


September 13th, 2018
Entity Extraction with New Lookup Table Feature in Rasa NLU
Tyler Hughes
Entity extraction is one of the most important tasks of any NLU system, where the goal is to extract meaningful information from text. For example, when building a weather bot, you might be given the sentence
"What's the weather going to be like in Berlin tomorrow"
and would like to extract the entities
{
"location": "Berlin",
"time": "tomorrow"
}
so that you know which information to return to the user.
Libraries like spaCy and Duckling do a great job at extracting commonly encountered entities, such as 'dates' and 'times'. But when you'd like to extract entities that are specific to your application, such as product names, there's a good chance that there are no pre-trained models available. In this case, one solution is to supply loads of training data and hope that the model learns to pick out your custom entities. This approach has drawbacks, because generating a bunch of examples programmatically will most likely generate a model that overfits to your templates.
To help with this, we've added a new feature in version 0.13.3 of Rasa NLU that allows you to add lookup tables to your training data. These lookup tables are designed to contain all of the known values you'd expect your entities to take on. For example, if you were interested in extracting 'employee' entities, they may contain the names of all employees at your company. As we'll see, including lookup tables can dramatically improve entity extraction and can reduce the number of training examples you'd need to use to get a great model!
Rather than directly returning matches, these lookup tables work by marking tokens in the training data to indicate whether they've been matched. This provides an extra set of features to the conditional random field entity extractor (ner_crf) This lets you identify entities that haven't been seen in the training data and also eliminates the need for any post-processing of the results.
In this post, we'll give a few demos to show how to use this new feature to improve entity extraction, and discuss some best practices for including lookup tables in your NLU application.
Lookup Table Demo
We'll be looking at how the lookup tables help performance on three different datasets. One is small (< 100 examples), one is medium-sized (~ 1,000 examples), and one is large (~ 10,000 examples). As we'll see, there are a few things to keep in mind when using this feature:
