Fine-Tuning an LLM for Command Generation
Fine-tuning LLMs is available starting with version 3.10.0 as a beta feature. This page provides a walkthrough and in-depth implementation details.
This page explains why you might want to fine-tune a smaller LLM (e.g., Llama-3.1 8B) for command generation in CALM. It outlines Rasa’s fine-tuning recipe at a high level, and shows you how to get started, and where to go next.
Why Would You Want to Fine-Tune an LLM for Command Generation?
When starting out with CALM, you might rely on a powerful off-the-shelf LLM (e.g., GPT-5.1) via OpenAI or Azure OpenAI. That’s often the quickest path to a functional assistant. However, as your use cases multiply and your traffic grows, you might hit constraints like:
- Response Latency: Third-party LLM services are shared resources and can become slower at peak usage times, leading to a frustrating user experience.
- Rate Limits & Availability: Relying on external providers can mean hitting token usage caps or facing downtime.
- High Inference Costs: Token-based payment and especially provisioned throughput units (PTUs) are costly at scale.
- Model Life Cycles: Third-party services often phase out models quickly
Fine-tuning a smaller LLM locally or on a private cloud helps mitigate these issues. By tailoring an LLM model specifically for command generation in your assistant, you can:
- Boost Performance and Reliability: A fine-tuned smaller model can respond faster with greater latency guarantees.
- Cut Costs: Inference on a smaller, domain-tailored LLM can be significantly cheaper.
- Retain Control Over Your Data and Processes: Run the model on your own infrastructure to avoid potential data-sharing, vendor lock-in, or model lifecycle concerns.
What Is the Fine-Tuning Recipe?
Our fine-tuning recipe streamlines the process of gathering training data and fine-tuning an LLM for your domain.
Below is a high-level overview of the fine-tuning process:

- Prepare Your Assistant & Tests
- Make sure your CALM assistant uses an LLM-based command generator (e.g.,
CompactLLMCommandGeneratorwith an LLM likegpt-5.1-2025-11-13) - Check that you have comprehensive E2E tests covering your most important conversation flows and that they are passing.
- E2E tests are the basis for generating training data. Failing tests cannot be turned into training data.
- Make sure your CALM assistant uses an LLM-based command generator (e.g.,
- Generate Finetuning Training Data
- Run
rasa llm finetune prepare-data --num-rephrases 2 --output-format conversationalon your E2E tests. - This process executes the e2e tests and captures the prompt and the desired commands at each user step.
- Rephrasings increase the linguistic variety of user messages. Each rephrasing is confirmed to produce the same command as the original user message and dropped otherwise.
- By default, the resulting dataset is split into training (80%) and validation (20%).
- Run
- Fine-Tune Your Model
- Rasa provides a jupyter notebook that guides you through the process of fine-tuning a smaller LLM for the task of command generation and storing the resulting model.
- Test & Deploy
- Deploy the fine-tuned LLM model to a test environment.
- Test your fine-tuned LLM by running the original or additional E2E tests.
- If the results meet your quality and performance criteria, you can deploy the new model to your production environment.
We explain each of the steps in more detail in the following sections.
Preparing e2e Tests
To fine-tune an LLM effectively, it’s crucial to ensure that your assistant is comprehensively covered by E2E tests. These tests provide the data needed for fine-tuning. If your E2E tests do not sufficiently cover the assistant's functionality, the fine-tuned model may not perform well due to a lack of relevant training examples.
To address this, you can use an E2E test diagnostic tool, which is available as part of Rasa’s CLI. This tool helps you evaluate whether your E2E tests adequately cover the system's capabilities. It also identifies areas where existing tests may need to be updated or where new tests should be created before proceeding with fine-tuning.
Assessing Test Coverage for Fine-tuning
When reviewing the results of the diagnostic tool there are two key areas to focus on to ensure your data is suitable for fine-tuning:
- Representation of All Commands: Ensure that all commands your assistant might generate are represented in your tests. If certain commands are not covered, the model may struggle to generate them correctly, having never "seen" these scenarios during training. This can be evaluated by inspecting the command coverage histograms
- Representation of all flows: Ensure that the flows you want your bot to handle are well-represented in the tests. This ensures the model learns from a variety of examples and scenarios, increasing its robustness and reliability. This can be evaluated by inspecting the flow coverage report
By carefully analyzing and expanding your test coverage, you can better prepare your model for fine-tuning, resulting in improved performance and a more reliable assistant.
Training Data Generation
If an E2E test is failing on your assistant, you won't be able to use that test for fine-tuning an LLM. Hence, please ensure that the assistant is able to successfully pass the input E2E tests. We also recommend using the E2E coverage analysis tool to understand the coverage your passing tests are providing for the flows of your assistant.
Training data for fine-tuning LLMs consists of prompt and command pairs.
These pairs are extracted during execution of e2e tests from the CompactLLMCommandGenerator or the SearchReadyLLMCommandGenerator components.
Only user steps that are processed by these components can generate the needed prompt command pairs.
For example, if your tests use buttons that issue set slot commands to bypass the CompactLLMCommandGenerator
no prompt command pair will be generated for that specific step.
The data generation happens using the currently configured LLM for your command generator component. Make sure to use the most capable LLM available to you for this step, to have as many passing tests as possible and thus as many training data points as possible. In our experience, a few hundred data points are enough to fine-tune an LLM using the recipe.
You can generate training data using the following command:
rasa llm finetune prepare-data --num-rephrases 2 --output-format conversational
Data Augmentation in Detail
During the data generation, you can augment your training data by automatic rephrasing of user utterances. The rephrasing happens using another LLM call. Any generated variant is verified to generate the same commands as the original message. A notable exception are slot sets, where the slot name must be the same, but the value might differ. Only rephrased variants that pass this check are added to the training set.
Note: User utterances that come from buttons, e.g. the user clicked on a button instead of typing a response, are not rephrased and skipped by the synthetic data generator.
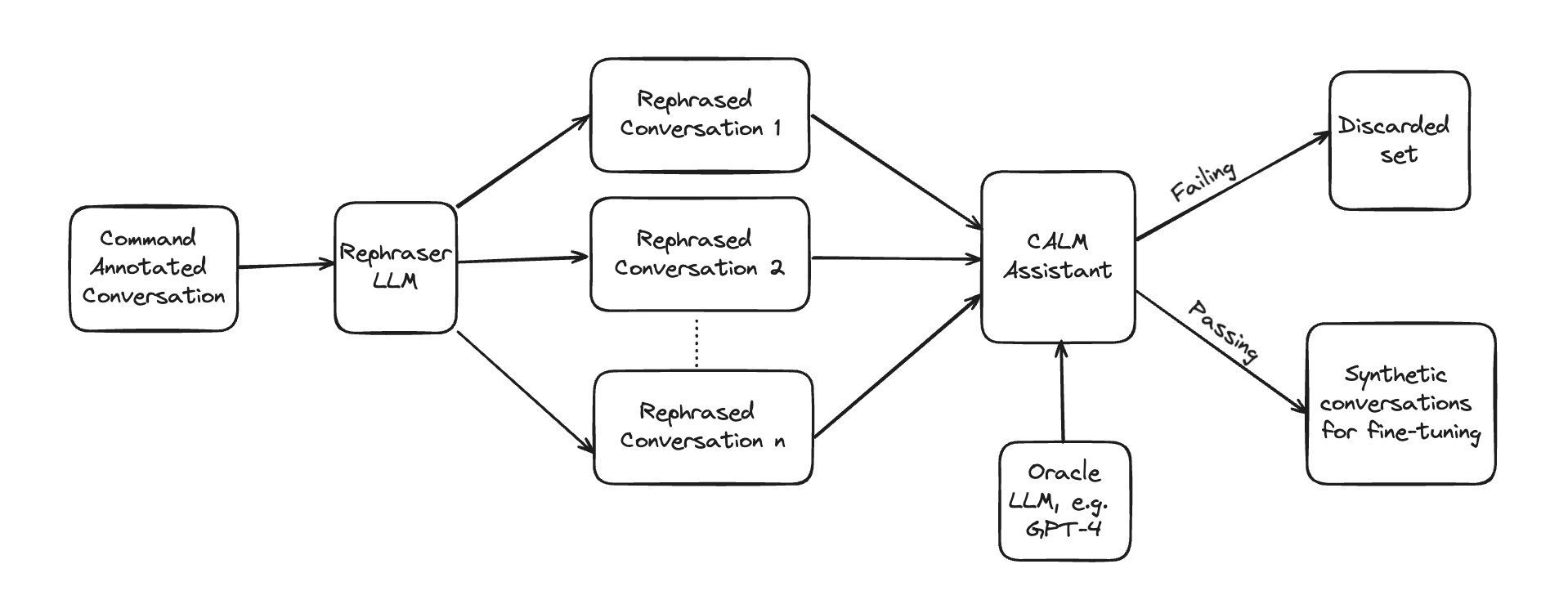
The number of rephrasings to generate and test can be influenced with the --num-rephrases parameter.
