



After previously discussing various ways of accelerating models like BERT, in this blog post we empirically evaluate the pruning approach. You can:
- read about the implementation of weight and neuron pruning with BERT (jump to the section),
- see how much faster and smaller we can make BERT (jump to the section),
- understand what neuron pruning can tell us - e.g that sometimes BERT doesn't need attention at all (jump to the section)
Introduction
Where we are
In the previous blog post, we discussed why accelerating big neural language models is desirable, popular model compression methods, and how far we can get with quantizing models. In this follow-up blog post, we will talk more about our hands-on experiences with pruning BERT. In particular, we use weight pruning and neuron pruning, i.e. removing either individual weight connections or entire neurons from BERT. Note that we treat this as a research project, and so the discovered trends are more important than absolute numbers, which can also differ across different hardware and datasets.
What are we pruning?
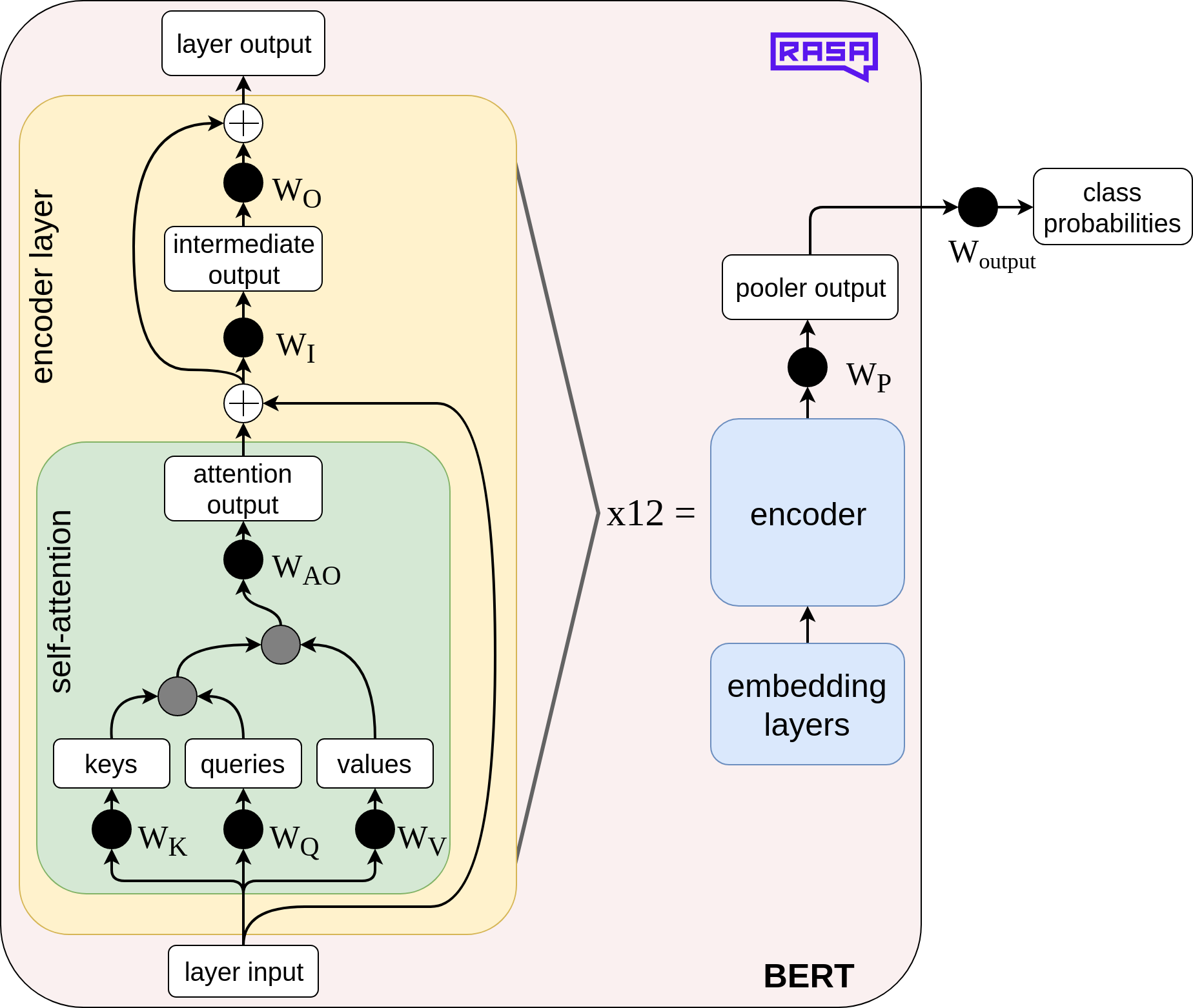
To better understand which components of BERT we can compress, let's remind ourselves of the weight matrices and matrix multiplications that make up the BERT architecture (in this case the "base" variant).
; the grey circles denote matrix multiplication of two tensors; the '+' circles mean addition of two tensors. Some tensors are labelled ("keys", "queries", etc.) for better understandability.")
Notice how the multi-headed self-attention is cleverly realized with only three matrices in total (WK, WQ, WV), instead of three matrices for each attentional head. Compared to the self-attention module's weight matrices, WI and WO are 4x larger. To significantly accelerate BERT, we need to shrink at least those two weight matrices. In our actual implementation, we prune WK, WQ, WV, WAO, WI, WO, and WP. We ignore Woutput because its dimensionality depends on the number of target classes in a particular task, and it is usually small relative to the other weight matrices.
The implementation
All the code is available inthis branchof the Rasa repository. For a higher-level theoretical overview of pruning, see ourprevious blog post.
Weight pruning
Our implementation is based mostly on the TensorFlow weight pruning implementation available as tf.contrib.model_pruning (recently also in TensorFlow's Model Optimization Toolkit). The codebase accompanying [1] provides a good example of weight pruning from tf.contrib.model_pruning applied to transformer components from the popular tensor2tensor library. This is great for any BERT users because BERT is built using exactly those components. Essentially, we just needed to replace all linear layers (tf.layers.dense) used in BERT with their altered versions that support pruning of the weight matrices and bias vectors.
Neuron pruning
Adapting the weight pruning implementation
To implement neuron pruning, we forked and adapted the weight pruning code from tf.contrib.model_pruning. The main changes were:
- Making the pruning operate over entire neurons instead of individual weights. To understand what this means, we visualize a simple linear layer and try to suppress one neuron's activation:
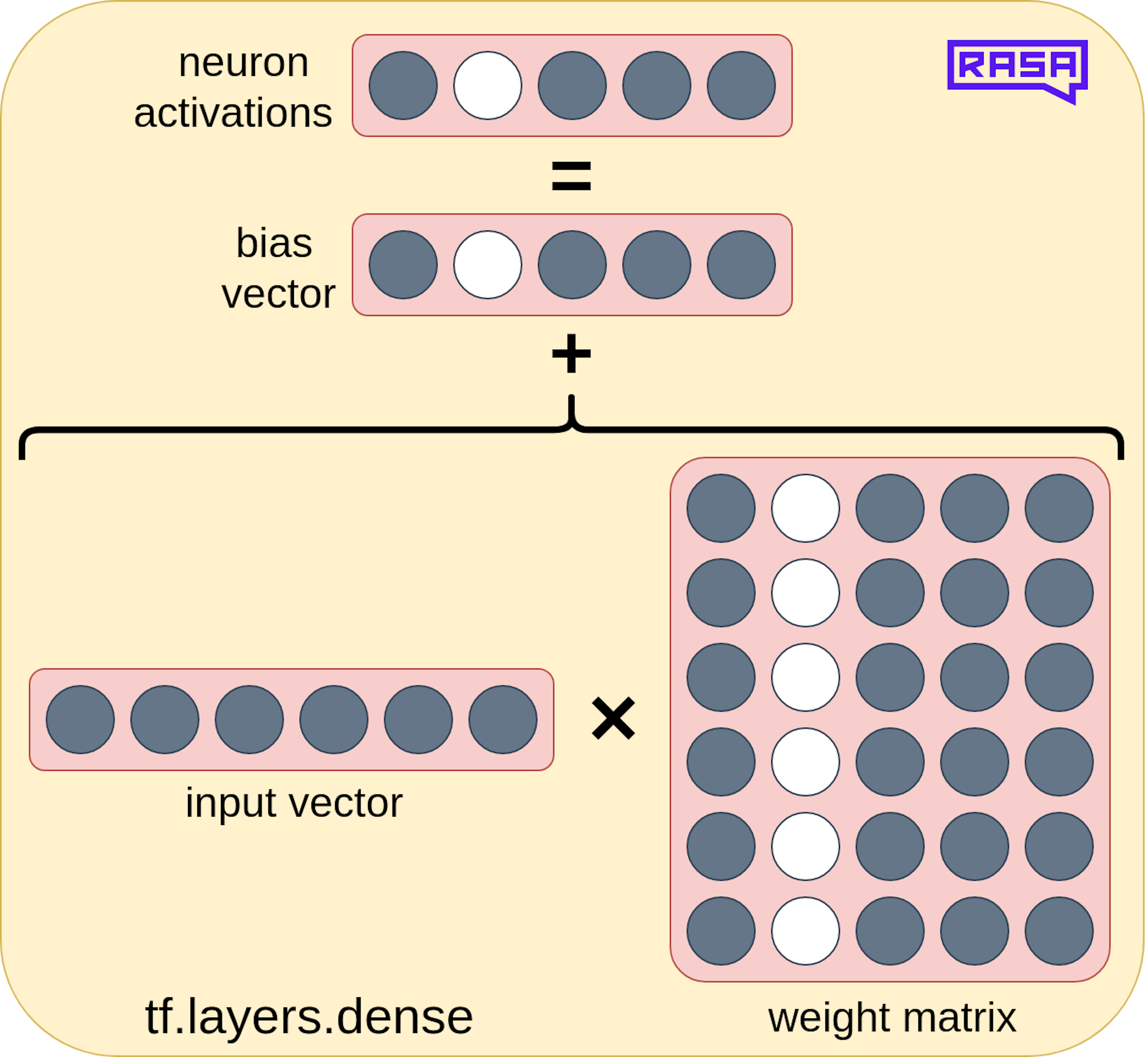
This figure illustrates how silencing a neuron translates to masking out the corresponding entry in the bias vector and the corresponding column in the weight matrix. This is exactly what we implemented.
- Using a different importance function to decide which neurons to silence. We used the method discussed in the previous blog post, proposed in [2]. This requires:
- accumulating over multiple mini-batches the activations and gradients of the training loss with respect to the activations,
- multiplying the activations with the gradients and L2-normalizing the product separately for each linear layer,
- silencing the neurons with the product closest to zero.
Physically removing neurons
To actually accelerate BERT, just masking out weight matrix elements as implemented in tf.contrib.model_pruning is not enough. We need to actually remove them to reduce the amount of matrix multiplication. However, immediately resizing the weight matrices would be too slow. It would require after each pruning step saving the resized matrices, re-building the computational graph with the updated matrix dimensions, and loading the weights into the graph. We propose a more efficient, 2-phase procedure:
- Iteratively mask out more and more neurons (by updating the pruning masks),
- After the time-consuming iterative part, actually remove the masked out neurons and save the down-sized weight matrices and bias vectors for inference.
Dealing with arbitrary sizes of layer activations
A pruned and down-sized dense layer produces activations with smaller dimensionality. To prevent dimensionality mismatch, we inflate the activations back to the original size so that any next layer which consumes the activations doesn't need to be adjusted. The inflation is implemented using tf.scatter_nd and is guided by the learned pruning mask as shown in the picture:
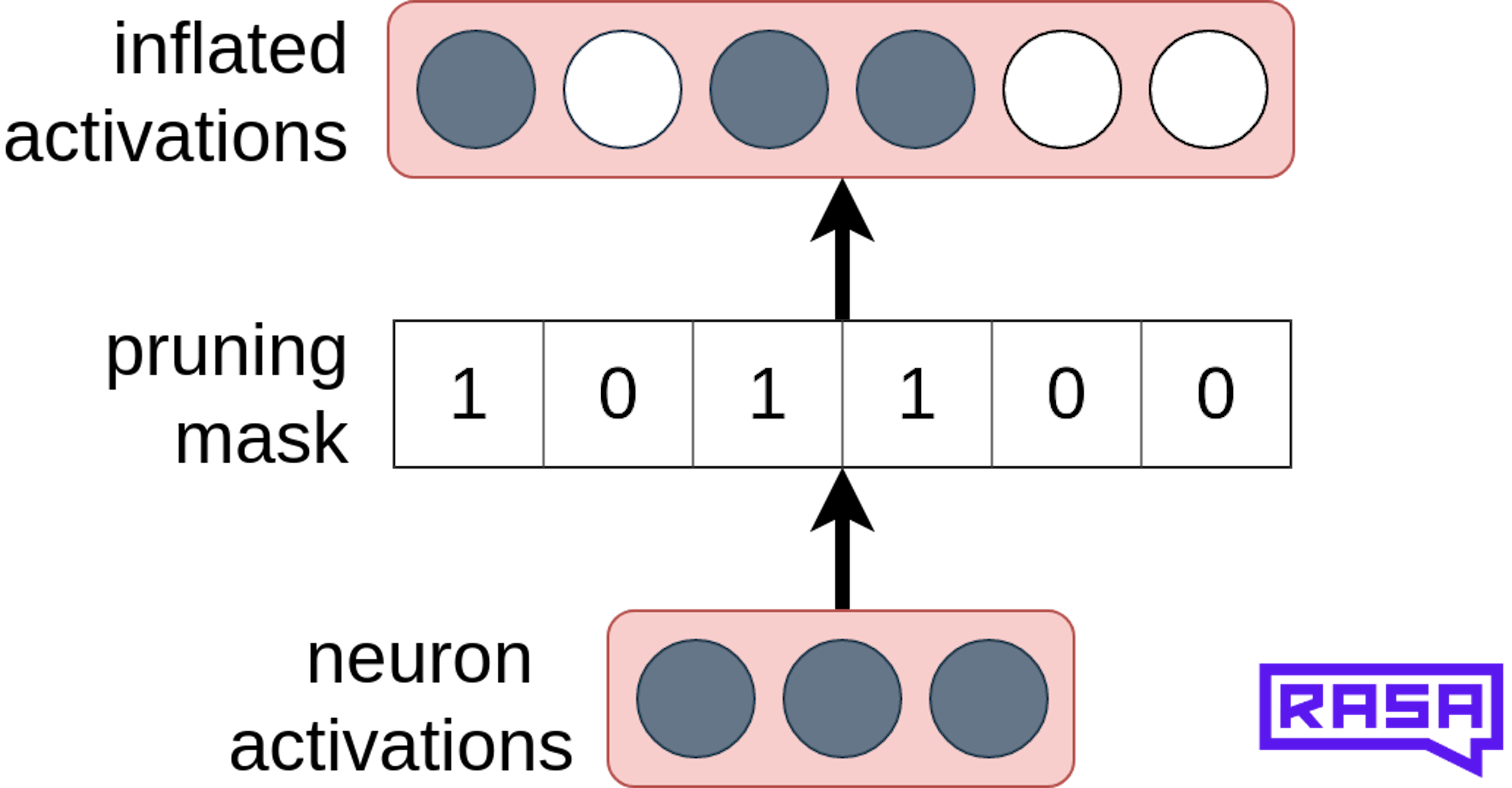
Even though this inflation adds some computational overhead and the mask has to be stored too, we later show that the positive effect of less matrix multiplication dominates.
Cross-pruning
You may think: the inflated activations contain a lot of zeros, the next layer surely can't benefit from those! Indeed, the inflation is done purely to simplify the dimensionality handling. There is a lot of matrix transposing, element-wise tensor addition and reshaping going on in BERT. Getting the sizes right can become a nightmare. Nevertheless, we can easily omit the inflation in the rare cases where the activations of one layer feed directly into the next layer. We adjust this next layer's weight matrix removing some of its rows. We call this cross-pruning of the weight matrix:
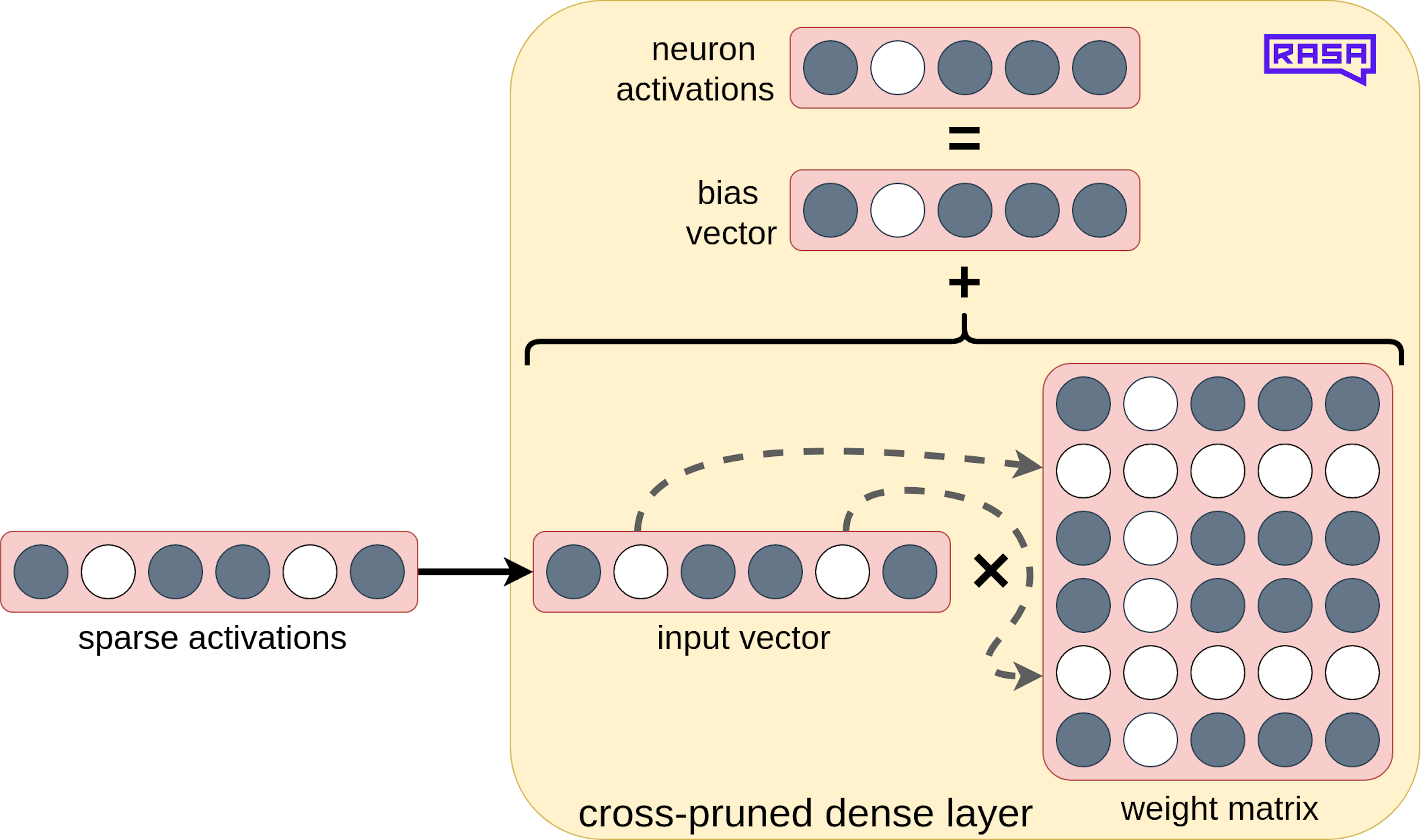
In BERT, cross-pruning is only possible in the case of WO, but it reduces the amount of matrix multiplication significantly because WO is one of the 2 largest weight matrices of the model.
