


November 18th, 2021
What's ahead in Rasa Open Source 3.0
Justina Petraitytė

We are getting very close to our new major release: Rasa Open Source 3.0. As we get ready for this big release, we are thrilled to give our community a sneak peek into what’s coming, including the most important changes and improvements.
Rasa Open Source 3.0 separated the model architecture from the framework architecture, enabling us to run arbitrary model architectures. It also comes with several enhancements focused on improving the developer experience when building conversational AI assistants with Rasa. The revamped computational backend empowers us to experiment with architectures, reducing maintenance costs, and enabling collaborative development at scale. There are improvements to slot mappings that will make it easier to implement desired slot behavior as well as forms. Last but not least we have markers: a new experimental feature, which is intended to help us figure out how to add a “semantic layer” on top of the tracker store of events that makes it easier to identify and track situations of interest in conversations.
Above is just a very short highlight of what we are going to ship with the new Rasa Open Source release. We are planning a very exciting full week of online events where we will cover everything in-depth and give you a chance to meet the Rasa team members who worked on the new features. So mark your calendars - each day from November 29th to December 3rd we will be going live on our YouTube channel for feature deep dives and community Q&As. We will be sharing a detailed events schedule very soon.
In the meantime here’s a small preview of what’s coming to Rasa Open Source with the release of the Rasa Open Source 3.0
Architecture Revamp
One of the major changes that will be introduced in Rasa Open Source 3.0 is an introduction of graph architecture. In the previous versions, the training pipeline resembled a sequence of components. This is about to change with the new release where the training pipeline will work as a graph rather than a sequence.
The change stems from a realization that came after the release of Rasa Open Source 2.2, which introduced end-to-end learning. End-to-end learning changed the way we see the interaction between policies and NLU pipelines - with end-to-end learning it became possible for policies to use some components from the NLU pipeline to make predictions.
The new graph architecture aims to make it easier to understand the relationship between the NLU and policy components in the pipeline. There are quite a few benefits we believe the new architecture will bring to Rasa developers:
- It makes Rasa more customizable. With the new graph architecture, it is much easier to define and modify the dependencies between the training pipeline components.
- It makes caching possible. In previous Rasa versions any change to any of the pipeline components required all components to be retrained. The beauty of graph architecture is that it makes it possible to save trained components on disc. This means that if a change is made to a specific component, only that component will need to be retrained. This should save a lot of computational resources and reduce training time.
- It’s easier to understand how components interact with each other. A graph architecture makes it much easier to visualize and understand the dependencies between different components, especially between NLU and policy components which formerly were treated separately. Now there is no need to worry about classifying components into NLU or policy components.
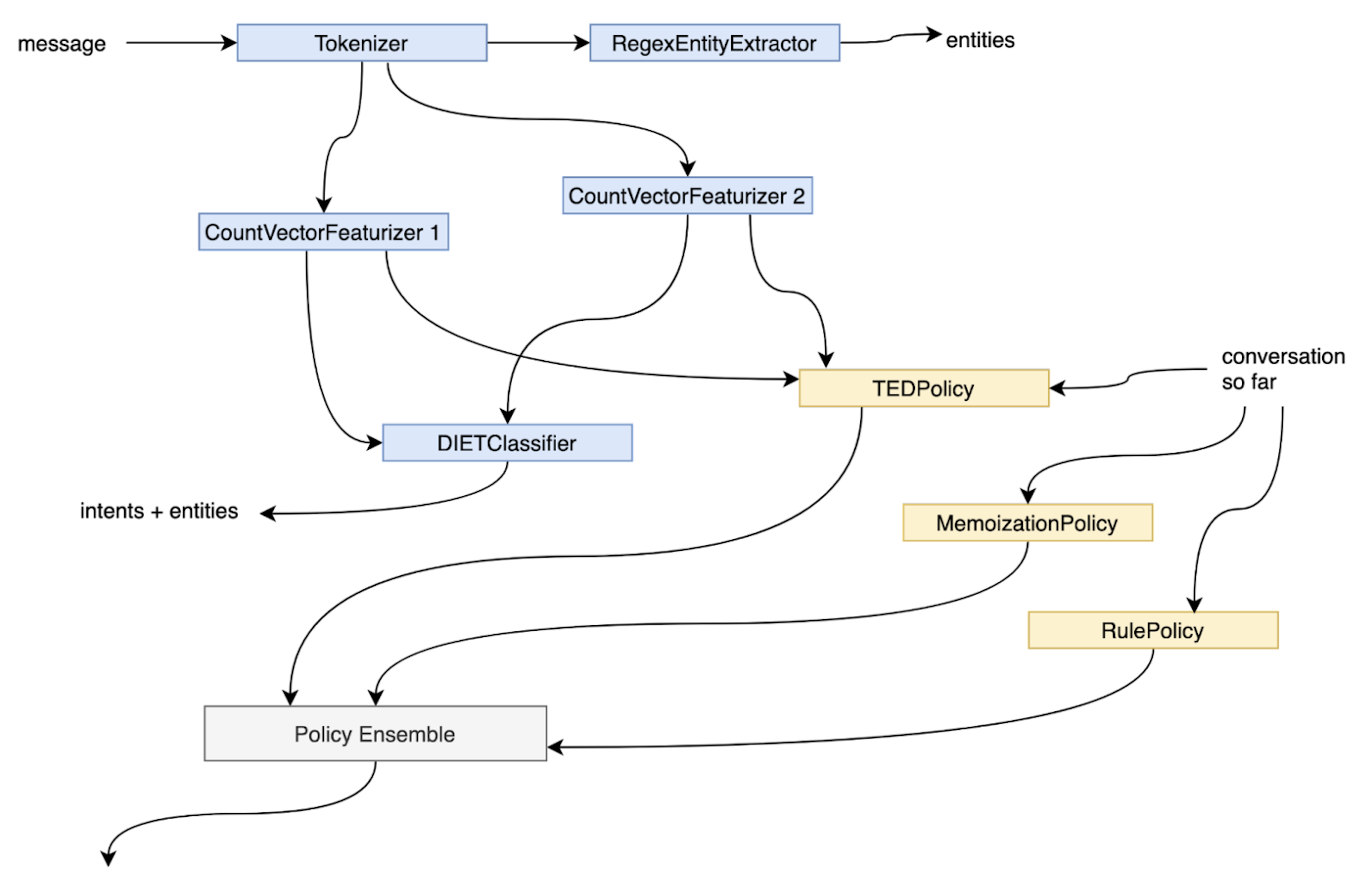
Although the graph architecture is a big conceptual change, the changes won’t require you to change your config.yml file. You will, however, need to migrate any custom components that you have written. As part of the release, we will share migration guides and educational content that will help you migrate. If you’re curious to learn more, we’ve published a blogpost which goes into more detail about the new Rasa architecture.
Slot Mappings Improvements
Another exciting update that we are shipping with the Rasa Open Source 3.0 release is slot mappings improvements. The improvements will alter the behavior of two previous functionalities which we believe will make it easier to use slots and implement forms.
In the past, if you had an entity and a slot defined with the same name, Rasa would automatically fill the slot with the value of the extracted entity. While this sometimes saved a little bit of development time, it has often led to undesired behaviors (slots being filled in when they shouldn’t have been) and confusion when implementing forms with slot mappings.
With Rasa Open Source 3.0 we are changing this behavior. From now on it will be necessary to define global slot mappings for all slots defined in a domain file. Those mappings will have to be defined inside of the slots section of your domain.

