Integrate RAG in Rasa
Many AI assistants need to handle both structured workflows and open-ended knowledge queries. Rasa's approach to Enterprise Search and Retrieval-Augmented Generation (RAG) enables you to build assistants that can blend these capabilities, ensuring users get the information and support they need.
Types of AI Assistant Conversations
Conversations with AI assistants typically fall into two categories: Transactional and Informational.
Transactional:
These conversations are structured, goal-oriented, and designed to complete specific tasks. They guide users through predefined processes—such as booking a flight, checking an account balance, or filing a support ticket—where every input and response is precisely managed to ensure a successful transaction.
Informational:
These conversations are designed to answer questions and provide insights. Whether users are inquiring about product features, technical details, or pricing, these dialogues rely on current data and strong contextual understanding to deliver clear, relevant answers.
Real conversations often mix both types - a user might start booking a flight (transactional) but then ask about baggage policies (informational) before completing their booking.
Understanding RAG
To enable building assistants that can handle different conversational usecases, Rasa enables you to integrate Retrieval-Augmented Generation (RAG) into your assistants. RAG is a method that leverages LLMs to produce more accurate and up-to-date responses by providing them access to external knowledge sources.
RAG involves three steps:
-
Retrieval: When a user asks a question, we search through a knowledge base (documents, databases, or other structured information) to find relevant information.
-
Augmentation: The retrieved information is combined with the user's query and conversation context to create a comprehensive prompt.
-
Generation: This enriched prompt is sent to an LLM which generates a response that incorporates the retrieved information.
How RAG Works in Rasa
Rasa enables assistants to handle informational dialogue at any point in the conversation.
When a user asks an informational question, Rasa's Dialogue Understanding component will produce a SearchAndReply command.
This command triggers the search pattern, which processes the knowledge query and then returns back to the ongoing conversation.
User: Yes the 17:30 flight to San Fransisco works fine.
Bot: Great! It's confirmed. You're going to SF at 17:30 tomorrow, anything else I can help you with?
User: Actually - how big a bag can I bring again?
Bot: One moment, let me check the latest baggage policy information for the flight.
Bot: I found that your flight includes one carry-on bag and one checked bag up to 50 lbs. Extra checked bags are available for an additional fee.
User: Thanks! Please add an extra checked bag to my booking.
Bot: Got it. I’ve updated your reservation to include an extra checked bag. Let’s proceed with your booking details.
📌 Pro tip: You can also trigger enterprise search at specific points in a conversation by adding it as a step in your flow.
Getting Started with Enterprise Search
Step One: Prep your Knowledge Base
Rasa offers flexible options for configuring your knowledge base when setting up Retrieval-Augmented Generation (RAG). You can choose from two primary storage methods:
Folder-Based Storage
For a quick and simple setup, you can store text documents in your project’s /docs folder. This approach is ideal for rapid development and prototyping, as it provides an easy-to-use source of information for the LLM to generate responses.
