Conversational AI with Language Models
CALM (Conversational AI with Language Models) is the dialogue system that runs Rasa text and voice assistants. It interprets user input, manages dialogue, and keeps interactions on track. By combining language model flexibility with predefined logic, Rasa enables fluent, high-trust conversations that reliably resolve user requests.
Key Benefits
- Separation of concerns: In CALM assistants, LLMs keep the conversation fluent but don't guess your business logic.
- Built-in conversational awareness: Detects and handles common conversational patterns like topic changes, corrections, and clarifications for smoother interactions.
- Deterministic execution: Follows structured workflows for reliable, debuggable interactions.
- Designed for efficiency: Optimized for smaller, fine-tuned models (e.g., Llama 8B) to reduce latency and inference costs.
- Works with your existing stack: Integrates with NLU classifiers, entity extractors, and tools, so you can enhance your assistant without starting from scratch.
Who is CALM For?
- AI/ML practitioners and developers looking to build scalable conversational assistants.
- Conversation designers who care about user experience and want to build high-trust AI assistants.
- Businesses seeking robust, next-gen AI applications without sacrificing control or reliability.
Note for researchers: If you use CALM in your research, please consider citing our research paper.
How CALM Works
CALM is a controlled framework that uses an LLM to interpret user input and suggest the next steps—ensuring the assistant follows predefined logic without guessing or inventing the next steps on the fly. Instead, it understands what the user wants and dynamically routes them through structured “Flows,” which are predefined business processes broken down into clear steps.
Let’s walk through how CALM processes user input to see how this works in practice.
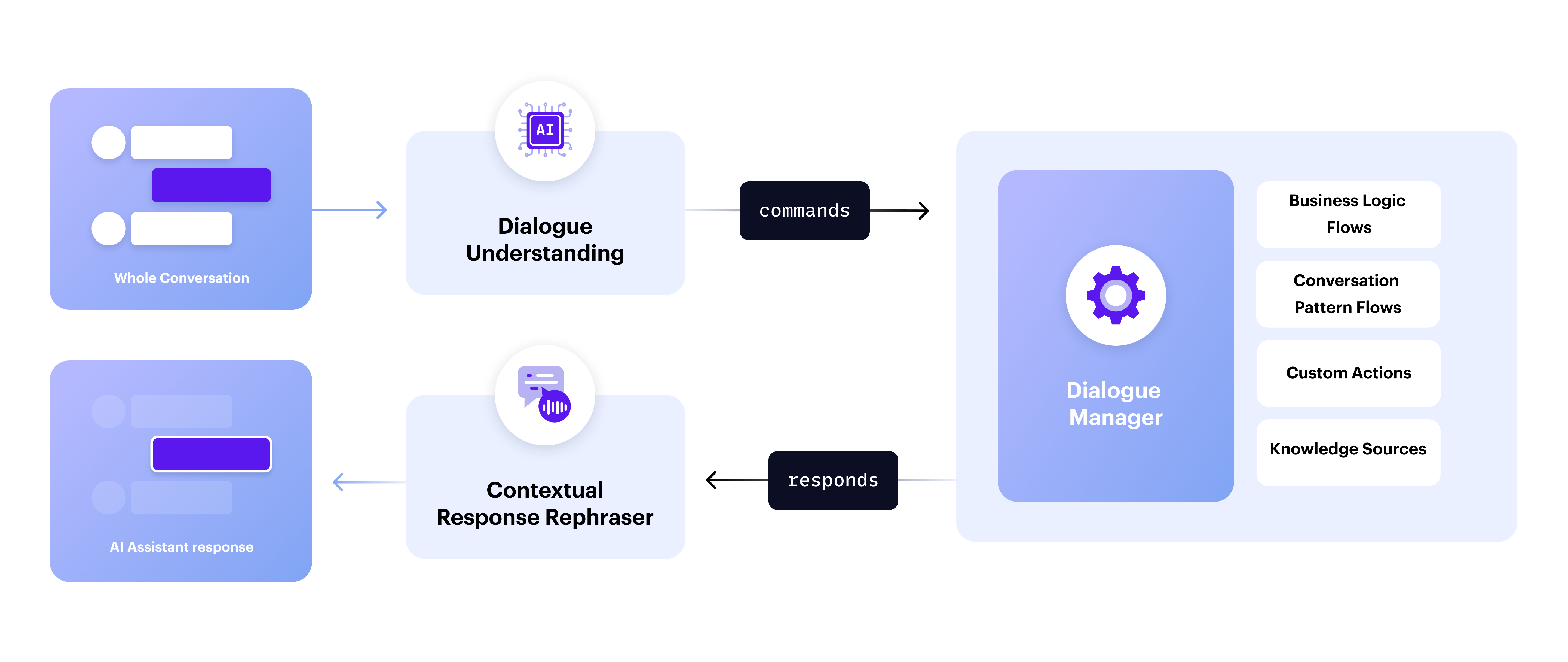
1. Dialogue Understanding
With every incoming user message, CALM performs dialogue understanding:
- Uses a language model to interpret the message in the context of the conversation
- Generates a set of internal commands that represent how the user wants to progress the conversation
- Passes these commands on to the Dialogue Manager to perform the next steps
2. Dialogue Management
Once commands are issued, the dialogue manager decides how to execute them. Commands could instruct the dialogue manager to:
- Start, stop, or resume a flow
- Leverage a conversation pattern flow to handle unexpected interactions automatically
- Activate a backend integration (custom action)
- Answer a question with a knowledge base using RAG (Retrieval Augmented Generation)
3. Contextual Response Rephraser
By default, your assistant sends templated messages to the user, however:
- You can optionally use the contextual response rephraser to improve fluency and coherence
- You can customize the rephraser's prompt and use it only for specific messages
CALM compared to ReAct-Style Agents & Classic Chatbots
This section compares CALM assistants with ReAct-style agents and classic NLU bots, highlighting key differences in how each approach handles user understanding, task execution, scalability, troubleshooting, and production costs.
