


December 2nd, 2020
Zooming in on Dialogue Management in Rasa 2.0
Vincent Warmerdam

In Rasa Open Source 2.0, there are three main dialogue policies. In this blog post we're going to highlight how they work together, and in doing so, we'll explain the motivation behind the RulePolicy. To investigate the interaction between policies we will zoom in on moodbot. It's the assistant that is created when you run `rasa init` on the command line.
Note that this blogpost is written with Rasa 2.0.6 in mind. The code examples should work in Rasa Open Source 3.x as well but there's been a slight change in how the components behave during training. The computational backend changed for the machine learning components. You can learn more about it here.
Three Policies
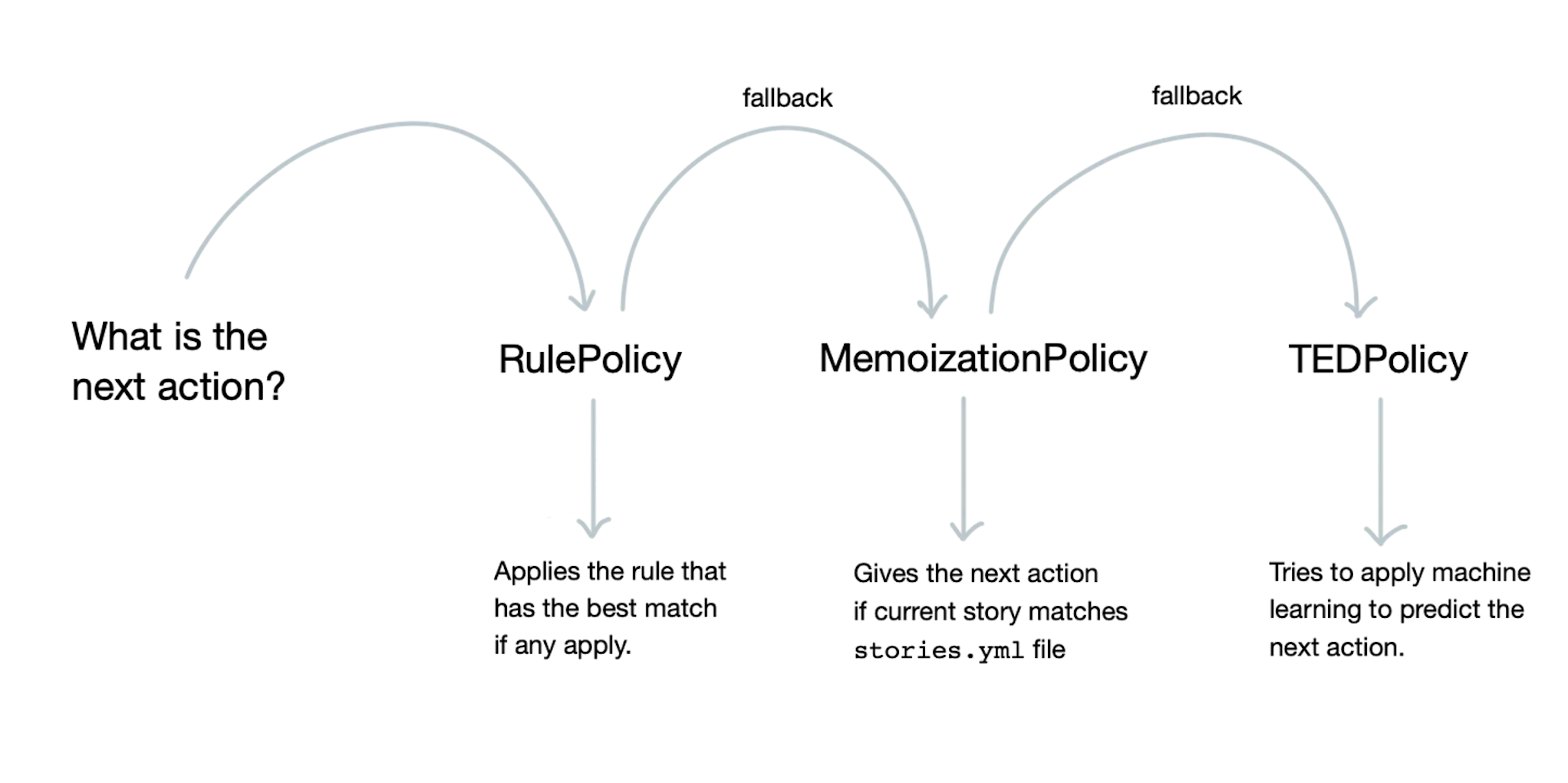
Your assistant uses policies to decide which action to take at each step in a conversation. There are three different policies that the default `config.yml` file starts out with:
- The RulePolicy handles conversations that match predefined rule patterns. It makes predictions based on any rules you have in your `rules.yml` file.
- The MemoizationPolicy checks if the current conversation matches any of the stories in your training data. If so, it will predict the next action from the matching stories.
- The TEDPolicy uses machine learning to predict the next best action. It is explained in full detail in our paper and on our YouTube channel.
These policies operate in a priority based hierarchy. If we assume the standard settings, then the RulePolicy is considered before the MemoizationPolicy which in turn is considered before TEDPolicy.
Let's zoom in on a basic example to see how these different policies get triggered.
Moodbot
To keep things simple we'll explore these policies using moodbot. It's the assistant that you get when you're starting a new Rasa project via `rasa init`. Moodbot has a simple function: to try to cheer you up if you're in a bad mood. It contains a few stories in the `data/stories.yml` file. These stories are memorized by the MemoizationPolicy and used by TED as training data.

