
notice
This is documentation for Rasa Documentation v2.x, which is no longer actively maintained.
For up-to-date documentation, see the latest version (3.x).
Testing Your Assistant
Rasa Open Source lets you validate and test dialogues end-to-end by running through test stories. In addition, you can also test the dialogue management and the message processing (NLU) separately.
Validating Data and Stories
Data validation verifies that no mistakes or major inconsistencies appear in your domain, NLU data, or story data. To validate your data, have your CI run this command:
If you pass a max_history value to one or more policies in your config.yml file, provide the
smallest of those values as
If data validation results in errors, training a model can also fail or yield bad performance, so it's
always good to run this check before training a model. By including the
--fail-on-warnings flag, this step will fail on warnings indicating more minor issues.
note
Running rasa data validate does not test if your rules are consistent with your stories.
However, during training, the RulePolicy checks for conflicts between rules and stories. Any such conflict will abort training.
To read more about the validator and all of the available options, see the documentation for
rasa data validate.
Writing Test Stories
Testing your trained model on test stories is the best way to have confidence in how your assistant will act in certain situations. Written in a modified story format, test stories allow you to provide entire conversations and test that, given certain user input, your model will behave in the expected manner. This is especially important as you start introducing more complicated stories from user conversations.
Test stories are like the stories in your training data, but include the user message as well.
Here are some examples:
- Basics
- Custom Actions
- Forms Happy Path
- Forms Unhappy Path
By default, the command will run tests on stories from any files with names starting with test_. You can also provide
a specific test stories file or directory with the --stories argument.
You can test your assistant against them by running:
Conversation testing is only as thorough and accurate as the test cases you include, so you should continue to grow your set of test stories as you make improvements to your assistant. A good rule of thumb to follow is that you should aim for your test stories to be representative of the true distribution of real conversations. Rasa X makes it easy to add test conversations based on real conversations.
See the CLI documentation on rasa test for
more configuration options.
Testing Custom Actions
Custom Actions are not executed as part of test stories. If your custom
actions append any events to the conversation, this has to be reflected in your test story
(e.g. by adding slot_was_set events to your test story).
To test the code of your custom actions, you should write unit tests for them and include these tests in your CI/CD pipeline.
Evaluating an NLU Model
In addition to testing stories, you can also test the natural language understanding (NLU) model separately. Once your assistant is deployed in the real world, it will be processing messages that it hasn't seen in the training data. To simulate this, you should always set aside some part of your data for testing. You can split your NLU data into train and test sets using:
Next, you can see how well your trained NLU model predicts the data from the test set you generated, using:
To test your model more extensively, use cross-validation, which automatically creates multiple train/test splits:
Comparing NLU Performance
If you've made significant changes to your NLU training data (e.g. splitting an intent into two intents or adding a lot of training examples), you should run a full NLU evaluation. You'll want to compare the performance of the NLU model without your changes to an NLU model with your changes.
You can do this by running NLU testing in cross-validation mode:
You could also train a model on a training set and testing it on a test set. If you use the train-test
set approach, it is best to shuffle and split your data using rasa data split as part of this CI step, as
opposed to using a static NLU test set, which can easily become outdated.
You can find the full list of options in the
CLI documentation on rasa test.
hyperparameter tuning
To further improve your model check out this tutorial on hyperparameter tuning.
Comparing NLU Pipelines
To get the most out of your training data, you should train and evaluate your model on different pipelines and different amounts of training data.
To do so, pass multiple configuration files to the rasa test command:
This performs several steps:
- Create a global 80% train / 20% test split from
data/nlu.yml. - Exclude a certain percentage of data from the global train split.
- Train models for each configuration on remaining training data.
- Evaluate each model on the global test split.
The above process is repeated with different percentages of training data in step 2 to give you an idea of how each pipeline will behave if you increase the amount of training data. Since training is not completely deterministic, the whole process is repeated three times for each configuration specified.
A graph with the mean and standard deviations of
f1-scores
across all runs is plotted.
The f1-score graph, along with all train/test sets, the trained models, classification and error reports,
will be saved into a folder called nlu_comparison_results.
Inspecting the f1-score graph can help you understand if you have enough data for your NLU model. If the graph shows that f1-score is still improving when all of the training data is used, it may improve further with more data. But if f1-score has plateaued when all training data is used, adding more data may not help.