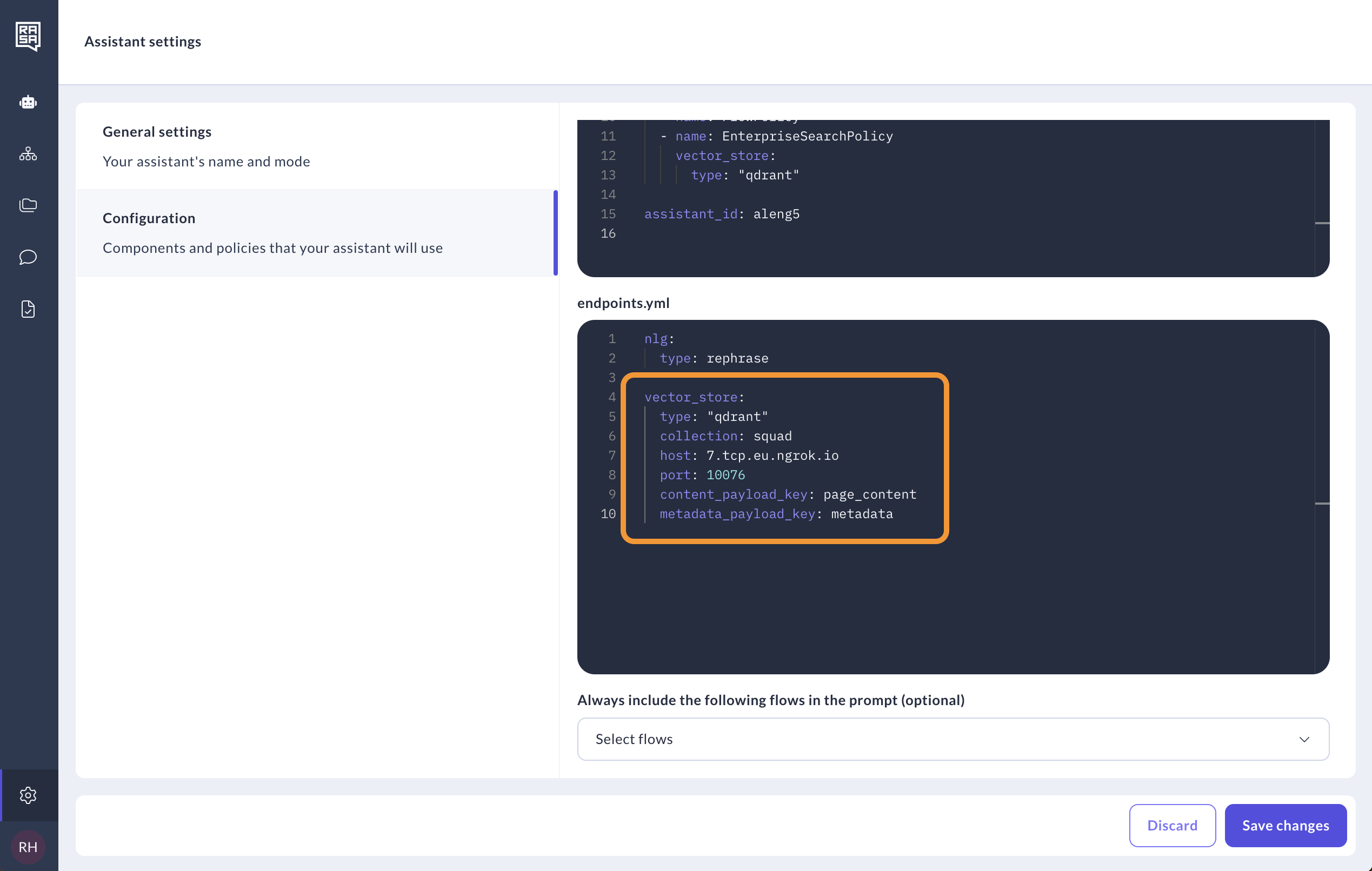
Vector Database
For a production-ready solution, consider connecting to a vector database like Qdrant or Milvus. This method supports dynamic updates and enables sharing your knowledge base among multiple assistants.
- Pro
- Studio
Note: In this example, we use the simple folder-based storage approach to demonstrate how to prepare your knowledge base, configure Enterprise Search, and override the search flow. This is a quickstart approach using Pro.
We have five type of cards: debit card, credit card, and loyalty card.
The price of a debit card is between 5 euros and 10, depending on the options you want to have.
Debit cards are directly linked to the user's bank account.
If the borrowed amount is not paid in full, credit card users may incur interest charges.
Loyalty cards are designed to reward customers for their repeat business.
Customers typically earn points or receive discounts based on their purchases.
Loyalty cards are often part of broader membership programs that may include additional benefits.
Note: In Studio it's more straightforward to integrate enterprise search when you have set up your vector database already.
