


February 23rd, 2021
Discover Actionable Ways to Improve your Training Data with Insights
Karen White

With the release of Rasa X 0.36.0, we've introduced Insights, a new feature designed to help you get better performance from your assistant. Insights analyzes your NLU training data and suggests next steps you can take to improve your data set. You'll see warnings flagging intents that are commonly confused with one another as well as intents with too few examples. Next to each warning, you'll see a suggestion letting you know which action to take to resolve the issue. Insights runs in the background of your deployment on a daily interval, so you can stay on top of potential issues as you grow and improve your data set.
Training data is one of the most important factors affecting the accuracy of your assistant, but it isn't always easy to see which next steps should be taken to improve performance. When training data is free of errors and accurately represents real-world conditions, it produces a model that performs well in production. On the other hand, data sets can accumulate mistakes over time, as new training examples are annotated and new intents created. Automating the process of checking your training data helps you identify and fix the types of training data errors that are most likely to impact your assistant's user experience.
By default, Insights runs a check on your training data at a daily interval. You can set the job to run at the same time each day, or you can run a training data check immediately (useful if you've just made changes to your training data and want to see their effect). Importantly, this allows you to see the impact of NLU data changes even before you train and deploy a new model, allowing you to flag and fix potential issues before they impact users.
Better, more accurate intent classification
Insights surfaces intents with low confidence and displays warnings for a few common causes of misclassification. These include examples that are too similar across different intents, incorrect annotations, and intents with too few training examples. Let's take a closer look at how these factors can affect NLU performance and strategies for resolving issues.
When two intents have training examples containing very similar language, the model has trouble distinguishing between them. Sometimes this happens during annotation, when a training example is labeled with the wrong intent by mistake. Or, intent confusion can result when intents overlap. In these cases, intent classification can be improved by merging multiple similar intents into one that's more general.
For instance below, the training examples for locate hair salon and locate auto mechanic are quite similar in their wording and construction. The main difference lies in the entity: the type of business. By merging both intents into a single locate business intent, we can greatly improve the accuracy of intent classification. We can create logic around the extracted business entity to tell the assistant which type of business to search for.
Overlapping intents (causing intent confusion):
Intent: locate hair salon
- I am looking for a [hair salon](business).
- Where is the closest [hair salon](business)
Intent: locate auto mechanic
- I am looking for a [mechanic](business)
- Where is the closest auto [mechanic](business)
Combined intent (resolving the intent confusion):
Intent: locate business
- I am looking for a [mechanic](business)
- Where is the closest auto [mechanic](business)
- I am looking for a [hair salon](business).
- Where is the closest [hair salon](business)
Misclassifications can also occur when an intent has too few training examples. In these cases, the model doesn't have enough data to accurately generalize when it's asked to classify a user message it hasn't seen before.
It can be difficult to identify these types of problems by scanning training data files by hand, particularly if you have a large project with a lot of training data. Automating this process means you can scale your assistant without losing track of problems that can affect your model's performance. With Insights, you can be sure that you're finding and fixing the issues that will have the most impact.