| Concern | LLM-Centric Approach (ReAct-Style Agents) | Hybrid Approach (CALM Assistants) | Classic Approach (NLU Bots) |
|---|---|---|---|
| Suitable Use Cases | Best for open-ended, exploratory tasks where flexibility outweighs structure and accuracy. | Ideal for structured tasks with clear goals, balancing conversational fluency and reliability. | Best for scenarios where you are not able to use an LLM, delivers deterministic outcomes. |
| Understanding the User | ReAct combines understanding and action into the same process. In each exchange, an LLM is used to process user input and decide what should happen next. | CALM uses LLM to understand user input in the context of the conversation. This is separate from task execution, which is handled by Flows. | NLU bots understand users by classifying the last user input, without the context of the full conversation. The model cannot understand messages that don’t fit into an intent. |
| Deciding the Next Step(s) | Business logic embedded in LLM prompts leads to inconsistent, on-the-fly decisions. | Business logic, step-by-step outlines of how to solve a problem, is defined in Flows. The LLM can dynamically route from flow to flow. | Business logic is predefined in large dialogue trees, breaking if users deviate from the expected path. |
| Scaling to a large number of tasks | Performance degrades as more agents/tasks are added, increasing resource use and introducing cascading errors that require complex guardrails. | Scales reliably to many topics and Flows. Reusable, modular Flows help maintain performance. | As NLU models scale, accuracy suffers due to topic overlap, and expanding dialogue trees becomes difficult to maintain. |
| Ease of Troubleshooting | Debugging is tough because you have to read through lots of unstructured text to guess why things went wrong, and fixing it means trying random changes until something works. | Simplifies debugging by separating reasoning from task execution. LLMs output discrete commands, allowing you to pinpoint why the system behaved a certain way. | NLU debugging and root cause analysis are straightforward since every part of the dialogue is pre-planned. However, it is often tough to implement a user-friendly fix due to rigidity. |
| Cost in Production | High costs and latency due to calling LLMs multiple times in series. | More cost-efficient, using smaller, fine-tuned models like Llama 8B to reduce latency and costs. | NLU models are very inexpensive and have low latency. |
Smaller Models, Big Results
CALM works out of the box with state-of-the-art models, such as OpenAI’s GPT 4. It is also designed to work with fine-tuned models as small as Llama 8B, enabling:
- Faster Response Times: Essential for real-time applications like voice assistants.
- Cost Efficiency: Shift from token-based pricing to predictable hosting costs with self-hosted models.
- Scalability: Deploy on Hugging Face or private infrastructure for better control over performance and security.
Learn more about CALM
Take the next step in building reliable, scalable conversational AI: