Introduction to Rasa X/Enterprise
Rasa X/Enterprise License
You'll need a license to get started with Rasa X/Enterprise. Talk with Sales
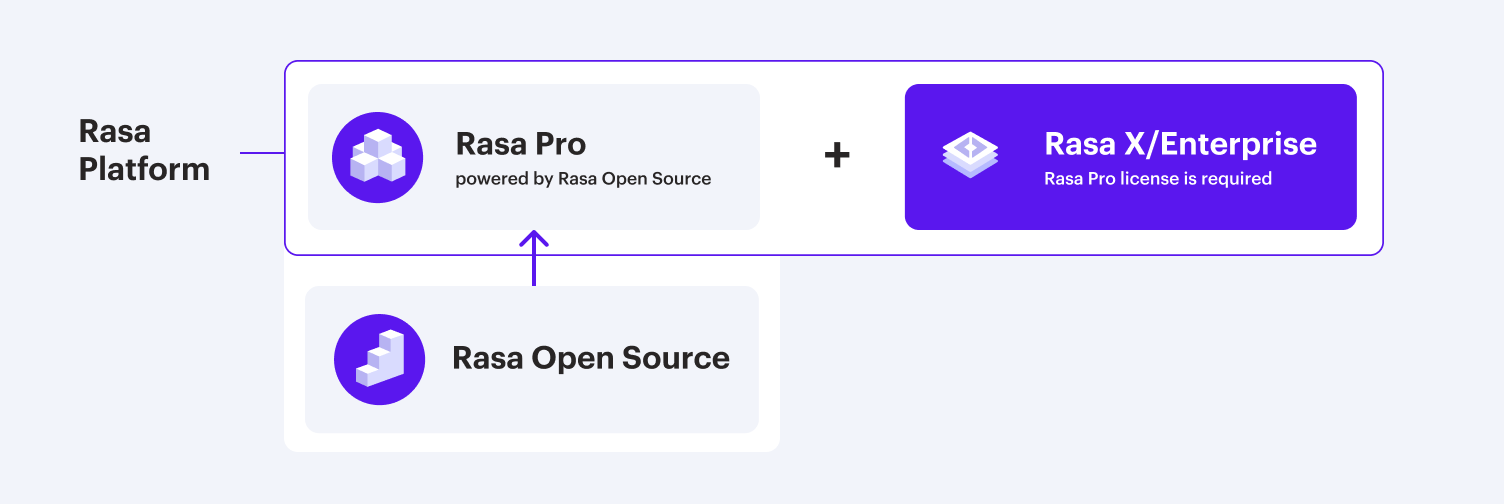
Rasa X/Enterprise is a low-code user interface built for multidisciplinary conversational AI teams working together to assess and improve AI Assistant performance at enterprise scale. In addition to an advanced annotation capabilities for conversation review, Rasa X/Enterprise gives your team the ability to manage content, share, and test the bot for continuous improvement.
Rasa X/Enterprise is a part of our enterprise solution, Rasa Platform. Another product that makes up of Rasa Platform is Rasa Pro. To learn more about Rasa Pro, see the Rasa Pro documentation.
In order to use Rasa X/Enterprise, you will need to also have a license for Rasa Pro to make sure you can take advantage of all enterprise capabilities. Customers running Rasa X/Enterprise with Rasa Open Source are encouraged to migrate or upgrade to Rasa Pro.