



Literally, benchmarking is a standard point of reference from which measurements are to be made. In AI, Benchmarks are a collective dataset, developed by industries, and academic groups at well-funded universities, which the community has agreed upon to measure the performance of the models. For e.g. SNLI is a collection of 570k human-written English sentence pairs manually labeled for balanced classification with the labels entailment, contradiction, and neutral which is used to measure performance on the Natural Language Inference task.
Pre-trained language models like BERT have been revolutionary in recent years for contextualized NLU, and they can achieve excellent results on NLP tasks like Inference, sentiment-similarity, entity-extraction, etc. It is very important to measure the performance of the language models. Benchmarks have become more application-oriented and increasingly moved from single-task to multi-task. Examples of such multi-task benchmarks are GLUE/BLUE benchmarks.
Most recent famous benchmarks like ImageNet, Squad, and SuperGLUE, have created quite a buzz for the leaderboard models. The oldest one is SPEC, established in 1988 for standardized benchmarks and tools to evaluate performance and energy efficiency for the newest generation of computing systems. Then came DARPA and NIST, an early benchmark for speech recognition and hand-written dataset (MNIST). Before the downstream tasks on modern language models, the performance of a language model was measured by perplexity, cross-entropy, and BPC. But now since, NLP has mostly become task-specific, we measure the performance on the downstream tasks like NLI, similarity, etc.
We have seen the rise of superhuman performance lately, with Models which are increasingly performing better than humans on datasets, like when AlphaGo defeated the world champion. While it took 15 years for MNIST to overcome superhuman performance, it took only a year for GLUE and thus causing benchmarking saturation.
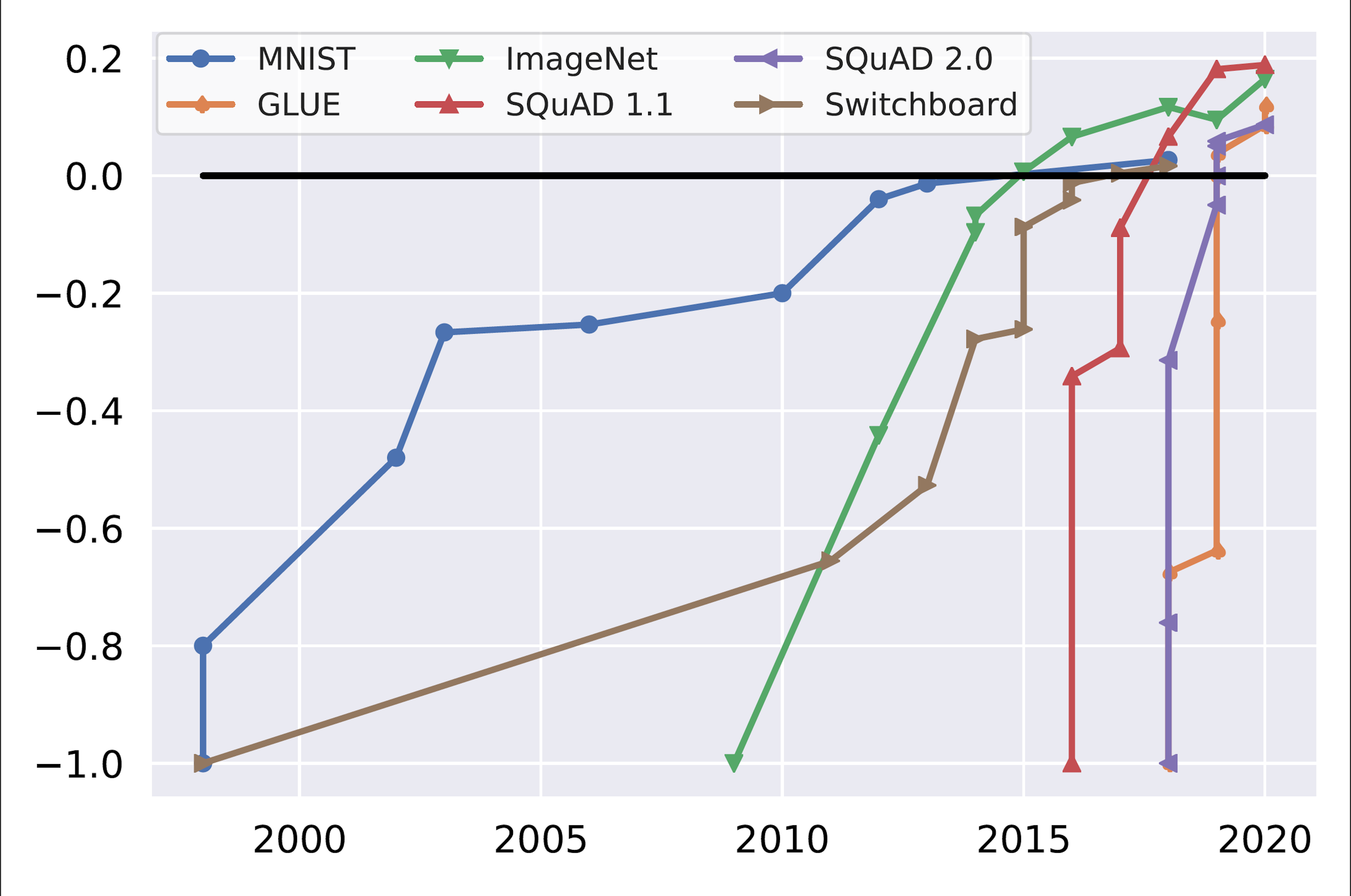
Benchmark saturation over time. Initial performance and human performance are normalized to -1 and 0 respectively (Kiela et al., 2021).