-
You should consider whether the entity is a good candidate for lookup tables. It is best to stick with lookup entities that have a well-defined and narrow scope. For example, "employee names", would be a much better option than "objects".
-
Related to this point, you should always curate your lookup tables to make sure that there are no elements that are matching unwanted tokens. There are many opportunities for just one wrong element in the table to mess up training. For example, if one of the elements is a word that may be encountered in other contexts in your data.
-
You should try to keep the lookup tables short (if possible) because the training and evaluation time scales with the size of the lookup table. As a rule of thumb, we've found that lookup tables with more than one million elements can take several minutes to an hour to finish training and evaluating. Also, keeping lookup tables short can reduce issues associated with the first two points.
We'll also go over the steps you should follow for getting the most success out of your lookup tables, which is summarized in the flow-chart below.
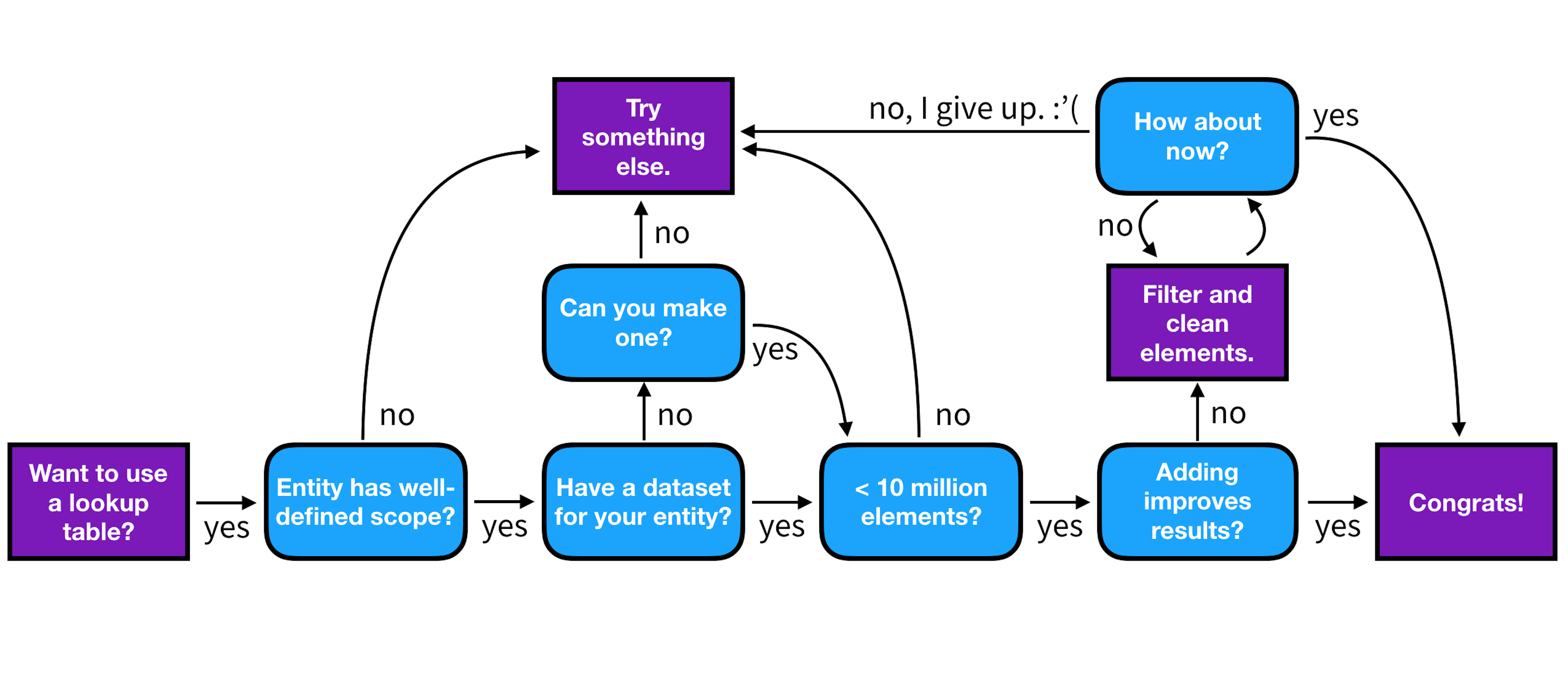
Now let's jump into the demo. If you want to follow along, the code for these examples is provided here.
Short Example: Restaurant
In this demo, we'll show how lookup tables work by training a restaurant search bot. Here we'll be focusing on extracting food entities from the text. In data/food/food_train.md, we've included a training set of just 36 examples with intent restaurant_search. For example:
Could you help me find an [empanada](food) place?
We'll train this model using the following configuration:
File: configs/config.yaml
language: "en"
pipeline:- name: "nlp_spacy"- name: "tokenizer_spacy"- name: "intent_entity_featurizer_regex"- name: "ner_crf" features: [ ["low", "title", "upper"], ["bias", "low", "prefix5", "prefix2", "suffix5", "suffix3", "suffix2", "upper", "title", "digit", "pattern"], ["low", "title", "upper"] ]Since tables use regular expressions for matching, we'll need intent_entity_featurizer_regex and the pattern feature in ner_crf.
Then we'll test our model on a test set food_data/data/food_test.md. This test set contains several food entities that were not seen by the model, so it should be difficult for the ner_crf component to extract those without any additional information.