The new approach has a number of benefits.
- It makes slot setting more consistent. All slots are set the same way regardless of whether or not they’re filled by an entity.
- It makes the implementation of forms more straightforward. With global slot mappings you don’t have to duplicate the code if multiple forms set the same slots.
- It’s easier to implement a common slot behavior - overwriting slots during the conversation.
As part of the release we will share migration guides and commands which will simplify the process of migrating slots from Rasa Open Source 2.x to Rasa Open Source 3.0. We will also update our educational content on the learning center to reflect these new settings.
Experimental Feature: Markers
One of the main questions we get from our community is “what are the ways to evaluate the performance of the assistant that go beyond model comparison and validation?”. It’s something we put a lot of thought into so far, but now we need your help to learn how we want to answer this question. This is why in Rasa Open Source 3.0, we are also delivering an experimental feature called Markers. Simply put, markers are conditions that allow you to describe and mark points of interest in the dialogue for evaluating your assistant. With markers you will be able to describe specific points, like when an action has been executed, intent has been classified correctly, or a slot has been set.

When the specific conditions are met, the markers will be set for further analysis.
There are a few reasons why we believe markers could be useful when developing your AI assistant as part of a larger evaluation workflow:
- They would allow you to set and track your assistant’s KPIs such as dialogue completion or task success. With that you would be able to evaluate your assistant’s performance as these events occur.
- Markers would allow you to diagnose and improve your assistant’s dialogue by surfacing important events for inspection. For example, you might observe that your assistant handles one task really well, but often fails when performing a different one. You could define a marker to quantify how often this behavior occurs and surface relevant dialogues for review as part of Conversation Driven Development (CDD).
We believe that to make CDD work for our developers, we have to enable them to easily measure success and quickly identify and fix the problems in their assistants. Shipping Markers in 3.0 is an important first of many steps in the journey to answering “what are the ways to evaluate the performance of the assistant that go beyond model comparison and validation?” If you have thoughts or feedback about Markers, please share them with us on Rasa Forum.
Join us for the release events and share your feedback!
With every Rasa Open Source release, we aim to make it easier for developers to build conversational AI assistants with Rasa. That’s why your feedback on all of the new features and improvements is crucial for us to make sure that the changes we make tackle the most pressing needs of our developer community. Join us for the Rasa Open Source 3.0 release events November 29th - December 3rd, attend the deep dives and share your questions and feedback in live Q&As. The detailed events schedule is coming very soon!
We can’t wait to share the Rasa Open Source 3.0 with you all!