If you want to change the number of runs or exclusion percentages, you can:
Interpreting the Output
Intent Classifiers
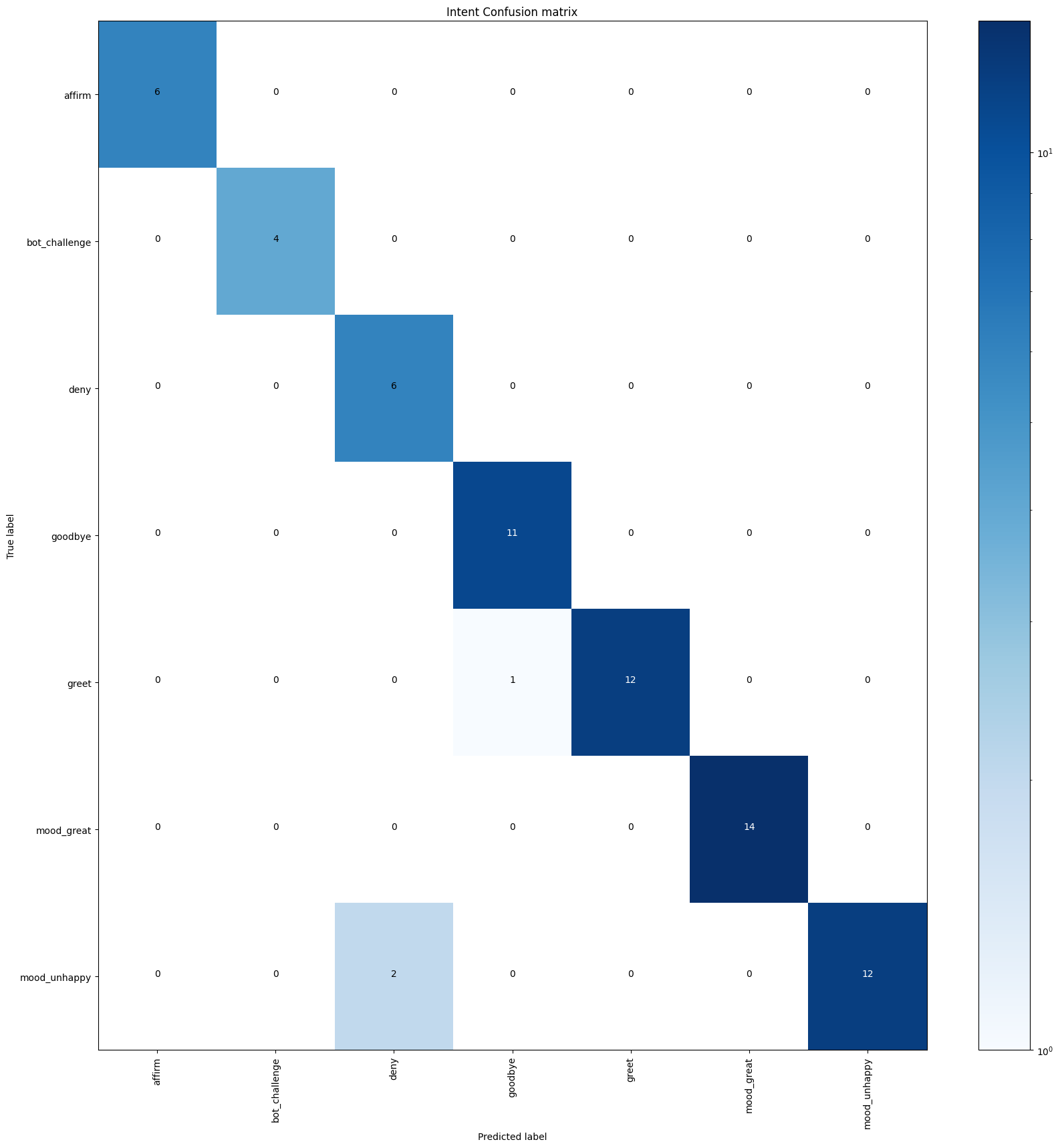
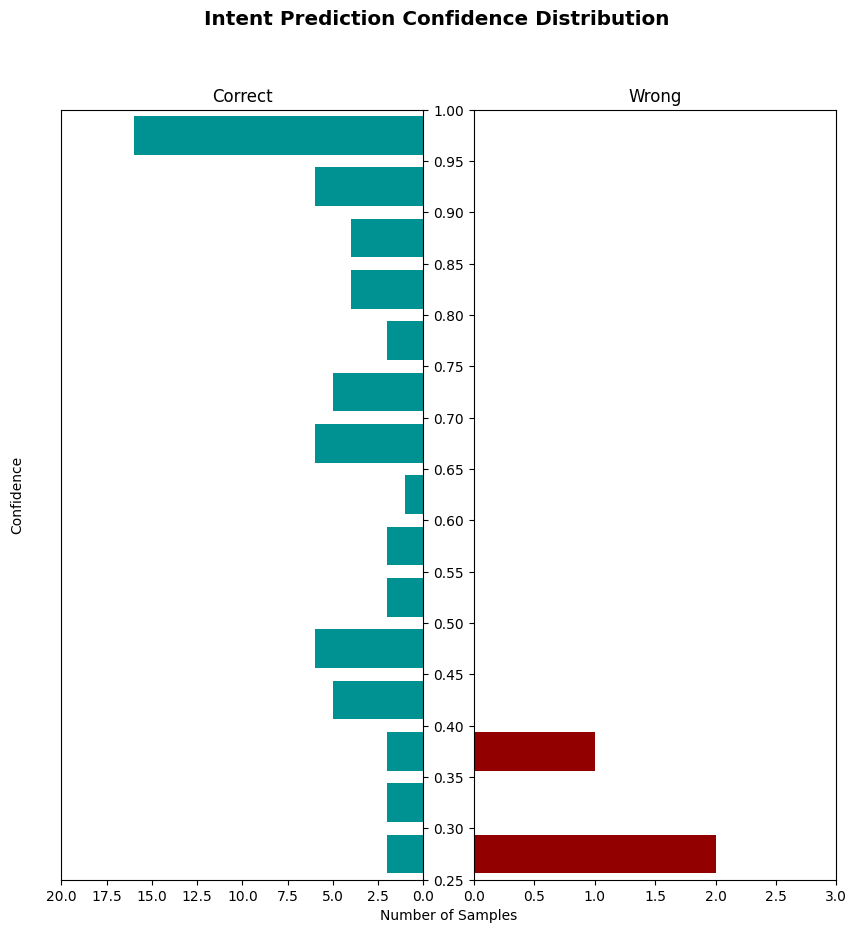
The rasa test script will produce a report (intent_report.json), confusion matrix (intent_confusion_matrix.png)
and confidence histogram (intent_histogram.png) for your intent classification model.
The report logs precision,
recall and
f1-score for each intent,
as well as providing an overall average. You can save these reports as JSON files using the --report argument.
The confusion matrix shows which intents are mistaken for others.
Any samples which have been incorrectly predicted are logged and saved to a file called errors.json for easier debugging.
The histogram allows you to visualize the confidence for all predictions, with the correct and incorrect predictions being displayed by blue and red bars respectively. Improving the quality of your training data will move the blue histogram bars up the plot and the red histogram bars down the plot. It should also help in reducing the number of red histogram bars itself.
Response Selectors
rasa test evaluates response selectors in the same way that it evaluates intent classifiers, producing a
report (response_selection_report.json), confusion matrix (response_selection_confusion_matrix.png),
confidence histogram (response_selection_histogram.png) and errors (response_selection_errors.json).
If your pipeline includes multiple response selectors, they are evaluated in a single report.
The report logs precision, recall and f1 measure for
each sub-intent of a retrieval intent and provides an overall average.
You can save these reports as JSON files using the --report argument.
Entity Extraction
rasa test reports recall, precision, and f1-score for each entity type that
your trainable entity extractors are trained to recognize.
Only trainable entity extractors, such as the DIETClassifier and CRFEntityExtractor are
evaluated by rasa test. Pretrained extractors like the DucklingHTTPExtractor are not evaluated.
If you have multiple entity extractors in your pipeline, or use some custom extractors, multiple entities might be associated with the same token. In this case, you can use a list notation in the test files, such as
incorrect entity annotations
If any of your entities are incorrectly annotated, your evaluation may fail. One common problem
is that an entity cannot stop or start inside a token.
For example, if you have an example for a name entity
like [Brian](name)'s house, this is only valid if your tokenizer splits Brian's into
multiple tokens.
Entity Scoring
To evaluate entity extraction we apply a simple tag-based approach. We don't consider
BILOU tags exactly, but only the
entity type tags on a per token basis. For location entity like “near Alexanderplatz” we
expect the labels LOC LOC instead of the BILOU-based B-LOC L-LOC.