In the code demo, we may do this step by running the script run_lookup.py with an argument of food:
python run_lookup.py food
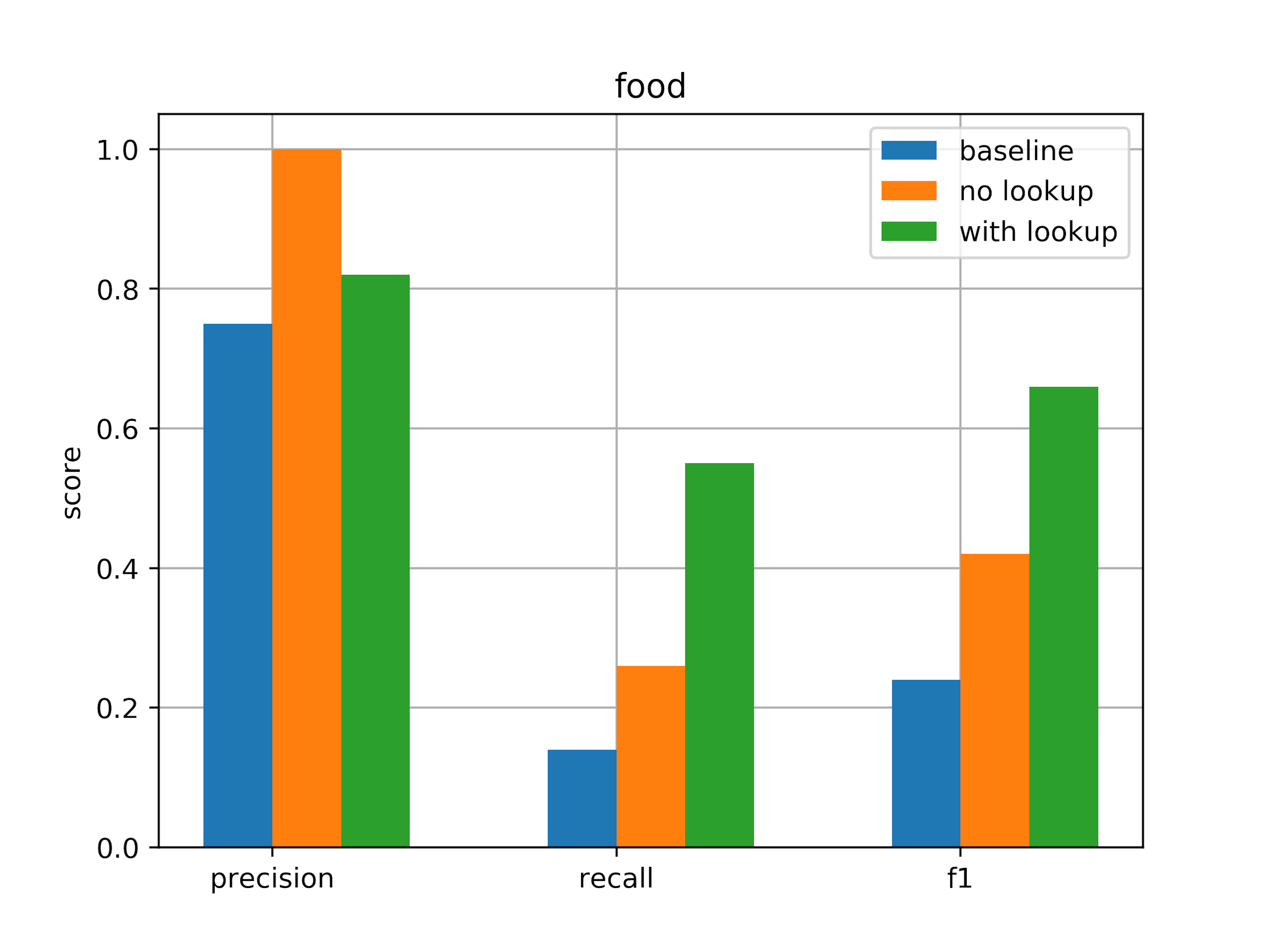
Here are the evaluation metrics for the food entity:
| Metric | Value |
|---|---|
| precision | 1.00 |
| recall | 0.26 |
| f1 score | 0.42 |
As expected, we see that recall score is very poor for food entities, which is unsurprising because the training set is very small and the test set contains many new food names. Testing on a basline model without any word features in the CRF gives an even lower recall of 0.14.
We'll try to improve the recall score by adding a lookup table to feed to our model. By adding a list of food names, we'll teach the model that matching on this table is a good indicator of being a food entity. Then, when it sees matches in the test set, it will be much more likely to tag them as food entities, even if that token has never been seen before.
To specify a lookup table in Rasa NLU, we can either specify a list of values or an external file consisting of newline-separated phrases. We've included a file data/food/food.txt containing several food names
mapo tofu
chana masala
sushi
pizza
...
and can load it by adding the following lines to the training data file
## lookup:food
data/food/food.txt
In json, this would look like
"lookup_tables": [
{
"name": "food",
"elements": "data/food/food.txt"
}
]
We've included the file data/food/food_train_lookup.md, which is exactly the same as the original training data but with the lookup table inserted.
