



The Rasa Masterclass is a weekly video series that takes viewers through the process of building an AI assistant, all the way from idea to production. Hosted by Head of Developer Relations Justina Petraityte, each episode focuses on a key concept of building sophisticated AI assistants with Rasa and applies those learnings to a hands-on project. At the end of the series, viewers will have built a fully-functioning AI assistant that can locate medical facilities in US cities.
To supplement the video content, we'll be releasing these handbooks to summarize each episode. You can follow along as you watch to reinforce your understanding, or you can use them as a quick reference. We'll also include links to additional resources you can use to help you along your journey.
Introduction
In Episode 5 of the Rasa Masterclass, we introduce dialogue management, which is controlled by a component called Rasa core. Dialogue management is the function that controls the next action the assistant takes during a conversation. Based on the intents and entities extracted by Rasa NLU, as well as other context, like the conversation history, Rasa core decides which text response should be sent back to the user or whether to execute custom code, like querying a database.
Previously in the Rasa Masterclass, we covered NLU models, including how to format NLU training data, how to choose a pipeline configuration and train a model, and an in-depth examination of NLU pipeline components. If you're just joining, be sure to catch up on previous episodes before moving on to Episode 5.
Machine Learning: a Better Alternative to State Machines
When building AI assistants, the most common approach to handling dialogue management is to use a set of rules, known as a state machine. Let's examine how a state machine works, and then discuss why Rasa does things differently.
What is a state machine?
A state machine exists in exactly one of a predefined set of states at any given time. The state machine consists of rules that determine the specific set of inputs or circumstances necessary to transition from one state to another. When we apply this concept to a conversation between a bot and a user, we can see how the state machine can control the way the conversation shifts from one phase to the next: 1) in the initial state, the bot greets the user and describes a task it can help with, like ordering a pizza 2) if the user confirms 3) the bot transitions to a new state and asks the user whether they would like a pizza for delivery or pickup.
The important thing to keep in mind about state machines is that every state, and the user input needed to transition from state to state, must be explicitly programmed. The assistant won't be able to transition to the next conversational state if it doesn't receive the expected input, which can create a very undesirable user experience. Let's imagine that instead of saying "delivery" in response to the bot's question, the user instead typed "This order is actually for next week." An assistant controlled by a state machine might find it difficult to recover from this unexpected input and transition to the proper state.
You could try to code a rule for every possible turn the conversation might take, but this gets complex very quickly, and you still might not anticipate everything users might say.
Dialogue Management with Rasa
Rasa takes a different approach. Instead of a state machine, Rasa core uses machine learning to pick up conversational patterns from example conversations. These example conversations are supplied as training data, much like the method we used to train the NLU model. Based on these patterns, the assistant can generalize, allowing the model to predict the next best action to take in a conversation.This allows the model to provide an appropriate response, even when the conversation doesn't exactly match any of the training examples seen before.
Importantly, this means you don't need to program every possible conversational turn into your assistant up front. You can supply training data containing a few conversation examples when you first build the assistant, and then gather new conversation data directly from real user interactions. Using machine learning, the assistant is able to improve over time, based on the things that users are actually saying.
Stories
In Rasa core, the basic unit of dialogue training data is called a story. You can think of a story as a script detailing the back and forth conversation between user and assistant, from beginning to end. Stories are written in a specific format and stored in the stories.md file. When you run the rasa init command to create a new starter project, the stories.md file is automatically created in the data directory, along with a few simple training stories.
Let's look at an example story and discuss each section:

Story Name
The beginning of a story is marked with a double hashtag (##), followed by its name. Naming your stories is not required, but it makes debugging much easier. For the same reason, it's a good idea to make story names descriptive so you can see at a glance what the story is about.
Messages from Users
Stories are structured as a series of messages from users, and your assistant's response to those messages. User messagesare marked by lines starting with an asterisk (*).
As you can see, the user message is not the actual text of the user message. Instead, the story contains the intent labels and entities extracted by the NLU model.
Assistant Responses
The assistant's response to each user message is marked by an indented line starting with a hyphen ( - ).
Assistant responses are classified as actions. There are two types of actions in Rasa:
- Utterances are hard-coded text strings representing what you want the assistant to say to the user. Within a story, an utterance is labelled with the prefix `utter_`
- Custom actions execute custom code, like fetching data from an API. In stories, custom actions are labeled with the prefix `action_`
Completing the Story
At the end of the story, create a new line and begin the next story with a double hashtag.
