2025-02-17[](#1120dev1---2025-02-17 "Direct link to [1.12.0.dev1] - 2025-02-17")
##### Features[](#features-6 "Direct link to Features")
* **Inspector mode:** Studio now includes Inspector Mode—a detailed debugging view that displays flow events, slot updates, and response details in real time. Users can easily switch between a simplified view and Inspector Mode to track their assistant’s behavior and resolve issues without leaving Studio.
[Learn more about Inspector mode](https://rasa.com/docs/docs/studio/test/try-your-assistant/)
##### Improvements[](#improvements-10 "Direct link to Improvements")
* **Support OR operator between logical conditions**: Users can now use the OR operator in conditions throughout Studio. This enhancement brings Studio closer to the Rasa Framework in functionality, giving you more flexibility in designing your flows. 
* **Improved navigation between invalid nodes in a flow**: Users can now quickly identify and fix validation errors, even in large flows. 
* **System Flow Reset Improvement**: Resetting system flows no longer clears their change log, ensuring the flow history remains intact.
* **Improved Flow List Ordering**: The Flow list is now ordered based on the last update made by users, ensuring it reflects direct user actions rather than system-driven changes.
* **Introduction of Superuser Group**: A new Superuser user group has been introduced. Members of this group have full access to all features provided by Studio.
#### \[1.11.4] - 2025-07-24[](#1114---2025-07-24 "Direct link to [1.11.4] - 2025-07-24")
##### Bugfixes[](#bugfixes-23 "Direct link to Bugfixes")
* Fixes a timeout issue in viewing conversation in Studio with bigger datasets
#### \[1.11.2] - 2025-04-17[](#1112---2025-04-17 "Direct link to [1.11.2] - 2025-04-17")
##### Bugfixes[](#bugfixes-24 "Direct link to Bugfixes")
* Fixed CVE-2025-32812
#### \[1.11.1] - 2025-02-05[](#1111---2025-02-05 "Direct link to [1.11.1] - 2025-02-05")
##### Bugfixes[](#bugfixes-25 "Direct link to Bugfixes")
* Fixed an issue where the slots list was not updating after creating new slots.
* Corrected the behavior to ensure landing on the correct response in the responses page when creating or editing responses.
* Other minor bug fixes.
#### \[1.11.0] - 2025-01-15[](#1110---2025-01-15 "Direct link to [1.11.0] - 2025-01-15")
##### Features[](#features-7 "Direct link to Features")
* **Responses in CMS:** We’re introducing a centralized hub for content managers and flow builders to manage all the responses used in an assistant project in one place.
[Learn more about Responses in CMS](https://rasa.com/docs/docs/reference/primitives/responses/)
* **Conditional Response Variations:** Conditional responses let your assistant choose specific response variations based on one or more slot values, enhancing personalization and flexibility in replies. This feature allows users to easily create multi-lingual assistants or segment responses based on different criteria.
[Learn more about Conditional Response Variations](https://rasa.com/docs/docs/studio/build/content-management/responses/#conditional-response-variations)
##### Bugfixes[](#bugfixes-26 "Direct link to Bugfixes")
* Fixed an issue on import of categorical slot type.
* Aligned Validation Rules between Rasa Studio and the Rasa Framework for configuring conditions where values are surrounded by double quotes.
* Other minor bug fixes.
#### \[1.10.2] - 2025-04-17[](#1102---2025-04-17 "Direct link to [1.10.2] - 2025-04-17")
##### Bugfixes[](#bugfixes-27 "Direct link to Bugfixes")
* Fixed CVE-2025-32812
#### \[1.10.1] - 2024-12-19[](#1101---2024-12-19 "Direct link to [1.10.1] - 2024-12-19")
##### Bugfixes[](#bugfixes-28 "Direct link to Bugfixes")
* Remove unwanted `model-service` database creation step from `db migration job` during Studio deployment.
#### \[1.10.0] - 2024-12-17[](#1100---2024-12-17 "Direct link to [1.10.0] - 2024-12-17")
##### Features[](#features-8 "Direct link to Features")
* **Simpler Training in Studio:** Enhanced Studio’s training architecture and performance to improve reliability, reduce failures, and simplify Deployment
* The old setup involved multiple services for model running and training, leading to more points of failure. These have been consolidated into a single “Simple Model Service”, reducing moving parts and making training more reliable. This brings down the number of container images in Studio to `5`.
* The new architecture allows for faster training times, with a `85%` improvement in training time.
* We’ve replaced NFS with new storage options to provide greater flexibility for storing trained models:
* **Disk Storage**: Simplified local storage for using Kubernetes Persistent Volume.
* **Cloud Integration**: Seamless integration with your preferred cloud storage solution.
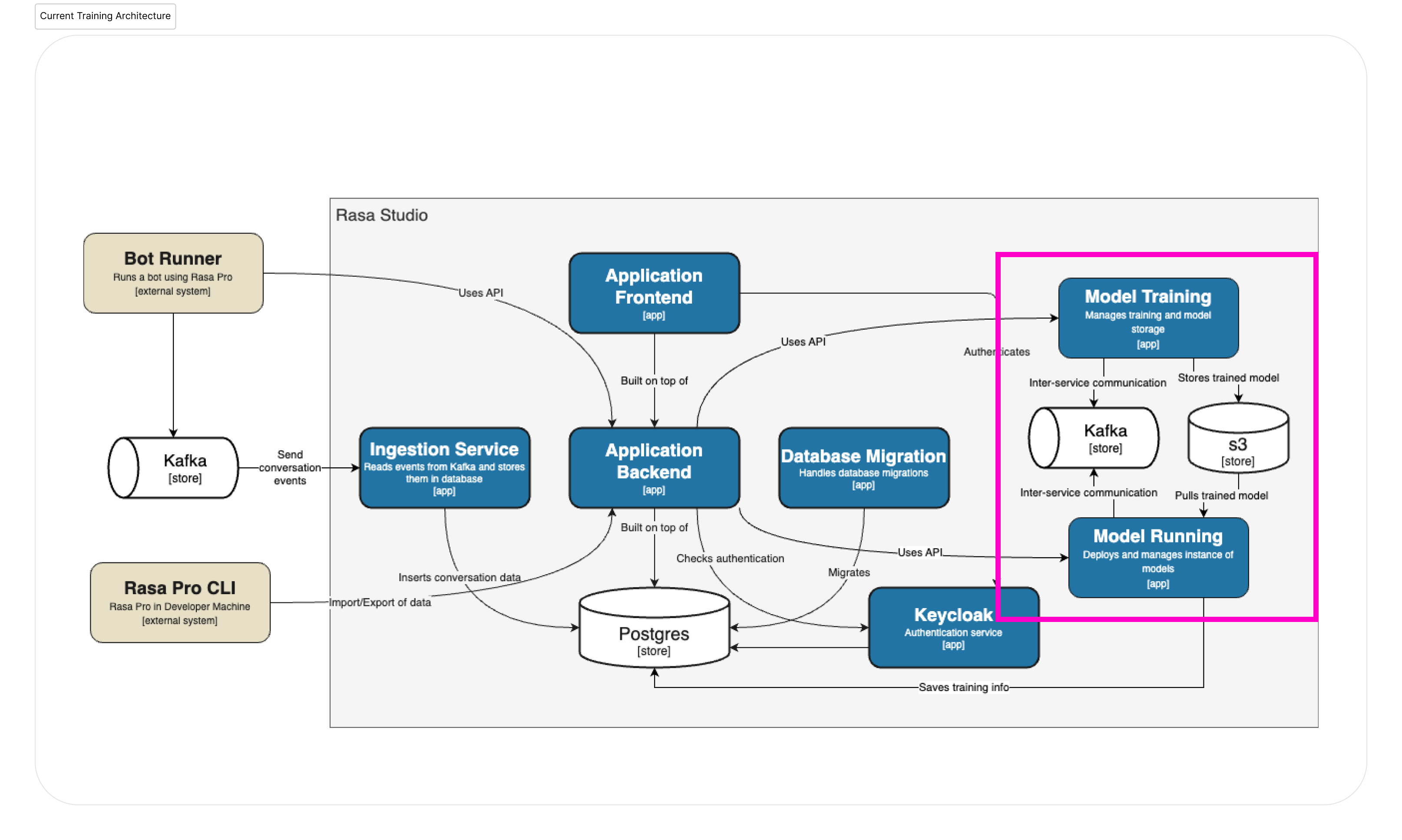
Old training architecture.
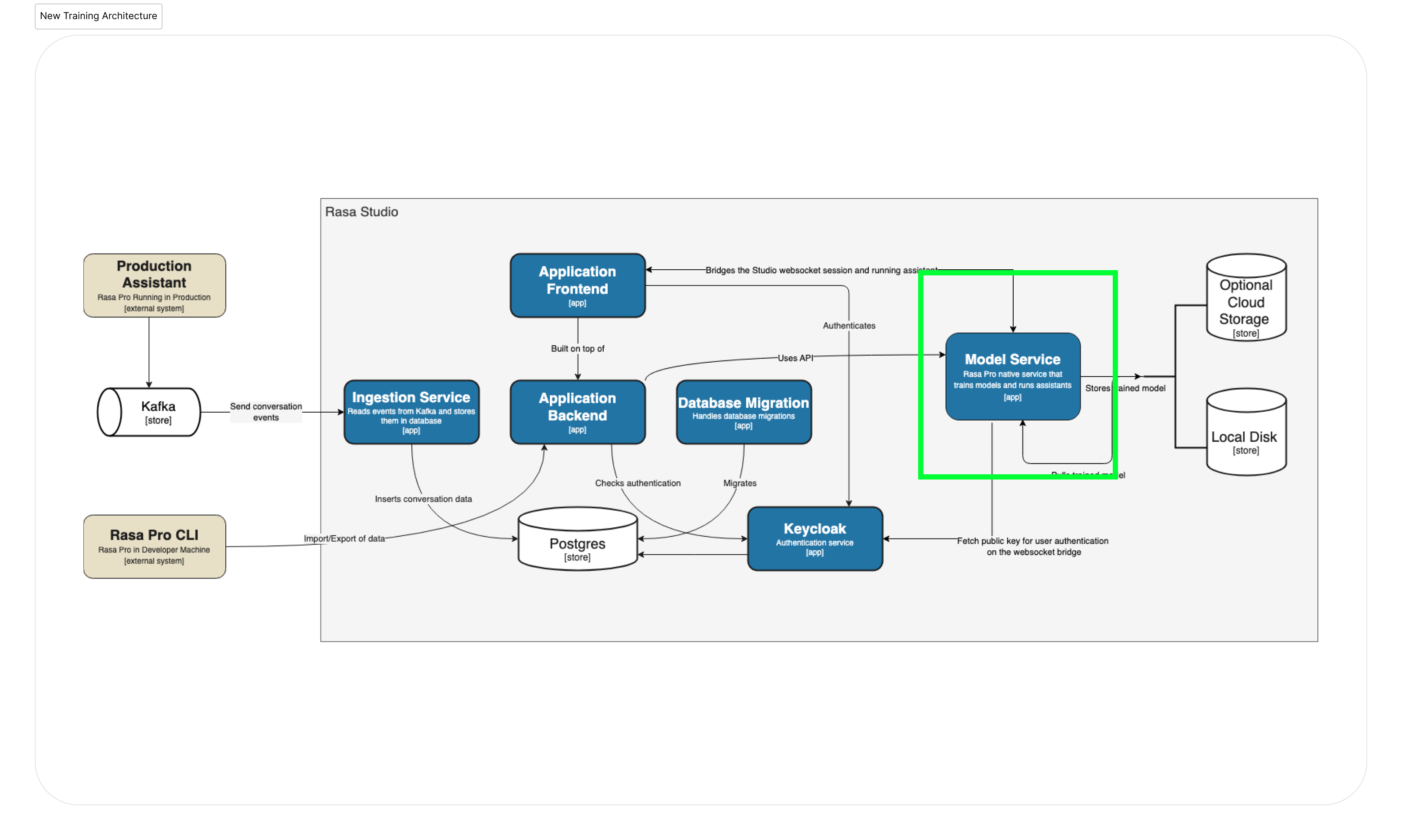
New training architecture.
* **Error UX Improvements:** Various training and deployment errors are now handled directly in the UI, allowing users to view errors in the popover without needing to download the training log.
Error during training.
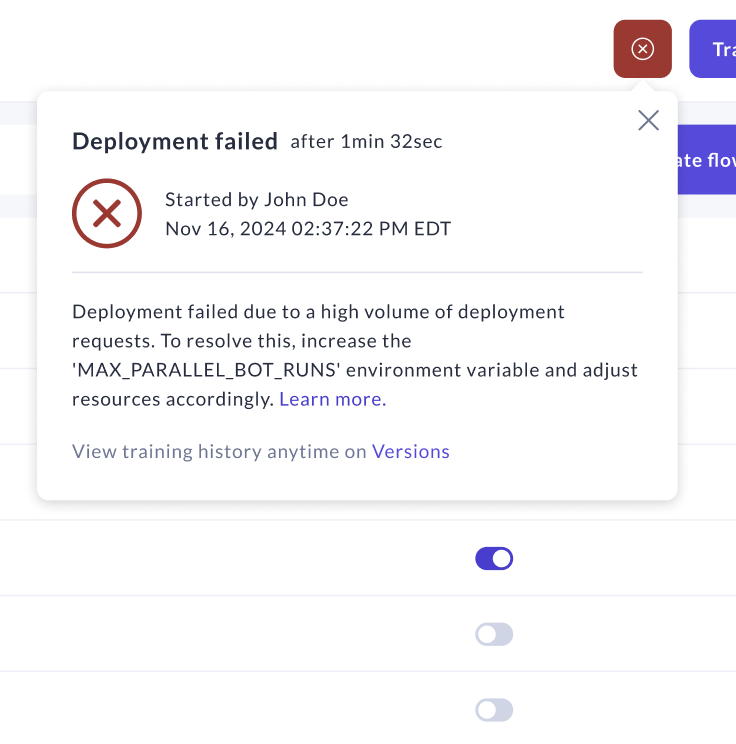
Error during Deployment, which goes right after successful training.
* **Model Download**: Model input data which was used to train a model can be downloaded from UI in YAML format.

##### Improvements[](#improvements-11 "Direct link to Improvements")
* **Performance Improvements**: Improved performance of the Studio application to support large assistants and complex flows. Performance improved for following features:
* Assistant pre-training validation
* Assistant export and training
* Toggling “ready for training” for flows linked from other flows
* Creating a Logic node
* System flows page
* Small performance improvements in a few other areas
* **Model Download API for CI Integration**: Updates to the Model Download API to support CI integration to support the new model service architecture.
##### Migration Guide[](#migration-guide "Direct link to Migration Guide")
* Make sure to use the latest Helm chart version `2.0.1` & above for deploying this release.
* Make sure to provision a Persistent Volume for storing trained models in the new architecture. Alternatively you can use cloud storage for storing trained models. More details can be found in the [deployment guide](https://rasa.com/docs/docs/reference/deployment/studio-hardware-requirements/).
* If you are migrating from an older version of Studio, you can safely delete the below pods and services from your Kubernetes cluster after deploying the latest version of Studio:
* Pods starting with `dsj-` for example `dsj-0f436992-895c-4fb3-92cb-045ea06c41df-4q7tx`
* Pods starting with `tsj-` for example `tsj-0f436992-895c-4fb3-92cb-045ea06c41df-4q7tx`
* Services starting with `dss-` for example `dss-048671c6-3086-49c0-afa7-a17043df2287`
#### \[1.9.0] - 2024-11-08[](#190---2024-11-08 "Direct link to [1.9.0] - 2024-11-08")
##### Features[](#features-9 "Direct link to Features")
* **Conversation Tagging API:** Expose API for tagging conversations for our clients. Key updates include:
* Keycloak client: Introduce `studio-external` Keycloak client ID to authenticate the API calls
* Simplified conversation query: Fetch conversations filtered by time range
* Delete conversations: A new API to delete conversations by ID
* Tag management: Tag IDs will be visible in the Studio UI to support integrations that use conversation tagging
* Assistant ID: Assistant UUID id is now visible for customers using API to leverage it
[Learn more about conversation tagging API](https://rasa.com/docs/docs/reference/api/studio/conversation-api/)
* **API for CI integration:** API for CI integration enables Studio users to automate the download of their assistant data via an API endpoint. Instead of manually exporting and pushing data to their infrastructure, technical users can now pull Studio's data directly into any CI platform. This is accomplished by exposing a query that returns raw YAML files and the trained model file (`model.tar.gz`). It is possible to download `latest` and all trained assistant versions.
[Learn more about API for CI integration](https://rasa.com/docs/docs/reference/api/studio/ci-integration-api/)
#### \[1.8.1] - 2024-10-30[](#181---2024-10-30 "Direct link to [1.8.1] - 2024-10-30")
##### Bugfixes[](#bugfixes-29 "Direct link to Bugfixes")
* Fixed an issue to prevent steps from being wrongly referenced in flow during export/download
#### \[1.8.0] - 2024-10-23[](#180---2024-10-23 "Direct link to [1.8.0] - 2024-10-23")
##### Features[](#features-10 "Direct link to Features")
* **Flow Version Control:** Flow Version Control allows you to save the flow version at any point, which will be logged in the flow history. From the flow history, you can restore previously saved versions, allowing you to revert any breaking or unwanted changes, giving you further control over the changes that you or your teammates have made to flows.
[Learn more about flow version control](https://rasa.com/docs/docs/studio/build/content-management/version-control/)
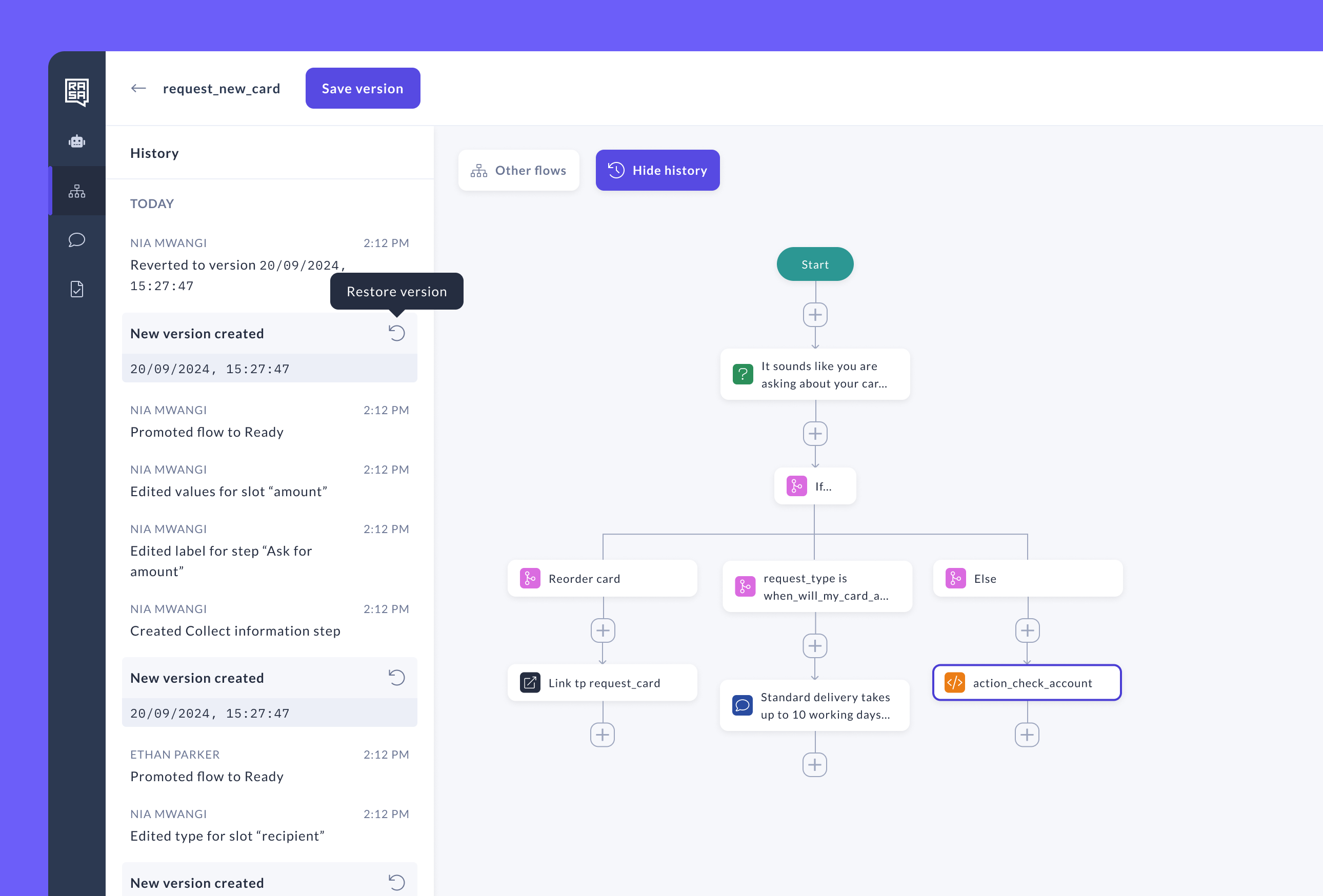
* **Button Payloads:** Button payloads allow you to assign commands to buttons, so when a user clicks on them, your assistant knows exactly what to do next. This can include:
* Setting slot values
* Triggering intents
* Passing entities to the assistant
* Sending predefined messages to guide the conversation
While Rasa Framework users have been enjoying this feature, we’re bringing this capability to Studio, making it even more powerful and flexible for building your conversational experiences.
