


June 10th, 2021
Rasa X Two Years Later: CDD, Data, and Customer Experience
Alan Nichol

Update: A lot of things have changed since this post was written. Rasa X, the freemium companion tool to Rasa Open Source, is no longer supported or maintained, and we are currently focused on the development of the Rasa Enterprise platform. To learn more about this, you can check out this blog post
I'm reflecting on how the market and product have evolved since Rasa X was released two years ago. For one, we are seeing a significant (and overdue!) shift in how enterprises value AI work. Advanced teams now view training data as the primary contributor to building AI that delivers results. In parallel, our product has evolved from serving individual technical practitioners to an enterprise platform for practicing conversation-driven development. Enterprises now know that quality training data is a key differentiator for customer experience, and have the tools to acquire it efficiently.
The market shift to data-centric AI
Companies at the leading edge now have significant experience running AI in production. They're seeing that actually, most of the value comes from having quality training data that faithfully reflects the business problem. But not everyone is there yet.

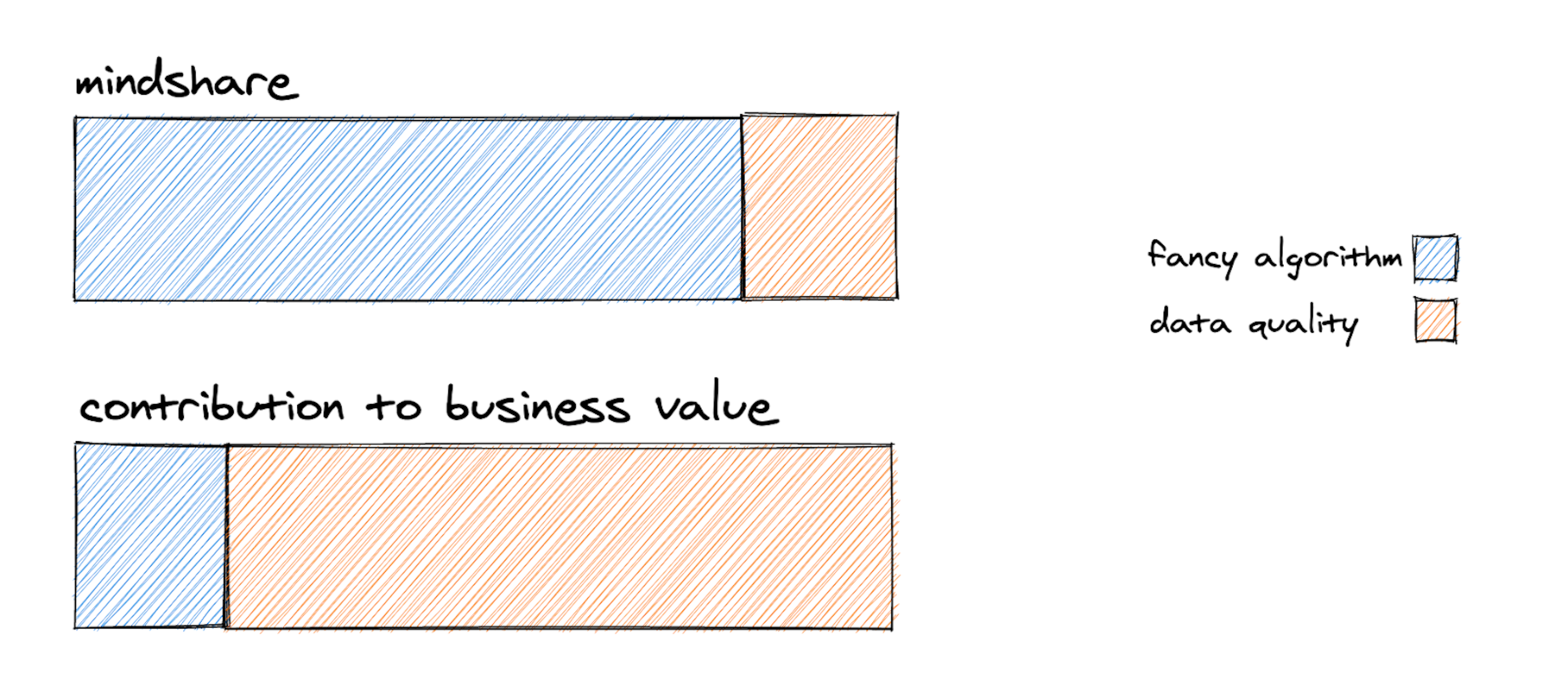
A recent paper by Google revealed that 92% of AI practitioners had experienced negative effects caused by AI/ML practices that undervalue data quality. The paper's title? _"_Everyone wants to do the model work, not the data work". As Chris Re puts it, models are commodities, and we should focus on systems that improve supervision. Or as Andrew Ng puts it, we are moving from model-centric to data-centric AI. Experts in the field know that progress tends to come from better data, less so classifiers. There's a reason "ImageNet moment" has come to mean "major breakthrough".
