


October 27th, 2021
Bending the ML Pipeline in Rasa 3.0
Vincent Warmerdam

Rasa Open Source 3.0 will start using a new computational backend. Conceptually, the machine learning pipeline will resemble a graph instead of a linear sequence of components. This blog post will explain what benefits to expect as a result of this change. Although it’s a big conceptual change, the changes won’t require you to change your config.yml.
How did we get here?
Back in Rasa Open Source version 0.x the rasa_core and rasa_nlu portions of the Rasa codebase lived in separate repositories. Later, in Rasa Open Source 1.0, these two got merged into the same repository, which we now know as Rasa Open Source. However, even though the code was merged into a single repository, the lines of code themselves are still separate.
Originally this was “fine” because there was a clear separation of concerns between what the NLU part of the pipeline and the policies in the Core module should do during training.
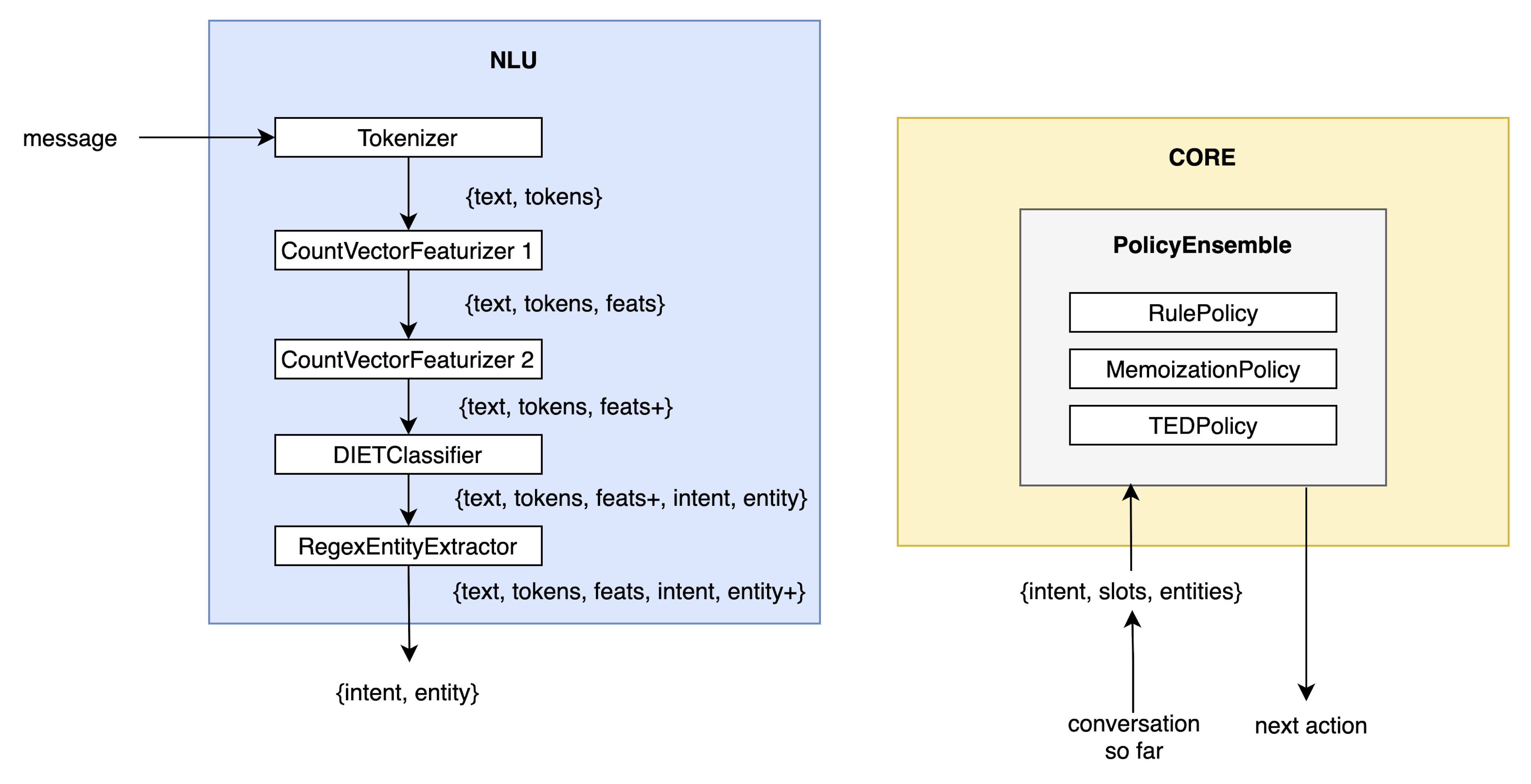
The NLU system was trained completely independently of the policies in the CORE system and resembled a linear pipeline of serially connected components. When an assistant is live the predictions from the NLU system would feed into the policies, but during training, these two systems are independent of each other.