[Learn more about buttons in Studio](https://rasa.com/docs/docs/studio/build/flow-building/collect/#buttons)
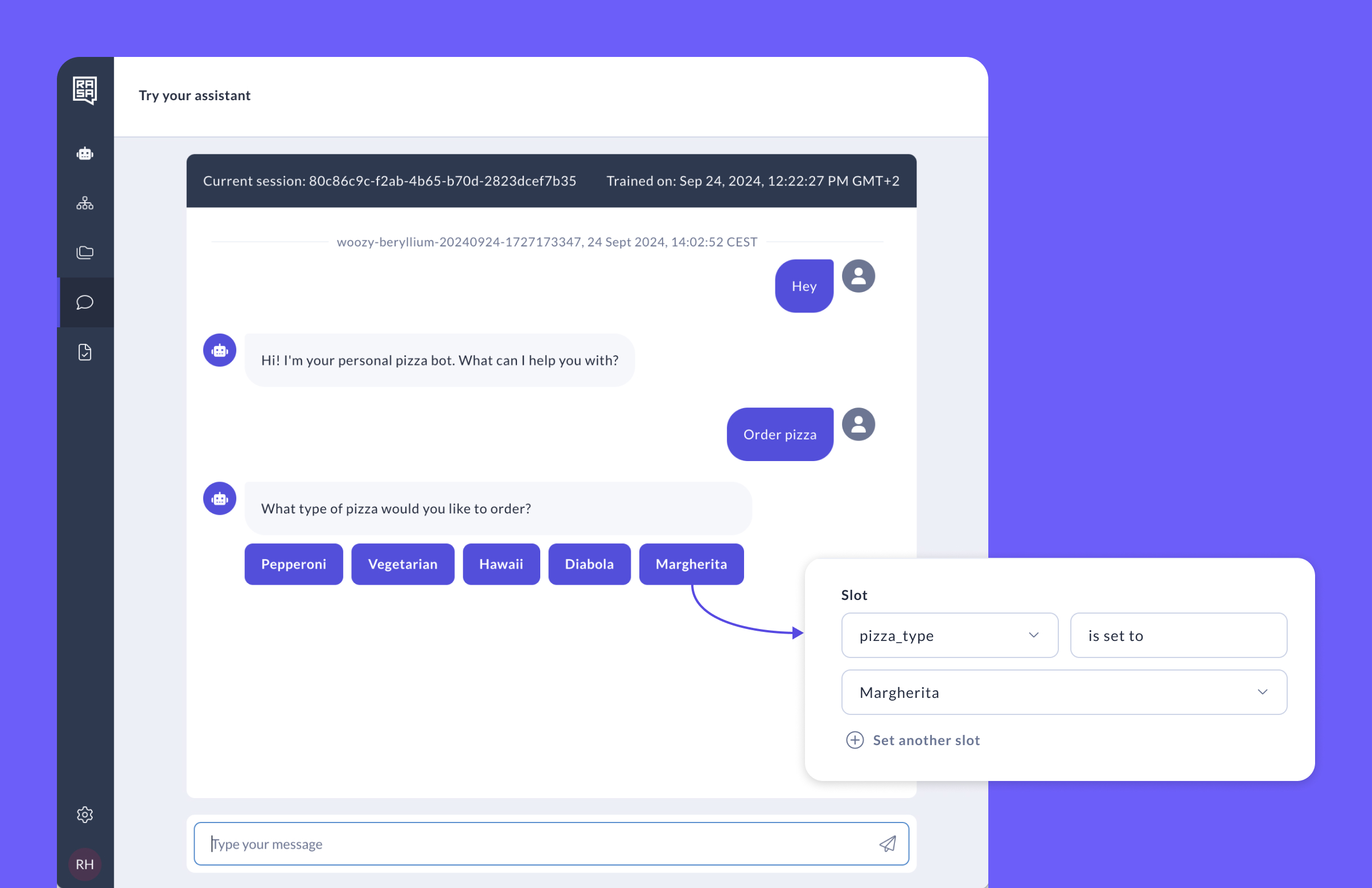
* **Download your assistant project** You can now download your entire assistant project, including all flows marked as "Ready for training," along with the NLU data and configuration files, all in one click.
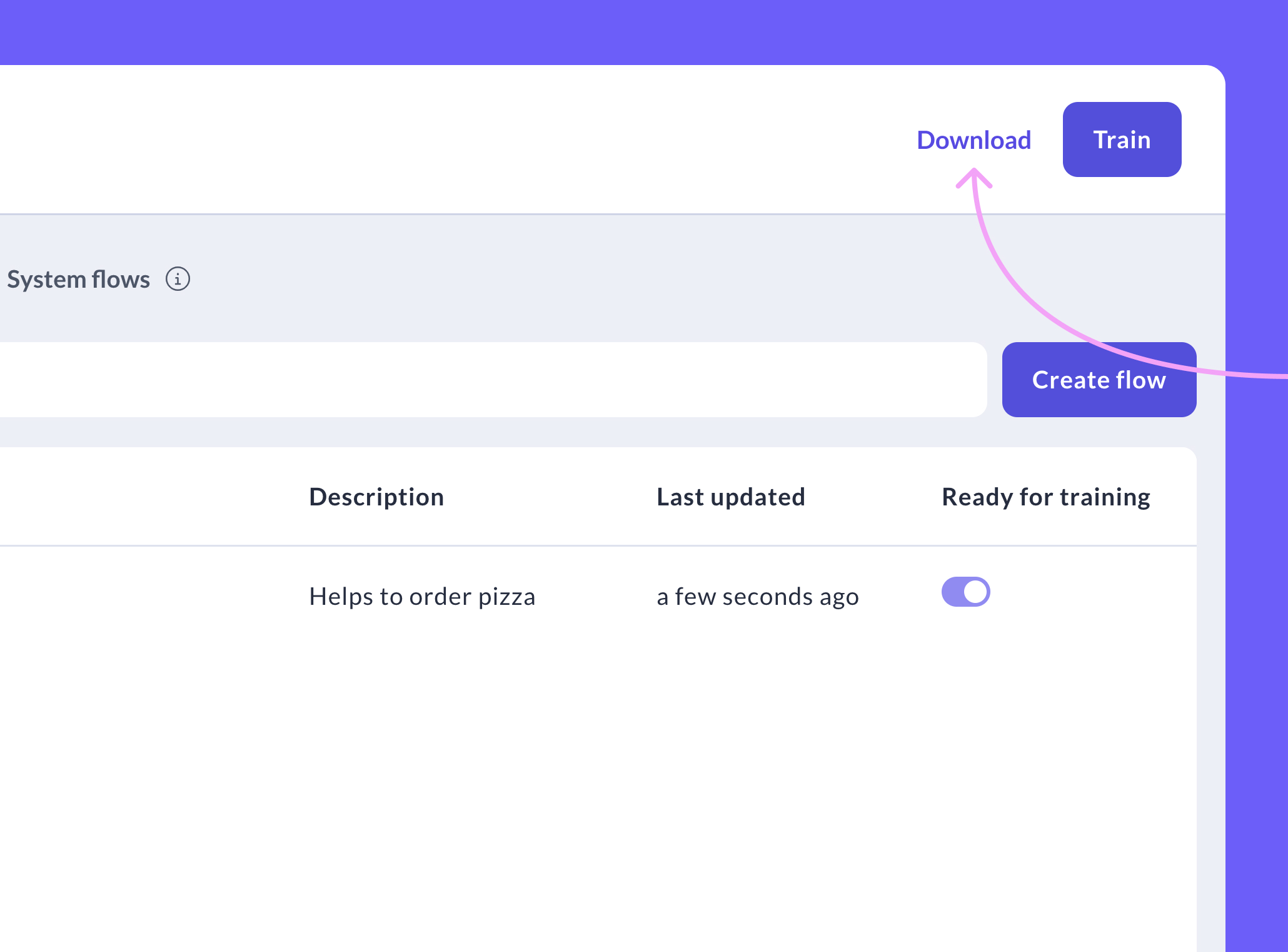
#### \[1.7.2] - 2024-10-04[](#172---2024-10-04 "Direct link to [1.7.2] - 2024-10-04")
##### Bugfixes[](#bugfixes-30 "Direct link to Bugfixes")
* Fixed a couple of issues with conditions of if in logic node.
* Fixed an issue where empty page was rendered if slot used in flow guard condition was deleted
#### \[1.7.1] - 2024-10-01[](#171---2024-10-01 "Direct link to [1.7.1] - 2024-10-01")
##### Bugfixes[](#bugfixes-31 "Direct link to Bugfixes")
* Fixed an issue where assistant couldn't be trained when a flow uses flow guards.
##### Improvements[](#improvements-12 "Direct link to Improvements")
* Added support for `jinga templates`.
#### \[1.7.0] - 2024-09-20[](#170---2024-09-20 "Direct link to [1.7.0] - 2024-09-20")
##### Features[](#features-11 "Direct link to Features")
* **Customizing patterns in Studio:** System flows, also known as patterns, are pre-built flows available out of the box, designed to handle conversations that go off track. For example, they help when:
* The assistant asks for information (like an amount of money), but the user responds with something else.
* The user interrupts the current flow and changes the topic.
* The user changes their mind about something they said earlier.
You can now fully customize these system flows in Studio in the “System flows” tab.
[Learn more about patterns in Studio](https://rasa.com/docs/docs/studio/build/flow-building/system-flows/)
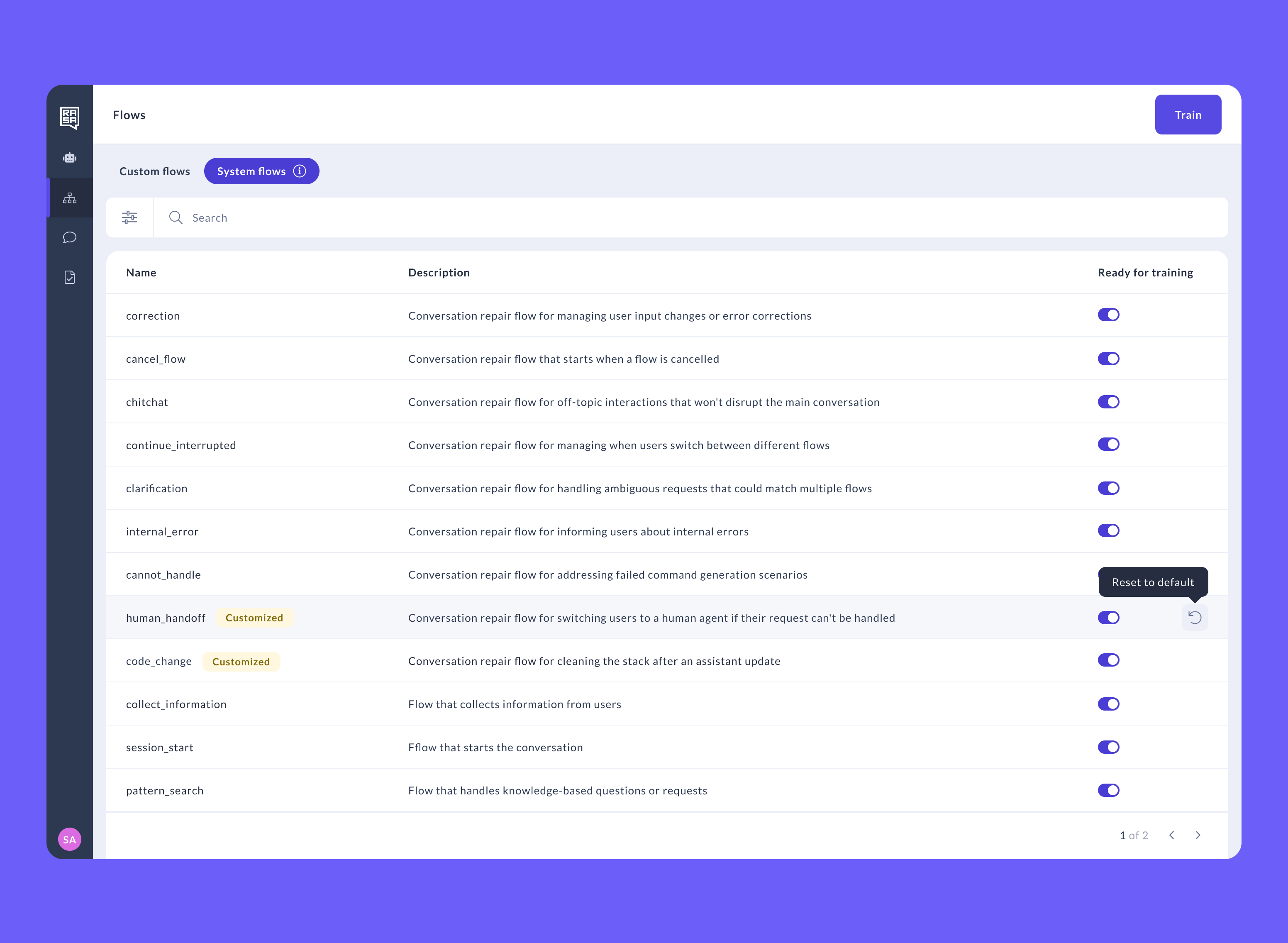
* **Custom actions in the Collect step:** Studio now supports collecting slot values via custom actions, in addition to the existing method of using responses. This feature, available from Rasa Pro 3.8, enhances the flexibility of the Collect step.
Instead of solely relying on templated responses, you can now employ a custom action to collect slot values. This is particularly useful when you need to display dynamic options fetched from a database, such as presenting available values as buttons.
[Learn more about different ways to collect information](https://rasa.com/docs/docs/studio/build/flow-building/collect/)
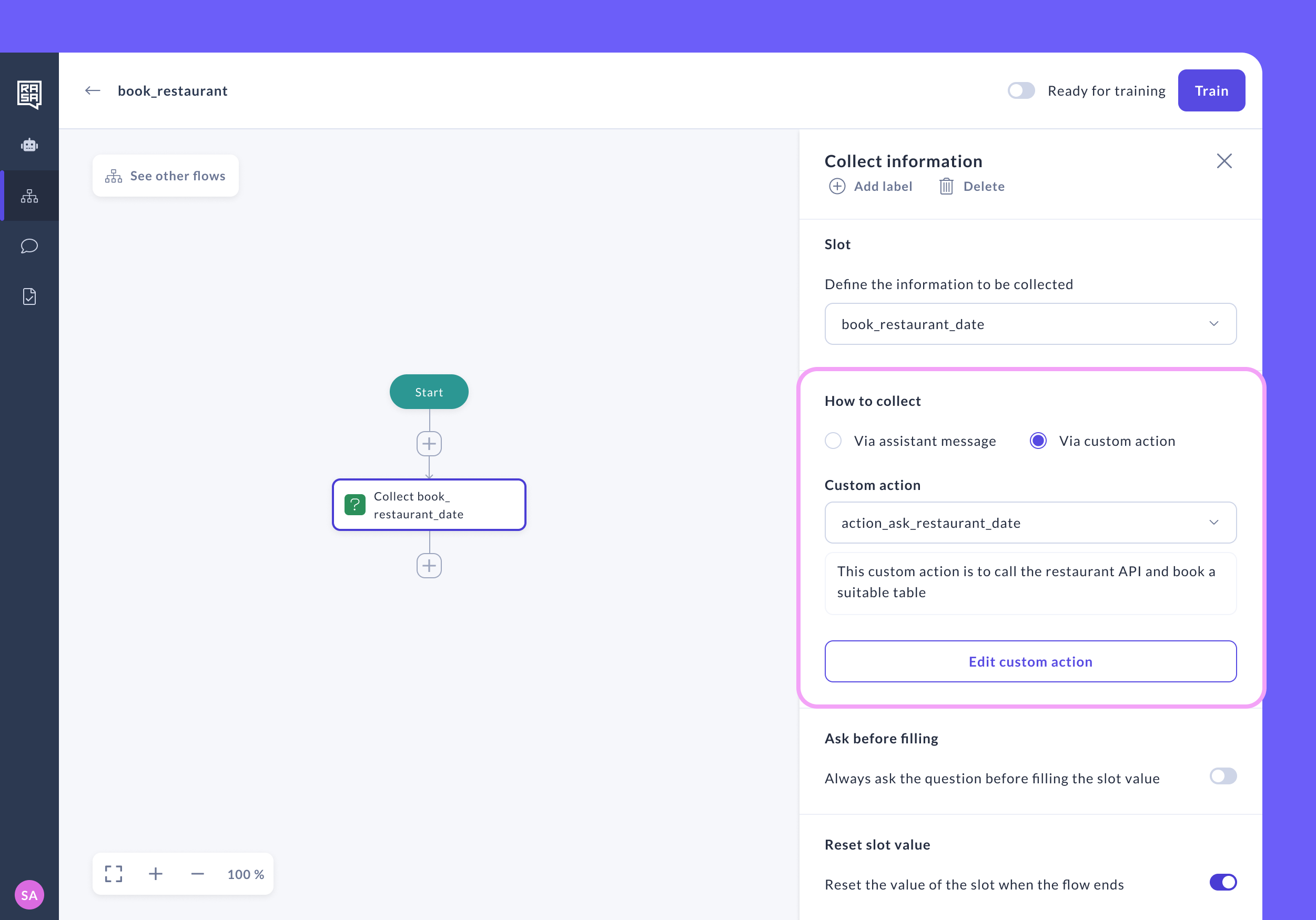
##### Improvements[](#improvements-13 "Direct link to Improvements")
* You can now export your flow as an image, making it easier to share and visualize your conversations.
#### \[1.6.1] - 2024-09-10[](#161---2024-09-10 "Direct link to [1.6.1] - 2024-09-10")
##### Bugfixes[](#bugfixes-32 "Direct link to Bugfixes")
* Fixed issue in upload/download assistant with entity slot mapping with roles.
* Prevent slot creation and update if name contains the dot character.
* Support `rasa studio import` to work with flows starting with condition step.
#### \[1.6.0] - 2024-08-30[](#160---2024-08-30 "Direct link to [1.6.0] - 2024-08-30")
##### Features[](#features-12 "Direct link to Features")
* **Assistant Settings:** The new "Assistant settings" page in Studio is designed to streamline how you manage and configure your assistant. This new page replaces the "Manage assistants" modal and features two key areas:
1. **General settings:** View and manage basic settings such as the assistant's name and mode.
2. **Configuration:** Allows users in `developer` role to directly edit the `config.yml` and `endpoints.yml` files, enabling real-time adjustments without leaving Studio.
This update makes it easier to see and adjust your assistant’s settings directly within Studio, enhancing control and flexibility.
[Learn more about Config in Studio](https://rasa.com/docs/studio/user-guide/configure/)

* **Scalable Command Generator:** The [flow-retrieval](https://rasa.com/docs/docs/reference/config/components/llm-command-generators/#retrieving-relevant-flows) feature, introduced in Rasa Pro 3.8, is now implemented in Studio. It ensures that only the flows relevant to the conversation context are included in the LLM prompt. This optimizes performance by managing the number of flows more efficiently and reduces LLM-related costs.
Enabled by default in the `config.yml` file accessible via the new Assistant settings page, this feature can be adjusted or disabled as required. It also allows users to designate specific flows as "always included" in the prompt, ideal for general flows like "welcome" and "chitchat" to ensure they are consistently retrievable.
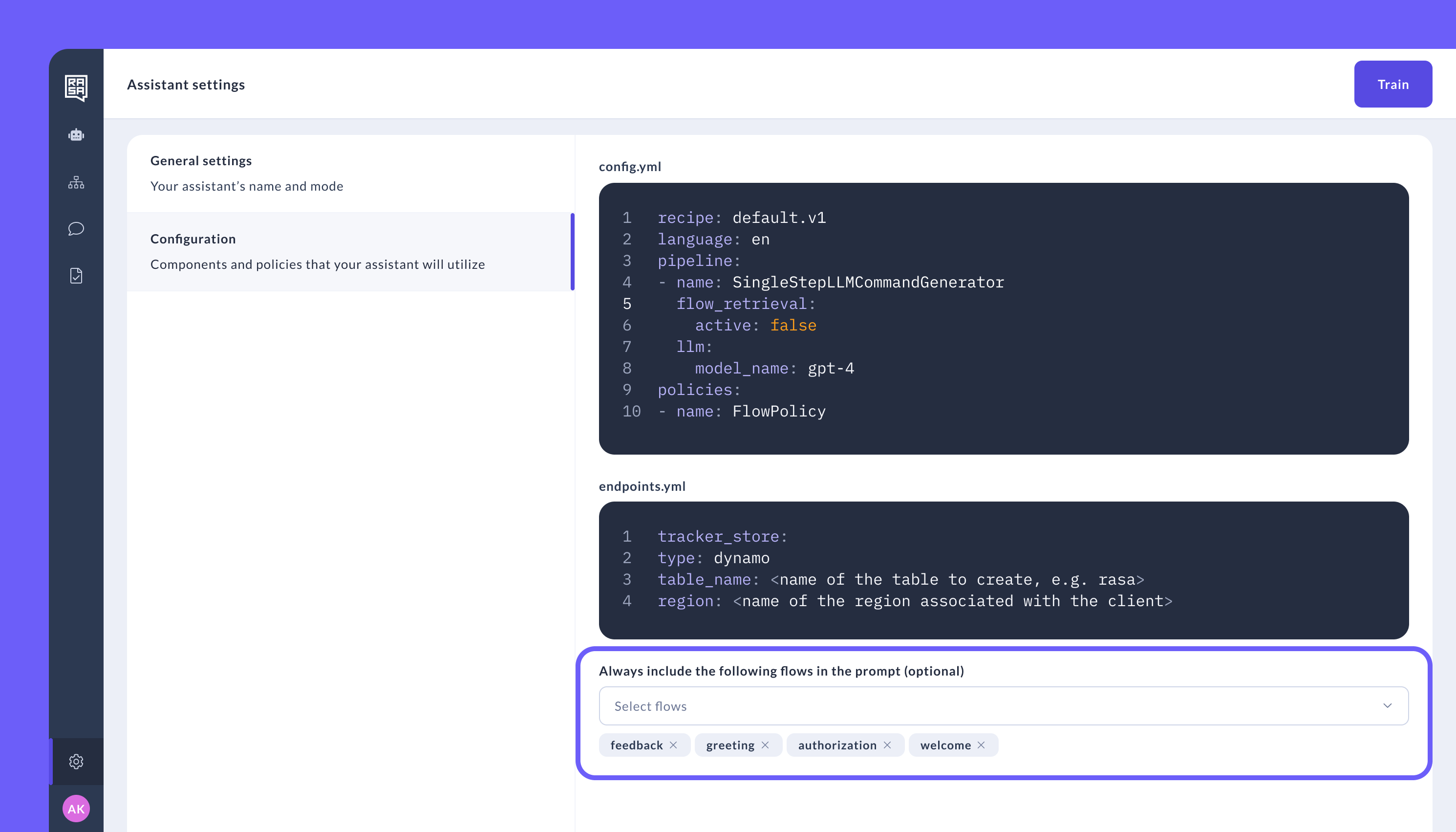
* **Slot Mappings:** Slot mappings are global settings that define how slot values should be extracted.
