Annotate NLU Examples
Improving your NLU model based on messages from real conversations is a crucial piece of building an assistant that can handle real users. Coming up with examples yourself can help you bootstrap at the beginning of a project, but when you’re going into production, less than 10% of your data should be synthetic.
In preparing for production, you should have already shared your bot with guest testers or other internal users. Looking through the messages from guest testers is key to building out your own examples to correctly respond to users who don’t know the inner workings of your assistant and what it can do.
Once your assistant is in production, annotating incoming messages can have an even bigger impact on your assistant’s success, as the messages are from actual end users. Annotating these users’ messages is a great way to understand your bot’s successes and failures and add data that reflects what real users say to your assistant.
Improving NLU performance using Rasa Enterprise
Rasa Enterprise provides you with insights on how to improve your NLU training data. It looks at the results of a cross-validation, the messages in your NLU inbox, and other metrics to calculate these insights. Rasa Enterprise presents the insights found together with suggestions on how to address them in the insights screen:
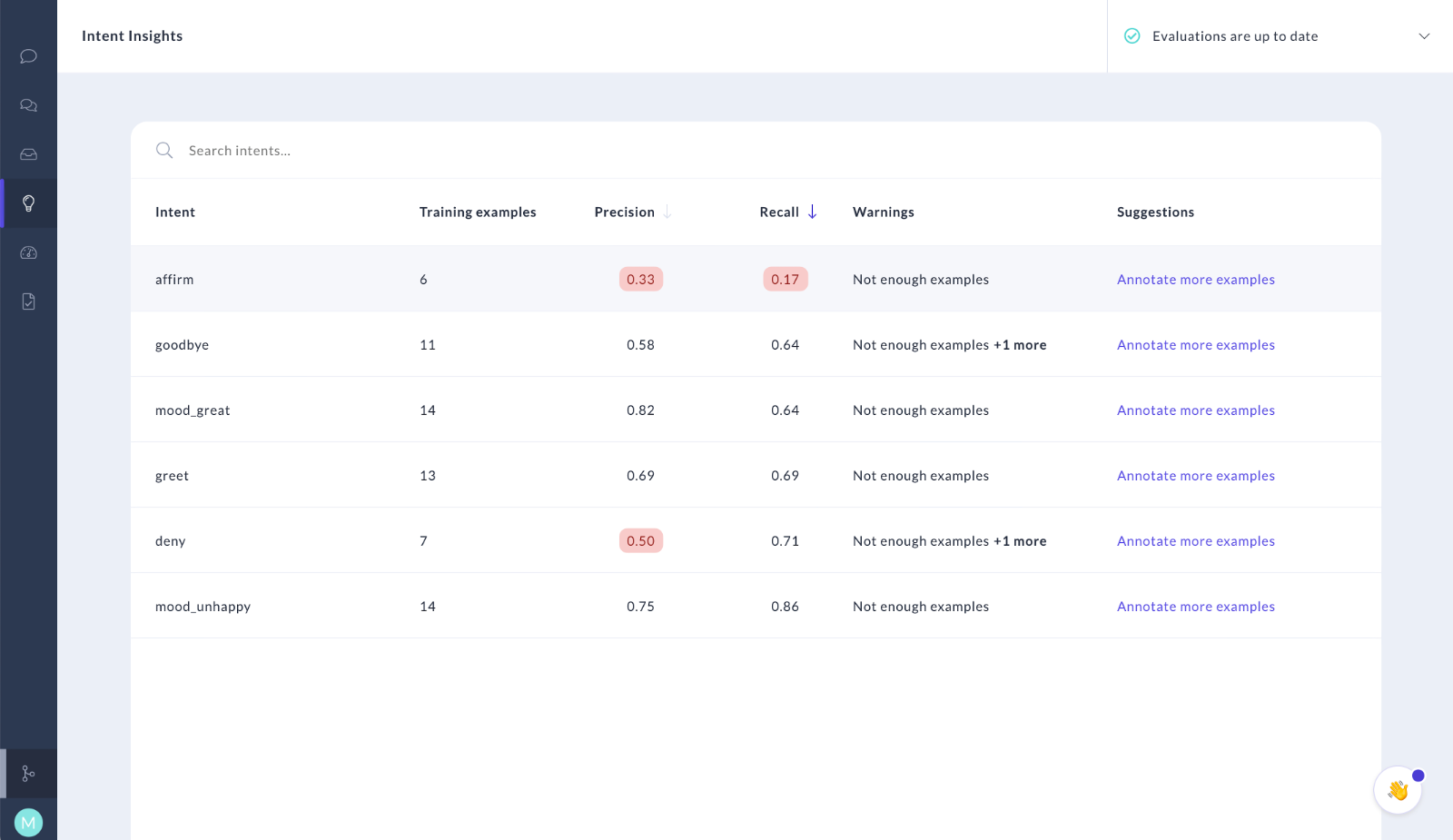
The insights can be used to help you practice Conversation-Driven Development. Use can use insights to:
- Decide how to best invest your time when annotating NLU messages
- Understand the impact of changes to your NLU training data
Changing the Schedule
Rasa Enterprise uses the results of a cross-validation,
