
Tuning Your NLU Model
Rasa will provide you with a suggested NLU config on initialization of the project, but as your project grows, it's likely that you will need to adjust your config to suit your training data.
NLU-based assistants
This section refers to building NLU-based assistants. If you are working with Conversational AI with Language Models (CALM), this content may not apply to you.
How to Choose a Pipeline
In Rasa, incoming messages are processed by a sequence of components.
These components are executed one after another in a so-called processing pipeline defined in your config.yml.
Choosing an NLU pipeline allows you to customize your model and finetune it on your dataset.
To get started, you can let the
Suggested Config feature choose a
default pipeline for you.
Just provide your bot's language in the config.yml file and leave the pipeline key
out or empty.
Sensible Starting Pipelines
If you're starting from scratch, it's often helpful to start with pretrained word embeddings. Pre-trained word embeddings are helpful as they already encode some kind of linguistic knowledge. For example, if you have a sentence like “I want to buy apples” in your training data, and Rasa is asked to predict the intent for “get pears”, your model already knows that the words “apples” and “pears” are very similar. This is especially useful if you don't have enough training data.
If you are getting started with a one of spaCy's supported languages, we recommend the following pipeline:
It uses the SpacyFeaturizer, which provides pre-trained word embeddings (see Language Models).
If you don't use any pre-trained word embeddings inside your pipeline, you are not bound to a specific language and can train your model to be more domain specific.
If there are no word embeddings for your language or you have very domain specific terminology, we recommend using the following pipeline:
This pipeline uses the CountVectorsFeaturizer to train on only the training data you provide. This pipeline can handle any language in which words are separated by spaces. If this is not the case for your language, check out alternatives to the WhitespaceTokenizer.
note
If you want to use custom components in your pipeline, see Custom NLU Components.
Component Lifecycle
Each component processes an input and/or creates an output. The order of the components is determined by
the order they are listed in the config.yml; the output of a component can be used by any other component that
comes after it in the pipeline. Some components only produce information used by other components
in the pipeline. Other components produce output attributes that are returned after
the processing has finished.
For example, for the sentence "I am looking for Chinese food", the output is:
This is created as a combination of the results of the different components in the following pipeline:
For example, the entities attribute here is created by the DIETClassifier component.
Every component can implement several methods from the Component base class; in a pipeline these different methods
will be called in a specific order. Assuming we added the following pipeline to our config.yml:
The image below shows the call order during the training of this pipeline:
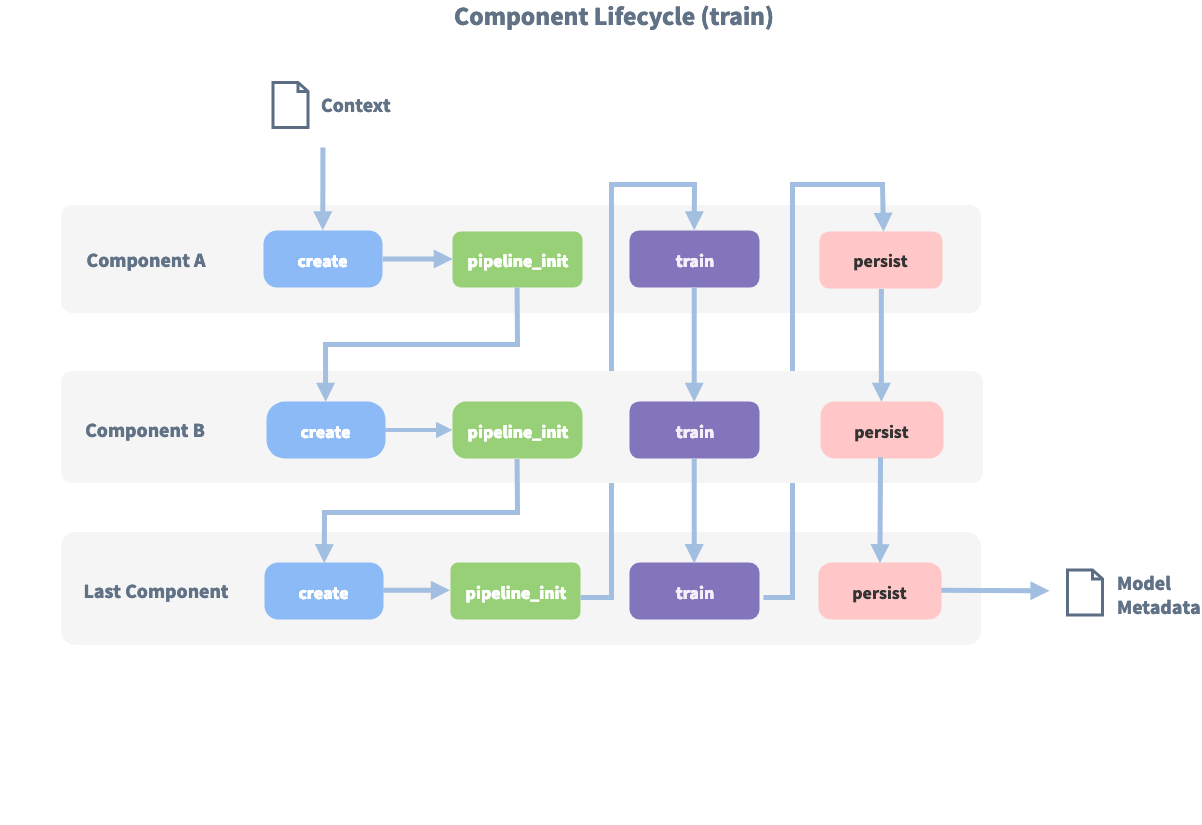
Before the first component is created using the create function, a so
called context is created (which is nothing more than a python dict).
This context is used to pass information between the components. For example,
one component can calculate feature vectors for the training data, store
that within the context and another component can retrieve these feature
vectors from the context and do intent classification.