But it's more than talk. Looking outside of conversational AI, we've just seen two leading companies announce data-centric ML products. Databricks announced Databricks ML and Google announced a new product called Know Your Data.
As enterprises move AI from the innovation lab into production, they are learning a key lesson: your data matters more than your algorithm. That's great news for anyone building conversational AI to improve customer experience. It means that you can create a competitive advantage by building up your own dataset that reflects how your customers talk to you. And it means that you can build better customer experiences today and progress through the 5 levels of Conversational AI using technology that already exists.
Enterprise-ready workflows for CDD
We launched Rasa X two years ago because algorithms alone won't solve conversational AI, something only a few people understood at the time. Mindsets are changing, and now datasets are receiving the attention they deserve. We've spent two years helping enterprises deliver better customer experience through better data, and evolving our tools into a platform for systematically improving conversational AI at scale. To illustrate this, I want to focus on a single feature - the NLU Inbox - and how it's evolved since launch.
From an NLU inbox to a repeatable engine for improvement
The NLU inbox is part of the feedback loop that is key to production ML applications. Your model makes predictions, humans review them (either confirming or making corrections), and these become part of your training data, improving your model over time.
The NLU inbox has evolved from this basic idea into a platform that gives enterprises a systematic way to improve their training data, and consequently their customer experience. We've done this by cleverly prioritizing where annotators should spend their time, by integrating our tool into a seamless development workflow, and by making the annotator experience as efficient as possible.
Investing your time efficiently
Here's how enterprises work with the NLU inbox today. First, the enterprise readiness scorecard rates the health of their NLU training data on a scale from 1 to 4.
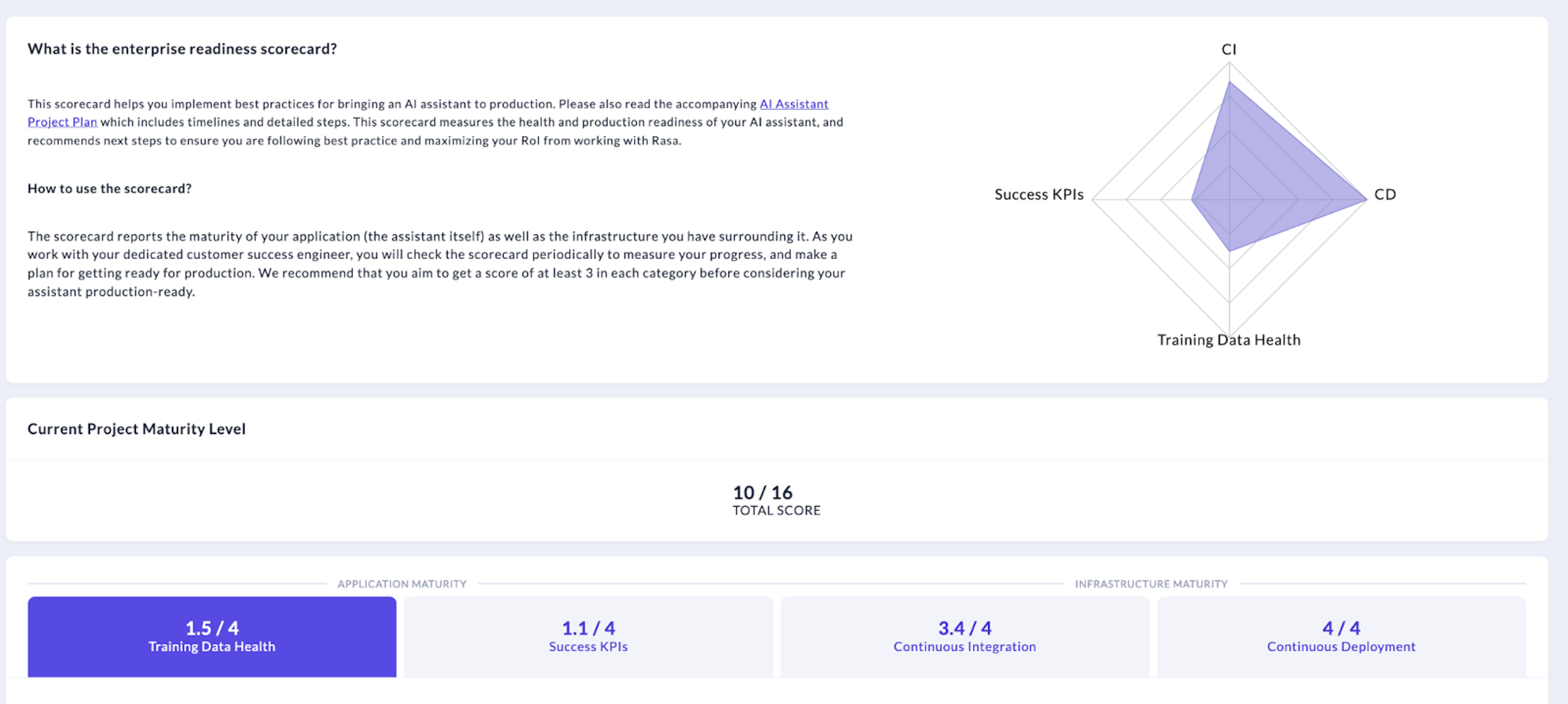
This score makes use of the NLU Insights feature, which runs a nightly analysis of your training data to find opportunities to improve.

Some of our customers' AI assistants handle hundreds of thousands of conversations every week, and the NLU insights feature zeroes in on the areas that need your attention. The table shows the performance of each intent, a list of warnings, and suggestions. If you click on a suggestion, you are taken to a filtered view of the NLU inbox containing just the messages you need to review to improve this intent's performance.
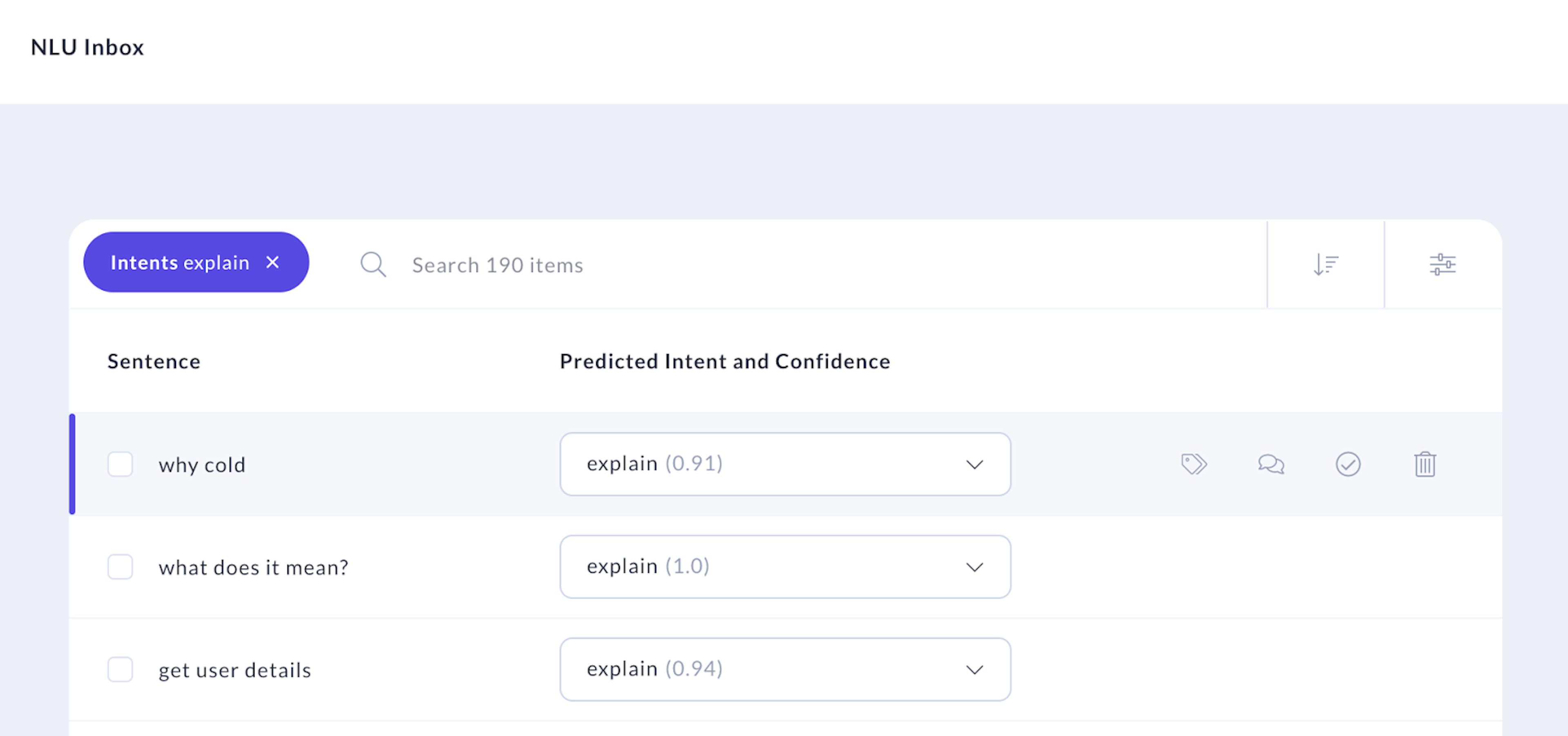
Once you're in the NLU inbox, you can also sort these examples by model confidence, so you can see cases where your model was least certain.
And in cases where you really need the whole context of the conversation to know what's going on, you can click the chat bubbles icon to see the conversation where this message was sent.
Bridging annotation and deployment with Integrated Version Control
By integrating Rasa X with git, changes to your training data are auditable, reversible, and automatically tested, packaged, and deployed. Integrated version control is a bridge that seamlessly integrates annotation into your delivery pipeline.
Divide and conquer - through team collaboration
We've made the annotator experience in Rasa X incredibly slick. We've completely re-engineered the inbox to maximise responsiveness, redesigned how entity annotation works, and added keyboard shortcuts and bulk actions to help you work at speed.
But CDD is a team effort and we've also made headway at creating a true multi-user experience. Tags in the NLU inbox allow teams to assign work to individual annotators. Workspaces are a new collaboration feature you can look forward to, which gives every user their own view of the data and enables a true multiplayer experience.
Where we go from here
We know that data holds the key to building assistants that add real value to the customer experience, but the right tooling and processes are essential. In the past two years, Rasa has delivered an enterprise workflow for improving your NLU model by learning from real end-user conversations.
Looking ahead, there's much more for us to do. Here are a few areas we're concentrating on as we look toward the next two years and beyond
- Building for the many faces of scale
- Building a similarly systematic approach to improving your dialogue model by automatically identifying conversations that need to be looked at
- Incorporating workflows beyond intents