among other things, to identify problems in your training data.
Depending on the amount of NLU training data you have, cross-validation can take several hours.
For a rough estimation of how long cross validation will take, you can take the average training time
of your model and multiply it by the used fold for cross-validation.
By default, the used fold is 4, which means Rasa Enterprise will train 4 models on 80 % of the
training data and evaluate it against the remaining 20 %.
Performance Implications
Rasa Enterprise will use rasa-worker to run the cross-validation so that the computationally
intense process will not impact production server performance. Note that ongoing
cross-validations might still affect model trainings which were triggered via the
Rasa Enterprise UI or API.
Run the insight calculation at night so that you have the latest results available the next day. By default, Rasa Enterprise will run the evaluation every day at 2am. If you want to deactivate intent insights or use a different time for the insight calculation, you can adjust the schedule in the insights screen:
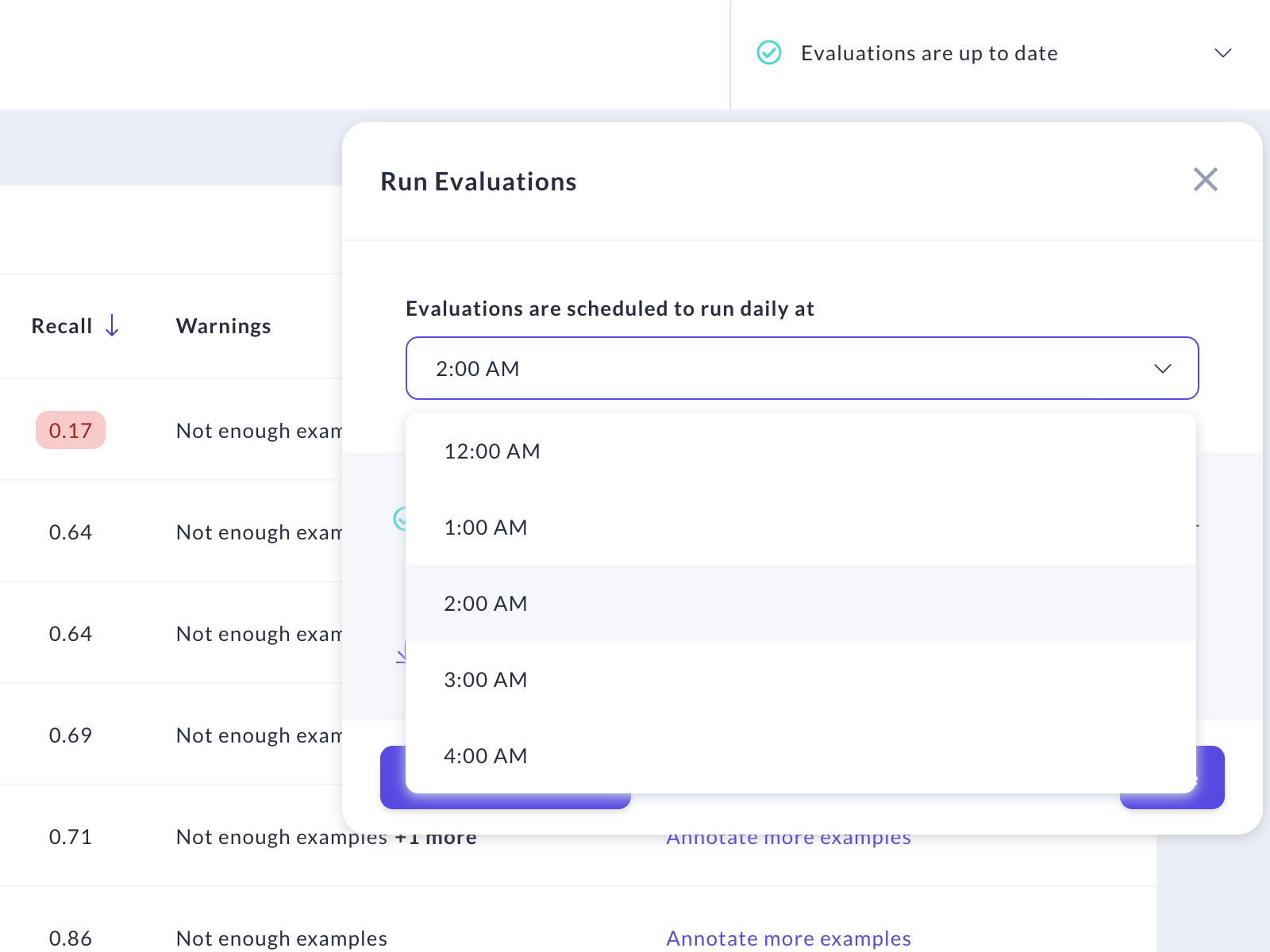
You can disable the scheduled runs by setting schedule to null
via this endpoint.
Insight Calculators
Configuration
The insight calculation uses the following calculators to calculate the insights. You can update the used calculators and their parameters via this endpoint.
For example, to set the MinimumExampleInsightCalculator to create
insights for every intent which has less than 100 examples, send the following request
(all other calculators will keep their default configuration):
To reset the calculator_configuration to the default settings, set
calculator_configuration to null:
note
Rasa Enterprise currently only calculates insights for intents and retrieval intents. Entities are not considered.
Available Calculators
MinimumExampleInsightCalculator
- Name:
MinimumExampleInsightCalculator - Description: Makes sure that each intent has at least the minimum required number of examples.
- Parameters:
required_number_of_examples_per_intent(default:20): Each intent has to have at least this number of examples. Otherwise, a new insight is created.
ConfusionInsightCalculator
- Name:
ConfusionInsightCalculator - Description: Checks if an intent is confused often. This can for example happen if the examples of two intents are too similar.
- Parameters:
top_x_percent_threshold(default:1.0): Only return new insights for intents with thetop_x_percent_thresholdpercent confusions.recall_threshold(default:0.85): An insight is only created if the recall for the intent is lower than this threshold. This avoids raising errors for intents which are confused because of a high bias.
ClassBiasInsightCalculator
- Name:
ClassBiasInsightCalculator - Description: Checks for intents which are which are predicted disproportionately often. This for example happens when there is a bias for this intent (e.g. because it has much more training data than other intents).
- Parameters:
maximal_precision(default:0.4): Only create insight if intent has precision lower than the given threshold. A low precision and high recall indicate that the intent is predicted often although it's actually a different one.minimum_recall(default:0.8): Only create insight if recall for intent is greater than recall threshold. Ifrecallis high, it's an indicator that the intent might be selected too often.
