

February 19th, 2019
Enhancing Rasa NLU models with Custom Components
Justina Petraitytė

We believe that customizing ML models is crucial for building successful AI assistants. The open source Rasa provides you with a strong foundation for building good NLU models for intent classification and entity extraction, but if you have ever wanted to enhance existing Rasa NLU models with your own custom components (sentiment analyzer, spell checker, character-level tokenizer, byte-pair encoder, etc), we put a lot of work into making Rasa NLU modular so that you can do this. Want to learn how to implement it? You came to the right place! In this tutorial, you will learn how to implement custom components and add them to the Rasa NLU pipeline to take your AI assistants to a whole new level!
Note! This blogpost was made with Rasa Open Source 1.x in mind. The code won't work for newer versions of Rasa.
Outline
- Introduction to the Rasa NLU pipeline
- Intro to Custom Components
- Adding a custom Sentiment Analysis Component to the Rasa NLU
- Summary
- Resources
Introduction to the Rasa NLU pipeline
A processing pipeline is the main building block of the Rasa NLU model. It defines what processing stages the incoming user messages will have to go through until the model output is produced. Those stages can be tokenization, featurization, intent classification, entity extraction, pattern matching, etc. By default, Rasa NLU comes with a bunch of pre-built components (and even fully designed pipelines) for you to use. Below is an example of a possible Rasa NLU pipeline configuration:
pipeline:- name: "SpacyNLP"- name: "SpacyTokenizer"- name: "SpacyFeaturizer"- name: "RegexFeaturizer"- name: "CRFEntityExtractor"- name: "EntitySynonymMapper"- name: "SklearnIntentClassifier" """Once the pipeline is defined, each component is called one after another and produces the output which is either directly added to the Rasa NLU model output, or used as an input for other components. It is important to keep in mind that how you define the components in the configuration file matters. If, for example, you define three components in your pipeline ['Component1', 'Component2', 'Component3'], the methods of the 'Component1' will be called first. An image below shows the component lifecycle:
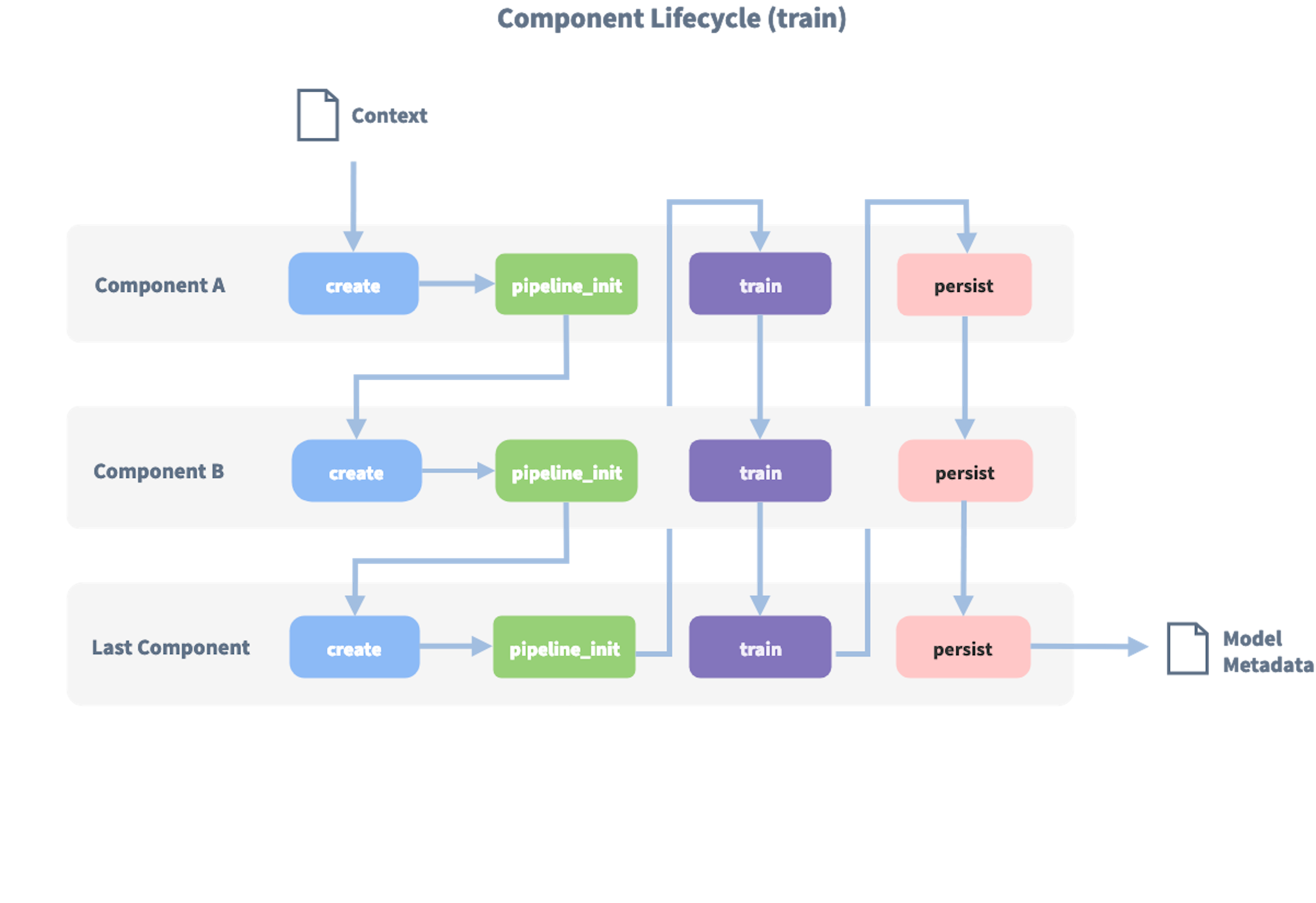
Components go through the three main stages:
- create: initialization of the component before the training
- train: the component trains itself using the context and potentially the output of the previous components
- persist: saving the trained component on disk for the future use
Before the first component is initialized, a so-called context is created which is used to pass the information between the components. For example, one component can calculate feature vectors for the training data, store that within the context and another component can retrieve these feature vectors from the context and do intent classification. Once all components are created, trained and persisted, the model metadata is created which describes the overall NLU model.
Intro to Custom Components