Step Two: Configure the Command Generator and Enterprise Search
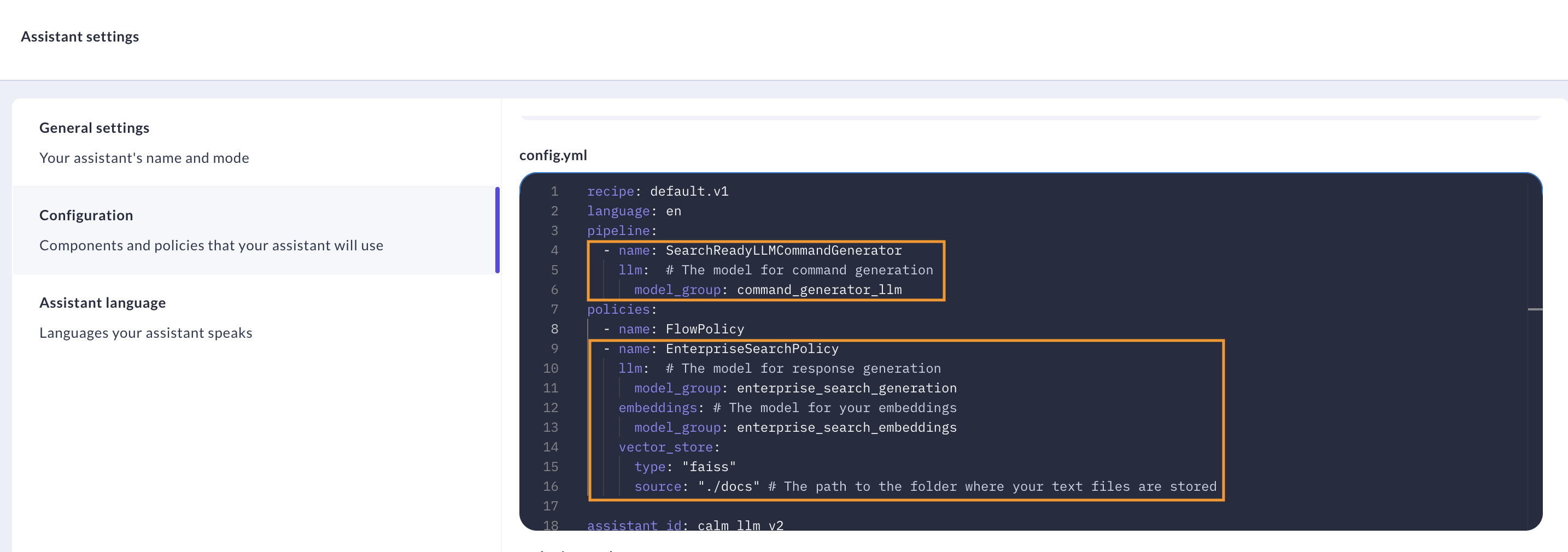
Include the correct command generator (SearchReadyLLMCommandGenerator) in your assistant's configuration -
- Pro
- Studio
pipeline:
- name: SearchReadyLLMCommandGenerator
llm: # The model for command generation
model_group: command_generator_llm
policies:
- name: EnterpriseSearchPolicy
llm: # The model for response generation
model_group: enterprise_search_generation
embeddings: # The model for your embeddings
model_group: enterprise_search_embeddings
vector_store:
type: "faiss"
source: "./docs" # The path to the folder where your text files are stored