Initially the context is filled with all configuration values. The arrows in the image show the call order and visualize the path of the passed context. After all components are trained and persisted, the final context dictionary is used to persist the model's metadata.
Doing Multi-Intent Classification
You can use multi-intent classification to predict multiple intents (e.g. check_balances+transfer_money), or to model hierarchical intent structure (e.g. feedback+positive being more similar to feedback+negative than chitchat).
To do multi-intent classification, you need to use the DIETClassifier in your pipeline. You'll also need to define these flags in whichever tokenizer you are using:
intent_tokenization_flag: Set it toTrue, so that intent labels are tokenized.intent_split_symbol: Set it to the delimiter string that splits the intent labels. In this case+, default_.
Here's an example configuration:
When to Use Multi-Intents
Let's say you have a financial services bot and you have examples for intents check_balances and transfer_money:
However, your bot receives incoming messages like this one, which combine both intents:
User: How much money do I have? I want to transfer some to savings.
If you see enough of these examples, you can create a new intent multi-intent check_balances+transfer_money and add the incoming examples to it, for example:
note
The model will not predict any combination of intents for which examples are not explicitly given in training data. As accounting for every possible intent combination would result in combinatorial explosion of the number of intents, you should only add those combinations of intents for which you see enough examples coming in from real users.
How to Use Multi-Intents for Dialogue Management
Multi-intent classification is intended to help with the downstream task of action prediction after a multi-intent. There are two complementary ways to use multi intents in dialogue training data:
- Add regular stories or rules for the multi-intent. For example, given the following two rules for each individual intent:
You could add another rule for the multi-intent that specifies a sequence of actions to address both intents:
- Allow a machine-learning policy to generalize to the multi-intent scenario from single-intent stories.
When using a multi-intent, the intent is featurized for machine learning policies using multi-hot encoding. That means the featurization of check_balances+transfer_money will overlap with the featurization of each individual intent. Machine learning policies (like TEDPolicy) can then make a prediction based on the multi-intent even if it does not explicitly appear in any stories. It will typically act as if only one of the individual intents was present, however, so it is always a good idea to write a specific story or rule that deals with the multi-intent case.
Comparing Pipelines
Rasa gives you the tools to compare the performance of multiple pipelines on your data directly. See Comparing NLU Pipelines for more information.
Choosing the Right Components
There are components for entity extraction, for intent classification, response selection, pre-processing, and others. If you want to add your own component, for example to run a spell-check or to do sentiment analysis, check out Custom NLU Components.
A pipeline usually consists of three main parts:
Tokenization
You can process whitespace-tokenized (i.e. words are separated by spaces) languages with the WhitespaceTokenizer. If your language is not whitespace-tokenized, you should use a different tokenizer. We support a number of different tokenizers, or you can create your own custom tokenizer.
note
Some components further down the pipeline may require a specific tokenizer. You can find those requirements
on the individual components' requires parameter. If a required component is missing inside the pipeline, an
error will be thrown.