Experiments
What and why
Our primary goal is to speed up BERT's inference while retaining accuracy. All our experiments are carried out on a real conversational dataset built from conversations people had with Sara, Rasa's demo bot. Our existing light-weight intent classifiers only take a few milliseconds to process a single message and achieve test-set macro-averaged F1 (or simply "F1") score of 0.86 on the test portion of the dataset. We managed to achieve F1 of ~0.92 with BERT, but it takes ~143ms to process one message. (Our previous implementation using tf.contrib.estimator and tf.contrib.predictor was slightly faster, but difficult to work with.) Across our experiments, we prune the fine-tuned BERT, hence starting with very good F1 and seeing how it changes after pruning. If we can significantly accelerate the inference and still stay well above the baseline value of F1=0.86, then we conclude that speeding up BERT is the way to go.
Weight pruning
We know this will not speed up BERT, but it can give us hints on how sparse we can make the model. We took the simplest approach, doing all the pruning at once. The model is not allowed any further training steps that would perhaps help it to "recover" after pruning. If the model still performs well, we are almost certain that with additional recovery time this could only get better. We tried pruning to different target sparsities and report F1:
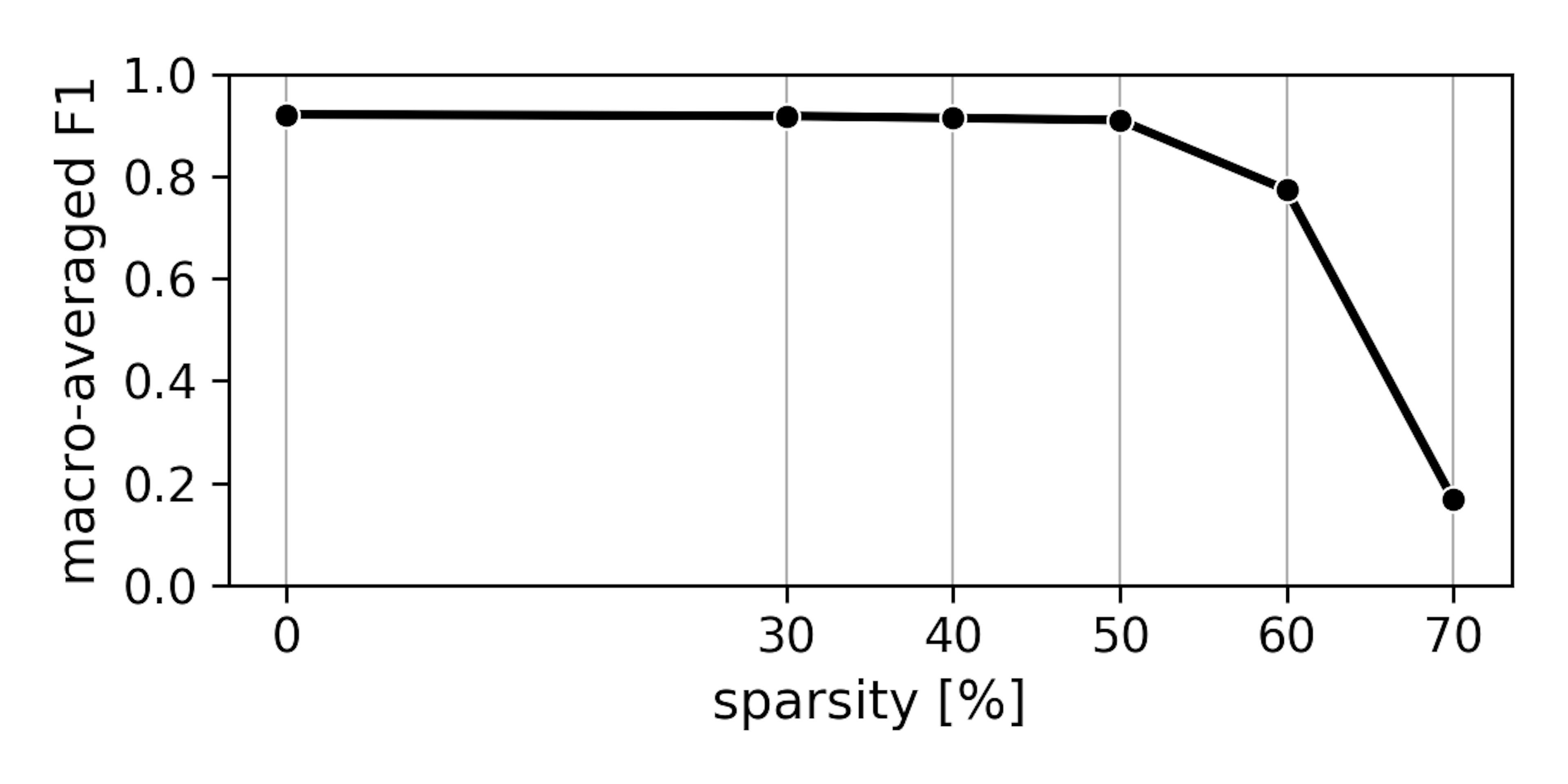
The results are convincing; we can remove up to 50% of all weight connections in one step without significant loss of accuracy. Hence, we hope we can also remove at least 50% of all neurons when using neuron pruning.
Neuron pruning
Here we actually expect to achieve acceleration as previously confirmed by others (see e.g. this blog post). The entire model is pruned to some overall target sparsity. This means letting each weight matrix to be pruned to a different extent, reflecting the matrix's importance. Note that in neuron pruning by "sparsity" we mean the neuron (column) sparsity of weight matrices.
Setup
Because it is time-consuming, the pruning was done using GPUs in Google Cloud Platform VMs (even so, it takes ~3 hours for 40 epochs). The inference speed was measured on a MacBook Pro, using CPUs. We measured the actual inference time, i.e. the runtime of the call to TensorFlow's session.run().
Pruning vs recovery
Naturally, neuron pruning requires some sweeps through the data to accumulate the activations and gradients. We call these the pruning epochs, during which we update the pruning masks at each pruning step. This pruning period is followed by a recovery period during which no further pruning happens and the model has an opportunity to further fine-tune its weights, perhaps recovering from too aggressive pruning. But how quickly should we prune the model and how much recovery time to give it? We decided to use 40 epochs overall, allocating the first few of them for pruning and the rest for recovery. We do pruning steps twice per epoch, and the sparsity increases linearly during the pruning period up to the target sparsity.
Initial exploration
To begin, we need to choose a good pruning strategy, i.e. decide how quickly to prune the model and how much recovery time to give it. With the total budget of 40 epochs and target sparsity of 60%, we tried different lengths of the pruning period (the transition from pruning to recover is marked by dashed lines):
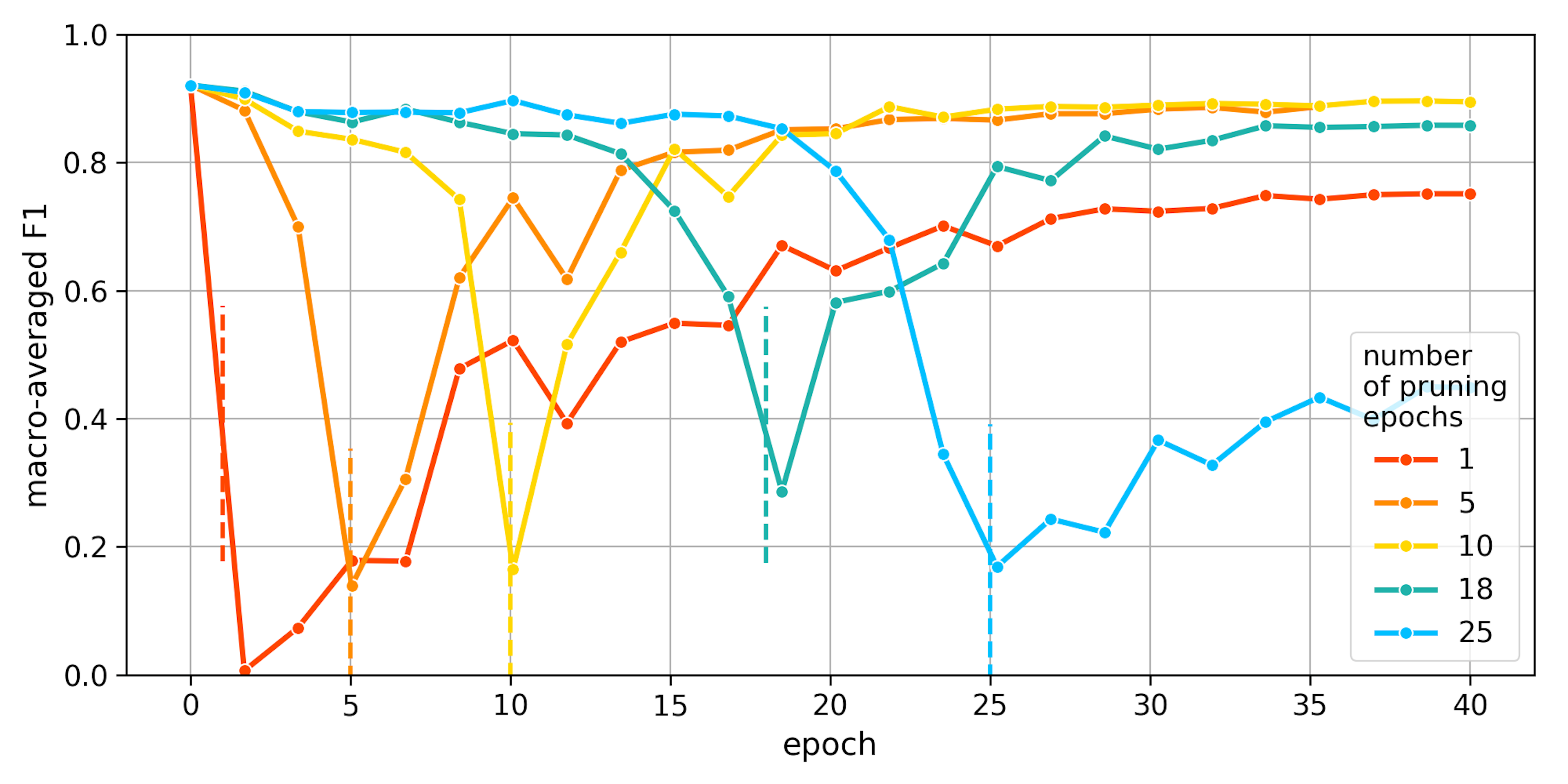
Indeed, the pruning strategy matters and pruning too eagerly (in just 1 epoch) harms the model too much. Even more interestingly, also pruning too slowly is harmful! We hypothesize that, as the pruning progresses, the remaining neurons react to the changes in their inputs in ways that can degrade the quality of their weights. This intuition is backed up by observing that for very slow pruning (18 or 25 epochs), the model takes longer to recover. We decided to use only 10 pruning epochs (+ 30 recovery epochs) in all further experiments.
How much can we prune BERT, and what about acceleration?