WrongAnnotationInsightCalculator
- Name:
WrongAnnotationInsightCalculator - Description: Checks for intents which are diluted by wrongly annotated training data.
- Parameters:
confidence_threshold(default:0.9): Only create insights if an intent is wrongly predicted with a confidence greater than threshold. If confidence is low, the model is probably not confident in general. If the confidence is high, it means that the model learned this (wrong) behavior somewhere.top_x_percent_threshold(default:0.1): Only return new insights for intents with thetop_x_percent_thresholdpercent of wrong annotations.
NLUInboxConfidenceInsightCalculator
- Name:
NLUInboxConfidenceInsightCalculator - Description: Searches the NLU Inbox for user message predictions with low confidence.
- Parameters:
lower_confidence_threshold(default:0.3): Only look for messages with confidences greater than or equal to the threshold. Avoids creating an insight for an intent if the model was very insecure as the top intent is most likely random in this case.upper_confidence_threshold(default:0.8): Only look for messages with confidence scores smaller than or equal to the threshold. Avoids creating an insight for messages which are classified with high confidence (could either be right prediction or bias for this intent).only_classifications_by_active_model(default:True): Only consider predictions which were performed by the currently active model.minimal_timestamp(default:0): Only look at message predictions which were done after the unix timestampminimal_timestamp.top_x_percent_threshold(default:0.1): Only return new insights for intents with thetop_x_percent_thresholdpercent of messages with low confidence.
Configuring the Cross-Validation Folds
By default, Rasa Enterprise will use a 4-fold cross-validation to analyze the quality of your training data. You can configure a different threshold via this endpoint.