Featurization
You need to decide whether to use components that provide pre-trained word embeddings or not. We recommend in cases of small amounts of training data to start with pre-trained word embeddings. Once you have a larger amount of data and ensure that most relevant words will be in your data and therefore will have a word embedding, supervised embeddings, which learn word meanings directly from your training data, can make your model more specific to your domain. If you can't find a pre-trained model for your language, you should use supervised embeddings.
Pre-trained Embeddings
The advantage of using pre-trained word embeddings in your pipeline is that if you have a training example like: “I want to buy apples”, and Rasa is asked to predict the intent for “get pears”, your model already knows that the words “apples” and “pears” are very similar. This is especially useful if you don't have enough training data. We support a few components that provide pre-trained word embeddings:
If your training data is in English, we recommend using the ConveRTFeaturizer. The advantage of the ConveRTFeaturizer is that it doesn't treat each word of the user message independently, but creates a contextual vector representation for the complete sentence. For example, if you have a training example, like: “Can I book a car?”, and Rasa is asked to predict the intent for “I need a ride from my place”, since the contextual vector representation for both examples are already very similar, the intent classified for both is highly likely to be the same. This is also useful if you don't have enough training data.
An alternative to ConveRTFeaturizer is the LanguageModelFeaturizer which uses pre-trained language models such as BERT, GPT-2, etc. to extract similar contextual vector representations for the complete sentence. See LanguageModelFeaturizer for a full list of supported language models.
If your training data is not in English you can also use a different variant of a language model which
is pre-trained in the language specific to your training data.
For example, there are chinese (bert-base-chinese) and japanese (bert-base-japanese) variants of the BERT model.
A full list of different variants of
these language models is available in the
official documentation of the Transformers library.
spacynlp also provides word embeddings in many different languages, so you can use this as another alternative, depending on the language of your training data.
Supervised Embeddings
If you don't use any pre-trained word embeddings inside your pipeline, you are not bound to a specific language and can train your model to be more domain specific. For example, in general English, the word “balance” is closely related to “symmetry”, but very different to the word “cash”. In a banking domain, “balance” and “cash” are closely related and you'd like your model to capture that. You should only use featurizers from the category sparse featurizers, such as CountVectorsFeaturizer, RegexFeaturizer or LexicalSyntacticFeaturizer, if you don't want to use pre-trained word embeddings.
Intent Classification / Response Selectors
Depending on your data you may want to only perform intent classification, entity recognition or response selection. Or you might want to combine multiple of those tasks. We support several components for each of the tasks. We recommend using DIETClassifier for intent classification and entity recognition and ResponseSelector for response selection.
By default all of these components consume all available features produced in the pipeline.
However, sometimes it makes sense to restrict the features that are used by a specific component.
For example, ResponseSelector is likely to perform better if no features from the
RegexFeaturizer or LexicalSyntacticFeaturizer are used.
To achieve that, you can do the following:
Set an alias for every featurizer in your pipeline via the option alias.
By default the alias is set the the full featurizer class name, for example, RegexFeaturizer.
You can then specify, for example, on the ResponseSelector via the option featurizers what features from
which featurizers should be used.
If you don't set the option featurizers all available features will be used.
Here is an example configuration file where the DIETClassifier is using all available features and the
ResponseSelector is just using the features from the ConveRTFeaturizer and the CountVectorsFeaturizer.
Entity Extraction
Entity extraction involves parsing user messages for required pieces of information. Rasa provides entity extractors for custom entities as well as pre-trained ones like dates and locations. Here is a summary of the available extractors and what they are best used for:
| Component | Requires | Model | Notes |
|---|---|---|---|
DIETClassifier | N/A | conditional random field on top of a transformer | good for training custom entities |
CRFEntityExtractor | sklearn-crfsuite | conditional random field | good for training custom entities |
SpacyEntityExtractor | spaCy | averaged perceptron | provides pre-trained entities |
DucklingEntityExtractor | running duckling | context-free grammar | provides pre-trained entities |
MitieEntityExtractor | MITIE | structured SVM | good for training custom entities |
EntitySynonymMapper | existing entities | N/A | maps known synonyms |
Improving Performance
Handling Class Imbalance
Classification algorithms often do not perform well if there is a large class imbalance,
for example if you have a lot of training data for some intents and very little training data for others.
To mitigate this problem, you can use a balanced batching strategy.