By default, in Rasa, the slot value is extracted from the user's message using an LLM. However, if users prefer to extract slots from a specific custom action, intent, entity, or the last user message instead of relying on LLM, they can now do so in Studio. [Learn more about slot mappings](https://rasa.com/docs/docs/studio/build/flow-building/collect/#slot-mappings-advanced)
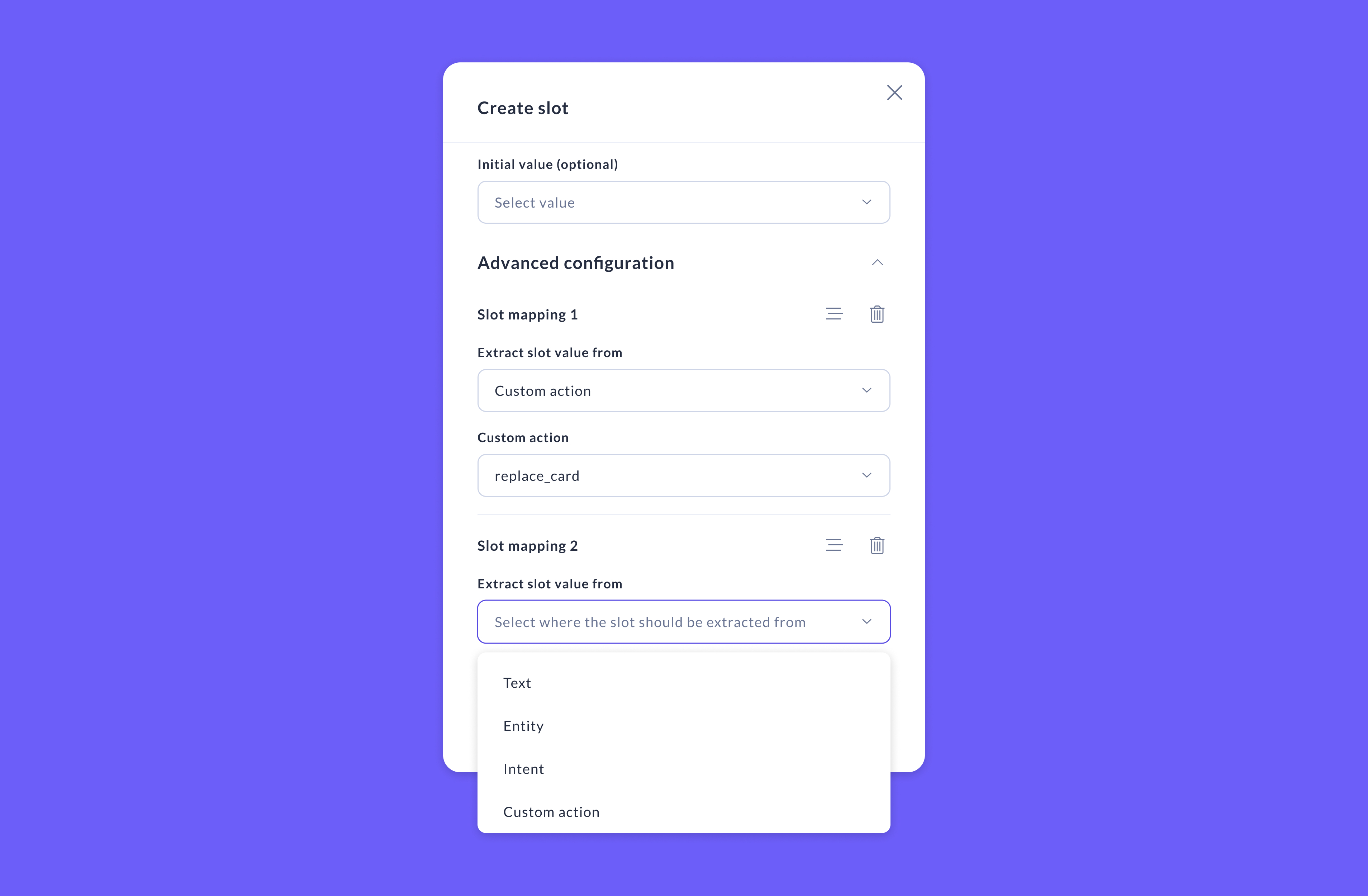
* **Flow Change Log:** To enhance collaboration and increase transparency in assistant development, we've introduced the flow change log. This feature provides a detailed history of each flow's changes, including details on who made the change and when. It aims to improve project management by allowing users to track modifications and eventually, revert to previous versions if necessary \[coming soon].
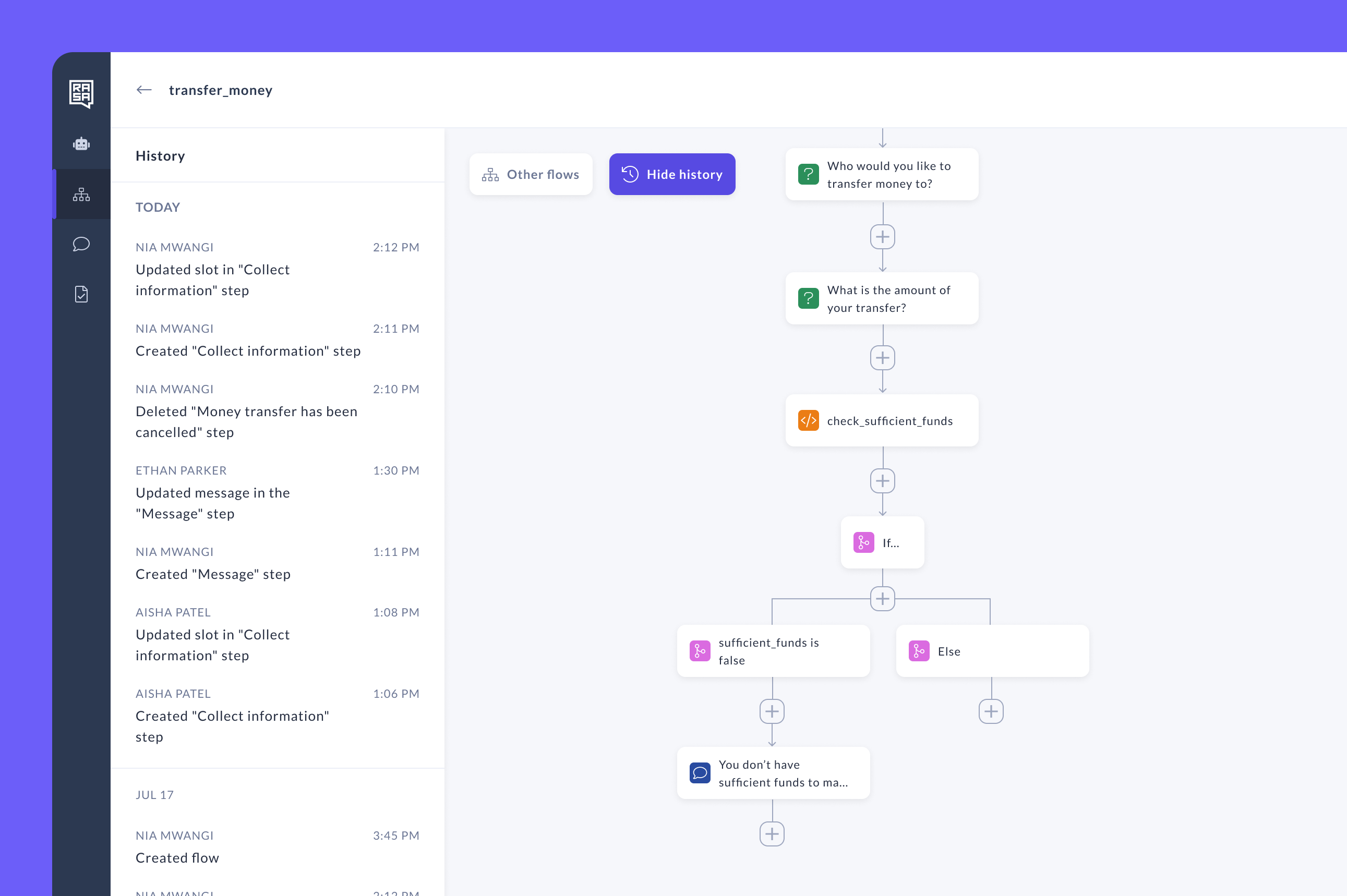
#### \[1.5.6] - 2024-10-31[](#156---2024-10-31 "Direct link to [1.5.6] - 2024-10-31")
##### Bugfixes[](#bugfixes-33 "Direct link to Bugfixes")
* Fixed an issue to prevent steps from being wrongly referenced in flow during export/download
#### \[1.5.5] - 2024-09-26[](#155---2024-09-26 "Direct link to [1.5.5] - 2024-09-26")
##### Bugfixes[](#bugfixes-34 "Direct link to Bugfixes")
* Increased database transaction timeout and made performance improvements to prevent errors during flow node creation.
#### \[1.5.4] - 2024-07-31[](#154---2024-07-31 "Direct link to [1.5.4] - 2024-07-31")
##### Bugfixes[](#bugfixes-35 "Direct link to Bugfixes")
* Fixed issue where in-development feature flags were not being respected
#### \[1.5.3] - 2024-07-30[](#153---2024-07-30 "Direct link to [1.5.3] - 2024-07-30")
##### Bugfixes[](#bugfixes-36 "Direct link to Bugfixes")
* Fixed performance issues related to flow validation
#### \[1.5.2] - 2024-07-26[](#152---2024-07-26 "Direct link to [1.5.2] - 2024-07-26")
##### Bugfixes[](#bugfixes-37 "Direct link to Bugfixes")
* Fixed validation issues related to linked flows
* Fixed issue where a new flow's `ready for training` button was disabled even after adding a valid node for the first time
* Other minor bug fixes
##### Improvements[](#improvements-14 "Direct link to Improvements")
* Update `studio-database-migration` container image and `studio-backend` image to support deployments in restrictive environments
#### \[1.5.1] - 2024-07-23[](#151---2024-07-23 "Direct link to [1.5.1] - 2024-07-23")
##### Improvements[](#improvements-15 "Direct link to Improvements")
* Update `studio-web-client` container image to use `nginx-unprivileged` base image to support deployments in restrictive environments
#### \[1.5.0] - 2024-07-19[](#150---2024-07-19 "Direct link to [1.5.0] - 2024-07-19")
##### Features[](#features-13 "Direct link to Features")
* **Flow Validation:** Users are provided with real-time error feedback during the flow creation process. This ensures that errors are caught before training starts and allows for explicit error messages to be displayed in the user interface.
**The feature includes:**
Mapping errors to specific fields where they occurred — allowing users to easily return to the flow and correct them at any time.
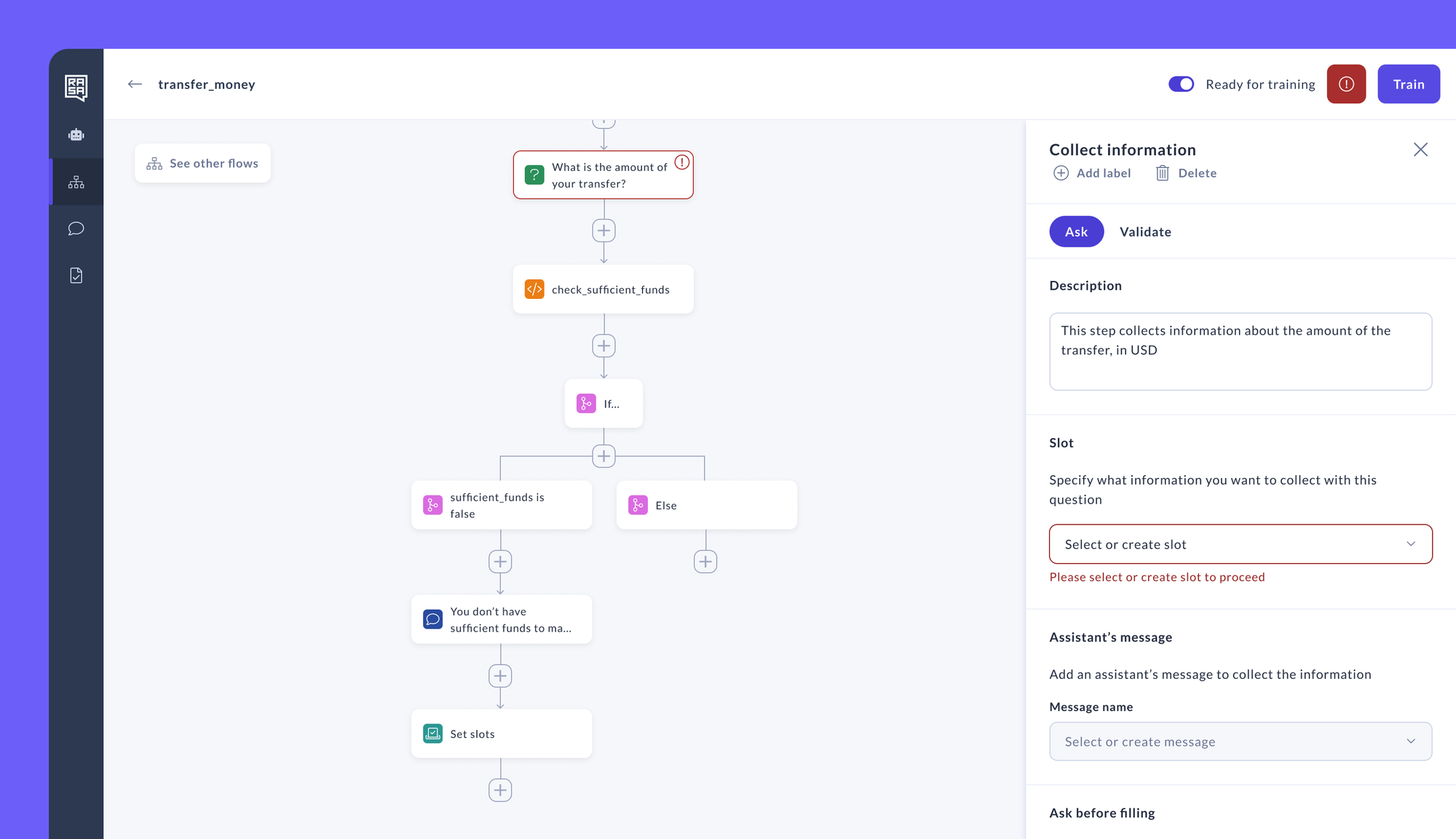
Error status on the assistant level - after clicking the "Train" button and before actual training begins, Studio performs a quick validation of all the flows marked as “Ready for training”, indicates if there are errors in any particular flows, and shows the list. This helps users navigate through all the errors until they’re all fixed before attempting to train the model again.

* **[Call a flow and return](https://rasa.com/docs/docs/studio/build/flow-building/linking-flows/):** This step enables control to jump from a parent flow to a child flow and then return to the original parent flow. The child flow is treated as part of the parent flow, which results in the following behaviors out of the box:
* Slots in the child flow can be filled upfront, without needing to reach the collect step of that slot.
* Slot values in the child flow can be corrected after they have been filled and control has returned to the parent flow.
* Slots in the child flow are not reset until the parent flow is completed.
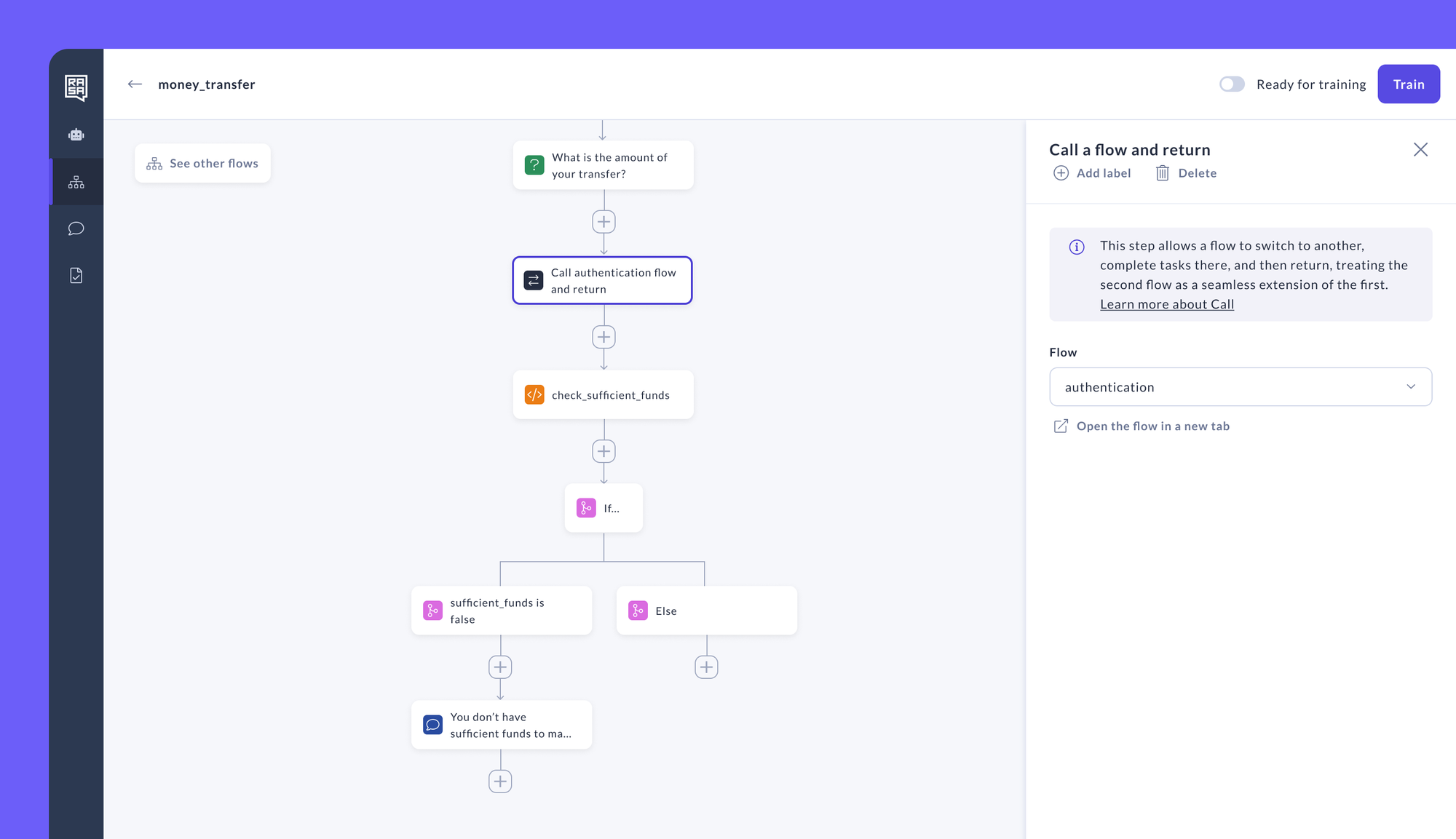
* **[Data retention policy](https://rasa.com/docs/docs/reference/deployment/automatic-conversation-deletion/):** Users can define a custom period for how long Studio should retain conversation data.
##### Bugfixes[](#bugfixes-38 "Direct link to Bugfixes")
* Fixed issue where the import of a CALM assistant fails when `nlu.yml` is missing or when no entities are present in the `nlu.yml` file
* Fixed import failure of a CALM assistant when slots are of `boolean` type
* Conversation view filter are now reset when user changes the assistant
##### Improvements[](#improvements-16 "Direct link to Improvements")
When logging in, the user is redirected to a specific page based on their role:
**In CALM-based assistant**:
* Flow Builder, NLU Editor, leadAnnotator, Developer and Business User are redirected to **Flows** page.