Accessing the Cross-Validation Results
Rasa Enterprise uses the cross-validation results among other data points to calculate insights for your NLU data. If you want to access the raw cross-validation results with all details, you can use this endpoint to retrieve the result.
Intent Warnings and Suggestions
The NLU insights screen also shows you warnings and suggestions of how your training data can be improved. The warnings come from insight calculators which means the data you see there depends on the configuration. There might be more than one warning, and to see all of them you need to hover your mouse over the text in the "Warnings" column for a specific intent.
The "Suggestions" column always contains a link to the specific intent on NLU Inbox screen. Use this link to annotate your training data, and then re-run the evaluation process to see the updated list of suggestions.
By using the NLU Inbox and the NLU insights screens in combination, you can improve your NLU model and make sure potential problems with intent classification are addressed as soon as possible.
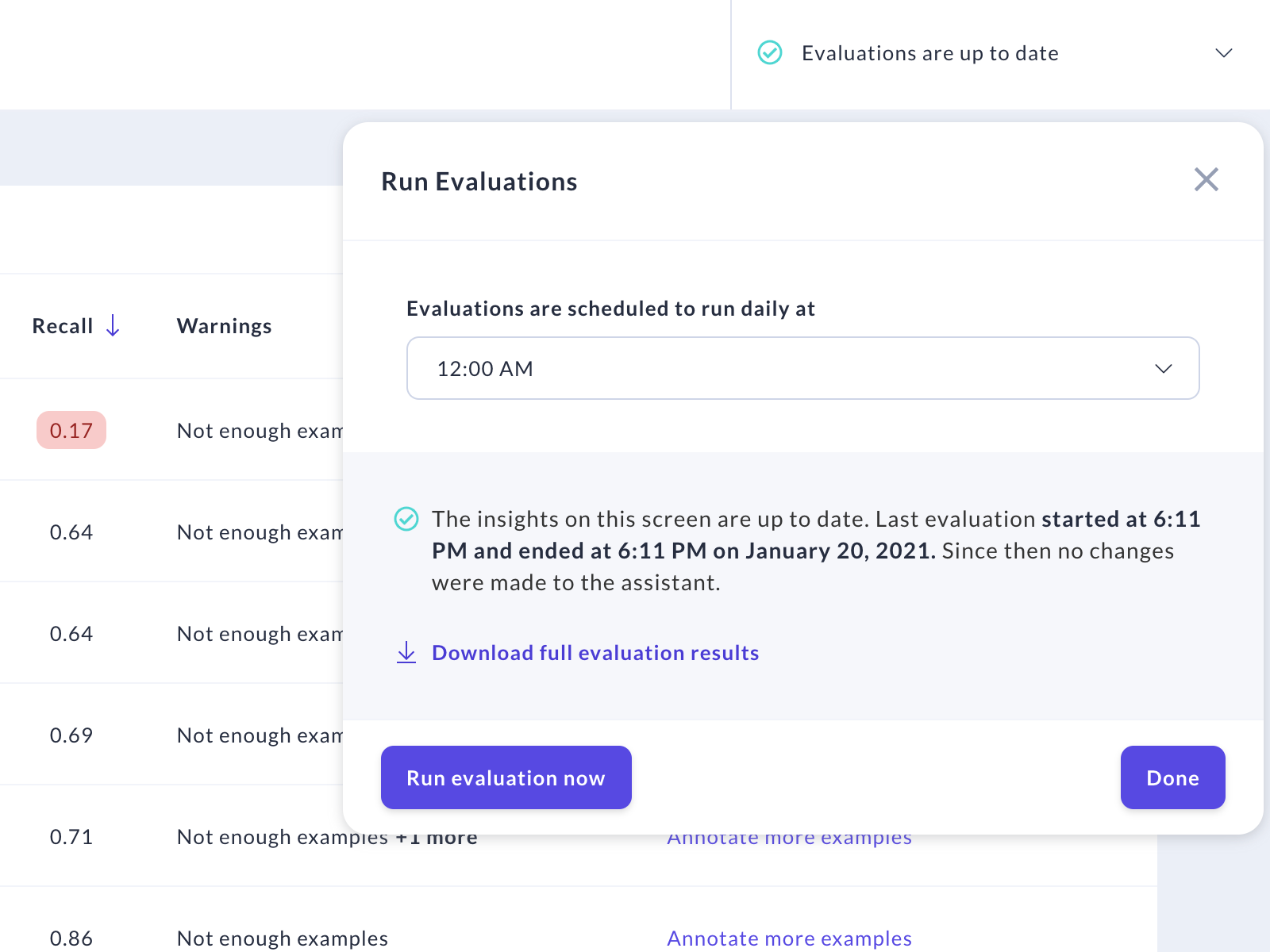
Downloading the NLU insights report
You can download the JSON report containing the results of the latest NLU insights evaluation. This report can be used to compare performance over time and to see more detailed results. To get it, click on the "Download full evaluation results" link in the "Run evaluations" popup:
You can also download intent insights reports manually or automatically using the API. Here is the endpoint you can use to get all the latest evaluations without any detailed information about them:
You can then use this endpoint to get the Rasa Open Source cross-validation results by evaluation ID:
The response you'll get will be equivalent to the one you can get by clicking the "Download full evaluation results" link.