This changed in Rasa Open Source 2.2 with the introduction of end-to-end learning.
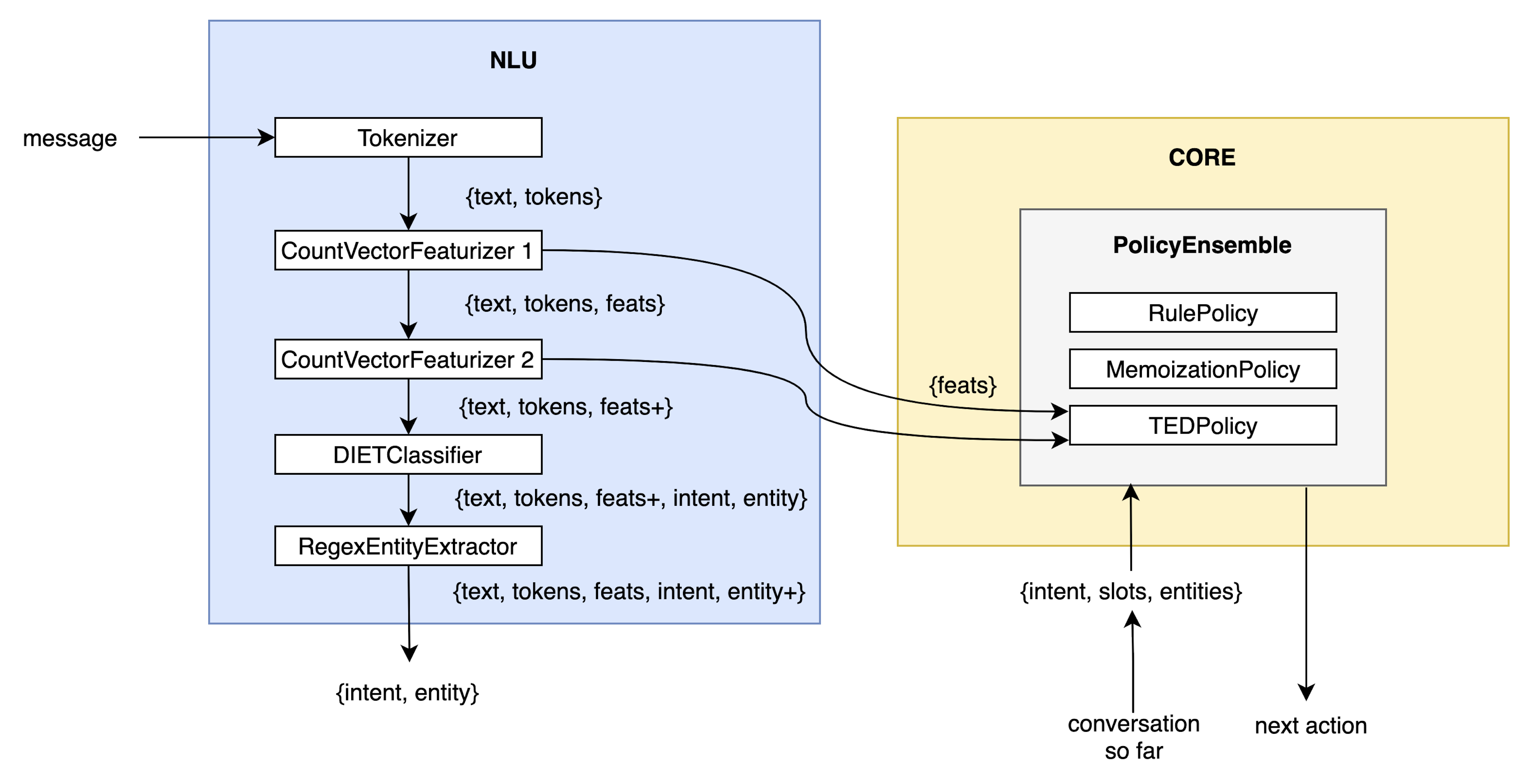
In the end-to-end scenario, TED is also able to use the featurizers in the NLU pipeline to make predictions for texts that don’t perfectly fit an intent. This is a feature that we need in order to move conversational AI forward, so you could wonder if it really makes sense to think of the machine learning system as two distinct NLU/CORE components.
