


January 19th, 2021
Reduce Training Time with Rasa’s New Incremental Training
Karen White

We're excited to announce the release of incremental training, a new experimental feature shipped in Rasa Open Source 2.2.0. Incremental training allows you to fine-tune an existing model after adding new training examples instead of training a new model from scratch. This cuts down training time significantly, reducing the time between annotating new data and testing its impact on model performance. Teams practicing conversation-driven development (CDD) benefit from greater efficiency, faster experimentation, and fewer bottlenecks.
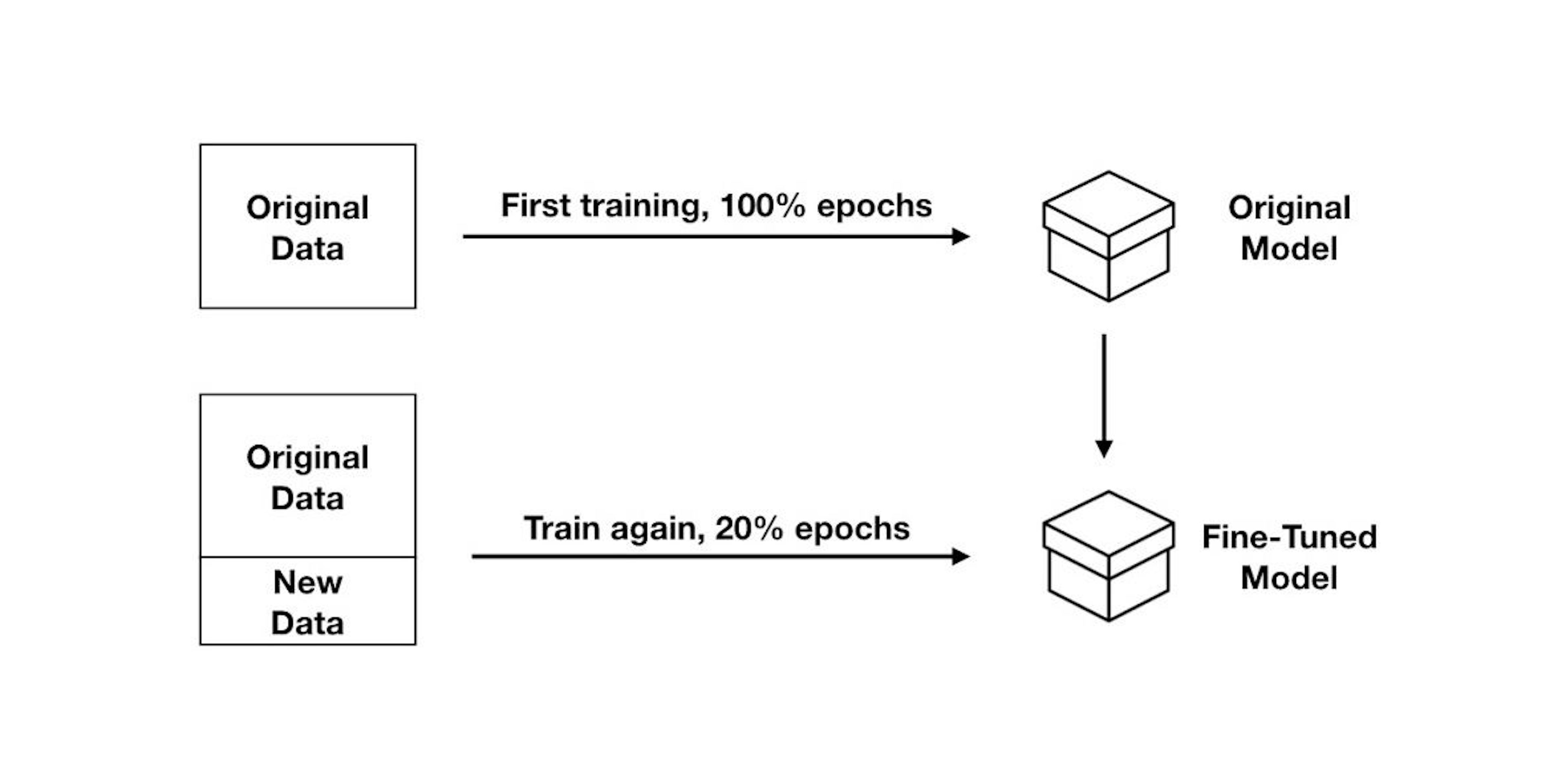
Incremental training works by leveraging the knowledge of the older model. When new examples are added to the training data set, incremental training loads the weights learned by the previous model, much like a pre-trained model. Next, the updated data set is used for training, but for a fraction of the time used to train a model from scratch. The fine-tuned model produced by this process contains awareness of the new examples and performs comparably to a from-scratch model. Compared to training a model from scratch, incremental training allows you to spend less time training and more time making meaningful improvements to your assistant.