To make things clear, we've constructed this lookup table such that each of its elements match with each of the food entities in both the training and test set. However, when using this feature for your application, you'll need to put some effort into constructing a comprehensive lookup table that covers most of the values you might care about. This will be easier or harder depending on the nature of the entity you wish to extract. For example, 'country' entities are a straightforward choice for a lookup table as it can simply contain a list of each country's name. However, for a more vague entity like 'object', the domain might be too large for a lookup table to cover all of the possible values.
After including the lookup table and training a new model, we get the following results:
| Metric | Value |
|---|---|
| precision | 0.82 |
| recall | 0.55 |
| f1 score | 0.66 |
This shows a solid improvement in food entity recognition. Note especially that the recall score improves from 0.26 to 0.55! It seems like the lookup table helped the model pick out entities in the test set that had not been seen in the training set. However, because the training set is still so small, you'd likely need a few hundred more examples to push this score to above 80% in practice.
Here we summarize the food entity extraction metrics, including a baseline, which is just the ner_crf component with low, prefix and suffix features removed.
Medium Example: Company Name Extraction
The lookup table performed well on a simple test case, but now let's try the same approach on a real world example with a bit more complexity. Here we'll train a model with multiple intents and entities and use over 1,000 training examples. Our goal will be to improve the entity extraction of company entities (company names) for a bot that is being trained to answer FAQs on a company website. For example:
I work for the [New York Times](company)
We've included the training examples in company_data/data/company_data.json. Let's first run the model without the lookup tables and see what we get. We can do this using the same run_lookup.py script by running