Adding Stories to the Medicare Locator Assistant
If you've been following along with the Masterclass, we've been building a contextual AI assistant that uses the Medicare.gov API to locate medical facilities in the US, like hospitals or nursing homes. For reference, you can find the completed code for the Medicare Locator assistant in the Rasa Masterclass GitHub repository.
In the meantime, let's keep working on building our Medicare Locator from scratch. Let's update the assistant's stories.md file and add some training data.
Locate the stories.md file in the data directory. Since we used the rasa init command to create the assistant earlier in the tutorial, we should see a few example stories used to train moodbot.
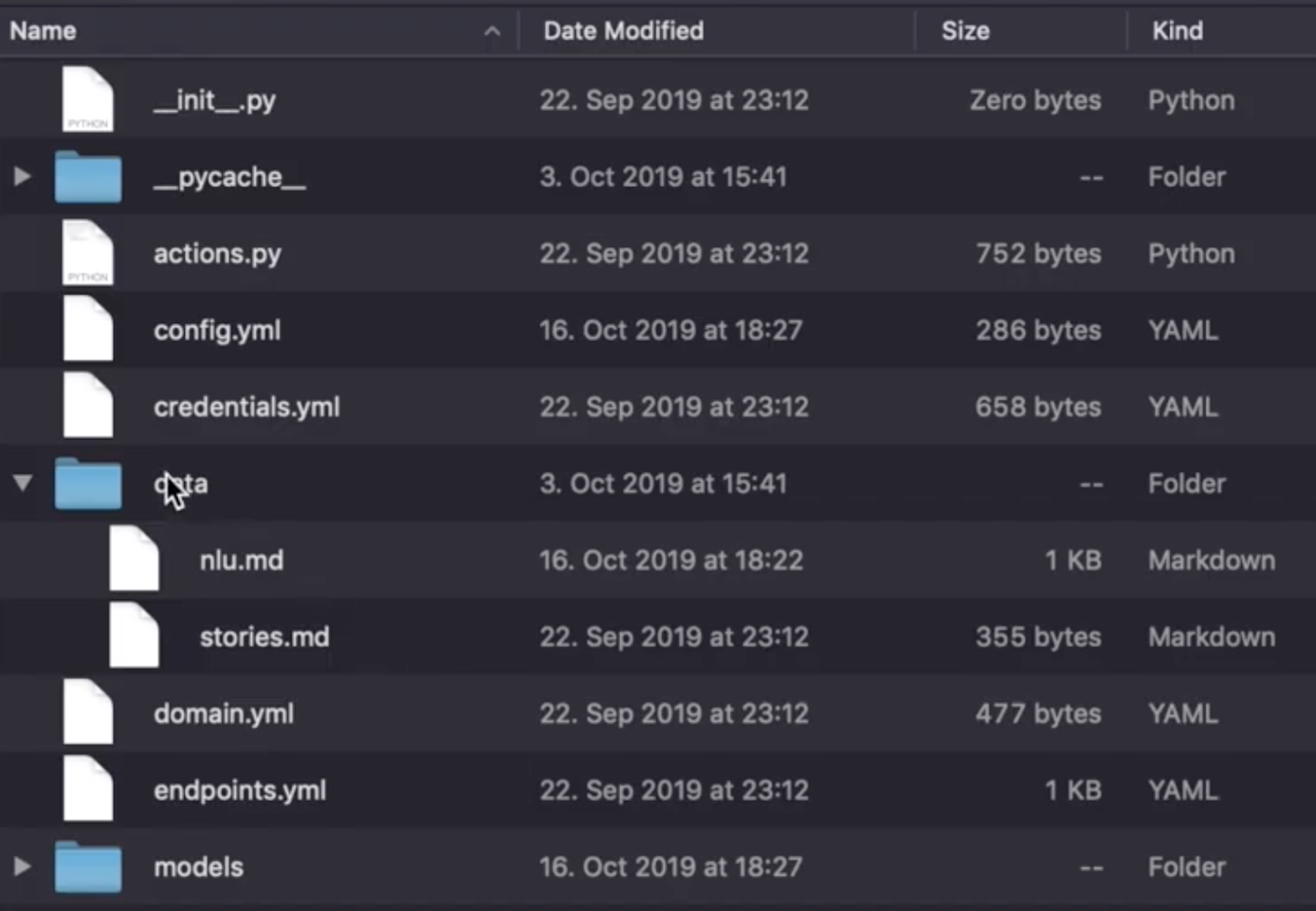
We'll add a few new stories to train the Medicare Locator.
Story 1: hospital search happy path
We'll start with a story where the user supplies all of the required information and the conversation goes as expected (what we'd call the "happy path").