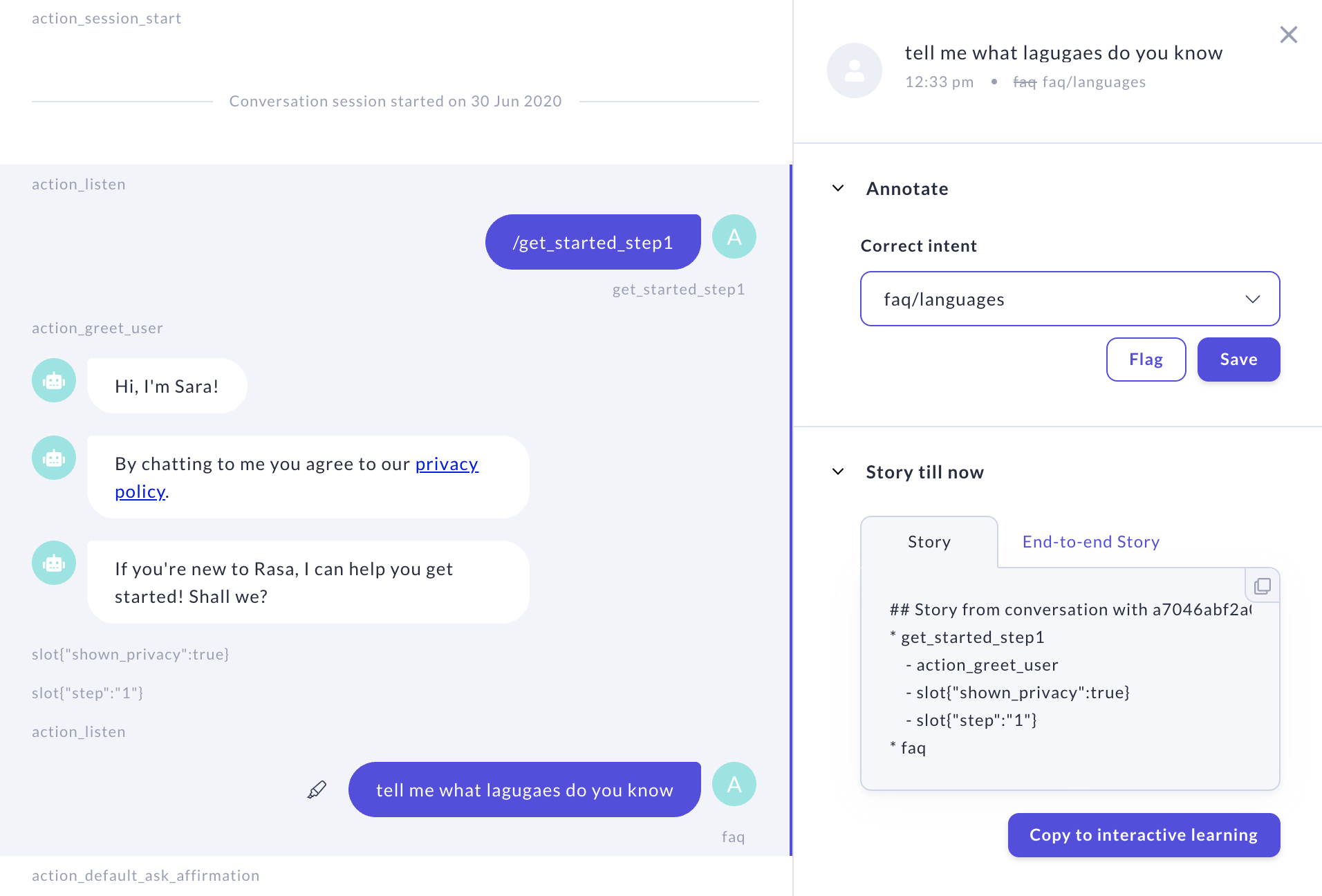
Annotating in the NLU Inbox
The NLU Inbox is a collection of all of the messages users have sent that aren’t already part of your training data. Whenever you get new messages, a badge in the sidebar will indicate that you have new data to process. Processing this inbox is the fastest way to improve your assistant’s NLU model.
Annotating User Messages
As messages from users come in, they will appear in the NLU inbox alongside the predicted intent and confidence of the prediction. Hovering over any entry brings up the Mark Correct and Delete icons. If a message’s prediction is correct, you can save it to your training data directly by selecting Mark Correct.

If the predicted intent is incorrect, select a different intent from the drop-down menu. If necessary, you can create a new intent by scrolling to Create new intent in the drop-down. Save the new prediction with the Mark Correct button.
If for some reason you do not want a user’s message saved to your training data (for example, you may not want to save personally identifiable information (PII) into your dataset), use the Delete button to remove the entry from the inbox.
