


September 23rd, 2020
Lexical Features from SpaCy for Rasa
Vincent Warmerdam

SpaCy is an excellent tool for NLP, and Rasa has supported it from the start. You might already be aware of the spaCy components in the Rasa library. Rasa includes support for a spaCy tokenizer, featurizer, and entity extractor. What you might not know is that spaCy can be used to add features to the LexicalSyntacticFeaturizer too. In this blog post, we'll explain how this works and why you might want to use it.
Language Features
Let's first discuss some of the features that spaCy provides. The code below shows how you might use spaCy to detect linguistic features in a string of text.
# Import the spacy library, you can install it via:
# python -m pip install spacy
import spacy
# Load the large English model, needs to be downloaded first via:
# python -m spacy download en_core_web_lg
nlp = spacy.load("en_core_web_lg")
# Turn a string of text into a proper spaCy document object.
doc = nlp("spaCy handles many use-cases.")
This doc object represents a parsed document. It contains a sequence of tokens instead of a mere string of text. SpaCy will automatically detect the linguistic properties of these tokens. We can demonstrate a few of these properties by using the displacy tool inside of spaCy.
from spacy import displacy
displacy.render(doc)
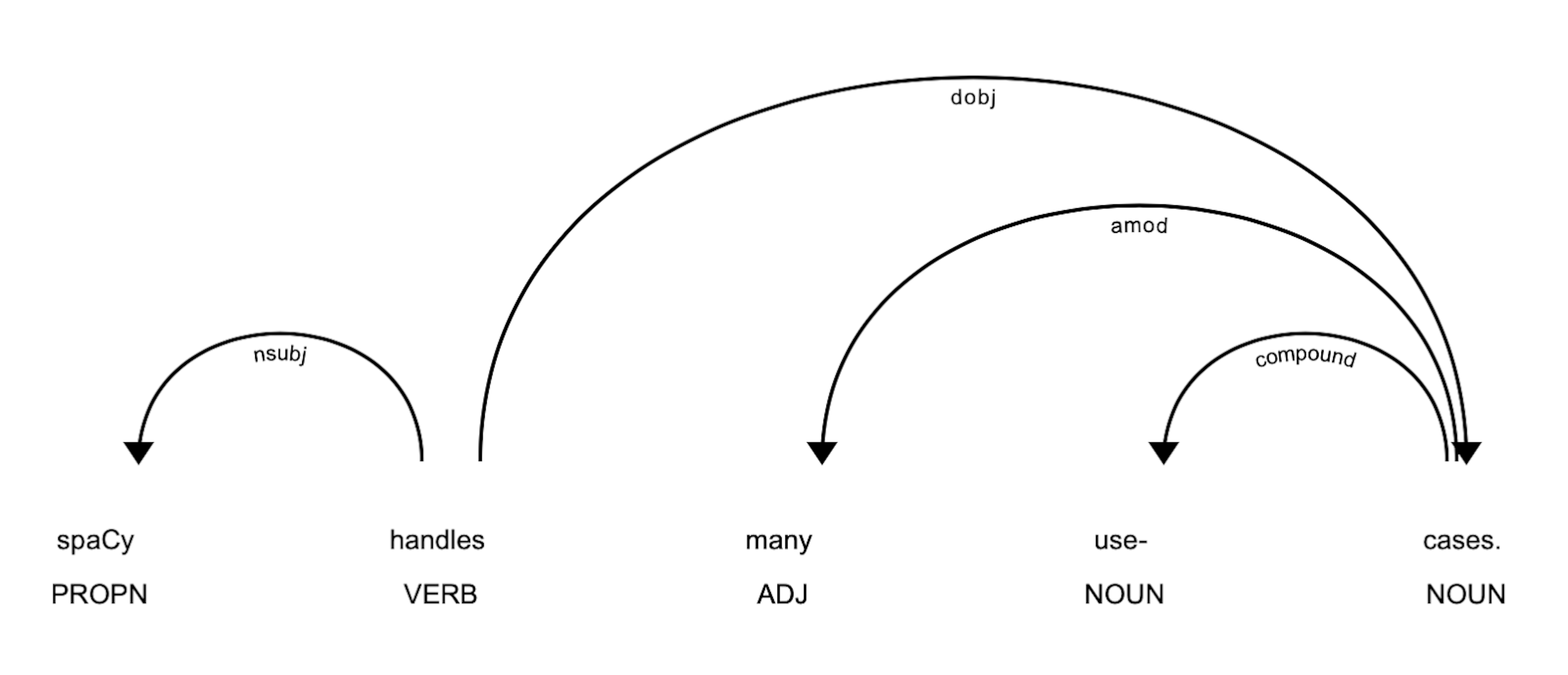
This visualization shows the predictions from the loaded spaCy model. When you load a model, like en_core_web_lg, you load a pipeline of models that spaCy runs on your behalf. One of these models is called the "tagger," and it predicts linguistic features for all of the tokens. The tagger is the model that indicates that "spaCy" is a proper noun (PROPN) in the sentence above, and that "handles" is a verb (VERB). The visualization also shows the syntactic dependencies between the tokens. Another model in the spaCy pipeline, the "parser", is responsible for predicting this grammatical structure.