Seeing that a 60%-sparse BERT can still achieve F1 close to 0.90, we wonder if we can go any further. We tried pruning to different sparsities and report the F1 as well as the inference speed:
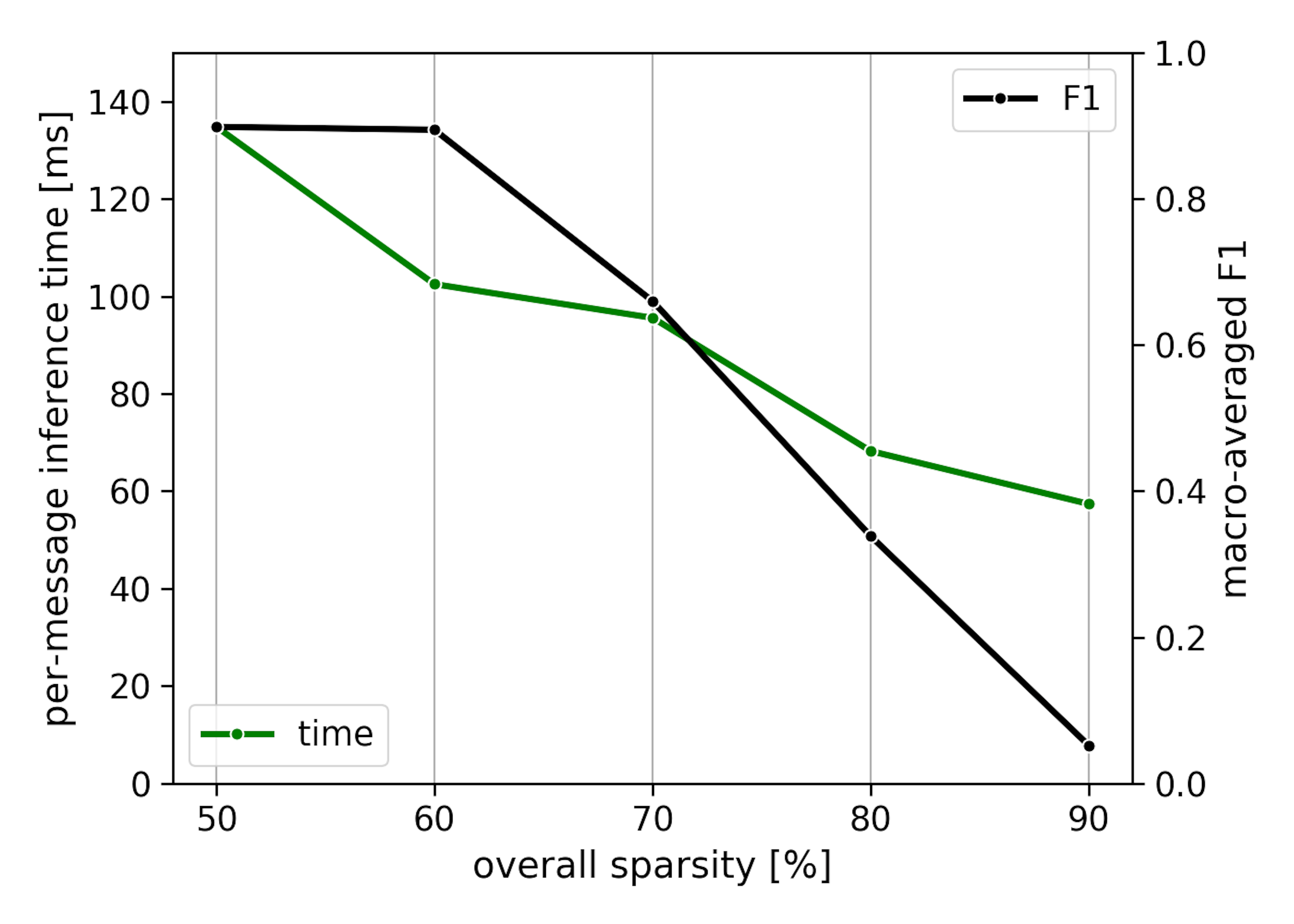
Clearly, sparsity and acceleration are positively correlated. The 60%-sparse model still achieves F1 ~0.895 (2.8% relative decrease) and is 28% faster! Unfortunately, going beyond 60% sparsity harms F1 too much. Note that even 90%-sparse BERT is about 20x slower than our light-weight classifier - apparently, BERT is just way too big to start with, partly due to the embedding lookup layers. Why does the 50%-sparse model provide almost no speed-up? It is due to the computational overhead introduced by inflating the activations, which we measured to be ~15ms. Also note that on GPUs - where matrix multiplication is very fast, but tf.scatter_nd is not optimized - this overhead outweighs the speed improvements unless you prune BERT to an extreme target sparsity such as 80%.
What about the model size?
Naturally, neuron pruning also makes BERT smaller. The original full BERT has ~406MB, while the 60%-sparse version has only ~197MB. Unfortunately, the embedding layers are big and even 90%-sparse BERT still has ~115MB. Even so, this shows that neuron pruning can help you if you just want to shrink a big model at little to no loss of accuracy.
Analysis of neuron pruning
What pruning tells us about BERT's components
We let the model decide which components to prune more and which less. So, what does it lead to? The component- and layer-specific sparsities of the 60%-sparse BERT are shown below:
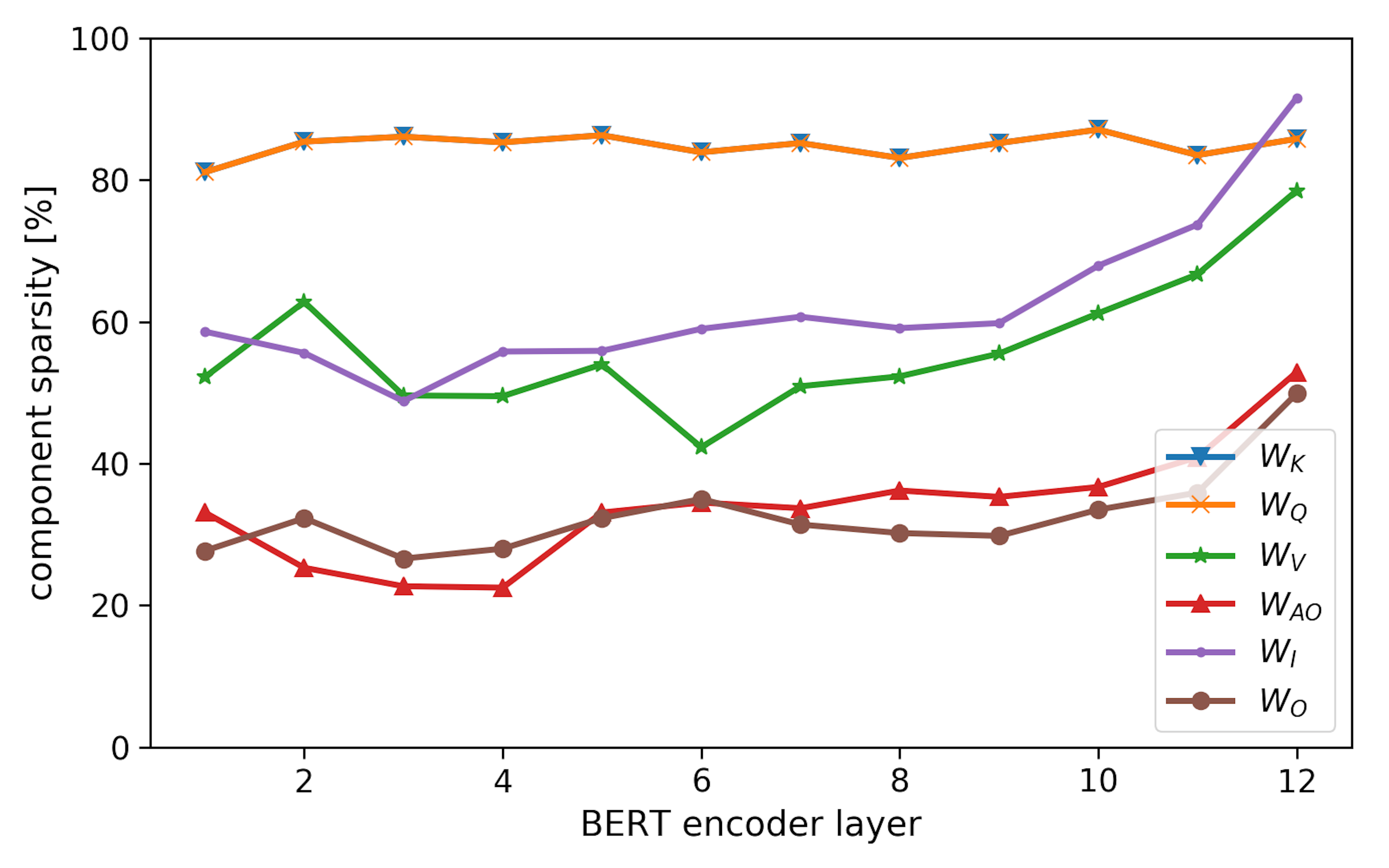
Apparently, the component-specific sparsity varies little across different layers, but in general the last 2-3 layers seem to be less important because they get pruned more. Interestingly, WQ and WK can be pruned very aggressively, telling us that the attentional weights can be computed using much fewer parameters. The attentional output (WAO) and layer output (WO) seem to be very important as they are pruned only a little.