**In Classic assistant:**
* Lead Annotator is redirected to **Annotation Dashboard**.
* Annotator is redirected to **Annotation Inbox**.
* Business User, NLU Editor, Flow Builder, Developer are redirected to **NLU**
Conversation Analyst is redirected to **Conversation View,** regardless of assistant mode.
#### \[1.4.0] - 2024-06-14[](#140---2024-06-14 "Direct link to [1.4.0] - 2024-06-14")
##### Features[](#features-14 "Direct link to Features")
* **Flow Guards:** [Flow Guard](https://rasa.com/docs/docs/studio/build/flow-building/trigger-flows/#flow-guards) enables users to define specific conditions for triggering a flow, ensuring that the flow is not activated solely by user request
##### Bugfixes[](#bugfixes-39 "Direct link to Bugfixes")
* Fixed issue related to primitives not being pre-selected in the Manage window
* The condition editor no longer disappears when a new slot is created
* Fixed issue where Slot is not being updated after a different slot is selected in the dropdown
* Other minor bug fixes
##### Improvements[](#improvements-17 "Direct link to Improvements")
* Updated label of condition nodes. We now provide a clear indication of the logic within the condition, allowing users to quickly understand the conditions at a glance
* Added validation to check that the slot name doesn't contain any special characters
* When creating a collect message for a categorical slot, only values of a categorical slot can be used to create buttons for the related message, so that wrong entries can be prevented
* In the Flows table long flow descriptions are now visible on hover over the description
* Users can share links to filtered views of the Conversation Table and to individual conversations
* Other minor application improvements
#### \[1.3.2] - 2024-06-05[](#132---2024-06-05 "Direct link to [1.3.2] - 2024-06-05")
##### Bugfixes[](#bugfixes-40 "Direct link to Bugfixes")
* Fixed issue where slots on different logical nodes got merged when exporting a flow to yml
#### \[1.2.1] - 2024-06-04[](#121---2024-06-04 "Direct link to [1.2.1] - 2024-06-04")
##### Bugfixes[](#bugfixes-41 "Direct link to Bugfixes")
* Fixed issue where slots on different logical nodes got merged when exporting a flow to yml
#### \[1.3.1] - 2024-05-30[](#131---2024-05-30 "Direct link to [1.3.1] - 2024-05-30")
##### Bugfixes[](#bugfixes-42 "Direct link to Bugfixes")
* Fixed issue where error raised during an unsupported yml import of a CALM assistant had an incorrect error message
##### Improvements[](#improvements-18 "Direct link to Improvements")
* Added support for entity annotation to CALM assistant import
#### \[1.3.0] - 2024-05-16[](#130---2024-05-16 "Direct link to [1.3.0] - 2024-05-16")
##### Features[](#features-15 "Direct link to Features")
* **Assistant Import:** CALM Assistant import allows Rasa Pro customers to import existing assistants into Rasa Studio. [Learn more](https://rasa.com/docs/docs/reference/api/command-line-interface/#import-of-calm-assistants).
##### Bugfixes[](#bugfixes-43 "Direct link to Bugfixes")
* Fixed issue where adding a new categorical slot value doesn't cause the if condition to not display the previously defined value anymore.
* Initial Value selection is now saved correctly for new categorical slots.
* In Flows, when adding a Logic step, the nodes order is now correct.
* Other minor bug fixes.
##### Improvements[](#improvements-19 "Direct link to Improvements")
* **Auto-format primitives**: Validation for message and action names is simplified: they don't need prefixes `utter_`, `utter_ask_` , `utter_invalid_`, or `action_` anymore.
* For all primitives that don't allow spaces in names, whitespace is automatically replaced with `_` during typing.
* Search option for managing slots is added.
* Behaviour of "Ready for training" checkbox is now consistent.
* **Support for additional events in Conversation Review event stream**: Users can now see the following additional events in the conversation stream: `FORM`, `ACTIVE_LOOP`, `FOLLOWUP_ACTION`, `RESTARTED`.
* **Review multiple conversations in Conversation Review**: Users can select multiple conversations and create a batch for review.
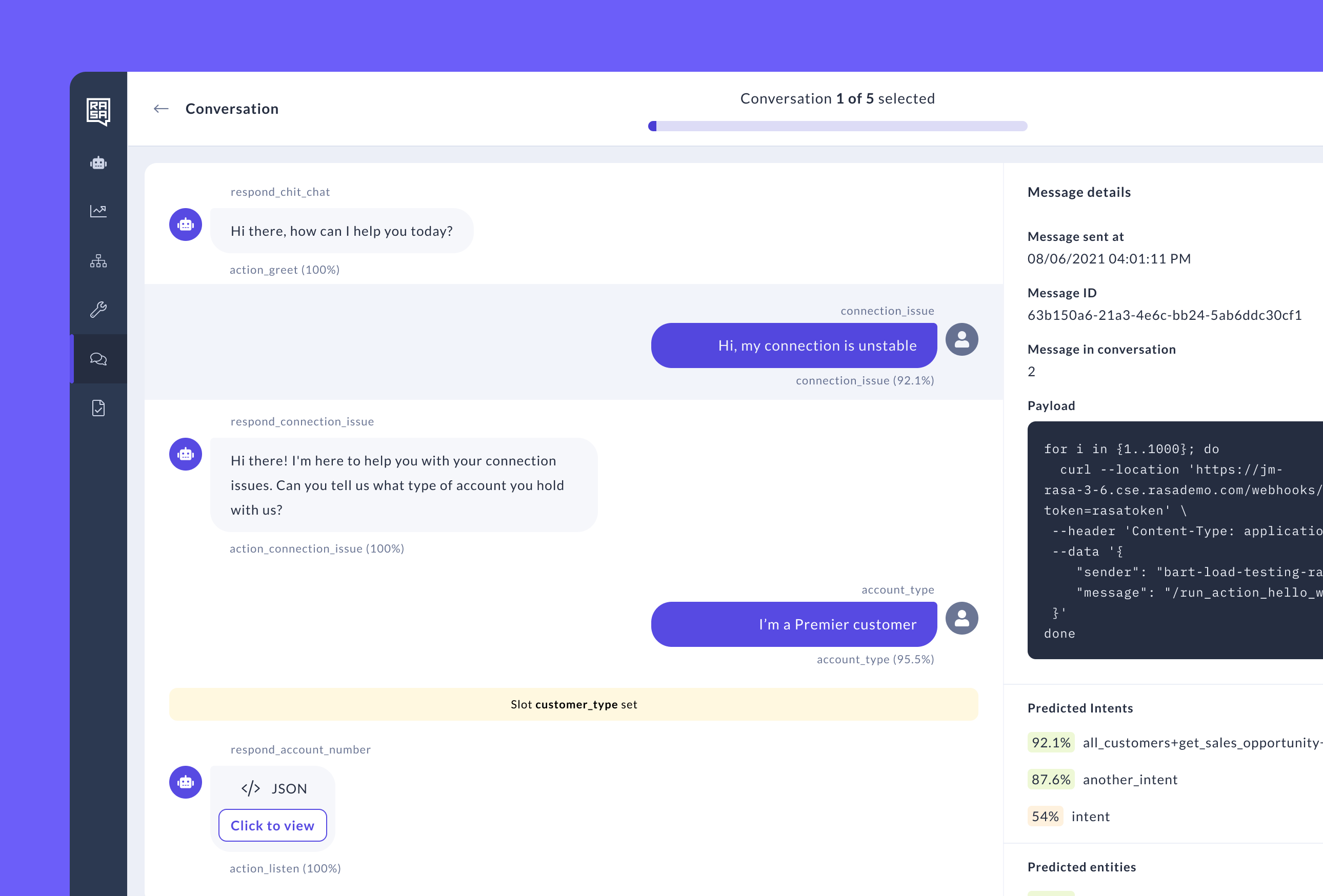
* **Conversation Review RBAC**: Admins can now assign a Conversation Analyst role to users. Only users with this role will be able to access and use the Conversation Review feature.
* Change default classifier from `DIETClassifier` to `LogisticRegressionClassifier` for assistants with NLU triggers.
* Other minor application improvements.
#### \[1.2.0] - 2024-04-18[](#120---2024-04-18 "Direct link to [1.2.0] - 2024-04-18")
##### Features[](#features-16 "Direct link to Features")
* **Conversation View:** Helps users identify ways to improve their NLU and CALM assistants by reading real user conversations. With [Conversation View](https://rasa.com/docs/docs/studio/analyze/conversation-review/), users can browse user conversations, apply filters to help surface conversations in need of analysis and then see a turn-by-turn breakdown of the conversation, along with relevant session and event data.
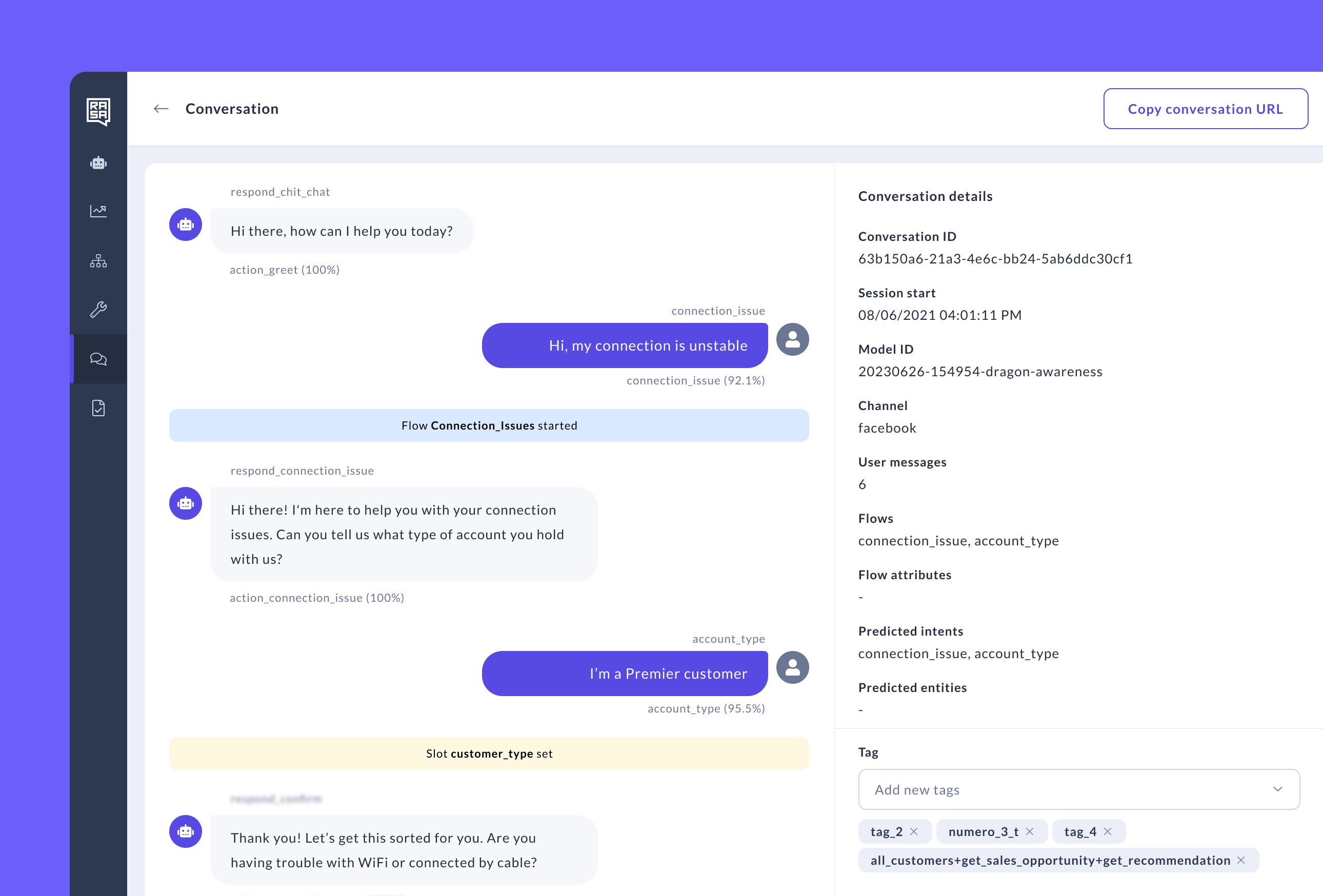
* **NLU Triggers:** Enable users to create intents in Modern assistants and use them as a method for triggering flows. [Start step](https://rasa.com/docs/docs/studio/build/flow-building/trigger-flows/) is used to provide a comprehensive view of what can initiate or hinder the start of a flow: CALM, [NLU Triggers](https://rasa.com/docs/docs/studio/build/flow-building/trigger-flows/#nlu-triggers), or [Links/Calls](https://rasa.com/docs/docs/studio/build/flow-building/trigger-flows/#links--calls).
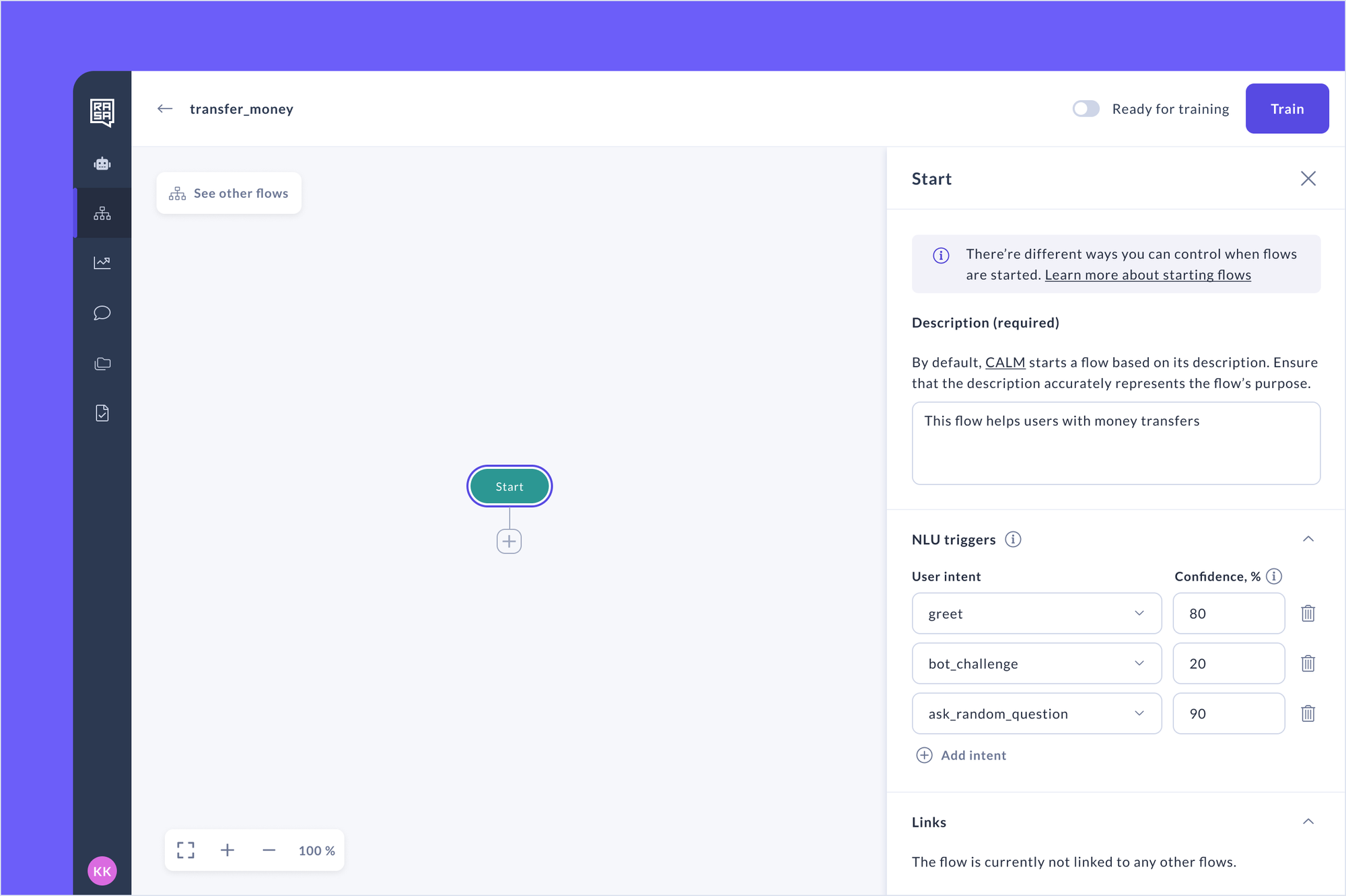
* **NLU page in Modern mode:** Bring NLU page into Modern assistants for managing intents, setting a precedent for future primitives management. Users can now create, edit, and delete intents in the NLU page.
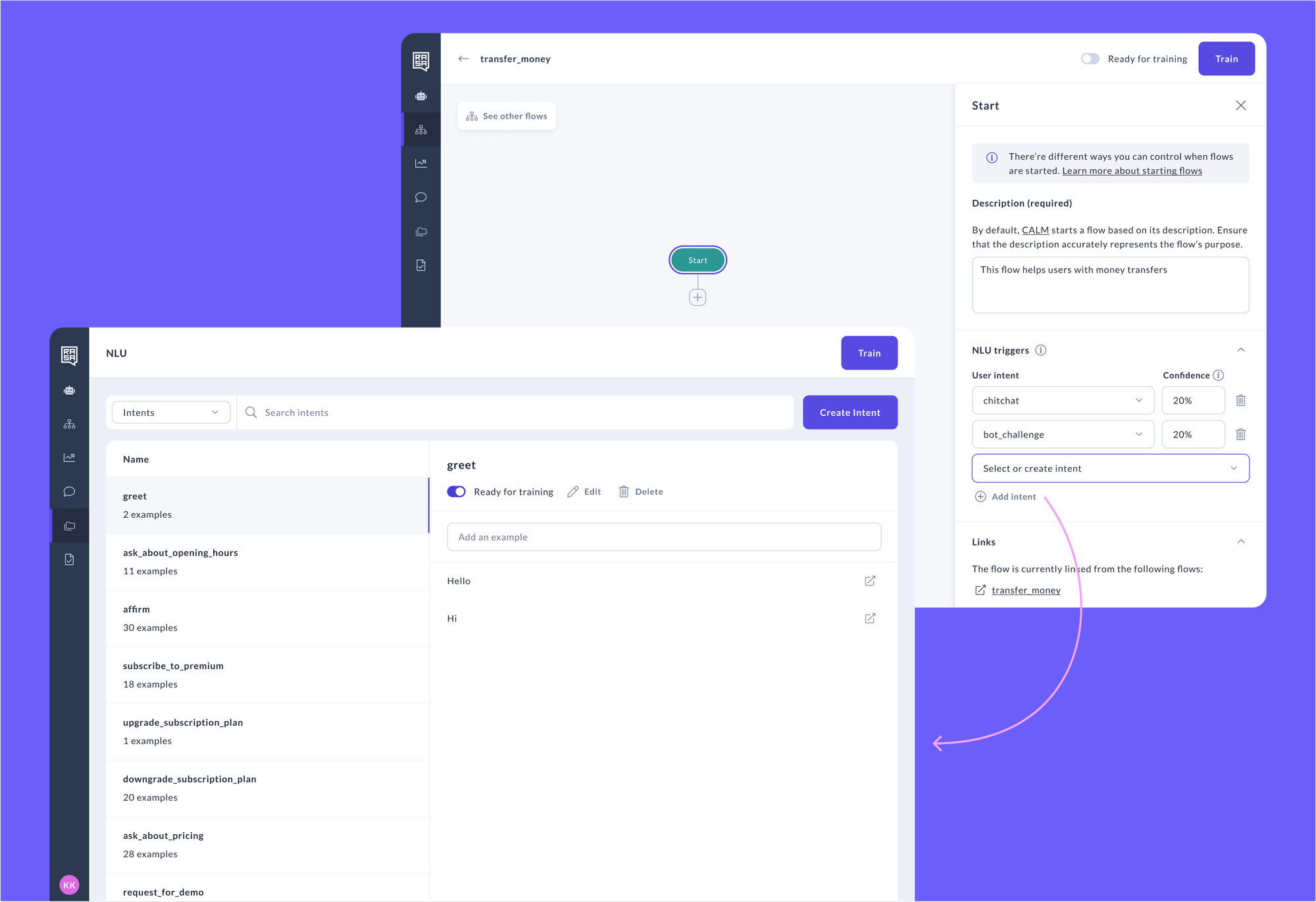
##### Bugfixes[](#bugfixes-44 "Direct link to Bugfixes")
* Fixed issue where the users were unable to export `else` node when it is in the end of the flow
* Fixed issues related to inconsistent state of `Manage Slots` modal
* Fixed issue where navigating back from a flow takes the user to the 1st page in the list of flow
* Other minor bug fixes
##### Improvements[](#improvements-20 "Direct link to Improvements")
* **Added an optional "Initial value" field to slots:** Let users specify an initial value for any slot, just as they can already do in Rasa Pro.
