


January 14th, 2021
Project Management for Conversational AI Teams [+Template]
Karen White

Taking an AI assistant from inception to launch requires coordination across many functions. User advocates and subject matter experts, machine learning engineers, conversation designers, product managers, and DevOps all play a role. With so many moving parts, effective project management is a key part of going to market on schedule.
Teams building AI assistants for the first time often wonder how experience building traditional software like mobile or web apps translates to building AI assistants. The good news is that much of this experience is transferable, especially as it relates to Agile methodology and engineering best practices. But, there are some important differences between traditional software and conversational technology.
First is the machine learning aspect, particularly the need to build machine learning models that don't just work in the controlled conditions of a lab or in testing, but out in the real world, interacting with customers. This "real world deployment" of machine learning models is often referred to as operationalizing AI.
Second is the conversational aspect. When a user interface consists of dialogue instead of menus and buttons, it requires a very different skill set and design approach.
To help teams navigate the project management requirements of building AI assistants, we've created a project plan that divides the development process into six phases. These phases reflect strategies for operationalizing AI as well as establishing a solid design and engineering foundation. Each phase includes specific tasks and timelines to help teams keep development on track and avoid overlooking critical steps.
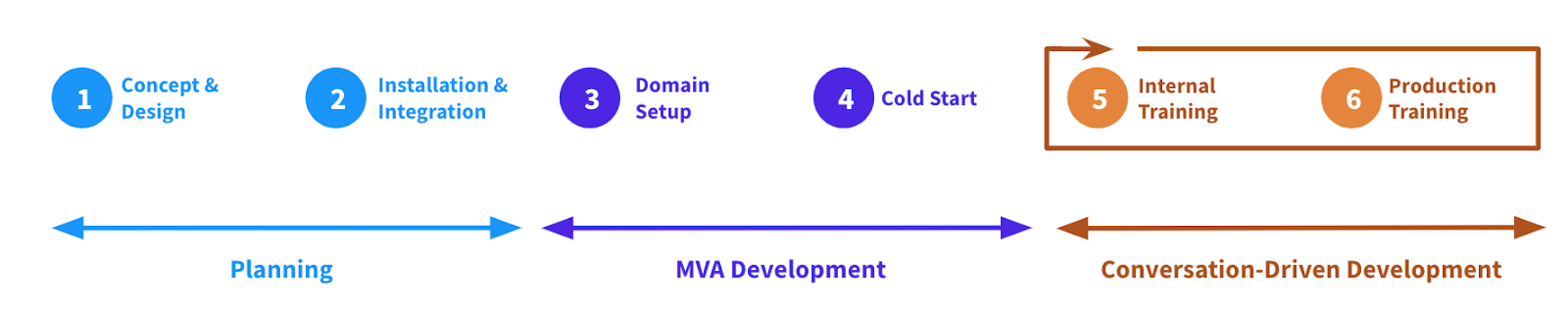
In this blog post, we discuss each stage of development in detail. We'll also discuss important project milestones and tasks to help set your project up for success. At the end of the post, you'll find a free AI Assistant Project Plan that you can use as a template. To use it, make a copy of the template and fill in the key dates and timeline specific to your project.
The Minimum Viable Assistant
Teams familiar with Agile will recognize the parallel with the idea of a minimum viable product, which is the leanest possible set of features that solves the customer's need. The goal is to start with a prototype that's quick to build, so the team can test the hypothesis of how best to solve the user's problem.
The idea of a minimum viable assistant is very much the same. A minimum viable assistant is a lean prototype that can handle a few of the basic conversation flows needed to help the user accomplish their goal. At this stage, we're not concerned with handling any edge cases-it's enough to handle the "happy path" dialogues, where the user is behaving as expected and providing requested information. Later, when the team is ready to test and iterate, you can start to identify ways the user might stray from the happy path and how to best account for it.
While a minimum viable assistant (or MVA) is an important milestone, it's only the beginning. The development cycles that follow are crucial. That's when the team incorporates feedback-first from testers, then from real users-and makes quick, iterative improvements. Again, echoing Agile: short, iterative cycles are the most effective way to run experiments and make quick course corrections based on observing how users interact with the software.