So let’s see if we can “redraw” the components and their relationship during training.

Instead of looking at the NLU pipeline like a linear sequence of steps, you can also represent it as a tree-like graph of computation. Specifically, this type of tree is often referred to as a DAG (Directed Acyclic Graph) because it has no cycles in it. When you represent the NLU pipeline as a graph, it suddenly also integrates nicely with the policy algorithms.
Each node in this graph can still represent a component like before but the edges now represent a dependence. For example, when you look at this graph it becomes clear that the DIET Classifier doesn’t need tokens that leave the Tokeniser, but it does need the numeric features from the CountVectorizers that are generated for each token. It also becomes clear that the RegexEntityExtractor only needs the tokens in order for it to extract entities.
There are a few benefits that you get when you think about machine learning pipelines this way.
- This is much more customizable. Do you want to send the count vector features to DIET but not to the policies? Conceptually, this feature is a lot easier to consider now that we have a graph in our minds.
- There’s room for parallelism too. For example, the regex entity extractor does not need the count vectors, so while featurisation is taking place the regex entity extractor can already start doing its inference.
- Instead of worrying about whether or not a component is an NLU component or a Policy component, a DAG allows thinking more in terms of “just another component”. Maybe in the future, we’ll want to predict entities based on the conversation so far and the current message. To implement this in the 2.x Rasa codebase would be a huge undertaking while in the DAG setting it’d be an easy experiment.
There’s also another big benefit that we can now consider as well: caching.
DAGs with Caches
In Rasa 2.x, a single change to the NLU pipeline file would trigger retraining of all the components in it. The pipeline was fingerprinted as a whole, which could cause Rasa to assume that all components deserved retraining even if only a small change occurred.
But if you represent the computational backend as a DAG, you’re suddenly open to more options. Let’s suppose we start out with the graph shown below. This graph represents a Rasa pipeline with end-to-end enabled.
