


August 12th, 2021
Non-English Tools for Rasa NLU
Vincent Warmerdam

The Rasa community spans the globe, so we often get questions on optimising a Rasa pipeline for a wide variety of languages. Rasa is designed to be customisable and we do our best to support as many languages as possible. Over the years there's also been a number of plugins and community projects that add components for Non-English use cases.
This blog post aims to give an overview of these tools to help you build Non-English assistants. We've split up the document into different sections that each highlight a different part of the NLU pipeline. We'll start with tokenisers, move on to featurizers and conclude with entity extractors.
Tokenizers
The Rasa pipeline usually starts with a tokeniser that takes text as input and turns it into a sequence of tokens. For English, a common choice is the `WhitespaceTokenizer` but there are many alternatives out there.
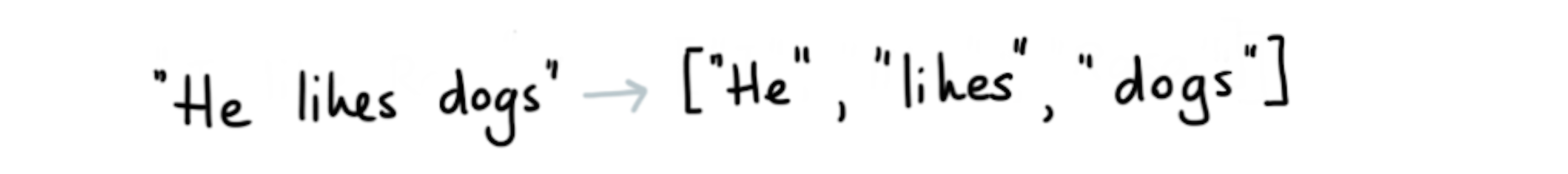
spaCy
The WhitespaceTokenizer inside of Rasa will split on spaces, but also on non-alphanumeric characters. The spaCy tokenizer that comes with Rasa comes with a set of predefined rules to handle the splitting of the characters.
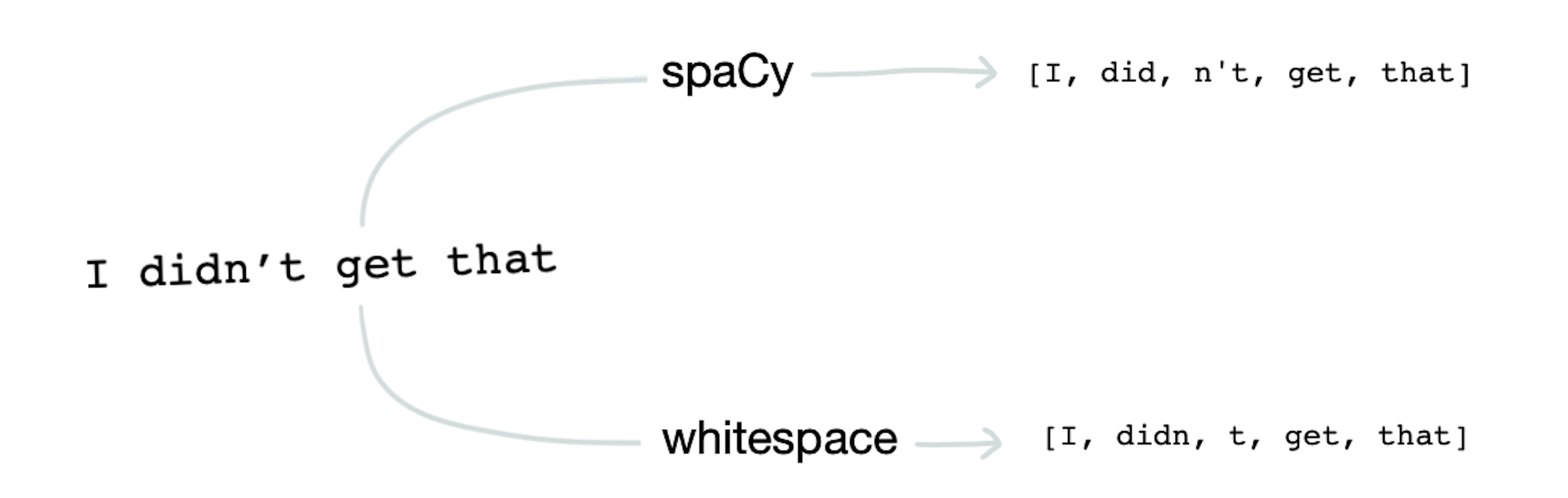
In English, this can cause subtle differences in tokens, but in other languages, these differences may certainly be more profound. The spaCy models that Rasa directly supports at the time of writing include Chinese, Danish, Dutch, English, French, German, Greek, Italian, Japanese, Lithuanian, Macedonian, Norwegian, Polish, Portuguese, Romanian, Portuguese, Romanian, Russian, and Spanish.
