Analytics
The Analytics Pipeline in Rasa streams conversation data from your deployed assistant to a data warehouse of your choice. By default, Rasa connects to your production assistant via Kafka and forwards any conversation events—user messages, commands from the LLM prompt, flow status updates, actions triggered, etc.—to a database. From there, you can hook up a Business Intelligence (BI) tool, data warehouse, or data-processing framework to visualize and process your conversation metrics.
Why No Out-of-the-Box Dashboards?
Rasa aims to be flexible enough to support an extensive range of use cases. Since every assistant has different requirements, business goals, and domain-specific metrics (e.g. drop-off rates in a financial flow vs. average handle time in a customer support flow), providing universal, out-of-the-box dashboards is rarely sufficient. Instead, Rasa outputs complete raw conversation data to your system of choice so you can build dashboards, analytics, and monitoring pipelines that best match your organization’s needs.
Some of the benefits of this approach:
- Full control of your data: You can choose a preferred data lake or warehouse solution (e.g. PostgreSQL, Redshift, BigQuery, Snowflake) and how to store, transform, or query events.
- Flexible analytics: You decide how to aggregate, slice, or visualize the data. Integrate with any BI tool, from open-source Metabase to enterprise-grade Tableau or Power BI.
- Customizable KPIs: You can easily blend conversation metrics with business data to track outcomes relevant to your specific domain (e.g. lead conversions, purchase completions, chat escalation reasons, etc.).
Installation Prerequisites
-
A Kafka Instance
Rasa Pro Services require a production-ready Kafka broker to stream real-time conversation data. Kafka is where all conversation events get published (e.g. user messages, commands from the LLM prompt). We recommend using a managed service such as Amazon MSK to simplify maintenance and scaling.
-
Rasa Pro Services
You need to deploy Rasa Pro Services alongside (or as part of) your assistant’s infrastructure. Rasa Pro Services handle the ingestion of events from Kafka and can transform them before streaming them to your configured data warehouse. Once set up, you can start computing analytics as soon as Rasa Pro Services connect successfully to Kafka and your data storage.
-
(Optional) A Data Warehouse
By default, you can configure Rasa to store raw conversation data in PostgreSQL or Redshift. If you prefer other warehousing solutions such as BigQuery or Snowflake, you can sync them via intermediate steps (e.g. streaming from PostgreSQL into Snowflake). This stage is optional in a local/testing setup but strongly recommended for production.
What Can You Track with Analytics?
Once your assistant is streaming events to the Analytics Pipeline, you can capture many types of conversation data. You can categorize these into four broad areas:
-
User Analytics
Identify who your assistant’s users are and how they feel about the assistant.
- Examples: user demographics, session frequency per user, feedback/sentiment
-
Usage Analytics
Discover overall traffic and assistant health.
- Examples: total number of sessions, average session duration, error rates, active channels
-
Conversation Analytics
Gain insights into how dialogues unfold.
- Examples: top flows triggered (in CALM-based assistants), top NLU intents (in NLU-based assistants), average number of turns, drop-off at specific flow steps, escalation or human-handoff patterns
-
Business Analytics
Measure how the assistant performs against business-critical objectives.
- Examples: ROI per line of business, containment rate (how many conversations were fully automated vs. handed to a human), interruption rates, success rates on business flows
In short, you can use these analytics to continuously refine and monitor your assistant’s behavior. For example, you might track how frequently users trigger a specific flow, whether that flow gets interrupted, how often those interruptions lead to a fallback pattern or a brand-new flow, or how many interactions escalate to a human agent.
Example Queries
This section helps you get started with analyzing your assistant's conversations. The examples use SQL queries together with an example visualization in Metabase.