python run_lookup.py company
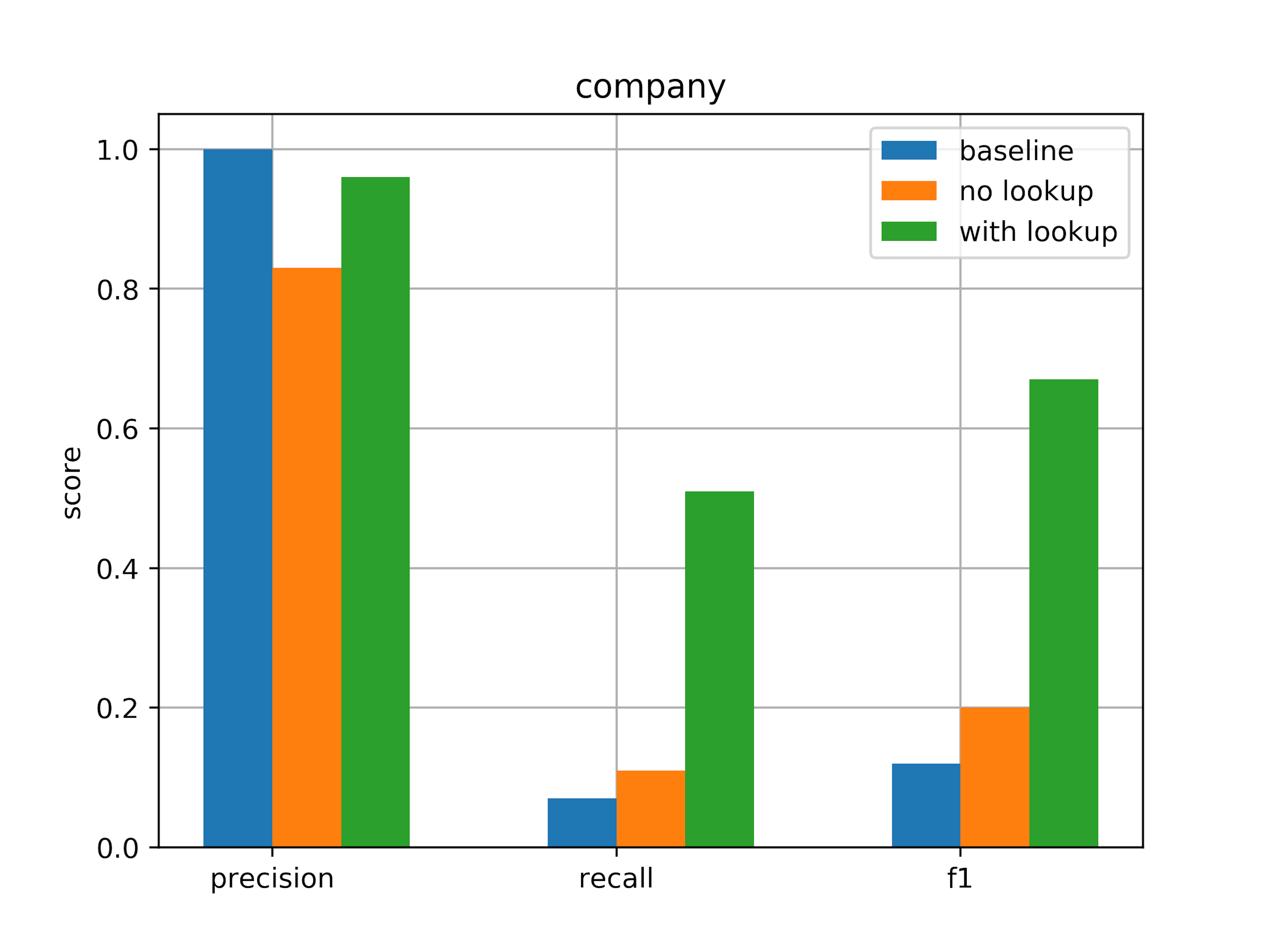
This gives us the following results
| Metric | Value |
|---|---|
| precision | 0.83 |
| recall | 0.11 |
| f1 score | 0.20 |
We can see that our company recall is 0.11, which is quite bad. Just like in the previous example, we'll now add a lookup table in order to improve this score. We incuded a dataset of 36k startup names in company_data/data/startups.csv. Then, we added the following lines to our training data to load this lookup table
{ "rasa_nlu_data": { "lookup_tables": [ { "name": "company", "elements": "data/company/startups.csv" } ], "common_examples": [ { "text": "I wanna talk to your sales people.", "intent": "contact_sales", "entities": [] }, ... ] }}When we add this dataset, we see an improvement in the recall from 0.11 to 0.22. However, we can still do much better than this. After inspecting the matches, we found that that there were several startups with names that are also regular english words. Some examples being companies called THE or cloud. These were getting matched with the wrong tokens in the training data, which was hurting performance.
To solve this problem, we cleaned up the lookup table by filtering out these troublesome elements. To do this, we wrote a lookup table filtering script filter_lookup.py, which can be run like
python filter_lookup.py <lookup_in> <cross_list> <lookup_out>
The script takes a lookup table <lookup_in>, removes elements that are contained in a cross list <cross_list>, and outputs another filtered lookup table <lookup_out>.
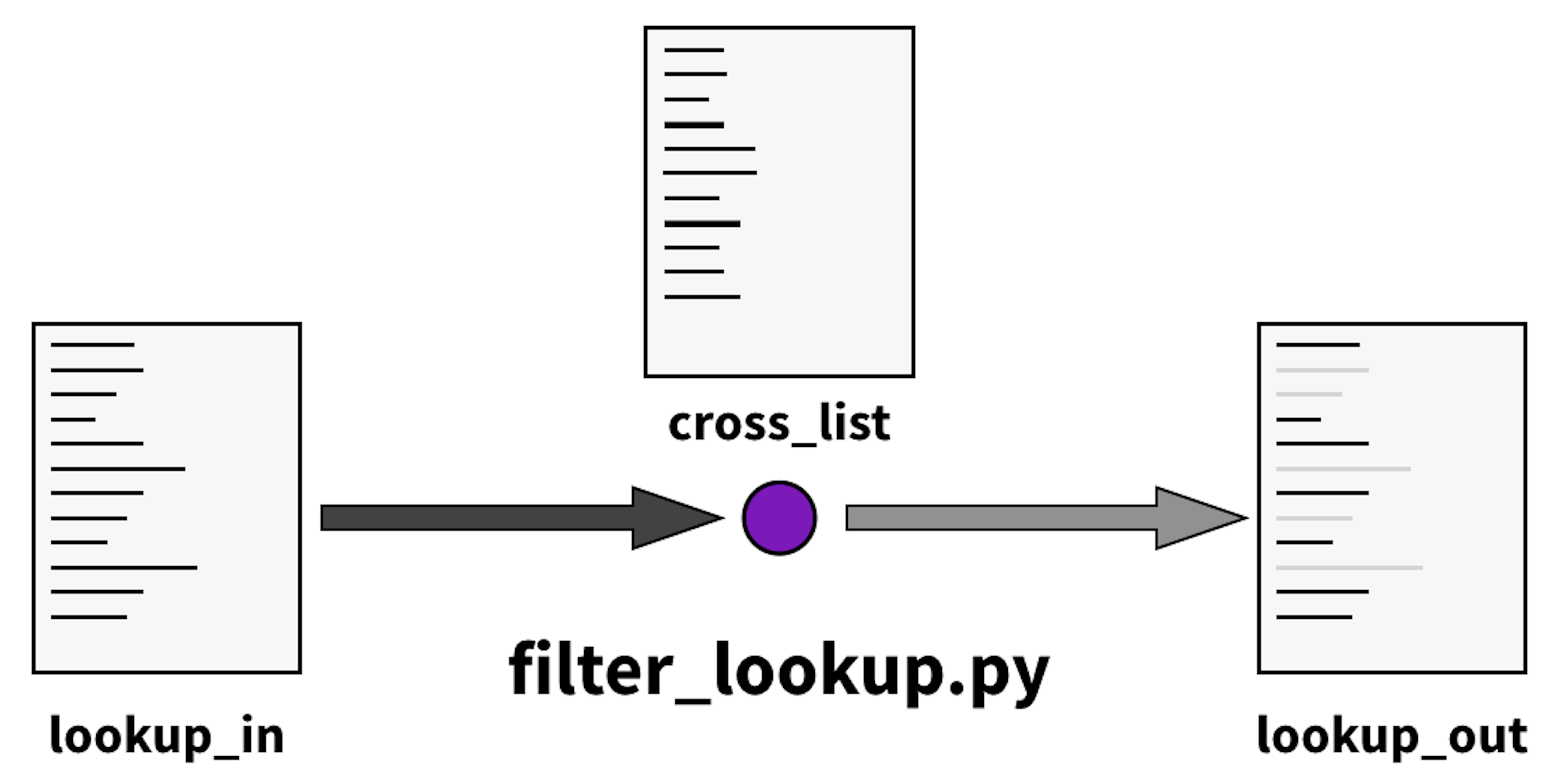
To filter regular english words, we used a cross list consisting of legal Scrabble words, which is included in data/company/english_scrabble.txt. The startups lookup table can then be filtered by running
python filter_lookup.py data/company/startups.csv data/company/english_scrabble.txt data/company/startups_filtered.csv
which generates a new list data/company/startups_filtered.csv that excludes most of the problematic startup names.
Now, running the tests with this new lookup table gives