It also has a few rules defined in the `data/rules.yml` file.

It also has a `config.yml` with our configured policies. To make it easier to explore the different policies, we've turned off fallback predictions for now. The relevant configuration looks like this:

Given all of these settings, let's try to explore the behavior of the assistant. Here's an example exchange that you might have when talking to moodbot via `rasa shell`.

To see what the policy mechanisms are doing in the background you can run `rasa shell --debug` locally. This will show any relevant debug information, which includes information that comes from the activated policies. The full logs show much more than you see here, but we'll focus on a summary to make things more digestible.
Here's the same conversation as before but now with the debug information attached.

There are a few things to observe in this exchange.
- Note that there is an `action_listen` that is triggered right before control is given back to the user. It's an action that's not directly visible in the shell but it is a very important action nonetheless. The assistant might need to do multiple actions in sequence before giving control back to the user. This is why "listening" is an explicit action in Rasa that needs to be triggered by a policy.
- Different parts of the conversation are handled by different policy mechanisms. For `utter_iamabot` and `utter_goodbye` we've got rules that can be directly applied. There are no predefined rules that apply for the `utter_greet` action. It is instead triggered by the MemoizationPolicy.
- The MemoizationPolicy is handling the `utter_greet` action because the dialogue follows the same pattern as all the stories in `stories.yml`.
Let's have a look at a longer exchange.

You should be able to confirm how these responses are generated by checking the stories and rules shown earlier. Since the conversation follows an example story we can mainly rely on the MemoizationPolicy but the final `goodbye` is handled by the RulePolicy because we've got a rule for it.
Triggering TED
In the previous two examples we didn't see TED getting triggered. Let's try and force that now by saying something very unexpected, like responding "no" when the bot asks how we are doing.

The reason why TED is triggered for the `utter_greet` action is because at that point in the conversation none of the rules match and none of the memorized stories apply. This means that TED will need to try to predict the next best action. Unfortunately though, it's having a very bad time. There isn't any training data that can help the algorithm understand what to do in this situation because a similar exchange hasn't happened before.
Remember that your stories are used as training data for TED. The moodbot only has three stories, and none of them look anything like this conversation. So when TED makes a prediction here, it does so with very low confidence.
We can configure our config.yml to deal with these situations more appropriately.