Conversational applications have a unique advantage though over graphical user interfaces: each user interaction is recorded word for word in the assistant's conversation data. The data to understand how users are succeeding or struggling is readily available and captured in high fidelity. This data informs future development decisions, but it can also be fed back into the machine learning model as training data. This real-world data is an important piece of the puzzle when it comes to operationalizing AI.
This speaks to a larger approach to building AI assistants that we call conversation-driven development. Conversation-driven development is a set of practices that help you better understand users' needs and use those insights to continually improve your assistant. The principles of conversation-driven development are the rationale behind each of the development phases we'll discuss in this post. If you'd like to dive deeper into conversation-driven development, we recommend checking out the CDD Playbook.
Phase 1: Concept and Design
The goal of the Concept and Design phase is to establish the scope and architecture of your assistant. At the end, you should have a clearly defined use case and a roadmap of the conversation flows, integrations, and hosting requirements your assistant will need.
The tasks in this phase begin with research-exploring and collecting data around proposed use cases-before narrowing the scope to one or two initial target use cases. Here, working closely with team members inside and outside of your business unit can provide important perspective. For example, interviewing agents and leads in a company call center can help to surface the types of common customer questions that lend themselves well to automation.
Then, before any development begins at all, the team begins to map out a few sample conversations to support the use case. Once you have an idea of what the dialogues look like, you can begin to translate them into the building blocks that make up the assistant's domain: intents, entities, slots, and actions.
These initial steps towards designing conversations aren't the only side of the Concept and Design Phase: the team also begins to map the architecture and determine hosting requirements. Rather than leaving these details until last, it's important to work closely with DevOps and IT functions early on to establish a plan for backend integrations and deployment.
Phase 2: Installation and Integration
In the first part of Phase 2, the team focuses on installing all systems that support the development of the assistant, including Rasa Open Source and Rasa X.
This includes securing the installation with SSL, connecting messaging channels, configuring databases to store conversation and application data, SSO (if configuring Rasa Enterprise for multiple users). It also includes establishing systems to support the ongoing deployment of changes during development and post-launch, including setting up a Git repository to store code and manage versioning, and setting up a CI/CD pipeline to automate deployment and testing.
The second part of Phase 2 concerns integration with backend systems. During Phase 1, the team identified which integrations with external systems would need to be built. These might include a CRM or database of customer data, internal APIs, or other systems the assistant needs to share data and interact with. At this stage, the backend engineers on the team work to build out the custom actions server and define methods for connecting to these services.
Phase 3: Domain Creation
The term domain is often used to describe an area of expertise: we talk about assistants in the healthcare domain, the banking domain, etc. In a Rasa assistant, domain has a very concrete meaning in addition to the more general usage. It refers to the assistant's domain.yml file, which is where all of the assistant's intents, entities, slots, actions, forms, and responses are listed. Together, these elements represent all of the things the assistant can understand, do, and remember.
During Phase 1, the team began to translate sample conversations into intents and actions. In Phase 3, the team forms a clearer understanding of which conversational building blocks are needed by building out the domain.yml file. This sets things up for Phase 4, when the team will actually begin to write training data.
Phase 4: Cold Start
Let's start with the obvious question: why do we call Phase 4 the Cold Start? It all has to do with training data, or rather, the lack of training data. When most teams begin building an assistant, they don't have access to representative training data. By that, we mean training data that exactly represents the conversations that the assistant will have once it's running in production: conversations that are between a human and a bot, specific to the assistant's use case. While teams might have other data that approximates real-world conditions, for example human-to-human chat transcripts from a call center, the way humans talk to a chatbot is different enough that this data will never be able to produce the best model.
Even without this representative data, we have to start somewhere. So, the first order of business in Phase 4 is writing an initial training data set.
We recommend beginning with NLU training data before moving on to writing stories and rules. If you have historical user data, like chat transcripts, you can pull example utterances from there. If you don't, you can create your own training examples for each intent by thinking of variations in ways a user might express the topic or goal. Don't worry about creating hundreds of examples-about 20 training examples per intent is plenty to get started with. During later phases, the team should focus on sourcing more examples from real user conversations, with a goal of reaching about 90% user-generated training examples by the time the assistant is shipped to production.