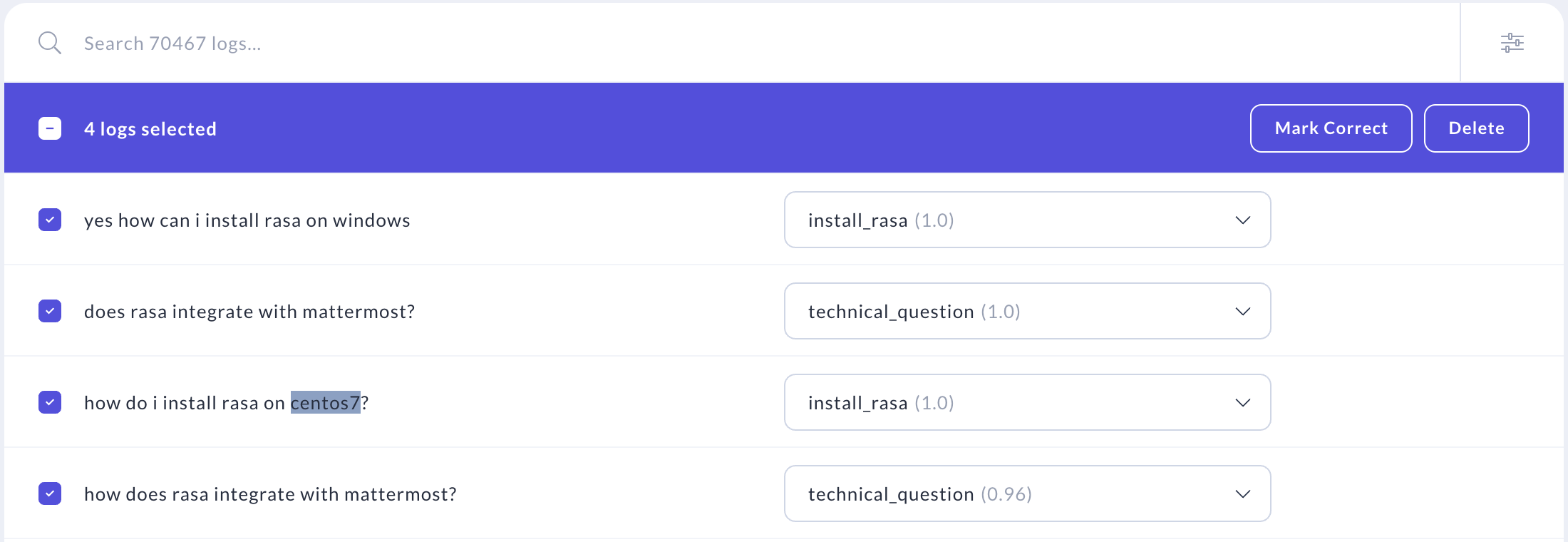
Annotating in Bulk
Once you are comfortable annotating NLU data by correcting predictions and marking correct ones, you can speed up your annotation workflow by making use of some helpful features:
Keyboard Shortcuts
The NLU Inbox is supported by keyboard shortcuts which help you save and delete messages
with less clicking. To select the initial message, push the j key. You can then
use the following keyboard shortcuts to interact with the NLU Inbox:
j: select the next messagek: select the previous messages: save the selected message (mark correct)d: delete the selected message
Bulk Actions
You can also use the select boxes next to each message to bulk annotate messages. To do so, select multiple messages that you would like to mark correct or delete. A header will appear that shows you how many messages you have selected and has buttons for bulk actions. Click either of the purple buttons in the header bar to mark all of your selections as correct or delete them.
Annotating in Conversations
While you’re reviewing conversations or fixing problems, you may notice an incorrect NLU prediction in a conversation. Instead of finding and fixing that prediction in the NLU Inbox, you can annotate it directly from the conversations page.
Select the incorrectly predicted message to bring up the annotation pane on the right-hand side. You’ll see a drop-down menu similar to the one in the NLU Inbox where the predicted intent is selected. Choose the correct intent from the drop-down and push the Save button to correct the intent.