The `RulePolicy` can be configured to fall back to a specific action if none of the policies are able to make a confident prediction. This setting is turned "on" by default and you can specify the confidence threshold as well as the action that needs to be triggered. Assuming you've got a `utter_rephrase` defined in your `domain.yml` file the virtual assistant will now follow a different path after retraining;

Understanding the Distinctions
We've just shown a few examples of "how" the policy mechanisms work together. You might still wonder "why" it's designed this way though. To help explain the design choices made, let's consider a more advanced conversation that you might want this assistant to be able to handle.

As a thought experiment, let's consider creating this assistant with just stories. That means that we only have our MemoizationPolicy and TEDPolicy at our disposal. Assuming that you've got plenty of example stories in your training data you can certainly get far with this approach. But your training data won't be able to cover all the possible conversational permutations.
Just as an example; just think of all the places in the above conversation where the user might ask "Are you a bot?".
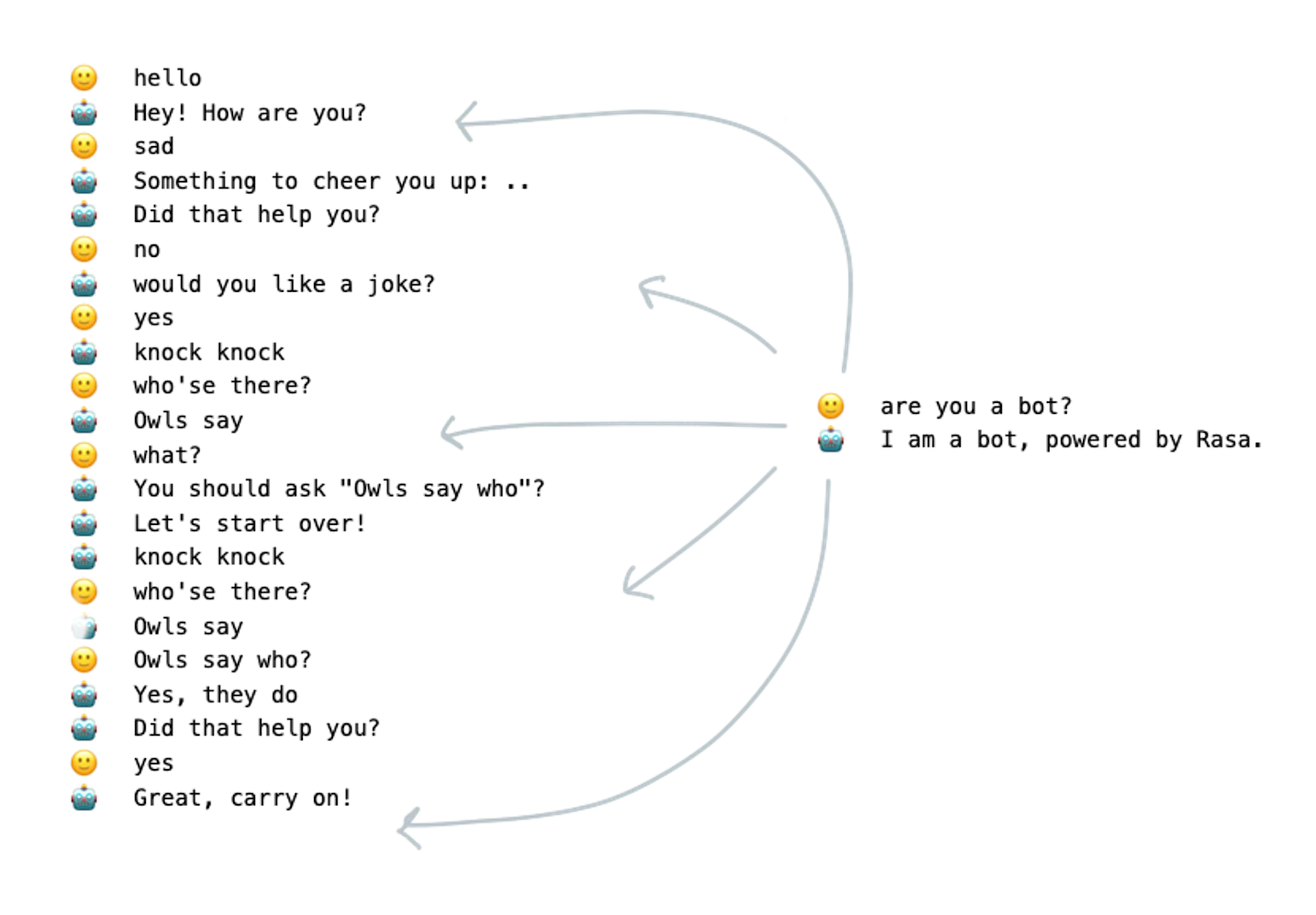
It's ethically important to us that our assistant is always able to answer this question correctly. But to ensure a correct response from the MemoizationPolicy we might need to create lots of stories. This won't be practical.
Our TEDPolicy could instead be trained to predict the correct action here, but TED is designed to untangle complicated conversations. The issue here is a mere single turn interaction so it feels like overkill to need something like TED. To see an example of TED handling a complex conversation task, see the example here.
We could improve the training data so that TED can perform correct inference, but maybe it's more pragmatic if we introduce another concept. Something that sits on a higher hierarchy than our stories. Something that will allow us to define what needs to happen at specific single-turn interactions. Something like; "no matter what, if we ever see the `challenge_bot` intent there is only one appropriate response".
What we need here is "rules". Rules make it easy to reason about how we should deal with specific situations in our dialogue and they give us more direct control of the conversation.
Rules don't Fix Everything