Once you've created the initial NLU training data set, you can turn your attention to stories (training dialogues). Each story consists of intents, which represent what the user said, followed by actions, which represent what the bot did in response. During phase 4, you should aim to write the minimum stories and rules required to cover each of your happy paths. For now, don't worry about writing stories for any edge cases.
At the end of Phase 4, you've reached an important turning point in your development: with an initial NLU training data set and stories to cover the happy paths, you now have a minimum viable assistant.
Phase 5: Internal Training
Once you have a minimum viable assistant, you can put the prototype to the test. Until this point, you've made many educated assumptions: which bot skills will help the user the most, how those conversations might play out, and how users will formulate their messages.
Conducting usability tests while your assistant is still early in development has two advantages. It allows you to validate the assumptions you've made about the assistant's design, and it allows you to capture the things test users say to the assistant and turn those messages into training data, further improving your model.
When selecting testers, try to recruit volunteers from outside of your development team. This is key because your development team has inside knowledge of the assistant's design. They already know what types of messages are in the NLU training data and which stories the bot has been trained to handle. Because of this, testers with too much knowledge of the assistant tend to stay on the happy path and don't stretch the assistant beyond what they know it's capable of.
The goal of internal testing is to capture conversation data from test sessions so it can be analyzed and turned into training data. Rasa X is an important tool at this phase because it allows you to easily share your assistant with a group of test users while you're still pre-launch. It also allows you review and annotate conversations, so you can convert them directly to NLU training examples and stories.
Finally, in this phase you'll also begin to build up a set of test conversations. Test conversations are used to validate that conversations that worked in the past continue to work as you release model updates. As you review conversations, look for successful interactions. These can be saved to the test conversation set, where they'll be checked during the testing steps of your CI/CD pipeline build. Setting up tests in your CI/CD pipeline establishes good habits early on, to ensure stable and reliable updates when you're in production.
Phase 6: Production Training
During Phase 6, the assistant is rolled out to production, where it encounters real end-users for the first time. While launch is an important milestone, it isn't the end of the assistant's development. Internal testing during Phase 5 prepares the assistant to handle a much wider range of interactions than it could when it was still a minimum viable assistant. But, production training is a critical-and ongoing-development phase that allows the assistant to fully mature.
The 'training' part of Production Training refers to model training using data collected from real user interactions. It's important to keep reviewing conversations you collect during this period to build up your data set and make iterative improvements based on the user behavior you observe.
During launch, we recommend using a tiered rollout strategy, where a percentage of user traffic is directed to the assistant initially and gradually increased over time. As you increase traffic, use load testing and performance monitoring to keep an eye on compute resources.
The final portion of Phase 6 is setting up a process for making ongoing progress with your assistant. Decide who on the team will review conversation data on a weekly basis, and talk through how messages in Rasa X will be annotated and added to the training data set.
AI Assistant Project Plan Template
Now that we've discussed the six phases that take an assistant from concept to production, we'll discuss how you can keep your team aligned and on track for a successful launch.
The Gantt chart template linked above breaks each phase into sub-tasks, along with start and end dates for each task, so you can track progress. Many tasks can be done concurrently, especially those that are performed by different functional areas of the team. To save time and keep the project moving, consider which projects are dependent on earlier tasks and which can be tackled at the same time. In the chart template, we've suggested a timeline, with compatible tasks overlapping.
