
notice
This is unreleased documentation for Rasa Documentation Main/Unreleased version.
For the latest released documentation, see the latest version (3.x).
Using LLMs for Intent Classification
Intent classification using Large Language Models (LLM) and a method called retrieval augmented generation (RAG).
Rasa Labs access - New in 3.7.0b1
Rasa Labs features are experimental. We introduce experimental features to co-create with our customers. To find out more about how to participate in our Labs program visit our Rasa Labs page.
We are continuously improving Rasa Labs features based on customer feedback. To benefit from the latest bug fixes and feature improvements, please install the latest pre-release using:
Key Features
- Few shot learning: The intent classifier can be trained with only a few examples per intent. New intents can be bootstrapped and integrated even if there are only a handful of training examples available.
- Fast Training: The intent classifier is very quick to train.
- Multilingual: The intent classifier can be trained on multilingual data and can classify messages in many languages, though performance will vary across LLMs.
Overview
The LLM-based intent classifier is a new intent classifier that uses large language models (LLMs) to classify intents. The LLM-based intent classifier relies on a method called retrieval augmented generation (RAG), which combines the benefits of retrieval-based and generation-based approaches.
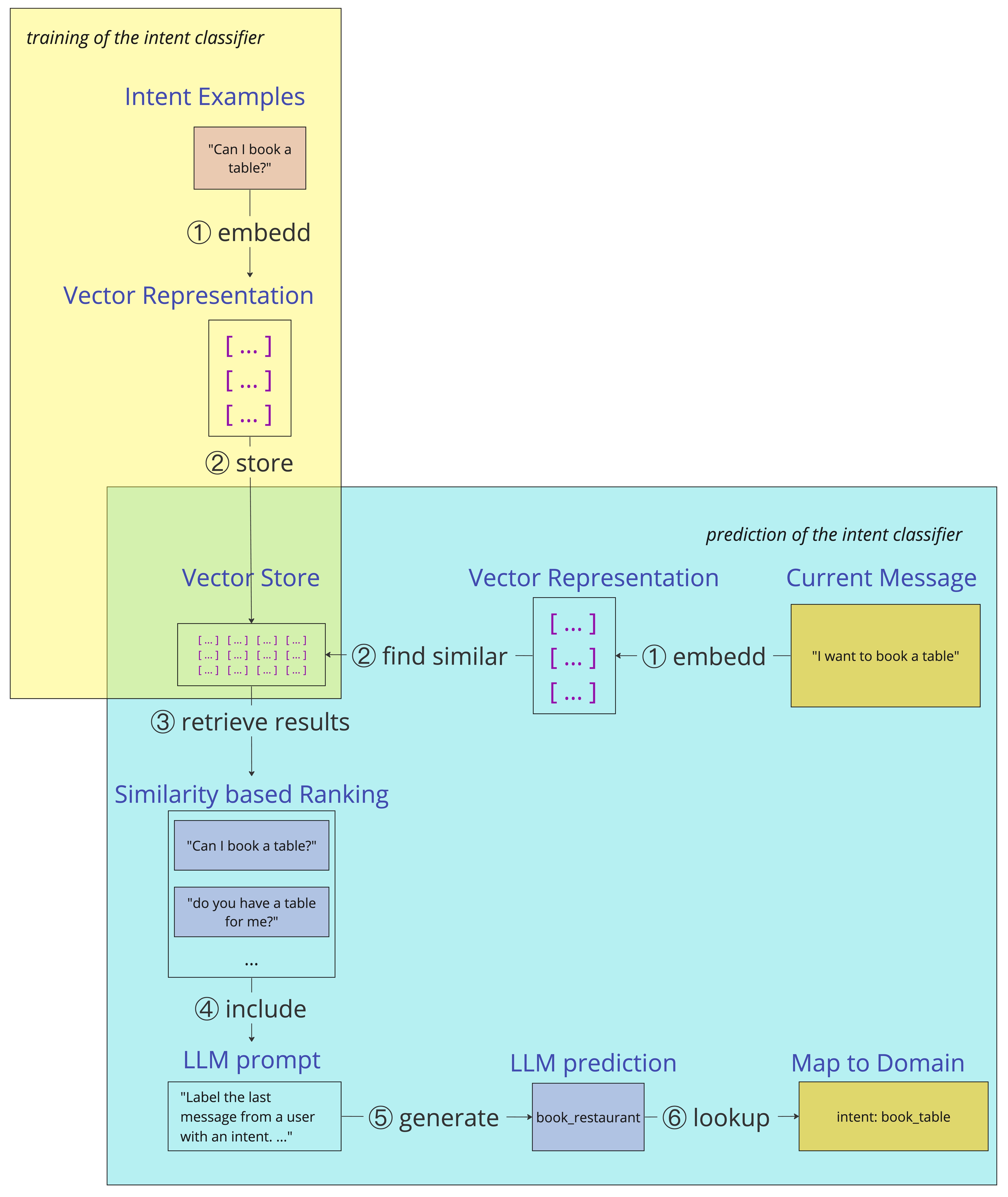
During trainin the classifier
- embeds all intent examples and
- stores their embeddings in a vector store.