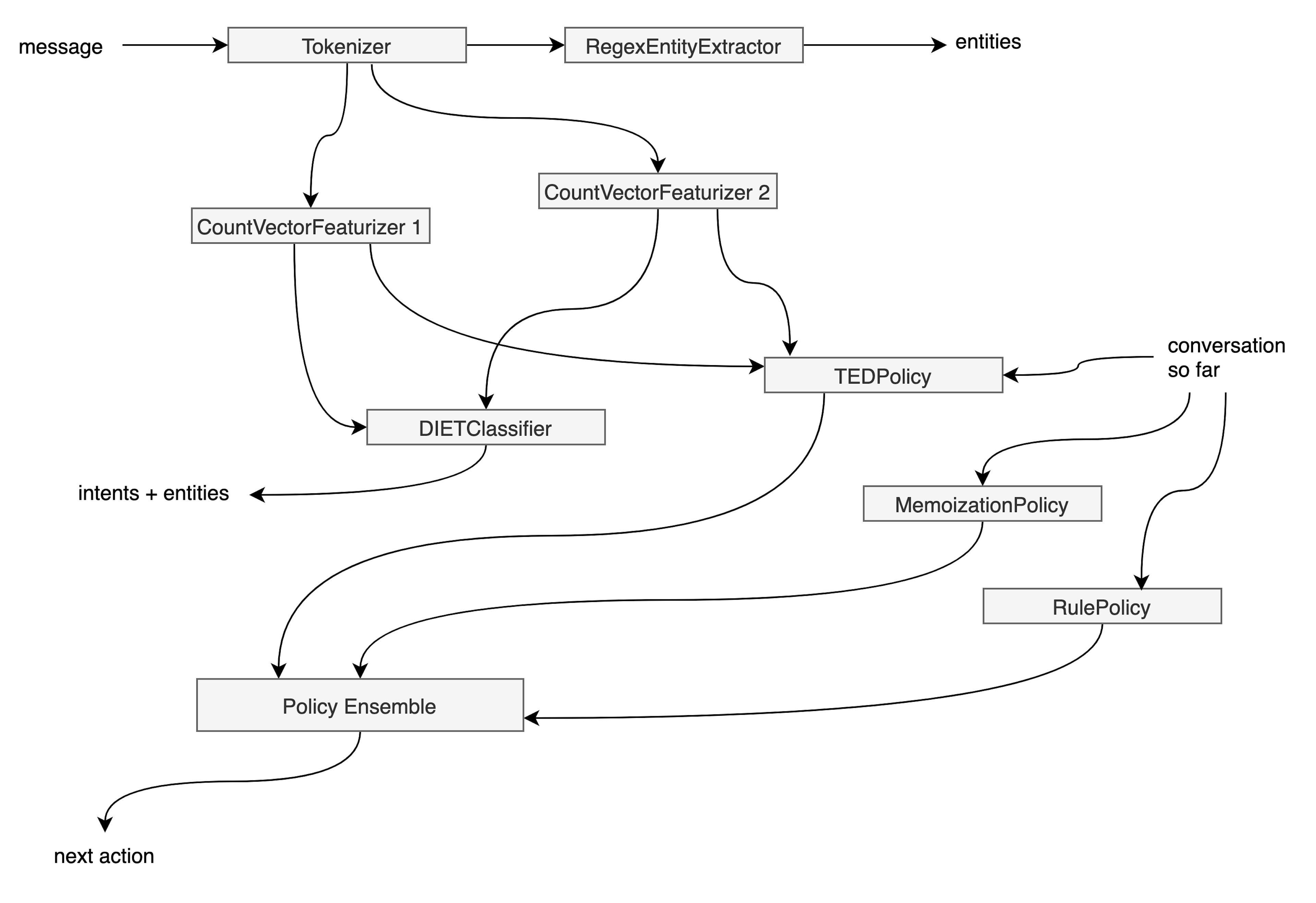
Let’s now imagine that we change a hyperparameter of the second CountVectorizer. This will impact the DIETClassifier, TED, and the Policy Ensemble. But the rest of the pipeline doesn’t need retraining.