| Metric | Value |
|---|---|
| precision | 0.96 |
| recall | 0.51 |
| f1 score | 0.67 |
Which gives a company F1 score of 0.51, so we see that removing these elements helped quite a bit!
This brings us to a very important warning about using lookup tables:
You must be careful to clean and filter your lookup table data!!
Besides choosing a narrow domain for the lookup table entities, it is also wise to remove common words and names from your lookup tables. Especially ones that you have reason to believe will be matched incorrectly in your training data. This is often trickier when your lookup tables are large.
Large Example: Address Extraction
Finally, we will try the same techniques with a very large dataset and multiple lookup tables. We will look at whether lookup tables can improve address recognition, for example, with training examples like
Take me to [123 Washington Street](address) please
We have a training data file with 11,894 examples, 3,633 of which have address entities. Because this data is under NDA, we've just included the evaluation results below
| Metric | Value |
|---|---|
| precision | 0.95 |
| recall | 0.93 |
| f1 score | 0.94 |
We see that Rasa NLU actually does quite well at extracting addresses! But we'll try to do even better by including two lookup tables, which we constructed using openaddresses:
-
a list of all city names in the US
-
a list of all street names in the US.
Both were filtered and cleaned as we did for the company names previous sections. These lookup tables are very large, containing 10s of thousands and 10s of millions of elements respectively, so cleaning them is quite time consuming.
After running the training and evaluation again with these new lookup tables, we get
| Metric | Value |
|---|---|
| precision | 0.95 |
| recall | 0.94 |
| f1 score | 0.94 |
So only the recall improves and very slightly from 0.93 to 0.94. Closer inspection reveals that there were still several street and city names still matching on the wrong tokens. For example, because many streets are named after people, the lookup table was matching names in the text.