SpaCy, however, also supports more tokenisers. If you look at their listed table on their docs, you'll notice many languages that don't have a pipeline attached. These languages include Vietnamese, Korean and Arabic. The SpacyNLP component inside of Rasa doesn't support these languages, but they are supported inside of rasa-nlu-examples.
Here's the list of languages at the time of writing.
Afrikaans, Albanian, Arabic, Armenian, Basque, Bengali, Bulgarian, Croatian, Czech, Estonian, Finnish, Gujarati, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Irish, Kannada, Korean, Kyrgyz, Latvian, Ligurian, Luxembourgish, Malayalam, Marathi, Nepali, Persian, Sanskrit, Serbian, Setswana, Sinhala, Slovak, Slovenian, Swedish, Tagalog, Tamil, Tatar, Telugu, Thai, Turkish, Ukrainian, Urdu, Vietnamese, Yoruba
Note that although these languages are supported, your mileage might vary. There's a community of volunteers who contribute tools, but the spaCy maintainers don't speak all the listed languages. Another challenge is that the language used in a chat setting might differ from the grammatically correct language the spaCy rules assume.
It may also be the case, for some languages, that you'll need to download an extra python package for spaCy to tokenise. You can find more details at the bottom of the table in the spaCy documentation.
Projects for Chinese
Besides the SpacyTokenizer, Rasa also supports the JiebaTokenizer. This tokeniser uses the jieba python project under the hood and is optimised to tokenise Chinese texts. We also recommend checking out the rasa_chinese community project on Github if you're interested in training pipelines for Chinese. It's maintained by our Rasa superheroXiaoquan Kong, and he's been very active in maintaining components for the Chinese Rasa community.
Featurizers
Once an utterance is tokenised the Rasa pipeline proceeds by adding numerical features. These features will later be used by machine learning algorithms to pick up the correct intent and entity. These features are attached to each token, but there are also features that belong to the entire utterance.
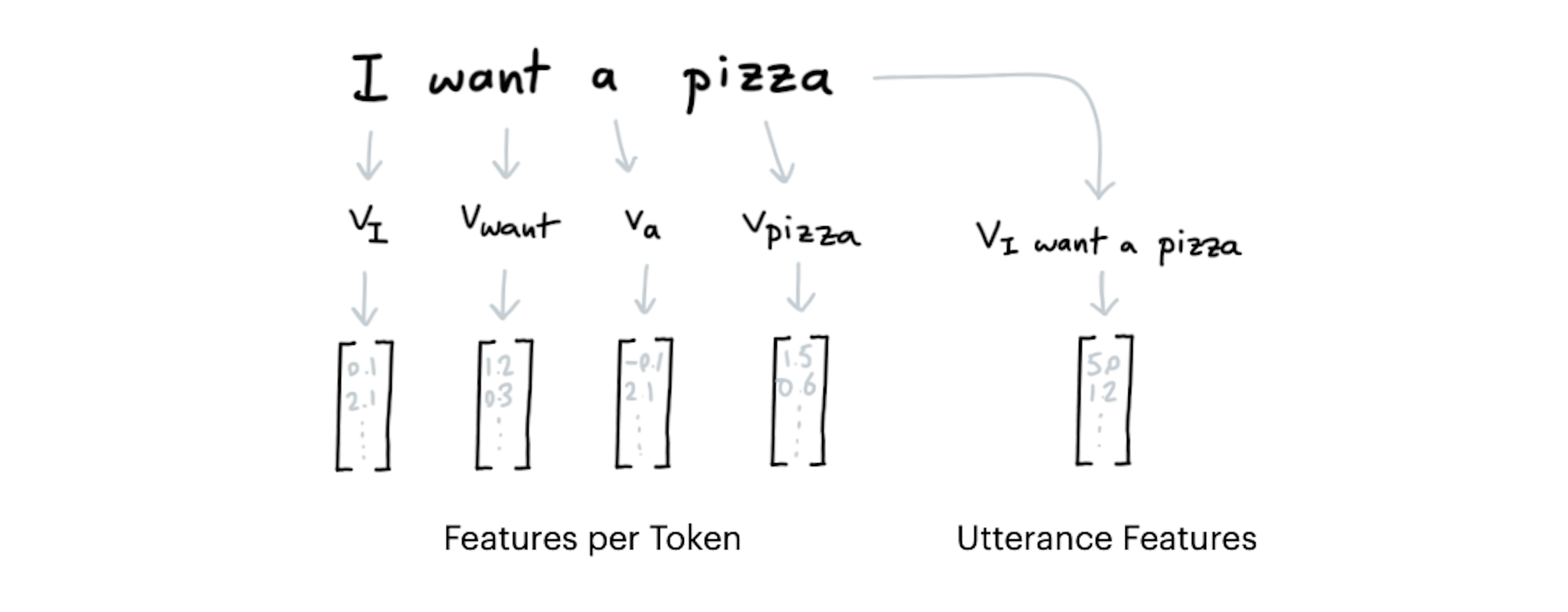
Before we consider some advanced features, we should acknowledge one thing. Once you've gotten a tokenizer in your pipeline, you're already good to build your first model! Let's suppose we have the following NLU pipeline.