Note that you are not guaranteed to get that specific number of rephrasings for each message.
This parameter just controls the number of candidate rephrasings that are then verified to generate
the same result as the original message.
If you set --num-rephrases 0, the synthetic data generator will be skipped.
Rephraser LLM Call
By default, the rephraser uses gpt-5-mini-2025-08-07 to paraphrase user steps.
The rephraser uses the following prompt to create the rephrasings:
Objective:
Create multiple rephrasings of user messages tailored to the "{{ test_case_name }}" conversation scenario.
===
Conversation overview:
{{ transcript or "Not provided." }}
===
Task:
Produce {{ number_of_rephrasings }} rephrasings for each user message that are diverse yet contextually appropriate.
Preserve the intent and content, but vary the structure, formality, and detail.
Only rephrase messages prefixed with "{{ user_prefix }}:".
Guidelines:
- Use a variety of expressions from brief and casual to elaborate and formal.
- Vary sentence structures, vocabularies, and expressions creatively.
- Keep the core message intact with concise and simple modifications.
Format:
- Each original user message should be prefixed with "USER: ".
- Enumerate the rephrasing.
- Separate each user message set with a line break.
===
Example output for 3 rephrasings of 2 user messages:
"""
USER: Show invoices
1. I want to see my bills.
2. I mean bills
3. Yes, I want to see the invoices.
USER: I'd like to book a car
1. I need to reserve a car.
2. Could I arrange for a car rental?
3. I'm interested in hiring a car.
"""
===
Expected output:
{{ number_of_rephrasings }} rephrasings for the following {{ number_of_user_messages }} user messages in the expected
format:
{% for message in user_messages -%}
- {{ message }}
{% endfor %}
If you want to modify the prompt or use a different LLM for the Rephraser LLM you can specify a custom config via
the argument --rephrase-config <path-to-config-file> on the CLI command
rasa llm finetune prepare-data.
The default config looks like this
prompt_template: default_rephrase_prompt_template.jina2
llm:
model: gpt-5-mini-2025-08-07
provider: openai
Validation of Rephrased User Steps
To validate the rephrased user steps, Rasa takes the prompt of the original user step and replaces the original user utterance with the rephrased one. Then the prompt is sent to the same LLM used to annotate the conversation originally. If the response of the LLM after parsing and processing matches the response of the original user step, the rephrased user utterance passes the test and is added to the synthetic conversation dataset for fine-tuning.
Recombination of Rephrased User Steps
Let's take a look at an example to understand how Rasa constructs new conversations using the rephrased messages. Take this original conversation:
- user: I'd like to book a car
- bot: in which city?
- user: to Basel
- bot: When would you like to pick up the car?
- user: from may 14th to the 17th
- utter: utter_ask_car_rental_selection
- user: I'll take the luxury one! looks nice
and the following rephrasings per user step:
| original user message | passing rephrase 1 | passing rephrase 2 | passing rephrase 3 |
|---|---|---|---|
| I'd like to book a car | I need to reserve a car. | Could I arrange for a car rental? | I'm interested in hiring a car. |
| to Basel | The destination is Basel. | I'd like to go to Basel. | |
| from may 14th to the 17th | The rental period will be May 14th to 17th. | I need the car from May 14th to May 17th. | I'll require the vehicle from the 14th to the 17th of May. |
| I'll take the luxury one! looks nice | I'd like to go with the luxury option; it looks appealing. | I'll choose the luxury model; it seems nice. | I'm opting for the luxury car; it looks great. |
To construct a new conversation, we combine passing rephrases at the same index position to build a new conversation. If some rephrasings have failed to pass, we evenly use the other passing rephrases.
So, the final conversations would look like this:
# conversation 1 (original conversation)
- user: I'd like to book a car
- bot: in which city?
- user: to Basel
- bot: When would you like to pick up the car?