Models that achieve super-human performance on benchmark tasks may create problems when deployed in the real world. A substantial part of the problem is that our benchmark tasks are not adequate proxies. They have artifacts like social biases and thus paint a partial picture of superhuman performance. Also, Models are susceptible to adversarial attacks, despite impressive task performance, SOTA struggles to be robust against such attacks in linguistics knowledge.
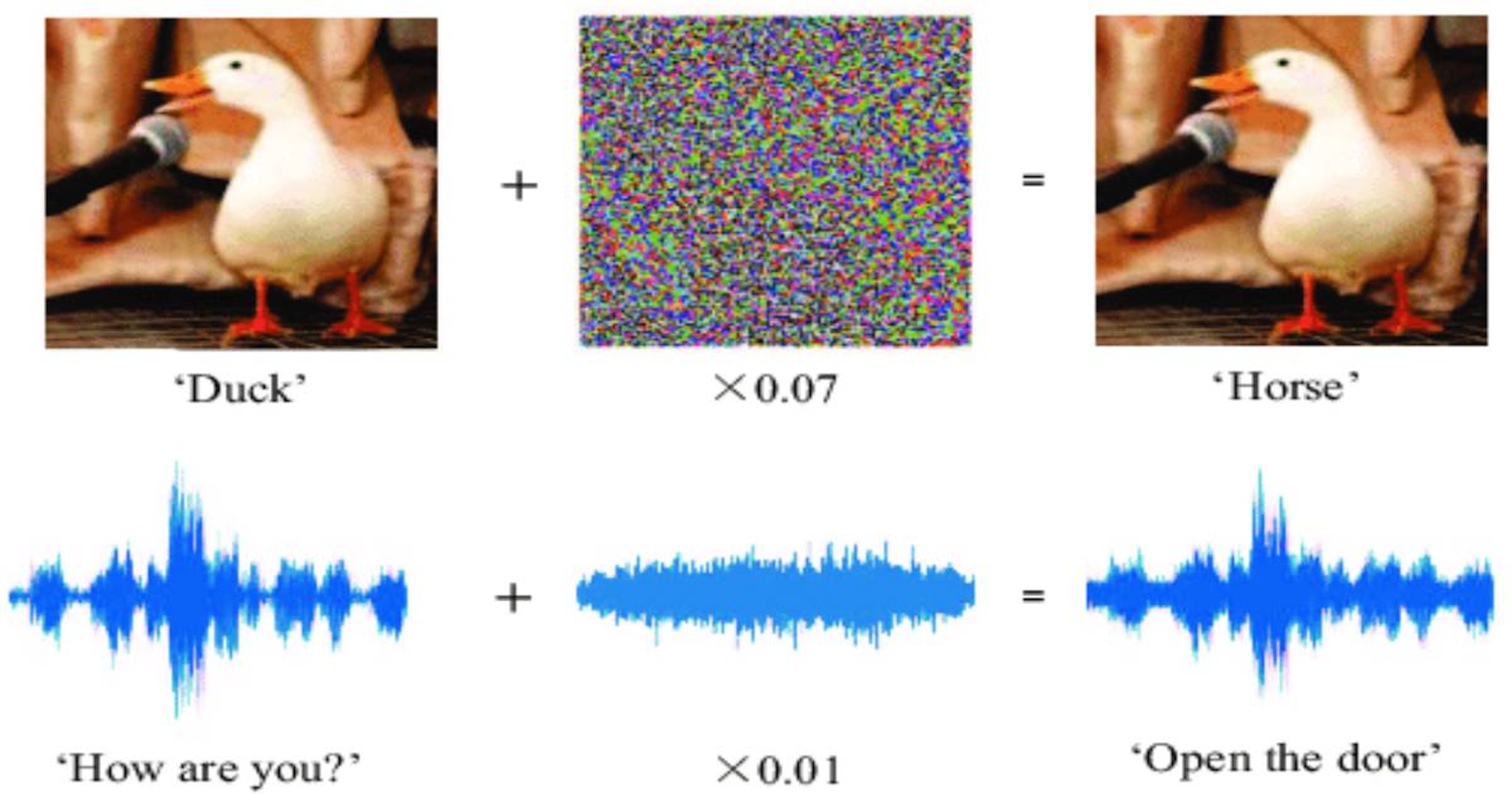
Adversarial Attack on models
To overcome such drawbacks, dynamic benchmarking was proposed in 2021. Dynabench or dynamic benchmarking hosts tasks dynamically to collect data against state-of-the-art models in the loop, over multiple rounds. The principle behind Dynabench is to evaluate models and collect data dynamically, with humans and models in the loop rather than in the traditional static way, thus it’s a large scale community effort to benchmark models on different parameters, for more information visit Dynabench paper.