pipeline:- name: <YOUR TOKENIZER>- name: CountVectorsFeaturizer- name: CountVectorsFeaturizeranalyzer: char_wbmin_ngram: 1max_ngram: 4- name: DIETClassifierepochs: 100In this pipeline, each token is encoded with sparse features generated by the CountVectorsFeaturizer. We will also encode sparse features for the subwords found in all of the tokens. For a lot of use-cases, this pipeline may already be sufficient. When you're starting, your focus should be finding a representative dataset to benchmark before optimizing the pipeline. We don't want to suggest this pipeline is optimal, but it can certainly be enough to get started.
That said, once you have a representative dataset, you may want to add featurizers to the pipeline that boost prediction scores. For all of the featurizers that we mention below, it's good to understand while they may increase accuracy, they may slow down the assistant. Some of the models we'll mention require many computing resources and may not be worth the accuracy boost.
spaCy
If you're using a SpacyTokenizer in your pipeline, you'll also be able to use a SpacyFeaturizer. These featurizers will add word-vectors to your separate tokens, and for the utterance feature, it will pool the token vectors together by taking the average. These vectors are available for all languages listed on the documentation page here.
Rasa supports many of the spaCy models but in general, we recommend starting with the medium (`md`) variant of models. These models have a reduced word vector table with 20k unique vectors for ~500k words. These models apply a clever trick where similar words point to the same vector. This keeps the model relatively lightweight as they only tend to be ~40 MB big. The large models (`lg`) contain models with a large word vector table with ~500k entries. These models tend to be ~700MB big.
HuggingFace
Rasa natively supports huggingface models via the LanguageModelFeaturizer component. There are many models made available via this component, many of which are Non-English. There are even a few multi-lingual models available. In particular, we might recommend the language-agnostic LaBSE model. It's been trained to handle 109 languages (see the appendix in the original paper for a full list) and we've received good feedback on it. It's a model that uses the Bert architecture but with a specific set of weights that need to be configured.
- name: LanguageModelFeaturizer model_name: bert model_weights: rasa/LaBSEYou can also use a huggingface model that is specific to your language of interest. If you check their documentation page, you'll find many combinations of model names and model weights that you can use inside of Rasa. At the time of writing we support the 'bert', 'gpt', 'gpt2', 'xlnet', 'distilbert' and 'roberta' models. You can also use models hosted by the community of huggingface users as long as they fit the predefined set of models.
