Rasa Architecture
The diagram below provides an overview of the Rasa Architecture.
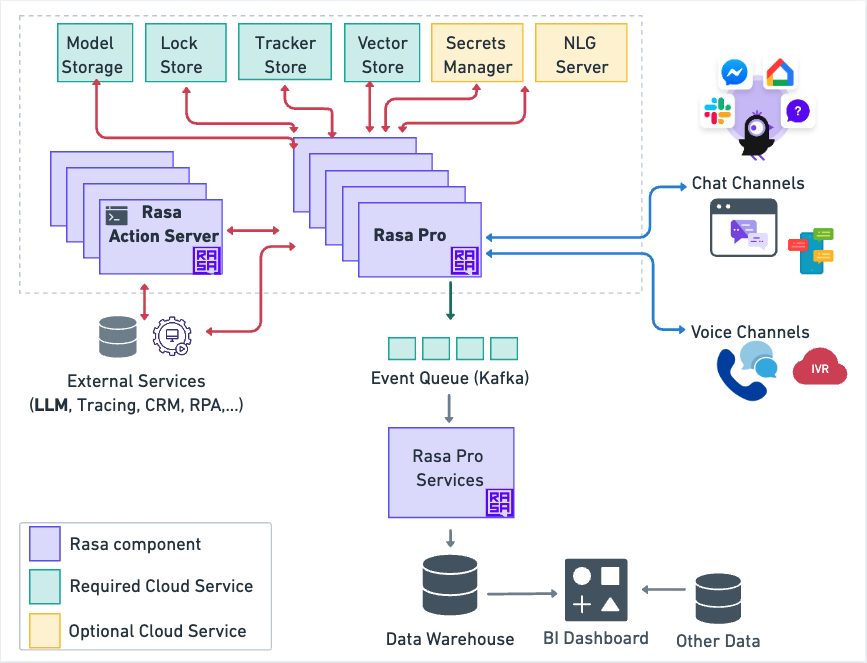
Action Server (custom actions)
Custom actions are used to implement business logic that cannot be handled by the Rasa bot. They include things like fetching customer information from a database, querying an API, or calling an external service.
Custom actions can be invoked via HTTP or gRPC. Rasa provides the Rasa SDK - a Python SDK to build custom actions. More details can be found at the rasa action server documentation.
Cloud Services
Your deployed assistant depends on a number of prerequisite cloud services that you need to provision.
Some of these prerequisite cloud services are required (green color), while others are optional (yellow color).
You are highly advised to use managed cloud services for their stability, performance and backup. There are many options available at each cloud provider, and the table below lists just a few of the available choices.
| What | AWS | Azure | |
|---|---|---|---|
| Model Storage | Amazon S3 | Azure Blob Storage | Google Cloud Storage |
| Lock Store | Amazon ElastiCache for Redis | Azure Cache for Redis | Memorystore for Redis |
| Tracker Store | Amazon RDS for PostgreSQL | Azure Database for PostgreSQL | Google Cloud SQL for PostgreSQL |
| Event Queue (Kafka) | Amazon Managed Streaming for Apache Kafka (MSK) | Azure Kafka Service | Confluent Cloud on Google Cloud Platform |
| Secrets Manager | HashiCorp Vault on AWS | HashiCorp Vault on Azure | HashiCorp Vault with Google Cloud |
Note that the NLG Server is an optional cloud service that you have to create and deploy yourself.
Next you will find a short description of the function of each cloud service.
Model Storage
The Model storage is a cloud service where the trained model is stored. Upon initialization or restart, Rasa will download that trained model and read it into memory.
Lock Store
The Lock Store is needed when you have a high-load scenario that requires the Rasa server to be replicated across multiple instances. It ensures that even with multiple servers, the messages for each conversation are handled in the correct sequence without any loss or overlap.
Tracker Store
Your assistant's conversations are stored within a tracker store.
Secrets Manager
The HashiCorp Vault Secrets Manager is integrated with Rasa to securely store and manage sensitive credentials.
NLG Server
The NLG Server in Rasa is used to outsource the response generation and separate it from the dialogue learning process. The benefit of using an NLG Server is that it allows for the dynamic generation of responses without the need to retrain the bot, optimizing workflows by decoupling response text from training data.
Event Queue (Kafka)
The Kafka Event Broker in Rasa is used to stream all events from the Rasa server to a Kafka topic for robust, scalable message handling and further processing.