Conclusions
These experiments demonstrate that lookup tables have the potential to be a very powerful tool for named entity recognition & entity extraction. However, when using them it is important to keep in mind the following considerations:
-
Keep them narrow. It is best to stick with lookup entities that have a well defined scope. For example, "employee names", would be a decent option for a given application but, as we found, "company names" and "street names" are actually risky options because they have so many overlaps with regular non-entity tokens.
-
Keep them clean. One must be very careful with the data being used in lookup tables, especially large ones. There are many opportunities for just one strange element in the table to mess with the training. Some of these can be cleaned up (like how I removed scrabble words) but some are just inherent in the data. For example, there were many street names that were not necessarily scrabble words, but still got matched on non-address tokens, like people's names. Therefore, a good amount of data cleaning might be necessary if you include a lookup table taken from a large dataset.
-
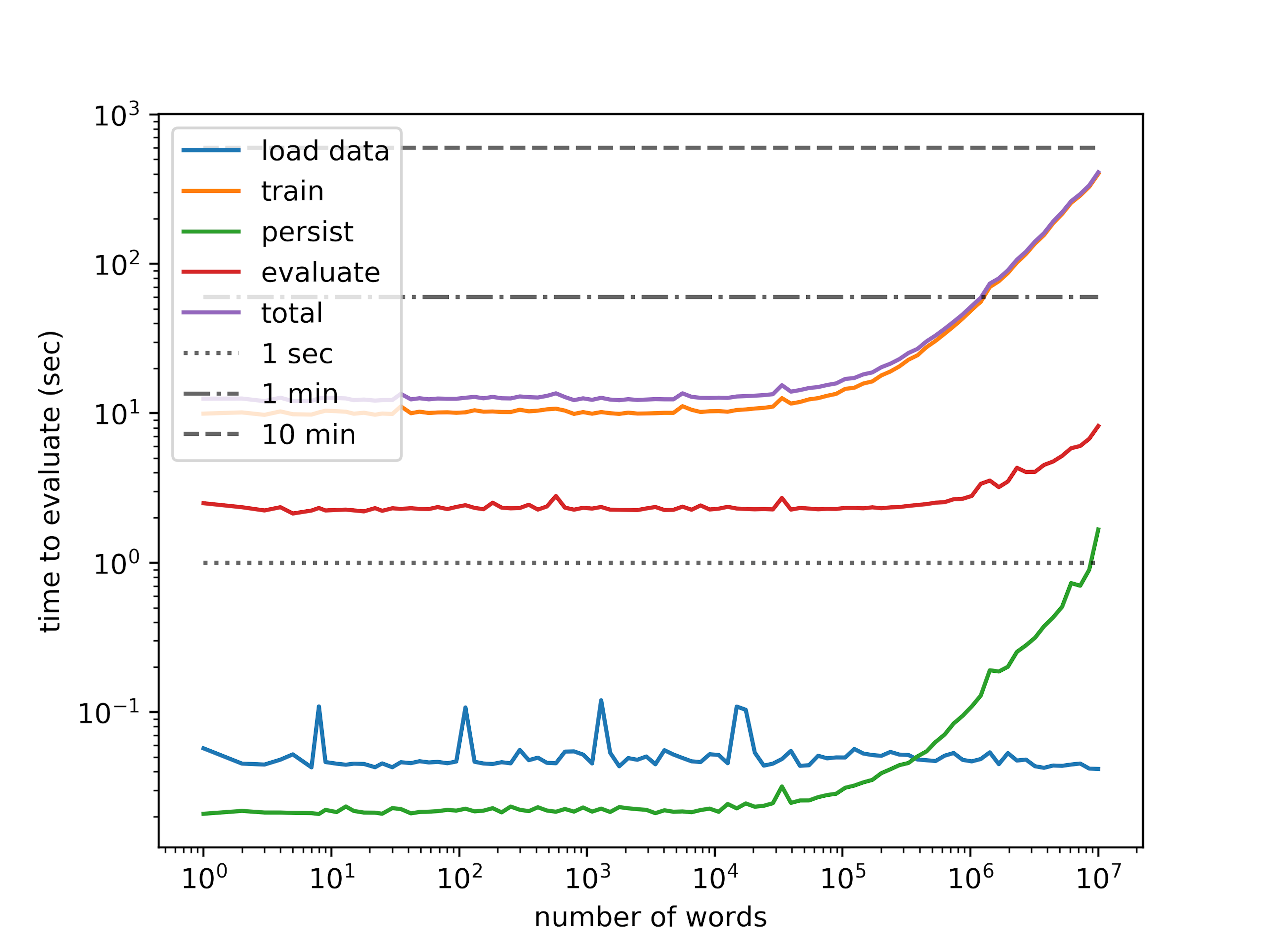
Keep them short. Giant lookup tables can also add a large amount of time to training. As a rule of thumb, if it's > 1m long, expect the training to take several minutes to an hour at least. Below is a plot of the the training and evaluation time as a function of the number of lookup elements. This was trained on the
companydemo training set.