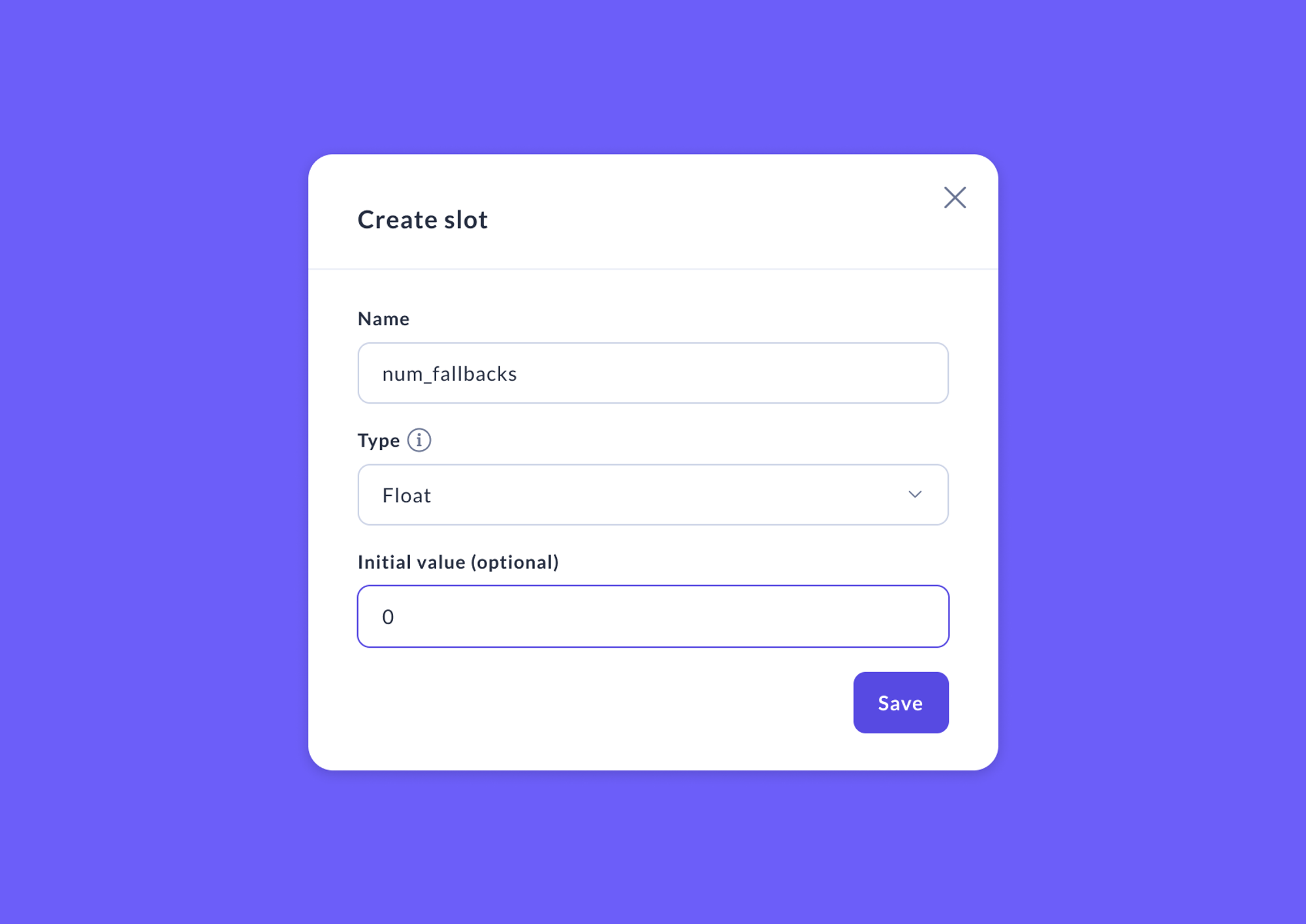
* Users no longer have to type `utter_` prefix when creating a message node
* Users no longer have to type `action_` prefix when a creating a custom action node
* Other minor application improvements
#### \[1.1.2] - 2024-03-27[](#112---2024-03-27 "Direct link to [1.1.2] - 2024-03-27")
##### Bugfixes[](#bugfixes-45 "Direct link to Bugfixes")
* Fixed issue where users were unable to update a slot under certain conditions
#### \[1.1.1] - 2024-03-26[](#111---2024-03-26 "Direct link to [1.1.1] - 2024-03-26")
##### Bugfixes[](#bugfixes-46 "Direct link to Bugfixes")
* Removed the alphabetical sort of categories in the "Manage slots" modal
* Fixed issue where "Open the flow in a new tab" did not open the selected flow
* "Show variations" button in a message node is only displayed if there are message variations present
* Fixed issue which caused the creation of orphan nodes in flow builder
* Else condition nodes now do not allow assigning conditions to them
* Fixed issue where the flow builder was not listing all the flows while creating a link node
* Fixed issue related to invalid training data with wrong reference ID
* Studio now displays the affected message name in the error toast when an incorrect slot name is used in a message node
* Other minor bug fixes
#### \[1.1.0] - 2024-03-18[](#110---2024-03-18 "Direct link to [1.1.0] - 2024-03-18")
##### Features[](#features-17 "Direct link to Features")
* Support the logic operators from the Pypred library that are currently missing in Studio
* `not`: Negates a condition
* `=`: Equal to
* `!=`: Not equal to
* `matches`: Uses regular expressions to match strings
* `not matches`: Uses regular expressions to negate strings.
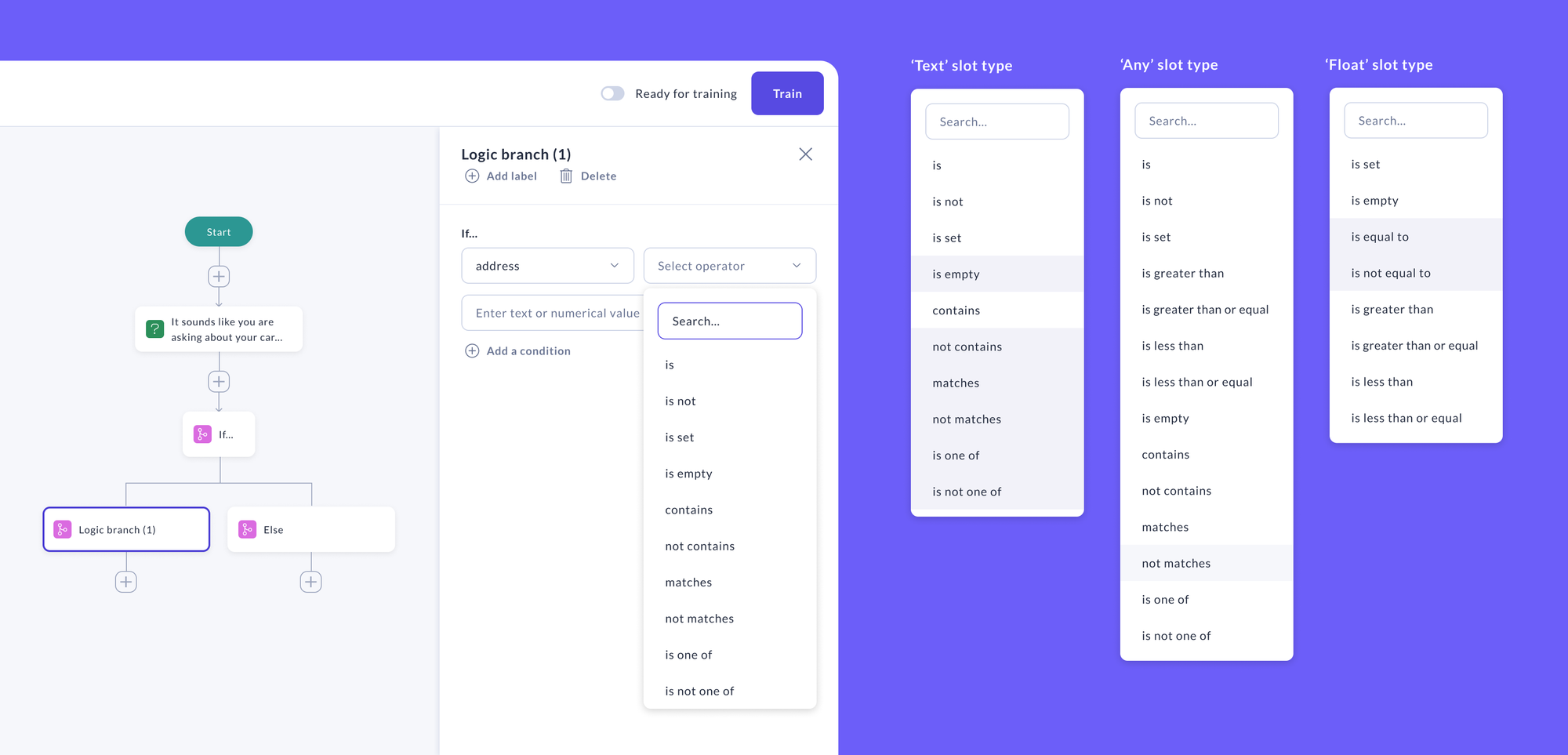
* Allow flow builders to assign slot values to slots directly in the flow without using custom actions or collecting user input. By doing so they can dictate the logic independently from user input. Slots can either be precomputed with a value or reset.
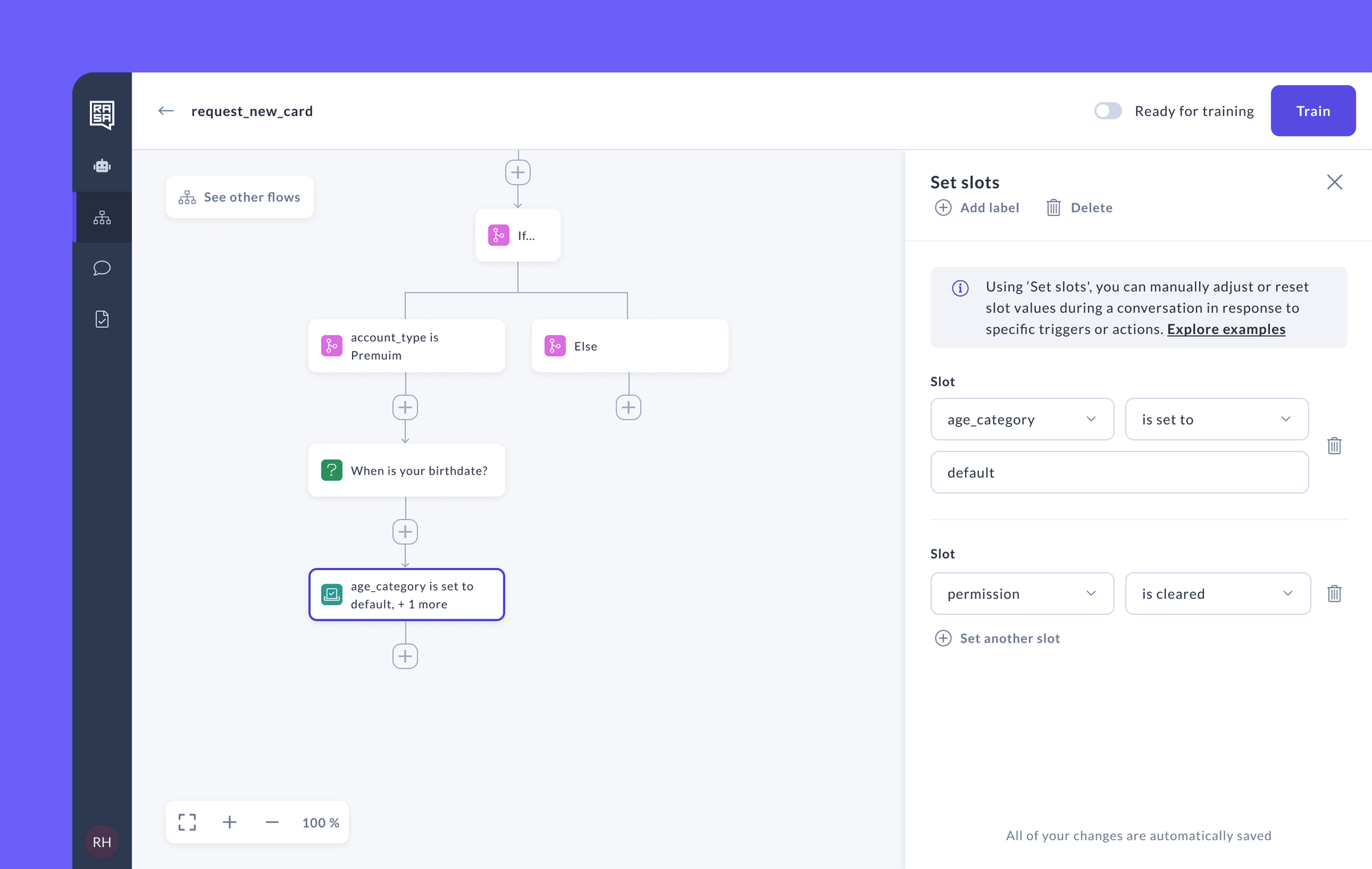
##### Improvements[](#improvements-21 "Direct link to Improvements")
* Enable users to select or unselect flows for training directly from the flow list
* Other minor application improvements
##### Bugfixes[](#bugfixes-47 "Direct link to Bugfixes")
* Annotator user is now prohibited from viewing options for editing NLU
* Chat history is now not shared between all assistants and user logins
* Fixed issue related to a race condition when changing categorical slots
* Improved error message when training is initiated with an invalid slot value and invalid config yaml
* Other minor bug fixes
#### \[1.0.4] - 2024-02-12[](#104---2024-02-12 "Direct link to [1.0.4] - 2024-02-12")
info
Make sure to use Rasa Studio Helm chart version `0.4.0` & above for deploying this release.
##### Features[](#features-18 "Direct link to Features")
* `Try your assistant` page now maintains chat history
Please note that the chat history is maintained in the local storage of the browser. The chat history is not maintained across different browsers
* Users can now search flows by flow description
##### Improvements[](#improvements-22 "Direct link to Improvements")
* Improved security of Studio container images. Studio now uses `non-root` user for running the application
* Simplified deployment time variables in the latest `0.4.0` Helm chart release
* Other minor application improvements
##### Bugfixes[](#bugfixes-48 "Direct link to Bugfixes")
* Fixed issues connected to `rasa studio download` cli failure due to absence of slots and empty flows
* Other minor bug fixes
#### \[1.0.3] - 2024-01-22[](#103---2024-01-22 "Direct link to [1.0.3] - 2024-01-22")
##### Features[](#features-19 "Direct link to Features")
* Users can now search for primitives by typing in the search bar
* Users can now use `Azure OpenAI API` with Studio to train their assistants. A new `RASA_CONFIG_FILE` environment variable can now be passed to the `backend` service to define the `config.yaml` file used for training the assistant
Please note that the contents of the `config.yaml` file needs to be `base64` encoded and passed to the new environment variable. The Studio `backend` service will decode the variable value and use it for training the assistant. Users can pass the `Azure OpenAI API` key to the existing `OPENAI_API_KEY_SECRET_KEY` environment variable
The `RASA_CONFIG_FILE` values overrides the `Advanced configuration` options defined in the `Create assistant Project` model in the Studio web client
Sample `config.yaml` file:
```
recipe: default.v1
language: en
pipeline:
- name: LLMCommandGenerator
llm:
model_name: gpt-3.5-turbo
api_type: azure
api_base: https://studio-testing.openai.azure.com
api_version: "2023-07-01-preview"
engine: gippity-35
policies:
- name: rasa.core.policies.flow_policy.FlowPolicy
```
Corresponding `base64` encoded `RASA_CONFIG_FILE` value:
```
cmVjaXBlOiBkZWZhdWx0LnYxCmxhbmd1YWdlOiBlbgpwaXBlbGluZToKICAtIG5hbWU6IExMTUNvbW1hbmRHZW5lcmF0b3IKICAgIGxsbToKICAgICAgbW9kZWxfbmFtZTogZ3B0LTMuNS10dXJibwogICAgICBhcGlfdHlwZTogYXp1cmUKICAgICAgYXBpX2Jhc2U6IGh0dHBzOi8vc3R1ZGlvLXRlc3Rpbmcub3BlbmFpLmF6dXJlLmNvbQogICAgICBhcGlfdmVyc2lvbjogMjAyMy0wNy0wMS1wcmV2aWV3CiAgICAgIGVuZ2luZTogZ2lwcGl0eS0zNQoKcG9saWNpZXM6CiAgLSBuYW1lOiByYXNhLmNvcmUucG9saWNpZXMuZmxvd19wb2xpY3kuRmxvd1BvbGljeQ
```
##### Improvements[](#improvements-23 "Direct link to Improvements")
* Improvements related to order of condition steps in flow export
* Better user notifications when there is a connection issue with a deployed model in `try your assistant` page
* Other minor application improvements
##### Bugfixes[](#bugfixes-49 "Direct link to Bugfixes")
* Fixed issue related to flow training when first step is the `Logic` step
* Users can now delete unused slot
* Other minor bug fixes
---
#### Studio Version Migration Guide
This page contains information about changes between major versions and how you can migrate from one version to another.
#### Rasa Studio v1.13.x → v1.14.x[](#rasa-studio-v113x--v114x "Direct link to Rasa Studio v1.13.x → v1.14.x")
##### What's New[](#whats-new "Direct link to What's New")
Studio version 1.14 introduces **AWS IAM Database Authentication** for RDS connections, significantly enhancing your deployment's security posture.
##### Before You Upgrade[](#before-you-upgrade "Direct link to Before You Upgrade")
Review the following guide to enable IAM authentication in your environment. The guide covers both database IAM authentication (new in v1.14) and S3 storage setup (for those migrating from persistent volumes).
##### Overview[](#overview "Direct link to Overview")
This version allows you to replace static database passwords with secure, temporary IAM tokens for enhanced security.
**Note**: S3 storage with IAM has always been supported in Studio. This guide focuses on the new IAM database authentication feature. S3 setup steps are applicable only if you're moving to S3 storage or setting it up for the first time.
This guide explains what you need to do to enable IAM database authentication in your environment.
***
##### ⚠️ Important: Model Retraining Required (Only When Moving to S3)[](#️-important-model-retraining-required-only-when-moving-to-s3 "Direct link to ⚠️ Important: Model Retraining Required (Only When Moving to S3)")
**If you are moving from persistent volumes to S3 for model storage, you will need to either copy your existing models to S3 or retrain all your assistants.**
###### When This Applies[](#when-this-applies "Direct link to When This Applies")
* ✅ **Applies if**: You currently use persistent volumes and are moving to S3 storage
* ❌ **Does NOT apply if**: You already use S3 storage (with or without IAM)
* ❌ **Does NOT apply if**: You are only enabling IAM database authentication (not changing storage)
###### Why Retraining is Needed (When Moving to S3)[](#why-retraining-is-needed-when-moving-to-s3 "Direct link to Why Retraining is Needed (When Moving to S3)")
* Current models stored in persistent volumes will not be accessible after moving to S3
* This is a one-time requirement when you first move to S3 storage
* Your training data and assistant configurations are not affected and remain available
* **Alternative**: You can copy models from persistent volumes to S3 instead of retraining
###### What You Need to Do (If Moving to S3)[](#what-you-need-to-do-if-moving-to-s3 "Direct link to What You Need to Do (If Moving to S3)")
1. **Choose Your Approach**:
* **Option A**: Copy existing models from persistent volumes to S3 (recommended to avoid retraining)
* **Option B**: Retrain all active assistants (if you prefer to regenerate models)
2. **Plan Ahead**: Schedule time for either copying models or retraining all active assistants
3. **Test Environment**: Consider testing in a staging environment first
###### If You Already Use S3[](#if-you-already-use-s3 "Direct link to If You Already Use S3")
* **No Retraining Required**: Your existing S3-stored models will continue to work
* **No Impact**: Enabling IAM database authentication does not affect your models
***
##### 🚀 How to Enable IAM Authentication[](#-how-to-enable-iam-authentication "Direct link to 🚀 How to Enable IAM Authentication")
###### Step 1: Set Up AWS Infrastructure[](#step-1-set-up-aws-infrastructure "Direct link to Step 1: Set Up AWS Infrastructure")
###### Create IAM Roles[](#create-iam-roles "Direct link to Create IAM Roles")
You need to create IAM roles that your application can use:
1. **Create RDS IAM Role**:
* Name: `your-app-rds-role`
* Trust policy: Allow EKS service accounts to assume this role (see example below)
* Attach policy for RDS database connection
2. **Create S3 IAM Role**:
* Name: `your-app-s3-role`
* Trust policy: Allow EKS service accounts to assume this role (see example below)
* Attach policy for S3 bucket access
**Example Trust Policy** (for both roles, replace YOUR-OIDC-PROVIDER-ARN and YOUR-OIDC-PROVIDER-URL):
```
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "YOUR-OIDC-PROVIDER-ARN"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"YOUR-OIDC-PROVIDER-URL:aud": "sts.amazonaws.com"
}
}
}
]
}
```
###### Required IAM Policies[](#required-iam-policies "Direct link to Required IAM Policies")
**RDS Policy** (attach to your RDS role):
```
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["rds-db:connect"],
"Resource": [
"arn:aws:rds-db:YOUR-REGION:YOUR-ACCOUNT-ID:dbuser:YOUR-DB-INSTANCE-ID/*"
]
}
]
}
```
**To find your DB instance ID:**
* Go to AWS RDS console → Your database instance
* The instance ID is shown in the instance details (e.g., `mydb-instance-1`)
* Or use AWS CLI: `aws rds describe-db-instances --query 'DBInstances[*].DBInstanceIdentifier'`
**S3 Policy** (attach to your S3 role):
```
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListBucketMultipartUploads",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::YOUR-BUCKET-NAME",
"arn:aws:s3:::YOUR-BUCKET-NAME/*"
]
}
]
}
```
###### Configure EKS Service Accounts[](#configure-eks-service-accounts "Direct link to Configure EKS Service Accounts")
**Service accounts are automatically created when you configure Helm chart annotations.**
1. **Create or Verify OIDC Provider**: Ensure your EKS cluster has an OIDC provider configured
**Check if OIDC provider exists:**
* Go to AWS IAM console → Identity providers
* Look for your EKS cluster's OIDC provider URL
**If it doesn't exist, create it:**
**Option 1: Using AWS CLI**
```
# Get your EKS cluster's OIDC issuer URL
aws eks describe-cluster --name YOUR-CLUSTER-NAME --query "cluster.identity.oidc.issuer" --output text
# Create the OIDC provider (replace with your actual issuer URL)
aws iam create-open-id-connect-provider \
--url https://oidc.eks.YOUR-REGION.amazonaws.com/id/YOUR-OIDC-ID \
--client-id-list sts.amazonaws.com \
--thumbprint-list YOUR-THUMBPRINT
```
**Option 2: Using AWS Console**
* Go to IAM → Identity providers → Add provider
* Select "OpenID Connect"
* Provider URL: `https://oidc.eks.YOUR-REGION.amazonaws.com/id/YOUR-OIDC-ID`
* Audience: `sts.amazonaws.com`
* Click "Add provider"
2. **Configure Helm Chart Annotations**:
* Add IAM role annotations to your Helm chart values for the following services
* Service accounts will be automatically created with the IAM role ARNs
**For Database (RDS IAM) access**, add annotations to:
* Backend service
* Event ingestion service
* Database migration job
**For S3 access**, add annotations to:
* Rasa Model Service
Example annotation format for database services:
```
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::YOUR-ACCOUNT-ID:role/your-app-rds-role
```
Example annotation format for S3 services:
```
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::YOUR-ACCOUNT-ID:role/your-app-s3-role
```
###### Step 2: Set Up RDS for IAM Authentication[](#step-2-set-up-rds-for-iam-authentication "Direct link to Step 2: Set Up RDS for IAM Authentication")
1. **Enable IAM Database Authentication** on your RDS instance:
* Go to AWS RDS console
* Select your RDS instance
* Click "Modify"
* Enable "IAM database authentication"
* Apply changes (may require restart)
For more information, see the [AWS documentation for modifying DB instances](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.DBInstance.Modifying.html) to enable IAM database authentication
2. **Create IAM Database User** (connect to your RDS instance as admin):
```
-- Create IAM database user
CREATE USER "studio_iam_user" WITH LOGIN;
-- Grant rds_iam role to IAM user (required for IAM auth)
-- Note: rds_iam is a built-in AWS RDS role available after enabling IAM auth
GRANT rds_iam TO "studio_iam_user";
```
3. **Grant Database Permissions**:
```
-- Grant ALL privileges on database to IAM user
GRANT ALL PRIVILEGES ON DATABASE "your_database_name" TO "studio_iam_user";
-- Grant schema privileges
GRANT ALL ON SCHEMA "public" TO "studio_iam_user";
-- Grant privileges on all existing tables and sequences
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA "public" TO "studio_iam_user";
GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA "public" TO "studio_iam_user";
-- Transfer ownership of all objects to IAM user (optional, if you want to change ownership)
REASSIGN OWNED BY "your_original_db_user" TO "studio_iam_user";
```
**Note**: Replace `your_original_db_user` with your current database user and `your_database_name` with your actual database name.