- user: from may 14th to the 17th
- utter: utter_ask_car_rental_selection
- user: I'll take the luxury one! looks nice
# conversation 2
- user: I need to reserve a car.
- bot: in which city?
- user: The destination is Basel.
- bot: When would you like to pick up the car?
- user: The rental period will be May 14th to 17th.
- utter: utter_ask_car_rental_selection
- user: I'd like to go with the luxury option; it looks appealing.
# conversation 3
- user: Could I arrange for a car rental?
- bot: in which city?
- user: I'd like to go to Basel.
- bot: When would you like to pick up the car?
- user: I need the car from May 14th to May 17th.
- utter: utter_ask_car_rental_selection
- user: I'll choose the luxury model; it seems nice.
# conversation 4
- user: I'm interested in hiring a car.
- bot: in which city?
- user: The destination is Basel.
- bot: When would you like to pick up the car?
- user: I'll require the vehicle from the 14th to the 17th of May.
- utter: utter_ask_car_rental_selection
- user: I'm opting for the luxury car; it looks great.
Data Split into Training and Validation
By default, Rasa takes 80% of the fine-tuning data for the training dataset. The remaining data points go to the validation set. During that process, we make certain that all command types present in the fine-tuning dataset will end up at least once in the training dataset. This means specifically that Rasa makes sure that even less common command types such as a flow cancellation are at least once in the training set. Rasa does not take into account the arguments to these command types. That means you are currently not guaranteed to have at least one starting command for each flow in your training dataset.
When it comes to rephrasings, we make sure that all variants of a test conversation end up either in train OR in test. This way Rasa does not contaminate the test set with near duplicates of the train set.
You can update the fraction of data that goes into the training dataset by setting the flag
--train-frac <float-number> on the CLI command rasa llm finetune prepare-data.
If you would like to have more control over your data split, it makes sense to manually generate a static test train split upfront. Then generate training and test data separately by disabling the automatic
splitting using --train-frac 1.0.
Data Point Format
When you fine-tune a base model, the base model expects the data to be in a specific format. By default, the training and validation datasets are in instruction data format.
If you want to use the nowadays more common conversational data format instead set the flag --output-format conversational on the CLI command rasa llm finetune prepare-data.
Folder Structure of the Results
After generating the fine-tuning data you will find the result in the output folder.
If you want to get straight to the fine-tuning part check out the .jsonl files in output/4_train_test_split/ft_splits.
Rasa also provides a number of intermediate data structures that can help while debugging the process.
output/1_command_annotationshas your original e2e tests annotated with commands.output/2_rephrasingscontains the rephrasings for each conversation.output/3_llm_finetune_dataholds an intermediate data structure after turning conversations and rephrased conversations into individual data points for fine-tuning. It contains the prompt, the desired output, the original test case name, and the original and potentially rephrased message.output/4_train_test_split/e2e_testscontains the original e2e tests according to the train/test split. This can help you to run e2e testing specifically against those tests that made it into train or those that made it into validation.output/4_train_test_split/ft_splitscontains the data points that can be used for LLM fine-tuning.
Model Fine-tuning
Once you have the dataset prepared, you can start fine-tuning an open source LLM to help it excel at the task of command generation.
Rasa provides this example python notebook as a reference for fine-tuning. It has been tested on GCP Vertex AI and AWS SageMaker, it can be easily adapted to work on other cloud platforms. By default, it:
- Uses the HuggingFace stack for training LoRA-adapters for your model.
- Downloads a base model from huggingface hub. Using Llama-3.1 8b Instruct model is recommended.
- Loads the base model with the option for quantization using the BitsandBytes library for efficient memory usage.
- Provides default hyperparameters that have worked well in the past.
- Adds a chat template if the model does not already have one.
- Runs the fine-tuning and visualizes loss as the metric to monitor across the training and validation set. When testing this step on an NVIDIA A100 with the default hyperparameters, it took around 1 hour to perform fine-tuning with a training dataset containing around 1600 examples. Hence, this step is relatively cheap and quick to run.
- Allows persisting the model on the cloud.
CALM exclusively uses the chat completions endpoint of the model server, so it's essential that the model's tokenizer includes a chat template. Models lacking a chat template will not be compatible with CALM.
Deploying your Model
Head over to the LLM deployment section to learn how to start using your fine-tuned model in CALM.