Do we need attention at all?
Seeing how eagerly WQ and WK are pruned, we tried a simple thing: pruning those two to 100% sparsity and keeping all other parameters unpruned. The resulting model achieved F1=0.897. This is the case where the self-attention produces context vectors without attentional weights, simply by averaging the value vectors across all time steps. The result practically tells us that, on this particular task and dataset, BERT doesn't need self-attention, which we find amazing. This result is good, but BERT would be accelerated much more if we could shrink the much larger WI. Hence, we tried a similar experiment, where we prune that weight matrix to 100% sparsity. We compare this with eliminating WQ and WK:
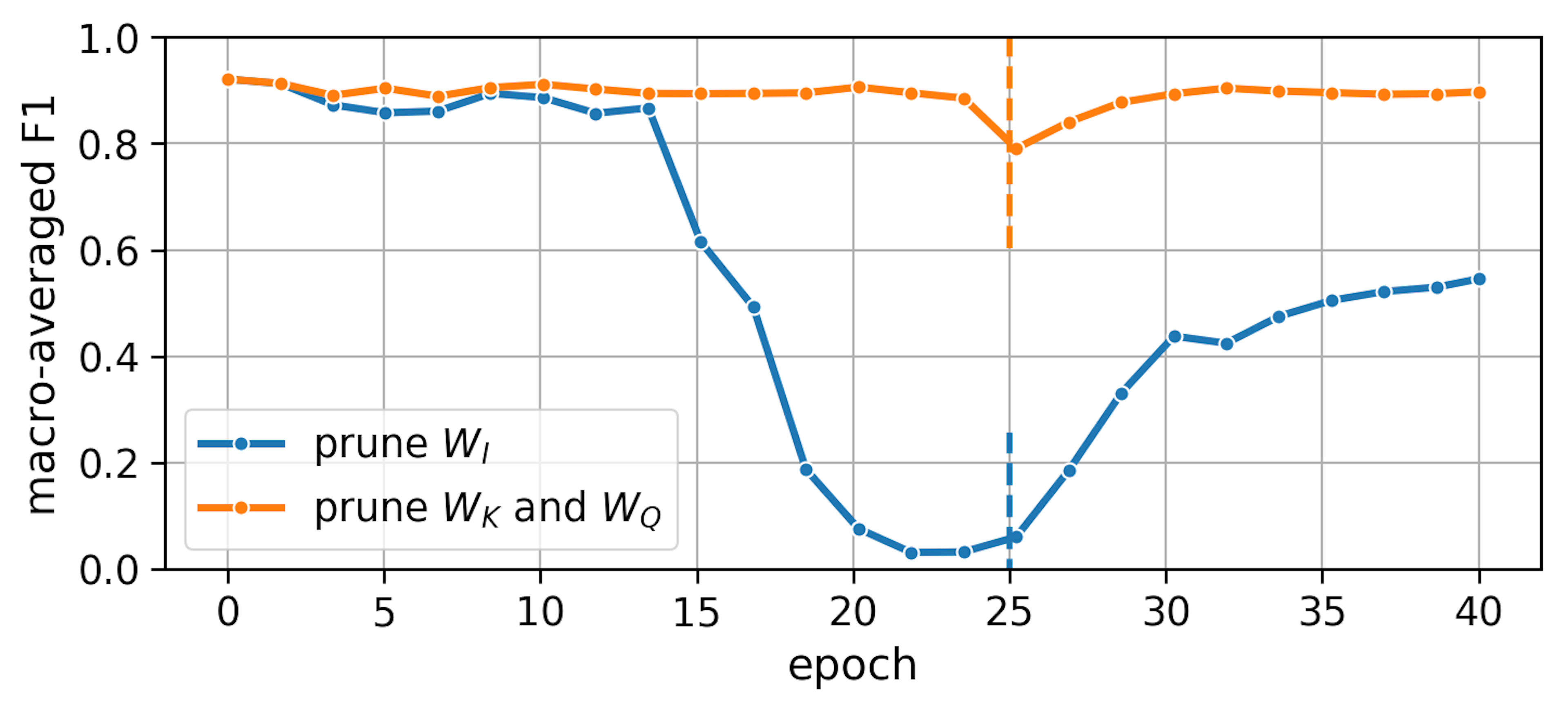
Apparently, the intermediate layer cannot be pruned this much - it is probably much more important than the self-attention. One interesting phenomenon is the sharp F1 drop during pruning in both cases (for self-attention, it occurs at ~90% sparsity, for WI it is at ~50% sparsity). We hypothesize that each component can have its characteristic maximum sparsity, going beyond which causes a "shock" to the model. So, when setting the target sparsity of a certain component, you better look at what sparsity it achieved in the "organic" pruning where the target sparsity was set at the model level. Simply listen to your models :-)
Can we improve neuron pruning?