The parts of speech features can be instrumental if you're interested in linguistic research, but they are also attractive when detecting entities in a sentence.
Example Problem: Programming Language
Let's say that you're interested in detecting programming languages as entities in Rasa. In that case, the programming language Go can be a nightmare. Since the word "go" is most commonly used as a verb, there are many situations where a machine learning pipeline will have trouble correctly detecting it. If instead we knew up front that the word "go" was used as a noun, things might be a lot easier.
Rasa offers two ways to integrate this information from spaCy into your NLP pipelines.
- You can create a custom model inside of spaCy that you can export directly to Rasa. This involves using spaCy as an entity extractor. While this is the most flexible approach, it also requires you to do more work.
- You can use the part of speech information from spaCy by configuring the
LexicalSyntacticFeaturizer. SpaCy will be used as a feature generating mechanism in this case. The machine learning pipeline will then be able to use these extra features and hopefully make better predictions.
Let's investigate option two now.
Configuring the LexicalSyntacticFeaturizer
The LexicalSyntacticFeaturizer is a component meant to create features that are useful when detecting entities. It moves with a sliding window over every token in the user message and creates features according to the configuration. Let's take a look at an example config.yml file.
language: "en"
pipeline:
- name: SpacyNLP
model: "en_core_web_lg"
- name: SpacyTokenizer
- name: LexicalSyntacticFeaturizer
"features": [
["title"], # features from token before current one
["title", "BOS", "EOS",], # features from current token
["title"], # features from token after the current one
]
Rasa does Natural Language Processing.
- name: CountVectorsFeaturizer
- name: CountVectorsFeaturizer
analyzer: "char_wb"
min_ngram: 1
max_ngram: 4
- name: DIETClassifier
epochs: 100
For every token in an utterance, the LexicalSyntacticFeaturizer will generate features. We're only showing a subset of the features that it can generate for the sake of simplicity. You can see all the available settings in the documentation. In the current configuration, it will generate these five features:
- Is the token before written as a title?
- Is the current token written as a title?
- Is the current token at the beginning of the sentence?
- Is the current token at the end of the sentence?
- Is the token after written as a title?
For example, if the LexicalSyntacticFeaturizer received the message "Rasa does Natural Language Processing," it would generate the following features for the "does" token.