Using the pre-built Rasa NLU components, you have a lot of freedom in customizing the models. However, in some situations, you might want to add a component which is not natively implemented in Rasa NLU. For example, you could add a sentiment analyzer which will enable your assistant to use different responses depending on the user's mood or maybe you would like to add a spell checker to correct the spelling mistakes inside the user messages before intents are classified and entities are extracted and used to make an API call or find records in a database. Adding custom components to the NLU pipeline is a process of implementing the custom component class with the necessary methods and referencing it inside the Rasa NLU pipeline configuration file. In general, there are two types of custom components you might want to use:
- Components which come as already pre-trained models (for example, trained on different datasets and packaged as python libraries, .pkl files, etc)
- Components which train on your Rasa NLU training data and improve as you make changes to the training examples or add more of them
In the next step of this post, you will learn how to implement both of these cases in practice.
Adding a custom Sentiment Analysis Component to the Rasa NLU
Let's take the actual example of adding a sentiment analyzer to the Rasa NLU pipeline. First, you will learn how to design it so that the performance of the component would improve as you add more training examples. Since sentiment analysis is a supervised classification problem, it means that for this specific example, you will have to assign one more label to the NLU training examples - the polarity of the sentiment (positive, negative, neutral). One of the ways to add these new labels is storing them in a separate file. For example, if your Rasa NLU training data looks like the following:
## intent: feedback- It's very helpful- I had the best experience speaking with you- no feedback- ok- You are the most stupid bot I have ever seen- the worstthe corresponding labels could look like this:
pos
pos
neu
neu
neg
neg
Next, it's all about building the actual component. Let's learn how to implement it!
Building a Custom Sentiment Analysis Component class
Custom Component class will define how the component will be trained, what details it will take as an input and what details it will produce. To define the component, create a new file (for example, sentiment.py) and start by setting the name of your custom component class as well as defining the main details which describe it:
- name: the name of the component
- provides: what output the custom component produces
- requires: what attributes of the message this component requires
- defaults: default configuration parameters of a component
- language_list: a list of languages compatible with the component
In the example below, the custom component class name is set as SentimentAnalyzer and the actual name of the component is sentiment. In order to enable the dialogue management model to access the details of this component and use it to drive the conversation based on the user's mood, the sentiment analysis results will be saved as entities. For this reason, the sentiment component configuration includes that the component provides entities. Since the sentiment model takes tokens as input, these details can be taken from other pipeline components responsible for tokenization. That's why the component configuration below states that the custom component requires tokens. Finally, since this example will include a sentiment analysis model which only works in the English language, include en inside the languages list.