Insights walkthrough
In server mode, Rasa X runs Insights on a nightly schedule by default. This schedule can be adjusted in your Evaluation Settings:
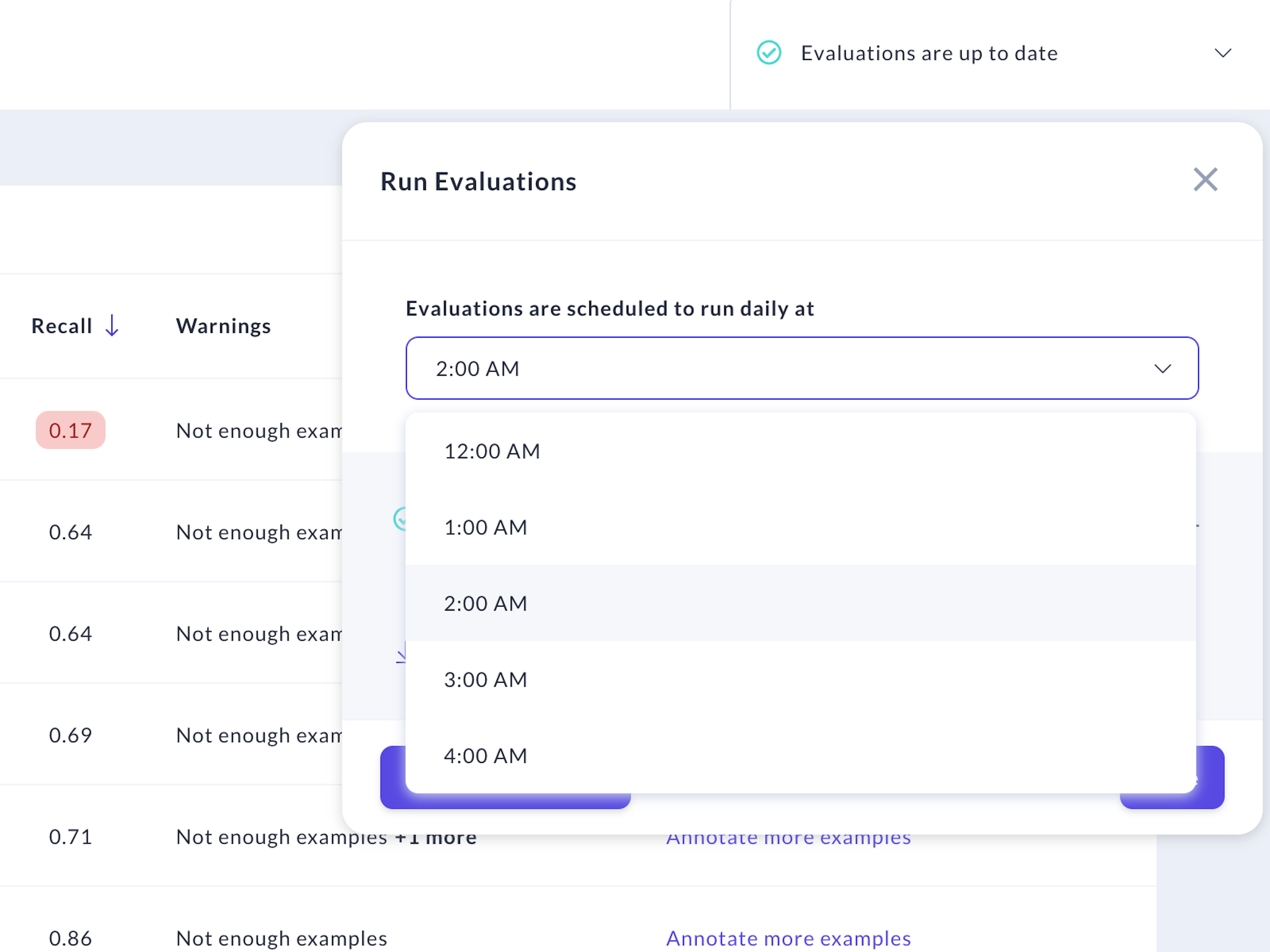
The evaluation results are produced using cross-validation, which is run by the rasa-worker service to avoid impacting production server performance. The evaluation process can take several hours to run on large data sets. For this reason, we recommend running the process overnight so you have the latest results when you log in the following morning.
