


December 12th, 2022
Applying Generative Models in Conversational AI
Alan Nichol

Unleashing a large language model (LLM) on your customers, generating answers to their support requests while representing your brand, is a spectacularly bad idea. Unless, of course, you’re comfortable with a chatbot that will invent its own facts , amplify biases, and produce convincing but inaccurate answers in ways that we do not know how to control. I wrote in 2016 that generative models and hand-coded logic make unhappy bedfellows. And while there’s been progress, marrying the two is far from a solved problem.
But I am very excited about the impact ChatGPT will have on how we build conversational AI. Generating responses to send to your users requires a level of trust in large language models that no sensible person would have, but use cases that allow for a tight iterative creative cycle between human and machine and hold immediate promise.

We’ve experimented with half a dozen different applications of generative models at Rasa and seen some interesting and promising results. This post describes some of our experiences using LLMs to build user simulators than can help us accelerate the development of AI systems.
Simulation for Machine Learning
Chatbots require training data that represents both what users are going to say and what the bot should do in response. At inception, you’re faced with a “cold start” problem: you don’t have the data to build your system, and you don’t have a working system to help you collect data. This is the case for many real-world applications of ML, and one way to pull yourself up by the bootstraps is to use a simulator. This approach is especially mature in autonomous driving, where major players have built products for simulation.
What if we could create a simulated user to kick the tires on chatbot and help us bootstrap conversation-driven development?
No Free Lunch
When building a user simulator, there’s a trade-off between faithfulness and variability. You can make a user simulator that’s very boring and always follows your instructions to the letter, but also produces very little surprising behavior and only tests your bot in ways you already anticipated. Or you can make a simulator that shows a great deal of variability but frequently goes its own way and strays from the instructions you provided.
Paraphrasing provides a nice illustration of this trade-off. We’ve done experiments (as have others) on using paraphrasing to augment NLU training data, but we haven’t seen convincing evidence that this meaningfully improves your model. Why? It’s the same trade-off. With high variability, you’ll end up creating some ‘paraphrases’ that no longer mean the same thing. With low variability, you’re just generating minor re-wordings that won’t teach your model anything new. There is, unfortunately, no free lunch. (If you did have a model that could take an utterance and generate many variations that are all semantically equivalent, you would already have a perfect model!)
User simulators are like paraphrasing models, but instead of just producing variations of a single utterance, they produce variations of whole conversations.
You might wonder why this is so hard. Is conversation really harder than self-driving cars? For your model to learn something non-trivial, your simulator needs to give you back more than what you’ve explicitly programmed in. A traffic simulator can generate complex situations through the interactions of many cars & pedestrians, each acting and reacting according to a few simple rules, like a flock of boids. I, for one, wouldn’t know how to write down equivalent behavior rules for conversation.
But we can do useful things with an imperfect user simulator. Instead of training our AI assistant based on its interactions with a simulated user, we can use the simulator for evaluation, or for QA.
Getting LLMs to act more like human testers
We carried out some experiments with carbon bot where we recruited human testers to get a carbon offset estimate and compared their success with an LLM-based user simulator. It’s important to remember that in this case human testers are also user simulators. Someone pretending to need something from a chatbot is never the same as someone who actually needs it, even if you try really hard to get them in character.