Once this is defined, you can move on to the implementation of the main methods of the class:
- init: initialization of the component
- train: a method which is responsible for training the component
- process: a method which will parse incoming user messages
- persist: a method which will save a trained component on disk for later use
The code below shows the implementation of the methods for this specific example. Let's go through them step by step:
- The init function initialises the custom component class using the component configuration which can be defined when referencing the custom component inside the pipeline configuration file.
- The train() function retrieves training examples in a form of tokens produced by previous components, loads the sentiment labels and after formatting the data trains a sentiment classifier.
- The process() function uses the tokens of the new user message and appends the sentiment analysis model predictions as entities to the message class.
- The persist() function saves a trained sentiment model as a .pkl file for the later use
- The load() function defines how the persisted sentiment model can be loaded.
from rasa.nlu.components import Componentfrom rasa.nlu import utilsfrom rasa.nlu.model import Metadata
import nltkfrom nltk.classify import NaiveBayesClassifierimport os
import typingfrom typing import Any, Optional, Text, Dict
SENTIMENT_MODEL_FILE_NAME = "sentiment_classifier.pkl"
class SentimentAnalyzer(Component): """A custom sentiment analysis component""" name = "sentiment" provides = ["entities"] requires = ["tokens"] defaults = {} language_list = ["en"] print('initialised the class')
def __init__(self, component_config=None): super(SentimentAnalyzer, self).__init__(component_config)
def train(self, training_data, cfg, **kwargs): """Load the sentiment polarity labels from the text file, retrieve training tokens and after formatting data train the classifier."""
with open('labels.txt', 'r') as f: labels = f.read().splitlines()
training_data = training_data.training_examples #list of Message objects tokens = [list(map(lambda x: x.text, t.get('tokens'))) for t in training_data] processed_tokens = [self.preprocessing(t) for t in tokens] labeled_data = [(t, x) for t,x in zip(processed_tokens, labels)] self.clf = NaiveBayesClassifier.train(labeled_data)
def convert_to_rasa(self, value, confidence): """Convert model output into the Rasa NLU compatible output format."""
entity = {"value": value, "confidence": confidence, "entity": "sentiment", "extractor": "sentiment_extractor"}
return entity
def preprocessing(self, tokens): """Create bag-of-words representation of the training examples.""" return ({word: True for word in tokens})
def process(self, message, **kwargs): """Retrieve the tokens of the new message, pass it to the classifier and append prediction results to the message class.""" if not self.clf: # component is either not trained or didn't # receive enough training data entity = None else: tokens = [t.text for t in message.get("tokens")] tb = self.preprocessing(tokens) pred = self.clf.prob_classify(tb)
sentiment = pred.max() confidence = pred.prob(sentiment)
entity = self.convert_to_rasa(sentiment, confidence)
message.set("entities", [entity], add_to_output=True)
def persist(self, file_name, model_dir): """Persist this model into the passed directory.""" classifier_file = os.path.join(model_dir, SENTIMENT_MODEL_FILE_NAME) utils.json_pickle(classifier_file, self) return {"classifier_file": SENTIMENT_MODEL_FILE_NAME}
@classmethod def load(cls, meta: Dict[Text, Any], model_dir=None, model_metadata=None, cached_component=None, **kwargs): file_name = meta.get("classifier_file") classifier_file = os.path.join(model_dir, file_name) return utils.json_unpickle(classifier_file)And that's it! You have just implemented a custom component which parses incoming user messages and returns the sentiment as an entity called 'sentiment'. To use this component, make sure to reference it inside the Rasa NLU pipeline configuration file. You can reference custom components the same way as you would reference python modules - module_name.class_name. Since this custom component requires tokens, you should add it after the component which produces them. The example pipeline configuration below means that the methods of the sentiment component will be called after the SpacyTokenizer component_,_ responsible for splitting sentences into tokens:
pipeline:- name: "SpacyNLP"- name: "SpacyTokenizer"- name: "sentiment.SentimentAnalyzer" - name: "SpacyFeaturizer"- name: "RegexFeaturizer"- name: "CRFEntityExtractor"- name: "EntitySynonymMapper"- name: "SklearnIntentClassifier" """After training the Rasa NLU model with the custom Sentiment Analysis component, you can test how it performs!