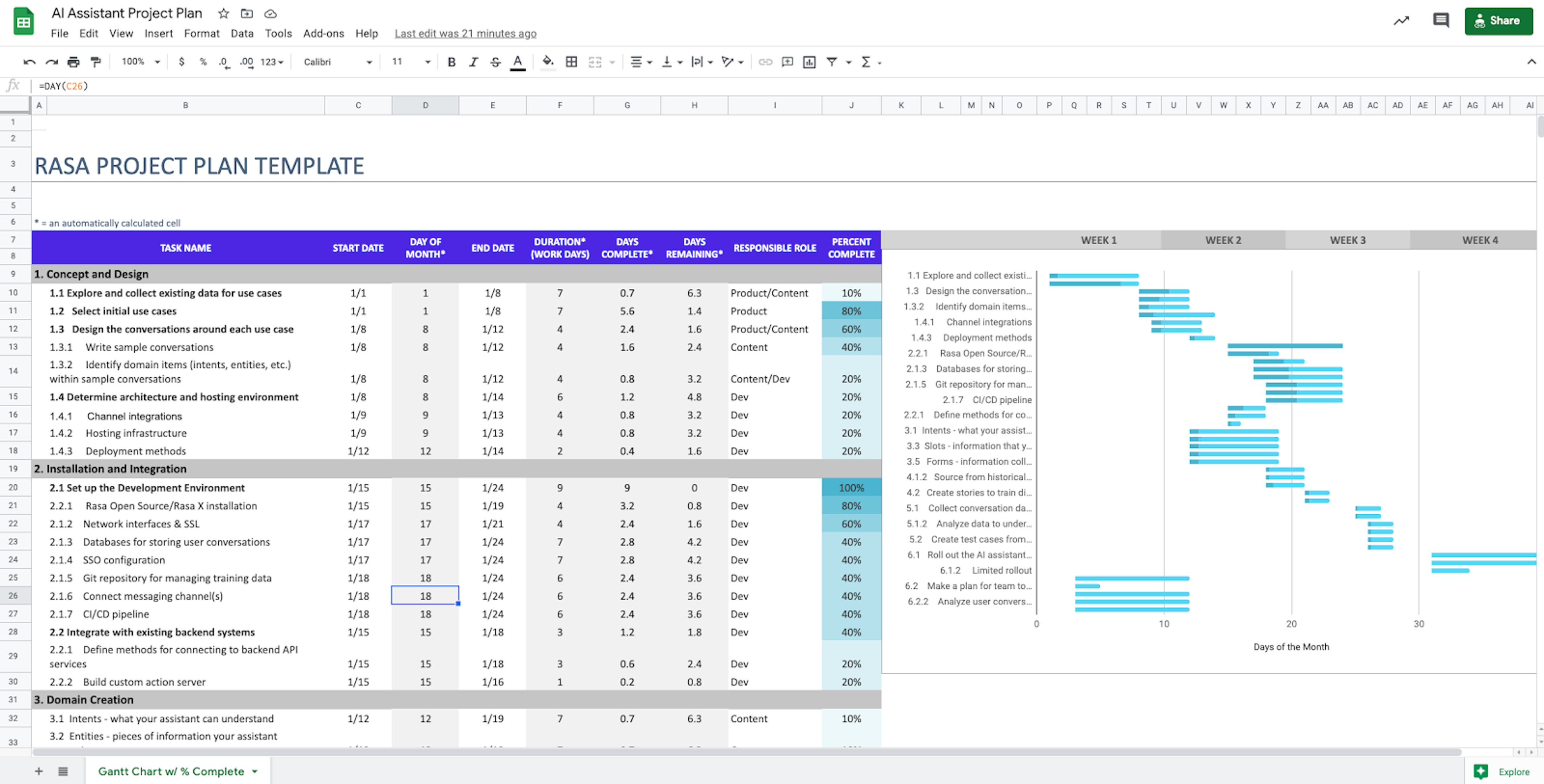
To use the chart for your own project, make a copy of the template (note: you will need to be logged into a Google account). Then, you can edit the dates to fit your own project timeline. During regular check-ins with your team, fill in the Percent Complete field to track the status. The dates and responsible roles are suggestions based on our observations working with conversational AI teams; feel free to edit these fields to reflect your own team's timeline and makeup.
Conclusion
Many teams approach building an assistant by spending months developing the assistant behind closed doors, finally launching a "fully finished" assistant to production. But, we've seen the most successful teams take a very different approach. Getting a prototype into the hands of users as early as possible, learning from early experiments, and training models on real data produces assistants that are more resilient under real-world conditions.
It's also important to note that iteration and improvement doesn't end with shipping the assistant to users. It's an ongoing process, one that takes its direction from users and ultimately serves those users better and better over time.
This project plan applies those same principles, helping teams follow conversation-driven development. Download the template, try it out, and let us know what you think. And finally, join the discussion on LinkedIn, where you'll find stories and ideas about developing better AI assistants, from the Rasa community.