Prompting an off-the-shelf (not fine-tuned) LLM to behave like a chatbot user, we noticed that our LLM, compared to human testers:
- successfully completed the task only half as often
- used a 2x larger vocabulary than our human testers
- produced much longer messages with significantly fewer typos
The LLM-based simulated user would also occasionally get stuck in an infinite loop - repeating the same thing over and over (and getting the same response as well). None of our human testers did this (though I know from our customers that the users of their chatbots will often send the same message over and over, hoping to get a different response).
As a second set of experiments, we fine-tuned our LLM on a few dozen of our test users’ conversations with carbon bot. This fine-tuned user simulator matched the length and vocabulary of real user utterances much more closely. Beyond a certain amount of fine-tuning, the LLM even surpassed humans’ task success rate, having learned “how to talk” to carbon bot. While our off-the-shelf LLM didn’t behave the way human testers did, it uncovered more ways the bot could fail. Our fine-tuned model acted more faithfully like a human, but in sacrificing variability became a less comprehensive tester of our bot.
What a user simulator can & cannot tell you
Evaluation
A fine-tuned LLM is not a substitute for real users interacting with your bot. But taken with a grain of salt, you can use a user simulator to run controlled experiments.
For example, we intuitively know that a quality NLU model is an essential component of an AI assistant. But if you improve your NLU model’s accuracy by 10%, what does that actually translate to in terms of improved user experience and better business outcomes? How strong is the correlation, and are there diminishing returns?
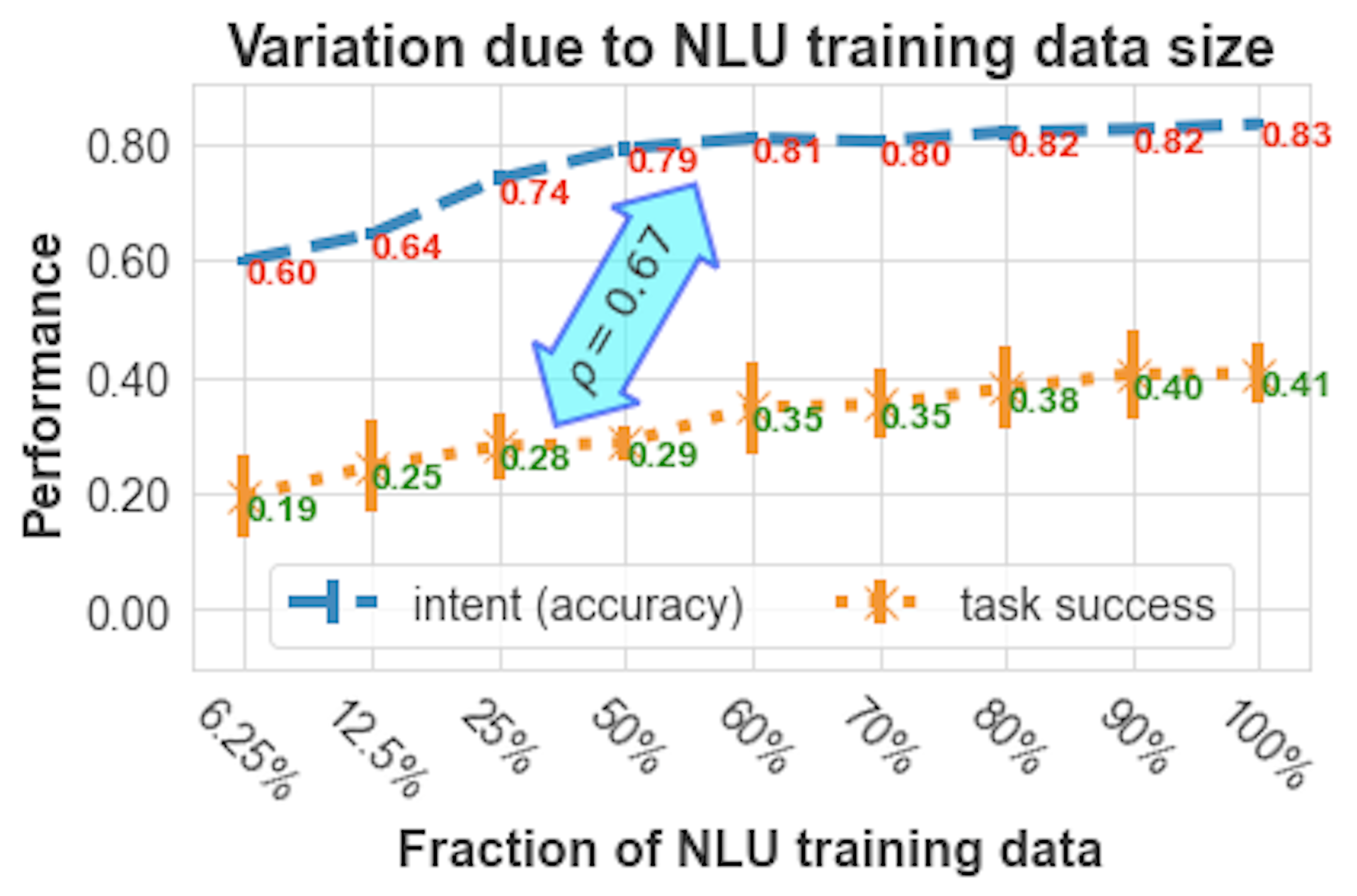
A user simulator is cheap to scale, so we can run evaluations against many different versions of our bot to produce plots like this one. As we progressively add more NLU data, we not only see our intent classification performance improve (blue line) but also see the corresponding increase in successful conversations (task success, yellow line). We used a similar setup to evaluate various dialogue policy hyperparameters and compare end-to-end and intent-based models.
Quality Assurance
"Program testing can be used to show the presence of bugs, but never to show their absence!” - Dijkstra
Even a not-perfectly-faithful user simulator can be an effective way to uncover failure modes in your chatbot. We’ve set up automated runs with user simulators inside CI/CD pipelines. It’s a helpful diagnostic that can identify regressions before they get merged (and show you exactly which conversations went wrong!). Some of the issues you uncover may be “false positives” - failure modes that real users would never encounter. But remembering Dijkstra’s quote, the best we can do in QA is uncover problems.
Conclusion
Over the last couple of years many of us have been surprised again and again by Generative AI models and LLMs in particular. A few years ago, it wasn't possible to automatically turn a few bullet points into a short essay. Now it’s becoming a table-stakes feature for writing apps. LLMs have serious limitations which mean they are almost never appropriate to use without a human in the loop. But they can still improve time-to-value for mission-critical conversational AI applications. If you'd like to learn more about what we're doing with LLMs at Rasa, please reach out!
Footnotes
- This post builds on work done by multiple colleagues, especially Chris Kedzie, Thomas Kober, Sam Sucik, and Daksh Varshneya.
- There is substantial academic literature on user simulation for dialogue systems, and recently multiple papers have been published on applying LLMs to this task. I’d recommend [1, 2, 3, 4] as starting points if you’re looking for a scholarly treatment of the subject.