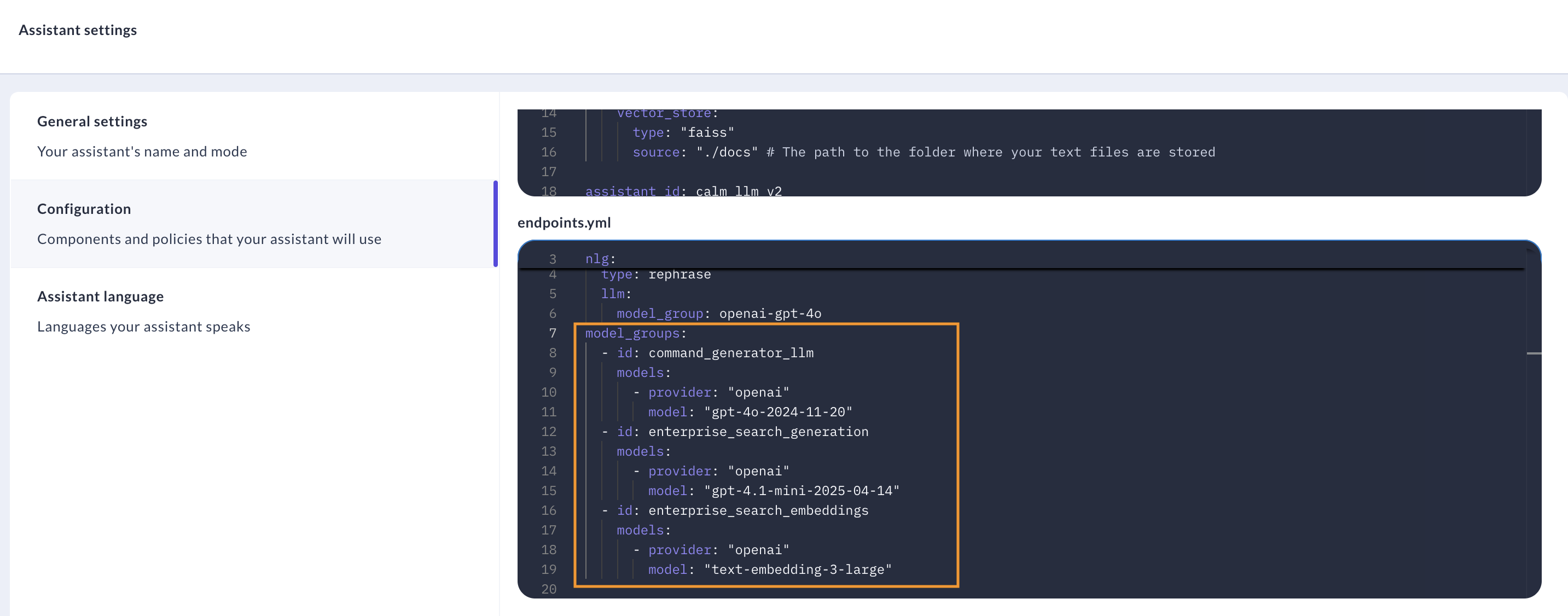
model_groups:
- id: command_generator_llm
models:
- provider: "openai"
model: "gpt-4o-2024-11-20"
- id: enterprise_search_generation
models:
- provider: "openai"
model: "gpt-4.1-mini-2025-04-14"
- id: enterprise_search_embeddings
models:
- provider: "openai"
model: "text-embedding-3-large"
Step Three: Override pattern_search
- Pro
- Studio
Modify flows.yml by adding a new system flow called pattern_search to trigger document search for knowledge-based questions:
flows:
pattern_search:
description: Handle knowledge-based questions.
steps:
- action: action_trigger_search
Go to the "System flows" tab and open pattern_search to modify it.