This might make you wonder "can't we use rules for everything then?" The answer is "no". You will still need stories in order to generalize. You will receive conversations from your users that won't perfectly fit your rules or your stories. If you were to do everything with rules, you would need to precisely define every possible interaction that a user might have. This would get unmaintainable very quickly, mainly because of all the different permutations you would need to keep track of.
By design, Rasa only allows you to write rules for short pieces of dialogue. This is to prevent you from creating an unmaintainable state machine. The goal of rules is to give you another way of customising how your assistant handles dialogue. It's not meant as a replacement for stories.
The common use-cases for rules include:
- Controlling fallback behaviour: you can combine rules with a FallbackClassifier to customise what happens when NLU models aren't confident about their predictions. You can also combine this with custom fallback classifiers.
- One-turn interactions: if you want to guarantee a specific outcome in a single-turn interaction then rules are a very convenient tool. You might have a situation where it's easy to define correct behaviour upfront even if you don't have perfect stories. There's an episode of the algorithm whiteboard that goes into more detail on this phenomenon here.
- Forms: The information that a user gives in a form needs to be handled with care. How a form is initiated, submitted, deactivated or checked is something that you can explicitly customise using rules and custom actions. Check the docs for more information.
Conclusion
In this blog post we've reviewed how different policy mechanisms inside of Rasa interact with each other and how these all play a role in designing a conversational assistant. The RulePolicy, MemoizationPolicy and TEDPolicy complement each other. Each policy allows you to customise towards a use-case but there's no single policy that's right for every scenario.
The RulePolicy was introduced because it makes it easier to implement specific tasks in a virtual assistant. Rules are considered before stories and therefore allow you to specifically steer the conversation in the appropriate direction. If you're interested in examples of how these rules might be used you're encouraged to check out our helpdesk assistant demo. It it demonstrates the flexibility of these new rules and might serve as a source of inspiration for your own project.
Happy hacking!