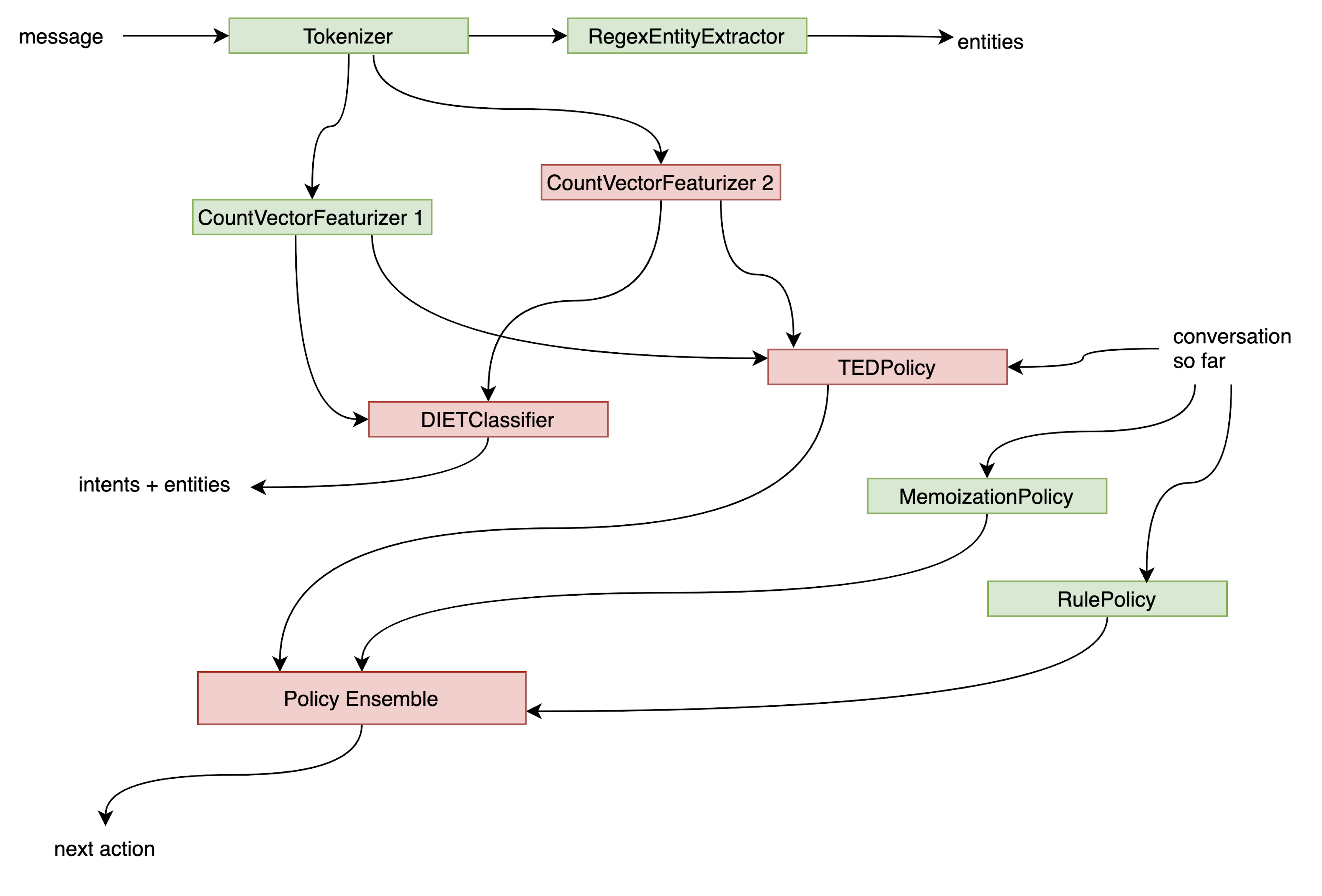
If we’re able to cache already trained components on disk would only need to train the red components and keep the green components as is. This can seriously prevent a whole lot of computation when you’re trying out new settings for your assistant.
An Example
If you install the main branch of Rasa Open Source today you can already experience a glimpse of what the caching experience may be like.
# Install the main branch of Rasa via pip.
python -m pip install --upgrade "rasa @ git+https://github.com/RasaHQ/rasa.git"
When you call rasa init with this version you’ll be able to start a quick demo project which you can also immediately train. The training experience is similar to before but now you’ll notice that a .rasa folder appears as a side-effect. This folder contains a SQLite file called cache.db as well as files and folders that represent cached results in the training graph.