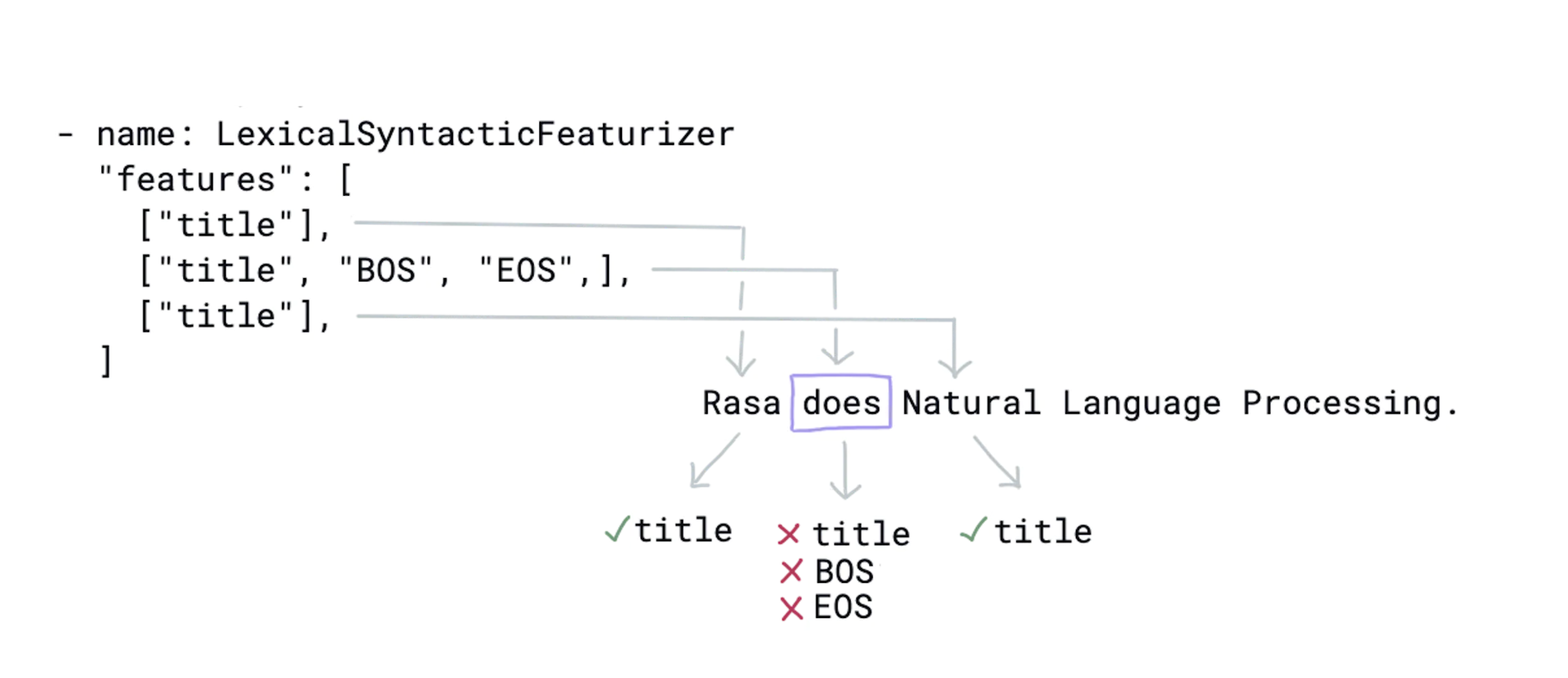
In general, these features are useful. Knowing that the previous, current, or next word is written as a title can help detect entities that typically start with capital letters. This includes the names of people, cities, and countries. But in the case of detecting the Go programming language, these features won't help. In such a scenario, you can change the configuration to include the part of speech information from spaCy.
You can add this information by making a small change to the LexicalSyntacticFeaturizer that we had before.
- name: LexicalSyntacticFeaturizer
"features": [
["title"],
["title", "BOS", "EOS", "pos"],
["title"],
]
The only thing we've changed in the configuration is that we've added "pos" to the list of features to extract. This setting will allow us to use the part of speech information from spaCy in our machine learning pipeline. Note that this configuration will only work if the `SpacyTokenizer` is in the pipeline.
To highlight the effect this change might have, we'll zoom in on some example utterances. The table below shows the features that are generated for the "go" token by this configuration.
| position | previous | current | current | current | current | next |
|---|---|---|---|---|---|---|
| setting | title | title | BOS | EOS | pos | title |
| i use the go lanauge | 0 | 0 | 0 | 0 | PROPN | 0 |
| i go and code | 0 | 0 | 0 | 0 | VERB | 0 |
| i write code with go | 0 | 0 | 0 | 1 | NOUN | 0 |
| i love writing Go code | 0 | 1 | 0 | 0 | NOUN | 0 |
| I go and write a lot of Go | 1 | 0 | 0 | 0 | VERB | 0 |
| I go and write a lot of Go | 0 | 1 | 0 | 1 | NOUN | 0 |
Note that, in this particular case, the main distinguishing feature for detecting the Go programming language is the part of speech.
Conclusion
The LexicalSyntacticFeaturizer is a component that we recommend starting out with. In many cases, it helps detect entities because of the features that it is able to extract. If you're also using spaCy in your pipeline, it can generate even more features for you. We've shown an example with the Go programming language where this feature is helpful, but there are many more applications where this information might make sense. Many entities are nouns, and you can considerably enhance your machine learning pipeline by adding this information.
The main caveat for this feature is that you need to use spaCy in your pipeline for it to work. It also deserves mentioning that spaCy uses a statistical model internally to predict the parts of speech, and the predictions won't be perfect. If you think this feature might be a good fit for your use case, try it out-benchmark the feature on your dataset and see if it improves your results.