Our approach is more lenient when it comes to evaluation, as it rewards partial extraction and does not penalize the splitting of entities. For example, given the aforementioned entity “near Alexanderplatz” and a system that extracts “Alexanderplatz”, our approach rewards the extraction of “Alexanderplatz” and penalizes the missed out word “near”.
The BILOU-based approach, however, would label this as a complete failure since it expects Alexanderplatz
to be labeled as a last token in an entity (L-LOC) instead of a single token entity (U-LOC). Note also that
a split extraction of “near” and “Alexanderplatz” would get full scores on our approach and zero on the
BILOU-based one.
Here's a comparison between the two scoring mechanisms for the phrase “near Alexanderplatz tonight”:
| extracted | Simple tags (score) | BILOU tags (score) |
|---|---|---|
[near Alexanderplatz](loc) [tonight](time) | loc loc time (3) | B-loc L-loc U-time (3) |
[near](loc) [Alexanderplatz](loc) [tonight](time) | loc loc time (3) | U-loc U-loc U-time (1) |
near [Alexanderplatz](loc) [tonight](time) | O loc time (2) | O U-loc U-time (1) |
[near](loc) Alexanderplatz [tonight](time) | loc O time (2) | U-loc O U-time (1) |
[near Alexanderplatz tonight](loc) | loc loc loc (2) | B-loc I-loc L-loc (1) |
Evaluating a Dialogue Model
You can evaluate your trained dialogue model on a set of test stories by using the test script:
This will print any failed stories to results/failed_test_stories.yml.
A story fails if at least one of the actions was predicted incorrectly.
The test script will also save a confusion matrix to a file called
results/story_confmat.pdf. For each action in your domain, the confusion
matrix shows how often the action was correctly predicted and how often an
incorrect action was predicted instead.
Interpreting the generated warnings
New in 2.8
Warnings for stories were added.
The test script will also generate a warnings file called results/stories_with_warnings.yml.
This file contains all test stories for which action_unlikely_intent
was predicted at any conversation turn but all actions from the original story were predicted correctly.
However, if a test story originally included an action_unlikely_intent, for example to ensure a rule is designed to
trigger the conversation path after an action_unlikely_intent but the ensemble of
policies failed to do so, then the corresponding story will end up in results/failed_test_stories.yml as
a failed story.
The stories are sorted by the severity of action_unlikely_intent's prediction.
This severity is calculated by UnexpecTEDIntentPolicy itself at prediction time.
The higher the severity, the more unlikely is the intent and hence reviewing that particular
conversation path becomes more critical.
Note, that action_unlikely_intent is predicted by
UnexpecTEDIntentPolicy which employs a machine learning based model
under the hood and hence can result in false warnings as well. You can choose to ignore such warnings
if the conversation paths in these stories are already present in the training stories.
Comparing Policy Configurations
To choose a configuration for your dialogue model, or to choose hyperparameters for a specific policy, you want to measure how well your dialogue model will generalize to conversations it hasn't seen before. Especially in the beginning of a project, when you don't have a lot of real conversations to train your bot on, you may not want to exclude some to use as a test set.
Rasa Open Source has some scripts to help you choose and fine-tune your policy configuration. Once you are happy with it, you can then train your final configuration on your full data set.
To do this, you first have to train models for your different configurations. Create two (or more) config files including the policies you want to compare, and then provide them to the train script to train your models:
Similar to how the NLU model was evaluated, the above command trains the dialogue model on multiple configurations and different amounts of training data. For each config file provided, Rasa Open Source will train dialogue models with 0, 5, 25, 50, 70 and 95% of your training stories excluded from the training data. This is repeated three times to ensure consistent results.
Once this script has finished, you can pass multiple models to the test script to compare the models you just trained:
This will evaluate each model on the stories in stories_folder
(can be either training or test set) and plot some graphs
to show you which policy performs best. Since the previous train command
excluded some amount of training data to train each model,
the above test command can measure how well your model predicts the held-out stories.
To compare single policies, create config files containing only one policy each.
note
This training process can take a long time, so we'd suggest letting it run somewhere in the background where it can't be interrupted.
Testing Action Code
The approach used to test your action code will depend on how it is implemented. For example, if you connect to external APIs, you should write integration tests to ensure that those APIs respond as expected to common inputs. However you test your action code, you should include these tests in your CI pipeline so that they run each time you make changes.
If you have any questions or problems, please share them with us in the dedicated testing section on our forum!