



Backstory
If every time your teammate messages you "Coffeeee?" your response is "Sorry, I'm testing my changes", you might want to think twice about your testing workflow. There are a lot of coffee lovers on the Rasa Engineering team, so we try to automate software development as much as possible. As a Senior DevOps Engineer at Rasa, one of my tasks is making sure that code updates and tests run smoothly so that the team can focus on more important things.
The latest tests we've automated to improve efficiency are the execution of Model Regression Tests, which provide the ability to track performance of our ML algorithms across multiple datasets.
During implementation, we faced several challenges and found interesting solutions, from rendering a help message to running tests on GPU instances. I have described some of our solutions and how they fit into our GitHub Actions environment, which you can use as a starting point for your projects.
For background, we had several assumptions and goals to achieve:
- Measure performance only for NLU models
- Model performance is defined as the accuracy of the model
- Make the workflow user-friendly - not everyone is DevOps :D
- Run tests against the PR that affects the model performance
- Run tests on either CPU or GPU
I hope this post inspires you to improve your pipelines and automate testing your changes, so that you'll have more time to build amazing things with Rasa!
Continuous Integration to the rescue!
At Rasa, we use GitHub Actions as our CI/CD environment. We wanted to use the ecosystem that we already had, which our developers are familiar with. The tests boil down to the execution of two commands, rasa train nlu and rasa test nlu. The rasa test nlu command generates report files containing all the information that we need to evaluate an NLU model's performance.
The report includes a lot of information, including intent classification, response selection, and entity prediction. For the model regression tests workflow, we wanted to return a summary of the results as a comment in the PR, which is easy to read and understandable to everyone. Additionally, we wanted Rasa engineers to be able to configure the workflow and decide what configuration or which dataset to use for the tests.
To display the final results in a digestible way, we needed a tool that was capable of rendering templates based on both the generated reports and the GitHub-based configurations. Here gomplate turned out to be extremely useful. Gomplate is a template renderer that supports different data sources, such as JSON, YAML, Hashicorp Vault secrets, and many more. We used it to generate a GitHub comment with a summary, render help messages, read configurations from comments and transform the configurations into the GitHub Action matrix syntax.
In the example below you can see a template for rendering the help message. In order to render the template, we need data from three sources. The first source is the GITHUB_ACTOR environment variable that is used to greet a person who runs the tests. The second data source is a JSON file that contains information about available datasets and configurations. The third data source is a file with examples of configuration syntax.
{{- /*
The template returns a comment message which is used as a help description
in a PR. The template reads the `.github/configs/mr-test-example.yaml` file
and include it as example content.
The help message is triggered by adding `status:model-regression-tests` label.
Comment with a help message is added if a PR doesn't contain a comment
with a configuration for the model regression tests.
*/ -}}
Hey @{{ .Env.GITHUB_ACTOR }}! :wave: To run model regression tests, comment with the `/modeltest` command and a configuration.
_Tips :bulb:: The model regression test will be run on `push` events. You can re-run the tests by re-add `status:model-regression-tests` label or use a `Re-run jobs` button in Github Actions workflow._
_Tips :bulb:: Every time when you want to change a configuration you should edit the comment with the previous configuration._
You can copy this in your comment and customize:
> /modeltest
> ~~~yml
>```yml
>##########
>## Available datasets
>##########
{{range (coll.Keys (datasource "mapping").datasets)}}># - "{{.}}"{{"\n"}}{{ end -}}
>
>##########
>## Available configurations
>##########
{{range (coll.Keys (datasource "mapping").configurations)}}># - "{{.}}"{{"\n"}}{{ end -}}
>
{{range split (file.Read ".github/configs/mr-test-example.yaml") "\n"}}>{{.}}{{"\n"}}{{ end -}}
>```
Here you can find the templates that we use for our workflow.
Adding tests
Every great journey begins with a single pull request. In our case, opening a pull request triggers the testing workflow. As I mentioned earlier, we only wanted to run tests against PRs that affect model performance. To do that we use labels to selectively trigger the Model Regression Tests workflow.