###### Step 3: Set Up S3 Bucket[](#step-3-set-up-s3-bucket "Direct link to Step 3: Set Up S3 Bucket")
1. **Create S3 Bucket**:
* Go to AWS S3 console
* Click "Create bucket"
* **Bucket name**: `your-app-shared-storage-ENVIRONMENT` (must be globally unique)
* **Region**: Choose your preferred region
* **Versioning**: Enable versioning
* **Default encryption**: Enable → Choose "AES-256"
* **Block public access**: Enable all 4 options:
* ✅ Block all public access
* ✅ Block public access to buckets and objects granted through new public bucket or access point policies
* ✅ Block public access to buckets and objects granted through any public bucket or access point policies
* ✅ Block public access to buckets and objects granted through new ACLs and uploading objects with public ACLs
* Click "Create bucket"
For more information, see the [AWS documentation for creating S3 buckets](https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html).
2. **Configure Bucket Policy**:
* In "Permissions" tab, find "Bucket policy"
* Click "Edit" and add this policy (replace YOUR-BUCKET-NAME and YOUR-ACCOUNT-ID):
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowSharedIAMRoleAccess",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::YOUR-ACCOUNT-ID:role/your-app-s3-role"
},
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListBucketMultipartUploads",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::YOUR-BUCKET-NAME",
"arn:aws:s3:::YOUR-BUCKET-NAME/*"
]
}
]
}
```
###### Step 4: Update Your Application Configuration[](#step-4-update-your-application-configuration "Direct link to Step 4: Update Your Application Configuration")
Add these configuration values to your Helm chart:
###### Database IAM Configuration[](#database-iam-configuration "Direct link to Database IAM Configuration")
Add to the `config.database` section of your Helm chart values:
```
config:
database:
useAwsIamAuth: "true"
awsRegion: "your-aws-region"
iamDbUsername: "studio_iam_user"
```
**These variables apply to:**
* Backend service
* Event ingestion service
* Database migration job
###### S3 Configuration (for Rasa Pro)[](#s3-configuration-for-rasa-pro "Direct link to S3 Configuration (for Rasa Pro)")
Add to the `rasa.rasa.overrideEnv` section of your Helm chart values:
```
rasa:
rasa:
overrideEnv:
- name: "BUCKET_NAME"
value: "your-app-shared-storage-ENVIRONMENT"
- name: "AWS_DEFAULT_REGION"
value: "your-aws-region"
- name: "RASA_REMOTE_STORAGE"
value: "aws"
```
**These variables apply to:**
* Rasa Model Service
###### Step 5: Deploy and Test[](#step-5-deploy-and-test "Direct link to Step 5: Deploy and Test")
1. **Deploy** your updated application
2. **Verify** database connections are working
3. **Retrain** your assistants (only if you're moving from persistent volumes to S3)
#### Rasa Studio v1.12.x → v1.13.x[](#rasa-studio-v112x--v113x "Direct link to Rasa Studio v1.12.x → v1.13.x")
##### What's New[](#whats-new-1 "Direct link to What's New")
We've made important improvements to Rasa Studio's database migrations:
* No more `superuser` required: In earlier versions, certain database migrations required a user with superuser privileges. This is no longer necessary. All migrations can now be completed using a standard database user.
##### Before You Upgrade[](#before-you-upgrade-1 "Direct link to Before You Upgrade")
If you're upgrading from a version before `v1.13.x`, please follow the below steps.
###### Step-by-Step Upgrade Instructions[](#step-by-step-upgrade-instructions "Direct link to Step-by-Step Upgrade Instructions")
1. **Upgrade to `v1.12.7` First**
This ensures that all necessary database migrations are applied before moving to the `1.13.x` version
2. **Mark Migrations as Complete**
After upgrading to `v1.12.7`, run the following SQL command on your Studio database:
```
insert into public._prisma_migrations (
id,
checksum,
finished_at,
migration_name,
started_at,
applied_steps_count)
values (
'08eb97ec-85fa-4578-921e-091d50c4a816',
'c0993f05c8c4021b096d2d8c78d7f3977e81388ae36e860387eddb2c3553a65b',
now(),
'000000000000_squashed_migrations',
now(),
1);
```
This tells the system the earlier migrations are already applied, so they won't run again.
3. **Upgrade to `v1.13.x` or Later**
After completing the steps above, you're ready to upgrade to the latest version of Rasa Studio.
---
### Channels
#### AudioCodes Voice Stream Channel
New in 3.12
From Rasa Pro 3.12, you can stream conversation audio directly from AudioCodes to your Rasa Assistant.
This channel is a voice-stream channel connector to AudioCodes where the conversation audio is streamed directly to Rasa. Rasa also offers a voice-ready channel connector with AudioCodes, read about it on [AudioCodes VoiceAI Connect](https://rasa.com/docs/docs/reference/channels/audiocodes-voiceai-connect/)
#### Configure Rasa Assistant[](#configure-rasa-assistant "Direct link to Configure Rasa Assistant")
Use the built-in channel `audiocodes_stream` to configure your Rasa Assistant. Create or edit the `credentials.yml` file at the root of your assistant directory to add `audiocodes_stream` channel. Here's an example:
credentials.yml
```
# websocket_url: wss:///webhooks/audiocodes_stream/websocket
audiocodes_stream:
server_url: ""
asr:
name: deepgram
tts:
name: cartesia
# Optional configurations
token: ""
```
This channel expects WebSocket requests on the URL described above as "websocket\_url". The channel configuration accepts the following properties:
* `server_url` (required): The domain at which Rasa server is available. Do not include protocol (ws:// or wss://). For example, if your server is deployed on `https://example.ngrok.app`, `server_url` should be `example.ngrok.app`.
* `asr` (required): Configuration for Automatic Speech Recognition. See [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/#automatic-speech-recognition-asr) for a list of ASR engines for which Rasa provides built-in integration with.
* `tts` (required): Configuration for Text-To-Speech. See [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/#text-to-speech-tts) for a list of TTS engines for which Rasa provides built-in integration with.
* `token` (optional): An authentication token configured in AudioCodes. This field is optional, as AudioCodes permits empty values. If no token is provided, authentication will be skipped.
You can run the assistant using the command `rasa run`. You'll need a URL accessible by AudioCodes for your Rasa assistant. For development, you can use tools like [ngrok](https://ngrok.com/) or [Cloudflare Tunnel](https://developers.cloudflare.com/cloudflare-one/connections/connect-networks/)
You can also run it with a development inspector using `rasa run --inspect`. To see all available parameters for this command, use `rasa run -h`.
Bot URLs for development
Visit this [section](https://rasa.com/docs/docs/reference/channels/messaging-and-voice-channels/#testing-channels-on-your-local-machine) to learn how to generate the required bot URL when testing the channel on your local machine.
#### Configuration on AudioCodes[](#configuration-on-audiocodes "Direct link to Configuration on AudioCodes")
This channel connector uses AudioCodes Voice Streaming API. Create a bot connection for Streaming Mode bots on AudioCodes, please refer to [AudioCodes Documentation](https://techdocs.audiocodes.com/livehub/#LiveHub/AudioCodesAPI-framework.htm#Create2) for detailed instructions.
1. On the **Bot Connections** page, click on **Add new voice bot connection**.
2. Select **AudioCodes Bot API**
3. Set an appropriate name for the Bot Connection. For "Bot connection API type", select "Streaming Mode".
4. Set the "Bot URL". Depending on the hostname and TLS configuration, the URL would be `wss:///webhooks/audiocodes_stream/websocket`
5. Set an authentication token, ensure that Rasa channel configuration has the same authentication token.
You can validate your Rasa Channel configuration with the button "Validate bot connection configuration". Ensure that the Rasa Server is running, AudioCodes will open a websocket on the Bot URL and send a "connection.validate" message.
6. On the next page, select **Enable voice streaming**. For 'Language' field, leave the default setting as it has no impact on Rasa Assistant
Click **Create** to create the bot connection. You can now define a Routing to connect the Bot Connection to a phone number.
#### Enable `playFinished` events[](#enable-playfinished-events "Direct link to enable-playfinished-events")
This channel connector requires `playFinished` events for certain features like silence handling and hanging up the call with `action_hangup` to work.
To enable these events, edit the bot connection that was created in the previous section. Go to the Advanced Tab and paste the following in,
```
{
"sendEventsToBot":["playFinished"]
}
```
#### Call Metadata[](#call-metadata "Direct link to Call Metadata")
Metadata about the call can be accessed by the slot `session_started_metadata` in the beginning of the call. Following fields are available:
| Field Name | Description | Source |
| ------------ | ------------------------------------------ | ---------------------------------------------------- |
| `call_id` | The unique call identifier from Audiocodes | `vaigConversationId` parameter as sent by Audiocodes |
| `user_phone` | The phone number of the user | `caller` parameter |
| `user_name` | The caller's display name | `callerDisplayName` parameter sent by Audiocodes |
| `user_host` | The caller's host | `callerHost` parameter sent by Audiocodes |
| `bot_phone` | The phone number of the bot | `callee` parameter |
| `bot_host` | The bot's host | `calleeHost` parameter sent by Audiocodes |
A [custom `action_session_start`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/default-actions#customization) can be used to store this information to a slot.
---
#### Audiocodes VoiceAI Connect
Use this channel to connect your Rasa assistant to [Audiocodes VoiceAI connect](https://www.audiocodes.com/solutions-products/voiceai/voiceai-connect).
#### Getting Credentials[](#getting-credentials "Direct link to Getting Credentials")
To get credentials, create a bot on the [VoiceAI connect portal](https://voiceaiconnect.audiocodes.io/).
1. Select **Bots** in the left sidebar.
2. Click on the **+** sign to create a new bot.
3. Select **Rasa Pro** as the Bot Framework
4. Set the bot URL and choose a token value.
5. "Validate the bot configuration" once you have completed the "Setting credentials" section and the bot is running. Validation will only succeed if the bot is running and the token is correctly set.
Setting the bot URL with a tunneling solution when testing locally
Visit this [section](https://rasa.com/docs/docs/reference/channels/messaging-and-voice-channels/#testing-channels-on-your-local-machine) to learn how to generate the required bot URL when testing the channel on your local machine.
#### Setting credentials[](#setting-credentials "Direct link to Setting credentials")
The token value chosen above will be used in the `credentials.yml`:
* Rasa Pro <=3.7.x
* Rasa Pro >=3.8.x
```
rasa_plus.channels.audiocodes.AudiocodesInput:
token: "token"
```
```
audiocodes:
token: "token"
```
You can also specify optional parameters:
| Parameter | Default value | Description |
| --------------- | ---------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `token` | No default value | The token to authenticate calls between your Rasa assistant and VoiceAI connect |
| `use_websocket` | `true` | If true, Rasa and AudioCodes will signal to each other over a websocket. If false, Rasa and AudioCodes will signal over HTTP API. Using websocket for signalling is better when bot needs to handle tasks which are more time consuming, thus not blocking the line so that other signals can come through. [See Audiocodes documentation for more details](https://techdocs.audiocodes.com/voice-ai-connect/Default.htm#Bot-API/ac-bot-api-mode-http.htm#Sending20Activities20over20WebSocket) |
| `keep_alive` | 120 | In seconds. For each ongoing conversation, VoiceAI Connect will periodically verify the conversation is still active on the Rasa side. |
Then restart your Rasa server to make the new channel endpoint available.
#### Usage[](#usage "Direct link to Usage")
New in 3.11
We have unified the call handling patterns across Voice Channel Connectors, all voice channels handle call starts, ends and metadata in a similar manner.
##### Call Metadata[](#call-metadata "Direct link to Call Metadata")
Metadata about the call can be accessed by the slot `session_started_metadata` in the beginning of the call. Following fields are available:
| Field Name | Description | Source |
| ------------ | ------------------------------------------ | ---------------------------------------------------- |
| `call_id` | The unique call identifier from Audiocodes | `vaigConversationId` parameter as sent by Audiocodes |
| `user_phone` | The phone number of the user | `caller` parameter |
| `user_name` | The caller's display name | `callerDisplayName` parameter sent by Audiocodes |
| `user_host` | The caller's host | `callerHost` parameter sent by Audiocodes |
| `bot_phone` | The phone number of the bot | `callee` parameter |
| `bot_host` | The bot's host | `calleeHost` parameter sent by Audiocodes |
A [custom `action_session_start`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/default-actions#customization) can be used to store this information to a slot.
##### Receiving messages from a user[](#receiving-messages-from-a-user "Direct link to Receiving messages from a user")
When a user speaks on the phone, VoiceAI Connect will send a text message (after it is processed by the speech-to-text engine) to your assistant like any other channel. This message will be interpreted by Rasa and handled by the dialogue engine, and the response will be sent back to VoiceAI Connect to be converted to a voice message and delivered to the user.
##### Sending messages to a user[](#sending-messages-to-a-user "Direct link to Sending messages to a user")
Your bot will respond with text messages like with any other channel. The text-to-speech engine will convert the text and deliver it as a voice message to the user.
Here is an example:
```
utter_greet:
- text: "Hello! isn’t every life and every work beautiful?"
```
note
Only text messages are allowed. Images, attachments, and buttons cannot be used with a voice channel.
##### DTMF and Other Events[](#dtmf-and-other-events "Direct link to DTMF and Other Events")
Rasa receives the intent `/vaig_event_DTMF` when receiving a DTMF tone (i.e user presses digit on the keyboard of the phone). The digit(s) sent will be passed in the `value` entity.
The general pattern is that for every Audiocodes `event`, the bot will receive the `vaig_event_` intent, with context information in entities.
Check the [VoiceAI Connect documentation](https://techdocs.audiocodes.com/voice-ai-connect/#VAIG_Combined/voiceai_connect.htm?TocPath=VoiceAI%2520Connect%257C_____0) for an exhaustive list of events.
note
Certain events like `playFinished` could disrupt the conversation with the assistant. We recommend that they should be disabled.
##### Configuring calls[](#configuring-calls "Direct link to Configuring calls")
You can send events from Rasa to VoiceAI Connect to make changes to the current call configuration. For example, you might want to receive a notification when the user stays silent for more than 5 seconds, or you might need to customize how DTMF digits are sent by VoiceAI Connect.
Call configuration events are sent with custom messages and are specific to the current conversation (sometimes to a message). Which means they must be part of your stories or rules so the same behaviour is applied to all conversations.
Those Rasa responses don't utter anything, they just configure the voice gateway. It is a good practice naming them differently, for example prefixing them with `utter_config_`
All the supported events are exhaustively documented in the [VoiceAI Connect documentation](https://techdocs.audiocodes.com/voice-ai-connect/#VAIG_Combined/voiceai_connect.htm?TocPath=VoiceAI%2520Connect%257C_____0). We will look at one example here to illustrate the use of custom messages and events.
###### Example: changing a pin code[](#example-changing-a-pin-code "Direct link to Example: changing a pin code")
In this example we create a flow to allow a user to change a pin code.
```
- rule: Set pin code
steps:
# User says "I want to change my pin code"
- intent: set_pin_code
# Send the noUserInput configuration event
- action: utter_config_no_user_input
# Send the DTMF format configuration event
- action: utter_config_dtmf_pin_code
# A standard Rasa form to collect the pin code from the user
- action: pin_code_form
- ...
```
In the domain, we can add the `utter_config_` responses:
[`noUserInput` event](https://techdocs.audiocodes.com/voice-ai-connect/#VAIG_Combined/inactivity-detection.htm?TocPath=Bot%2520integration%257CReceiving%2520notifications%257C_____3)
```
utter_config_no_user_input:
- custom:
type: event
name: config
sessionParams:
# If user stays silent for 5 seconds or more, the notification will be sent
userNoInputTimeoutMS: 5000
# If you want to allow for more than one notification during a call
userNoInputRetries: 2
# Enable the noUserInput notification
userNoInputSendEvent: true
```
[`DTMF` event](https://techdocs.audiocodes.com/voice-ai-connect/#VAIG_Combined/receive-dtmf.htm?TocPath=Bot%2520integration%257CReceiving%2520notifications%257C_____2)
```
utter_config_dtmf_pin_code:
- custom:
type: event
name: config
sessionParams:
# Enable grouped collection (i.e will send all digits in a single payload)
dtmfCollect: true
# If more than 5 secs have passed since a digit was pressed,
# the input is considered completed and will be sent to the bot
dtmfCollectInterDigitTimeoutMS: 5000
# If 6 digits are collected, VoiceAI will send those 6 digits
# even if the user keeps pressing buttons
dtmfCollectMaxDigits: 6
# If the user presses '#' the input is considered complete
dtmfCollectSubmitDigit: "#"
```
Now you can configure the `pin_code` slot in the `pin_code_form` to extract the pin code from the `value` entity with the `vaig_event_DTMF` intent:
```
pin_code:
type: text
influence_conversation: false
mappings:
- type: from_entity
entity: value
intent: vaig_event_DTMF
not_intent: vaig_event_noUserInput
conditions:
- active_loop: pin_code_form
requested_slot: pin_code
```
Notice how `vaig_event_noUserInput` was declared in the `not_intent` field.
Since the `vaig_event_noUserInput` intent is sent by VoiceAI Connect when the user stays silent as per our configuration, we must deactivate the form so we can pick up the conversation from a rule or a story and gracefully handle the failure.
In the following example, we simply cancel the current flow if we receive the `vaig_event_noUserInput` intent (i.e. user stays silent) while the `pin_code_form` loop is active.
```
- rule: Set pin code - happy path
steps:
- intent: set_pin_code
- action: utter_config_no_user_input
- action: utter_config_dtmf_pin_code
- action: pin_code_form
- active_loop: pin_code_form
- active_loop: null
- slot_was_set:
- requested_slot: null
- action: utter_pin_code_changed
- action: action_pin_code_cleanup
- rule: Set pin code - no response - cancel.
condition:
- active_loop: pin_code_form
steps:
- intent: vaig_event_noUserInput
- action: utter_cancel_set_pin_code
- action: action_deactivate_loop
- active_loop: null
```
---
#### Cisco Webex Teams
You first have to create a cisco webex app to get credentials. Once you have them you can add these to your `credentials.yml`.