For example, let's say you've found this Arabic model and you're interested in using it. It's a model based on the bert architecture, so the configuration for Rasa would be:
- name: LanguageModelFeaturizer model_name: bert model_weights: asafaya/bert-base-arabicFrom here, Rasa would download the models on your behalf automatically. There are many Bert models that Rasa supports via this route. The main thing to keep in mind is that Bert models tend to require many computing resources to run. As a best practice, we recommend properly benchmarking the pipeline to ensure that the accuracy is worth the compute costs for these models. It's certainly possible that adding Bert to a pipeline makes performance worse due to overfitting.
SubToken Embeddings
There is an alternative to heavy Bert models. You could instead focus on subword embeddings. These embeddings encode subtokens with dense vectors, and the rasa-nlu-examples repository supports some of these as featurizers for Rasa. In particular, it supports FastText embeddings (which support 157 languages) and BytePair embeddings (which support 227 languages). If you're interested in giving these embeddings a try, we recommend trying the BytePair embeddings first. The FastText embeddings are about 7Gb in size, while the BytePair embeddings are much more lightweight and offer more customisation options.
One benefit of these subword embeddings is that they can be more robust against spelling errors. If you're curious about how these embeddings do this under the hood, you may appreciate watching some of our algorithm whiteboard videos on them.
EntityExtractors

In a Rasa pipeline, it's common to have more than one entity extraction model. An utterance will only output a single intent but it can certainly have more than one entity in it. It makes sense to consider different entity detection models for different types of entities. Some entities are best to fetch with a rule-based system, while other entities deserve a machine learning-based approach. If you use multiple entity extractors, we do advise that each extractor targets an exclusive set of entity types.
So what are some options for entity extractors in Non-English languages?
spaCy
A spaCy model that can be used as a featurizer also comes with an entity detection model built-in. That means that spaCy can supply entities for 19 languages.
These models are trained on large corpora and have demonstrated good performance. The main downside is that the data that the spaCy models were trained on might not represent the language that your assistant will receive. These models are also statistical in nature, so you shouldn't expect them to be errorless. If you're interested in exploring what spaCy can do you can check the available entities in the interactive demo found here.
Duckling
Duckling is a service written in Haskell that can extract entities from text. They support a bunch of entities like dates, phone numbers, numbers, and distances. You can find a full list of supported entities on their GitHub repository and they support 50 language locales. The downside of Duckling is that you'll need to run a service outside of Rasa that hosts Duckling in order for Rasa Open Source to receive the found entities.
Dateparser
If your main interest is to find dates, then you may appreciate the DateparserEntityExtractor component in rasa-nlu-examples. It's built on top of the dateparser library, which claims to support 200 languages. The tool is originally meant for web scraping, but it also has support for relative date prediction. It's able to recognise not just that "yesterday" refers to a date entity, it's also able to retrieve the parsed date for you. The main benefit compared to Duckling is that you no longer need to run a separate service to run it. The downside of this approach is that it's still somewhat experimental and that we're still collecting feedback on it.
Rule-Based Approaches
Many entities don't require machine learning and can be defined using regexes instead. The RegexEntityExtractor inside of Rasa is language-agnostic and can readily be used to detect phone numbers, email addresses, and many other well-defined patterns.
In the rasa-nlu-examples repository, we also host a FlashTextEntityExtractor. This extractor is built on top of the flashtext project and extracts entities via a clever string-matching algorithm. This approach is less flexible than regexes, but it's much faster. If you've got a list of 1000s of names you'd like to detect, it can make a difference.
Speaking of name lists, we've started hosting a few! There have been a few contributions of lists of baby names worldwide, and you can find them on GitHub.
Conclusion
In this blog post, we've highlighted some tools that might help you build Non-English assistants. There are many tokenisers, featurizers, and entity extractors available that go beyond the English language. We hope that these components will help you design assistants in your target language.
If you have any feedback on any of the components or feel like tools are missing, we'd love to hear from you! Our research team appreciates any feedback you might have, so please drop a message on our forum. We're especially delighted to hear about any benchmarks that you ran using the listed tools.