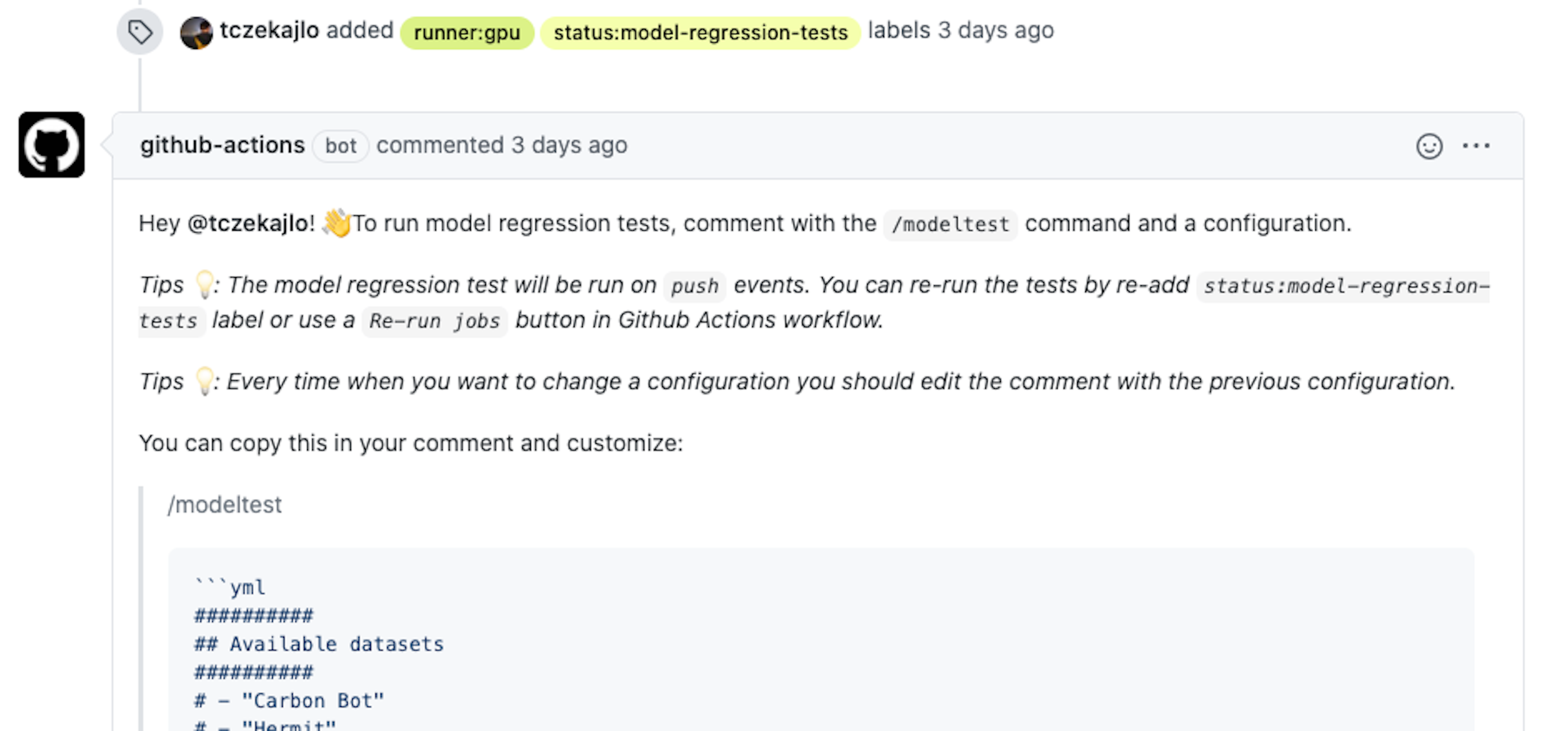
As you can see in the picture above, the "status:model-regression-tests" label triggered tests. In the PR, you can see a comment with a help message that explains how to run the tests. This lets someone running the tests for the first time get started without a deep dive into the documentation. The other label that is available is the "runner:gpu" label, and as you probably already figured out, it configures running the tests on instances with GPU.