#### Getting Credentials[](#getting-credentials "Direct link to Getting Credentials")
**How to get the Cisco Webex Teams credentials:**
You need to set up a bot. Check out the [Cisco Webex for Developers documentation](https://developer.webex.com/docs/bots) for information about how to create your bot.
After you have created the bot through Cisco Webex Teams, you need to create a room in Cisco Webex Teams. Then add the bot in the room the same way you would add a person in the room.
You need to note down the room ID for the room you created. This room ID will be used in `room` variable in the `credentials.yml` file.
Please follow this link below to find the room ID `https://developer.webex.com/endpoint-rooms-get.html`
In the OAuth & Permissions section, add the URL of the Rasa endpoint that Webex should forward the messages to. The endpoint for receiving Cisco Webex Teams messages is `http://:/webhooks/webexteams/webhook`, replacing the host and port with the appropriate values from your running Rasa server.
#### Running on Cisco Webex Teams[](#running-on-cisco-webex-teams "Direct link to Running on Cisco Webex Teams")
Add the Webex Teams credentials to your `credentials.yml`:
```
webexteams:
access_token: "YOUR-BOT-ACCESS-TOKEN"
room: "YOUR-CISCOWEBEXTEAMS-ROOM-ID"
```
Restart your Rasa server to make the new channel endpoint available for Cisco Webex Teams to send messages to.
note
If you do not set the `room` keyword argument, messages will by delivered back to the user who sent them.
---
#### Connecting to Messaging and Voice Channels
Installation Requirements
To use most channel connectors, you need to install the `channels` dependency group:
```
pip install 'rasa-pro[channels]'
```
For more information about dependency groups, see our [Python Versions and Dependencies](https://rasa.com/docs/docs/reference/python-versions-and-dependencies/) reference page.
#### Connecting to A Channel[](#connecting-to-a-channel "Direct link to Connecting to A Channel")
##### Text & Chat[](#text--chat "Direct link to Text & Chat")
Learn how to make your assistant available on:
* [Your Own Website](https://rasa.com/docs/docs/reference/channels/your-own-website/)
* [Facebook Messenger](https://rasa.com/docs/docs/reference/channels/facebook-messenger/)
* [Slack](https://rasa.com/docs/docs/reference/channels/slack/)
* [Telegram](https://rasa.com/docs/docs/reference/channels/telegram/)
* [Twilio](https://rasa.com/docs/docs/reference/channels/twilio/)
* [Microsoft Bot Framework](https://rasa.com/docs/docs/reference/channels/microsoft-bot-framework/)
* [Cisco Webex Teams](https://rasa.com/docs/docs/reference/channels/cisco-webex-teams/)
* [RocketChat](https://rasa.com/docs/docs/reference/channels/rocketchat/)
* [Mattermost](https://rasa.com/docs/docs/reference/channels/mattermost/)
* [Google Hangouts Chat](https://rasa.com/docs/docs/reference/channels/hangouts/)
* [Custom Connectors](https://rasa.com/docs/docs/reference/channels/custom-connectors/)
##### Voice[](#voice "Direct link to Voice")
Learn how to build voice assistants with:
* [Audiocodes VoiceAI Connect](https://rasa.com/docs/docs/reference/channels/audiocodes-voiceai-connect/)
* [Jambonz](https://rasa.com/docs/docs/reference/channels/jambonz/)
* [Twilio Voice](https://rasa.com/docs/docs/reference/channels/twilio-voice/)
* [Twilio Media Streams](https://rasa.com/docs/docs/reference/channels/twilio-media-streams/)
To learn more about integration ASR and TTS engines, head over to [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/).
#### Testing Channels on Your Local Machine[](#testing-channels-on-your-local-machine "Direct link to Testing Channels on Your Local Machine")
If you're running a Rasa server on `localhost`, most external channels won't be able to find your server URL, since `localhost` is not open to the internet.
To make a port on your local machine publicly available on the internet, you can use [ngrok](https://ngrok.com/). Alternatively, see this [list](https://github.com/anderspitman/awesome-tunneling) tracking and comparing other tunneling solutions.
After installing ngrok, run:
```
ngrok http 5005; rasa run
```
When you follow the instructions to make your assistant available on a channel, use the ngrok URL. Specifically, wherever the instructions say to use `https://:/webhooks//webhook`, use `/webhooks//webhook`, replacing `` with the randomly generated URL displayed in your ngrok terminal window. For example, if connecting your bot to Slack, your URL should resemble `https://26e7e7744191.ngrok.io/webhooks/slack/webhook`.
caution
With the free-tier of ngrok, you can run into limits on how many connections you can make per minute. As of writing this, it is set to 40 connections / minute.
Alternatively you can make your assistant listen on a specific address using the `-i` command line option:
```
rasa run -p 5005 -i 192.168.69.150
```
This is particularly useful when your internet facing machines connect to backend servers using a VPN interface.
---
#### Custom Connectors
Channels in Rasa are the abstraction that allows you to connect the Rasa Assistant to your desired platform where your users are. If the built-in channels in Rasa do not fit your needs, you can create a custom channel.
A custom channel connector must be implemented as a Python class. When building a custom channel, think of it like a two-way conversation between your desired platform and Rasa. You need:
* **InputChannel**: Receives messages from users on your platform and forwards them to Rasa for processing.
* **OutputChannel**: Takes Rasa's responses and sends them back to users on your platform.
The flow is simple: User sends message → InputChannel receives it → Rasa processes → OutputChannel sends response back to user.
This separation lets you customize how messages come in (webhook, WebSocket, etc.) independently from how responses go out (REST API calls, real-time streaming, etc.).
#### InputChannel[](#inputchannel "Direct link to InputChannel")
A custom connector class must subclass `rasa.core.channels.channel.InputChannel` and implement at least `blueprint` and `name` methods.
##### The `name` method[](#the-name-method "Direct link to the-name-method")
The `name` method defines the url prefix for the connector's webhook. It also defines the channel name you should use in any [channel specific response variations](https://rasa.com/docs/docs/reference/primitives/responses/#channel-specific-response-variations) and the name you should pass to the `output_channel` query parameter on the [trigger intent endpoint](https://rasa.com/docs/docs/reference/api/pro/http-api/).
For example, if your custom channel is named `myio`, you would define the `name` method as:
```
from rasa.core.channels.channel import InputChannel
class MyIO(InputChannel):
def name() -> Text:
"""Name of your custom channel."""
return "myio"
```
You would write a response variation specific to the `myio` channel as:
domain.yml
```
responses:
utter_greet:
- text: Hi! I'm the default greeting.
- text: Hi! I'm the custom channel greeting
channel: myio
```
The webhook you give to the custom channel to call would be `http://:/webhooks/myio/webhook`, replacing the host and port with the appropriate values from your running Rasa server.
##### The `blueprint` method[](#the-blueprint-method "Direct link to the-blueprint-method")
The `blueprint` method must create a [Sanic blueprint](https://sanicframework.org/en/guide/best-practices/blueprints.html#overview) that can be attached to a sanic server. Your blueprint should have at least the two routes: `health` on the route `/`, and `receive` on the route `/webhook` (see example custom channel below).
As part of your implementation of the `receive` endpoint, you will need to tell Rasa to handle the user message. You do this by calling
```
on_new_message(
rasa.core.channels.channel.UserMessage(
text,
output_channel,
sender_id
)
)
```
Calling `on_new_message` will send the user message to the [`handle_message`](https://github.com/RasaHQ/rasa/blob/c922253fe890bb4903329d4ade764e0711d384ec/rasa/core/agent.py#L511_) method.
See more details on the `UserMessage` object [here](https://legacy-docs-oss.rasa.com/docs/rasa/reference/rasa/core/channels/channel#usermessage-objects).
##### Optional InputChannel Methods[](#optional-inputchannel-methods "Direct link to Optional InputChannel Methods")
You can override these methods for additional functionality:
* **`from_credentials(credentials)`** - Class method to create channel instance from credentials configuration.
#### OutputChannel[](#outputchannel "Direct link to OutputChannel")
The [`OutputChannel`](https://legacy-docs-oss.rasa.com/docs/rasa/reference/rasa/core/channels/channel#outputchannel-objects) class is responsible for sending Rasa's responses back to users on your platform. There are two main options:
1. **Use [`CollectingOutputChannel`](https://legacy-docs-oss.rasa.com/docs/rasa/reference/rasa/core/channels/channel#collectingoutputchannel-objects)** - Collects all bot responses in a list that you can return in your webhook response (good for REST-style channels).
2. **Create your own OutputChannel subclass** - Implement custom logic for sending responses directly to your platform (good for real-time channels like WebSocket, Slack, etc.).
##### Using CollectingOutputChannel[](#using-collectingoutputchannel "Direct link to Using CollectingOutputChannel")
CollectingOutputChannel only collects sent messages in a list (doesn't send them anywhere). The collected messages can be accessed via the `messages` property. Here is an example of a custom Rasa channel that uses it:
custom\_channel.py
```
import asyncio
import inspect
from sanic import Blueprint, response
from sanic.request import Request
from sanic.response import HTTPResponse
from typing import Text, Dict, Any, Optional, Callable, Awaitable
import rasa.utils.endpoints
from rasa.core.channels.channel import (
InputChannel,
CollectingOutputChannel,
UserMessage,
)
class MyIO(InputChannel):
def name() -> Text:
"""Name of your custom channel."""
return "myio"
def blueprint(
self, on_new_message: Callable[[UserMessage], Awaitable[None]]
) -> Blueprint:
custom_webhook = Blueprint(
"custom_webhook_{}".format(type(self).__name__),
inspect.getmodule(self).__name__,
)
@custom_webhook.route("/", methods=["GET"])
async def health(request: Request) -> HTTPResponse:
return response.json({"status": "ok"})
@custom_webhook.route("/webhook", methods=["POST"])
async def receive(request: Request) -> HTTPResponse:
sender_id = request.json.get("sender") # method to get sender_id
text = request.json.get("text") # method to fetch text
input_channel = self.name() # method to fetch input channel
metadata = self.get_metadata(request) # method to get metadata
collector = CollectingOutputChannel()
# include exception handling
await on_new_message(
UserMessage(
text,
collector,
sender_id,
input_channel=input_channel,
metadata=metadata,
)
)
return response.json(collector.messages)
return custom_webhook
```
Example Implementation
For a complete example of a custom channel using CollectingOutputChannel, see the [custom\_channel.py](https://github.com/RasaHQ/rasa-calm-demo/blob/minimal-llm-assistant/addons/custom_channel.py) implementation in the rasa-calm-demo repository.
##### Creating a Custom OutputChannel[](#creating-a-custom-outputchannel "Direct link to Creating a Custom OutputChannel")
To create your own OutputChannel, subclass `rasa.core.channels.channel.OutputChannel` and implement at minimum the `send_text_message` method:
custom\_output\_channel.py
```
from rasa.core.channels.channel import OutputChannel
from typing import Text, Any
class MyCustomOutputChannel(OutputChannel):
def __init__(self, webhook_url: str):
super().__init__()
self.webhook_url = webhook_url
async def send_text_message(self, recipient_id: Text, text: Text, **kwargs: Any) -> None:
"""Required method: Send a simple text message."""
# Your implementation to send text to your platform
# e.g., make HTTP request, send via WebSocket, etc.
pass
```
##### Required Methods[](#required-methods "Direct link to Required Methods")
**`send_text_message(recipient_id, text, **kwargs)`** - The only method you must implement. This handles basic text responses from Rasa.
##### Optional Methods for Enhanced Capabilities[](#optional-methods-for-enhanced-capabilities "Direct link to Optional Methods for Enhanced Capabilities")
Override these async methods to support rich message types; these methods are asynchronous and return `None`:
* **`send_image_url(recipient_id, image, **kwargs)`** - Send an image by URL. Default will just post the url as a string.
* **`send_attachment(recipient_id, attachment, **kwargs)`** - Send a file attachment. Default will just post as a string.
* **`send_text_with_buttons(recipient_id, text, buttons, **kwargs)`** - Send text with interactive buttons. Default implementation will just post the buttons as a string.
* **`send_quick_replies(recipient_id, text, quick_replies, **kwargs)`** - Send text with quick reply options. Default implementation will just send as buttons.
* **`send_elements(recipient_id, elements, **kwargs)`** - Send carousel/card elements. Default implementation will just post the elements as a string.
* **`send_custom_json(recipient_id, json_message, **kwargs)`** - Send custom JSON payloads. Default implementation will just post the json contents as a string.
#### Streaming Generative Responses[](#streaming-generative-responses "Direct link to Streaming Generative Responses")
If your Assistant uses generative responses from Rephraser or Enterprise Search Policy, the channel can stream these responses as soon as the tokens are generated, instead of waiting for the entire response to be prepared.
The OutputChannel class can be modified to enable streaming of responses. To implement response streaming for your channel, you can override these three optional methods (mentioned in the code snippet below) to stream the generated chunks of the response. By default, they do nothing (`pass` statement).
The OutputChannel functions described above (`send_text_message`, etc) will still be called once the complete response is ready. It is the channel's responsibility to ensure that a response is NOT sent to the platform twice.
```
class MyCustomOutputChannel(OutputChannel):
# ... other methods ...
async def send_response_chunk_start(self, recipient_id, **kwargs):
"""Invoked once at the beginning of response."""
# TODO: Initialize streaming connection
pass
async def send_response_chunk(self, recipient_id, chunk, **kwargs):
"""Invoked multiple times for each generated chunk/token."""
# TODO: Send chunk to platform
pass
async def send_response_chunk_end(self, recipient_id, **kwargs):
"""Invoked once at the end of response."""
# TODO: Finalize streaming connection
pass
```
Example Implementation
For a complete example of a custom channel with WebSocket support and response streaming, see the [websocket\_channel.py](https://github.com/RasaHQ/rasa-calm-demo/blob/minimal-llm-assistant/addons/websocket_channel.py) implementation in the rasa-calm-demo repository.
`recipient_id` is the Rasa Sender ID and the argument `chunk` contains the text of the response chunk that is being generated. These functions are called at different points during the generation of response. See this sequence diagram for more context,

##### Considerations when Streaming Responses[](#considerations-when-streaming-responses "Direct link to Considerations when Streaming Responses")
###### Avoid Blocking Calls[](#avoid-blocking-calls "Direct link to Avoid Blocking Calls")
Avoid making any blocking calls in these functions as they would impact the assistant's latency. If you need to do anything more than simply sending the message on a WebSocket, consider using async tasks.
For example, voice channels create a task with `asyncio.create_task` for reading the audio from TTS WebSocket and sending it to the client.
###### Handle Duplicates[](#handle-duplicates "Direct link to Handle Duplicates")
OutputChannel must ensure that a generative response is not sent twice, once during generation from `send_response_chunk()` and later when the complete response is ready from `send_text_message()`.
OutputChannel objects are isolated per conversation. Therefore, you can use a flag to mark when the responses have been streamed. The streaming methods will always be called in order for a single response:
* `send_response_chunk_start()` - called once.
* `send_response_chunk()` - called multiple times.
* `send_response_chunk_end()` - called once.
After streaming completes, Rasa will still call `send_text_message()` with the full response text. At this point, the channel can check the flag to skip sending the response twice.
#### Common Use Cases[](#common-use-cases "Direct link to Common Use Cases")
##### Accessing Conversation State[](#accessing-conversation-state "Direct link to Accessing Conversation State")
The `tracker_state` property contains comprehensive conversation data including slots, active flows, intents, custom actions called, and other state information.
This information can be used to enrich the responses of your channel.
##### Passing Metadata to Rasa[](#passing-metadata-to-rasa "Direct link to Passing Metadata to Rasa")
If you need to use extra information from your front end in your custom actions, you can pass this information using the `metadata` key of your user message. This information will accompany the user message through the Rasa server into the action server when applicable, where you can find it stored in the `tracker`. Message metadata will not directly affect NLU classification or action prediction.
tip
If you want to access the metadata which was sent with the user message that triggered the session start, you can access the special slot `session_started_metadata`. Read more about it in [action\_session\_start](https://rasa.com/docs/docs/reference/primitives/default-actions/#customization).
#### Credentials for Custom Channels[](#credentials-for-custom-channels "Direct link to Credentials for Custom Channels")
To use a custom channel, you need to supply credentials for it in a credentials configuration file called `credentials.yml`. This credentials file has to contain the **module path** (not the channel name) of your custom channel and any required configuration parameters.
For example, for a custom connector class called `MyIO` saved in a file `addons/custom_channel.py`, the module path would be `addons.custom_channel.MyIO`, and the credentials could look like:
credentials.yml
```
addons.custom_channel.MyIO:
username: "user_name"
another_parameter: "some value"
```
Example Configuration
For an example of configuring custom channels in credentials.yml, see the [credentials.yml](https://github.com/RasaHQ/rasa-calm-demo/blob/ac9a7ca9c574a3d5e6ba983b8f22654da59cc93d/credentials.yml#L58-L64) file in the rasa-calm-demo repository.
To make the Rasa server aware of your custom channel, specify the path to `credentials.yml` to the Rasa server at startup with the command line argument `--credentials` .
#### Testing the Custom Connector Webhook[](#testing-the-custom-connector-webhook "Direct link to Testing the Custom Connector Webhook")
To test your custom connector, you can `POST` messages to the webhook using a JSON body with the following format:
```
{
"sender": "test_user", // sender ID of the user sending the message
"message": "Hi there!",
"metadata": {} // optional, any extra info you want to add for processing in NLU or custom actions
}
```
For a locally running Rasa server, the curl request would look like this:
```
curl --request POST \
--url http://localhost:5005/webhooks/myio/webhook \
--header 'Content-Type: application/json' \
--data '{
"sender": "test_user",
"message": "Hi there!",
"metadata": {}
}'
```
---
#### Facebook Messenger
#### Facebook Setup[](#facebook-setup "Direct link to Facebook Setup")
You first need to set up a facebook page and app to get credentials to connect to Facebook Messenger. Once you have them you can add these to your `credentials.yml`.
##### Getting Credentials[](#getting-credentials "Direct link to Getting Credentials")
**How to get the Facebook credentials:** You need to set up a Facebook app and a page.
1. To create the app head over to [Facebook for Developers](https://developers.facebook.com/) and click on **My Apps** → **Add New App**.
2. Go onto the dashboard for the app and under **Products**, find the **Messenger** section and click **Set Up**. Scroll down to **Token Generation** and click on the link to create a new page for your app.
3. Create your page and select it in the dropdown menu for the **Token Generation**. The shown **Page Access Token** is the `page-access-token` needed later on.
4. Locate the **App Secret** in the app dashboard under **Settings** → **Basic**. This will be your `secret`.
5. Use the collected `secret` and `page-access-token` in your `credentials.yml`, and add a field called `verify` containing a string of your choice. Start `rasa run` with the `--credentials credentials.yml` option.
6. Set up a **Webhook** and select at least the **messaging** and **messaging\_postback** subscriptions. Insert your callback URL, which will look like `https://:/webhooks/facebook/webhook`, replacing the host and port with the appropriate values from your running Rasa server.
Insert the **Verify Token** which has to match the `verify` entry in your `credentials.yml`.
configure https
Facebook Messenger only forwards messages to endpoints via `https`, so take appropriate measures to add it to your setup. For local testing of your bot, see [Testing Channels on Your Local Machine](https://rasa.com/docs/docs/reference/channels/messaging-and-voice-channels/#testing-channels-on-your-local-machine).
For more detailed steps, visit the [Messenger docs](https://developers.facebook.com/docs/graph-api/webhooks).
##### Running On Facebook Messenger[](#running-on-facebook-messenger "Direct link to Running On Facebook Messenger")
Add the Facebook credentials to your `credentials.yml`:
```
facebook:
verify: "rasa-bot"
secret: "3e34709d01ea89032asdebfe5a74518"
page-access-token: "EAAbHPa7H9rEBAAuFk4Q3gPKbDedQnx4djJJ1JmQ7CAqO4iJKrQcNT0wtD"
```
Restart your Rasa server to make the new channel endpoint available for Facebook Messenger to send messages to.
#### Supported response attachments[](#supported-response-attachments "Direct link to Supported response attachments")
In addition to typical text, image, and custom responses, the Facebook Messenger channel supports the following additional response attachments:
* [Buttons](https://developers.facebook.com/docs/messenger-platform/send-messages/buttons) are structured the same as other Rasa buttons. Facebook API limits the amount of buttons you can sent in a message to 3. If more than 3 buttons are provided in a message, Rasa will ignore all provided buttons.
* [Quick Replies](https://developers.facebook.com/docs/messenger-platform/send-messages/quick-replies) provide a way to present a set of up to 13 buttons in-conversation that contain a title and optional image, and appear prominently above the composer. You can also use quick replies to request a person's email address or phone number.
```
utter_fb_quick_reply_example:
- text: Hello World!
quick_replies:
- title: Text quick reply
payload: /example_intent
- title: Image quick reply
payload: /example_intent
image_url: http://example.com/img/red.png
# below are Facebook provided quick replies
# the title and payload will be filled
# with the user's information from their profile
- content_type: user_email
title:
payload:
- content_type: user_phone_number
title:
payload:
```
note
Both Quick Reply and Button titles in Facebook Messenger have a character limit of 20. Titles longer than 20 characters will be truncated.