We saw that the number of pruning epochs matters. What about the recovery? And what about sparsities other than 60%? We show F1 for a range of sparsities (the dashed line shows the beginning of recovery epochs):
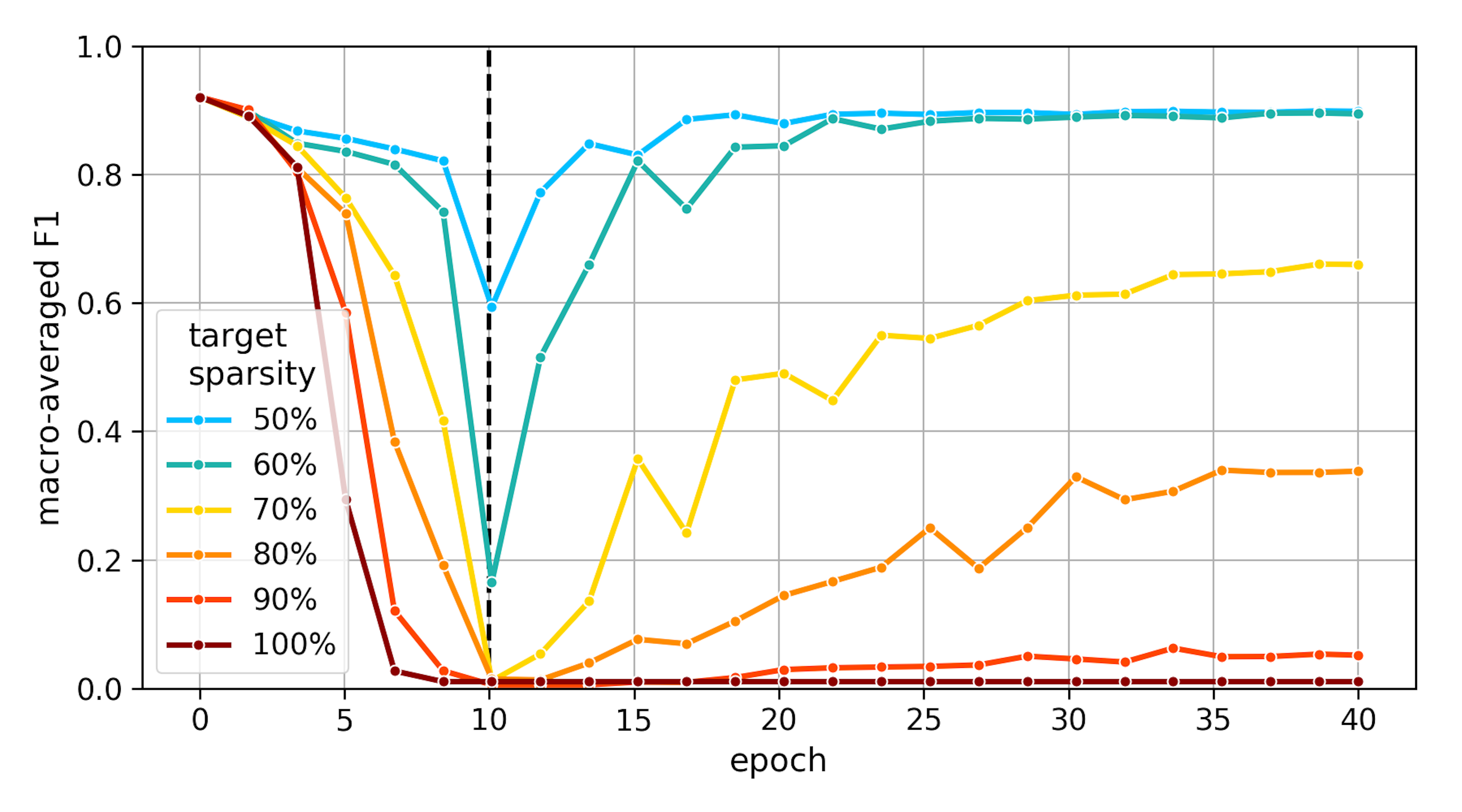
{kind=link}
The recovery epochs are clearly important, taking us back up from very low F1 values. However, at least for the used pruning strategy, the more the model is pruned, the slower it recovers. Beyond 60% sparsity, it cannot recover to the full accuracy and beyond 80% sparsity, it doesn't seem capable of recovery at all. Still, it is possible that even the 70%-sparse model could recover with more time or when using a different pruning strategy.
Where do we go from here?
Even though BERT can be successfully sped up using neuron pruning, we decided not to proceed with this idea. We believe that BERT is too big (and perhaps also too powerful) for the kind of classification needed in dialogue NLU. Even the 100%-sparse version is still very slow compared to our existing classifier. One interesting direction for further research remains to be knowledge distillation. Recently, the Hugging Face team managed to distil BERT into a 2x smaller version of itself (still a big model, having 66M parameters!), achieving 60% acceleration. In [3], the authors distil BERT's knowledge into a small Bi-LSTM with less than 1M parameters, but at the expense of slightly worse accuracy.
Conclusion
We've successfully adapted weight pruning and neuron pruning for BERT. We observe that as much as 60% of neurons can be removed while retaining solid test-set macro-averaged F1 on an extended version of the conversational dataset behind our demo bot Sara. This also leads to 28% relative inference acceleration and 51% smaller model size. Unfortunately, it still leaves BERT much slower than our existing classifier. We think that for our task and dataset BERT might simply be unnecessarily big and slow - an intuition confirmed by getting good results even without the attention weights.
We open-source our implementation, based on this original adaptation of BERT as a Rasa intent classifier. Our code supports weight and neuron pruning and we highly encourage you to try it. We are also eager to discuss with you anything related to model compression in our community forum.
Sources
[1] Gale, T., Elsen, E., & Hooker, S. (2019). The State of Sparsity in Deep Neural Networks. Retrieved from https://arxiv.org/abs/1902.09574
[2] Molchanov, P., Tyree, S., Karras, T., Aila, T., & Kautz, J. (2016). Pruning Convolutional Neural Networks for Resource Efficient Inference. Retrieved from https://arxiv.org/abs/1611.06440
[3] Tang, R., Lu, Y., Liu, L., Mou, L., Vechtomova, O., & Lin, J. (2019). Distilling Task-Specific Knowledge from BERT into Simple Neural Networks. Retrieved from https://arxiv.org/abs/1903.12136v1