How to get started with incremental training
To fine-tune an existing model using incremental training, append the --finetune flag to the rasa train CLI command.
rasa train --finetune
By default, incremental training uses the most recent model in the /models directory as the base model, although you can specify another model by providing its path as an additional parameter:
rasa train --finetune <path to model to finetune>
Fine-tuning a model saves time by training for fewer epochs. During a single epoch, the machine learning algorithm passes over every training example in the dataset; typically, a model is trained over multiple epochs. The number of epochs used for a from-scratch training cycle is specified in an assistant's config.yml file.
You can control how many epochs are used for a fine-tuning training cycle using the --epoch-fraction flag. The --epoch-fraction flag tells the incremental training process to run for a fraction of the epochs specified in the model configuration. For example, if a normal training cycle was set to 100 epochs, the command below would run a fine-tuning training cycle for 20 epochs:
rasa train --finetune --epoch-fraction 0.2
Alternatively, you can specify the number of fine-tuning epochs in the config.yml file. This is useful if you want to fine-tune different machine learning components for a different number of epochs, depending on the amount of new data that has been added.
Incremental training FAQs
Q: Does incremental training replace training from scratch?
In short, incremental training supplements training from scratch, but it isn't intended to replace it. Incremental training is a fast way to incorporate new data, but we recommend periodically training your production model from scratch to get the full benefit of longer training time.
It's important to note that incremental training can only be performed when updates are limited to adding new NLU training examples to existing intents. Other changes, like adding or merging intents, creating a new entity, or adding slots and actions to the domain, require training from scratch.
Q: Which model configuration settings do I need to consider?
Incremental training requires the base model to be the same shape and size as the fine-tuned model. Aside from epoch, you should keep your model configuration the same when creating your base model and performing incremental training.
In addition, there are a few extra hyperparameters you should add to your config.yml file if you use RegexFeaturizer or CountVectorsFeaturizer (follow the links for more details in the docs). These additional hyperparameters ensure that the sparse features are of a fixed size between the base and fine-tuned models.
Q: How does the performance of a fine-tuned model compare to training from scratch?
Our early experiments have shown that the performance of a fine-tuned model is very close to the performance of a model trained from scratch. For teams who do frequent annotation and testing, a fine-tuned model provides an accurate representation of how a production model would perform with the new data.
To learn more about our benchmarking experiments and get a deep dive into the inner workings of incremental training, check out our latest Algorithm Whiteboard video.
Fast tracking conversation-driven development
One of the challenges of building AI assistants is assembling a data set that accurately reflects the way your users talk. The messages users send to your assistant are captured in Rasa X, where they can be annotated and saved to your NLU training data file.
This annotation workflow is an important part of conversation-driven development, and many teams who practice CDD annotate messages on a daily or weekly basis. Incremental training allows teams to save time when making frequent updates by re-training an existing model. When combined with CI/CD automation, incremental training creates a seamless workflow for moving changes from Rasa X to a deployed assistant. Learn more about conversation-driven development and setting up CI/CD for your assistant in the Rasa docs.
Conclusion
Incremental training has been a frequently-requested feature, and we're excited for the community to try it out. To get started, make the upgrade to Rasa Open Source 2.2.0 and check out the docs for details on usage.
Lastly, incremental training is currently an experimental feature, and we need your help testing and refining the feature based on your feedback. If you've tried incremental training, let us know how it performed on your data set. We'd particularly like to know how training times compared when fine-tuning vs training from scratch, as well as how the fine-tuned model performed. Share your feedback in the Rasa forum!