During prediction the classifier
- embeds the current message and
- uses the embedding to find similar intent examples in the vector store.
- The retrieved examples are ranked based on similarity to the current message and
- the most similar ones are included in an LLM prompt. The prompt guides the LLM to predict the intent of the message.
- LLM predicts an intent label.
- The generated label is mapped to an intent of the domain. The LLM can also predict a label that is not part of the training data. In this case, the intent from the domain with the most similar embedding is predicted.
Using the LLM-based Intent Classifier in Your Bot
To use the LLM-based intent classifier in your bot, you need to add the
LLMIntentClassifier to your NLU pipeline in the config.yml file.
The LLM-based intent classifier requires access to an LLM model API. You can use any
OpenAI model that supports the /completions endpoint.
We are working on expanding the list of supported
models and model providers.
Customizing
You can customize the LLM by modifying the following parameters in the
config.yml file. All of the parameters are optional.
Fallback Intent
The fallback intent is used when the LLM predicts an intent that wasn't part of
the training data. You can set the fallback intent by adding the following
parameter to the config.yml file.
Defaults to out_of_scope.
LLM / Embeddings
You can choose the OpenAI model that is used for the LLM by adding the llm.model_name
parameter to the config.yml file.
Defaults to text-davinci-003. The model name needs to be set to a generative
model using the completions API of
OpenAI.
If you want to use Azure OpenAI Service, you can configure the necessary parameters as described in the Azure OpenAI Service section.
Using Other LLMs / Embeddings
By default, OpenAI is used as the underlying LLM and embedding provider.
The used LLM provider and embeddings provider can be configured in the
config.yml file to use another provider, e.g. cohere:
For more information, see the LLM setup page on llms and embeddings
Temperature
The temperature parameter controls the randomness of the LLM predictions. You
can set the temperature by adding the llm.temperature parameter to the config.yml
file.
Defaults to 0.7. The temperature needs to be a float between 0 and 2. The
higher the temperature, the more random the predictions will be. The lower the
temperature, the more likely the LLM will predict the same intent for the same
message.
Prompt
The prompt is the text that is used to guide the LLM to predict the intent of
the message. You can customize the prompt by adding the following parameter to
the config.yml file.
The prompt is a Jinja2 template that can be used to customize the prompt. The following variables are available in the prompt:
examples: A list of the closest examples from the training data. Each example is a dictionary with the keystextandintent.message: The message that needs to be classified.intents: A list of all intents in the training data.
The default prompt template results in the following prompt:
Number of Intent Examples
The number of examples that are used to guide the LLM to predict the intent of
the message can be customized by adding the number_of_examples parameter to the
config.yml file:
Defaults to 10. The examples are selected based on their similarity to the
current message. By default, the examples are included in the prompt like this:
Security Considerations
The intent classifier uses the OpenAI API to classify intents. This means that your users conversations are sent to OpenAI's servers for classification.
The response generated by OpenAI is not send back to the bot's user. However, the user can craft messages that will lead the classification to fail for their message.
The prompt used for classification won't be exposed to the user using prompt injection. This is because the generated response from the LLM is mapped to one of the existing intents, preventing any leakage of the prompt to the user.
More detailed information can be found in Rasa's webinar on LLM Security in the Enterprise.
Evaluating Performance
- Run an evaluation by splitting the NLU data into training and testing sets and comparing the performance of the current pipeline with the LLM-based pipeline.
- Run cross-validation on all of the data to get a more robust estimate of the performance of the LLM-based pipeline.
- Use the
rasa test nlucommand with multiple configurations (e.g., one with the current pipeline and one with the LLM-based pipeline) to compare their performance. - Compare the latency of the LLM-based pipeline with that of the current pipeline to see if there are any significant differences in speed.