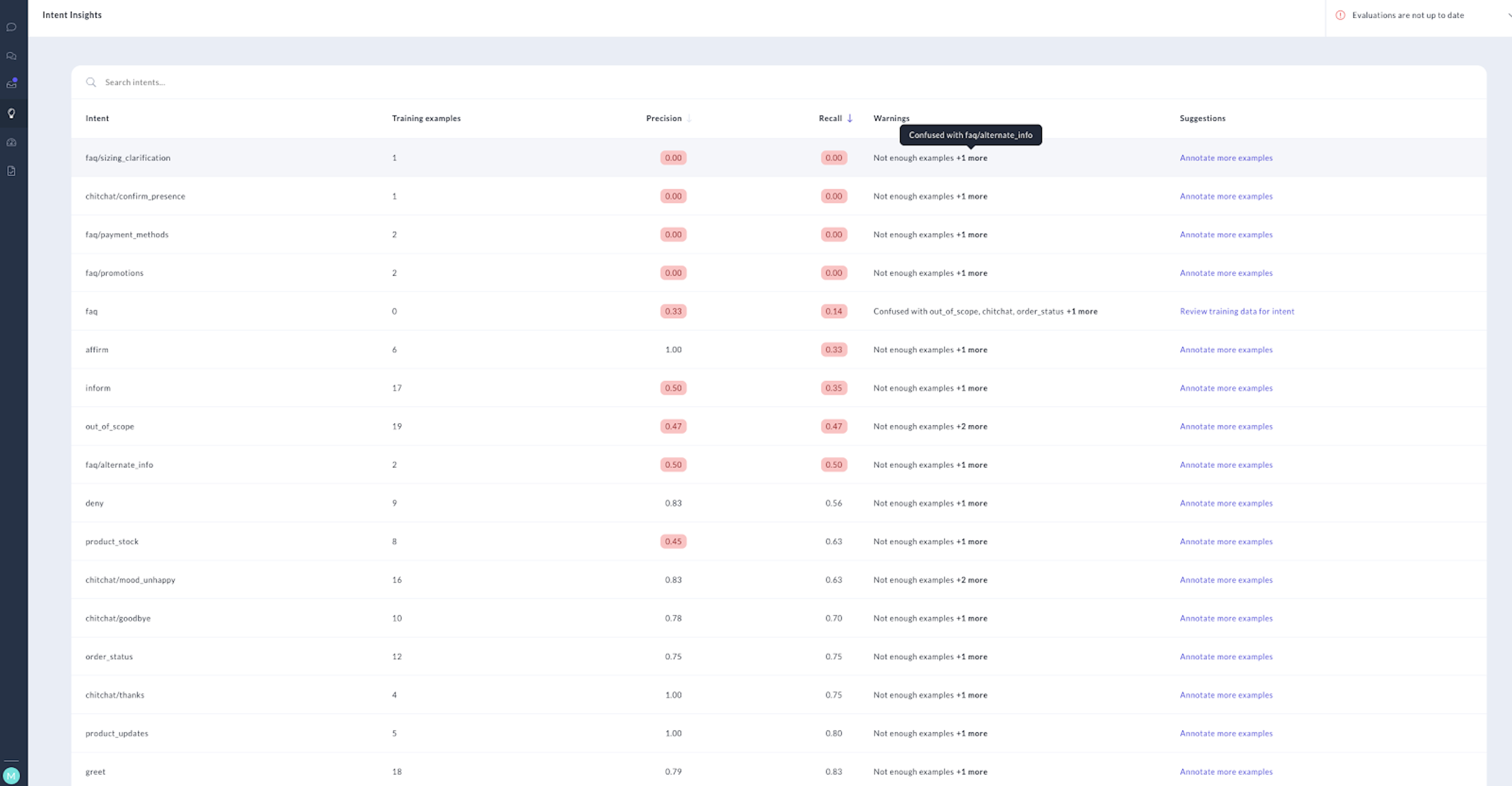
Insights is also available in Rasa X local mode, although evaluations must be run manually instead of scheduled to run automatically. Rasa X local mode uses the latest cross-validation results saved to your project's /results directory to display Insights. You can run a fresh evaluation by executing the rasa test nlu --cross-validation CLI command in your project directory. When you start Rasa X, it will reference these results on the Insights page.
Conclusion
Today, Insights is focused on helping you achieve higher accuracy for intent classification. Long term, this feature supports the goal of helping conversation teams work smarter, by automatically surfacing the things that need the team's attention.
For more background on why we built Insights and how it helps you build better assistants, check out the latest Algorithm Whiteboard video.
And lastly, upgrade to Rasa X 0.36.0 to try out Insights and see what the tool reveals about your data set. Share your first impressions and results in the Rasa forum. Your feedback helps us shape the next iterations of this feature, so let us know what you think!