If we were to write out the full conversation, it might look something like this:
User: Hello
Medicare Locator: Hi. I am a Medicare Locator. I can help you find hospitals, nursing homes or other medical facilities in your preferred location. How can I help?
User: I need a hospital in San Francisco
Medicare Locator: The address is 1001 Potrero Ave.
User: Thank you.
Medicare Locator: You are very welcome. Goodbye.
Let's translate the conversation above into the training story format.
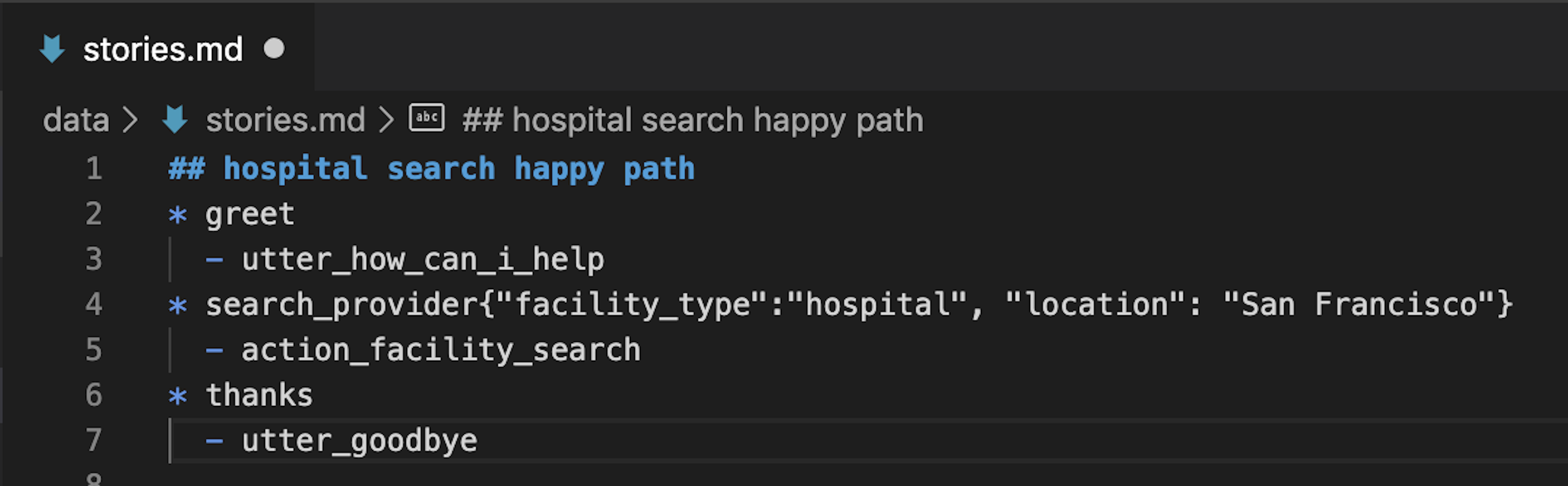
First, we'll name the story: hospital search happy path.
## hospital search happy path
Because the user will likely start out with a greeting like 'Hello' or 'Hi there,' we start the story with the user intent: greet, which is an intent we defined when we created the assistant's NLU training data. In response, the assistant responds with an utterance: a hard-coded message that prints out "Hi. I am a Medicare Locator. I can help you find hospitals, nursing homes or other medical facilities in your preferred location. How can I help?"
## hospital search happy path
* greet
- utter_how_can_i_help
The user responds with "I need a hospital in San Francisco," which matches the search_provider intent we defined in the NLU training data. The user provides the two entities needed to conduct the search: the facility_type and the location. Next, the assistant responds by executing a custom action, in this case, making an API call to locate hospitals in San Francisco.
* search_provider{"facility_type":"hospital", "location": "San Francisco"}
- action_facility_search
We end the conversation with the user thanking the assistant and the assistant uttering goodbye.
* thanks
- utter_goodbye
Story 2: hospital search + location
In order for the assistant to learn, we need to supply more than one training story. So let's add another conversation to our training data.