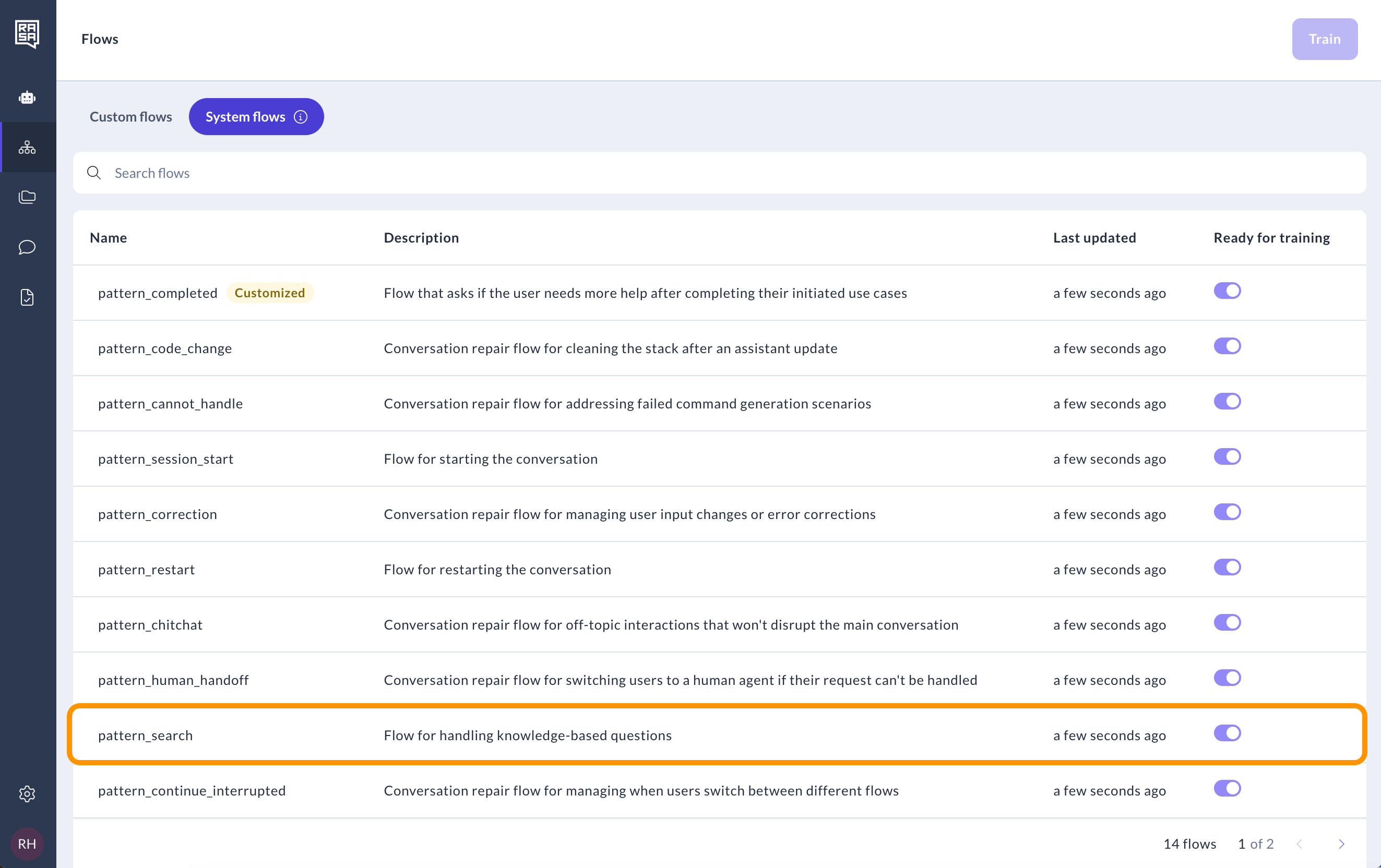
Delete the message and add the custom action step instead. In the right panel, select the action named action_trigger_search.