The next step in the workflow is to configure the tests by adding a comment to the PR (this step is manual and the comment with the configuration has to be added by a real person :D). The engineer submitting the PR has the option to define which datasets and configurations they want to use for the tests. The syntax is very similar to the GitHub Actions matrix syntax but with one extra option: an "all" shortcut to define all available configurations or datasets, e.g., "config: ["all"]".
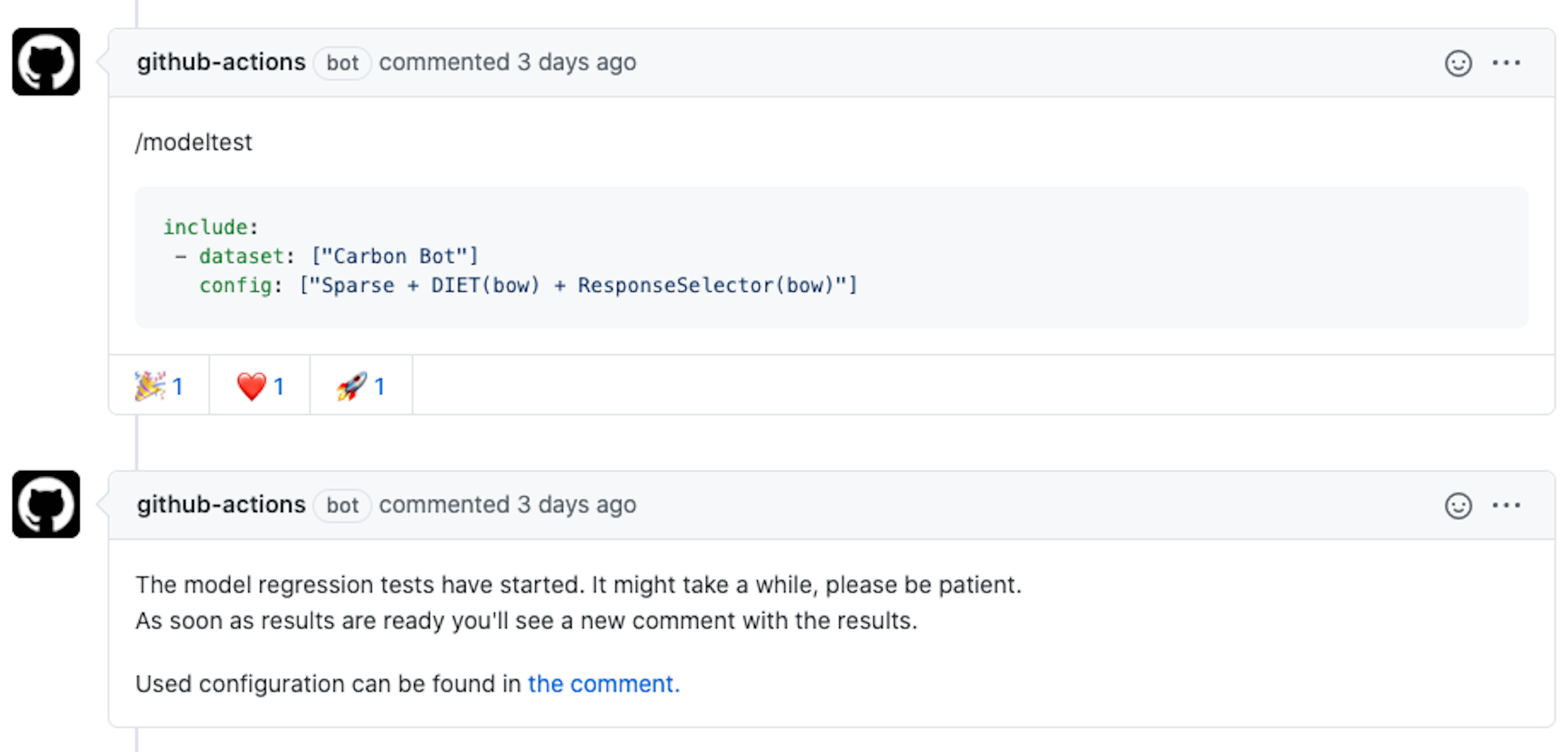
It was very important to us to keep the engineer in the loop and notify them at every step. Above is an example where a comment with configuration has been added and read by the workflow.