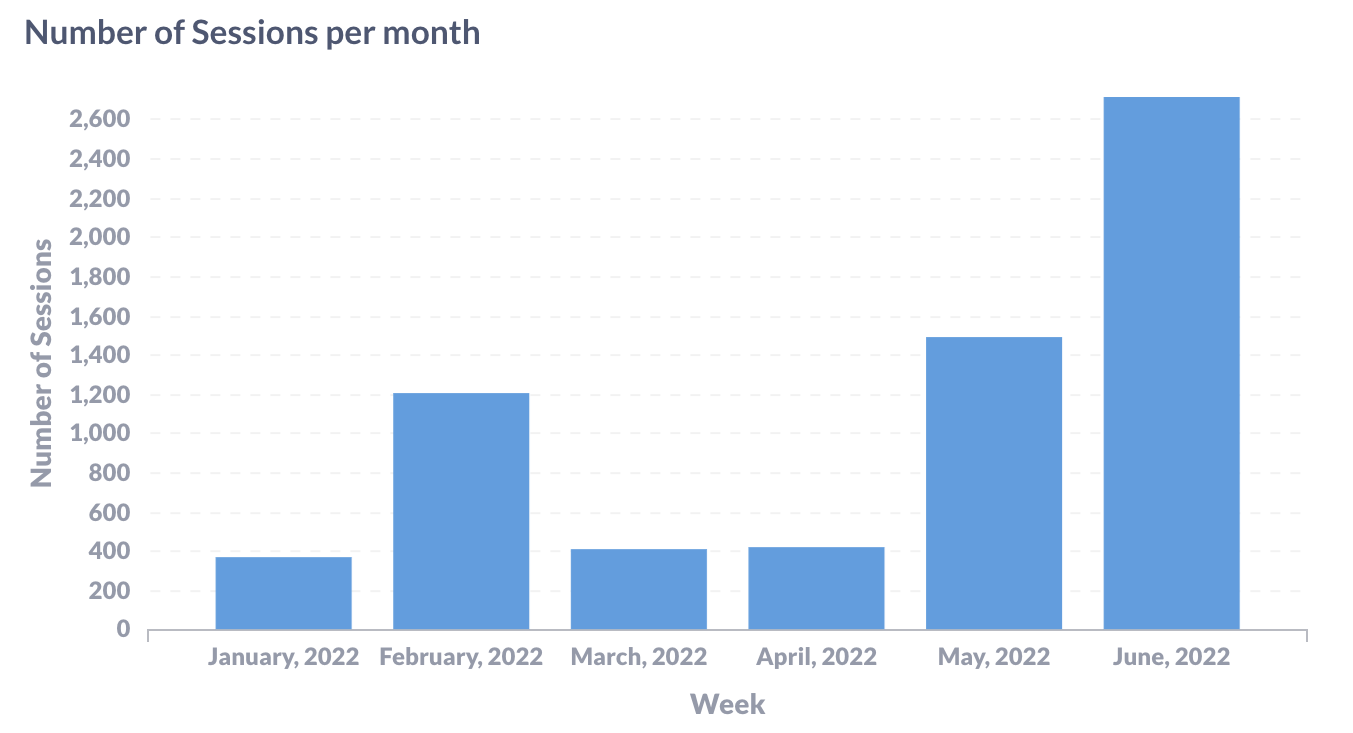
Number of Sessions per Month
A common high-level usage metric of your assistant is the number of sessions per month. Here is how it would look as an SQL query:
SELECT
date_trunc('month', "public"."rasa_session"."timestamp") AS "first_seen",
count(*) AS "count"
FROM "public"."rasa_session"
GROUP BY 1
ORDER BY 1 ASC
Number of Sessions per Channel
If you're connecting your assistant to multiple channels, it could be useful to look at the number of sessions per channel, let's say per week. The query you would need for this metric is:
SELECT
"public"."rasa_sender"."channel" AS "channel",
"public"."rasa_sender"."first_seen" AS "timestamp",
count(distinct "public"."rasa_sender"."sender_key") AS "count"
FROM "public"."rasa_sender"
GROUP BY 1, 2
ORDER BY 1 ASC, 2 ASC
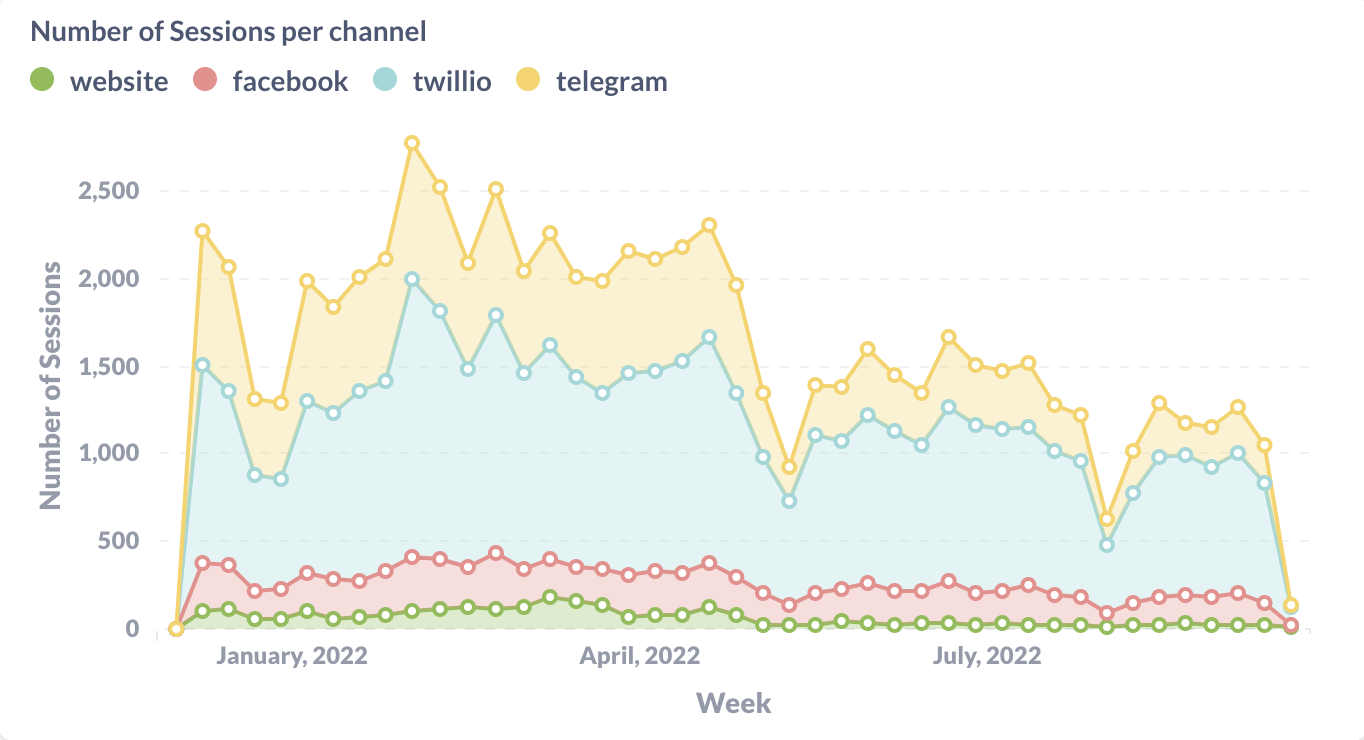
The number of sessions per channel as visualized in Metabase.
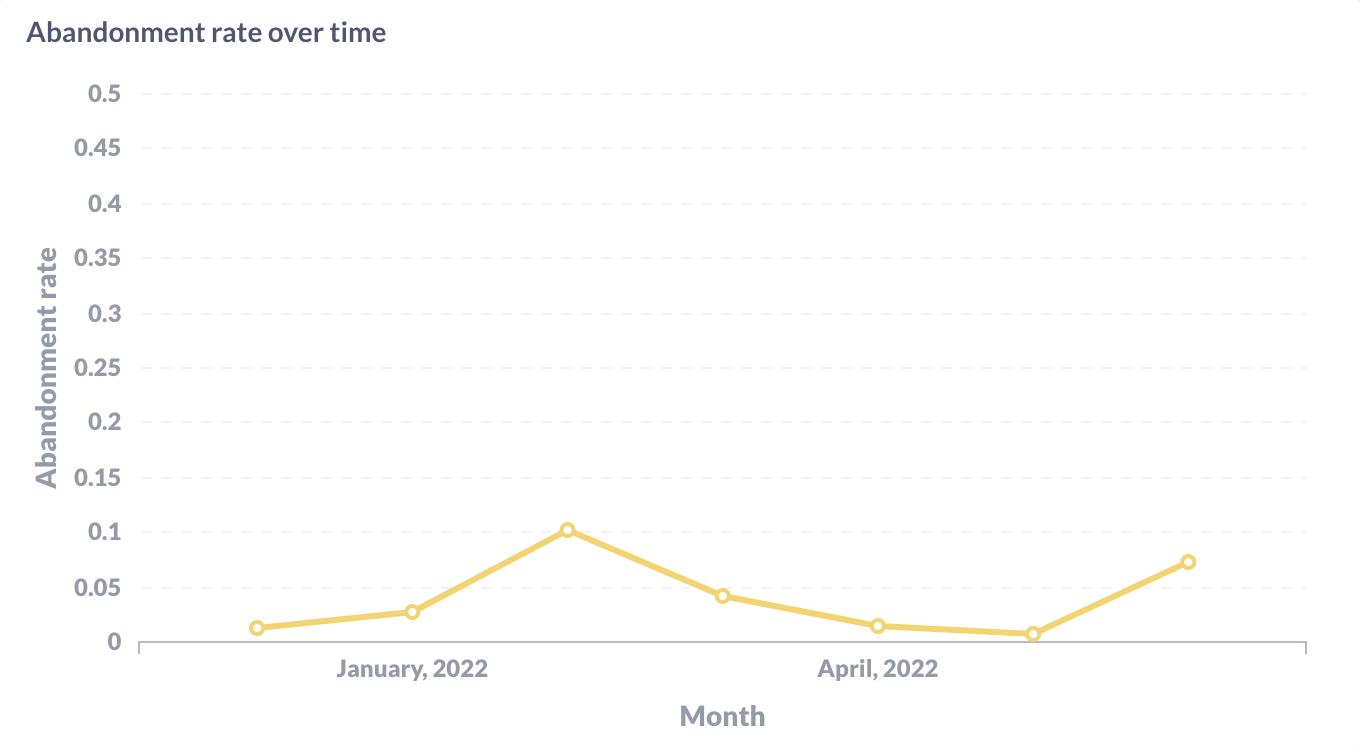
Abandonment Rate
Abandonment rate can be defined in many different custom ways,
however here we'll define it as a session ending without a user message after a
specific message was uttered by the bot, e.g. utter_ask_name.
You could adapt the metric to detect sessions ending without a user message
after a specific set of intents. The SQL query would look like this:
WITH "sessions" AS (
SELECT
DISTINCT ON ("public"."rasa_event"."session_id") "public"."rasa_event"."session_id",
"public"."rasa_event"."timestamp" AS "timestamp",
(
CASE
WHEN "public"."rasa_bot_message"."template_name" = 'utter_ask_name'
THEN 1 ELSE 0
END
) AS "is_abandoned"
FROM "public"."rasa_event"
INNER JOIN "public"."rasa_bot_message"
ON "public"."rasa_event"."id" = "public"."rasa_bot_message"."event_id"
WHERE "public"."rasa_event"."event_type" = 'bot'
ORDER BY 1, 2 DESC
)
SELECT
date_trunc('month', "timestamp") AS "timestamp",
SUM("is_abandoned")::float / count(*) AS "abandonment_rate"
FROM "sessions"
GROUP BY 1
ORDER BY 1 ASC
Top N Flows in a Given Time Period
The query below selects the top 5 flows in a given time period (e.g. last 7 days):
SELECT rasa_flow_status.flow_identifier, COUNT(DISTINCT rasa_flow_status.session_id) AS "count"
FROM rasa_flow_status
# we only want the top 5 user defined flows, not the built-in flow usage
WHERE rasa_flow_status.flow_identifier NOT LIKE 'pattern_%' AND rasa_flow_status.inserted_at >= NOW() AT TIME ZONE 'UTC' - INTERVAL '7 days'
GROUP BY 1
ORDER BY 2 DESC, 1 ASC
LIMIT 5;
Escalation Rate
To calculate the escalation rate for CALM-based assistants, you can use this query:
WITH "sessions" AS (
SELECT
rasa_llm_command.session_id AS "session_id",
date_trunc('month', rasa_llm_command.inserted_at) AS "timestamp",
(
CASE rasa_llm_command.command
WHEN 'human handoff'
THEN 1 ELSE 0
END
) AS "has_handoff_to_support"
FROM rasa_llm_command
),
"sessions_with_handoff" AS (
SELECT
"session_id",
"timestamp",
SUM("has_handoff_to_support") AS "has_handoff_to_support"
FROM "sessions"
GROUP BY 1, 2
)
SELECT
"timestamp",
100.0 * SUM("has_handoff_to_support") / count(*) AS "escalation_rate"
FROM "sessions_with_handoff"
GROUP BY 1
ORDER BY 1 ASC;
Resolution Rate
The resolution rate is a measure of the number of conversations the assistant can resolve without human intervention.