Beyond Exact Matches
We've shown how lookup tables can improve entity extraction by looking for exact matches in the training and test data. In this section, we'll discuss some other strategies that are worth trying if you want to get the maximum performance on your application. These features are in the Rasa research pipeline and may be added to Rasa NLU in future releases.
Fuzzy matching
As designed right now, lookup tables only match phrases when an exact match is found. However, this is a potential problem when dealing with typos, different word endings (like pluralization), and other sources of noise in your data. "Fuzzy matching" is a promising alternative to manually adding each of the possible variations of each entity to the lookup table.
Libraries like Fuzzy Wuzzy provide tools to perform fuzzy matching between strings. When integrated with a lookup table, fuzzy matching gives you a measure of how closely each token matches the table. From there you can decide whether to mark a match, perhaps based on some tunable threshold.
Our initial experiments of fuzzy matching have shown that it has some promise to improve recall and robustness. However, this approach is much slower than regular lookup tables. Therefore it is a better strategy to try when you have short lookup tables (< 1000 elements)
Character-ngrams
When doing entity extraction, in some cases the features within the word may be more important than the full phrases. One of the most straightforward sub-word features to look at are "character n-grams", which just refer to sequences of characters that may show up in your text data. For example, the statement:
"Ban bananas!"
Has the following set of character ngrams of length 3
("ban", "an_", "n_b", "_ba", "ana", "nan", "nas", "as!")
Notice that ban and ana each showed up twice in this phrase.
Character ngrams can be used to improve entity extraction if you know that some ngrams are more likely to appear in certain entities. For example, if you were building a company name entity extractor, some character n-grams to look out for would be
("llc", "corp", "gmbh", "com", "tech", "plex")
However, In many cases this information could be unknown or might take too much time to construct by hand. To handle this, we've included a tool to do ngram extraction automatically in the ngrams/ directory of the demo repo.
The basic process is as follows:
-
We first construct a labelled dataset with:
a. the values we expect our entities to take on.
b. other non-entity values. we've used scrabble words combined with common names for this.
-
Then, we transform each example to express it in terms of the number of each character n-gram within the example. For example:
Ban bananas! -> { 'ban':2, 'an_':1, 'n_b':1, '_ba':1, 'ana':2, 'nan':1, 'nas':1, 'as!':1 } -
From this form, we use randomized logistic regression to extract the ngrams that have the most predictive power in classifying the data.
-
Now, we sort these ngrams by whether they are positive or negative influence on the entity prediction. To do this, we simply train a regular logistic regression model on the original dataset and filter by the sign of the final coefficients.
-
Finally, the positive and negative influencer ngrams may be put into separate lookup tables and inserted into the training data and used on our NLU problem.
Disclaimer: In the current release of Rasa NLU, the lookup tables only match if there are word boundaries around the elements. The line of code that makes this regular expression is copied here
regex_string = '(?i)(\\b' + '\\b|\\b'.join(elements_sanitized) + '\\b)'
Therefore, character ngrams can not be matched unless they are stand-alone tokens. However, the ability to turn these word boundaries on and off is coming in later release.
You can play with the way lookup tables are matched by editing the _generate_lookup_regex method in rasa_nlu/featurizers/regex_featurizer.py of your fork of Rasa NLU.
Conclusion
We hope you get some use out of this new feature in Rasa NLU. If you have any demos or other ideas please feel free to share with us!