* [Elements](https://developers.facebook.com/docs/messenger-platform/send-messages/template/generic) provide a way to create a horizontally scrollable list up to 10 content elements that integrate buttons, images, and more alongside text a single message.
```
utter_fb_element_example:
- text: Hello World!
elements:
- title: Element Title 1
subtitle: Subtitles are supported
buttons: # note the button limit still applies here
- title: Example button A
payload: /example_intent
- title: Example button B
payload: /example_intent
- title: Example button C
payload: /example_intent
- title: Element Title 2
image_url: http://example.com/img/red.png
buttons:
- title: Example button D
payload: /example_intent
- title: Example button E
payload: /example_intent
- title: Example button F
payload: /example_intent
```
---
#### Genesys Cloud
New in 3.12
The Genesys Cloud connector is available from Rasa Pro 3.12
There are two ways to connect a Voice Assistant to Genesys Cloud:
* Using the built-in Genesys Channel to stream conversation audio from Genesys to your Rasa Assistant. This is a Voice-Stream channel connector. Steps for setting this up are described in section [Stream Conversation Audio From Genesys](#stream-conversation-audio-from-genesys)
* A Voice Ready channel connector can also be made using [Data Actions](https://help.mypurecloud.com/articles/about-genesys-cloud-data-actions-integration/) where transcription (speech-recognition) and speech-to-text is handled within Genesys Architect. Go to [Integration With Data Action](#integration-with-data-action) section for more details
#### Stream Conversation Audio From Genesys[](#stream-conversation-audio-from-genesys "Direct link to Stream Conversation Audio From Genesys")
Genesys Channel Connector allows you to stream conversation audio to your Voice Assistant from Genesys using AudioConnector Integration.
Before you begin, ensure:
* You have [AudioConnector Integration](https://help.mypurecloud.com/articles/audio-connector-overview/) available on your Genesys Account
* You have the required permissions for creating [Architect](https://help.mypurecloud.com/articles/architect-overview/) flows for Inbound or Outbound Calls
* You have permissions to create/modify Call Routing
##### Prepare Rasa Assistant[](#prepare-rasa-assistant "Direct link to Prepare Rasa Assistant")
Create a file `credentials.yml` at the root of Rasa assistant project and add Genesys channel configuration:
credentials.yml
```
# websocket_url: wss:///webhooks/genesys/websocket
genesys:
api_key: ""
client_secret: ""
server_url: ""
asr:
name: deepgram
tts:
name: cartesia
```
`wss` or `ws`?
Depending on your domain's TLS configuration, the WebSocket URL could be `ws://example.com` or `wss://example.com`.
Genesys channel configuration accepts the following properties:
* `api_key` (required): API Key configured on Genesys with AudioConnector integration. It is the value of `X-Api-Key` header.
* `server_url` (required): The domain at which Rasa server is available. Do not include protocol (ws:// or wss://). For example, if your server is deployed on `https://example.ngrok.app`, `server_url` should be `example.ngrok.app`.
* `asr` (required): Configuration for Automatic Speech Recognition. See [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/#automatic-speech-recognition-asr) for a list of ASR engines for which Rasa provides built-in integration with.
* `tts` (required): Configuration for Text-To-Speech. See [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/#text-to-speech-tts) for a list of TTS engines for which Rasa provides built-in integration with.
* `client_secret` (optional): Client Secret configured on Genesys with AudioConnector Integration. It is used to sign connection requests. It must be base-64 encoded. Signature verification is skipped if `client_secret` is not provided.
You can run the assistant using the command `rasa run`. You can also run it with a development inspector using `rasa run --inspect`. To see all available parameters, use `rasa run -h`.
##### Install AudioConnector Integration[](#install-audioconnector-integration "Direct link to Install AudioConnector Integration")
To install & configure AudioConnector Integration,
1. Go to **Integrations** Page, it should be listed on Genesys Cloud Admin Home.
2. Click "+ Integrations" button on the top right corner to install a new Integration.
3. Search for "AudioConnector" and install it. If you cannot find it, make sure that your Genesys Account has access to it. You might want to speak to your Genesys Account Manager or Customer Support if you have further issues.
4. Now that you have installed AudioConnector Integration, you can add an appropriate name and description. Go to the Configuration page to set a Base Connection URI to your Rasa Assistant, this would be the domain where your assistant is deployed.
The webhook URL will be in the format, (attention, with a trailing slash!)
* With TLS: `wss://example.com/webhooks/genesys/`
* Without TLS: `ws://example.com/webhooks/genesys/`
WebSocket URL
If the Rasa WebSocket URL is `wss:///webhooks/genesys/websocket`. In this documentation we split it into:
* Base URI: `wss:///webhooks/genesys/`
* Connector ID: `websocket`
However any other combination should also work just OK.
5. Advanced Tab can be left blank. In Credentials tab, create a credential with an API Key and an optional client secret.
6. Hit Save button and change the status of Integration to **Active**. You will not see the Integration on Architect if it is not active.
##### Create a Call Flow in Architect[](#create-a-call-flow-in-architect "Direct link to Create a Call Flow in Architect")
Once you have installed the AudioConnector Integration, you can use it in a Call Flow with Genesys Architect.
Create a new call flow in Architect. In this call flow, create a reusable task. This task should use "Call Audio Connector" action from Toolbox (Listed under "🤖 Bot"). Set the Connector ID to `websocket`
Ensure that the Reusable Task is connected to an option in the Main Menu. Once you are done, "Publish" the flow.
##### Set Call Routing[](#set-call-routing "Direct link to Set Call Routing")
If you have created an Inbound Call Flow in the previous step, then you will need to setup a Call Route to connect a Phone Number to this Call Flow.
1. Navigate to Admin Home > Routing > Call Routing.
2. Create a new Call Route or modify an existing one. Select Inbound numbers that you would like to activate for the flow.
Don't see any phone numbers?
In case you do not see any phone numbers, please reach out to a Genesys Expert within your organization or to Genesys Support. It could be possible that the DID numbers are not made available for Call Routing
3. In the section "What call flow should be used?" select the Architect flow that you created in the previous step.
Once you save the call route, you should be able to call the phone number to connect to the Architect flow you created. Using the options in the Main Menu, you can connect to your Rasa voice assistant.
##### Rate Limits[](#rate-limits "Direct link to Rate Limits")
Audio is sent to Genesys over WebSocket as binary messages. Genesys enforces rate limits on binary messages which could impact your assistant.
These rate limits are,
* The allowed average rate per second of inbound binary data (`global.inbound.binary.average.rate.per.second`): 5
* The maximum number of inbound binary data messages that can be sent instantaneously (`global.inbound.binary.max`): 25
You can read more about these rate limits on [Genesys Documentation](https://developer.genesys.cloud/organization/organization/limits#audiohook)
To avoid rate limit Errors, Rasa buffers the audio messages and sends them only if,
* Audio Buffer is more than 32KB
* Audio Synthesis is complete
While Designing Flows
Please keep in mind these rate limits when designing flows for a Rasa Voice Assistant. Avoid using two or more utterances consecutively in flows as these will be sent as multiple binary messages.
#### Call Metadata[](#call-metadata "Direct link to Call Metadata")
Metadata about the call can be accessed by the slot `session_started_metadata` in the beginning of the call. Following fields are available:
| Field Name | Description | Source |
| ------------ | --------------------------------------- | --------------------------------------------- |
| `call_id` | The unique call identifier from Genesys | `conversationId` parameter as sent by Genesys |
| `user_phone` | The phone number of the user | `ani` parameter, with `tel:` prefix removed |
| `bot_phone` | The phone number of the bot | `dnis` parameter as sent by Genesys |
A [custom `action_session_start`](https://rasa.com/docs/rasa-pro/nlu-based-assistants/default-actions#customization) can be used to store this information to a slot.
#### Integration With Data Action[](#integration-with-data-action "Direct link to Integration With Data Action")
A voice-ready channel connector with Genesys can also be created using Rasa's REST channel connector and using Genesys Data Actions. This requires more familiarity with Genesys Architect and Data Actions.
You can create a Call flow in Architect with a reusable-task that would:
* Capture caller's speech using Transcribe action.
* Send the transcribed text to Rasa using Call Data Action.
* Get the bot's response and play it back to the caller using Play Audio action.
These steps can be done in a loop based on the response of Rasa. Genesys also allows using 3rd Party services for Transcription (Speech-To-Text) and Text-To-Speech. You can read more about [Speech-To-Text Engines in Genesys here](https://help.mypurecloud.com/articles/about-speech-to-text-stt-engines/) and [Text-To-Speech Engines in Genesys here](https://help.mypurecloud.com/articles/about-text-to-speech-tts-engines/)
##### Prepare Rasa Assistant[](#prepare-rasa-assistant-1 "Direct link to Prepare Rasa Assistant")
Add the REST channel to your credentials.yml:
credentials.yml
```
# webhook URL: https:///webhooks/rest/webhook
rest:
# you don't need to provide anything here - this channel doesn't
# require any credentials
```
You can run the assistant using the command `rasa run`. You can also run it with a development inspector using `rasa run --inspect`. To see all available parameters, use `rasa run -h`.
You can test your Rasa server with a curl request,
```
curl -X POST \
http://localhost:5005/webhooks/rest/webhook \
-H 'Content-Type: application/json' \
-d '{
"sender": "unique-sender-id",
"message": "Hi bot, what can you do?"
}'
```
##### Create a Data Action[](#create-a-data-action "Direct link to Create a Data Action")
On Genesys, create a [Data Action](https://help.mypurecloud.com/articles/about-the-data-actions-integrations/). You will need to specifically create a [Web Services Data Action Integration](https://help.mypurecloud.com/articles/about-web-services-data-actions-integration/).
Ensure that the payload sent by the Data Action to Rasa is in the following format:
```
{
"sender": "",
"message": ""
}
```
The `sender` key must have a unique key to identify the conversation while `message` contains the result of Speech-To-Text component.
##### Disconnecting a Call[](#disconnecting-a-call "Direct link to Disconnecting a Call")
You cannot use a Data Action to perform actions on conversations, like disconnecting the call. [Genesys documentation specifies](https://help.mypurecloud.com/faqs/can-i-use-genesys-cloud-data-actions-to-perform-actions-on-conversations/) that "Only direct participants in a conversation, such as an agent or a customer, can modify the conversation using call controls."
You can, however, modify your Architect Call Flow to disconnect a call based on the response from Data Action.
---
#### Google Hangouts Chat
#### Hangouts Chat Setup[](#hangouts-chat-setup "Direct link to Hangouts Chat Setup")
This channel works similar to the standard Rasa REST channel. For each request from the channel, your bot will send one response. The response will be displayed to the user either as text or a so-called card (for more information, see the Cards section).
In order to connect your Rasa bot to Google Hangouts Chat, you first need to create a project in Google Developer Console that includes the Hangouts API. There you can specify your bot's endpoint. This endpoint should look like `https://:/webhooks/hangouts/webhook`, replacing the host and port with the appropriate values from your running Rasa server.
configure https
Hangouts Chat only forwards messages to endpoints via `https`, so take appropriate measures to add it to your setup. For local testing of your bot, see [Testing Channels on Your Local Machine](https://rasa.com/docs/docs/reference/channels/messaging-and-voice-channels/#testing-channels-on-your-local-machine).
In the Google Developer console, obtain your project id (also known as project number or app ID), which determines the scope for the OAuth2 authorization in case you want to use OAuth2. The Hangouts Chat API sends a Bearer token with every request, but it is up to the bot to actually verify the token, hence the channel also works without this. For more information see the [Google Hangouts documentation](https://developers.google.com/hangouts/chat). If you want the verification to be done, be sure to include `project_id` inside your `credentials.yml` file as shown below.
The possibility to implement asynchronous communication between Hangouts Chat and bot exists, but due to the usually synchronous nature of Rasa bots, this functionality is not included in this channel.
##### Running On Hangouts Chat[](#running-on-hangouts-chat "Direct link to Running On Hangouts Chat")
Add the Hangouts credentials to your `credentials.yml`:
```
hangouts:
# no credentials required here
```
If you want to use OAuth2, add the project id obtained from the Google Developer Console:
```
hangouts:
project_id: "12345678901"
```
Restart your Rasa server to make the new channel endpoint available for Google Hangouts to send messages to.
##### Cards and Interactive Cards[](#cards-and-interactive-cards "Direct link to Cards and Interactive Cards")
There are two ways in which Hangouts Chat will display bot messages, either as text or card. For each received request, your bot will send all messages in one response. If one of those messages is a card (e.g. an image), all other messages are converted to card format as well.
Interactive cards trigger the `CARD_CLICKED` event for user interactions, e.g. when a button is clicked. When creating an interactive card, e.g. via `dispatcher.utter_button_message()` in your `actions.py`, you can specify a payload for each button that is going to be returned with the `CARD_CLICKED` event and extracted by the `HangoutsInput` channel (for example `buttons=[{"text":"Yes!", "payload":"/affirm"}, {"text":"Nope.", "payload":"/deny"}])`. Updating cards is not yet supported.
For more detailed information on cards, visit the [Hangouts docs](https://developers.google.com/hangouts/chat/reference).
##### Other Hangouts Chat Events[](#other-hangouts-chat-events "Direct link to Other Hangouts Chat Events")
Except for `MESSAGE` and `CARD_CLICKED`, Hangouts Chat knows two other event types, `ADDED_TO_SPACE` and `REMOVED_FROM_SPACE`, which are triggered when your bot is added or removed from a direct message or chat room space. The default intent names for these events can be modified in the `HangoutsInput` constructor method.
---
#### Jambonz as Voice Gateway
New in 3.11
The Jambonz connector has been made generally available in Rasa Pro 3.11. It was released as a beta feature in Rasa Pro 3.10.
Use this channel to connect your Rasa assistant to [Jambonz](https://www.jambonz.org/). Jambonz is a Voice Gateway that can interface with various customer support platforms like Genesys, Avaya, and Twilio using SIP.
#### Basic Rasa configuration[](#basic-rasa-configuration "Direct link to Basic Rasa configuration")
Create or edit your `credentials.yml` and add a new channel configuration:
credentials.yml
```
jambonz:
# Basic Authentication
username: ""
password: ""
```
Basic Authentication
Support for `username` and `password` parameters is only available on Rasa Pro 3.11.8+, Rasa Pro 3.12.7+ and later releases.
Jambonz channel can be secured by Basic Authentication with these parameters:
* `username` (optional): Basic authentication username for Jambonz channel.
* `password` (optional): Basic authentication password for Jambonz channel.
You can run that assistant using `rasa run`. To configure the Jambonz channel, you will need a URL to your Rasa assistant. You can use a tunneling solution like [ngrok](https://ngrok.com/) to expose your assistant for development.
Bot URLs for development
Visit this [section](https://rasa.com/docs/docs/reference/channels/messaging-and-voice-channels/#testing-channels-on-your-local-machine) to learn how to generate the required bot URL when testing the channel on your local machine.
#### Configuring Jambonz[](#configuring-jambonz "Direct link to Configuring Jambonz")
To route calls to your Rasa assistant, you need to have a Jambonz deployment, an account and a phone number.
1. Sign up for [Jambonz cloud](https://jambonz.cloud/) or use your own on-premise deployment.
2. Once logged in, create a *Carrier* which will provide your phone number (e.g. twilio).
3. Create an *Application*. To route calls to your assistant, Jambonz needs a webhook URL. You'll either need to deploy your assistant to a server and expose it to Jambonz or for development use a tunneling solution like [ngrok](https://ngrok.com/).
The webhook URL will be in the format `wss:///webhooks/jambonz/websocket`
or in the case of ngrok look like this: `wss://recently-communal-duckling.ngrok-free.app/webhooks/jambonz/websocket`
4. If your channel is secured by Basic Authentication in the above step, then select "Use HTTP basic authentication" and fill Username, Password fields.
5. Set up a "Phone Number". The configuration of the phone number should point to the application you created in the previous step.
#### Usage[](#usage "Direct link to Usage")
##### Receiving messages from a user[](#receiving-messages-from-a-user "Direct link to Receiving messages from a user")
When a user speaks on the phone, Jambonz will send a text message (after it is processed by the speech-to-text engine) to your assistant like any other channel. This message will be interpreted by Rasa and you can then drive the conversation with flows.
##### Sending messages to a user[](#sending-messages-to-a-user "Direct link to Sending messages to a user")
Your bot will respond with text messages like with any other channel. The text-to-speech engine will convert the text and deliver it as a voice message to the user.
Here is an example:
```
utter_greet:
- text: "Hello! isn’t every life and every work beautiful?"
```
note
Only text messages are allowed. Images, attachments, and buttons cannot be used with a voice channel.
##### Handling conversation events[](#handling-conversation-events "Direct link to Handling conversation events")
New in 3.11
We have unified the call handling patterns across Voice Channel Connectors, all voice channels handle call starts, ends and metadata in a similar manner.
Non-voice events can also be handled by the bot. Here are a few examples:
| Event | intent | Description |
| ------- | --------------- | -------------------------------------------------------------------------------------------------------------------------------------------------- |
| `start` | `session_start` | Jambonz will send this intent when it picks-up a phone call. By default, this intent triggers the `pattern_session_start` which you can customize. |
| `end` | `session_end` | Jambonz will send this intent when the call is disconnected by the user. |
| `DTMF` | - | Jambonz will send DTMF (numbers on the phone pressed by a user ) as normal text messages with confidence 1.0. |
Here is a simple modification of the default session start to greet the user with an utterance:
```
flows:
pattern_session_start:
description: flow used to start the conversation
name: pattern session start
nlu_trigger:
- intent: session_start
steps:
- action: utter_greet
```
---
#### Jambonz Voice Stream Channel
New in 3.13
From Rasa Pro 3.13, you can stream conversation audio directly from Jambonz to your Rasa Assistant.
This channel is a voice-stream channel connector to Jambonz where the conversation audio is streamed directly to Rasa. Rasa also offers a voice-ready channel connector with Jambonz, read about it on [Jambonz as Voice Gateway](https://rasa.com/docs/docs/reference/channels/jambonz/).
#### Configure Rasa Assistant[](#configure-rasa-assistant "Direct link to Configure Rasa Assistant")
Use the built-in channel `jambonz_stream` to configure your Rasa Assistant. Create or edit the `credentials.yml` file at the root of your assistant directory to add `jambonz_stream` channel. Here's an example:
credentials.yml
```
jambonz_stream:
server_url: ""
asr:
name: deepgram
tts:
name: cartesia
# Optional configurations
username: ""
password: ""
```
The channel configuration accepts the following properties:
* `server_url` (required): The domain at which Rasa server is available. Do not include protocol (ws:// or wss://). For example, if your server is deployed on `https://example.ngrok.app`, `server_url` should be `example.ngrok.app`.
* `asr` (required): Configuration for Automatic Speech Recognition. See [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/#automatic-speech-recognition-asr) for a list of ASR engines for which Rasa provides built-in integration with.
* `tts` (required): Configuration for Text-To-Speech. See [Speech Integrations](https://rasa.com/docs/docs/reference/integrations/speech-integrations/#text-to-speech-tts) for a list of TTS engines for which Rasa provides built-in integration with.
* `username` (optional): Basic authentication username for Jambonz Stream channel.
* `password` (optional): Basic authentication password for Jambonz Stream channel.
* `interruptions` (optional): Configuration for interruption handling. This allows the assistant to detect when users interrupt while the assistant is speaking and respond more naturally. See [Interruption Handling](https://rasa.com/docs/docs/reference/primitives/patterns/#interruption-handling) for more information.
You can run the assistant using the command `rasa run`. You'll need a URL accessible by Jambonz for your Rasa assistant. For development, you can use tools like [ngrok](https://ngrok.com/) or [Cloudflare Tunnel](https://developers.cloudflare.com/cloudflare-one/connections/connect-networks/).
You can also run it with a development inspector using `rasa run --inspect`. To see all available parameters for this command, use `rasa run -h`.
Bot URLs for development
Visit this [section](https://rasa.com/docs/docs/reference/channels/messaging-and-voice-channels/#testing-channels-on-your-local-machine) to learn how to generate the required bot URL when testing the channel on your local machine.
#### Configuration on Jambonz[](#configuration-on-jambonz "Direct link to Configuration on Jambonz")
This channel connector uses Jambonz Voice Streaming API. You'll need a Jambonz deployment, an account, and a phone number to route calls to your Rasa assistant.
##### Prerequisites[](#prerequisites "Direct link to Prerequisites")
Before you begin, ensure:
* You have access to [Jambonz Cloud](https://jambonz.cloud/) or your own on-premise deployment
* You have the required permissions for creating applications and phone number configurations
* You have a carrier configured that provides your phone number (e.g., Twilio)
##### Setup Steps[](#setup-steps "Direct link to Setup Steps")
1. **Create an Application**
Log into your Jambonz console and create a new application. Depending on your domain, the webhook URL will be with method POST,
```
https:///webhooks/jambonz_stream/webhook
```
For development with ngrok, it would look like:
```
https://recently-communal-duckling.ngrok-free.app/webhooks/jambonz_stream/webhook
```
2. **Configure Basic Authentication (Optional)**
If your Rasa channel is secured with basic authentication, select "Use HTTP basic authentication" in the application configuration and provide the username and password that match your Rasa credentials.
3. **Set up Phone Number**
Configure a phone number in Jambonz and point it to the application you created in the previous step. This phone number will be used to receive calls that will be routed to your Rasa assistant.
4. **Configure Call Status Webhook (Optional)**
For additional call monitoring, you can configure a call status webhook URL:
```
https://