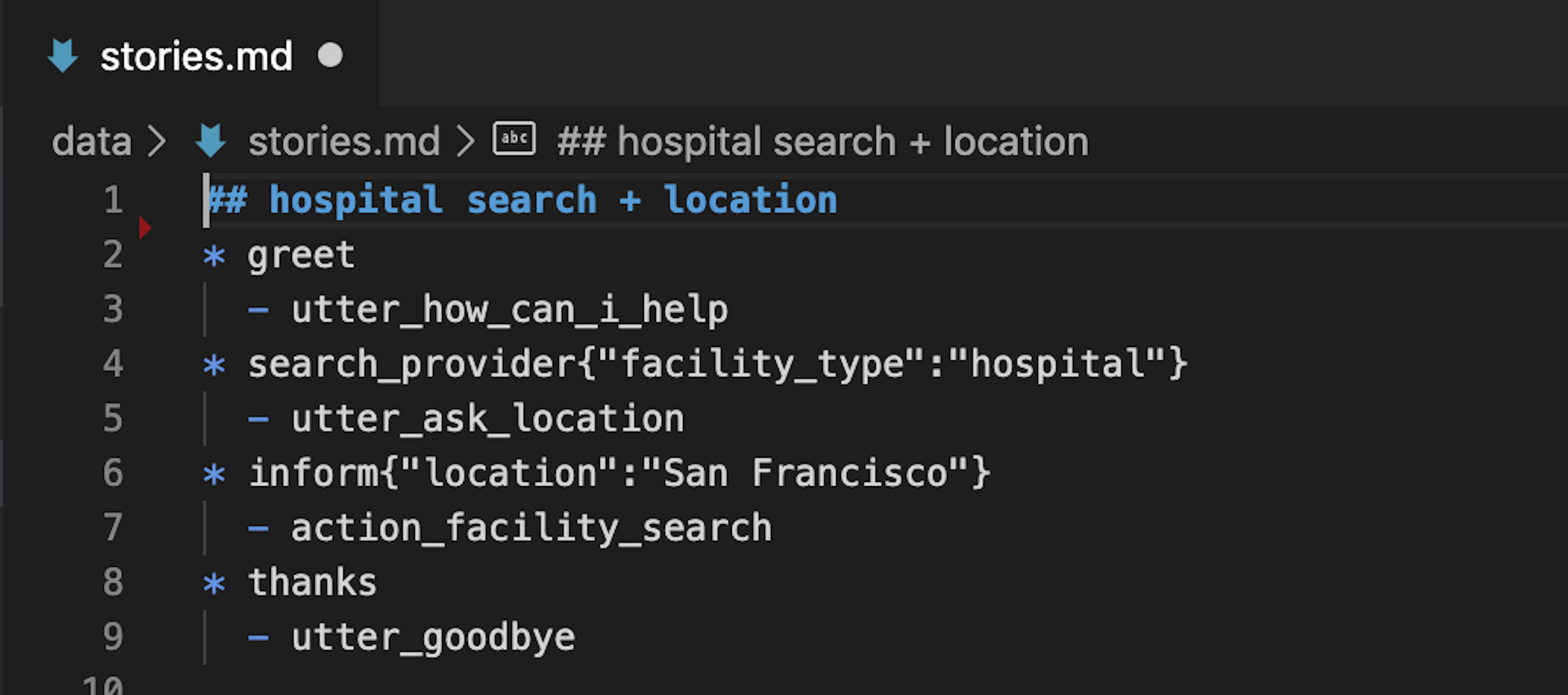
In this story, the user doesn't specify their location right away, so the assistant will need to ask for it. We'll call this story: hospital search + location.
You'll notice this story looks much like the story we wrote for hospital search happy path, except this time, the user's search_provider message only includes one entity: facility_type. Instead of executing the action_facility_search custom action, the assistant responds with an utterance prompting the user for their location. Once the location entity has been supplied, the assistant executes the custom action searching the facility, and the conversation ends with a thank you and a goodbye.
Training Data Tips
While there isn't a firm rule for the number of stories you should have in your training data, there are 2 things to keep in mind:
The more training examples you have, the better. Remember, you don't need to provide a training example for every possible conversational turn, but you do need diverse training examples so the model can learn, start to generalize, and handle previously unseen user inputs.
Examples from real user interactions are preferable to training stories you make up yourself. With this in mind, you should focus first on building an assistant that can handle a simple skill and then share the assistant with real users as soon as possible. Data generated by conversations with real users is the best training data you can possibly get.
It can be challenging to improve your assistant with real user input, which is why we created Rasa X. The Rasa Masterclass will cover Rasa X in detail in later episodes. For now, create as many training stories as you need to cover what you want your assistant to be able to do, and know that you'll need to test it with real users to make it better, later.
Conclusion
If you're coding along, try adding a few more training story examples to your stories.md file. Start by writing down different conversations you think the assistant might have with users and then convert the dialogues into the Rasa training data format.
So far, we've just scratched the surface of dialogue management. In Episode 6, we'll go deeper, covering domain, custom actions, and slots. And in Episode 7, we'll talk dialogue policies-the machine learning components that determine the behavior of Rasa core. Keep up the progress, and if you get stuck, ask us a question in the Community forum.