This algorithm ensures that all classes are represented in every batch, or at least in
as many subsequent batches as possible, still mimicking the fact that some classes are more frequent than others.
Balanced batching is used by default. In order to turn it off and use a classic batching strategy include
batch_strategy: sequence in your config file.
Accessing Diagnostic Data
To gain a better understanding of what your models do, you can access intermediate results of the prediction process.
To do this, you need to access the diagnostic_data field of the Message
and Prediction objects, which contain
information about attention weights and other intermediate results of the inference computation.
You can use this information for debugging and fine-tuning, e.g. with RasaLit.
After you've trained a model, you can access diagnostic data for DIET, given a processed message, like this:
And you can access diagnostic data for TED like this:
Configuring Tensorflow
TensorFlow allows configuring options in the runtime environment via
TF Config submodule. Rasa supports a smaller subset of these
configuration options and makes appropriate calls to the tf.config submodule.
This smaller subset comprises of configurations that developers frequently use with Rasa.
All configuration options are specified using environment variables as shown in subsequent sections.
Deterministic Operations
If you are using GPUs and have one or more sparse featurizer(s) in
your pipeline, and/or use any of TEDPolicy, UnexpecTEDIntentPolicy, DIETClassifier,
or ResponseSelector, training and testing will fail if you set the environment variable
TF_DETERMINISTIC_OPS=1, because there are no deterministic GPU implementations of
underlying tensorflow ops tf.sparse.sparse_dense_matmul,
tf.nn.sparse_softmax_cross_entropy_with_logits,
and tf.math.unsorted_segment ops. For more information see here
For the above reasons, the models are also not guaranteed to yield the exact same performance when trained on GPU across multiple runs. This even applies to situations where training is run multiple times on the same training data, with the same config and random seeds set appropriately, while evaluating on a standard held-out test set. Internal experiments have shown the following fluctuation in model performance when trained and evaluated on a held-out test set on a variety of datasets (experiments were run 5 times on each dataset):
The above experiments were run on an Nvidia Tesla P4 GPU. You can expect similar fluctuations in the model performance when you evaluate on your dataset. Across different pipeline configurations tested, the fluctuation is more pronounced when you use sparse featurizers in your pipeline. You can see which featurizers are sparse here, by checking the "Type" of a featurizer.
Model performance on the above tasks should still be reproducible across multiple runs when trained on a CPU and none of these have changed:
- Training data
- Test data
- Configuration pipeline
- Random Seed in configuration's components.
- Hardware and Software Environment (Operating system, CUDA version, environmental variables etc.)
Optimizing CPU Performance
note
We recommend that you configure these options only if you are an advanced TensorFlow user and understand the implementation of the machine learning components in your pipeline. These options affect how operations are carried out under the hood in Tensorflow. Leaving them at their default values is fine.
Depending on the TensorFlow operations a NLU component or Core policy uses, you can leverage multi-core CPU parallelism by tuning these options.
Parallelizing One Operation
Set TF_INTRA_OP_PARALLELISM_THREADS as an environment variable to specify the maximum number of threads that can be used
to parallelize the execution of one operation. For example, operations like tf.matmul() and tf.reduce_sum can be executed
on multiple threads running in parallel. The default value for this variable is 0 which means TensorFlow would
allocate one thread per CPU core.
Parallelizing Multiple Operations
Set TF_INTER_OP_PARALLELISM_THREADS as an environment variable to specify the maximum number of threads that can be used
to parallelize the execution of multiple non-blocking operations. These would include operations that do not have a
directed path between them in the TensorFlow graph. In other words, the computation of one operation does not affect the
computation of the other operation. The default value for this variable is 0 which means TensorFlow would allocate one thread per CPU core.
To understand more about how these two options differ from each other, refer to this stackoverflow thread.
Optimizing GPU Performance
Limiting GPU Memory Growth
TensorFlow by default blocks all the available GPU memory for the running process. This can be limiting if you are running
multiple TensorFlow processes and want to distribute memory across them. To prevent Rasa from blocking all
of the available GPU memory, set the environment variable TF_FORCE_GPU_ALLOW_GROWTH to True.
Restricting Absolute GPU Memory Available
You may want to limit the absolute amount of GPU memory that can be used by a Rasa process.
For example, say you have two visible GPUs(GPU:0 and GPU:1) and you want to allocate 1024 MB from the first GPU
and 2048 MB from the second GPU. You can do this by setting the environment variable TF_GPU_MEMORY_ALLOC to "0:1024, 1:2048".