This metric can help you gain a better understanding of what happens during a conversation.
To understand which conversations are resolved, you can identify which flows are completed in the rasa_flow_status table.
You'll get the resolution rate for a particular flow with this sample query for CALM-based assistants:
WITH "completed_sessions" AS (
SELECT COUNT(DISTINCT rasa_flow_status.session_id) as "completed_count"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'transfer_money' AND rasa_flow_status.flow_status = 'completed'
)
SELECT 100 * (SELECT "completed_sessions". "completed_count" FROM "completed_sessions") / NULLIF(COUNT(DISTINCT rasa_flow_status.SESSION_ID), 0) as "resolution_rate_percentage"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'transfer_money' AND rasa_flow_status.flow_status = 'started';
Drop-Off Rate for a specific Flow
The drop-off rate is a measure of the number of conversations that do not result in a completed flow. This metric is the inverse of the resolution rate (e.g. 100% - resolution_rate).
You can further drill down in finding the interruption rate for a specific flow:
WITH "interrupted_sessions" AS (
SELECT COUNT(DISTINCT rasa_flow_status.session_id) as "interrupted_count"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'setup_recurrent_payment' AND rasa_flow_status.flow_status = 'interrupted'
)
SELECT 100 * (SELECT "interrupted_sessions". "interrupted_count" FROM "interrupted_sessions") / NULLIF(COUNT(DISTINCT rasa_flow_status.SESSION_ID), 0) as "resumption_rate_percentage"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'setup_recurrent_payment' AND rasa_flow_status.flow_status = 'started';
In addition, you can also calculate the % of interrupted flows which were resumed:
WITH "resumed_sessions" AS (
SELECT COUNT(DISTINCT rasa_flow_status.session_id) as "resumed_count"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'book_restaurant' AND rasa_flow_status.flow_status = 'resumed'
)
SELECT 100 * (SELECT "resumed_sessions". "resumed_count" FROM "resumed_sessions") / NULLIF(COUNT(DISTINCT rasa_flow_status.SESSION_ID), 0) as "resumption_rate_percentage"
FROM rasa_flow_status
WHERE rasa_flow_status.flow_identifier = 'book_restaurant' AND rasa_flow_status.flow_status = 'interrupted';
Funnel Metrics
Funnel metrics are a great way to understand how users are interacting with your assistant. You can use funnel metrics to understand how many users are completing each step of a flow or how many users are progressing through linked flows.
Count of Unique Sessions for Each Step in a Flow
The query below selects the number of unique sessions for each step in a flow:
SELECT DISTINCT t1.flow_step_id, COUNT(DISTINCT t1.session_id) AS "session_count"
FROM rasa_dialogue_stack_frame t1
JOIN rasa_flow_status t2 ON t1.session_id = t2.session_id
WHERE t1.active_flow_identifier = 'setup_recurrent_payment' AND t2.flow_status NOT IN ('cancelled', 'completed')
GROUP BY 1
ORDER BY 1;
We remove the flows that were cancelled or completed to get a better understanding of the drop-off numbers.
Count of Unique Sessions for each Linked Flow
The query below selects the number of unique sessions for each linked flow in the chain formed of flow replace_card
linking to flow replace_eligible_card:
SELECT
COUNT(DISTINCT CASE WHEN active_flow_identifier='replace_card' THEN session_id ELSE null END) as "replace_card_starts",
COUNT(DISTINCT CASE WHEN active_flow_identifier='replace_eligible_card' THEN session_id ELSE null END) as "replace_eligible_card_starts"
FROM rasa_dialogue_stack_frame;