
July 21st, 2017
Building with Rasa: eLearning chatbot
Rasa

Nishank Mahore, engineer passionate about data science and conversational AI, used the Rasa NLU library to build a chatbot to help participants of elearning platforms and webinars. Read on to find out how! Interested in building chatbots, natural language understanding and conversational AI? Join our Rasa community chat!
Hi Nishank, tell us a little bit about yourself.
As a computer engineer I am passionate about finding relevant solutions to problems using data science. I have spent the last three years at Predictly Tech Labs. I focus mostly on researching and implementing machine learning algorithms tailored to specific business needs. I see a tremendous opportunity in building products using ML which will help us generate insights and reduce human effort in traditional workloads.
What did you build using Rasa?
I focused on solving the problems faced by the organizers of eLearning platforms or webinars, who are not able to answer every question asked by the attendees of their course or session. Using Rasa, I built a chatbot which interacts with the course attendees and answers their questions.

What training data did you use?
The usual approach is to start with a small set of questions, invite others to chat with the bot, save all inputs from every user, and use them to get answers from other people. The problem with this model is that it takes a long time to gain accuracy.
The first question I asked myself is what dataset should I use, one which would contain a variety of intents pertaining to my business. The breakthrough was to use real email conversations, which contain rich information related to my client's business.
What did you do to extract the relevant intents from these emails?
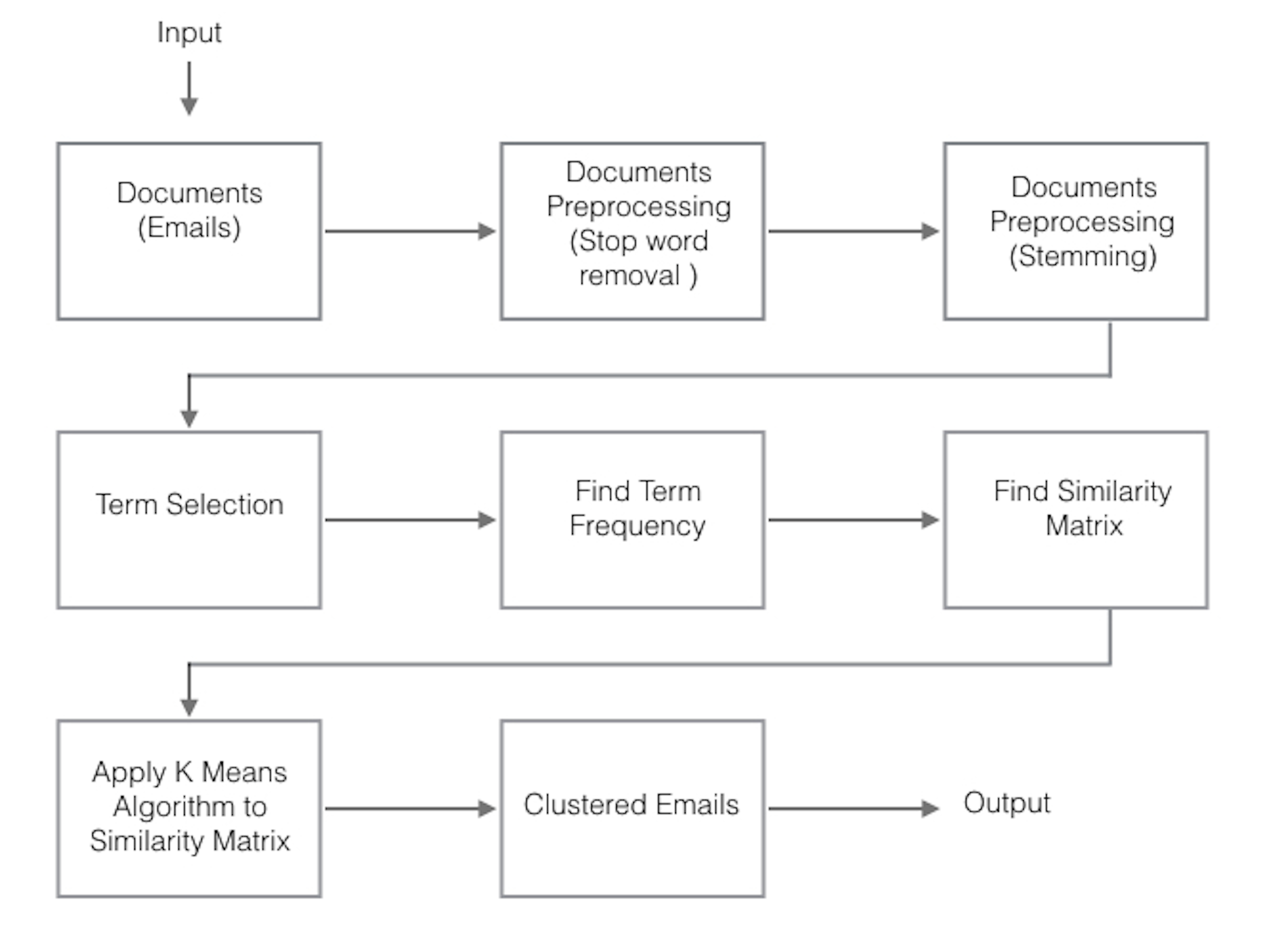
I had approximately 50K emails in the data set. I used a combination of keyword searches, unsupervised learning, and TF-IDF to preprocess and understand the data.
The key to the approach was to find the natural clusters of these emails. Clustering aims at grouping similar documents in one group and to separate this as much as possible from all other topics. That being done, I wanted to find out what the top keywords in those emails were. That allowed me to define the intents I wanted to use to train a Rasa model.
Could you sum up the preprocessing steps for us?
-
Cleaning the text by removing stopwords and stemming
-
Identifying keywords
-
Calculating term frequencies
-
K-means clustering in the space of term frequency vectors.
What was the biggest challenge you encountered?
There were a lot of emails in the dataset which weren't necessarily spam but still included words like offer or discount, and many which were completely unrelated to the questions I wanted the bot to answer. Separating those out and creating a clean dataset was the biggest challenge.
Thank you so much for walking us through this process!