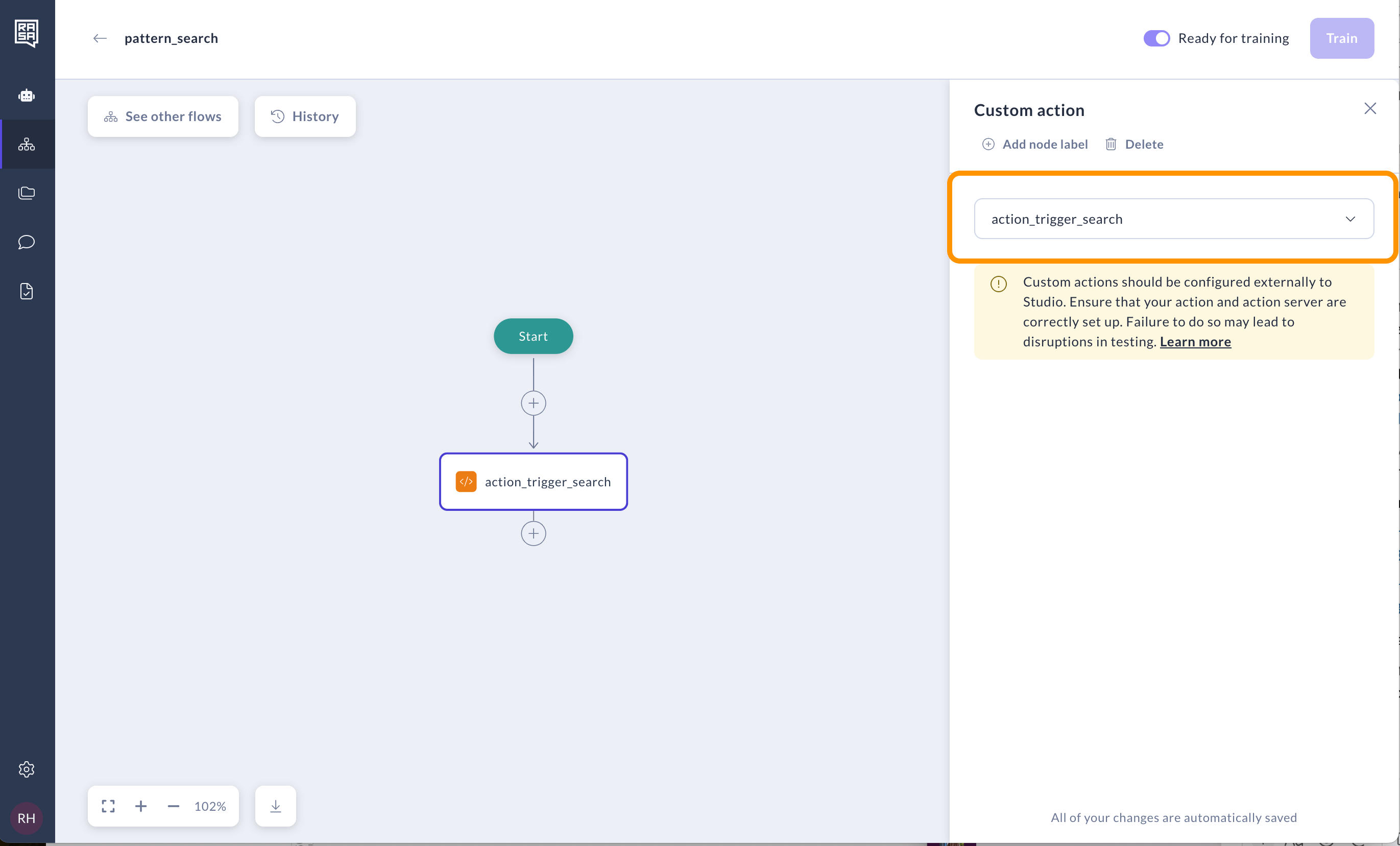
This will send relevant queries to the default action action_trigger_search.
Step Four: Try out your assistant
Once you have indexed your documents and trained your assistant, you should be ready to try out your new informational conversation!

Customization Options
LLM and Prompt Customization (Optional)
Rasa ships with default prompts for RAG interactions, but you can customize these to better match your use case. This ensures that generated responses align with your specific needs.
You can also choose the LLM that best fits your needs. Rasa supports various LLM providers and can also work with your hosted LLMs, allowing you to balance factors like response quality, speed, and cost. For more details on customizing your model configuration see this reference.
Extractive Search (Optional)
For scenarios where you want to deliver pre-approved answers from your knowledge base directly to your user, Rasa supports Extractive Search. This method bypasses the LLM generation step, reducing both cost and latency and ensuring complete control and consistency over responses. You can read more about this feature in the technical reference.