Note: To make sure that Rasa picks up your component, make sure to add your project directory to PYTHONPATH. To do that, you can run:
_export PYTHONPATH=/path_to_your_project_dir/:$PYTHONPATH_
Below is an example of how the output of the Rasa NLU model with a custom Sentiment Analysis component looks like when the assistant is greeted by a rather impolite user:
{ 'intent':{ 'name':'greet', 'confidence':0.44503513568867775 }, 'entities':[ { 'value':'neg', 'confidence':0.9933702940854111, 'entity':'sentiment', 'extractor':'sentiment_extractor' } ], 'intent_ranking':[ { 'name':'greet', 'confidence':0.44503513568867775 }, { 'name':'chitchat', 'confidence':0.20129539551108508 }, { 'name':'inform', 'confidence':0.09576408290307896 }, { 'name':'goodbye', 'confidence':0.08987117551991658 }, { 'name':'decline', 'confidence':0.08840002616908385 }, { 'name':'affirm', 'confidence':0.04842063587016189 }, { 'name':'restaurant', 'confidence':0.03121354833799584 } ], 'text':'Hello stupid bot'}What if I want to use a pre-trained Sentiment Analysis model?
The custom component example above includes a rather simple sentiment model which would improve as you add more NLU training examples. If you prefer using a pre-trained model instead, the implementation of the custom component class would be very similar, except for a few details:
- You wouldn't have to implement train() and persist() methods class because your component is already trained and persisted (potentially as a python module or a persisted model).
- You might change what details are passed to your model inside the process() method. Example: your pre-trained sentiment model takes unprocessed text messages as inputs instead of tokens.
To illustrate this case, let's modify the code of previously implemented custom component and instead of training a custom sentiment model, let's use a pre-trained SentimentIntensityAnalyzer model provided by the NLTK natural language toolkit:
from rasa.nlu.components import Componentfrom rasa.nlu import utilsfrom rasa.nlu.model import Metadata
import nltkfrom nltk.sentiment.vader import SentimentIntensityAnalyzerimport os
class SentimentAnalyzer(Component): """A pre-trained sentiment component"""
name = "sentiment" provides = ["entities"] requires = [] defaults = {} language_list = ["en"]
def __init__(self, component_config=None): super(SentimentAnalyzer, self).__init__(component_config)
def train(self, training_data, cfg, **kwargs): """Not needed, because the the model is pretrained""" pass
def convert_to_rasa(self, value, confidence): """Convert model output into the Rasa NLU compatible output format.""" entity = {"value": value, "confidence": confidence, "entity": "sentiment", "extractor": "sentiment_extractor"}
return entity
def process(self, message, **kwargs): """Retrieve the text message, pass it to the classifier and append the prediction results to the message class."""
sid = SentimentIntensityAnalyzer() res = sid.polarity_scores(message.text) key, value = max(res.items(), key=lambda x: x[1])
entity = self.convert_to_rasa(key, value)
message.set("entities", [entity], add_to_output=True)
def persist(self, model_dir): """Pass because a pre-trained model is already persisted"""
passIn this case, methods train() and persist() pass because the model is already pre-trained and persisted as an NLTK method. Also, since the model takes the unprocessed text as input, the method process() retrieves actual messages and passes them to the model which does all the processing work and makes predictions.
Summary
In this tutorial, you have learned how to create custom components and add them to the Rasa NLU pipeline. There are no specific limitations on what custom components you can add, but it's important to understand how they fit with the other processing components and what output they should produce - pass something to other components of your pipeline or add something to the output of the model. If you have integrated custom components to your Rasa NLU models, we would love to hear about your experience! Share it with us by replying to this thread on the Rasa Community Forum!
Useful resources:
In this tutorial, we used the NLTK Vader model: Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model forSentiment Analysis of Social Media Text. Eighth International Conference onWeblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.