📂 /workspace/rasa-examples/example/.rasa/cache
┣━━ 📂 tmp3qs8_jkv
┣━━ 📂 tmpdbttxq00
┃ ┣━━ 📄 featurizer.json (160 bytes)
┃ ┗━━ 📄 memorized_turns.json (1.9 kB)
┣━━ 📂 tmperp36t42
┃ ┗━━ 📄 feature_to_idx_dict.pkl (784 bytes)
┣━━ 📂 tmpfc04vxlq
┃ ┣━━ 📄 checkpoint (131 bytes)
┃ ┣━━ 📄 DIETClassifierGraphComponent.data_example.pkl (2.0 kB)
┃ ┣━━ 📄 DIETClassifierGraphComponent.entity_tag_specs.json (2 bytes)
┃ ┣━━ 📄 DIETClassifierGraphComponent.index_label_id_mapping.json (120 bytes)
┃ ┣━━ 📄 DIETClassifierGraphComponent.label_data.pkl (1.8 kB)
┃ ┣━━ 📄 DIETClassifierGraphComponent.sparse_feature_sizes.pkl (75 bytes)
┃ ┣━━ 📄 DIETClassifierGraphComponent.tf_model.data-00000-of-00001 (28.3 MB)
┃ ┗━━ 📄 DIETClassifierGraphComponent.tf_model.index (11.5 kB)
┣━━ 📂 tmpmj913uyf
┃ ┣━━ 📄 featurizer.json (160 bytes)
┃ ┣━━ 📄 rule_only_data.json (52 bytes)
┃ ┗━━ 📄 rule_policy.json (1.6 kB)
┣━━ 📂 tmpmn1t44si
┃ ┗━━ 📄 patterns.pkl (2 bytes)
┣━━ 📂 tmptwx0omrg
┣━━ 📂 tmpukyg7ozw
┃ ┣━━ 📄 checkpoint (95 bytes)
┃ ┣━━ 📄 featurizer.json (1.0 kB)
┃ ┣━━ 📄 ted_policy.data_example.pkl (1.2 kB)
┃ ┣━━ 📄 ted_policy.entity_tag_specs.json (2 bytes)
┃ ┣━━ 📄 ted_policy.fake_features.pkl (817 bytes)
┃ ┣━━ 📄 ted_policy.label_data.pkl (2.0 kB)
┃ ┣━━ 📄 ted_policy.meta.pkl (2.0 kB)
┃ ┣━━ 📄 ted_policy.priority.pkl (1 byte)
┃ ┣━━ 📄 ted_policy.tf_model.data-00000-of-00001 (3.5 MB)
┃ ┗━━ 📄 ted_policy.tf_model.index (8.3 kB)
┣━━ 📂 tmpyt5kdd6p
┃ ┣━━ 📄 oov_words.json (2 bytes)
┃ ┗━━ 📄 vocabularies.pkl (1.7 kB)
┣━━ 📂 tmpzmwofb5s
┃ ┣━━ 📄 oov_words.json (2 bytes)
┃ ┗━━ 📄 vocabularies.pkl (8.5 kB)
┗━━ 📄 cache.db (16.4 kB)
You can inspect the files to confirm that component data has been cached. You can also confirm that certain components don't retrain when you change your config.yml file. If you were to add a RegexEntityExtractor to the config.yml file and configured your domain.yml file to recognize a new entity then you’ll be able to confirm from the logs that the DIETClassifier does not retrain. In Rasa Open Source 2.x the last trained model would be the cached model state while now we have a global cache on all components separately.
Changes for Components
The graph in Rasa Open Source 3.0 is designed such that, as a user, you’ll not directly interact with it. As shown in the previous example; you’ll still interact with a config.yml file and don’t need to worry about the graph schema. This is generated on your behalf.
That said, there is one consequence of our new computational backend. If you have custom components then they will need to be migrated. The new architecture unifies many existing concepts in Rasa and this leads to changes. One of the main changes is that you’ll need to register your components such that the graph is aware of them. We’re currently working on a migration guide which we will share soon with the community.
Conclusion
We hope this document helps explain the motivation behind the new computational backend in Rasa Open Source 3.x. We skipped over a lot of implementations but we hope it’s clear that this new backend will introduce many benefits in the long run. You don’t need to worry about big changes to your config.yml file though. While the computational backend is changing, the config.yml file will remain your main interface with machine learning in Rasa.