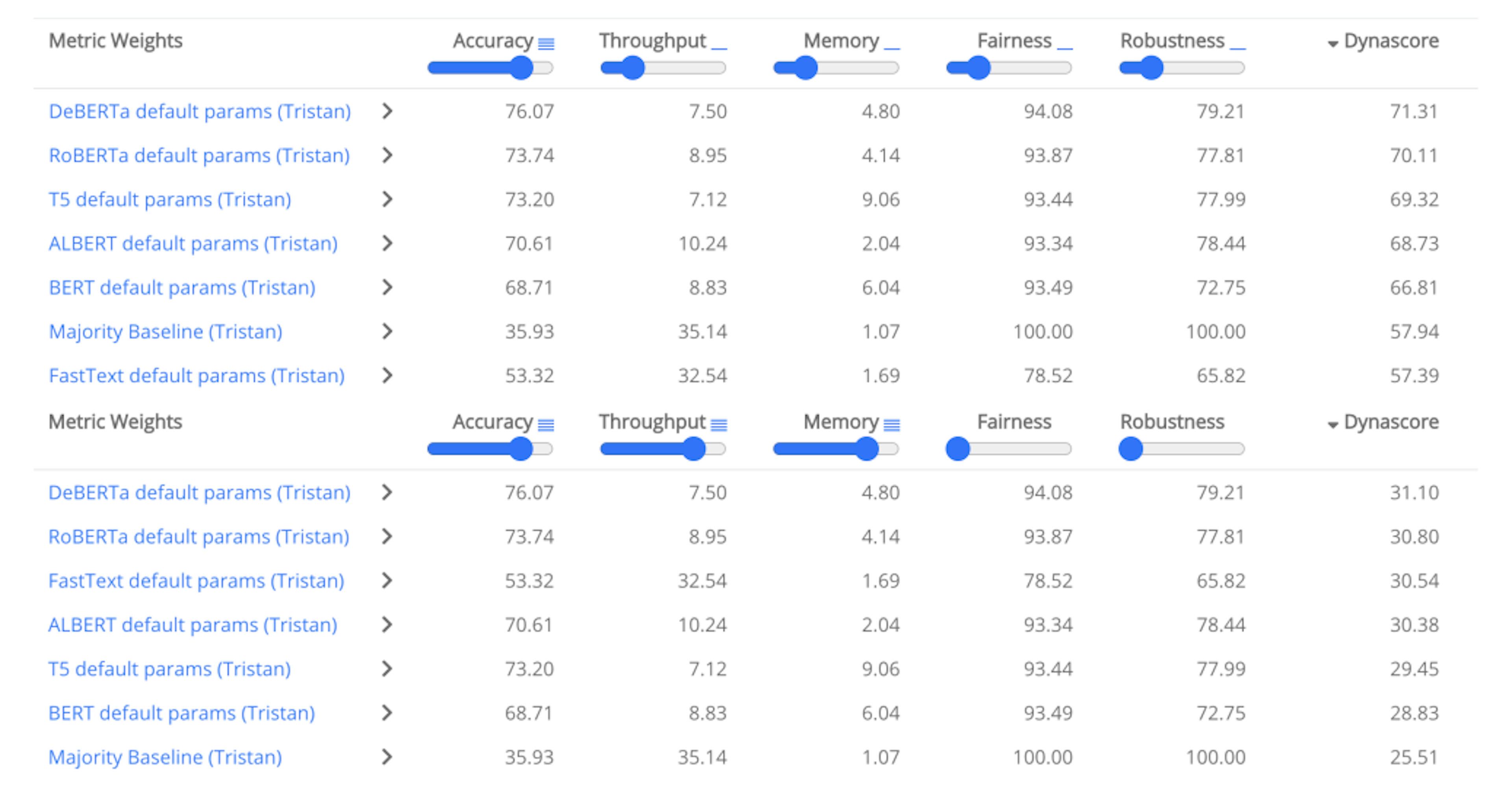
An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking. Dynaboard
Benchmarks provide an useful common goal for the community to focus on, but that also means researchers may collectively overfit on specific tasks. To overcome this, we can loop humans to adversarially attack the model and find the weak points to fool the model. This can lead to gauge SOTA models and in the process leads to the data creation that can better serve as SOTA model, thus improving it at every iteration.