The last step in our workflow is publishing the results. One publishing method is a GitHub comment, which includes information such as: the commit SHA the tests were run against, the dataset name and configuration, the run time, and the test results.
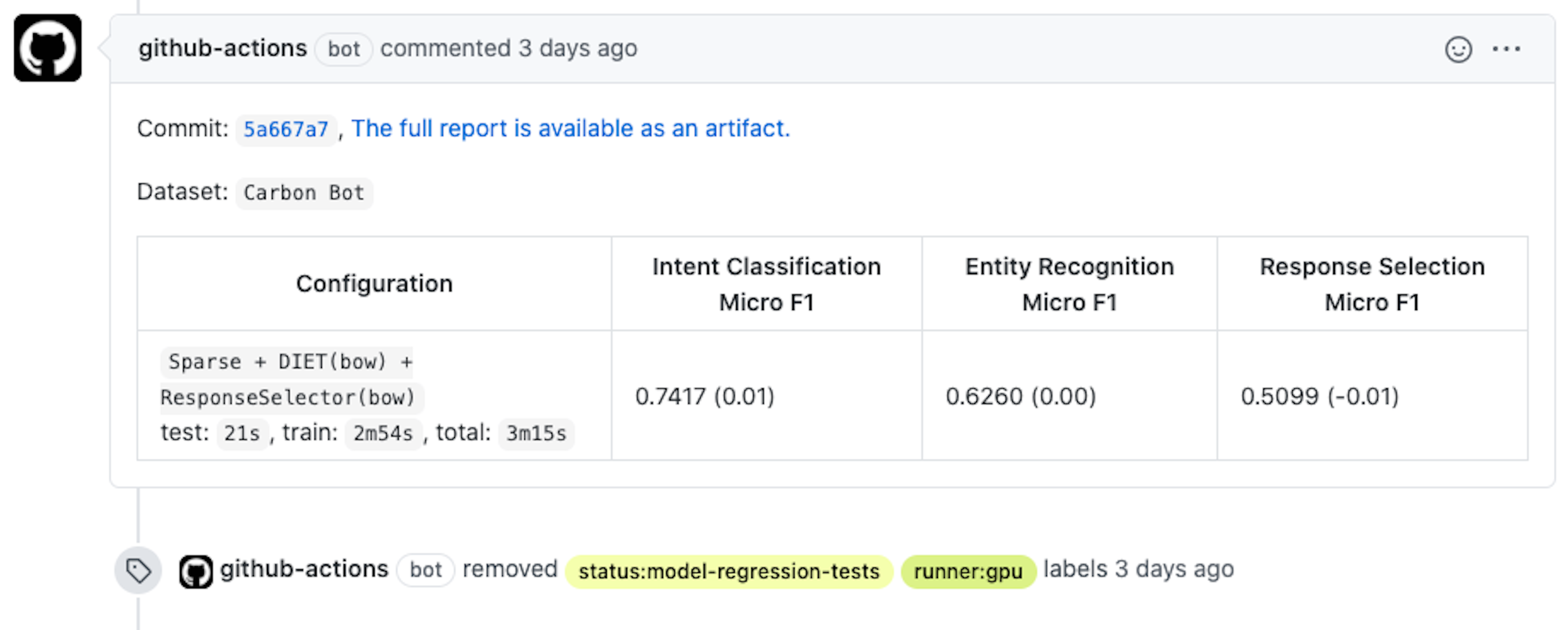
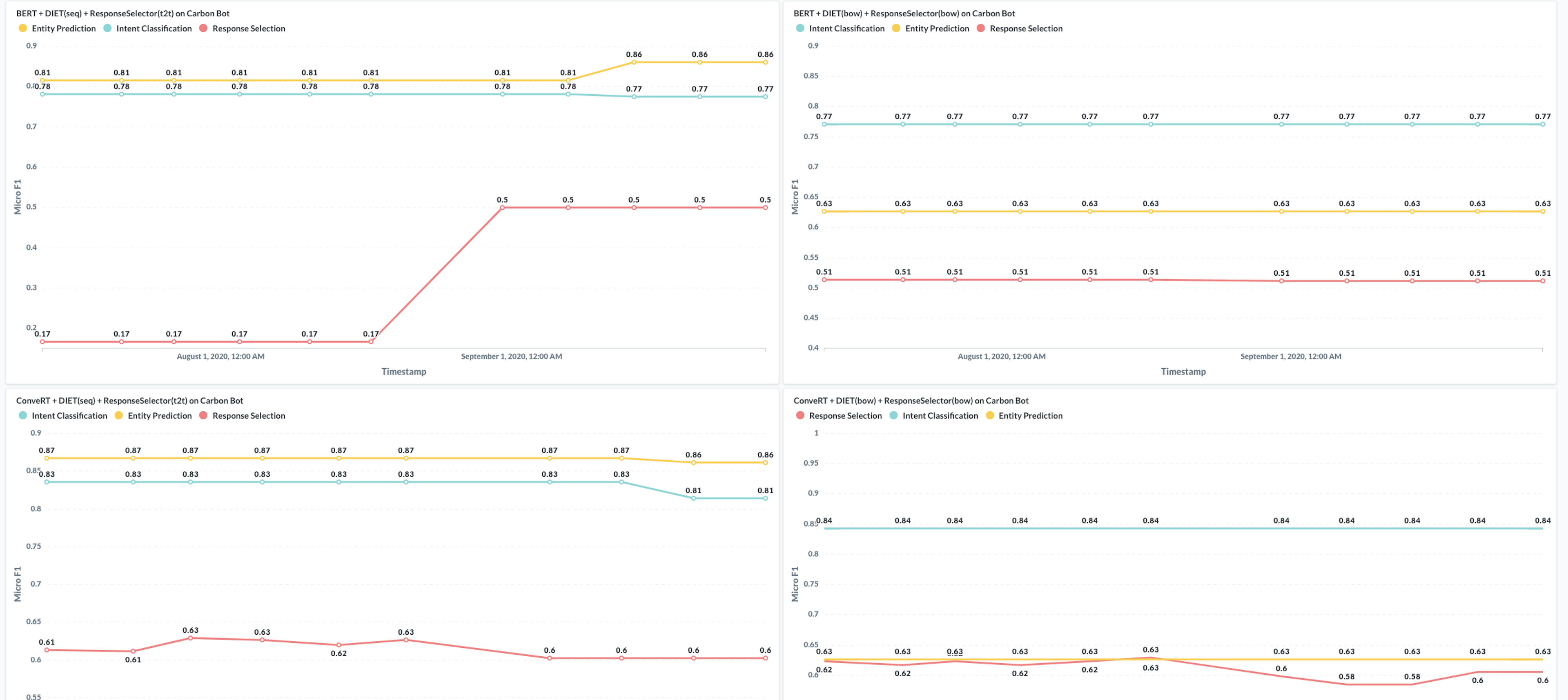
In addition to the summary posted in a PR comment, the results are published as an artifact which includes more detailed information. The data is sent to an external system that helps us create a dashboard to illustrate performance over time.
Takeaways
Developers using Rasa Open Source to build cool things might not always think about what goes on behind the scenes and the processes the Rasa Engineering team puts in place to make sure updates are reliable. In this case, testing ML algorithm performance helps us validate that changes are improving performance with each update.
If you'd like to take a closer look, all of the code used to run the model regression tests is available in the Rasa Open Source repository.
Check out the Rasa docs for more information about setting up CI/CD for your project, and see you in the Rasa community :D
PS. We're hiringSenior DevOps EngineerandDevOps working studentroles. If you're passionate about deployment infrastructure and testing, join my team!